数据分析三剑客之Pandas
1.引入
前面一篇文章我们介绍了numpy,但numpy的特长并不是在于数据处理,而是在它能非常方便地实现科学计算,所以我们日常对数据进行处理时用的numpy情况并不是很多,我们需要处理的数据一般都是带有列标签和index索引的,而numpy并不支持这些,这时我们就需要pandas上场啦!
2.WHAT?
Pandas是基于Numpy构建的库,在数据处理方面可以把它理解为numpy加强版,同时Pandas也是一项开源项目 。不同于numpy的是,pandas拥有种数据结构:Series和DataFrame:

下面我们就来生成一个简单的series对象来方便理解:
In [1]: from pandas import Series,DataFrame
In [2]: import pandas as pd
In [3]: data = Series([1,2,3,4],index = ['a','b','c','d'])
In [4]: data
Out[4]:
a 1
b 2
c 3
d 4
dtype: int64Series是一种类似一维数组的数据结构,由一组数据和与之相关的index组成,这个结构一看似乎与dict字典差不多,我们知道字典是一种无序的数据结构,而pandas中的Series的数据结构不一样,它相当于定长有序的字典,并且它的index和value之间是独立的,两者的索引还是有区别的,Series的index是可变的,而dict字典的key值是不可变的。
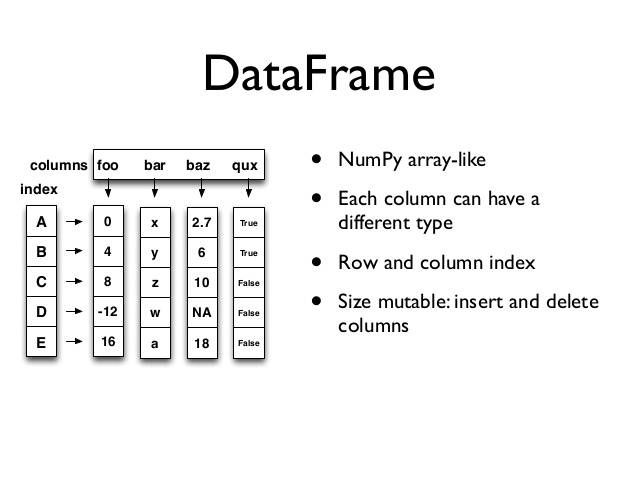
下面照例生成一个简单的DataFrame对象:
In [8]: data = {'a':[1,2,3],'b':['we','you','they'],'c':['btc','eos','ae']}
In [9]: df = DataFrame(data)
In [10]: df
Out[10]:a b c
0 1 we btc
1 2 you eos
2 3 they aeDataFrame这种数据结构我们可以把它看作是一张二维表,DataFrame长得跟我们平时使用的Excel表格差不多,DataFrame的横行称为columns,竖列和Series一样称为index,DataFrame每一列可以是不同类型的值集合,所以DataFrame你也可以把它视为不同数据类型同一index的Series集合。
3.WHY?
科学计算方面numpy是优势,但在数据处理方面DataFrame就更胜一筹了,事实上DataFrame已经覆盖了一部分的数据操作了,对于数据挖掘来说,工作可大概分为读取数据-数据清洗-分析建模-结果展示:
先说说读取数据,Pandas提供强大的IO读取工具,csv格式、Excel文件、数据库等都可以非常简便地读取,对于大数据,pandas也支持大文件的分块读取;
接下来就是数据清洗,面对数据集,我们遇到最多的情况就是存在缺失值,Pandas把各种类型数据类型的缺失值统一称为NaN(这里要多说几句,None==None这个结果是true,但np.nan==np.nan这个结果是false,NaN在官方文档中定义的是float类型,有关于NaN和None的区别以及使用,有位博主已经做好整理:None vs NaN),Pandas提供许多方便快捷的方法来处理这些缺失值NaN。
最重要的分析建模阶段,Pandas自动且明确的数据对齐特性,非常方便地使新的对象可以正确地与一组标签对齐,有了这个特性,Pandas就可以非常方便地将数据集进行拆分-重组操作。
最后就是结果展示阶段了,我们都知道Matplotlib是个数据视图化的好工具,Pandas与Matplotlib搭配,不用复杂的代码,就可以生成多种多样的数据视图。
4.HOW?
Series
Series的两种生成方式:
In [19]: data = Series([222,'btc',234,'eos'])
In [20]: data
Out[20]:
0 222
1 btc
2 234
3 eos
dtype: object虽然我们在生成的时候没有设置index值,但Series还是会自动帮我们生成index,这种方式生成的Series结构跟list列表差不多,可以把这种形式的Series理解为竖起来的list列表。
In [21]: data = Series([1,2,3,4],index = ['a','b','c','d'])
In [22]: data
Out[22]:
a 1
b 2
c 3
d 4
dtype: int64这种形式的Series可以理解为numpy的array外面披了一件index的马甲,所以array的相关操作,Series同样也是支持的。结构非常相似的dict字典同样也是可以转化为Series格式的:
In [29]: dic = {'a':1,'b':2,'c':'as'}
In [30]: dicSeries = Series(dic)查看Series的相关信息:
In [32]: data.index
Out[32]: Index(['a', 'b', 'c', 'd'], dtype='object')In [33]: data.values
Out[33]: array([1, 2, 3, 4], dtype=int64)In [35]: 'a' in data #in方法默认判断的是index值
Out[35]: TrueSeries的NaN生成:
In [46]: index1 = [ 'a','b','c','d']
In [47]: dic = {'b':1,'c':1,'d':1}
In [48]: data2 = Series(dic,index=index1)
In [49]: data2
Out[49]:
a NaN
b 1.0
c 1.0
d 1.0
dtype: float64从这里我们可以看出Series的生成依据的是index值,index‘a’在字典dic的key中并不存在,Series自然也找不到’a’的对应value值,这种情况下Pandas就会自动生成NaN(not a number)来填补缺失值,这里还有个有趣的现象,原本dtype是int类型,生成NaN后就变成了float类型了,因为NaN的官方定义就是float类型。
NaN的相关查询:
In [58]: data2.isnull()
Out[58]:
a True
b False
c False
d False
dtype: boolIn [59]: data2.notnull()
Out[59]:
a False
b True
c True
d True
dtype: boolIn [60]: data2[data2.isnull()==True] #嵌套查询NaN
Out[60]:
a NaN
dtype: float64In [64]: data2.count() #统计非NaN个数
Out[64]: 3切记切记,查询NaN值切记不要使用np.nan==np.nan这种形式来作为判断条件,结果永远是False,==是用作值判断的,而NaN并没有值,如果你不想使用上方的判断方法,你可以使用is作为判断方法,is是对象引用判断,np.nan is np.nan,结果就是你要的True。
Series自动对齐:
In [72]: data1
Out[72]:
a 1
asd 1
b 1
dtype: int64In [73]: data
Out[73]:
a 1
b 2
c 3
d 4
dtype: int64In [74]: data+data1
Out[74]:
a 2.0
asd NaN
b 3.0
c NaN
d NaN
dtype: float64从上面两个Series中不难看出各自的index所处位置并不完全相同,这时Series的自动对齐特性就发挥作用了,在算术运算中,Series会自动寻找匹配的index值进行运算,如果index不存在匹配则自动赋予NaN,值得注意的是,任何数+NaN=NaN,你可以把NaN理解为吸收一切的黑洞。
Series的name属性:
