读书笔记:多Transformer的双向编码器表示法(Bert)-1
多Transformer的双向编码器表示法
Bidirectional Encoder Representations from Transformers,即Bert;

本笔记主要是对谷歌Bert架构的入门学习:
- 介绍Transformer架构,理解编码器和解码器的工作原理;
- 掌握Bert模型架构的各个部分,了解如何进行模型的预训练、模型微调(将预训练的结果用于下游任务);
- 学习Bert的不同变体、基于知识蒸馏的变体;
- 一些其他模型架构;
- 用于获取句子特征的Sentence-Bert模型以及一些用于特定领域的Bert模型(医学or生物学);
- VideoBert模型;
目标是熟练掌握Bert及其变体来执行实际的自然语言处理任务;利用Bert模型超强的理解能力来简化自然语言处理任务;
章节目录
- 第1章 Transformer概览
- 第2章 了解Bert模型(掩码语言模型构建和下句预测)
- 第3章 Bert实战
- 第4章 Bert变体:ALBERT、RoBERTa、ELECTRA和SpanBERT
- 第5章 Bert变体:基于知识蒸馏
- 第6章 用于文本摘要任务的BERTSUM模型
- 第7章 将Bert模型应用于其他语言
- 第8章 Sentence-Bert模型和特定领域的Bert模型
- 第9章 VideoBERT模型和BART模型
要求环境 Python3
第一部分 开始使用BERT
- 第1章 Transformer概览
- 第2章 了解Bert模型(掩码语言模型构建和下句预测)
- 第3章 Bert实战
第1章 Transformer概览
自注意力机制
Transformer完全依赖于注意力机制,并摒弃了循环;使用了一种特殊的注意力机制,称为自注意力(self-attention);
实例:文本翻译(从英文翻译为法文)
- 向编码器输入一句话(原句)
- 让其学习到这句话的特征1;
- 在将特征作为输入传输给解码器;
- 最后通过解码器生成输出句(目标句);
N个编码器:
Transformer中的编码器不止一个,而是由一组N个编码器串联而成,一个编码器的输出作为下一个编码器的输入;
原句的特征会由最后一个编码器输出,编码器的作用就是提取原句中的特征;
Transformer原论文中“Attention is all your need”中,作者使用的N=6;
关于Transformer的学习可以参考之前总结的blog:
- 《Transformer应用实践(学习篇)》
- 《Transformer应用实践(补充)》
每个编码器的组成:
I am good -> 【多头注意力层 -> 前馈网络层 】-> …
每一个编码器的构造都是相同的,并且包含两个部分:
- 多头注意力层
- 前馈网络层
首先我们要了解“自注意力机制”:
以一句话为例:“A dog ate the food beacause it was hungry”,计算机模型要理解it的意思是dog还是food,自注意力机制有助解决该问题;
模型会一次计算每个单词的特征值,当计算每个词的特征值时,模型都需要遍历每个词与句子中其他词的关系;模型可以通过词与词之间的关系来更好的理解当前词的意思;
- it的特征值 由它本身与句子中其他词的关系计算所得;
- 关系越紧密,相应的注意力表示权重也就也大;
我们以一个简单的句子“I am good”为例:
- 首先,需要将词转化为其他对应的词嵌入向量;需要注意的是,嵌入只是
词的特征向量,这个特征向量也是需要通过训练获得的; - 这个句子的词嵌入向量,可以表示为矩阵X =
[x1, x2, x3];矩阵X的维度是[句子的长度 x 词嵌入向量维度],可以是512; - 现在,通过X创建3个新的矩阵:
- 查询query矩阵Q:相当于问题提示
- 键key矩阵K:类似问题的标准答案
- 值value矩阵V:相当于我们期待的答案
关于三个新的矩阵QKV我们来具体看下:
- 要创建这三个矩阵,需要先创建另外三个权重矩阵,分别为WQ/WK/W^V,用矩阵X分别乘以权重矩阵,就会得到Q、K、V三个矩阵;
- 值得注意的是:三个权重矩阵的初始值是随机的,其最优值需要通过训练获得;
- 这些权重矩阵的值越优,通过计算所得的查询矩阵、键矩阵、值矩阵也会越精确;
Q、K、V三个矩阵的行数与X一致,它们的每一行分别表示一个单词的q、k、v向量;向量的维度由参与计算的权重矩阵决定,可以是64;
那么,为什么要使用Q、K、V三个矩阵?如何才能用自注意力模型?我民额继续;
理解注意力机制:
已经计算得到Q、K、V矩阵,是要应用于注意力机制的;我们知道,要计算一个词的特征值,自注意力机制会使该词与给定句子中所有词联系起来;了解一个词与句子中所有词相关程度有助于更精确地计算特征值;
自注意力机制的4个步骤:
- 1.计算Q与K^T的点积:
- Q和K的shape一致,KT表示K矩阵的转置;Q的每一行代表一个词的查询向量q,KT的每一列表示相应词的键向量k,那么点积的结果是一个 词数x词数的矩阵,它的每一行计算的是 q1和k1、k2、k3的点积;
- 通过计算两个向量的点积可以知道它们之间的相似度;这样通过计算q1和k1、k2、k3的点积,就可以了解单词“I”与句子“I am good”中所有单词的相似度,显然q1与k1的点积值最大,因为“I”这个词与自己的关系要比与其他词的关系更紧密;
- 综上,计算Q和K^T的点积,得到了句子中每个词与所有其他词的相似度分数矩阵,即
Q·K^T;
- 2.将Q·K^T 矩阵除以键向量维度的平方根:
- 这样做的目的,主要是为了获得稳定的梯度;
- 如果用dk 表示键向量维度(这里使用64),那么它的平方根就是8;
- 3.使用softmax函数对目前所得相似度分数进行归一化处理:
- 应用softmax函数可以将数值分布在0~1的范围内,且每一行(向量)的所有数之和等于1(即百分之百);
- 然后得到的矩阵,成为“分数矩阵”,通过这些分数,可以了解到句子中每个词与所有词的相关程度,
softmax(Q·K^T/√dk);
- 4.计算注意力矩阵Z:
- 注意力矩阵要包含的是句子中每个单词的注意力值,通过将分数矩阵乘以值矩阵V得到;
- 注意力矩阵Z就是值分量(WordNum x 64)与分数(WordNum x WordNum)加权之后求和的结果,即“分数加权的值向量之和”,
Z = softmax(Q·K^T/√dk)V(WordNum x 1);
注意:自注意力机制的4个步骤中, Z = softmax(Q·K^T/√dk)V 将Z的shape标记为了【WordNum x 1】,这可能是不对的,实际应该是【WordNum x EmbeddingDim】,而这一句“注意力矩阵Z就是值分量(WordNum x 64)与分数(WordNum x WordNum)加权之后求和的结果”应调整为“注意力矩阵Z的词注意力分量是其值分量(WordNum x 64)与分数(WordNum x WordNum)加权之后求和的结果”;
import numpy as np
test_a = np.array([[1,2,3],[4,5,6],[4,5,6]])
test_b = np.array([[1,4,5,6],[2,7,8,9],[3,10,11,12]])
print(test_a.shape,test_b.shape)
# 点积计算
np.matmul(test_a, test_b)
(3, 3) (3, 4)array([[ 14, 48, 54, 60],[ 32, 111, 126, 141],[ 32, 111, 126, 141]])
# 求和
np.matmul(test_a, test_b).sum(axis=1)
array([176, 410, 410])
单词“I”的自注意力值:假设“I”的分数向量是[0.9, 0.07, 0.03],那么其自注意力值就包含了90%的值向量v1(I)、7%的值向量v2(am)、3%的值向量v3(good);
再看之前的例子,“A dog ate the food beacause it was hungry”,计算机模型要理解it的意思是dog还是food,可以计算it这个词的自注意力值,它对dog词的值分量的权重会更大;
这也说明了:通过自注意力机制,我们可以了解一个词与句子中所有词的相关程度;
注意力矩阵Z由句子中所有单词的自注意力值组成,公式为Z = softmax(Q·K^T/√dk)V;
自注意力机制也被称为“缩放点积注意力机制”;
多头注意力层:
- 指我们使用多个注意力头,而不只是一个,使用的计算注意力矩阵方法,同求Z;
- 以之前it指代的例子来说,它实际上是由其他词(这里是dog)的值向量控制(假设权重是100%),由于这个词的含义是模糊的,此时这种控制关系是有用的,但为了确保结果准确,不能依赖单一的注意力矩阵,应该设计多个,并将其结果串联起来;
使用多头注意力的逻辑为:使用多个注意力矩阵,可以提高注意力矩阵的准确性;
我们知道:为了计算注意力矩阵,需要创建三个新的矩阵QKV,为此还要引入三个新的权重矩阵;要计算多个注意力矩阵,就需要这样的多组数据;
假设我们有8个注意力矩阵,Z1到Z8,将所有的注意力头(就是注意力矩阵)串联起来,并将结果乘以一个新的权重矩阵W0,从而得到最终的注意力矩阵;
Multi-head attention = Concatenate(Z1,Z2...,Z8) W0
位置编码
位置编码:(position encoding)
指词在句子中的位置编码;仍以“I am good”为例,在循环神经网络RNN中,句子是逐字送入学习网络,最终完全理解整个句子;但在Transformer网络则是将句子中所有词并行输入到神经网络(并行有助于缩短训练时间,同时有利于学习长期依赖);
既然是并行输入,那么就无法保留词序,而词序有很重要,因此也要为Transformer输入一些关于词序的信息;
对于给定的句子:
- 首先计算每个单词在句子中的嵌入值,词嵌入维度可以表示为dmodel,那么输入矩阵的维度就是
[句子长度 x 嵌入维度],如3 x 512; - 如果把输入矩阵直接传给Transformer,模型就无法理解词序,因此需要给输入矩阵添加一些表明词序的信息,以便神经网络可以理解句子含义,这里要用到的技术就是“位置编码”技术;
位置编码矩阵P,其shape与X相同,只需将P添加到X中,再输入神经网络,就可以让输入矩阵既包含词的嵌入,也包含词在句子中的位置信息,X = X + P;
一种计算位置编码矩阵P的方式——“使用正弦函数来计算位置编码”
- pos表示词在句子中的位置,i表示在输入矩阵中的位置;
- 当i是偶数时,使用sin函数,i为奇数时,使用cos函数(示意图中10000^0,表示10000的0次幂);
- I的pos=0,am的pos=1,。。。
- 最后将输入矩阵X与计算所得位置编码矩阵P进行逐元素相加即可输入到编码器模块;

