Kakfa - Producer机制原理与调优
Producer是Kakfa模型中生产者组件,也就是Kafka架构中数据的生产来源,虽然其整体是比较简单的组件,但依然有很多细节需要细品一番。比如Kafka的Producer实现原理是什么,怎么发送的消息?IO通讯模型是什么?在实际工作中,怎么调优来实现高效性?
简单的生产者程序:

一、客户端初始化 KafkaProducer
new KafkaProducer() 是Producer初始化过程,比如Interceptor、Serializer、Partitioner、RecordAccumulator等。当我们使用KafkaProducer发送消息的时候,消息会经过拦截器(Interceptor)、序列化器(Serializer)和分区器(Partitioner),最后会暂存到消息收集器(RecordAccumulator)中,最终读取按批次发送。
以下跟踪比较核心的机制流程:
1、 初始化RecordAccumulator记录累加器
简单介绍:RecordAccumulator可以理解为Producer发送数据缓冲区,Producer数据发送时并不会直接连接Broker后,一条一条的发送,而是会将数据(Record)放入RecordAccumulator中按批次发送。
2、初始化Sender的Iothread,在Producer在初始化过程中,会额外的创建一个ioThread。


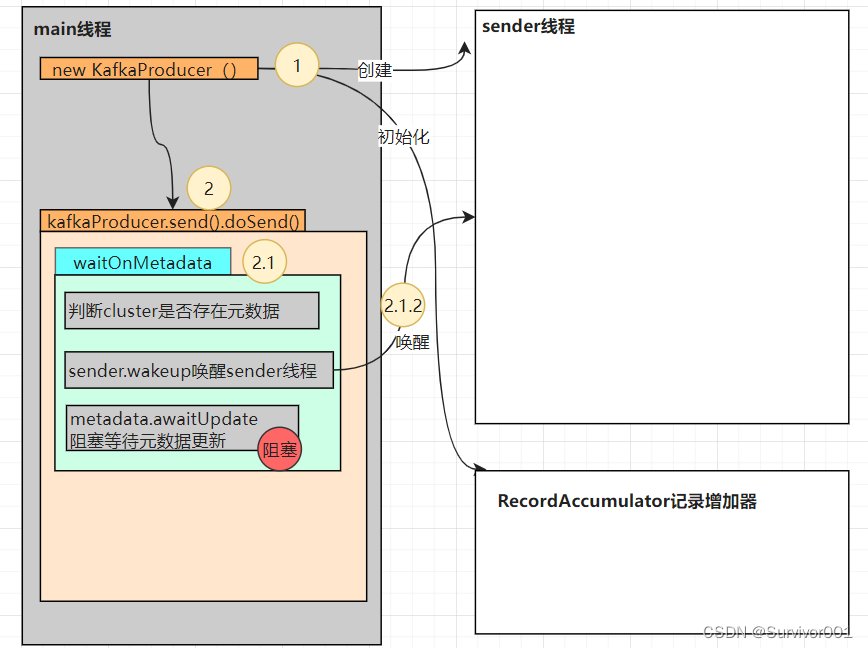
二、Send方法
到此位置Kafka只是做了一些初始化的工作,没有与kafka集群建立连接,更没有相关元数据信息。那继续看send中的doSend方法。
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {TopicPartition tp = null;try {try {// waitOnMetadata更新元数据clusterAndWaitTime = this.waitOnMetadata(record.topic(),record.partition(), this.maxBlockTimeMs);} catch (KafkaException var19) {Cluster cluster = clusterAndWaitTime.cluster;........byte[] serializedKey;try {// 序列化serializedKey = this.keySerializer.serialize(record.topic(), record.headers(), record.key());} catch (ClassCastException var18) {........byte[] serializedValue;try {serializedValue = this.valueSerializer.serialize(record.topic(), record.headers(), record.value());} // 获取元数据中partition信息int partition = this.partition(record, serializedKey, serializedValue, cluster);// ..........// 数据append到accumulator中RecordAppendResult result = this.accumulator.append(tp, timestamp, serializedKey, serializedValue, headers, interceptCallback, remainingWaitMs);..........return result.future;1、WaitonMetadat元数据更新
方法内部会优先判断当前Cluster是否存在元数据partitions,如果不存在意味着还没有建立连接获取元数据,此时它会wakeup唤醒sender线程。