In [84]: data.index.name = 'abc'
In [85]: data.name = 'test'
In [86]: data
Out[86]:
abc
a 1
b 2
c 3
d 4
Name: test, dtype: int64Series对象本身及其索引index都有一个name属性,name属性主要发挥作用是在DataFrame中,当我们把一个Series对象放进DataFrame中,新的列将根据我们的name属性对该列进行命名,如果我们没有给Series命名,DataFrame则会自动帮我们命名为0。
5.DataFrame
DataFrame的生成:
In [87]: data = {'name': ['BTC', 'ETH', 'EOS'], 'price':[50000, 4000, 150]}
In [88]: data = DataFrame(data)
In [89]: data
Out[89]:name price
0 BTC 50000
1 ETH 4000
2 EOS 150DataFrame的生成与Series差不多,你可以自己指定index,也可不指定,DataFrame会自动帮你补上。
查看DataFrame的相关信息:
In [95]: data.index
Out[95]: RangeIndex(start=0, stop=3, step=1)In [96]: data.values
Out[96]:
array([['BTC', 50000],['ETH', 4000],['EOS', 150]], dtype=object)In [97]: data.columns #DataFrame的列标签
Out[97]: Index(['name', 'price'], dtype='object')DataFrame的索引:
In [92]: data.name
Out[92]:
0 BTC
1 ETH
2 EOS
Name: name, dtype: objectIn [93]: data['name']
Out[93]:
0 BTC
1 ETH
2 EOS
Name: name, dtype: objectIn [94]: data.iloc[1] #loc['name']查询的是行标签
Out[94]:
name ETH
price 4000
Name: 1, dtype: object其实行索引,除了iloc,loc还有个ix,ix既可以进行行标签索引,也可以进行行号索引,但这也大大增加了它的不确定性,有时会出现一些奇怪的问题,所以pandas在0.20.0版本的时候就把ix给弃用了。
6.DataFrame的常用操作
简单地增加行、列:
In [105]: data['type'] = 'token' #增加列In [106]: data
Out[106]:name price type
0 BTC 50000 token
1 ETH 4000 token
2 EOS 150 token
In [109]: data.loc['3'] = ['ae',200,'token'] #增加行In [110]: data
Out[110]:name price type
0 BTC 50000 token
1 ETH 4000 token
2 EOS 150 token
3 ae 200 token删除行、列操作:
In [117]: del data['type'] #删除列In [118]: data
Out[118]:name price
0 BTC 50000
1 ETH 4000
2 EOS 150
3 ae 200
In [120]: data.drop([2]) #删除行
Out[120]:name price
0 BTC 50000
1 ETH 4000
3 ae 200In [121]: data
Out[121]:name price
0 BTC 50000
1 ETH 4000
2 EOS 150
3 ae 200这里需要注意的是,使用drop()方法返回的是Copy而不是视图,要想真正在原数据里删除行,就要设置inplace=True:
In [125]: data.drop([2],inplace=True)In [126]: data
Out[126]:name price
0 BTC 50000
1 ETH 4000
3 ae 200设置某一列为index:
In [131]: data.set_index(['name'],inplace=True)In [132]: data
Out[132]:price
name
BTC 50000
ETH 4000
ae 200In [133]: data.reset_index(inplace=True) #将index返回回dataframe中In [134]: data
Out[134]:name price
0 BTC 50000
1 ETH 4000
2 ae 200处理缺失值:
In [149]: data
Out[149]:name price
0 BTC 50000.0
1 ETH 4000.0
2 ae 200.0
3 eos NaNIn [150]: data.dropna() #丢弃含有缺失值的行
Out[150]:name price
0 BTC 50000.0
1 ETH 4000.0
2 ae 200.0In [151]: data.fillna(0) #填充缺失值数据为0
Out[151]:name price
0 BTC 50000.0
1 ETH 4000.0
2 ae 200.0
3 eos 0.0还是需要注意:这些方法返回的是copy而不是视图,如果想在原数据上改变,别忘了inplace=True。
数据合并:
In [160]: data
Out[160]:name price
0 BTC 50000.0
1 ETH 4000.0
2 ae 200.0
3 eos NaNIn [161]: data1
Out[161]:name other
0 BTC 50000
1 BTC 4000
2 EOS 150In [162]: pd.merge(data,data1,on='name',how='left') #以name为key进行左连接
Out[162]:name price other
0 BTC 50000.0 50000.0
1 BTC 50000.0 4000.0
2 ETH 4000.0 NaN
3 ae 200.0 NaN
4 eos NaN NaN平时进行数据合并操作,更多的会出一种情况,那就是出现重复值,DataFrame也为我们提供了简便的方法:
data.drop_duplicates(inplace=True)
数据的简单保存与读取:
In [165]: data.to_csv('test.csv')In [166]: pd.read_csv('test.csv')
Out[166]:Unnamed: 0 name price
0 0 BTC 50000.0
1 1 ETH 4000.0
2 2 ae 200.0
3 3 eos NaN为什么会出现这种情况呢,从头看到尾的同学可能就看出来了,增加第三行时,我用的是loc[‘3’]行标签来增加的,而read_csv方法是默认index是从0开始增长的,此时只需要我们设置下index参数就ok了:
In [167]: data.to_csv('test.csv',index=None) #不保存行索引
In [168]: pd.read_csv('test.csv')
Out[168]:name price
0 BTC 50000.0
1 ETH 4000.0
2 ae 200.0
3 eos NaN其他的还有header参数, 这些参数都是我们在保存数据时需要注意的。
相关文章:
数据分析三剑客之Pandas
1.引入 前面一篇文章我们介绍了numpy,但numpy的特长并不是在于数据处理,而是在它能非常方便地实现科学计算,所以我们日常对数据进行处理时用的numpy情况并不是很多,我们需要处理的数据一般都是带有列标签和index索引的࿰…...

