学习python和anaconda的经验
PYTHON
1 常用命令
1.1
1.1 注释
Python注释多行的方法有以下三种:使用ctrl+/实现多行注释、在每一行的开头使用shift+#键、输入’‘’ ‘’'或者"“” “”",将要注释的代码插在中间
1.2 def init( ):函数
区分两个函数:
1.def init(self):
这种形式在__init__方法中,只有一个self,指的是实例的本身,但是在方法的类部,包含两个属性:name、year。它允许定义一个空的结构,当新数据来时,可以直接添加。实例化时,需要实例化之后,再进行赋值。
2.def init(self, 参数1,参数2,···,参数n):
这种形式在定义方法时,就直接给定了两个参数name和grade,且属性值不允许为空。实例化时,直接传入参数。
这两种初始化形式,就类似于C++类中的构造函数。
形式1:def_init_(self)
class Student_Grade:
def init(self): # 类似于c++中的默认构造函数
self.name = None
self.grade = None
def print_grade(self):print("%s grade is %s" % (self.name,self.grade))
这种形式在__init__方法中,只有一个self,指的是实例的本身,但是在方法的类部,包含两个属性,name, grade。它允许定义一个空的结构,当新数据来时,可以直接添加。实例化时,需要实例化之后,再进行赋值。
形式2:def_init_(self, 参数1,参数2,···,参数n)
class Student_Grade:
def init(self, name, grade): #类似于C++中的有参构造函数
self.name = name
self.grade = grade
这种形式在定义方法时,就直接给定了两个参数name和grade,且属性值不允许为空。实例化时,直接传入参数。
总结:
1、self是形式参数,当执行s1 = Student(“Tom”, 8)时,self等于s1;当执行s2 = Student(“sunny”, 7)时,self=s2。
2、两种方法的区别在于定义函数时属性赋值是否允许为空和实例化时是否直接传入参数,个人觉得第二种更为简洁。
————————————————
版权声明:本文为CSDN博主「沫燃清荷」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_26005373/article/details/99942134
2 常用函数(、np/pd)
内置函数、Numpy and pandas
2.1 内置函数
2.1.1 reversed 函数
reversed 函数返回一个反转的迭代器。
reversed(seq)
参数:seq – 要转换的序列,可以是 tuple, string, list 或 range。
返回值:返回一个反转的迭代器。
2.1.2 random
random模块使用Mersenne Twister算法来计算生成随机数。这是一个确定性算法,但是可以通过random.seed()函数修改初始化种子。
random.seed() # Seed based on system time or os.urandom()
random.seed(12345) # Seed based on integer given
random.seed(b’bytedata’) # Seed based on byte data
对于random.seed(n),如果使用相同的n值,则随机数生成函数每次生成的随机数序列都相同;如果不设置这个值,则系统根据时间来自己选择这个值,此时每次生成的随机数序列因时间差异而不同。
本例中,每次循环时random.random( )都采用9作为初始化的种子,生成相同的随机数序列。多次运行这个示例代码,所得结果都是一样的,因为在本例中,使用的seed()值都是9,所以random.random()每次生成的随机数序列都相同。
在本例中,使用的seed()值都是9,所以random.random( )每次生成的随机数序列都相同,但是random.seed(9)在循环内部,print(random.random( ))这行命令每一次输出时都定位到所生成的随机数列表的第一个元素。
2.2 Numpy
Import numpy as np
2.2.1 numpy.random.uniform介绍:
函数原型: numpy.random.uniform(low,high,size)
功能:从一个均匀分布[low,high)中随机采样,注意定义域是左闭右开,即包含low,不包含high.
参数介绍:
low: 采样下界,float类型,默认值为0;
high: 采样上界,float类型,默认值为1;
size: 输出样本数目,为int或元组(tuple)类型,例如,size=(m,n,k), 则输出mnk个样本,缺省时输出1个值。
返回值:ndarray类型,其形状和参数size中描述一致。
这里顺便说下ndarray类型,表示一个N维数组对象,其有一个shape(表维度大小)和dtype(说明数组数据类型的对象),使用zeros和ones函数可以创建数据全0或全1的数组,原型:
numpy.ones(shape,dtype=None,order=‘C’),
其中,shape表数组形状(m*n),dtype表类型,order表是以C还是fortran形式存放数据。
2.2.2 类似uniform,还有以下随机数产生函数:
a. randint: 原型:numpy.random.randint(low, high=None, size=None, dtype=‘l’),产生随机整数;
b. random_integers: 原型: numpy.random.random_integers(low, high=None, size=None),在闭区间上产生随机整数;
c. random_sample: 原型: numpy.random.random_sample(size=None),在[0.0,1.0)上随机采样;
d. random: 原型: numpy.random.random(size=None),和random_sample一样,是random_sample的别名;
e. rand: 原型: numpy.random.rand(d0, d1, …, dn),产生d0 - d1 - … - dn形状的在[0,1)上均匀分布的float型数。
f. randn: 原型:numpy.random.randn(d0,d1,…,dn),产生d0 - d1 - … - dn形状的标准正态分布的float型数。
————————————————