- I am good
- 词嵌入矩阵 + 位置编码矩阵
- 输入编码器,提取特征值
而一个编码器模块是由 多头注意力层 和前馈网络层 两部分组成,而此前我们已经了解了多头注意力层,接下来看下前馈网络层;
理解编码器
前馈网络层:
在编码器模块中,前馈网络层 接在 多头注意力层后;它由两个有ReLU激活函数的全连接层组成,前馈网络的参数在句子的不同位置是相同的,但在不同的编码器模块上是不同的;
编码器的“叠加和归一组件”:
- 它同时连接一个子层的输入和输出,示意如下:
| 输入矩阵 | 编码器模块 | 编码器模块 | 编码器模块 | 编码器模块 | 编码器模块 | |
|---|---|---|---|---|---|---|
| 输入 | → | 多头注意力层→ | 叠加和归一组件 | → | 前馈网络层→ | 叠加和归一组件 |
| ↓ | ↑ | ↓ | ↑ | |||
| → | → | → | → | → | → |
- 叠加和归一化组件实际上包含了一个残差连接与层的归一化;层的归一化可以防止每层的值剧烈变化,从而提高模型训练速度;
现在回顾下编码器及前后的部分:
- 输入值的嵌入:将输入转换为嵌入矩阵(即输入矩阵);
- 位置编码:将位置编码嵌入输入矩阵;
- 编码器1 … 编码器N:使用输入矩阵作为编码器输入;
- 编码器接受输入,在内部:
- 首先将其送入多头注意力层,该子层运算后输出注意力矩阵;
- 将注意力矩阵输入到下一子层,即前馈网络层,输出特征值;
- 后续编码器的输入是前一编码器的输出;
N个叠加的编码器的输出特征值记为R,再把R作为输入传给解码器,解码器将基于这个输入生成目标句;
理解解码器
I am good => 通过编码器学习原句,并计算特征值 => 解码器将特征值作为输入,生成目标句”我很好“;
类似编码器叠加N个,解码器也可以有N个叠加,一个解码器的输入会作为输入传给下一个解码器;值得注意的是:编码器输出的特征值,将作为输入传给所有解码器,因此一个解码器有两个输入,一个是来自前一解码器的输出,另一个是编码器输出的特征值;
生成目标句的过程:
- 使用t表示时间步,当t=1时,解码器输入
<sos>表示句子开始,生成目标句的第一个词”我“; - t=2时,解码器使用当前的输入和上一步(t-1)生成的单词,预测句子中的下一个单词,即将
<sos>和”我“作为输入,并试图生成目标句中的下一个词; - 在每一步中,解码器都将上一步新生成的单词与输入的词结合起来,并预测下一个单词;
- 在最后一步t=4时,解码器的输入是
<sos>、我、很、好作为输入,试图生成下一个词,如果生成的标记为<eos>则表示句子结束;就意味着解码器已经完成了对目标句的生成;
对于解码器的输入,实际同样需要将其转换为嵌入矩阵,为其添加位置编码;
解码器模块:
| 解码器模块 | 解码器模块 | 解码器模块 | ||
|---|---|---|---|---|
| → | 带掩码的多头注意力层→ | 多头注意力层→ | 前馈网络层 | → |
内部包含三个子层:
- 带掩码的多头注意力层
- 多头注意力层
- 前馈网络层
相比编码器模块,多了带掩码的多头注意力层;
带掩码的多头注意力层:
- 以翻译任务为例,参与训练的样本需要包含两部分,即原句和目标句;
- 解码器可以直接将整个目标句稍作修改作为输入,将
<sos>标记添加到目标句的开头,并在每一步将下一个预测词与输入结合起来,以预测目标句;
过程举例说明如下:
- 将
<sos>我很好输入解码器(实际输入是添加了位置编码的嵌入矩阵X),预测输出为我很好<eos>; - 解码器中的第一层 带掩码的多头注意力层,与编码器中的多头注意力层有一点不同:
- 为了运行自注意力机制,我们需要创建三个新矩阵Q K V,由于是多头,因此Q K V一共创建h组;每组中的Q K V可通过X分别乘以权重矩阵W^Q W^K W^V而得;
- 而自注意力机制会将一个单词与句子中的所有单词联系起来,从而提取每个词的更多信息,但是,在测试期间,解码器只将
上一步生成的词作为输入; - 如t=2时,解码器的输入应只有
[<sos>, "我"],并没有其他词;我也也需要实现这样的方式来训练模型:模型的注意力机制应该只与该词之前的单词有关; - 要做到这一点,可以掩盖后边所有还没有被模型预测的词,如当预测
<sos>相邻的词,模型应只看见<sos>,那么就应该掩盖<sos>后边的词;
<sos> 掩码 掩码 掩码
<sos> 我 掩码 掩码
<sos> 我 很 掩码
<sos> 我 很 好
这样的掩码有助于自注意力机制只注意模型在测试期间可以使用的词;
我们知道:
- 计算注意力矩阵的第一步是计算 查询矩阵Q与键矩阵转置的点积,第二步除以键向量维度的平方根以缩放,第三步应用softmax函数,将分值归一化;
- 我们需要在应用softmax前,完成对数值的掩码转换;可以使用负无穷大来掩盖,测试代码如下;
- 最后将softmax函数的结果与V相乘,得到注意力矩阵Z,h个注意力矩阵串联,结果乘以新的权重矩阵W,即可得到最终的注意力矩阵M;
import numpy as np
test_a = np.array([[1,2,3],[4,5,6],[4,5,6]], dtype=np.float32)
