Pytorch 多卡并行(3)—— 使用 DDP 加速 minGPT 训练
- 前文 并行原理简介和 DDP 并行实践 和 使用 torchrun 进行容错处理 在简单的随机数据上演示了使用 DDP 并行加速训练的方法,本文考虑一个更加复杂的 GPT 类模型,说明如何进行 DDP 并行实战
- MinGPT 是 GPT 模型的一个流行的开源 PyTorch 复现项目,其实现简洁干净可解释,因而颇具教育意义。关于 MinGPT 的详细介绍可以参考 minGPT 代码详解(训练 GPT 模型执行两位数加法)
- 本文参考自:Pytorch 官方教程
- 完整代码下载:wxc971231/ddp-tutorial-series
文章目录
- 0. 项目组织
- 1. 参数准备
- 2. 数据准备
- 3. 程序入口
- 4. 定义模型
- 5. 定义 Trainer
0. 项目组织
- 本文改写 MinGPT 库中的 chargpt 例程,这是一个 character-level 语言模型项目,组织如下
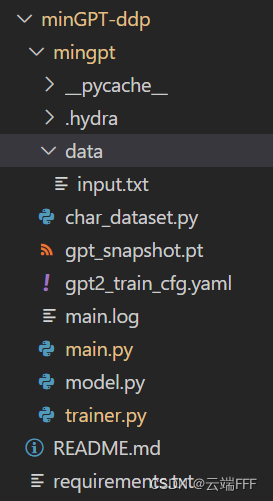
- 说明一下主要文件内容
- data/input.txt 是训练用的数据集
- char_dataset.py 定义了一个 char-level 的 torch.utils.data.Dataset
- gpt_snapshot.pt 是程序运行过程中保存的快照,使用 torchrun 时可以从此重启所有进程的训练
- gpt2_train_cfg.yaml 是 yaml 配置文件,记录了训练超参数
- main.log 是 hydra 生成的 logging 文件
- main.py 是程序入口,符合前文 使用 torchrun 进行容错处理 第1节给出的标准形式
- model.py 定义了 GPT 模型结构和 optimizer 的构造方法
- trainer.py 定义了训练过程,包括快照保存和加载等操作
1. 参数准备
- 本项目使用 YAML文件存储超参数设置。YAML 是一种轻量级的数据序列化格式。相较于JSON等其他格式,YAML 更加易读易写,也更加适合用于配置文件等场景。YAML的语法结构主要包含键值对、列表、注释等几种元素
data_config:path: ./data/input.txtblock_size: 128 # 输入序列长度train_split: 0.9 # 训练集和测试集划分truncate: 0.02 # 只用5%的数据进行训练 gpt_config:n_layer: 8n_head: 8n_embd: 512 trainer_config:max_epochs: 10batch_size: 216data_loader_workers: 4grad_norm_clip: 1.0snapshot_path: gpt_snapshot.ptsave_every: 3use_amp: True optimizer_config:weight_decay: 0.1learning_rate: 0.0003hydra:run:dir: ./使用yaml文件时,可以使用
${node.key}的方式引用yaml中的其他变量;如果超参数的值缺失,可以使用???输入缺失值,或使用null输入空值。 - 使用 Hydra 来管理超参数,它可以以装饰器的形式方便地加载不同路径下的 yaml 配置文件,最小用例如下
这样就把 ./configs/config.yaml 文件的参数加载到 main 函数中了,使用import hydra from omegaconf import DictConfig@hydra.main(version_base=None, config_path='configs', config_name='config') def main(cfg: DictConfig) -> None:cfg['key'] # 获得对应的参数值if __name__ == '__main__':main()cfg['key']这样的形式获取参数值 - 使用 Hydra 还有一个好处是它对 logging 标准库进行了包装。在 hydra.main 装饰器中对 log 输出格式规范为
"[%(asctime)s][%(name)s][%(levelname)s] - %(message)s",并设置 level 为info,运行程序就会自动生成 main.log 日志文件。可以通过命令行的hydra.verbose 参数修改 log 的显示 level
2. 数据准备
- 使用的数据是 tiny-shakespear 数据集,它是一个记录了一些英文对话的文本文档,截取如下
First Citizen: Before we proceed any further, hear me speak.All: Speak, speak.First Citizen: You are all resolved rather to die than to famish?All: Resolved. resolved.First Citizen: First, you know Caius Marcius is chief enemy to the people.All: We know't, we know't.First Citizen: Let us kill him, and we'll have corn at our own price. Is't a verdict?All: No more talking on't; let it be done: away, away! - 下面来构造数据集,思路是把 txt 文件中所有字符去重排序生成 vocab table;样本生成时先把 txt 内容全部读取进来,然后构造 n-gram 样本。如下
import torch from torch.utils.data import Dataset import fsspec from dataclasses import dataclass""" Adapted from https://github.com/karpathy/minGPT/blob/master/projects/chargpt/chargpt.py """@dataclass class DataConfig:path: str = Noneblock_size: int = None # 输入序列长度 train_split: float = None # 训练集和测试集划分truncate: float = 1.0 # 用于训练的数据占全体数据的比例class CharDataset(Dataset):def __init__(self, data_cfg: DataConfig): #data_path: str, block_size):# 加载所需比例的数据data = fsspec.open(data_cfg.path).open().read().decode('utf-8')data = data[ : int(len(data) * data_cfg.truncate)]# Set 去重,转 list 后排序得到数据集中的唯一字符列表作为词表chars = sorted(list(set(data))) data_size, vocab_size = len(data), len(chars)print('Data has %d characters, %d unique.' % (data_size, vocab_size))# 得到字符和词表索引之间的双射self.stoi = {ch: i for i, ch in enumerate(chars)} # 字符 -> 词表索引self.itos = {i: ch for i, ch in enumerate(chars)} # 词表索引 -> 字符self.block_size = data_cfg.block_size # 模型输入序列长度self.vocab_size = vocab_size # 词表尺寸self.data = datadef __len__(self):return len(self.data) - self.block_sizedef __getitem__(self, idx):# grab a chunk of (block_size + 1) characters from the datachunk = self.data[idx:idx + self.block_size + 1]# encode every character to an integerdix = [self.stoi[s] for s in chunk]x = torch.tensor(dix[:-1], dtype=torch.long)y = torch.tensor(dix[1:], dtype=torch.long)return x, y
3. 程序入口
- 使用 torchrun 命令进行容错,按前文 使用 torchrun 进行容错处理 给出的标准形式来编写程序入口(mian.py),如下
import os import torch from torch.utils.data import random_split from torch.distributed import init_process_group, destroy_process_group from model import GPT, GPTConfig, OptimizerConfig, create_optimizer from trainer import Trainer, TrainerConfig from char_dataset import CharDataset, DataConfig from omegaconf import DictConfig import hydradef ddp_setup():os.environ["MASTER_ADDR"] = "localhost" # 由于这里是单机实验所以直接写 localhostos.environ["MASTER_PORT"] = "12355" # 任意空闲端口init_process_group(backend="nccl")torch.cuda.set_device(int(os.environ["LOCAL_RANK"]))def get_train_objs(gpt_cfg: GPTConfig, opt_cfg: OptimizerConfig, data_cfg: DataConfig):dataset = CharDataset(data_cfg)train_len = int(len(dataset) * data_cfg.train_split)train_set, test_set = random_split(dataset, [train_len, len(dataset) - train_len])gpt_cfg.vocab_size = dataset.vocab_sizegpt_cfg.block_size = dataset.block_sizemodel = GPT(gpt_cfg)optimizer = create_optimizer(model, opt_cfg)return model, optimizer, train_set, test_set@hydra.main(version_base=None, config_path=".", config_name="gpt2_train_cfg") def main(cfg: DictConfig):# 初始化进程池ddp_setup()# 从 yaml 文件读取超参数gpt_cfg = GPTConfig(**cfg['gpt_config'])opt_cfg = OptimizerConfig(**cfg['optimizer_config'])data_cfg = DataConfig(**cfg['data_config'])trainer_cfg = TrainerConfig(**cfg['trainer_config'])# 创建训练对象model, optimizer, train_data, test_data = get_train_objs(gpt_cfg, opt_cfg, data_cfg)trainer = Trainer(trainer_cfg, model, optimizer, train_data, test_data)# 开始训练trainer.train()# 训练完成后,销毁进程池destroy_process_group()if __name__ == "__main__":main() - 注意其中使用 hydra.main 装饰器来加载参数;运行时使用以下命令指定 GPU 运行
CUDA_VISIBLE_DEVICES=1,2 torchrun --standalone --nproc_per_node=gpu main.py
4. 定义模型
- 整个模型定义部分相比 MinGPT 原始代码逻辑上没有区别,只是换了一下写法看起来更清晰一点。首先定义两个
