@Cacheable 注解
1. 功能说明
@Cacheable 注解在方法上,表示该方法的返回结果是可以缓存的。也就是说,该方法的返回结果会放在缓存中,以便于以后使用相同的参数调用该方法时,会返回缓存中的值,而不会实际执行该方法。
注意,这里强调了一点:参数相同。这一点应该是很容易理解的,因为缓存不关心方法的执行逻辑,它能确定的是:对于同一个方法,如果参数相同,那么返回结果也是相同的。但是如果参数不同,缓存只能假设结果是不同的,所以对于同一个方法,你的程序运行过程中,使用了多少种参数组合调用过该方法,理论上就会生成多少个缓存的 key(当然,这些组合的参数指的是与生成 key 相关的)。下面来了解一下 @Cacheable 的一些参数:
2. cacheNames & value
@Cacheable 提供两个参数来指定缓存名:value、cacheNames,二者选其一即可。这是 @Cacheable 最简单的用法示例:
@Override@Cacheable("menu")public Menu findById(String id) {Menu menu = this.getById(id);if (menu != null){System.out.println("menu.name = " + menu.getName());}return menu;}在这个例子中,findById 方法与一个名为 menu 的缓存关联起来了。调用该方法时,会检查 menu 缓存,如果缓存中有结果,就不会去执行方法了。
3. 关联多个缓存名
其实,按照官方文档,@Cacheable 支持同一个方法关联多个缓存。这种情况下,当执行方法之前,这些关联的每一个缓存都会被检查,而且只要至少其中一个缓存命中了,那么这个缓存中的值就会被返回。示例:
@Override@Cacheable({"menu", "menuById"})public Menu findById(String id) {Menu menu = this.getById(id);if (menu != null){System.out.println("menu.name = " + menu.getName());}return menu;}---------@GetMapping("/findById/{id}")public Menu findById(@PathVariable("id")String id){Menu menu0 = menuService.findById("fe278df654adf23cf6687f64d1549c0a");Menu menu2 = menuService.findById("fb6106721f289ebf0969565fa8361c75");return menu0;}4. key & keyGenerator
一个缓存名对应一个被注解的方法,但是一个方法可能传入不同的参数,那么结果也就会不同,这应该如何区分呢?这就需要用到 key 。在 spring 中,key 的生成有两种方式:显式指定和使用 keyGenerator 自动生成。
4.1. KeyGenerator 自动生成
当我们在声明 @Cacheable 时不指定 key 参数,则该缓存名下的所有 key 会使用 KeyGenerator 根据参数 自动生成。spring 有一个默认的 SimpleKeyGenerator ,在 spring boot 自动化配置中,这个会被默认注入。生成规则如下:
a. 如果该缓存方法没有参数,返回 SimpleKey.EMPTY ;
b. 如果该缓存方法有一个参数,返回该参数的实例 ;
c. 如果该缓存方法有多个参数,返回一个包含所有参数的 SimpleKey ;
默认的 key 生成器要求参数具有有效的 hashCode() 和 equals() 方法实现。另外,keyGenerator 也支持自定义, 并通过 keyGenerator 来指定。关于 KeyGenerator 这里不做详细介绍,有兴趣的话可以去看看源码,其实就是使用 hashCode 进行加乘运算。跟 String 和 ArrayList 的 hash 计算类似。
4.2. 显式指定 key
相较于使用 KeyGenerator 生成,spring 官方更推荐显式指定 key 的方式,即指定 @Cacheable 的 key 参数。
即便是显式指定,但是 key 的值还是需要根据参数的不同来生成,那么如何实现动态拼接呢?SpEL(Spring Expression Language,Spring 表达式语言) 能做到这一点。下面是一些使用 SpEL 生成 key 的例子。
@Override@Cacheable(value = {"menuById"}, key = "#id")public Menu findById(String id) {Menu menu = this.getById(id);if (menu != null){System.out.println("menu.name = " + menu.getName());}return menu;}@Override@Cacheable(value = {"menuById"}, key = "'id-' + #menu.id")public Menu findById(Menu menu) {return menu;}@Override@Cacheable(value = {"menuById"}, key = "'hash' + #menu.hashCode()")public Menu findByHash(Menu menu) {return menu;}注意:官方说 key 和 keyGenerator 参数是互斥的,同时指定两个会导致异常。
5. cacheManager & cacheResolver
CacheManager,缓存管理器是用来管理(检索)一类缓存的。通常来讲,缓存管理器是与缓存组件类型相关联的。我们知道,spring 缓存抽象的目的是为使用不同缓存组件类型提供统一的访问接口,以向开发者屏蔽各种缓存组件的差异性。那么 CacheManager 就是承担了这种屏蔽的功能。spring 为其支持的每一种缓存的组件类型提供了一个默认的 manager,如:RedisCacheManager 管理 redis 相关的缓存的检索、EhCacheManager 管理 ehCache 相关的缓等。
CacheResolver,缓存解析器是用来管理缓存管理器的,CacheResolver 保持一个 cacheManager 的引用,并通过它来检索缓存。CacheResolver 与 CacheManager 的关系有点类似于 KeyGenerator 跟 key。spring 默认提供了一个 SimpleCacheResolver,开发者可以自定义并通过 @Bean 来注入自定义的解析器,以实现更灵活的检索。
大多数情况下,我们的系统只会配置一种缓存,所以我们并不需要显式指定 cacheManager 或者 cacheResolver。但是 spring 允许我们的系统同时配置多种缓存组件,这种情况下,我们需要指定。指定的方式是使用 @Cacheable 的 cacheManager 或者 cacheResolver 参数。
注意:按照官方文档,cacheManager 和 cacheResolver 是互斥参数,同时指定两个可能会导致异常。
6. sync
是否同步,true/false。在一个多线程的环境中,某些操作可能被相同的参数并发地调用,这样同一个 value 值可能被多次计算(或多次访问 db),这样就达不到缓存的目的。针对这些可能高并发的操作,我们可以使用 sync 参数来告诉底层的缓存提供者将缓存的入口锁住,这样就只能有一个线程计算操作的结果值,而其它线程需要等待,这样就避免了 n-1 次数据库访问。
sync = true 可以有效的避免缓存击穿的问题。
7. condition
调用前判断,缓存的条件。有时候,我们可能并不想对一个方法的所有调用情况进行缓存,我们可能想要根据调用方法时候的某些参数值,来确定是否需要将结果进行缓存或者从缓存中取结果。比如当我根据年龄查询用户的时候,我只想要缓存年龄大于 35 的查询结果。那么 condition 能实现这种效果。
condition 接收一个结果为 true 或 false 的表达式,表达式同样支持 SpEL 。如果表达式结果为 true,则调用方法时会执行正常的缓存逻辑(查缓存-有就返回-没有就执行方法-方法返回不空就添加缓存);否则,调用方法时就好像该方法没有声明缓存一样(即无论传入了什么参数或者缓存中有些什么值,都会执行方法,并且结果不放入缓存)
8. unless
执行后判断,不缓存的条件。unless 接收一个结果为 true 或 false 的表达式,表达式支持 SpEL。当结果为 true 时,不缓存。
可以看到,两次调用的结果都没有缓存。说明在这种情况下,condition 比 unless 的优先级高。总结起来就是:
condition 不指定相当于 true,unless 不指定相当于 false
当 condition = false,一定不会缓存;
当 condition = true,且 unless = true,不缓存;
当 condition = true,且 unless = false,缓存;
相关文章:

