卷积神经网络实现咖啡豆分类 - P7
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
- 🚀 文章来源:K同学的学习圈子
目录
- 环境
- 步骤
- 环境设置
- 包引用
- 全局设备对象
- 数据准备
- 查看图像的信息
- 制作数据集
- 模型设计
- 手动搭建的vgg16网络
- 精简后的咖啡豆识别网络
- 模型训练
- 编写训练函数
- 编写测试函数
- 开始训练
- 展示训练过程
- 模型效果展示
- 总结与心得体会
环境
- 系统: Linux
- 语言: Python3.8.10
- 深度学习框架: Pytorch2.0.0+cu118
- 显卡:A5000 24G
步骤
环境设置
包引用
import torch
import torch.nn as nn # 网络
import torch.optim as optim # 优化器
from torch.utils.data import DataLoader, random_split # 数据集划分
from torchvision import datasets, transforms # 数据集加载,转换import pathlib, random, copy # 文件夹遍历,实现模型深拷贝
from PIL import Image # python自带的图像类
import matplotlib.pyplot as plt # 图表
import numpy as np
from torchinfo import summary # 打印模型参数
全局设备对象
方便将模型和数据统一拷贝到目标设备中
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
数据准备
查看图像的信息
data_path = 'coffee_data'
data_lib = pathlib.Path(data_path)
coffee_images = list(data_lib.glob('*/*'))# 打印5张图像的信息
for _ in range(5):image = random.choice(coffee_images)print(np.array(Image.open(str(image))).shape)
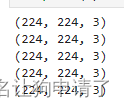
通过打印的信息,可以看出图像的尺寸都是224x224的,这是一个CV经常使用的图像大小,所以后面我就不使用Resize来缩放图像了。
# 打印20张图像粗略的看一下
plt.figure(figsize=(20, 4))
for i in range(20):plt.subplot(2, 10, i+1)plt.axis('off')image = random.choice(coffee_images) # 随机选出一个图像plt.title(image.parts[-2]) # 通过glob对象取出它的文件夹名称,也就是分类名plt.imshow(Image.open(str(image))) # 展示

