数据采集: selenium 自动翻页接口调用时的验证码处理
写在前面
- 工作中遇到,简单整理
- 理解不足小伙伴帮忙指正
对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所有其它的路都是不完整的,是人的逃避方式,是对大众理想的懦弱回归,是随波逐流,是对内心的恐惧 ——赫尔曼·黑塞《德米安》
在数据采集的过程中,有部分页面会在接口调用到一定次数之后,每次获取数据调用接口之后,弹出一个验证码的校验,作为一种反爬措施,对于这种接口调用验证码,一般情况下,是只要请求就跳转,有部分页面是随机的,比如页面中有好多搜索框,可能每个搜索框的change 事件都会发生一次接口调用,这个时候使用 selenium 自动化提提取数据,会导致处理的页面不是想要的的页面,所以对于这种验证码的处理,我们需要在页面任意位置,提供一个检测跳转验证码验证页面的方法,同时对验证码做校验处理。
下面为一个 Demo
def cap(driver):"""@Time : 2023/08/29 03:38:33@Author : liruilonger@gmail.com@Version : 1.0@Desc : 验证码处理Args:driverReturns:void"""import ddddocrocr = ddddocr.DdddOcr()time.sleep(3)while len(driver.find_elements(By.XPATH,"//h1[contains(text(),'输入验证码刷新') ] " )) > 0:element = driver.find_element(By.XPATH, "//img[ @id='vcodeimg' ]")# 清空验证码数据driver.execute_script("arguments[0].value = ''", element)#定位元素并获取截图文件: element.screenshot("element.png")with open("element.png", "rb") as f:image_bytes = f.read()#image_bytes = BytesIO(base64.b64decode(screenshot))text = ocr.classification(image_bytes)if len(text) >4:text = text[1:5]driver.find_element(By.XPATH, "//input[@id='vcode']").send_keys(text)time.sleep(3)driver.find_element(By.XPATH, "//input[@class='isOK']").click()time.sleep(3)# 验证失败重新验证if len(driver.find_elements(By.XPATH,"//h1[contains(text(),'输入验证码刷新') ] " )) > 0:driver.get("https://icp.chinaz.com/captcha")在实际的编写中需要注意的地方:
- 获取验证码图片的方式,是通过对元素截图,还是对照片路径请求下载获取,需要注意有些验证码图片,在通过
requests库下载图片时,每次调用都是不同的图片,所以只能使用截图的方式 - 验证码识别的方式,可以考虑使用
ocr或者深度学习模型,或者一些商业接口,上面使用的pip install ddddocr - 对于识别不准的情况,可以考虑做一些后期的约束处理,比如上面的验证码,4位数字,但是在第一位会出现一个干扰字符,ocr 偶尔会识别为字符,需要做切割处理。
- 进行识别的时机,以及识别后的处理,对于如何开始识别,可以通过关键字来进行判断,放到入口处,对于识别后验证失败的处理也需要考虑,上面的页面在识别验证成功会进行跳转,错了不发生跳转
- 对于错误的情况,可以使用死循环的,重新请求,获取新的验证码,直到识别验证成功。
下面为一个数据采集的实际脚本中的使用。
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
"""
@File : icp_reptile.py
@Time : 2023/08/23 23:07:46
@Author : Li Ruilong
@Version : 1.0
@Contact : liruilonger@gmail.com
@Desc : 验证码版本
"""# here put the import libfrom selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import re
import pandas as pd
import csv
import sys
import os
import json
import requests
import ddddocr
from io import BytesIO
import base64
import pytesseract
from PIL import Imagea_name = ['河北']
ocr = ddddocr.DdddOcr()"""
自动登陆,需要提前保存登陆cookie 信息
"""
driver = webdriver.Chrome()
with open('C:\\Users\山河已无恙\\Documents\GitHub\\reptile_demo\\demo\\cookie_vip.json', 'r', encoding='u8') as f:cookies = json.load(f)driver.get('https://icp.chinaz.com/provinces')
for cookie in cookies:driver.add_cookie(cookie)driver.get('https://icp.chinaz.com/provinces')wait = WebDriverWait(driver, 30)## 查询条件准备"""
查询条件准备
