面试总结归纳
面试总结
注:循序渐进,由点到面,从技术点的理解到项目中的使用,
要让面试官知道,我所知道的要比面试官更多
一、Mybatis
为ORM半持久层框架,它封装了JDBC,开发时只需要关注sql语句就可以了,不需要去花费精力去处理加载驱动,创建连接等过程。mybatis的灵活度很高,支持动态sql。mybatis还支持二级缓存机制,优点为降低磁盘IO,提高数据库性能。一级缓存为sqlSession下的缓存,只针对当前sql会话层,不能垮sqlSession访问。二级缓存为namespace下的缓存,它的作用域范围为namespace下,所以作用范围是大于一级缓存。通常执行查询语句时,是先去查询二级缓存,如不存在,则在去寻找一级缓存。缓存的数据结构其实就是一个HashMap。mysql在默认情况下一级缓存是默认被开启的,二级缓存需要手动配置开启。一般针对那种读多写少的情况,我们可以开启二级缓存,因为所有的增删改都会刷新二级缓存,导致二级缓存失效,所以适合在查询为主的应用中使用。SqlSessionFactory对象的实例可以通过SqlSessionFactoryBuilder获得,每一个mybatis实例都是已一个SqlSessionFactory对象为核心,在运行期间都是存在的,所以不需要重复创建,是一种单例模式。另外SqlSessionFactory是SqlSession的创建工厂。mybatis支持sql预编译(#{}为预编译),所以可以防止sql注入,保证数据库的安全
二、SQL调优/MySQL
1.针对SQL优化,我们可以配置借助工具记录慢查询日志等,来记录哪些sql属于慢查询。2.首先查看慢查询的SQL,是否有新建索引,并且是否有使用到索引。比如在项目中where条件后面用到的比较多的字段,我们可以设置为索引字段,针对查询经常用到的字段并且唯一值比较多的可以设置为索引。对那种唯一值比较少的,比如类型字段,则没有必要设置索引,如果设置了索引反而会影响到更新和新增的效率。3.使用MySQL的explain来查看慢sql的执行计划,查看该sql是否有使用到索引,有没有做全表扫描。我们可以根据执行计划中的访问类型type字段,来判断SQL的访问效率。访问效率从最好到最坏依次为:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般情况下访问类型至少要能达到range,最好是达到ref以上。4.避免全量查询,避免使用*,争取降低IO,提高查询效率。阿里开发手册规定禁止三张表以上的JOIN,减少子查询。另外在数据库设计的时候,对一些字段可以做适当的冗余,不一定要遵循三范式的设计原则。5.避免索引失效的情况,比如like模糊查询时,模糊查询字段中开头用到‘%’会导致索引失效。6.隐式转换也会导致所以的失效,比如数据库类型为int,然后的时候传参为String。7.在使用表达式的情况下,也会导致索引的失效。8.在组合索引下,如果未按照最左匹配原则会导致索引失效。9.再就是MySQL的版本在搭建选型时,可选择高一点的版本,比如MySQL 5.6以上有索引下推的优化,降低了网络IO。以及要注意在InoDB的聚合索引下,需要知道回表和索引覆盖的情况等。10.当数据量很大时也会导致索引的失效,可以考虑使用强制索引force index或者对数据量比较大的表可以做水平拆分、垂直拆分来提高查询效率。比如我们可以新建多个数据库实例通过中间件比如Mycat、sharding-jdbc来实现数据库集群,来提高数据库的查询能力和容灾能力。如果单个mysql实例下,我们也可以采用表分区的办法来提高查询性能,像单表数据达到500W以上时就可以做表分区操作,分区可以按照时间分片、取模分片、hash分片等。11.在分布式情况下,可以使用雪花算法生成分布式id。因为B+树下,除了会维护一个从上到下的顺序,还会维护一个从左到右的查询顺序。而雪花算法生成的分布式id是有序的,所以更加符合B+树的特性。12.查询条件中带有or,除非所有的查询条件都建有索引,否则索引失效。
-
随机主键会导致也分裂
主键顺序插入的话,相对效率会更高一些,因为在B+树中只需要不断往后叠加即可。但是如果主键是非顺序插入,效率就会低很多,因为肯能会涉及到页分裂的问题,假设现在多个节点有存多条数据(每个节点存33条记录),主键值分别为1、2、3、4、5…10等,然后我们要插入一条主键值为4.5的记录,那么就需要把主键值为5的记录向后移动,进而导致主键为9的记录也要往后移动。页分裂会导致数据插入效率降低并且占用更多的存储空间。
-
MySQL的底层原理面试
1.mysql的空洞效应和页分裂如何产生如何优化
答:因大量数据的前提下,系统使用期间有数据的删除操作,导致mysql的B+树存储数据失去了从左到右的连续性,形成空洞效应,导致慢查询。Mysql5.6以上可以根据专门的sql定位到对应的空洞数据,然后再来做相应的整理。
2.mysql的乐观锁和悲观锁
3.redo.log和undo.log,已经mysql的bilong日志有哪几种类型,主从模式下应该选择哪一种
答:bilong日志类型有Statement、Row以及Mixed,如果要支持主从复制,在数据库服务器性能还可以的情况下,可以选择使用RAW的数据格式。
4.mysql的MVCC概念,间隙锁等
5.
a、回表
是针对普通索引来说的。比如员工表主键为id,name为普通索引。
select * from emp where name = ‘张三’
索引的执行过程为首先利用索引name到b+tree索引的叶子节点找到主键索引id,主键索引id,在到b+tree上查找相应的数据。简单来说就是name的索引在B+tree上保存的数据是主键id。而主键id对应的b+tree的叶子节点保存的才是行数据。
b、覆盖索引
select id from emp where name=1
查找的列正好是主键,就不需要去b+tree上查找,可直接返回
c、最左匹配
首先索引必须是组合索引。
索引(name,age)select * from emp where age =1 不会走索引
select * from emp where name=‘张三’ 走索引
因此合理的索引应该建立两个一个是(name,age)一个是age; d、索引下推
select * from emp where name =1 and age= 18
是指在数据返回server的时候,数据引擎就讲name =1 和 age= 18的数据进行了过滤。在版本5.7之前的数据引擎先过滤掉name =1的数据返回,在server处过滤age=18的数据。相比较之前的返回,返回数据少,减少io
6.mysql 缓冲池(buffer pool),buffer pool默认大小为128MB,InnoDB将buffer pool分为多个page页,每个页的大小为16KB。
注意点:预读失效,buffer pool污染
避免每次访问都造成磁盘IO,以提高性能加速访问的作用
缓冲池通常以page页的单位数据存在
缓冲池常用的算法为LRU
InnoDB对LRU进行了优化:将缓冲池分为老生代和新生代,老生代默认占3/8,不过可以根据innodb_old_blocks_pct这个参数来调整比例,优先会访问老生代,才进入新生代。 -
数据库的三范式
1NF: 即表的列的具有原子性,不可再分解,即列的信息,不能分解, 只有数据库是关系型数据库 (mysql/oracle/db2/informix/sysbase/sql server),就自动的满足1NF;
2NF: 表中的记录是唯一的, 就满足2NF, 通常我们设计一个主键来实现;
3NF: 即表中不要有冗余数据, 就是说,表的信息,如果能够被推导出来,就不应该单独的设计一个字段来存放. 比如下面的设计就是不满足3NF。 -
sql的执行顺序
执行顺序:from… where…group by… having… select … order
-
MySQL 8.0和MySQL 5.7的区别
1.隐藏索引,MySQL 8.0中的隐藏索引可以被显示和隐藏,如果索引被隐藏,他是不会被查询优化器使用,方便进行性能调式;
2.用户创建,修改和授权,就是创建用户和授权时需要分开执行sql;
3.UTF-8编码,从MySQL 8.0开始,数据库的缺省编码将修改为utf8mb4,这个编码包含了所有emoji字符(表情符号)。
4.性能提升,官方表示性能要比5.7快2倍,尤其是在高负载、高竞争时,IO性能有很大提升。
-
MVCC,乐观锁和悲观锁,共享锁
1.MVCC理解:多版本并发控制
当前读,快照读,undo.log
2.乐观锁和悲观锁,共享锁
SELECT … LOCK IN SHARE MODE走的是IS锁(意向共享锁),即在符合条件的rows上都加了共享锁,这样的话,其他session可以读取这些记录,也可以继续添加IS锁,但是无法修改这些记录直到你这个加锁的session执行完成(否则直接锁等待超时)
当select …for update 锁住的是索引或者主键时,只会锁住当前行,为行锁。如果锁住的是其他普通字段的时候,就是锁住整张表,为表锁。
3.READ-COMMITTED和REPEATABLE-READ下的InnoDB快照读有何不同
在READ-COMMITTED的隔离级别下,是每个快照读都会生成并获取最新的Read view。而在REPEATABLE-READ的隔离级别下,是同一个事务下的第一个快照读才会创建Read view,之后的快照读获取的都是同一个Read view。
-
事物传播机制
request
request_new
support
no_support
-
事物的隔离级别
隔离级别有:
READ-UNCOMMITTED
READ-COMMITTED
REPEATABLE-READ
SERIALIZABLE
ACID:
原子性—要么都成功,要么都失败 undo.log
一致性—最核心和最本质的要求
隔离性:锁,MVCC(多版本并发控制)
持久性:redo.log
-
Mycat、sharding-jdbc
mycat、sharding-jdbc用来做读写分离,分库分表
mycat主要有三个配置文件:
server.xml—主要就是mycat的配置文件,设置账号、参数,以及端口;
schema.xml—mycat对应的物理数据库和数据表的配置;
rule.xml----mycat分片的规则,(主要分片规则:hash,范围,取模,日期等);
