CUDA By Example(八)——流
文章目录
- 页锁定主机内存
- 可分页内存函数
- 页锁定内存函数
- CUDA流
- 使用单个CUDA流
- 使用多个CUDA流
- GPU的工作调度机制
- 高效地使用多个CUDA流
- 遇到的问题(未解决)
页锁定主机内存
在之前的各个示例中,都是通过 cudaMalloc() 在GPU上分配内存,以及通过标准的C库函数 malloc() 在主机上分配内存。除此之外,CUDA运行时还提供了自己独有的机制来分配主机内存:cudaHostAlloc()。如果 malloc() 已经能很好地满足C程序员的需求,那么为什么还要使用这个函数?
事实上,malloc() 分配的内存与 cudaHostAlloc() 分配的内存之间存在着一个重要差异。C库函数 malloc() 将分配标准的、可分页的(Pagable) 主机内存,而 cudaHostAlloc() 将分配页锁定的主机内存。页锁定内存也称为固定内存(Pinned Memory)或者不可分页内存,它有一个重要的属性:操作系统将不会对这块内存分页并交换到磁盘上,从而确保了该内存始终驻留在物理内存中。因此,操作系统能够安全地使某个应用程序访问该内存的物理地址,因为这块内存将不会被破坏或者重新定位。
由于GPU知道内存的物理地址,因此可以通过 “直接内存访问(Direct Memory Access, DMA)” 技术来在GPU和主机之间复制数据。由于DMA在执行复制时无需CPU的介入,这也就同样意味着,CPU很可能在DMA的执行过程中将目标内存交换到磁盘上,或者通过更新操作系统的可分页表来重新定位目标内存的物理地址。CPU可能会移动可分页的数据,这就可能对DMA操作造成延迟。因此,在DMA复制过程中使用固定内存是非常重要的。事实上,当使用可分页内存进行复制时,CUDA驱动程序仍然会通过DMA把数据传输给GPU。因此,复制操作将执行两遍:
- 第一遍从可分页内存复制到一块 ”临时的“ 页锁定内存
- 然后再从这个页锁定内存复制到GPU上
因此,每当从可分页内存中执行复制操作时,复制速度将受限于PCIE传输速度和系统前端总线速度相对较低的一方。在某些系统中,这些总线在带宽上有着巨大的差异。因此当在GPU和主机间复制数据时,这种差异会使页锁定主机内存的性能比标准可分页内存的性能要高大约2倍。即使PCIE的速度与前端总线的速度相等,由于可分页内存需要更多一次由CPU参与的复制操作,因此会带来额外的开销。
然而,你也不能进入另一个极端:查找每个 malloc 调用并将其替换为 cudaHostAlloc() 调用。固定内存是一把双刃剑。当使用固定内存时,你将失去虚拟内存的所有功能。特别是,在应用程序中使用每个页锁定内存时都需要分配物理内存,因为这些内存不能交换到磁盘上。这意味着,与使用标准的malloc()调用相比,系统将更快地耗尽内存。因此,应用程序在物理内存较少的机器上会运行失败,而且意味着应用程序将影响在系统上运行的其他应用程序的性能。
这些情况并不是说不使用 cudaHostAlloc(),而是提醒你应该清楚页锁定内存得到隐含作用。我们建议,仅对 cudaMemcpy() 调用中的源内存或者目标内存,才使用页锁定内存,并且在不再需要使用它们时立即施放,而不是等到应用程序关闭时才施放。cudaHostAlloc() 与到目前为止学习的其他内容一样简单,下面通过一个示例,说明如何分配固定内存,以及它对于标准可分页内存的性能优势。
这里要做的就是分配一个GPU缓冲区,以及一个大小相等的主机缓冲区,然后在这两个缓冲区之间执行一些复制操作。我们允许用户指定复制的方向,例如为 “上”(从主机到设备)或者为 “下”(从设备到主机)。为了获得精确的时间统计,我们为复制操作的起始时刻和结束时刻分别设置了CUDA事件。
可分页内存函数
首先为 size 个整数分别分配主机缓冲区和GPU缓冲区
float cuda_malloc_test(int size, bool up) {cudaEvent_t start, stop;int* a, * dev_a;float elapsedTime;HANDLE_ERROR(cudaEventCreate(&start));HANDLE_ERROR(cudaEventCreate(&stop));a = (int*)malloc(size * sizeof(*a));HANDLE_NULL(a);HANDLE_ERROR(cudaMalloc((void**)&dev_a, size * sizeof(*dev_a)));
然后执行100次复制操作,并由参数 up 来指定复制方向,在完成复制操作后停止计时器。
HANDLE_ERROR(cudaEventRecord(start, 0));for (int i = 0; i < 100; i++) {if (up)HANDLE_ERROR(cudaMemcpy(dev_a, a, size * sizeof(*dev_a), cudaMemcpyHostToDevice));elseHANDLE_ERROR(cudaMemcpy(a, dev_a, size * sizeof(*dev_a), cudaMemcpyDeviceToHost));}HANDLE_ERROR(cudaEventRecord(stop, 0));HANDLE_ERROR(cudaEventSynchronize(stop));HANDLE_ERROR(cudaEventElapsedTime(&elapsedTime, start, stop));
在执行了 100 次复制操作后,释放主机缓冲区和GPU缓冲区,并且销毁计时事件。
free(a);HANDLE_ERROR(cudaFree(dev_a));HANDLE_ERROR(cudaEventDestroy(start));HANDLE_ERROR(cudaEventDestroy(stop));return elapsedTime;
}
页锁定内存函数
与可分页内存函数的区别就在于,使用 cudaHostAlloc() 分配内存,使用 cudaFreeHost() 施放内存
float cuda_host_alloc_test(int size, bool up) {cudaEvent_t start, stop;int* a, * dev_a;float elapsedTime;HANDLE_ERROR(cudaEventCreate(&start));HANDLE_ERROR(cudaEventCreate(&stop));HANDLE_ERROR(cudaHostAlloc((void**)&a, size * sizeof(*a), cudaHostAllocDefault));HANDLE_ERROR(cudaMalloc((void**)&dev_a, size * sizeof(*dev_a)));HANDLE_ERROR(cudaEventRecord(start, 0));for (int i = 0; i < 100; i++) {if (up)HANDLE_ERROR(cudaMemcpy(dev_a, a, size * sizeof(*dev_a), cudaMemcpyHostToDevice));elseHANDLE_ERROR(cudaMemcpy(a, dev_a, size * sizeof(*dev_a), cudaMemcpyDeviceToHost));}HANDLE_ERROR(cudaEventRecord(stop, 0));HANDLE_ERROR(cudaEventSynchronize(stop));HANDLE_ERROR(cudaEventElapsedTime(&elapsedTime, start, stop));HANDLE_ERROR(cudaFreeHost(a));HANDLE_ERROR(cudaFree(dev_a));HANDLE_ERROR(cudaEventDestroy(start));HANDLE_ERROR(cudaEventDestroy(stop));return elapsedTime;
}
完整代码
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "../../common/book.h"#include <stdio.h>
#include <iostream>#define SIZE (10*1024*1024)float cuda_malloc_test(int size, bool up) {cudaEvent_t start, stop;int* a, * dev_a;float elapsedTime;HANDLE_ERROR(cudaEventCreate(&start));HANDLE_ERROR(cudaEventCreate(&stop));a = (int*)malloc(size * sizeof(*a));HANDLE_NULL(a);HANDLE_ERROR(cudaMalloc((void**)&dev_a, size * sizeof(*dev_a)));HANDLE_ERROR(cudaEventRecord(start, 0));for (int i = 0; i < 100; i++) {if (up)HANDLE_ERROR(cudaMemcpy(dev_a, a, size * sizeof(*dev_a), cudaMemcpyHostToDevice));elseHANDLE_ERROR(cudaMemcpy(a, dev_a, size * sizeof(*dev_a), cudaMemcpyDeviceToHost));}HANDLE_ERROR(cudaEventRecord(stop, 0));HANDLE_ERROR(cudaEventSynchronize(stop));HANDLE_ERROR(cudaEventElapsedTime(&elapsedTime, start, stop));free(a);HANDLE_ERROR(cudaFree(dev_a));HANDLE_ERROR(cudaEventDestroy(start));HANDLE_ERROR(cudaEventDestroy(stop));return elapsedTime;
}float cuda_host_alloc_test(int size, bool up) {cudaEvent_t start, stop;int* a, * dev_a;float elapsedTime;HANDLE_ERROR(cudaEventCreate(&start));HANDLE_ERROR(cudaEventCreate(&stop));HANDLE_ERROR(cudaHostAlloc((void**)&a, size * sizeof(*a), cudaHostAllocDefault));HANDLE_ERROR(cudaMalloc((void**)&dev_a, size * sizeof(*dev_a)));HANDLE_ERROR(cudaEventRecord(start, 0));for (int i = 0; i < 100; i++) {if (up)HANDLE_ERROR(cudaMemcpy(dev_a, a, size * sizeof(*dev_a), cudaMemcpyHostToDevice));elseHANDLE_ERROR(cudaMemcpy(a, dev_a, size * sizeof(*dev_a), cudaMemcpyDeviceToHost));}HANDLE_ERROR(cudaEventRecord(stop, 0));HANDLE_ERROR(cudaEventSynchronize(stop));HANDLE_ERROR(cudaEventElapsedTime(&elapsedTime, start, stop));HANDLE_ERROR(cudaFreeHost(a));HANDLE_ERROR(cudaFree(dev_a));HANDLE_ERROR(cudaEventDestroy(start));HANDLE_ERROR(cudaEventDestroy(stop));return elapsedTime;
}int main(void) {float elapsedTime;float MB = (float)100 * SIZE * sizeof(int) / 1024 / 1024;elapsedTime = cuda_malloc_test(SIZE, true);std::cout << "Time using cudaMalloc: " << elapsedTime << " ms\n";std::cout << "\tMB/s during copy up: " << MB / (elapsedTime / 1000) << std::endl;elapsedTime = cuda_malloc_test(SIZE, false);std::cout << "Time using cudaMalloc: " << elapsedTime << " ms\n";std::cout << "\tMB/s during copy down: " << MB / (elapsedTime / 1000) << std::endl;elapsedTime = cuda_host_alloc_test(SIZE, true);std::cout << "Time using cudaHostAlloc: " << elapsedTime << " ms\n";std::cout << "\tMB/s during copy up: " << MB / (elapsedTime / 1000) << std::endl;elapsedTime = cuda_host_alloc_test(SIZE, false);std::cout << "Time using cudaHostAlloc: " << elapsedTime << " ms\n";std::cout << "\tMB/s during copy down: " << MB / (elapsedTime / 1000) << std::endl;
}运行结果