Spring Boot自动装配原理
简介 Spring Boot是一个开源的Java框架,旨在简化Spring应用程序的搭建和开发。它通过自动装配的机制,大大减少了繁琐的配置工作,提高了开发效率。本文将深入探讨Spring Boot的自动装配原理。 自动装配的概述 在传统的Spring框架中…...

VMware Workstation虚拟机网络配置及配置自动启动
目录 一、网络配置二、配置自动启动1.VMware 中配置虚拟机自启动2.系统服务中配置 VMware 服务自启动 一、网络配置 本文将虚拟机 IP 与主机 IP 设置为同一个网段。 点击 “编辑” -> “虚拟网络编辑器(N)…”: 点击 “更改设置”: 将 VMnet0 设置…...

智能语音机器人竞品调研
一、腾讯云-智能客服机器人 链接地址:智能客服机器人_在线智能客服_智能客服解决方案 - 腾讯云 二、阿里云-智能语音机器人 链接地址:智能对话机器人-阿里云帮助中心 链接地址:智能外呼机器人的业务架构_智能外呼机器人-阿里云帮助中心 三、火…...
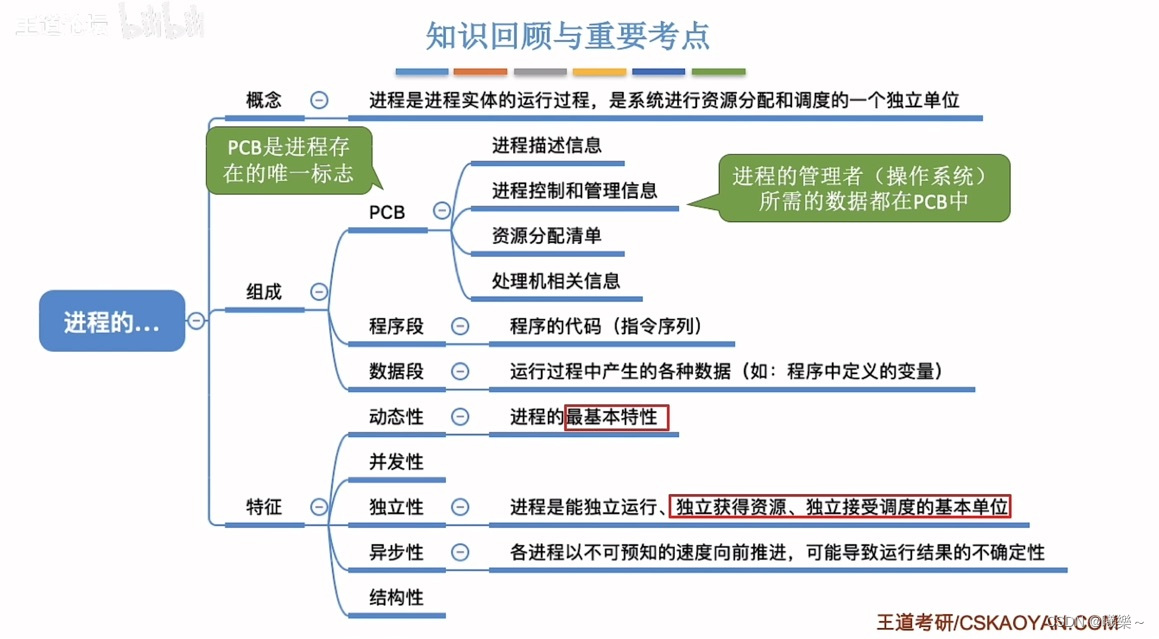
【操作系统】进程的概念、组成、特征
概念组成 程序:静态的放在磁盘(外存)里的可执行文件(代码) 作业:代码+数据+申请(JCB)(外存) 进程:程序的一次执行过程。 …...

大二第二周总结
问题: 想到了之前追的辩论赛,主题是“被误解是表达者的宿命”, 反方认为被误解不是表达者的宿命: 由于表达者表意含混造成误解的可能性是人力可控的,表达者可在真诚沟通的基础之上,根据对方反应不断调整…...

JDK、eclipse软件的安装
一、打开JDK安装包 二、复制路径 三、点击我的电脑,找到环境变量 四、新建环境 变量名:JAVA_HOME 变量值就是刚刚复制的路径 五、在path中建立新变量 双击path 打印以下文字 最后一直双击确定,安装环境完成。 六、双击eclipse 选择好安装…...

