GFS分布式文件系统
1、GlusterFS简介
GlusterFS(GFS)是一个开源的分布式文件系统
由存储服务器、客户端以及NFS/Samba 存储网关(可选,根据需要选择使用)组成。
MFS
传统的分布式文件系统大多通过元服务器来存储元数据,元数据包含存储节点上的目录信息和目录结构等;
能够高效的浏览目录;但无法应对单点故障,一旦元数据服务器出现故障,整个存储系统也将崩溃GFS分布式文件系统基于无元服务器的设计,数据横向扩展能力强,具备较高的可靠性及存储效率在存储数据方面具有强大的横向扩展能力,能够支持数PB存储容量和处理数千客户端
2、GFS的特点:
扩展性和高性能
GlusterFS利用双重特性来提供高容量存储解决方案。
(1)Scale-Out架构允许通过简单地增加存储节点的方式来提高存储容量和性能(磁盘、计算和I/O资源都可以独立增加),支持10GbE和 InfiniBand等高速网络互联。
(2)Gluster弹性哈希(ElasticHash)解决了GlusterFS对元数据服务器的依赖,改善了单点故障和性能瓶颈,真正实现了并行化数据访问。GlusterFS采用弹性哈希算法在存储池中可以智能地定位任意数据分片(将数据分片存储在不同节点上),不需要查看索引或者向元数据服务器查询
高可用性:
GlusterFS可以对文件进行自动复制,如镜像或多次复制,从而确保数据总是可以访问,甚至是在硬件故障的情况下也能正常访问。
当数据出现不一致时,自我修复功能能够把数据恢复到正确的状态,数据的修复是以增量的方式在后台执行,几乎不会产生性能负载。
GlusterFS可以支持所有的存储,因为它没有设计自己的私有数据文件格式,而是采用操作系统中主流标准的磁盘文件系统(如EXT3、XFS等)来存储文件,因此数据可以使用传统访问磁盘的方式被访问。
全局统一命名空间
分布式存储中,将所有节点的命名空间整合为统一命名空间,将整个系统的所有节点的存储容量组成一个大的虚拟存储池,供前端主机访问这些节点完成数据读写操作。
弹性卷管理
GlusterFS通过将数据储存在逻辑卷中,逻辑卷从逻辑存储池进行独立逻辑划分而得到。
逻辑存储池可以在线进行增加和移除,不会导致业务中断。逻辑卷可以根据需求在线增长和缩减,并可以在多个节点中实现负载均衡。
文件系统配置也可以实时在线进行更改并应用,从而可以适应工作负载条件变化或在线性能调优。
基于标准协议
Gluster 存储服务支持 NFS、CIFS、HTTP、FTP、SMB 及 Gluster原生协议,完全与 POSIX 标准(可移植操作系统接口)兼容。
现有应用程序不需要做任何修改就可以对Gluster 中的数据进行访问,也可以使用专用 API 进行访问。
3、GlusterFS 术语☆☆☆
Brick(存储块):
指可信主机池中由主机提供的用于物理存储的专用分区,是GlusterFS中的基本存储单元,同时也是可信存储池中服务器上对外提供的存储目录。存储目录的格式由服务器和目录的绝对路径构成,表示方法为 SERVER:EXPORT,如 192.168.10.14:/data/mydir/。Volume(逻辑卷):
一个逻辑卷是卷上进行的。一组 Brick 的集合。卷是数据存储的逻辑设备,类似于 LVM 中的逻辑卷。大部分 Gluster 管理操作是在FUSE:
是一个内核模块,允许用户创建自己的文件系统,无须修改内核代码。
伪文件系统 VFS:
内核空间对用户空间提供的访问磁盘的接口。 虚拟端口Glusterd(后台管理进程): 服务端
在存储群集中的每个节点上都要运行。模块化堆栈式架构
GlusterFS 采用模块化、堆栈式的架构。
通过对模块进行各种组合,即可实现复杂的功能。例如 Replicate 模块可实现 RAID1,Stripe 模块可实现 RAID0, 通过两者的组合可实现 RAID10 和 RAID01,同时获得更高的性能及可靠性。
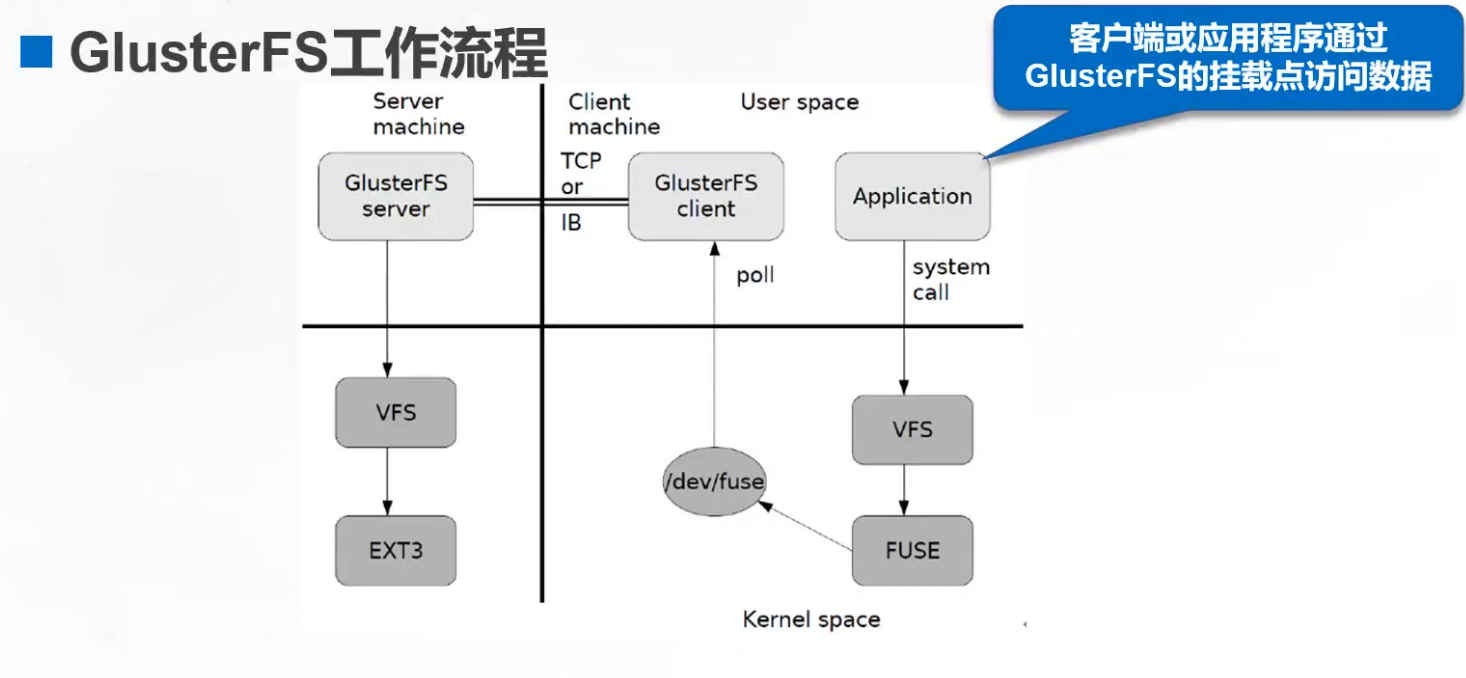
GlusterFS 的工作流程☆☆☆
(1)客户端或应用程序通过 GlusterFS 的挂载点访问数据。
(2)linux系统内核通过 VFS API 收到请求并处理。
(3)VFS 将数据递交给 FUSE 内核文件系统,并向系统注册一个实际的文件系统 FUSE,而 FUSE 文件系统则是将数据通过 /dev/fuse 设备文件递交给了 GlusterFS client 端。可以将 FUSE 文件系统理解为一个代理。通过poll指向客户端
(4)GlusterFS client 收到数据后,client 根据配置文件的配置对数据进行处理。
(5)经过 GlusterFS client 处理后,通过网络将数据传递至远端的 GlusterFS Server,并且将数据通过VFS接口写入到服务器存储设备上。
弹性 HASH 算法
弹性 HASH 算法是 Davies-Meyer 算法的具体实现,通过 HASH 算法可以得到一个 32 位的整数范围的 hash 值,
假设逻辑卷中有 N 个存储单位 Brick,则 32 位的整数范围将被划分为 N 个连续的子空间,每个空间对应一个 Brick。
当用户或应用程序访问某一个命名空间时,通过对该命名空间计算 HASH 值,根据该 HASH 值所对应的 32 位整数空间定位数据所在的 Brick。
#弹性 HASH 算法的优点:
保证数据平均分布在每一个 Brick 中。
解决了对元数据服务器的依赖,进而解决了单点故障以及访问瓶颈。
文件存储
linux7以前用ext4
linux7及之后用xfs
对象存储
GFS、Ceph、fastdfs
云端
OSS、阿里云
GlusterFS的卷类型
支持七种类型卷,即分布式卷、条带卷、复制卷、分布式条带卷、分布式复制卷、条带复制卷和分布式条带复制卷
分布式卷:以文件为单位通过hash值散列在各个brick中,不具备冗余能力
条带卷:把文件数据进行分块,轮询的分布在各个brick中,不具备冗余能力
复制卷:把文件在各个brick中做镜像存储,具备冗余能力
分布式条带卷:不具备冗余能力,至少需要4个brick,brick数量>=条带数的2倍
分布式复制卷:具备冗余能力,至少需要4个brick,brick数量>=副本数的2倍分布式卷
没有对文件进行分块处理
通过扩展文件属性保存hash值
支持的底层文件系统有EXT3、EXT4、ZFS、XFS等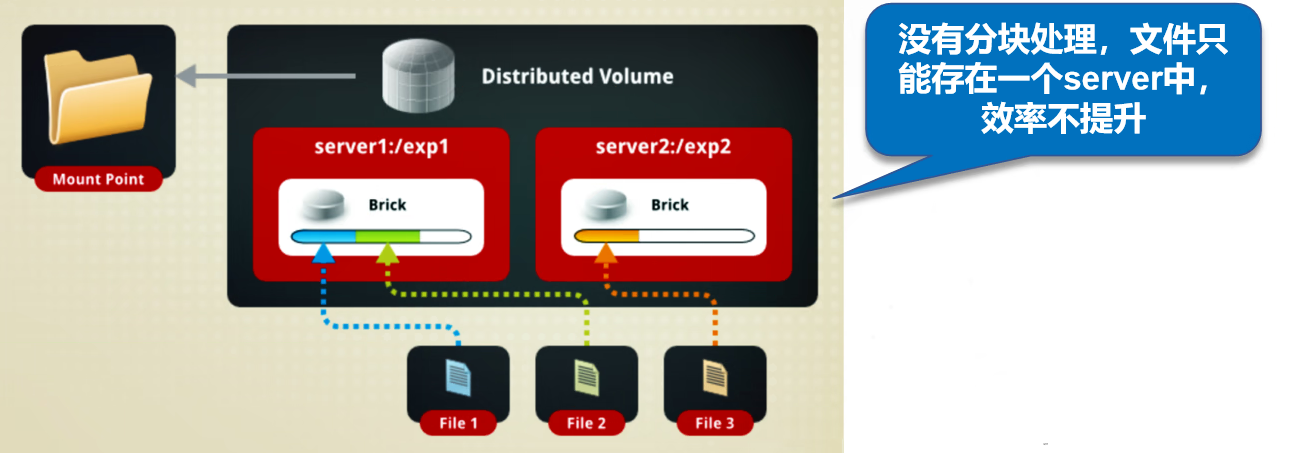

