爬虫 — 验证码反爬
目录
- 一、超级鹰
- 二、图片验证模拟登录
- 1、页面分析
- 1.1、模拟用户正常登录流程
- 1.2、识别图片里面的文字
- 2、代码实现
- 三、滑块模拟登录
- 1、页面分析
- 2、代码实现(通过对比像素获取缺口位置)
- 四、openCV
- 1、简介
- 2、代码
- 3、案例
- 五、selenium 反爬
- 六、百度智能云 —— EasyDL
- 1、简介
- 2、使用步骤
一、超级鹰
是一个智能图片验证码识别、图片分类平台。
工具网址:https://www.chaojiying.com/
步骤:
1、注册账号密码进行登录;
2、进入登录界面之后,点击软件 ID,生成一个软件 ID;

3、填入对应的软件名称和软件说明,软件 KEY 不用改,最后点击提交按钮;

4、点击”开发文档“选项,选择“超级鹰图像识别 Python 语言 Demo 下载”选项,将对应代码的压缩包下载下来,解压;

5、解压后的文件里,找到.py文件,通过 pycharm 打开后,按提示修改以下代码。
if __name__ == '__main__':#用户中心>>软件ID 生成一个替换 96001chaojiying = Chaojiying_Client('超级鹰用户名', '超级鹰用户名的密码', '96001')#本地图片文件路径 来替换 a.jpg 有时WIN系统须要//im = open('a.jpg', 'rb').read()#1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()print(chaojiying.PostPic(im, 1902))#print chaojiying.PostPic(base64_str, 1902) #此处为传入 base64代码
二、图片验证模拟登录
目标网站:https://www.bilibili.com/
需求:模拟登录
1、页面分析
采用 selenium 技术进行模拟登录
1.1、模拟用户正常登录流程
- 在网站首页点击登录按钮;
- 弹出框输入账号和密码,点击登录按钮;
- 出现验证码图片识别。
1.2、识别图片里面的文字
- 获取要识别的文字(通过 selenium 的截图功能,先截全屏,然后将验证码图片抠出来);
- 使用超级鹰识别验证码图片文字,获取文字的坐标;
- 根据文字坐标进行点击;
- 点击完成,最后点击确认按钮。
2、代码实现
import time # 导入 time 模块,用于时间相关操作
from PIL import Image # 导入 Image 模块,用于图像处理
from selenium import webdriver # 导入 webdriver 模块,用于自动化测试和控制浏览器
from selenium.webdriver import ActionChains # 导入 ActionChains 类,用于模拟用户操作
from selenium.webdriver.common.by import By # 导入 By 类,用于定位元素
from selenium.webdriver.support.wait import WebDriverWait # 导入 WebDriverWait 类,用于等待元素加载
from selenium.webdriver.support import expected_conditions as EC # 导入 EC 模块,用于预期条件判断
from chaojiying_Python.chaojiying import Chaojiying_Client # 引入超级鹰验证码识别 API 客户端class Bili_login(object):# 初始法方法,用户名跟密码def __init__(self, username, password):# 加载驱动self.driver = webdriver.Chrome()# 窗口最大化self.driver.maximize_window()# 目标 urlself.url = 'https://www.bilibili.com/'# 用户名self.username = username# 密码self.password = password# 显示等待,判断驱动是否加载出来self.wait = WebDriverWait(self.driver, 100)# 加载得到验证码图片def get_img(self):# 加载网站self.driver.get(self.url)# 等待2秒time.sleep(2)# 点击登录self.driver.find_element(By.CLASS_NAME, 'header-login-entry').click()# 显示等待,判断账号与密码输入框是否加载出来self.wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'login-pwd-wp')) # 注意方法里面要填元组)# 输入账号self.driver.find_element(By.XPATH, '//form[@class="tab__form"]/div[1]/input').send_keys(self.username)# 等待0.5秒time.sleep(0.5)# 输入密码self.driver.find_element(By.XPATH, '//form[@class="tab__form"]/div[3]/input').send_keys(self.username)# 点击登录self.driver.find_element(By.CLASS_NAME, 'btn_primary ').click()# 判断验证码元素是否加载出来self.wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'geetest_item_img')))# 保存验证码图片div_img = self.save_img()# 返回验证码图片return div_img# 下载验证码图片到本地def save_img(self):# 等待2秒time.sleep(2)# 截全屏图片self.driver.save_screenshot('images/back_img.png')# 获取验证码图片的元素div_img = self.driver.find_element(By.CLASS_NAME, 'geetest_panel_next')# 获取左上角的坐标,返回 x,y 的坐标location = div_img.location# 获取宽度和高度size = div_img.size# 获取左上角的坐标x1, y1 = int(location['x']), int(location['y'])# 获取右下角的坐标x2, y2 = x1 + size['width'], y1 + size['height']# 加载背景图back_img = Image.open('images/back_img.png')# 截图,截图建议电脑缩放比例为100%img = back_img.crop((x1, y1, x2, y2))# 保存图片img.save('images/验证码图片.png')# 返回验证码图片的元素return div_img# 点击文字做验证def click_font(self, loc_dic, div_img):# 循环依次点击for x, y in loc_dic.items():# 鼠标行为链action = ActionChains(self.driver)# 鼠标移动点击action.move_to_element_with_offset(div_img, int(x), int(y)).click().perform()# 等待1秒time.sleep(1)# 点击确定self.driver.find_element(By.CLASS_NAME, 'geetest_commit_tip').click()# 主逻辑处理def main(self):# 加载得到验证码图片div_img = self.get_img()# 用超级鹰识别位置chaojiying = Chaojiying_Client('替换超级鹰用户名', '替换超级鹰用户名的密码', '949117')# 本地图片文件路径im = open('images/验证码图片.png', 'rb').read()# 验证码类型log_list = chaojiying.PostPic(im, 9004)['pic_str'].split('|')# 处理坐标数据loc_dic = {i.split(',')[0]: i.split(',')[1] for i in log_list}# 打印位置坐标# print(loc_dic)# 点击图片内文字self.click_font(loc_dic, div_img)# 主程序
if __name__ == '__main__':# 创建了一个对象b = Bili_login('123456', '123456')# 调用 main 方法b.main()
三、滑块模拟登录
目标网站:https://www.geetest.com/demo/slide-float.html
需求:模拟登录
1、页面分析
点击“点击按钮进行验证",会出现滑块。
滑块验证一般使用 selenium 实现,需要先确定滑动的距离。
获取缺口位置(三种方法)
- 通过对比像素获取缺口位置
- 通过 openCV 的方式,得到缺口位置
- 百度智能云(机器学习)识别缺口位置
使用 selenium 进行滑动。
2、代码实现(通过对比像素获取缺口位置)
将图片保存下来,通过像素识别,需要获取两张图片。一张背景图片(有缺口),一张完整图片。对比像素,拿到缺口位置的坐标,使用 selenium 进行滑动。
import random # 导入 random 模块,用于生成随机数
import time # 导入 time 模块,用于时间相关操作
import pyautogui # 导入 pyautogui 模块,用于控制鼠标和键盘
from PIL import Image # 导入 Image 模块,用于图像处理
from selenium.webdriver.support.wait import WebDriverWait # 导入 WebDriverWait 类,用于等待元素加载
from selenium import webdriver # 导入 webdriver 模块,用于自动化测试和控制浏览器
from selenium.webdriver.support import expected_conditions as EC # 导入 EC 模块,用于预期条件判断