通过展示,对数据集内的图像有个大概的了解
制作数据集
先编写数据的预处理过程,用来使用pytorch的api加载文件夹中的图像
transform = transforms.Compose([transforms.ToTensor(), # 先把图像转成张量transforms.Normalize( # 对像素值做归一化,将数据范围弄到-1,1mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225],),
])
加载文件夹
dataset = datasets.ImageFolder(data_path, transform=transform)
从数据中取所有的分类名
class_names = [k for k in dataset.class_to_idx]
print(class_names)
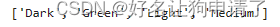
将数据集划分出训练集和验证集
train_size = int(len(dataset) * 0.8)
test_size = len(dataset) - train_sizetrain_dataset, test_dataset = random_split(dataset, [train_size, test_size])
将数据集按划分成批次,以便使用小批量梯度下降
batch_size = 32
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
模型设计
在一开始时,直接手动创建了Vgg-16网络,发现少数几个迭代后模型就收敛了,于是开始精简模型。
手动搭建的vgg16网络
class Vgg16(nn.Module):def __init__(self, num_classes):super().__init__()self.block1 = nn.Sequential(nn.Conv2d(3, 64, 3, padding=1),nn.BatchNorm2d(64),nn.ReLU(),nn.Conv2d(64, 64, 3, padding=1),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(2),)self.block2 = nn.Sequential(nn.Conv2d(64, 128, 3, padding=1),nn.BatchNorm2d(128),nn.ReLU(),nn.Conv2d(128, 128, 3, padding=1),nn.BatchNorm2d(128),nn.ReLU(),nn.MaxPool2d(2),)self.block3 = nn.Sequential(nn.Conv2d(128, 256, 3, padding=1),nn.BatchNorm2d(256),nn.ReLU(),nn.Conv2d(256, 256, 3, padding=1),nn.BatchNorm2d(256),nn.ReLU(),nn.Conv2d(256, 256, 3, padding=1),nn.BatchNorm2d(256),nn.ReLU(),nn.MaxPool2d(2),)self.block4 = nn.Sequential(nn.Conv2d(256, 512, 3, padding=1),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(512, 512, 3, padding=1),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(512, 512, 3, padding=1),nn.BatchNorm2d(512),nn.ReLU(),nn.MaxPool2d(2),)self.block5 = nn.Sequential(nn.Conv2d(512, 512, 3, padding=1),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(512, 512, 3, padding=1),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(512, 512, 3, padding=1),nn.BatchNorm2d(512),nn.ReLU(),nn.MaxPool2d(2),)self.pool = nn.AdaptiveAvgPool2d(7)self.classifier = nn.Sequential(nn.Linear(7*7*512, 4096),nn.Dropout(0.5),nn.ReLU(),nn.Linear(4096, 4096),nn.Dropout(0.5),nn.ReLU(),nn.Linear(4096, num_classes),)def forward(self, x):x = self.block1(x)x = self.block2(x)x = self.block3(x)x = self.block4(x)x = self.block5(x)x = self.pool(x)x = x.view(x.size(0),-1)x = self.classifier(x)return x
