详解Hugging Face Transformers的TrainingArguments
前言:
TrainingArguments是Hugging Face Transformers库中用于训练模型时需要用到的一组参数,用于控制训练的流程和效果。
使用示例:
from transformers import Trainer,TrainingArguments
training_args = TrainingArguments(output_dir="result")
trainer = Trainer(model=model,args=training_args,compute_metrics=compute_metrics,train_dataset=tokenized_emotions["train"],eval_dataset=tokenized_emotions["validation"])具体参数介绍:
1、output_dir (`str`):
模型预测和检查点输出的目录
2、overwrite_output_dir (`bool`, *optional*, defaults to `False`)
如果该参数为True,在输出目录output_dir已经存在的情况下将删除该目录并重新创建。默认值是False
3、do_train (`bool`, *optional*, defaults to `False`)
是否进行训练。Trainer没有直接使用此参数,它应用在我们写的training/evaluation脚本。
4、do_eval (`bool`, *optional*)
是否对验证集进行评估,evaluation_strategy如果不是no的话,应该设置为true,Trainer没有直接使用此参数,它应用在我们写的training/evaluation脚本。
5、do_predict (`bool`, *optional*, defaults to `False`)
是否在测试集上进行预测,Trainer没有直接使用此参数,它应用在我们写的training/evaluation脚本。
6、evaluation_strategy (`str` or [`~trainer_utils.IntervalStrategy`], *optional*, defaults to `"no"`):
训练期间采用的评估策略,可选的值有:
- "no":训练期间不进行评估
- "steps"`:每一个`eval_steps`阶段之后都进行评估
- "epoch":每一个epoch之后进行评估
7、prediction_loss_only (`bool`, *optional*, defaults to `False`):
当执行评估和预测的时候,是否仅仅返回损失
8、per_device_train_batch_size (`int`, *optional*, defaults to 8):
每一个GPU/TPU 或者CPU核心训练的批次大小
9、per_device_eval_batch_size (`int`, *optional*, defaults to 8):
每一个GPU/TPU 或者CPU核心评估的批次大小
10、gradient_accumulation_steps (`int`, *optional*, defaults to 1):
在执行向后/更新过程之前,用于累积梯度的更新步骤数。
11、eval_accumulation_steps (`int`, *optional*):
在将结果移动到CPU之前,累积输出张量的预测步骤数。如果如果未设置,则在移动到CPU之前,整个预测都会在GPU/TPU上累积(速度更快需要更多的内存)。
12、eval_delay (`float`, *optional*):
在执行第一次评估之前要等待的epoch或step,具体取决于evaluation_strategy。
13、learning_rate (`float`, *optional*, defaults to 5e-5):
`AdamW`优化器初始化的学习率
14、weight_decay (`float`, *optional*, defaults to 0):
在`AdamW`优化器中,除了bias和LayerNorm权重,如果weight_decay不是零,则应用于所有层
15、adam_beta1 (`float`, *optional*, defaults to 0.9):
`AdamW`优化器的beta1超参
16、adam_beta2 (`float`, *optional*, defaults to 0.999):
`AdamW`优化器的beta2超参
17、adam_epsilon (`float`, *optional*, defaults to 1e-8):
`AdamW`优化器的epsilon超参
18、max_grad_norm (`float`, *optional*, defaults to 1.0):
最大梯度范数(用于梯度剪裁)
19、num_train_epochs(`float`, *optional*, defaults to 3.0):
要执行的训练epoch的次数(如果不是整数,将执行停止训练前的最后一个epoch的小数部分百分比)。
20、max_steps (`int`, *optional*, defaults to -1):
如果设置为正数,则表示要执行的训练step的次数。覆盖`num_train_epochs'。在使用有限可迭代数据集的情况下,训练可能在所有数据还没训练完成时因达到设定的步数而停止
21、lr_scheduler_type (`str` or [`SchedulerType`], *optional*, defaults to `"linear"`):
选择什么类型的学习率调度器来更新模型的学习率。可选的值有:
- "linear"
- "cosine"
- "cosine_with_restarts"
- "polynomial"
- "constant"
- "constant_with_warmup"
22、warmup_ratio (`float`, *optional*, defaults to 0.0):