from selenium.webdriver.common.by import By # 导入 By 类,用于定位元素class FloatSlide(object):# 初始化方法def __init__(self):# 确定 urlself.url = 'https://www.geetest.com/demo/slide-float.html'# 加载驱动self.driver = webdriver.Chrome()# 最大化窗口self.driver.maximize_window()# 显示等待self.wait = WebDriverWait(self.driver, 100)# 缺口图片保存位置self.gap_img = 'images/gap.png'# 完整图片保存位置self.intact_img = 'images/intact.png'# 加载图片并截取图片def load_img(self):# 加载网站self.driver.get(self.url)# 等待2秒time.sleep(2)# 点击按钮self.driver.find_element(By.CLASS_NAME, 'geetest_radar_tip').click()# 用显示判断,图片是否加载出来self.wait.until(EC.presence_of_element_located((By.XPATH, '//div[@class="geetest_slicebg geetest_absolute"]')))# 修改样式,获取缺口图片self.driver.execute_script('document.querySelectorAll("canvas")[1].style="opacity: 1; display: none;"')# 找到验证码图片的标签元素div_img = self.driver.find_element(By.CLASS_NAME, 'geetest_window')# 等待1秒time.sleep(1)# 缺口图片的保存位置div_img.screenshot(self.gap_img)# 修改样式,获取完整图片self.driver.execute_script('document.querySelectorAll("canvas")[2].style=""')# 完整图片的保存位置div_img.screenshot(self.intact_img)# 恢复样式self.driver.execute_script('document.querySelectorAll("canvas")[1].style="opacity: 1; display: block;"')# 对比验证图片,获取缺口位置def get_gap(self):# 加载缺口图片gap_img = Image.open(self.gap_img)# 加载完整图片intact_img = Image.open(self.intact_img)# 从第一个位置开始做对比left = 0# 嵌套循环做对比for x in range(0, gap_img.size[0]):for y in range(0, gap_img.size[1]):# 判断像素if not self.is_pixel_equal(gap_img, intact_img, x, y):# 相同赋值给 leftleft = x# 不相同,返回 x 坐标return left# 判断像素def is_pixel_equal(self, gap_img, intact_img, x, y):# 加载缺口图片位置pixel1 = gap_img.load()[x, y]# 加载完整图片位置pixel2 = intact_img.load()[x, y]# 打印图片位置# print(pixel1, pixel2)# 阈值threshold = 60# 对比 RGBif abs(pixel1[0] - pixel2[0]) < threshold and abs(pixel1[1] - pixel2[1]) < threshold and abs(pixel1[2] - pixel2[2]) < threshold:# 在阈值内相似返回 Truereturn True# 不在阈值内不相似返回 False,缺口找到return False# 滑动滑块def move_slide(self, offset_x, offset_y, left):# pip install pyautogui 导入 pyautogui 模块,用于控制鼠标和键盘# 将鼠标移动到指定位置 (offset_x, offset_y)pyautogui.moveTo(offset_x, offset_y, duration=0.1 + random.uniform(0, 0.1 + random.randint(1, 100) / 100))# 按下鼠标,准备开始滑动pyautogui.mouseDown()# 在当前 offset_y 的基础上增加一个随机值offset_y += random.randint(9, 19)# 将鼠标移动到偏移位置 (offset_x + int(left * 随机值), offset_y)pyautogui.moveTo(offset_x + int(left * random.randint(15, 25) / 20), offset_y, duration=0.28)# 在当前 offset_y 的基础上减少一个随机值offset_y += random.randint(-9, 0)# 将鼠标移动到偏移位置 (offset_x + int(left * 随机值), offset_y)pyautogui.moveTo(offset_x + int(left * random.randint(17, 23) / 20), offset_y,duration=random.randint(20, 31) / 100)# 在当前 offset_y 的基础上增加一个随机值offset_y += random.randint(0, 8)# 将鼠标移动到偏移位置 (offset_x + int(left * 随机值), offset_y)pyautogui.moveTo(offset_x + int(left * random.randint(19, 21) / 20), offset_y,duration=random.randint(20, 40) / 100)# 在当前 offset_y 的基础上增加或减少一个随机值offset_y += random.randint(-3, 3)# 将鼠标移动到偏移位置 (left + offset_x + 随机值, offset_y)pyautogui.moveTo(left + offset_x + random.randint(-3, 3), offset_y,duration=0.5 + random.randint(-10, 10) / 100)# 在当前 offset_y 的基础上增加或减少一个随机值offset_y += random.randint(-2, 2)# 将鼠标移动到偏移位置 (left + offset_x + 随机值, offset_y)pyautogui.moveTo(left + offset_x + random.randint(-2, 2), offset_y, duration=0.5 + random.randint(-3, 3) / 100)# 松开鼠标左键,结束滑动操作pyautogui.mouseUp()# 等待3秒time.sleep(3)# 主函数def main(self):# 加载图片并截取图片self.load_img()# 对比验证图片,获取缺口位置left = self.get_gap()# 误差值left -= 6# 根据位置滑动滑块(测量一下浏览器左上角到滑块按钮的距离)x = 1260y = 490# 滑动滑块self.move_slide(x, y, left)# 主程序
if __name__ == '__main__':# 创建了一个对象f = FloatSlide()# 调用 main 方法f.main()
四、openCV
1、简介
OpenCV(Open Source Computer Vision)是一个开源的计算机视觉库,它提供了丰富的图像和视频处理函数,可用于开发计算机视觉相关的应用程序。
2、代码
识别缺口位置,获取缺口距离。
# pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
import cv2def identify_gap(bg_image, tp_image, out="images/new_image.png"):"""通过cv2计算缺口位置:param bg_image: 有缺口的背景图片文件:param tp_image: 缺口小图文件图片文件:param out: 绘制缺口边框之后的图片:return: 返回缺口位置"""# 读取背景图片和缺口图片bg_img = cv2.imread(bg_image) # 背景图片tp_img = cv2.imread(tp_image) # 缺口图片# 识别图片边缘# 因为验证码图片里面的目标缺口通常是有比较明显的边缘 所以可以借助边缘检测算法结合调整阈值来识别缺口# 目前应用比较广泛的边缘检测算法是Canny John F.Canny在1986年所开发的一个多级边缘检测算法 效果挺好的bg_edge = cv2.Canny(bg_img, 100, 200)tp_edge = cv2.Canny(tp_img, 100, 200)print(bg_edge, tp_edge)# 转换图片格式# 得到了图片边缘的灰度图,进一步将其图片格式转为RGB格式bg_pic = cv2.cvtColor(bg_edge, cv2.COLOR_GRAY2RGB)tp_pic = cv2.cvtColor(tp_edge, cv2.COLOR_GRAY2RGB)# 缺口匹配# 一幅图像中找与另一幅图像最匹配(相似)部分 算法:cv2.TM_CCOEFF_NORMED# 在背景图片中搜索对应的缺口res = cv2.matchTemplate(bg_pic, tp_pic, cv2.TM_CCOEFF_NORMED)# res为每个位置的匹配结果,代表了匹配的概率,选出其中「概率最高」的点,即为缺口匹配的位置# 从中获取min_val,max_val,min_loc,max_loc分别为匹配的最小值、匹配的最大值、最小值的位置、最大值的位置min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res) # 寻找最优匹配# 绘制方框th, tw = tp_pic.shape[:2]tl = max_loc # 左上角点的坐标br = (tl[0] + tw, tl[1] + th) # 右下角点的坐标cv2.rectangle(bg_img, tl, br, (0, 0, 255), 2) # 绘制矩形cv2.imwrite(out, bg_img) # 保存在本地# 返回缺口的X坐标return tl[0]# 传入两张图片,返回缺口位置
left = identify_gap('images/jindong_bg.png', 'images/jingdong_gap.png')
3、案例
需求:用 selenium 进行模拟登录
目标网站:https://passport.jd.com/new/login.aspx
页面分析
- 切换密码登录模式
- 输入账号和密码
- 点击登录按钮
- 加载完滑块之后,获取滑块验证码图片
- 识别缺口位置,获取距离,进行滑动
代码实现
1、搭建框架
import random # 导入 random 模块,用于生成随机数
import time # 导入 time 模块,用于添加时间延迟