@dataclass保存模型和优化器参数from dataclasses import dataclass import math import torch import torch.nn as nn from torch.nn import functional as F@dataclass class GPTConfig:model_type: str = 'gpt2'# model configurationsn_layer: int = Nonen_head: int = Nonen_embd: int = None# openai's values for gpt2vocab_size: int = 50257 block_size: int = 1024# dropout hyperparametersembd_pdrop: float = 0.1resid_pdrop: float = 0.1attn_pdrop: float = 0.1@dataclass class OptimizerConfig:learning_rate: float = 3e-4weight_decay: float = 0.1 - 定义多头 masked self-attention 模块,原本 MinGPT 库是全部手写的,这里则用了 pytorch 自己的多头注意力模块。具体做法是使用
torch.nn.MultiheadAttention定义普通多头注意力层,在 forward 方法中用同一个序列输入构造 qkv 实现 self-attention,再用过对注意力输出设置遮盖实现 maskclass MultiheadAttentionLayer(nn.Module):"""A multi-head masked self-attention layer with a projection at the end."""def __init__(self, config, device="cpu", dtype=torch.float32):super().__init__()assert config.n_embd % config.n_head == 0self.resid_drop = nn.Dropout(config.resid_pdrop)# output projectionself.c_proj = nn.Linear(config.n_embd, config.n_embd, device=device, dtype=dtype)# Causal mask。注意这个mask是通过 self.register_buffer 方法登记的# 这样登记过的张量可以求梯度也可以随模型在 CPU/GPU 之间移动,但是不进行参数优化self.register_buffer("mask", torch.tril(torch.ones(config.block_size, config.block_size)).view(1, 1, config.block_size, config.block_size))self.attn = torch.nn.MultiheadAttention(embed_dim=config.n_embd,num_heads=config.n_head,dropout=config.attn_pdrop,batch_first=True,device=device,dtype=dtype)def forward(self, x):_, seq_size, _ = x.size() # batch size, sequence length, embedding dimensionality (n_embd)y = self.attn(x, x, x, attn_mask=self.mask[0, 0, :seq_size, :seq_size])[0]y = self.resid_drop(self.c_proj(y))return y我感觉这里
self.attn(x, x, x, attn_mask=self.mask[0, 0, :seq_size, :seq_size])[0]的调用有问题,因为torch.nn.MultiheadAttention的前向过程需要输入 query,key 和 value 三个 tensor,这里应该把x用三个线性层变换后再作为输入。如果读者有其他想法可以和我讨论。考虑到本文主要说明 DDP 并行,暂不关注此问题 - 定义 Transformer block
class Block(nn.Module):""" an unassuming Transformer block """def __init__(self, config: GPTConfig):super().__init__()self.ln1 = nn.LayerNorm(config.n_embd)self.ln2 = nn.LayerNorm(config.n_embd)self.attn = MultiheadAttentionLayer(config)self.mlp = nn.Sequential(nn.Linear(config.n_embd, 4 * config.n_embd),nn.GELU(),nn.Linear(4 * config.n_embd, config.n_embd),nn.Dropout(config.resid_pdrop),)def forward(self, x):x = x + self.attn(self.ln1(x))x = x + self.mlp(self.ln2(x))return x - 定义字符嵌入层,用
nn.Embedding嵌入 token,再设置一个nn.Parameter作为可学习的位置编码class EmbeddingStem(nn.Module):def __init__(self, config: GPTConfig, device="cpu", dtype=torch.float32):super().__init__()self.tok_emb = nn.Embedding(config.vocab_size, config.n_embd, device=device, dtype=dtype)self.pos_emb = nn.Parameter(torch.zeros(1, config.block_size, config.n_embd, device=device, dtype=dtype))self.drop = nn.Dropout(config.embd_pdrop)self.block_size = config.block_sizedef reset_parameters(self): self.tok_emb.reset_parameters() # 将 nn.Embedding 层参数初始化为正态分布采样def forward(self, idx):b, t = idx.size()assert t <= self.block_size, f"Cannot forward sequence of length {t}, block size is only {self.block_size}"token_embeddings = self.tok_emb(idx) # each index maps to a (learnable) embedding vectorposition_embeddings = self.pos_emb[:, :t, :] # each position maps to a (learnable) position vectorreturn self.drop(token_embeddings + position_embeddings) - 把以上组件合在一起,定义 GPT 模型
class GPT(nn.Module):""" GPT Language Model """def __init__(self, config: GPTConfig):super().__init__()self.block_size = config.block_sizeconfig = self._set_model_config(config)# input embedding stemself.emb_stem = EmbeddingStem(config)# transformerself.blocks = nn.Sequential(*[Block(config) for _ in range(config.n_layer)])# decoder headself.ln_f = nn.LayerNorm(config.n_embd)self.head = nn.Linear(config.n_embd, config.vocab_size, bias=False)# init all weights, and apply a special scaled init to the residual projections, per GPT-2 paperself.apply(self._init_weights)for pn, p in self.named_parameters():if pn.endswith('c_proj.weight'):p.data.normal_(mean=0.0, std=0.02/math.sqrt(2 * config.n_layer))# report number of parameters (note we don't count the decoder parameters in lm_head)n_params = sum(p.numel() for p in self.blocks.parameters())print("number of parameters: %.2fM" % (n_params/1e6,))def _set_model_config(self, config):type_given = config.model_type is not Noneparams_given = all([config.n_layer is not None, config.n_head is not None, config.n_embd is not None])# assert type_given ^ params_given # exactly one of these (XOR)if type_given and not params_given:# translate from model_type to detailed configurationconfig.__dict__.update({# names follow the huggingface naming conventions# GPT-1'openai-gpt': dict(n_layer=12, n_head=12, n_embd=768), # 117M params# GPT-2 configs'gpt2': dict(n_layer=12, n_head=12, n_embd=768), # 124M params'gpt2-medium': dict(n_layer=24, n_head=16, n_embd=1024), # 350M params'gpt2-large': dict(n_layer=36, n_head=20, n_embd=1280), # 774M params'gpt2-xl': dict(n_layer=48, n_head=25, n_embd=1600), # 1558M params# Gophers'gopher-44m': dict(n_layer=8, n_head=16, n_embd=512),# (there are a number more...)