LLM - 批量加载 dataset 并合并

目录
一.引言
二.Dataset 生成
1.数据样式
2.批量加载
◆ 主函数调用
◆ 基础变量定义
◆ 多数据集加载
3.数据集合并
◆ Concat
◆ interleave
◆ stopping_strategy
◆ interleave_probs
三.总结
一.引言
LLM 模型基于 transformer 进行训练,需要先生成 dataset,再将 dataset 根据任务需求生成对应的 input_ids、label_ids 等,本文介绍生成 dataset 的方法,即读取多个文件最终生成一个 dataset,后续介绍不同任务需求下 dataset 的转化。
Tips:
本文数据集与代码主要参考 Github LLaMA-Efficient-Tuning。
二.Dataset 生成
1.数据样式
◆ alpaca_data_zh_51k.json

◆ alpaca_gpt4_data_zh.json

数据集为 json 文件,其中每条 json 记录包含 3 个 key:
- instruction 可以理解为 prompt
- input 输入,即我们说的 Question
- output 输出,与 Question 对应的 Answer
上面的 3 个 key也可以简化,前面也提到过 LLM - Baichuan7B Tokenizer 生成训练数据,这里只用了 q、a 两个字段。 这里字段是什么其实并不重要,只要最后生成 input_ids 相关数据可以区分开就可以。
2.批量加载
def getBatchDataSet(_base_path, _data_files, _strategy):max_samples = 9999# support multiple datasetsall_datasets: List[Union["Dataset", "IterableDataset"]] = []for input_path in _data_files:data_path = EXT2TYPE.get(input_path.split(".")[-1], None)dataset = load_dataset(data_path,data_files=[os.path.join(_base_path, input_path)],split="train",cache_dir=None,streaming=None,use_auth_token=True)if max_samples is not None:max_samples_temp = min(len(dataset), max_samples)dataset = dataset.select(range(max_samples_temp))print(dataset.features)all_datasets.append(dataset)if len(all_datasets) == 1:return all_datasets[0]elif _strategy == "concat":return concatenate_datasets(all_datasets)elif _strategy == "interleave":# all_exhaustedstopping_strategy = "first_exhausted"interleave_probs = [0.5, 0.5]return interleave_datasets(all_datasets, interleave_probs, stopping_strategy=stopping_strategy)else:raise ValueError("UnKnown mixing strategy")下面分步骤拆解下代码:
◆ 主函数调用
import os.path
from datasets import load_dataset, concatenate_datasets, interleave_datasets
from typing import TYPE_CHECKING, Any, Dict, Generator, List, Literal, Union, Tuple
from transformers import GPT2Tokenizer
from itertools import chain
import tiktokenif __name__ == '__main__':# 多文件地址base_path = "/Users/LLaMA-Efficient-Tuning-main/data"data_files = ['alpaca_data_zh_51k.json', 'alpaca_gpt4_data_zh.json']strategy = 'concat'train_dataset = getBatchDataSet(base_path, data_files, strategy)这里给定我们需要遍历的两个 json 文件以及对应的合并策略,策略后面再说。
◆ 基础变量定义
EXT2TYPE = {"csv": "csv","json": "json","jsonl": "json","txt": "text"
}tokenizer = GPT2Tokenizer.from_pretrained("gpt2")max_samples = 9999# support multiple datasets
all_datasets: List[Union["Dataset", "IterableDataset"]] = []EXT2TYPE 为文件格式对应的 map,第二个 tokenizer 我们为了演示直接使用 Transformer 自带的 gpt2,max_samples 定义数据集截断,最后的 all_datasets 用于存储多个数据集。
◆ 多数据集加载
for input_path in _data_files:data_path = EXT2TYPE.get(input_path.split(".")[-1], None)dataset = load_dataset(data_path,data_files=[os.path.join(_base_path, input_path)],split="train",cache_dir=None,streaming=None,use_auth_token=True)if max_samples is not None:max_samples_temp = min(len(dataset), max_samples)dataset = dataset.select(range(max_samples_temp))print(dataset.features)all_datasets.append(dataset)遍历文件列表的文件与后缀,通过 from datasets import load_dataset 加载声称数据集,max_samples 配合 select 完成数据集的截断,最后将 dataset 添加到 all_datasets 中。这里 dataset.features 类似于 dataframe 的 schema,用于描述每一列的基础信息:
{'instruction': Value(dtype='string', id=None), 'input': Value(dtype='string', id=None), 'output': Value(dtype='string', id=None)}
下图为两个数据集记载打印的日志,由于之前已经做了 cache,所以直接读取 arrow 文件:

3.数据集合并
if len(all_datasets) == 1:return all_datasets[0]elif _strategy == "concat":return concatenate_datasets(all_datasets)elif _strategy == "interleave":# all_exhaustedstopping_strategy = "first_exhausted"interleave_probs = [0.5, 0.5]return interleave_datasets(all_datasets, interleave_probs, stopping_strategy=stopping_strategy)else:raise ValueError("UnKnown mixing strategy")由于训练只需要一个 dataset,所以多个文件读取的 dataset 需要合并为一个,上面展示了不同的合并策略,length == 1 的情况就不多说了,除此之外多数据集有两种合并策略:
◆ Concat
cocnat 方法直接顺序拼接多个数据集
dataset-1 => A,B,C
dataset-2 => D,E,F
concat(dataset-1, dataset-2) => A,B,C,D,E,F◆ interleave
interleave 方法用于实现数据交错从而防止过拟合。交错数据集是将两个或更多数据集混合在一起形成一个新的数据集。这样做的目的是使模型在训练时不会总是看到相同的数据顺序,从而提高模型的泛化能力。
dataset-1 => A,B,C
dataset-2 => D,E,F
interleave(dataset-1, dataset-2) => A,E,B,C,D,F◆ stopping_strategy
stopping_strategy 用于定义数据集合并何时停止,有 first_exhausted 和 all_exhausted 两种交错策略:
- first_exhausted (先耗尽策略)
数据集会按照他被添加到 interleave 方法的顺序进行处理,当一个数据集被遍历完会停止生成数据,该方法适用于你希望遍历完第一个数据集就停止迭代。
- all_exhausted (全部耗尽策略)
数据集会按照他被添加到 interleave 方法的顺序进行处理,当全部数据集被遍历完会停止生成数据,该方法适用于你希望遍历完全部数据集就停止迭代。
这两种策略的主要区别在于何时停止迭代并抛出异常。first_exhausted 策略在遍历完第一个数据集后停止,而 all_exhausted 策略在遍历完所有数据集后停止。选择哪种策略取决于你的具体需求和数据集的特性。
◆ interleave_probs
在 interleave_datasets 方法中,interleave_probs 是一个可选参数,用于指定每个数据集的交错概率。当使用 interleave_datasets 方法交错多个数据集时,你可以通过 interleave_probs 参数为每个数据集指定一个概率。这个概率表示在生成交错数据集时,每个数据集被选择的概率。
例如,假设你有两个数据集 A 和 B,并且你设置 interleave_probs=[0.5, 0.5]。这意味着在生成交错数据集时,A 和 B 被选择的概率都是 0.5。
如果你设置 interleave_probs=[0.3, 0.7],则 A 被选择的概率是 0.3,而 B 被选择的概率是 0.7。
这个参数允许你根据需要对不同的数据集进行加权,以便在交错数据集时更倾向于选择某些数据集。
三.总结
LLM 大模型我们大部分时间是调用框架,调用现成模型去微调,熟悉一些工具的使用可以更方便我们在调优的时候对不同部分进行修改,本文主要用于加载原始数据生成 dataset,后续我们基于上面得到的 dataset 生成不同任务所需的数据集。
相关文章:
LLM - 批量加载 dataset 并合并
目录 一.引言 二.Dataset 生成 1.数据样式 2.批量加载 ◆ 主函数调用 ◆ 基础变量定义 ◆ 多数据集加载 3.数据集合并 ◆ Concat ◆ interleave ◆ stopping_strategy ◆ interleave_probs 三.总结 一.引言 LLM 模型基于 transformer 进行训练,需要先…...