"""#wait.until(EC.presence_of_element_located((By.XPATH, "//span[ @title='chinaz_7052291' ]")))def cap(driver):"""@Time : 2023/08/29 03:38:33@Author : liruilonger@gmail.com@Version : 1.0@Desc : 验证码处理Args:Returns:void"""time.sleep(3)while len(driver.find_elements(By.XPATH,"//h1[contains(text(),'输入验证码刷新') ] " )) > 0:element = driver.find_element(By.XPATH, "//img[ @id='vcodeimg' ]")# 清空验证码数据driver.execute_script("arguments[0].value = ''", element)#定位元素并获取截图文件: element.screenshot("element.png")with open("element.png", "rb") as f:image_bytes = f.read()#image_bytes = BytesIO(base64.b64decode(screenshot))text = ocr.classification(image_bytes)if len(text) >4:text = text[1:5]driver.find_element(By.XPATH, "//input[@id='vcode']").send_keys(text)time.sleep(3)driver.find_element(By.XPATH, "//input[@class='isOK']").click()time.sleep(3)if len(driver.find_elements(By.XPATH,"//h1[contains(text(),'输入验证码刷新') ] " )) > 0:driver.get("https://icp.chinaz.com/captcha")time.sleep(5)
# 触发验证码处理
all_butt_cap = driver.find_element(By.XPATH,"//h1[contains(text(),'输入验证码刷新') ] " )# 处理验证码的情况cap(driver)time.sleep(5)### 查询条件准备# 备案时间
all_butt = driver.find_element(By.XPATH,"//div/a[contains(@href,'all') and @class='pr10' ] " )
driver.execute_script("arguments[0].click();", all_butt)
cap(driver)
# 单位性质
all_butt = driver.find_element(By.XPATH,"//div[contains(text(),'全部') and @class='MainCateW-cont SearChoese'] " )
driver.execute_script("arguments[0].click();", all_butt)
time.sleep(3)
cap(driver)
# 企业
all_butt = driver.find_element(By.XPATH,"//a[contains(text(),'企业') and @val='企业' ]" )
driver.execute_script("arguments[0].click();", all_butt)
time.sleep(2)cap(driver)
# 状态
all_butt = driver.find_element(By.XPATH,"//div[contains(text(),'全部') and @id='webStatus_txt' and @class='MainCateW-cont SearChoese w90'] " )driver.execute_script("arguments[0].click();", all_butt)
time.sleep(2)
# 已开通
all_butt = driver.find_element(By.XPATH,"//a[contains(text(),'已开通') and @val='1' ]" )driver.execute_script("arguments[0].click();", all_butt)
time.sleep(2)
cap(driver)# 地区
all_butt = driver.find_element(By.XPATH,"//strong[contains(text(),'地区:') and @class='CateTit' ]" )
next_element = all_butt.find_element(By.XPATH,"following-sibling::*[1]")
driver.execute_script("arguments[0].click();", next_element)
time.sleep(2)def area(p_name,driver,p_data):"""@Time : 2023/08/24 04:24:50@Author : liruilonger@gmail.com@Version : 1.0@Desc : 备案数据获取Args:Returns:void"""all_butt = driver.find_element(By.XPATH,"//a[contains(text(),'"+p_name+"') ]" )driver.execute_script("arguments[0].click();", all_butt)#all_butt.click()time.sleep(2)# 页数太对分盟市处理,后面的数据没办法直接处理all_butt = driver.find_element(By.XPATH,"//div[contains(text(),'全部') and @id='addrctxt' ]" )time.sleep(2)driver.execute_script("arguments[0].click();", all_butt)all_ui = driver.find_element(By.XPATH,"//ul[ @id='addrclst'] " )citys = all_ui.find_elements(By.TAG_NAME,'a')for city in citys:try:c_n =city.textexcept:print("页面异常")continueif c_n == '全部':continueprint("处理市:",c_n)time.sleep(2)driver.execute_script("arguments[0].click();", city)time.sleep(5)# 