原文链接:https://blog.csdn.net/u013920434/article/details/52507173
####################################################
-- coding: utf-8 --
import matplotlib.pyplot as plt
import numpy as np
s = np.random.uniform(0,1,1200) # 产生1200个[0,1)的数
count, bins, ignored = plt.hist(s, 12, normed=True)
“”"
hist原型:
matplotlib.pyplot.hist(x, bins=10, range=None, normed=False, weights=None,
cumulative=False, bottom=None, histtype=‘bar’, align=‘mid’,
orientation=‘vertical’,rwidth=None, log=False, color=None, label=None,
stacked=False, hold=None,data=None,**kwargs)
输入参数很多,具体查看matplotlib.org,本例中用到3个参数,分别表示:s数据源,bins=12表示bin
的个数,即画多少条条状图,normed表示是否归一化,每条条状图y坐标为n/(len(x)`dbin),整个条状图积分值为1
输出:count表示数组,长度为bins,里面保存的是每个条状图的纵坐标值
bins:数组,长度为bins+1,里面保存的是所有条状图的横坐标,即边缘位置
ignored: patches,即附加参数,列表或列表的列表,本例中没有用到。
“”"
plt.plot(bins, np.ones_like(bins), linewidth=2, color=‘r’)
plt.show()
————————————————
版权声明:本文为CSDN博主「ma_studd」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u013920434/article/details/52507173
2.2.3 np.argmax()函数
np.argmax是用于取得数组中每一行或者每一列的的最大值。常用于机器学习中获取分类结果、计算精确度等。
函数:numpy.argmax(array, axis)
array:代表输入数组;axis:代表对array取行(axis=0)或列(axis=1)的最大值
2.2.4 numpy.array()函数
numpy.array(object, dtype=None)
各个参数意义:
object:创建的数组的对象,可以为单个值,列表,元胞等。
dtype:创建数组中的数据类型。
返回值:给定对象的数组。
2.2.5 numpy.random.randint
numpy.random.randint(low, high=None, size=None, dtype=‘l’)
函数的作用是,返回一个随机整型数,范围从低(包括)到高(不包括),即[low, high)。
如果没有写参数high的值,则返回[0,low)的值。
参数如下:
low: int
生成的数值最低要大于等于low。
(hign = None时,生成的数值要在[0, low)区间内)
high: int (可选)
如果使用这个值,则生成的数值在[low, high)区间。
size: int or tuple of ints(可选)
输出随机数的尺寸,比如size = (m * n* k)则输出同规模即m * n* k个随机数。默认是None的,仅仅返回满足要求的单一随机数。
dtype: dtype(可选):
想要输出的格式。如int64、int等等
输出:
out: int or ndarray of ints
返回一个随机数或随机数数组
————————————————
版权声明:本文为CSDN博主「安ann」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u011851421/article/details/83544853
2.3 pandas
import pandas as pd
2.3.1 Pandas写入Excel函数
Pandas写入Excel函数——to_excel 技术总结
Pandas作为Python数据分析的一个常用包,经常会与Excel交互。
最近经常使用pandas的to_excel函数,发现坑还不少。经常报错,覆盖写入,让人烦躁。甚至Run一遍后,excel文件里只剩一个sheet或者文件根本打不开。
一、单个sheet写入:
import pandas as pd
df1 = pd.DataFrame({‘One’: [1, 2, 3]})
df1.to_excel(‘excel1.xlsx’, sheet_name=‘Sheet1’, index=False) # index false为不写入索引,true为写入索引
#####excel1.xlsx 不存在的话,则会新建文件,再写入 Sheet1。excel1.xlsx 已存在的话,则会新建,写入,再覆盖。所以无论 excel1.xlsx 是否存在,上述代码的结果是一样的。它的作用就是新建 excel1.xlsx(文件已存在则覆盖),写入 Sheet1。excel1.xlsx 中最后只有一个表 Sheet1。
当Pandas要写入多个sheet时,to_excel第一个参数excel_writer要选择ExcelWriter对象,不能是文件的路径。否则,就会覆盖写入。ExcelWriter可以通过上下文管理器来执行,省去save(),优雅。
二、多个sheet写入到同一个Excel
import pandas as pd
df1 = pd.DataFrame({‘One’: [1, 2, 3]})
df2 = pd.DataFrame({‘Two’: [4, 5, 6]})
with pd.ExcelWriter(‘excel1.xlsx’) as writer:
df1.to_excel(writer, sheet_name=‘Sheet1’, index=False)
df2.to_excel(writer, sheet_name=‘Sheet2’, index=False)
###########Once a workbook has been saved it is not possible write further data without rewriting the whole workbook.
to_excel的Doc中有上面一句话,所以,ExcelWriter可以看作一个容器,一次性提交所有to_excel语句后再保存,从而避免覆盖写入
相关文章:

学习python和anaconda的经验
PYTHON 1 常用命令 1.1 1.1 注释 Python注释多行的方法有以下三种:使用ctrl+/实现多行注释、在每一行的开头使用shift+#键、输入’‘’ ‘’或者"“” “”",将要注释的代码插在中间 1.2 def init( ):函数 区分两个函数: 1.def init(self): 这种形式在__init_…...

【Linux】多线程【上】
文章目录 前言1、Linux线程概念1-1、什么是线程?1-1-1、如何看待页表1-1-2、回顾进程地址空间1-1-3、页表怎么进行虚拟地址到物理地址的映射的?1-1-4、Linux中线程的概念(重点)1-1-5、原生线程库1-1-6、代码测试1-1-7、知识点&…...

生成式人工智能在高等教育 IT 中的作用
作者:Jared Pane 通过将你大学的数据与公共 LLMs 和 Elasticsearch 安全集成来找到你需要的答案。 根据 2023 年 4 月 EDUCAUSE 的一项调查,83% 的受访者表示,生成式人工智能将在未来三到五年内深刻改变高等教育。 学术界很快就询问和想象生…...

黑龙江省DCMM认证、CSMM认证、CMMM认证、知识产权等政策奖励
2023年8月28日 为深入落实党的二十大精神,认真落实省第十三次党代会关于创新龙江建设的部署要求,全面贯彻新发展理念,融入和服务构建新发展格局,实施创新驱动发展战略,着力建设创新龙江,不断塑造振兴发展新…...

腾讯云2023年云服务器优惠活动价格表
腾讯云经常推出各种云产品优惠活动,为了帮助大家更好地了解腾讯云服务器的价格和优惠政策,下面给大家分享腾讯云最新云服务器优惠活动价格表,助力大家轻松上云! 一、轻量应用服务器优惠活动价格表 1、轻量应用服务器:…...

