2023美赛C题Wordle二三问分布预测和难度分类预测
文章目录
- 前言
- 题目介绍
- 人数分布预测
- 首先建立字母词典,加上时间特征
- 数据预处理
- 训练和预测函数
- 保存模型函数
- 位置编码
- 模型及其参数设置
- 模型训练以及训练曲线可视化
- 预测人数分布
- 难度分类预测
- 总结
前言
2023美赛选了C题,应该很多人会选,一看就好做,一看拿奖也难,没事,注重过程就好。
题目介绍
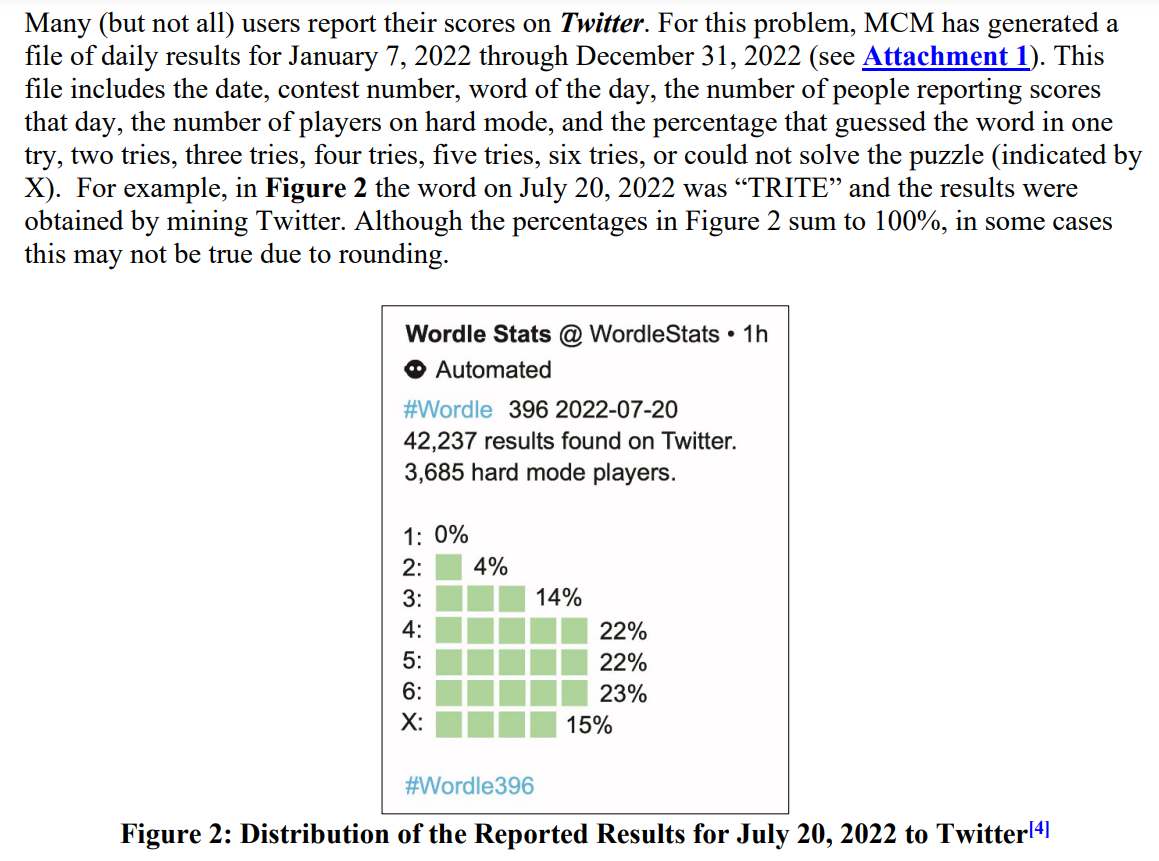
能点开这篇博客的应该都知道题目吧…(随便截点题目意思意思)


