深度学习面试八股文(2023.9.06)
一、优化器
1、SGD是什么?
- 批梯度下降(Batch gradient descent):遍历全部数据集算一次损失函数,计算量开销大,计算速度慢,不支持在线学习。
- 随机梯度下降(Stochastic gradient descent,SGD)每次随机选择一个数据计算损失函数,求梯度并更新参数,计算速度快,但收敛性能可能不太好。
- 批量随机梯度下降(Min-batch SGD):用小批量样本来近似全部,将样本分为m个mini-batch,每个mini-batch包含n个样本。
- 使用动量(Momentum)的随机梯度下降法(SGD): 在随机梯度的学习算法中,每一步的步幅都是固定的,而在动量学习算法中,每一步走多远不仅依赖于本次的梯度大小还取决于过去的速度。速度是累积各轮训练参数的梯度。动量主要解决SGD的两个问题:一是随机梯度方法引入的噪声;二是Hessian矩阵病态问题,可以理解为SGD在收敛过程中和正确梯度相比来回摆动比较大的问题。
2、简单介绍下Adam算法
RMSprop将学习率分解成一个平方梯度的指数衰减的平均。Adam中动量直接并入了梯度一阶矩(指数加权)的估计。其次,相比于缺少修正因子导致二阶矩估计可能在训练初期具有很高偏置的RMSProp,Adam还包括偏置修正,修正从原点初始化的一阶矩(动量项)和(非中心的)二阶矩估计。本质上是带有动量项的RMSProp,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要是经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。
3、Adam和SGD的区别
- SGD缺点是其更新方向完全依赖于当前batch计算出的梯度,因而十分不稳定。
- Adam的优点主要在于:①考虑历史步中的梯度更新信息,能够降低梯度更新噪声。②此外经过偏差和校正后,每一次迭代学习率都有个确定单位,使得参数比较平稳。
- 但Adam可能对前期出现的特征过拟合,后期才出现的特征很难纠正前期的拟合效果。且SGD和Adam都没法很好的避免局部最优问题。
二、过拟合
1、过拟合指什么?造成的原因是什么?解决方法有哪些?
- 定义:模型在训练集上表现很好,但在测试集和新数据上表现很差。
- 出现的原因:①模型的复杂度过高、参数过多②训练数据比较小 ③训练集和测试集的分布不一致④样本里面的噪声数据干扰过大,导致模型过分记住了噪声特征
- 解决方法:①降低模型的复杂度 ②数据增强 ③正则化(l1, l2, dropout)④早停
2、过拟合与欠拟合的比较
过拟合:模型在训练集上表现很好,但在测试集和新数据上表现很差。输出结果高方差Variance,模型很好的适配训练样本,但在测试集上表现很糟,有一个很大的方差。
欠拟合:模型在训练集和测试机上的性能都较差,输出结果高偏差bias,模型不能适配训练样本,有很大的偏差。
3、偏差和方差的区别
- 偏差:偏差度量了学习算法的期望预测和真实结果的偏离程度,刻画了学习算法本身的拟合能力。
- 方差:方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响。
三、归一化
1、批量归一化(BN)是什么?有什么作用?
- 批量归一化(BN)的计算公式如下:

- 作用:加快网络的训练与收敛的速度;控制梯度爆炸,防止梯度消失。
2、训练与推理时BN中的均值、方差计算差异是什么?
- 训练时,均值、方差分别是该批次内数据相应维度的均值和方差。
- 推理时,均值、方差是基于所有批次的期望计算得到的。其中在推理时所用的均值和方差时通过移动平均计算得到的,可以减少存储每个batch均值方差的内存。
3、LN(layer normalization)和BN的区别
LN和BN相比,只考虑单个sample内的统计变量,因此也不用使用BN实现中的running mean, running var。LN也完全不用考虑输入batch_size的问题。
4、transformer中为什么不适用BN归一化?
- 一种解释是,cv和nlp数据特性不同,对于nlp数据,前向和反向传播中,batch统计量及其梯度都不太稳定,一个batch中每个句子对应位置分量不一定有意义。
- 要能在某个维度做独立同分布假设,才能合理归一化。对于cv来说,batch之间的图像是独立的,但nlp的文本本质上可以看成一个时间序列,而时间序列是不定长的,长度不同的序列原则上属于不同的统计对象,所以很难得到稳定的统计量,得不到稳定的统计量,BN就无法成立,因为BN依靠滑动平均来获得一组预测用的统计量。
5、梯度消失和梯度爆炸的主要原因
- 梯度消失:主要是网络层较深,其次是采用了不合适的损失函数,会使得靠近输入层的参数更新缓慢。导致在训练时,只等价于后面几层的浅层网络的学习。
- 梯度爆炸:一般出现在深层网络和权值初始化值太大的情况下。在深层神经网络或循环神经网络中,误差的梯度可在更新中累积相乘。如果网络层之间的梯度值大于1.0,那么重复相乘会导致梯度呈指数级增长,梯度会变得非常大,然后导致网络权重的大幅更新,并因此使网络变得不稳定。梯度爆炸会使得训练过程中,权重的值变得非常大,以至于溢出,导致模型损失变成NaN等。
- 解决方法:梯度剪切,对梯度设定阈值,权重正则化,BN,残差网络的捷径(shortcut)
6、Pytorch中的乘法
- 数乘运算:torch.mul
- 向量点积:torch.dot,计算两个张量的点乘积(内积),两个张量都为一维向量。
- 矩阵乘运算:torch.mm, 输入的两个tensor shape分别使n x c, c x m,输出使n x m;
- torch.matmul,对二维张量执行的操作就是torch.mm, 此外还可以用于高维张量运算。
- @符号乘法相当于矩阵乘torch.mm,严格按照第一个参数的列数要等于第二个参数的行数。
四、神经网络
1、什么是卷积网络?
对图像和滤波矩阵做内积的操作就是卷积操作。
其中图像是指不同的数据窗口数据;滤波矩阵是指一组固定的权重,因为每个神经元的多个权重固定,所以又可以看作一个恒定的滤波器fliter;内积是指逐个元素相乘再求和的操作。
2、什么是CNN的池化pooling层?
池化是指取区域平均或者最大,即平均池化或最大池化。
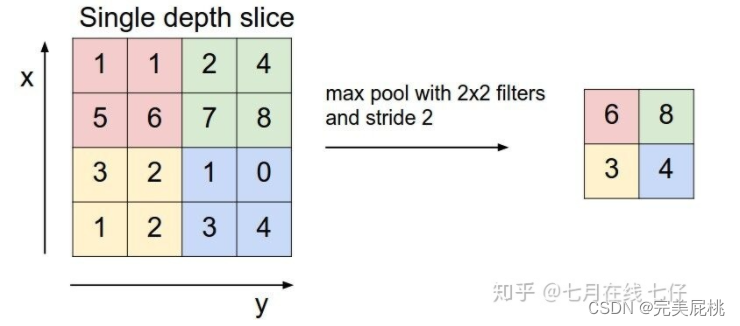
上图所展示的是取区域最大,即上图左边部分中 左上角2x2的矩阵中6最大,右上角2x2的矩阵中8最大,左下角2x2的矩阵中3最大,右下角2x2的矩阵中4最大,所以得到上图右边部分的结果:6 8 3 4
3、如何确定CNN的卷积核通道数和卷积输出层的通道数?
CNN的卷积核通道数 = 卷积输入层的通道数
CNN的卷积输出层通道数 = 卷积核的个数
4、简述下什么是生成对抗网络(GAN)?
假设有两个模型,一个是生成模型(Generative Model,下文简写为G),一个是判别模型(Discriminative Model,下文简写为D),判别模型(D)的任务就是判断一个实例是真实的还是由模型生成的,生成模型(G)的任务是生成一个实例来骗过判别模型(D),两个模型相互对抗,最终使得生成模型生成的实例域真实的没有区别,判别模型无法区分自然的还是模型生成的。