235. 二叉搜索树的最近公共祖先 Python
文章目录 一、题目描述示例 1示例 2 二、代码三、解题思路 一、题目描述 给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足…...
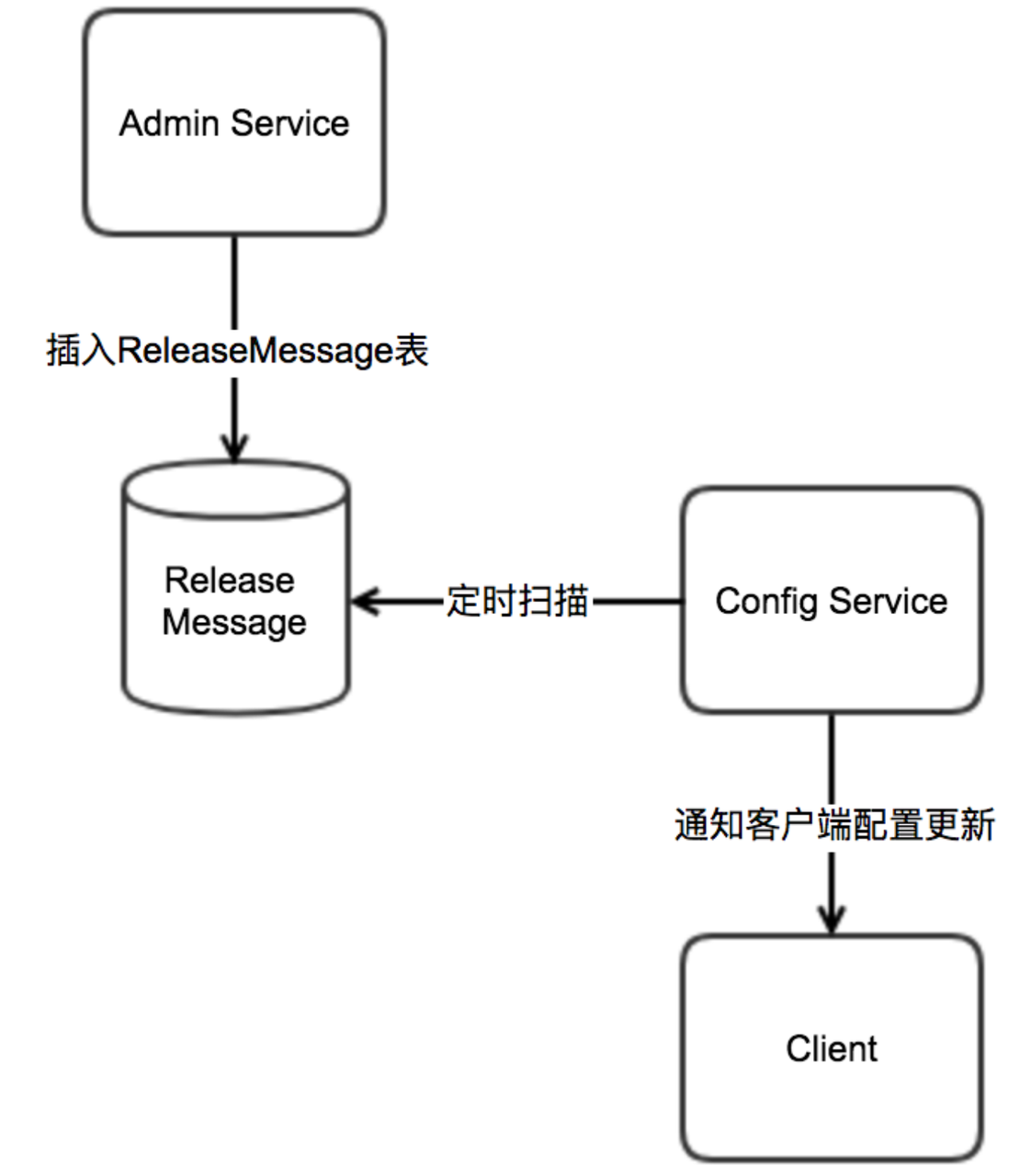
Apollo介绍和入门
文章目录 Apollo介绍配置中心介绍apollo介绍主流配置中心功能特性对比 Apollo简介 入门简单的执行流程Apollo具体的执行流程Apollo对象执行流程分步执行流程 核心概念应用,环境,集群,命名空间企业部署方案灰度发布全量发布 配置发布的原理发送…...
一文看懂Oracle 19c OCM认证考试(需要Oracle OCP证书)
Oracle OCM的认证全称是Oracle Certified Master,是比OCP更高一级的认证,姚远老师的很多OCP学员都对OCM考试有兴趣,这里跟大家做个介绍。 OCM考试全部是上机的实操考试,没有笔试,要到Oracle原厂参加两天的考试。参加1…...
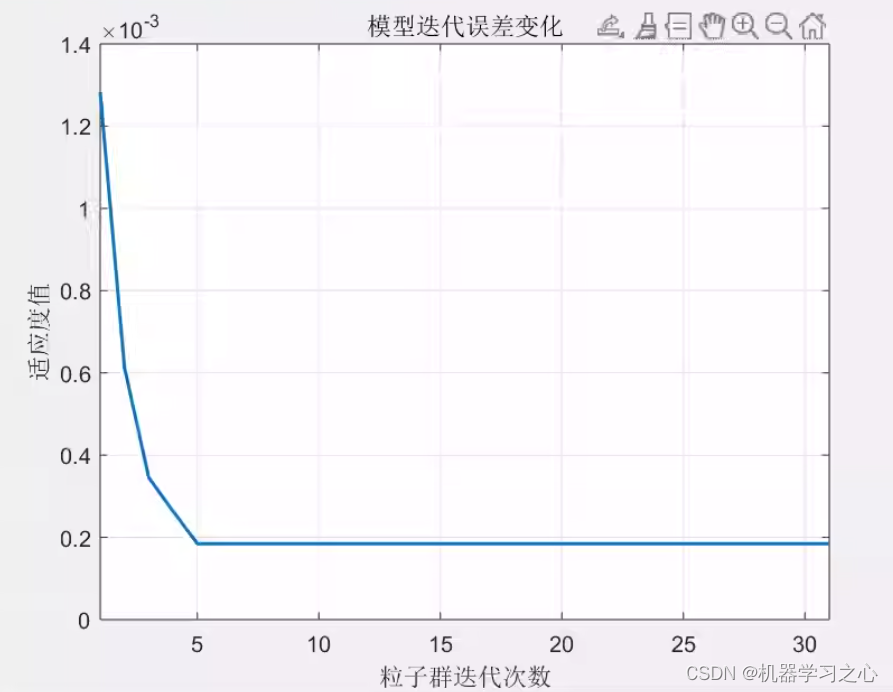
回归预测 | MATLAB实现PSO-SDAE粒子群优化堆叠去噪自编码器多输入单输出回归预测(多指标,多图)
回归预测 | MATLAB实现PSO-SDAE粒子群优化堆叠去噪自编码器多输入单输出回归预测(多指标,多图) 目录 回归预测 | MATLAB实现PSO-SDAE粒子群优化堆叠去噪自编码器多输入单输出回归预测(多指标,多图)效果一览…...
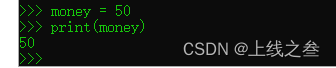
python自学
自学第一步 第一个简单的基础,向世界说你好 启动python 开始 print是打印输出的意思,就是输出引号内的内容。 标点符号必须要是英文的,因为他只认识英文的标点符号。 exit()推出python。 我们创建一个文本文档&…...
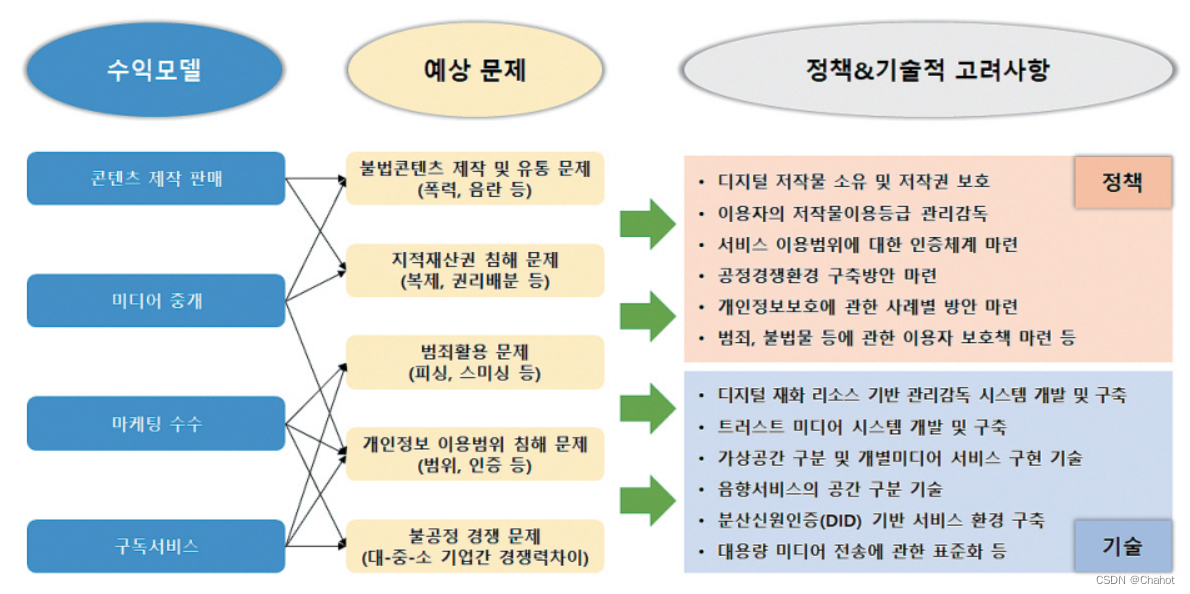
元宇宙安全与著作权相关市场与技术动态:韩国视角
元宇宙市场动态 元宇宙安全与著作权维护技术现状 元宇宙有可能为商业创造巨大价值,尤其是在零售和时尚领域。时尚产品的象征性价值不仅在物理空间中得以保持,在虚拟空间中也是如此。通过元宇宙平台,企业可以开发虚拟产品,降低供…...