@Cacheable 注解
1. 功能说明 Cacheable 注解在方法上,表示该方法的返回结果是可以缓存的。也就是说,该方法的返回结果会放在缓存中,以便于以后使用相同的参数调用该方法时,会返回缓存中的值,而不会实际执行该方法。 注意,这…...
vue3+ts项目打包后的本地访问
注意:打包之后不可直接点击html访问,需要给项目安装本地服务! 1、安装servenpm i -g serve 2、打包项目npm run build 生成dist文件夹 3、本地访问serve dist 运行service dist之后的控制台 可复制下方的地址运行打包后的项目,运行…...

探索程序员需要掌握的算法?
文章目录 一:引言二:常见算法介绍三:重点算法总结 🎉欢迎来到数据结构学习专栏~探索程序员需要掌握的算法? ☆* o(≧▽≦)o *☆嗨~我是IT陈寒🍹✨博客主页:IT陈寒的博客🎈该系列文章…...
性能测试 —— Jmeter定时器
固定定时器 如果你需要让每个线程在请求之前按相同的指定时间停顿,那么可以使用这个定时器;需要注意的是,固定定时器的延时不会计入单个sampler的响应时间,但会计入事务控制器的时间 1、使用固定定时器位置在http请求中…...

mp4视频太大怎么压缩?几种常见压缩方法
mp4视频太大怎么压缩?科技的飞速发展使得视频成为人们生活中不可或缺的一部分。然而,随着视频质量的不断提高,视频文件的大小也与日俱增,给我们的存储和传输带来了巨大的挑战和困扰。特别是MP4格式的视频,由于其出色的…...

