Stable-Baselines 3 部分源代码解读 2 on_policy_algorithm.py
Stable-Baselines 3 部分源代码解读 ./common/on_policy_algorithm.py
前言
阅读PPO相关的源码,了解一下标准库是如何建立PPO算法以及各种tricks的,以便于自己的复现。
在Pycharm里面一直跳转,可以看到PPO类是最终继承于基类,也就是这个py文件的内容。
所以阅读源码就先从这里开始。: )
import 包
import sys
import time
from typing import Any, Dict, List, Optional, Tuple, Type, TypeVar, Unionimport numpy as np
import torch as th
from gym import spacesfrom stable_baselines3.common.base_class import BaseAlgorithm
from stable_baselines3.common.buffers import DictRolloutBuffer, RolloutBuffer
from stable_baselines3.common.callbacks import BaseCallback
from stable_baselines3.common.policies import ActorCriticPolicy
from stable_baselines3.common.type_aliases import GymEnv, MaybeCallback, Schedule
from stable_baselines3.common.utils import obs_as_tensor, safe_mean
from stable_baselines3.common.vec_env import VecEnv
OnPolicyAlgorithm 类
这个类是PPO算法类的中间曾,夹在底层基类和上层PPO类的之间。
主要是同策略算法,例如:A2C和PPO算法。
policy、env和learning_rate三者与基类base-class.py的一致
n_steps表示每次更新前需要经过的时间步,作者在这里给出了n_steps * n_envs的例子,可能的意思是,如果环境是重复的多个,打算做并行训练的话,那么就是每个子环境的时间步乘以环境的数量
batch_size经验回放的最小批次信息
gamma、gae_lambda、clip_range、clip_range_vf均是具有默认值的参数,分别代表“折扣因子”、“GAE奖励中平衡偏置和方差的参数”、“为网络参数而限制幅度的范围”、“为值函数网络参数而限制幅度的范围”
normalize_advantage标志是否需要归一化优势(advantage)
ent_coef、vf_coef损失计算的熵系数
max_grad_norm最大的梯度长度,梯度下降的限幅
use_sde、sde_sample_freq是状态独立性探索,只适用于连续环境,与基类base-class.py的一致
target_kl限制每次更新时KL散度不能太大,因为clipping限幅不能防止大量更新
monitor_wrapper标志是否需要Gym库提供的监视器包装器
_init_setup_model是否建立模型,也就是是否在创建这个实例过程中创建初始化模型
class OnPolicyAlgorithm(BaseAlgorithm):"""The base for On-Policy algorithms (ex: A2C/PPO).:param policy: The policy model to use (MlpPolicy, CnnPolicy, ...):param env: The environment to learn from (if registered in Gym, can be str):param learning_rate: The learning rate, it can be a functionof the current progress remaining (from 1 to 0):param n_steps: The number of steps to run for each environment per update(i.e. batch size is n_steps * n_env where n_env is number of environment copies running in parallel):param gamma: Discount factor:param gae_lambda: Factor for trade-off of bias vs variance for Generalized Advantage Estimator.Equivalent to classic advantage when set to 1.:param ent_coef: Entropy coefficient for the loss calculation:param vf_coef: Value function coefficient for the loss calculation:param max_grad_norm: The maximum value for the gradient clipping:param use_sde: Whether to use generalized State Dependent Exploration (gSDE)instead of action noise exploration (default: False):param sde_sample_freq: Sample a new noise matrix every n steps when using gSDEDefault: -1 (only sample at the beginning of the rollout):param tensorboard_log: the log location for tensorboard (if None, no logging):param monitor_wrapper: When creating an environment, whether to wrap itor not in a Monitor wrapper.:param policy_kwargs: additional arguments to be passed to the policy on creation:param verbose: Verbosity level: 0 for no output, 1 for info messages (such as device or wrappers used), 2 fordebug messages:param seed: Seed for the pseudo random generators:param device: Device (cpu, cuda, ...) on which the code should be run.Setting it to auto, the code will be run on the GPU if possible.:param _init_setup_model: Whether or not to build the network at the creation of the instance:param supported_action_spaces: The action spaces supported by the algorithm."""def __init__(self,policy: Union[str, Type[ActorCriticPolicy]],env: Union[GymEnv, str],learning_rate: Union[float, Schedule],n_steps: int,gamma: float,gae_lambda: float,ent_coef: float,vf_coef: float,max_grad_norm: float,use_sde: bool,sde_sample_freq: int,tensorboard_log: Optional[str] = None,monitor_wrapper: bool = True,policy_kwargs: Optional[Dict[str, Any]] = None,verbose: int = 0,seed: Optional[int] = None,device: Union[th.device, str] = "auto",_init_setup_model: bool = True,supported_action_spaces: Optional[Tuple[spaces.Space, ...]] = None,):super().