mycat会有全量表(或者叫广播表),比如那些字典表在每一个库中都需要保证一份全量的数据,父子表等。
sharding-jdbc:
主要是通过jar的方式引入,无需proxy代理层,DBA也无需改变原来的运维方式,然后通过在项目中配置.property的文件就可以实现分库分表操作。由阿里开源。 Sharding-JDBC直接封装JDBC API,可以理解为增强版的JDBC驱动,旧代码迁移成本几乎为零 。支持多种连接池(比如DBCP、C3P0、Druid等)。目前只支持mysql,但已有支持sql server、Oracle的计划。
三、系统如何保证安全,防止攻击
1.Sql注入2.有哪两种跨站攻击XSS:跨站脚本(Cross-site scripting)CSRF:跨站请求伪造(Cross-site request forgery)XSS跨站攻击,本质上是注入攻击的一种,其特点是不对服务器造成伤害。就是通过站内的正常交互途径,发布一些JavaScrept脚本,这时服务端没有过滤这些脚本,例如发布评论中含有JavaScrept的内容,把这个作为内容发布到页面上,其他用户访问这个页面时关不掉这些窗口。例如:while (true) {alert("你关不掉我~");};如何预防:我们可以在HTML进行转义或者过滤来预防XSS攻击CSRF跨站请求伪造,比如用户已经我们的网站并拿到了Token,然后弹出一个钓鱼的链接,然后用户点击后用户的cookie就会被盗用,从而导致服务器被攻击。如何预防:可以使用动态token,并使用过滤器来校验Token。
四、过滤器和拦截器的区别
1.Filter需要在web.xml中配置,依赖于Servlet2.Interceptor需要在SpringMVC中配置,依赖于框架;3.Filter的执行顺序在Interceptor之前4.两者的本质区别:拦截器(Interceptor)是基于Java的反射机制,而过滤器(Filter)是基于函数回调。从灵活性上说拦截器功能更强大些,Filter能做的事情,都能做,而且可以在请求前,请求后执行,比较灵活。Filter主要是针对URL地址做一个编码的事情、过滤掉没用的参数、安全校验(比较泛的,比如登录不登录之类),太细的话,还是建议用interceptor。不过还是根据不同情况选择合适的
五、JWT、Spring security
jwt和spring security知识点
jwt只是一个生成token的机制,而Spring Security、Shiro这两个框架是用来后台做权限认证,管理,筛选的框架JWT由Header、Payload、Signature组成Header由token的类型和算法名称组成json,然后base64编码后的数据。Payload为声明部分,通常就是一些用户信息和其他数据的声明,然后base64编码后的数据。Signature为签名部分,必要条件是具备Header和Payload,然后再加一个秘钥,根据Header中规定的算法生成签名。Spring security是一个能够为基于Spring应用系统提供的安全访问控制解决方案的框架,充分利用了Spring IOC,Spring AOP功能,为系统提供了声明式的安全访问控制能力,不需要企业为了安全控制去重复编写代码,一个轻量级的框架。可以基于角色的权限控制对用户的访问权限进行控制,其核心思想是通过一系列的filter来进行控制。spring mvc的时代用shiro比较多,然后springBoot用Spring security的比较多。向每次新建springBoot项目时都可以主动去选择关联Spring security来新建项目,用起来很方便。Spring security对应有好多注解这里面@DenyAll 和 @PermitAll 相信就不用多说了 代表拒绝和通过。@RolesAllowed({"USER", "ADMIN"})代表标注的方法只要具有USER, ADMIN任意一种权限就可以访问*****详细可以查看面试Spring Sercurity专题--基于Spring Sercurity的用户角色权限
token超时刷新策略
1,字段参数
jwt(或者叫 accesstoken):用户正常访问接口时提交的token,过期时间设置长一些,
refreshJwt(或者叫 refreshtoken):刷新token 过期时间可以设置为jwt的两倍,甚至更长,用于动态刷新token时候提交后台验证
tokenPeriodTime:token过期时间戳,前端每次调用接口前需要主动判断是否已经过期,如果过期则提交refreshJwt访问token刷新的接口进行刷新
2.动态刷新
前端检测到token过期后,携带refreshJwt访问后台刷新token的接口,服务端在拦截器中依然对refreshJwt进行解析鉴权
假如refreshJwt也过期了,提示登录过期,强制跳转登录页
假如refreshJwt还在有效期,则签发新的token返回(并且也会刷新refreshtoken的有效期),前端使用最新的token进行接口请求
3.总结
如果是活跃用户,那么允许他在refreshJwt过期时间与token过期时间的差值这段时间内,不停的动态刷新token,使其做到无感知的状态下一直保持登录状态
如果用户不活跃,在refreshJwt过期时间到了,依然没有使用系统,那么将判定为不活跃用户,此时应当重定向到登录页了
六、Spring (待完成)、SpringBoot
SpringBoot简化spring应用开发,约定大于配置,去繁化简。SpringBoot内置了各种servelt容器,Tomcat/jetty等,所以不需要打war到容器中去运行。直接打jar就可以直接运行。SpringBoot主要有三部分组成:pom.xml主要定义项目的构建、打包方式、以及引入类库和类库的版本控制;配置文件yml,相比properties,yml类型的配置文件更强大。properties只支持key value的键值数据格式,yml支持的更加广泛,除了支持key value,还支持对象、数组等多种数据格式,所以yml配置文件更加灵活;启动类和注解@SpringBootApplication,以及它对应的三大注解:1.@SpringBootConfiguration:标记该类为一个配置类2.@EnableAutoConfiguration:开启自动配置扫描3.@ComponentScan:具体扫码哪些包哪些类另外SpringBoot有集成多种标准得模板类,使用起来很方便。比如:RestTemplate、RedisTemplate、RibbitMqTemplate、ElasticsearchTemplate等SpringBoot还默认性能很好的额连接池为HikariCP。如果为了监控也可以替换为国内优秀的连接池Druid。redis的客户端工具可以选择性能更好非阻塞I/O的Letture、RedisSon,不去使用阻塞IO的Jedis客户端等。Jedis的方法调用是同步阻塞I/O的方式,需要等待sockets执行完成才能执行,性能先对较差。Letture、RedisSon是基于Netty框架,其方法调用是非阻塞I/O,所以可以用单个Letture或RedisSon连接完成各种操作。spring AOP和Spring IOCspringAOPJDK动态代理和CGlib动态代理,springAOP可能会问到事务,然后事务失效有哪些场景(比如同方法中没有通过对象来调用方法,或者非RuntimeException需要在 @Transactional(rollbackFor = Exception.class),因为默认为RuntimeException才会回滚)
spring bean 的生命周期
spring 事务传播机制
spring 如何解决依赖循环的问题
spring 中涉及到的设计模式
七、设计模式以及设计模式在项目中的使用
1.单例模式
2.工厂模式
3.代理模式
4.适配器模式
5.观察者模式
八、微服务Spring Cloud
微服务的优点:降低耦合、独立部署、选型灵活、容错机制、灵活扩展微服务项目用到的五大组件,Eureka/Zookeeper/Nacos、Zuul/Getaway、Hystrix、Robbin、Feign,其他的比如全局配置Spring Cloud ConfigSpring Cloud Bus 消息总线,比如在更改ConfigServer服务端全局配置后,需要触发消息总线来通知其他的Config客户端同步全局配置Spring Cloud Sleuth 链路追踪-
注册与发现
注册中心主要有:Eureka、Zookeeper、NacosEureka属于C(一致性)A(可用性)P(分区容错性)定理中的AP。并且Eureka可集群部署,支持高可用和高性能。Eureka集群中是没有主从之分的,每个节点都是平等。Eureka的心跳续约机制:默认为30s钟会发起续约Renew,然后将注册信息同步到Eureka自己的缓存中(registry、readWriteCacheMap、readOnlyCacheMap),如果90s都未被续约的节点会被移除掉。心跳续约可以自行设置调整。Eureka自我保护机制:在最近15分钟收到心跳续约renew低于85%(阈值可调整),则会触发自我保护机制,Eureka就会认为客户端与注册中心出现了网络故障,Eureka Server就会进入自我保护机制。会有以下几种情况:1.此时Eureka就不会移除因长时间有没收到心跳而过期的服务;2.Eureka Server依然可以接受新的服务注册,但是无法同步到其他节点;3.当网络恢复稳定时,新的注册信息会自动同步到其他节点。Eureka自我保护机制默认打开状态,建议生产环境打开此配置,测试环境频繁发版本的情况下,可以关闭掉。Zookeeper属于CAP定理中的CP,如果追求系统的强一致性,可以选择Zookeeper作为注册中心。并且ZK遵循Paxos算法中一致性协议的轻量级实现ZAB原子广播。Zookeeper集群模式下有三种角色,Leader、Follower、Observer,其中Observer不参与选主,只提供性能上的增强。Nacos为阿里开源项目,性能强大,同时支持AP和CP模式,并且Nacos还可以做全局配置中心。 -
Hystrix