可以发现使用页锁定内存比使用可分页内存的读写速度快了2倍多。
CUDA流
在之前的文章中,我们引入了CUDA事件的概念。当时并没有介绍 cudaEventRecord() 的第二个参数,而只是简要地指出这个参数用于指定插入事件的流(Stream)。
cudaEvent_t start;
cudaEventCreate(&start);
cudaEventRecord(start, 0);
CUDA流在加速应用程序方面起着重要的作用。CUDA流表示一个GPU操作队列,并且该队列中的操作将以指定的顺序执行。我们可以在流中添加一些操作,例如核函数启动、内存复制、以及事件的启动和结束等。将这些操作添加到流的顺序也就是它们的执行顺序。你可以将每个流视为GPU上的一个任务,并且这些任务可以并行执行。
下面将首先介绍如何使用流,然后介绍如何使用流来加速应用程序。
使用单个CUDA流
下面首先通过在应用程序中使用单个流来说明流的用法。假设有一个CUDA C核函数,该函数带有两个输入数据缓冲区,a 和 b。核函数将对这些缓冲区中相应位置上的值执行某种计算,并将生成的结果保存到输出缓冲区 c。下面这个示例中,将计算 a 中三个值和 b 中三个值的平均值:
__global__ void kernel(int* a, int* b, int* c) {int idx = threadIdx.x + blockIdx.x * blockDim.x;if (idx < N) {int idx1 = (idx + 1) % 256;int idx2 = (idx + 2) % 256;float as = (a[idx] + a[idx1] + a[idx2]) / 3.0f;float bs = (b[idx] + b[idx1] + b[idx2]) / 3.0f;c[idx] = (as + bs) / 2;}
}
这个核函数很简单,下面重要的是函数 main() 中与流相关的代码
int main(void) {cudaDeviceProp prop;int whichDevice;HANDLE_ERROR(cudaGetDevice(&whichDevice));HANDLE_ERROR(cudaGetDeviceProperties(&prop, whichDevice));if (!prop.deviceOverlap) {std::cout << "Device will not handle overlaps, so no speed up from streams" << std::endl;return 0;}
首先选择一个支持设备重叠(Device Overlap)功能的设备。支持设备重叠功能的GPU能够在执行一个CUDA C核函数的同时,还能在设备与主机之间执行复制操作。
正如前面提到的,我们将使用多个流来实现这种计算与数据传输的重叠,但首先来看看如何创建和使用一个流。与其他需要测量性能提升(或者降低)的示例一样,首先创建和启动一个事件计时器:
cudaEvent_t start, stop;float elapsedTime;// 启动计时器HANDLE_ERROR(cudaEventCreate(&start));HANDLE_ERROR(cudaEventCreate(&stop));HANDLE_ERROR(cudaEventRecord(start, 0));
启动计时器之后,创建在应用程序中使用的流:
// 初始化流cudaStream_t stream;HANDLE_ERROR(cudaStreamCreate(&stream));
这就是创建流需要的全部工作,接下来是数据分配操作
int* host_a, * host_b, * host_c;int* dev_a, * dev_b, * dev_c;// 在GPU上分配内存HANDLE_ERROR(cudaMalloc((void**)&dev_a, N * sizeof(int)));HANDLE_ERROR(cudaMalloc((void**)&dev_b, N * sizeof(int)));HANDLE_ERROR(cudaMalloc((void**)&dev_c, N * sizeof(int)));// 分配由流使用的页锁定内存HANDLE_ERROR(cudaHostAlloc((void**)&host_a, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault));HANDLE_ERROR(cudaHostAlloc((void**)&host_b, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault));HANDLE_ERROR(cudaHostAlloc((void**)&host_c, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault));for (int i = 0; i < FULL_DATA_SIZE; i++) {host_a[i] = rand();host_b[i] = rand();}
我们在GPU和主机上分别分配好了输入内存和输出内存。注意,由于程序将使用主机上的固定内存,因此调用 cudaHostAlloc() 来执行内存分配操作。
使用固定内存的原因并不只在于使复制操作执行得更快,还存在另外一个好处。会在后面进行详细地分析,我们将使用一种新的 cudaMemcpy() 函数,并且在这个新函数中需要页锁定主机内存。在分配完输入内存后,调用C的库函数rand()并用随机整数填充主机内存。
在创建了流和计时事件,并且分配了设备内存和主机内存后,就准备好了执行一些计算。通常,我们会将这个阶段一带而过,只是将两个输入缓冲区复制到GPU,启动核函数,然后将输出缓冲区复制回主机。我们将再次沿用这种模式,只是进行了一些小修改。
首先,我们不将输入缓冲区整体都复制到GPU,而是将输入缓冲区划分为更小的块,并在每个块上执行一个包含三个步骤的过程。我们将一部分输入缓冲区复制到GPU,在这部分缓冲区上运行核函数,然后将输出缓冲区中的这部分结果复制回主机。
想象一下需要使用这种方法的一种情形:GPU的内存远少于主机内存,由于整个缓冲区无法一次性填充到GPU,因此需要分块进行计算。
执行"分块"计算的代码如下所示:
//在整体数据上循环,每个数据块的大小为Nfor (int i = 0; i < FULL_DATA_SIZE; i += N) {// 将锁定内存以异步方式复制到设备上HANDLE_ERROR(cudaMemcpyAsync(dev_a, host_a + i, N * sizeof(int), cudaMemcpyHostToDevice, stream));HANDLE_ERROR(cudaMemcpyAsync(dev_b, host_b + i, N * sizeof(int), cudaMemcpyHostToDevice, stream));kernel << <N / 256, 256, 0, stream >> > (dev_a, dev_b, dev_c);// 将数据从设备复制到锁定内存HANDLE_ERROR(cudaMemcpyAsync(host_c + i, dev_c, N * sizeof(int), cudaMemcpyDeviceToHost, stream));}
注意到,代码没有使用熟悉的 cudaMemcpy(),而是通过一个新函数 cudaMemcpyAsync() 在GPU与主机之间复制数据。这些函数之间的差异虽然很小,但却很重要。cudaMemcpy() 的行为类似于C库函数 memcpy()。尤其是,这个函数将以同步方式执行,这意味着,当函数返回时,复制操作就已经完成,并且在输出缓冲区中包含了复制进去的内容。
异步函数的行为与同步函数相反,通过名字 cudaMemcpyAsync()就可以知道。在调用 cudaMemcpyAsync() 时,只是放置一个请求,表示在流中执行一次内存复制操作,这个流是通过参数 stream 来指定的。当函数返回时,我们无法确保复制操作是否已经启动,更无法保证它是否已经结束。我们能够得到的保证是,复制操作肯定会当下一个被放入流中的操作之前执行。任何传递给 cudaMemcpyAsync() 的主机内存指针都必须已经通过 cudaHostAlloc() 分配好内存。也就是,你只能以异步方式对页锁定内存进行复制操作。