5、简要介绍下tensorflow的计算图?
tensorflow的计算图也叫数据流图。数据流图用节点(nodes)和边(edges)的有向图来描述数学计算。节点一般用来表示施加的数学操作,但也可以表示数据输入(feed in)的起点和输出(push out)的终点,或者是读取/写入持久变量(persistent variable)的终点。“边”表示“节点”之间的输入/输出关系,这些数据“边”可以输运“size可动态调整”的多维数据数组,即“张量tensor”。张量从图中流过的直观图像是这个工具取名为“tensorflow"的原因。一旦输入端的所有张量都准备好,节点将被分配到各种计算设备完成异步并行地执行运算。
6、有哪些深度学习(RNN、CNN)调参的经验?
CNN调参主要是在优化函数、emdbedding 的维度、以及残差网络的层数几个方面。
- 优化函数方面有两个选择:SGD,Adam,相对来说Adam要简单很多,不需要设置参数,效果也还不错。
- embedding随着维度的增大会出现一个最大值点,也就是开始时是随维度的增加效果逐渐比那好,到达一个点后,而后随维度的增加,效果会变差。
- 残差网络的层数与embedding的维度有关系,随层数测增加,效果变化也是一个凸函数。
- 可能包含激活函数、dropout层和BN层的使用。激活函数推荐使用relu, dropout层数不宜设置过大,过大会导致不收敛,调节步长可以是0.05,一般调整到0.5或0.5就可以找到最佳值。
7、为什么不同的机器学习领域都可以使用CNN,CNN解决了这些领域哪些共性问题?他是如何解决的?
CNN的关键是卷积运算,卷积核和卷积输入层进行局部连接可以获取整个输入的局部特征信息或者说是每个输入特征的组合特征。所以CNN的本质是完成了特征提取或者说是对原始特征的特征组合工作,从而增加模型的表达能力。不同领域的机器学习都是通过数据的特征进行建模,从而解决该领域的问题。故CNN解决了不同领域的特征提取问题,所用的方法是基于局部连接/权值共享/池化操作/多层次结构。
8、LSTM结构为什么比RNN好?
LSTM有forget gate, input gate, cell state, hidden information等的变化;因为LSTM有进有出,且当前的cell information是通过input gate控制之后叠加的,RNN是叠乘,因此LSTM可以防止梯度小时或者爆炸。
9、Sigmoid, Tanh, Relu这三个激活函数有什么有优点和缺点?
- sigmoid函数,①优点:输出范围在(0,1)之间,适合用于二分类问题,可以将输出解释为概率;具有平滑的导数,可以利用梯度下降等优化算法进行训练。②缺点:sigmoid函数存在梯度饱和问题,当输入很大或很小时,梯度接近于零,导致梯度消失,训练速度变慢;且sigmoid输出不是以零为中心的,这可能导致神经网络在训练过程中不稳定;计算sigmoid函数的指数运算较为昂贵。
- Tanh函数:①优点:输出范围在(-1,1),相对于sigmoid,均值更接近零,有助于减轻梯度消失问题;具有平滑的导数,可用于梯度下降等优化算法。②缺点:仍然存在梯度饱和的问题,当输入很大或很小时,梯度接近于零,导致梯度消失。计算Tanh函数的指数运算也较为昂贵。
- Relu函数(Rectified Linear Unit):①优点:计算简单,只需比较输入是否大于零,因此训练速度快。相比于前两种激活函数,relu函数激活时不会饱和,避免了梯度消失问题。②缺点:部分神经元可能会“死亡”(输出始终为零,不更新),这会导致网络的稀疏性;Relu对于负数输入的梯度为零,这可能导致梯度爆炸问题,输出不受限制,可能会导致梯度爆炸问题。
- 为了克服以上缺点,研究人员开发了各种改进的激活函数,如Leaky Relu, Parametric Relu,ELU和Swish等。这些函数在一定程度上解决了梯度饱和、梯度爆炸和神经元死亡等问题。