这里主要对于二三问,对于这个单词困难模式下的的人数分布百分比预测以及对这个单词的难度分类的预测。
首先看到他给的数据是这样的
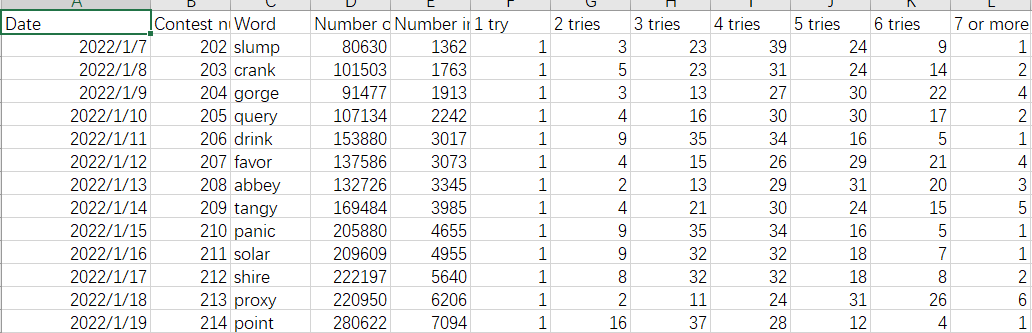
第二问中有让我们预测EERIE这个单词的1-7try人数的百分比,因此思路很简单:单词特征作为输入,人数百分比作为输出,可以看作一个回归问题。
第三问中有让我们预测EERIE这个单词的难度等级,那么首先需要对所有单词进行难度划分,然后得到难度标签,最后也是单词特征作为输入,单词难度作为输出,看作一个分类问题。
人数分布预测
这个问题,思路很简单,难点就是将单词向量化来表示,如何寻找合适、有效的特征就是预测能不能做好的关键,并且还需要将时间考虑进去,因为问题里说对未来的某个时间的单词进行预测。
因为找特征,确实是令人头大,预测选择采用深度学习,将字母向量表示通过BiLSTM编码为单词的向量表示,然后进行分布的预测,这样就不用找特征了。
当然我们第一问也找了些特征,顺便一起放进去了
这里因为还需要考虑时间,我直接灵机一动,Transformer不就有个位置编码吗,它那里每句话中每个词加上位置编码表示词的序列位置,我这里就是每个词的特征加入位置编码,用于表示每个词的出现时间不同。
ok,因此我们的模型图如下:
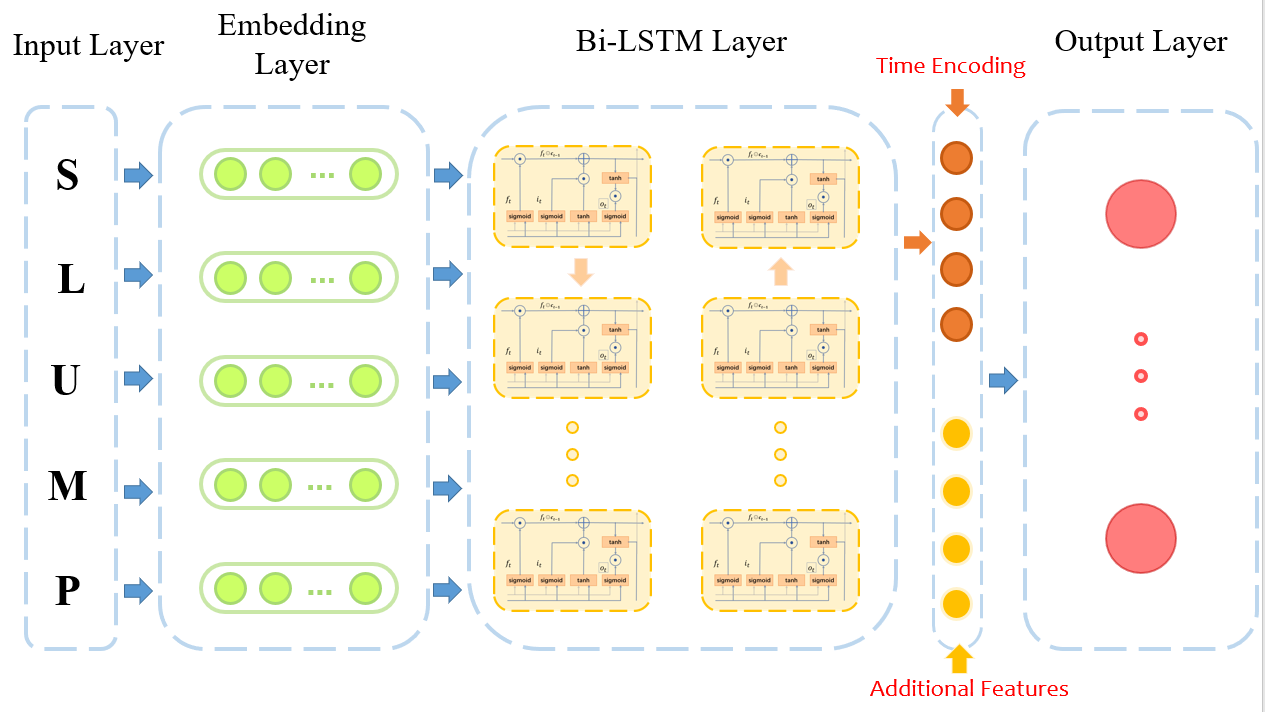
这里输出层经过softmax得到0-1之间的分布,然后进行分布的损失计算,损失函数使用MSELoss,就是均方误差最小,进行回归训练。
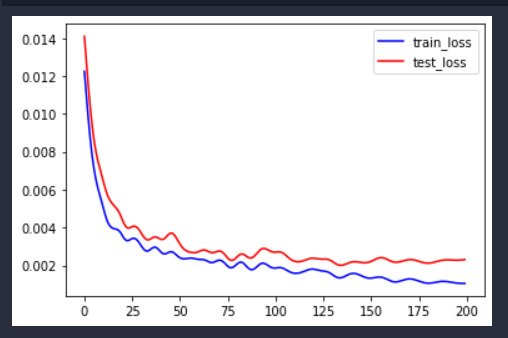
看得出训练误差能够不断减小。
先给出数据集部分展示:
wordle4.0.csv:
Date,Contest number,Word,Number of reported results,Number in hard mode,1 try,2 tries,3 tries,4 tries,5 tries,6 tries,7 or more tries (X),hard rate,commonality,letter_utilization,type_num,first_type,vowel_num,repeat_num
2022/1/7,202,slump,80630,1362,1,3,23,39,24,9,1,0.016891976,0.0221816151464392,0.2097406223034364,2,4,1,0
2022/1/8,203,crank,101503,1763,1,5,23,31,24,14,2,0.017368945,0.0746155017511801,0.3107710268514289,4,3,1,0
2022/1/9,204,gorge,91477,1913,1,3,13,27,30,22,4,0.02091236,0.0466981371503984,0.2672453174965737,4,3,2,1
cluster.csv:
Date,Contest number,Word,Number of reported results,Number in hard mode,1 try,2 tries,3 tries,4 tries,5 tries,6 tries,7 or more tries (X),hard rate,commonality,letter_utilization,commonality.1,letter_utilization.1,commonality.1.1,letter_utilization.1.1,w2v_tsne1,w2v_tsne2,dbscan,k++
2022/1/7,202.0,slump,80630.0,1362.0,1.0,3.0,23.0,39.0,24.0,9.0,1.0,0.016891976,0.0221816151464392,0.2097406223034364,0.0221816151464392,0.2097406223034364,0.0221816151464392,0.2097406223034364,2.337936,-1.1862806,-1,4
2022/1/8,203.0,crank,101503.0,1763.0,1.0,5.0,23.0,31.0,24.0,14.0,2.0,0.017368945,0.0746155017511801,0.3107710268514289,0.0746155017511801,0.3107710268514289,0.0746155017511801,0.3107710268514289,-9.112271,-1.1925219,-1,3
2022/1/9,204.0,gorge,91477.0,1913.0,1.0,3.0,13.0,27.0,30.0,22.0,4.0,0.02091236,0.0466981371503984,0.2672453174965737,0.0466981371503984,0.2672453174965737,0.0466981371503984,0.2672453174965737,-4.010186,9.088285,-1,2
代码实现:
首先建立字母词典,加上时间特征
import pandas as pd
import numpy as np
data = pd.read_csv("wordle_4.0.csv")
word = data["Word"].values
dic = {}
ww = []
for w in word:ww.extend(list(w))
ww = set(ww)
i = 0
for w in ww:dic[i] = wdic[w] = ii += 1
# 加上时间位置,之后在位置编码取出对应的位置编码
data["date"] = data.index.values
数据预处理
将单词向量化,且取出每个单词额外抽取的特征。
因为单词固定5个字母长度,而且也就只有26个字母,因此处理起来会简单一些。
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
import random
import math
import osseed = 1314
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed) # CPU
torch.cuda.manual_seed(seed) # GPU
torch.cuda.manual_seed_all(seed) # All GPU
os.environ['PYTHONHASHSEED'] = str(seed) # 禁止hash随机化
torch.backends.cudnn.deterministic = True # 确保每次返回的卷积算法是确定的
torch.backends.cudnn.benchmark = False # True的话会自动寻找最适合当前配置的高效算法,来达到优化运行效率的问题。False保证实验结果可复现
import torch.utils.data.dataloader as dataloader
from torch.utils.data import TensorDataset
import torch.nn as nn
from torch.autograd import Variablefrom sklearn.model_selection import train_test_splitdata_addition = pd.read_csv("cluster.csv")
data_addition = data_addition[["w2v_tsne1","w2v_tsne2"]]data_word = data[["Word", "date", "commonality", "letter_utilization", "type_num", "vowel_num", "repeat_num"]]
data_word = pd.concat([data_word, data_addition], axis=1)data_word = data_word.values
