python萌新爬虫学习笔记【建议收藏】
文章目录
- 1. 如何何请求解析url
- 2. 如何获取标签里面的文本
- 3. 如何解析JSON格式
- 4. 如何添加常用的header
- 5. 如何合并两个div
- 6. 如何删除html dom的部分结构
- 7. 如何一次性获取所有div标签里的文本
- 8. python爬虫如何改变响应文本字符集编码
- 9. 如何进行字符集转码
- 11. response.text 和 respone.content的区别
- 12. 如何发送post请求访问页面
- 13. 如何获取 url 中的参数
1. 如何何请求解析url
- 要解析 Python 中 Request 返回的 HTML DOM,你可以使用解析库,如 BeautifulSoup 或 lxml,来处理 HTML 文档。下面是使用 Beautiful Soup 和 lxml 的示例代码:
- 首先,确保你已经安装了所需的库。对于 Beautiful Soup,你可以使用 pip install beautifulsoup4 进行安装。对于 lxml,你可以使用 pip install lxml 进行安装。
- 使用 Beautiful Soup 库:
- BeautifulSoup 是一个 Python 库,用于网络爬虫目的。它提供了一种方便和高效的方式来从 HTML 和 XML 文档中提取数据。使用 BeautifulSoup,你可以解析和遍历 HTML 结构,搜索特定元素,并从网页中提取相关数据。
- 该库支持不同的解析器,如内置的 Python 解析器、lxml 和 html5lib,允许你根据特定需求选择最适合的解析器。BeautifulSoup 的优势在于它能够处理格式混乱或损坏的 HTML 代码,使其成为处理复杂情况下的网络爬虫任务的强大工具。
import requests
from bs4 import BeautifulSoup# 发送请求获取 HTML
response = requests.get(url)
html = response.text# 创建 Beautiful Soup 对象
soup = BeautifulSoup(html, 'html.parser')# 通过选择器选择 DOM 元素进行操作
element = soup.select('#my-element')
- 在上面的示例中,requests.get(url) 发送请求并获取HTML响应。然后,我们使用 response.text 获取响应的HTML内容,并将其传递给 Beautiful Soup 构造函数 BeautifulSoup(html, ‘html.parser’),创建一个 Beautiful Soup 对象 soup。
- 接下来,你可以使用 Beautiful Soup 提供的方法和选择器,如 select(),来选择 HTML DOM 中的特定元素。在上述示例中,我们通过选择器 #my-element 选择具有 id 为 my-element 的元素。
- 使用 lxml 库:
import requests
from lxml import etree# 发送请求获取 HTML
response = requests.get(url)
html = response.text# 创建 lxml HTML 解析器对象
parser = etree.HTMLParser()# 解析 HTML
tree = etree.fromstring(html, parser)# 通过XPath选择 DOM 元素进行操作
elements = tree.xpath('//div[@class="my-element"]')
- 在上面的示例中,我们首先使用 requests.get(url) 发送请求并获取HTML响应。然后,我们创建一个 lxml HTML 解析器对象 parser。
- 接下来,我们使用 etree.fromstring(html, parser) 解析 HTML,并得到一个表示 DOM 树的对象 tree。
- 最后,我们可以使用 XPath 表达式来选择 DOM 元素。在上述示例中,我们使用 XPath 表达式 //div[@class=“my-element”] 选择所有 class 属性为 “my-element” 的 div 元素。
- 无论是使用 Beautiful Soup 还是 lxml,都可以使用各自库提供的方法和属性来操作和提取选择的 DOM 元素。
2. 如何获取标签里面的文本
在Python中,你可以使用多种库和方法来获取HTML标签里面的文本。以下是几种常见的方法:
- 方式一:使用BeautifulSoup库:
from bs4 import BeautifulSoup# 假设html为包含标签的HTML文档soup = BeautifulSoup(html, 'html.parser')# 获取所有标签内的文本text = soup.get_text()# 获取特定标签内的文本(例如p标签)p_text = soup.find('p').get_text()
- 方式二:使用lxml库:
from lxml import etree# 假设html为包含标签的HTML文档tree = etree.HTML(html)# 获取所有标签内的文本text = tree.xpath('//text()')# 获取特定标签内的文本(例如p标签)p_text = tree.xpath('//p/text()')
- 方式三:使用正则表达式:
import re# 假设html为包含标签的HTML文档pattern = re.compile('<[^>]*>')text = re.sub(pattern, '', html)
这些方法可以根据你的需求选择其中之一,它们都可以帮助你提取出HTML标签里面的文本内容。请注意,这些方法在处理复杂的HTML文档时可能会有一些限制,因此建议使用专门的HTML解析库(如BeautifulSoup、lxml)来处理HTML文档以获得更好的灵活性和准确性。
3. 如何解析JSON格式
- 要获取 JSON 数据中的 title 属性的值,你可以使用 Python 的 json 模块来解析 JSON 数据。在你的示例数据中,title 属性位于 data 字典中的 pageArticleList 列表中的每个元素中。
- 下面是一个示例代码,演示如何获取 title 属性的值:
import json# 假设你已经获取到了 JSON 数据,将其存储在 json_data 变量中
json_data = '''
{"status": 200,"message": "success","datatype": "json","data": {"pageArticleList": [{"indexnum": 0,"periodid": 20200651,"ordinate": "","pageid": 2020035375,"pagenum": "6 科协动态","title": "聚焦“科技创新+先进制造” 构建社会化大科普工作格局"}]}
}
'''# 解析 JSON 数据
data = json.loads(json_data)# 提取 title 属性的值
title = data["data"]["pageArticleList"][0]["title"]# 输出 title 属性的值
print(title)
-
在上述示例中,我们将示例数据存储在 json_data 字符串中。然后,我们使用 json.loads() 函数将字符串解析为 JSON 数据,将其存储在 data 变量中。
-
然后,我们可以通过字典键的层级访问方式提取 title 属性的值。在这个示例中,我们使用 data[“data”][“pageArticleList”][0][“title”] 来获取 title 属性的值。
-
最后,我们将结果打印出来或根据需求进行其他处理。
-
或者是用get()获取具体属性的值
list = json.loads(res.text)for i in list:print(i.get('edition'))