验证码处理cap(driver)time.sleep(5)# 查询cap(driver)# 选择全部all_butt = driver.find_element(By.XPATH,"//div/a[contains(@href,'all') and @val='all' ] " )driver.execute_script("arguments[0].click();", all_butt)time.sleep(5)cap(driver)#all_butt = driver.find_element(By.XPATH,"//input[ @type='button' and @id='btn_search' and @value='点击搜索'] " )#driver.execute_script("arguments[0].click();", all_butt)#time.sleep(4)#cap(driver)time.sleep(10)def all_break(driver):if len(driver.find_elements(By.XPATH,"//span[contains(text(),'页,到第') and @class='col-gray02'] " )) == 0:all_butt = driver.find_element(By.XPATH,"//div/a[contains(@href,'all') and @val='all' ] " )driver.execute_script("arguments[0].click();", all_butt)time.sleep(5)cap(driver)time.sleep(10)#all_break(driver)# 总页数获取page_butt = driver.find_element(By.XPATH,"//span[contains(text(),'页,到第') and @class='col-gray02'] " )page_c = int(re.search(r'\d+', page_butt.text).group())# 盟市页数太多分时间段处理 # 当前页数据处理tbody = driver.find_element(By.XPATH,"//tbody[ @class='result_table' and @id='result_table' ]")rows = tbody.find_elements(By.TAG_NAME,'tr')for row in rows:# 获取当前行中的所有单元格cells = row.find_elements(By.TAG_NAME, "td")# 打印单元格数据data = {}data['域名']=cells[0].textdata['主办单位名称']=cells[1].textdata['网站首页网址']=cells[5].textp_data.append(data)# 其他页数据处理 if page_c >= 101:page_c = 101 for page_i in range(1,page_c):try:print(f"{c_n} :处理页数",page_i)nextPage = driver.find_element(By.XPATH,"//a[ @title='下一页' and @id='nextPage' ]")driver.execute_script("arguments[0].click();", nextPage)time.sleep(3)cap(driver)all_break(driver)cap(driver)#nextPage.click()time.sleep(6)tbody = driver.find_element(By.XPATH,"//tbody[ @class='result_table' and @id='result_table' ]")rows = tbody.find_elements(By.TAG_NAME,'tr')print(tbody.text)for row in rows:# 获取当前行中的所有单元格cells = row.find_elements(By.TAG_NAME, "td")# 打印单元格数据data = {}data['域名']=cells[0].textdata['主办单位名称']=cells[1].textdata['网站首页网址']=cells[5].textp_data.append(data)time.sleep(6)except:print(f"第 { page_i} 页发生了异常,跳过了")pass finally: fieldnames = ['域名', '主办单位名称', '网站首页网址']with open('省份_'+a+'_'+"ICP"+'.csv', 'w', newline='',encoding='utf-8') as file:writer = csv.DictWriter(file, fieldnames=fieldnames)writer.writeheader() # 写入列名writer.writerows(p_data) # 写入字典数据print("数据已保存为CSV文件",' CDN_M_省份_'+a+'_'+'ICP'+'.csv') return p_data if __name__ == '__main__':for a in a_name:p_data= []try:p_data = area(a,driver,p_data)except:continuepassfinally:fieldnames = ['域名', '主办单位名称', '网站首页网址']with open('省份_'+a+'_'+"ICP"+'.csv', 'w', newline='',encoding='utf-8') as file:writer = csv.DictWriter(file, fieldnames=fieldnames)writer.writeheader() # 写入列名writer.writerows(p_data) # 写入字典数据print("数据已保存为CSV文件",' CDN_M_省份_'+a+'_'+'ICP'+'.csv') time.sleep(55555)博文部分内容参考
© 文中涉及参考链接内容版权归原作者所有,如有侵权请告知 😃
© 2018-2023 liruilonger@gmail.com, All rights reserved. 保持署名-非商用-相同方式共享(CC BY-NC-SA 4.0)
相关文章:

数据采集: selenium 自动翻页接口调用时的验证码处理
写在前面 工作中遇到,简单整理理解不足小伙伴帮忙指正 对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所有其它的路都是不完整的,是人的逃避方式,是对大…...
IDEA安装翻译插件
IDEA安装翻译插件 File->Settings->Plugins 在Marketplace中,找到Translation,点击Install 更换翻译引擎 勾选自动翻译文档 翻译 鼠标右击->点击Translate...

DBeaver使用
一、导出表结构 二、导出数据CSV 导出数据时DBeaver并没有导出表结构,所以表结构需要额外保存; 导入数据CSV 导入数据时会因外键、字段长度导致失败;...

Nougat:一种用于科学文档OCR的Transformer 模型
随着人工智能领域的不断进步,其子领域,包括自然语言处理,自然语言生成,计算机视觉等,由于其广泛的用例而迅速获得了大量的普及。光学字符识别(OCR)是计算机视觉中一个成熟且被广泛研究的领域。它有许多用途,…...

redis八股1
参考Redis连环60问(八股文背诵版) - 知乎 (zhihu.com) 1.是什么 本质上是一个key-val数据库,把整个数据库加载到内存中操作,定期通过异步操作把数据flush到硬盘持久化。因为纯内存操作,所以性能很出色,每秒可以超过10…...

人工智能基础-趋势-架构
在过去的几周里,我花了一些时间来了解生成式人工智能基础设施的前景。在这篇文章中,我的目标是清晰概述关键组成部分、新兴趋势,并重点介绍推动创新的早期行业参与者。我将解释基础模型、计算、框架、计算、编排和矢量数据库、微调、标签、合…...
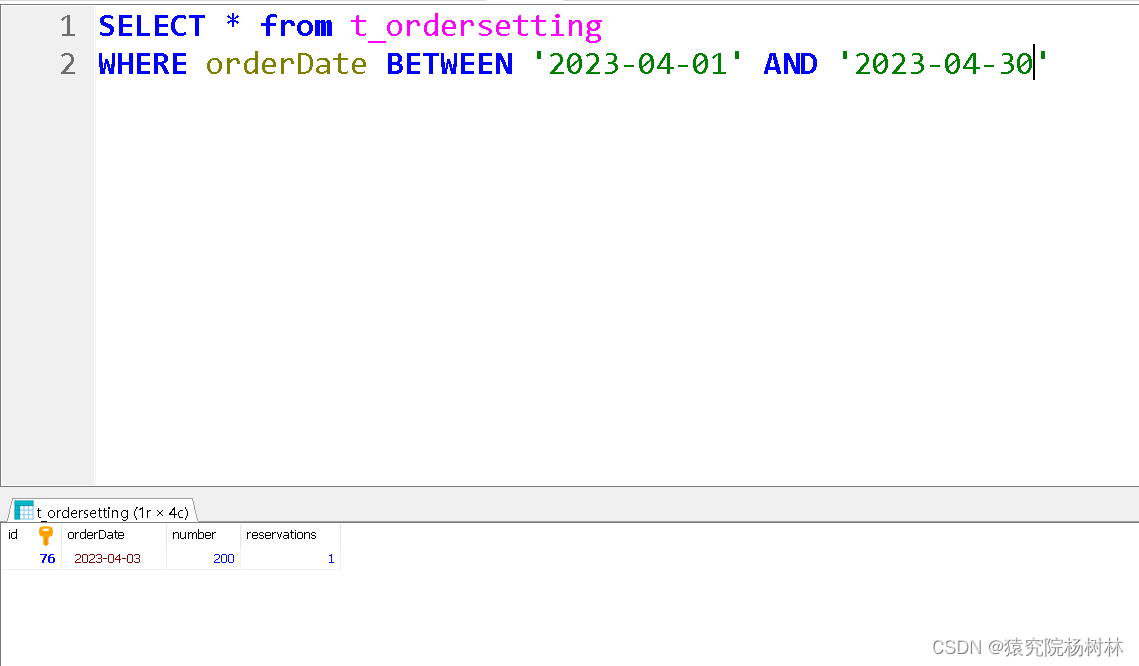
Date日期工具类(数据库日期区间问题)
文章目录 前言DateUtils日期工具类总结 前言 在我们日常开发过程中,当涉及到处理日期和时间的操作时,字符串与Date日期类往往要经过相互转换,且在SQL语句的动态查询中,往往月份的格式不正确,SQL语句执行的效果是不同的…...

