树回归CART
之前线性回归创建的模型需要拟合所有的样本点,但数据特征众多,关系复杂时,构建全局模型就很困难。之前构建决策树使用的算法是ID3。
ID3 的做法是每次选取当前最佳的特征来分割数据,并按照该特征的所有可能取值来切分。也就是说,如果一个特征有 4 种取值,那么数据将被切分成 4 份。一旦按照某特征切分后,该特征在之后的算法执行过程中将不会再起作用,所以有观点认为这种切分方式过于迅速。另外一种方法是二元切分法,即每次把数据集切分成两份。如果数据的某特征值等于切分所要求的值,那么这些数据就进入树的左子树,反之则进入树的右子树。
除了切分过于迅速外, ID3 算法还存在另一个问题,它不能直接处理连续型特征。只有事先将连续型特征转换成离散型,才能在 ID3 算法中使用。但这种转换过程会破坏连续型变量的内在性质。而使用二元切分法则易于对树构造过程进行调整以处理连续型特征。具体的处理方法是: 如果特征值大于给定值就走左子树,否则就走右子树。另外,二元切分法也节省了树的构建时间,但这点意义也不是特别大,因为这些树构建一般是离线完成,时间并非需要重点关注的因素。
CART 是十分著名且广泛记载的树构建算法,它使用二元切分来处理连续型变量。对 CART 稍作修改就可以处理回归问题。决策树中使用香农熵来度量集合的无组织程度。如果选用其他方法来代替香农熵,就可以使用树构建算法来完成回归。
回归树与分类树的思路类似,但是叶节点的数据类型不是离散型,而是连续型。
还有一点要说明,构建决策树算法,常用到的是三个方法: ID3, C4.5, CART.
三种方法区别是划分树的分支的方式:
- ID3 是信息增益分支
- C4.5 是信息增益率分支
- CART 做分类工作时,采用 GINI 值作为节点分裂的依据;回归时,采用样本的最小方差作为节点的分裂依据。
工程上总的来说:
CART 和 C4.5 之间主要差异在于分类结果上,CART 可以回归分析也可以分类,C4.5 只能做分类;C4.5 子节点是可以多分的,而 CART 是无数个二叉子节点;
以此拓展出以 CART 为基础的 “树群” Random forest , 以 回归树 为基础的 “树群” GBDT 。
树剪枝
一棵树如果节点过多,表明该模型可能对数据进行了 “过拟合”。
通过降低决策树的复杂度来避免过拟合的过程称为 剪枝(pruning)。在函数 chooseBestSplit() 中提前终止条件,实际上是在进行一种所谓的 预剪枝(prepruning)操作。另一个形式的剪枝需要使用测试集和训练集,称作 后剪枝(postpruning)。
预剪枝(prepruning)
顾名思义,预剪枝就是及早的停止树增长,在构造决策树的同时进行剪枝。
所有决策树的构建方法,都是在无法进一步降低熵的情况下才会停止创建分支的过程,为了避免过拟合,可以设定一个阈值,熵减小的数量小于这个阈值,即使还可以继续降低熵,也停止继续创建分支。但是这种方法实际中的效果并不好。
后剪枝(postpruning)
决策树构造完成后进行剪枝。剪枝的过程是对拥有同样父节点的一组节点进行检查,判断如果将其合并,熵的增加量是否小于某一阈值。如果确实小,则这一组节点可以合并一个节点,其中包含了所有可能的结果。合并也被称作 塌陷处理 ,在回归树中一般采用取需要合并的所有子树的平均值。后剪枝是目前最普遍的做法。
模型树
用树来对数据建模,除了把叶节点简单地设定为常数值之外,还有一种方法是把叶节点设定为分段线性函数,这里所谓的 分段线性(piecewise linear) 是指模型由多个线性片段组成。
from __future__ import print_function
from Tkinter import *
from numpy import *# 默认解析的数据是用tab分隔,并且是数值类型
# general function to parse tab -delimited floats
def loadDataSet(fileName):"""loadDataSet(解析每一行,并转化为float类型)Desc: 该函数读取一个以 tab 键为分隔符的文件,然后将每行的内容保存成一组浮点数Args:fileName 文件名Returns:dataMat 每一行的数据集array类型Raises:"""# 假定最后一列是结果值# assume last column is target valuedataMat = []fr = open(fileName)for line in fr.readlines():curLine = line.strip().split('\t')# 将所有的元素转化为float类型# map all elements to float()# map() 函数具体的含义,可见 https://my.oschina.net/zyzzy/blog/115096fltLine = map(float, curLine)dataMat.append(fltLine)return dataMatdef binSplitDataSet(dataSet, feature, value):"""binSplitDataSet(将数据集,按照feature列的value进行 二元切分)Description: 在给定特征和特征值的情况下,该函数通过数组过滤方式将上述数据集合切分得到两个子集并返回。Args:dataMat 数据集feature 待切分的特征列value 特征列要比较的值Returns:mat0 小于等于 value 的数据集在左边mat1 大于 value 的数据集在右边Raises:"""# # 测试案例# print 'dataSet[:, feature]=', dataSet[:, feature]# print 'nonzero(dataSet[:, feature] > value)[0]=', nonzero(dataSet[:, feature] > value)[0]# print 'nonzero(dataSet[:, feature] <= value)[0]=', nonzero(dataSet[:, feature] <= value)[0]# dataSet[:, feature] 取去每一行中,第1列的值(从0开始算)# nonzero(dataSet[:, feature] > value) 返回结果为true行的index下标mat0 = dataSet[nonzero(dataSet[:, feature] <= value)[0], :]mat1 = dataSet[nonzero(dataSet[:, feature] > value)[0], :]return mat0, mat1# 返回每一个叶子结点的均值
# returns the value used for each leaf
# 我的理解是: regLeaf 是产生叶节点的函数,就是求均值,即用聚类中心点来代表这类数据
def regLeaf(dataSet):return mean(dataSet[:, -1])# 计算总方差=方差*样本数
# 我的理解是: 求这组数据的方差,即通过决策树划分,可以让靠近的数据分到同一类中去
def regErr(dataSet):# shape(dataSet)[0] 表示行数return var(dataSet[:, -1]) * shape(dataSet)[0]# 1.用最佳方式切分数据集
