Pytorch从零开始实战04
Pytorch从零开始实战——猴痘病识别
本系列来源于365天深度学习训练营
原作者K同学
文章目录
- Pytorch从零开始实战——猴痘病识别
- 环境准备
- 数据集
- 模型选择
- 模型训练
- 数据可视化
- 其他模型
- 图片预测
环境准备
本文基于Jupyter notebook,使用Python3.8,Pytorch2.0.1+cu118,torchvision0.15.2,需读者自行配置好环境且有一些深度学习理论基础。本次实验的目的是学习模型的保存和预测单张图片的结果。
第一步,导入常用包。
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvision
import torch.nn.functional as F
import torchvision.transforms as transforms
import random
import time
import numpy as np
import pandas as pd
import datetime
import gc
import pathlib
import os
import PIL
os.environ['KMP_DUPLICATE_LIB_OK']='True' # 用于避免jupyter环境突然关闭
torch.backends.cudnn.benchmark=True # 用于加速GPU运算的代码
创建设备对象
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
设置随机数种子
torch.manual_seed(428)
torch.cuda.manual_seed(428)
torch.cuda.manual_seed_all(428)
random.seed(428)
np.random.seed(428)
数据集
本次实验使用猴痘病图片数据集,共2142张图片,分别为有猴痘病的图片和没有猴痘病的图片,
两种类别的图片分别存在两个文件夹中。
data_dir = './data/monkeydata'
data_dir = pathlib.Path(data_dir)data_paths = list(data_dir.glob('*'))
classNames = [str(path).split("/")[2] for path in data_paths]
classNames # ['Monkeypox', 'Others']
对数据通过dataset读取,并且将文件夹名设置为标签。
total_datadir = './data/monkeydata'
train_transforms = transforms.Compose([transforms.Resize([224, 224]),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])
])
total_data = torchvision.datasets.ImageFolder(total_datadir, transform=train_transforms)