条带卷
根据偏移量将文件分成N块(N个条带节点),轮询的存储在每个Brick Srever节点
存储大文件时,性能突出
不具备冗余性,类似Raid0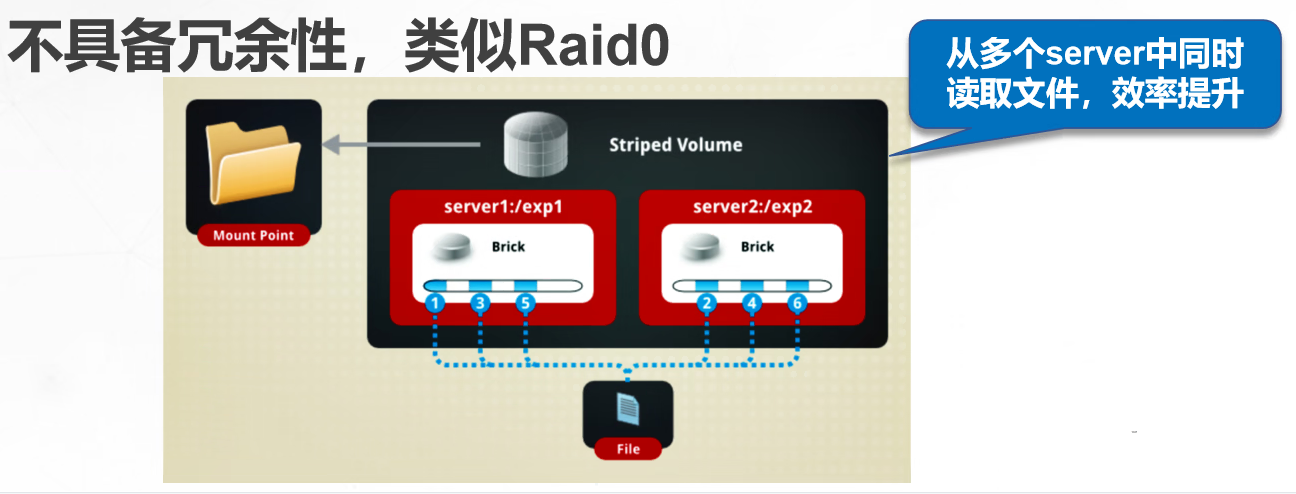