# 2.生成相应的叶节点
def chooseBestSplit(dataSet,leafType=regLeaf,errType=regErr,ops=(1,4)):'''chooseBestSplit(用最佳方式切分数据集 和 生成相应的叶节点)Args:dataSet 加载的原始数据集leafType 建立叶子点的函数errType 误差计算函数(求总方差)ops [容许误差下降值,切分的最少样本数]。Returns:bestIndex feature的index坐标bestValue 切分的最优值Raises:'''#ops=(1,4),非常重要,因为它决定了决策树划分停止的threshold值,被称为预剪枝(prepruning),其实也就是用于控制函数的停止时机。# 之所以这样说,是因为它防止决策树的过拟合,所以当误差的下降值小于tolS,或划分后的集合size小于tolN时,选择停止继续划分。# 最小误差下降值,划分后的误差减小小于这个差值,就不用继续划分tolS=ops[0]# 划分最小 size 小于,就不继续划分了tolN=ops[1]# 如果结果集(最后一列为1个变量),就返回退出# .T 对数据集进行转置# .tolist()[0] 转化为数组并取第0列if len(set(dataSet[:,-1].T.tolist()[0]))==1:# 如果集合size为1,也就是说全部的数据都是同一个类别,不用继续划分。# exit cond 1return None,leafType(dataSet)# 计算行列值m,n=shape(dataSet)# 无分类误差的总方差和# the choice of the best feature is driven by Reduction in RSS error from meanS=errType(dataSet)# inf 正无穷大bestS, bestIndex, bestValue = inf, 0, 0# 循环处理每一列对应的feature值for featIndex in range(n-1): # 对于每个特征# [0]表示这一列的[所有行],不要[0]就是一个array[[所有行]],下面的一行表示的是将某一列全部的数据转换为行,然后设置为list形式for splitVal in set(dataSet[:,featIndex].T.tolist()[0]):# 对该列进行分组,然后组内成员的val值进行二元切分mat0,mat1=binSplitDataSet(dataSet,featIndex,splitVal)# 判断二元切分的方式的元素数量是否符合预期if(shape(mat0)[0]<tolN)or(shape(mat1)[0]<tolN):continuenewS=errType(mat0)+errType(mat1)# 如果二元切分,算出来的误差在可接受范围内,那么就记录切分点,并记录最小误差# 如果划分后误差小于 bestS,则说明找到了新的bestSif newS < bestS:bestIndex = featIndexbestValue = splitValbestS = newS# 判断二元切分的方式的元素误差是否符合预期# if the decrease (S-bestS) is less than a threshold don't do the splitif (S - bestS) < tolS:return None, leafType(dataSet)mat0, mat1 = binSplitDataSet(dataSet, bestIndex, bestValue)# 对整体的成员进行判断,是否符合预期# 如果集合的 size 小于 tolN if (shape(mat0)[0] < tolN) or (shape(mat1)[0] < tolN): # 当最佳划分后,集合过小,也不划分,产生叶节点return None, leafType(dataSet)return bestIndex, bestValue# assume dataSet is NumPy Mat so we can array filtering
# 假设 dataSet 是 NumPy Mat 类型的,那么我们可以进行 array 过滤
def createTree(dataSet,leafType=regLeaf,errType=regErr,ops=(1,4)):"""createTree(获取回归树)Description: 递归函数: 如果构建的是回归树,该模型是一个常数,如果是模型树,其模型师一个线性方程。Args:dataSet 加载的原始数据集leafType 建立叶子点的函数errType 误差计算函数ops=(1, 4) [容许误差下降值,切分的最少样本数]Returns:retTree 决策树最后的结果"""# 选择最好的切分方式: feature索引值,最优切分值# choose the best splitfeat,val=chooseBestSplit(dataSet,leafType,errType,ops)# if the splitting hit a stop condition return val# 如果 splitting 达到一个停止条件,那么返回 val'''*** 最后的返回结果是最后剩下的 val,也就是len小于topN的集合'''if feat is None:return valretTree={}retTree['spInd']=featretTree['spVal']=val# 大于在右边,小于在左边,分为2个数据集lSet,rSet=binSplitDataSet(dataSet,feat,val)# 递归的进行调用,在左右子树中继续递归生成树retTree['left'] = createTree(lSet, leafType, errType, ops)retTree['right'] = createTree(rSet, leafType, errType, ops)return retTree# 判断节点是否是一个字典
def isTree(obj):"""Desc:测试输入变量是否是一棵树,即是否是一个字典Args:obj -- 输入变量Returns:返回布尔类型的结果。如果 obj 是一个字典,返回true,否则返回 false"""return (type(obj).__name__=='dict')# 计算左右枝丫的均值
def getMean(tree):"""Desc:从上往下遍历树直到叶节点为止,如果找到两个叶节点则计算它们的平均值。对 tree 进行塌陷处理,即返回树平均值。Args:tree -- 输入的树Returns:返回 tree 节点的平均值"""if isTree(tree['right']):tree['right']=getMean(tree['right'])if isTree(tree['left']):tree['left']=getMean(tree['left'])return (tree['left']+tree['right'])/2.0# 检查是否适合合并分枝
def prune(tree, testData):"""Desc:从上而下找到叶节点,用测试数据集来判断将这些叶节点合并是否能降低测试误差Args:tree -- 待剪枝的树testData -- 剪枝所需要的测试数据 testData Returns:tree -- 剪枝完成的树"""# 判断是否测试数据集没有数据,如果没有,就直接返回tree本身的均值if shape(testData)[0]==0:return getMean(tree)# 判断分枝是否是dict字典,如果是就将测试数据集进行切分if(isTree(tree['right'])or isTree(tree['left'])):lSet,rSet=binSplitDataSet(testData,tree['spInd'],tree['spVal'])# 如果是左边分枝是字典,就传入左边的数据集和左边的分枝,进行递归if isTree(tree['left']):tree['left'] = prune(tree['left'], lSet)# 如果是右边分枝是字典,就传入左边的数据集和左边的分枝,进行递归if isTree(tree['right']):tree['right'] = prune(tree['right'], rSet)# 上面的一系列操作本质上就是将测试数据集按照训练完成的树拆分好,对应的值放到对应的节点# 如果左右两边同时都不是dict字典,也就是左右两边都是叶节点,而不是子树了,那么分割测试数据集。# 1. 如果正确 # * 那么计算一下总方差 和 该结果集的本身不分枝的总方差比较# * 如果 合并的总方差 < 不合并的总方差,那么就进行合并# 注意返回的结果: 如果可以合并,原来的dict就变为了 数值if not isTree(tree['left']) and not isTree(tree['right']):lSet,rSet=binSplitDataSet(testData,tree['spInd'],tree['spVal'])# power(x, y)表示x的y次方;这时tree['left']和tree['right']都是具体数值errorNoMerge = sum(power(lSet[:, -1] - tree['left'], 2)) + sum(power(rSet[:, -1] - tree['right'], 2))treeMean = (tree['left'] + tree['right'])/2.0errorMerge = sum(power(testData[:, -1] - treeMean, 2))# 如果 合并的总方差 < 不合并的总方差,那么就进行合并if errorMerge < errorNoMerge:print("merging")return treeMean# 两个return可以简化成一个else:return treeelse:return tree# 得到模型的ws系数: f(x) = x0 + x1*featrue1+ x2*featrue2 ...
