2023年五一杯数学建模B题快递需求分析问题求解全过程论文及程序
2023年五一杯数学建模
B题 快递需求分析问题
原题再现:
网络购物作为一种重要的消费方式,带动着快递服务需求飞速增长,为我国经济发展做出了重要贡献。准确地预测快递运输需求数量对于快递公司布局仓库站点、节约存储成本、规划运输线路等具有重要的意义。附件1、附件2、附件3为国内某快递公司记录的部分城市之间的快递运输数据,包括发货日期、发货城市以及收货城市(城市名已用字母代替,剔除了6月、11月、12月的数据)。请依据附件数据,建立数学模型,完成以下问题:
问题1:附件1为该快递公司记录的2018年4月19日—2019年4月17日的站点城市之间(发货城市-收货城市)的快递运输数据,请从收货量、发货量、快递数量增长/减少趋势、相关性等多角度考虑,建立数学模型,对各站点城市的重要程度进行综合排序,并给出重要程度排名前5的站点城市名称,将结果填入表1。

问题2:请利用附件1数据,建立数学模型,预测2019年4月18日和2019年4月19日各“发货-收货”站点城市之间快递运输数量,以及当日所有“发货-收货”站点城市之间的总快递运输数量,并在表2中填入指定的站点城市之间的快递运输数量,以及当日所有“发货-收货”站点城市之间的总快递运输数量。
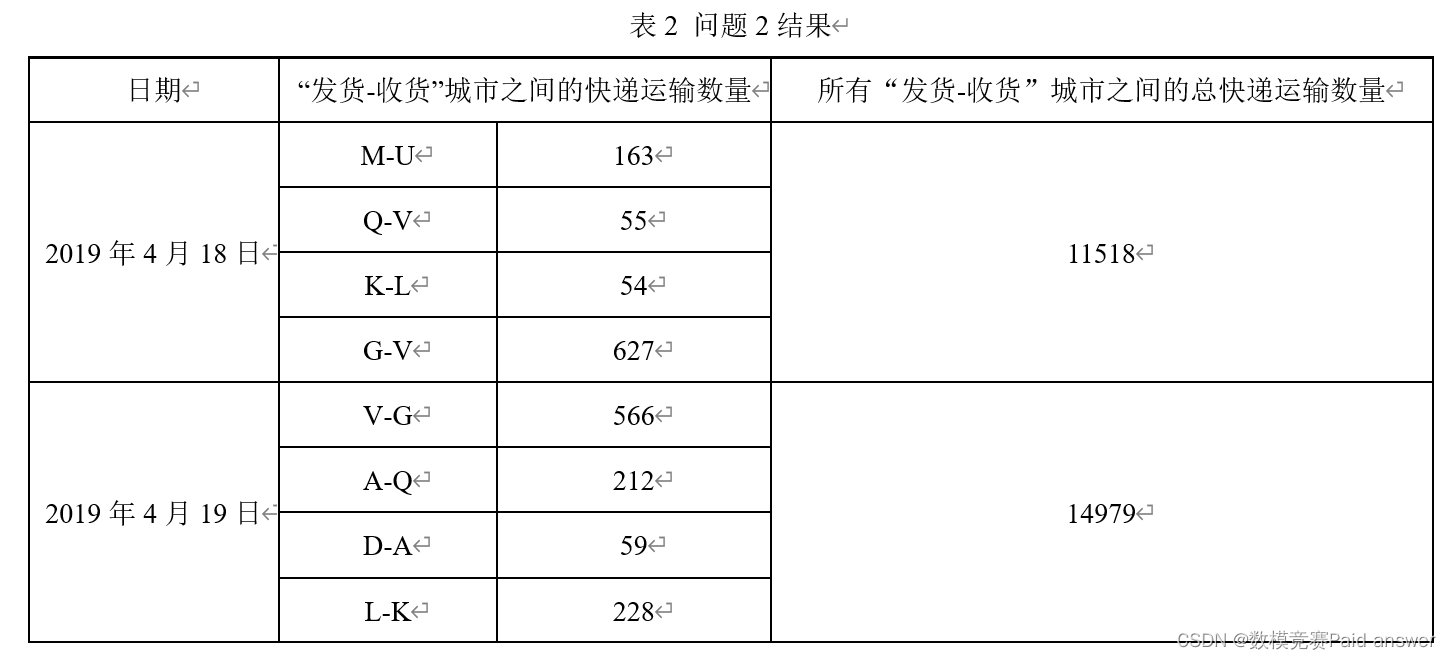
问题3:附件2为该快递公司记录的2020年4月28日—2023年4月27日的快递运输数量。由于受到突发事件影响,部分城市之间快递线路无法正常运输,导致站点城市之间无法正常发货或收货(无数据表示无法正常收发货,0表示无发货需求)。请利用附件2数据,建立数学模型,预测2023年4月28日和2023年4月29日可正常“发货-收货”的站点城市对(发货城市-收货城市),并判断表3中指定的站点城市对是否能正常发货,如果能正常发货,给出对应的快递运输数量,并将结果填入表3。
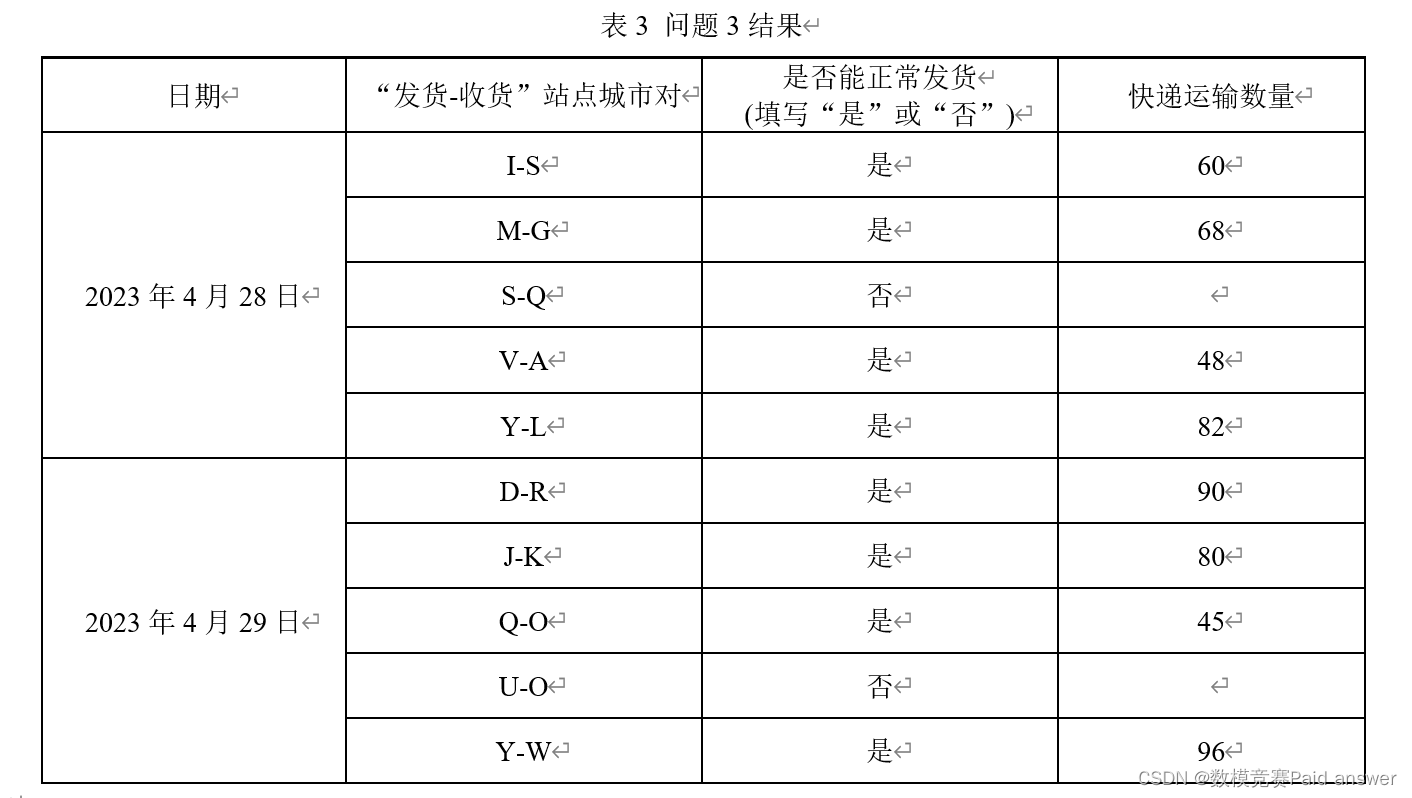
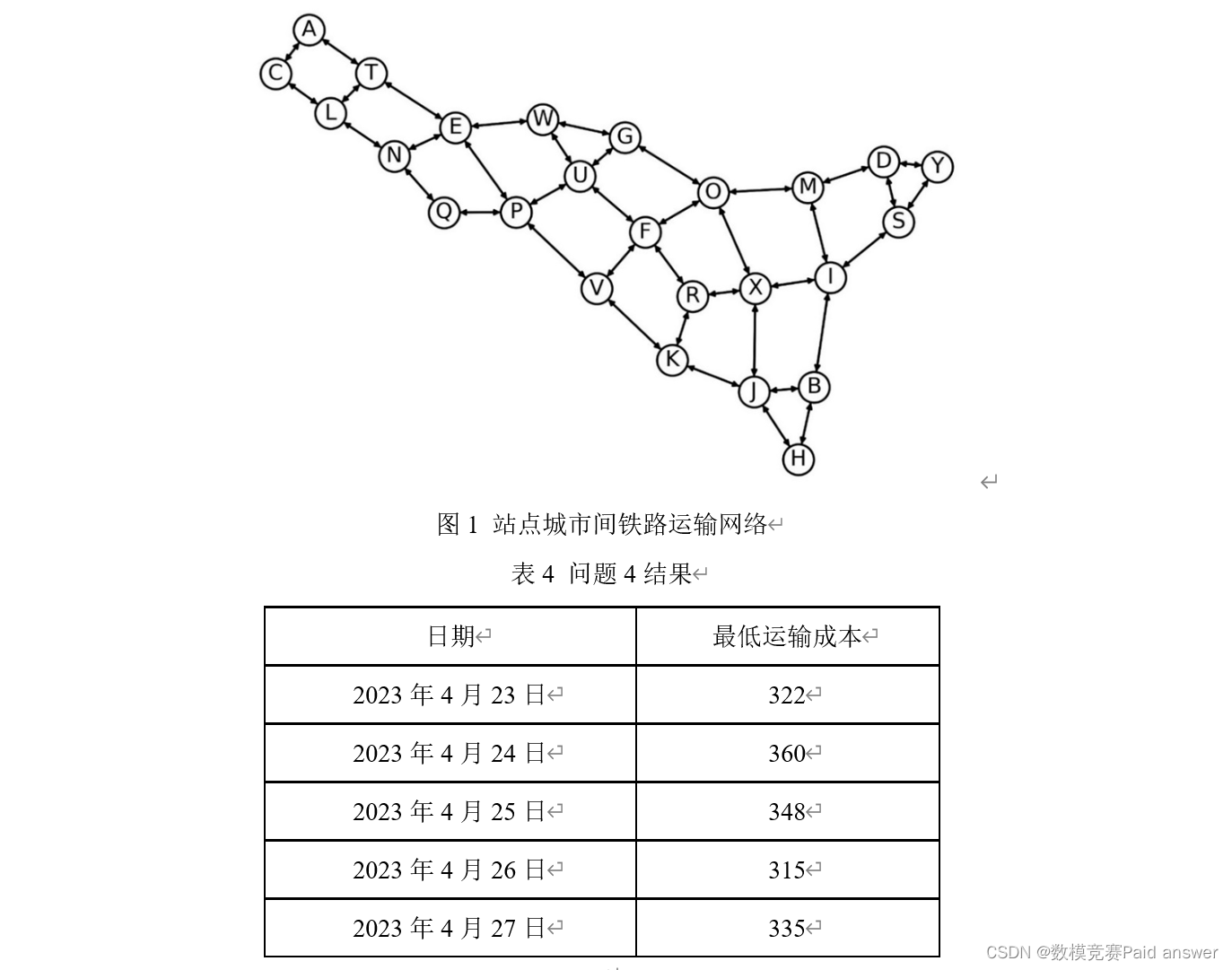
