Java开发面试--Redis专区
1、 什么是Redis?它的主要特点是什么?
答:
Redis是一个开源的、基于内存的高性能键值对存储系统。它主要用于缓存、数据存储和消息队列等场景。
- 高性能:Redis将数据存储在内存中,并采用单线程的方式处理请求,使得其读写速度非常快,能够达到10万+的读写操作每秒。
- 数据结构丰富:Redis支持多种数据结构,包括字符串、列表、哈希表、集合、有序集合等。这些数据结构的灵活性使得Redis可以应对各种场景的需求。
- 持久化支持:Redis提供两种持久化方式,即RDB和AOF。RDB是将当前数据的快照保存到磁盘上,而AOF则是将操作日志追加到文件中。这两种方式可根据需求进行选择配置。
- 高并发访问:Redis具有内置的事务功能和乐观锁机制,可以有效处理并发访问的问题。同时,Redis还提供了一些原子性的操作指令,如INCR、DECR等,能够保证多个操作的原子性执行。
- 分布式支持:Redis提供了集群模式,可以将数据分布在多个节点上。通过数据分片和复制机制,实现了数据的高可用性和扩展性。
- 发布/订阅模式:Redis支持发布/订阅模式,能够实现消息的广播和订阅功能。这对于构建实时消息系统或者事件驱动的应用非常有用。
2、 Redis与其他常见的关系型数据库(如MySQL)有什么区别?
答:
Redis与关系型数据库(如MySQL)在很多方面有着显著的区别,下面是一些主要区别的介绍:
- 数据模型:Redis是一个键值对存储系统,它使用简单的键值对来存储数据。而MySQL是基于关系模型的数据库,使用表格的形式来存储结构化数据。
- 存储方式:Redis将数据存储在内存中,这使得它能够快速地读写数据。而MySQL通常将数据存储在磁盘上,访问速度相对较慢。
- 数据查询:Redis的查询操作主要依赖于键,通过键来获取对应的值。而MySQL支持复杂的SQL查询语言,可以使用多种条件和关联来查询数据。
- 事务处理:Redis支持简单的事务处理(multi/exec/discard),但不支持回滚操作。而MySQL支持复杂的事务处理,包括ACID特性的支持,可以实现更复杂的事务逻辑。
- 数据持久化:Redis提供了数据持久化机制,包括RDB和AOF两种方式,可以将数据保存到磁盘上。而MySQL则是默认将数据保存在磁盘上,并提供了多种持久化方式,如InnoDB的事务日志和二进制日志等。
- 扩展性:由于Redis将数据存储在内存中,并使用单线程处理请求,它能够轻松地扩展到多个节点。而MySQL的扩展往往需要通过主从复制或分片等方式来实现。
- 数据一致性:Redis默认情况下是将数据保存在内存中,并没有强一致性的保证。而MySQL是通过ACID特性来确保数据的一致性。
3、 Redis的数据结构有哪些?请分别介绍它们的用途。
答:
- 字符串(String):字符串是Redis最基本的数据结构,它可以存储字符串、整数和浮点数等类型的值。字符串在Redis中的使用非常广泛,比如存储用户信息、缓存数据、计数器等。
- 列表(List):列表是一个有序的字符串元素集合,可以在列表的两端进行快速的插入和删除操作。列表可以用于实现队列、栈等数据结构,也可以用于存储日志、消息队列等。
- 哈希表(Hash):哈希表是一个键值对的集合,其中的键和值都是字符串类型。哈希表适用于存储和读取对象属性,比如存储用户信息、商品信息等。通过哈希表,可以方便地对单个属性进行读写操作。
- 集合(Set):集合是一个无序且不重复的字符串元素集合。集合可以进行交集、并集、差集等操作,还可以对集合进行去重和判断某个元素是否存在。集合常用于存储标签、好友关系等。
- 有序集合(Sorted Set):有序集合是一个有序的字符串元素集合,每个元素都关联一个分数,通过分数进行排序。有序集合常用于排行榜、最新消息列表等场景,可以根据分数进行范围查询,也可以根据元素获取其排名。
- 地理位置(Geospatial):Redis支持地理位置数据结构,可以存储经度和纬度的坐标,并对坐标进行距离计算和范围查询。地理位置数据结构适用于附近的人、地点推荐等场景。
4、 Redis支持的数据持久化方式有哪些?请描述它们的区别。
答:
Redis支持的两种数据持久化方式 :
- RDB(Redis Database):RDB是Redis的默认持久化方式。它通过将数据以二进制格式快照的方式保存到磁盘上,包含了当前数据库中所有键值对的数据。RDB的优点是数据保存在紧凑的二进制文件中,对于大规模的数据集和定期备份来说十分高效。同时,RDB在恢复数据时加载速度较快。但是,RDB保存的是快照数据,因此如果Redis发生意外停机,可能会丢失最后一次快照之后的数据。
- AOF(Append-Only File):AOF是另一种Redis的数据持久化方式。它通过将每条写命令追加到文件的末尾来记录对数据库的操作,以此来恢复数据。AOF的优点是可以保证数据更加持久,即使Redis发生意外宕机,也能够通过回放日志来恢复数据。此外,AOF还支持不同的持久化策略,如每秒钟同步一次、每修改一次同步一次等。然而,由于AOF以文本方式记录每条写命令,所以相比RDB,AOF文件通常会更大,恢复速度也会相对较慢。
这两种数据持久化方式在使用上有一些区别:
- RDB适用于数据备份和快速恢复。它生成紧凑的二进制文件,适合用于定期备份且对数据完整性要求不是非常高的场景。
- AOF适用于数据持久性要求较高的场景。它通过记录每条写命令来实现持久化,可以提供更好的数据安全性和灾难恢复能力。不过,由于每条写命令都需要追加到文件末尾,所以相较于RDB,AOF在写入性能上可能会稍差。
5、 在Java开发中,如何使用Redis进行缓存和数据存储?
答:
- 添加依赖:首先需要添加Redis客户端库的依赖,在Maven项目中可以添加Jedis或Lettuce库或Sa-Token等一些框架集成的依赖。
- 创建Redis客户端连接:使用Jedis或Lettuce等Redis客户端创建连接,并设置连接信息(如host、port、password等)。
- 使用Redis缓存数据:将Java对象序列化为字符串后,通过set方法将其存储到Redis缓存中。在读取数据时,使用get方法获取缓存中的数据并将其反序列化为Java对象。
- 使用Redis存储数据:与缓存类似,将Java对象序列化为字符串后,可以通过set方法将其存储到Redis中。但是,这里需要注意,在存储数据时需要设置过期时间(如20分钟、1小时等),以免数据无限期占用内存。
- 对缓存和数据存储进行适当的优化:可以使用Redis提供的哈希表、列表、集合等数据结构来存储不同类型的数据,以提高访问效率。同时,还可以合理设置缓存的过期时间和LRU策略,以控制内存占用和缓存命中率。
6、 Redis的使用场景有哪些?请举例说明。
答:
-
缓存:Redis最常见的使用场景之一是作为缓存。通过将热点数据存储在Redis内存中,可以极大地提高系统的读取速度和性能。
示例:在电子商务网站中,可以将商品信息、用户会话信息等经常访问的数据存储到Redis缓存中,以减轻数据库的负载并提高页面响应速度。
-
会话存储:Redis也可以用作会话存储数据库,特别是对于分布式或微服务架构而言。将会话数据存储在Redis中可以提供快速的读写能力,并支持会话的分布式管理。
示例:一个在线多人游戏应用中,可以将用户登录状态和游戏会话数据存储在Redis中,以便快速识别用户和共享游戏状态。
-
消息队列:Redis提供了发布-订阅功能,让开发者可以实现简单的消息队列系统。它可以用于解耦和异步处理任务。
示例:在一个电子商务系统中,当用户下订单时,可以将订单信息发布到Redis消息队列中,然后由订单处理系统异步地从消息队列中消费订单数据进行处理。
-
实时排行榜:Redis提供了有序集合(Sorted Set)和计数器等数据结构,可以用于实时排行榜的实现。通过存储和更新分数,可以快速获取最高分或排名情况。
示例:一个游戏应用中,可以将玩家得分作为分数存储在Redis有序集合中,并根据分数快速获取排行榜信息。
-
分布式锁:Redis提供了原子性操作和过期时间设置,可以实现分布式锁机制,用于控制对共享资源的访问。
示例:在一个分布式系统中,多个节点需要对某个资源进行互斥访问,可以使用Redis的分布式锁来保证只有一个节点可以获得对该资源的访问权限。
7、 Redis的并发访问如何处理?有哪些解决方案?
答:
在高并发环境下,对Redis的访问需要考虑并发读写的安全性和性能问题。
解决方案:
- 使用事务(Transaction):Redis支持事务操作,可以通过MULTI、EXEC、WATCH等命令来实现。使用事务可以将一组操作打包在一起,并保证这些操作按顺序执行,使得多个操作具备原子性。
- 使用锁(Lock):可以使用Redis的分布式锁来实现并发控制。通过获取锁来保证同一时间只有一个线程可以对关键资源进行访问,其他线程需要等待锁的释放。
- 使用乐观锁(Optimistic Locking):通过使用版本号(或者时间戳)来识别数据是否被其他线程修改。在读取数据后,再次校验版本号,如果变化则说明发生了并发修改,需要重新尝试。
- 使用分布式锁实现限流(Rate Limiting):可以使用Redis的分布式锁来控制对某一资源的访问频率,以限制并发请求的数量。例如,可以设置一个时间窗口内允许的最大请求数,并在每个请求到达时尝试获取锁,如果锁已被其他请求占用,则拒绝该请求。
8、 Redis的数据淘汰策略有哪些?请简要描述它们的原理和应用场景。
答:
Redis是一个内存数据库,当内存不足时,需要使用数据淘汰策略来决定哪些数据应该被清理出内存,以便为新的数据腾出空间。
以下是几种常见的数据淘汰策略:
-
LRU(Least Recently Used):最近最少使用。LRU算法会根据键的最近访问时间进行排序,当内存不足时,会优先淘汰最近最少被访问的数据。
原理:该策略基于"如果数据最近被访问过,那么将来被访问的概率也较高"的思想。
应用场景:适用于访问模式较为集中,有明显热点数据的场景,能够保留访问频率较高的数据。
-
LFU(Least Frequently Used):最不经常使用。LFU算法会根据键被访问的次数进行排序,当内存不足时,会优先淘汰访问次数最少的数据。
原理:该策略基于"如果数据被访问次数较多,那么将来被访问的概率也较高"的思想。
应用场景:适用于访问模式相对平均,各个数据被访问次数相差不大的场景,能够保留频繁访问的数据。
-
Random(随机):随机淘汰。该策略会随机选择一部分数据进行淘汰,没有明确的排序规则。