matrix = np.triu(np.ones(test_a.shape) * -np.inf, 1)
test_a = test_a + matrix
test_a
array([[ 1., -inf, -inf],[ 4., 5., -inf],[ 4., 5., 6.]])
def softmax(x):e_x = np.exp(x - np.max(x))return e_x / e_x.sum(axis=0)# 使用-inf掩盖的向量,在计算softmax时,不会分摊权重
test_a[0],softmax(test_a[0])
(array([ 1., -inf, -inf]), array([1., 0., 0.]))
带掩码的多头注意力层输出的注意力矩阵M,送到解码器的下一个子层,这是一个多头注意力层;
多头注意力层:
我们之前提到过:编码器输出的特征值,将作为输入传给所有解码器,更准确的描述是:将作为输入传给所有解码器的多头注意力子层;即解码器中的多头注意力层有两个输入:一个来自带掩码的多头注意力层,另一个是编码器输出的特征值;
由于涉及编码器与解码器的交互,解码器的这一子层也被称为
编码器-解码器注意力层;
我们用R来表示编码器输出的特征值(每个词都对应一个特征向量,因此这里的R实际是一个矩阵),用M表示由带掩码的多头注意力层输出的注意力矩阵;我们知道多头注意力机制第1步就是创建Q K V三个矩阵(通过将输入矩阵乘以权重矩阵),但是R和M两个输入,究竟用谁?
答案是:我们使用M作为输入矩阵来创建查询矩阵Q,使用R作为输入矩阵创建K和V矩阵;
- 这里查询矩阵Q是从M求得,所以本质上包含了目标句的特征;
- 键矩阵和值矩阵用R计算,则包含了原句的特征;
细节的:
- Q·K^T:其第一行是查询向量q1(
<sos>)与所有键向量k1(I)、k2(am)、k3(good)的点积,因此第1行表示目标词<sos>与原句中所有词的相似度;最终得到的所有行对应 查询矩阵(目标句特征)与键矩阵(原句特征)的相似度; - 经过维度平方根的缩放,和softmax函数,得到分数矩阵,再乘以值矩阵V,即注意力矩阵Z,目标句的注意力矩阵Zi是通过分数加权的值向量之和计算的(每一个目标句词都对应了一个注意力向量),实际的可能是这样:Z2的注意力向量包含了0.98个值向量v1(I)、0.02个值向量v2(am)、0.00的值向量v3(good),这个结果可以帮助模型理解目标词我指代原词I;
计算h个注意力矩阵后,将它们串联起来,乘以一个新的权重矩阵,得到最终的注意力矩阵;将其输入解码器的下一个子层,即前馈网络层;
前馈网络层:
- 其工作原理与解码器中一致;
- 解码器的前馈网络层中的叠加和归一化组件同样连接子层的输入和输出,而且需要注意的是:解码器的三个子层都使用了叠加和归一化组件连接了子层的输入和输出;
- 前馈网络层输出解码后的特征(最后一个解码器输出将是目标句的特征);
关于线性层和softmax层:
- 解码器学习了目标句特征之后,需要将顶层(叠加的最后一个)解码器的输出送入线性层和softmax层;
- 线性层将生成一个logit3(是一种概率分布)向量,其大小等于原句中的
词汇量(这个应该是指词源量,而不是原句的词量,输出的词的索引值,也是要对应到总词汇表的); - 接下来,再使用softmax函数将logit向量转换成概率,然后将输出具有高概率值的词的索引值,即通过概率得到预测的词;
整合编码器和解码器
即Transformer架构;
- 编码器学习原句特征并将其发送给解码器;
- 解码器又会生成目标句;
训练Transformer
可以通过最小化损失函数来训练Transformer网络,解码器预测的是词汇的概率分布,并选择概率最高的词作为输出,因此损失函数的选择,需要让预测的概率分布和实际的概率分布之间的差异最小化,这样可以将损失函数定义为交叉熵损失函数,并使用Adam算法来优化训练过程;
需要注意的是,为了防止过拟合,可以将dropout方法应用于每个子层的输出,以及嵌入和位置编码的总和(这里说的可能是输入矩阵);
小结
了解了Transformer 编码器-解码器架构,了解使用的不同子层;我们了解到自注意力机制将一个词与句子中的所有词联系起来,以便更好的理解这个词;使用Q K V三个矩阵计算自注意力值;如何计算位置编码,以及如何用它来捕捉词序;
下一章,我们将学习Bert,以及它如何使用Transformer来对上下文嵌入进行学习。
相关文章:
读书笔记:多Transformer的双向编码器表示法(Bert)-1
多Transformer的双向编码器表示法 Bidirectional Encoder Representations from Transformers,即Bert; 本笔记主要是对谷歌Bert架构的入门学习: 介绍Transformer架构,理解编码器和解码器的工作原理;掌握Bert模型架构…...
第二证券:股利支付率和留存收益率的关系?
股利付出率和留存收益率是股票出资中非常重要的目标,它们可以反映公司的盈余才能和未来开展的潜力。那么,二者之间究竟有什么联系呢? 一、股利付出率和留存收益率的定义 股利付出率是指公司向股东分配的股息占当期净利润的比例,通…...