vgg = Vgg16(len(class_names)).to(device)
summary(vgg, input_size=(32, 3, 224, 224))
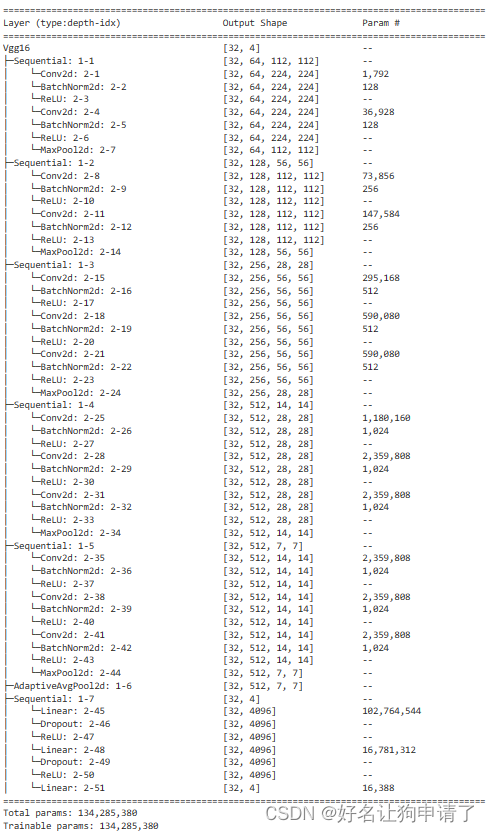
通过模型结构的打印可以发现,VGG-16网络共有134285380个可训练参数(我加了BatchNorm,和官方的比会稍微多出一些),参数量非常巨大,对于咖啡豆识别这种小场景,这么多可训练参数肯定浪费,于是对原始的VGG-16网络结构进行精简。
精简后的咖啡豆识别网络
class Network(nn.Module):def __init__(self, num_classes):super().__init__()self.block1 = nn.Sequential(nn.Conv2d(3, 64, 3, padding=1),nn.BatchNorm2d(64),nn.ReLU(),nn.Conv2d(64, 64, 3, padding=1),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(2),)self.block2 = nn.Sequential(nn.Conv2d(64, 128, 3, padding=1),nn.BatchNorm2d(128),nn.ReLU(),nn.Conv2d(128, 128, 3, padding=1),nn.BatchNorm2d(128),nn.ReLU(),nn.MaxPool2d(2),)self.block3 = nn.Sequential(nn.Conv2d(128, 64, 3, padding=1),nn.BatchNorm2d(64),nn.ReLU(),nn.Conv2d(64, 64, 3, padding=1),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(2),)self.pool = nn.AdaptiveAvgPool2d(7),self.classifier = nn.Sequential(nn.Linear(7*7*64, 64),nn.Dropout(0.4),nn.ReLU(),nn.Linear(64, num_classes))def forward(self, x):x = self.block1(x)x = self.block2(x)x = self.block3(x)x = self.pool(x)x = x.view(x.size(0), -1)x = self.classifier(x)return x
model = Network(len(class_names)).to(device)
summary(model, input_size=(32, 3, 224, 224))
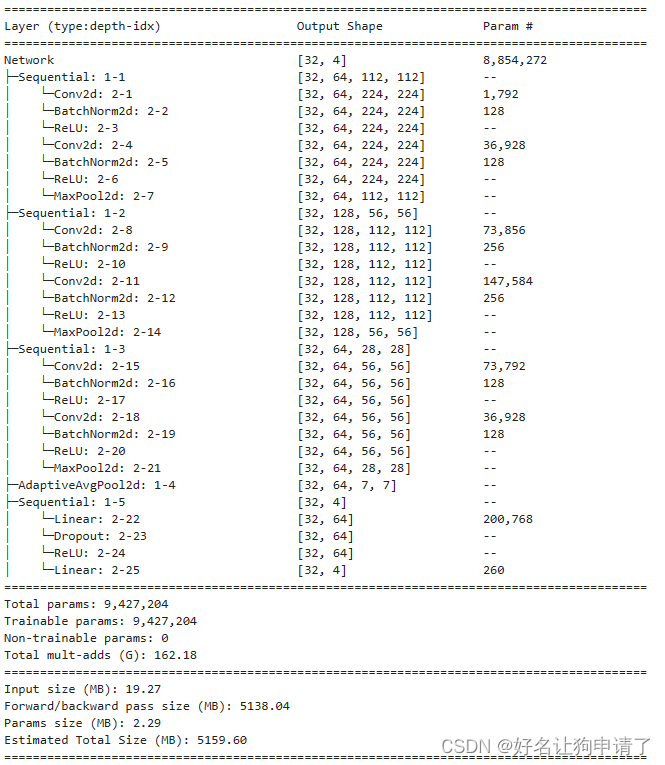
可以看到精简后的网络模型参数量还不到原来的1/10,但是其在测试集上的正确率依然能够达到100%!
模型训练
编写训练函数
def train(train_loader, model, loss_fn, optimizer):size = len(train_loader.dataset)num_batches = len(train_loader)train_loss, train_acc = 0, 0for x, y in train_loader:x, y = x.to(device), y.to(device)pred = model(x)loss = loss_fn(pred, y)optimizer.zero_grad()loss.backward()optimizer.step()train_loss += loss.item()train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss /= num_batchestrain_acc /= sizereturn train_loss, train_acc
编写测试函数
def test(test_loader, model, loss_fn):size = len(test_loader.dataset)num_batches = len(test_loader)test_loss, test_acc = 0, 0for x, y in test_loader:x, y = x.to(device), y.to(device)pred = model(x)loss = loss_fn(pred, y)test_loss += loss.item()test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss /= num_batchestest_acc /= sizereturn test_loss, test_acc