import cv2 # 导入 OpenCV 模块,用于图像处理
import pyautogui # 导入 pyautogui 模块,用于模拟鼠标和键盘操作
from selenium.webdriver.support.wait import WebDriverWait # 导入 WebDriverWait 类,用于等待条件
from selenium import webdriver # 导入 webdriver 模块,用于控制浏览器
from selenium.webdriver.support import expected_conditions as EC # 导入 expected_conditions 模块,用于指定预期条件
from selenium.webdriver.common.by import By # 导入 By 模块,用于指定元素定位方式
from PIL import Image # 导入 Image 模块,用于图像处理
import urllib.request # 导入 urllib.request 模块,用于进行网络请求class JinDong_Logic(object):# 初始化操作def __init__(self, username, password):pass# 获取缺口图片def login(self):pass# 计算缺口位置def identify_gap(self, bg_image, tp_image, out="images/new_image.png"):pass# 滑动函数def move_slide(self, offset_x, offset_y, left):pass# 主程序
if __name__ == '__main__':# 创建对象l = JinDong_Logic('123', 'abcd')# 调用 login 方法l.login()
2、初始化操作
# 初始化操作def __init__(self, username, password):# 确定 urlself.url = 'https://passport.jd.com/new/login.aspx'# 账号self.username = username# 密码self.password = password# 加载驱动self.driver = webdriver.Chrome()# 窗口最大化self.driver.maximize_window()# 显示等待self.wait = WebDriverWait(self.driver, 100)# 设置图片保存位置# 有缺口的背景图片self.bg_img = 'images/bg_img.png'# 缺口小图片self.gap_img = 'images/gap_img.png'
3、获取缺口图片
# 获取缺口图片def login(self):# 加载 urlself.driver.get(self.url)# 等待1秒time.sleep(1)# 切换登录方式self.driver.find_element(By.CLASS_NAME, 'login-tab-r').click()# 输入账号self.driver.find_element(By.ID, 'loginname').send_keys(self.username)# 输入密码self.driver.find_element(By.ID, 'nloginpwd').send_keys(self.password)# 等待0.5秒time.sleep(0.5)# 点击登录按钮self.driver.find_element(By.ID, 'loginsubmit').click()# 显示等待判断图片是否加载出来self.wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'JDJRV-slide ')))# 获取背景图片(向图片链接发请求,获取图片)bg_img_url = self.driver.find_element(By.XPATH, '//div[@class="JDJRV-bigimg"]/img').get_attribute('src')# 保存图片urllib.request.urlretrieve(bg_img_url, self.bg_img)# 获取缺口图片gap_img_url = self.driver.find_element(By.XPATH, '//div[@class="JDJRV-smallimg"]/img').get_attribute('src')# 保存图片urllib.request.urlretrieve(gap_img_url, self.gap_img)# 修改背景图片的尺寸im = Image.open(self.bg_img)# 重新设置图片尺寸image = im.resize((278, 108))# 保存图片image.save('images/1.png')# 修改缺口图片的尺寸im1 = Image.open(self.gap_img)# 重新设置图片尺寸image1 = im1.resize((39, 39))# 保存图片image1.save('images/2.png')# 获取两张图片,计算缺口位置,识别距离left = self.identify_gap('images/1.png', 'images/2.png')# 根据位置滑动滑块(测量一下浏览器左上角到滑块按钮的距离)x, y = 1485, 485# 滑动self.move_slide(x, y, left)
4、计算缺口位置
# 计算缺口位置def identify_gap(self, bg_image, tp_image, out="images/new_image.png"):"""通过cv2计算缺口位置:param bg_image: 有缺口的背景图片文件:param tp_image: 缺口小图文件图片文件:param out: 绘制缺口边框之后的图片:return: 返回缺口位置"""# 读取背景图片和缺口图片bg_img = cv2.imread(bg_image) # 背景图片tp_img = cv2.imread(tp_image) # 缺口图片# 识别图片边缘# 因为验证码图片里面的目标缺口通常是有比较明显的边缘 所以可以借助边缘检测算法结合调整阈值来识别缺口# 目前应用比较广泛的边缘检测算法是Canny John F.Canny在1986年所开发的一个多级边缘检测算法 效果挺好的bg_edge = cv2.Canny(bg_img, 100, 200)tp_edge = cv2.Canny(tp_img, 100, 200)print(bg_edge, tp_edge)# 转换图片格式# 得到了图片边缘的灰度图,进一步将其图片格式转为RGB格式bg_pic = cv2.cvtColor(bg_edge, cv2.COLOR_GRAY2RGB)tp_pic = cv2.cvtColor(tp_edge, cv2.COLOR_GRAY2RGB)# 缺口匹配# 一幅图像中找与另一幅图像最匹配(相似)部分 算法:cv2.TM_CCOEFF_NORMED# 在背景图片中搜索对应的缺口res = cv2.matchTemplate(bg_pic, tp_pic, cv2.TM_CCOEFF_NORMED)# res为每个位置的匹配结果,代表了匹配的概率,选出其中「概率最高」的点,即为缺口匹配的位置# 从中获取min_val,max_val,min_loc,max_loc分别为匹配的最小值、匹配的最大值、最小值的位置、最大值的位置min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res) # 寻找最优匹配# 绘制方框th, tw = tp_pic.shape[:2]tl = max_loc # 左上角点的坐标br = (tl[0] + tw, tl[1] + th) # 右下角点的坐标cv2.rectangle(bg_img, tl, br, (0, 0, 255), 2) # 绘制矩形cv2.imwrite(out, bg_img) # 保存在本地# 返回缺口的X坐标return tl[0]
5、滑动函数
# 滑动函数def move_slide(self, offset_x, offset_y, left):# pip install pyautogui 导入 pyautogui 模块,用于控制鼠标和键盘# 将鼠标移动到指定位置 (offset_x, offset_y)pyautogui.moveTo(offset_x, offset_y, duration=0.1 + random.uniform(0, 0.1 + random.randint(1, 100) / 100))# 按下鼠标,准备开始滑动pyautogui.mouseDown()# 在当前 offset_y 的基础上增加一个随机值offset_y += random.randint(9, 19)# 将鼠标移动到偏移位置 (offset_x + int(left * 随机值), offset_y)pyautogui.moveTo(offset_x + int(left * random.randint(15, 25) / 20), offset_y, duration=0.28)# 在当前 offset_y 的基础上减少一个随机值offset_y += random.randint(-9, 0)# 将鼠标移动到偏移位置 (offset_x + int(left * 随机值), offset_y)pyautogui.moveTo(offset_x + int(left * random.randint(17, 23) / 20), offset_y,duration=random.randint(20, 31) / 100)# 在当前 offset_y 的基础上增加一个随机值offset_y += random.randint(0, 8)# 将鼠标移动到偏移位置 (offset_x + int(left * 随机值), offset_y)pyautogui.moveTo(offset_x + int(left * random.randint(19, 21) / 20), offset_y,duration=random.randint(20, 40) / 100)# 在当前 offset_y 的基础上增加或减少一个随机值offset_y += random.randint(-3, 3)# 将鼠标移动到偏移位置 (left + offset_x + 随机值, offset_y)pyautogui.moveTo(left + offset_x + random.randint(-3, 3), offset_y,duration=0.5 + random.randint(-10, 10) / 100)# 在当前 offset_y 的基础上增加或减少一个随机值offset_y += random.randint(-2, 2)# 将鼠标移动到偏移位置 (left + offset_x + 随机值, offset_y)pyautogui.moveTo(left + offset_x + random.randint(-2, 2), offset_y, duration=0.5 + random.randint(-3, 3) / 100)# 松开鼠标左键,结束滑动操作pyautogui.mouseUp()# 等待3秒time.sleep(3)
完整代码
