Scrapy的基本介绍、安装及工作流程
一.Scrapy介绍
Scrapy是什么?
Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架(异步爬虫框架) 通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。 Scrapy使用了Twisted异步网络框架,可以加快我们的下载速度
-
异步和非阻塞的区别
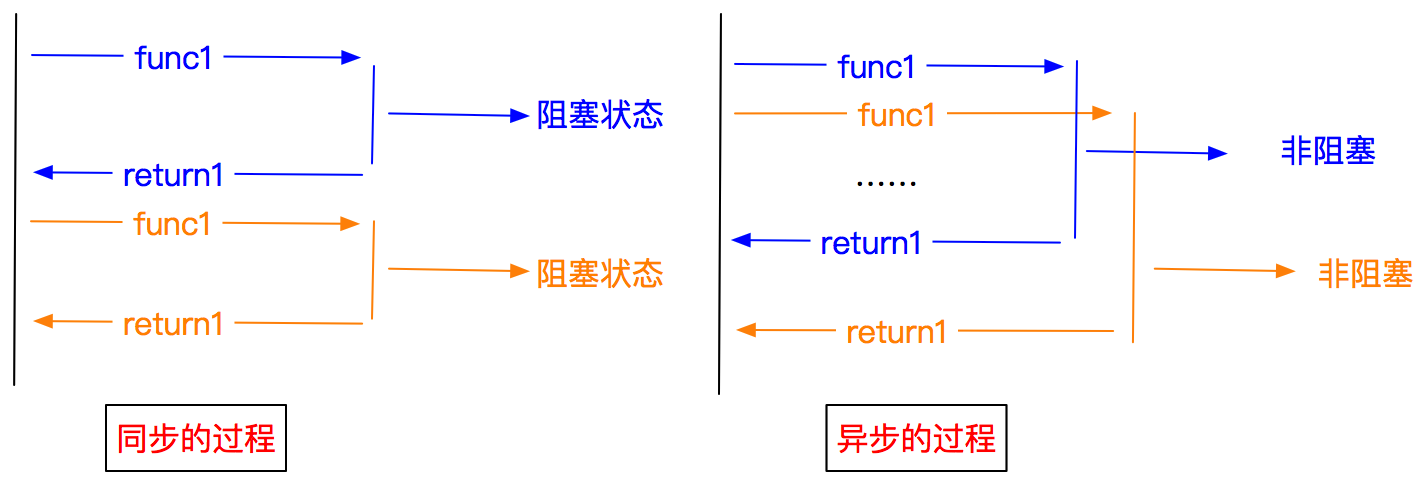
异步:调用在发出之后,这个调用就直接返回,不管有无结果 非阻塞:关注的是程序在等待调用结果时的状态,指在不能立刻得到结果之前,该调用不会阻塞当前线程 <a name="owIjs"></a>
Scrapy的优势
爬虫必备的技术 - 能够使我们的爬虫程序更加稳定 效率更高(多线程) - 配置和可扩展性非常强(很灵活) - downloader 下载器(基于多线程的) 发送请求 获取响应的 <a name="oAAzH"></a>
Scrapy的安装
pip install scrapy==2.5.1 -i Simple Index <a name="yDdn4"></a>
Scrapy工作流程
一种爬虫方式
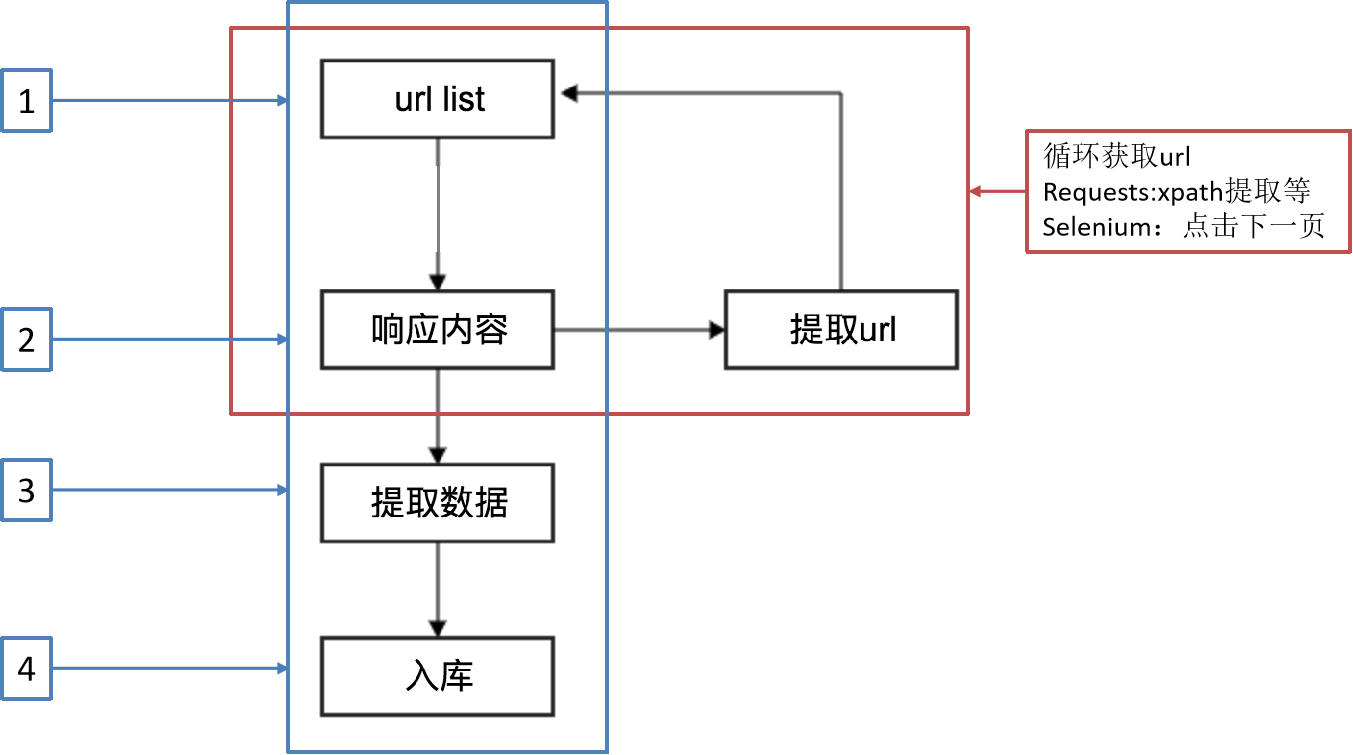
另一种爬虫方式