4. 如何添加常用的header
- 如果想在实际的代码中设置HTTP请求头,可以通过使用相应编程语言和HTTP库的功能来完成。下面是一个示例,显示如何使用Python的requests库添加常用的请求头:
import requestsurl = "https://example.com"
headers = {"User-Agent": "Mozilla/5.0","Accept-Language": "en-US,en;q=0.9","Referer": "https://example.com",# 添加其他常用请求头...
}response = requests.get(url,stream=True, headers=headers)
- 在上述示例中,我们创建了一个headers字典,并将常用的请求头键值对添加到字典中。然后,在发送请求时,通过传递headers参数将这些请求头添加到GET请求中。
请注意,实际使用时,可以根据需要自定义请求头部。常用的请求头包括 “User-Agent”(用户代理,用于识别客户端浏览器/设备)、“Accept-Language”(接受的语言)、“Referer”(来源页面)等。
5. 如何合并两个div
try:html = ""<html><body></body></html>""soup = BeautifulSoup(html, 'html.parser')# 创建新的div标签new_div = soup.new_tag('div')temp_part1 = html_dom.find('div', 'detail-title')new_div.append(temp_part1)temp_part2 = html_dom.find("div", "detail-article")new_div.append(temp_part2)card = {"content": "", "htmlContent": ""}html_dom=new_div
except:return6. 如何删除html dom的部分结构
- 要在 Python 中删除已获取的 DOM 结构的一部分,你可以使用 Beautiful Soup 库来解析和操作 HTML。下面是一个示例代码,演示如何删除 DOM 结构的一部分:
from bs4 import BeautifulSoup# 假设你已经获取到了 DOM 结构,将其存储在 dom 变量中
dom = '''
<div class="container"><h1>Hello, World!</h1><p>This is a paragraph.</p>
</div>
'''# 创建 Beautiful Soup 对象
soup = BeautifulSoup(dom, 'html.parser')# 找到要删除的部分
div_element = soup.find('div', class_='container')
div_element.extract()# 输出修改后的 DOM 结构
print(soup.prettify())
- 在上述示例中,我们首先将 DOM 结构存储在 dom 变量中。然后,我们使用 Beautiful Soup 创建了一个解析对象 soup。
接下来,我们使用 find() 方法找到了要删除的部分,这里是 <div class=“container”>。然后,我们使用 extract() 方法将该元素从 DOM 结构中删除。 - 最后,我们使用 prettify() 方法将修改后的 DOM 结构输出,以便查看结果。
在实际应用中,需要根据要删除的部分的选择器和属性进行适当的调整。
7. 如何一次性获取所有div标签里的文本
- 要一次性获取所有<div>标签里的文本,你可以使用BeautifulSoup库或lxml库进行解析。以下是使用这两个库的示例代码:
- 方式一:使用BeautifulSoup库:
from bs4 import BeautifulSoup# 假设html为包含标签的HTML文档
soup = BeautifulSoup(html, 'html.parser')# 查找所有div标签并获取其文本内容
div_texts = [div.get_text() for div in soup.find_all('div')]
- 方式二:使用lxml库:
from lxml import etree# 假设html为包含标签的HTML文档
tree = etree.HTML(html)# 使用XPath查找所有div标签并获取其文本内容
div_texts = tree.xpath('//div//text()')
- 使用这些代码,你可以一次性获取所有的<div>标签里的文本内容。请注意,这些方法返回的结果是一个列表,列表中的每个元素对应一个<div>标签的文本内容。你可以根据需要进一步处理这些文本内容。
