【跟小嘉学 Rust 编程】二十九、Rust 中的零拷贝序列化解决方案(rkyv)
系列文章目录
【跟小嘉学 Rust 编程】一、Rust 编程基础
【跟小嘉学 Rust 编程】二、Rust 包管理工具使用
【跟小嘉学 Rust 编程】三、Rust 的基本程序概念
【跟小嘉学 Rust 编程】四、理解 Rust 的所有权概念
【跟小嘉学 Rust 编程】五、使用结构体关联结构化数据
【跟小嘉学 Rust 编程】六、枚举和模式匹配
【跟小嘉学 Rust 编程】七、使用包(Packages)、单元包(Crates)和模块(Module)来管理项目
【跟小嘉学 Rust 编程】八、常见的集合
【跟小嘉学 Rust 编程】九、错误处理(Error Handling)
【跟小嘉学 Rust 编程】十一、编写自动化测试
【跟小嘉学 Rust 编程】十二、构建一个命令行程序
【跟小嘉学 Rust 编程】十三、函数式语言特性:迭代器和闭包
【跟小嘉学 Rust 编程】十四、关于 Cargo 和 Crates.io
【跟小嘉学 Rust 编程】十五、智能指针(Smart Point)
【跟小嘉学 Rust 编程】十六、无畏并发(Fearless Concurrency)
【跟小嘉学 Rust 编程】十七、面向对象语言特性
【跟小嘉学 Rust 编程】十八、模式匹配(Patterns and Matching)
【跟小嘉学 Rust 编程】十九、高级特性
【跟小嘉学 Rust 编程】二十、进阶扩展
【跟小嘉学 Rust 编程】二十一、网络编程
【跟小嘉学 Rust 编程】二十三、Cargo 使用指南
【跟小嘉学 Rust 编程】二十四、内联汇编(inline assembly)
【跟小嘉学 Rust 编程】二十五、Rust命令行参数解析库(clap)
【跟小嘉学 Rust 编程】二十六、Rust的序列化解决方案(Serde)
【跟小嘉学 Rust 编程】二十七、Rust 异步编程(Asynchronous Programming)
【跟小嘉学 Rust 编程】二十八、Rust中的日期与时间
【跟小嘉学 Rust 编程】二十九、Rust 中的零拷贝序列化解决方案(rkyv)
文章目录
- 系列文章目录
- @[TOC](文章目录)
- 前言
- 一、rkyv介绍
- 二、零拷贝反序列化(Zero-Copy Deserialization)
- 2.1、零拷贝反序列化(Zero-Copy Deserialization)
- 2.2、部分零拷贝(Partial Zero-Copy)
- 2.3、完全零拷贝(Total Zero-Copy)
- 三、体系结构
- 3.1、相对指针(Relative pointers)
- 3.2、存档(Archive)
- 3.3、序列化(Serialize)
- 3.4、反序列化(Deserialize)
- 3.5、对齐(Alignment)
- 四、rkyv 使用
- 总结
文章目录
- 系列文章目录
- @[TOC](文章目录)
- 前言
- 一、rkyv介绍
- 二、零拷贝反序列化(Zero-Copy Deserialization)
- 2.1、零拷贝反序列化(Zero-Copy Deserialization)
- 2.2、部分零拷贝(Partial Zero-Copy)
- 2.3、完全零拷贝(Total Zero-Copy)
- 三、体系结构
- 3.1、相对指针(Relative pointers)
- 3.2、存档(Archive)
- 3.3、序列化(Serialize)
- 3.4、反序列化(Deserialize)
- 3.5、对齐(Alignment)
- 四、rkyv 使用
- 总结
前言
本章节讲解 Rust的另外一个序列化的解决方案:零拷贝序列化解决方案(rkyv库)
主要教材参考 《The Rust Programming Language》
主要教材参考 《Rust For Rustaceans》
主要教材参考 《The Rustonomicon》
主要教材参考 《Rust 高级编程》
主要教材参考 《Cargo 指南》
主要教材参考 《Rust 异步编程》
一、rkyv介绍
rkyv 是 Dusk network 赞助的第一个 ZKP(Zero-Knowledge Recrusion)研究项目
代码仓库地址:https://github.com/rkyv/rkyv
rkyv 是纯 Rust 语言实现的 零拷贝序列化框架,它的主要特征就是零拷贝。 rkyv 允许在代码中定义所有序列化类型,并且可以序列化其他类型无法序列化的各种类型。
rkyv 的目的就是为了提高性,实现这一目标的方式,在内存使用、正确性、安全性方面取得进展。
如果你熟悉其他序列化框架以及传统序列化的工作原理会有帮助,但是对于理解 rkyv 的工作原理并不是必须的。
大多数的序列化框架定义了一个内部数据模型,该模型由基本类型(例如原语、字符串和字节数组)组成。这就将序列化的工作可分为两个阶段:前端和后端。前端采用某种类型,并将其分解为数据模型的可序列化类型,然后后端获取数据模型类型,并使用JSON、Bincode、TOML等数据格式写入它们。这就允许在类型的序列化和写入类型的数据格式之间进行清晰的分离。