data_label = data[["1 try","2 tries","3 tries","4 tries","5 tries","6 tries","7 or more tries (X)"]] * 0.01
X_train, X_test, y_train, y_test = train_test_split(data_word, data_label, test_size=0.2, random_state=42)# device = 'cpu'def char2vec(data):data_vec = np.zeros((data.shape[0], 5))i = 0for word in data:data_vec[i] = np.array([dic[w] for w in list(word)])i += 1return data_vecx_train_vec = char2vec(X_train[:, 0])
x_test_vec = char2vec(X_test[:, 0])
y_label_train = y_train.values
y_label_test = y_test.valuesdef get_dataloader(data, X, label):print(X[0])train_data = torch.from_numpy(data).to(torch.float32).to(device)train_label = torch.from_numpy(label).to(torch.float32).to(device)X = torch.from_numpy(X.astype(np.float32)).to(torch.float32).to(device)train_data = torch.cat((train_data, X), dim=-1)dataset = TensorDataset(train_data, train_label)train_loader = dataloader.DataLoader(dataset=dataset, shuffle=False, batch_size=16) # return train_loadertrain_loader = get_dataloader(x_train_vec, X_train[:, 1:], y_label_train)
test_loader = get_dataloader(x_test_vec, X_test[:, 1:], y_label_test)
训练和预测函数
def run_epoch(model, train_iterator, optimzer, loss_fn): # 训练模型''':param model:模型:param train_iterator:训练数据的迭代器:param optimzer: 优化器:param loss_fn: 损失函数'''losses = []model.train()for i, batch in enumerate(train_iterator):if torch.cuda.is_available():input = batch[0].cuda()label = batch[1]else:input = batch[0]label = batch[1]pred = model(input) # 预测loss = loss_fn(pred, label) # 计算损失值loss.backward() # 误差反向传播losses.append(loss.cpu().data.numpy()) # 记录误差optimzer.step() # 优化一次return np.mean(losses)def evaluate_model(model, dev_iterator, loss_fn): # 评价模型''':param model:模型:param dev_iterator:待评价的数据:return:评价(准确率)'''losses = []model.eval()for i, batch in enumerate(dev_iterator):if torch.cuda.is_available():input = batch[0].cuda()label = batch[1]else:input = batch[0]label = batch[1]y_pred = model(input) # 预测loss = loss_fn(y_pred, label).cpu().data.numpy() # 计算损失值losses.append(loss)return np.mean(losses)
保存模型函数
每次选择训练测试集损失最小的模型保存
def save_model(model):model_name = "lstm.net" # 模型名称with open(model_name, 'wb') as f:torch.save(model.state_dict(), f) # 将模型参数写入文件,model即为已经实例化训练好的model
位置编码
用于单词时间的位置表示,可以参考transformer的一些理解以及逐层架构剖析与pytorch代码实现
class PositionalEncoding(nn.Module):def __init__(self, d_model, max_len=5000):# d_model:词嵌入维度# dropout:置零比率# max_len:每个句子最大的长度super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(0)pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(1000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0)self.register_buffer("pe", pe)def forward(self, x):return Variable(self.pe[:, x], requires_grad=False).squeeze()
模型及其参数设置
class my_config():embedding_size = 16 # 词向量大小hidden_size = 20 # 隐藏层大小num_layers = 2 # 网络层数dropout = 0.1 # 遗忘程度output_size = 7 # 输出大小lr = 0.0001 # 学习率epoch = 200 # 训练次数use_add = True # 使用额外特征use_date = True # 使用位置编码
config = my_config()class myLSTM(nn.Module):def __init__(self, config):super(myLSTM, self).__init__() # 初始化self.vocab_size = 26self.config = configself.embeddings = nn.Embedding(self.vocab_size, self.config.embedding_size) # 配置嵌入层,计算出词向量self.lstm = nn.LSTM(input_size=self.config.embedding_size, # 输入大小为转化后的词向量hidden_size=self.config.hidden_size, # 隐藏层大小num_layers=self.config.num_layers, # 堆叠层数,有几层隐藏层就有几层dropout=self.config.dropout, # 遗忘门参数bidirectional=True # 双向LSTM)self.dropout = nn.Dropout(self.config.dropout)self.fc_word = nn.Linear(self.config.num_layers * self.config.hidden_size * 2, # 因为双向所有要*2self.config.hidden_size)self.fc_add = nn.Linear(X_train.shape[1]-2, self.config.hidden_size)self.fc = nn.Linear(self.config.hidden_size * 