__init__(policy=policy,env=env,learning_rate=learning_rate,policy_kwargs=policy_kwargs,verbose=verbose,device=device,use_sde=use_sde,sde_sample_freq=sde_sample_freq,support_multi_env=True,seed=seed,tensorboard_log=tensorboard_log,supported_action_spaces=supported_action_spaces,)self.n_steps = n_stepsself.gamma = gammaself.gae_lambda = gae_lambdaself.ent_coef = ent_coefself.vf_coef = vf_coefself.max_grad_norm = max_grad_normself.rollout_buffer = None# 调用基类的_setup_model()模型if _init_setup_model:self._setup_model()def _setup_model(self) -> None:# 初始化学习率,让他可以调用self._setup_lr_schedule()# 设置随机数种子self.set_random_seed(self.seed)# 设置经验池子的类,如果观测空间是spaces.Dict类那么就赋值DictRolloutBuffer# 如果观测空间不是spaces.Dict类那么就赋值RolloutBufferbuffer_cls = DictRolloutBuffer if isinstance(self.observation_space, spaces.Dict) else RolloutBuffer# 根据类初始化实例经验池子# 初始化经验池子的是时候将设备信息、折扣率、GAE超参数和环境的数量也传进去了self.rollout_buffer = buffer_cls(self.n_steps,self.observation_space,self.action_space,device=self.device,gamma=self.gamma,gae_lambda=self.gae_lambda,n_envs=self.n_envs,)# 初始化策略,直接输入状态空间、动作空间、可调用的学习率、是否使用状态独立性探索,以及自己制定策略# 的时候自己家的模型的参数和激活函数self.policy = self.policy_class( # pytype:disable=not-instantiableself.observation_space,self.action_space,self.lr_schedule,use_sde=self.use_sde,**self.policy_kwargs # pytype:disable=not-instantiable)# 将策略放到GPU/CPU中self.policy = self.policy.to(self.device)def collect_rollouts(self,env: VecEnv,callback: BaseCallback,rollout_buffer: RolloutBuffer,n_rollout_steps: int,) -> bool:# 收集环境交互数据# 这个方法使用当前的策略并将交互历史填充到RolloutBuffer经验池子中# rollout的意思是无模型的概念,而不是有模型的RL或规划里面的rollout的概念# env 用于训练的环境# callback 在每个时间步都会调用的回调函数# rollout_buffer 将收集的经验放置到rollout_buffer中# 在每个环境中需要收集的条数# 返回值是True:如果rollout_buffer收集了这么多的经验;返回值是False:如果回调函数提前终止了# 这个rollouts。"""Collect experiences using the current policy and fill a ``RolloutBuffer``.The term rollout here refers to the model-free notion and should notbe used with the concept of rollout used in model-based RL or planning.:param env: The training environment:param callback: Callback that will be called at each step(and at the beginning and end of the rollout):param rollout_buffer: Buffer to fill with rollouts:param n_rollout_steps: Number of experiences to collect per environment:return: True if function returned with at least `n_rollout_steps`collected, False if callback terminated rollout prematurely."""assert self._last_obs is not None, "No previous observation was provided"# 将策略转变到评估模式# Switch to eval mode (this affects batch norm / dropout)self.policy.set_training_mode(False)# 重置经验池子,如果使用状态独立性探索,那么就重置策略的噪声n_steps = 0rollout_buffer.reset()# Sample new weights for the state dependent explorationif self.use_sde:self.policy.reset_noise(env.num_envs)# 回调函数执行on_rollout_start()命令,跳转定义时候没有看到具体定义callback.on_rollout_start()while n_steps < n_rollout_steps:# 如果使用了状态独立性探索,并且达到了探索频率的节点,那么就重置策略的噪声if self.use_sde and self.sde_sample_freq > 0 and n_steps % self.sde_sample_freq == 0:# Sample a new noise matrixself.policy.reset_noise(env.num_envs)# 在断开梯度的情况下,转换观测数据到tensor张量内,然后输入到策略中输出动作、价值和对数概率# 最后再将动作数据转移到numpy中with th.no_grad():# Convert to pytorch tensor or to TensorDictobs_tensor = obs_as_tensor(self._last_obs, self.device)actions, values, log_probs = self.policy(obs_tensor)actions = actions.cpu().numpy()# Rescale and perform action# 归一化动作信息,限制在动作空间的上下界clipped_actions = actions# Clip the actions to avoid out of bound errorif isinstance(self.action_space, spaces.Box):clipped_actions = np.clip(actions, self.action_space.low, self.action_space.high)# 将动作信息输入到环境中,输出新的观测、奖励数值、是否完成以及其他信息。