复制卷
同一文件保存一份或多份副本
因为要保存副本,所以磁盘利用率较低
若多个节点上的储存空间不一致,将按照木桶效应取最低节点的容量作为该卷的总容量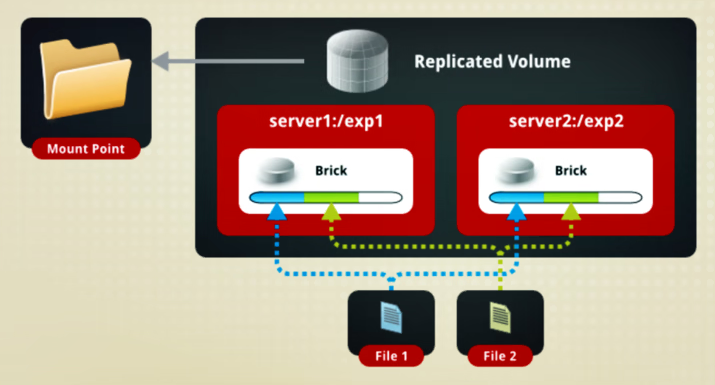

分布式条带卷
兼顾分布式卷和条带卷的功能
主要用于大文件访问处理
至少需要四台服务器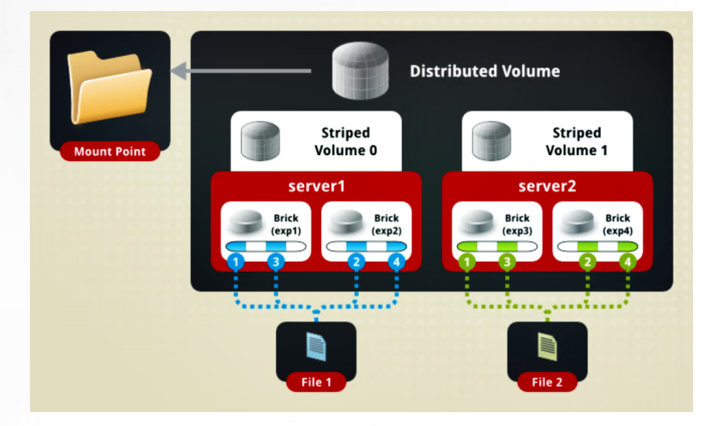