import random # 导入 random 模块,用于生成随机数
import time # 导入 time 模块,用于添加时间延迟
import cv2 # 导入 OpenCV 模块,用于图像处理
import pyautogui # 导入 pyautogui 模块,用于模拟鼠标和键盘操作
from selenium.webdriver.support.wait import WebDriverWait # 导入 WebDriverWait 类,用于等待条件
from selenium import webdriver # 导入 webdriver 模块,用于控制浏览器
from selenium.webdriver.support import expected_conditions as EC # 导入 expected_conditions 模块,用于指定预期条件
from selenium.webdriver.common.by import By # 导入 By 模块,用于指定元素定位方式
from PIL import Image # 导入 Image 模块,用于图像处理
import urllib.request # 导入 urllib.request 模块,用于进行网络请求class JinDong_Logic(object):# 初始化操作def __init__(self, username, password):# 确定 urlself.url = 'https://passport.jd.com/new/login.aspx'# 账号self.username = username# 密码self.password = password# 加载驱动self.driver = webdriver.Chrome()# 窗口最大化self.driver.maximize_window()# 显示等待self.wait = WebDriverWait(self.driver, 100)# 设置图片保存位置# 有缺口的背景图片self.bg_img = 'images/bg_img.png'# 缺口小图片self.gap_img = 'images/gap_img.png'# 获取缺口图片def login(self):# 加载 urlself.driver.get(self.url)# 等待1秒time.sleep(1)# 切换登录方式self.driver.find_element(By.CLASS_NAME, 'login-tab-r').click()# 输入账号self.driver.find_element(By.ID, 'loginname').send_keys(self.username)# 输入密码self.driver.find_element(By.ID, 'nloginpwd').send_keys(self.password)# 等待0.5秒time.sleep(0.5)# 点击登录按钮self.driver.find_element(By.ID, 'loginsubmit').click()# 显示等待判断图片是否加载出来self.wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'JDJRV-slide ')))# 获取背景图片(向图片链接发请求,获取图片)bg_img_url = self.driver.find_element(By.XPATH, '//div[@class="JDJRV-bigimg"]/img').get_attribute('src')# 保存图片urllib.request.urlretrieve(bg_img_url, self.bg_img)# 获取缺口图片gap_img_url = self.driver.find_element(By.XPATH, '//div[@class="JDJRV-smallimg"]/img').get_attribute('src')# 保存图片urllib.request.urlretrieve(gap_img_url, self.gap_img)# 修改背景图片的尺寸im = Image.open(self.bg_img)# 重新设置图片尺寸image = im.resize((278, 108))# 保存图片image.save('images/1.png')# 修改缺口图片的尺寸im1 = Image.open(self.gap_img)# 重新设置图片尺寸image1 = im1.resize((39, 39))# 保存图片image1.save('images/2.png')# 获取两张图片,计算缺口位置,识别距离left = self.identify_gap('images/1.png', 'images/2.png')# 根据位置滑动滑块(测量一下浏览器左上角到滑块按钮的距离)x, y = 1485, 485# 滑动self.move_slide(x, y, left)# 计算缺口位置def identify_gap(self, bg_image, tp_image, out="images/new_image.png"):"""通过cv2计算缺口位置:param bg_image: 有缺口的背景图片文件:param tp_image: 缺口小图文件图片文件:param out: 绘制缺口边框之后的图片:return: 返回缺口位置"""# 读取背景图片和缺口图片bg_img = cv2.imread(bg_image) # 背景图片tp_img = cv2.imread(tp_image) # 缺口图片# 识别图片边缘# 因为验证码图片里面的目标缺口通常是有比较明显的边缘 所以可以借助边缘检测算法结合调整阈值来识别缺口# 目前应用比较广泛的边缘检测算法是Canny John F.Canny在1986年所开发的一个多级边缘检测算法 效果挺好的bg_edge = cv2.Canny(bg_img, 100, 200)tp_edge = cv2.Canny(tp_img, 100, 200)print(bg_edge, tp_edge)# 转换图片格式# 得到了图片边缘的灰度图,进一步将其图片格式转为RGB格式bg_pic = cv2.cvtColor(bg_edge, cv2.COLOR_GRAY2RGB)tp_pic = cv2.cvtColor(tp_edge, cv2.COLOR_GRAY2RGB)# 缺口匹配# 一幅图像中找与另一幅图像最匹配(相似)部分 算法:cv2.TM_CCOEFF_NORMED# 在背景图片中搜索对应的缺口res = cv2.matchTemplate(bg_pic, tp_pic, cv2.TM_CCOEFF_NORMED)# res为每个位置的匹配结果,代表了匹配的概率,选出其中「概率最高」的点,即为缺口匹配的位置# 从中获取min_val,max_val,min_loc,max_loc分别为匹配的最小值、匹配的最大值、最小值的位置、最大值的位置min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res) # 寻找最优匹配# 绘制方框th, tw = tp_pic.shape[:2]tl = max_loc # 左上角点的坐标br = (tl[0] + tw, tl[1] + th) # 右下角点的坐标cv2.rectangle(bg_img, tl, br, (0, 0, 255), 2) # 绘制矩形cv2.imwrite(out, bg_img) # 保存在本地# 返回缺口的X坐标return tl[0]# 滑动函数def move_slide(self, offset_x, offset_y, left):# pip install pyautogui 导入 pyautogui 模块,用于控制鼠标和键盘# 将鼠标移动到指定位置 (offset_x, offset_y)pyautogui.moveTo(offset_x, offset_y, duration=0.1 + random.uniform(0, 0.1 + random.randint(1, 100) / 100))# 按下鼠标,准备开始滑动pyautogui.mouseDown()# 在当前 offset_y 的基础上增加一个随机值offset_y += random.randint(9, 19)# 将鼠标移动到偏移位置 (offset_x + int(left * 随机值), offset_y)pyautogui.moveTo(offset_x + int(left * random.randint(15, 25) / 20), offset_y, duration=0.28)# 在当前 offset_y 的基础上减少一个随机值offset_y += random.randint(-9, 0)# 将鼠标移动到偏移位置 (offset_x + int(left * 随机值), offset_y)pyautogui.moveTo(offset_x + int(left * random.randint(17, 23) / 20), offset_y,duration=random.randint(20, 31) / 100)# 在当前 offset_y 的基础上增加一个随机值offset_y += random.randint(0, 8)# 将鼠标移动到偏移位置 (offset_x + int(left * 随机值), offset_y)pyautogui.moveTo(offset_x + int(left * random.randint(19, 21) / 20), offset_y,duration=random.randint(20, 40) / 100)# 在当前 offset_y 的基础上增加或减少一个随机值offset_y += random.randint(-3, 3)# 将鼠标移动到偏移位置 (left + offset_x + 随机值, offset_y)pyautogui.moveTo(left + offset_x + random.randint(-3, 3), offset_y,duration=0.5 + random.randint(-10, 10) / 100)# 在当前 offset_y 的基础上增加或减少一个随机值offset_y += random.randint(-2, 2)# 将鼠标移动到偏移位置 (left + offset_x + 随机值, offset_y)pyautogui.moveTo(left + offset_x + random.randint(-2, 2), offset_y, duration=0.5 + random.randint(-3, 3) / 100)# 松开鼠标左键,结束滑动操作pyautogui.mouseUp()# 等待3秒time.sleep(3)# 主程序
if __name__ == '__main__':# 创建对象l = JinDong_Logic('123', 'abcd')# 调用 login 方法l.login()
五、selenium 反爬