8. python爬虫如何改变响应文本字符集编码
-
在Python爬虫中,你可以通过以下几种方法来改变响应文本的字符集编码:
-
方式一:使用response.encoding属性:当使用requests库发送请求并获取到响应对象后,可以通过response.encoding属性来指定响应文本的字符集编码。根据响应中的内容,可以尝试不同的编码进行设置,例如UTF-8、GBK等。示例代码如下:
import requestsresponse = requests.get('https://example.com')
response.encoding = 'UTF-8' # 设置响应文本的字符集编码为UTF-8
print(response.text)
apparent_encoding用于获取响应内容的推测字符集编码,是一个只读属性,它只返回推测的字符集编码,并不能用于设置或更改字符集编码。如果需要更改字符集编码,请使用response.encoding属性进行设置
- 方式二:使用chardet库自动检测字符集编码:如果你不确定响应的字符集编码是什么,可以使用chardet库来自动检测响应文本的字符集编码。该库可以分析文本中的字符分布情况,并猜测出可能的字符集编码。示例代码如下:
import requests
import chardetresponse = requests.get('https://example.com')
encoding = chardet.detect(response.content)['encoding'] # 检测响应文本的字符集编码
response.encoding = encoding # 设置响应文本的字符集编码
print(response.text)
- 方式三:使用Unicode编码:如果你无法确定响应文本的正确字符集编码,你可以将文本内容转换为Unicode编码,这样就不需要指定字符集编码了。示例代码如下:
import requestsresponse = requests.get('https://example.com')
text = response.content.decode('unicode-escape')
print(text)
- 以上是三种常见的方法来改变响应文本的字符集编码。根据具体情况选择最适合的方法来处理爬取的网页内容。记住,在处理字符集编码时,要注意处理异常情况,例如编码错误或无法识别字符集等。
9. 如何进行字符集转码
-
字符集转码是指将文本从一种字符集编码转换为另一种字符集编码的过程。在Python中,可以使用**encode()和decode()**方法进行字符集转码操作。
-
方式一: encode(encoding) 将文本从当前字符集编码转换为指定的编码。其中,encoding参数是目标编码格式的字符串表示。示例代码如下:
text = "你好"
encoded_text = text.encode('utf-8') # 将文本从当前编码转换为UTF-8编码
print(encoded_text)
- 方式二:decode(encoding) 将文本从指定的编码格式解码为当前字符集编码。其中,encoding参数是原始编码格式的字符串表示。示例代码如下:
encoded_text = b'\xe4\xbd\xa0\xe5\xa5\xbd' # UTF-8 编码的字节串
decoded_text = encoded_text.decode('utf-8') # 将字节串从UTF-8解码为Unicode文本
print(decoded_text)
- 在进行字符集转码时,需要确保原始文本和目标编码相匹配。如果不确定原始字符集,可以先使用字符集检测工具(如chardet)来确定原始编码,然后再进行转码操作。
- 使用正确的字符集编码进行转码操作可以确保文本在不同环境中的正确显示和处理。
11. response.text 和 respone.content的区别
在许多编程语言的HTTP请求库中,比如Python的requests库,有两个常用的属性用于获取HTTP响应的内容:response.text和response.content。区别如下:
- response.text:
1. response.text返回的是一个字符串,表示HTTP响应的内容。
2. 这个字符串是根据HTTP响应的字符编码来解码的,默认使用UTF-8编码。
3. 如果响应中包含了其他编码的内容,那么可以通过指定response.encoding属性来手动指定相应的编码方式进行解码。
- response.content:
1. response.content返回的是一个字节流,表示HTTP响应的内容。
2. 这个字节流是原始的二进制数据,没有进行任何编码解码操作。