2, self.config.output_size)self.noisy_flag = 0self.pos = PositionalEncoding(self.config.hidden_size)if self.config.use_add != True:self.fc_word = nn.Linear(self.config.num_layers * self.config.hidden_size * 2, # 因为双向所有要*2self.config.output_size)self.softmax = nn.Softmax(dim=-1)def forward(self, x):seq = x[:, :5].type(torch.cuda.LongTensor)time = x[:, 5].type(torch.cuda.LongTensor)pos_embed = self.pos(time)addfeature = x[:, 6:].type(torch.cuda.FloatTensor)# if self.noisy_flag == 0:# data_mean = [0.075763,0.283814,2.222841,1.788301,0.295265]# for i in range(len(data_mean)):# p = (torch.randint(low=4, high=10, size=(16,1)) / 100 * data_mean[i]).to(device)# addfeature[:, i] += p[:, 0]# self.noisy_flag = 1embedded = self.embeddings(seq)embedded = embedded.permute(1, 0, 2)lstm_out, (h_n, c_n) = self.lstm(embedded)feature = self.dropout(h_n)# 这里将所有隐藏层进行拼接来得出输出结果,没有使用模型的输出feature_map = torch.cat([feature[i, :, :] for i in range(feature.shape[0])], dim=-1)if self.config.use_add != True:out = self.fc_word(feature_map)else:out1 = self.fc_word(feature_map)if self.config.use_date:out1 = out1 + pos_embedout2 = self.fc_add(addfeature)out1 = torch.relu(out1)out2 = torch.relu(out2)out = torch.cat((out1, out2), dim=-1)out = self.fc(out)return self.softmax(out)
模型训练以及训练曲线可视化
model = myLSTM(config).to(device)
optimzer = torch.optim.Adam(model.parameters(), lr=config.lr, weight_decay=2e-5) # 优化器
loss_fn = nn.MSELoss()
# loss_fn = nn.KLDivLoss(reduction='batchmean', log_target=True)train_losses = []
test_losses = []
best_loss = 100
for i in range(config.epoch):print(f'epoch:{i + 1}')model.train()run_epoch(model, train_loader, optimzer, loss_fn)# 训练一次后评估一下模型model.eval()train_loss = evaluate_model(model, train_loader, loss_fn)test_loss = evaluate_model(model, test_loader, loss_fn)if best_loss > test_loss:best_loss = test_losssave_model(model)print('#' * 20)print('train_loss:{:.4f}'.format(train_loss))print('test_acc:{:.4f}'.format(test_loss))train_losses.append(train_loss)test_losses.append(test_loss)
print("best_loss", best_loss)import matplotlib.pyplot as plt
x = [i for i in range(len(train_losses))]
fig = plt.figure()
plt.plot(x, train_losses, label="train_loss", color="blue")
plt.plot(x, test_losses, label="test_loss", color="red")
plt.legend()
plt.show()
至此,我们可以选择最优模型来预测EERIE的人数分布:
预测人数分布
def pred():import torchdevice = 'cuda' if torch.cuda.is_available() else 'cpu'model = myLSTM(config).to(device) # 因为我们保存的模型参数,因此原来的刚实例化的模型我们需要将参数填进去以此作为我们能够进行预测的模型model.load_state_dict(torch.load("0.0018655956_lstm.net")) # 将保存好的文件中的参数载入model。model.eval()print(evaluate_model(model, test_loader, loss_fn))# EERIE# ,,,,,,,,,,,,,,,,,,,-0.46785906,-1.4528121,-1,4word = torch.tensor([[23, 23, 13, 1, 23, 418, 0.06580884219075174, 0.40309628952845034, 1, 5, 3, -0.46785906,-1.4528121]])pred_y = model(word)torch.save(model.embeddings.weight.data, "lstm_embed.pt")return pred_y
result = pred()[0]
得到的结果就是我们问题中的结果了。
个人感觉,这个模型应该还是有点竞争力的,模型得到词向量直接预测,和得到词向量后加上我们前面提取的特征丰富词向量,其实结果差不太多,提升就只有一奈奈,但是当加入时间信息,即得到词向量后每个词加入时间位置编码,模型的训练集损失下架了很多,大概下降了有10-15%左右,所以说,这个时间信息是很重要的,如何解释呢?可能就是后面人们掌握到这个游戏的窍门了,也可能这个题目出的词和时间有种莫名的关系等等。
难度分类预测
最开始,还没想到用深度学习的时候,在想着聚类什么什么,后来第二问做了,发现原来想法真是格局小了,我直接把第二问模型,输出维度改改,损失函数改成分类用的交叉熵损失函数,不是就结束了吗?
总结
美赛熬夜确实难受,唯一让我欣慰的是模型图画的还是蛮漂亮的(多亏了队友)
相关文章:
2023美赛C题Wordle二三问分布预测和难度分类预测
文章目录前言题目介绍人数分布预测首先建立字母词典,加上时间特征数据预处理训练和预测函数保存模型函数位置编码模型及其参数设置模型训练以及训练曲线可视化预测人数分布难度分类预测总结前言 2023美赛选了C题,应该很多人会选,一看就好做&…...
gdb的简单练习
题目来自《ctf安全竞赛入门》1.用vim写代码vim gdb.c#include "stdio.h" #include "stdlib.h" void main() {int i 100;int j 101;if (i j){printf("bingooooooooo.");system("/bin/sh");}elseprintf("error............&quo…...