煤矿虚拟仿真 | 采煤工人VR虚拟现实培训系统
随着科技的发展,虚拟现实(VR)技术已经逐渐渗透到各个行业,其中包括煤矿行业。VR技术可以为煤矿工人提供一个安全、真实的环境,让他们在虚拟环境中进行实际操作和培训,从而提高他们的技能水平和安全意识。 由广州华锐互动开发的采煤…...
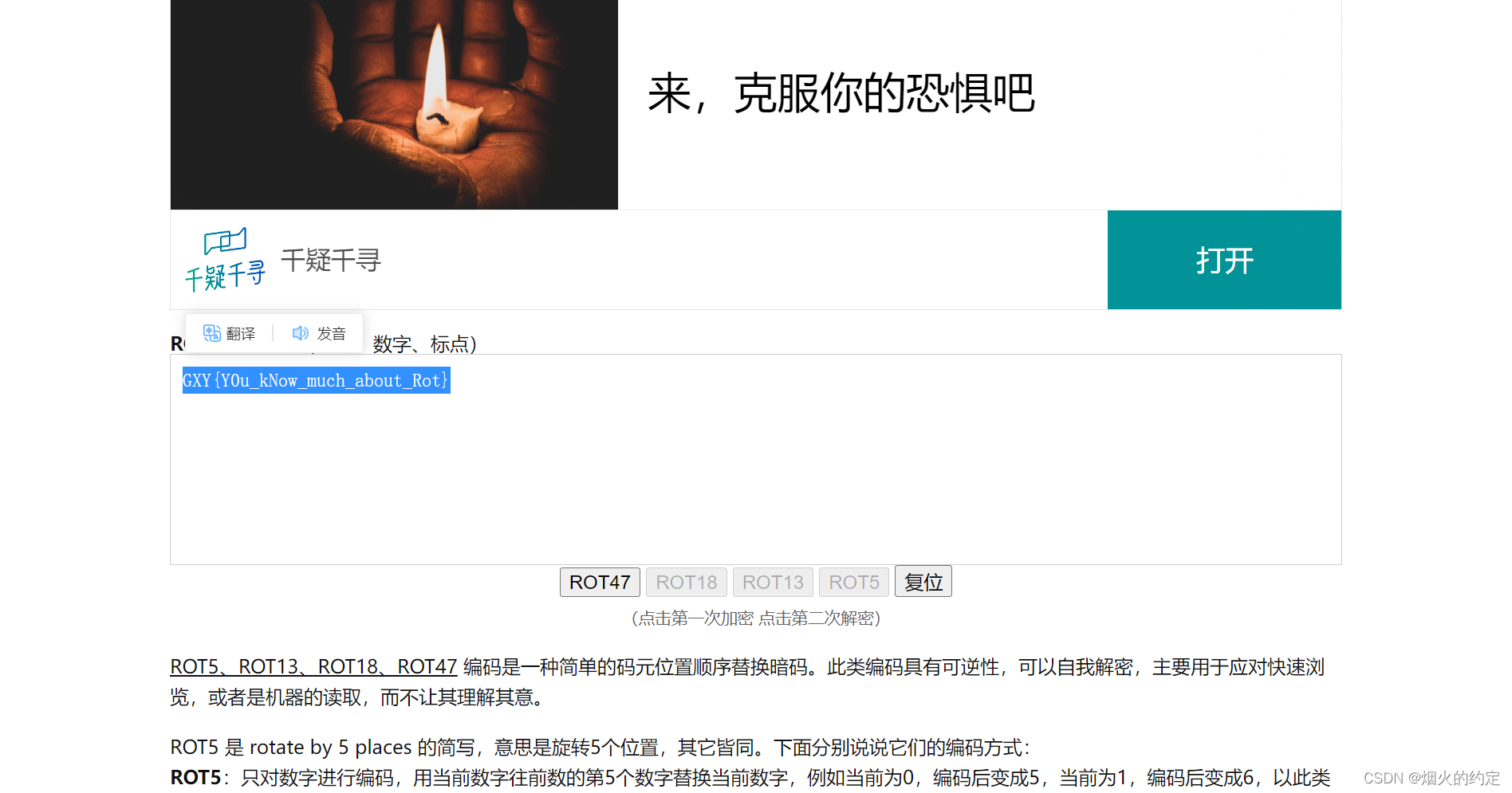
buuctf crypto 【[GXYCTF2019]CheckIn】解题记录
1.打开文件,发现密文 2.一眼base64,解密一下 3.解密后的字符串没有什么规律,看了看大佬的wp,是rot47加密,解密一下(ROT5、ROT13、ROT18、ROT47位移编码)...