注意:此时Cluster并不是完全时空的,它已经有指定的Node列表信息。
![]()
在早期版本的时候元数据是存储在zookeeper中的, 元数据指的是集群中分区信息、节点信息、以及节点、主题、分区的映射关系等。在生产者启动的时候没有元数据的支撑,是无法进行数据的发送的,等于瞎子。但是zookeeper存储元数据,在并发场景下会对zookeeper产生网卡压力,那就意味着要保障Kakfa可靠性的前提就要保障zookeeper的可靠性。
所以在1.0版本之后,Kafka将元数据维护在了Broker节点中。Producer可以通过Borker获取元数据,减少对zookeeper的依赖。只有一些核心的内容交给zookeeper做分布式协调。
2、Sender线程run方法
Sender线程中run方法,一个while(runing),这是一中Loop过程一种常见的响应式编程方式,比如Redis服务中也是一种EventLoop事件轮询过程。

其内部核心方法NetWorkClient.poll实现了客户端连接、数据发送、事件处理工作。

metadataUpdater.maybeUpdate方法在第一次被执行时,因为没有元数据节点信息,会执行this.maybeUpdate(now, node)方法,方法内部实现了initiateConnect方法用于客户端建立连接,其底层就是使用的Java Nio的Selector多路复用器。
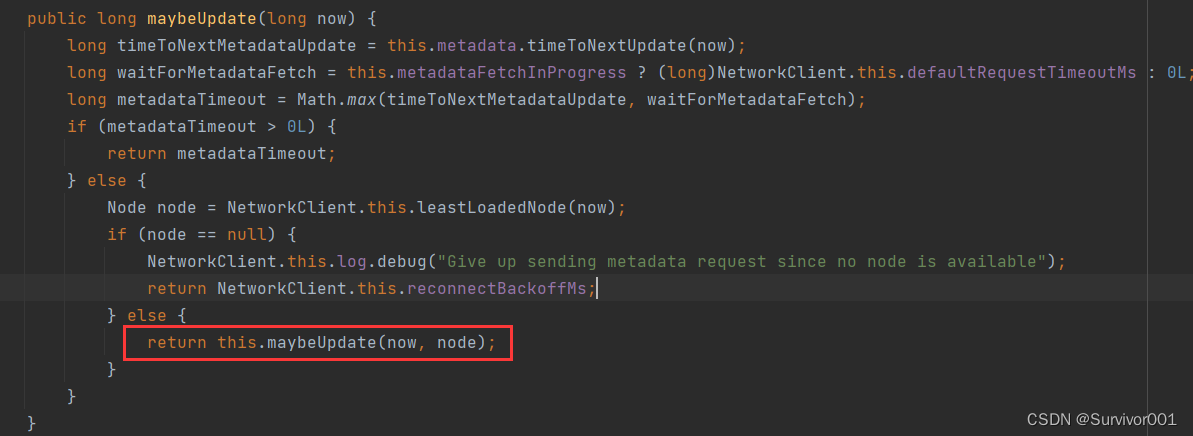

建立连接之后,nioSelector.select()等待事件响应。
之后触发handleCompletedReceives处理器进行元数据同步过程。
注意: 在完成元数据更新以后,metadata.update会调用 this.notifyAll(),唤醒阻塞的main线程,进行数据发送工作。