线性预热从0达到`learning_rate`时,每步学习率的增长率
23、warmup_steps (`int`, *optional*, defaults to 0):
线性预热从0达到`learning_rate`时,预热阶段的步数,它会覆盖`warmup_ratio`的设置
24、log_level (`str`, *optional*, defaults to `passive`):
设置主进程上使用的日志级别。可选择的值:
- 'debug'
- 'info'
- 'warning'
- 'error'
- 'critical'
- 'passive' (不设置任何值,由应用进行设置)
25、log_level_replica (`str`, *optional*, defaults to `passive`):
控制训练过程中副本节点的日志级别,设置参数和log_level一样
26、log_on_each_node (`bool`, *optional*, defaults to `True`):
在多节点分布式训练中,是每个节点使用“log_level”进行一次日志记录,还是仅在主节点
27、logging_dir (`str`, *optional*):
日志目录,默认记录在:*output_dir/runs/**CURRENT_DATETIME_HOSTNAME***
28、logging_strategy (`str` or [`~trainer_utils.IntervalStrategy`], *optional*, defaults to `"steps"`):
训练期间采用的日志策略,可选的值有:
- "no":训练期间不记录日志
- "steps"`:每一个`logging_steps`阶段之后都记录日志
- "epoch":每一个epoch之后记录日志
29、logging_first_step (`bool`, *optional*, defaults to `False`):
global_step 表示训练的全局步数。当训练开始时,global_step 被初始化为 0,每次更新模型时,global_step 会自动递增。是否打印日志和评估第一个`global_step`
30、logging_steps (`int`, *optional*, defaults to 500):
如果 `logging_strategy="steps"`,则两个日志中更新step的数量
31、logging_nan_inf_filter (`bool`, *optional*, defaults to `True`):
是否在日志中过滤掉 `nan` 和 `inf` 损失,如果设置为 `True`,每步的损失如果是 `nan`或者`inf`将会被过滤,将会使用平均损失记录在日志当中。
32、save_strategy (`str` or [`~trainer_utils.IntervalStrategy`], *optional*, defaults to `"steps"`):
训练过程中,checkpoint的保存策略,可选择的值有:
- "no":训练过程中,不保存checkpoint
- "epoch":每个epoch完成之后保存checkpoint
- "steps":每个`save_steps`完成之后checkpoint
33、save_steps (`int`, *optional*, defaults to 500):
如果`save_strategy="steps",则两个checkpoint 保存的更新步骤数
34、save_total_limit (`int`, *optional*):
如果设置了值,则将限制checkpoint的总数量,`output_dir`里面超过数量的老的checkpoint将会被删掉
35、save_on_each_node (`bool`, *optional*, defaults to `False`):
当进行多节点分布式训练,是否在每个节点上保存模型和checkpoint还是仅仅在主节点上保存。当不同节点使用相同的存储时,不应激活此选项,因为文件将以相同的名称保存到每个节点
36、no_cuda (`bool`, *optional*, defaults to `False`):
当有CUDA可以使用时,是否不使用CUDA
37、seed (`int`, *optional*, defaults to 42):
训练开始时设置的随机种子,为了确保整个运行的可再现性,可使用`~Trainer.model_init`函数来初始化模型的随机初始化参数。
38、data_seed (`int`, *optional*):
数据采样器的随机种子,它将用于数据采样器的可重现性,其独立于模型种子。
39、jit_mode_eval (`bool`, *optional*, defaults to `False`):
是否使用PyTorch jit trace来进行推理
40、use_ipex (`bool`, *optional*, defaults to `False`):
当PyTorch 的intel扩展可用时,是否使用
41、bf16 (`bool`, *optional*, defaults to `False`):
是否使用bf16 16位 (mixed) 精度训练替代32位训练. 要求Ampere或者更高的NVIDIA架构,或者使用CPU训练.
42、fp16 (`bool`, *optional*, defaults to `False`):
是否使用bf16 16位 (mixed) 精度训练替代32位训练.
43、fp16_opt_level (`str`, *optional*, defaults to 'O1'):
`fp16`训练时, Apex AMP 优化级别选择,可选择的值有: ['O0', 'O1', 'O2', 'O3']Apex 是 NVIDIA 开发的一个混合精度训练和优化工具库,主要用于加速深度学习模型的训练过程。
44、fp16_backend (`str`, *optional*, defaults to `"auto"`):
此参数已经废弃,使用`half_precision_backend`替代