springboot整合neo4j--采用Neo4jClient和Neo4jTemplate方式
1.背景 看了spring-boot-starter-data-neo4j的源码之后发现,该starter内已经实现了Neo4jClient和Neo4jTemplate,我们只需要使用Autowire就能直接使用它操作neo4j。 Neo4jClient方式与我的另一篇springboot整合neo4j-使用原生cypher Java API博客方式一样…...
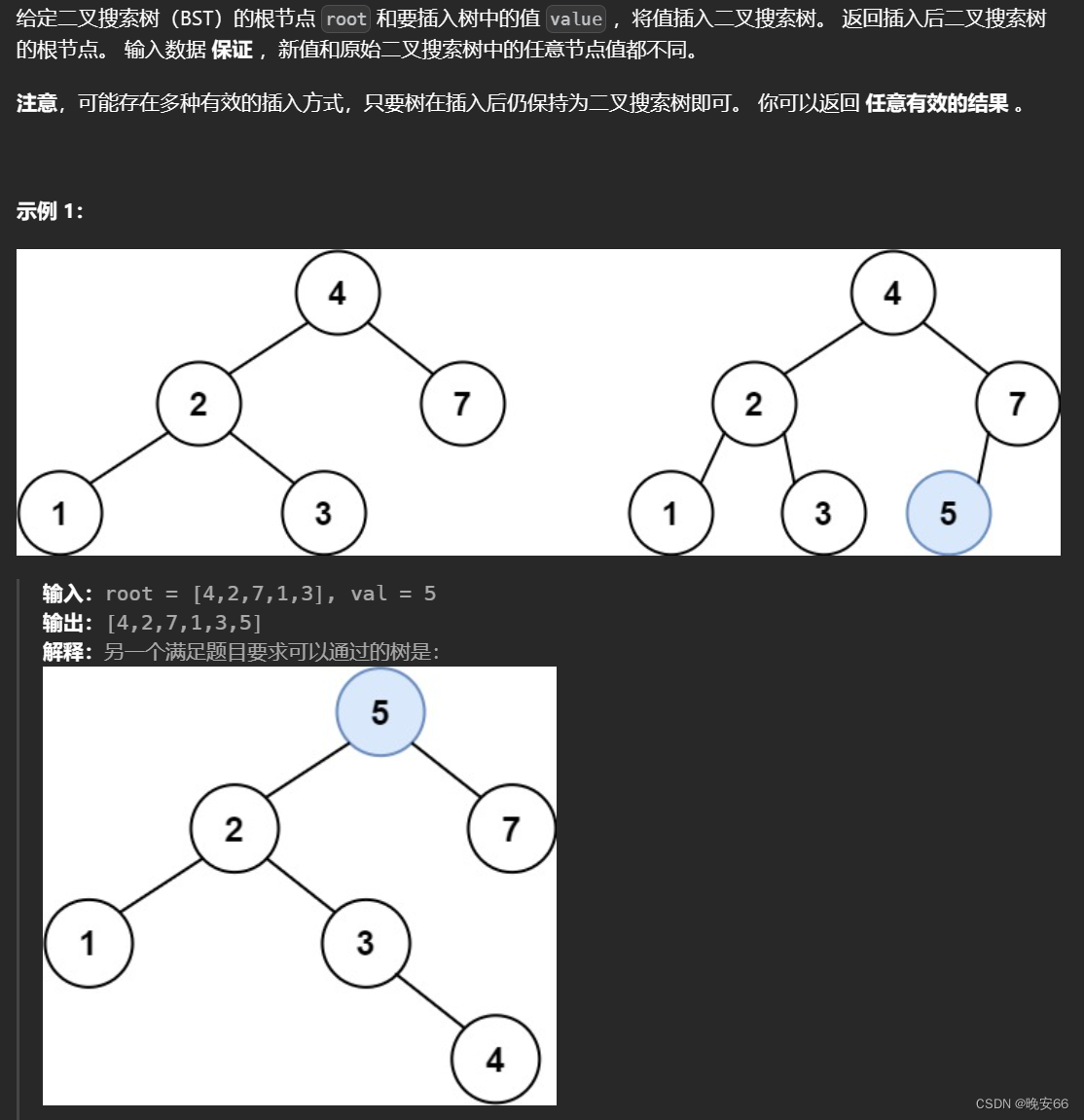
【算法与数据结构】701、LeetCode二叉搜索树中的插入操作
文章目录 一、题目二、解法三、完整代码 所有的LeetCode题解索引,可以看这篇文章——【算法和数据结构】LeetCode题解。 一、题目 二、解法 思路分析:这道题关键在于分析插入值的位置,不论插入的值是什么(插入值和原有树中的键值都…...
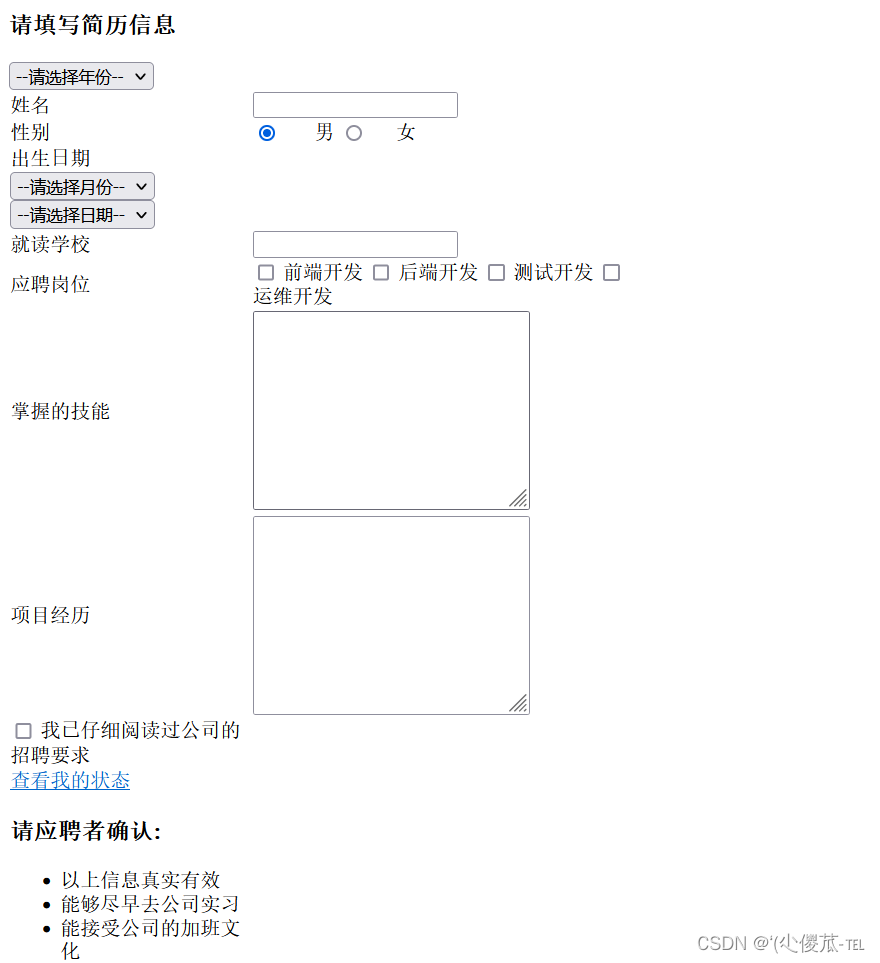
前端--HTML
文章目录 HTML结构快速生成代码框架HTML常见标签 表格标签 编写简历信息 填写简历信息 Emmet 快捷键 HTML 特殊字符 一、HTML结构 1.认识HTML标签 HTML 代码是由 "标签" 构成的. 形如: <body>hello</body> 标签名 (body) 放到 < > 中 大部分标…...