去除 selenium 标志:
1、进入 chrome 路径
2、在文件路径出输入cmd ,回车,打开终端
3、导入 ChromeOptions 类,用于配置 Chrome 浏览器选项
from selenium.webdriver.chrome.options import Options
4、加入代码
# 创建 Options 对象,用于配置浏览器选项
options = Options()
# 连接浏览器到指定的调试地址
options.add_experimental_option('debuggerAddress', '127.0.0.1:9222')
# 加载驱动
self.driver = webdriver.Chrome(options=options)
5、把谷歌浏览器全部关闭,在终端里启动命令
chrome --remote-debugging-port=9222
6、在 PyCharm 里运行代码
案例
import random # 导入 random 模块,用于生成随机数
import time # 导入 time 模块,用于添加时间延迟
import cv2 # 导入 OpenCV 模块,用于图像处理
import pyautogui # 导入 pyautogui 模块,用于模拟鼠标和键盘操作
from selenium.webdriver.chrome.options import Options # 导入 ChromeOptions 类,用于配置 Chrome 浏览器选项
from selenium.webdriver.support.wait import WebDriverWait # 导入 WebDriverWait 类,用于等待条件
from selenium import webdriver # 导入 webdriver 模块,用于控制浏览器
from selenium.webdriver.support import expected_conditions as EC # 导入 expected_conditions 模块,用于指定预期条件
from selenium.webdriver.common.by import By # 导入 By 模块,用于指定元素定位方式
from PIL import Image # 导入 Image 模块,用于图像处理
import urllib.request # 导入 urllib.request 模块,用于进行网络请求class JinDong_Logic(object):# 初始化操作def __init__(self, username, password):# 确定 urlself.url = 'https://passport.jd.com/new/login.aspx'# 账号self.username = username# 密码self.password = password# 创建 Options 对象,用于配置浏览器选项options = Options()# 连接浏览器到指定的调试地址options.add_experimental_option('debuggerAddress', '127.0.0.1:9222')# 加载驱动self.driver = webdriver.Chrome(options=options)# 窗口最大化self.driver.maximize_window()# 显示等待self.wait = WebDriverWait(self.driver, 100)# 设置图片保存位置# 有缺口的背景图片self.bg_img = 'images/bg_img.png'# 缺口小图片self.gap_img = 'images/gap_img.png'# 获取缺口图片def login(self):# 加载 urlself.driver.get(self.url)# 等待1秒time.sleep(1)# 切换登录方式self.driver.find_element(By.CLASS_NAME, 'login-tab-r').click()# 输入账号self.driver.find_element(By.ID, 'loginname').send_keys(self.username)# 输入密码self.driver.find_element(By.ID, 'nloginpwd').send_keys(self.password)# 等待0.5秒time.sleep(0.5)# 点击登录按钮self.driver.find_element(By.ID, 'loginsubmit').click()# 显示等待判断图片是否加载出来self.wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'JDJRV-slide ')))# 获取背景图片(向图片链接发请求,获取图片)bg_img_url = self.driver.find_element(By.XPATH, '//div[@class="JDJRV-bigimg"]/img').get_attribute('src')# 保存图片urllib.request.urlretrieve(bg_img_url, self.bg_img)# 获取缺口图片gap_img_url = self.driver.find_element(By.XPATH, '//div[@class="JDJRV-smallimg"]/img').get_attribute('src')# 保存图片urllib.request.urlretrieve(gap_img_url, self.gap_img)# 修改背景图片的尺寸im = Image.open(self.bg_img)# 重新设置图片尺寸image = im.resize((278, 108))# 保存图片image.save('images/1.png')# 修改缺口图片的尺寸im1 = Image.open(self.gap_img)# 重新设置图片尺寸image1 = im1.resize((39, 39))# 保存图片image1.save('images/2.png')# 获取两张图片,计算缺口位置,识别距离left = self.identify_gap('images/1.png', 'images/2.png')# 根据位置滑动滑块(测量一下浏览器左上角到滑块按钮的距离)x, y = 1485, 455# 滑动self.move_slide(x, y, left)# 计算缺口位置def identify_gap(self, bg_image, tp_image, out="images/new_image.png"):"""通过cv2计算缺口位置:param bg_image: 有缺口的背景图片文件:param tp_image: 缺口小图文件图片文件:param out: 绘制缺口边框之后的图片:return: 返回缺口位置"""# 读取背景图片和缺口图片bg_img = cv2.imread(bg_image) # 背景图片tp_img = cv2.imread(tp_image) # 缺口图片# 识别图片边缘# 因为验证码图片里面的目标缺口通常是有比较明显的边缘 所以可以借助边缘检测算法结合调整阈值来识别缺口# 目前应用比较广泛的边缘检测算法是Canny John F.Canny在1986年所开发的一个多级边缘检测算法 效果挺好的bg_edge = cv2.Canny(bg_img, 100, 200)tp_edge = cv2.Canny(tp_img, 100, 200)print(bg_edge, tp_edge)# 转换图片格式# 得到了图片边缘的灰度图,进一步将其图片格式转为RGB格式bg_pic = cv2.cvtColor(bg_edge, cv2.COLOR_GRAY2RGB)tp_pic = cv2.cvtColor(tp_edge, cv2.COLOR_GRAY2RGB)# 缺口匹配# 一幅图像中找与另一幅图像最匹配(相似)部分 算法:cv2.TM_CCOEFF_NORMED# 在背景图片中搜索对应的缺口res = cv2.matchTemplate(bg_pic, tp_pic, cv2.TM_CCOEFF_NORMED)# res为每个位置的匹配结果,代表了匹配的概率,选出其中「概率最高」的点,即为缺口匹配的位置# 从中获取min_val,max_val,min_loc,max_loc分别为匹配的最小值、匹配的最大值、最小值的位置、最大值的位置min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res) # 寻找最优匹配# 绘制方框th, tw = tp_pic.shape[:2]tl = max_loc # 左上角点的坐标br = (tl[0] + tw, tl[1] + th) # 右下角点的坐标cv2.rectangle(bg_img, tl, br, (0, 0, 255), 2) # 绘制矩形cv2.imwrite(out, bg_img) # 保存在本地# 返回缺口的X坐标return tl[0]# 滑动函数def move_slide(self, offset_x, offset_y, left):# pip install pyautogui 导入 pyautogui 模块,用于控制鼠标和键盘# 将鼠标移动到指定位置 (offset_x, offset_y)pyautogui.moveTo(offset_x, offset_y, duration=0.1 + random.uniform(0, 0.1 + random.randint(1, 100) / 100))# 按下鼠标,准备开始滑动pyautogui.mouseDown()# 在当前 offset_y 的基础上增加一个随机值offset_y += random.randint(9, 19)# 将鼠标移动到偏移位置 (offset_x + int(left * 随机值), offset_y)pyautogui.moveTo(offset_x + int(left * random.randint(15, 25) / 20), offset_y, duration=0.28)# 在当前 offset_y 的基础上减少一个随机值offset_y += random.randint(-9, 0)# 将鼠标移动到偏移位置 (offset_x + int(left * 随机值), offset_y)pyautogui.moveTo(offset_x + int(left * random.randint(17, 23) / 20), offset_y,duration=random.randint(20, 31) / 100)# 在当前 offset_y 的基础上增加一个随机值offset_y += random.randint(0, 8)# 将鼠标移动到偏移位置 (offset_x + int(left * 随机值), offset_y)pyautogui.moveTo(offset_x + int(left * random.randint(19, 21) / 20), offset_y,duration=random.randint(20, 40) / 100)# 在当前 offset_y 的基础上增加或减少一个随机值offset_y += random.randint(-3, 3)# 将鼠标移动到偏移位置 (left + offset_x + 随机值, offset_y)pyautogui.moveTo(left + offset_x + random.randint(-3, 3), offset_y,duration=0.5 + random.randint(-10, 10) / 100)# 在当前 offset_y 的基础上增加或减少一个随机值offset_y += random.randint(-2, 2)# 将鼠标移动到偏移位置 (left + offset_x + 随机值, offset_y)pyautogui.moveTo(left + offset_x + random.randint(-2, 2), offset_y, duration=0.5 + random.randint(-3, 3) / 100)# 松开鼠标左键,结束滑动操作pyautogui.mouseUp()# 等待3秒time.sleep(3)# 主程序
if __name__ == '__main__':# 创建对象l = JinDong_Logic('123', 'abcd')# 调用 login 方法l.login()
六、百度智能云 —— EasyDL
1、简介
百度智能云的 EasyDL 是一个基于深度学习的图像识别和目标检测平台,它提供了简单易用的接口和工具,使开发者可以轻松构建自己的图像识别模型。
准备该网站有缺口的背景图片,做一个训练集,运用了机器学习知识。将这些训练集导入百度智能云,在此平台标注出每一张图片的缺口位置,根据图片以及标注缺口位置,就能训练出一个模型。
有了该模型,如果传入类似的图片,就可以识别缺口位置,获取缺口的距离。
2、使用步骤
2.1、打开网站 EasyDL-零门槛AI开发平台;
2.2、点击“立即使用”;