微服务05-Docker基本操作
Docker的定义 1.什么是Docker Docker是一个快速交付应用、运行应用的技术: 可以将程序及其依赖、运行环境一起打包为一个镜像,可以迁移到任意Linux操作系统运行时利用沙箱机制形成隔离容器,各个应用互不干扰启动、移除都可以通过一行命令完…...

OpenHarmony创新赛|赋能直播第三期
开放原子开源大赛OpenHarmony创新赛赋能直播间持续邀请众多技术专家一起分享应用开发技术知识,本期推出OpenHarmony应用开发之音视频播放器和三方库的使用和方法,助力开发者掌握多媒体应用技术的开发能力和使用三方库提升应用开发的效率和质量࿰…...
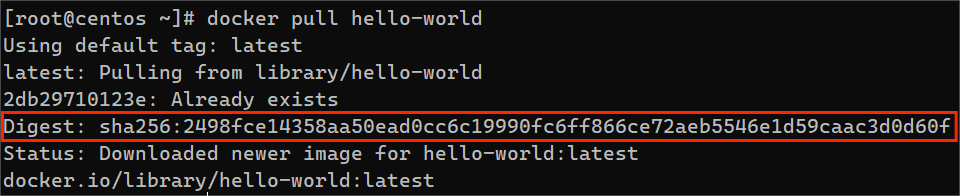
docker镜像详解
目录 什么是docker镜像镜像相关命令docker pulldocker imagesdocker searchdocker rmi导出 / 导入镜像 镜像分层镜像摘要镜像摘要的作用分发散列值 什么是docker镜像 Docker镜像是Docker容器的基础组件,它包含了运行一个应用程序所需的一切,包括代码、运…...
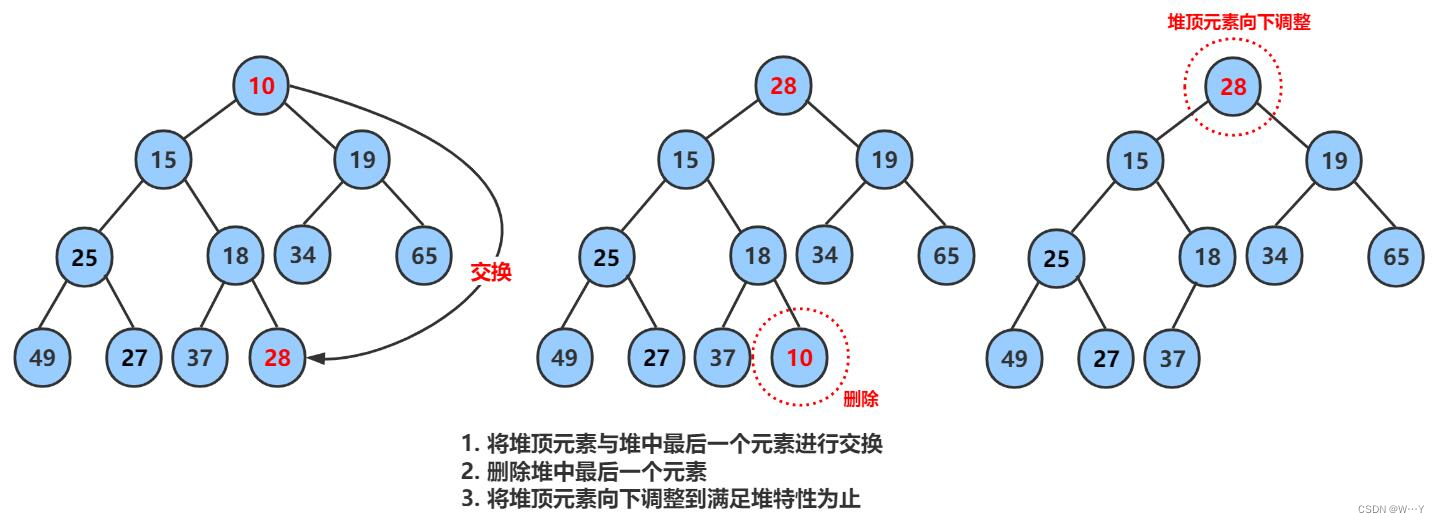
二叉树的顺序结构以及堆的实现——【数据结构】
W...Y的主页 😊 代码仓库分享 💕 上篇文章,我们认识了什么是树以及二叉树的基本内容、表示方法……接下来我们继续来深入二叉树,感受其中的魅力。 目录 二叉树的顺序结构 堆的概念及结构 堆的实现 堆的创建 堆的初始化与…...