工作流程

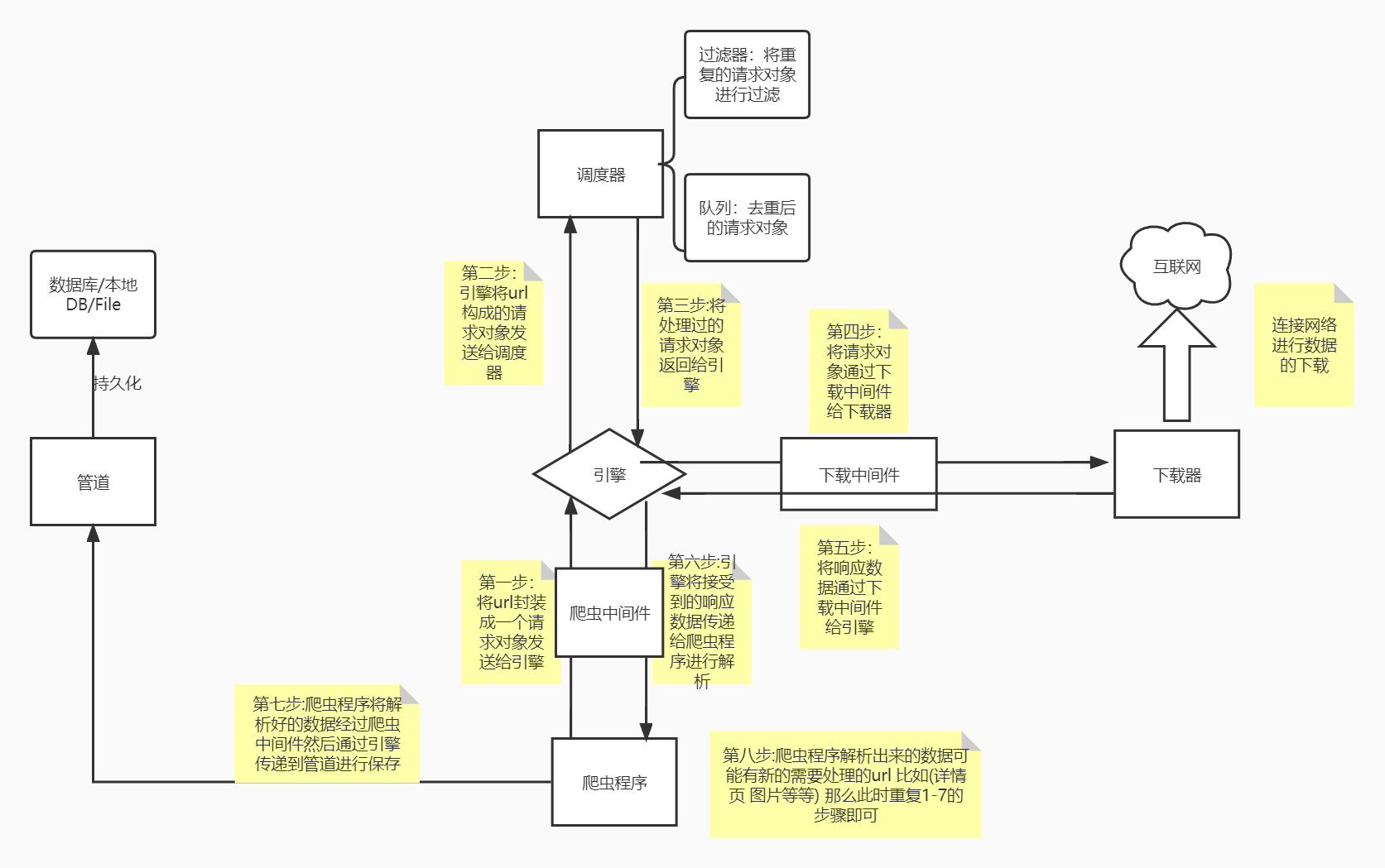
各个组件的功能介绍
| Scrapy engine(引擎) | 总指挥:负责数据和信号的在不同模块间的传递 | scrapy已经实现 |
|---|---|---|
| Scheduler(调度器) | 一个队列,存放引擎发过来的request请求 | scrapy已经实现 |
| Downloader(下载器) | 下载把引擎发过来的requests请求,并返回给引擎 | scrapy已经实现 |
| Spider(爬虫) | 处理引擎发来的response,提取数据,提取url,并交给引擎 | 需要手写 |
| Item Pipline(管道) | 处理引擎传过来的数据,比如存储 | 需要手写 |
| Downloader Middlewares(下载中间件) | 可以自定义的下载扩展,比如设置代理 | 一般不用手写 |
| Spider Middlewares(中间件) | 可以自定义requests请求和进行response过滤 | 一般不用手写 |
1 引擎(engine) scrapy已经实现 scrapy的核心, 所有模块的衔接, 数据流程梳理 2 调度器(scheduler) scrapy已经实现 本质上这东西可以看成是一个队列,里面存放着一堆我们即将要发送的请求,可以看成是一个url的容器 它决定了下一步要去爬取哪一个url,通常我们在这里可以对url进行去重操作。 3 下载器(downloader) scrapy已经实现 它的本质就是用来发动请求的一个模块,小白们完全可以把它理解成是一个requests.get()的功能, 只不过这货返回的是一个response对象. 4 爬虫(spider) 需要手写 这是我们要写的第一个部分的内容, 负责解析下载器返回的response对象,从中提取到我们需要的数据 5 管道(Item pipeline) 这是我们要写的第二个部分的内容, 主要负责数据的存储和各种持久化操作 6 下载中间件(downloader Middlewares) 一般不用手写 可以自定义的下载扩展 比如设置代理 处理引擎与下载器之间的请求与响应(用的比较多) 7 爬虫中间件(Spider Middlewares) 一般不用手写 可以自定义requests请求和进行response过滤(处理爬虫程序的响应和输出结果以及新的请求)
Scrapy入门与总结
Scrapy入门
前提:路径切换 cd copy path 复制绝对路径
1. 创建scrapy项目
scrapy startproject mySpider
scrapy startproject(固定的)
mySpider(不固定的 需要创建的项目的名字)
2. 进入项目里面:cd mySpider
3. 创建爬虫程序
scrapy genspider example example.com
scrapy genspider:固定的
example:爬虫程序的名字(不固定的)
example.com:可以允许爬取的范围(不固定的) 是根据你的目标url来指定的 其实很重要 后面是可以修改的
目标url:https://www.baidu.com/
scrapy genspider bd baidu.com
4. 执行爬虫程序
scrapy crawl bd
scrapy crawl:固定的
db:执行的爬虫程序的名字
可以通过start.py文件执行爬虫项目:
from scrapy import cmdline
cmdline.execute("scrapy crawl bd".split())
Scrapy文件说明