如何使用python AI快速比对两张人脸图像?
本篇文章的代码块的实现主要是为了能够快速的通过python第三方非标准库对比出两张人脸是否一样。 实现过程比较简单,但是第三方python依赖的安装过程较为曲折,下面是通过实践对比总结出来的能够支持的几个版本,避免大家踩坑。 python版本&a…...
C#传智:变量基础(第二天))
(2)C#传智:变量基础(第二天)
一、注释符 不写注释是流氓,名字瞎起是扯蛋。 注释作用:解释与注销 命名: 以字母、_、开头,里面只能有_与特殊符,其它不得出现如%*&^等。 不能与关键字重复。区分大小写,Num…...
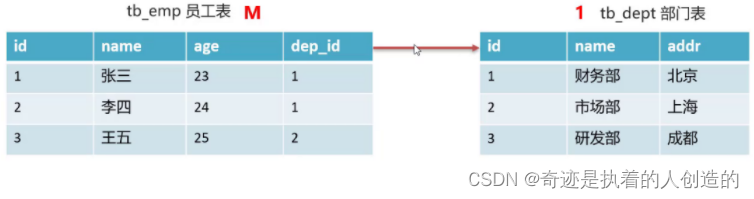
02-mysql高级-
文章目录mysql高级1,约束1.1 概念1.2 分类1.3 非空约束1.4 唯一约束1.5 主键约束1.6 默认约束1.7 约束练习1.8 外键约束1.8.1 概述1.8.2 语法1.8.3 练习2,数据库设计2.1 数据库设计简介2.2 表关系(一对多)mysql高级 今日目标 掌握约束的使用 掌握表关系…...
存储空间占用)
windows 使用everything 查看文件(夹)存储空间占用
起因 总是那个原因,C: D: E:全都红了,下的游戏太多了,然后就这样了,之前也有过不少这种情况.几年前,就在智能手机上见过类似的功能. 大概就是遍历文件系统,统计每个文件的大小,然后父节点记录所有子节点的和,然后可以显示占用百分比之类的. 经过 在windows 上我最开始使用ex…...

