python爬虫爬取电影数据并做可视化
思路:
1、发送请求,解析html里面的数据
2、保存到csv文件
3、数据处理
4、数据可视化
需要用到的库:
import requests,csv #请求库和保存库
import pandas as pd #读取csv文件以及操作数据
from lxml import etree #解析html库
from pyecharts.charts import * #可视化库注意:后续用到分词库jieba以及词频统计库nltk
环境:
python 3.10.5版本
编辑器:vscode -jupyter
使用ipynb文件的扩展名 vscode会提示安装jupyter插件
一、发送请求、获取html
#请求的网址
url='https://ssr1.scrape.center/page/1'#请求头
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
}#发起请求,获取文本数据
reponse=requests.get(url,url,headers=headers)
print(reponse)
二、使用xpath提取html里面的数据并存到csv
#创建csv文件
with open('电影数据.csv',mode='w',encoding='utf-8',newline='') as f:#创建csv对象csv_save=csv.writer(f)#创建标题csv_save.writerow(['电影名','电影上映地','电影时长','上映时间','电影评分'])for page in range(1,11): #传播关键1到10页的页数#请求的网址url='https://ssr1.scrape.center/page/{}'.format(page)print('当前请求页数:',page)#请求头headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"}response=requests.get(url,url,headers=headers,verify=False)print(response)html_data=etree.HTML(response.text)#获取电影名title=html_data.xpath('//div[@class="p-h el-col el-col-24 el-col-xs-9 el-col-sm-13 el-col-md-16"]/a/h2/text()')#获取电影制作地gbs=html_data.xpath('//div[@class="p-h el-col el-col-24 el-col-xs-9 el-col-sm-13 el-col-md-16"]/div[2]/span[1]/text()')#获取电影时长time=html_data.xpath('//div[@class="m-v-sm info"]/span[3]/text()')#获取电影上映时间move_time=html_data.xpath('//div[@class="p-h el-col el-col-24 el-col-xs-9 el-col-sm-13 el-col-md-16"]/div[3]/span/text()')#电影评分numder=html_data.xpath('//p[@class="score m-t-md m-b-n-sm"]/text()')for name,move_gbs,times,move_times,numders in zip(title,gbs,time,move_time,numder):print('电影名:',name,' 电影上映地址:',move_gbs,' 电影时长:',times,' 电影上映时间:',move_times,' 电影评分:',numders)#name,move_gbs,times,move_times,numders#写入csv文件csv_save.writerow([name,move_gbs,times,move_times,numders])效果:
三、使用pandas打开爬取的csv文件
data=pd.read_csv('电影数据.csv',encoding='utf-8')
print(data)四、对电影名进行分词以及词频统计
注意:使用jieba分词,nltk分词
这里的停用此表可以自己创建一个 里面放无意义的字,比如:的、不是、不然这些
每个字独占一行即可
import jiebatitle_list=[]for name in data['电影名']:#进行精准分词lcut=jieba.lcut(name,cut_all=False)
# print(lcut)for i in lcut :
# print(i)#去除无意义的词#打开停用词表文件file_path=open('停用词表.txt',encoding='utf-8')#将读取的数据赋值给stop_words变量stop_words=file_path.read()#遍历后的值 如果没有在停用词表里面 则添加到net_data列表里面if i not in stop_words:title_list.append(i)
# print(title_list)#计算词语出现的频率
from nltk import FreqDist #该模块提供了计算频率分布的功能#FreqDist对象将计算net_data中每个单词的出现频率,,并将结果存储在freq_list中
freq_list=FreqDist(title_list)
print(freq_list) #结果:FreqDist 有1321个样本和5767个结果 #该方法返回一个包含最常出现单词及其出现频率的列表。将该列表赋值给most_common_words变量。
most_common_words=freq_list.most_common()
print(most_common_words) #结果:('The这个词',出现185次)效果:
五、词云可视化
# 创建一个 WordCloud类(词云) 实例
word_cloud = WordCloud() # 添加数据和词云大小范围 add('标题', 数据, word_size_range=将出现频率最高的单词添加到词云图中,并设置单词的大小范围为 20 到 100。)
word_cloud.add('词云图', most_common_words, word_size_range=[20, 100]) # 设置全局选项,包括标题
word_cloud.set_global_opts(title_opts=opts.TitleOpts(title='电影数据词云图')) # 在 Jupyter Notebook 中渲染词云图
word_cloud.render_notebook()#也可以生成html文件观看
word_cloud.render('result.html')运行效果:
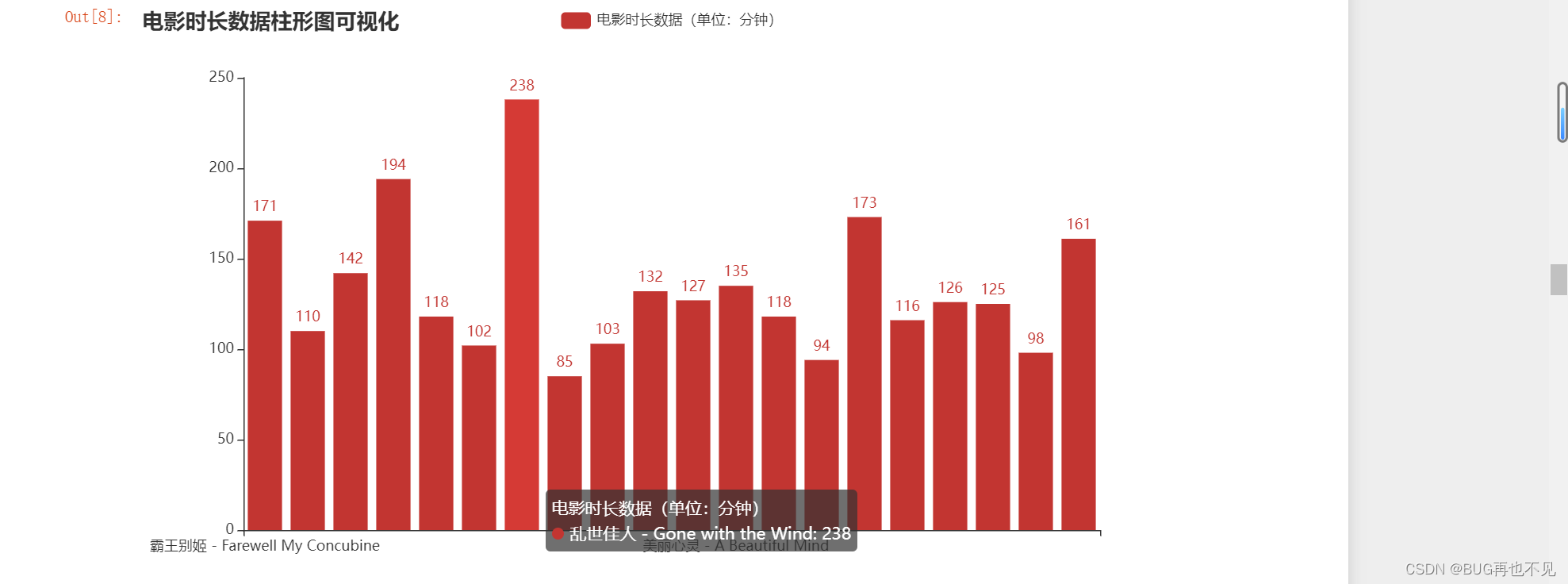
六、对电影时长进行统计并做柱形图可视化
#电影时长 去除分钟和,号这个 转为int 然后再转为列表 只提取20条数据,总共100条
move_time=data['电影时长'].apply(lambda x: x.replace('分钟', '').replace(',', '')).astype('int').tolist()[0:20]
# print(move_time)#电影名 只提取20条数据
move_name=data['电影名'].tolist()[0:20]