论文复制ChatGPT按钮被发表,撤回后再曝多个类似案例;Midjourney 生成大师级的人像
🦉 AI新闻 🚀 论文复制ChatGPT按钮被发表,撤回后再曝多个类似案例 摘要:一篇物理论文复制了ChatGPT按钮内容,经过两个月同行评审并在杂志上发表。这一现象被知名打假人发现后,发表商决定撤回该论文。此外…...
Python自动化测试 史上最全的进阶教程
Python自动化测试就是把以前人为测试转化为机器测试的一种过程。自动化测试是一种比手工测试更快获得故障反馈的方法。 随着时代的变革,也许在未来测试这个职位的需求会越来越少甚至消失,但是每一个组织,每一个客户对软件质量的要求是永远不…...

centos pip失效
在 CentOS 上安装和配置 pip3 可能需要以下步骤: 确保 Python 3 已正确安装:请确保您已经正确地安装了 Python 3。在 CentOS 上,Python 3 可能默认安装在 /usr/bin/python3 路径下。您可以通过运行以下命令来验证 Python 3 是否正确安装&…...
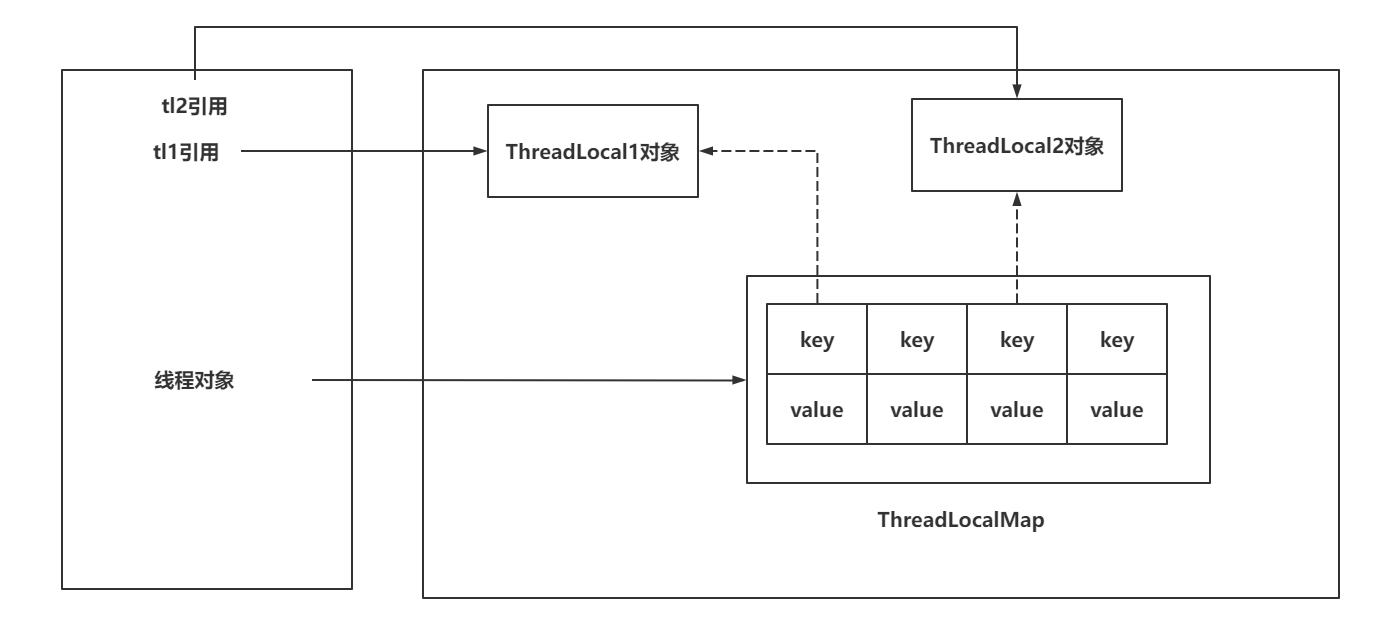
Java——》ThreadLocal
推荐链接: 总结——》【Java】 总结——》【Mysql】 总结——》【Redis】 总结——》【Kafka】 总结——》【Spring】 总结——》【SpringBoot】 总结——》【MyBatis、MyBatis-Plus】 总结——》【Linux】 总结——》【MongoD…...