原理:该策略简单直接,随机选择数据进行淘汰。
应用场景:适用于对数据访问模式无特殊要求的场景,对数据淘汰的顺序没有特定需求。
-
TTL(Time To Live):生存时间。使用TTL设置过期时间,在到达过期时间后,数据会自动被淘汰。
原理:该策略基于设置数据的生命周期,通过定义过期时间来淘汰数据。
应用场景:适用于具有明确生命周期的数据,比如缓存数据、临时数据等,能够根据需求灵活地控制数据的存储时间。
9、 字节一面,Redis为什么那么快?
答:
- 内存存储:Redis是基于内存的数据库,将数据存储在内存中而不是磁盘上。相比于传统的磁盘存储方式,内存访问速度更快,因此能够提供更高的性能。
- 单线程模型:Redis采用单线程模型,通过避免多线程之间的竞争和同步开销来提高性能。由于单线程的特性,Redis能够充分利用CPU的缓存,减少了线程切换和同步的开销。
- 高效数据结构:Redis内置了多种高效的数据结构,如字符串、列表、哈希表、集合和有序集合等。这些数据结构在底层实现上经过精细优化,能够快速执行各种操作,例如插入、删除、查找等。
- 异步IO:Redis使用了异步IO技术,通过使用事件驱动模型和非阻塞IO操作,能够处理大量并发请求并保持高效的响应速度。这使得Redis能够在处理IO操作时不会阻塞其他请求的执行。
- 高度优化:Redis在底层实现上对各种操作进行了高度优化,例如采用了MurmurHash算法来进行快速哈希计算,使用压缩列表和跳表等数据结构来节省内存空间,并对关键路径进行了精细的优化。
10、 Redis和MySQL如何保证数据一致性?
答:
首先,需要明确的是,Redis和MySQL是两种不同类型的数据库,它们在数据一致性的保证上有着不同的机制和策略。
在Redis中,为了保证数据的一致性,可以采用以下几种方式:
- 写操作的持久化:通过配置Redis的持久化机制,将数据写入硬盘,以防止系统崩溃或断电时数据丢失。Redis提供了两种持久化方式:RDB快照和AOF日志。RDB快照是将数据库在某个时间点的状态保存到磁盘上,而AOF日志则是将每个写操作追加到文件中。这些持久化方式可以在Redis重启后恢复数据一致性。
- 主从复制:Redis支持主从复制机制,在主节点上进行写操作后,会将数据同步到从节点上。通过配置合适的复制拓扑结构和复制策略,可以实现数据在主从节点之间的同步,提高数据的可用性和一致性。
- Redis事务:Redis支持事务处理,可以将一组操作打包成一个原子性的操作,要么全部执行成功,要么全部失败。使用Redis事务可以确保一系列操作的原子性,保障数据的一致性。
而在MySQL中,主要通过以下方式来保证数据一致性:
- 事务:MySQL支持ACID特性的事务,可以将一系列操作封装在一个事务中,并使用事务的隔离级别来控制并发访问。通过事务的提交和回滚机制,可以保证数据在多个操作之间的一致性。
- 锁机制:MySQL通过锁机制来控制并发访问,包括行级锁和表级锁。通过适当的锁粒度和锁策略,可以避免数据的冲突和不一致问题。
- 主从复制:和Redis类似,MySQL也支持主从复制机制。在主节点上进行写操作后,会将数据同步到从节点上,确保数据在多个节点之间的一致性。
11、 Redis存在线程安全问题吗?为什么?
答:
在Redis中,存在一些特定情况下的线程安全问题。主要包括以下几点:
- 命令的原子性:虽然Redis是单线程的,但在执行某些命令时,可能会涉及多个操作步骤,例如对某个键进行操作时,可能需要先获取该键的值,再进行计算或修改,最后再将结果写回。这个过程并非原子操作,因此在多线程环境下,可能会出现竞态条件或数据不一致的问题。
- 竞争条件:虽然Redis内部使用了单线程模型来避免多线程的同步问题,但在某些情况下,可能会发生竞争条件。例如,在多个客户端同时对同一个键进行写操作时,如果不进行合适的同步控制,可能会导致数据不一致的问题。
- 分布式环境下的一致性:在Redis的分布式部署中,由于数据的分片和节点之间的通信,可能会面临分布式一致性的问题。例如,在集群环境中,当某个节点宕机或网络分区发生时,可能会导致数据的不一致或丢失。
为了解决这些线程安全问题,可以采取以下措施:
- 对需要保证原子性的操作,使用Redis的事务功能,将一组操作打包成一个原子性的操作。
- 在多线程环境下,对涉及到的共享资源加锁进行同步控制,以避免竞态条件和数据不一致的问题。
- 在Redis的分布式部署中,通过合适的复制机制、故障转移和数据同步策略,来保证数据的一致性和高可用性。
12、 请说一下你对分布式锁的理解,以及分布式锁的实现?
答:
分布式锁是用于在分布式系统中对共享资源进行访问控制的一种机制。它的作用是保证在分布式环境下多个节点或进程之间对同一资源的互斥访问,从而确保数据的一致性和避免竞态条件。
对于分布式锁的实现方式,常见的有以下几种:
- 基于数据库:使用数据库的事务和唯一约束来实现分布式锁。通过在数据库中创建一个特殊的表或行记录来表示锁的状态,当需要获取锁时,尝试插入该行记录或更新特定字段,并利用数据库的唯一约束来保证只有一个线程或进程成功获取到锁。