45、half_precision_backend (`str`, *optional*, defaults to `"auto"`):
半精度计算的后端实现,必须是这几个值:
- "auto":具体是使用CPU/CUDA AMP 还是APEX依赖于PyTorch版本检测
- "cuda_amp"
- "apex"
- "cpu_amp"
46、bf16_full_eval (`bool`, *optional*, defaults to `False`):
是否使用完整的bfloat16评估而不是32位。这将更快并节省内存,但可能会造成指标的损伤。
47、fp16_full_eval (`bool`, *optional*, defaults to `False`):
是否使用完整的float16评估而不是32位。这将更快并节省内存,但可能会造成指标的损伤。
48、tf32 (`bool`, *optional*):
是否启用TF32 模式,可以在Ampere 和更新的GPU架构上使用,默认值依赖于PyTorch的`torch.backends.cuda.matmul.allow_tf32`的默认值。
49、local_rank (`int`, *optional*, defaults to -1):
分布式训练中进程的编号。在分布式训练中,每个进程(一般对应支持多线程的 GPU 卡)都会有一个特定的 local_rank,用于标识该进程对应的 GPU 编号。local_rank 的起始编号为 0,后续的编号依次递增。
50、xpu_backend (`str`, *optional*):
xpu分布式训练中的后端,只能是 `"mpi"` 或者 `"ccl"`其中之一
51、tpu_num_cores (`int`, *optional*):
当使用TPU训练时,TPU核心数 (自动通过启动脚本传递)
52、dataloader_drop_last (`bool`, *optional*, defaults to `False`):
是否删除最后一个不完整的批次(如果数据集的长度不能被批次大小整除)
53、eval_steps (`int`, *optional*):
如果 `evaluation_strategy="steps"`,两个评估之间更新step的数量Number of update steps,如果没有设置,则使用与 `logging_steps`一样的值。
54、dataloader_num_workers (`int`, *optional*, defaults to 0):
数据加载的子进程数量(用于PyTorch ). 0表示数据由主进程加载
55、past_index (`int`, *optional*, defaults to -1):
有些模型比如[TransformerXL](../model_doc/transformerxl)或者[XLNet](../model_doc/xlnet)使用过去隐藏状态进行预测。如果这个参数设置为正数,则 `Trainer`使用相应的输出(通常是索引2)作为过去的状态,并将其作为 `mems`参数提供给模型的下一个训练step
56、run_name (`str`, *optional*):
运行描述符。通常用于[wandb](https://www.wandb.com/)以及[mlflow](https://www.mlflow.org/)日志记录。
57、disable_tqdm (`bool`, *optional*):
是否禁用在Jupyter Notebooks中由`~notebook.NotebookTrainingTracker`生成的tqdm进度条和指标表格。如果日志级别设置为warn或者更低的基本则默认值为`True`,否则为`False`
58、remove_unused_columns (`bool`, *optional*, defaults to `True`):
是否自动删除模型forward方法不使用的列 (`TFTrainer`暂时还没有实现该功能)
59、label_names (`List[str]`, *optional*):
我们的输入字典的key列表相一致的标签,最终都将默认为`["labels"]`,除非使用`XxxForQuestionAnswering`系列的模型,该系列的模型最终默认为`["start_positions", "end_positions"]`
60、load_best_model_at_end (`bool`, *optional*, defaults to `False`):
是否在训练结束时加载训练期间发现的最佳模型。当设置为“True”时,参数“save_strategy”需要与“evaluation_strategy”相同,并且在这种情况下, "steps"和 `save_steps` 必须是`eval_steps`的整数倍.
61、metric_for_best_model (`str`, *optional*):
与`load_best_model_at_end`一起使用,指定用于比较两个不同模型。必须是评估返回的度量的名称,带或不带前缀“eval_”。如果没有设定且`load_best_model_at_end=True`,则默认使用 `"loss"`,如果我们设置了这个值,则`greater_is_better`需要设置为 `True`。如果我们的度量在较低时更好,请不要忘记将其设置为“False”。
62、greater_is_better (`bool`, *optional*):
与`load_best_model_at_end` 和 `metric_for_best_model`一起使用,说明好的模型是否应该有更好的度量值。默认值:
- `True`:如果`metric_for_best_model`设置了值,并且该值不是`"loss"` 或者 `"eval_loss"`
- `False`:如果`metric_for_best_model`没有设置值,或者该值是`"loss"`或者 `"eval_loss"`.
63、ignore_data_skip (`bool`, *optional*, defaults to `False`):