baidu.py爬虫文件 # 爬虫程序的名字name = 'bd'# 可以爬取的范围# 有可能我们在实际进行爬取的时候 第一页可能是xxx.com 第三页可能就变成了xxx.cn # 或者xxx.yy 那么可能就会爬取不到数据# 所以我们需要对allowed_domains进行一个列表的添加allowed_domains = ['baidu.com']# 起始url地址 会根据我们的allowed_domains对网页前缀进行一定的补全 # 但有时候补全的url不对 所以我们也要去对他进行修改start_urls = ['https://www.baidu.com/']
# 专门用于解析数据的def parse(self, response): items.py 数据封装的
middlewares.py 中间件(爬虫中间件和下载中间件)
pipelines.py 管道(保存数据的)
settings.py Scrapy的配置项
# 1 自动生成的配置,无需关注,不用修改
BOT_NAME = 'mySpider'
SPIDER_MODULES = ['mySpider.spiders']
NEWSPIDER_MODULE = 'mySpider.spiders'
# 2 取消日志
LOG_LEVEL = 'WARNING'
# 3 设置UA,但不常用,一般都是在MiddleWare中添加
USER_AGENT = 'mySpider (+http://www.yourdomain.com)'
# 4 遵循robots.txt中的爬虫规则,很多人喜欢False,当然我也喜欢....
ROBOTSTXT_OBEY = True
# 5 对网站并发请求总数,默认16
CONCURRENT_REQUESTS = 32
# 6 相同网站两个请求之间的间隔时间,默认是0s。相当于time.sleep()
DOWNLOAD_DELAY = 3
# 7 禁用cookie,默认是True,启用
COOKIES_ENABLED = False
# 8 默认的请求头设置
DEFAULT_REQUEST_HEADERS = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'en',
}
# 9 配置启用爬虫中间件,Key是class,Value是优先级
SPIDER_MIDDLEWARES = {'mySpider.middlewares.MyspiderSpiderMiddleware': 543,
}
# 10 配置启用Downloader MiddleWares下载中间件
DOWNLOADER_MIDDLEWARES = {'mySpider.middlewares.MyspiderDownloaderMiddleware': 543,
}
# 11 开启管道 配置启用Pipeline用来持久化数据
ITEM_PIPELINES = {'mySpider.pipelines.MyspiderPipeline': 300,
}settings配置项更多参考: https://www.cnblogs.com/seven0007/p/scrapy_setting.html <a name="rAA8o"></a>
Scrapy总结
scrapy其实就是把我们平时写的爬虫进行了四分五裂式的改造. 对每个功能进行了单独的封装, 并且, 各个模块之间互相的不做依赖. 一切都由引擎进行调配. 这种思想希望你能知道–解耦. 让模块与模块之间的关联性更加的松散. 这样我们如果希望替换某一模块的时候会非常的容易. 对其他模块也不会产生任何的影响。
相关文章:
Scrapy的基本介绍、安装及工作流程
一.Scrapy介绍 Scrapy是什么? Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架(异步爬虫框架) 通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。 Scrapy使用了Twisted异步网络框架&…...