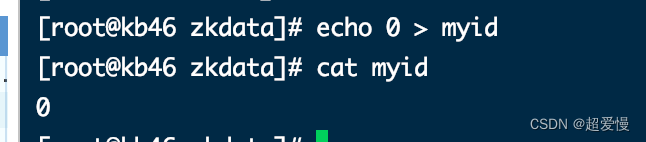
安装配置 zookeeper(单机版)
目录 一 准备并解压安装包 二 修改zoo.cfg文件 三 创建相应两个目录 四 创建文件myid 五 修改环境变量 六 启动 zookeeper 一 准备并解压安装包 这里提供了网盘资源 http://链接: https://pan.baidu.com/s/1BybwSQ_tQUL23OI6AWxwFw?pwdd4cf 提取码: d4cf 这里的安装包是…...
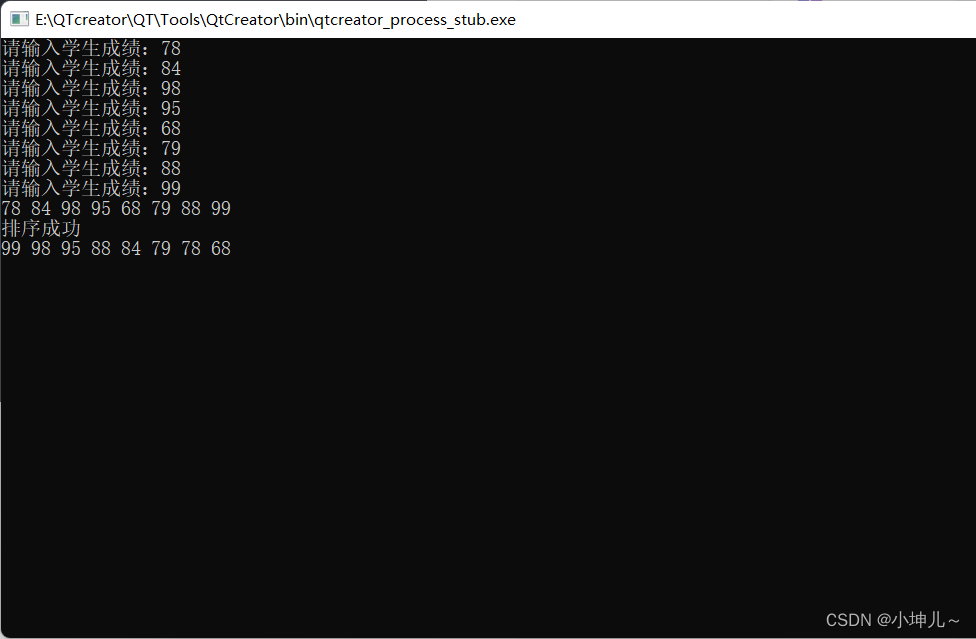
2023/9/7 -- C++/QT
作业 1> 思维导图 2> 封装一个结构体,结构体中包含一个私有数组,用来存放学生的成绩,包含一个私有变量,用来记录学生个数, 提供一个公有成员函数,void setNum(int num)用于设置学生个数 提供一个…...
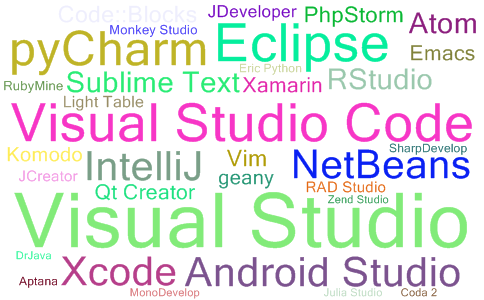
2023年09月IDE流行度最新排名
点击查看最新IDE流行度最新排名(每月更新) 2023年09月IDE流行度最新排名 顶级IDE排名是通过分析在谷歌上搜索IDE下载页面的频率而创建的 一个IDE被搜索的次数越多,这个IDE就被认为越受欢迎。原始数据来自谷歌Trends 如果您相信集体智慧&am…...