手写一个摸鱼神器:使用python手写一个看小说的脚本,在ide中输出小说内容,同事直呼“还得是你”
文章目录 一、准备python环境二、分析小说网的章节目录三、分析小说网的章节内容四、编写python脚本五、验证一下吧 一、准备python环境 windows从0搭建python3开发环境与开发工具 Python爬虫基础(一):urllib库的使用详解 Python爬虫基础&a…...
【Python 实战】---- 实现批量图片的切割
1. 需求场景 在实际开发中,我们会遇到一种很无聊,但是又必须实现的需求,就是比如协议、大量的宣传页面、大量的静态介绍页面、或者大量静态页面,但是页面高度很高,甚至高度可能会达到50000px,但是为了渲染…...
MAYA粒子基础_场
重力场 牛顿场 径向场 均匀场和重力场的区别 空气场 推动物体 阻力场 推动物体 涡流场 湍流场 体积轴场...

趣解设计模式之《我买了宝马,为啥不让我停这?》
〇、小故事 我们怎么识别一辆汽车是宝马品牌的汽车呢?虽然宝马汽车车辆型号非常的多,而且外型也各不相同,但是只要是宝马品牌的汽车,它的车头一定会有宝马汽车的logo,那么这个就是大家最直观去确认一辆车是不是宝马牌…...

MyBatis Plus 中 LocalDateTime 引发的一些问题和解决办法
简介 在使用 MyBatis Plus 进行数据库操作时,我们经常会遇到处理日期时间类型的需求。然而,在某些情况下,使用 LocalDateTime 类型可能会引发一些问题。本文将详细介绍这些问题,并提供相应的解决办法。 问题描述: 1…...
谁懂啊!自制的科普安全手册居然火了
自制的科普安全手册居然火了 谁懂啊! 嗨嗨嗨!小仙女们,有没有见过这样的可以翻页的电子安全手册呢?自己随手就能轻松制作手册,结果一晚浏览量这么多!这可真是让人又惊又喜啊!快来分享一下我的喜…...
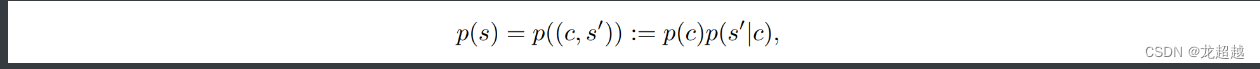
强化学习-论文调研-泛化性能力度量
1.[ICML2019]Quantifying Generalization in Reinforcement Learning 文章提出16000多个单智能体闯关游戏CoinRun,通过智能体在分割开的训练环境和测试环境上表现的性能作为RL泛化性的度量。具体而言作者通过”奔跑硬币泛化曲线“ (CoinRun Gener…...

CSS中图片旋转超出父元素解决办法
下面的两种解决办法都会导致图片缩小,可以给图片进行初始化的宽高设置 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge">…...