# I made these tiny models up'gpt-mini': dict(n_layer=6, n_head=6, n_embd=192),'gpt-micro': dict(n_layer=4, n_head=4, n_embd=128),'gpt-nano': dict(n_layer=3, n_head=3, n_embd=48),}[config.model_type])return configdef _init_weights(self, module):if isinstance(module, (nn.Linear, nn.Embedding)):module.weight.data.normal_(mean=0.0, std=0.02)if isinstance(module, nn.Linear) and module.bias is not None:module.bias.data.zero_()elif isinstance(module, nn.LayerNorm):module.bias.data.zero_()module.weight.data.fill_(1.0)def forward(self, idx, targets=None):x = self.emb_stem(idx)x = self.blocks(x)x = self.ln_f(x)logits = self.head(x)# if we are given some desired targets also calculate the lossloss = Noneif targets is not None:loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)return logits, loss@torch.no_grad()def generate(self, idx, max_new_tokens, temperature=1.0, do_sample=False, top_k=None):"""Take a conditioning sequence of indices idx (LongTensor of shape (b,t)) and completethe sequence max_new_tokens times, feeding the predictions back into the model each time.Most likely you'll want to make sure to be in model.eval() mode of operation for this."""for _ in range(max_new_tokens):# if the sequence context is growing too long we must crop it at block_sizeidx_cond = idx if idx.size(1) <= self.block_size else idx[:, -self.block_size:]# forward the model to get the logits for the index in the sequencelogits, _ = self(idx_cond)# pluck the logits at the final step and scale by desired temperaturelogits = logits[:, -1, :] / temperature# optionally crop the logits to only the top k optionsif top_k is not None:v, _ = torch.topk(logits, top_k)logits[logits < v[:, [-1]]] = -float('Inf')# apply softmax to convert logits to (normalized) probabilitiesprobs = F.softmax(logits, dim=-1)# either sample from the distribution or take the most likely elementif do_sample:idx_next = torch.multinomial(probs, num_samples=1)else:_, idx_next = torch.topk(probs, k=1, dim=-1)# append sampled index to the running sequence and continueidx = torch.cat((idx, idx_next), dim=1)return idx - 最后我们来定义优化器,
这里主要是通过权重衰减方法来进行正则化避免过拟合。注意到作者通过一个二重遍历考察 GPT 模型所有 sub module 的所有 parameters,仅对所有def create_optimizer(model: torch.nn.Module, opt_config: OptimizerConfig):"""This long function is unfortunately doing something very simple and is being very defensive:We are separating out all parameters of the model into two buckets: those that will experienceweight decay for regularization and those that won't (biases, and layernorm/embedding weights).We are then returning the PyTorch optimizer object."""# separate out all parameters to those that will and won't experience regularizing weight decaydecay = set()no_decay = set()whitelist_weight_modules = (torch.nn.Linear, )blacklist_weight_modules = (torch.nn.LayerNorm, torch.nn.Embedding)for mn, m in model.named_modules():for pn, p in m.named_parameters():fpn = '%s.%s' % (mn, pn) if mn else pn # full param name# random note: because named_modules and named_parameters are recursive# we will see the same tensors p many many times. but doing it this way# allows us to know which parent module any tensor p belongs to...if pn.endswith('bias'):# all biases will not be decayedno_decay.add(fpn)elif pn.endswith('weight') and isinstance(m, whitelist_weight_modules):# weights of whitelist modules will be weight decayeddecay.add(fpn)elif pn.endswith('in_proj_weight'):# MHA projection layerdecay.add(fpn)elif pn.endswith('weight') and isinstance(m, blacklist_weight_modules):# weights of blacklist modules will NOT be weight decayedno_decay.add(fpn)elif pn.endswith('pos_emb'):# positional embedding shouldn't be decayedno_decay.add(fpn)# validate that we considered every parameterparam_dict = {pn: p for pn, p in model.named_parameters()}inter_params = decay & no_decayunion_params = decay | no_decayassert len(inter_params) == 0, "parameters %s made it into both decay/no_decay sets!" % (str(inter_params), )assert len(param_dict.keys() - union_params) == 0, "parameters %s were not separated into either decay/no_decay set!" \% (str(param_dict.keys() - union_params), )# create the pytorch optimizer objectoptim_groups = [{"params": [param_dict[pn] for pn in sorted(list(decay))], "weight_decay": opt_config.weight_decay},{"params": [param_dict[pn] for pn in sorted(list(no_decay))], "weight_decay": 0.0},]optimizer = torch.optim.AdamW(optim_groups, lr=opt_config.learning_rate, betas=(0.9, 0.95))return optimizertorch.nn.Linear层的weight参数进行衰减,bias参数及所有torch.nn.LayerNorm、torch.nn.Embedding模块的参数都不做处理。由于模块是递归组织的,这个二重遍历会重复访问很多参数,所以通过set自动去重,最后根据处理结果定义torch.optim.AdamW优化器返回关于权重衰减的理论说明,参考:机器学习基础(6)—— 使用权重衰减和丢弃法缓解过拟合问题
5. 定义 Trainer
-
Trainer 定义和原始 MinGPT 库主要有两个区别
-
按指定周期要求 rank0 进程保存 snapshot,本项目中应包含 epoch、模型参数和优化器参数三部分内容;初始化 Trainer 时应当加载可能存在的 snapshot 文件,这样在 torchrun 自动重启进程时可以从最近的 snapshot 恢复训练
-
可以使用
torch.cuda.amp.GradScaler进行混合精度训练混合精度训练(Mixed Precision Training)是一种训练深度学习模型的技术,旨在提高模型的训练速度和效率。它利用了现代GPU可以混合计算精度的硬件特性,使用FP16数据类型对模型中的某些操作进行加速。具体而言,模型的参数通常使用FP32数据类型,而输入数据和梯度则使用FP16数据类型,从而减少内存开销,加速计算速度,提高模型的训练效率。此外,混合精度训练还可以通过减少浮点运算和内存访问,降低能源消- 混合精度训练的主要困难在于 fp16 的表示范围有限,在训练中常出现
溢出问题,尤其是下溢出,因为在网络训练的后期,模型的梯度往往很小;另外还有舍入误差问题,这是指当梯度过小,小于当前区间内的最小间隔时,该次梯度更新可能会失效 - 解决以上问题的方法包括
损失缩放和FP32权重备份等,前者对计算出的 loss 值进行缩放(scale),这样梯度也会被缩放进而平移到 FP16 的有效范围内存储,在进行梯度更新之前先将缩放后的梯度转化为 FP32 再unscale回去;后者将模型权重、激活值、梯度等数据用 FP16 来存储,同时维护一份 FP32 的模型权重副本用于更新。在反向传播得到 FP16 的梯度以后,将其转化成 FP32 并 unscale,最后更新 FP32 的模型权重。因为整个更新过程是在 FP32 的环境中进行的,所以不会出现舍入误差 - 有一些代码库可以帮助我们快速实现混合精度训练,而无需大幅修改代码,包括 nvidia 的 apex 库和 pytorch 1.6 后引入的 amp 库等
本项目使用 pytorch 的 amp 库进行混合精度训练,主要用到 GradScaler 和 autocast 两个组件。其中 Gradscalar 对会检查梯度是否发现溢出,并对优化器进行控制 (将丢弃的batches转换为 no-op);autocast 是一个上下文管理器,当进入 autocast 上下文后,tensor 的数据类型会自动转换为半精度浮点型,从而在不损失训练精度的情况下加快运算,而不需要手动调用 .half()。 一个最小实践示例为
from torch.cuda.amp import autocast as autocast, GradScaler ''' other code '''# 在训练最开始之前实例化一个GradScaler对象 scaler = GradScaler() ''' other code '''# 前向过程(model + loss)开启 autocastwith autocast():output = model(input)loss = loss_fn(output, target)# Scales loss,这是因为半精度的数值范围有限,因此需要用它放大scaler.scale(loss).backward()# scaler.step() unscale之前放大后的梯度,但是scale太多可能出现inf或NaN# 故其会判断是否出现了inf/NaN# 如果梯度的值不是 infs 或者 NaNs, 那么调用optimizer.step()来更新权重,# 如果检测到出现了inf或者NaN,就跳过这次梯度更新,同时动态调整scaler的大小scaler.step(optimizer)# 查看是否要更新scaler,这个要注意不能丢scaler.update()''' other code '''
-
-
下面开始分析 trainer 代码,首先定义两个
@dataclass存储 Trainer 参数和 snapshot 参数@dataclass class TrainerConfig:max_epochs: int = Nonebatch_size: int = Nonedata_loader_workers: int = Nonegrad_norm_clip: float = Nonesnapshot_path: Optional[str] = Nonesave_every: int = Noneuse_amp: bool = None@dataclass class Snapshot:model_state: 'OrderedDict[str, torch.Tensor]'optimizer_state: Dict[str, Any]finished_epoch: int -