total_data

我们可以查看所有标签
total_data.class_to_idx # {'Monkeypox': 0, 'Others': 1}
接下来划分数据集,以8比2划分训练集和测试集
# 划分数据集
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_ds, test_ds = torch.utils.data.random_split(total_data, [train_size, test_size])
len(train_ds), len(test_ds)
随机查看5张图片
def plotsample(data):fig, axs = plt.subplots(1, 5, figsize=(10, 10)) #建立子图for i in range(5):num = random.randint(0, len(data) - 1) #首先选取随机数,随机选取五次#抽取数据中对应的图像对象,make_grid函数可将任意格式的图像的通道数升为3,而不改变图像原始的数据#而展示图像用的imshow函数最常见的输入格式也是3通道npimg = torchvision.utils.make_grid(data[num][0]).numpy()nplabel = data[num][1] #提取标签 #将图像由(3, weight, height)转化为(weight, height, 3),并放入imshow函数中读取axs[i].imshow(np.transpose(npimg, (1, 2, 0))) axs[i].set_title(nplabel) #给每个子图加上标签axs[i].axis("off") #消除每个子图的坐标轴plotsample(train_ds)
使用DataLoader划分批次和打乱数据集
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_ds, batch_size=batch_size, shuffle=True)
test_dl = torch.utils.data.DataLoader(test_ds, batch_size=batch_size, shuffle=True)
for X, y in test_dl:print(X.shape) # 32, 3, 224, 224print(y) # 1, 0, 1, 1, 1, 1, 0....break
print(len(train_dl.dataset) + len(test_dl.dataset)) # 2142
模型选择
本次实验第一次选择的是一个简单的卷积神经网络,经过卷积+卷积+池化+卷积+卷积+池化+线性层,并中间进行数据归一化处理。