10、为什么引入非线性激励函数?
深度学习的前提是神经网络的隐层加上了非线性激活函数,提升了模型的非线性表达能力,使得神经网络可以逼近任意复杂的函数。假设有一个100层的全连接神经网络,其隐层的激活函数都是线性的,则从输入层到输出层实际上可以用一层全连接来等价替换,这样无法实现真正的深度学习。举例:线性函数 f(x)=2x+3 对 x 经过三次相同的线性变换等价于对 x 只进行一次线性变换:f(f(f(x)))=2(2(2x+3)+3)+3=8x+21。
11、为什么LSTM模型既存在sigmoid又存在tanh两种激活函数,而不是选择统一一种sigmoid或者tanh?这样做的目的是什么?
- sigmoid函数用在了各种gate上,产生0-1之间的值,这个一般只有sigmoid最直接了,相当于要么是1被记住,要么是0被忘带。
- tanh用在了状态和输出上,是对数据的处理,这个用其他激活函数或许可以。
12、如何解决RNN梯度爆炸和弥散的问题?
为了解决梯度爆炸问题,Thomas Mikolov首先提出了简单的启发性解决方案,就是当梯度大于定阈值时,将它截断为一个较小的数。

13、什么样的数据集不适合用深度学习?
- 数据集太小,数据集样本不足时,深度学习相比于其他机器学习,没有明显优势
- 数据集没有局部相关特性,目前深度学习表现比较好的领域主要是图像/语音/自然语言处理等,这些领域的一个共性是局部相关性。图像中像素组成物体,语音信号中音位组合成单词,文本数据中单词组合成句子,这些特征元素的组合一旦被打乱,表示的含义同时也被改变。对于没有这样的局部相关性的数据集,不适于使用深度学习算法进行处理。举个例子:预测一个人的健康状况,相关的参数会有年龄、职业、收入、家庭状况等各种元素,将这些元素打乱,并不会影响相关的结果。
14、广义线性模型是怎样应用在深度学习中的?
深度学习从统计学角度,可以看作递归的广义线性模型。广义线性模型相对于经典的线性模型,核心在于引入了连接函数g(.),形式变为y=g−1(wx+b)。深度学习时递归的广义线性模型,神经元的激活函数,即广义线性模型的连接函数。逻辑回归(广义线性模型的一种)的Logistic函数即为神经元激活函数中的sigmoid函数,很多类似的方法在统计学和神经网络中的名称不一样,容易引起困惑。
15、神经网络的简单发展史
- sigmoid会饱和,造成梯度消失。于是有了ReLU。
- ReLU负半轴是死区,造成梯度变0。于是有了LeakyReLU,PReLU。
- 强调梯度和权值分布的稳定性,由此有了ELU,以及较新的SELU。
- 太深了,梯度传不下去,于是有了highway。
- 干脆连highway的参数都不要,直接变残差,于是有了ResNet。
16、神经网络中激活函数的真正意义?
- 非线性:即导数不是常数。这个条件是多层神经网络的基础,保证多层网络不退化成单层线性网络。这也是激活函数的意义所在。
- 几乎处处可微:可微性保证了在优化中梯度的可计算性。传统的激活函数如sigmoid等满足处处可微。对于分段线性函数比如ReLU,只满足几乎处处可微(即仅在有限个点处不可微)。对于SGD算法来说,由于几乎不可能收敛到梯度接近零的位置,有限的不可微点对于优化结果不会有很大影响。
- 计算简单:非线性函数有很多。极端的说,一个多层神经网络也可以作为一个非线性函数,类似于Network In Network[2]中把它当做卷积操作的做法。但激活函数在神经网络前向的计算次数与神经元的个数成正比,因此简单的非线性函数自然更适合用作激活函数。这也是ReLU之流比其它使用Exp等操作的激活函数更受欢迎的其中一个原因。
17、深度神经网络容易收敛到局部最优,为什么应用广泛?
深度神经网络“容易收敛到局部最优”,很可能是一种想象,实际情况是,我们可能从来没有找到过“局部最优”,更别说全局最优了。很多人都有一种看法,就是“局部最优是神经网络优化的主要难点”。这来源于一维优化问题的直观想象。在单变量的情形下,优化问题最直观的困难就是有很多局部极值。