2.3、点击“物体检测”;

2.4、点击“数据总览”,点击“创建数据集”;

2.5、填写数据集名称后,点击“创建并导入”;

2.6、导入图片后,点击“确认并返回”;

2.7、点击“查看与标注”;

2.8、点击“添加标签”;

2.9、填入标签名称后,点击“确定”;

2.10、点击“标注图片”;

2.11、将每一张图片的缺口位置标注出来;

2.12、标注好之后的图片;

2.13、点击“我的模型”,点击“训练模型”;

2.14、个人信息可选“学生”,其它信息按情况填写好后,点击“完成创建”;

2.15、选择好要训练的数据集后,点击“下一步”;

2.16、训练方式选择“常规训练”,训练环境选择第一个后,点击“开始训练”;

2.17、等待训练完成;

2.18、训练完成,点击“校验”;

2.19、点击“启动模型校验服务”;

2.20、点击“点击添加图片”;

2.21、选择一张图片验证;

2.22、验证没有问题,可以点击“申请发布”;

2.23、填写“服务名称”和“接口地址”后,点击“提交申请”;

2.24、点击“服务详情”,点击“查看API文档”;

2.25、点击“EasyDL版控制台“;

2.26、登录之后,选择”公有云部署“,选择”应用列表“,点击”创建应用“;

2.27、填写”应用名称“,”应用归属“选择”个人“,简单填写一下”应用描述“,点击”立即创建“;

2.28、点击“返回应用列表”;

2.29、查看“API Key”,“Secret Key”值;

2.30、回到“接口赋权”页面,点击“物体检测API调用文档”,找到“请求代码示例”,点击“Python3”,复制代码;

"""
EasyDL 物体检测 调用模型公有云API Python3实现
"""import json
import base64
import requests
"""
使用 requests 库发送请求
使用 pip(或者 pip3)检查我的 python3 环境是否安装了该库,执行命令pip freeze | grep requests
若返回值为空,则安装该库pip install requests
"""# 目标图片的 本地文件路径,支持jpg/png/bmp格式
IMAGE_FILEPATH = "【您的测试图片地址,例如:./example.jpg】"# 可选的请求参数
# threshold: 默认值为建议阈值,请在 我的模型-模型效果-完整评估结果-详细评估 查看建议阈值
PARAMS = {"threshold": 0.3}# 服务详情 中的 接口地址
MODEL_API_URL = "【您的API地址】"# 调用 API 需要 ACCESS_TOKEN。若已有 ACCESS_TOKEN 则于下方填入该字符串
# 否则,留空 ACCESS_TOKEN,于下方填入 该模型部署的 API_KEY 以及 SECRET_KEY,会自动申请并显示新 ACCESS_TOKEN
ACCESS_TOKEN = "【您的ACESS_TOKEN】"
API_KEY = "【您的API_KEY】"
SECRET_KEY = "【您的SECRET_KEY】"print("1. 读取目标图片 '{}'".format(IMAGE_FILEPATH))
with open(IMAGE_FILEPATH, 'rb') as f:base64_data = base64.b64encode(f.read())base64_str = base64_data.decode('UTF8')
print("将 BASE64 编码后图片的字符串填入 PARAMS 的 'image' 字段")
PARAMS["image"] = base64_strif not ACCESS_TOKEN:print("2. ACCESS_TOKEN 为空,调用鉴权接口获取TOKEN")auth_url = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials"\"&client_id={}&client_secret={}".format(API_KEY, SECRET_KEY)auth_resp = requests.get(auth_url)auth_resp_json = auth_resp.json()ACCESS_TOKEN = auth_resp_json["access_token"]print("新 ACCESS_TOKEN: {}".format(ACCESS_TOKEN))
else:print("2. 使用已有 ACCESS_TOKEN")print("3. 向模型接口 'MODEL_API_URL' 发送请求")
request_url = "{}?access_token={}".format(MODEL_API_URL, ACCESS_TOKEN)
response = requests.post(url=request_url, json=PARAMS)
response_json = response.json()
response_str = json.dumps(response_json, indent=4, ensure_ascii=False)
print("结果:\n{}".format(response_str))
2.31、将“图片地址”,“API地址”,“ACESS_TOKEN”,“API_KEY”,“SECRET_KEY“等值替换成自己的
"""
EasyDL 物体检测 调用模型公有云API Python3实现
"""import json
import base64
import requests
"""
使用 requests 库发送请求
使用 pip(或者 pip3)检查我的 python3 环境是否安装了该库,执行命令pip freeze | grep requests
若返回值为空,则安装该库pip install requests
"""# 目标图片的 本地文件路径,支持jpg/png/bmp格式
IMAGE_FILEPATH = "images/1.png"# 可选的请求参数
# threshold: 默认值为建议阈值,请在 我的模型-模型效果-完整评估结果-详细评估 查看建议阈值
PARAMS = {"threshold": 0.3}# 服务详情 中的 接口地址
MODEL_API_URL = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/detection/jdyanzheng"# 调用 API 需要 ACCESS_TOKEN。若已有 ACCESS_TOKEN 则于下方填入该字符串
# 否则,留空 ACCESS_TOKEN,于下方填入 该模型部署的 API_KEY 以及 SECRET_KEY,会自动申请并显示新 ACCESS_TOKEN
ACCESS_TOKEN = ""
API_KEY = "替换API_KEY"
SECRET_KEY = "替换SECRET_KEY"print("1. 读取目标图片 '{}'".format(IMAGE_FILEPATH))
with open(IMAGE_FILEPATH, 'rb') as f:base64_data = base64.b64encode(f.read())base64_str = base64_data.decode('UTF8')
print("将 BASE64 编码后图片的字符串填入 PARAMS 的 'image' 字段")
PARAMS["image"] = base64_strif not ACCESS_TOKEN:print("2. ACCESS_TOKEN 为空,调用鉴权接口获取TOKEN")auth_url = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials"\"&client_id={}&client_secret={}".format(API_KEY, SECRET_KEY)auth_resp = requests.get(auth_url)auth_resp_json = auth_resp.json()ACCESS_TOKEN = auth_resp_json["access_token"]print("新 ACCESS_TOKEN: {}".format(ACCESS_TOKEN))
else:print("2. 使用已有 ACCESS_TOKEN")print("3. 向模型接口 'MODEL_API_URL' 发送请求")
request_url = "{}?access_token={}".format(MODEL_API_URL, ACCESS_TOKEN)
response = requests.post(url=request_url, json=PARAMS)
response_json = response.json()
response_str = json.dumps(response_json, indent=4, ensure_ascii=False)
print("结果:\n{}".format(response_str))
2.32、运行之后,可显示缺口的坐标位置。

记录学习过程,欢迎讨论交流,尊重原创,转载请注明出处~
相关文章:
爬虫 — 验证码反爬
目录 一、超级鹰二、图片验证模拟登录1、页面分析1.1、模拟用户正常登录流程1.2、识别图片里面的文字 2、代码实现 三、滑块模拟登录1、页面分析2、代码实现(通过对比像素获取缺口位置) 四、openCV1、简介2、代码3、案例 五、selenium 反爬六、百度智能云…...

视频图像处理算法opencv模块硬件设计图像颜色识别模块
1、Opencv简介 OpenCV是一个基于Apache2.0许可(开源)发行的跨平台计算机视觉和机器学习软件库,可以运行在Linux、Windows、Android和Mac OS操作系统上 它轻量级而且高效——由一系列 C 函数和少量 C 类构成,同时提供了Python、Rub…...

目标检测网络之Fast-RCNN
文章目录 Fast RCNN解决的问题Fast RCNN网络结构RoI pooling layer合并损失函数及其传播统一的损失函数损失函数的反向传播过程Fast RCNN的训练方法样本选择方法SGD参数设置多尺度图像训练SVD压缩全连接层对比实验对比实验使用到的网络结构VOC2010和VOC2012数据集结果VOC2007数…...
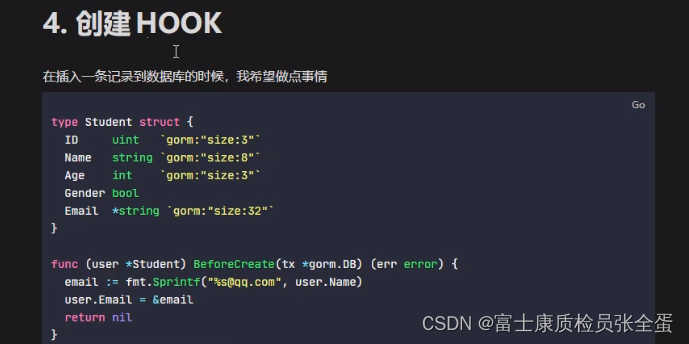
Golang Gorm 创建HOOK
创建的时候,在插入数据之前,想要做一些事情。钩子函数比较简单,就是实现before create的一个方法。 package mainimport ("gorm.io/driver/mysql""gorm.io/gorm" )type Student struct {ID int64Name string gorm:&q…...