问题4:图1给出了所有站点城市间的铁路运输网络,铁路运输成本由以下公式计算:成本=固定成本×[1+(实际装货量/额定装货量)^3 ]。在本题中,假设实际装货量允许超过额定装货量。所有铁路的固定成本、额定装货量在附件3中给出。在运输快递时,要求每个“发货-收货”站点城市对之间使用的路径数不超过5条,请建立数学模型,给出该快递公司成本最低的运输方案。利用附件2和附件3的数据,计算该公司2023年4月23—27日每日的最低运输成本,填入表4。
备注:为了方便计算,不对快递重量和大小进行区分,假设每件快递的重量为单位1。仅考虑运输成本,不考虑中转等其它成本。
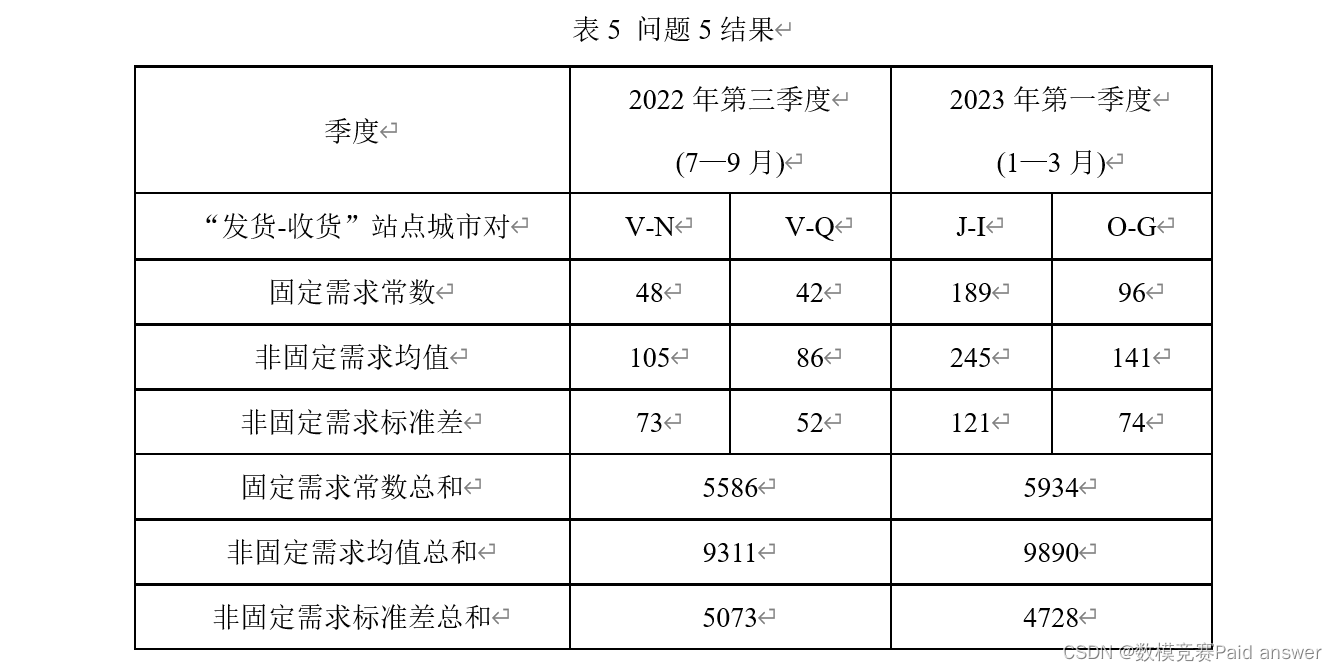
问题5:通常情况下,快递需求由两部分组成,一部分为固定需求,这部分需求来源于日常必要的网购消费(一般不能简单的认定为快递需求历史数据的最小值,通常小于需求的最小值);另一部分为非固定需求,这部分需求通常有较大波动,受时间等因素的影响较大。假设在同一季度中,同一“发货-收货”站点城市对的固定需求为一确定常数(以下简称为固定需求常数);同一“发货-收货”站点城市对的非固定需求服从某概率分布(该分布的均值和标准差分别称为非固定需求均值、非固定需求标准差)。请利用附件2中的数据,不考虑已剔除数据、无发货需求数据、无法正常发货数据,解决以下问题。
(1) 建立数学模型,按季度估计固定需求常数,并验证其准确性。将指定季度、指定“发货-收货”站点城市对的固定需求常数,以及当季度所有“发货-收货”城市对的固定需求常数总和,填入表5。
(2) 给出非固定需求概率分布估计方法,并将指定季度、指定“发货-收货”站点城市对的非固定需求均值、标准差,以及当季度所有“发货-收货”城市对的非固定需求均值总和、非固定需求标准差总和,填入表5。
整体求解过程概述(摘要)
网络购物正带动着快递服务需求快速增长,为我国经济发展做出了重要贡献。为节约成本,规划运输线路等问题,急需准确预测快递运输需求数量。
针对问题 1,对附件 1 数据进行描述性统计分析,计算不同站点城市的发货和收货快递数量总和,对站点城市进行重要性初步排序。然后随机选择几个站点城市,绘制非线性拟合曲线图,探究快递数量和日期的联系。结合收发货量和时间日期的影响,对站点城市进行重要程度排名。
针对问题 2,首先对数据进行可视化处理,对附件 1 的数据,绘制 M-U,Q-V,K-L,G-V,V-G,A-Q,D-A,L-K 八条线路快递运输数量的质量分布直方图,对数据进行可视化处理以得到不同路线的缺失值情况。根据缺失值占比不同情况,分布将不同线路数据带入非平稳时间序列模型,预测题中要求站点城市指定日期快递运输数量。