定义 Trianer 的初始化方法
class Trainer:def __init__(self, trainer_config: TrainerConfig, model, optimizer, train_dataset, test_dataset=None):self.config = trainer_config# set torchrun variablesself.local_rank = int(os.environ["LOCAL_RANK"]) # 在所有node的所有进程中当前GPU进程的rankself.global_rank = int(os.environ["RANK"]) # 在当前node中当前GPU进程的rank# data stuffself.train_dataset = train_datasetself.train_loader = self._prepare_dataloader(train_dataset)self.test_loader = self._prepare_dataloader(test_dataset) if test_dataset else None# initialize train statesself.epochs_run = 0self.model = model.to(self.local_rank)self.optimizer = optimizer self.save_every = self.config.save_every# load snapshot if available. only necessary on the first node.if self.config.snapshot_path is None:self.config.snapshot_path = "snapshot.pt"self._load_snapshot()# wrap with DDP. this step will synch model across all the processes.self.model = DDP(self.model, device_ids=[self.local_rank])# torch.cuda.amp.GradScaler 是一个用于自动混合精度训练的 PyTorch 工具,它可以帮助加速模型训练并减少显存使用量# 具体来说,GradScaler 可以将梯度缩放到较小的范围,以避免数值下溢或溢出的问题,同时保持足够的精度以避免模型的性能下降if self.config.use_amp: self.scaler = torch.cuda.amp.GradScaler()注意几点
- torchrun 帮助我们自动分发进程,通过环境变量获取当前运行代码的 GPU rank 信息
- 初始化 Trainer 时加载可能存在的 snapshot,实现断点续训
- 模型使用 DDP 进行包装
- 定义混合精度训练所需的
torch.cuda.amp.GradScaler()
-
定义 DataLoder,注意使用
DistributedSampler来分发训练数据def _prepare_dataloader(self, dataset: Dataset):return DataLoader(dataset,batch_size=self.config.batch_size,pin_memory=True,shuffle=False,num_workers=self.config.data_loader_workers,sampler=DistributedSampler(dataset) # 这个 sampler 自动将数据分块后送个各个 GPU,它能避免数据重叠) -
定义 snapshot 的加载和保存方法
def _save_snapshot(self, epoch):# capture snapshotmodel = self.modelraw_model = model.module if hasattr(model, "module") else modelsnapshot = Snapshot(model_state=raw_model.state_dict(),optimizer_state=self.optimizer.state_dict(),finished_epoch=epoch)# save snapshotsnapshot = asdict(snapshot)torch.save(snapshot, self.config.snapshot_path)print(f"Snapshot saved at epoch {epoch}")def _load_snapshot(self):try:snapshot = fsspec.open(self.config.snapshot_path) # fsspec 为各种后端存储系统提供统一的 Python 接口,可以用相同的语法打开本地、AWS S3 和 GCS 等各种云存储平台的文件with snapshot as f:snapshot_data = torch.load(f, map_location="cpu")except FileNotFoundError:print("Snapshot not found. Training model from scratch")return snapshot = Snapshot(**snapshot_data)self.model.load_state_dict(snapshot.model_state)self.optimizer.load_state_dict(snapshot.optimizer_state)self.epochs_run = snapshot.finished_epochprint(f"Resuming training from snapshot at Epoch {self.epochs_run}") -
定义训练流程
def _run_batch(self, source, targets, train: bool = True) -> float:with torch.set_grad_enabled(train), torch.cuda.amp.autocast(dtype=torch.float16, enabled=(self.config.use_amp)):_, loss = self.model(source, targets)if train:self.optimizer.zero_grad(set_to_none=True)if self.config.use_amp: self.scaler.scale(loss).backward()torch.nn.utils.clip_grad_norm_(self.model.parameters(), self.config.grad_norm_clip)self.scaler.step(self.optimizer)self.scaler.update()else:loss.backward()torch.nn.utils.clip_grad_norm_(self.model.parameters(), self.config.grad_norm_clip)self.optimizer.step()#return loss.item()return lossdef _run_epoch(self, epoch: int, dataloader: DataLoader, train: bool = True):dataloader.sampler.set_epoch(epoch)for iter, (source, targets) in enumerate(dataloader):step_type = "Train" if train else "Eval"source = source.to(self.local_rank)targets = targets.to(self.local_rank)batch_loss = self._run_batch(source, targets, train)if iter % 100 == 0:#print(f"[GPU{self.global_rank}] Epoch {epoch} | Iter {iter} | {step_type} Loss {batch_loss.item():.5f}")if train:print(f"[GPU{self.global_rank}] Epoch {epoch} | Iter {iter} | {step_type} Loss {batch_loss.item():.5f}")else:eval_loss_list = [torch.zeros_like(batch_loss) for _ in range(int(os.environ['WORLD_SIZE']))]dist.gather(batch_loss,eval_loss_list if self.local_rank == 0 else None, dst=0)if self.local_rank == 0:for i, loss in enumerate(eval_loss_list):print(f"[GPU{i}] Epoch {epoch} | Iter {iter} | {step_type} Loss {loss.item():.5f}")def train(self):for epoch in range(self.epochs_run, self.config.max_epochs):epoch += 1# train for one epochself._run_epoch(epoch, self.train_loader, train=True)# 各个 GPU 上都在跑一样的训练进程,这里指定 rank0 进程保存 snapshot 以免重复保存if self.local_rank == 0 and epoch % self.save_every == 0:self._save_snapshot(epoch)# eval runif self.test_loader:self._run_epoch(epoch, self.test_loader, train=False)这里需要注意几点:
- 指定 rank0 进程保存 snapshot 以免重复保存
_run_batch方法中,计算 loss 的部分设置在 torch.amp.autocast 上下文中,启动混合精度训练_run_epoch方法中,使用torch.distributed.gather原语汇聚各个 GPU 的验证损失信息到 rank0 上,常用这种操作进行 log 训练信息。除此以外 Pytorch 一共提供了六个进程通信原语,如下
其中 op 操作有四种import torch.distributed as distdist.broadcast(tensor, src, group) # 将 tensor 从 src 复制到所有其他进程。 dist.reduce(tensor, dst, op, group) # 将 op 应用于每个 tensor 并将结果存储在 dst 中。 dist.all_reduce(tensor, op, group) # 与 reduce 相同,但结果存储在所有进程中。 dist.scatter(tensor, scatter_list, src, group) # 复制 tensor scatter_lost[i] 到 进程 dist.gather(tensor,gather_list, dst, group) # 从 dst 中的所有进程复制 tensor。 dist.all_gather(tensor_list, tensor, group) # 将所有进程的 tensor 复制到所有进程上的 tensor_list。 dist.barrier(group) # 阻塞组中的所有进程,直到每个进程都进入该函数。
这些方法在需要手动汇聚或分发信息时特别有用,具体用法可以参考 pytorch 官方文档dist.ReduceOp.SUM, dist.ReduceOp.PRODUCT, dist.ReduceOp.MAX, dist.ReduceOp.MIN.
相关文章:
Pytorch 多卡并行(3)—— 使用 DDP 加速 minGPT 训练
前文 并行原理简介和 DDP 并行实践 和 使用 torchrun 进行容错处理 在简单的随机数据上演示了使用 DDP 并行加速训练的方法,本文考虑一个更加复杂的 GPT 类模型,说明如何进行 DDP 并行实战MinGPT 是 GPT 模型的一个流行的开源 PyTorch 复现项目ÿ…...
IAM、EIAM、CIAM、RAM、IDaaS 都是什么?
后端程序员在做 ToB 产品或者后台系统时,都不可避免的会遇到账号系统、登录系统、权限系统、日志系统等这些核心功能。这些功能一般都是以 SSO 系统、RBAC 权限管理系统等方式命名,但这些系统合起来有一个专有名词:IAM。 IAM IAM 是 Identi…...
STM32 Cubemx 通用定时器 General-Purpose Timers同步
文章目录 前言简介cubemx配置 前言 持续学习stm32中… 简介 通用定时器是一个16位的计数器,支持向上up、向下down与中心对称up-down三种模式。可以用于测量信号脉宽(输入捕捉),输出一定的波形(比较输出与PWM输出&am…...