18、如何确定是否出现梯度爆炸?
- 模型无法从训练数据中获得更新,如低损失
- 模型不稳定,导致更新过程中损失出现显著变化
- 训练过程中,模型损失变为NaN
19、GRU和LSTM的区别?
GRU是Gated Recurrent Units,是循环神经网络的一种。
- GRU只有两个门(update和reset),GRU直接将hidden state 传给下一个单元。
- LSTM有三个门(forget,input,output),LSTM用memory cell 把hidden state 包装起来。
相关文章:
深度学习面试八股文(2023.9.06)
一、优化器 1、SGD是什么? 批梯度下降(Batch gradient descent):遍历全部数据集算一次损失函数,计算量开销大,计算速度慢,不支持在线学习。随机梯度下降(Stochastic gradient desc…...
Linux入门-网络基础|网络协议|OSI七层模型|TCP/IP五层模型|网络传输基本流程
文章目录 一、网络基础 二、网络协议 1.OSI七层模型 2.TCP/IP五层(或四层)模型 三、网络传输基本流程 1.网络传输流程图 2.数据包封装和分用 四、网络中的地址管理 1.IP地址 2.MAC地址 一、网络基础 网络发展最初是独立模式,即计算…...

docker系列(2) - 常用命令篇
文章目录 2. docker常用命令2.1 参数说明(tomcat案例)2.2 基本命令2.3 高级命令2.4 其他 2. docker常用命令 2.1 参数说明(tomcat案例) 注意如果分成多行,\后面不能有空格 # 拉取运行 docker run \ -d \ -p 8080:8080 \ --privilegedtrue \ --restartalways \ -m…...

Debian11安装MySQL8.0,链接Navicat
图文小白教程 1 下载安装MySQL1.1 从MySQL官网下载安装文件1.2 安装MySQL1.3 登录MySQL 2 配置Navicat远程访问2.1 修改配置2.2 Navicat 连接 end: 卸载 MySQL 记录于2023年9月,Debian11 、 MySQL 8.0.34 1 下载安装MySQL 1.1 从MySQL官网下载安装文件 打开 MySQ…...
vue项目中使用特殊字体的步骤
写在前面 在项目中使用特殊字体,需要注意,所使用的特殊字体是否被允许商用或是个人开发,以及如何使用,切记不要侵权。 首先需要在对应字体网站下载字体文件,取出里面后缀名为.ttf的文件 然后把该文件放到src -> ass…...
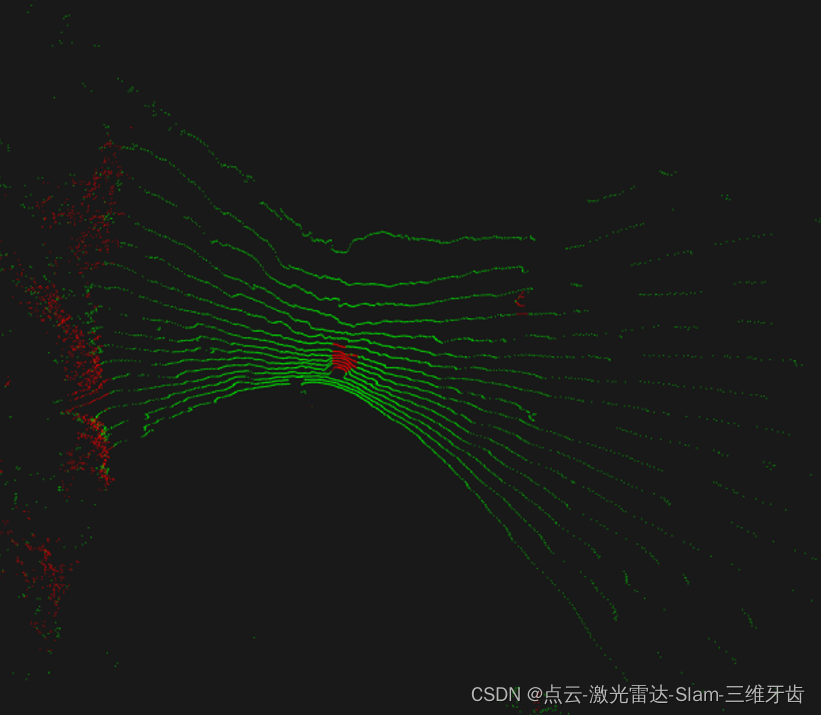
激光雷达检测负障碍物(附大概 C++ 代码)
检测效果如图,红色是正负的障碍物点: 障碍物根据其相对于地面的高度可以分为两类:正向障碍物和负向障碍物。在室外环境中,负障碍物是沟渠、悬崖、洞口或具有陡峭负坡度的地形,可能会造成安全隐患。 不慎通过道路坑洼处…...