3. response.content适用于处理二进制文件,比如图片、音视频文件等。
简而言之,response.text适用于处理文本内容,会自动进行编码解码操作,而response.content适用于处理二进制内容,返回的是原始字节流。
使用哪个属性取决于你处理的内容类型和需求。如果你处理的是文本内容,比如HTML、JSON数据等,那么通常使用response.text。如果你处理的是二进制文件,比如图像或音视频文件,那么使用response.content更合适。
12. 如何发送post请求访问页面
解析一个请求主要关注以下几个方面
- 请求路径
- 请求参数(post请求是隐含参数,浏览器发送的是post请求)
- 请求头
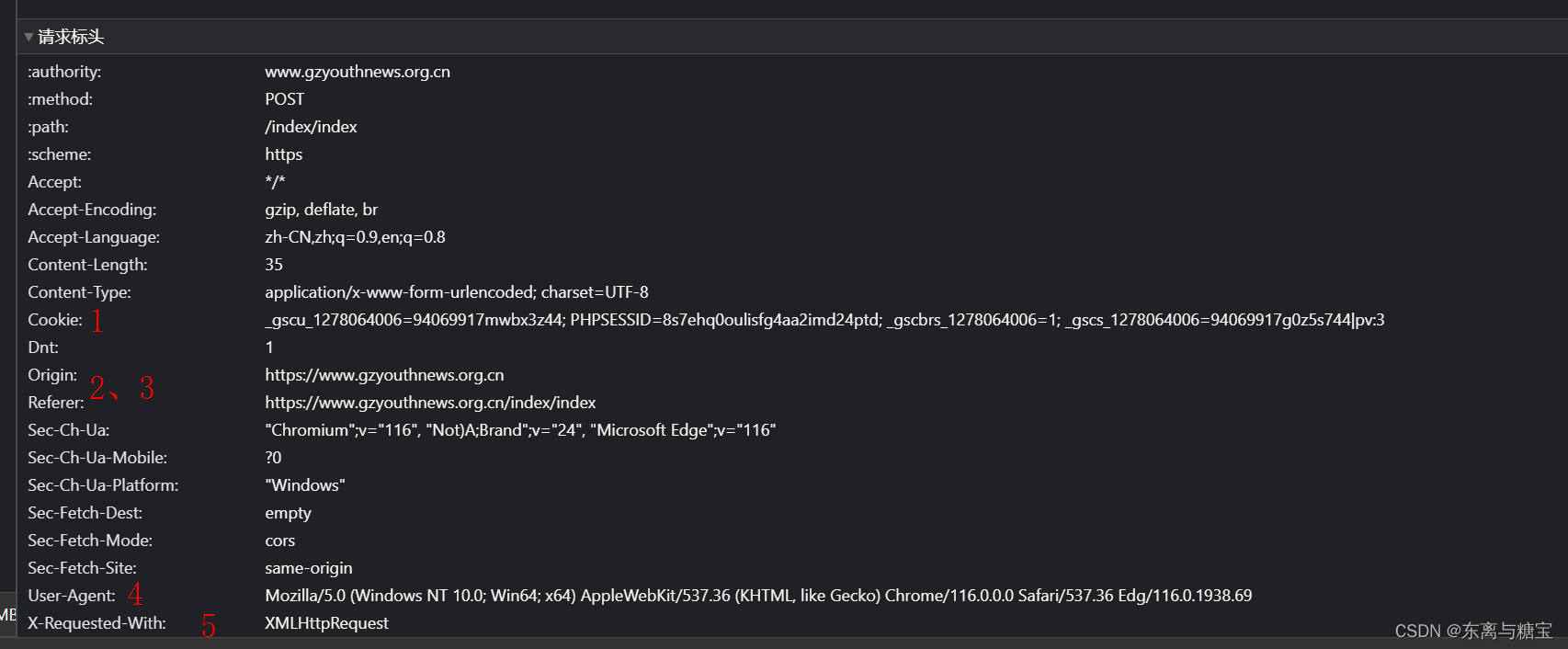
- 请求类型
以下是一个示例代码
import jsonimport requests
def main():url = 'https://www.gzyouthnews.org.cn/index/index'header = {'X-Requested-With':'XMLHttpRequest'}data={'act':'list','date':'2023-08-10','paper_id':1}res = requests.post(url=url,headers=header,data=data)list = json.loads(res.text)for i in list:print(i.get('edition'))if __name__ == '__main__':main()
13. 如何获取 url 中的参数
要从给定的 URL 中获取参数 page=100,你可以使用 URL 解析库来解析 URL,并提取出所需的参数。
以下是使用 Python 的 urllib.parse 模块解析 URL 参数的示例代码:
from urllib.parse import urlparse, parse_qsurl = "https://blog.csdn.net/phoenix/web/v1/comment/list/131760390?page=100&size=10&fold=unfold&commentId="parsed_url = urlparse(url)
query_params = parse_qs(parsed_url.query)page_value = query_params.get("page", [None])[0]
print(page_value)
在上述示例中,我们首先使用 urlparse 函数解析 URL,然后使用 parse_qs 函数解析查询参数部分。parse_qs 函数将查询参数解析为字典,其中键是参数名称,值是参数值的列表。
然后,我们使用 query_params.get(“page”, [None])[0] 从字典中获取名为 page 的参数值。这将返回参数的值,如果该参数不存在,则返回 None。
输出结果将是 100,这是从 URL https://blog.csdn.net/phoenix/web/v1/comment/list/131760390?page=100&size=10&fold=unfold&commentId= 中提取的 page 参数的值。
请注意,如果 URL 的参数值是字符串形式,你可能需要根据需要进行进一步的类型转换。
相关文章:
python萌新爬虫学习笔记【建议收藏】
文章目录 1. 如何何请求解析url2. 如何获取标签里面的文本3. 如何解析JSON格式4. 如何添加常用的header5. 如何合并两个div6. 如何删除html dom的部分结构7. 如何一次性获取所有div标签里的文本8. python爬虫如何改变响应文本字符集编码9. 如何进行字符集转码11. response.text…...
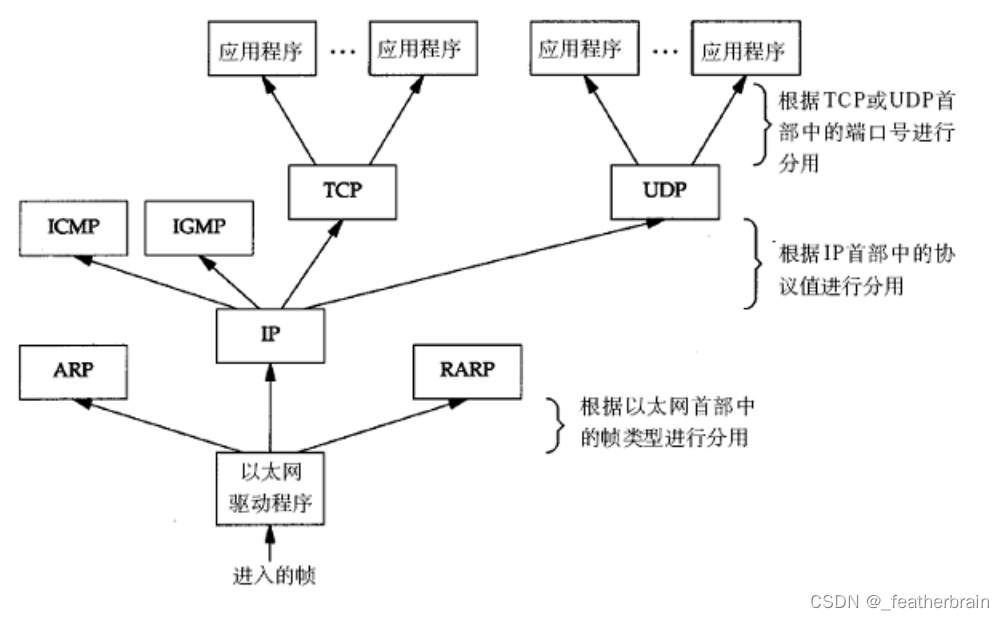
网络编程——基础知识
全文目录 网络发展协议OSI七层模型TCP/IP五层(或四层)模型 网络传输网络地址IP地址MAC地址 网络通信的本质 网络发展 网络没有出来之前计算机都是相互独立的: 网络就是将独立的计算机连接在一起,局域网和广域网的区别只是范围上的大小: 局域…...
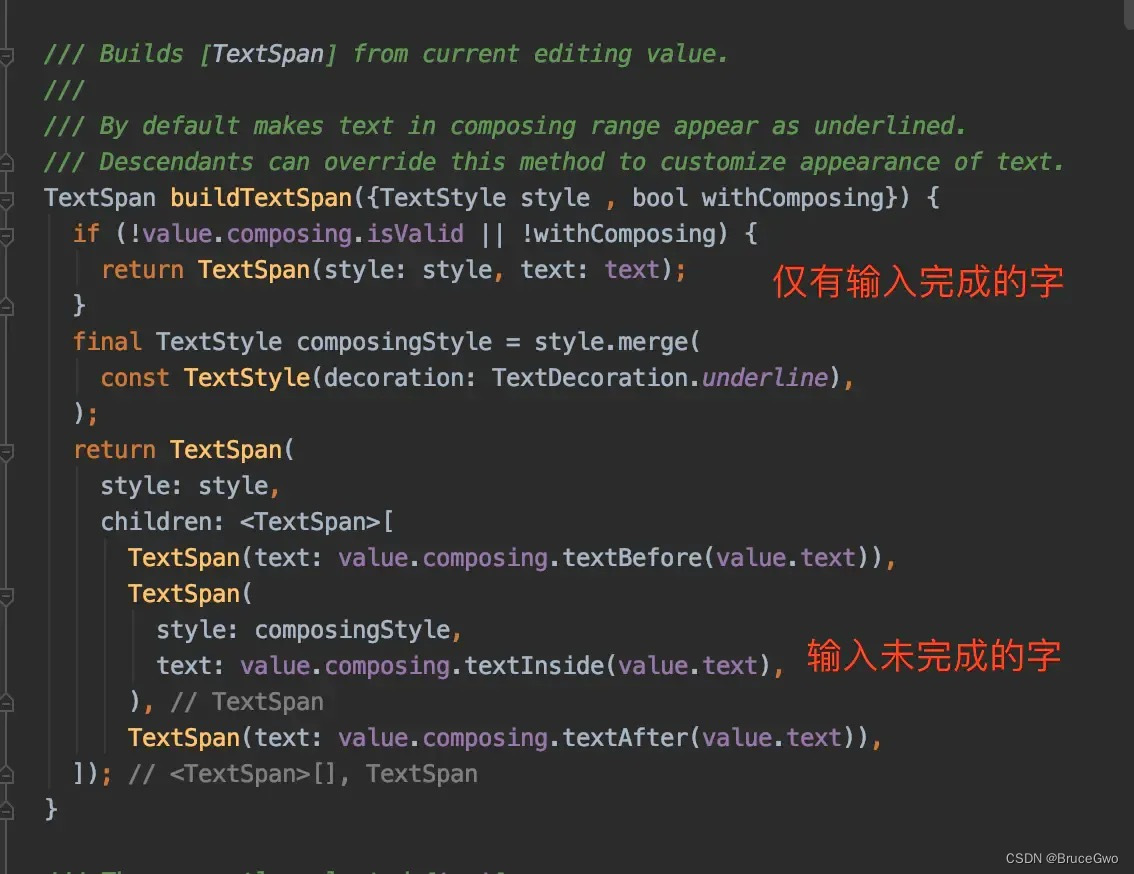
flutter聊天界面-TextField输入框实现@功能等匹配正则表达式展示高亮功能
flutter聊天界面-TextField输入框实现功能等匹配正则表达式展示高亮功能 一、简要描述 描述: 最近有位朋友讨论的时候,提到了输入框的高亮展示。在flutter TextField中需要插入特殊样式的标签,比如:“请 张三 回答一下”&#x…...