class Model(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(3, 12, kernel_size=5, stride=1, padding=0)self.bn1 = nn.BatchNorm2d(12)self.conv2 = nn.Conv2d(12, 12, kernel_size=5, stride=1, padding=0)self.bn2 = nn.BatchNorm2d(12)self.pool = nn.MaxPool2d(2)self.conv3 = nn.Conv2d(12, 24, kernel_size=5, stride=1, padding=0)self.bn3 = nn.BatchNorm2d(24)self.conv4 = nn.Conv2d(24, 24, kernel_size=5, stride=1, padding=0)self.bn4 = nn.BatchNorm2d(24)self.fc1 = nn.Linear(24 * 50 * 50, len(classNames))def forward(self, x):x = F.relu(self.bn1(self.conv1(x)))x = F.relu(self.bn2(self.conv2(x))) x = self.pool(x)x = F.relu(self.bn3(self.conv3(x))) x = F.relu(self.bn4(self.conv4(x))) x = self.pool(x) x = x.view(-1, 24 * 50 * 50)x = self.fc1(x)return x;
使用summary查看模型
from torchsummary import summary
# 将模型转移到GPU中
model = Model().to(device)
summary(model, input_size=(3, 224, 224))
模型训练
训练函数
def train(dataloader, model, loss_fn, opt):size = len(dataloader.dataset)num_batches = len(dataloader)train_acc, train_loss = 0, 0for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)opt.zero_grad()loss.backward()opt.step()train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss
测试函数
def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)test_acc, test_loss = 0, 0with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss += loss.item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss
定义一些超参数,经实验,将学习率设置为0.01效果最好。
loss_fn = nn.CrossEntropyLoss()
learn_rate = 0.01
opt = torch.optim.SGD(model.parameters(), lr=learn_rate)
开始训练,epochs设置为20,并且将训练集的最优结果保存。