注意,在核函数调用的尖括号中还可以带有一个流参数。此时核函数调用将是异步的,就像之前与GPU之间的内存复制操作一样。从技术上来说,当循环迭代完一次时,有可能不会启动任何内存复制或核函数执行。
这里只能确保的是:第一次放入流中的复制操作将在第二次复制操作之前执行。第二个复制操作将在核函数启动之前完成,而核函数将在第三次复制操作开始之前完成。流就像一个有序的工作队列,GPU从该队列中依次取出工作并执行。
当 for() 循环结束时,在队列中应包含了许多等待GPU执行的工作。如果想要确保GPU执行完了计算和内存复制等操作,那么就需要将GPU与主机同步。也就是说,主机在继续执行之前,要首先等待GPU执行完成。可以调用 cudaStreamSynchronize() 并指定想要等待的流:
//将计算结果从页锁定内存复制到主机内存HANDLE_ERROR(cudaStreamSynchronize(stream));
当程序执行到 stream 与主机同步之后的代码时,所有的计算和复制操作都已经完成,因此可以停止计时器,收集性能数据,并释放输入缓冲区和输出缓冲区。
HANDLE_ERROR(cudaEventRecord(stop, 0));HANDLE_ERROR(cudaEventSynchronize(stop));HANDLE_ERROR(cudaEventElapsedTime(&elapsedTime, start, stop));std::cout << "Time taken: " << elapsedTime << " ms" << std::endl;//释放流和内存HANDLE_ERROR(cudaFreeHost(host_a));HANDLE_ERROR(cudaFreeHost(host_b));HANDLE_ERROR(cudaFreeHost(host_c));HANDLE_ERROR(cudaFree(dev_a));HANDLE_ERROR(cudaFree(dev_b));HANDLE_ERROR(cudaFree(dev_c));
最后,在退出应用程序之前,记得销毁对GPU操作进行排队的流。
HANDLE_ERROR(cudaStreamDestroy(stream));return 0;
}
这个示例并没有充分说明流的强大功能。当然,如果当主机正在执行一些工作时,GPU也正忙于处理填充到流的工作,那么即使使用单个流也有助于应用程序速度的提升。但即使不需要在主机上做太多的工作,我们仍然可以通过使用流来加速应用程序。
完整代码
#include "../../common/book.h"
#include "cuda_runtime.h"
#include "device_launch_parameters.h"#include <stdio.h>
#include <iostream>#define N (1024*1024)
#define FULL_DATA_SIZE (N*20)__global__ void kernel(int* a, int* b, int* c) {int idx = threadIdx.x + blockIdx.x * blockDim.x;if (idx < N) {int idx1 = (idx + 1) % 256;int idx2 = (idx + 2) % 256;float as = (a[idx] + a[idx1] + a[idx2]) / 3.0f;float bs = (b[idx] + b[idx1] + b[idx2]) / 3.0f;c[idx] = (as + bs) / 2;}
}int main(void) {cudaDeviceProp prop;int whichDevice;HANDLE_ERROR(cudaGetDevice(&whichDevice));HANDLE_ERROR(cudaGetDeviceProperties(&prop, whichDevice));if (!prop.deviceOverlap) {std::cout << "Device will not handle overlaps, so no speed up from streams" << std::endl;return 0;}cudaEvent_t start, stop;float elapsedTime;// 启动计时器HANDLE_ERROR(cudaEventCreate(&start));HANDLE_ERROR(cudaEventCreate(&stop));HANDLE_ERROR(cudaEventRecord(start, 0));// 初始化流cudaStream_t stream;HANDLE_ERROR(cudaStreamCreate(&stream));int* host_a, * host_b, * host_c;int* dev_a, * dev_b, * dev_c;// 在GPU上分配内存HANDLE_ERROR(cudaMalloc((void**)&dev_a, N * sizeof(int)));HANDLE_ERROR(cudaMalloc((void**)&dev_b, N * sizeof(int)));HANDLE_ERROR(cudaMalloc((void**)&dev_c, N * sizeof(int)));// 分配由流使用的页锁定内存HANDLE_ERROR(cudaHostAlloc((void**)&host_a, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault));HANDLE_ERROR(cudaHostAlloc((void**)&host_b, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault));HANDLE_ERROR(cudaHostAlloc((void**)&host_c, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault));for (int i = 0; i < FULL_DATA_SIZE; i++) {host_a[i] = rand();host_b[i] = rand();}//在整体数据上循环,每个数据块的大小为Nfor (int i = 0; i < FULL_DATA_SIZE; i += N) {// 将锁定内存以异步方式复制到设备上HANDLE_ERROR(cudaMemcpyAsync(dev_a, host_a + i, N * sizeof(int), cudaMemcpyHostToDevice, stream));HANDLE_ERROR(cudaMemcpyAsync(dev_b, host_b + i, N * sizeof(int), cudaMemcpyHostToDevice, stream));kernel << <N / 256, 256, 0, stream >> > (dev_a, dev_b, dev_c);// 将数据从设备复制到锁定内存HANDLE_ERROR(cudaMemcpyAsync(host_c + i, dev_c, N * sizeof(int), cudaMemcpyDeviceToHost, stream));}//将计算结果从页锁定内存复制到主机内存HANDLE_ERROR(cudaStreamSynchronize(stream));HANDLE_ERROR(cudaEventRecord(stop, 0));HANDLE_ERROR(cudaEventSynchronize(stop));HANDLE_ERROR(cudaEventElapsedTime(&elapsedTime, start, stop));std::cout << "Time taken: " << elapsedTime << " ms" << std::endl;//释放流和内存HANDLE_ERROR(cudaFreeHost(host_a));HANDLE_ERROR(cudaFreeHost(host_b));HANDLE_ERROR(cudaFreeHost(host_c));HANDLE_ERROR(cudaFree(dev_a));HANDLE_ERROR(cudaFree(dev_b));HANDLE_ERROR(cudaFree(dev_c));HANDLE_ERROR(cudaStreamDestroy(stream));return 0;
}
运行结果