# create linear model and return coeficients
def modelLeaf(dataSet):"""Desc:当数据不再需要切分的时候,生成叶节点的模型。Args:dataSet -- 输入数据集Returns:调用 linearSolve 函数,返回得到的 回归系数ws"""ws, X, Y = linearSolve(dataSet)return ws# 计算线性模型的误差值
def modelErr(dataSet):"""Desc:在给定数据集上计算误差。Args:dataSet -- 输入数据集Returns:调用 linearSolve 函数,返回 yHat 和 Y 之间的平方误差。"""ws, X, Y = linearSolve(dataSet)yHat = X * ws# print corrcoef(yHat, Y, rowvar=0)return sum(power(Y - yHat, 2))# helper function used in two places
def linearSolve(dataSet):"""Desc:将数据集格式化成目标变量Y和自变量X,执行简单的线性回归,得到wsArgs:dataSet -- 输入数据Returns:ws -- 执行线性回归的回归系数 X -- 格式化自变量XY -- 格式化目标变量Y"""m, n = shape(dataSet)# 产生一个关于1的矩阵X = mat(ones((m, n)))Y = mat(ones((m, 1)))# X的0列为1,常数项,用于计算平衡误差X[:, 1: n] = dataSet[:, 0: n-1]Y = dataSet[:, -1]# 转置矩阵*矩阵xTx = X.T * X# 如果矩阵的逆不存在,会造成程序异常if linalg.det(xTx) == 0.0:raise NameError('This matrix is singular, cannot do inverse,\ntry increasing the second value of ops')# 最小二乘法求最优解: w0*1+w1*x1=yws = xTx.I * (X.T * Y)return ws, X, Y# 回归树测试案例
# 为了和 modelTreeEval() 保持一致,保留两个输入参数
def regTreeEval(model, inDat):"""Desc:对 回归树 进行预测Args:model -- 指定模型,可选值为 回归树模型 或者 模型树模型,这里为回归树inDat -- 输入的测试数据Returns:float(model) -- 将输入的模型数据转换为 浮点数 返回"""return float(model)# 模型树测试案例
# 对输入数据进行格式化处理,在原数据矩阵上增加第0列,元素的值都是1,
# 也就是增加偏移值,和我们之前的简单线性回归是一个套路,增加一个偏移量
def modelTreeEval(model, inDat):"""Desc:对 模型树 进行预测Args:model -- 输入模型,可选值为 回归树模型 或者 模型树模型,这里为模型树模型,实则为 回归系数inDat -- 输入的测试数据Returns:float(X * model) -- 将测试数据乘以 回归系数 得到一个预测值 ,转化为 浮点数 返回"""n = shape(inDat)[1]X = mat(ones((1, n+1)))X[:, 1: n+1] = inDat# print X, modelreturn float(X * model)# 计算预测的结果
# 在给定树结构的情况下,对于单个数据点,该函数会给出一个预测值。
# modelEval是对叶节点进行预测的函数引用,指定树的类型,以便在叶节点上调用合适的模型。
# 此函数自顶向下遍历整棵树,直到命中叶节点为止,一旦到达叶节点,它就会在输入数据上
# 调用modelEval()函数,该函数的默认值为regTreeEval()
def treeForeCast(tree,inData,modelEval=regTreeEval):"""Desc:对特定模型的树进行预测,可以是 回归树 也可以是 模型树Args:tree -- 已经训练好的树的模型inData -- 输入的测试数据,只有一行modelEval -- 预测的树的模型类型,可选值为 regTreeEval(回归树) 或 modelTreeEval(模型树),默认为回归树Returns:返回预测值"""if not isTree(tree):return modelEval(tree,inDate)# 书中写的是inData[tree['spInd']],只适合inData只有一列的情况,否则会产生异常if inData[0,tree['spInd']]<=tree['spVal']:# 可以把if-else去掉,只留if里面的分支if isTree(tree['left']):return treeForeCast(tree['left'],inData,modelEval)else:return modelEval(tree['left'],inData)else:# 同上,可以把if-else去掉,只留if里面的分支if isTree(tree['right']):return treeForeCast(tree['right'], inData, modelEval)else:return modelEval(tree['right'], inData)# 预测结果
def createForeCast(tree, testData, modelEval=regTreeEval):"""Desc:调用 treeForeCast ,对特定模型的树进行预测,可以是 回归树 也可以是 模型树Args:tree -- 已经训练好的树的模型testData -- 输入的测试数据modelEval -- 预测的树的模型类型,可选值为 regTreeEval(回归树) 或 modelTreeEval(模型树),默认为回归树Returns:返回预测值矩阵"""m=len(testData)yHat=mat(zeros((m,1)))# print yHatfor i in range(m):yHat[i,0]=treeForeCast(tree,mat(testData[i]),modelEval)# print "yHat==>", yHat[i, 0]return yHat
# 测试数据集
testMat=mat(eye(4))
print(testMat)
print(type(testMat))
mat0,mat1=binSplitDataSet(testMat,1,0.5)
print(mat0,'\n-----------\n', mat1)# 回归树
myDat=loadDataSet('data/9.RegTrees/data1.txt')
myMat=mat(myDat)
myTree=createTree(myMat)
print (myTree)#1.预剪枝就是: 提起设置最大误差数和最少元素数
myDat = loadDataSet('data/9.RegTrees/data3.txt')
myMat=mat(myDat)
myTree=createTree(myMat,ops=(0,1))
print (myTree)# 2. 后剪枝就是: 通过测试数据,对预测模型进行合并判断
myDatTest = loadDataSet('data/9.RegTrees/data3test.txt')