new_obs, rewards, dones, infos = env.step(clipped_actions)# 处理回调函数和更新经验池子self.num_timesteps += env.num_envs# Give access to local variablescallback.update_locals(locals())if callback.on_step() is False:return Falseself._update_info_buffer(infos)n_steps += 1# 如果动作空间是离散空间的话,那么就转变成一个列向量if isinstance(self.action_space, spaces.Discrete):# Reshape in case of discrete actionactions = actions.reshape(-1, 1)# 判断数据是否是终止的# 终止之后计算累计奖励# Handle timeout by bootstraping with value function# see GitHub issue #633for idx, done in enumerate(dones):if (doneand infos[idx].get("terminal_observation") is not Noneand infos[idx].get("TimeLimit.truncated", False)):terminal_obs = self.policy.obs_to_tensor(infos[idx]["terminal_observation"])[0]with th.no_grad():terminal_value = self.policy.predict_values(terminal_obs)[0]rewards[idx] += self.gamma * terminal_value# 经验池子输入的是上一个状态、动作、奖励、上一个回合的开始状态、价值列表以及对数概率rollout_buffer.add(self._last_obs, actions, rewards, self._last_episode_starts, values, log_probs)self._last_obs = new_obsself._last_episode_starts = dones# 计算下一个状态的价值with th.no_grad():# Compute value for the last timestepvalues = self.policy.predict_values(obs_as_tensor(new_obs, self.device))# 计算回报和优势rollout_buffer.compute_returns_and_advantage(last_values=values, dones=dones)callback.on_rollout_end()return Truedef train(self) -> None:# 这个是父类的方法# 在子类的实际PPO类中做了重写"""Consume current rollout data and update policy parameters.Implemented by individual algorithms."""raise NotImplementedErrordef learn(self: SelfOnPolicyAlgorithm,total_timesteps: int,callback: MaybeCallback = None,log_interval: int = 1,tb_log_name: str = "OnPolicyAlgorithm",reset_num_timesteps: bool = True,progress_bar: bool = False,) -> SelfOnPolicyAlgorithm:iteration = 0# 初始化模型total_timesteps, callback = self._setup_learn(total_timesteps,callback,reset_num_timesteps,tb_log_name,progress_bar,)callback.on_training_start(locals(), globals())while self.num_timesteps < total_timesteps:# 这里开始执行上面的函数,在环境中收集数据,收集完了就继续训练# 如果出了故障了,就在接下来跳出循环continue_training = self.collect_rollouts(self.env, callback, self.rollout_buffer, n_rollout_steps=self.n_steps)if continue_training is False:break# 跌带次数+1,并根据当前的训练次数更新学习率iteration += 1self._update_current_progress_remaining(self.num_timesteps, total_timesteps)# 在控制台按照预先定义的频率输出相关信息# Display training infosif log_interval is not None and iteration % log_interval == 0:time_elapsed = max((time.time_ns() - self.start_time) / 1e9, sys.float_info.epsilon)fps = int((self.num_timesteps - self._num_timesteps_at_start) / time_elapsed)self.logger.record("time/iterations", iteration, exclude="tensorboard")if len(self.ep_info_buffer) > 0 and len(self.ep_info_buffer[0]) > 0:self.logger.record("rollout/ep_rew_mean", safe_mean([ep_info["r"] for ep_info in self.ep_info_buffer]))self.logger.record("rollout/ep_len_mean", safe_mean([ep_info["l"] for ep_info in self.ep_info_buffer]))self.logger.record("time/fps", fps)self.logger.record("time/time_elapsed", int(time_elapsed), exclude="tensorboard")self.logger.record("time/total_timesteps", self.num_timesteps, exclude="tensorboard")self.logger.dump(step=self.num_timesteps)self.train()callback.on_training_end()return selfdef _get_torch_save_params(self) -> Tuple[List[str], List[str]]:state_dicts = ["policy", "policy.optimizer"]return state_dicts, []
相关文章:

Stable-Baselines 3 部分源代码解读 2 on_policy_algorithm.py
Stable-Baselines 3 部分源代码解读 ./common/on_policy_algorithm.py 前言 阅读PPO相关的源码,了解一下标准库是如何建立PPO算法以及各种tricks的,以便于自己的复现。 在Pycharm里面一直跳转,可以看到PPO类是最终继承于基类,也…...

15. Qt中OPenGL的参数传递问题
1. 说明 在OPenGL中,需要使用GLSL语言来编写着色器的函数,在顶点着色器和片段着色器之间需要参数值的传递,且在CPU中的数据也需要传递到顶点着色器中进行使用。本文简单介绍几种参数传递的方式: (本文内容仅个人理解&…...
注意,这本2区SCI期刊最快18天录用,还差一步录用只因犯了这个错
发表案例分享: 2区医学综合类SCI,仅18天录用,录用后28天见刊 2023.02.10 | 见刊 2023.01.13 | Accepted 2023.01.11 | 提交返修稿 2022.12.26 | 提交论文至期刊部系统 录用截图来源:期刊部投稿系统 见刊截图来源:…...
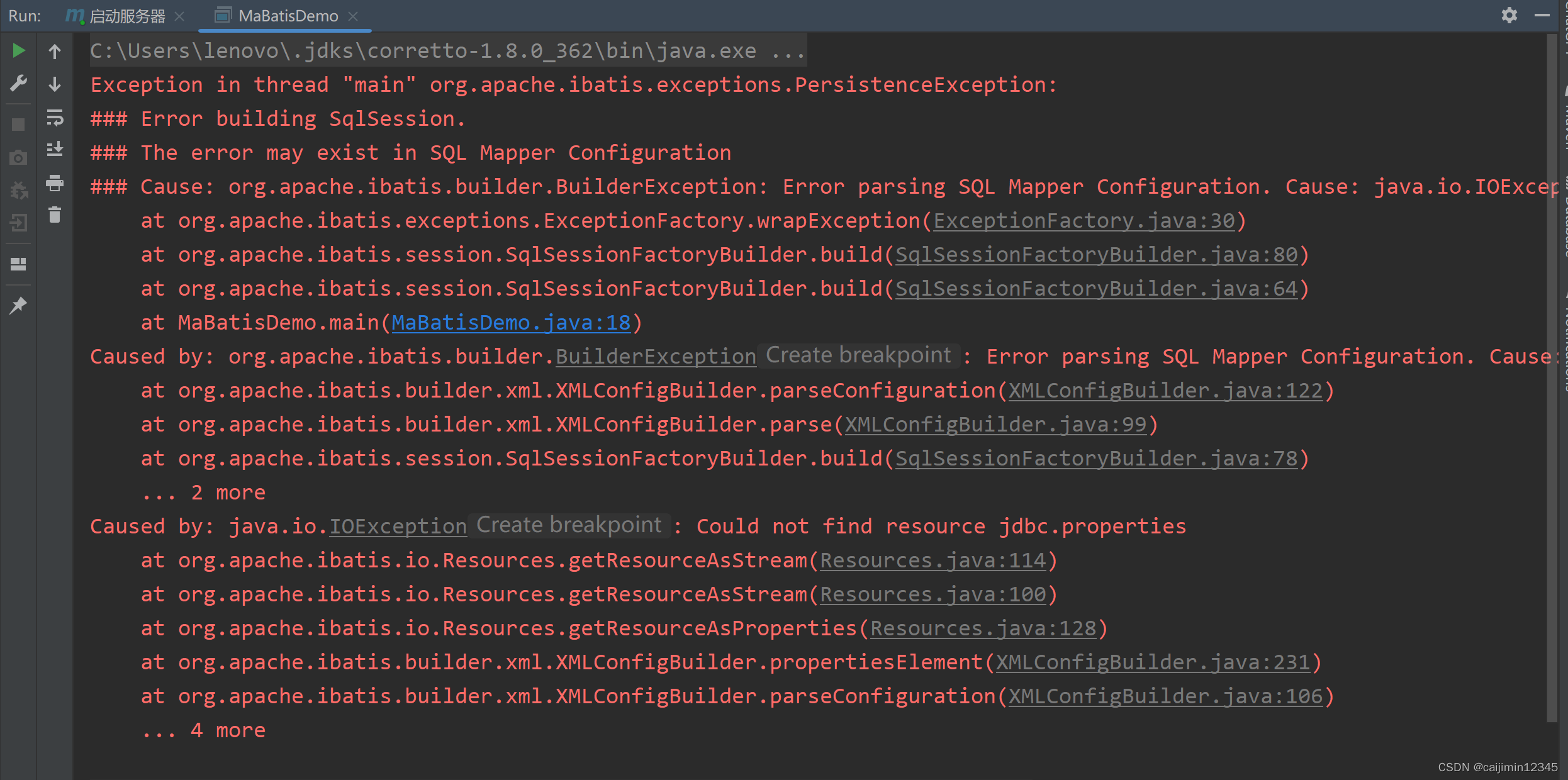
Could not find resource jdbc.properties问题的解决
以如下开头的内容: Exception in thread "main" org.apache.ibatis.exceptions.PersistenceException: ### Error building SqlSession. ### The error may exist in SQL Mapper Configuration 出现以上问题是没有在src/main/resources下创建jdbc.prop…...
也一定为true吗?泛型特点与好处)
【面试题】==与equals区别、Hashcode作用、hashcode相同equals()也一定为true吗?泛型特点与好处
文章目录1. 和 equals 的区别是什么?2.Hashcode的作用3. 两个对象的hashCode() 相同, 那么equals()也一定为 true吗?4.泛型常用特点5.使用泛型的好处?1. 和 equals 的区别是什么? “” 对于基本类型和引用类型 的作…...