Ubuntu 20.04降级clang-format
1. 卸载clang-format sudo apt purge clang-format 2. 安装clang-format-6.0 sudo apt install clang-format-6.0 3. 软链接clang-format sudo ln -s /usr/bin/clang-format-6.0 /usr/bin/clang-format...

激活函数总结(三十四):激活函数补充(FReLU、CReLU)
激活函数总结(三十四):激活函数补充 1 引言2 激活函数2.1 FReLU激活函数2.2 CReLU激活函数 3. 总结 1 引言 在前面的文章中已经介绍了介绍了一系列激活函数 (Sigmoid、Tanh、ReLU、Leaky ReLU、PReLU、Swish、ELU、SELU、GELU、Softmax、Sof…...

【LeetCode-简单题KMP】459. 重复的子字符串
文章目录 题目方法一:移动匹配方法二:KMP算法 题目 方法一:移动匹配 class Solution {//移动匹配public boolean repeatedSubstringPattern(String s) {StringBuffer str new StringBuffer(s);//ababstr.append(s);//拼接一份自己 abababab…...

Lua脚本
基本语法 注释 print(“script lua win”) – 单行注释 – [[ 多行注释 ]] – 标识符 类似于:java当中 变量、属性名、方法名。 以字母(a-z,A-Z)、下划线 开头,后面加上0个或多个 字母、下划线、数字。 不要用下划线大写字母…...