如何做好利益相关方的期望管理?
利益相关方对项目而言非常重要,有效管理利益相关方的期望可以帮助项目团队更好地满足利益相关方的需求,助于建立良好的合作伙伴关系,提高项目的可持续性和成功率。 如果项目团队无法满足利益相关方的需求,可能会引发冲突、争议或其…...

【K8S系列】深入解析k8s网络插件—Canal
序言 做一件事并不难,难的是在于坚持。坚持一下也不难,难的是坚持到底。 文章标记颜色说明: 黄色:重要标题红色:用来标记结论绿色:用来标记论点蓝色:用来标记论点 在现代容器化应用程序的世界中…...
从单页面应用角度去解决不跳转页面,也能更改浏览器url地址
正常来说不刷新页面,也能更改浏览器url地址的方法有很多,我们在网上搜的话可以看到有pushState、replaceState、popstate等方法,那还有没有其他方法呢? 答案是有的! 最近做一个vue商城项目的时候,用户点击支…...
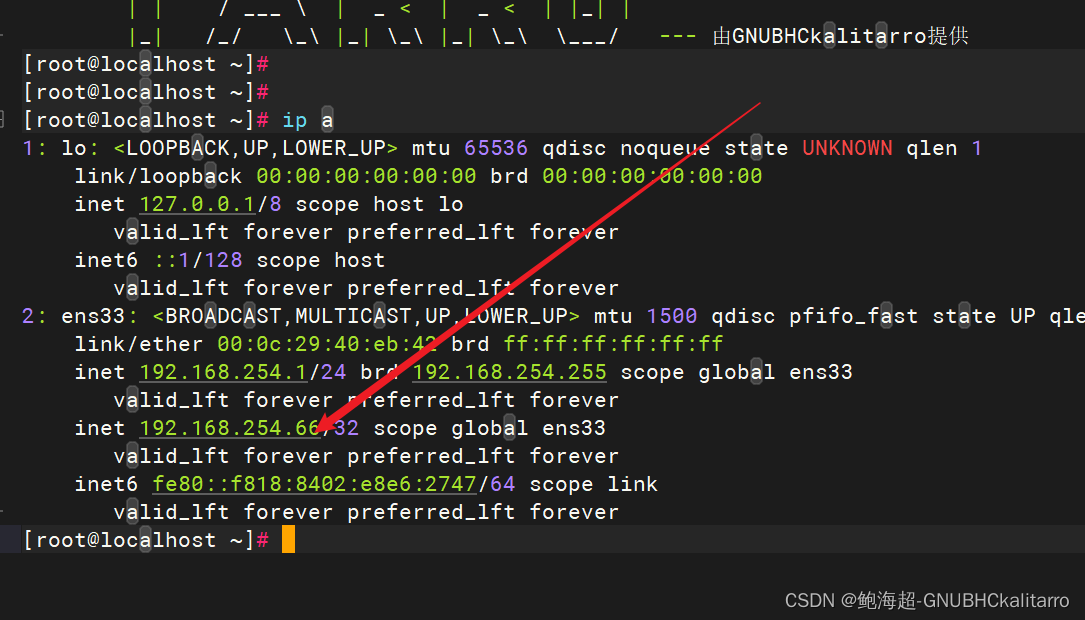
Linux:keepalived + ipvsadm
介绍 Linux:keepalived 双热备份(基础备份web)_鲍海超-GNUBHCkalitarro的博客-CSDN博客https://blog.csdn.net/w14768855/article/details/132815057?spm1001.2014.3001.5501 环境 一台 centos7 keepalived ipvsadm (主…...

Linux基础命令(示例代码 + 解释)
查看目录下文件 ls [-a -l -h] [路径] -a(全部) -l(细节) -h(大小) ls ls / ls -a ls -l ls -h ls -alh ls -l -h -a ls -lah /切换目录 cd [路径] change di…...

巨人互动|Google企业户Google“自动采纳建议”应该如何使用
在数字化时代,Google已经成为了人们获取信息的主要渠道之一。而在使用Google搜索时,你可能会发现下拉框中自动提供的搜索建议。这些搜索建议是基于用户搜索行为和相关数据进行推测,旨在使用户更快速地找到所需信息。而Google还提供了一项名为…...