# print(move_name)#创建Bar实例
Bar_obj=Bar()#添加x轴数据标题
Bar_obj.add_xaxis(move_name)#添加y轴数据
Bar_obj.add_yaxis('电影时长数据(单位:分钟)',move_time)#设置标题
Bar_obj.set_global_opts(title_opts={'text': '电影时长数据柱形图可视化'})# 显示图表
Bar_obj.render_notebook()
效果:
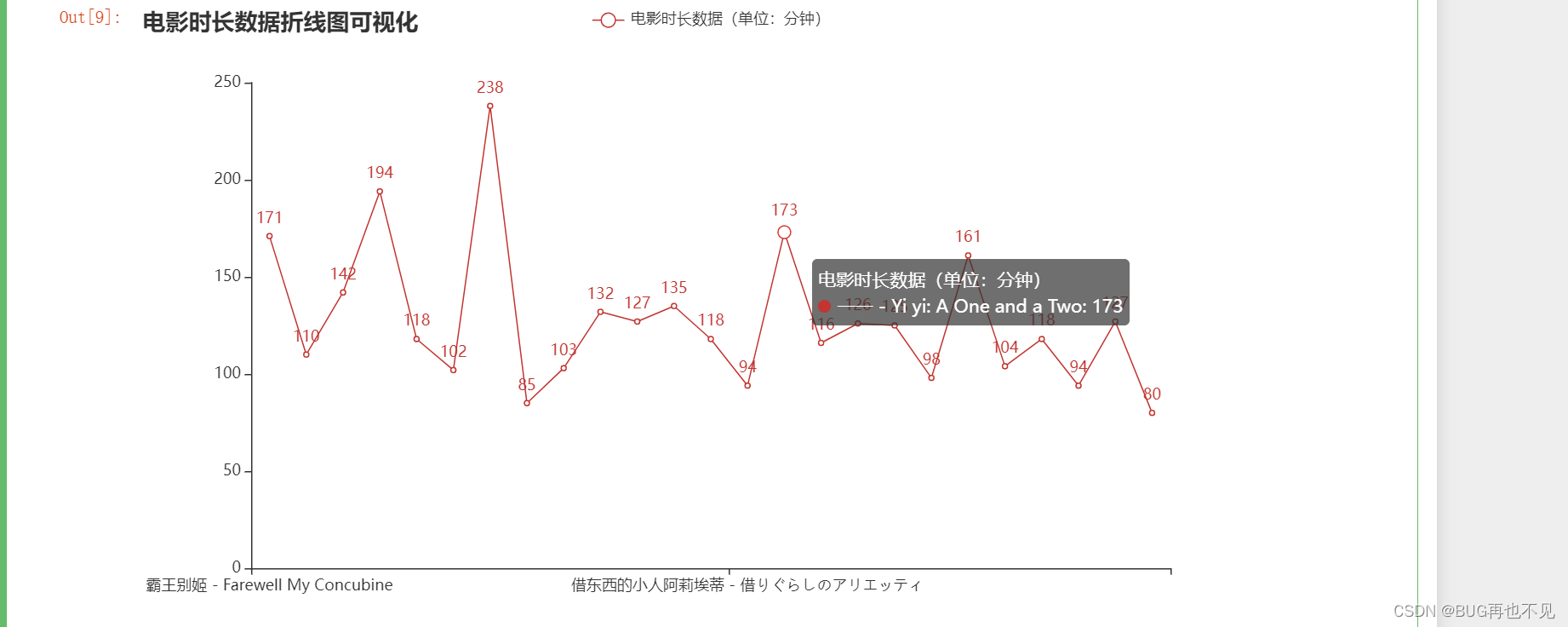
七、电影时长折线图可视化
#去除分钟和,号这个 转为int 然后再转为列表 只提取25条数据
move_time=data['电影时长'].apply(lambda x: x.replace('分钟', '').replace(',', '')).astype('int').tolist()[0:25]
# print(move_time)#电影名 只提取25条数据
move_name=data['电影名'].tolist()[0:25]
# print(move_name)#创建Bar实例
Bar_obj=Line()#添加x轴数据标题
Bar_obj.add_xaxis(move_name)#添加y轴数据
Bar_obj.add_yaxis('电影时长数据(单位:分钟)',move_time)#设置标题
Bar_obj.set_global_opts(title_opts={'text': '电影时长数据折线图可视化'})# 显示图表
Bar_obj.render_notebook()效果:
八、统计每个国家电影上映的数量
import jiebatitle_list=[]#遍历电影上映地这一列
for name in data['电影上映地']:#进行精准分词lcut=jieba.lcut(name,cut_all=False)
# print(lcut)for i in lcut :
# print(i)#去除无意义的词#打开停用词表文件file_path=open('停用词表.txt',encoding='utf-8')#将读取的数据赋值给stop_words变量stop_words=file_path.read()#遍历后的值 如果没有在停用词表里面 则添加到net_data列表里面if i not in stop_words:title_list.append(i)
# print(title_list)#计算词语出现的频率
from nltk import FreqDist #该模块提供了计算频率分布的功能#FreqDist对象将计算net_data中每个单词的出现频率,,并将结果存储在freq_list中
freq_list=FreqDist(title_list)
print(freq_list) #结果:FreqDist 有1321个样本和5767个结果 #该方法返回一个包含最常出现单词及其出现频率的列表。将该列表赋值给most_common_words变量。
most_common_words=freq_list.most_common()
print(most_common_words) #结果:('单人这个词',出现185次)#电影名 使用列表推导式来提取most_common_words中每个元素中的第一个元素,即出现次数,然后将它们存储在一个新的列表中
map_data_title = [count[0] for count in most_common_words]
print(map_data_title)#电影数
map_data=[count[1] for count in most_common_words]
print(map_data)效果:

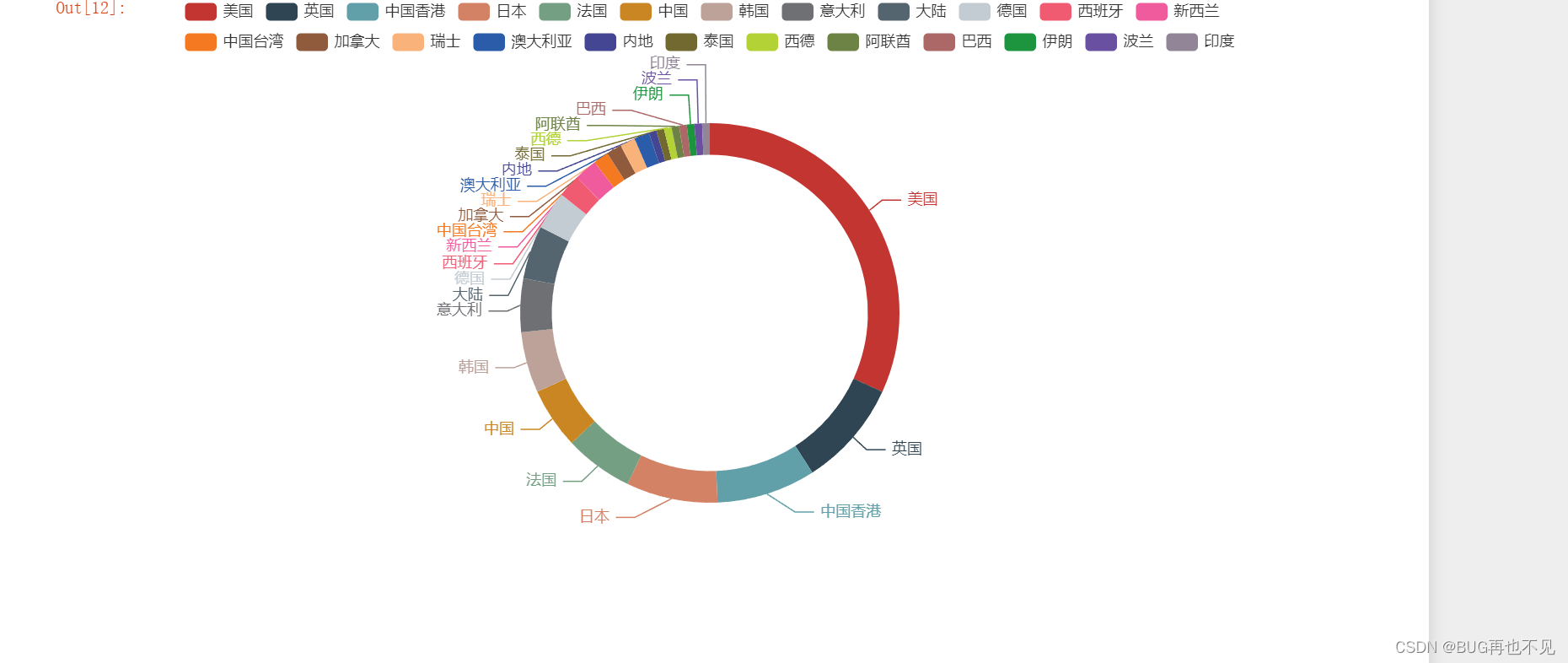
九、对每个国家电影上映数量饼图可视化
#获取map_data_title的长度,决定循环次数,赋值给遍历i 在通过下标取值
result = [[map_data_title[i], map_data[i]] for i in range(len(map_data_title))]
print(result)# 创建Pie实例
chart=Pie()#添加标题和数据 radius=['圆形空白处百分比','色块百分比(大小)'] 可不写
chart.add('电影上映数饼图(单位:个)',result,radius=['50%','60%'])#显示
chart.render_notebook()效果:
觉得有帮助的话,点个赞!
相关文章:
python爬虫爬取电影数据并做可视化
思路: 1、发送请求,解析html里面的数据 2、保存到csv文件 3、数据处理 4、数据可视化 需要用到的库: import requests,csv #请求库和保存库 import pandas as pd #读取csv文件以及操作数据 from lxml import etree #解析html库 from …...
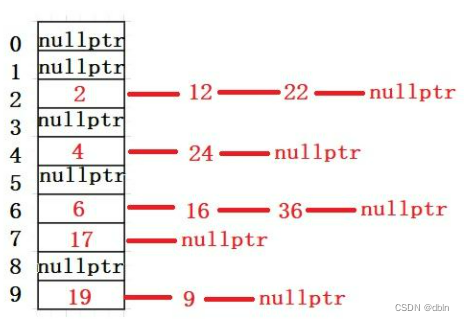
哈希及哈希表的实现
目录 一、哈希的引入 二、概念 三、哈希冲突 四、哈希函数 常见的哈希函数 1、直接定址法 2、除留余数法 五、哈希冲突的解决 1、闭散列 2、开散列 一、哈希的引入 顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找…...
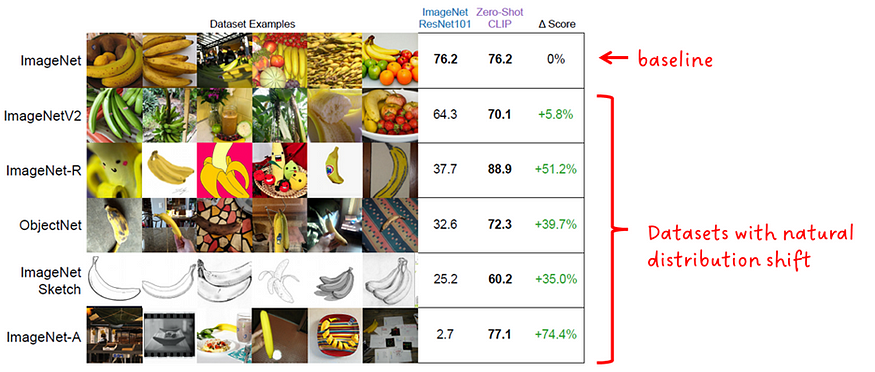
CLIP 基础模型:从自然语言监督中学习可转移的视觉模型
一、说明 在本文中,我们将介绍CLIP背后的论文(Contrastive Language-I mage Pre-Training)。我们将提取关键概念并分解它们以使其易于理解。此外,还对图像和数据图表进行了注释以澄清疑问。 图片来源: 论文:…...