【C语言】指针的进阶(二)—— 回调函数的讲解以及qsort函数的使用方式
目录 1、函数指针数组 1.1、函数指针数组是什么? 1.2、函数指针数组的用途:转移表 2、扩展:指向函数指针的数组的指针 3、回调函数 3.1、回调函数介绍 3.2、回调函数的案例:qsort函数 3.2.1、回顾冒泡排序 3.2.1、什么是qso…...
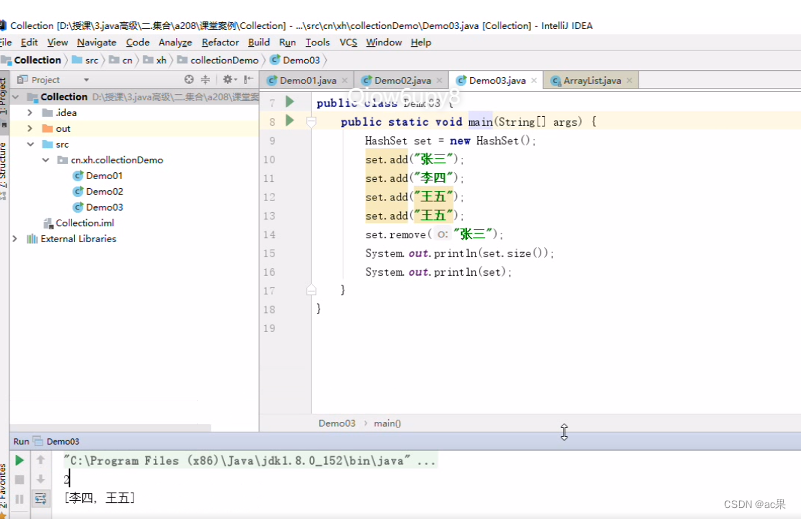
Java集合之HashSet接口
Set Set接口、HashSet类、TreeSet类 Set(组、集):表示无序,元素不能重复的集合,组中的元素必须唯一 Set接口 Set接口定义了组/集/集合(Set)。他扩展了Collection接口,并声明了不允…...
uniapp----微信小程序 日历组件(周日历 月日历)【Vue3+ts+uView】
uniapp----微信小程序 日历组件(周日历&& 月日历)【Vue3tsuView】 用Vue3tsuView来编写日历组件;存在周日历和月日历两种显示方式;高亮显示当天日期,红点渲染有数据的日期,点击显示数据 1. calenda…...
【记录】深度学习环境配置(pytorch版)
1080面对Transformer连勉强也算不上了,还是要去用小组的卡 完整记一个环境配置,方便后面自用✍️ 目前要简单许多,因为显卡驱动已经装好,后安装的库版本与其对应即可。 nvidia-smi查看GPU信息 ** CUDA版本12.2 conda -V查询conda…...