- 基于缓存:使用分布式缓存如Redis或Memcached来实现分布式锁。通过在缓存中设置一个特定的键作为锁,并利用缓存的原子操作来实现对锁的获取和释放。例如,在Redis中可以使用SETNX命令来尝试获取锁,如果返回值是1,则说明获取成功;否则表示锁已被其他进程获取,需要等待或进行重试。
- 基于ZooKeeper:使用ZooKeeper这样的分布式协调服务来实现分布式锁。ZooKeeper提供了有序临时节点的功能,可以通过创建临时节点表示获取锁,并利用ZooKeeper的顺序特性来判断节点的先后顺序。通过监视前一个节点的删除事件,可以判断自己是否获取到了锁。
需要注意的是,在实现分布式锁时,还需考虑以下几点:
- 死锁和活锁:设计锁的获取和释放机制时,需避免死锁和活锁的发生,即所有参与者都无法前进或陷入无限循环的情况。
- 锁的超时机制:为防止某个节点出现故障或异常情况导致锁一直不释放,可以引入锁的自动超时机制,即设置一个合理的锁超时时间,在超过该时间后强制释放锁。
- 容错和高可用:在分布式系统中,要考虑节点故障、网络分区等问题,需要实现容错和高可用的分布式锁方案,保证锁可以正常工作并具备恢复能力。
13、 说说Redis的缓存雪崩和缓存穿透和缓存击穿的理解,以及如何避免?
答:
- 缓存雪崩:指在某个时间点,缓存中的大量数据同时失效或过期,导致大量请求直接打到数据库上,造成数据库压力剧增,甚至引起数据库崩溃的情况。主要原因可能是缓存的失效时间设置过于集中或缓存服务器故障。
避免缓存雪崩的方法:
- 设置合理的缓存失效时间,避免所有缓存同时失效。
- 采用多级缓存结构,例如引入本地缓存和分布式缓存,减小单点故障的风险。
- 实现缓存预热机制,在缓存失效前主动更新或加载数据,避免在高并发时突然全部失效。
- 缓存穿透:指查询一个不存在于缓存中的数据,导致每次请求都直接访问数据库,消耗数据库资源,这可能是恶意攻击或查询非常罕见的数据时出现。攻击者通过构造特定的请求,绕过缓存直接访问数据库,从而加重数据库的负载。
避免缓存穿透的方法:
- 对于查询返回空结果的请求,也将其缓存,并设置较短的过期时间,避免重复查询数据库。
- 使用布隆过滤器(Bloom Filter)等技术对不存在的数据进行预先过滤,减少对数据库的查询压力。
- 缓存击穿:指某个热点数据突然失效或过期,此时大量请求同时涌入,由于都无法从缓存中获取数据,会直接打到数据库上,造成数据库压力激增。
避免缓存击穿的方法:
- 为热点数据设置永不过期或较长的过期时间,避免在高并发时同时失效。
- 使用互斥锁或分布式锁,在缓存失效时,只有一个线程去加载数据到缓存,其他线程等待获取缓存中的数据。
14、 说说Redis的主从哨兵和集群的理解?
答:
- Redis的主从复制(主从哨兵): 主从复制是指通过将一个Redis实例(称为主节点)的数据复制到其他Redis实例(称为从节点)上,实现数据的冗余备份和读写分离。主节点负责处理写操作,并将修改的数据同步给从节点,而从节点只负责提供读操作,不接受客户端写操作。
主从复制的优点:
- 提高系统的可靠性和容灾能力,当主节点发生故障时,可以快速切换到从节点继续提供服务。
- 支持读写分离,从节点可以承担部分读取请求,减轻主节点的压力,提高系统的并发性能。
- Redis的集群: Redis集群是指将数据分布在多个Redis节点上,形成一个逻辑上的集群,通过数据的分片和数据迁移,实现数据的高可用性和水平扩展。在Redis集群中,各个节点彼此独立,相互协作完成数据的存储和读写操作。
Redis集群的特点:
- 数据分布:Redis将数据按照一定的规则进行分片,并将数据分散存储在不同的节点上,提高了存储容量和性能。
- 高可用性:Redis集群采用主从复制和故障转移的机制,当节点发生故障时,可以自动进行主从切换,保证数据的连续可用性。
- 水平扩展:通过增加节点数量,Redis集群可以实现横向扩展,提供更高的并发处理能力。
15、 说说Redis的缓存预热、缓存更新、缓存降级的理解?
答:
- 缓存预热: 缓存预热是指在系统启动或高峰期之前,提前将部分常用的数据加载到缓存中,以提高系统的性能和响应速度。通过缓存预热,可以避免系统刚启动时大量请求直接打到数据库上,减少数据库的负载压力。
缓存预热的实施步骤:
- 在系统启动或高峰期之前,通过程序主动加载常用的数据到缓存中。
- 设置合理的过期时间,使得缓存中的数据在有限的时间内失效,以便及时获取最新数据。
- 缓存更新: 缓存更新是指当数据发生变化时,需要及时更新缓存中的数据,保证缓存与数据库的一致性。当数据更新时,需要更新缓存中的对应数据,使得下次读取时可以获取最新的数据。
常用的缓存更新策略:
- 更新缓存:当数据发生变化时,从数据库中获取最新数据,并将其更新到缓存中,保持数据的一致性。可以使用钩子函数或触发器在数据更新时同步更新缓存。
- 删除缓存:当数据发生变化时,直接从缓存中删除对应的数据,下次读取时会重新从数据库中加载最新数据。
- 缓存降级: 缓存降级是指在缓存失效或缓存服务异常时,为了保证系统的可用性,暂时放弃使用缓存,直接从数据库或其他数据源获取数据。缓存降级可以避免因缓存故障而导致整个系统不可用。
常见的缓存降级策略:
- 设置适当的缓存失效时间,当缓存失效时,及时从数据库或其他数据源获取数据。
- 引入熔断机制,当缓存出现故障时,使用备用方案或默认值处理请求,保证系统的正常运行。
盈若安好,便是晴天
相关文章:

Java开发面试--Redis专区
1、 什么是Redis?它的主要特点是什么? 答: Redis是一个开源的、基于内存的高性能键值对存储系统。它主要用于缓存、数据存储和消息队列等场景。 高性能:Redis将数据存储在内存中,并采用单线程的方式处理请求…...
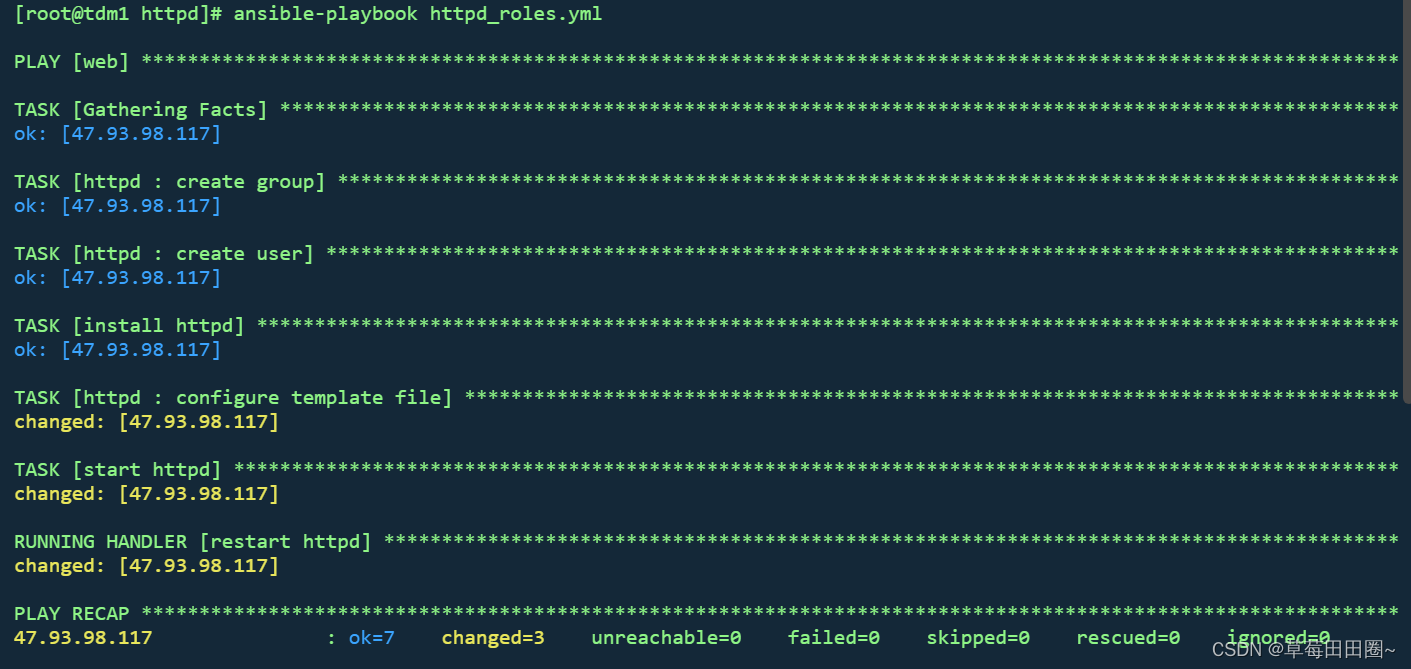
Ansible-roles学习
目录 一.roles角色介绍二.示例一.安装httpd服务 一.roles角色介绍 roles能够根据层次型结构自动装载变量文件,tasks以及handlers登。要使用roles只需在playbook中使用include指令即可。roles就是通过分别将变量,文件,任务,模块以…...
python3如何安装各类库的小总结
我的python3的安装路径是: C:\Users\Administrator\AppData\Local\Programs\Python\Python38 C:\Users\Administrator\AppData\Local\Programs\Python\Python38\python3.exeC:\Users\Administrator\AppData\Local\Programs\Python\Python38\Scripts C:\Users\Admin…...