解读性能指标TP50、TP90、TP99、TP999
TP指标说明 TP指标: 指在一个时间段内,统计该方法每次调用所消耗的时间,并将这些时间按从小到大的顺序进行排序, 并取出结果为:总次数*指标数对应TP指标的值,再取出排序好的时间。 TPTop Percentile,Top百分数&#…...

【无标题】mysql 截取两个,之间字符串
截取两个,之间字符串 select area,SUBSTRING_INDEX(et.area,,,1) as XZQH1,if(length(et.area)-length(replace(et.area,,,))>1,SUBSTRING_INDEX(SUBSTRING_INDEX(et.area,,,2),,,-1),NULL) AS XZQH2,if(length(et.area)-length(replace(et.area,,,))>2,SUBS…...

全局的键盘监听事件
一、设定全局键盘监听事件 放在vue 的created()或者mounted ()中,可对整个文档进行键盘事件监听。 new Vue({ created() { window.addEventListener(keydown, this.handleKeydown); }, beforeDestroy() { window.removeEventListener(keydown, this.handleK…...
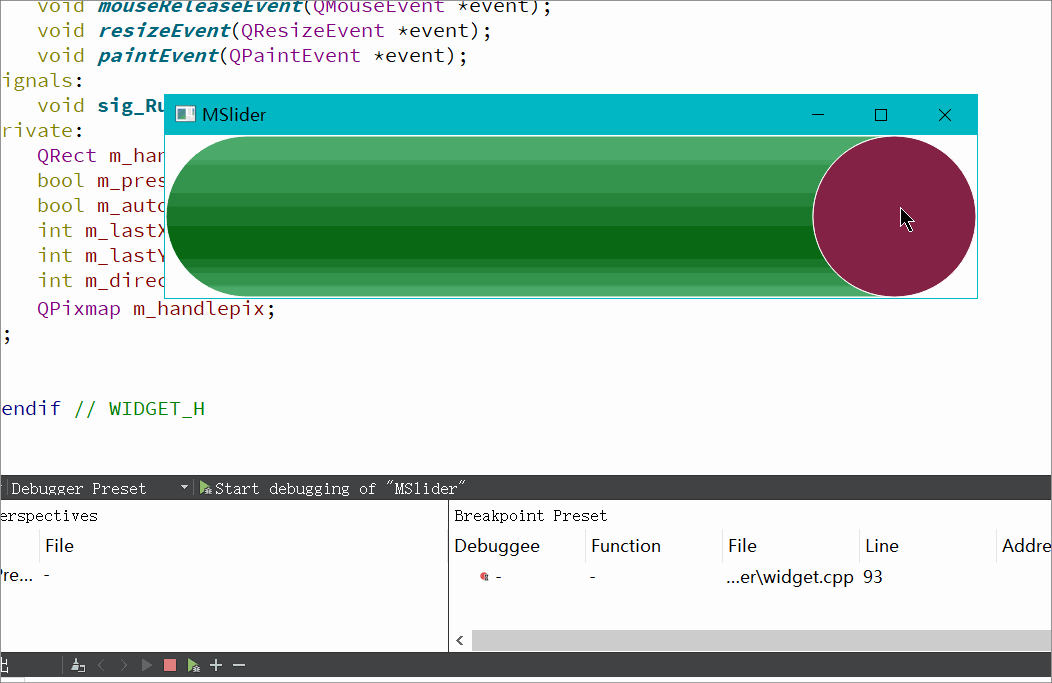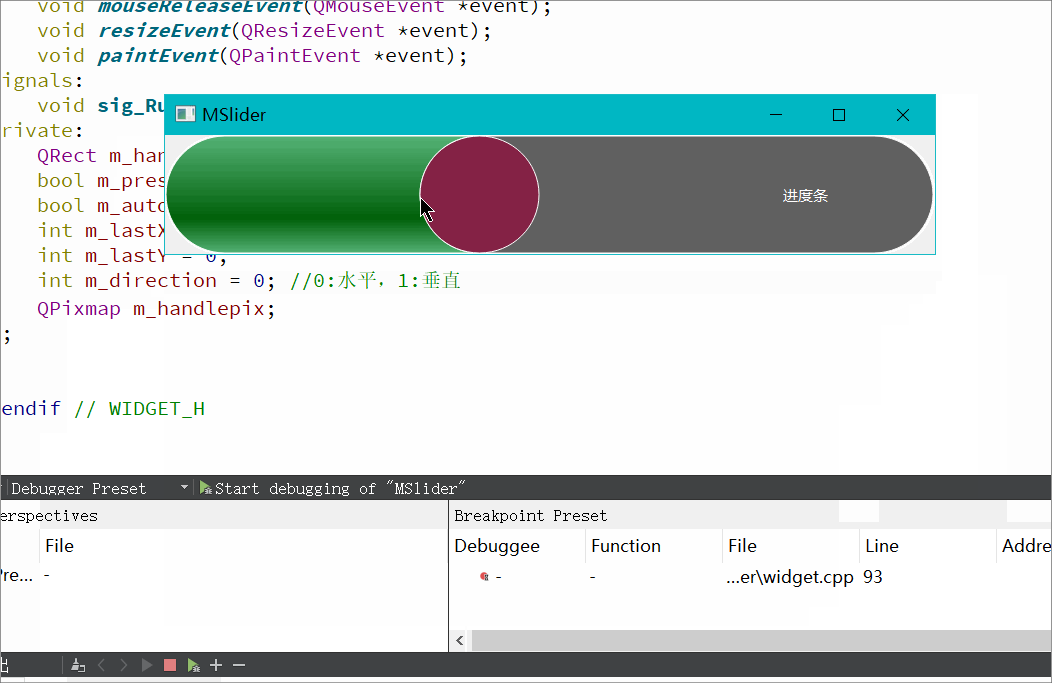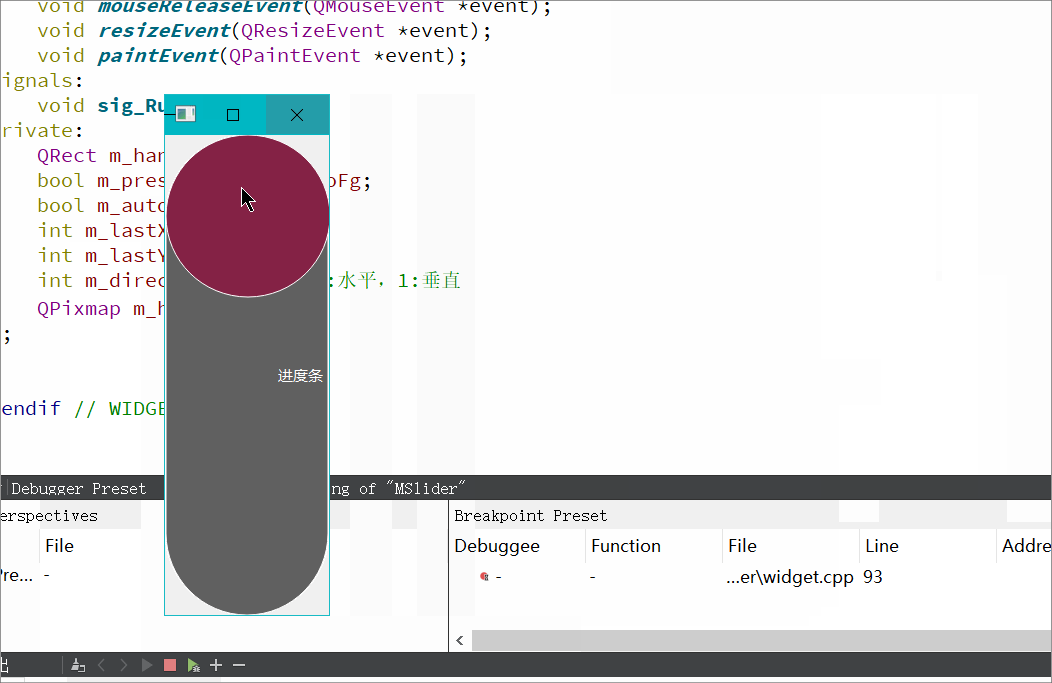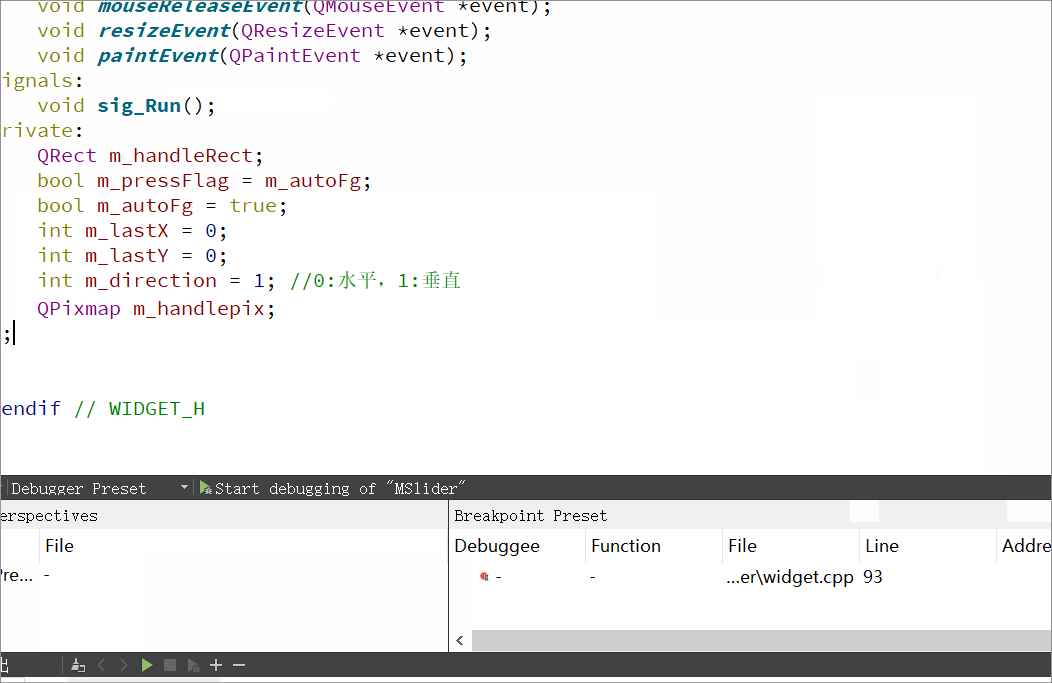
Qt自定义QSlider(支持水平垂直)
实现背景: Qt本身有自己的QSlider,为什么我们还要自定义实现呢,因为Qt自带的QSlider存在一个问题,当首尾为圆角时,滑动滚动条到首尾时会出现圆角变成矩形的问题。当然如果QSS之间的margin和滑动条的圆角控制的好的话是…...