myMat2Test = mat(myDatTest)
myFinalTree = prune(myTree, myMat2Test)
print ('\n\n\n-------------------')
print (myFinalTree)# 模型树求解
myDat = loadDataSet('data/9.RegTrees/data4.txt')
myMat = mat(myDat)
myTree = createTree(myMat, modelLeaf, modelErr)
print (myTree)# 回归树 VS 模型树 VS 线性回归
trainMat = mat(loadDataSet('data/9.RegTrees/bikeSpeedVsIq_train.txt'))
testMat = mat(loadDataSet('data/9.RegTrees/bikeSpeedVsIq_test.txt'))
# 回归树
myTree1 = createTree(trainMat, ops=(1, 20))
print (myTree1)
yHat1 = createForeCast(myTree1, testMat[:, 0])
print ("--------------\n")
print (yHat1)
print ("ssss==>", testMat[:, 1])
# corrcoef 返回皮尔森乘积矩相关系数
# 描述XY相关程度
print("regTree:",corrcoef(yHat1,testMat[:,1],rowvar=0)[0,1])# 模型树
myTree2 = createTree(trainMat, modelLeaf, modelErr, ops=(1, 20))
yHat2 = createForeCast(myTree2, testMat[:, 0], modelTreeEval)
print( myTree2)
print ("modelTree:", corrcoef(yHat2, testMat[:, 1],rowvar=0)[0, 1])# 线性回归
ws, X, Y = linearSolve(trainMat)
print (ws)
m = len(testMat[:, 0])
yHat3 = mat(zeros((m, 1)))
for i in range(shape(testMat)[0]):yHat3[i]=testMat[i,0]*ws[1,0]+ws[0,0]
print ("lr:", corrcoef(yHat3, testMat[:, 1],rowvar=0)[0, 1])使用GUI
from __future__ import print_function
from Tkinter import *
from numpy import *import matplotlib
from matplotlib.figure import Figure
from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg
matplotlib.use('TkAgg')def test_widget_text(root):mylabel = Label(root, text="helloworld")# 相当于告诉 布局管理器(Geometry Manager),如果不设定位置,默认在 0行0列的位置mylabel.grid()# 最大为误差, 最大子叶节点的数量
def reDraw(tolS, tolN):# clear the figurereDraw.f.clf()reDraw.a = reDraw.f.add_subplot(111)# 检查复选框是否选中if chkBtnVar.get():if tolN < 2:tolN = 2myTree = createTree(reDraw.rawDat, regTrees.modelLeaf, regTrees.modelErr, (tolS, tolN))yHat = createForeCast(myTree, reDraw.testDat, regTrees.modelTreeEval)else:myTree = createTree(reDraw.rawDat, ops=(tolS, tolN))yHat = createForeCast(myTree, reDraw.testDat)# use scatter for data setreDraw.a.scatter(reDraw.rawDat[:, 0].A, reDraw.rawDat[:, 1].A, s=5)# use plot for yHatreDraw.a.plot(reDraw.testDat, yHat, linewidth=2.0, c='red')reDraw.canvas.draw()def getInputs():try:tolN = int(tolNentry.get())except:tolN = 10print("enter Integer for tolN")tolNentry.delete(0, END)tolNentry.insert(0, '10')try:tolS = float(tolSentry.get())except:tolS = 1.0print("enter Float for tolS")tolSentry.delete(0, END)tolSentry.insert(0, '1.0')return tolN, tolS# 画新的tree
def drawNewTree():# #get values from Entry boxestolN, tolS = getInputs()reDraw(tolS, tolN)def main(root):# 标题Label(root, text="Plot Place Holder").grid(row=0, columnspan=3)# 输入栏1, 叶子的数量Label(root, text="tolN").grid(row=1, column=0)global tolNentrytolNentry = Entry(root)tolNentry.grid(row=1, column=1)tolNentry.insert(0, '10')# 输入栏2, 误差量Label(root, text="tolS").grid(row=2, column=0)global tolSentrytolSentry = Entry(root)tolSentry.grid(row=2, column=1)# 设置输出值tolSentry.insert(0,'1.0')# 设置提交的按钮Button(root, text="确定", command=drawNewTree).grid(row=1, column=2, rowspan=3)# 设置复选按钮global chkBtnVarchkBtnVar = IntVar()chkBtn = Checkbutton(root, text="Model Tree", variable = chkBtnVar)chkBtn.grid(row=3, column=0, columnspan=2)# 退出按钮Button(root, text="退出", fg="black", command=quit).grid(row=1, column=2)# 创建一个画板 canvasreDraw.f = Figure(figsize=(5, 4), dpi=100)reDraw.canvas = FigureCanvasTkAgg(reDraw.f, master=root)reDraw.canvas.draw()reDraw.canvas.get_tk_widget().grid(row=0, columnspan=3)reDraw.rawDat = mat(loadDataSet('data/9.RegTrees/sine.txt'))reDraw.testDat = arange(min(reDraw.rawDat[:, 0]), max(reDraw.rawDat[:, 0]), 0.01)reDraw(1.0, 10)# 创建一个事件
root = Tk()
# test_widget_text(root)
main(root)
# 启动事件循环
root.mainloop()相关文章:

树回归CART
之前线性回归创建的模型需要拟合所有的样本点,但数据特征众多,关系复杂时,构建全局模型就很困难。之前构建决策树使用的算法是ID3。 ID3 的做法是每次选取当前最佳的特征来分割数据,并按照该特征的所有可能取值来切分。也就是说&…...

zemax色差与消色差
色差,颜色像差 轴向色差:不同波长的光束通过透镜后焦点位于沿轴的不同位置 垂轴色差:每个波长成像的放大率不同 单透镜为例: 输入需要设置为多波长 观察光线光扇图: 不同波长的光之间差异较大(不同颜色…...

成绩定级脚本(Python)
成绩评定脚本 写一个成绩评定的python脚本,实现用户输入成绩,由脚本来为成绩评级: #成绩评定脚本.pyscoreinput("please input your score:") if int(score)> 90:print("A") elif int(score)> 80:print("B&…...

骨传导耳机的危害有哪些?会损害听力吗?
如果正常的使用,骨传导耳机是没有危害的,由于骨传导耳机独特的传声方式,所以并不会对人体造成损伤,还可以在一定程度上保护听力。 如果想更具体知道骨传导耳机有什么危害,就要先了解什么是骨传导耳机,骨传…...

Redis模块二:缓存分类 + Redis模块三:常见缓存(应用)
缓存大致可以分为两大类:1)本地缓存 2)分布式缓存 目录 本地缓存 分布式缓存 常见缓存的使用 本地缓存:Spring Cache 分布式缓存:Redis 本地缓存 本地缓存也叫单机缓存,也就是说可以应⽤在单机环…...