CMS 三色标记【JVM调优】
文章目录 1. 垃圾回收器2. CMS 原理3. 三色标记算法 1. 垃圾回收器 ① Serial:最原始的垃圾回收器,用于新生代,是单线程的,GC 时需要停止其它所有的工作,算法简单,但它只能在内存较小时勉强使用;…...
使用 CSS 伪类的attr() 展示 tooltip
效果图: 使用场景: 使用React渲染后台返回的数据, 遍历以列表的形式展示, 可能简要字段内容需要鼠标放上去才显示的 可以借助DOM的自定义属性和CSS伪类的attr来实现 所有代码: <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-…...

在命令窗口便捷快速复制输出结果到剪贴板
在macOS上,将命令的输出结果复制到剪贴板 在日常的工作中, 经常使用命令的小伙伴可能会遇到一个场景, 就是把命令执行的结果复制出来另作它用. 每次都需要通过鼠标进行选择然后复制, 虽然 macOS 的命令行的复制快捷键和普通的复制是一样的, 非常友好, 但是还要选择…...
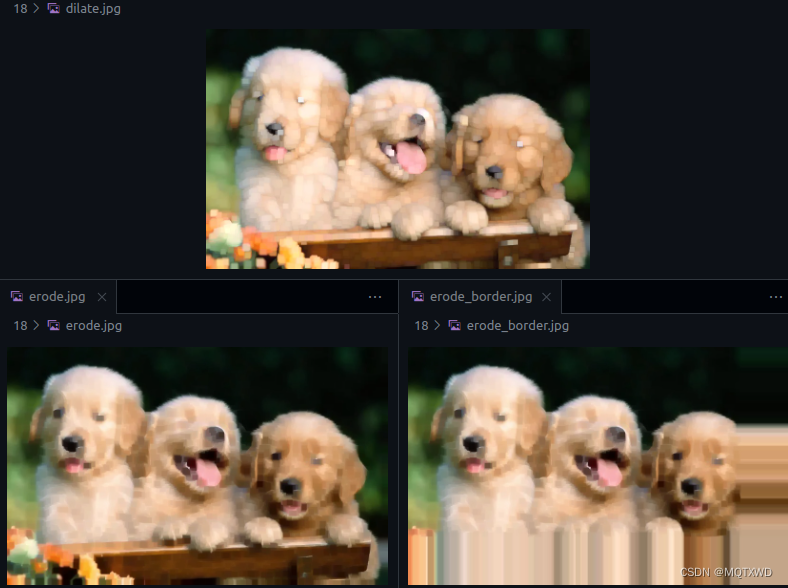
CUDA小白 - NPP(8) 图像处理 Morphological Operations
cuda小白 原始API链接 NPP GPU架构近些年也有不少的变化,具体的可以参考别的博主的介绍,都比较详细。还有一些cuda中的专有名词的含义,可以参考《详解CUDA的Context、Stream、Warp、SM、SP、Kernel、Block、Grid》 常见的NppStatus…...