vue 封装一个Dialog组件
基于element-plus封装一个Dialog组件 <template><section class"dialog-wrap"><el-dialog :title"title" v-model"visible" :close-on-click-modal"false"><section class"content-wrap"><Form…...
外包干了2个月,技术退步明显。。。。。
先说一下自己的情况,大专生,18年通过校招进入武汉某软件公司,干了接近4年的功能测试,今年年初,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落!而我已经在一个企业干了四年的功能测试…...
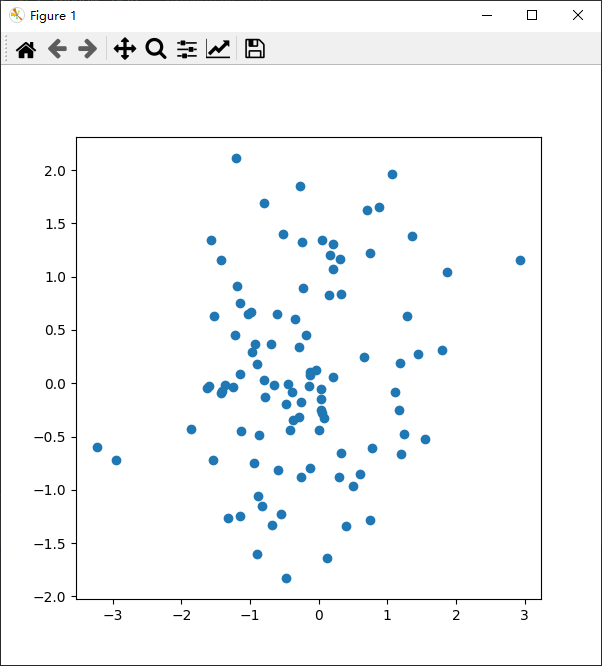
python科研作图
1、气泡图 气泡图是一种在xy轴上显示三个维度的数据的有效方式。在气泡图中,基本上,每个气泡代表一个数据点。横坐标和纵坐标的位置代表两个维度,气泡的大小则代表第三个维度。 在这个例子中,我们用numpy库生成了一些随机数据&a…...