【每日一题】9.13 PING是怎么工作的?
PING命令的作用是什么? PING命令是计算机网络中常用的命令之一,它的作用是测试两台计算机之间的连通性以及测量数据包往返的时间。 PING命令的工作原理是什么? PING命令的工作原理涉及到ICMP(Internet Control Message Protocol)和网络协议栈的操作: 1.发送ICMP …...
)
【Python百日进阶-Web开发-Peewee】Day279 - SQLite 扩展(四)
文章目录 12.2.10 class FTSModel 12.2.10 class FTSModel class FTSModel与FTS3 和 FTS4 全文搜索扩展VirtualModel一起使用的子类。 FTSModel 子类应该正常定义,但是有几个注意事项: 不支持唯一约束、非空约束、检查约束和外键。字段索引和多列索引…...
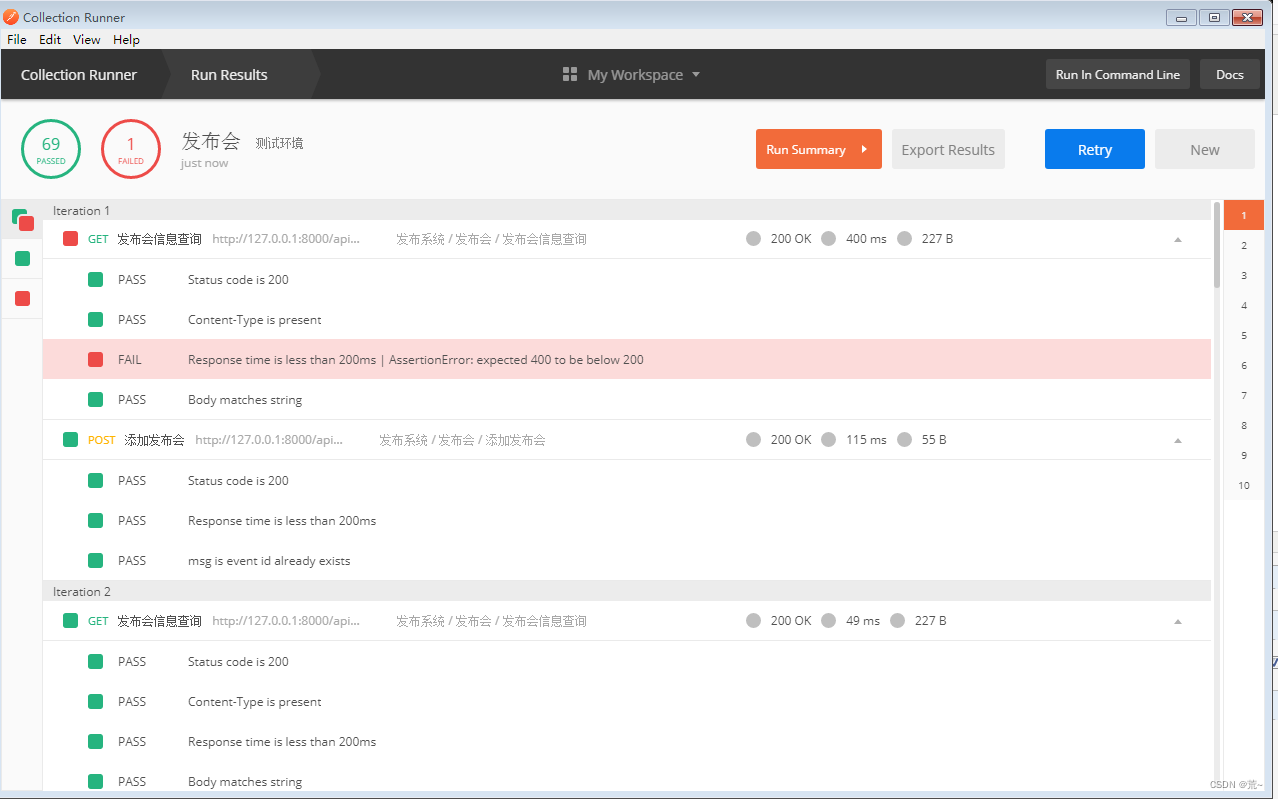
Postman接口压力测试 ---- Tests使用(断言)
所谓断言,主要用于测试返回的数据结果进行匹配判断,匹配成功返回PASS,失败返回FAIL。 下图方法一,直接点击右侧例子函数,会自动生成出现在左侧窗口脚本,只需修改数据即可。 方法二:直接自己写脚…...
nvue文件中@click.stop失效
在nvue文件中在子元素使用click.stop失效,父元素的事件触发了 在uniapp开发中nvue文件是跟vue文件是不一样的,就比如click.stop阻止点击事件继续传播就失效了,这时我们需要在子元素事件中添加条件编译,这样就会解决这个问题 // …...