ffmpeg 特效 转场 放大缩小
案例 ffmpeg \ -i input.mp4 \ -i image1.png \ -i image2.png \ -filter_complex \ [1:v]scale100:100[img1]; \ [2:v]scale1280:720[img2]; \ [0:v][img1]overlay(main_w-overlay_w)/2:(main_h-overlay_h)/2[bkg];\ [bkg][img2]overlay0:0 \ -y output.mp4 -i input.mp4//这…...

【GNN 03】PyG
工具包安装: 不要pip安装 https://github.com/pyg-team/pytorch_geometrichttps://github.com/pyg-team/pytorch_geometric import torch import networkx as nx import matplotlib.pyplot as pltdef visualize_graph(G, color):plt.figure(figsize(7, 7))plt.xtic…...

每日刷题-5
目录 一、选择题 二、算法题 1、不要二 2、把字符串转换成整数 一、选择题 1、 解析:printf(格式化串,参数1,参数2,.….),格式化串: printf第一个参数之后的参数要按照什么格式打印,比如%d--->按照整形方式打印&am…...
)
RNN简介(深入浅出)
目录 简介1. 基本理论 简介 要快速掌握RNN,可以考虑以下步骤: 学习基本理论:了解RNN的原理、结构和工作原理。掌握RNN的输入输出形式、时间步、隐藏状态、记忆单元等关键概念。学习常见的RNN变体:了解LSTM(Long Shor…...