Hystrix 熔断降级组件,它内部提供了两种执行逻辑:信号量、线程池。默认情况下使用的为线程池隔离。线程池模式:通过下游调用之间的线程分离,来达到资源隔离的作用。当线程被打满,来不及处理新的请求时,可以快速失败,避免扩散到其他的服务,防止雪崩发生。因为线程池模式会有大量线程上下文的切换,所以会导致负载过高的情况。信号量模式:优点在于不存在上下文之间的切换导致的性能开销,为同步执行,不支持异步。并且信号量模式不支持超时。所以针对并发量大并且耗时长的采用线程池策略,并发量大并且耗时短的采用信号量策略降级:设置一个阈值,当请求量达到规定值后,可以快速失败,执行降级逻辑。 -
网关Zuul、Getaway
Getaway基于Netty的NIO调用方式,为非阻塞式的,更加符合高并发的场景。Zuul是微服务中的网关,为奈非公司产品,使用BIO阻塞调用方式,相比Getaway性能要差。网关主要是做鉴权和限流的控制。网关底层源码就是过滤器,其中过滤器类型共分为4大类:pre、routing、post、error。限流算法:漏桶算法可以很好的控制容量池的大小,防止流量的暴增。如果漏桶溢出,数据包就会被丢弃。漏桶算法可以控制端口的流量输出速率,可以提供稳定的流量令牌桶算法,根据限流大小往桶中添加令牌,令牌桶中存在令牌,则允许发送流量;而如果令牌桶中不存在令牌,则不允许发送流量。 -
Ribbon
Ribbon使用的是客户端负载均衡,像Nginx、F5都是属于服务端的负载均衡,所以不能混淆了。如果客户端之间的调用使用的RestTemple,则在RestTemple添加一个@LoadBalanced就可以实现负载均衡。Feign调用的时候,默认是有集成Ribbon的,所以不用手动去添加。Ribbon的几种负载均衡策略:随机策略、轮询策略、加权策略、重试策略、区域权衡策略、最低并发策略等,默认使用的是区域内轮询策略。 -
Feign
声明式的调用方式,内部有集成Ribbon
九、分布式锁
redis分布式锁的底层实现主要是根据setNx的方法演变而来,执行setNx(key, value, expre),如果返回true表示加锁成功,返回false表示加锁失败。在高并发的场景下,直接使用setNx加锁会导致提前释放别个人锁的问题。比如setNx中的有效时间expre设置为10s,但是加锁的业务代码确执行了15s,因为自己的锁在10s的时候已经失效了,所以15s时释放的是其他人的锁。redis官网对分布式建议是直接使用redisSon客户端工具,里面有内置一个看门狗的监听程序,假如加锁key的有效期为15s,当加锁时间达到1/3(5s)时间的时候,看门狗会判断当前业务代码是否有执行完成,如果没有执行完成,则将key的有效期直接再加5s延长1/3的时间,让锁的有效时间重新变为15s,这样就可以防止提前释放别个锁的操作。另外在集群情况下要保证高可用,redisSon还支持红锁的操作,假如redis集群下共有5个节点,其中过半以上的节点加锁成功(3个节点以上)时红锁才会生效,但是红锁性能会比较差,可根据实际场景使用。一般在工作中,分布式锁可以结合SpringAop使用,可以直接通过注解的方式加锁,优点使用代码更简洁、无侵入。在使用分布式锁的时候,加锁会导致业务串行化,会代码影响性能,所以一般分布式时是分段加锁,类似于HasnMap源码中的锁分段,只对当前桶加锁,不去影响其他桶的操作。zookeeper的分布式锁,zookeeper中有永久、临时两种类型的节点,而分布式锁底层所使用的就是临时节点的特性。当临时节点生效时,就会触发await通知事件,然后执行下一个逻辑。zookeeper遵循cap中的cp,zk在集群环境下的节点共有三种角色:Leader、Follower、Observer,其中Observer不参与选主,只提供性能上的增强,所以在强一致性的前提下,也可以保证高性能。可以根据使用场景选择分布式锁的种类,如果业务代码比较追求一致性,可以选择ZK作为分布式锁。
十一、秒杀总结
具体秒杀的架构设计可以参考黄老师讲的内容。1.这里只是对秒杀中分布式锁性能提升做对应的总结:对分布式锁由串行化修改为并行化,需要修改为分段加锁去实现(类似于hashMap的槽位锁分段技术);例如一千件商品分为10等份,每份商品对应一把锁,哪个线程抢到锁,就去执行对应业务逻辑,其他线程为等待状态,就不会有超卖的发生。但是,想想应该会有另一种异常情况出现,客户抢不到秒杀商品、商家的商品咩有卖完的情况。因为有可能10等份的商品中,其中一部分可能先被抢完,后面客户端的请求会命中到没有商品的锁,所以这边需要在代码层面写一个for循环去判断,当该把锁下对应的商品被抢完后,应该去抢其他锁下的商品。2.扣库存时也要注意,如何防止超卖的发生?因为数据库的事务隔离级别一般都不是串行化(serializable),根据事务的特性,在并发的情况下,可能会导致写覆盖的问题,所以我们一般会使用select 。。for update 的悲观锁机制,完成扣除库存时再提交事务,只是在分布式系统中来说对数据库的压力会比较大。也可以选择使用乐观锁的机制,如果客户A和客户B同时读取到100的库存,在更新的时候,会有一个操作失败,这种方式可以大大提高并发性,另外我们在代码中做好重试次数和重试时间的控制,可以防止过多的重试带来的数据库压力。十二、分表分库总结
1、mycat的几个xml的配置文件①.schema.xml,配置逻辑库表,分片和读写分离②.rule.xml,具体的分片规则和分片算法③.配置默认的数据库和用户,表权限另外就是全量表等等,并不是所有的表都需要进行分表分库2.shareding-jdbc比较新的工具,已经开放到apche顶级项目
十三、redis(待完成)
1.redis面试的知识点
Redis中有序集合zset需要使用skiplist作为存储数据结构,跳表的结构是怎么样的;Redis的String类型中的bitmap(位图),是用一个bit位来标记某个元素对应的Value,在Java中,int占4字节,1字节=8位(1 byte = 8 bit),节省存储空间,统计用户每天的登陆情况下游用到;布隆过滤器也有用到如何保证redis和mysql的双写一致性,(比如可以说下阿里的开源中间件canal,通过开启mysql的bilong日志,由canal同步,redis开启发布订阅来进行接收);redis的冷热备份,AOF和RDB的区别,LRU和LFU删除策略;以及过期key删除的方式:定时删除和惰性删除;
redis的雪崩、穿透、击穿。
布隆过滤器/布谷鸟过滤器如何防止穿透,redisson的分布式锁以及看门狗机制等;redis的主从,高可用,集群saveof psync 全量同步 增量同步 2.缓存和数据库一致性问题
关于缓存和数据库一致性的问题需取得两点共识:
1.缓存必须要有过期时间
2.保持跟数据库的最终一致性即可,不必追求强一致性一般都会有四种方案:(按照分析套路:①.假如第一次成功,第二次失败, ②.分别判断异常和高并发会造成什么问题,③.同时A线程和B线程去更新,高并发下线程有快有慢)
1.先更新缓存,再更新数据库
2.先更新数据库,再更新缓存
3.先删除缓存,再更新数据库
4.先更新数据库,在删除缓存分析上面四种方案是否可行,不需要死记硬背,只需要记住下面两个场景会不会带来严重的问题即可:
1.其中第一个操作成功,第二个失败会导致什么问题
2.在高并发情况下会不会造成数据读取不一致的问题分析:
第一种:先更新缓存,再更新数据库;如果更新缓存成功,更新数据库失败,就会导致缓存为最新数据,数据库为旧数据,两者数据不一致,那缓存就是脏数据。
第二种:先更新数据库,再更新缓存;如果更新数据库成功,更新缓存失败,数据库为最新数据,缓存为旧数据,两者数据也不一致,和第一种类似。
第三种:先删除缓存,再更新数据库如果删除缓存成功,再更新数据库失败。假设有两个线程,写请求A和读请求B。首先写请求A先删除缓存成功,在更新数据库的时候发生卡屯,就会导致数据库依然是旧值。然后读请求B进来发现缓存没有值,就会去数据库中查询得到旧值,然后再把旧值set到缓存中。这时写请求A不卡了,就会继续去更新数据库,更新数据成功后,也会导致缓存和数据库不一致。
第四种:先更新数据库,在删除缓存假如更新数据库成功,删除缓存失败怎么办? --- 我们可以把这两步放在一个事务下面,如果删除缓存失败就回滚。可是高并发环境下,这种方案就不变太合适,容易出现大事务,导致死锁。我们可以使用重试机制,比如删除缓存时我们可以重试三次,如果三次都失败则记录日志到数据库,然后使用XXL-JOB,高并发场景之下,重试应当采用异步方式,比如可以使用MQ来进行异步解耦来处理。或者使用Canal框架来订阅MySQL bilong日志,监听对应的更新请求,执行删除对应缓存的操作。读取MySQL bilong日志异步删除:1.更新数据库;2.数据库会把操作信息记录到bilong日志中;3.使用Canel订阅bilong获取目标数据和key;4.缓存删除系统获得Canel的数据,解析目标key,并进行删除操作;5.如果删除缓存失败,则将消息发送到MQ消息队列;6.然后缓存删除系统仔从消息队列获取数据,继续进行删除操作。
以上为了尽可能是的保持数据一致性,除了重试机制,还可以结合延迟双删的策略:先删除缓存,在更新数据,然后休眠500ms再删除缓存。正常情况下这样子最多只会出现500ms的脏数据,这500ms还是要根据各自项目的读请求的具体耗时来确定。##如果非要保持缓存和数据库的一致性,我们可以先给出结论:没有办法做到绝对的一致性,这是由CAP理论决定的,缓存系统使用的场景就是非强一致的场景,所以他属于CAP中的AP。所以,我们就得委曲求全,可以做到BASE理论中的最终一致性,尽可能的使缓存和数据库保持一致。
3.redis是单线程还是多线程(待完成)
redis是在6.0及以上版本才正式引入多线程,
4.redis其他面试点(待完成)
-
介绍一下 Redis 的线程模型;
-
单线程的 Redis 怎么执行内存淘汰策略;
-
redis 的全量同步和增量同步;
-
redis master 宕机后,怎么在 slave 中选举出一个作为新的 master;
-
redis 的哨兵模式,master 的选举机制
十四、MQ(待完成)