如何将项目推送到GitHub中
将项目推送到 GitHub 仓库并管理相关操作,遵循以下步骤: 创建 GitHub 账户:如果您没有 GitHub 账户,首先需要在 GitHub 官网 上创建一个账户。 创建新仓库:在 GitHub 页面上,点击右上角的加号图标…...
数据库直连提示 No suitable driver found for jdbc:postgresql
背景:我在代码里使用直连的方式在数据库中创建数据库等,由于需要适配各个数据库服务所以我分别兼容了mysql、postgresql、oracal等。但是在使用过程中会出现错误: No suitable driver found for jdbc:postgresql 但是我再使用mysql的直连方式…...

Stability AI推出Stable Audio;ChatGPT:推荐系统的颠覆者
🦉 AI新闻 🚀 Stability AI推出Stable Audio,用户可以生成个性化音乐片段 摘要:Stability AI公司发布了一款名为Stable Audio的工具,用户可以根据自己的文本内容自动生成音乐或音频。免费版可生成最长20秒音乐片段&a…...

HTML中的<canvas>元素
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ canvas元素⭐ 用途⭐ 示例⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 欢迎来到前端入门之旅!感兴趣的可以订阅本专栏哦!这个专栏是为那些对Web开发感兴趣、刚刚踏入前端领域的朋友们…...

【论文阅读】MARS:用于自动驾驶的实例感知、模块化和现实模拟器
【论文阅读】MARS:用于自动驾驶的实例感知、模块化和现实模拟器 Abstract1 Introduction2 Method2.1 Scene Representation2.3 Towards Realistic Rendering2.4 Optimization3.1 Photorealistic Rendering3.2 Instance-wise Editing3.3 The blessing of moduler des…...

Leetcode 2856. Minimum Array Length After Pair Removals
Leetcode 2856. Minimum Array Length After Pair Removals 1. 解题思路2. 代码实现 题目链接:2856. Minimum Array Length After Pair Removals 1. 解题思路 这一题思路而言个人觉得还是挺有意思的,因为显然这道题没法直接用greedy的方法进行处理&am…...

深入了解Vue.js框架:构建现代化的用户界面
目录 一.Vue前言介绍 二.Vue.js框架的核心功能与特性 三.MVVM的介绍 四.Vue的生命周期 五.库与框架的区别 1.库(Library): 2.框架(Framework): 六.Vue常用指令演示 1.v-model 2.v-on:click&…...

力扣 -- 673. 最长递增子序列的个数
小算法: 通过一次遍历找到数组中最大值出现的次数: 利用这个小算法求解这道题就会非常简单了。 参考代码: class Solution { public:int findNumberOfLIS(vector<int>& nums) {int nnums.size();vector<int> len(n,1);auto…...

43.248.189.X网站提示风险,存在黑客攻击页面被篡改,改如何解决呢?
当用户百度搜索我们的网站,准备打开该网站时,访问页面提示风险,告知被黑客攻击并有被篡改的情况,有哪些方案可以查看解决问题? 当遇到网站提示风险到时候,可以考虑采用下面几个步骤来解决问题:…...

Java8中判断一个对象不为空存在一个类对象是哪个
Java8中判断一个对象不为空存在一个类对象是哪个? 在Java 8中,你可以使用java.util.Optional类来处理可能为空的对象。Optional类可以帮助你优雅地处理空值情况,而不需要显式地进行空值检查。 这是一个简单的Optional示例: imp…...