传统的序列化的一个主要缺点就是:从序列化的值读取、解析和重构类型需要花费相当多的时间。
例如:在JSON中,字符串通过双引号包裹内容并转义其中的无效字符来编码。数字可能也被转换为字符,甚至大多数情况下可能隐式的字段名也被转换为字符串。
所有的这些角色不仅占据空间,也占据了时间。每次我们读取和解析JSON时,都在挑选这些字符,以便找出值是什么,并在内存中重现,f32类型只有4个字节的内存,但是它是用9个字节编码的,我们仍然需要把这9个字符转换成正确的f32。
这种反序列化操作起来很快,但是在游戏和媒体编辑等数据密集型应用程序中,它可能就会存在累积加载时间。
rkyv 通过一种称为零拷贝反序列化的序列化技术提供了一种解决方案。
二、零拷贝反序列化(Zero-Copy Deserialization)
2.1、零拷贝反序列化(Zero-Copy Deserialization)
零拷贝反序列化是一种通过直接引用序列化形式的字节来减少访问和使用数据所需的时间和内存的技术。
这利用了我们必须在内存中加载一些数据以便对其进行反序列化的优势。
{ "quote": "I don't know, I didn't listen." }
例如我们有上述JSON,我们不是将字符拷贝到字符串中,我们可以从JSON缓冲区中借用它作为&str。 &str 的生命周期将取决于缓冲区,并且我们删除了正在使用的字符串之前,不允许删除它。
2.2、部分零拷贝(Partial Zero-Copy)
Serde 和其他工具支持部分零拷贝反序列化,其中反序列化数据的一小部分从序列化形式中借用。例如,字符串可以直接从编码(bincode)的序列化形式只能够借用字节,而不执行任何字符转义。但是,仍然必须创建一个字符串对象来保存反序列化的长度并指向借来的字符。
考虑这个问题的好方法是,即使我们从缓冲区中借用了大量数据,我们仍然需要解析结构。
struct Example<'a> {quote: &'a str,a: &'a [u8; 12],b: u64,c: char,
}
所以缓冲区可能会想这样
I don't know, I didn't listen.AAAAAAAAAAAABBBBBBBBCCCC
^-----------------------------^-----------^-------^---quote: str a: [u8; 12] b: u64 c: charExample {quote: str::from_utf8(&buffer[0..30]).unwrap(),a: &buffer[30..42],b: u64::from_le_bytes(&buffer[42..50]),c: char::from_u32(u32::from_le_bytes(&buffer[50..54]))).unwrap(),
}
我们不能借用像 u64 或 char这样有对齐要求的类型,因为我们的缓冲区可能没有正确对齐。我们必须立即解析并存储它们!尽管我们借用了缓冲区的42字节,但我们错过了最后的12个字节,并且仍然必须解析缓冲区以找出所有内容的位置。
部分零拷贝反序列化可以显著改善内存的使用,并且通常会加快某些反序列化的速度,但是我们需要做一些工作,我们可以走得更远。
2.3、完全零拷贝(Total Zero-Copy)
rkyv 实现了完全零拷贝反序列化,这保证了在反序列化过程中不复制数据,也不做反序列化数据的工作,它通过结构化其编码来实现这一点,使其与源类型的内存表示相同
struct Example {quote: String,a: [u8; 12],b: u64,c: char,
}
缓冲区可能像这样
I don't know, I didn't listen.__QOFFQLENAAAAAAAAAAAABBBBBBBBCCCC
^----------------------------- ^---^---^-----------^-------^---quote bytes pointer a b cand len^-------------------------------Example
在这种情况下,字节被填充到正确的对齐方式,并且 Example 的字段布局与它们所在的内存布局完全相同,反序列化代码可以简单很多。
unsafe { &*buffer.as_ptr().add(32).cast() }
这个操作几乎是零工作量,更重要的是,它不会随我们的数据扩展,不管我们有多少数据,访问数据的方法总是指针偏移和强制类型转换。
这样就开启了极快的数据加载,并使得数据访问速度比传统序列化快几个数量级。
三、体系结构
rkyv的核心是围绕相对指针和三个核心特征构建的:Archive, Serialize, 和 Deserialize。这些特征都有一个相应的变体,支持未知大小的类型:ArchiveUnsized, SerializeUnsized, 和 DeserializeUnsized.