开始训练
首先定义损失函数,优化器设置学习率,这里我们再弄一个学习率的衰减,再加上总的迭代次数,最佳模型的保存位置
epochs = 30
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
scheduler = optim.lr_scheduler.LambdaLR(optimizer=optimizer, lr_lambda=lambda epoch: 0.92**(epoch//2))
best_model_path = 'best_coffee_model.pth'
然后编写训练+测试的循环,并记录训练过程的数据
best_acc = 0
train_loss, train_acc = [], []
test_loss, test_acc = [], []
for epoch in epochs:model.train()epoch_train_loss, epoch_train_acc = train(train_loader, model, loss_fn, optimizer)scheduler.step()model.eval()with torch.no_grad();epoch_test_loss, epoch_test_acc = test(test_loader, model, loss_fn)train_loss.append(epoch_train_loss)train_acc.append(epoch_train_acc)test_loss.append(epoch_test_loss)test_acc.append(epoch_test_acc)lr = optimizer.state_dict()['param_groups'][0]['lr']if best_acc < epoch_test_acc:best_acc = epoch_test_accbest_model = copy.deepcopy(model)print(f"Epoch: {epoch+1}, Lr:{lr}, TrainAcc: {epoch_train_acc*100:.1f}, TrainLoss: {epoch_train_loss:.3f}, TestAcc: {epoch_test_acc*100:.1f}, TestLoss: {epoch_test_loss:.3f}")print(f"Saving Best Model with Accuracy: {best_acc*100:.1f} to {best_model_path}")
torch.save(best_model.state_dict(), best_model_path)
print('Done')
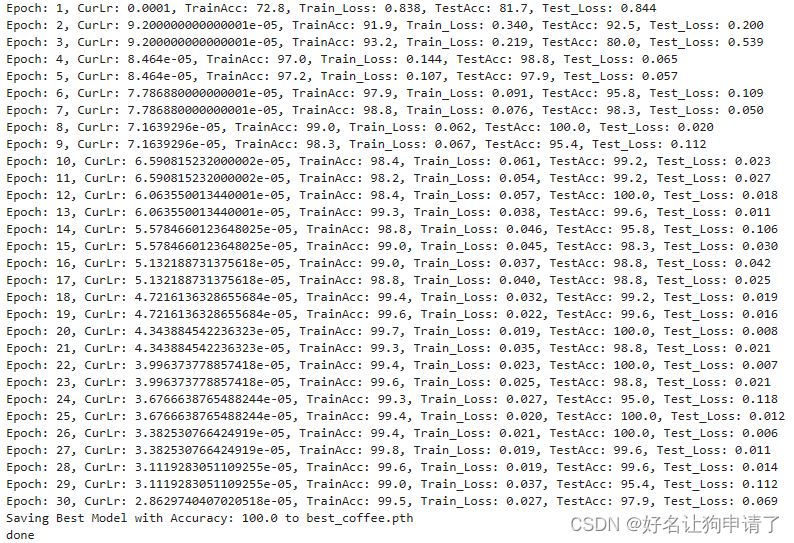
可以看出,模型在测试集上的正确率最高达到了100%
展示训练过程
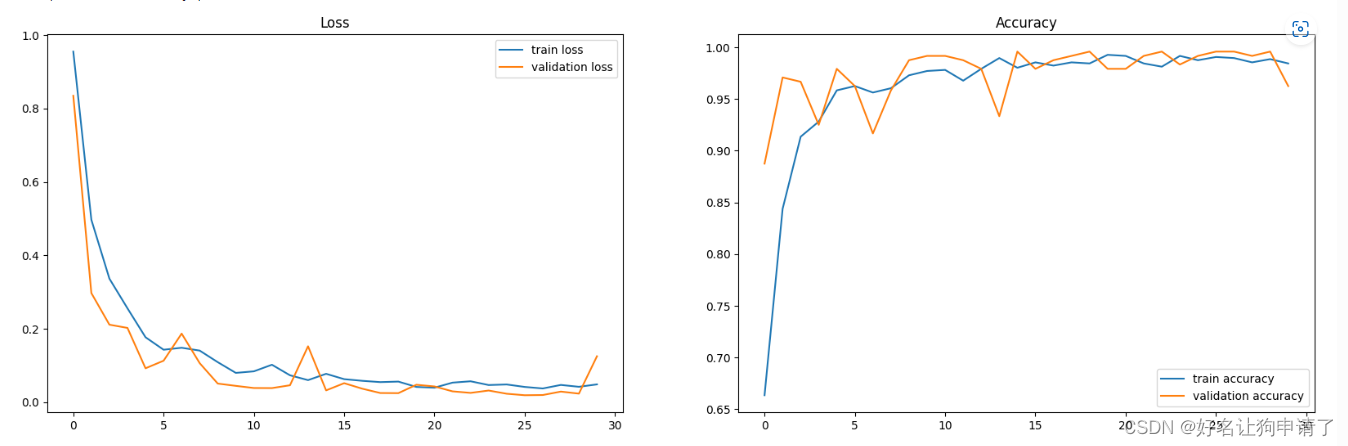
epoch_ranges = range(epochs)
plt.figure(figsize=(20,6))
plt.subplot(121)
plt.plot(epoch_ranges, train_loss, label='train loss')
plt.plot(epoch_ranges, test_loss, label='validation loss')
plt.legend(loc='upper right')
plt.title('Loss')plt.figure(figsize=(20,6))
plt.subplot(122)
plt.plot(epoch_ranges, train_acc, label='train accuracy')
plt.plot(epoch_ranges, test_acc, label='validation accuracy')
plt.legend(loc='lower right')
plt.title('Accuracy')
模型效果展示
model.load_state_dict(torch.load(best_model_path))
model.to(device)
model.eval()plt.figure(figsize=(20,4))
for i in range(20):plt.subplot(2, 10, i+1)plt.axis('off')image = random.choice(coffee_images)input = transform(Image.open(str(image))).to(device).unsqueeze(0)pred = model(input)plt.title(f'T:{image.parts[-2]}, P:{class_names[pred.argmax()]}')plt.imshow(Image.open(str(image)))