import time
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []T1 = time.time()best_acc = 0
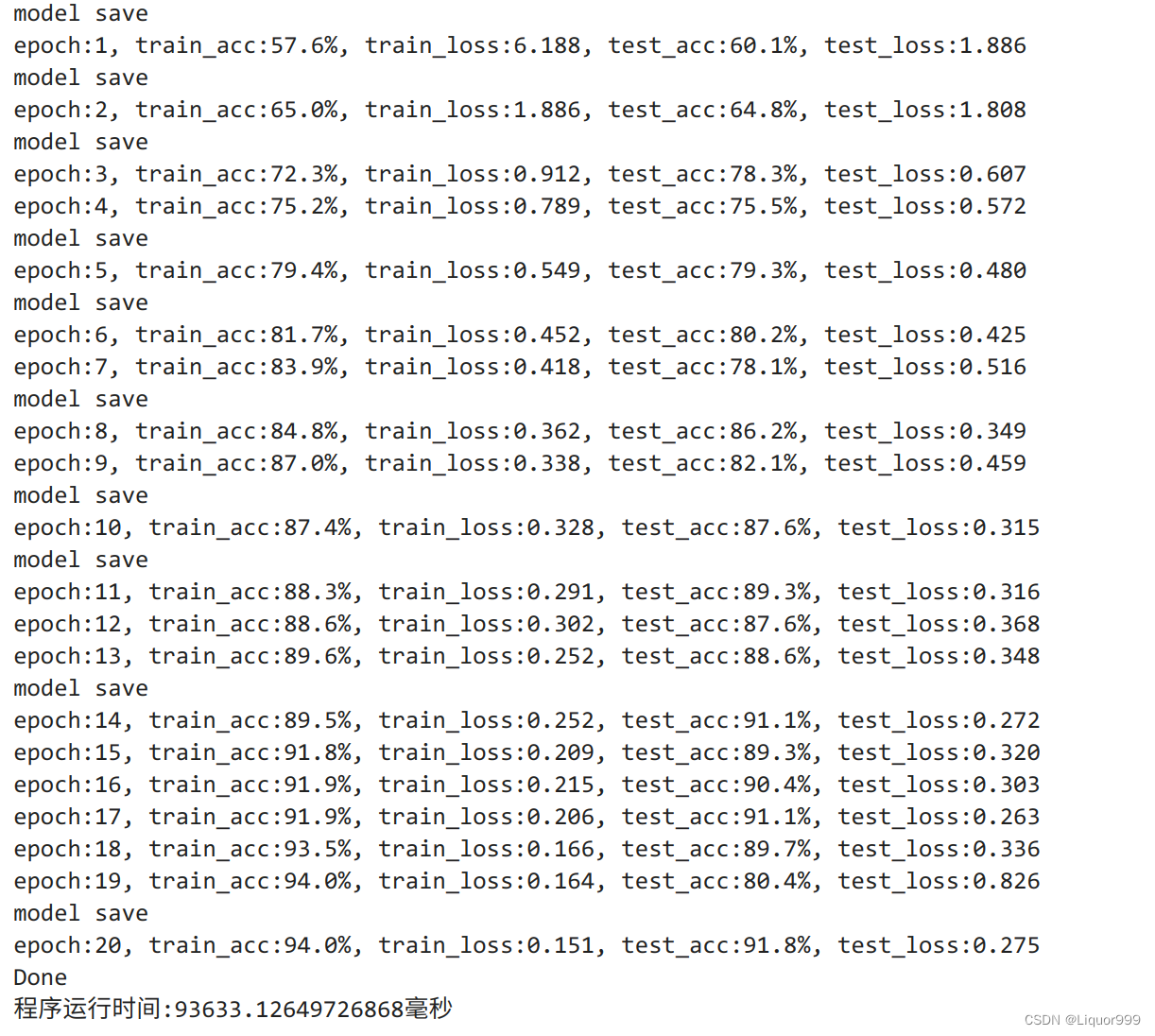
PATH = './my_model.pth'for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)model.eval() # 确保模型不会进行训练操作epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)if epoch_test_acc > best_acc:best_acc = epoch_test_acctorch.save(model.state_dict(), PATH)print("model save")train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)print("epoch:%d, train_acc:%.1f%%, train_loss:%.3f, test_acc:%.1f%%, test_loss:%.3f"% (epoch + 1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss))
print("Done")
T2 = time.time()
print('程序运行时间:%s毫秒' % ((T2 - T1)*1000))
可以看到,最好的时候,测试集准确率达到百分之91.8
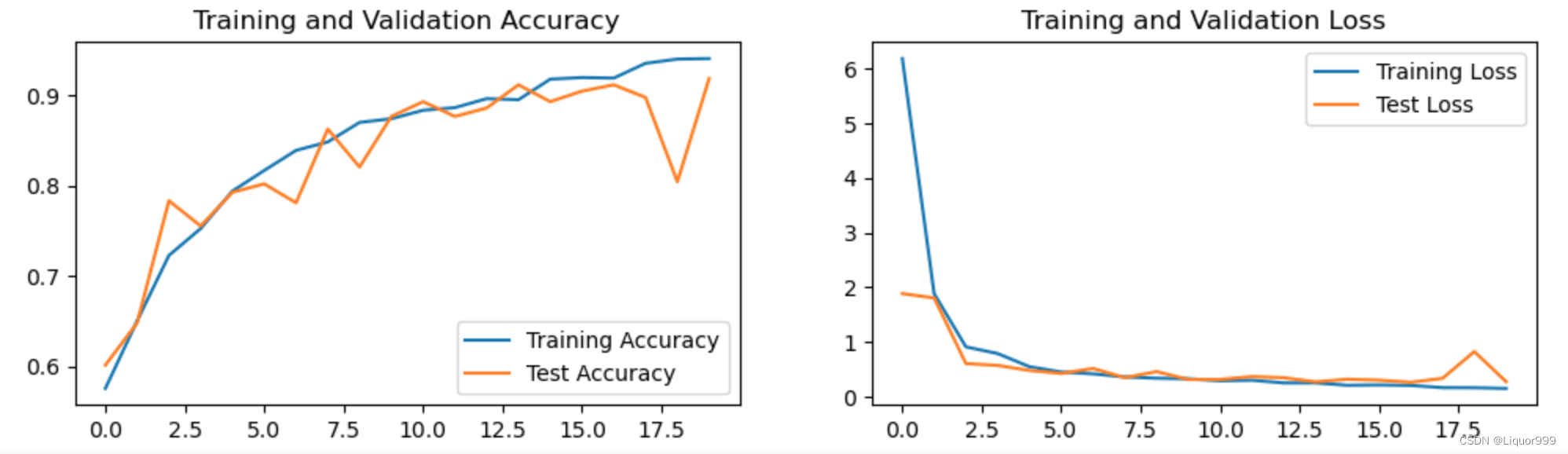
数据可视化
使用matplotlib进行数据可视化。
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
其他模型
本次实验也使用了ResNet模型,虽然参数量较大,但训练效果较好
定义模型
class Model(nn.Module):def __init__(self):super().__init__()# 创建预训练的ResNet-18模型self.resnet = torchvision.models.resnet18(pretrained=True)# 将ResNet的最后一层(全连接层)替换为适合二分类问题的新全连接层self.resnet.fc = nn.Linear(self.resnet.fc.in_features, len(classes))def forward(self, x):return self.resnet(x)from torchsummary import summary
# 将模型转移到GPU中
model = Model().to(device)
经实验,把学习率设置为0.001,效果较好
import time
epochs = 50
train_loss = []
train_acc = []
test_loss = []
test_acc = []loss_fn = nn.CrossEntropyLoss()