14.1MQ的特性:异步,解耦,削峰问的深一点就是:如何防止消息的丢失和重复消费、以及消息的堆积等MQ之间的对比差异Rabbitmq Rocketmq kafka等防止消息的丢失:confom ack offset14.2rabbitMq通常都是topic模式,由生产者发送消息到交换机,然后交换机找到对应的队列。confirm模式来确保生产者不丢消息一旦消息被投递到所有匹配的队列之后,rabbitMQ就会发送一个Ack给生产者14.3Rocketmq的延迟队列和事务消息角色:Producer、Broker、ConsumerRocketmq如何防止消息的丢失:①.生产者将消息发送到Broker,需要Broker的响应,响应回来的消息都需要做好try-catch,妥善的处理好响应。如果Broker返回写入失败,则需要做好重试发送,当多次失败后需要做好报警和日志记录。这样生产者阶段就不会丢失消息。②.存储消息的阶段,需要在消息刷盘成功后再给生产者响应,加入消息收到就直接写入缓存然后就响应给生产者,那么机器突然断电消息就会丢失掉,而生产者以为发送成功了。如果broker是集群部署,那消息不仅要保证当前broker已经刷盘,还要保证副本也要刷盘成功,才可以响应给生产者消费成功。③.消费消息阶段,可能有些同学在消息者拿到消息后就放入内存队列中,然后就直接给broker发送响应消费成功,这是不对的。你需要去考虑如果消费消息的机器宕机了应该怎么办。所以我们应该在消费者真正执行完业务后,再发送给Broker消费成功。只是说有可能因为网络抖动导致Broker端没有收到消费成功的响应,Broker就不会剔除该条消息,导致消息重复消费的问题,这些就需要做幂等校验了。14.4kafka pattion 零拷贝 顺序写 kafka的角色分为:broker:一台kafka服务器就是一台broker,一个broker可以对应多个topicbroker就是接受生产者的消息,为消息设置偏移量,并保存到磁盘broker为消费者提供服务,对读取分区的请求作出响应,返回给消费者曾经生产者已提交到磁盘的消息。produer:Consumer:Topic:kafka的消息通过Topic来进行分类。主题Topic就好比数据库里面的表Partition:分区,一个Topic可以分为多个Partition,每个Partion都是一个有序的队列,并且保证先后读取的顺序Offset:偏移量Zookeeper:Kafka使用 Zookeeper保持集群的元数据信息和消费者信息,来保证集群的可用性kafka集群中只有一个lead,其他的都是follower,这都需要Zookeeper来保证。
十五、BIO NIO Netty(待完成)
liunx系统下一切接文件,所以每次调用都是系统调用,外部请求由用户态发起后,都会切换为内核态,因为内核态速率要比用户态处理速度要慢,当请求量大的时候,就会出现阻塞的情况。所以就有BIO阻塞性的IO。以及非阻塞IO就是NIO(注:在java被称为new IO,和liunx不一样)。多路复用器epoll,epoll主要为三个函数(epoll_create(size):创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大,epoll_ctle:poll的事件注册函数,epoll_await等待事件的产生)和两个数据结构(红黑树和链表);提高了效率,时间复杂度为O(1),不会随着系统访问的增大而成正比的增大面试上用的比较多的NIO的框架为Netty,Netty包括三部分(channel读取数据,ByteBuffer缓冲,Selector就是epoll)。有很多工具和中间件有集成Netty,比如通信框架RPC,reids的客户端工具:Redisson,letty,tomcat8.5以上,Getaway网关等。epoll不负责数据的读写,只是负责读书的事件。
内存IO,网络IO,磁盘IO
用户空间:应用层、表示层、会话层
内核空间:传输控制层、网络层、链路层、物理层
NioEventLoopGroup事件循环组
shell中查看端口22服务:netstat -natp | grep 22
十六、安全、防止攻击XSS等
除了最基本的sql攻击,预编译可以解决
1.跨站脚本攻击
2.跨站请求攻击,token盗用等以及还有涉及到的加密算法:
对称加密/非对称加密
openJDK精简版本中涉及的加密可能需要坐下增强,比如JCE下面需要引入Security的一些jar包
十七、JVM
一.ClassLoader 类加载器明细:
1.BootstrapClassLoader C++类,String,Object 等
2.ExtensionClassLoader 加载Java\jdk1.8.0_144\jre\lib\ext下的文件 扩展类库
3.App 加载classPath下的文件
4.customClassLoader 自定义加载器二、面试点:双亲委派机制作用
打破双亲委派机制--可以重写loadClass()
load-默认-初始值 (对象:申请内存-赋初始值) 三、JMM
cache line 缓存行 64字节(bytes),缓存行中的伪共享---使用缓存行对齐来解决伪共享
DCL要加volatitle 四、GC
引用计数法 、Root Searching 根可达算法
GC的常用算法:
1.标记清除(Mark-Sweep) : 容易产生碎片, 扫描两次
2.复制算法(copying) : 空间浪费,适用对象存活较少的区域
3.标记整理压缩 : 扫描两次,需要移动对象,不会产生碎片
ZGC之前至少在逻辑上都是分代回收算法,
G1是逻辑分代,物理不分代STW
serial + serialOld
ps+po JDK1.8默认 并行处理垃圾
CMS+perNow
CMS的缺点:浮动垃圾,内存碎片化,CMS有用到标记清理
CMS分为四个阶段:初始标记、并发标记、重复标记、并发清理
G1为并发处理垃圾,和应用线程交替执行(有别于ps+po的并行执行)CMS的并发标记阶段:三色标记算法+incremental Update
G1用到三色标记算法+SATB
JDK1.9默认的是G1CMS和G1的清理垃圾流程
1)初始标记
2)并发标记
3)重新标记
4)并发清除五、垃圾收集器跟内存大小的关系
Serial --- 十几兆
PS ---- 几个G
CMS---20G
G1---上百G
ZGC--- 4T六、GC调优参数配置
-Xmn10M -Xms40M -Xmx60M -XX:+PrintCommandLineFlags -XX:+PrintGC HelloGC PrintGCDetails PrintGCTimeStamps PrintGCCauses七、G1
分而治之、Rset、Region
三色标记会有漏标的情况
为什么G1用SATB?
十八、线程池
-
线程池分为哪两大类: Threadpool和FrokjoinPool
线程池分为哪两大类: Threadpool和FrokjoinPool Threadpoool的具体实现类总共有四个,是哪些? 1)newCachedThreadPool 可缓存的线程池 2)newFixedThreadPool 定长的线程池,可控制线程的最大并发数,超出则在队列中等待 3)newScheduledThreadPool 支持定时及周期的线程池 4)newSingleThreadExecutor 单线程化的线程池,它会用唯一的线程来执行任务,它可以按照指定顺序执行 -
线成池里面的七大参数
阿里规范建议,使用线程池时,我们一般都是重写ThreadPoolExecutor,它里面有七大参数 1)corePoolSize 核心线程池大小 2)maximumPoolSize 最大线程池大小 3)keepAliveTime 线程最大空闲时间 4)unit 时间单位 5)workQueue 线程工作队列 6)threadFactory 线程创建工厂线程池中参数的线程生成工厂threadFactory可以命名线程的名称,方便其他后面的排查比如知道线程池中线程的名称,后面在jvm调优的时候方便快速定位到对应的具体的代码位置 7)handler 拒绝策略 -
线程池的拒绝策略
在前面提到过,当工作任务队列达到最大值并且线程池的容量也达到了最大线程数时,当有新的任务进来时,则会触发拒绝策略;在JDK中一共提供了4种拒绝策略,分别如下:
1、CallerRunsPolicy
该策略下,在调用者线程中直接执行被拒绝任务的run方法,除非线程池已经shutdown,则直接抛弃任务。
2、AbortPolicy
该策略下,直接丢弃任务,并抛出RejectedExecutionException异常。
3、DiscardPolicy
该策略下,直接丢弃任务,什么都不做。
4、DiscardOldestPolicy
该策略下,抛弃进入队列最早的那个任务,然后尝试把这次拒绝的任务放入队列
-
线程工作队列分类
在jdk中,一共提供了4种工作任务队列,分别如下所示:
1、ArrayBlockingQueue:通过名字我们可以推测出,当前队列是基于Array数组实现的,数组的特性是初始化时需要指定数组的大小,也就是指定了存储的工作任务上限;ArrayBlockingQueue是一个基于数据的有界的阻塞队列,新加入的任务放到队列的队尾,等待被调度;如果队列已经满了,则会创建新线程;如果线程池数量也满了,则会执行拒绝策略;
2、LinkedBlockingQuene:通过名字我们可以推测出,当前队列是基于Linked链表来实现的,链表的特性是没有初始容量,也就意味着这个队列是无界的,最大容量可以达到Integer.MAX。也由于LinkedBlockingQuene的无界特性,当有新的任务进来,会一直存储在当前队列中,等待调度任务来进行调度;在此场景下,参数maximumPoolSize是无效的;LinkedBlockingQuene可能会带来资源耗尽的问题;
3、SynchronousQuene:同步队列,一个不缓存任务的阻塞队列,生产者放入一个任务必须等到消费者取出任务,直接被调度任务调度执行当前任务;如果没有空闲的可用线程,则直接创建新的线程进行处理,当线程池数量达到maximumPoolSize时,则触发拒绝策略;
4、PriorityBlockingQueue:优先考虑无界阻塞队列,优先级可以通过Comparator来实现;
-
ThreadLocal弱引用,使用不当会导致内存泄漏
ThreadLocal 线程的局部变量 内存泄露 ectry数组 key是只向对应的ThreadLocal所以是弱引用,value是类似Map的具体对象值所以强引用,JVM垃圾回收的时候,弱引用会被直接回收,value是强引用,就会有内存泄漏的情况 ThreadLocal其实有在Spring声明式事务中使用,保证多线程环境下的安全问题。 -