Leetcode137. 某一个数字出现一次,其余数字出现3次
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 给你一个整数数组 nums ,除某个元素仅出现 一次 外,其余每个元素都恰出现 三次 。请你找出并返回那个只出现了一次的元素。 你必须设计并实现线性时间复杂度的算法且使用常数级空…...
)
原子化CSS(Atomic CSS)
UnoCSS,它不是像TailWind CSS和Windi CSS属于框架,而是一个引擎,它没有提供预设的原子化CSS工具类。引用自掘金,文章中实现相同的功能,构建后的体积TailWind 远> Windi > UnoCSS,体积会小很多。 像这种原子性的…...

pandas 筛选数据的 8 个骚操作
日常用Python做数据分析最常用到的就是查询筛选了,按各种条件、各种维度以及组合挑出我们想要的数据,以方便我们分析挖掘。 东哥总结了日常查询和筛选常用的种骚操作,供各位学习参考。本文采用sklearn的boston数据举例介绍。 from sklearn …...
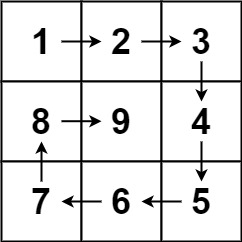
【随想】每日两题Day.3(实则一题)
题目:59.螺旋矩阵|| 给你一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。 示例 1: 输入:n 3 输出:[[1,2,3],[8,9,4],[7,6,5]]示例 2: …...

阿里后端开发:抽象建模经典案例【文末送书】
文章目录 写作前面1.抽象思维2.软件世界中的抽象3. 经典抽象案例4. 抽象并非一蹴而就!需要不断假设、验证、完善5. 推荐一本书 写作末尾 写作前面 在互联网行业,软件工程师面对的产品需求大都是以具象的现实世界事物概念来描述的,遵循的是人…...
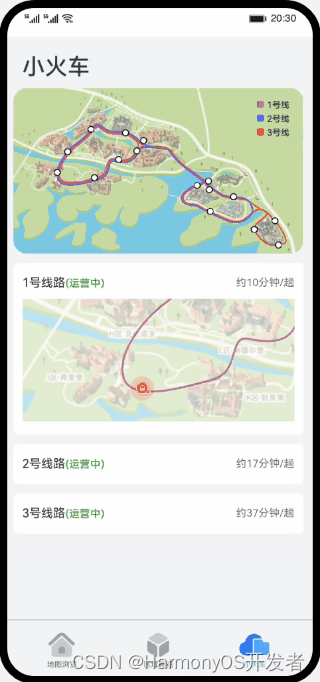
HarmonyOS Codelab 优秀样例——溪村小镇(ArkTS)
一、介绍 溪村小镇是一款展示溪流背坡村园区风貌的应用,包括园区内的导航功能,小火车行车状态查看,以及各区域的风景展览介绍,主要用于展示HarmonyOS的ArkUI能力和动画效果。具体包括如下功能: 打开应用时进入启动页&a…...

Mybatis---第二篇
系列文章目录 文章目录 系列文章目录一、#{}和${}的区别是什么?二、简述 Mybatis 的插件运行原理,如何编写一个插件一、#{}和${}的区别是什么? #{}是预编译处理、是占位符, KaTeX parse error: Expected EOF, got # at position 27: …接符。 Mybatis 在处理#̲{}时,会将…...
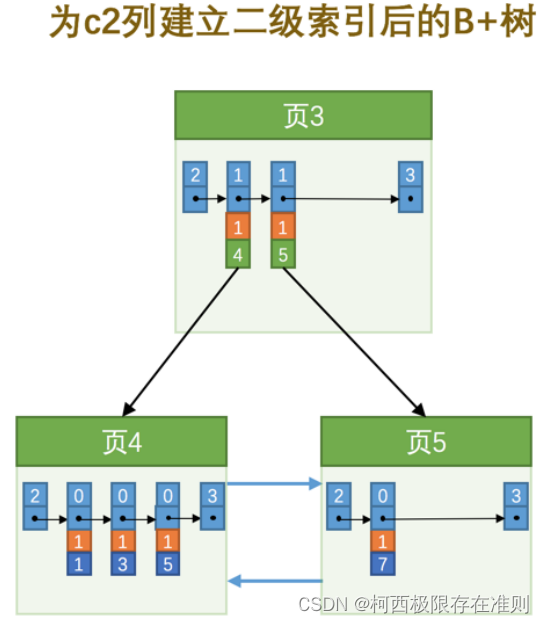
6.2.3 【MySQL】InnoDB的B+树索引的注意事项
6.2.3.1 根页面万年不动窝 B 树的形成过程是这样的: 每当为某个表创建一个 B 树索引(聚簇索引不是人为创建的,默认就有)的时候,都会为这个索引创建一个 根节点 页面。最开始表中没有数据的时候,每个 B 树…...
)
前端面试话术集锦第 12 篇:高频考点(Vue常考基础知识点)
这是记录前端面试的话术集锦第十二篇博文——高频考点(Vue常考基础知识点),我会不断更新该博文。❗❗❗ 这一章节我们将来学习Vue的一些经常考到的基础知识点。 1. 生命周期钩子函数 在beforeCreate钩子函数调用的时候,是获取不到props或者data中的数据的,因为这些数据的…...