已知大小的类型是构建未知大小类型的基础,rkyv是精确构建的,以便你可以安全和可组合的方式从低级机器中构建更复杂的抽象。
rkyv_dyn 库增加了对trait 对象的支持,它引入了新的trait,并定义了它们如何构建,从而允许对trait 对象进行序列化和反序列化。
3.1、相对指针(Relative pointers)
相对指针是完全零拷贝反序列化的基础,它完全取代了普通指针的使用。考虑磁盘上的零拷贝数据,在使用它之前,我们需要将它加载到内存中,但是我们无法控制它在内存中的加载位置,每次我们加载它,它都可能位于不同的地址,因此它里面的对象将位于不同的地址。
其中一个主要的原因是安全性,每次运行程序时,它都可能在内存中完全不同的随机位置运行,这被称为地址空间布局随机化,它有助于防止利用内存损坏漏洞。
我们最多只能控制零拷数据的对齐,我们需要在这些约束下工作。
这就意味着,我们不能在数据内部或外部存储指向该数据的任何指针,当我们重新加载数据时,它可能不在同一个地址,这将使指针垂悬,并且几乎肯定会导致内存访问冲突,其他一些库(abomonation)存储一些额外的数据,并执行代替反序列化的快速修复步骤。
为了执行修复步骤,abomonation 要求缓冲区具有可变的支持,对于许多用例来说,这是可以的,但有些情况下,我们将无法改变我们的缓冲区,例如我们使用内存映射文件。
普通指针在内存中保存绝对地址,而相对指针保存地址的偏移量,而这将改变指针在移动时的行为
| 指针 | 自身可以移动 | 自身和目标可以移动 |
|---|---|---|
| 普通指针 | 目标仍然是一个地址 | 目标不在是一个地址 |
| 相对指针 | 相对距离改变 | 自己和目标相对距离不便 |
这正是我们构建完全零拷贝反序列化的数据结构所需要的属性,通过使用相对指针,我们在内存中的任意位置加载数据,并且其中仍然有有效的指针。相对指针也不需要对内存进行写访问,因此我们对整个文件进行内存映射,并以结构化的方式立即访问它们的数据。
具体实现,我们可以查看 RelPtr
3.2、存档(Archive)
实现了 Archive 的类型具有支持零拷贝反序列化的替代表示,分为下面两个步骤
- 序列化:该类型的任何依赖项都被序列化,对于字符串,它将是字符串的字符,对于 box 将是 box 的值,对于向量,它将是包含的任何元素。此步骤的任何记录都将保定 Resolver 类型中,并保留以供以后使用,这就是序列化的步骤
- 解析步骤:解析器和原始值用于构造输出缓冲区中的存档值,对于字符串,解析器将是字符的位置,对于 box,解析将是已经装箱值的位置,对于向量,解析器嫁给你存元素的位置,将原始值和解析起结合起来,就可以构造存档版本了。
let value = ("hello".to_string(), "world".to_string());
上述的元组规定需要两个字符串紧挨着
0x0000 AA AA AA AA BB BB BB BB
0x0008 CC CC CC CC DD DD DD DD
A 和 B 可能是元组第一个字符串的长度和指针,C 和 D 可能是第二个字符串的长度和指针。
在归档时,我们可能回你先序列化并解析第一个字符串,然后再序列化解析第二个字符串,但是这可能会将第二个字符串的字节方在这两个字符串之间。相反,我们需要为这两个字符串写出字节,然后完成它们的归档,元组不知道字符串需要什么信息来完成字节的归档,所以它们必须通过它们的鸡诶稀奇将它提供给元组。
这样元组就可以
- 存档第一个字符串(保存解析器)
- 存档第二个字符串(保存解析器)
- 用解析器解析第一个字符串
- 用解析器解析第二个字符串
我们可以保证两个字符串想我们需要的那样紧挨着放在一起。
3.3、序列化(Serialize)
Serialize 为某个对象创建解析器,然后 Archive 将值和该解析器转换为 Archive 类型,拥有一个单独的 Serialize 特征是必要的,因为尽管一个类型可能只有一个存档表示,但是为了创建一个类型,你可以选择满足那些要求。
Serialize 特征在序列化器上进行参数化,Serializer 是一个可变对象,它可以帮助类型序列化自身,像u32和char 这样的最基本类型没有绑定它们的序列化器类型,因为它们可以用任何类型的序列化器序列化自己。而更复杂的类型则需要字节实现 Serializer 的序列化器,Rc和Vec 需要另外实现 SharedSerializeRegistry 和 ScratchSpace。
与 Serialize 不同,Archive 不会对用于生成它的序列化器进行参数化,解析器是用什么序列化器创建的并不中歌谣,更重要的是它是正确创建的。
rkyv 提供了序列化器,提供了序列化标准库类型所需的所有功能,以及其他序列化器组合成所具有组件功能的单个对象的序列化球。
所提供的序列化器提供了广泛的策略和功能,单大多数用例最适合 AllocSerializer。
许多类型需要临时空间来序列化,这是一些额外分配的空间,他们可以临时使用,并在完成后返回,例如 Vec 可能会请求临时空间来存储其元素的解析器,直刀能够系列化所有元素为止。