QML、C++ 和 JS 三者之间的交互
QML、C++ 和 JS 三者之间的交互是 Qt Quick 应用开发的核心。以下是它们之间交互的常见方式: 从 QML 调用 C++ 函数要从 QML 调用 C++ 函数,您可以使用 Qt 的 QML 注册机制,例如 qmlRegisterType,将 C++ 类注册为 QML 类型。 C++ 代码: #include <QGuiApplication>…...
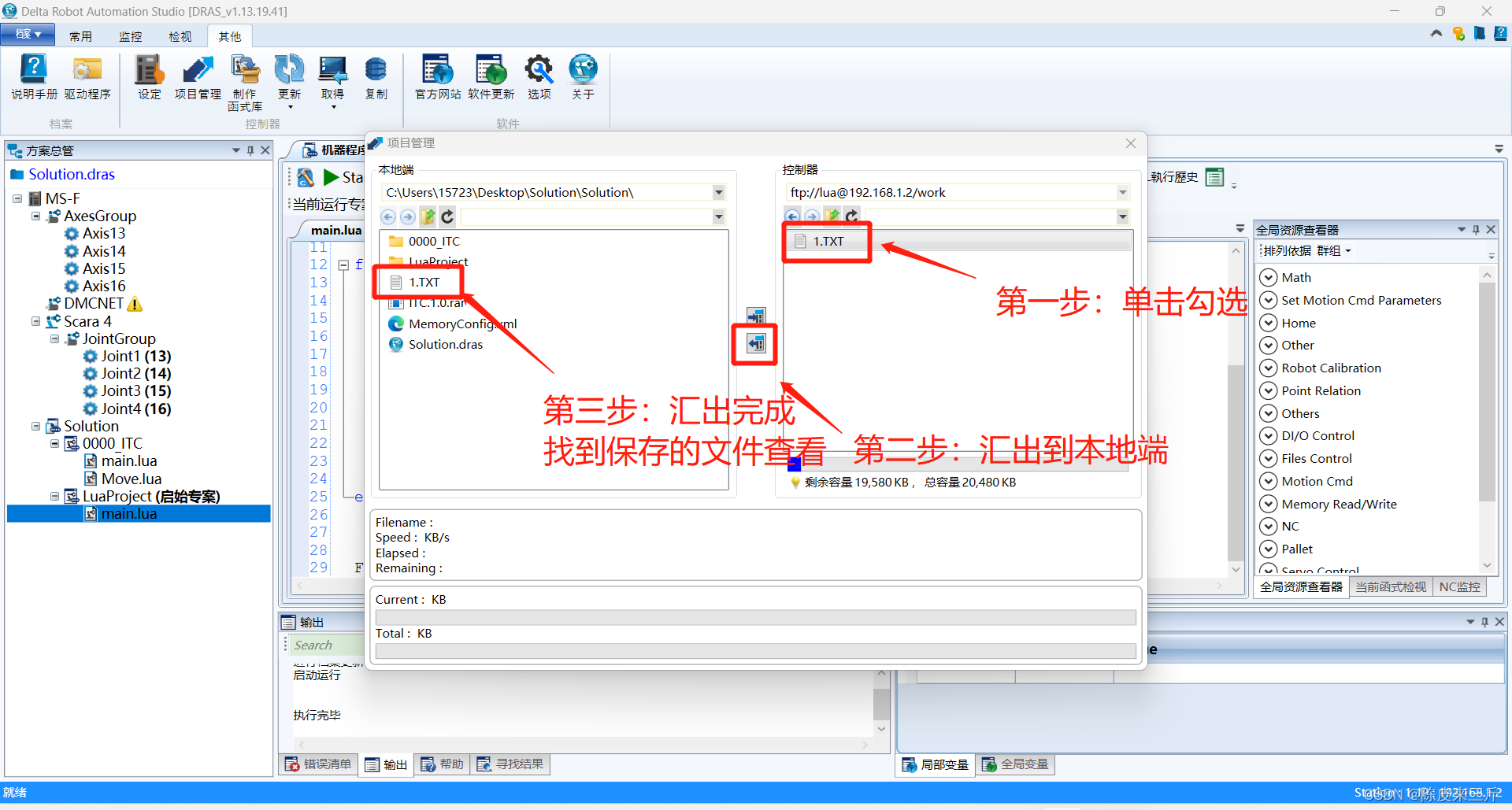
ProEasy机器人:TCP无协议通讯(socket通讯)时打印log日志
打印日志需要调用lua中的io相关文件函数与os相关时间函数,代码如下 --------TCP无协议视觉通讯------- function open_client_Vision() --连接视觉服务器 打开以太网作为客户端 repeat FreePort.ECM_CloseAll() --关闭所有链接 …...
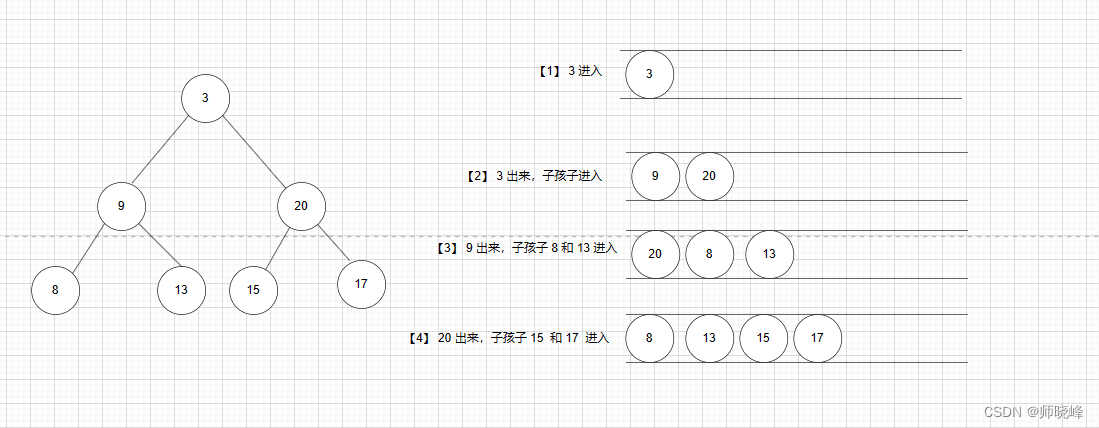
算法通过村第六关-树白银笔记|层次遍历
文章目录 前言1. 层次遍历介绍2. 基本的层次遍历与变换2.1 二叉树的层次遍历2.2 层次遍历-自底向上2.3 二叉树的锯齿形层次遍历2.4 N叉树的层次遍历 3. 几个处理每层元素的题目3.1 在每棵树行中找出最大值3.2 在每棵树行中找出平均值3.3 二叉树的右视图3.4 最底层最左边 总结 前…...