Debian 初始化命令备忘
本文地址:blog.lucien.ink/archives/541 以 Debian 11 为例,主要用于备忘。 deb https://mirrors.tuna.tsinghua.edu.cn/debian/ bullseye main contrib non-free deb https://mirrors.tuna.tsinghua.edu.cn/debian/ bullseye-updates main contrib non…...

二维矩阵的DFS算法框架
二维矩阵的DFS算法框架 关于岛屿的相似题目: 岛屿数量 – 二维矩阵的dfs算法封闭岛屿数量 – 二维矩阵的dfs算法统计封闭岛屿的数目统计子岛屿不同岛屿的数量 # 二叉树遍历框架 def traverse(root):if not root:return # 前序遍历traverse(root.left)# 中序遍历t…...

pytest实现日志按用例输出到指定文件中
场景 执行自动化用例时,希望日志按用例生成一个文件,并且按用例所在文件生成目录,用例失败时便于查看日志记录 实现方式 pytest.ini文件 在pytest.ini配置文件中设置配置项(定义日志输出级别和格式) log_clitrue l…...

程序员面试逻辑题
红白帽子推理 答案: 这个题有点像数学归纳法,就是假设有 A A A和 B B B两个人是黑色的帽子,这样的话第一次开灯, A A A看到 B B B是黑色的,其他人都是白色的,那么 A A A会觉得 B B B是那个黑色的࿰…...

自动创建设备节点udev机制实现
自动创建设备节点udev机制实现过程: 1.当插入设备,内核会向udev发送一个事件,其中包含着设备的信息。 2.udev会根据收到的设备信息匹配相应的规则文件。 3.udev会根据规则文件中的配置,创建一个唯一的设备节点文件。通常存储在/d…...

目标检测YOLO实战应用案例100讲-基于小样本学习和空间约束的濒危动物目标检测
目录 前言 相关技术介绍 2.1 卷积神经网络 2.1.1 基本结构 2.1.2 网络训练...

苹果数据恢复软件:Omni Recover Mac
Omni Recover是一款十分实用的Mac数据恢复软件,为用户提供了简单、安全、快速和高效的数据恢复服务。如果您遇到了Mac或iOS设备中的数据丢失和误删情况,不要着急,不妨尝试一下Omni Recover,相信它一定会给您带来惊喜。 首先&…...

树回归CART
之前线性回归创建的模型需要拟合所有的样本点,但数据特征众多,关系复杂时,构建全局模型就很困难。之前构建决策树使用的算法是ID3。 ID3 的做法是每次选取当前最佳的特征来分割数据,并按照该特征的所有可能取值来切分。也就是说&…...

zemax色差与消色差
色差,颜色像差 轴向色差:不同波长的光束通过透镜后焦点位于沿轴的不同位置 垂轴色差:每个波长成像的放大率不同 单透镜为例: 输入需要设置为多波长 观察光线光扇图: 不同波长的光之间差异较大(不同颜色…...

成绩定级脚本(Python)
成绩评定脚本 写一个成绩评定的python脚本,实现用户输入成绩,由脚本来为成绩评级: #成绩评定脚本.pyscoreinput("please input your score:") if int(score)> 90:print("A") elif int(score)> 80:print("B&…...

骨传导耳机的危害有哪些?会损害听力吗?
如果正常的使用,骨传导耳机是没有危害的,由于骨传导耳机独特的传声方式,所以并不会对人体造成损伤,还可以在一定程度上保护听力。 如果想更具体知道骨传导耳机有什么危害,就要先了解什么是骨传导耳机,骨传…...

Redis模块二:缓存分类 + Redis模块三:常见缓存(应用)
缓存大致可以分为两大类:1)本地缓存 2)分布式缓存 目录 本地缓存 分布式缓存 常见缓存的使用 本地缓存:Spring Cache 分布式缓存:Redis 本地缓存 本地缓存也叫单机缓存,也就是说可以应⽤在单机环…...