learn_rate = 0.001
opt = torch.optim.SGD(model.parameters(), lr=learn_rate)T1 = time.time()best_acc = 0
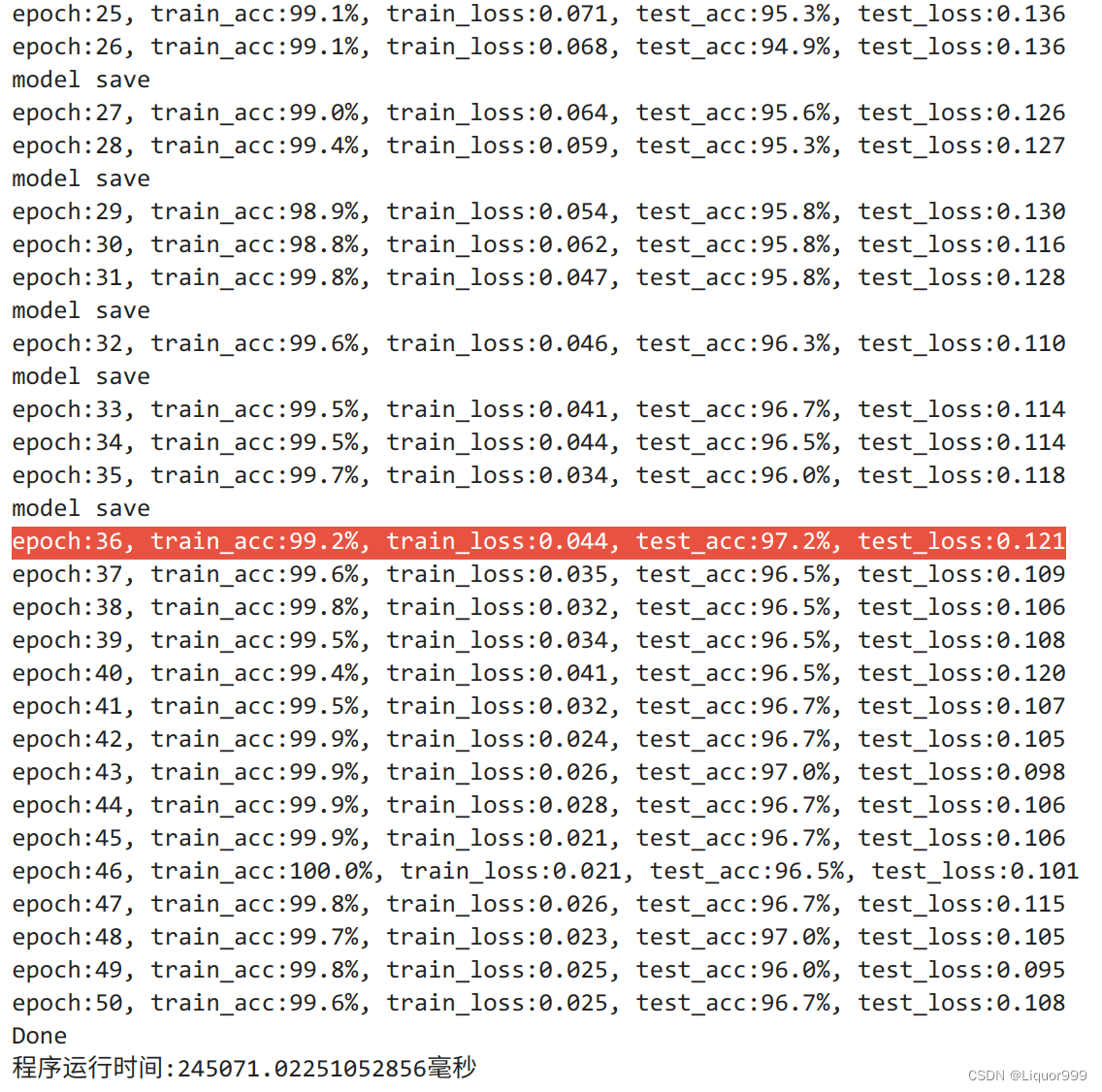
PATH = './my_model.pth'for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)model.eval() # 确保模型不会进行训练操作epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)if epoch_test_acc > best_acc:best_acc = epoch_test_acctorch.save(model.state_dict(), PATH)print("model save")train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)print("epoch:%d, train_acc:%.1f%%, train_loss:%.3f, test_acc:%.1f%%, test_loss:%.3f"% (epoch + 1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss))
print("Done")
T2 = time.time()
print('程序运行时间:%s毫秒' % ((T2 - T1)*1000))
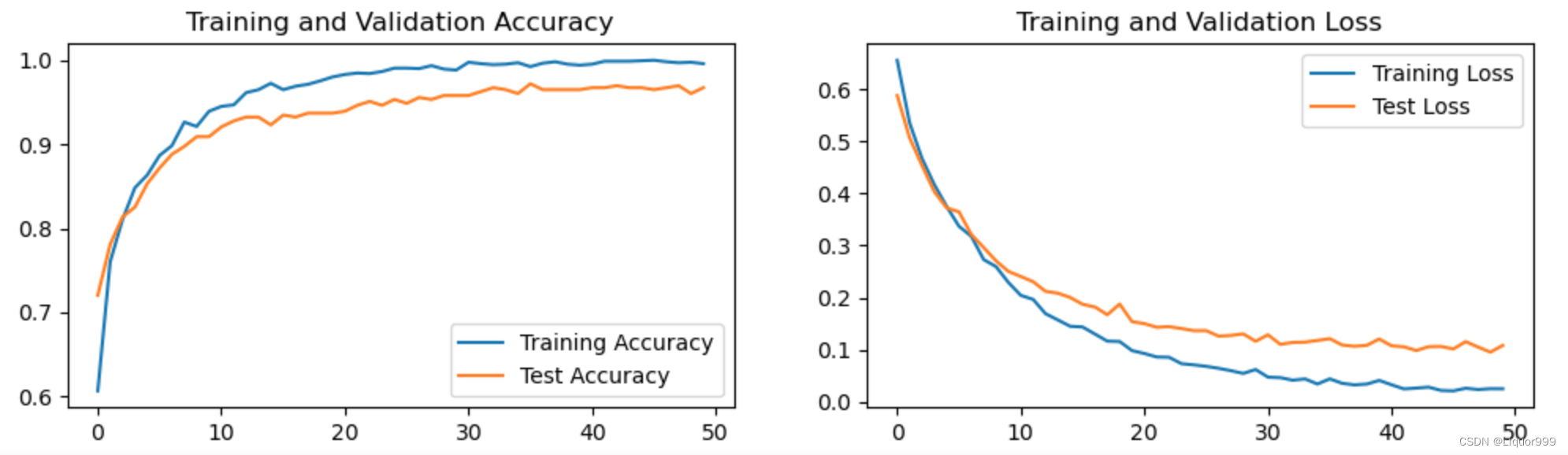
最终在测试集的准确率可达到97.2%。
可视化训练过程
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
图片预测
img_path:要进行预测的图像文件的路径。
model:用于进行图像分类预测的深度学习模型。
transform:用于对图像进行预处理的数据转换函数。
classes:包含类别标签的列表,用于将模型的输出索引映射回类别标签。
大致意思是图像与训练时的输入数据格式相匹配,模型接受批量输入,因此我们需要在维度上添加一个批次维度,从而进行预测
classes = list(total_data.class_to_idx)
def predict_img(img_path, model, transform, classes):test_img = Image.open(img_path).convert('RGB')test_img = transform(test_img)img = test_img.to(device).unsqueeze(0)model.eval()output = model(img)_, pred = torch.max(output, 1) # 在张量的第一个维度上取最大值操作pred_class = classes[pred]print(f'预测结果是:{pred_class}')
开始预测