针对问题 3,首先对附件 2 中指定站点城市快递运输缺失日期进行数据挖掘,比对分析不同站点城市的快递运输缺失日期,得出影响站点城市快递运输数量变化的主要因素为节假日,并考虑实际因素,如疫情和政策等因素。接着,使用灰色关联分析方法,结合多种影响因素,得出不同影响因素的权重,并基于此预测指定站点城市的发货情况和快递运输数量。
针对问题 4,建立基于最短路径算法的成本优化模型,根据所给的铁路运输线路图和数据信息,找到源点到其余所有点的最短路径。通过聚类,将四个点分成两部分,分别以发货点和收获点为中心向对应路径进行遍历。综合处理后,每个节点之间的连线和节点均满足约束条件,将连线长度作为权重构建赋权图,使用 Dijkstra算法求得 2023 年 4 月 23-27 日每日的最低运输成本。
针对问题 5,根据问题五中(1)的要求,采用季节系数法估计以 2022 年第三季度V 为发货城市,N 和 Q 为收货城市;以 2023 年第一季度 J 和 O 为发货城市,I 和 G为收货城市的季度需求常数,预测所有城市 2022 年第三季度和 2023 年第一季度的城市固定需求常数总和。对于问题五中(2)的要求,结合问题三结论,不同季度对于快递运输数量的影响权重也不一致。它们可以促进快递运输数量的增大或减少,其不同季节时间段的快递运输数量服从连续型数据的高斯分布。使用 Python 软件编程,对指定季度指定站点城市对的非固定需求均值、标准差进行计算,并计算当季度所有“发货-收货”城市对的非固定需求均值总和、非固定需求标准差总和。
模型假设:
1. 假设快递运输数量随时间变化而变化,即同一站点城市对的快递运输数量会因为时间的推移而有所变化。
2. 假设不同站点城市对的快递运输数量存在一定的相关性,即某些站点城市之的快递运输数量之间存在一定的相关性。
3. 假设快递运输数量的增长/减少趋势具有一定的周期性,即某些站点城市之间的
快递运输数量会有周期性的变化。
4. 假设不同站点城市对的快递运输数量之间可能存在非线性的相关性,即某些站点城市之间的快递运输数量之间可能存在非线性的关系。
5. 假设站点城市的重要程度与其他城市之间的快递运输量有关,即快递运输量越大的站点城市越重要。
6. 假设站点城市之间的快递运输数量与两个城市之间的距离成反比例关系,即两个城市之间的距离越远,快递运输数量越小。