视锥体裁剪射线的算法
射线Ray(直线情况)需要满足的条件: 在视野中显示的粗细均匀,需要分段绘制,每段的粗细根据到视野的距离计算射线model的顶点尽量少以节省性能损耗要满足条件2的话需要对射线进行裁剪,只绘制射线在视锥体内的部分,因此需要计算射线被视锥体裁剪后新的起点和终点 1. 计算三角…...
)
程序员在线周刊(投稿篇)
嗨,大家好!作为一名程序员,并且是一名互联网文章作者,我非常激动地向大家宣布,我们计划推出一份在线周刊,专门为程序员们提供有趣、实用的文章和资讯。而现在,我们正在征集投稿! 是…...
uniapp——实现聊天室功能——技能提升
这里写目录标题 效果图聊天室功能代码——html部分代码——js部分代码——其他部分 首先声明一点:下面的内容是从一个uniapp的程序中摘录的,并非本人所写,先做记录,以免后续遇到相似需求抓耳挠腮。 效果图 聊天室功能 发送图片 …...

脚本:用python实现五子棋
文章目录 1. 语言2. 效果3. 脚本4. 解读5. FutureReference 1. 语言 Python 无环境配置、无库安装。 2. 效果 以第一回合为例 玩家X 玩家0 3. 脚本 class GomokuGame:def __init__(self, board_size15):self.board_size board_sizeself.board [[ for _ in range(board_…...
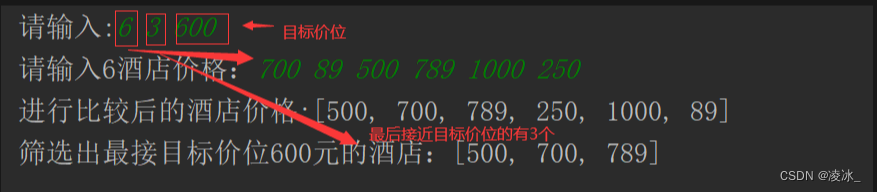
Java-华为真题-预定酒店
需求: 放暑假了,小王决定到某旅游景点游玩,他在网上搜索到了各种价位的酒店(长度为n的数组A),他的心理价位是x元,请帮他筛选出k个最接近x元的酒店(n>k>0)ÿ…...
win10 自带虚拟机软件 虚拟CentOS系统
win10 下使用需要虚拟一个系统,不需要额外安装VMware、Virtual box等软件。使用win10 自带虚拟机软件即可 步骤1 确保启动Hyper-V 功能启用 控制面板 -> 程序 -> 启用或关闭Windows功能 步骤 2 创建虚拟机 2.1 打开Typer-V 2.2 创建虚拟机 2.2.1 操作 -&g…...
【深度学习】 Python 和 NumPy 系列教程(十):NumPy详解:2、数组操作(索引和切片、形状操作、转置操作、拼接操作)
目录 一、前言 二、实验环境 三、NumPy 0、多维数组对象(ndarray) 1. 多维数组的属性 1、创建数组 2、数组操作 1. 索引和切片 a. 索引 b. 切片 2. 形状操作 a. 获取数组形状 b. 改变数组形状 c. 展平数组 3. 转置操作 a. 使用.T属性 b…...