Revit SDK 内容摘要: 8.0 -8.1
前提 不包含已单独写博客部分。 Revit SDK Samples 8.0 AnalyticalViewer 分析模型,VB,略。 namespace Autodesk.Revit.DB.Structure {public class AnalyticalModel : Element{public AnalyticalRigidLinksOption RigidLinksOption { get; set; }p…...
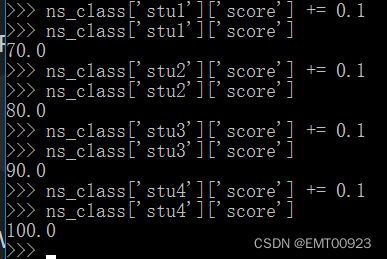
列表和字典练习
定义四个学生信息 在Python环境下,用列表定义: >>> stu1[xiaoming,True,21,79.9] >>> stu1[lihong,False,22,69.9] >>> stu1[zhangqiang,True,20,89.9] >>> stu1[EMT,True,23,99.9]如图,定义了四个列表…...
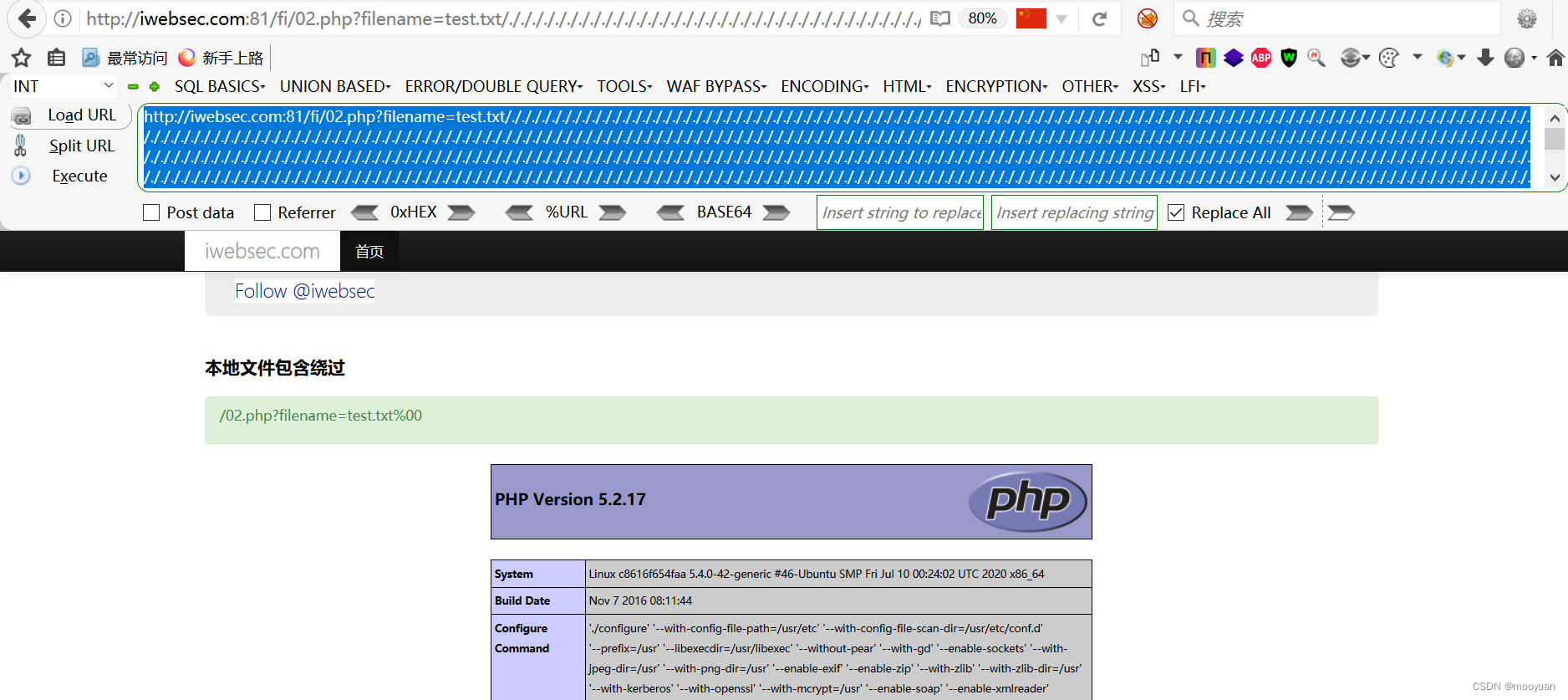
iwebsec靶场 文件包含漏洞通关笔记2-文件包含绕过(截断法)
目录 前言 1.%00截断 2.文件字符长度截断法(又名超长文件截断) 方法1(路径截断法) 方法2(点号截断法) 第02关 文件包含绕过 1.打开靶场 2.源码分析 3.00文件截断原理 4.00截断的条件 5.文件包含00截断绕过 …...
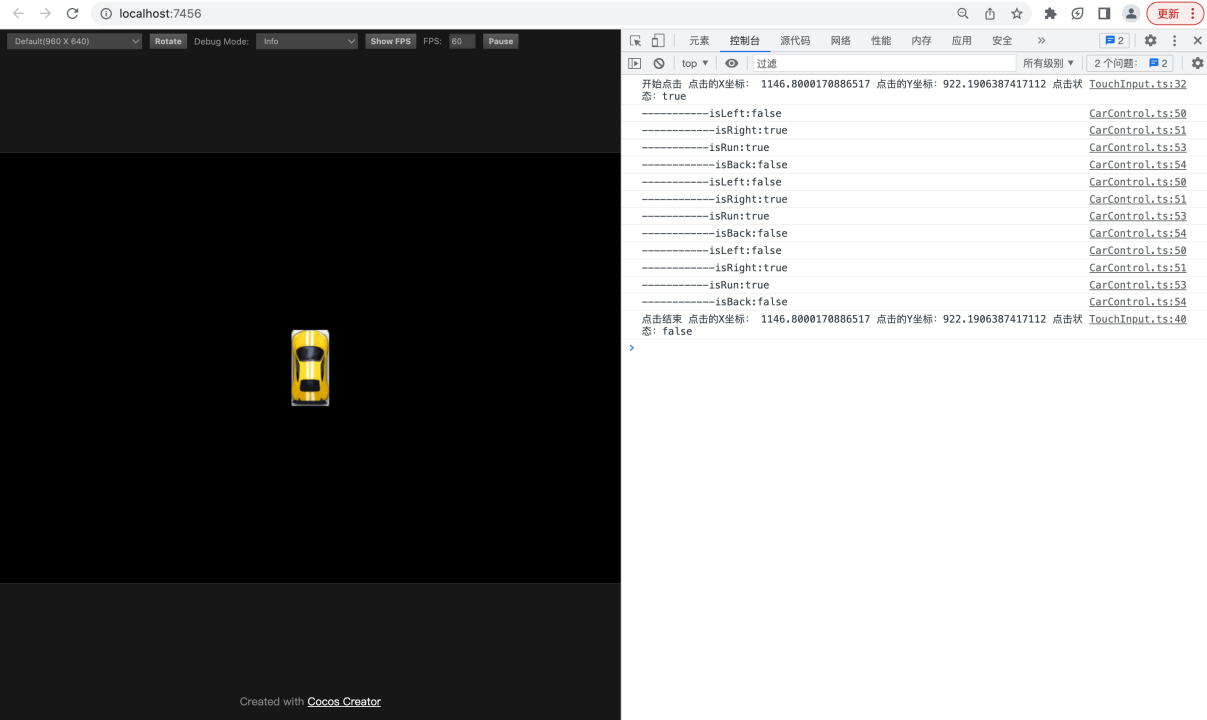
【基于Cocos Creator实现的赛车游戏】9.实现汽车节点的控制逻辑
转载知识星球 | 深度连接铁杆粉丝,运营高品质社群,知识变现的工具 项目地址:赛车小游戏-基于Cocos Creator 3.5版本实现: 课程的源码,基于Cocos Creator 3.5版本实现 在上一节的课程中,您已经实现了通过触控给刚体施…...