当恢复训练时,是否跳过之前训练时epoch和batch加载的数据,如果设置为`True`, 训练将会更快的开始,但是也不会产生与中断训练生成的相同的结果。
64、sharded_ddp (`bool`, `str` or list of [`~trainer_utils.ShardedDDPOption`], *optional*, defaults to `False`):
是否启用分片式分布式数据并行(Sharded Distributed Data Parallel,简称ShardedDDP),以加快训练速度和效率。可选项有:
- `"simple"`:
- `"zero_dp_2"`
- `"zero_dp_3"`
- `"offload"`
如果入参是字符串,它将会使用空格进行分隔,如果入参是了bool,它将被转换为空“False”的列表和["simple"]的“True”列表。
65、fsdp (`bool`, `str` or list of [`~trainer_utils.FSDPOption`], *optional*, defaults to `False`):
使用PyTorch 分布式并行训练(仅仅用在分布式训练)。可选项:
- `"full_shard"`
- `"shard_grad_op"
- "offload"
- "auto_wrap":使用 `default_auto_wrap_policy`自动递归
66、fsdp_min_num_params (`int`, *optional*, defaults to `0`):
用于指定使用 Fully Sharded Data Parallel (FSDP)时,最小可分片的参数数量。(仅在传递“fsdp”字段时有用)
67、deepspeed (`str` or `dict`, *optional*):
使用[Deepspeed](https://github.com/microsoft/deepspeed)。这是一个实验性功能,其API可能
在未来发展。
68、label_smoothing_factor (`float`, *optional*, defaults to 0.0):
要使用的标签平滑因子。它的取值范围在 0 到 1 之间。当 label_smoothing_factor 的值为 0 时,表示不使用标签平滑技术,此时模型接受到完整的 one-hot 标签,当 label_smoothing_factor 的值大于 0 时,表示使用标签平滑技术,此时真实标签将是一个加权平均值,其中每个标签的概率都等于 (1-label_smoothing_factor)/num_classes,其中 num_classes 表示标签的数量。
69、debug (`str` or list of [`~debug_utils.DebugOption`], *optional*, defaults to `""`):
启用一个或多个调试功能。这是一个实验特性。可选项有:
- `"underflow_overflow"`:检测模型的输入/输出中的溢出,并报告导致事件的最后一帧
- `"tpu_metrics_debug"`:在TPU上打印度量
这些选项通过空格进行分隔。
70、optim (`str` or [`training_args.OptimizerNames`], *optional*, defaults to `"adamw_hf"`):
可以使用的优化器:
- adamw_hf
- adamw_torch
- adamw_apex_fused
- adafactor
71、adafactor (`bool`, *optional*, defaults to `False`):
此参数已经废弃,使用 `--optim adafactor` 替代
72、group_by_length (`bool`, *optional*, defaults to `False`):
是否将训练数据集中长度大致相同的样本分组在一起(以最大限度地减少所应用的填充并提高效率)。仅在应用动态填充时有用。
73、length_column_name (`str`, *optional*, defaults to `"length"`):
预计算列名的长度,如果列存在,则在按长度分组时使用这些值,而不是在训练启动时计算这些值。例外情况是:`group_by_length`设置为true,且数据集是`Dataset`的实例
74、report_to (`str` or `List[str]`, *optional*, defaults to `"all"`):
报告结果和日志的integration列表,支持的平台有:`"azure_ml"`, `"comet_ml"`, `"mlflow"`, `"tensorboard"` 和`"wandb"`. 使用 `"all"`则报告到所有安装的integration,配置为`"none"`则不报报告到任何的integration。
75、ddp_find_unused_parameters (`bool`, *optional*):
使用分布式训练时,通过`find_unused_parameters`把该值传递给`DistributedDataParallel`。如果使用梯度checkpoint,则默认为false,否则为true。
76、ddp_bucket_cap_mb (`int`, *optional*):
使用分布式训练时,传递给“DistributedDataParallel”的标志“bucket_cap_mb”的值`
77、dataloader_pin_memory (`bool`, *optional*, defaults to `True`):
当设置为True 时,在数据加载过程中,batch 数据会被放入 CUDA 中固定的固定内存,从而避免了从主内存到 GPU 内存的冗余拷贝开销,提升了数据读取的效率。
78、skip_memory_metrics (`bool`, *optional*, defaults to `True`):
是否跳过将内存探查器报告添加到度量中。默认情况下会跳过此操作,因为它会降低训练和评估速度。
79、push_to_hub (`bool`, *optional*, defaults to `False`):
每次当模型保存的时候,是否把模型推送到Hub