【微信小程序开发】宠物预约医疗项目实战-开发功能介绍
【微信小程序开发】宠物医院项目实战-开发功能介绍 前言 本项目主要带领大家学习微信小程序开发技术,通过一个完整的项目系统的学习微信小程序的开发过程。鉴于一些同学对视频教学跟不上节奏,为此通过图文描述的方式,完整的将系统开发过程记…...
vue网页缓存页面与不缓存页面处理
在主路由页面 <template><div style"height: 100%"><!-- 缓存 --><keep-alive><router-view v-if"$route.meta.keepAlive"></router-view></keep-alive><!-- 不缓存 --><router-view v-if"!$rou…...
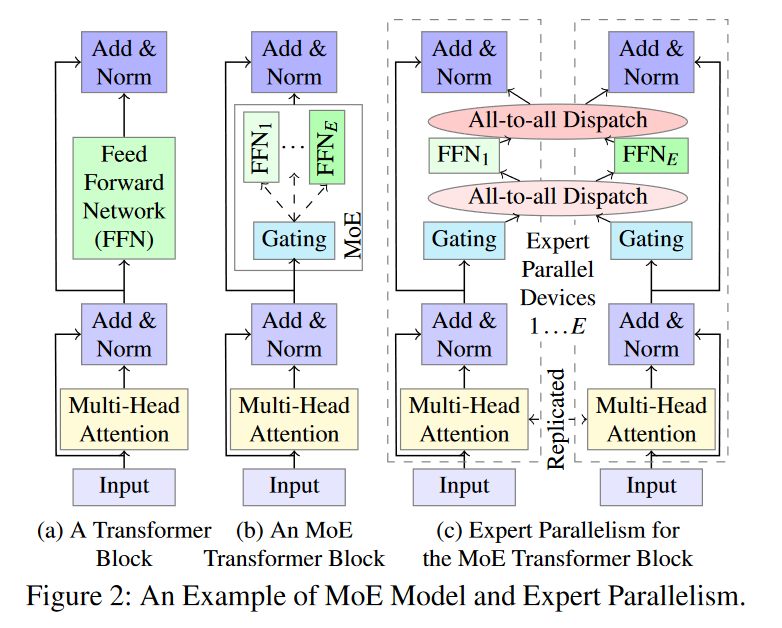
AI系统论文阅读:SmartMoE
提出稀疏架构是为了打破具有密集架构的DNN模型中模型大小和计算成本之间的连贯关系的——最著名的MoE。 MoE模型将传统训练模型中的layer换成了多个expert sub-networks,对每个输入,都有一层special gating network 来将其分配到最适合它的expert中&…...
AD20多层板设计中的平电层设计规则
一般情况下的多层板设计非常复杂,尤其层叠的次序以及平电层的电源层设计,Gnd层的设计比较简单,不需要过多的关注,但是电源层的设计非常关键,常常让人感到无法下手的感觉,这里介绍一个简单的防盲很快的让你上…...