java获取音频,文本准转语音时长
jar 以上传到资源中 <dependency><groupId>it.sauronsoftware</groupId><artifactId>jave</artifactId><version>1.0.2</version></dependency> mvn install:install-file -DfileD:\xxx\xxx\jave-1.0.2.jar -DgroupIdit.sauro…...
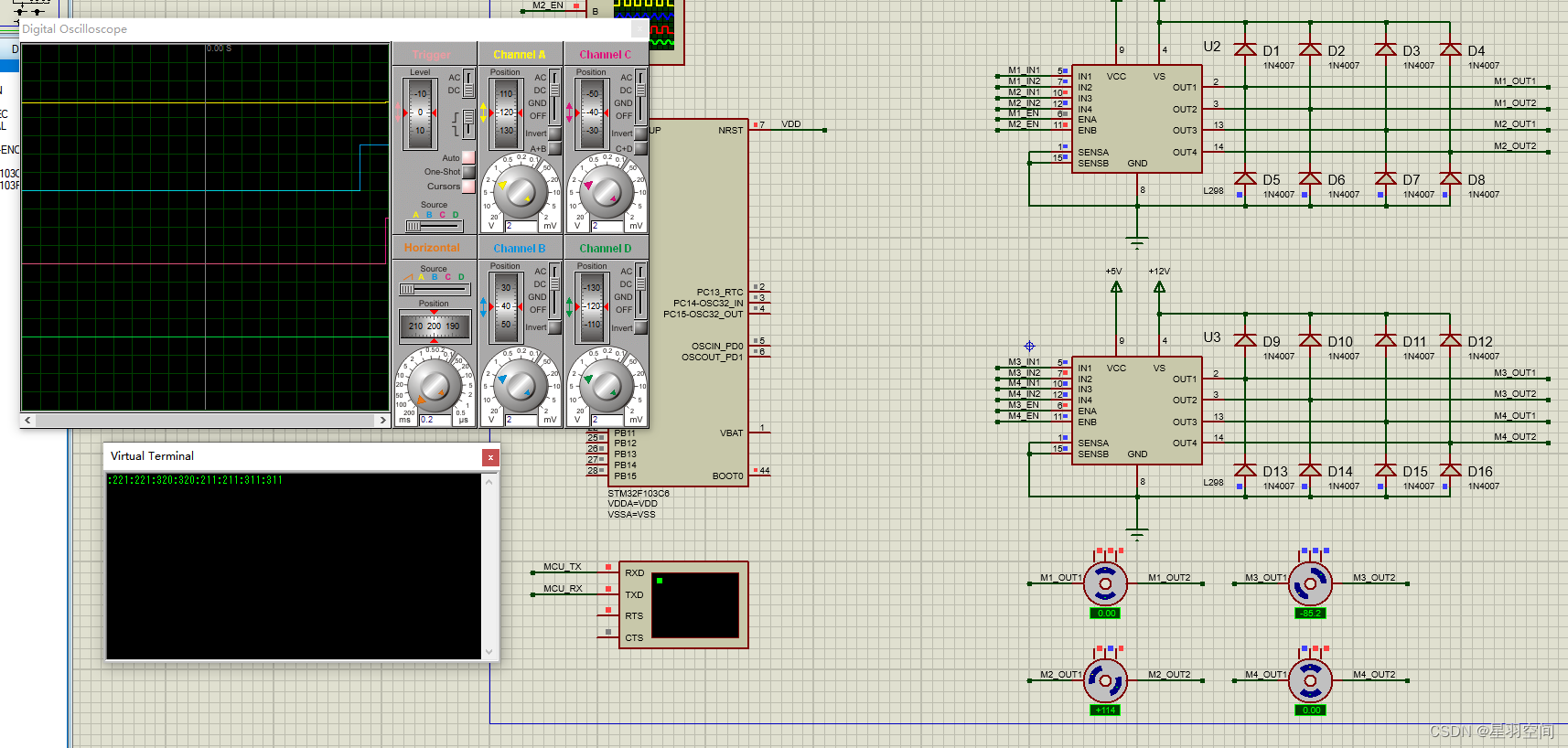
基于串口通讯的多电机控制技术研究