元宇宙全球市场规模到2030年将达9805亿美元!
元宇宙是一种新兴的概念,它指的是一个虚拟的世界,由人工智能、虚拟现实、区块链等技术构建而成。元宇宙的起源可以追溯到上世纪90年代的虚拟世界“第二人生”,但直到近年来,随着技术的不断发展,它才逐渐成为了人们关注…...

《向量数据库指南》——向量数据库内核面临的技术挑战及应对措施
最近一年,以 ChatGPT、LLaMA 为代表的大语言模型的兴起,将向量数据库的发展推向了新的高度。 向量数据库是一种在机器学习和人工智能领域日益流行的新型数据库,它能够帮助支持基于神经网络而不是关键字的新型搜索引擎。向量数据库不同于传统的…...

API对接中需要注意的事项
API对接是一个复杂的过程,需要对接双方准确地理解和遵循一系列步骤。以下是一些在API对接中需要注意的事项,以及每个步骤的详细解释和可能遇到的问题。 一、API定义和规划 明确API需求:在开始对接前,必须明确API的具体需求和使用场…...

linux 6中4T磁盘识别并分区格式化
存储端划分4T的LUN后,主机端操作如下 1、主机识别,本例中hba卡的端口是host11和host12 [rootdb1 ~]# echo "- - -" > /sys/class/scsi_host/host11/scan [rootdb1 ~]# echo "- - -" > /sys/class/scsi_host/host12/scan …...
WebServer 解析HTTP 响应报文
一、基础API部分,介绍stat、mmap、iovec、writev、va_list 1.1 stat 作用:获取文件信息 #include <sys/types.h> #include <sys/stat.h> #include <unistd.h>// 获取文件属性,存储在statbuf中 int stat(const char *…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

中医有效性探讨
文章目录 西医是如何发展到以生物化学为药理基础的现代医学?传统医学奠基期(远古 - 17 世纪)近代医学转型期(17 世纪 - 19 世纪末)现代医学成熟期(20世纪至今) 中医的源远流长和一脉相承远古至…...

技术栈RabbitMq的介绍和使用
目录 1. 什么是消息队列?2. 消息队列的优点3. RabbitMQ 消息队列概述4. RabbitMQ 安装5. Exchange 四种类型5.1 direct 精准匹配5.2 fanout 广播5.3 topic 正则匹配 6. RabbitMQ 队列模式6.1 简单队列模式6.2 工作队列模式6.3 发布/订阅模式6.4 路由模式6.5 主题模式…...