Sleuth--链路追踪
1 链路追踪介绍 在大型系统的微服务化构建中,一个系统被拆分成了许多模块。这些模块负责不同的功能,组合成系统,最终可以提供丰富的功能。在这种架构中,一次请求往往需要涉及到多个服务。互联网应用构建在不同的软件模块集上&…...
MyBatis初级
文章目录 一、mybatis1、概念2、JDBC缺点2.1、之前jdbc操作2.2 、原始jdbc操作的分析 3、mybatis的使用3.1、导入maven依赖3.2、新建表3.3、实体类3.4、编写mybatis的配置文件3.5、编写接口 和 映射文件3.6、编写测试类3.7、注意事项 4、代理方式开发5、mybatis和spring整合5.1…...
AOP)
Spring 学习(二)AOP
一、什么是AOP Aspect Oriented Programming,即面向切面编程。对一个大型项目的代码而言,整个系统要求关注安全检查、日志、事务等功能,这些功能实际上“横跨”多个业务方法。在一般的OOP编程里,需要在每一个业务方法内添加相关非…...
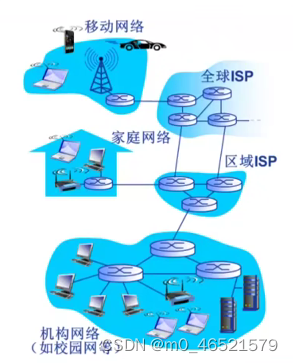
笔记1.1 计算机网络基本概念
计算机网络是通信技术与计算机技术紧密结合的产物 通信系统模型: 计算机网络是一种通信网络 计算机网络是互连的、自洽的计算机集合。 互连:互联互通 自洽:无主从关系 通过交换网络互连主机 Internet:数以百万计的互连的计算设…...

液压切管机配套用液压泵站比例阀放大器
液压切管机配套用液压泵站是液压系统的动力源,可按机械设备工况需要提供一定压力、流量和清洁度的工作介质。它由泵组、油箱组件、控温组件、滤油器组件及蓄能器组件等组合而成,液压泵站主要服务于大型管道工程。...

C++ Primer Plus 第七章笔记
目录 函数基本知识 没有返回值的函数:void函数 有返回值的函数: 函数原型 1.为什么需要函数原型? 2.函数原型的语法 3.函数原型的功能 按值传递函数参数 形参和实参 局部变量 参数问题 使用const指针参数 调用自身的函数…...
常用数据库的 API - 开篇
API API 这个词在大多数人看来可能和 CNS 差不多,前者天天听说就是用不上,后者天天读就是发不了。 不过,通过今天的一个简短介绍,今后 API 这个东西你就用上了,因为在文章最后我将会展示一个最最基础且高频的 API 使…...

C++之生成详细汇编代码(二百一十六)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 人生格言: 人生…...
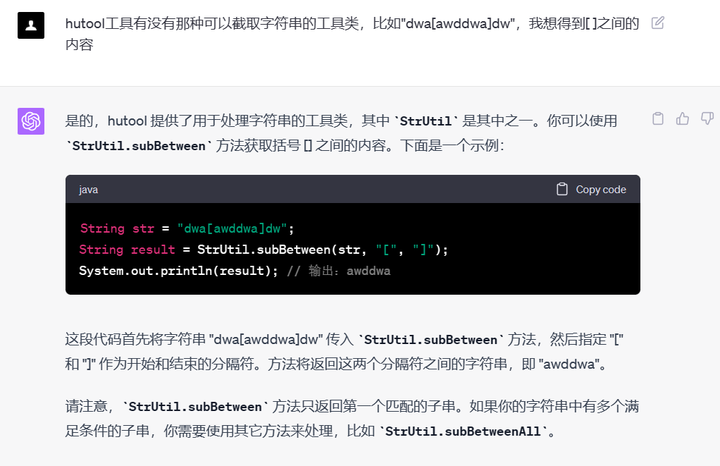
AIGC|当一个程序员学会用AI来辅助编程实践
一、辅助编程 作为主要以 JAVA 语言为核心的后端开发者,其实,早些时间我也用过比如 Codota、Tabnine、Github 的 Copilot、阿里的 AI Coding Assistant 等 IDEA 插件,但是我并没有觉得很惊奇,感觉就是生成一些代码片段罢了&#x…...

9.14号作业
仿照vector手动实现自己的myVector,最主要实现二倍扩容功能 有些功能,不会 #include <iostream>using namespace std; //创建vector类 class Vector { private:int *data;int size;int capacity; public://无参构造Vector(){}//拷贝构造Vector(c…...