7. 假设在同一天内,快递运输量与发货城市、收货城市以及运输路线有关。
问题分析:
本题涉及多个数学模型及算法,主要探究影响给定站点城市快递运输数量主要因素,并以此为依据,结合不同题目要求进行预测。
问题一分析:
通过对附件1中的数据进行描述性统计分析,对站点城市重要度进行初步排序。在此基础上建立数学模型,对不同路线快递运输数量进行非线性拟合,对影响站点城市快递运输数量的因素进行拟合探究,得到重要城市排名。
问题二分析:
通过对附件 1 的数据进行数据处理,检查数据完整性。对不完整度达到 30%及以上的数据建立非平稳时间序列模型进行以预测指定日期站点城市快递运输数量。
问题三分析:
通过对历史数据的日期,发货成事,收货城市,快递运输数量关联分析,数据挖掘出指定城市之间快递线路不同时间段内的快递运输数量变化规律,并以此建立数学模型来预测 2023 年 4 月 28 日,29 日指定城市的快递运输数量。
问题四分析:
根据题中所给所有站点城市间的铁路运输线路图,结合附件 2 和附件 3 所给所有站点城市的发货城市、收货城市、快递运输数量、额定装货量、固定成本数据信息,建立基于最短路径算法的成本优化模型,为了使快递公司的运输路线要尽可能的使得成本达到最低,而快递经由中间城市数量越多则距离路径越繁琐,成本越大,需鉴于不同城市不同日期对于快递运输数量的影响权重,对最短路径的成本优化模型进行求解。
问题五分析:
根据问题五中(1)的要求,以 2022 年第三季度 V 为发货城市、以 N 和 Q 为收货城市;以 2023 年第一季度 J 和 O 为发货城市、以 I 和 G 为收货城市作为基础数据采用季节系数法估计其季度需求常数,并将应用合理准确的季节系数分别预测所有城市 2022 年第三季度和 2023 年第一季度的城市固定需求常数总和。针对问题五中(2)的要求,结合上述问题三中得出的快递运输数量与日期时间的变化趋势可视图及问题三中得出的结论,不同季度对于快递运输数量的影响权重也不一致,或是起到促进快递运输数量的增大或是使得快递运输数量减少,其不同季节时间段的快递运输数量服从连续型数据的高斯分布,使用 python 软件编程对指定季度指定“发货-收货”站点城市对的非固定需求均值、标准差,以及当季度所有“发货-收货”城市对的非固定需求均值总和、非固定需求标准差总和进行计算求解。
模型的建立与求解整体论文缩略图