从序列化器请求临时空间允许多次重复临时空间,这减少在序列化时执行的缓冲内存分配的数量。
3.4、反序列化(Deserialize)
与序列化类似,Deserialize 将参数化病接受反序列化器,并将类型从其存档形式转换回原始形式。与序列化不同的是反序列化在单个步骤中发生,并且没有对应的解析器。
反序列化还对要反序列化到的类型进行参数化,这将允许根据请求将相同的归档类型反序列化为多个不同的非归档类型,这有助于实现多个非常强大的抽象,但可能需要您在反序列化的时候注释类型。
这或多或少提供了一种传统的反序列化,并通过具有非常兼容的表示在一定程度上加快了速度,她还会导致传统反序列化的内容和性能损失,因此在使用它之前,请确保她是你所需要的。自己要可以通过归档版本访问归档数据,就不需要反序列化。
即使是性能最高的序列化框架也会因为需要执行的内存分配量而达到反序列化速度限制。
反序列化的一个很好的用途就是反序列化归档的部分。您可以轻松地遍历归档数据以定位某个子对象,然后只对该部分进行反序列化,而不是整个规定进行反序列化,这种粒度方法提供是零拷贝反序列化和传统反序列化的区别。
反序列化器与序列化器一样,在反序列化期间为对象提供功能。大多数类型不绑定它们的反序列化器,但有些类型(如Rc)需要特殊的反序列化器才能正确地反序列化内存。
3.5、对齐(Alignment)
类型的对齐限制了它在内存中的位置,优化硬件负载和存储。因为rkyv创建对位于序列化字节中的值的引用,所以它确保哦它创建的引用对象类型进行正确对齐。
为了对数据执行算术和逻辑操作,现代cpu 需要将内存中的数据加载到寄存器中,但是 CPU 访问数据的方式通常有硬件限制:它只能访问从字边界开始的数据。 这些字就是 CPU 工作的自然大小,32位机器的字长为4字节,64位机器的字长为8字节。
四、rkyv 使用
use rkyv::{Archive, Deserialize, Serialize};
use rkyv::ser::{Serializer, serializers::AllocSerializer};#[derive(Archive, Deserialize, Serialize, Debug, PartialEq)]
// This will generate a PartialEq impl between our unarchived and archived types
#[archive(compare(PartialEq))]
// We can pass attributes through to generated types with archive_attr
#[archive_attr(derive(Debug))]
struct Test {int: u8,string: String,option: Option<Vec<i32>>,
}fn main(){let value = Test {int: 42,string: "hello world".to_string(),option: Some(vec![1, 2, 3, 4]),};let mut serializer = AllocSerializer::<0>::default();serializer.serialize_value(&value).unwrap();let bytes = serializer.into_serializer().into_inner();// You can use the safe API with the validation feature turned on,// or you can use the unsafe API (shown here) for maximum performancelet archived = unsafe { rkyv::archived_root::<Test>(&bytes[..]) };assert_eq!(archived, &value);println!("{:#?}", archived);// And you can always deserialize back to the original typelet deserialized: Test = archived.deserialize(&mut rkyv::Infallible).unwrap();assert_eq!(deserialized, value);
}总结
本章节讲解了零拷贝反序列化的原理和体系结构,以及rkyv的使用
相关文章:
)
【跟小嘉学 Rust 编程】二十九、Rust 中的零拷贝序列化解决方案(rkyv)
系列文章目录 【跟小嘉学 Rust 编程】一、Rust 编程基础 【跟小嘉学 Rust 编程】二、Rust 包管理工具使用 【跟小嘉学 Rust 编程】三、Rust 的基本程序概念 【跟小嘉学 Rust 编程】四、理解 Rust 的所有权概念 【跟小嘉学 Rust 编程】五、使用结构体关联结构化数据 【跟小嘉学…...