【面试题】C/C++ 中指针和引用的区别
指针是一个独立的对象,它可以指向不同的变量或对象,可以重新赋值给其他变量。而引用是已存在的变量的别名,它必须在定义时初始化,并且不能重新绑定到另一个变量。指针可以是空指针(nullptr),它不…...
spring boot 整合多数据源
多数据源产生的场景 一般情况下,不会有多数据源这样的场景出现,但老项目或者特殊需求的项目,可能会有这样的场景 同一个应用需要访问两个数据库不用数据库中间件的读写分离 注入数据源选择的时机 声明两个数据源实例,在getConnect…...
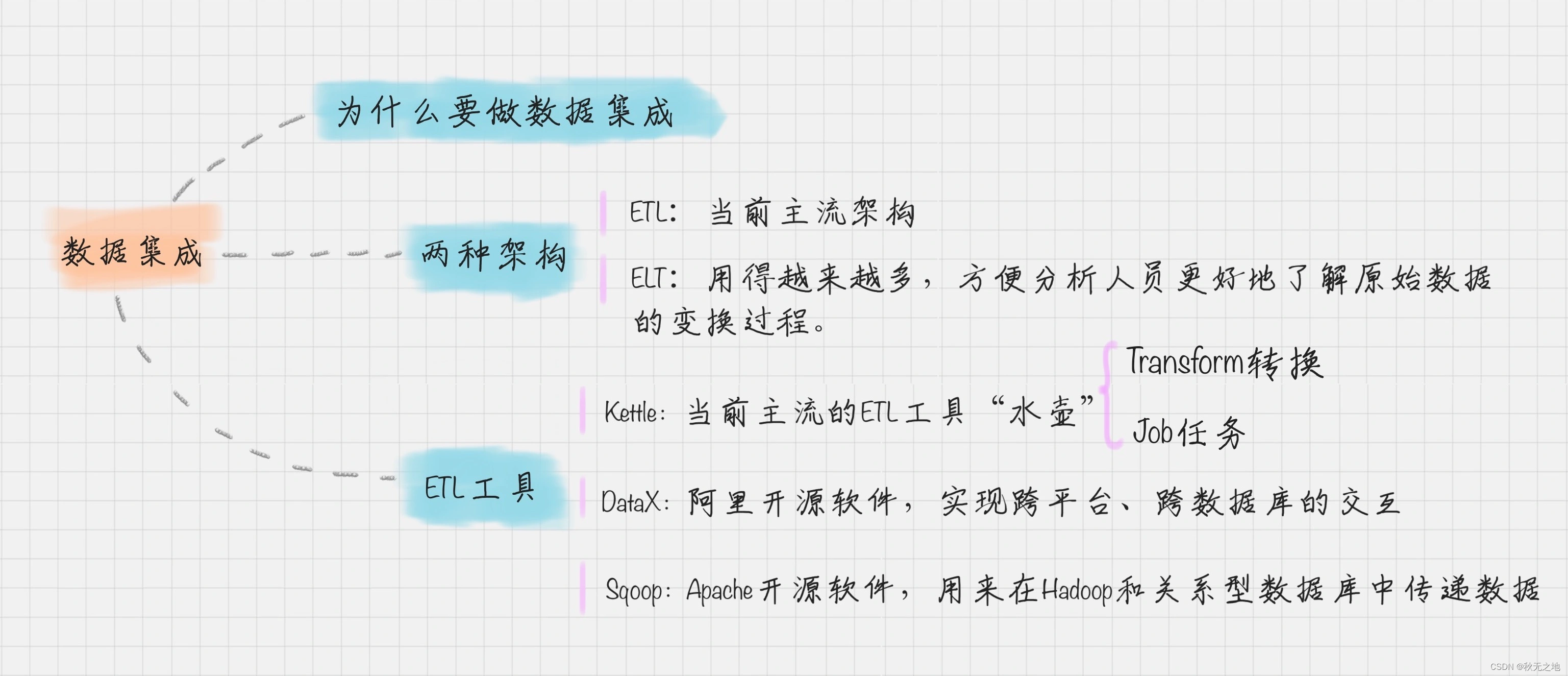
数据集成:数据挖掘的准备工作之一
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️ 🐴作者:秋无之地 🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据…...