2023该好好赚钱了,推荐三个下班就能做的副业
在过去的两年里,越来越多的同事选择辞职创业。许多人通过互联网红利赚到了他们的第一桶金。随着短视频的兴起,越来越多的人吹嘘自己年收入百万,导致很多刚进入职场的年轻人逐渐迷失自我,认为钱特别容易赚。但事实上,80…...

vue3如何进行数据监听watch/watchEffect
我们都知道监听器的作用是在每次响应式状态发生变化时触发,在组合式 API 中,我们可以使用 watch()函数和watchEffect()函数, 当你更改了响应式状态,它可能会同时触发 Vue 组件更新和侦听器回调。 默认情况下,用户创建的侦听器回…...
Wgcloud安装和使用(性能监控)
一、Wgcloud说明 官网:https://www.wgstart.com/ WGCLOUD支持主机各种指标监测(cpu使用率,cpu温度,内存使用率,磁盘容量,磁盘IO,硬盘SMART健康状态,系统负载,连接数量&…...

前端如何实现本地图片上传?
前端如何实现本地图片上传? 摘要 对于学习前端的小伙伴都有一个困惑,就是平常想上手小项目,但碍于不想购买服务器,实践受到了限制。 一般我选择node.js搭建服务器,毕竟基于JavaScript语言,简直不是一家人…...