路由器端口转发
什么是路由器端口转发 路由器端口转发是一种网络配置技术,用于将公共网络(如互联网)上的请求转发到私有网络中的特定设备或服务。它允许外部设备通过路由器访问内部网络中的设备或服务,实现网络上的通信和互动。 路由器端口转发…...
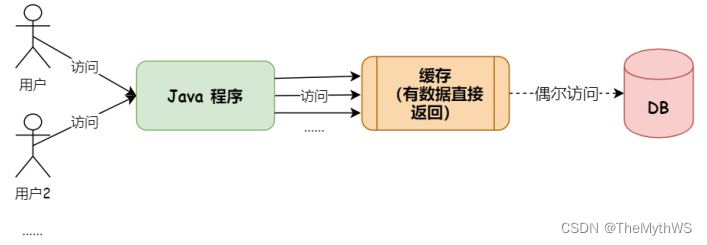
Redis模块一:缓存简介
目录 缓存的定义 应用 生活案例 程序中的缓存 缓存优点 缓存的定义 缓存是⼀个高速数据交换的存储器,使用它可以快速的访问和操作数据。 应用 1.CPU缓存:CPU缓存是位于CPU和内存之间的临时存储器,它的容量通常远小于内存࿰…...

【去除若依首页】有些小项目不需要首页,去除方法
第一步 // // // // // // // // // // // // // // // // // // 修改登录页 Login.vue 中 大概144行 ,注释掉原有跳转。替换为自己的跳转路径 // // // // // // // // // // // // // this.$router.push({ path: this.redirect || …...