为什么需要 TIME_WAIT 状态
还是用一下上一篇文章画的图 TCP 的 11 个状态,每一个状态都缺一不可,自然 TIME_WAIT 状态被赋予的意义也是相当重要,咱们直接结论先行 上文我们提到 tcp 中,主动关闭的一边会进入 TIME_WAIT 状态, 另外 Tcp 中的有 …...

Linux——(第七章)文件权限管理
目录 一、基本介绍 二、文件/目录的所有者 1.查看文件的所有者 2.修改文件所有者 三、文件/目录的所在组 1.修改文件/目录所在组 2.修改用户所在组 四、权限的基本介绍 五、rwx权限详解 1.rwx作用到文件 2.rwx作用到目录 六、修改权限 一、基本介绍 在Linux中&…...

Scala在大数据领域的崛起:当前趋势和未来前景
文章首发地址 Scala在大数据领域有着广阔的前景和现状。以下是一些关键点: Scala是一种具有强大静态类型系统的多范式编程语言,它结合了面向对象编程和函数式编程的特性。这使得Scala非常适合处理大数据,因为它能够处理并发、高吞吐量和复杂…...

前端面试经典题--页面布局
题目 假设高度已知,请写出三栏布局,其中左、右栏宽度各为300px,中间自适应。 五种解决方式代码 浮动解决方式 绝对定位解决方式 flexbox解决方式 表格布局 网格布局 源代码 <!DOCTYPE html> <html lang"en"> <…...

【webrtc】接收/发送的rtp包、编解码的VCM包、CopyOnWriteBuffer
收到的rtp包RtpPacketReceived 经过RtpDepacketizer 解析后变为ParsedPayloadRtpPacketReceived 分配内存,执行memcpy拷贝:然后把 RtpPacketReceived 给到OnRtpPacket 传递:uint8_t* media_payload = media_packet.AllocatePayload(rtx_payload.size());RTC...

Bash常见快捷键
生活在 Bash Shell 中,熟记以下快捷键,将极大的提高你的命令行操作效率。 编辑命令 Ctrl a :移到命令行首Ctrl e :移到命令行尾Ctrl f :按字符前移(右向)Ctrl b :按字符后移&a…...
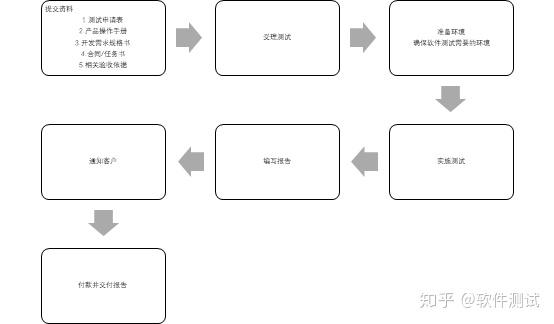
软件验收测试
1. 服务流程 验收测试 2. 服务内容 测试过程中,根据合同要求制定测试方案,验证工程项目是否满足用户需求,软件质量特性是否达到系统的要求。 3. 周期 10-15个工作日 4. 报告用途 可作为进行地方、省级、国家、部委项目的验收࿰…...

Java 与零拷贝
零拷贝是由操作系统实现的,使用 Java 中的零拷贝抽象类库在支持零拷贝的操作系统上运行才会实现零拷贝,如果在不支持零拷贝的操作系统上运行,并不会提供零拷贝的功能。 简述内核态和用户态 Linux 的体系结构分为内核态(内核空间…...