分布式复制卷
兼顾分布式卷和复制卷的功能
用于需要冗余的情况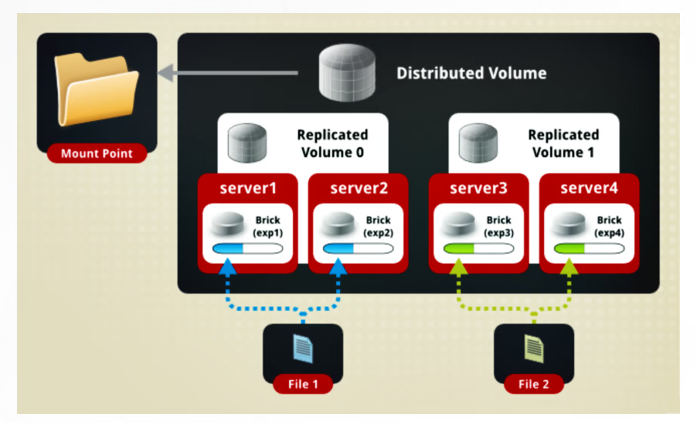

部署GlusterFS群集
准备环境(在所有node节点上操作)
机器
Node1节点:node1/192.168.220.101
磁盘:/dev/sdb1 挂载点:/data/sdb1/dev/sdc1 /data/sdc1/dev/sdd1 /data/sdd1/dev/sde1 /data/sde1Node2节点:node2/192.168.220.102
磁盘:/dev/sdb1 挂载点:/data/sdb1/dev/sdc1 /data/sdc1/dev/sdd1 /data/sdd1/dev/sde1 /data/sde1Node3节点:node3/192.168.220.103
磁盘:/dev/sdb1 挂载点:/data/sdb1/dev/sdc1 /data/sdc1/dev/sdd1 /data/sdd1/dev/sde1 /data/sde1Node4节点:node4/192.168.220.104
磁盘:/dev/sdb1 挂载点:/data/sdb1/dev/sdc1 /data/sdc1/dev/sdd1 /data/sdd1/dev/sde1 /data/sde1客户端节点:192.168.220.20
1.关闭防火墙
systemctl stop firewalld
setenforce 02.磁盘分区,并挂载
vim /opt/fdisk.sh
#!/bin/bash
NEWDEV=`ls /dev/sd* | grep -o 'sd[b-z]' | uniq`
for VAR in $NEWDEV
doecho -e "n\np\n\n\n\nw\n" | fdisk /dev/$VAR &> /dev/nullmkfs.xfs /dev/${VAR}"1" &> /dev/nullmkdir -p /data/${VAR}"1" &> /dev/nullecho "/dev/${VAR}"1" /data/${VAR}"1" xfs defaults 0 0" >> /etc/fstab
done
mount -a &> /dev/nullchmod +x /opt/fdisk.sh
cd /opt/
./fdisk.sh3.修改主机名,配置/etc/hosts文件
#以Node1节点为例:
hostnamectl set-hostname node1
suecho "192.168.220.101 node1" >> /etc/hosts
echo "192.168.220.102 node2" >> /etc/hosts
echo "192.168.220.103 node3" >> /etc/hosts
echo "192.168.220.104 node4" >> /etc/hostscat /etc/hosts安装、启动GlusterFS(所有node节点上操作)
#将gfsrepo 软件上传到/opt目录下
cd /etc/yum.repos.d/
mkdir repo.bak
mv *.repo repo.bakvim glfs.repo
[glfs]
name=glfs
baseurl=file:///opt/gfsrepo
gpgcheck=0
enabled=1yum clean all && yum makecache#yum -y install centos-release-gluster #如采用官方 YUM 源安装,可以直接指向互联网仓库
yum -y install glusterfs glusterfs-server glusterfs-fuse glusterfs-rdmasystemctl start glusterd.service
systemctl enable glusterd.service
systemctl status glusterd.service故障原因是版本过高导致
yum remove glusterfs-api.x86_64 glusterfs-cli.x86_64 glusterfs.x86_64 glusterfs-libs.x86_64 glusterfs-client-xlators.x86_64 glusterfs-fuse.x86_64 -y
添加节点到存储信任池中(在 node1 节点上操作)
#只要在一台Node节点上添加其它节点即可
gluster peer probe node1
gluster peer probe node2
gluster peer probe node3
gluster peer probe node4#在每个Node节点上查看群集状态
gluster peer status创建卷
#根据规划创建如下卷:
卷名称 卷类型 Brick
dis-volume 分布式卷 node1(/data/sdb1)、node2(/data/sdb1)
stripe-volume 条带卷 node1(/data/sdc1)、node2(/data/sdc1)
rep-volume 复制卷 node3(/data/sdb1)、node4(/data/sdb1)
dis-stripe 分布式条带卷 node1(/data/sdd1)、node2(/data/sdd1)、node3(/data/sdd1)、node4(/data/sdd1)
dis-rep 分布式复制卷 node1(/data/sde1)、node2(/data/sde1)、node3(/data/sde1)、node4(/data/sde1)1.创建分布式卷
#创建分布式卷,没有指定类型,默认创建的是分布式卷
gluster volume create dis-volume node1:/data/sdb1 node2:/data/sdb1 force #查看卷列表
gluster volume list#启动新建分布式卷
gluster volume start dis-volume#查看创建分布式卷信息
gluster volume info dis-volume
2.创建条带卷
#指定类型为 stripe,数值为 2,且后面跟了 2 个 Brick Server,所以创建的是条带卷
gluster volume create stripe-volume stripe 2 node1:/data/sdc1 node2:/data/sdc1 force
gluster volume start stripe-volume
gluster volume info stripe-volume3.创建复制卷
#指定类型为 replica,数值为 2,且后面跟了 2 个 Brick Server,所以创建的是复制卷
gluster volume create rep-volume replica 2 node3:/data/sdb1 node4:/data/sdb1 force
gluster volume start rep-volume
gluster volume info rep-volume4.创建分布式条带卷
#指定类型为 stripe,数值为 2,而且后面跟了 4 个 Brick Server,是 2 的两倍,所以创建的是分布式条带卷
gluster volume create dis-stripe stripe 2 node1:/data/sdd1 node2:/data/sdd1 node3:/data/sdd1 node4:/data/sdd1 force
gluster volume start dis-stripe
gluster volume info dis-stripe5.创建分布式复制卷
指定类型为 replica,数值为 2,而且后面跟了 4 个 Brick Server,是 2 的两倍,所以创建的是分布式复制卷
gluster volume create dis-rep replica 2 node1:/data/sde1 node2:/data/sde1 node3:/data/sde1 node4:/data/sde1 force
gluster volume start dis-rep
gluster volume info dis-rep #查看当前所有卷的列表
gluster volume list部署 Gluster 客户端
1.安装客户端软件
#将gfsrepo 软件上传到/opt目下
cd /etc/yum.repos.d/
mkdir repo.bak
mv *.repo repo.bakvim glfs.repo
[glfs]
name=glfs
baseurl=file:///opt/gfsrepo
gpgcheck=0
enabled=1yum clean all && yum makecacheyum -y install glusterfs glusterfs-fuse2.创建挂载目录
mkdir -p /test/{dis,stripe,rep,dis_stripe,dis_rep}
ls /test3.配置 /etc/hosts 文件
echo "192.168.10.13 node1" >> /etc/hosts
echo "192.168.10.14 node2" >> /etc/hosts
echo "192.168.10.15 node3" >> /etc/hosts
echo "192.168.10.16 node4" >> /etc/hosts4.挂载 Gluster 文件系统
#临时挂载
mount.glusterfs node1:dis-volume /test/dis
mount.glusterfs node1:stripe-volume /test/stripe
mount.glusterfs node1:rep-volume /test/rep
mount.glusterfs node1:dis-stripe /test/dis_stripe
mount.glusterfs node1:dis-rep /test/dis_repdf -Th#永久挂载
vim /etc/fstab
node1:dis-volume /test/dis glusterfs defaults,_netdev 0 0
node1:stripe-volume /test/stripe glusterfs defaults,_netdev 0 0
node1:rep-volume /test/rep glusterfs defaults,_netdev 0 0
node1:dis-stripe /test/dis_stripe glusterfs defaults,_netdev 0 0
node1:dis-rep /test/dis_rep glusterfs defaults,_netdev 0 0测试 Gluster 文件系统
1.卷中写入文件,客户端操作
cd /opt
dd if=/dev/zero of=/opt/demo1.log bs=1M count=40
dd if=/dev/zero of=/opt/demo2.log bs=1M count=40
dd if=/dev/zero of=/opt/demo3.log bs=1M count=40
dd if=/dev/zero of=/opt/demo4.log bs=1M count=40
dd if=/dev/zero of=/opt/demo5.log bs=1M count=40ls -lh /optcp /opt/demo* /test/dis
cp /opt/demo* /test/stripe/
cp /opt/demo* /test/rep/
cp /opt/demo* /test/dis_stripe/
cp /opt/demo* /test/dis_rep/2.查看文件分布
#查看分布式文件分布
[root@node1 ~]# ls -lh /data/sdb1 #数据没有被分片
总用量 160M
-rw-r--r-- 2 root root 40M 12月 18 14:50 demo1.log
-rw-r--r-- 2 root root 40M 12月 18 14:50 demo2.log
-rw-r--r-- 2 root root 40M 12月 18 14:50 demo3.log
-rw-r--r-- 2 root root 40M 12月 18 14:50 demo4.log
[root@node2 ~]# ll -h /data/sdb1
总用量 40M
-rw-r--r-- 2 root root 40M 12月 18 14:50 demo5.log#查看条带卷文件分布
[root@node1 ~]# ls -lh /data/sdc1 #数据被分片50% 没副本 没冗余