全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
程序代码:
部分程序如下:
import pandas as pd
df = pd.read_excel("附件 1.xlsx")
df.groupby("发货城市")["快递运输数量
"].sum().reset_index().sort_values(by="快递运输数量")
df.groupby("发货城市")["快递运输数量
"].sum().reset_index().sort_values(by="快递运输数量").to_excel("发货
量.xlsx")
df.groupby("收货城市")["快递运输数量
"].sum().reset_index().sort_values(by="快递运输数量").to_excel("收货
量.xlsx")
from pyecharts import Line
asds = pd.read_excel("分组结果.xlsx",sheet_name='G-L')
line = Line("G-L 城市快递运输数量拟合曲线图")
line.add("",asds['日期'],asds['快递运输数量
'],mark_line=["average"],is_smooth=True ,is_label_show=True,is_random=Tr
ue)
line.render('G-L 城市快递运输数量拟合曲线图.html')
from pyecharts import Line
import pandas as pd
year_population_age=pd.read_excel("分组结果.xlsx",sheet_name='A-O')
line3 = Line("A-O 城市快递运输数量堆叠面积图")
line3.add("",year_population_age['日期'],year_population_age['快递运输数量'],is_fill=True,area_opacity=0.3,is_smooth=True,#是否显示平滑曲线, 默认为 Falsemark_point=['max'],is_random=True,is_stack=True)
line3.render('A-O 城市快递运输数量堆叠面积图.html')
#计算需求常数、均值、标准差
import pandas as pd
df = pd.read_excel("附件 2.xlsx",sheet_name='2022-3')
df.groupby(["发货城市","收货城市"])["快递运输数量
"].mean().reset_index().sort_values(by="快递运输数量")
df1 = df.groupby(["发货城市","收货城市"])["快递运输数量
"].mean().reset_index().sort_values(by="快递运输数量")
df1.to_excel("2022 第三季度.xlsx")
pf = pd.read_excel("附件 2.xlsx",sheet_name='2023-1')
pf.groupby(["发货城市","收货城市"])["快递运输数量
"].mean().reset_index().sort_values(by="快递运输数量")
pf1.to_excel("2023 第一季度.xlsx")
import numpy as np
tf1 = pd.read_excel("附件 2.xlsx",sheet_name='V-N')
tf2 = pd.read_excel("附件 2.xlsx",sheet_name='V-Q')
tf3 = pd.read_excel("附件 2.xlsx",sheet_name='J-I')
tf4 = pd.read_excel("附件 2.xlsx",sheet_name='O-G')
np.std(tf1['快递运输数量'])
np.std(tf2['快递运输数量'])
np.std(tf3['快递运输数量'])
np.std(tf4['快递运输数量'])
df.groupby(["发货城市","收货城市"])["快递运输数量
"].std().reset_index().sort_values(by="快递运输数量").to_excel("2022 第
三季度标准差和.xlsx")
pf.groupby(["发货城市","收货城市"])["快递运输数量
"].std().reset_index().sort_values(by="快递运输数量").to_excel("2023 第
一季度标准差和.xlsx")
全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
相关文章:
2023年五一杯数学建模B题快递需求分析问题求解全过程论文及程序
2023年五一杯数学建模 B题 快递需求分析问题 原题再现: 网络购物作为一种重要的消费方式,带动着快递服务需求飞速增长,为我国经济发展做出了重要贡献。准确地预测快递运输需求数量对于快递公司布局仓库站点、节约存储成本、规划运输线路等具…...
华为云征文|华为云云耀云服务器L实例使用教学(一)
目录 国内免费云服务器(体验) 认识国内免费云服务器 如何开通国内免费云服务器 云耀云服务器 HECS HECS适用于哪些场景? 网站搭建 电商建设 开发测试环境 云端学习环境 为什么选择华为云耀云服务器 HECS 国内免费云服务器ÿ…...