线程池的使用场景
首先线程的使用率提升后,线程的创建和销毁,都会浪费服务器的使用资源。 ① 任务数多但资源占用不大。比如,电商环境下的发送短信的或消息推送通知,对于该场景下所需要处理的消息对象内容比较简单,占用资源少,但是再高并发环境下面,可能会瞬间产生大量的任务数,并且里面每个任务的处理速率都比较高,因此重点在于控制并发的线程数,不要因为大量的线程使用以及线程的上下文频繁切换,导致内存和CPU的使用率过高,系统宕机的情况。通常都是设置大点的队列数,最大线程数设置为CPU的2-4倍即可。 ② 任务数不多但资源占用量大。比如批量数的处理、日志收集、文件流等。像这种场景如果使用单线程就会导致资源的损耗过大。因此就可以适当的加大最大线程数,减少任务列队的长度,来节省不必要的开销。
十九、HashMap
1.haspMap在1.7中是数组+链表的组合,1.8中变为数组+链表+红黑树,数组里面每个地方都存的是key-value的实例,在jdk7中叫Entry,jdk8中叫Node,
2.hashMap初始容量为16,为2的整数次方,扩容的负载因子为0.75,每次扩容后的长度都是原来长度的2倍,为位运算效率最高。扩容(resize)分为两步:①.扩容,先创建一个新的Entry空数组,长度是原数组的2倍;②.Rehash,遍历原来的Entry数组,把所有的Entry重新hash到新的数组中。注意点:因为hash值的计算公式和数组的长度有关,所以每次扩容之后hash都会重新计算。
3.当产生hash冲突的时候,就会生成链表,jdk7时插入链表的方式为头插法,jdk后修改为尾插法,是为了防止死循环,因为修改为尾插法后,原先链表里面的元素顺序是没有变化的,新增的元素只要在尾部新增插入即可。
4.链表的长度大于8时,链表就会转换为红黑树,红黑树相比链表,链表的查找方式为从头到尾或从尾到头的一个个查找,时间复杂度为O(n)。红黑树其实是对二叉树和AVL(平衡树)的一种优化,为二分化查找其时间复杂度为O(logn),器查询效率要优于链表的O(n),从而可以降低IO提高查询效率。注意点:那为什么不使用二叉树、平衡树,而是选择使用红黑树①在理想情况下,二叉树的时间复杂度为O(logn),最坏的情况下为O(n),导致最坏的情况是因为二叉树中所有的数据都集中在左子树或者右子数一侧。②.AVL平衡树是更加严格的平衡,从根节点到叶子节点的最短路径和最长路径之差最多为1,而红黑树中,最多为2倍。因此AVL平衡树更适合查询密集型任务,但AVL平衡树为了保持平衡通常需要经过多次复杂的旋转,红黑树最多需要2次旋转就可以达到平衡,红黑树插入和修改的效率要比AVL平衡树更高。③.为什么链表长度大于8时,就会转换为红黑树呢?---因为根据统计学中的泊松分布。
5.那HashMap是如何保证线程安全呢?面对线程安全的使用场景,我们一般都会想到HashTable和CurrentHashMap,或者通过Collections.synchronizedMap得到一个线程安全的MapHashTable都是通过get和push直接加synchronized锁的方式,效率不高;synchronizedMap里面是维护一个map对象,通过排他锁是锁对象,当有线程操作Map进行上锁;ConcurrentHashMap在进行put操作的还是比较复杂的,大致可以分为以下步骤:①根据 key 计算出 hashcode 。②判断是否需要进行初始化。③即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。④如果当前位置的 hashcode == MOVED == -1,则需要进行扩容。⑤如果都不满足,则利用 synchronized 锁写入数据。⑥如果数量大于 TREEIFY_THRESHOLD 则要转换为红黑树6.Arraylist底层为数组Object[] elementData,初始长度为10,扩容后15的长度;HashSet的底层实现逻辑其实就是HashMap。7.一致性hash算法传统hash算法和节点个数有关hash(object)%N。如果节点数增加和减少,就会导致hash映射的公式产生变化hash(object)%(N+1)和hash(object)%(N-1),导致之前所有的缓存失效产生雪崩。优点:加入和删除节点,只是会影响顺时针方向的节点,如果最初有3台后面又增加一台则只会影响(0-33%)的数据准确性,防止雪崩。所以扩容时只会影响哀悼少部分chan节点。缺点:数据的分布和节点位置有关,数据并不会均匀分布再节点上,所以新增节点并不会缓解所有节点的压力。针对数据分布不均匀的问题,一致性hash算法有做升级,引入虚拟节点均匀分布在哈希环上,从而尽可能的让数据更加均匀。十八、ETCD对比redis
十九、文档数据库mongoDB(待完成)
二十、 Spark与hadoop ,Fink
1.Hadoop有两个核心模块,分布式存储模块HDFS和分布式计算模块Mapreduce
2.spark本身并没有提供分布式文件系统,因此spark的分析大多依赖于Hadoop的分布式文件系统HDFS
3.Hadoop的Mapreduce与spark都可以进行数据计算,而相比于Mapreduce,spark的速度更快并且提供的功能更加丰富
二十一、进程和线程
进程是操作系统分配资源的单位,线程是调度执行的基本单位,线程之间共享进程资源
二十二、分布式事务
1.2PC也叫二阶段提交,是一种强一致性设计,2PC引入了一个事务协调者的角色来协调管理各个事务的参与者的提交和回滚,二阶段提交分为准备和提交两个阶段,准备阶段是协调者给各参与者发送准备命令,注意提交阶段不一定是提交事务,也有可能是回滚事务。2PC为同步阻塞协议,像第一阶段协调者会等待所有参与者响应后才会进行下一步操作,当然如果因为网络原因导致一直收不到参与者的响应,所以第一阶段会有一个超时机制,如果超时事务就会回滚操作。第二阶段因为没有超时机制,所以当协调者和参与者出现单点故障后,事务资源处于锁定状态,很可能会导致资源锁定阻塞,还会锁定一些公共资源导致其他系统操作阻塞。2PC是一种尽量保持强一致性的分布式事务,因此它是同步阻塞的,同步阻塞会导致资源锁定的问题,总体来说效率低下,并且单点故障下会存在数据不一致的风险。2.3PC为三阶段提交,它的出现是为了解决2PC的一些问题,相比2PC它在参与者中引入了超时机制,新增了一个阶段来统一各个参与者的状态,3PC分为准备阶段、预提交阶段、提交阶段。准备阶段只是询问各个参与者是否已经准备好了(和2PC的准备阶段不同,2PC的准备阶段是除了事务的提交其他搞作的都做了)。3PC相比2PC引入了参与者的超时机制,并且增加了一个预提交阶段使得故障恢复后协调者的决策复杂度降低,但整体交互时间更长了,性能还有所下降,极端情况下也会有数据不一致的情况。并且3PC只是纯理论上的东西,好像市面上也没有具体的实现。3.2PC和3PC都是数据库DB层面的,而TCC则是业务层面的分布式事务。TCC分为三个操作try--confrim--cancel。TCC对业务的入侵性比较大和业务高度耦合,需要根据特定的场景和业务来设计,所以TCC的开发量也更大,代码上也更不好写。4.RocketMq的事务消息 Haif Message,是指暂不能被Consumer消费的消息。Producer已经把消息成功发送到Broker端,但此消息暂不能投递状态,处于此种状态就被称为半消息,需要Producer对消息进行第二次确认后,Consumer才能去消费它。消息回查,由于网络抖动,生产者重启导致Producer端一直没有对Haif Message消息进行第二次确认,这时Broker的服务器中的定时器扫描那些长期处于半消息状态的消息,主动去问询Producer端,然后再根据Producer端的回查结果确定是commit或rollback,该过程称为消息回查。5.RabbitMq+本地消息表,保存一条状态为未发送的消息到本地事务表中,并保证和当前业务的原子性,然后再定义一个定时器来扫描本地事务表,将状态为未发送的消息推送到MQ。消息发送成功,执行confirm回调,修改表状态为已发送。
然后消息者手动ack进行相应,来保证消息的一致性,不丢失。
二十三、代码层面优化总结
1.各种工具的选择,zuul/gateway,redisson/letty,tomcat8.5以上,mysql8.0以上
二十四、各种锁
AQS、 synchronized 、CAS、 ReentrantLock 公平锁和非公平锁
Volatile关键字
吞吐量为程序执行时间的总量
二十五、运维面试点
谷歌三剑客:grep,sed,awk
杀进程的命令:kill -9 ,kill -15
CentOS6和CentOS7的区别:
1.部分命令不一样,查看IP 命令,CentOS6为ip a,CentOS7为 ifconfig
2.CentOS6里面有vim,CentOS7里面需要自己安装包
3.最主要的区别是,内核不一样,CentOS6的内核版本为2.xx版本,如果集成docker就比较麻烦。
liunx里面修改文件权限的命令chmod、chgrp、chown:
1.chmod,一般用于改变文件或目录的访问权限。用户用它来控制文件或目录的权限
比如:chmod -R 777 /opt/activepivot/dataset/env1
2.chgrp,改变文件或目录的所属组。
3.chown,更改文件或目录的属主和属组。例如root用户把自己的一个文件拷贝给用户yusi,为了让用户yusi能够存取这个文件,所以root应该把这个文件的属主设为yusi,否则,用户yusi无法存取这个文件。
在liunx中根据关键字grep到进程号,并kill掉进程
ps -ef|grep %s|grep -v grep|awk ‘{print $2}’|xargs kill -9
使用command启动service
su - trvcradm -c “cd /opt/activepivot/dataset/uat/datasetmanager;./startup.sh”
在liunx中更新.sh文件为unix格式(比如在window修改sh文件后copy到liunx,则需要设置格式)
set ff=unix
相关文章:

面试总结归纳
面试总结 注:循序渐进,由点到面,从技术点的理解到项目中的使用, 要让面试官知道,我所知道的要比面试官更多 一、Mybatis 为ORM半持久层框架,它封装了JDBC,开发时只需要关注sql语句就可以了…...
【刷题篇】贪心算法(一)
文章目录 分割平衡字符串买卖股票的最佳时机Ⅱ跳跃游戏钱币找零 分割平衡字符串 class Solution { public:int balancedStringSplit(string s) {int lens.size();int cnt0;int balance0;for(int i0;i<len;i){if(s[i]R){balance--;}else{balance;}if(balance0){cnt;}}return …...

从维基百科通过关键字爬取指定文本内容
通过输入搜索的关键字,和搜索页数范围,爬出指定文本内内容并存入到txt文档。代码逐行讲解。 使用re、res、BeautifulSoup包读取,代码已测,可以运行。txt文档内容不乱码。 import re import requests from bs4 import BeautifulS…...
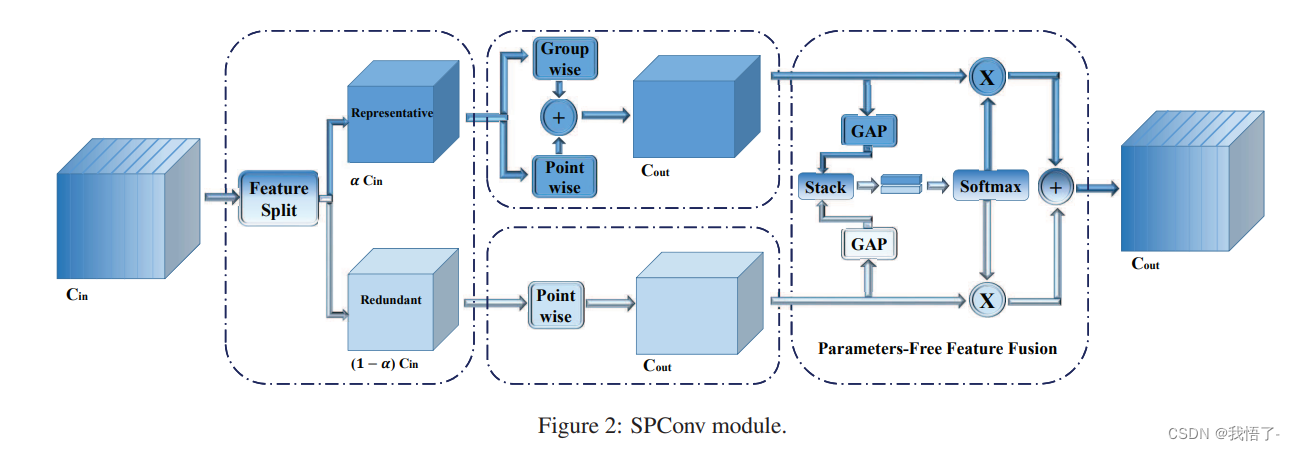
pytorch代码实现之SAConv卷积
SAConv卷积 SAConv卷积模块是一种精度更高、速度更快的“即插即用”卷积,目前很多方法被提出用于降低模型冗余、加速模型推理速度,然而这些方法往往关注于消除不重要的滤波器或构建高效计算单元,反而忽略了特征内部的模式冗余。 原文地址&am…...