基于STM32CubeMX生成keil工程 基于proteus 8.7版本进行程序验证 采用了简单的串口通讯协议 基本效果如图 先对电机旋转方向进行指令设置 :221 :320 分别实现对第二个电机正转、第三个电机反转设置 为了方便观测,程序对接受到的串口数据会进行回显。 然后使能电…...
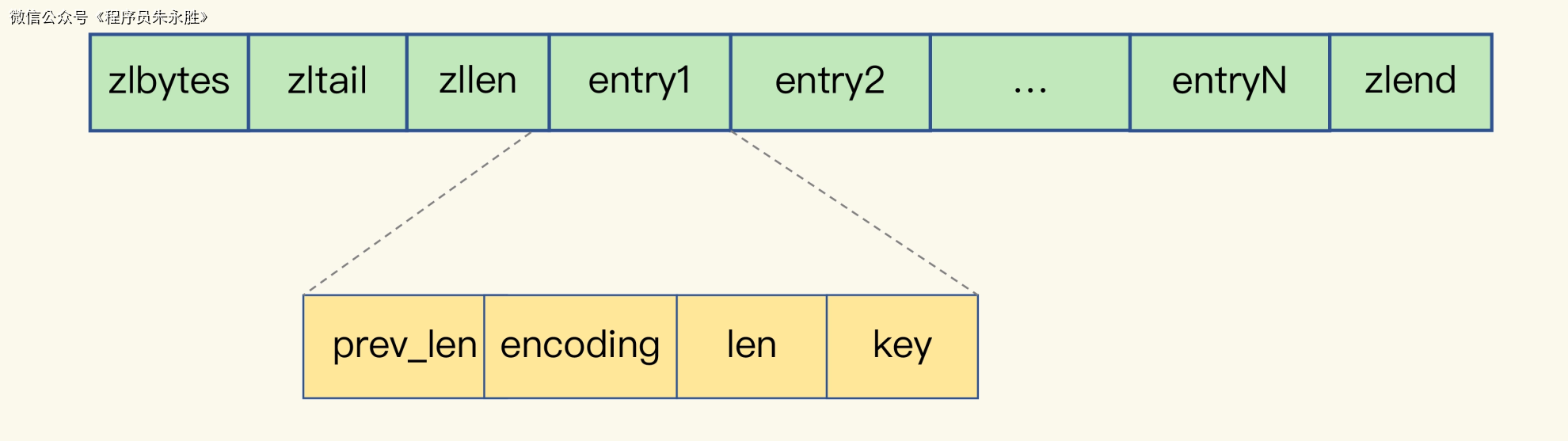
【深入解读Redis系列】(五)Redis中String的认知误区,详解String数据类型
有时候博客内容会有变动,首发博客是最新的,其他博客地址可能会未同步,请认准https://blog.zysicyj.top 首发博客地址 系列文章地址 需求描述 现在假设有这样一个需求,我们要开发一个图像存储系统。要求如下: 该系统能快…...