MyBatis基础之概念简介
文章目录 基本概念1. 关于 MyBatis2. MyBatis 的体系结构3. 使用 XML 构建 SqlSessionFactory4. SqlSession5. 默认的别名6. 补充 [注意] 放前面前 很多人可能在使用 MyBatis-plus 进行代码开发,MyBatis的这部分内容是用来更好的讲述之后的内容。 基本概念 1. 关于…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...

UDP(Echoserver)
网络命令 Ping 命令 检测网络是否连通 使用方法: ping -c 次数 网址ping -c 3 www.baidu.comnetstat 命令 netstat 是一个用来查看网络状态的重要工具. 语法:netstat [选项] 功能:查看网络状态 常用选项: n 拒绝显示别名&#…...

关于iview组件中使用 table , 绑定序号分页后序号从1开始的解决方案
问题描述:iview使用table 中type: "index",分页之后 ,索引还是从1开始,试过绑定后台返回数据的id, 这种方法可行,就是后台返回数据的每个页面id都不完全是按照从1开始的升序,因此百度了下,找到了…...

【第二十一章 SDIO接口(SDIO)】
第二十一章 SDIO接口 目录 第二十一章 SDIO接口(SDIO) 1 SDIO 主要功能 2 SDIO 总线拓扑 3 SDIO 功能描述 3.1 SDIO 适配器 3.2 SDIOAHB 接口 4 卡功能描述 4.1 卡识别模式 4.2 卡复位 4.3 操作电压范围确认 4.4 卡识别过程 4.5 写数据块 4.6 读数据块 4.7 数据流…...

DingDing机器人群消息推送
文章目录 1 新建机器人2 API文档说明3 代码编写 1 新建机器人 点击群设置 下滑到群管理的机器人,点击进入 添加机器人 选择自定义Webhook服务 点击添加 设置安全设置,详见说明文档 成功后,记录Webhook 2 API文档说明 点击设置说明 查看自…...

嵌入式常见 CPU 架构
架构类型架构厂商芯片厂商典型芯片特点与应用场景PICRISC (8/16 位)MicrochipMicrochipPIC16F877A、PIC18F4550简化指令集,单周期执行;低功耗、CIP 独立外设;用于家电、小电机控制、安防面板等嵌入式场景8051CISC (8 位)Intel(原始…...