使用多个CUDA流
下面将单个流的版本改为使用两个不同的流。改进这个程序的思想很简单:分块计算以及内存复制和核函数执行的重叠。
即在第 0 个流执行核函数的同时,第一个流将输入缓冲区复制到GPU。然后,在第 0 个流将计算结果复制回主机的同时,第 1 个流将执行核函数…
如下图所示,这里假设内存复制操作和核函数执行的时间大致相,且GPU可以同时执行一个内存复制操作和一个核函数,因此空的方框表示一个流正在等待执行哦某个操作的时刻,这个操作不能与其他流的操作相互重叠。
事实上,实际的执行时间线可能比上图给出的更好看,在一些新的 NVIDIA GPU 中同时支持核函数和两次内存复制操作,一次是从主机到设备,另一次是从设备到主机。在任何支持内存复制和核函数的执行相互重叠的设备上,当使用多个流时,应用程序的整体性能都会提升。
核函数代码保持不变:
__global__ void kernel(int* a, int* b, int* c) {int idx = threadIdx.x + blockIdx.x * blockDim.x;if (idx < N) {int idx1 = (idx + 1) % 256;int idx2 = (idx + 2) % 256;float as = (a[idx] + a[idx1] + a[idx2]) / 3.0f;float bs = (b[idx] + b[idx1] + b[idx2]) / 3.0f;c[idx] = (as + bs) / 2;}
}
与使用单个流的版本一样,我们将判断设备是否支持计算与内存复制操作的重叠。如果设备支持重叠,那么就像前面一样创建CUDA事件并对应用程序计时。
int main( void ) {cudaDeviceProp prop;int whichDevice;HANDLE_ERROR(cudaGetDevice(&whichDevice));HANDLE_ERROR(cudaGetDeviceProperties(&prop, whichDevice));if (!prop.deviceOverlap) {std::cout << "Device will not handle overlaps, so no speed up from streams" << std::endl;return 0;}cudaEvent_t start, stop;float elapsedTime;// 启动计时器HANDLE_ERROR(cudaEventCreate(&start));HANDLE_ERROR(cudaEventCreate(&stop));HANDLE_ERROR(cudaEventRecord(start, 0));
接下来创建两个流,创建方式与前面单个流的版本完全一样。
// 初始化流cudaStream_t stream0, stream1;HANDLE_ERROR(cudaStreamCreate(&stream0));HANDLE_ERROR(cudaStreamCreate(&stream1));
假设在主机上仍然是两个输入缓冲区和一个输出缓冲区。输入缓冲区中填充的是随机数据,与使用单个流的应用程序采样的方式一样。然而,现在我们将使用两个流来处理数据,分配两组相同的GPU缓冲区,这样每个流都可以独立地在输入数据块上执行工作。
int* host_a, * host_b, * host_c;int* dev_a0, * dev_b0, * dev_c0; // 为第0个流分配的GPU内存int* dev_a1, * dev_b1, * dev_c1; // 为第1个流分配的GPU内存// 在GPU上分配内存HANDLE_ERROR(cudaMalloc((void**)&dev_a0, N * sizeof(int)));HANDLE_ERROR(cudaMalloc((void**)&dev_b0, N * sizeof(int)));HANDLE_ERROR(cudaMalloc((void**)&dev_c0, N * sizeof(int)));HANDLE_ERROR(cudaMalloc((void**)&dev_a1, N * sizeof(int)));HANDLE_ERROR(cudaMalloc((void**)&dev_b1, N * sizeof(int)));HANDLE_ERROR(cudaMalloc((void**)&dev_c1, N * sizeof(int)));// 分配由流使用的页锁定内存HANDLE_ERROR(cudaHostAlloc((void**)&host_a, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault));HANDLE_ERROR(cudaHostAlloc((void**)&host_b, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault));HANDLE_ERROR(cudaHostAlloc((void**)&host_c, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault));for (int i = 0; i < FULL_DATA_SIZE; i++) {host_a[i] = rand();host_b[i] = rand();}
然后,程序在输入数据块上循环。然而,由于现在使用了两个流,因此在 for() 循环的迭代中需要处理的数据量也是原来的两倍。在 stream() 中,我们首先将 a 和 b 的异步复制操作放入GPU的队列,然后将一个核函数执行放入队列,接下来再将一个复制回 c 的操作放入队列:
//在整体数据上循环,每个数据块的大小为Nfor (int i = 0; i < FULL_DATA_SIZE; i += N*2) {// 将锁定内存以异步方式复制到设备上HANDLE_ERROR(cudaMemcpyAsync(dev_a0, host_a + i, N * sizeof(int), cudaMemcpyHostToDevice, stream0));HANDLE_ERROR(cudaMemcpyAsync(dev_b0, host_b + i, N * sizeof(int), cudaMemcpyHostToDevice, stream0));kernel << <N / 256, 256, 0, stream0 >> > (dev_a0, dev_b0, dev_c0);// 将数据从设备复制到锁定内存HANDLE_ERROR(cudaMemcpyAsync(host_c + i, dev_c0, N * sizeof(int), cudaMemcpyDeviceToHost, stream0));
在将这些操作放入 stream0 的队列后,再把下一个数据块上的相同操作放入 stream1 的队列中。
// 将锁定内存以异步方式复制到设备上HANDLE_ERROR(cudaMemcpyAsync(dev_a1, host_a + i + N, N * sizeof(int), cudaMemcpyHostToDevice, stream1));HANDLE_ERROR(cudaMemcpyAsync(dev_b1, host_b + i + N, N * sizeof(int), cudaMemcpyHostToDevice, stream1));kernel << <N / 256, 256, 0, stream1 >> > (dev_a1, dev_b1, dev_c1);// 将数据从设备复制到锁定内存HANDLE_ERROR(cudaMemcpyAsync(host_c + i + N, dev_c1, N * sizeof(int), cudaMemcpyDeviceToHost, stream1));}
这样,在 for() 循环的迭代过程中,将交替地把每个数据块放入这两个流的队列,直到所有待处理的输入数据都被放入队列。在结束了 for() 循环后,在停止应用程序的计时器之前,首先将 GPU 与 GPU进行同步。由于使用了两个流,因此需要对二者都进行同步。
HANDLE_ERROR(cudaStreamSynchronize(stream0)); HANDLE_ERROR(cudaStreamSynchronize(stream1));
之后,停止计时器,显示经历的时间,并且执行清理工作。当然,我们要记住,现在需要销毁两个流,并且需要释放两倍的GPU内存。
HANDLE_ERROR(cudaEventRecord(stop, 0));HANDLE_ERROR(cudaEventSynchronize(stop));HANDLE_ERROR(cudaEventElapsedTime(&elapsedTime, start, stop));std::cout << "Time taken: " << elapsedTime << " ms" << std::endl;//释放流和内存HANDLE_ERROR(cudaFreeHost(host_a));HANDLE_ERROR(cudaFreeHost(host_b));HANDLE_ERROR(cudaFreeHost(host_c));HANDLE_ERROR(cudaFree(dev_a0));HANDLE_ERROR(cudaFree(dev_b0));HANDLE_ERROR(cudaFree(dev_c0));HANDLE_ERROR(cudaFree(dev_a1));HANDLE_ERROR(cudaFree(dev_b1));HANDLE_ERROR(cudaFree(dev_c1));HANDLE_ERROR(cudaStreamDestroy(stream0));HANDLE_ERROR(cudaStreamDestroy(stream1));return 0;
}
完整代码
#include "../../common/book.h"
#include "cuda_runtime.h"
#include "device_launch_parameters.h"#include <stdio.h>
#include <iostream>#define N (1024*1024)
#define FULL_DATA_SIZE (N*20)__global__ void kernel(int* a, int* b, int* c) {int idx = threadIdx.x + blockIdx.x * blockDim.x;if (idx < N) {int idx1 = (idx + 1) % 256;int idx2 = (idx + 2) % 256;float as = (a[idx] + a[idx1] + a[idx2]) / 3.0f;float bs = (b[idx] + b[idx1] + b[idx2]) / 3.0f;c[idx] = (as + bs) / 2;}
}int main(void) {cudaDeviceProp prop;int whichDevice;HANDLE_ERROR(cudaGetDevice(&whichDevice));HANDLE_ERROR(cudaGetDeviceProperties(&prop, whichDevice));if (!prop.deviceOverlap) {std::cout << "Device will not handle overlaps, so no speed up from streams" << std::endl;return 0;}cudaEvent_t start, stop;float elapsedTime;// 启动计时器HANDLE_ERROR(cudaEventCreate(&start));HANDLE_ERROR(cudaEventCreate(&stop));HANDLE_ERROR(cudaEventRecord(start, 0));// 初始化流cudaStream_t stream0, stream1;HANDLE_ERROR(cudaStreamCreate(&stream0));HANDLE_ERROR(cudaStreamCreate(&stream1));int* host_a, * host_b, * host_c;int* dev_a0, * dev_b0, * dev_c0; // 为第0个流分配的GPU内存int* dev_a1, * dev_b1, * dev_c1; // 为第1个流分配的GPU内存// 在GPU上分配内存HANDLE_ERROR(cudaMalloc((void**)&dev_a0, N * sizeof(int)));HANDLE_ERROR(cudaMalloc((void**)&dev_b0, N * sizeof(int)));HANDLE_ERROR(cudaMalloc((void**)&dev_c0, N * sizeof(int)));HANDLE_ERROR(cudaMalloc((void**)&dev_a1, N * sizeof(int)));HANDLE_ERROR(cudaMalloc((void**)&dev_b1, N * sizeof(int)));HANDLE_ERROR(cudaMalloc((void**)&dev_c1, N * sizeof(int)));// 分配由流使用的页锁定内存HANDLE_ERROR(cudaHostAlloc((void**)&host_a, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault));HANDLE_ERROR(cudaHostAlloc((void**)&host_b, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault));HANDLE_ERROR(cudaHostAlloc((void**)&host_c, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault));for (int i = 0; i < FULL_DATA_SIZE; i++) {host_a[i] = rand();host_b[i] = rand();}//在整体数据上循环,每个数据块的大小为Nfor (int i = 0; i < FULL_DATA_SIZE; i += N*2) {// 将锁定内存以异步方式复制到设备上HANDLE_ERROR(cudaMemcpyAsync(dev_a0, host_a + i, N * sizeof(int), cudaMemcpyHostToDevice, stream0));HANDLE_ERROR(cudaMemcpyAsync(dev_b0, host_b + i, N * sizeof(int), cudaMemcpyHostToDevice, stream0));kernel << <N / 256, 256, 0, stream0 >> > (dev_a0, dev_b0, dev_c0);// 将数据从设备复制到锁定内存HANDLE_ERROR(cudaMemcpyAsync(host_c + i, dev_c0, N * sizeof(int), cudaMemcpyDeviceToHost, stream0));// 将锁定内存以异步方式复制到设备上HANDLE_ERROR(cudaMemcpyAsync(dev_a1, host_a + i + N, N * sizeof(int), cudaMemcpyHostToDevice, stream1));HANDLE_ERROR(cudaMemcpyAsync(dev_b1, host_b + i + N, N * sizeof(int), cudaMemcpyHostToDevice, stream1));kernel << <N / 256, 256, 0, stream1 >> > (dev_a1, dev_b1, dev_c1);// 将数据从设备复制到锁定内存HANDLE_ERROR(cudaMemcpyAsync(host_c + i + N, dev_c1, N * sizeof(int), cudaMemcpyDeviceToHost, stream1));}HANDLE_ERROR(cudaStreamSynchronize(stream0));HANDLE_ERROR(cudaStreamSynchronize(stream1));HANDLE_ERROR(cudaEventRecord(stop, 0));HANDLE_ERROR(cudaEventSynchronize(stop));HANDLE_ERROR(cudaEventElapsedTime(&elapsedTime, start, stop));std::cout << "Time taken: " << elapsedTime << " ms" << std::endl;//释放流和内存HANDLE_ERROR(cudaFreeHost(host_a));HANDLE_ERROR(cudaFreeHost(host_b));HANDLE_ERROR(cudaFreeHost(host_c));HANDLE_ERROR(cudaFree(dev_a0));HANDLE_ERROR(cudaFree(dev_b0));HANDLE_ERROR(cudaFree(dev_c0));HANDLE_ERROR(cudaFree(dev_a1));HANDLE_ERROR(cudaFree(dev_b1));HANDLE_ERROR(cudaFree(dev_c1));HANDLE_ERROR(cudaStreamDestroy(stream0));HANDLE_ERROR(cudaStreamDestroy(stream1));return 0;
}
运行结果