Razor编程中@Html的方法使用大全
文章目录 1. 基础HTML辅助方法1.1 Html.ActionLink()1.2 Html.RouteLink()1.3 Html.Display() / Html.DisplayFor()1.4 Html.Editor() / Html.EditorFor()1.5 Html.Label() / Html.LabelFor()1.6 Html.TextBox() / Html.TextBoxFor() 2. 表单相关辅助方法2.1 Html.BeginForm() …...
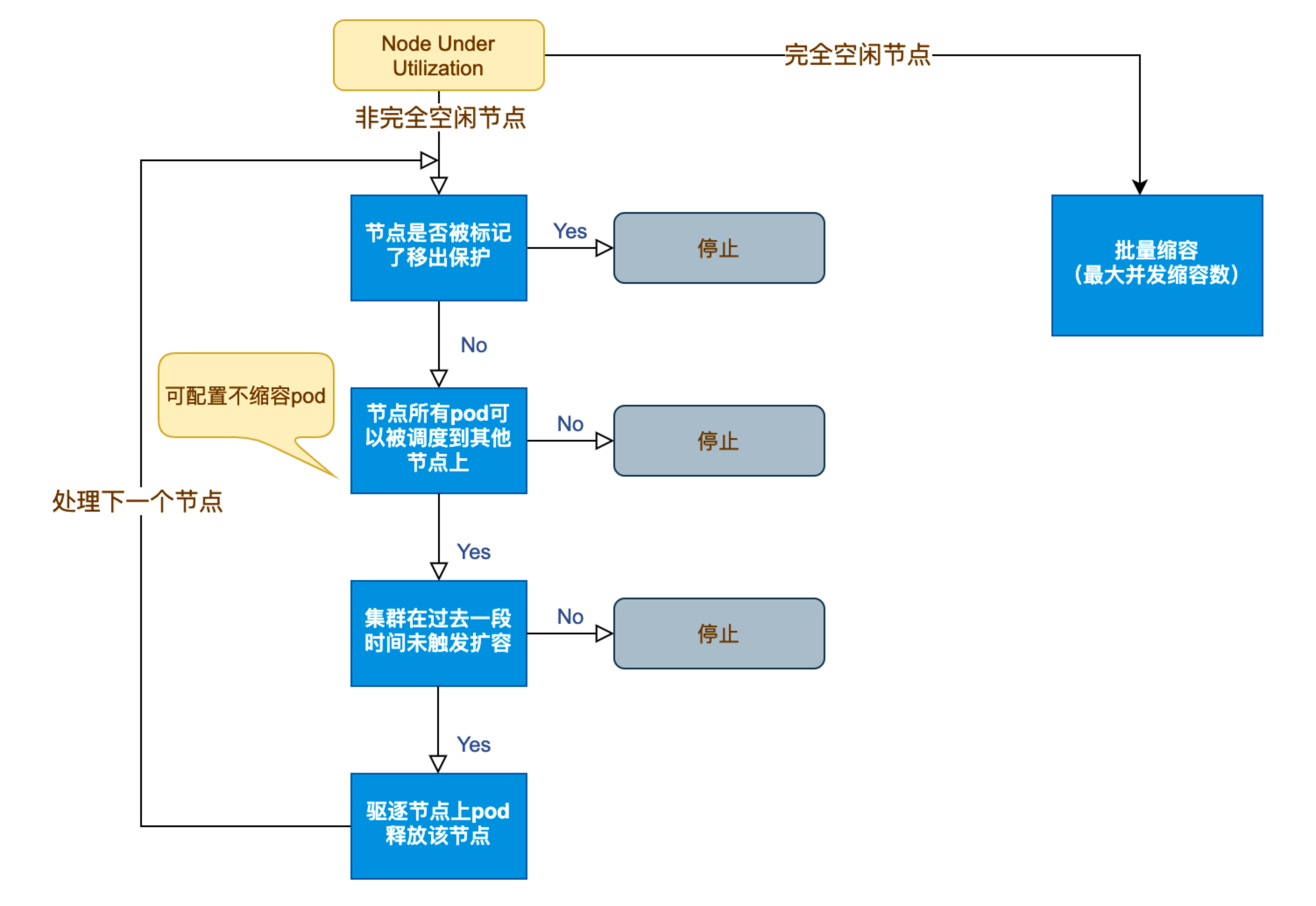
Kubernetes 节点自动伸缩(Cluster Autoscaler)原理与实践
在 Kubernetes 集群中,如何在保障应用高可用的同时有效地管理资源,一直是运维人员和开发者关注的重点。随着微服务架构的普及,集群内各个服务的负载波动日趋明显,传统的手动扩缩容方式已无法满足实时性和弹性需求。 Cluster Auto…...

【免费数据】2005-2019年我国272个地级市的旅游竞争力多指标数据(33个指标)
旅游业是一个城市的重要产业构成。旅游竞争力是一个城市竞争力的重要构成部分。一个城市的旅游竞争力反映了其在旅游市场竞争中的比较优势。 今日我们分享的是2005-2019年我国272个地级市的旅游竞争力多指标数据!该数据集源自2025年4月发表于《地理学报》的论文成果…...

TCP/IP 网络编程 | 服务端 客户端的封装
设计模式 文章目录 设计模式一、socket.h 接口(interface)二、socket.cpp 实现(implementation)三、server.cpp 使用封装(main 函数)四、client.cpp 使用封装(main 函数)五、退出方法…...

用 Rust 重写 Linux 内核模块实战:迈向安全内核的新篇章
用 Rust 重写 Linux 内核模块实战:迈向安全内核的新篇章 摘要: 操作系统内核的安全性、稳定性至关重要。传统 Linux 内核模块开发长期依赖于 C 语言,受限于 C 语言本身的内存安全和并发安全问题,开发复杂模块极易引入难以…...

2.2.2 ASPICE的需求分析
ASPICE的需求分析是汽车软件开发过程中至关重要的一环,它涉及到对需求进行详细分析、验证和确认,以确保软件产品能够满足客户和用户的需求。在ASPICE中,需求分析的关键步骤包括: 需求细化:将从需求收集阶段获得的高层需…...
OPENCV图形计算面积、弧长API讲解(1)
一.OPENCV图形面积、弧长计算的API介绍 之前我们已经把图形轮廓的检测、画框等功能讲解了一遍。那今天我们主要结合轮廓检测的API去计算图形的面积,这些面积可以是矩形、圆形等等。图形面积计算和弧长计算常用于车辆识别、桥梁识别等重要功能,常用的API…...