论文阅读:LLM4Drive: A Survey of Large Language Models for Autonomous Driving
地址:LLM4Drive: A Survey of Large Language Models for Autonomous Driving 摘要翻译 自动驾驶技术作为推动交通和城市出行变革的催化剂,正从基于规则的系统向数据驱动策略转变。传统的模块化系统受限于级联模块间的累积误差和缺乏灵活性的预设规则。…...
实现跳一跳小游戏)
鸿蒙(HarmonyOS5)实现跳一跳小游戏
下面我将介绍如何使用鸿蒙的ArkUI框架,实现一个简单的跳一跳小游戏。 1. 项目结构 src/main/ets/ ├── MainAbility │ ├── pages │ │ ├── Index.ets // 主页面 │ │ └── GamePage.ets // 游戏页面 │ └── model │ …...
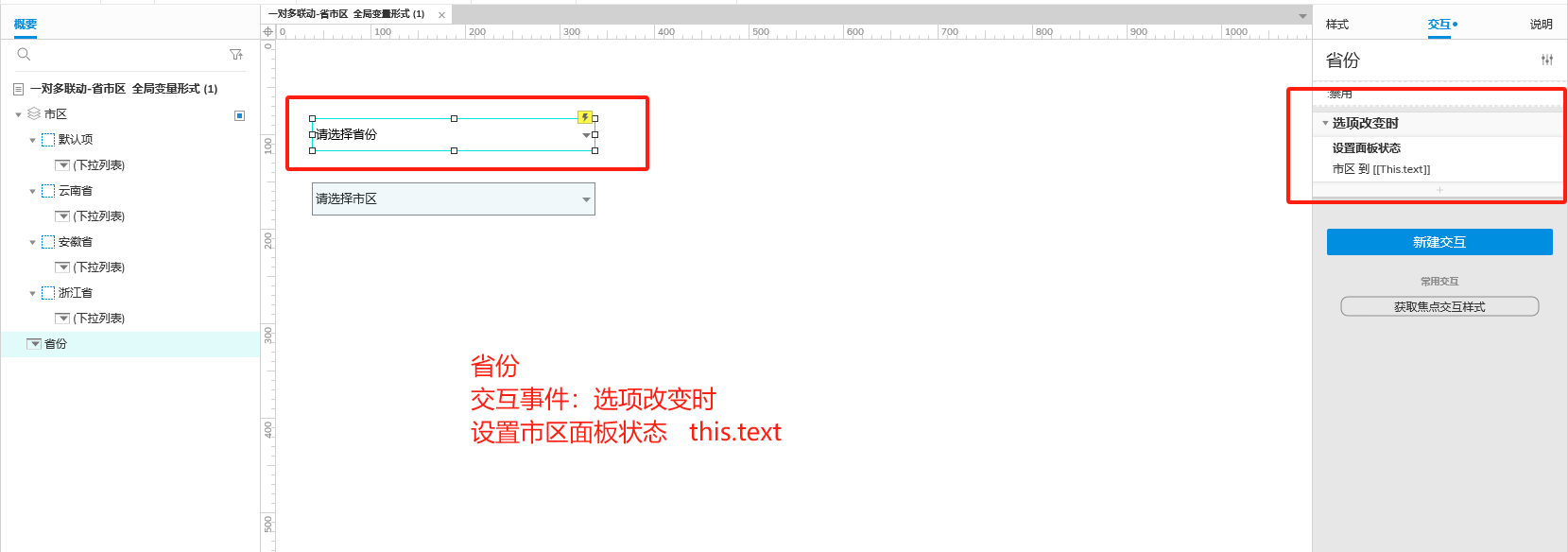
Axure 下拉框联动
实现选省、选完省之后选对应省份下的市区...
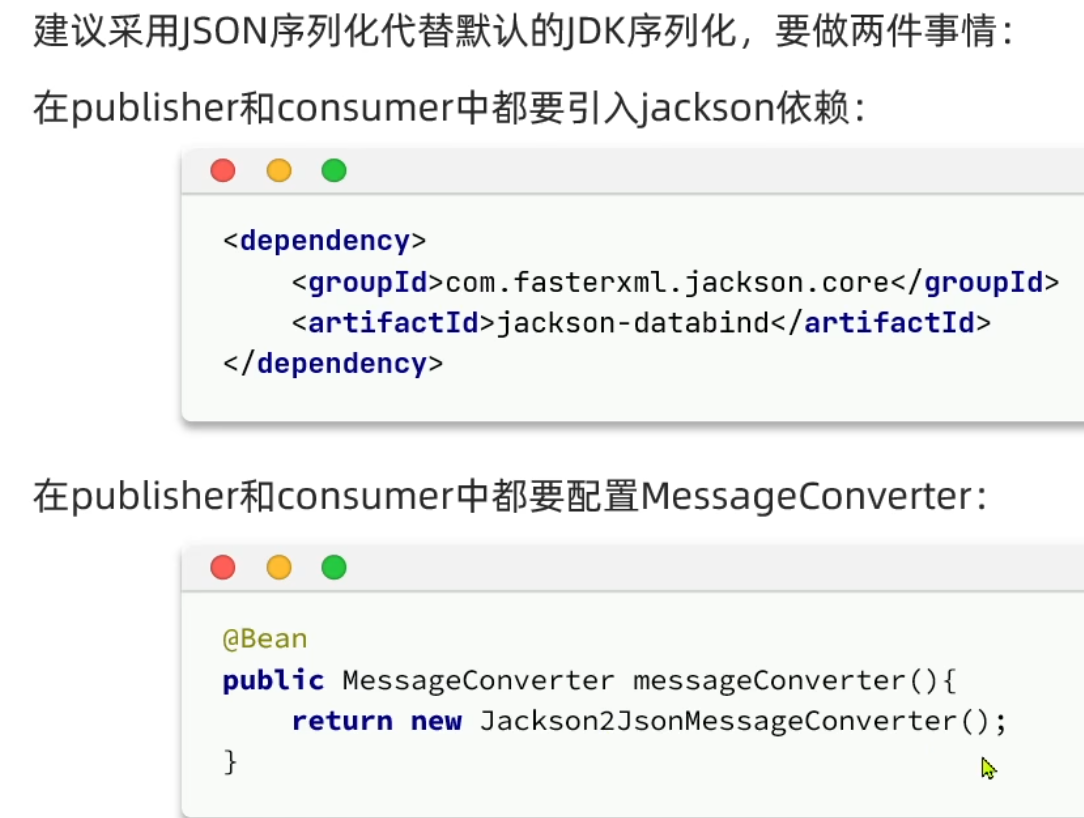
RabbitMQ 各类交换机
为什么要用交换机? 交换机用来路由消息。如果直发队列,这个消息就被处理消失了,那别的队列也需要这个消息怎么办?那就要用到交换机 交换机类型 1,fanout:广播 特点 广播所有消息:将消息…...