一文解析-通过实例讲解 Linux 内存泄漏检测方法
一、mtrace分析内存泄露 mtrace(memory trace),是 GNU Glibc 自带的内存问题检测工具,它可以用来协助定位内存泄露问题。它的实现源码在glibc源码的malloc目录下,其基本设计原理为设计一个函数 void mtrace ()&#x…...

Spring Boot常用的参数验证技巧和使用方法
简介 Spring Boot是一个使用Java编写的开源框架,用于快速构建基于Spring的应用程序。在实际开发中,经常需要对输入参数进行验证,以确保数据的完整性和准确性。Spring Boot提供了多种方式来进行参数验证,并且可以很方便地集成到应…...

手机+卫星的科技狂想
最近硬件圈最火热的话题之一,应该就是突然上线、遥遥领先的华为Mate 60 Pro了。 其中,CPU和类5G网速是怎么实现的,是大家特别关注的问题。相比之下,卫星通话这个功能,讨论度就略低一些(没有说不火的意思&am…...
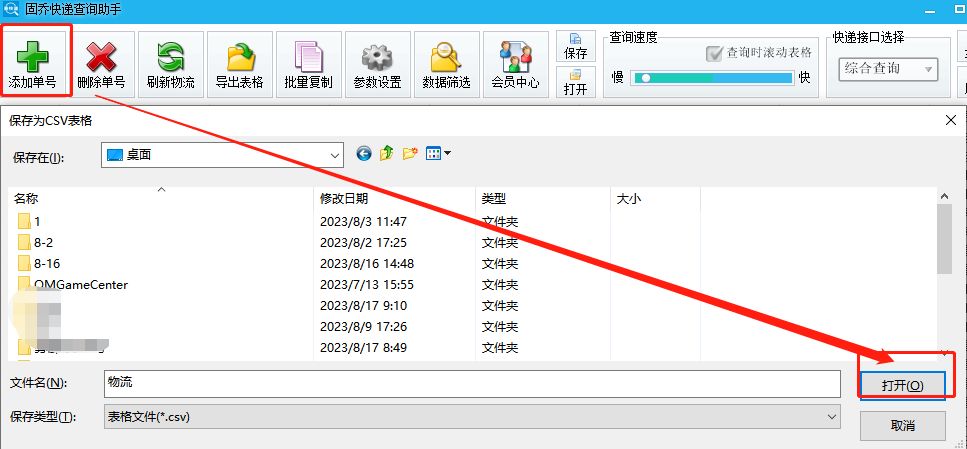
便捷查询中通快递,详细物流信息轻松获取
在如今快节奏的生活中,快递已成为人们生活中不可或缺的一部分。然而,快递查询却常常让人头疼,因为需要分别在不同的快递公司官网上进行查询,耗费时间和精力。为了解决这个问题,固乔科技推出了一款便捷的快递查询助手&a…...
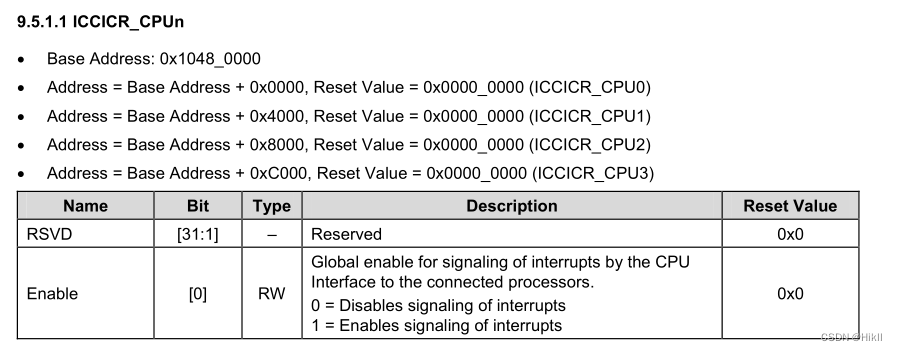
ARM接口编程—Interrupt(exynos 4412平台)
CPU与硬件的交互方式 轮询 CPU执行程序时不断地询问硬件是否需要其服务,若需要则给予其服务,若不需要一段时间后再次询问,周而复始中断 CPU执行程序时若硬件需要其服务,对应的硬件给CPU发送中断信号,CPU接收到中断信号…...
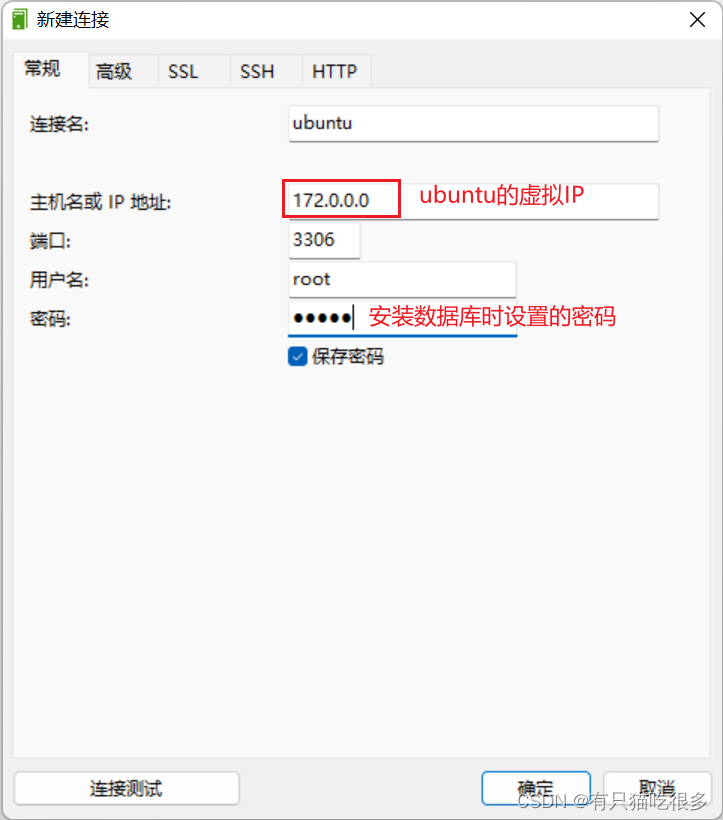
适用于Linux的Windows子系统(PHP搭建lmap、redis、swoole环境)
目录 前言 一、Windows安装Linux子系统 二、Ubuntu搭建PHP开发环境 1.PHP 安装 2.Apache2 安装 3.MySQL安装 4.Redis安装 5.Swoole安装 总结 前言 系列分为三章(从安装到项目使用): 一、适用于Linux的Windows子系统(系统安装步骤…...
Vue3+Ts+Vite项目(第十二篇)——echarts安装与使用,vue3项目echarts组件封装
概述 技术栈:Vue3 Ts Vite Echarts 简介: 图文详解,教你如何在Vue3项目中引入Echarts,封装Echarts组件,并实现常用Echarts图例 文章目录 概述一、先看效果1.1 静态效果1.2 动态效果 二、话不多数,引入 …...