【基础算法】差分的应用(一维差分和二维差分)
🌹作者:云小逸 📝个人主页:云小逸的主页 📝Github:云小逸的Github 🤟motto:要敢于一个人默默的面对自己,强大自己才是核心。不要等到什么都没有了,才下定决心去做。种一颗树,最好的时间是十年前…...

第49章 API统一集中管理
1 关于统一集中管理API的一些思考 1、统一集中管理是保证工程性项目得保质、保量、成功实施,并对后期维护提供数据支撑的最有效,最节省资源和时间的技能和做法,软件做为一种特殊的工程性项目,也符合上述特性。 2、由于在前台实现中…...

carla0.9.13-UE4添加4轮车模型(Linux系统)
前期准备建模工具:blender:v3.4.1;可以在Ubuntu Software商店直接下载虚拟引擎:carla-UE4 (carla v0.9.13),无需额外安装UE4,carla中自带插件编译carla参照官方文档:https://carla.readthedocs.io/en/0.9.1…...
对比yolov4和yolov3
目录 1. 网络结构的不同 1.1 Backbone 1.1.1 Darknet53 1.1.2 CSPDarknet53 1.2 Neck 1.2.1 FPN 1.2.2 PAN 1.2.3 SPP 1.3 Head 2. 数据增强 2.1 CutMix 2.2 Mosaic 3. 激活函数 4. 损失函数 5. 正则化方法 知识点 记录备忘。 总体而言&…...

Android ServiceManager
1.ServiceManager ServiceManager在init进程启动后启动,用来管理系统中的Service。 一般开机过程分为三个阶段: ①OS级别,由bootloader载入linux内核后,内核开始初始化,并载入built-in的驱动程序,内核完成开机后,载入init process,切换至user-space后,结束内核的循…...
数据挖掘,计算机网络、操作系统刷题笔记53
数据挖掘,计算机网络、操作系统刷题笔记53 2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开 测开的话,你就得学数据库,sql,orac…...

地球板块运动vr交互模拟体验教学提高学生的学习兴趣
海陆变迁是地球演化史上非常重要的一个过程,它不仅影响着地球的气候、地貌、生物多样性等方面,还对人类文明的演化产生了深远的影响。为了帮助学生更加深入地了解海陆变迁的过程和机制,很多高校教育机构开始采用虚拟现实技术进行教学探究。 V…...