predict_img(img_path='./data/monkeydata/Monkeypox/M01_01_00.jpg', model=model, transform=train_transforms, classes=classes)
# 预测结果是:Monkeypox
相关文章:
Pytorch从零开始实战04
Pytorch从零开始实战——猴痘病识别 本系列来源于365天深度学习训练营 原作者K同学 文章目录 Pytorch从零开始实战——猴痘病识别环境准备数据集模型选择模型训练数据可视化其他模型图片预测 环境准备 本文基于Jupyter notebook,使用Python3.8,Pytor…...

北大C++课后记录:文件读写的I/O流
前言 文件和平常用到的cin、cout流其实是一回事,可以将文件看作一个有限字符构成的顺序字符流,基于此,也可以像cin、cout读键盘数据那样对文件进行读写。 读写指针 输入流的read指针 输出流的write指针 注:这里的指针并不是普…...

详解Linux的grep命令
2023年9月19日,周二晚上 先写这么多吧,以后有空再更新,还要一些作业没写完.... 目录 概述查看grep命令的所有选项grep的常用选项选项-i选项-v选项-n选项-c编辑选项-l组合使用 概述 grep命令在Linux系统中是一个很重要的文本搜索工具和过…...

spark6. 如何设置spark 日志
spark yarn日志全解 一.前言二.开启日志聚合是什么样的2.1 开启日志聚合MapReduce history server2.2 如何开启Spark history server 三.不开启日志聚合是什么样的四.正确使用log4j.properties 一.前言 本文只讲解再yarn 模式下的日志配置。 二.开启日志聚合是什么样的 在ya…...

glibc: strlcpy
https://zine.dev/2023/07/strlcpy-and-strlcat-added-to-glibc/ https://sourceware.org/git/?pglibc.git;acommit;h454a20c8756c9c1d55419153255fc7692b3d2199 https://linux.die.net/man/3/strlcpy https://lwn.net/Articles/612244/ 从这里看,这个strlcpy、st…...

如何在 Buildroot 中配置 Samba
在 Buildroot 中配置 Samba 在 Buildroot 中配置 Samba 可以通过以下步骤完成: 1. 进入 Buildroot 的根目录。 2. 执行 make menuconfig 命令,打开 Buildroot 的配置菜单。 3. 在配置菜单中,使用键盘导航到 "Target packages" 选…...

SSM02
SSM02 此时我们已经做好了登录模块接下来可以做一下学生管理系统的增删改查操作 首先,我们应当有一个登录成功后的主界面 在webapp下新建 1.main.html <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"&…...