编写算法对输入的一个整数,判断它能否被 3,5,7 整除
任务描述 本关任务,编写算法对输入的一个整数,判断它能否被 3,5,7 整除,并输出以下信息之一: 能同时被 3,5,7 整除; 能被其中两数(要指出哪两个)…...

Linux CentOS7设置时区
在Linux系统中,默认使用的是UTC时间。 即使在安装系统的时候,选择的时区是亚洲上海,Linux默认的BIOS时间(也称:硬件时间)也是UTC时间。 在重启之后,系统时间会和硬件时间同步,如果…...

HBase 记录
HBase 管理命令 hbase hbck -details TABLE_NAME hbase hbck -repair TABLE_NAMEHBase概览 Master、RegionServer作用 RegionServer与Region关系 数据定位原理 https://blogs.apache.org/hbase/entry/hbase_who_needs_a_master RegionServer HBase Essentials.pdf (P25)…...
Fiddler抓http数据
目录 参考博客 一、Fiddler配置二、分析Http请求1. Http消息结构简介1.1 Request请求消息1.2 Response响应消息 2. 分析Get接口2.1 请求示例2.2 查看Get请求2.3 查看Get响应 3 分析Post接口 参考博客 一、Fiddler配置 首先需要对Fiddler抓取Https请求进行相关配置:…...

【MySQL】redo log 、 undo log、脏页这些概念是什么?
redo log(重做日志)redo log 是什么redo log 的主要作用Redo 的组成redo如何保证 事务的持久性 undo log(撤销日志/回滚日志)undo log 是什么redo log 的主要作用undo的存储位置 如何区分 redo log和undo log感谢 💖参…...

05ShardingSphere-JDBC水平分片
1、准备服务器 随着业务的扩大,订单表数据量不断增加,数据库面临存储压力,开始考虑对订单表进行水平分片。 将t_order表扩展为server-order0中的t_order0和t_order1、server-order1中的t_order0和t_order1 服务器规划:使用dock…...

Java多线程并发面试题
文章目录 Java并发基础并行和并发有什么区别?说说什么是进程和线程?Java线程创建方式?Runnable和Callable接口的区别?为什么调用start()方法时会执行run()方法,不直接调用run()方法?sleep()和wait()的区别&…...
ELK学习笔记1:简介及安装
ELK学习笔记1:简介及安装 ELK的简介 ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。新增了一个FileBeat,它是一个轻量级的日志收集处理工具(Agent),Filebeat占用资源少&a…...
uniapp——实现电子签名功能——基础积累
话说,2020年刚来杭州的时候,有用到过uniapp,距今已有三年时间了,果然全忘了,哈哈[笑中带泪] 昨天遇到一个需求:就是要实现pdf文件的预览,着实费了我很多的时间,连晚饭都没有吃好。。…...

【Flink实战系列】Hash collision on user-specified ID “Kafka Source”
Hash collision on user-specified ID “Kafka Source” 在使用 fromSource 构建 Kafka Source 的时候,遇到下面的报错,下面就走进源码,分析一下原因。 Exception in thread "main" java.lang.IllegalArgumentException: Hash collision on user-specified ID &…...

面对 HR 的空窗期提问,你会如何回答?
原文链接 面对 HR 的空窗期提问,你会如何回答? 你是否有过这样的经历,在一段时间内,你离开了工作岗位,或者在寻找新的工作机会,这段时间我们称之为“空窗期”。 对于这段时间,我们该如何看待&…...