压力测试有哪些评价指标
在进行压力测试时,您可以评估多个指标来确定系统的性能和稳定性。以下是一些常见的压力测试评价指标: 响应时间(Response Time): 平均响应时间:请求的平均处理时间。 最大响应时间:最长处理时…...

简单 php结合WebUploader实现文件上传功能
WebUploader 资源下载 http://fex.baidu.com/webuploader/download.html WebUploader 使用方法 http://fex.baidu.com/webuploader/getting-started.html php 上传代码 <?php header(Content-type:text/html;charsetutf-8);if($_FILES[file][error] 0){ // 判断上传是…...

Pandas数据分析一览-短期内快速学会数据分析指南(文末送书)
前言 三年耕耘大厂数据分析师,有些工具是必须要掌握的,尤其是Python中的数据分析三剑客:Pandas,Numpy和Matplotlib。就以个人经验而已,Pandas是必须要掌握的,它提供了易于使用的数据结构和数据操作工具&am…...

应用程序分类与相关基本概念介绍
0、引言 在从事软件开发的过程中,由于笔者并不是计算机专业的同学,所以时常会对一些概念感到困惑。比如: 前些年很火的前端和后端是什么意思?什么是 GUI?什么是 CLI?计算机的应用程序分为哪些种类&#x…...

springcloude gateway的意义
应用场景 1、南北向流量 需要流量网关和微服务网关配合使用,将内部的微服务能力,以统一的 HTTP 接入点对外提供服务。 流量网管主要是接入流量进行负载均衡,上游的微服务网关地址和数量变化不大,对服务发现要求不高。 微服务网…...

重新定义每天进步一点点
日拱一卒,每天进步一点点~ 这个主题之前写过一次,今天看了《全情投入》又有了新的感触,于是将其记录下来。 关于目标的设定问题 目标不是改变自己的日常行动,而是改变进行活动时的思维! 有些事情,坚持下…...

【kafka】Golang实现分布式Masscan任务调度系统
要求: 输出两个程序,一个命令行程序(命令行参数用flag)和一个服务端程序。 命令行程序支持通过命令行参数配置下发IP或IP段、端口、扫描带宽,然后将消息推送到kafka里面。 服务端程序: 从kafka消费者接收…...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...

C++:std::is_convertible
C++标志库中提供is_convertible,可以测试一种类型是否可以转换为另一只类型: template <class From, class To> struct is_convertible; 使用举例: #include <iostream> #include <string>using namespace std;struct A { }; struct B : A { };int main…...

反向工程与模型迁移:打造未来商品详情API的可持续创新体系
在电商行业蓬勃发展的当下,商品详情API作为连接电商平台与开发者、商家及用户的关键纽带,其重要性日益凸显。传统商品详情API主要聚焦于商品基本信息(如名称、价格、库存等)的获取与展示,已难以满足市场对个性化、智能…...

【WiFi帧结构】
文章目录 帧结构MAC头部管理帧 帧结构 Wi-Fi的帧分为三部分组成:MAC头部frame bodyFCS,其中MAC是固定格式的,frame body是可变长度。 MAC头部有frame control,duration,address1,address2,addre…...

UDP(Echoserver)
网络命令 Ping 命令 检测网络是否连通 使用方法: ping -c 次数 网址ping -c 3 www.baidu.comnetstat 命令 netstat 是一个用来查看网络状态的重要工具. 语法:netstat [选项] 功能:查看网络状态 常用选项: n 拒绝显示别名&#…...

linux 错误码总结
1,错误码的概念与作用 在Linux系统中,错误码是系统调用或库函数在执行失败时返回的特定数值,用于指示具体的错误类型。这些错误码通过全局变量errno来存储和传递,errno由操作系统维护,保存最近一次发生的错误信息。值得注意的是,errno的值在每次系统调用或函数调用失败时…...
:滤镜命令)
ffmpeg(四):滤镜命令
FFmpeg 的滤镜命令是用于音视频处理中的强大工具,可以完成剪裁、缩放、加水印、调色、合成、旋转、模糊、叠加字幕等复杂的操作。其核心语法格式一般如下: ffmpeg -i input.mp4 -vf "滤镜参数" output.mp4或者带音频滤镜: ffmpeg…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

Map相关知识
数据结构 二叉树 二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子 节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只 有左子节点,有的节点只有…...