xml配置文件密码特殊字符处理
错误姿势: 正确姿势:采取转义符的方式 常用转义符:...
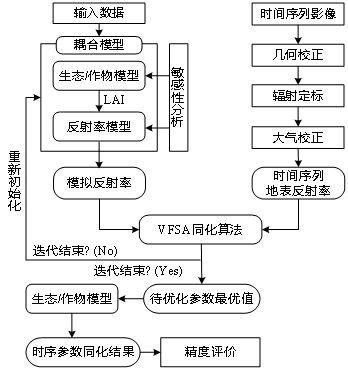
遥感数据与作物模型同化
基于过程的作物生长模拟模型DSSAT是现代农业系统研究的有力工具,可以定量描述作物生长发育和产量形成过程及其与气候因子、土壤环境、品种类型和技术措施之间的关系,为不同条件下作物生长发育及产量预测、栽培管理、环境评价以及未来气候变化评估等提供了…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

【python异步多线程】异步多线程爬虫代码示例
claude生成的python多线程、异步代码示例,模拟20个网页的爬取,每个网页假设要0.5-2秒完成。 代码 Python多线程爬虫教程 核心概念 多线程:允许程序同时执行多个任务,提高IO密集型任务(如网络请求)的效率…...

Linux --进程控制
本文从以下五个方面来初步认识进程控制: 目录 进程创建 进程终止 进程等待 进程替换 模拟实现一个微型shell 进程创建 在Linux系统中我们可以在一个进程使用系统调用fork()来创建子进程,创建出来的进程就是子进程,原来的进程为父进程。…...

如何在网页里填写 PDF 表格?
有时候,你可能希望用户能在你的网站上填写 PDF 表单。然而,这件事并不简单,因为 PDF 并不是一种原生的网页格式。虽然浏览器可以显示 PDF 文件,但原生并不支持编辑或填写它们。更糟的是,如果你想收集表单数据ÿ…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...

Fabric V2.5 通用溯源系统——增加图片上传与下载功能
fabric-trace项目在发布一年后,部署量已突破1000次,为支持更多场景,现新增支持图片信息上链,本文对图片上传、下载功能代码进行梳理,包含智能合约、后端、前端部分。 一、智能合约修改 为了增加图片信息上链溯源,需要对底层数据结构进行修改,在此对智能合约中的农产品数…...

保姆级教程:在无网络无显卡的Windows电脑的vscode本地部署deepseek
文章目录 1 前言2 部署流程2.1 准备工作2.2 Ollama2.2.1 使用有网络的电脑下载Ollama2.2.2 安装Ollama(有网络的电脑)2.2.3 安装Ollama(无网络的电脑)2.2.4 安装验证2.2.5 修改大模型安装位置2.2.6 下载Deepseek模型 2.3 将deepse…...