Ardupilot — EKF3使用光流室内定位代码梳理
文章目录 前言 1 Copter.cpp 1.1 void IRAM_ATTR Copter::fast_loop() 1.2 void Copter::read_AHRS(void) 1.3 对象ahrs说明 2 AP_AHRS_NavEKF.cpp 2.1 void AP_AHRS_NavEKF::update(bool skip_ins_update) 2.2 void AP_AHRS_NavEKF::update_EKF3(void) 2.3 对象EKF3说…...

【Linux】自动化构建工具 —— make/makefileLinux第一个小程序 - 进度条
📝个人主页:Sherry的成长之路 🏠学习社区:Sherry的成长之路(个人社区) 📖专栏链接:Linux 🎯长路漫漫浩浩,万事皆有期待 上一篇博客:Linux编译…...

tensorflow的unet模型
import tensorflow as tf from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, Dropout, UpSampling2D, concatenate# 定义 U-Net 模型 def unet(input_size(256, 256, 3)):inputs Input(input_size)# 编码器部分conv1 Conv2D(64, 3, activationrelu, padding…...
(2023 最新版)IntelliJ IDEA 下载安装及配置教程
IntelliJ IDEA下载安装教程(图解) IntelliJ IDEA 简称 IDEA,由 JetBrains 公司开发,是 Java 编程语言开发的集成环境,具有美观,高效等众多特点。在智能代码助手、代码自动提示、重构、J2EE 支持、各类版本…...

react 实现拖动元素
demo使用create-react-app脚手架创建 删除一些文件,创建一些文件后 结构目录如下截图com/index import Movable from ./move import { useMove } from ./move.hook import * as Operations from ./move.opMovable.useMove useMove Movable.Operations Operationse…...

【EI会议】第二届声学,流体力学与工程国际学术会议(AFME 2023)
第二届声学,流体力学与工程国际学术会议 2023 2nd International Conference on Acoustics, Fluid Mechanics and Engineering(AFME 2023) 声学、流体力学两个古老的学科发展至今,无时无刻都在影响着我们的生活。小到日常使用的耳…...

Android StringFog 字符串自动加密
一、StringFog 作用 一款自动对dex/aar/jar文件中的字符串进行加密Android插件工具,正如名字所言,给字符串加上一层雾霭,使人难以窥视其真面目。可以用于增加反编译难度,防止字符串代码重复。 支持java/kotlin。支持app打包生成…...

上四休三,未来的期许
近日“少上一天班,究竟香不香”引发关注,英国媒体2月21日报道,一项全世界目前为止参加人数最多的“四天工作制”试验,不久前在英国取得了成功。很多人表示上过四天班之后,给多少钱也回不去五天班的时代了。 来百度APP畅…...
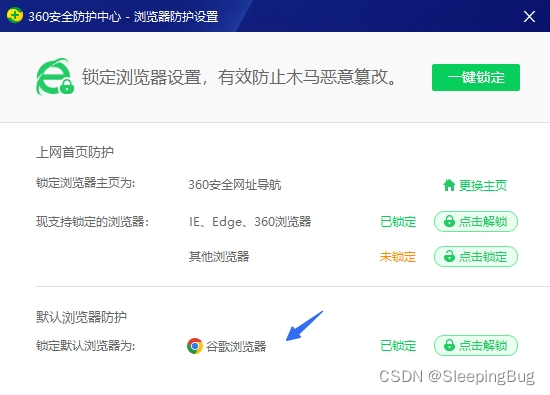
怎么防止360安全卫士修改默认浏览器?
默认的浏览器 原先选项是360极速浏览器(如果有安装的话),我这里改成了Chrome。 先解锁 才能修改。...

调整参数提高mysql读写速度
要提升MySQL的写入速度,您可以采取一些参数调整和优化措施,这些措施可以根据您的具体应用和环境进行调整。以下是一些常见的参数和优化建议: InnoDB存储引擎: 如果您使用的是InnoDB存储引擎,确保以下参数被设置得合理: innodb_buffer_pool_size:增加内存池大小,以便更多…...

Go expvar包
介绍与使用 expvar 是 exposed variable的简写 expvar包[1]是 Golang 官方为暴露Go应用内部指标数据所提供的标准对外接口,可以辅助获取和调试全局变量。 其通过init函数将内置的expvarHandler(一个标准http HandlerFunc)注册到http包ListenAndServe创建的默认Serve…...

Yolo v8代码逐行解读
train.py文件 1.FILE Path(__file__).resolve() __file__代表的是train.py文件,Path(__file__).resolve()结果是train.py文件的绝对路径。 2.ROOT FILE.parents[0] 获得train.py父目录的绝对路径 3.sys.path 是一个列表list,里面包含了已经添加到系…...