Revit SDK 内容摘要: 8.0 -8.1
前提 不包含已单独写博客部分。 Revit SDK Samples 8.0 AnalyticalViewer 分析模型,VB,略。 namespace Autodesk.Revit.DB.Structure {public class AnalyticalModel : Element{public AnalyticalRigidLinksOption RigidLinksOption { get; set; }p…...
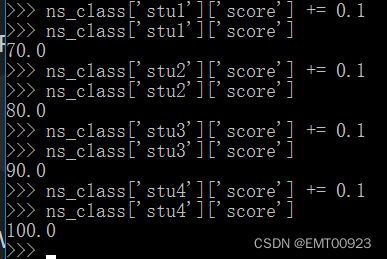
列表和字典练习
定义四个学生信息 在Python环境下,用列表定义: >>> stu1[xiaoming,True,21,79.9] >>> stu1[lihong,False,22,69.9] >>> stu1[zhangqiang,True,20,89.9] >>> stu1[EMT,True,23,99.9]如图,定义了四个列表…...
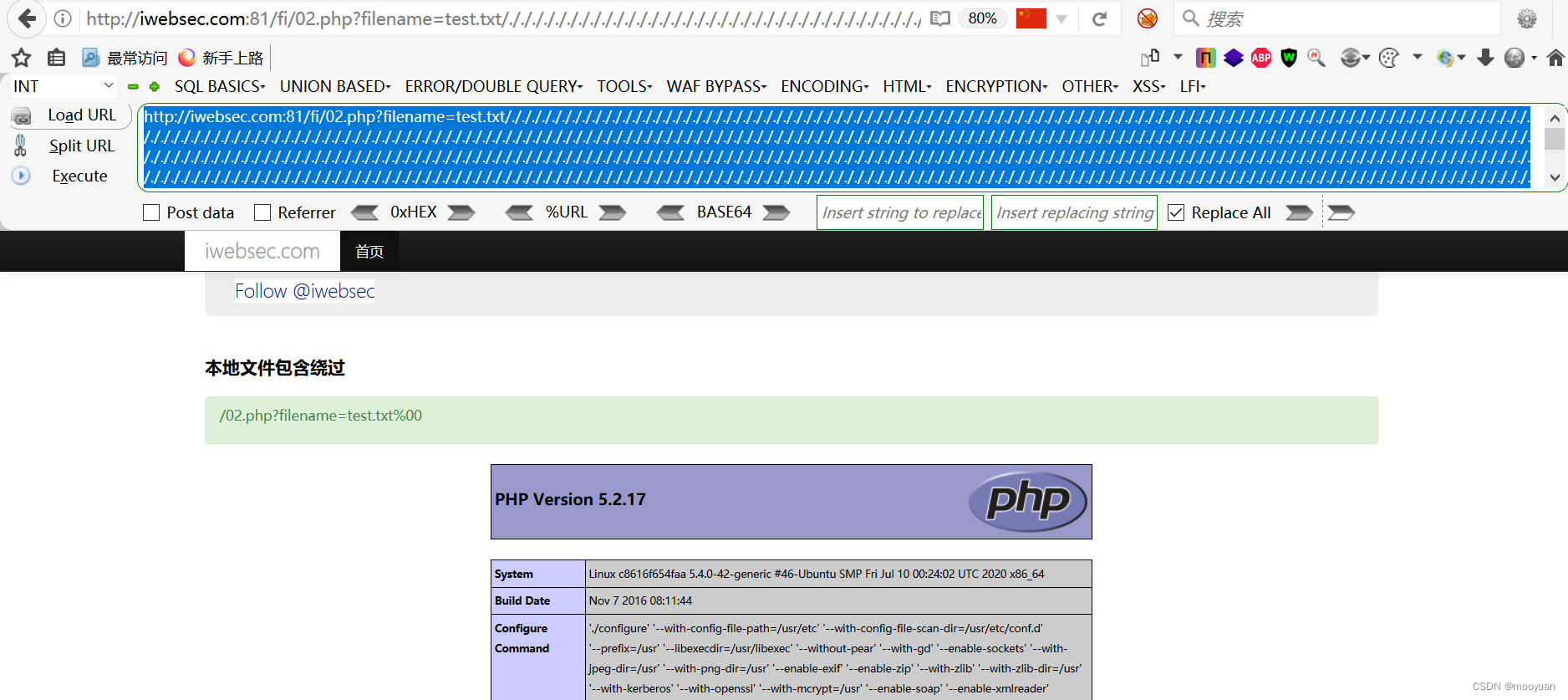
iwebsec靶场 文件包含漏洞通关笔记2-文件包含绕过(截断法)
目录 前言 1.%00截断 2.文件字符长度截断法(又名超长文件截断) 方法1(路径截断法) 方法2(点号截断法) 第02关 文件包含绕过 1.打开靶场 2.源码分析 3.00文件截断原理 4.00截断的条件 5.文件包含00截断绕过 …...
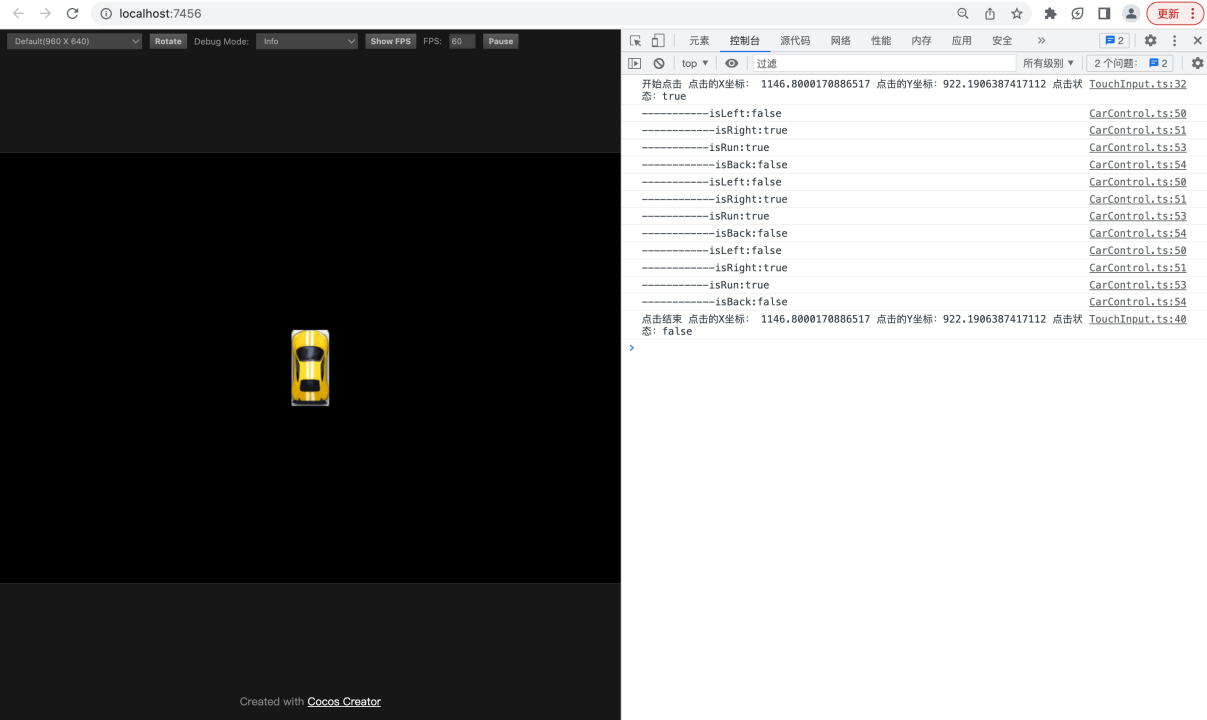
【基于Cocos Creator实现的赛车游戏】9.实现汽车节点的控制逻辑
转载知识星球 | 深度连接铁杆粉丝,运营高品质社群,知识变现的工具 项目地址:赛车小游戏-基于Cocos Creator 3.5版本实现: 课程的源码,基于Cocos Creator 3.5版本实现 在上一节的课程中,您已经实现了通过触控给刚体施…...