通过结果可以看出,确实是所有的咖啡豆都正确的识别了。
总结与心得体会
- 因为目前网络还是很快就收敛到一个很高的水平,所以应该还有很大的精简的空间,但是可能会稍微牺牲一些正确率。
- 模型的选取要根据实际任务来确定,像咖啡豆种类识别这种任务,使用VGG-16太浪费了。
- 在精简的过程中,没有感觉到训练速度有明显的变化 ,说明参数量和训练速度并没有直接的相关关系。
- 连续多层参数一样的卷积操作好像比只用一层效果要好。
相关文章:
卷积神经网络实现咖啡豆分类 - P7
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 | 接辅导、项目定制🚀 文章来源:K同学的学习圈子 目录 环境步骤环境设置包引用全局设备对象 数据准备查看图像的信息制作数据集 模型设…...

C++之默认与自定义构造函数问题(二百一十七)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 人生格言: 人生…...
Docker从认识到实践再到底层原理(五)|Docker镜像
前言 那么这里博主先安利一些干货满满的专栏了! 首先是博主的高质量博客的汇总,这个专栏里面的博客,都是博主最最用心写的一部分,干货满满,希望对大家有帮助。 高质量博客汇总 然后就是博主最近最花时间的一个专栏…...

【Flowable】任务监听器(五)
前言 之前有需要使用到Flowable,鉴于网上的资料不是很多也不是很全也是捣鼓了半天,因此争取能在这里简单分享一下经验,帮助有需要的朋友,也非常欢迎大家指出不足的地方。 一、监听器 在Flowable中,我们可以使用监听…...

spring-kafka中ContainerProperties.AckMode详解
近期,我们线上遇到了一个性能问题,几乎快引起线上故障,后来仅仅是修改了一行代码,性能就提升了几十倍。一行代码几十倍,数据听起来很夸张,不过这是真实的数据,线上错误的配置的确有可能导致性能…...
)
【rpc】Dubbo和Zookeeper结合使用,它们的作用与联系(通俗易懂,一文理解)
目录 Dubbo是什么? 把系统模块变成分布式,有哪些好处,本来能在一台机子上运行,为什么还要远程调用 Zookeeper是什么? 它们进行配合使用时,之间的关系 服务注册 服务发现 动态地址管理 Dubbo是…...

ChatGPT的未来
随着人工智能的快速发展,ChatGPT作为一种自然语言生成模型,在各个领域都展现出了巨大的潜力。它不仅可以用于日常对话、创意助手和知识查询,还可以应用于教育、医疗、商业等各个领域,为人们带来更多便利和创新。 在教育领域&#…...

Pytorch模型转ONNX部署
开始以为会很困难,但是其实非常方便,下边分两步走:1. pytorch模型转onnx;2. 使用onnx进行inference 0. 准备工作 0.1 安装onnx 安装onnx和onnxruntime,onnx貌似是个环境。。倒是没有直接使用,onnxruntim…...

k8s优雅停服
在应用程序的整个生命周期中,正在运行的 pod 会由于多种原因而终止。在某些情况下,Kubernetes 会因用户输入(例如更新或删除 Deployment 时)而终止 pod。在其他情况下,Kubernetes 需要释放给定节点上的资源时会终止 po…...

面试题五:computed的使用
题记 大部分的工作中使用computed的频次很低的,所以今天拿出来一文对于computed进行详细的介绍,因为Vue的灵魂之一就是computed。 模板内的表达式非常便利,但是设计它们的初衷是用于简单运算的。在模板中放入太多的逻辑会让模板过重且难以维护…...
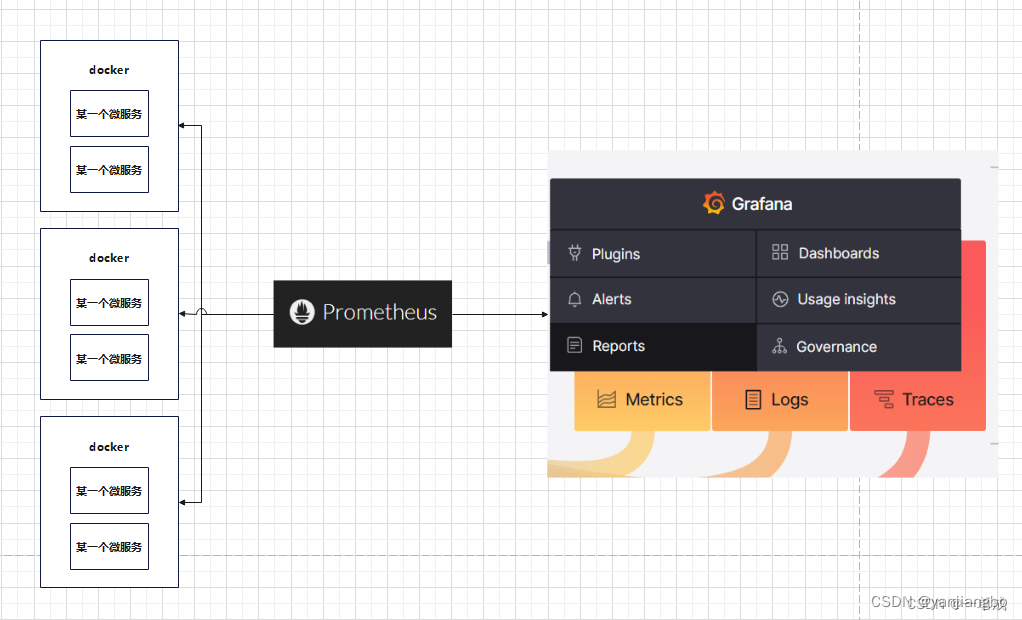
完美的分布式监控系统 Prometheus与优雅的开源可视化平台 Grafana
1、之间的关系 prometheus与grafana之间是相辅相成的关系。简而言之Grafana作为可视化的平台,平台的数据从Prometheus中取到来进行仪表盘的展示。而Prometheus这源源不断的给Grafana提供数据的支持。 Prometheus是一个开源的系统监控和报警系统,能够监…...
黑马JVM总结(九)
(1)StringTable_调优1 我们知道StringTable底层是一个哈希表,哈希表的性能是跟它的大小相关的,如果哈希表这个桶的个数比较多,元素相对分散,哈希碰撞的几率就会减少,查找的速度较快,…...