9.18号作业
完善登录框 点击登录按钮后,判断账号(admin)和密码(123456)是否一致,如果匹配失败,则弹出错误对话框,文本内容“账号密码不匹配,是否重新登录”,给定两个按钮…...
)
Spring源码阅读(spring-framework-5.2.24)
spring-aop spring-aspects spring-beans spring-context 等等 第一步: Tags spring-projects/spring-framework GitHub 找到相应的release版本 第二步: 下载相应版本的gardle,如何看版本 spring-framework/gradle/wrapper /gradl…...
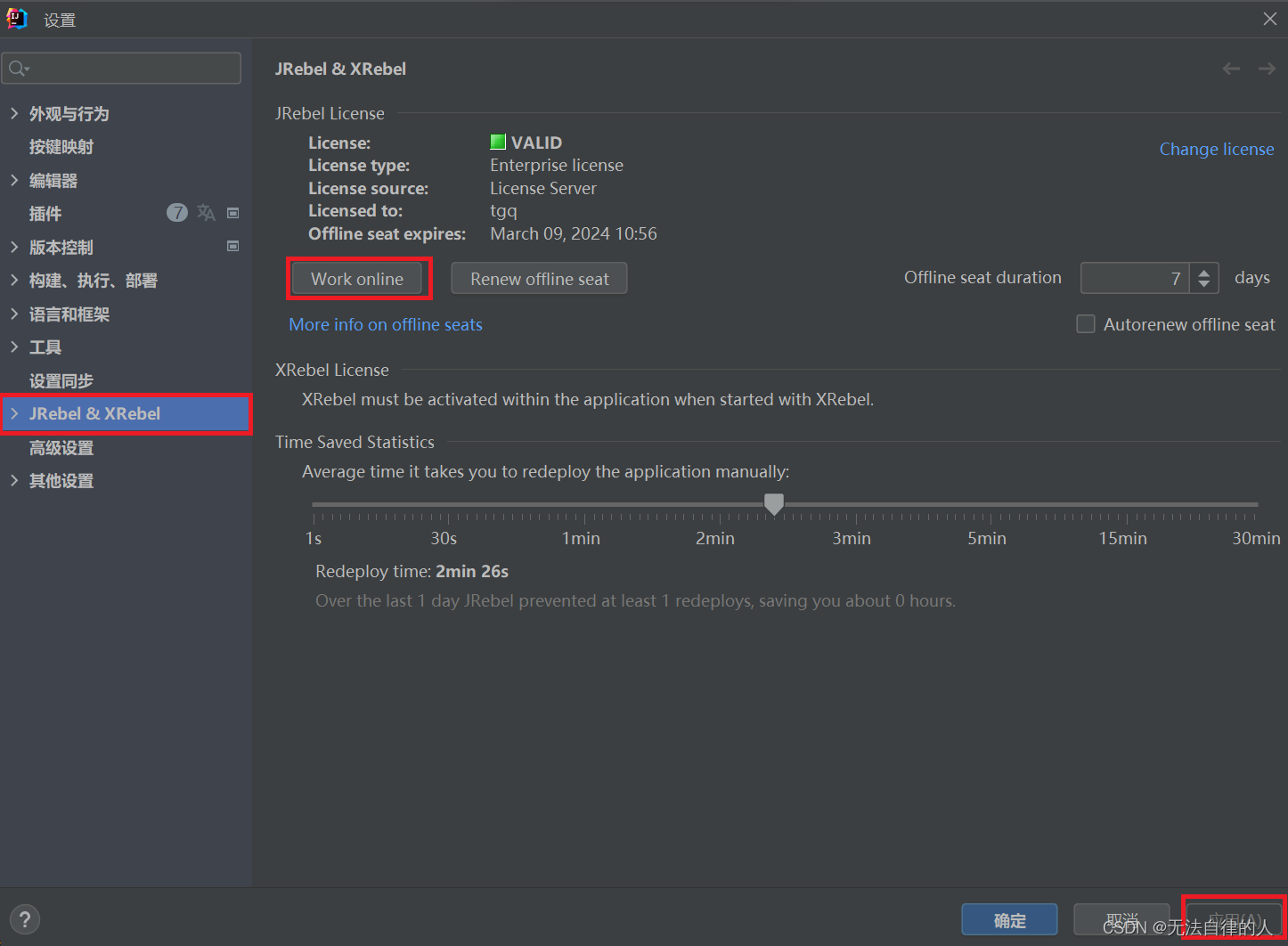
【SpringMVC】文件上传与下载、JREBEL使用
目录 一、引言 二、文件的上传 1、单文件上传 1.1、数据表准备 1.2、添加依赖 1.3、配置文件 1.4、编写表单 1.5、编写controller层 2、多文件上传 2.1、编写form表单 2.2、编写controller层 2.3、测试 三、文件下载 四、JREBEL使用 1、下载注册 2、离线设置 一…...