性能测试、负载测试、压力测试、稳定性测试简单区分
是一个总称,可细分为性能测试、负载测试、压力测试、稳定性测试。 性能测试 以系统设计初期规划的性能指标为预期目标,对系统不断施加压力,验证系统在资源可接受范围内,是否能达到性能瓶颈。 关键词提取理解 有性能指标&#…...
如何理解恒流源的阻抗为无穷大
最近在看模拟CMOS集成电路设计一书,在阅读过程中有句话让我难以理解:“电流源引入的阻抗为无穷大。“,经查阅资料,明白了为什么这样解释。 可以这样思考:假设我们现在有一个恒流源加上一个电阻的简单电路,那…...
彻底掌握Protobuf编码原理与实战
目录 1.类型2.VARINT 2.1 无符号数2.2 有符号数3.定长 3.1 I64类型3.2 I32类型4.LEN5.代码 学习这些有什么用? - 如果你是后端开发者,掌握这个对工作非常有用 - 如果你是求职者,面试时可以临危不惧 1.类型 最近看到有直接操作wire type相关的…...

移动测试之语音识别功能如何测试?
移动测试之语音识别功能如何测试? 要知道语音识别功能如何测试,我们先了解智能产品语音交互流程: 所以,要进行测试的话,我们需要从以下几个维度来准备测试点: 基础功能测试: 1、声纹的录入&…...
Python 图形化界面基础篇:使用网格布局( Grid Layout )排列元素
Python 图形化界面基础篇:使用网格布局( Grid Layout )排列元素 引言什么是 Tkinter 的网格布局?步骤1:导入 Tkinter 模块步骤2:创建 Tkinter 窗口步骤3:创建网格步骤4:将元素放置在…...

MongoDB副本集搭建
版本 > db.version() 4.4.24 > 集群相关命令 rs.status()## id 要和配置文件定义的replSetName一致 cfg{_id:"knight",members:[{_id:0,host:182.27.239.17:27017,priority:1}]}## id 要和配置文件定义的replSetName一致 cfg{_id:"knight",memb…...
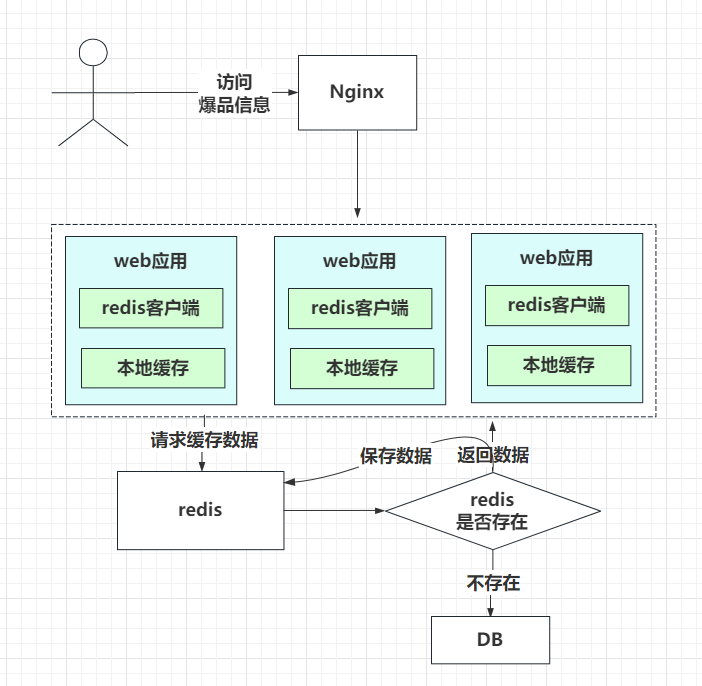
【面试】Redis的热key问题如何发现和解决?
文章目录 背景一、怎么发现热key1.1 方法一:凭借业务经验,进行预估哪些是热key1.2 方法二:在客户端进行收集1.3 方法三:在Proxy层做收集1.4 方法四:用redis自带命令1.5 方法五:自己抓包评估 二、如何解决2.1. 利用二级缓存2.2. 备份热key2.3 永不过期2.4 分布式锁 三…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...