计算机视觉的应用15-图片旋转验证码的角度计算模型的应用,解决旋转图片矫正问题
大家好,我是微学AI,今天给大家介绍一下计算机视觉的应用15-图片旋转验证码的角度计算模型的应用,解决旋转图片矫正问题,在CV领域,图片旋转验证码的角度计算模型被广泛应用于解决旋转图片矫正问题,有效解决机…...
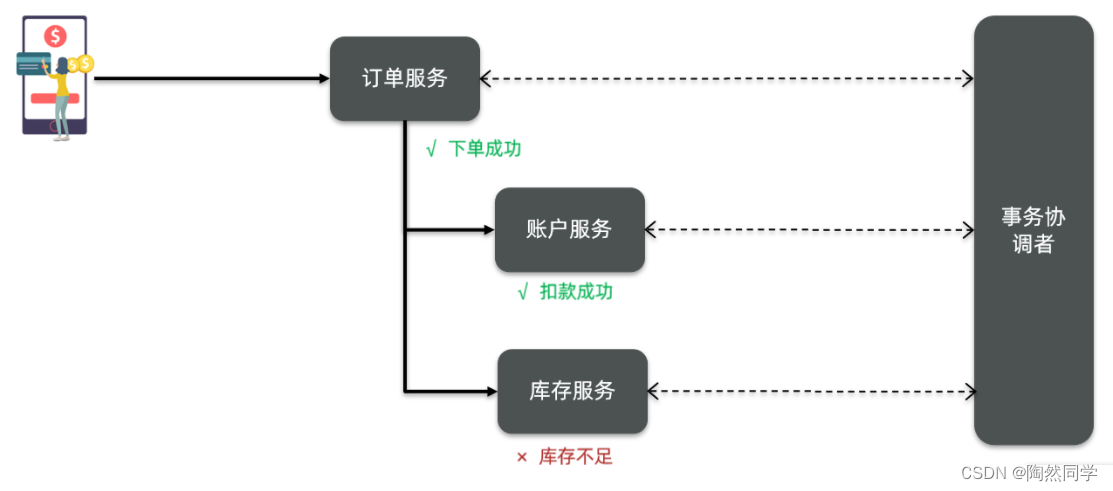
【Seata】分布式事务问题和理论基础
目录 1.分布式事务问题 1.1本地事务 1.2分布式事务 2.理论基础 2.1CAP定理 2.1.1一致性 2.1.2可用性 2.1.3分区容错 2.1.4矛盾 2.2BASE理论 2.3解决分布式事务的思路 1.分布式事务问题 1.1本地事务 本地事务,也就是传统的单机事务。在传统数据库事务中…...
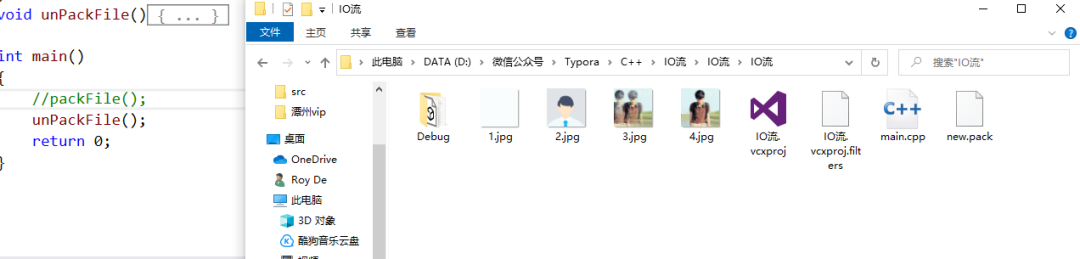
文件打包解包的方法
在很多情况下,软件需要隐藏一些图片,防止用户对其更改,替换。例如腾讯QQ里面的资源图片,哪怕你用Everything去搜索也搜索不到,那是因为腾讯QQ对这些资源图片进行了打包,当软件运行的时候解包获取资源图片。…...
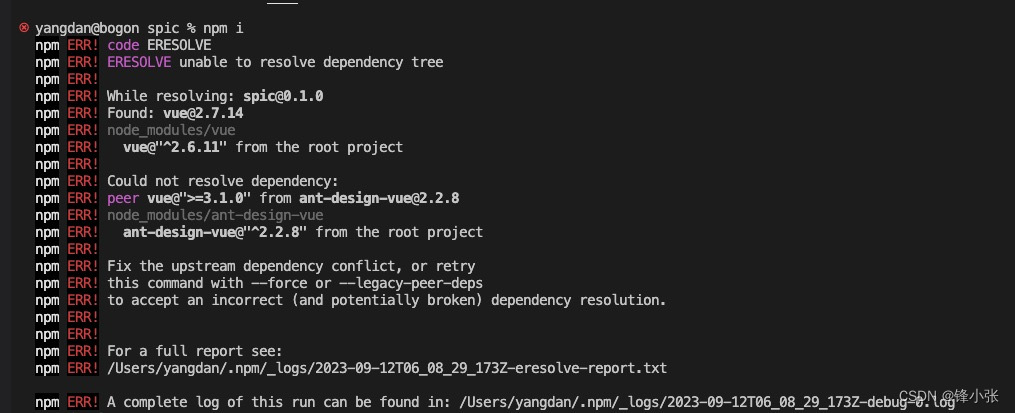
npm 清缓存(重新安装node-modules)
安装node依赖包的会出现失败的情况,如下图所示: 此时 提示有些依赖树有冲突,根据提示 “ this command with --force or --legacy-peer-deps” 执行命令即可。 具体步骤如下: 1、先删除本地node-modules包 2、删掉page-loacl…...
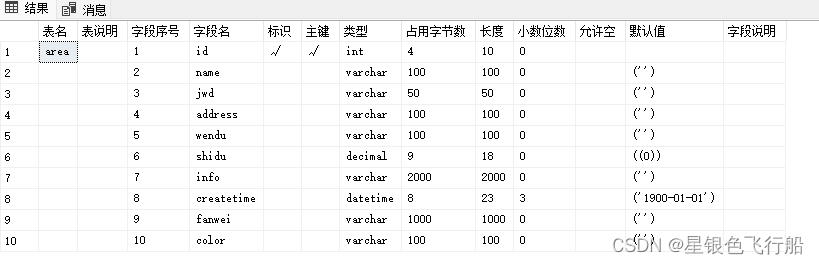
sqlserver查询表中所有字段信息
精简 SELECT 字段名 a.name,主键 case when exists(SELECT 1 FROM sysobjects where xtypePK and parent_obja.id and name in (SELECT name FROM sysindexes WHERE indid in( SELECT indid FROM sysindexkeys WHERE id a.id AND colida.colid))) then √ else …...
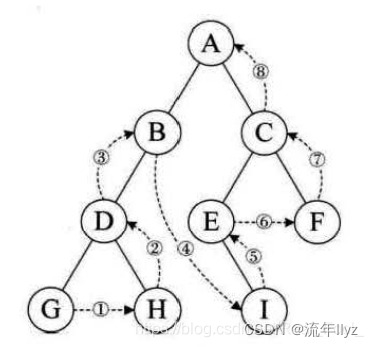
二叉树的概念、存储及遍历
一、二叉树的概念 1、二叉树的定义 二叉树( binary tree)是 n 个结点的有限集合,该集合或为空集(空二叉树),或由一个根结点与两棵互不相交的,称为根结点的左子树、右子树的二叉树构成。 二叉树的…...
【面试题】智力题
文章目录 腾讯1000瓶毒药里面只有1瓶是有毒的,问需要多少只老鼠才能在24小时后试出那瓶有毒。有两根不规则的绳子,两根绳子从头烧到尾均需要一个小时,现在有一个45分钟的比赛,裁判员忘记带计时器,你能否通过烧绳子的方…...
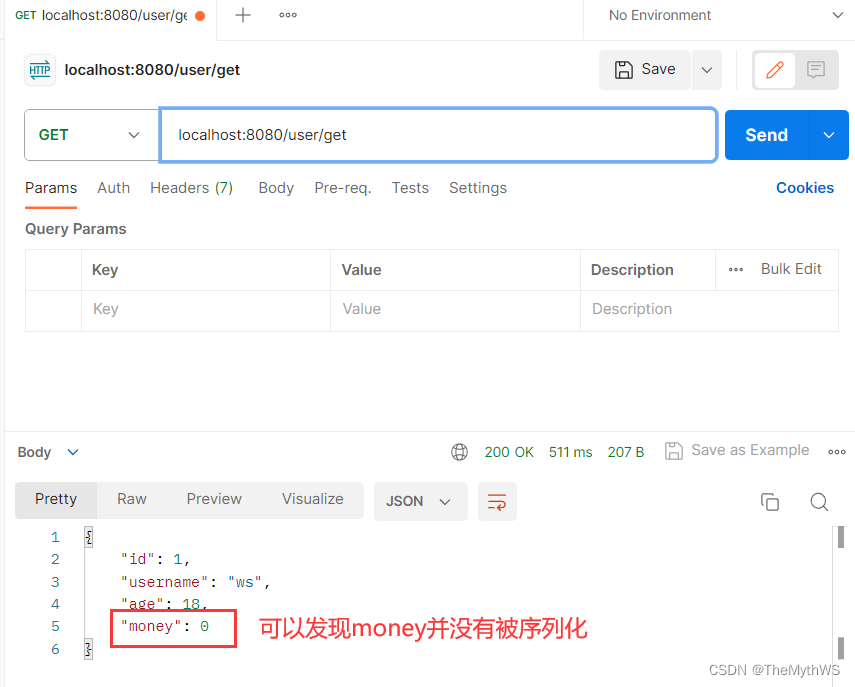
【SpringBoot集成Redis + Session持久化存储到Redis】
目录 SpringBoot集成Redis 1.添加 redis 依赖 2.配置 redis 3.手动操作 redis Session持久化存储到Redis 1.添加依赖 2.修改redis配置 3.存储和读取String类型的代码 4.存储和读取对象类型的代码 5.序列化细节 SpringBoot集成Redis 1.添加 redis 依赖 …...