SAR ADC工作原理与内部结构详解
逐次逼近型ADC内部结构与工作原理深度解析1. SAR ADC基本原理概述逐次逼近寄存器型模数转换器(SAR ADC)是现代嵌入式系统中应用最广泛的ADC架构之一。这种转换器以其适中的转换速度、较高的分辨率和较低的功耗特性,成为STM32等微控制器内置ADC的首选方案。SAR ADC的…...

水墨江南模型SolidWorks渲染融合:工业设计中的中国风元素
水墨江南模型SolidWorks渲染融合:工业设计中的中国风元素 最近和几个做工业设计的朋友聊天,大家都有个共同的感受:现在的产品设计,尤其是消费电子和家电,外观越来越“卷”。金属、玻璃、极简线条,看多了总…...

Ruffle完整教程:3步快速上手Rust编写的Flash模拟器
Ruffle完整教程:3步快速上手Rust编写的Flash模拟器 【免费下载链接】ruffle A Flash Player emulator written in Rust 项目地址: https://gitcode.com/GitHub_Trending/ru/ruffle 还在为无法访问历史Flash内容而烦恼吗?Ruffle为你提供了完美的解…...

【硬核横评】别神话DeepSeek了!2026基准测试15款降AI工具:这几款才是95%降至5.8%的保命底牌
昨天半夜后台有个粉丝私信我诉说:“看了网上的教程用免费GPT改论文,结果论文降ai不成,AI率反而从40%飙到了85%,下周就要盲审了,我是不是要延毕了?” 说实话,看到这种情况我真的感同身受。今年各…...

Topgrade社区分支对比:如何选择最适合的版本继续使用
Topgrade社区分支对比:如何选择最适合的版本继续使用 【免费下载链接】topgrade Upgrade everything 项目地址: https://gitcode.com/gh_mirrors/to/topgrade Topgrade是一款强大的系统升级工具,能够自动检测并更新您系统中所有的软件包管理器。这…...

企业级AI聚合平台架构解析:ChatNio分布式多模型支持与性能优化实战
企业级AI聚合平台架构解析:ChatNio分布式多模型支持与性能优化实战 【免费下载链接】chatnio 🚀 强大精美的 AI 聚合聊天平台,适配OpenAI,Claude,讯飞星火,Midjourney,Stable Diffusion…...

实用干货分享:对象存储安全密钥轮换周期规划与存储安全提升方案
在当今数字化时代,对象存储已成为企业数据管理的核心支柱,但随之而来的安全挑战也不容忽视。作为深耕数据安全领域多年的从业者,我发现密钥管理是多数企业的共性痛点,尤其是密钥轮换周期的把控,往往让企业感到困惑。今…...

XUnity.AutoTranslator深度技术解析:游戏多语言翻译实战指南
XUnity.AutoTranslator深度技术解析:游戏多语言翻译实战指南 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator XUnity.AutoTranslator是一款专为Unity游戏设计的智能翻译插件,通过创…...

PLC毕业设计效率提升实战:从重复编码到模块化开发的演进
最近在指导几位学弟学妹做PLC毕业设计时,发现一个普遍现象:大家往往把大量时间花在了重复写代码和“抓虫”调试上,项目进度缓慢,人也疲惫不堪。这让我回想起自己当初做毕设时踩过的坑,以及后来在工作中摸索出的一套效率…...

Swift-All零基础入门:5分钟搞定600+大模型下载与推理
Swift-All零基础入门:5分钟搞定600大模型下载与推理 1. 认识Swift-All:大模型一站式工具箱 1.1 什么是Swift-All? Swift-All是魔搭社区推出的开源大模型全流程工具包,它让普通开发者也能轻松驾驭600大模型和300多模态模型。想象…...