CSS设置元素的宽度根据其内容自动调整
width: fit-content 是 CSS 中的一个属性值,用于设置元素的宽度根据其内容自动调整,确保宽度刚好容纳内容而不会超出。 效果对比 默认情况(width: auto): 块级元素(如 <div>)会占满父容器…...
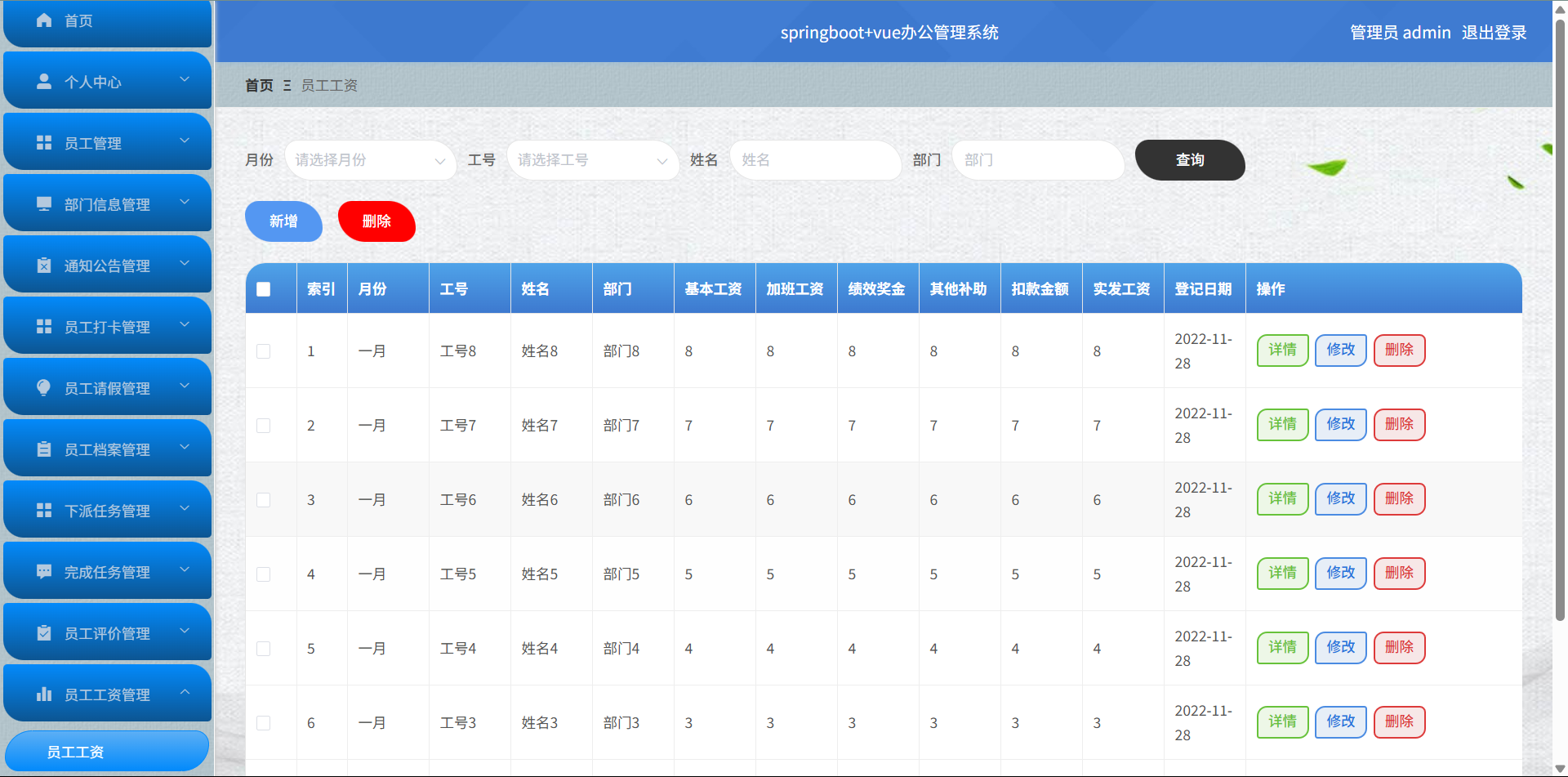
基于Springboot+Vue的办公管理系统
角色: 管理员、员工 技术: 后端: SpringBoot, Vue2, MySQL, Mybatis-Plus 前端: Vue2, Element-UI, Axios, Echarts, Vue-Router 核心功能: 该办公管理系统是一个综合性的企业内部管理平台,旨在提升企业运营效率和员工管理水…...

Web中间件--tomcat学习
Web中间件–tomcat Java虚拟机详解 什么是JAVA虚拟机 Java虚拟机是一个抽象的计算机,它可以执行Java字节码。Java虚拟机是Java平台的一部分,Java平台由Java语言、Java API和Java虚拟机组成。Java虚拟机的主要作用是将Java字节码转换为机器代码&#x…...

作为测试我们应该关注redis哪些方面
1、功能测试 数据结构操作:验证字符串、列表、哈希、集合和有序的基本操作是否正确 持久化:测试aof和aof持久化机制,确保数据在开启后正确恢复。 事务:检查事务的原子性和回滚机制。 发布订阅:确保消息正确传递。 2、性…...
)
安卓基础(Java 和 Gradle 版本)
1. 设置项目的 JDK 版本 方法1:通过 Project Structure File → Project Structure... (或按 CtrlAltShiftS) 左侧选择 SDK Location 在 Gradle Settings 部分,设置 Gradle JDK 方法2:通过 Settings File → Settings... (或 CtrlAltS)…...

提升移动端网页调试效率:WebDebugX 与常见工具组合实践
在日常移动端开发中,网页调试始终是一个高频但又极具挑战的环节。尤其在面对 iOS 与 Android 的混合技术栈、各种设备差异化行为时,开发者迫切需要一套高效、可靠且跨平台的调试方案。过去,我们或多或少使用过 Chrome DevTools、Remote Debug…...
【Post-process】【VBA】ETABS VBA FrameObj.GetNameList and write to EXCEL
ETABS API实战:导出框架元素数据到Excel 在结构工程师的日常工作中,经常需要从ETABS模型中提取框架元素信息进行后续分析。手动复制粘贴不仅耗时,还容易出错。今天我们来用简单的VBA代码实现自动化导出。 🎯 我们要实现什么? 一键点击,就能将ETABS中所有框架元素的基…...