Flex布局中的flex属性
1.flex-grow,flex-shrink,flex-basis取值含义 flex-grow: 延申性描述。在满足“延申条件”时,flex容器中的项目会按照设置的flex-grow值的比例来延申,占满容器剩余空间。 取值情况: 取负值无效。取0值表示不…...

SpringBoot + Ant Design Pro Vue实现动态路由和菜单的前后端分离框架
Ant Design Pro Vue默认路由和菜单配置是采用中心化的方式,在 router.config.js统一配置和管理,同时也提供了动态获取路由和菜单的解决方案,并将在2.0.3版本中提供,因到目前为止,官方发布的版本为2.0.2,所以…...

robotframework自动化测试环境搭建
环境说明 win10 python版本:3.8.3rc1 安装清单 安装配置 selenium安装 首先检查pip命令是否安装: C:\Users\name>pipUsage:pip <command> [options]Commands:install Install packages.download Do…...
尚硅谷《Redis7》(小白篇)
尚硅谷《Redis7 》(小白篇) 02 redis 是什么 官方网站: https://redis.io/ 作者 Git Hub https://github.com/antirez 03 04 05 能做什么 06 去哪下 Download https://redis.io/download/ redis中文文档 https://www.redis.com.cn/docu…...

并非从0开始的c++ day6
并非从0开始的c day6二级指针练习-文件读写位运算位逻辑运算符按位取反 ~位于(AND):&位或(OR): |位异或: ^移位运算符左移<<右移>>多维数组一维数组数组名一维数组名传入到函数参数中数组指…...

PMP考前冲刺2.22 | 2023新征程,一举拿证
承载2023新一年的好运让我们迈向PMP终点一起冲刺!一起拿证!每日5道PMP习题助大家上岸PMP!!!题目1-2:1.在新产品开发过程中,项目经理关注到行业排名第一的公司刚刚发布同类型的产品。相比竞品&am…...

RxJava的订阅过程
要使用Rxjava首先要导入两个包,其中rxandroid是rxjava在android中的扩展 implementation io.reactivex:rxandroid:1.2.1implementation io.reactivex:rxjava:1.2.0首先从最基本的Observable的创建到订阅开始分析 Observable.create(new Observable.OnSubscribe<S…...

【2.22】MySQL、Redis、动态规划
认识Redis Redis是一种基于内存的数据库,对数据的读写操作都是在内存中完成的,因此读写速度非常快,常用于缓存,消息队列,分布式锁等场景。 Redis提供了多种数据类型来支持不同的业务场景,比如String(字符串…...
2年手动测试,裸辞后找不到工作怎么办?
我们可以从以下几个方面来具体分析下,想通了,理解透了,才能更好的利用资源提升自己。一、我会什么?先说第一个我会什么?第一反应:我只会功能测试,在之前的4年的中我只做了功能测试。内心存在一种…...

Leetcode6. N字形变换
一、题目描述: 将一个给定字符串 s 根据给定的行数 numRows ,以从上往下、从左到右进行 Z 字形排列。 比如输入字符串为 “PAYPALISHIRING” 行数为 3 时,排列如下: 之后,你的输出需要从左往右逐行读取,产…...
)
将Nginx 核心知识点扒了个底朝天(十)
ngx_http_upstream_module的作用是什么? ngx_http_upstream_module用于定义可通过fastcgi传递、proxy传递、uwsgi传递、memcached传递和scgi传递指令来引用的服务器组。 什么是C10K问题? C10K问题是指无法同时处理大量客户端(10,000)的网络套接字。 Nginx是否支持将请求压…...

GPU显卡环境配置安装
前言 最近公司购买了一张RTX3090的显卡和一台新的服务器,然后对机器的GPU环境进行了安装和配置,然后简单记录一下 环境版本 操作系统:Centos7.8 显卡型号:RTX3090 Python版本:3.7.6 Tensorflow版本:2…...

CIMCAI super unmanned intelligent gate container damage detect
世界港航人工智能领军者企业CIMCAI中集飞瞳打造全球最先进超级智能闸口无人闸口ceaspectusG™视频流动态感知集装箱箱况残损检测箱况残损识别率99%以上,箱信息识别率99.95%以上World port shipping AI leader CIMCAIThe worlds most advanced super intelligent gat…...

web概念概述
软件架构:1. C/S: Client/Server 客户端/服务器端* 在用户本地有一个客户端程序,在远程有一个服务器端程序* 如:QQ,迅雷...* 优点:1. 用户体验好* 缺点:1. 开发、安装,部署,维护 麻烦…...