到此为止主线程waitOnMetadata方法完成元数据的更新。
之后main就开始处理Serializer序列化,获取partition元数据信息,以及数据发送工作。
3、RecordAccumulator 记录累加器
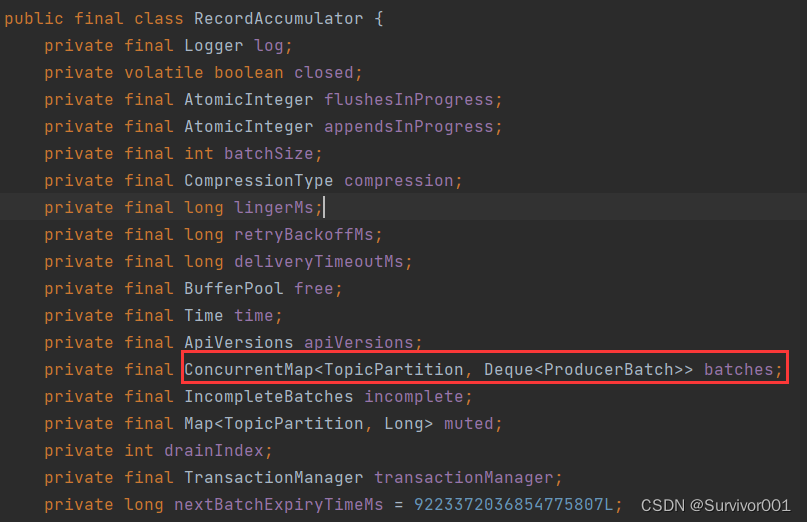
生产者在发送数据时,并不是建立连接后每消息发送的,而是会将消息按批次发送。RecordAccumulator 对象中batches会为每一个TopicPartition维护一个双端队列。用于缓存record数据。
ConcurrentMap<TopicPartition, Deque<ProducerBatch>> batches
TopicPartition 主题分区:缓冲区按照主题分为不同的双端队列
Deque<ProducerBatch> 双端队列,ProducerBatch:一批次的数据(多个数据,默认容量16k)
结构如下:

生产者在往batches中添加数据时,使用了Sychronized,所以Producer在多线程场景下是线程安全的。

为什么要有RecordAccumulator ?
RecordAccumulator的主要作用是暂存Main Thread发送过来的消息,然后Sender Thread就可以从RecordAccumulator中批量的获取到消息,减少单个消息获取的请求次数,减少网卡IO压力,提升性能效率。
相关参数配置以及调优点:
1、RecordAccumulator buffer.memory默认大小32mb
指每一个new KafkaProducer中RecordAccumulator的batches所有承载的最大buffer.memory=32mb。

设置方式:properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 3210241024);
如果RecordAccumulator 缓存空间满时,会进行阻塞,等待数据被消费,如果指定时间内消息没有发送除去,即仍然是满状态,则抛出异常,默认60s。
设置方式:properties.put(ProducerConfig.MAX_BLOCK_MS_CONFIG, 60*1000);
优化点: 根据业务需求,如果TopicPartition较多,而数据量很大时,这是及时单个TopicPartition中batche很少,可能总的容量也超过32mb,这时可以扩大buffer_memery大小。
2、Kafka中单个batche大小默认为16k。
指每个batche大小为16k。batche用于存储数据Record。
如果record < 16k,则batche可以存储多个数据,此时batche空间是会被重复利用的。
如果record > 16k,则当前record会额外申请存储空间,使用完后销毁。