项目:点餐系统
项目扩展: 1.订单操作 2.用户管理(临时用户生成用户注册与登录) 项目有可能涉及到的面试: 说说你的项目 为什么要做这个项目 服务器怎么搭建的 最初我自己写了一个简单的服务器,但是不太稳定,比较粗…...
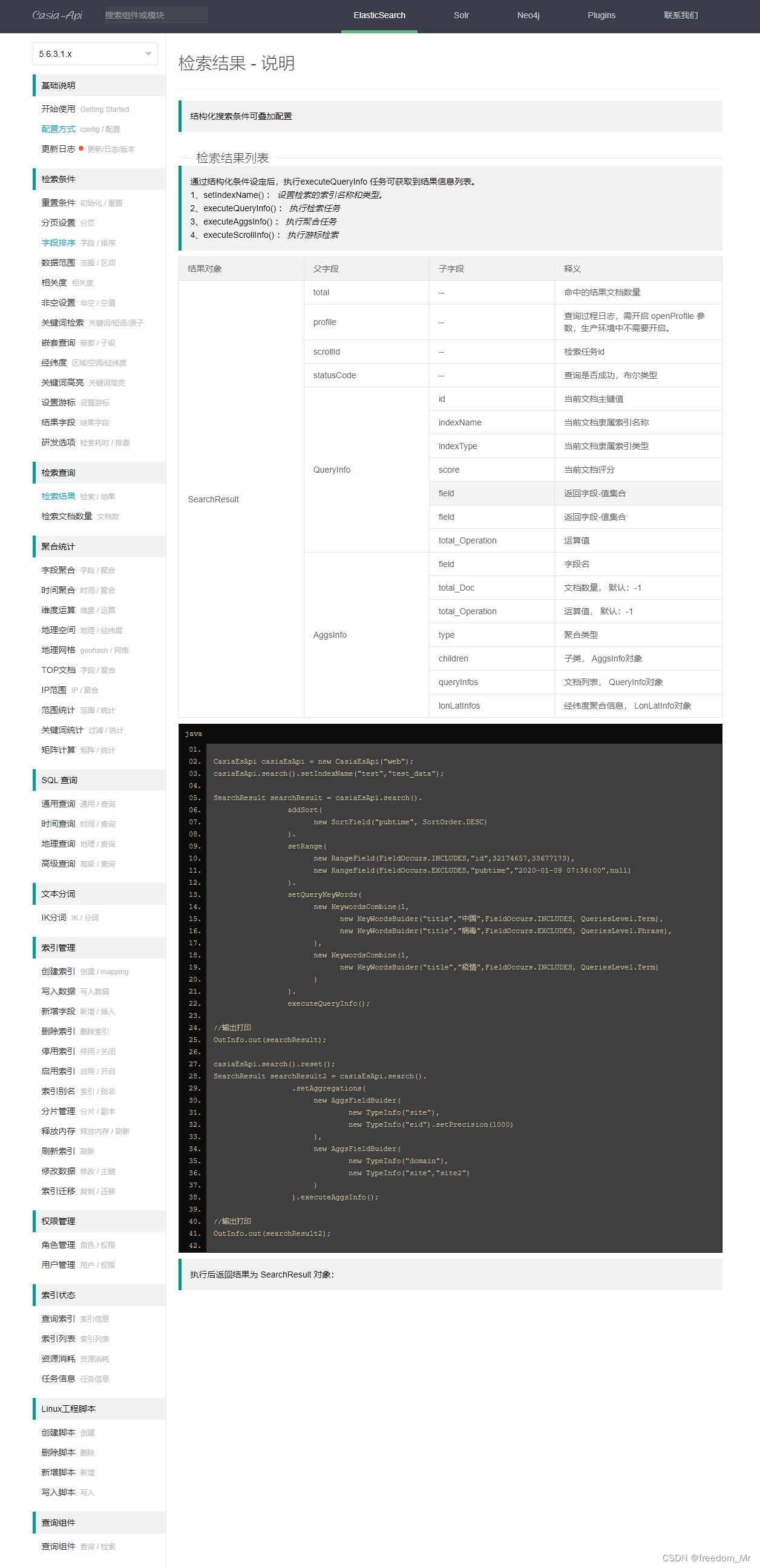
ElasticSearch 5.6.3 自定义封装API接口
在实际业务中,查询 elasticsearch 时会遇到很多特殊查询,官方接口包有时不便利,特殊情况需要自定义接口,所以为了灵活使用、维护更新 编写了一套API接口,仅供学习使用 当前自定义API接口依赖 elasticsearch 5.6.3 版本…...
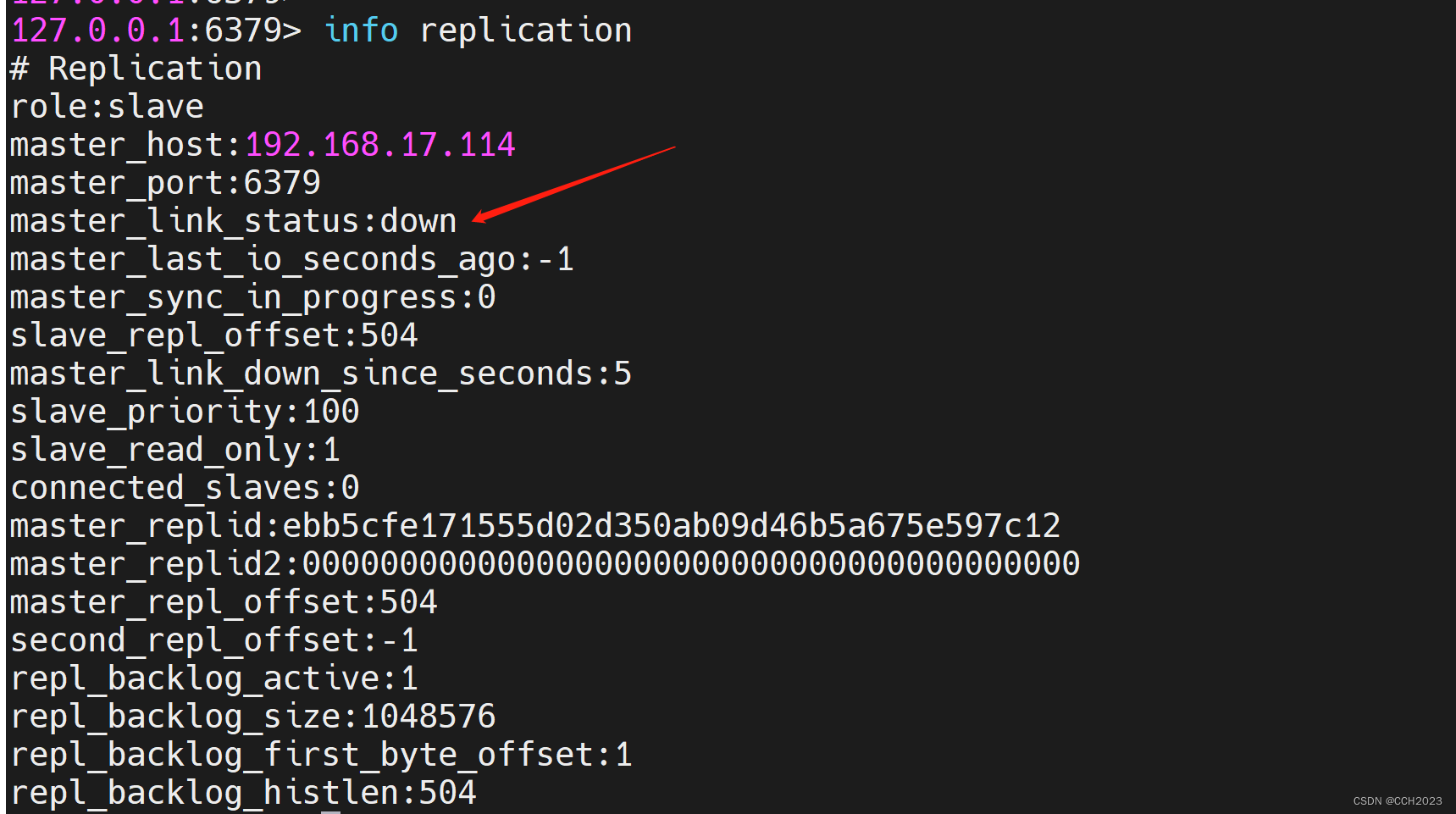
企业架构LNMP学习笔记51
企业案例使用: 主从模式: 缓存集群结构示意图: 去实现Redis的业务分离: 读的请求分配到从服务器上,写的请求分配到主服务器上。 Redis是没有中间件来进行分离的。 是通过业务代码直接来进行读写分离。 准备两台虚…...
Pixel Couplet Gen 惊艳像素春联作品集:AI与传统文化的创意碰撞
Pixel Couplet Gen 惊艳像素春联作品集:AI与传统文化的创意碰撞 1. 开篇:当像素艺术遇上传统春联 春节贴春联是中国人延续千年的传统习俗,而如今人工智能为这一古老文化注入了全新活力。Pixel Couplet Gen模型通过独特的像素艺术风格&#…...