GruntJS-前端自动化任务运行器从入门到实战
Grunt 完全指南:从入门到实战 一、Grunt 是什么? Grunt是一个基于 Node.js 的前端自动化任务运行器,主要用于自动化执行项目开发中重复性高的任务,例如文件压缩、代码编译、语法检查、单元测试、文件合并等。通过配置简洁的任务…...
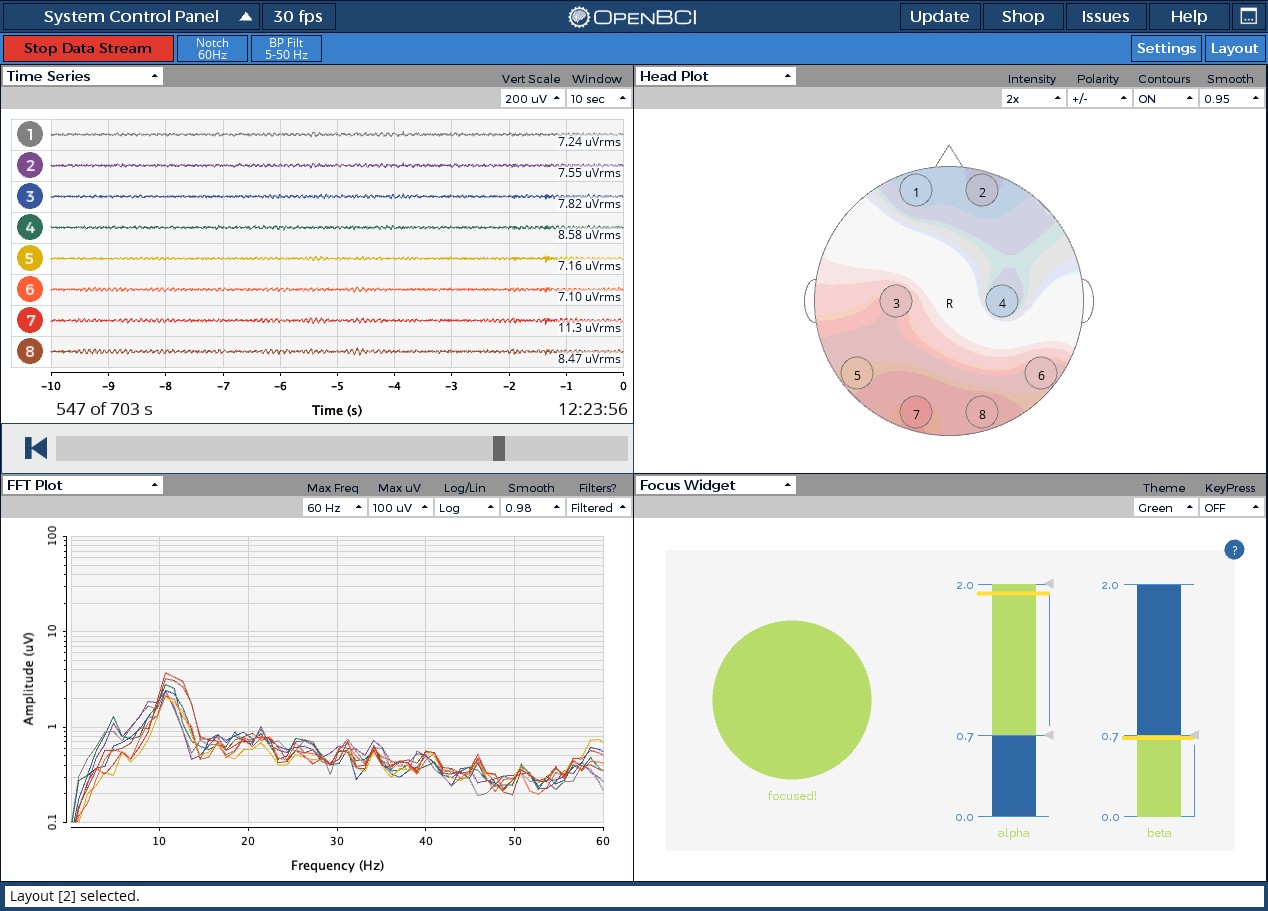
脑机新手指南(七):OpenBCI_GUI:从环境搭建到数据可视化(上)
一、OpenBCI_GUI 项目概述 (一)项目背景与目标 OpenBCI 是一个开源的脑电信号采集硬件平台,其配套的 OpenBCI_GUI 则是专为该硬件设计的图形化界面工具。对于研究人员、开发者和学生而言,首次接触 OpenBCI 设备时,往…...
:工厂方法模式、单例模式和生成器模式)
上位机开发过程中的设计模式体会(1):工厂方法模式、单例模式和生成器模式
简介 在我的 QT/C 开发工作中,合理运用设计模式极大地提高了代码的可维护性和可扩展性。本文将分享我在实际项目中应用的三种创造型模式:工厂方法模式、单例模式和生成器模式。 1. 工厂模式 (Factory Pattern) 应用场景 在我的 QT 项目中曾经有一个需…...