【Android玩机】跟大家聊聊面具Magisk的使用(安装、隐藏)
目录:1、Magisk中文网2、隐藏面具和Root(一共3种方法)1、Magisk中文网 (1)首先Magisk有一个中文网,对新手非常友好 (2)这网站里面主要包含:6 部分 (3)按照他给…...

DACS: Domain Adaptation via Cross-domain Mixed Sampling 学习笔记
DACS介绍方法Naive MixingDACSClassMix算法流程实验结果反思介绍 近年来,基于卷积神经网络的语义分割模型在众多应用中表现出了显著的性能。然而当应用于新的领域时&…...

python并发编程(并发与并行,同步和异步,阻塞与非阻塞)
最近在学python的网络编程,学了socket通信,并利用socket实现了一个具有用户验证功能,可以上传下载文件、可以实现命令行功能,创建和删除文件夹,可以实现的断点续传等功能的FTP服务器。但在这当中,发现一些概…...

【杂谈】-递归进化:人工智能的自我改进与监管挑战
递归进化:人工智能的自我改进与监管挑战 文章目录 递归进化:人工智能的自我改进与监管挑战1、自我改进型人工智能的崛起2、人工智能如何挑战人类监管?3、确保人工智能受控的策略4、人类在人工智能发展中的角色5、平衡自主性与控制力6、总结与…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

Leetcode 3576. Transform Array to All Equal Elements
Leetcode 3576. Transform Array to All Equal Elements 1. 解题思路2. 代码实现 题目链接:3576. Transform Array to All Equal Elements 1. 解题思路 这一题思路上就是分别考察一下是否能将其转化为全1或者全-1数组即可。 至于每一种情况是否可以达到…...

YSYX学习记录(八)
C语言,练习0: 先创建一个文件夹,我用的是物理机: 安装build-essential 练习1: 我注释掉了 #include <stdio.h> 出现下面错误 在你的文本编辑器中打开ex1文件,随机修改或删除一部分,之后…...

OPenCV CUDA模块图像处理-----对图像执行 均值漂移滤波(Mean Shift Filtering)函数meanShiftFiltering()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 在 GPU 上对图像执行 均值漂移滤波(Mean Shift Filtering),用于图像分割或平滑处理。 该函数将输入图像中的…...

SQL慢可能是触发了ring buffer
简介 最近在进行 postgresql 性能排查的时候,发现 PG 在某一个时间并行执行的 SQL 变得特别慢。最后通过监控监观察到并行发起得时间 buffers_alloc 就急速上升,且低水位伴随在整个慢 SQL,一直是 buferIO 的等待事件,此时也没有其他会话的争抢。SQL 虽然不是高效 SQL ,但…...

STM32HAL库USART源代码解析及应用
STM32HAL库USART源代码解析 前言STM32CubeIDE配置串口USART和UART的选择使用模式参数设置GPIO配置DMA配置中断配置硬件流控制使能生成代码解析和使用方法串口初始化__UART_HandleTypeDef结构体浅析HAL库代码实际使用方法使用轮询方式发送使用轮询方式接收使用中断方式发送使用中…...

Scrapy-Redis分布式爬虫架构的可扩展性与容错性增强:基于微服务与容器化的解决方案
在大数据时代,海量数据的采集与处理成为企业和研究机构获取信息的关键环节。Scrapy-Redis作为一种经典的分布式爬虫架构,在处理大规模数据抓取任务时展现出强大的能力。然而,随着业务规模的不断扩大和数据抓取需求的日益复杂,传统…...

Ubuntu系统复制(U盘-电脑硬盘)
所需环境 电脑自带硬盘:1块 (1T) U盘1:Ubuntu系统引导盘(用于“U盘2”复制到“电脑自带硬盘”) U盘2:Ubuntu系统盘(1T,用于被复制) !!!建议“电脑…...

【Linux】Linux安装并配置RabbitMQ
目录 1. 安装 Erlang 2. 安装 RabbitMQ 2.1.添加 RabbitMQ 仓库 2.2.安装 RabbitMQ 3.配置 3.1.启动和管理服务 4. 访问管理界面 5.安装问题 6.修改密码 7.修改端口 7.1.找到文件 7.2.修改文件 1. 安装 Erlang 由于 RabbitMQ 是用 Erlang 编写的,需要先安…...