蓝蓝设计为教育行业提供软件UI交互设计服务
在教育行业,软件的用户体验设计对于提供优质教育体验至关重要。教育行业软件用户体验设计需要考虑到学生和教师的需求,以及教育环境的特殊性。为了确保设计的成功,选择一家专业的设计公司是至关重要的,而北京蓝蓝设计公司就是您的…...

Java从入门到精通-类和对象(二)
0. 类和对象 3. 类的构造方法 构造方法是一种特殊的方法,用于创建和初始化对象。构造方法的名称必须与类名相同,它没有返回值,并且在创建对象时自动调用。构造方法的主要作用是确保对象在创建时具有合适的初始状态。 以下是构造方法的基本概…...

Python解析MDX词典数据并保存到Excel
原始数据和处理结果: https://gitcode.net/as604049322/blog_data/-/tree/master/mdx 下载help.mdx词典后,我们无法直接查看,我们可以使用readmdict库来完成对mdx文件的读取。 安装库: pip install readmdict对于Windows平台还…...

使用VSCode开发Django指南
使用VSCode开发Django指南 一、概述 Django 是一个高级 Python 框架,专为快速、安全和可扩展的 Web 开发而设计。Django 包含对 URL 路由、页面模板和数据处理的丰富支持。 本文将创建一个简单的 Django 应用,其中包含三个使用通用基本模板的页面。在此…...

Vue3 + Element Plus + TypeScript中el-transfer穿梭框组件使用详解及示例
使用详解 Element Plus 的 el-transfer 组件是一个强大的穿梭框组件,常用于在两个集合之间进行数据转移,如权限分配、数据选择等场景。下面我将详细介绍其用法并提供一个完整示例。 核心特性与用法 基本属性 v-model:绑定右侧列表的值&…...

前端开发面试题总结-JavaScript篇(一)
文章目录 JavaScript高频问答一、作用域与闭包1.什么是闭包(Closure)?闭包有什么应用场景和潜在问题?2.解释 JavaScript 的作用域链(Scope Chain) 二、原型与继承3.原型链是什么?如何实现继承&a…...

AI编程--插件对比分析:CodeRider、GitHub Copilot及其他
AI编程插件对比分析:CodeRider、GitHub Copilot及其他 随着人工智能技术的快速发展,AI编程插件已成为提升开发者生产力的重要工具。CodeRider和GitHub Copilot作为市场上的领先者,分别以其独特的特性和生态系统吸引了大量开发者。本文将从功…...

爬虫基础学习day2
# 爬虫设计领域 工商:企查查、天眼查短视频:抖音、快手、西瓜 ---> 飞瓜电商:京东、淘宝、聚美优品、亚马逊 ---> 分析店铺经营决策标题、排名航空:抓取所有航空公司价格 ---> 去哪儿自媒体:采集自媒体数据进…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...

佰力博科技与您探讨热释电测量的几种方法
热释电的测量主要涉及热释电系数的测定,这是表征热释电材料性能的重要参数。热释电系数的测量方法主要包括静态法、动态法和积分电荷法。其中,积分电荷法最为常用,其原理是通过测量在电容器上积累的热释电电荷,从而确定热释电系数…...

音视频——I2S 协议详解
I2S 协议详解 I2S (Inter-IC Sound) 协议是一种串行总线协议,专门用于在数字音频设备之间传输数字音频数据。它由飞利浦(Philips)公司开发,以其简单、高效和广泛的兼容性而闻名。 1. 信号线 I2S 协议通常使用三根或四根信号线&a…...

Go语言多线程问题
打印零与奇偶数(leetcode 1116) 方法1:使用互斥锁和条件变量 package mainimport ("fmt""sync" )type ZeroEvenOdd struct {n intzeroMutex sync.MutexevenMutex sync.MutexoddMutex sync.Mutexcurrent int…...

CppCon 2015 学习:Time Programming Fundamentals
Civil Time 公历时间 特点: 共 6 个字段: Year(年)Month(月)Day(日)Hour(小时)Minute(分钟)Second(秒) 表示…...