小红书视频下载神器:三步搞定无水印批量下载,新手也能轻松上手
小红书视频下载神器:三步搞定无水印批量下载,新手也能轻松上手 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果…...

从对话到执行:OpenTiny NEXT 如何重塑前端智能化开发范式
文章目录 每日一句正能量引言:前端开发的"智能体"时刻一、MCP与WebMCP:让大模型"看懂"前端工程1.1 什么是MCP?为什么前端需要它?1.2 WebMCP:浏览器端的上下文协议1.3 实战:用WebMCP实现…...

突破限制!无需模拟器的3种Windows APK安装方案
突破限制!无需模拟器的3种Windows APK安装方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer Windows APK安装一直是跨平台应用的痛点,传统模拟…...

3大突破重构教育评价:OCRAutoScore智能阅卷系统实战指南
3大突破重构教育评价:OCRAutoScore智能阅卷系统实战指南 【免费下载链接】OCRAutoScore OCR自动化阅卷项目 项目地址: https://gitcode.com/gh_mirrors/oc/OCRAutoScore OCRAutoScore是一款开源AI自动阅卷系统,通过融合OCR识别、语义分析和自动化…...

终极指南:如何用PoeCharm中文版轻松规划你的《流放之路》角色构建
终极指南:如何用PoeCharm中文版轻松规划你的《流放之路》角色构建 【免费下载链接】PoeCharm Path of Building Chinese version 项目地址: https://gitcode.com/gh_mirrors/po/PoeCharm 还在为《流放之路》复杂的角色构建系统感到头疼吗?面对海量…...

Graphormer效果展示:同一分子不同SMILES写法下的预测一致性验证
Graphormer效果展示:同一分子不同SMILES写法下的预测一致性验证 1. 模型概述 Graphormer是一种基于纯Transformer架构的图神经网络,专门为分子图(原子-键结构)的全局结构建模与属性预测而设计。该模型在OGB(Open Graph Benchmark)和PCQM4M等分子基准测…...

AppleRa1n激活锁绕过工具:技术解析与合规应用指南
AppleRa1n激活锁绕过工具:技术解析与合规应用指南 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 激活锁机制在保护用户数据安全的同时,也为合法设备所有者带来了使用障碍。本文…...

番茄小说下载器完整指南:3种方法永久保存你喜爱的小说
番茄小说下载器完整指南:3种方法永久保存你喜爱的小说 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 番茄小说下载器是一个功能强大的开源工具,专门用于批量下载和…...

终极指南:如何用Obsidian PDF++插件将PDF阅读效率提升300%
终极指南:如何用Obsidian PDF插件将PDF阅读效率提升300% 【免费下载链接】obsidian-pdf-plus PDF: the most Obsidian-native PDF annotation & viewing tool ever. Comes with optional Vim keybindings. 项目地址: https://gitcode.com/gh_mirrors/ob/obsid…...