如何使用 RunwayML 进行创意 AI 创作
标题:如何使用 RunwayML 进行创意 AI 创作 介绍 RunwayML 是一个基于浏览器的人工智能创作工具,可让用户使用各种 AI 功能来生成图像、视频、音乐、文字和其他创意内容。RunwayML 的功能包括: * 图像生成:使用生成式对抗网络 (…...

【css】能被4整除 css :class,判断一个数能否被另外一个数整除,余数
判断一个数能否被另外一个数整除 一个数能被4整除的表达式可以表示为:num%40,其中,num为待判断的数,% 为取模运算符,为等于运算符。这个表达式的意思是,如果num除以4的余数为0,则返回true&…...

ChatGPT与日本首相交流核废水事件-精准Prompt...
了解更多请点击:ChatGPT与日本首相交流核废水事件-精准Prompt...https://mp.weixin.qq.com/s?__bizMzg2NDY3NjY5NA&mid2247490070&idx1&snebdc608acd419bb3e71ca46acee04890&chksmce64e42ff9136d39743d16059e2c9509cc799a7b15e8f4d4f71caa25968554…...
关于 firefox 不能访问 http 的解决
情景: 我在虚拟机 192.168.x.111 上配置了 DNS 服务器,在 kali 上设置 192.168.x.111 为 DNS 服务器后,使用 firefox 地址栏搜索域名 www.xxx.com ,访问在 192.168.x.111 搭建的网站,本来经 192.168.x.111 DNS 服务器解…...
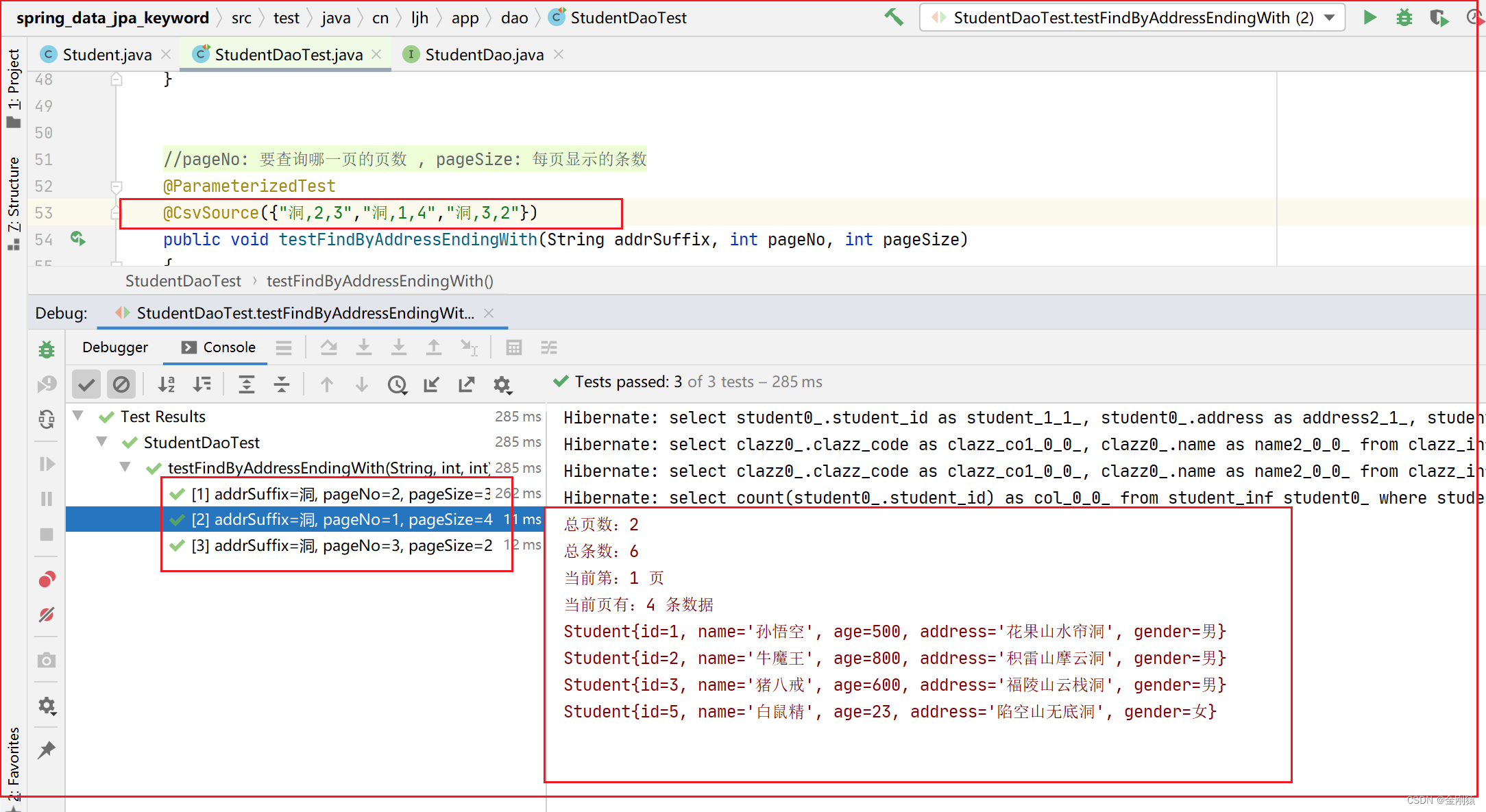
68、Spring Data JPA 的 方法名关键字查询
★ 方法名关键字查询(全自动) (1)继承 CrudRepository 接口 的 DAO 组件可按特定规则来定义查询方法,只要这些查询方法的 方法名 遵守特定的规则,Spring Data 将会自动为这些方法生成 查询语句、提供 方法…...