80、resume_from_checkpoint (`str`, *optional*):
我们模型的有效checkpoint的文件夹的路径。此参数不是由直接给[`Trainer`]使用,它用于我们写的训练和评估脚本。
81、hub_model_id (`str`, *optional*):
与本地的 *output_dir*保持同步的仓库名称。它可以是将会推送到我们的命名空间里的一个非常简单的模型ID . 否则它将需要完整的仓库名称,比如 `"user_name/model"`,它允许我们推送到一个我们是一个组织的成员之一(`"organization_name/model"`)的仓库。默认设置为`user_name/output_dir_name`,其中*output_dir_name* 是`output_dir`的值.
82、hub_strategy (`str` or [`~trainer_utils.HubStrategy`], *optional*, defaults to `"every_save"`):
定义推送到hub的内容的范围以及何时推送到hub,可能的值有:
- `"end"`:当`~Trainer.save_model`方法被调用的时候,会推送模型,推送它的配置、tokenizer(如果传给了`Trainer`)和model card 的草稿。
- `"every_save"`:在每次模型保存的时候,都会推送,推送它的配置、tokenizer(如果传给了`Trainer`)和model card 的草稿。推送是异步的,不会影响模型的训练,如果模型保存的非常频繁,则新的推送只会在旧的推送完成之后进行推送,最后的一个推送是在模型训练完成之后
- `"checkpoint"`:类似于 `"every_save"`,只是最后一个 checkpoint会被推送到名字为 last-checkpoint的子目录,它将方便我们使用 `trainer.train(resume_from_checkpoint="last-checkpoint")`重新开始训练。
- `"all_checkpoints"`: 类似于 `"checkpoint"` ,只是所有的checkpoints都推送,就像它们出现在输出目录一样 (这样你就可以在最终的仓库里面获取每一个checkpoint)
83、hub_token (`str`, *optional*):
用于将模型推送到Hub的token。默认将使用`huggingface-cli login`获得的缓存文件夹中的令牌
84、hub_private_repo (`bool`, *optional*, defaults to `False`):
如果为True, Hub repo将会被设置为私有的
85、gradient_checkpointing (`bool`, *optional*, defaults to `False`):
如果为True,则使用梯度检查点以节省内存为代价降低向后传递速度。
86、include_inputs_for_metrics (`bool`, *optional*, defaults to `False`):
是否将输入传递给“compute_metrics”函数。这适用于需要在Metric类中进行评分计算的输入、预测和参考的度量
87、auto_find_batch_size (`bool`, *optional*, defaults to `False`)
是否通过指数衰减自动找到适合内存的batch size,避免CUDA内存不足错误.需要安装 accelerate (`pip install accelerate`)
88、full_determinism (`bool`, *optional*, defaults to `False`)
如果为 `True`,则使用`enable_full_determinism`替代`set_seed`来确保在分布式训练下获得可重复的结果
89、torchdynamo (`str`, *optional*):
用于设置TorchDynamo后端编译器的token。可能的选择是[“eager”,“nvfuser]。这是一个实验性API,可能会更改。
90、ray_scope (`str`, *optional*, defaults to `"last"`):
Ray Tune 是一个开元的分布式超参数优化库,可以用于自动搜索最佳的超参数配置,以及并行化训练作业。使用Ray进行超参搜索的范围
我训练模型时关注的参数:
- output_dir
- num_train_epochs
- lr_scheduler_type
- load_best_model_at_end
- metric_for_best_model
- greater_is_better
- optim
- group_by_length
- length_column_name
相关文章:
详解Hugging Face Transformers的TrainingArguments
前言: TrainingArguments是Hugging Face Transformers库中用于训练模型时需要用到的一组参数,用于控制训练的流程和效果。 使用示例: from transformers import Trainer,TrainingArguments training_args TrainingArguments(output_dir&q…...
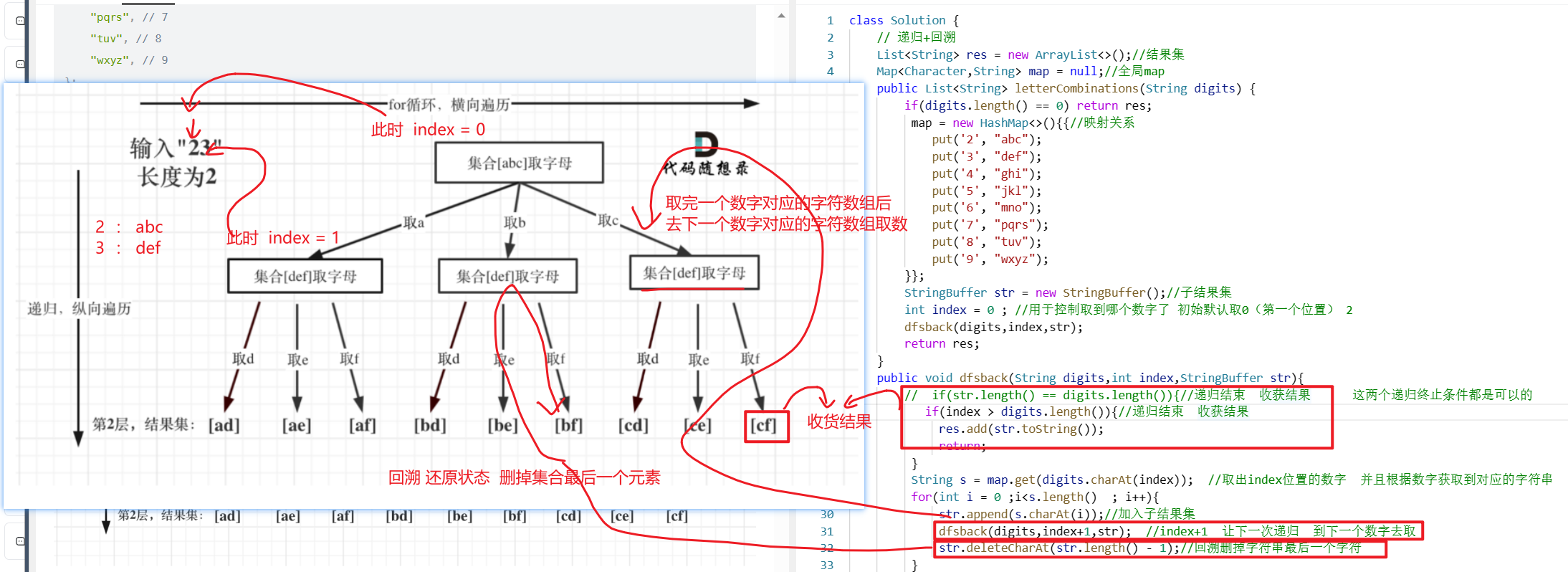
【LeetCode-中等题】17. 电话号码的字母组合
文章目录 题目方法一:递归回溯 题目 方法一:递归回溯 参考讲解:还得用回溯算法!| LeetCode:17.电话号码的字母组合 首先可以画出树图: 先将数字对应的字符集合 加入到一个map集合 这里需要一个index来控…...
读高性能MySQL(第4版)笔记06_优化数据类型(上)
1. 良好的逻辑设计和物理设计是高性能的基石 1.1. 反范式的schema可以加速某些类型的查询,但同时可能减慢其他类型的查询 1.2. 添加计数器和汇总表是一个优化查询的好方法,但它们的维护成本可能很 1.3. 将修改schema作为一个常见事件来规划 2. 让事情…...