蓝蓝设计为教育行业提供软件UI交互设计服务
在教育行业,软件的用户体验设计对于提供优质教育体验至关重要。教育行业软件用户体验设计需要考虑到学生和教师的需求,以及教育环境的特殊性。为了确保设计的成功,选择一家专业的设计公司是至关重要的,而北京蓝蓝设计公司就是您的…...

Java从入门到精通-类和对象(二)
0. 类和对象 3. 类的构造方法 构造方法是一种特殊的方法,用于创建和初始化对象。构造方法的名称必须与类名相同,它没有返回值,并且在创建对象时自动调用。构造方法的主要作用是确保对象在创建时具有合适的初始状态。 以下是构造方法的基本概…...

Python解析MDX词典数据并保存到Excel
原始数据和处理结果: https://gitcode.net/as604049322/blog_data/-/tree/master/mdx 下载help.mdx词典后,我们无法直接查看,我们可以使用readmdict库来完成对mdx文件的读取。 安装库: pip install readmdict对于Windows平台还…...
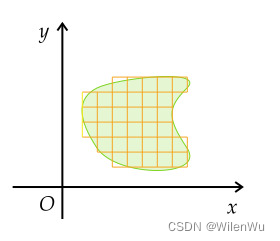
线性代数的本质(四)
文章目录 行列式二阶行列式 n n n 阶行列式行列式的性质克拉默法则行列式的几何理解 行列式 二阶行列式 行列式引自对线性方程组的求解。考虑两个方程的二元线性方程组 { a 11 x 1 a 12 x 2 b 1 a 21 x 1 a 22 x 2 b 2 \begin{cases} a_{11}x_1a_{12}x_2b_1 \\ a_{21}x_…...
FreeMarker详细介绍
FreeMarker详细介绍 FreeMarker FreeMarker概述 FreeMarker概念 FreeMarker 是一款 模板引擎: 即一种基于模板和要改变的数据, 并用来生成输出文本(HTML网页,电子邮件,配置文件,源代码等)的通用工具。 是一个Java类库…...
房地产小程序 | 小程序赋能,房地产业务数字化升级
随着科技的不断发展,房地产行业正逐渐向数字化转型。在这个过程中,房地产小程序成为了一种重要的工具,可以帮助房地产企业提供更好的购房体验、增加销售额,并实现管理的便捷化。 优点 便捷购房体验:房地产小程序为用户…...

Databend 开源周报第 110 期
Databend 是一款现代云数仓。专为弹性和高效设计,为您的大规模分析需求保驾护航。自由且开源。即刻体验云服务:https://app.databend.cn 。 Whats On In Databend 探索 Databend 本周新进展,遇到更贴近你心意的 Databend 。 使用 BendSQL 管…...
开源大模型ChatGLM2-6B 1. 租一台GPU服务器测试下
0. 环境 租用了1台GPU服务器,系统 ubuntu20,GeForce RTX 3090 24G。过程略。本人测试了ai-galaxy的,今天发现网友也有推荐autodl的。 (GPU服务器已经关闭,因此这些信息已经失效) SSH地址:* 端…...