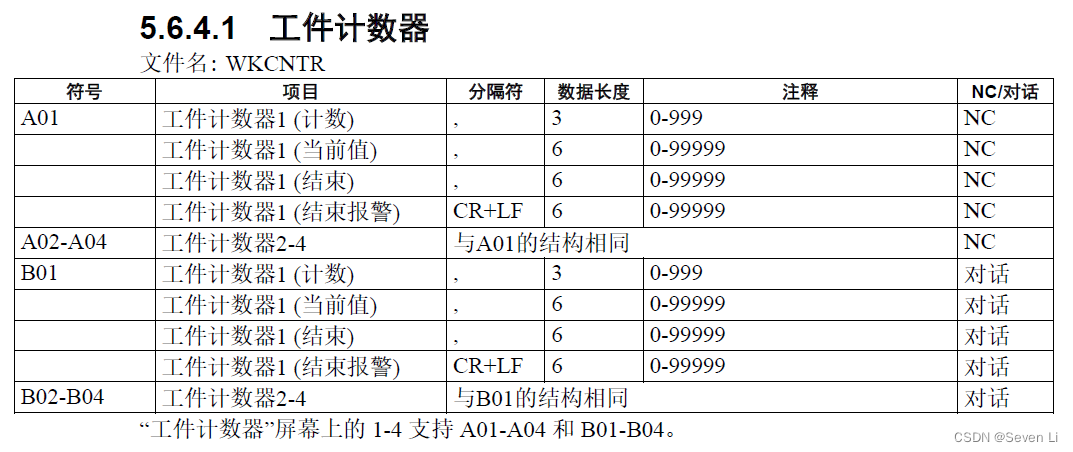
Brother CNC联网数采集和远程控制
兄弟CNC IP地址设定参考:https://www.sohu.com/a/544461221_121353733没有能力写代码的兄弟可以提前下载好网络调试助手NetAssist,这样就不用写代码来测试连接CNC了。 以上是网络调试助手抓取CNC的产出命令,结果有多个行string需要自行解析&…...
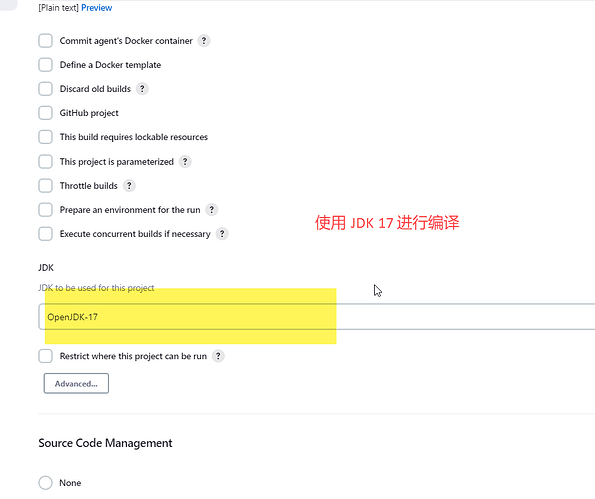
Jenkins 编译 Maven 项目提示错误 version 17
在最近使用集成工具的时候,对项目进行编译提示下面的错误信息: maven-compiler-plugin:3.11.0:compile (default-compile) on project mq-service: Fatal error compiling: error: release version 17 not supported 问题和解决 上面提示的错误信息原…...
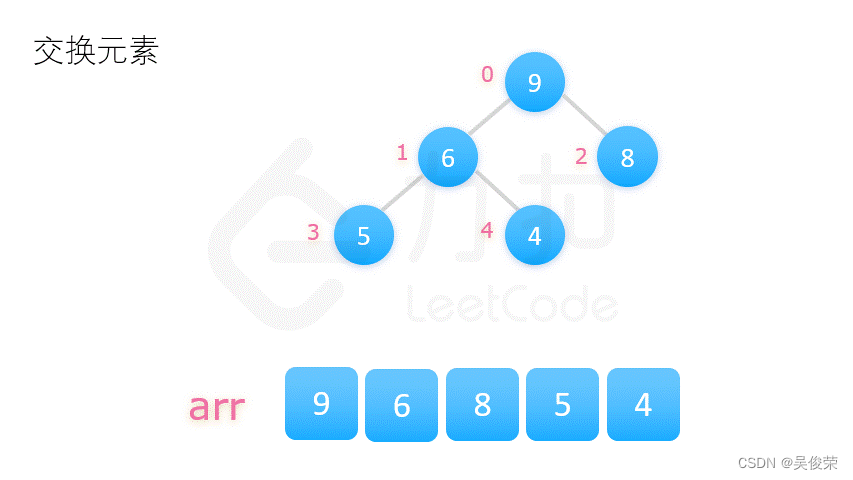
数据结构——排序算法——堆排序
堆排序过程如下: 1.用数列构建出一个大顶堆,取出堆顶的数字; 2.调整剩余的数字,构建出新的大顶堆,再次取出堆顶的数字; 3.循环往复,完成整个排序。 构建大顶堆有两种方式: 1.从 0 开…...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院挂号小程序
一、开发准备 环境搭建: 安装DevEco Studio 3.0或更高版本配置HarmonyOS SDK申请开发者账号 项目创建: File > New > Create Project > Application (选择"Empty Ability") 二、核心功能实现 1. 医院科室展示 /…...