3D视觉测量:复现Gocator的间隙面差
文章目录 0. 测试效果1. Gocator实现基本内容1.1 实现步骤1.2 参数说明 2. 未作 or TODO3. 开发说明 目标:使用C PCL复现Gocator中的间隙面差前置说明:因为没有拿到Gocator中用到的原始数据,仅是拿到与之类似的数据,因此最后测试的…...

文献综述怎么写?(以利用Zotero的文献管理软件为例)
文章目录 文章内容总结前言一. 利用文献管理软件建立文献库1. 创建文献分类2. 在论文库中搜索关键词并导入到文献管理软件中以web of science 为例以 IEEE Xplore为例 二、 导出文献、阅读摘要并记录关键字三、寻找一两篇本方向的文献综述,分析借鉴其文章结构四、写…...
中尺度混凝土二维有限元求解——运行弯曲、运行光盘、运行比较、运行半圆形(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

付费内容访问难题如何破解?开源工具的创新解决方案
付费内容访问难题如何破解?开源工具的创新解决方案 【免费下载链接】bypass-paywalls-chrome-clean 项目地址: https://gitcode.com/GitHub_Trending/by/bypass-paywalls-chrome-clean 在数字内容付费阅读日益普及的今天,如何合法合规地获取所需…...

Qwen3.5-35B-A3B-AWQ-4bit企业应用:HR招聘简历图识别+关键资质自动核验系统
Qwen3.5-35B-A3B-AWQ-4bit企业应用:HR招聘简历图识别关键资质自动核验系统 1. 企业招聘场景的痛点分析 在传统HR招聘流程中,简历筛选和资质核验是最耗费人力的环节之一。每天面对堆积如山的纸质简历和PDF文件,HR需要: 手动翻阅…...

【架构实战】健康检查与故障转移机制
一、为什么需要健康检查 在分布式系统中,服务实例可能因为各种原因变得不可用,而调用方却毫不知情,继续向故障实例发送请求,导致大量失败。常见的服务不可用场景:- 进程假死:Java进程存在但无法响应请求&am…...

LangChain 1.0 中间件实战:5个钩子函数让你的Agent像专业工程师一样思考
LangChain 1.0中间件深度实践:5个钩子函数打造工程级Agent思维 当我们在2023年首次接触LangChain时,它还是一个以Chain为核心的实验性框架。如今,LangChain 1.0的发布标志着AI Agent开发正式进入生产就绪阶段。本文将带您深入探索其最具革命性…...

MyBatis批量更新避坑指南:从`<foreach>`拼接SQL到`allowMultiQueries`配置的完整流程
MyBatis批量更新实战:从基础实现到性能调优全解析 批量更新操作是后端开发中绕不开的高频需求,但很多开发者在初次接触MyBatis批量更新时,往往会陷入各种"坑"中。本文将带你系统掌握两种主流实现方案,从基础用法到性能优…...

突破B站缓存限制:m4s-converter视频格式转换完全指南
突破B站缓存限制:m4s-converter视频格式转换完全指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 当旅行途中想离线观看缓存视频却…...
)
Python MCP服务部署卡在step3?揭秘92%开发者忽略的config.toml权限校验机制(配置失效终极诊断指南)
第一章:Python MCP服务部署卡在step3的典型现象与问题定位当执行 Python MCP(Model Control Platform)服务自动化部署脚本时,step3(即服务容器化构建与镜像推送阶段)常出现长时间无响应、日志停滞于 Buildi…...

Phi-4-mini-reasoning企业落地案例:集成至内部知识库的逻辑问答模块
Phi-4-mini-reasoning企业落地案例:集成至内部知识库的逻辑问答模块 1. 项目背景与需求 企业内部知识库系统通常面临一个共同挑战:员工在查找专业问题时,往往需要花费大量时间筛选信息,特别是涉及数学计算、逻辑推理等需要多步分…...

【算法实战】分支限界法解电路布线:从理论到代码实现
1. 电路布线问题与分支限界法初探 电路布线问题就像是在一个布满障碍物的迷宫中寻找最短路径。想象一下,你手里拿着一根电线,需要在布满元件的电路板上找到一条最短的路径连接两个点,而且电线只能走直线或者直角转弯。这就是电路布线问题的现…...

Psins实战:从零解析SINS/GPS松组合导航中的Kalman滤波器初始化与调参
1. 初识SINS/GPS松组合导航与Kalman滤波 刚接触导航算法的朋友可能会被"SINS/GPS松组合"这个术语吓到,其实拆开看很简单。SINS(捷联惯性导航系统)就像是个不知疲倦的计步器,通过IMU(惯性测量单元)…...