总用量 101M
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo1.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo2.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo3.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo4.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo5.log[root@node2 ~]# ll -h /data/sdc1 #数据被分片50% 没副本 没冗余
总用量 101M
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo1.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo2.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo3.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo4.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo5.log#查看复制卷分布
[root@node3 ~]# ll -h /data/sdb1 #数据没有被分片 有副本 有冗余
总用量 201M
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo1.log
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo2.log
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo3.log
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo4.log
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo5.log[root@node4 ~]# ll -h /data/sdb1 #数据没有被分片 有副本 有冗余
总用量 201M
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo1.log
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo2.log
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo3.log
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo4.log
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo5.log#查看分布式条带卷分布
[root@node1 ~]# ll -h /data/sdd1 #数据被分片50% 没副本 没冗余
总用量 81M
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo1.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo2.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo3.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo4.log[root@node2 ~]# ll -h /data/sdd1
总用量 81M
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo1.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo2.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo3.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo4.log[root@node3 ~]# ll -h /data/sdd1
总用量 21M
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo5.log[root@node4 ~]# ll -h /data/sdd1
总用量 21M
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo5.log#查看分布式复制卷分布 #数据没有被分片 有副本 有冗余
[root@node1 ~]# ll -h /data/sde1
总用量 161M
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo1.log
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo2.log
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo3.log
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo4.log[root@node2 ~]# ll -h /data/sde1
总用量 161M
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo1.log
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo2.log
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo3.log
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo4.log[root@node3 ~]# ll -h /data/sde1
总用量 41M
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo5.log
[root@node3 ~]# [root@node4 ~]# ll -h /data/sde1
总用量 41M
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo5.log破坏性测试
#挂起 node2 节点或者关闭glusterd服务来模拟故障
[root@node2 ~]# systemctl stop glusterd.service#在客户端上查看文件是否正常
#分布式卷数据查看
[root@localhost test]# ll /test/dis/ #在客户机上发现少了demo5.log文件,这个是在node2上的
总用量 163840
-rw-r--r-- 1 root root 41943040 12月 18 14:50 demo1.log
-rw-r--r-- 1 root root 41943040 12月 18 14:50 demo2.log
-rw-r--r-- 1 root root 41943040 12月 18 14:50 demo3.log
-rw-r--r-- 1 root root 41943040 12月 18 14:50 demo4.log#条带卷
[root@localhost test]# cd /test/stripe/ #无法访问,条带卷不具备冗余性
[root@localhost stripe]# ll
总用量 0#分布式条带卷
[root@localhost test]# ll /test/dis_stripe/ #无法访问,分布条带卷不具备冗余性
总用量 40960
-rw-r--r-- 1 root root 41943040 12月 18 14:51 demo5.log#分布式复制卷
[root@localhost test]# ll /test/dis_rep/ #可以访问,分布式复制卷具备冗余性
总用量 204800
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo1.log
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo2.log
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo3.log
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo4.log
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo5.log#挂起 node2 和 node4 节点,在客户端上查看文件是否正常
#测试复制卷是否正常
[root@localhost rep]# ls -l /test/rep/ #在客户机上测试正常 数据有
总用量 204800
-rw-r--r-- 1 root root 41943040 12月 18 14:51 demo1.log
-rw-r--r-- 1 root root 41943040 12月 18 14:51 demo2.log
-rw-r--r-- 1 root root 41943040 12月 18 14:51 demo3.log
-rw-r--r-- 1 root root 41943040 12月 18 14:51 demo4.log
-rw-r--r-- 1 root root 41943040 12月 18 14:51 demo5.log#测试分布式条卷是否正常
[root@localhost dis_stripe]# ll /test/dis_stripe/ #在客户机上测试没有数据
总用量 0#测试分布式复制卷是否正常
[root@localhost dis_rep]# ll /test/dis_rep/ #在客户机上测试正常 有数据
总用量 204800
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo1.log
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo2.log
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo3.log
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo4.log
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo5.log##### 上述实验测试,凡是带复制数据,相比而言,数据比较安全 #####
#扩展其他的维护命令:
1.查看GlusterFS卷
gluster volume list 2.查看所有卷的信息
gluster volume info3.查看所有卷的状态
gluster volume status4.停止一个卷
gluster volume stop dis-stripe5.删除一个卷,注意:删除卷时,需要先停止卷,且信任池中不能有主机处于宕机状态,否则删除不成功
gluster volume delete dis-stripe6.设置卷的访问控制
#仅拒绝
gluster volume set dis-rep auth.deny 192.168.80.100#仅允许
gluster volume set dis-rep auth.allow 192.168.80.* #设置192.168.80.0网段的所有IP地址都能访问dis-rep卷(分布式复制卷)安装报错:版本过高,先解除依赖关系
yum remove glusterfs-api.x86_64 glusterfs-cli.x86_64 glusterfs.x86_64 glusterfs-libs.x86_64 glusterfs-client-xlators.x86_64 glusterfs-fuse.x86_64 -y相关文章:
GFS分布式文件系统
1、GlusterFS简介 GlusterFS(GFS)是一个开源的分布式文件系统 由存储服务器、客户端以及NFS/Samba 存储网关(可选,根据需要选择使用)组成。MFS 传统的分布式文件系统大多通过元服务器来存储元数据,元数据…...