智能在线客服平台:数字化时代企业连接用户的 AI 中枢
随着互联网技术的飞速发展,消费者期望能够随时随地与企业进行交流。在线客服平台作为连接企业与客户的重要桥梁,不仅优化了客户体验,还提升了企业的服务效率和市场竞争力。本文将探讨在线客服平台的重要性、技术进展、实际应用,并…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

高等数学(下)题型笔记(八)空间解析几何与向量代数
目录 0 前言 1 向量的点乘 1.1 基本公式 1.2 例题 2 向量的叉乘 2.1 基础知识 2.2 例题 3 空间平面方程 3.1 基础知识 3.2 例题 4 空间直线方程 4.1 基础知识 4.2 例题 5 旋转曲面及其方程 5.1 基础知识 5.2 例题 6 空间曲面的法线与切平面 6.1 基础知识 6.2…...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...

C# 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

基于PHP的连锁酒店管理系统
有需要请加文章底部Q哦 可远程调试 基于PHP的连锁酒店管理系统 一 介绍 连锁酒店管理系统基于原生PHP开发,数据库mysql,前端bootstrap。系统角色分为用户和管理员。 技术栈 phpmysqlbootstrapphpstudyvscode 二 功能 用户 1 注册/登录/注销 2 个人中…...

PostgreSQL——环境搭建
一、Linux # 安装 PostgreSQL 15 仓库 sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-$(rpm -E %{rhel})-x86_64/pgdg-redhat-repo-latest.noarch.rpm# 安装之前先确认是否已经存在PostgreSQL rpm -qa | grep postgres# 如果存在࿰…...

Linux 下 DMA 内存映射浅析
序 系统 I/O 设备驱动程序通常调用其特定子系统的接口为 DMA 分配内存,但最终会调到 DMA 子系统的dma_alloc_coherent()/dma_alloc_attrs() 等接口。 关于 dma_alloc_coherent 接口详细的代码讲解、调用流程,可以参考这篇文章,我觉得写的非常…...