GPU的工作调度机制
虽然从逻辑上来看,不同的流之间是相互独立的,但事实上这种理解并不完全符合GPU的队列机制。程序员可以将流视为有序的操作序列,其中既包含内存复制操作,又包含核函数调用。
然而,在硬件中并没有流的概念,而是包含一个或多个引擎来执行内存复制操作,以及一个引擎来执行核函数。这些引擎彼此独立地对操作进行排队,因此将导致如下图所示的任务调度情形。图中的箭头说明了硬件引擎如何调度流中队列的操作并实际执行。

因此,在某种程度上,用户与硬件关于GPU工作的排队方式有着完全不同的理解,而CUDA驱动程序则负责对用户和硬件进行协调。首先,在操作被添加到流的顺序中包含了重要的依赖性。
如上图中,第 0 个流对 A 的内存复制需要在对 B 的内存复制之前完成,而对 B 的复制又要在核函数 A 启动之前完成。然而,一旦这些操作放入到硬件的内存复制引擎和核函数执行引擎的队列中,这些依赖性将丢失,因此CUDA驱动程序需要确保硬件的执行单元不破坏内部的依赖性。
这意味着说明?之前在代码中,应用程序基本上是对 a 调用一次 cudaMemcpyAsync(),对 b 调用一次 cudaMemcpyAsync(),然后再是执行核函数以及调用 cudaMemcpyAsync() 将 c 复制回主机。应用程序首先将对第 0 个流的所有操作放入队列,然后是第 1 个流的所有操作。CUDA 驱动程序负责按照这些操作的顺序把它们调度到硬件上执行,这就维持了流内部的依赖性。下图说明了这些依赖性,其中从复制操作到核函数的箭头表示,复制操作要等核函数执行完成之后才能开始。