段指导-示例
RDBMS 19.20 参考文档: Database Administrator’s Guide 19 Managing Space for Schema Objects 19.3.2.4 Running the Segment Advisor Manually 针对表SOE.CUSTOMERS进行段指导 -- 创建段指导 variable id number; begindeclarename varchar2(100);descr …...

LeetCode 面试题 04.02. 最小高度树
文章目录 一、题目二、C# 题解 一、题目 给定一个有序整数数组,元素各不相同且按升序排列,编写一个算法,创建一棵高度最小的二叉搜索树。 点击此处跳转题目。 示例: 给定有序数组: [-10,-3,0,5,9], 一个可能的答案是:[0,-3,9,-10…...

华为云云耀云服务器L实例评测|初始化centos镜像到安装nginx部署前端vue、react项目
文章目录 ⭐前言⭐购买服务器💖 选择centos镜像 ⭐在控制台初始化centos镜像💖配置登录密码 ⭐在webstorm ssh连接 服务器⭐安装nginx💖 wget 下载nginx💖 解压运行 ⭐添加安全组⭐nginx 配置⭐部署vue💖 使用默认的ng…...
python项目制作docker镜像,加装引用模块,部署运行!
一、创建Dockerfile # 基于python:3.10.4版本创建容器 FROM python:3.10.4 # 在容器中创建工作目录 RUN mkdir /app # 将当前Dockerfile目录下的所有文件夹和文件拷贝到容器/app目录下 COPY . /app# 由于python程序用到了requests模块和yaml模块, # python:3.10.4基…...
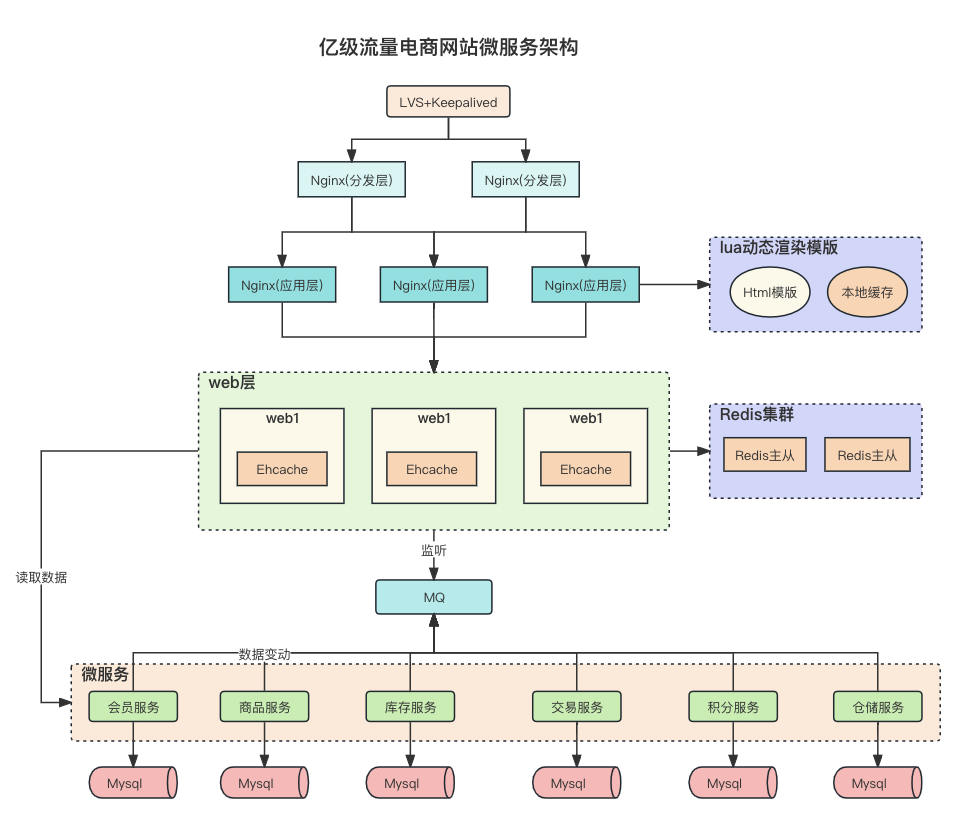
Redis缓存设计与性能优化
多级缓存架构 缓存设计 缓存穿透 缓存穿透是指查询一个根本不存在的数据, 缓存层和存储层都不会命中, 通常出于容错的考虑, 如果从存储层查不到数据则不写入缓存层。缓存穿透将导致不存在的数据每次请求都要到存储层去查询, 失去…...
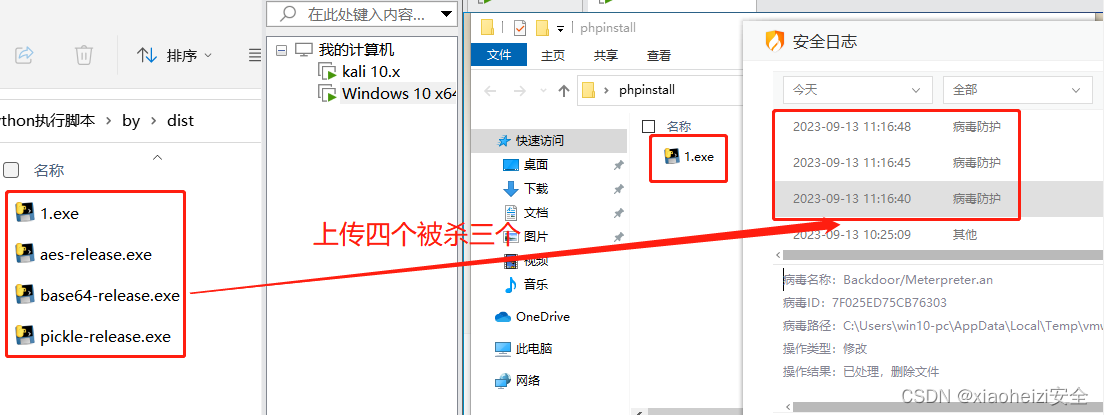
免杀对抗-Python-混淆算法+反序列化-打包生成器-Pyinstall
Python-MSF/CS生成shellcode-上线 cs上线 1.生成shellcode-c或者python 2.打开pycharm工具,创建一个py文件,将原生态执行代码复制进去 shellcode执行代码: import ctypesfrom django.contrib.gis import ptr#cs#shellcodebytearray(b"生…...