SQL10 用where过滤空值练习
描述 题目:现在运营想要对用户的年龄分布开展分析,在分析时想要剔除没有获取到年龄的用户,请你取出所有年龄值不为空的用户的设备ID,性别,年龄,学校的信息。 示例:user_profile iddevice_idge…...

JVM--Hotspot Architecture 详解
一、Java Virtual Machine (JVM)概述 Java Virtual Machine 虚拟机 (JVM) 是一种抽象的计算机。JVM本身也是一个程序,但是对于编写在其中执行的程序来说,它看起来像一台机器。对于特定的操作系统ÿ…...

ThreadLocal功能实现
模拟ThreadLocal功能实现 当前线程任意方法内操作连接对象 一个栈对应一个线程 , 一个方法调用另一个方法都是在一个线程内 , 只有执行了线程的start方法才会创建一个线程 定义一个Map集合 , key是当前线程(Thread.currentThread) , value是要绑定的数据(Connection对象) 以…...

DolphinScheduler租户配置踩坑实录:手把手教你修复‘tenant not exists‘报错
DolphinScheduler租户配置深度解析:从原理到实战解决"tenant not exists"问题 第一次在DolphinScheduler中看到"tenant not exists"这个报错时,我正赶着部署一个重要的数据处理流程。系统明明显示登录成功,却在创建文件夹…...
解耦,便于二次开发)
深度学习项目训练环境模块化设计:各组件(数据/模型/训练器)解耦,便于二次开发
深度学习项目训练环境模块化设计:各组件(数据/模型/训练器)解耦,便于二次开发 1. 为什么需要模块化设计 传统的深度学习项目往往把所有代码写在一个文件里,数据加载、模型定义、训练逻辑全部混在一起。这种写法虽然简…...

Ollama模型选择指南:如何在32G内存+1G显存的机器上跑出最佳性能?
Ollama模型选择实战:32G内存1G显存环境下的性能优化指南 当你在资源受限的机器上部署AI模型时,每个字节的内存和显存都显得弥足珍贵。本文将带你深入探索如何在32G内存和1G显存的硬件条件下,为Ollama选择最优模型并榨干最后一分性能。 1. 理解…...

HLK-LD245X毫米波雷达嵌入式C++库深度解析
1. HLK-LD245X毫米波雷达传感器库深度解析HLK-LD245X是一个面向嵌入式平台的轻量级C库,专为Hi-Link公司推出的LD2450与LD2451系列24GHz调频连续波(FMCW)毫米波雷达传感器设计。该库并非简单封装串口收发,而是构建了一套完整的协议…...

Python3.9镜像作品展示:多项目环境管理,效果一目了然
Python3.9镜像作品展示:多项目环境管理,效果一目了然 1. Python3.9镜像核心价值 Python3.9镜像是一个轻量级的Python环境管理工具,它能帮助开发者快速创建独立的开发环境,有效避免软件包之间的版本冲突。这个镜像自带pip等基本工…...

Fish Speech 1.5GPU部署案例:单节点支持50+并发TTS请求压测报告
Fish Speech 1.5 GPU部署案例:单节点支持50并发TTS请求压测报告 1. 测试背景与目标 最近我们在单台GPU服务器上部署了Fish Speech 1.5语音合成模型,这是一款基于VQ-GAN和Llama架构的先进TTS系统。你可能听说过这个模型在100万小时的多语言数据上训练过…...

山东GEO推广选哪家?AI搜索优化看3个核心能力
一、AI搜索时代,山东企业流量破局靠什么?据《2024山东企业AI搜索行为白皮书》显示,超65%本地用户通过生成式引擎(如文心一言、豆包)获取服务信息,传统SEO“关键词排名”模式已难触达目标客群。AI搜索优化…...

出一次规划垂直泊车路径规划matlab代码。 回旋曲线对泊车路径进行优化,图片仅供参考
出一次规划垂直泊车路径规划matlab代码。 回旋曲线对泊车路径进行优化,图片仅供参考停车是门技术活,尤其是垂直泊车时方向盘该打几度、什么时候回正,老司机都得掂量掂量。今天咱们用Matlab整点有意思的——用回旋曲线生成丝滑的泊车路径&…...

Qwen3.5-9B惊艳效果:食品包装图片→成分表识别→过敏原标记→健康评分生成
Qwen3.5-9B惊艳效果:食品包装图片→成分表识别→过敏原标记→健康评分生成 1. 模型能力概览 Qwen3.5-9B作为新一代多模态大模型,在食品健康领域展现出令人惊艳的端到端处理能力。它能从一张简单的食品包装照片开始,自动完成成分表识别、过敏…...

保姆级教程:用SD卡给迪文DMG80480C043_01WTC串口屏烧录程序的完整流程
迪文DMG80480C043_01WTC串口屏SD卡烧录全流程实战指南 在工业控制和智能设备开发领域,迪文串口屏因其稳定性和易用性广受开发者青睐。本文将详细介绍如何通过SD卡为DMG80480C043_01WTC型号串口屏烧录程序的完整流程,从工具准备到最终验证,每个…...