骨传导耳机危害有哪些?值得入手吗?
事实上,只要是正常使用,骨传导耳机并不会对身体造成伤害,并且在众多耳机种类中,骨传导耳机可以说是相对健康的一种耳机,这种耳机最独特的地方便是声波不经过外耳道和鼓膜, 而是直接将人体骨骼结构作为传声介…...

网络爬虫-----初识爬虫
目录 1. 什么是爬虫? 1.1 初识网络爬虫 1.1.1 百度新闻案例说明 1.1.2 网站排名(访问权重pv) 2. 爬虫的领域(为什么学习爬虫 ?) 2.1 数据的来源 2.2 爬虫等于黑客吗? 2.3 大数据和爬虫又有啥关系&…...

vue 功能:点击增加一项,点击减少一项
功能介绍: 默认为一列,当点击右侧"" 号,增加一列;点击 “-” 号,将当前列删除; 功能截图: 功能代码: //HTML <el-col :span"24"><el-form-item lab…...

我的编程学习笔记
1. 引言: 在开始编写任何代码之前,都需要理解编程的基本概念。编程是人与计算机进行交流的方式,它让计算机可以理解和执行特定的任务。编程语言是这种交流的工具,而学习编程就是学习如何用特定的语言表达出我们想要的计算机行为。…...

[特殊字符] 智能合约中的数据是如何在区块链中保持一致的?
🧠 智能合约中的数据是如何在区块链中保持一致的? 为什么所有区块链节点都能得出相同结果?合约调用这么复杂,状态真能保持一致吗?本篇带你从底层视角理解“状态一致性”的真相。 一、智能合约的数据存储在哪里…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

synchronized 学习
学习源: https://www.bilibili.com/video/BV1aJ411V763?spm_id_from333.788.videopod.episodes&vd_source32e1c41a9370911ab06d12fbc36c4ebc 1.应用场景 不超卖,也要考虑性能问题(场景) 2.常见面试问题: sync出…...

Prompt Tuning、P-Tuning、Prefix Tuning的区别
一、Prompt Tuning、P-Tuning、Prefix Tuning的区别 1. Prompt Tuning(提示调优) 核心思想:固定预训练模型参数,仅学习额外的连续提示向量(通常是嵌入层的一部分)。实现方式:在输入文本前添加可训练的连续向量(软提示),模型只更新这些提示参数。优势:参数量少(仅提…...

centos 7 部署awstats 网站访问检测
一、基础环境准备(两种安装方式都要做) bash # 安装必要依赖 yum install -y httpd perl mod_perl perl-Time-HiRes perl-DateTime systemctl enable httpd # 设置 Apache 开机自启 systemctl start httpd # 启动 Apache二、安装 AWStats࿰…...
` 方法)
深入浅出:JavaScript 中的 `window.crypto.getRandomValues()` 方法
深入浅出:JavaScript 中的 window.crypto.getRandomValues() 方法 在现代 Web 开发中,随机数的生成看似简单,却隐藏着许多玄机。无论是生成密码、加密密钥,还是创建安全令牌,随机数的质量直接关系到系统的安全性。Jav…...

【JVM】- 内存结构
引言 JVM:Java Virtual Machine 定义:Java虚拟机,Java二进制字节码的运行环境好处: 一次编写,到处运行自动内存管理,垃圾回收的功能数组下标越界检查(会抛异常,不会覆盖到其他代码…...

如何在看板中有效管理突发紧急任务
在看板中有效管理突发紧急任务需要:设立专门的紧急任务通道、重新调整任务优先级、保持适度的WIP(Work-in-Progress)弹性、优化任务处理流程、提高团队应对突发情况的敏捷性。其中,设立专门的紧急任务通道尤为重要,这能…...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

JDK 17 新特性
#JDK 17 新特性 /**************** 文本块 *****************/ python/scala中早就支持,不稀奇 String json “”" { “name”: “Java”, “version”: 17 } “”"; /**************** Switch 语句 -> 表达式 *****************/ 挺好的ÿ…...