虚函数、纯虚函数、多态
一.虚函数 在基类的函数前加上virtual关键字,在派生类中重写该函数,运行时将会根据所指对象的实际类型来调用相应的函数,如果对象类型是派生类,就调用派生类的函数,如果对象类型是基类,就调用基类的函数。 …...
QGIS学习3 - 安装与管理插件
QGIS安装与管理插件主要是使用了菜单栏安装与管理插件这个菜单。 1、通过压缩文件等添加非官方插件 通过压缩文件添加有可能会提示存在安全问题等,直接点是即可。 之后点击install plugins即可完成。安装后导入插件 但是load失败了应该是安装没有成功。只能通过u…...

LeetCode377. 组合总和 Ⅳ
377. 组合总和 Ⅳ 文章目录 [377. 组合总和 Ⅳ](https://leetcode.cn/problems/combination-sum-iv/)一、题目二、题解方法一:完全背包一维数组动态规划思路代码分析 方法二:动态规划二维数组 一、题目 给你一个由 不同 整数组成的数组 nums ࿰…...

QT将数据写入文件,日志记录
项目场景: 在QT应用中,有时候需要将错误信息记录在log文件里面,或者需要将数据输出到文件中进行比对查看使用。 创建log文件,如果文件存在则不创建 QDir dir(QCoreApplication::applicationDirPath()"/recv_data");if(…...

vue2与vue3的使用区别与组件通信
1. 脚手架创建项目的区别: vue2: vue init webpack “项目名称”vue3: vue create “项目名称” 或者vue3一般与vite结合使用: npm create vitelatest yarn create vite2. template中结构 vue2: template下只有一个元素节点 <template><div><div…...

亚信科技与中国信通院达成全方位、跨领域战略合作
9月11日,亚信科技(中国)有限公司「简称:亚信科技」与中国信息通信研究院「简称:中国信通院」在京达成战略合作,双方将在关键技术研发、产业链协同等方面展开全方位、跨领域、跨行业深度合作,共促…...

华为Linux系统开发工程师面试
在Linux系统开发工程师的面试中,你可能会遇到以下一些问题: 在同一个网站中,当客户访问的时候,会出现有的页面访问的速度快而有的慢,系统和服务完全正常、网络带宽正常,你如何诊断这个问题?你以…...

Qt利用QTime实现sleep效果分时调用串口下发报文解决串口下发给下位机后产生的粘包问题
Qt利用QTime实现sleep效果分时调用串口下发报文解决串口下发给下位机后产生的粘包问题 文章目录 Qt利用QTime实现sleep效果分时调用串口下发报文解决串口下发给下位机后产生的粘包问题现象解决方法 现象 当有多包数据需要连续下发给下位机时,比如下载数据等&#x…...
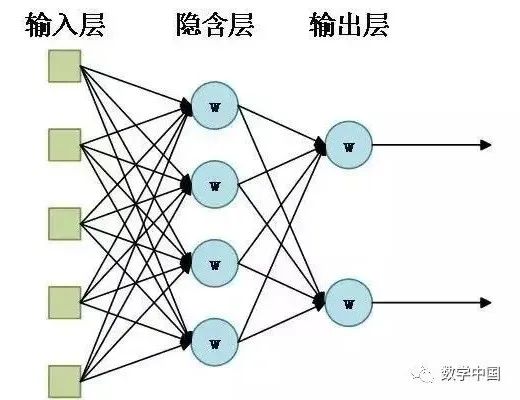
人工智能:神经细胞模型到神经网络模型
人工智能领域中的重要流派之一是:从神经细胞模型(Neural Cell Model)到神经网络模型(Neural Network Model)。 一、神经细胞模型 第一个人工神经细胞模型是“MP”模型,它是由麦卡洛克、匹茨合作࿰…...

Redisson分布式锁实战
实战来源 此问题基于电商 这周遇见这么一个问题,简略的说一下 由MQ发布了两个消息,一个是订单新增,一个是订单状态变更 由于直接付款之后,这两个消息的发布时间不分先后,可能会造成两种情况,1、订单状态变更…...

JavaScript中循环遍历数组、跳出循环和继续循环
循环遍历数组 上个文章我们简单的介绍for循环,接下来,我们使用for循环去读取数据的数据,之前我们写过这样的一个数组,如下: const ITshareArray ["张三","二愣子","2033-1997","…...

Java——》Synchronized和Lock区别
推荐链接: 总结——》【Java】 总结——》【Mysql】 总结——》【Redis】 总结——》【Kafka】 总结——》【Spring】 总结——》【SpringBoot】 总结——》【MyBatis、MyBatis-Plus】 总结——》【Linux】 总结——》【MongoD…...