SpringCloud理解篇
一、微服务概述 1、什么是微服务 目前的微服务并没有一个统一的标准,一般是以业务来划分将传统的一站式应用,拆分成一个个的服务,彻底去耦合,一个微服务就是单功能业务,只做一件事。 与微服务相对的叫巨石 。 2、微服…...

Noi:整合多 AI 服务的新利器能否突出重围?
Noi:一站式 AI 服务整合新体验Noi 是一款图形用户界面(GUI)应用程序,它的核心亮点在于将所有 AI 服务整合到一处。用户通过单一用户界面(UI)就能访问 ChatGPT、Claude、Gemini、Perplexity 等多个服务&…...

cv_unet_image-colorization效果展示:看AI如何为历史照片智能上色
cv_unet_image-colorization效果展示:看AI如何为历史照片智能上色 1. 引言:让历史重现色彩的魅力 黑白照片承载着珍贵的记忆,但缺乏色彩总让人感觉少了些什么。想象一下,如果能将祖辈的老照片恢复成彩色,看到他们当年…...

C#运动控制库大比拼:HALCON vs Leadshine,哪个更适合你的项目?
C#运动控制库深度评测:HALCON与Leadshine的工业级对决 在工业自动化领域,选择合适的运动控制库往往决定着项目的成败。作为C#开发者,我们常面临一个关键抉择:是选择功能全面的HALCON,还是专注运动控制的Leadshine&…...

OpenClaw+Qwen3-32B自动化办公:会议纪要生成与飞书同步实战
OpenClawQwen3-32B自动化办公:会议纪要生成与飞书同步实战 1. 为什么需要自动化会议纪要 每次开完会最痛苦的事情是什么?对我来说就是整理会议纪要。作为技术负责人,每周要参加5-6个不同主题的会议,会后需要花大量时间回听录音、…...

DanKoe 视频笔记:通用时代崛起:如何通过多种兴趣茁壮成长
在本教程中,我们将探讨为何在当今的“创作者经济”中,拥有广泛兴趣和技能的“通才”比只精通一门的“专家”更具优势。我们将分析背后的原因,并提供一套实用的步骤,帮助你作为一名通才,在数字世界中建立个人品牌、吸引…...

智慧电子元器件识别 电子废弃物场景下的物料分类与元器件识别 元器件分拣数据集 电子废弃物自动分拣 电容数据集 保险丝数据集 第10617期
电子废弃物分类与元器件检测数据集 README 项目概述 本数据集专注于电子废弃物场景下的物料分类与元器件识别任务,为固废资源化利用、智能拆解及环保检测领域提供高质量标注数据,助力电子废弃物的高效回收与无害化处理。核心数据信息维度内容数据类别共1…...

PCB开窗技术:设计要点与工程应用解析
PCB开窗技术详解:设计要点与工程应用1. PCB开窗基础概念1.1 开窗的定义与物理特性PCB开窗是指去除印刷电路板导线表面阻焊油墨层的工艺处理,使底层铜箔直接暴露。在标准PCB制造流程中,所有信号走线默认覆盖阻焊层(Solder Mask&…...

Adafruit GPS库:轻量级NMEA 0183解析器设计与嵌入式实践
1. Adafruit GPS 库概述Adafruit_GPS 是 Adafruit 公司为嵌入式平台(尤其是基于 Arduino 生态的 MCU)开发的轻量级、高鲁棒性 GPS 数据解析库。其核心目标并非驱动 GPS 模块硬件,而是专注于从串行流中可靠提取、校验并结构化解析 NMEA 0183 协…...

基于FPGA的智能车牌识别系统Verilog代码详解:含OV5640图像采集与HDMI显示功能...
基于FPGA的车牌识别系统verilog代码,包含verilog仿真代码,matlab仿真 OV5640采集图像,HDMI显示图像,车牌字符显示在车牌左上角,并且把车牌用红框框起。 正点原子达芬奇或者达芬奇pro都可以直接使用,fpga芯片…...
)
Elsevier投稿遇Publishing Options卡死?别慌,试试这3个亲测有效的急救方案(附Edge浏览器操作)
Elsevier投稿遇Publishing Options卡死?3个急救方案与Edge浏览器实战指南 凌晨三点,实验室的灯光依然亮着。张教授盯着屏幕上那个纹丝不动的"Publishing Options"页面,手指无意识地敲击着桌面。距离返修截止只剩不到12小时…...