优化点:batche大小需要根据业务评估,不要有过多大record存在,确保每一个batche可以容纳record,尽量减少内存空间的频繁申请和销毁,以及内存碎片化。
3、同步阻塞和非阻塞的选择
RecordAccumulator用于支持分批次发送数据。在KafkaProducer中send方法是异步接口,通过 send.get()方法可以使其阻塞,等待数据返回。
实现同步的发送数据,需要等待kafka接收了record后响应,producer才会进行下一个record发送。此时虽然会有更高一致性,但RecordAccumulator就失去了意义。
非阻塞send情况下,当生产和消费端IO不对称时,可以通过LINGRE_MS_CONFG 30 来要求sender线程每次拉取RecordAccumulator中数据时,等待一段时间再拉取,尽量确保按批次拉取,减少更多的网络IO。
设置方式:properties.put(ProducerConfig.LINGRE_MS_C0NFG , 0);
继续内容分析
到此当Main线程将数据append到RecordAccumulator容器后,其核心的工作就结束了,此时它也会调用sender.wakeup,告知已经有数据需要处理了,并确保sender线程不会select阻塞住。
Sender线程是一个Loop过程,在发送数据过程中,会从RecordAccumulator中拉取批次数据进行打包发送,并不是一个个batche发送。默认封装的包大小为1mb。
设置方式:pp.setProperty(ProducerConfig.MAX_REQUEST_SIZE_CONFIG , String.valueOf(1 * 1024 * 1024))
Sender线程在真正发送数据前,还额外存储了Request数据到InFilgntRequest(飞行中的包),InFilgntRequest 默认大小为5,意思是指生产者向kafka发送5个包request后,都没有回应时,则停止发送变成阻塞状态。
这种设计在同步发送过程没有作用的,因为同步过程是每请求返回的。

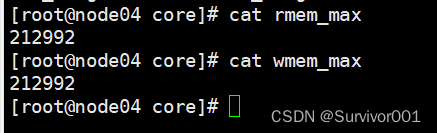
SEND_BUFFER_CONFIG 发送缓冲区配置、RECEIVE_BUFFER_CONFIG 接收缓冲区配置,这两个就是IO层的缓冲区配置了,不同的操作系统可能不一样。设置成-1,代表默认使用系统分配大小。
pp.setProperty(ProducerConfig.SEND_BUFFER_CONFIG , String.valueOf(32 * 1024)); pp.setProperty(ProducerConfig.RECEIVE_BUFFER_CONFIG , String.valueOf(32 * 1024));
查看内核默认配置:

到此Producer整个数据发送流程机制就清楚了,Ack的设定涉及到Broker数据同步和Consumer消费状态,这块单独再进行分析。
总结一下:
1、Producer的实现是由Main线程和Sender线程组合完成的。
Main线程核心完成了数据的输入、Producer初始化和数据append到RecordAccumulator工作,具体的元数据的更新、数据发送等IO操作都是都Sender线程完成。
Sender线程工作模式是中间件中比较常见的响应式编程模式。其在Loop过程中进行客户端连接、元数据更新、数据打包发送等工作。
2、Kakfa中IO操作封装了Java中Nio的实现(Selector),底层是多路复用器的实现,而不是netty。
3、Producer发送数据过程并不是简单的一条一条数据发送,其内部封装RecordAccumulator、Batche、Request包,可以实现按批次发送数据,减少IO次数。同时结合FilghtRequest飞行中请求大小限制,确保kafka未正常响应时,抛出异常防止数据丢失。在开发过程中,可以通过调整参数,来达到优化目的。
相关文章:
Kakfa - Producer机制原理与调优
Producer是Kakfa模型中生产者组件,也就是Kafka架构中数据的生产来源,虽然其整体是比较简单的组件,但依然有很多细节需要细品一番。比如Kafka的Producer实现原理是什么,怎么发送的消息?IO通讯模型是什么?在实…...
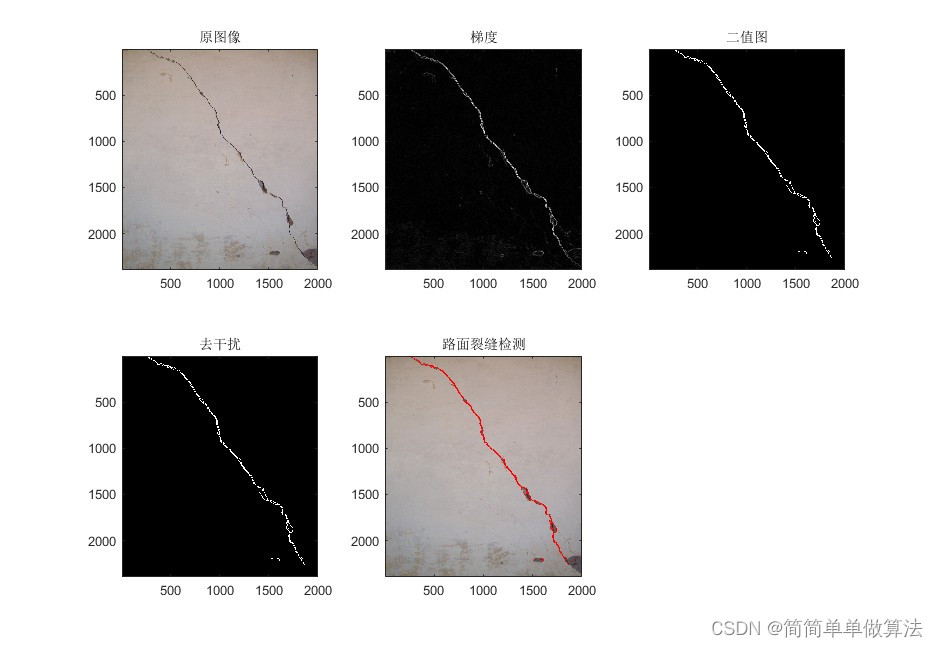
基于图像形态学处理和边缘提取算法的路面裂痕检测matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022a 3.部分核心程序 [Rr,Cc] size(Image1);% 获取 Image1 矩阵的大小(行数和列数) % 创…...
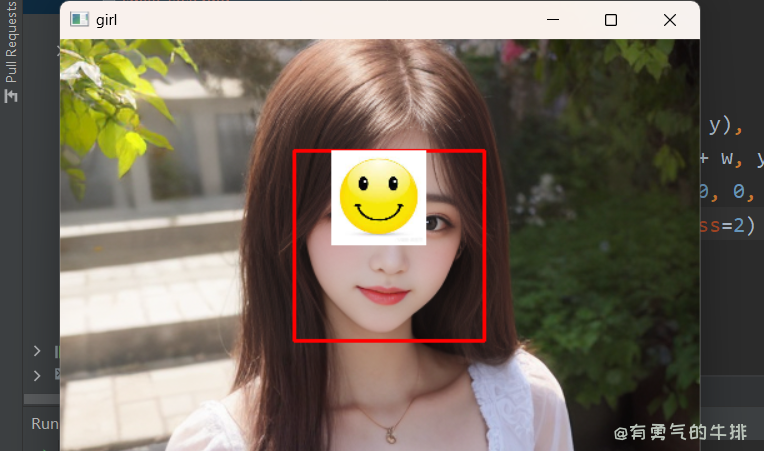
opencv 基础(持续更新中)
1 前言 https://www.couragesteak.com/ 2 安装 3 基础属性demo 打开一张图片: import cv2img cv2.imread(./girl.jpg)print(img.shape) # (1536, 1024, 3) 数组形状 print(type(img)) # numpy 数组 print(img) # 三维数组(彩色图片&am…...

科普现场!万博智云参加第五届张江汇智科普节
9月15日,第五届张江汇智科普节在汇智国际商业中心如期开展,展会中汇集了众多信息科技领域的新兴产品,展示内容主要分为国产替代和元宇宙场景展示两个方面。展现国产化最新科技成果,践行技术普惠理念,把高、精、专的技术…...
并记录过程产生的BUG问题。)
【记录】实现从Linux下载下载文件(文件导出功能)并记录过程产生的BUG问题。
前言 导出功能的实现,主要记录总结导出过程中出现的一些问题。 代码实现导出功能 public R templateDown(HttpServletResponse response) {String fileName "template.xlsx";// 清空responseresponse.reset();response.setCharacterEncoding("UTF…...