会话控制学习
文章目录 介绍cookieexpress中使用cookie获取cookie session配置区别 介绍 cookie express中使用cookie 退出登录就是删除cookie 获取cookie 添加中间键后,直接获取 session 配置 区别...

dweb-browser阅读
dweb-browser阅读 核心模块js.browser.dwebjmm.browser.dwebmwebview.browser.dwebnativeui.browser.dweb.sys.dweb plaoc插件 核心模块 js.browser.dweb 它是一个 javascript-runtime,使用的是 WebWorker 作为底层实现。它可以让您在 dweb-browser 中运行 javasc…...

ChatGPT:使用fastjson读取JSON数据问题——如何使用com.alibaba.fastjson库读取JSON数据的特定字段
ChatGPT:使用fastjson读取JSON数据问题——如何使用com.alibaba.fastjson库读取JSON数据的特定字段 有一段Json字符串: {"code": 200,"message": "success","data": {"total": "1","l…...
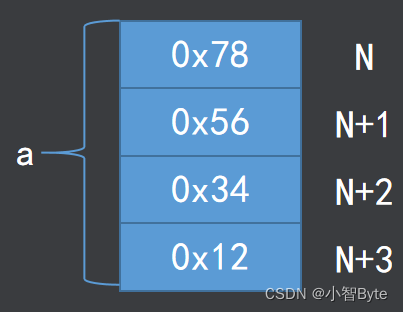
2、ARM处理器概论
一、ARM处理器概述 1、ARM的含义 ARM(Advanced RISC Machines)有三种含义,一个公司的名称、一类处理器的通称、一种技术 ARM公司: 成立于1990年11月,前身为Acorn计算机公司主要设计ARM系列RISC处理器内核授权ARM内…...
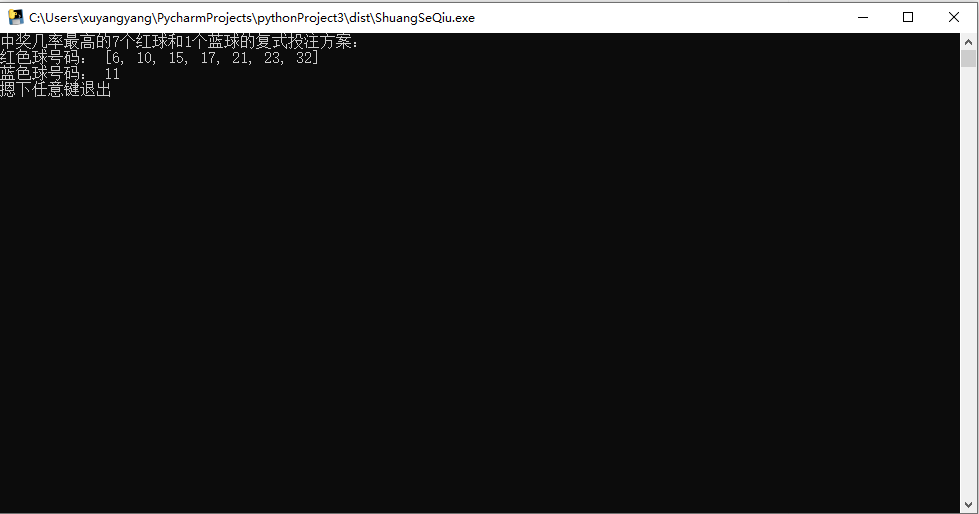
【Python】福利彩票复式模拟选号程序
【效果】 【注意】 逻辑是用Random模拟10000次复试彩票选号,然后给出最大可能性一组。但是模拟终究是模拟,和现实彩票结果没有任何联系,下载下来玩就是了,没人能保证模拟出中奖号码,不要投机,不要投机! 【修改】 代码很简单,如果想改成不是复式的,自行修改即可。 如…...