假定理解了 GPU 的工作调度原理后,我们可以得到关于这些操作再硬件上执行的时间线,如下图所示
由于第 0 个流中将 c 复制回主机的操作要等待核函数执行完成,因此第 1 个流中将 a 和 b 复制到 GPU 的操作虽然是完全独立的,但却被阻塞了,这是因为GPU引擎是按照指定的顺序来执行工作。这种情况也说明了为什么上面使用了两个流却没有获得很大的速度提升。
这个问题的直接原因是我们没有意识到硬件的工作方式与CUDA流编程模型的方式是不同的。
硬件在处理内存复制和核函数执行时分别采用了不同的引擎,因此我们需要知道,将操作放入流中队列中的顺序将影响着 CUDA 驱动程序调度这些操作以及执行的方式。下面,我们将看到如何帮助硬件实现内存复制操作与核函数执行的重叠。
高效地使用多个CUDA流
如上节所看到的,如果同时调度某个流的所有操作,那么容易在无意中阻塞另一个流的复制操作或者核函数执行。要解决这个问题,在将操作放入流的队列时应采用宽度优先方式,而非深度优先方式。
也就是说,不是首先添加第 0 个流的所有四个操作(即a的复制、b的复制、核函数以及c的复制),然后再添加第 1 个流的所有四个操作。而是将这两个流之间的操作交叉添加。首先,将 a 的复制操作添加到第 0 个流,然后将 a 的复制操作添加到第 1 个流。接着,将 b 的复制操作添加到第 0 个流,再将 b 的复制操作添加到第 1 个流。接下来,将核函数调用添加到第 0 个流,再将相同的操作添加到第 1 个流中。最后,将 c 的复制操作添加到第 0 个流中,然后将相同的操作添加到第 1 个流中。
下面给出具体的代码,只需要修改 for() 循环内的代码。
for (int i = 0; i < FULL_DATA_SIZE; i += N*2) {// 将复制a的操作放入stream0和stream1的队列HANDLE_ERROR(cudaMemcpyAsync(dev_a0, host_a + i, N * sizeof(int), cudaMemcpyHostToDevice, stream0));HANDLE_ERROR(cudaMemcpyAsync(dev_a1, host_a + i + N, N * sizeof(int), cudaMemcpyHostToDevice, stream1));// 将复制b的操作放入stream0和stream1的队列HANDLE_ERROR(cudaMemcpyAsync(dev_b0, host_b + i, N * sizeof(int), cudaMemcpyHostToDevice, stream0));HANDLE_ERROR(cudaMemcpyAsync(dev_b1, hos + i + N, N * sizeof(int), cudaMemcpyHostToDevice, stream1));// 将核函数的执行放入stream0和stream1的队列中kernel << <N / 256, 256, 0, stream0 >> > (dev_a0, dev_b0, dev_c0);kernel << <N / 256, 256, 0, stream1 >> > (dev_a1, dev_b1, dev_c1);// 将复制c的操作放入stream0和stream1的队列中HANDLE_ERROR(cudaMemcpyAsync(host_c + i, dev_c0, N * sizeof(int), cudaMemcpyDeviceToHost, stream0));HANDLE_ERROR(cudaMemcpyAsync(host_c + i + N, dev_c1, N * sizeof(int), cudaMemcpyDeviceToHost, stream1));}
如果内存复制操作的时间与核函数执行的时间大致相当,那么新的执行时间线将如下图所示。引擎箭的依赖性通过箭头表示,可以看到在新的调度顺序中,这些依赖性仍然能得到满足。

由于采用了宽度优先方式将操作放入各个流的队列中,因此第0个流对c的复制操作将不会阻塞第1个流对a和b的内存复制操作。这使得GPU能够并行地执行复制操作和核函数,从而使应用程序的运行速度显著加快。
完整代码
#include "../../common/book.h"
#include "cuda_runtime.h"
#include "device_launch_parameters.h"#include <stdio.h>
#include <iostream>#define N (1024*1024)
#define FULL_DATA_SIZE (N*20)__global__ void kernel(int* a, int* b, int* c) {int idx = threadIdx.x + blockIdx.x * blockDim.x;if (idx < N) {int idx1 = (idx + 1) % 256;int idx2 = (idx + 2) % 256;float as = (a[idx] + a[idx1] + a[idx2]) / 3.0f;float bs = (b[idx] + b[idx1] + b[idx2]) / 3.0f;c[idx] = (as + bs) / 2;}
}int main(void) {cudaDeviceProp prop;int whichDevice;HANDLE_ERROR(cudaGetDevice(&whichDevice));HANDLE_ERROR(cudaGetDeviceProperties(&prop, whichDevice));if (!prop.deviceOverlap) {std::cout << "Device will not handle overlaps, so no speed up from streams" << std::endl;return 0;}cudaEvent_t start, stop;float elapsedTime;// 启动计时器HANDLE_ERROR(cudaEventCreate(&start));HANDLE_ERROR(cudaEventCreate(&stop));HANDLE_ERROR(cudaEventRecord(start, 0));// 初始化流cudaStream_t stream0, stream1;HANDLE_ERROR(cudaStreamCreate(&stream0));HANDLE_ERROR(cudaStreamCreate(&stream1));int* host_a, * host_b, * host_c;int* dev_a0, * dev_b0, * dev_c0; // 为第0个流分配的GPU内存int* dev_a1, * dev_b1, * dev_c1; // 为第1个流分配的GPU内存// 在GPU上分配内存HANDLE_ERROR(cudaMalloc((void**)&dev_a0, N * sizeof(int)));HANDLE_ERROR(cudaMalloc((void**)&dev_b0, N * sizeof(int)));HANDLE_ERROR(cudaMalloc((void**)&dev_c0, N * sizeof(int)));HANDLE_ERROR(cudaMalloc((void**)&dev_a1, N * sizeof(int)));HANDLE_ERROR(cudaMalloc((void**)&dev_b1, N * sizeof(int)));HANDLE_ERROR(cudaMalloc((void**)&dev_c1, N * sizeof(int)));// 分配由流使用的页锁定内存HANDLE_ERROR(cudaHostAlloc((void**)&host_a, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault));HANDLE_ERROR(cudaHostAlloc((void**)&host_b, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault));HANDLE_ERROR(cudaHostAlloc((void**)&host_c, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault));for (int i = 0; i < FULL_DATA_SIZE; i++) {host_a[i] = rand();host_b[i] = rand();}//在整体数据上循环,每个数据块的大小为Nfor (int i = 0; i < FULL_DATA_SIZE; i += N*2) {// 将锁定内存以异步方式复制到设备上HANDLE_ERROR(cudaMemcpyAsync(dev_a0, host_a + i, N * sizeof(int), cudaMemcpyHostToDevice, stream0));HANDLE_ERROR(cudaMemcpyAsync(dev_a1, host_a + i + N, N * sizeof(int), cudaMemcpyHostToDevice, stream1));// 将锁定内存以异步方式复制到设备上HANDLE_ERROR(cudaMemcpyAsync(dev_b0, host_b + i, N * sizeof(int), cudaMemcpyHostToDevice, stream0));HANDLE_ERROR(cudaMemcpyAsync(dev_b1, host_b + i + N, N * sizeof(int), cudaMemcpyHostToDevice, stream1));kernel << <N / 256, 256, 0, stream0 >> > (dev_a0, dev_b0, dev_c0);kernel << <N / 256, 256, 0, stream1 >> > (dev_a1, dev_b1, dev_c1);// 将数据从设备复制到锁定内存HANDLE_ERROR(cudaMemcpyAsync(host_c + i, dev_c0, N * sizeof(int), cudaMemcpyDeviceToHost, stream0));// 将数据从设备复制到锁定内存HANDLE_ERROR(cudaMemcpyAsync(host_c + i + N, dev_c1, N * sizeof(int), cudaMemcpyDeviceToHost, stream1));}HANDLE_ERROR(cudaStreamSynchronize(stream0));HANDLE_ERROR(cudaStreamSynchronize(stream1));HANDLE_ERROR(cudaEventRecord(stop, 0));HANDLE_ERROR(cudaEventSynchronize(stop));HANDLE_ERROR(cudaEventElapsedTime(&elapsedTime, start, stop));std::cout << "Time taken: " << elapsedTime << " ms" << std::endl;//释放流和内存HANDLE_ERROR(cudaFreeHost(host_a));HANDLE_ERROR(cudaFreeHost(host_b));HANDLE_ERROR(cudaFreeHost(host_c));HANDLE_ERROR(cudaFree(dev_a0));HANDLE_ERROR(cudaFree(dev_b0));HANDLE_ERROR(cudaFree(dev_c0));HANDLE_ERROR(cudaFree(dev_a1));HANDLE_ERROR(cudaFree(dev_b1));HANDLE_ERROR(cudaFree(dev_c1));HANDLE_ERROR(cudaStreamDestroy(stream0));HANDLE_ERROR(cudaStreamDestroy(stream1));return 0;
}
运行结果
遇到的问题(未解决)
我发现使用多个流实际并没有产生运行速度的提升,我试了单个流、两个流、四个流发现消耗的时间基本没有差别,暂时不知道是什么原因导致的,欢迎大佬解答。
相关文章:
CUDA By Example(八)——流
文章目录页锁定主机内存可分页内存函数页锁定内存函数CUDA流使用单个CUDA流使用多个CUDA流GPU的工作调度机制高效地使用多个CUDA流遇到的问题(未解决)页锁定主机内存 在之前的各个示例中,都是通过 cudaMalloc() 在GPU上分配内存,以及通过标准的C库函数 …...
02- pandas 数据库 (数据库)
pandas 数据库重点: pandas 的主要数据结构: Series (一维数据)与 DataFrame (二维数据)。 pd.DataFrame(data np.random.randint(0,151,size (5,3)), # 生成pandas数据 index [Danial,Brandon,softpo,Ella,Cindy], # 行索引 …...