可扩展性表设计方案
文章目录 1 使用预留字段2 使用JSON字段3 使用单表继承4 构建属性表5 直接构建新表6 适当冗余 1 使用预留字段 在表设计初期,可以预留一些命名通用的备用字段,例如field1、field2、field3。当业务需要增加新字段时,就直接使用这些预留字段,无…...
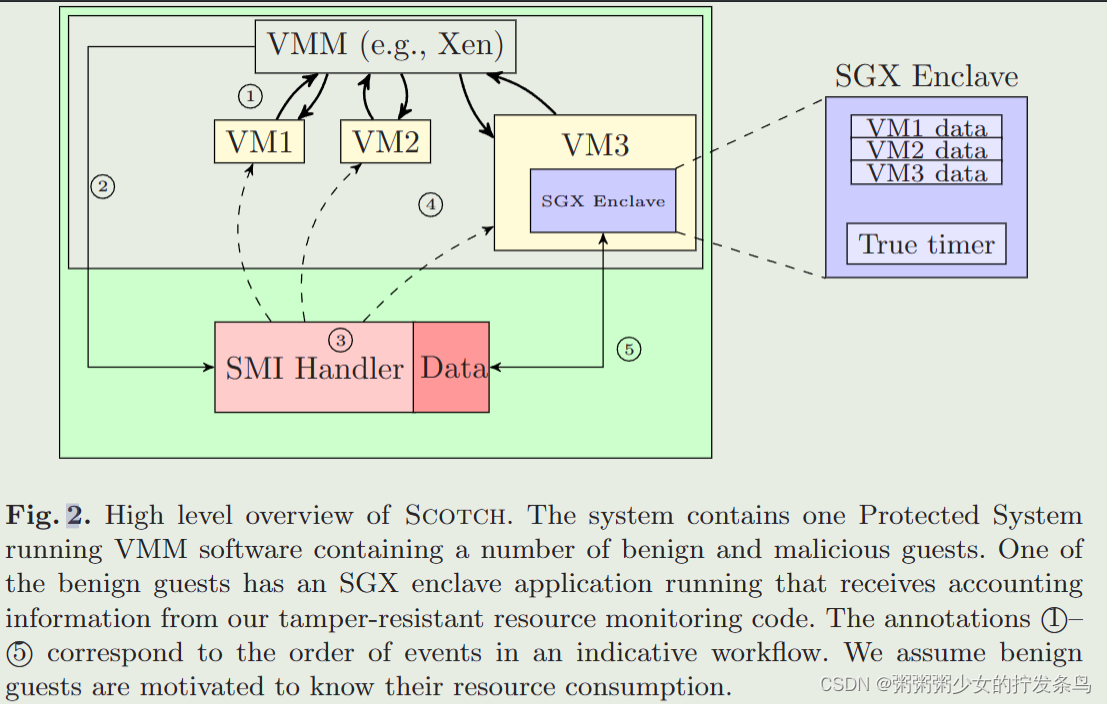
Scotch: Combining SGX and SMM to Monitor Cloud Resource Usage【TEE的应用】
目录 摘要引言贡献 背景SMMXen Credit Scheduler与资源核算SGX 威胁模型Scheduler attacksResource interference attacksVM Escape attacks 架构Resource Accounting WorkflowCost of Accounting 具体的部署和评估见论文相关工作Resource Accounting基于SMM的方法基于SGX的系统…...