Pytorch 机器学习专业基础知识+神经网络搭建相关知识
文章目录 一、三种学习方式二、机器学习的一些专业术语三、模型相关知识四、常用的保留策略五、数据处理六、解决过拟合与欠拟合七、成功的衡量标准 一、三种学习方式 有监督学习: 1、分类问题 2、回归问题 3、图像分割 4、语音识别 5、语言翻译 无监督学习 1、聚类…...

torch 和paddle 的GPU版本可以放在同一个conda环境下吗
新建conda 虚拟环境,python 版本3.8.17 虚拟机,系统centos 7,内核版本Linux fastknow 3.10.0-1160.92.1.el7.x86_64 ,显卡T4,nvidia-smi ,460.32.03,对应cuda 11.2,安装cuda 11.2和cudnn,conda…...

MYBATIS-PLUS入门使用、踩坑记录
转载: mybatis-plus入门使用、踩坑记录 - 灰信网(软件开发博客聚合) 首先引入MYBATIS-PLUS依赖: SPRING BOOT项目: <dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus…...
的区别)
C# 静态类和sealed类(密封类)的区别
网上看到很多文章写静态类,和密封类,但是鲜有它们的对比总结,在此简单总结一下: 静态类(Static Class): 静态类不能被实例化,其成员都是静态的,可以通过类名直接访问。静…...

el-table如何实现自动缩放,提示隐藏内容
前提问题:大屏展示中某一个区域是表格内容,当放大或缩小网页大小时,表格宽度随之缩放,但表格内容未进行缩放,需要表格内容与网页大小同时进行缩放,且表头和表格内容宽度不够未显示全时,需要进行…...
CRM客户管理软件对出海企业的帮助与好处
2023我们走出了疫情的阴霾,经济下行压力大,面对内需的不足,国内企业纷纷选择出海,拓展海外业务增加企业营收。企业出海不是一件易事,有了CRM系统可以让公司事半功倍,下面就来说一说CRM客户管理软件能为出海…...
【QT--使用百度地图API显示地图并绘制路线】
QT--使用百度地图API显示地图并绘制路线 前言准备工作申请百度地图密钥(AK)安装开发环境 开发过程新建项目ui界面GPSManager类主窗口Map 效果展示 前言 先吐槽一下下,本身qt学的就不咋滴,谁想到第一件事就是让写一个上位机工具,根据CAN总线传…...

C数据结构二.练习题
一.求级数和 2.求最大子序列问题:设给定一个整数序列 ai.az..,a,(可能有负数).设计一个穷举算法,求a 的最大值。例如,对于序列 A {1,-1,1,-1,-1,1,1,1,1.1,-1,-1.1,-1,1,-1},子序列 A[5..9](1,1,1,1,1)具有最大值5 3.设有两个正整数 m 和n,编写一个算法 gcd(m,n),求它们的最大公…...
结构体的进阶应用)
基于算法竞赛的c++编程(28)结构体的进阶应用
结构体的嵌套与复杂数据组织 在C中,结构体可以嵌套使用,形成更复杂的数据结构。例如,可以通过嵌套结构体描述多层级数据关系: struct Address {string city;string street;int zipCode; };struct Employee {string name;int id;…...

华为云AI开发平台ModelArts
华为云ModelArts:重塑AI开发流程的“智能引擎”与“创新加速器”! 在人工智能浪潮席卷全球的2025年,企业拥抱AI的意愿空前高涨,但技术门槛高、流程复杂、资源投入巨大的现实,却让许多创新构想止步于实验室。数据科学家…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

ssc377d修改flash分区大小
1、flash的分区默认分配16M、 / # df -h Filesystem Size Used Available Use% Mounted on /dev/root 1.9M 1.9M 0 100% / /dev/mtdblock4 3.0M...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

【解密LSTM、GRU如何解决传统RNN梯度消失问题】
解密LSTM与GRU:如何让RNN变得更聪明? 在深度学习的世界里,循环神经网络(RNN)以其卓越的序列数据处理能力广泛应用于自然语言处理、时间序列预测等领域。然而,传统RNN存在的一个严重问题——梯度消失&#…...

【磁盘】每天掌握一个Linux命令 - iostat
目录 【磁盘】每天掌握一个Linux命令 - iostat工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景 注意事项 【磁盘】每天掌握一个Linux命令 - iostat 工具概述 iostat(I/O Statistics)是Linux系统下用于监视系统输入输出设备和CPU使…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院挂号小程序
一、开发准备 环境搭建: 安装DevEco Studio 3.0或更高版本配置HarmonyOS SDK申请开发者账号 项目创建: File > New > Create Project > Application (选择"Empty Ability") 二、核心功能实现 1. 医院科室展示 /…...
)
【HarmonyOS 5 开发速记】如何获取用户信息(头像/昵称/手机号)
1.获取 authorizationCode: 2.利用 authorizationCode 获取 accessToken:文档中心 3.获取手机:文档中心 4.获取昵称头像:文档中心 首先创建 request 若要获取手机号,scope必填 phone,permissions 必填 …...

Linux --进程控制
本文从以下五个方面来初步认识进程控制: 目录 进程创建 进程终止 进程等待 进程替换 模拟实现一个微型shell 进程创建 在Linux系统中我们可以在一个进程使用系统调用fork()来创建子进程,创建出来的进程就是子进程,原来的进程为父进程。…...