mac如何创建mysql数据库
使用mac创建mysql数据库十分简单,我们只需要按照以下步骤即可完成。 首先,我们需要安装mysql,我们可以通过官网下载对应的安装包,或者通过Homebrew进行安装。 接下来,我们需要启动mysql服务,在终端中输入以…...

Ceph入门到精通-centos8 install brctl
在centos7上是可以直接yum安装bridge-utils的,但是centos8不行 经过分析 brctl有提供centos的rpm包,里面只有一个二进制脚本,所以直接下载安装即可 rpm -ivh http://mirror.centos.org/centos/7/os/x86_64/Packages/bridge-utils-1.5-9.el7…...
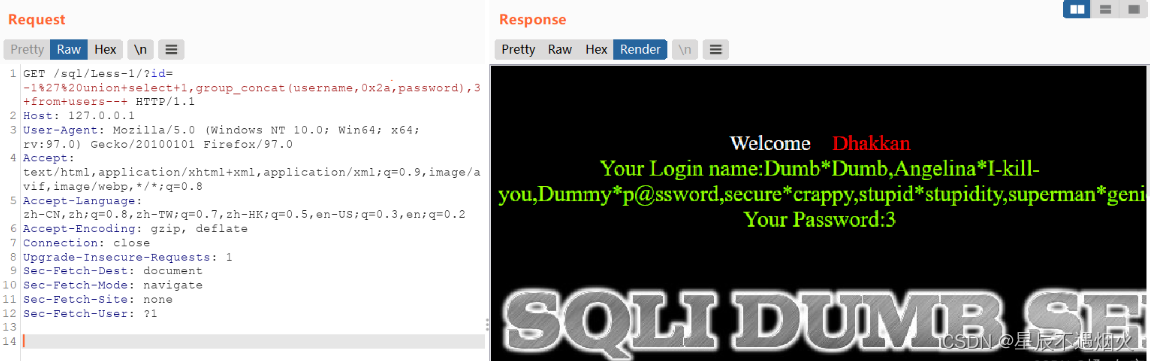
sqli第一关
1.在下使用火狐访问sqlilabs靶场并使用burpsuite代理火狐。左为sqlilabs第一关,右为burpsuite。 2.输入?id1 and 11 与?id1 and 12试试 可以看出没有变化哈,明显我们输入的语句被过滤了。在?id1后面尝试各种字符,发现单引号 包…...