腾讯mini项目-【指标监控服务重构】2023-08-19
今日已办 benchmark How can we create a configuration for gobench with -benchmem – IDEs Support (IntelliJ Platform) | JetBrains 本机进行watermill-benchmark 使用 apifox 自动化测试上报固定数量的消息 启动watermill-pub/sub的 benchmark 函数 func BenchmarkPu…...

go实现grpc-快速开始
准备工作 Go, 最新版的 如果不会安装看Getting Started. Protocol buffer compiler, protoc, version 3. 想要安装, 请读Protocol Buffer Compiler Installation. 为 protocol compiler安装Go plugins: 想要安装运行以下命令: $ go install google.golang.org/protobuf/cmd/…...

linux上的init 0-6指令作用以及一些快捷键和系统指令
目录 linux上的init 0-6指令作用 CtrlAltF1-F7作用 Linux常用系统指令 查看linux内核版本 ubuntu和centos查看系统版本信息以及硬件信息 linux上的init 0-6指令作用 在Linux系统中,运行级别(也称为init级别)用来表示系统的不同状态或操作…...

Mixin 混入
Mixin 混入 混入 (mixin) 提供了一种非常灵活的方式,来分发 Vue 组件中的可复用功能。一个混入对象可以包含任意组件选项。当组件使用混入对象时,所有混入对象的选项将被“混合”进入该组件本身的选项。 怎么理解呢,就是每一个组件都会有一…...

pycharm快捷键
CtrlAltL 代码规范化 CtrlHome 回到代码最开始 CtrlEnd 回到代码最后面 shift回车 鼠标任意位置的下一行 altj 一直按可以选中相同的变量 alt鼠标左键 可以选择多个需要修改的变量或值 将光标放在某一行,home到最前面,end到最后…...

【面试刷题】——Linux基础命令
Linux基础命令是在Linux操作系统中执行常见任务的一组命令。以下是一些常用的Linux基础命令,它们用于管理文件系统、执行系统任务、查看文件内容等。 文件和目录操作: ls: 列出目录中的文件和子目录。 pwd: 显示当前工作目录的路径。 cd: 更改当前工作…...

第四步 Vue2 配置ESLint
ESLint 是一个广泛使用的 JavaScript 代码检查工具,可以帮助开发者在编写代码时发现并修复潜在的问题和错误。 在 第一步 创建工程 时虽然已经选择了包含 ESLint 预设配置,但还需要做一些调整,让我们使用起来能够更加的丝滑。 vue.config.j…...

[.NET学习笔记] - Thread.Sleep与Task.Delay在生产中应用的性能测试
场景 有个Service类,自己在内部实现生产者/消费者模式。即多个指令输入该服务后对象后,Service内部有专门的消费线程执行传入的指令。每个指令的执行间隔为1秒。这里有两部分组成, 工作线程的载体。new Thread与Task.Run。执行等待的方法。…...

【单线图的系统级微电网仿真】基于 PQ 的可再生能源和柴油发电机组微电网仿真(Simulink)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
人脸识别技术应用安全管理规定(试行)|企业采用人脸打卡方式,这4条规定值得关注
近日,为规范人脸识别技术应用,国家互联网信息办公室起草了,并向全社会公开征求意见。该规定一共列举了25条,企业如借助人脸识别技术采集考勤打卡数据,以下4条规定值得关注。 第四条 只有在具有特定的目的和充分的必要…...

leetcode 817. 链表组件(java)
链表组件 题目描述HashSet 模拟 题目描述 给定链表头结点 head,该链表上的每个结点都有一个 唯一的整型值 。同时给定列表 nums,该列表是上述链表中整型值的一个子集。 返回列表 nums 中组件的个数,这里对组件的定义为:链表中一段…...
分布式事务基础理论
基础概念 什么是事务 什么是事务?举个生活中的例子:你去小卖铺买东西,“一手交钱,一手交货”就是一个事务的例子,交钱和交货必 须全部成功,事务才算成功,任一个活动失败,事务将撤销…...

《打造高可用PostgreSQL:策略与工具》
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🐅🐾猫头虎建议程序员必备技术栈一览表📖: 🛠️ 全栈技术 Full Stack: 📚…...