less常用语法总结
CSS预处理器 CSS 预处理器是什么?一般来说,它们基于 CSS 扩展了一套属于自己的 DSL,来解决我们书写 CSS 时难以解决的问题: 语法不够强大,比如无法嵌套书写导致模块化开发中需要书写很多重复的选择器;没有变量和合理的样式复用机制,使得逻辑上相关的属性值必须以字面量…...
DHCP Relay中继实验
DHCP Relay实验拓扑图设备配置结果验证拓扑图 要求PC1按照地址池自动分配,而PC要求分配固定的地址,网段信息已经在图中进行标明。 设备配置 AR1: AR1作为DHCP Server基本配置跟DHCP Server没区别,不过要加一条静态路由ÿ…...

“1+1>2”!《我要投资》与天际汽车再度“双向奔赴”!
文|螳螂观察 作者| 图霖 胡海泉老师重磅回归、创始人现场真情告白……新一季的《我要投资》,不仅维持了往季在专业度上的高水准,也贡献了不少高话题度的“出圈”时刻。 在竞争激烈的的综艺节目竞技场,能举办数季的节目,往往都是…...
【分享】订阅金蝶KIS集简云连接器同步OA付款审批数据至金蝶KIS
方案简介 集简云基于钉钉连接平台完成与钉钉的深度融合,实现钉钉OA审批与数百款办公应用软件(如金蝶KIS、用友等)的数据互通,让钉钉的OA审批流程与企业内部应用软件的采购、付款、报销、收款、人事管理、售后工单、立项申请等环节…...

dubbo服务消费
dubbo在服务消费时调用的方法栈比较深,所以得一边看一边记,还是比较费力的。在dubbo服务发现中,我们看到通过ReferenceConfig#get()返回的是要调用接口的代理对象,因此通过接口的代理对象调用方法时是调用InvocationHandler(Invok…...
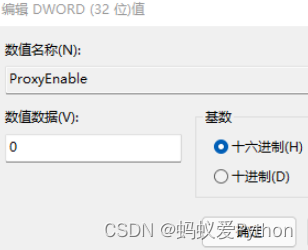
Python调用API接口,实现人脸识别
人生苦短,我用Python 在开始之前,先问问大家: 什么是百度Aip模块? 百度AI平台提供了很多的API接口供开发者快速的调用运用在项目中 本文写的是使用百度AI的**在线接口SDK模块(baidu-aip)**进行实现人脸识…...

2月10日刷题总结
编辑距离题目描述设 AA 和 BB 是两个字符串。我们要用最少的字符操作次数,将字符串 AA 转换为字符串 BB。这里所说的字符操作共有三种:删除一个字符;插入一个字符;将一个字符改为另一个字符。A, BA,B 均只包含小写字母。输入格式第…...
C++学习/温习:新型源码学编程(三)
写在前面(祝各位新春大吉!兔年如意!) 【本文持续更新中】面向初学者撰写专栏,个人原创的学习C/C笔记(干货)所作源代码输出内容为中文,便于理解如有错误之处请各位读者指正请读者评论回复、参与投票…...

阿里云ecs服务器搭建CTFd(ubuntu20)
1.更新apt包索引 sudo apt-get update更新源 1、使用快捷键【ctrlaltt】打开终端。 2、输入以下命令备份原有软件源文件。 cp /etc/apt/sources.list /etc/apt/sources.list.bak_yyyymmdd 3、再输入以下命令打开sources.list文件并添加新的软件源地址。 vim /etc/apt/sources.…...
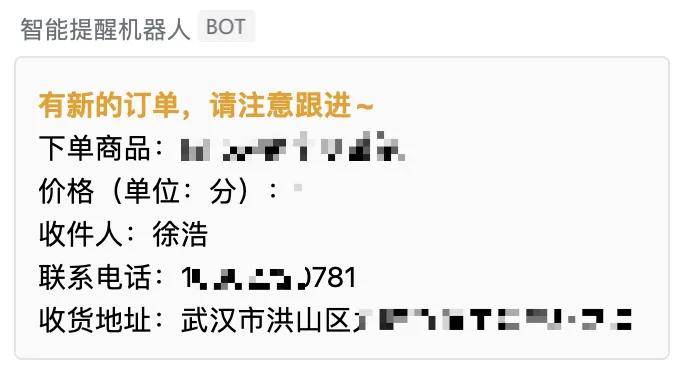
视频号小店新订单如何实时同步企业微信
随着直播带货的火热,视频号小店也为商家提供商品信息服务、商品交易,支持商家在视频号运营电商,许多企业也将产品的零售路径渗透至视频号小店中了。如果我们希望在视频号小店接收到订单后,能尽快及时发货,给用户较好的…...

ag-Grid Enterprise
ag-Grid Enterprise Ag-Grid被描述为一种商业产品,已在EULA下分发,它非常先进,性能就像Row分组一样,还有范围选择、master和case、行的服务器端模型等等。 ag Grid Enterprise的巨大特点: 它具有以下功能和属性&#x…...