C#__线程池的简单介绍和使用
/*线程池原理:(有备无患的默认备用后台线程)特点:线程提前建好在线程池;只能用于运行时间较短的线程。*/class Program{static void Main(string[] args){for (int i 0; i < 10; i){ThreadPool.QueueUserWorkItem(Download); …...
)
安全员(岗位职责)
一、 安全员 是工程项目安全生产、文明施工的直接管理者和责任人,在业务上向 公司 负责; 二、贯彻安全条例和文明施工标准是安全员 工作 准则,执行相关规章、规程是安全员的责任; 三、办理开工前安全监审和安全开工审批,编制项目工程安全监督计划,上报安全措施和分项工程安全施…...
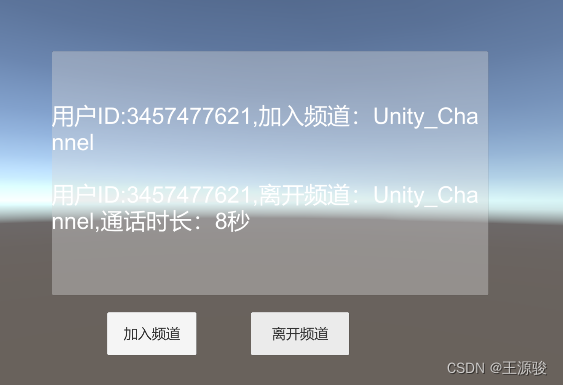
unity 使用声网(Agora)实现语音通话
第一步、先申请一个声网账号 [Agora官网链接](https://console.shengwang.cn/) 第二步在官网创建项目 ,选择无证书模式,证书模式需要tokenh和Appld才能通话 第三步 官网下载SDK 然后导入到unity,也可以直接在unity商店…...
vue2.X 中使用 echarts5.4.0实现项目进度甘特图
vue2.X 中使用 echarts5.4.0实现项目进度甘特图 效果图: 左侧都是名称,上面是时间,当中的内容是日志内容 组件: gantt.vue <template><div id"main" style"width: 100%; height: 100%"></…...

《PostgreSQL与NoSQL:合作与竞争的关系》
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🐅🐾猫头虎建议程序员必备技术栈一览表📖: 🛠️ 全栈技术 Full Stack: 📚…...

【FAQ】视频监控管理平台/视频汇聚平台EasyCVR安全检查相关问题及解决方法3.0
智能视频监控系统/视频云存储/集中存储/视频汇聚平台EasyCVR具备视频融合汇聚能力,作为安防视频监控综合管理平台,它支持多协议接入、多格式视频流分发,视频监控综合管理平台EasyCVR支持海量视频汇聚管理,可应用在多样化的场景上&…...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

Mybatis逆向工程,动态创建实体类、条件扩展类、Mapper接口、Mapper.xml映射文件
今天呢,博主的学习进度也是步入了Java Mybatis 框架,目前正在逐步杨帆旗航。 那么接下来就给大家出一期有关 Mybatis 逆向工程的教学,希望能对大家有所帮助,也特别欢迎大家指点不足之处,小生很乐意接受正确的建议&…...

AtCoder 第409场初级竞赛 A~E题解
A Conflict 【题目链接】 原题链接:A - Conflict 【考点】 枚举 【题目大意】 找到是否有两人都想要的物品。 【解析】 遍历两端字符串,只有在同时为 o 时输出 Yes 并结束程序,否则输出 No。 【难度】 GESP三级 【代码参考】 #i…...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

智能仓储的未来:自动化、AI与数据分析如何重塑物流中心
当仓库学会“思考”,物流的终极形态正在诞生 想象这样的场景: 凌晨3点,某物流中心灯火通明却空无一人。AGV机器人集群根据实时订单动态规划路径;AI视觉系统在0.1秒内扫描包裹信息;数字孪生平台正模拟次日峰值流量压力…...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...

HashMap中的put方法执行流程(流程图)
1 put操作整体流程 HashMap 的 put 操作是其最核心的功能之一。在 JDK 1.8 及以后版本中,其主要逻辑封装在 putVal 这个内部方法中。整个过程大致如下: 初始判断与哈希计算: 首先,putVal 方法会检查当前的 table(也就…...

AI病理诊断七剑下天山,医疗未来触手可及
一、病理诊断困局:刀尖上的医学艺术 1.1 金标准背后的隐痛 病理诊断被誉为"诊断的诊断",医生需通过显微镜观察组织切片,在细胞迷宫中捕捉癌变信号。某省病理质控报告显示,基层医院误诊率达12%-15%,专家会诊…...