day49:QT day2,信号与槽、对话框
一、完善登录框 点击登录按钮后,判断账号(admin)和密码(123456)是否一致,如果匹配失败,则弹出错误对话框,文本内容“账号密码不匹配,是否重新登录”,给定两个…...

Meta分析核心技术
Meta分析是针对某一科研问题,根据明确的搜索策略、选择筛选文献标准、采用严格的评价方法,对来源不同的研究成果进行收集、合并及定量统计分析的方法,最早出现于“循证医学”,现已广泛应用于农林生态,资源环境等方面。…...

Gof23设计模式之责任链模式
1.概述 责任链模式又名职责链模式,为了避免请求发送者与多个请求处理者耦合在一起,将所有请求的处理者通过前一对象记住其下一个对象的引用而连成一条链;当有请求发生时,可将请求沿着这条链传递,直到有对象处理它为止…...

数字孪生和元宇宙:打造未来的数字边界
数字孪生和元宇宙是近两年来被热议的两个概念,但由于技术的交叉两者也极易被混淆。本文希望带大家深入探讨一下这两者之间的关系,以及它们如何一起构建了数字时代的新格局。 1. 数字孪生的本质 数字孪生是一种虚拟模型,它通过数字手段对现实…...

【新版】系统架构设计师 - 软件架构设计<新版>
个人总结,仅供参考,欢迎加好友一起讨论 文章目录 架构 - 软件架构设计<新版>考点摘要概念架构的 4 1 视图架构描述语言ADL基于架构的软件开发方法ABSDABSD的开发模型ABSDMABSD(ABSDM模型)的开发过程 软件架…...

Linux面试题
当准备 Linux 面试时,以下是一些可能会遇到的常见 Linux 面试题: 1. 什么是Linux?解释一下Linux操作系统的特点。 2. 什么是Linux内核?Linux内核的作用是什么? 3. 如何在Linux系统上查看当前的IP地址和子网掩码&#…...

NODEJS版本管理工具
一、使用NVM 下载 Linux下载 curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.0/install.sh widows下载地址 https://github.com/coreybutler/nvm-windows/releases 安装Node.js版本: nvm install 14.16.0 切换Node.js版本: nvm use …...

【个人笔记本】本地化部署 类chatgpt模型 详细流程
不推荐小白,环境配置比较复杂 全部流程 下载原始模型:Chinese-LLaMA-Alpaca-2linux部署llamacpp环境使用llamacpp将Chinese-LLaMA-Alpaca-2模型转换为gguf模型windows部署Text generation web UI 环境使用Text generation web UI 加载模型并进行对话 准…...

【OSG学习笔记】Day 18: 碰撞检测与物理交互
物理引擎(Physics Engine) 物理引擎 是一种通过计算机模拟物理规律(如力学、碰撞、重力、流体动力学等)的软件工具或库。 它的核心目标是在虚拟环境中逼真地模拟物体的运动和交互,广泛应用于 游戏开发、动画制作、虚…...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...

DIY|Mac 搭建 ESP-IDF 开发环境及编译小智 AI
前一阵子在百度 AI 开发者大会上,看到基于小智 AI DIY 玩具的演示,感觉有点意思,想着自己也来试试。 如果只是想烧录现成的固件,乐鑫官方除了提供了 Windows 版本的 Flash 下载工具 之外,还提供了基于网页版的 ESP LA…...

管理学院权限管理系统开发总结
文章目录 🎓 管理学院权限管理系统开发总结 - 现代化Web应用实践之路📝 项目概述🏗️ 技术架构设计后端技术栈前端技术栈 💡 核心功能特性1. 用户管理模块2. 权限管理系统3. 统计报表功能4. 用户体验优化 🗄️ 数据库设…...

Webpack性能优化:构建速度与体积优化策略
一、构建速度优化 1、升级Webpack和Node.js 优化效果:Webpack 4比Webpack 3构建时间降低60%-98%。原因: V8引擎优化(for of替代forEach、Map/Set替代Object)。默认使用更快的md4哈希算法。AST直接从Loa…...

[USACO23FEB] Bakery S
题目描述 Bessie 开了一家面包店! 在她的面包店里,Bessie 有一个烤箱,可以在 t C t_C tC 的时间内生产一块饼干或在 t M t_M tM 单位时间内生产一块松糕。 ( 1 ≤ t C , t M ≤ 10 9 ) (1 \le t_C,t_M \le 10^9) (1≤tC,tM≤109)。由于空间…...

Django RBAC项目后端实战 - 03 DRF权限控制实现
项目背景 在上一篇文章中,我们完成了JWT认证系统的集成。本篇文章将实现基于Redis的RBAC权限控制系统,为系统提供细粒度的权限控制。 开发目标 实现基于Redis的权限缓存机制开发DRF权限控制类实现权限管理API配置权限白名单 前置配置 在开始开发权限…...

aurora与pcie的数据高速传输
设备:zynq7100; 开发环境:window; vivado版本:2021.1; 引言 之前在前面两章已经介绍了aurora读写DDR,xdma读写ddr实验。这次我们做一个大工程,pc通过pcie传输给fpga,fpga再通过aur…...
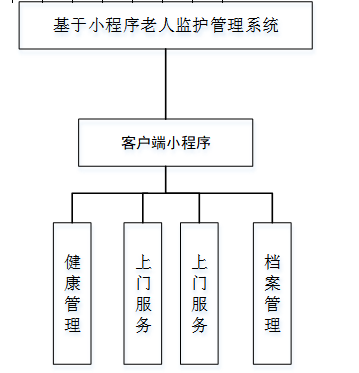
基于小程序老人监护管理系统源码数据库文档
摘 要 近年来,随着我国人口老龄化问题日益严重,独居和居住养老机构的的老年人数量越来越多。而随着老年人数量的逐步增长,随之而来的是日益突出的老年人问题,尤其是老年人的健康问题,尤其是老年人产生健康问题后&…...
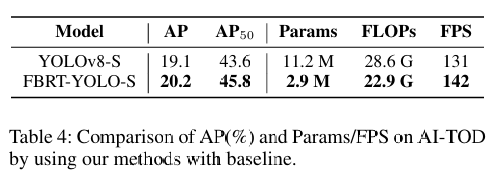
Yolo11改进策略:Block改进|FCM,特征互补映射模块|AAAI 2025|即插即用
1 论文信息 FBRT-YOLO(Faster and Better for Real-Time Aerial Image Detection)是由北京理工大学团队提出的专用于航拍图像实时目标检测的创新框架,发表于AAAI 2025。论文针对航拍场景中小目标检测的核心难题展开研究,重点解决…...