编译原理笔记(1)绪论
文章目录1.什么是编译2.编译系统的结构3.词法分析概述4.语法分析概述5.语义分析概述6.中间代码生成和后端概述1.什么是编译 编译的定义:将高级语言翻译成汇编语言或机器语言的过程。前者称为源语言,后者称为目标语言。 高级语言源程序的处理过程&#…...
 显卡排行榜 天梯图)
top50 BF16算力(TFLOPS) 显卡排行榜 天梯图
排名显卡型号BF16算力(TFLOPS)售价(元)单TFLOPS价格(元)1B200(SXM)45002200000488.892H200(SXM)19801200000606.063MI300X1307750000573.834H100 SXM519501100000564.105RTX PRO 6000 Blackwell1150780000678.266H100 PCIe 80GB1560850000544.877RTX 50906803400050.008A100 80…...

Hirschmann RS20-0800M4M4SDAE工业以太网交换机
Hirschmann RS20-0800M4M4SDAE 工业以太网交换机产品特点:端口配置:共8个端口,含6个RJ45电口和2个ST光纤接口。端口速率:所有端口均为100Mbps快速以太网。光纤类型:2个光纤端口为多模、ST接头。管理类型:二…...

[智能体-69]:重新认知MCP:协议不生产智能,只是AI全域交互的标准化基石
MCP只是提供了大模型、编排调度、外部工具能够进行结构化交流的标准,而整个系统的智能主要依赖编排调度,与外部软件系统的交互取决于外部工具,包括外部语音交互、视觉交互、数字化交互。当下MCP(Model Context Protocol࿰…...

苏州创新药20年,站上全球产业洗牌暴风眼
一个城市的创新药产业集群如何从无到有,又如何在全球化临界点寻找自己的位置。文|徐鑫编|任晓渔过去一年多,苏州是全球创新药产业版图中一个绕不过去的城市。大额海外授权交易频繁传出,在中国高端制造走出去的背景下&a…...

MySQL GROUP BY 原理与优化
我刚工作的时候,有次统计每个用户的订单总金额,写了 SELECT user_id, SUM(amount) FROM orders GROUP BY user_id,结果执行了 60 秒还没出结果。DBA 帮我一看执行计划,发现没走索引,导致 Using temporary(用…...

MobX社区资源大全:10个必备工具、插件和扩展库推荐 [特殊字符]
MobX社区资源大全:10个必备工具、插件和扩展库推荐 🚀 【免费下载链接】MobX-Docs-CN MobX 中文文档 项目地址: https://gitcode.com/gh_mirrors/mo/MobX-Docs-CN MobX作为一个简单、可扩展的状态管理库,已经成为React开发者不可或缺的…...

Hindsight测试策略:单元测试、集成测试和端到端测试
Hindsight测试策略:单元测试、集成测试和端到端测试 【免费下载链接】hindsight Hindsight: Agent Memory That Learns 项目地址: https://gitcode.com/GitHub_Trending/hindsight2/hindsight Hindsight作为一款专注于Agent Memory的开源项目,其可…...

Qri高级功能:如何使用JSON Schema验证和描述数据集结构
Qri高级功能:如何使用JSON Schema验证和描述数据集结构 【免费下载链接】qri youre invited to a data party! 项目地址: https://gitcode.com/gh_mirrors/qr/qri Qri是一个强大的开源数据协作工具,它提供了丰富的功能来帮助用户管理、共享和验证…...
)
CentOS 8.5最小化安装后,这5个必做的安全与效率优化设置(附一键脚本)
CentOS 8.5最小化安装后的5个必做安全与效率优化刚完成CentOS 8.5最小化安装的系统就像一张白纸——干净但缺乏生产力。作为运维老手,我见过太多人跳过基础优化直接部署应用,结果在后续使用中频繁遇到权限混乱、软件安装慢、SSH爆破等问题。本文将分享我…...

机器学习与深度学习在社交媒体心理健康检测中的权衡与选择
1. 项目概述:当AI遇见心灵,社交媒体心理健康检测的技术十字路口在社交媒体成为我们数字生活延伸的今天,海量的文本数据无意中记录着用户的情感波动与心理状态。作为一名长期混迹于数据科学和自然语言处理(NLP)一线的从…...