JDK20 + SpringBoot 3.1.0 + JdbcTemplate 使用
JDK20 SpringBoot 3.1.0 JdbcTemplate 使用 一.测试数据库 Postgres二.SpringBoot项目1.Pom 依赖2.配置文件3.启动类4.数据源配置类5.实体对象类包装类6.测试用实体对象1.基类2.扩展类 7.测试类 通过 JdbcTemplate 直接执行 SQL 语句,结合源码动态编译即可方便实现…...
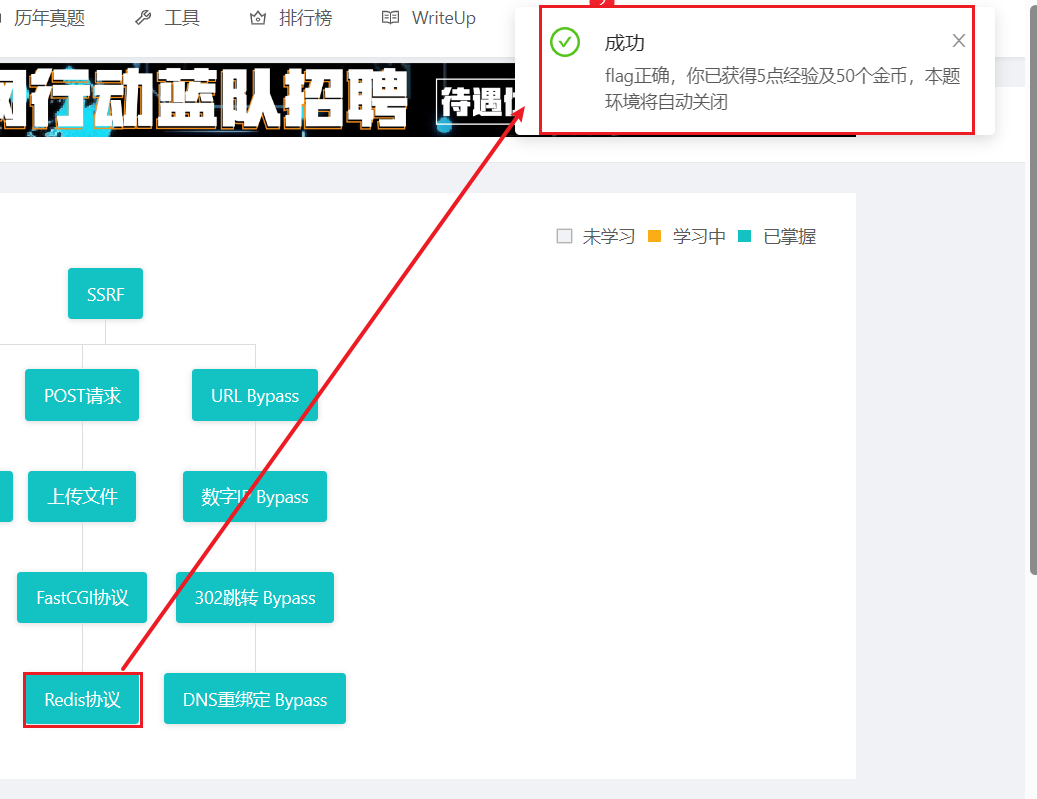
CTFhub_SSRF靶场教程
CTFhub SSRF 题目 1. Bypass 1.1 URL Bypass 请求的URL中必须包含http://notfound.ctfhub.com,来尝试利用URL的一些特殊地方绕过这个限制吧 1.利用?绕过限制urlhttps://www.baidu.com?www.xxxx.me 2.利用绕过限制urlhttps://www.baidu.comwww.xxxx.me 3.利用斜…...

【华为OD机试】单词接龙【2023 B卷|100分】
【华为OD机试】-真题 !!点这里!! 【华为OD机试】真题考点分类 !!点这里 !! 题目描述: 单词接龙的规则是:可用于接龙的单词首字母必须要前一个单词的尾字母相同; 当存在多个首字母相同的单词时,取长度最长的单词,如果长度也相等, 则取字典序最小的单词;已经参与接龙…...