AI性能指标解析:误触率与错误率
简介:随着人工智能(AI)技术的不断发展,它越来越多地渗透到我们日常生活的各个方面。从个人助手到自动驾驶,从语音识别到图像识别,AI正不断地改变我们与世界的互动方式。但你有没有想过,如何准确…...

count(*) 和 count(1) 有什么区别?哪个性能最好?
哪种 count 性能最好? count() 是什么? count() 是一个聚合函数,函数的参数不仅可以是字段名,也可以是其他任意表达式,该函数的作用是统计符合查询条件的记录中,函数指定的参数不为 NULL 的记录由多少条。…...

橡胶密封件为什么会老化?
橡胶密封件以其优良的密封性能被广泛应用于各个行业。然而,随着时间的推移,这些橡胶密封件往往会恶化和老化。在这篇文章中,我们将探讨橡胶密封件老化的原因。 1,导致橡胶密封件老化的主要因素之一是暴露在阳光和紫外线(UV)辐射下…...

Uboot中bootargs以及bootcmd设置
Uboot命令 一、Uboot基础命令 查看帮助信息: uboot#help打印环境变量: uboot#printenv其他命令: uboot#help ? - 帮助命令,等同于 help base - 打印或设置地址偏移量 bdinfo - 打印板级信息结构 boot …...

冠达管理:减肥药概念再度爆发,常山药业两连板,翰宇药业等大涨
减肥药概念12日盘中再度拉升,到发稿,常山药业“20cm”涨停,翰宇药业涨超14%,德展健康涨停,金凯生科涨近9%,争气股份、普利制药、昊帆生物涨约5%,诺泰生物、圣诺生物、华森制药等涨超4%。 常山药…...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...
)
Java入门学习详细版(一)
大家好,Java 学习是一个系统学习的过程,核心原则就是“理论 实践 坚持”,并且需循序渐进,不可过于着急,本篇文章推出的这份详细入门学习资料将带大家从零基础开始,逐步掌握 Java 的核心概念和编程技能。 …...

爬虫基础学习day2
# 爬虫设计领域 工商:企查查、天眼查短视频:抖音、快手、西瓜 ---> 飞瓜电商:京东、淘宝、聚美优品、亚马逊 ---> 分析店铺经营决策标题、排名航空:抓取所有航空公司价格 ---> 去哪儿自媒体:采集自媒体数据进…...
-HIve数据分析)
大数据学习(132)-HIve数据分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言Ǵ…...

USB Over IP专用硬件的5个特点
USB over IP技术通过将USB协议数据封装在标准TCP/IP网络数据包中,从根本上改变了USB连接。这允许客户端通过局域网或广域网远程访问和控制物理连接到服务器的USB设备(如专用硬件设备),从而消除了直接物理连接的需要。USB over IP的…...

Golang——6、指针和结构体
指针和结构体 1、指针1.1、指针地址和指针类型1.2、指针取值1.3、new和make 2、结构体2.1、type关键字的使用2.2、结构体的定义和初始化2.3、结构体方法和接收者2.4、给任意类型添加方法2.5、结构体的匿名字段2.6、嵌套结构体2.7、嵌套匿名结构体2.8、结构体的继承 3、结构体与…...

LOOI机器人的技术实现解析:从手势识别到边缘检测
LOOI机器人作为一款创新的AI硬件产品,通过将智能手机转变为具有情感交互能力的桌面机器人,展示了前沿AI技术与传统硬件设计的完美结合。作为AI与玩具领域的专家,我将全面解析LOOI的技术实现架构,特别是其手势识别、物体识别和环境…...

c# 局部函数 定义、功能与示例
C# 局部函数:定义、功能与示例 1. 定义与功能 局部函数(Local Function)是嵌套在另一个方法内部的私有方法,仅在包含它的方法内可见。 • 作用:封装仅用于当前方法的逻辑,避免污染类作用域,提升…...

DeepSeek源码深度解析 × 华为仓颉语言编程精粹——从MoE架构到全场景开发生态
前言 在人工智能技术飞速发展的今天,深度学习与大模型技术已成为推动行业变革的核心驱动力,而高效、灵活的开发工具与编程语言则为技术创新提供了重要支撑。本书以两大前沿技术领域为核心,系统性地呈现了两部深度技术著作的精华:…...