扫雷——C语言【详解+全部码源】
前言:今天我们学习的是C语言中另一个比较熟知的小游戏——扫雷 下面开始我们的学习吧! 文章目录游戏整体思路游戏流程游戏菜单的打印创建数组并初始化布置雷排查雷完整代码game.hgame.ctest.c游戏整体思路 我们先来看一下网上的扫雷游戏怎么玩 需要打印…...
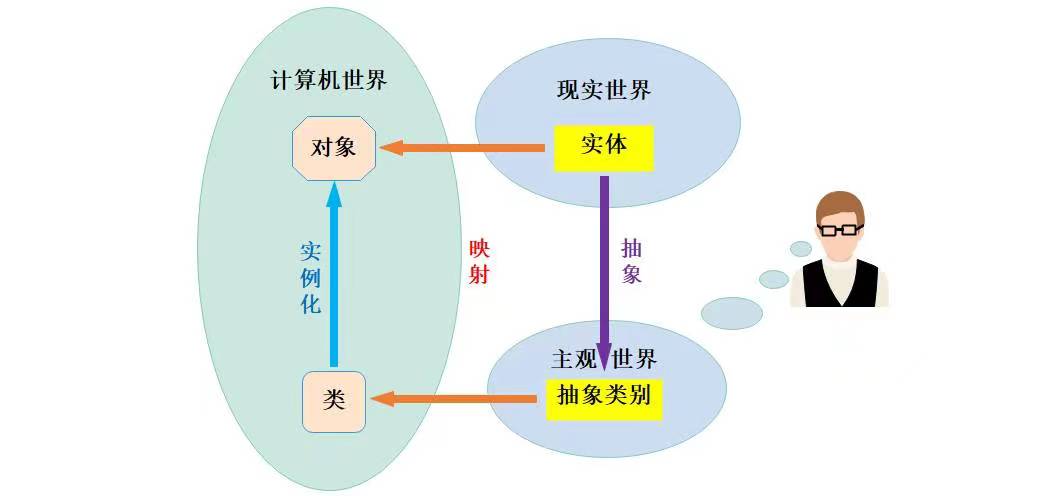
【C++】类和对象(下)
文章目录1. 再谈构造函数1.1 初始化列表1.2 explicit关键字2. static成员2.1 概念2.2 特性3. 友元3.1 友元函数3.1 友元类4. 内部类5. 匿名对象6. 拷贝对象时的一些编译器优化7. 再次理解类和对象1. 再谈构造函数 1.1 初始化列表 在创建对象时,编译器通过调用构造…...

计算机网络
TCP和UDP TCP如何保证传输的可靠性 基于数据块传输:应用数据被分割成TCP认为最适合的数据块,传输给网络层,称为报文段连接管理:三次握手和四次挥手对失序数据包重新排序以及去重:每个数据包有一个序列号,…...
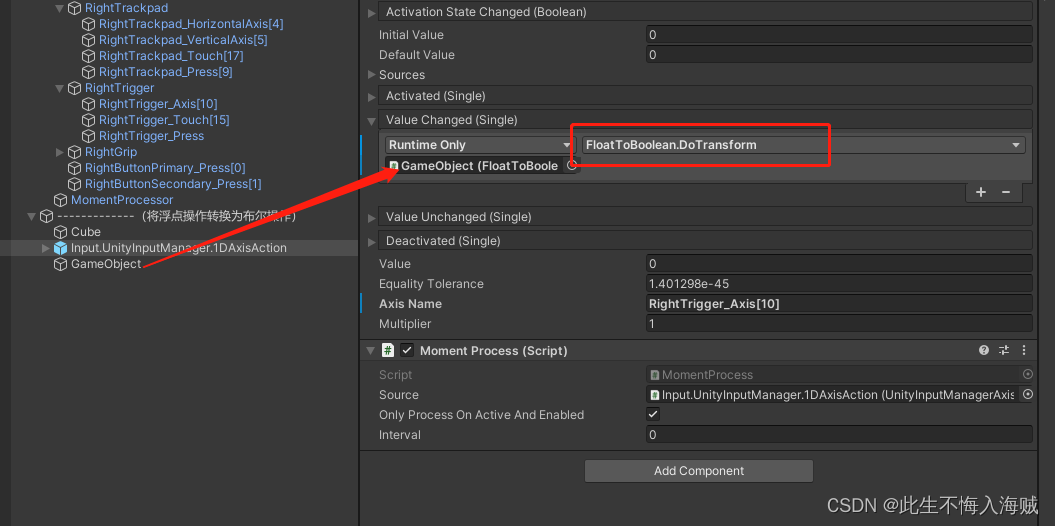
【Unity VR开发】结合VRTK4.0:将浮点操作转换为布尔操作
语录: 奈何桥上奈何愁,奈何桥下浣溪流,奈何人人奈何泪,奈何奈何洗春秋。 前言: 有时,您可能希望使用 一个值来激活或停用操作类型。例如,按下控制器上的扳机轴会导致在完全按下扳机时发生操作。…...

error when starting dev server:Error: Failed to resolve vue/compiler-sfc.
对于node 的包管理工具,我一般习惯用 yarn,但是最近使用 yarn 创建前端项目的时候出了一些问题。yarn create vite vite-project报错如下:error when starting dev server:Error: Failed to resolve vue/compiler-sfc.vitejs/plugin-vue requ…...
Vue2之完整基础介绍和指令与过滤器
Vue2之基础介绍和指令与过滤器一、简介1、概念2、vue的两个特性2.1 数据驱动视图2.2 双向数据绑定3、MVVM二、vue基础用法1、导入vue.js的script脚本文件2、在页面中声明一个将要被vue所控制的DOM区域3、创建vm实例对象(vue实例对象)4、样例完整代码三、…...

JY-7A/3DK/220 19-130V静态【电压继电器】
系列型号 JY-7A/1DK不带辅助电源电压继电器;JY-7B/1DK不带辅助电源电压继电器; JY-7/1DK/120不带辅助电源电压继电器;JY-7/1DK/120不带辅助电源电压继电器; JY-7A/1DKQ不带辅助电源电压继电器;JY-7B/1DKQ不带辅助电源…...

RestClient
什么是RestClient RestClient 是 Elasticsearch 官方提供的 Java 低级 REST 客户端,它允许HTTP与Elasticsearch 集群通信,而无需处理 JSON 序列化/反序列化等底层细节。它是 Elasticsearch Java API 客户端的基础。 RestClient 主要特点 轻量级ÿ…...

生成xcframework
打包 XCFramework 的方法 XCFramework 是苹果推出的一种多平台二进制分发格式,可以包含多个架构和平台的代码。打包 XCFramework 通常用于分发库或框架。 使用 Xcode 命令行工具打包 通过 xcodebuild 命令可以打包 XCFramework。确保项目已经配置好需要支持的平台…...

UDP(Echoserver)
网络命令 Ping 命令 检测网络是否连通 使用方法: ping -c 次数 网址ping -c 3 www.baidu.comnetstat 命令 netstat 是一个用来查看网络状态的重要工具. 语法:netstat [选项] 功能:查看网络状态 常用选项: n 拒绝显示别名&#…...

Python实现prophet 理论及参数优化
文章目录 Prophet理论及模型参数介绍Python代码完整实现prophet 添加外部数据进行模型优化 之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

Linux云原生安全:零信任架构与机密计算
Linux云原生安全:零信任架构与机密计算 构建坚不可摧的云原生防御体系 引言:云原生安全的范式革命 随着云原生技术的普及,安全边界正在从传统的网络边界向工作负载内部转移。Gartner预测,到2025年,零信任架构将成为超…...

服务器--宝塔命令
一、宝塔面板安装命令 ⚠️ 必须使用 root 用户 或 sudo 权限执行! sudo su - 1. CentOS 系统: yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh2. Ubuntu / Debian 系统…...

《C++ 模板》
目录 函数模板 类模板 非类型模板参数 模板特化 函数模板特化 类模板的特化 模板,就像一个模具,里面可以将不同类型的材料做成一个形状,其分为函数模板和类模板。 函数模板 函数模板可以简化函数重载的代码。格式:templa…...

处理vxe-table 表尾数据是单独一个接口,表格tableData数据更新后,需要点击两下,表尾才是正确的
修改bug思路: 分别把 tabledata 和 表尾相关数据 console.log() 发现 更新数据先后顺序不对 settimeout延迟查询表格接口 ——测试可行 升级↑:async await 等接口返回后再开始下一个接口查询 ________________________________________________________…...