如何优雅的实现无侵入性参数校验之spring-boot-starter-validation
在开发过程中,参数校验是一个非常重要的环节。但是,传统的参数校验方法往往需要在代码中手动添加大量的 if-else 语句,这不仅繁琐,而且容易出错。为了解决这个问题,我们可以使用无侵入性参数校验的方式来简化代码并提高…...
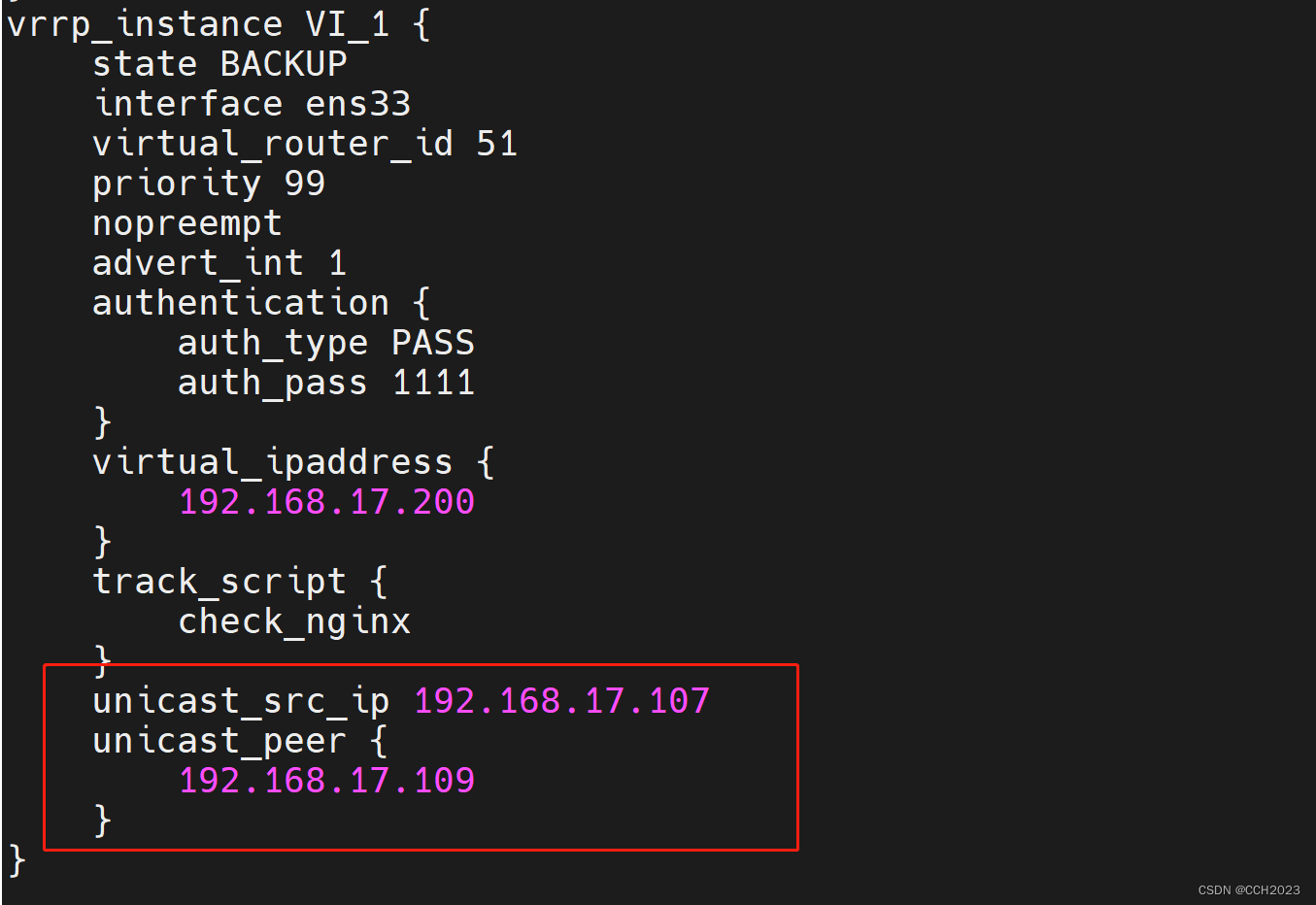
企业架构LNMP学习笔记27
Keepalived的配置补充: 脑裂(裂脑):vip出现在了多台机器上。网络不通畅,禁用了数据包,主备服务器没法通讯,造成备服务器认为主服务器不可用,绑定VIP,主服务器VIP不会释放…...

品牌策划经理工作内容|工作职责|品牌策划经理做什么?
一位美国作家曾说过“品牌是一系列期望、记忆、故事和关系,他们共同构成了消费者最终原则一个产品或者服务的原因。” 所以,品牌经理这个岗位主要是创造感知价值主张,激发消费者购买这个品牌后带来的感知价值,这种回报的本质相对…...
【设计模式】三、概述分类+单例模式
文章目录 概述设计模式类型 单例模式饿汉式(静态常量)饿汉式(静态代码块)懒汉式(线程不安全)懒汉式(线程安全,同步方法)懒汉式(线程安全,同步代码块)双重检查静态内部类枚举单例模式在 JDK 应用的源码分析 …...

浅谈 React Hooks
React Hooks 是 React 16.8 引入的一组 API,用于在函数组件中使用 state 和其他 React 特性(例如生命周期方法、context 等)。Hooks 通过简洁的函数接口,解决了状态与 UI 的高度解耦,通过函数式编程范式实现更灵活 Rea…...

ES6从入门到精通:前言
ES6简介 ES6(ECMAScript 2015)是JavaScript语言的重大更新,引入了许多新特性,包括语法糖、新数据类型、模块化支持等,显著提升了开发效率和代码可维护性。 核心知识点概览 变量声明 let 和 const 取代 var…...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...

visual studio 2022更改主题为深色
visual studio 2022更改主题为深色 点击visual studio 上方的 工具-> 选项 在选项窗口中,选择 环境 -> 常规 ,将其中的颜色主题改成深色 点击确定,更改完成...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

深入解析C++中的extern关键字:跨文件共享变量与函数的终极指南
🚀 C extern 关键字深度解析:跨文件编程的终极指南 📅 更新时间:2025年6月5日 🏷️ 标签:C | extern关键字 | 多文件编程 | 链接与声明 | 现代C 文章目录 前言🔥一、extern 是什么?&…...

智能分布式爬虫的数据处理流水线优化:基于深度强化学习的数据质量控制
在数字化浪潮席卷全球的今天,数据已成为企业和研究机构的核心资产。智能分布式爬虫作为高效的数据采集工具,在大规模数据获取中发挥着关键作用。然而,传统的数据处理流水线在面对复杂多变的网络环境和海量异构数据时,常出现数据质…...

Unity | AmplifyShaderEditor插件基础(第七集:平面波动shader)
目录 一、👋🏻前言 二、😈sinx波动的基本原理 三、😈波动起来 1.sinx节点介绍 2.vertexPosition 3.集成Vector3 a.节点Append b.连起来 4.波动起来 a.波动的原理 b.时间节点 c.sinx的处理 四、🌊波动优化…...
Reasoning over Uncertain Text by Generative Large Language Models
https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829 1. 概述 文本中的不确定性在许多语境中传达,从日常对话到特定领域的文档(例如医学文档)(Heritage 2013;Landmark、Gulbrandsen 和 Svenevei…...
相比,优缺点是什么?适用于哪些场景?)
Redis的发布订阅模式与专业的 MQ(如 Kafka, RabbitMQ)相比,优缺点是什么?适用于哪些场景?
Redis 的发布订阅(Pub/Sub)模式与专业的 MQ(Message Queue)如 Kafka、RabbitMQ 进行比较,核心的权衡点在于:简单与速度 vs. 可靠与功能。 下面我们详细展开对比。 Redis Pub/Sub 的核心特点 它是一个发后…...