入行IC | 新人入行IC选择哪个岗位更好?
很多同学入行不知道怎么选择岗位。IC的岗位一般有设计、验证、后端、封装、测试、FPGA等等。但是具体到每个人身上,就要在开始的时候确定下你要找的职位,可以有两个或三个,但是要分出主次,主次不分会让你纠结整个找工作的过程。 …...

时间旅行的Bug 奇怪的输入Bug
故事一:时间旅行的Bug 在一个普通的工作日,程序员小明正在开发一个时间旅行的应用程序。这个应用程序可以让用户选择一个特定的日期和时间,然后将用户的意识传送到过去或未来的那个时刻。小明对这个项目非常兴奋,他认为这将是一个…...

解决nbsp;不生效的问题
代码块 {{title}} title:附 \xa0\xa0\xa0件,//或者 <span v-html"title"></span> title:附 件:,效果图...

【Lidar】Cloud Compare介绍安装包
CloudCompare是一款基于GPL开源协议的3D点云处理软件,最初被设计用来对稠密的三维点云进行直接比较。它依赖于一种特定的八叉树结构,在进行点云对比这类任务时具有出色的性能。在2005年后,CloudCompare实现了点云和三角形网格之间的比较。 Cl…...

Java中的Maven是什么?
Maven是一个开源的项目管理和构建工具,用于Java项目的构建、依赖管理和项目信息管理。它提供了一种标准的项目结构、规范的构建过程和丰富的插件生态系统,简化了项目的管理和构建过程。 Maven基于项目对象模型(Project Object Model…...
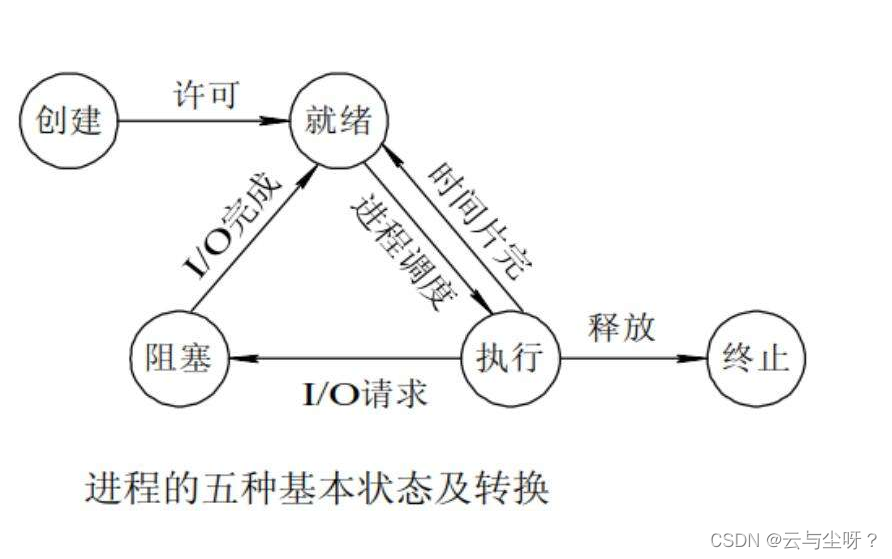
计算机操作系统
计算机操作系统 1.进程管理 1.1 基础概念 进程&线程 进程是操作系统资源分配的基本单位。一个进程运行时,会获取必要的CPU、内存地址空间,以及运行时必要的IO设备。 线程则是执行调度的最小单位。一个进程会由一个线程或者多个线程执行调度任务。…...

海学会读《乡村振兴战略下传统村落文化旅游设计》2023年度许少辉八一新书
海学会读《乡村振兴战略下传统村落文化旅游设计》2023年度许少辉八一新书...

tkinter树形图组件
文章目录 初步回调函数绑定滚动条 初步 Treeview是ttk中的树形表组件,功能十分强大,非常适用于系统路径的表达。为了知道属性图到底是什么,下面先做个最简单的树形图 其代码如下 import tkinter as tk from tkinter import ttkdct {"…...

多线程的创建
一、基本概念 1 cpu CPU的中文名称是中央处理器,是进行逻辑运算用的,主要由运算器、控制器、寄存器三部分组成,从字面意思看就是运算就是起着运算的作用,控制器就是负责发出cpu每条指令所需要的信息,寄存器就是保存运…...