hive location更新hive元数据表详解
1.hive location更新方式 一、通过修改表DDL: alter table table_name set location hdfs://nm:8020/table_path 二、直接修改hive 的meta info: update DBS set DB_LOCATION_URI replace(DB_LOCATION_URI,"oldpath","newpath")update SDS…...

【SpringBoot】统一功能处理
目录 🎃1 拦截器 🎀1.1 拦截器的代码实现 🎨1.2 拦截器的实现原理 🧶2 拦截器应用——登录验证 🦺3 异常统一处理 🎭4 统一数据返回格式 🧤4.1 为什么需要统一数据返回格式 🧣4.2 统…...
)
分布式数据库-架构真题(二十六)
构件组装成软件系统的过程分为三个不同的层次()。(2018年) 初始化、互连和集成连接、集成和演化定制、集成和扩展集成、扩展和演化 答案:C (2018年)CORBA服务端构件模型中,&#x…...

MyWebServer开发日记-socket
打算把 tinyWebServer 重写成跨平台(Windows and Linux)的。 这里首先需要跨平台的 sokcet,主要参考 尹圣雨 的 TCP/IP 网络编程 来着: 代码写的有些笨,欢迎批评: 首先是一个 socket 类,主要…...

图书管理信息系统分析与设计
一、系统开发的可行性分析 (一)系统背景.必要性及意义 随着社会经济的迅速发展和科学技术的全面进步,计算机事业的飞速发展,以计算机与通信技术为基础的信息系统正处于蓬勃发展的时期。随着经济文化水平的显著提高,人…...

Charles基础使用指南
##Charles 基本使用指南 Charles 在本地构建一个HTTP代理服务器,可以实现对HTTP、HTTPS请求的抓取,也就是我们常说的抓包,以及对请求响应的修改等。 Charles 官网地址 https://www.charlesproxy.com/ ###一、移动端的抓包实现 1. PC端开启…...

Android12之/proc/pid/status参数含义(一百六十五)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 人生格言: 人生…...
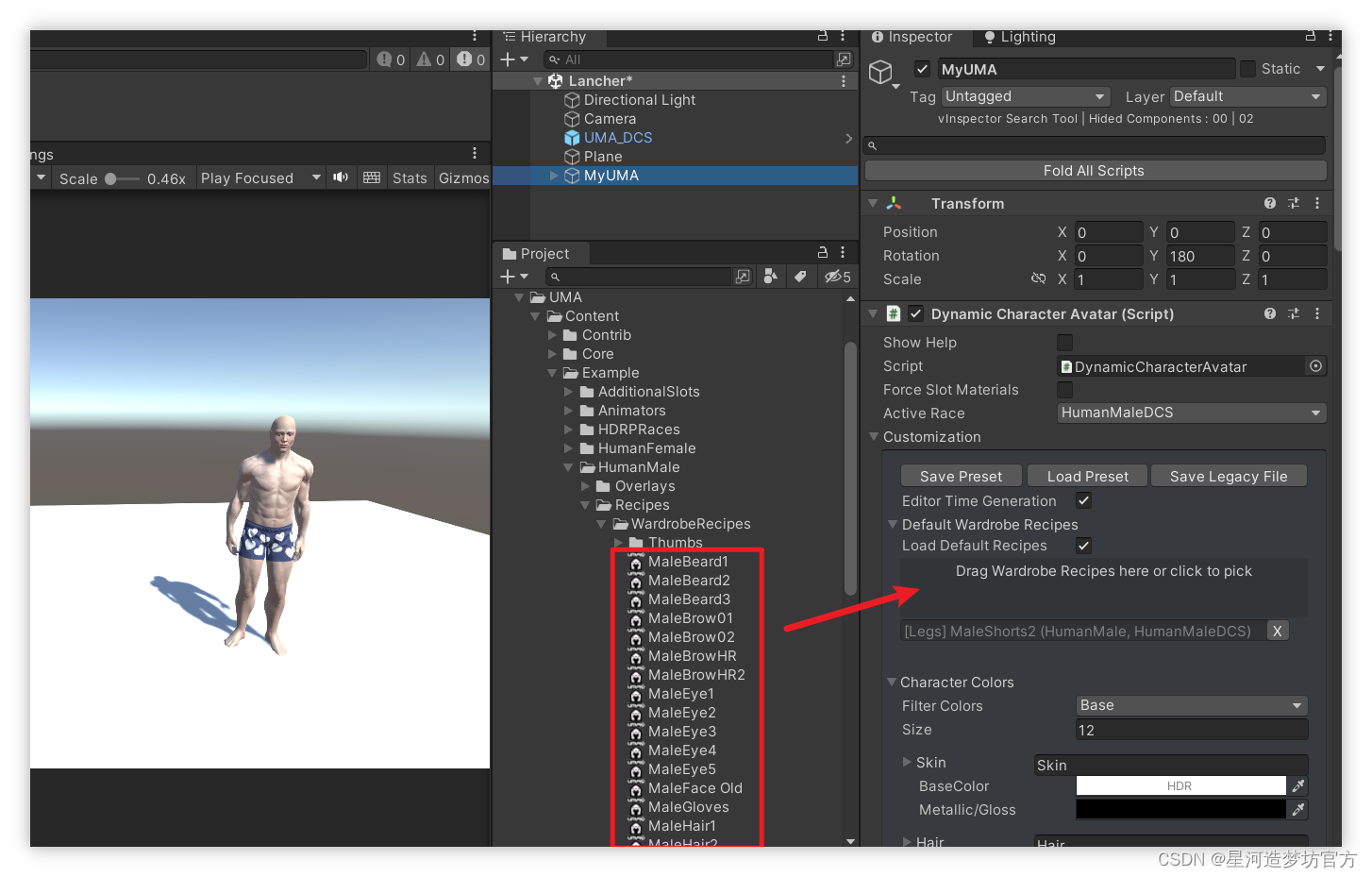
UMA 2 - Unity Multipurpose Avatar☀️三.给UMA设置默认服饰Recipes
文章目录 🟥 项目基础配置🟧 给UMA配置默认服饰Recipes🟨 设置服饰Recipes属性🟥 项目基础配置 将 UMA_DCS 预制体放到场景中创建空物体,添加DynamicCharacterAvatar 脚本,选择 HumanMaleDCS作为我们的基本模型配置默认Animator 🟧 给UMA配置默认服饰Recipes 服饰Re…...
uniapp-小程序登录授权框
微信官方文档 不弹出授权框原因 因为版本问题,目前的最新的版本是不支持 wx.getUserInfo 去主动弹出授权框 只能引导用户去点击 butten 去授权 解决方法 我的思路是参考了其他的微信微信小程序, 就是跳转到我的页面的时候 在钩子函数内去触发一个封装的模态框,状…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

在WSL2的Ubuntu镜像中安装Docker
Docker官网链接: https://docs.docker.com/engine/install/ubuntu/ 1、运行以下命令卸载所有冲突的软件包: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done2、设置Docker…...

python执行测试用例,allure报乱码且未成功生成报告
allure执行测试用例时显示乱码:‘allure’ �����ڲ����ⲿ���Ҳ���ǿ�&am…...

Web 架构之 CDN 加速原理与落地实践
文章目录 一、思维导图二、正文内容(一)CDN 基础概念1. 定义2. 组成部分 (二)CDN 加速原理1. 请求路由2. 内容缓存3. 内容更新 (三)CDN 落地实践1. 选择 CDN 服务商2. 配置 CDN3. 集成到 Web 架构 …...

【Go语言基础【13】】函数、闭包、方法
文章目录 零、概述一、函数基础1、函数基础概念2、参数传递机制3、返回值特性3.1. 多返回值3.2. 命名返回值3.3. 错误处理 二、函数类型与高阶函数1. 函数类型定义2. 高阶函数(函数作为参数、返回值) 三、匿名函数与闭包1. 匿名函数(Lambda函…...

深入浅出深度学习基础:从感知机到全连接神经网络的核心原理与应用
文章目录 前言一、感知机 (Perceptron)1.1 基础介绍1.1.1 感知机是什么?1.1.2 感知机的工作原理 1.2 感知机的简单应用:基本逻辑门1.2.1 逻辑与 (Logic AND)1.2.2 逻辑或 (Logic OR)1.2.3 逻辑与非 (Logic NAND) 1.3 感知机的实现1.3.1 简单实现 (基于阈…...