Qwen2-VL-2B-Instruct模型压缩与量化教程:在边缘设备部署视觉语言模型
Qwen2-VL-2B-Instruct模型压缩与量化教程:在边缘设备部署视觉语言模型 想让一个能看懂图片、还能跟你聊天的AI模型,在你的树莓派或者开发板上跑起来吗?听起来有点天方夜谭,毕竟这类视觉语言模型通常都是“大块头”,对…...

【安卓开发实战指南】Google Play服务集成与常见问题排查
1. Google Play服务集成基础 作为安卓开发者,你可能经常遇到需要集成Google Play服务的情况。无论是地图定位、身份验证还是应用内支付,这些功能都离不开Google Play服务的支持。但说实话,第一次集成时我也踩了不少坑,今天就和大家…...

Qwen3.5-35B-A3B-AWQ-4bit企业落地:银行柜面业务凭证图智能填单、证券开户材料图要素抽取
Qwen3.5-35B-A3B-AWQ-4bit企业落地:银行柜面业务凭证图智能填单、证券开户材料图要素抽取 1. 金融场景下的多模态AI应用价值 在银行柜面和证券开户业务中,每天需要处理大量纸质凭证和开户材料。传统人工录入方式存在效率低、错误率高、成本高等问题。Q…...

YOLO-v5效果实测:对比不同模型变体,找到性价比最高的方案
YOLO-v5效果实测:对比不同模型变体,找到性价比最高的方案 1. 引言:为什么需要对比YOLO-v5变体? 在目标检测领域,YOLO系列模型一直以"快准狠"著称。作为该系列的最新代表作,YOLO-v5提供了从超轻…...

STM32嵌入式小说阅读器:从硬件架构到中文点阵显示
1. 项目概述1.1 系统定位与设计目标本项目构建的是一款面向嵌入式学习者与电子爱好者的轻量级小说阅读器,其核心价值不在于替代商业电子书设备,而在于提供一个技术闭环完整、可深度剖析的实践平台。系统以STM32F103ZET6为控制中枢,围绕“文本…...

RN2483 LoRa模块mbed嵌入式驱动开发与低功耗实践
1. RN2483 LoRa模块嵌入式驱动库深度解析与工程实践RN2483是Microchip(原Semtech)推出的高集成度LoRa广域网通信模块,采用ARM Cortex-M0内核,内置LoRa调制解调器、射频前端、电源管理单元及完整LoRaWAN协议栈。该模块通过UART接口…...

PSO-GPR多变量时间序列预测的Matlab代码实现
基于粒子群优化算法优化高斯过程回归(PSO-GPR)的多变量时间序列预测 PSO-GPR多变量时间序列 matlab代码 注:暂无Matlab版本要求 -- 推荐 2018B 版本及以上最近在搞时间序列预测的项目,发现传统高斯过程回归(GPR)调参真是让人头秃。…...

大学生python作业
import math a float(input("请输入直角三角形的直角边1(>0): ")) b float(input("请输入直角三角形的直角边2(>0): ")) c math.sqrt(a ** 2 b ** 2) print("直角三角形的斜边为: {:.2f}".format(c))principal float(input("请输…...

StructBERT模型处理长文本效果展示:技术文档与法律条款的相似度分析
StructBERT模型处理长文本效果展示:技术文档与法律条款的相似度分析 不知道你有没有过这样的经历:面对一份几十页的技术白皮书,或者一份满是专业术语的法律合同,想快速找到其中与某个特定主题相关的段落,或者想对比两…...

Crunch性能大比拼:为什么它比其他PNG优化工具更胜一筹
Crunch性能大比拼:为什么它比其他PNG优化工具更胜一筹 【免费下载链接】Crunch Insane(ly slow but wicked good) PNG image optimization 项目地址: https://gitcode.com/gh_mirrors/cr/Crunch 在当今的Web开发中,PNG图像优化已成为提升网站性能…...