【django】APPEND_SLASH 路由末尾的斜杠问题
url路由末尾是否加斜杠的规范 加斜杠:表示是目录不加斜杠: 表示是文件 在django中的setting中,默认APPEND_SLASH True, 即当请求的路由末尾没有加斜杠, 如果尝试加上斜杠后,能在后端路由里匹配到,则会自…...
iOS16.0:屏幕旋转
此文写于2022年08月03日,距离iOS16正式版推出还有一个多月的时间,iOS16 beta版本有很多API的修改,今天讨论的是屏幕旋转,基于Xcode 14.0 beta4。 之前的屏幕旋转会报错: [Orientation] BUG IN CLIENT OF UIKIT: Settin…...
Carla学习笔记(二)服务器跑carla,本地运行carla-ros-bridge并用rviz显示
一、服务器跑carla 详见Carla学习笔记(一)服务器跑carla本地显示窗口_Zero_979的博客-CSDN博客 只需要启动服务器端就行: ./CarlaUE4.sh -carla-rpc-port2000 -RenderOffScreen -graphicsadaper1 二、本地下载 carla-ros-bridge 官方库&…...
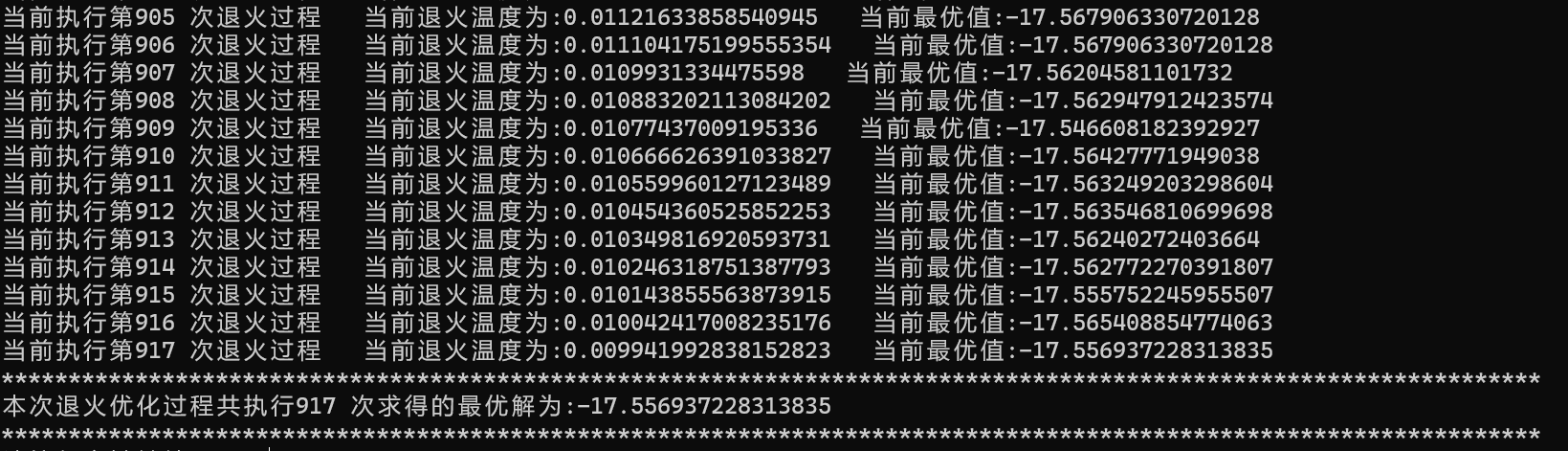
数学建模--退火算法求解最值的Python实现
目录 1.算法流程简介 2.算法核心代码 3.算法效果展示 1.算法流程简介 """ 1.设定退火算法的基础参数 2.设定需要优化的函数,求解该函数的最小值/最大值 3.进行退火过程,随机产生退火解并且纠正,直到冷却 4.绘制可视化图片进行了解退火整体过程 &…...

地理地形sdk:Tatuk GIS Developer Kernel for .NET Crack
Tatuk GIS Developer Kernel for .NET 是一个变体,它是受控代码和 .NET GIS SDK,用于为用户 Windows 操作系统创建专业 GIS 软件的过程。它被认为是一个完全针对Win Forms 的.NET CIL,WPF 框架是针对C# 以及VB.NET、VC、Oxy 以及最终与.NET 的…...

观成科技:隐蔽隧道工具Ligolo-ng加密流量分析
1.工具介绍 Ligolo-ng是一款由go编写的高效隧道工具,该工具基于TUN接口实现其功能,利用反向TCP/TLS连接建立一条隐蔽的通信信道,支持使用Let’s Encrypt自动生成证书。Ligolo-ng的通信隐蔽性体现在其支持多种连接方式,适应复杂网…...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...

Java如何权衡是使用无序的数组还是有序的数组
在 Java 中,选择有序数组还是无序数组取决于具体场景的性能需求与操作特点。以下是关键权衡因素及决策指南: ⚖️ 核心权衡维度 维度有序数组无序数组查询性能二分查找 O(log n) ✅线性扫描 O(n) ❌插入/删除需移位维护顺序 O(n) ❌直接操作尾部 O(1) ✅内存开销与无序数组相…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

从深圳崛起的“机器之眼”:赴港乐动机器人的万亿赛道赶考路
进入2025年以来,尽管围绕人形机器人、具身智能等机器人赛道的质疑声不断,但全球市场热度依然高涨,入局者持续增加。 以国内市场为例,天眼查专业版数据显示,截至5月底,我国现存在业、存续状态的机器人相关企…...

五年级数学知识边界总结思考-下册
目录 一、背景二、过程1.观察物体小学五年级下册“观察物体”知识点详解:由来、作用与意义**一、知识点核心内容****二、知识点的由来:从生活实践到数学抽象****三、知识的作用:解决实际问题的工具****四、学习的意义:培养核心素养…...
基础光照(Basic Lighting))
C++.OpenGL (10/64)基础光照(Basic Lighting)
基础光照(Basic Lighting) 冯氏光照模型(Phong Lighting Model) #mermaid-svg-GLdskXwWINxNGHso {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-GLdskXwWINxNGHso .error-icon{fill:#552222;}#mermaid-svg-GLd…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...