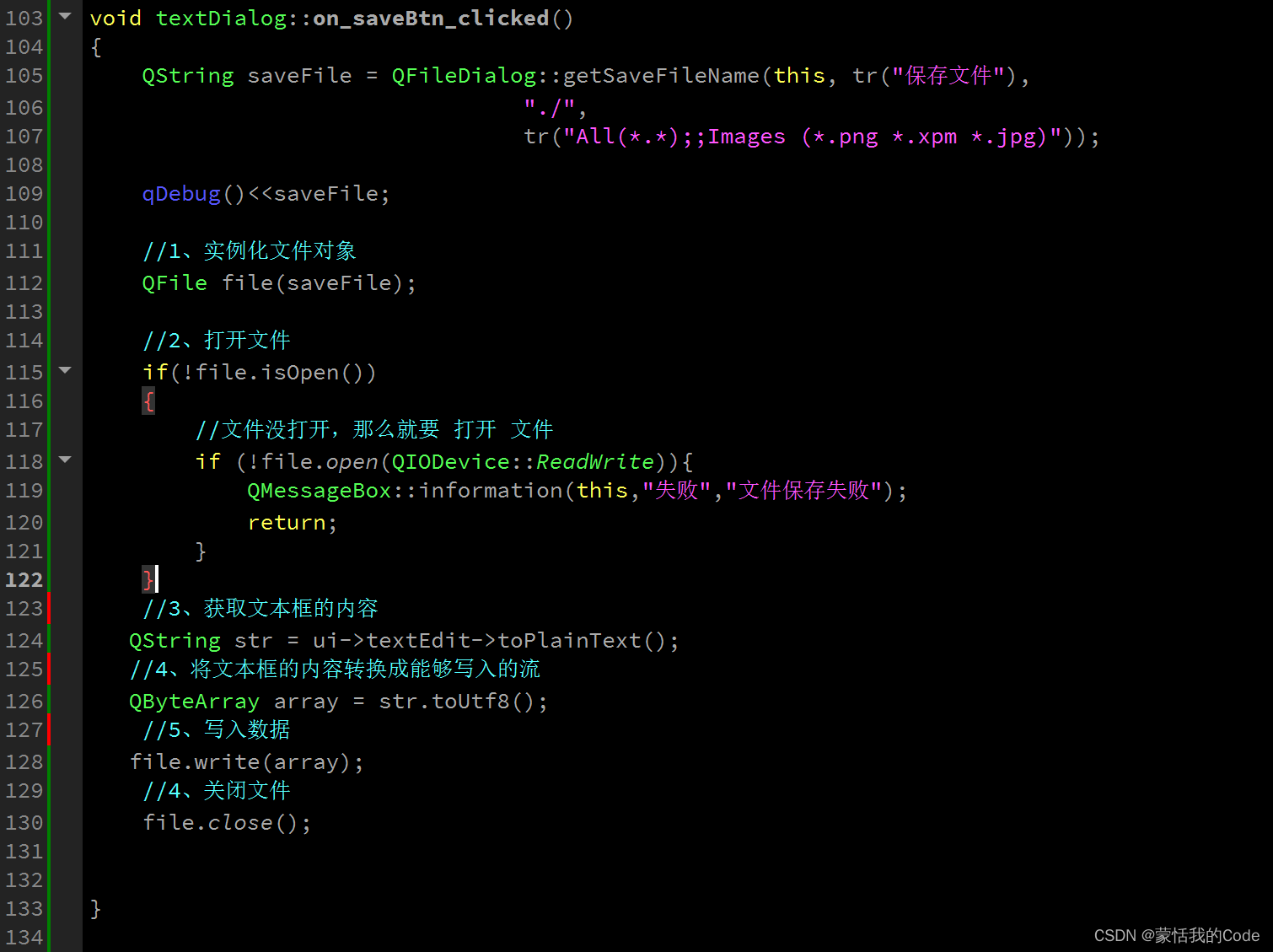
day3_QT
day3_QT 1、文件保存2、始终事件 -闹钟 1、文件保存 2、始终事件 -闹钟 widget.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QTimerEvent> #include <QTime> #include <QTextToSpeech>QT_BEGIN_NAMESPACE namespace Ui { clas…...

js-map方法中调用服务器接口
在 Array.prototype.map() 方法中调用服务器接口时,可以使用异步函数来处理。 示例: async function fetchData() {try {const response await fetch(https://api.example.com/data); // 通过 fetch 发送请求const data await response.json(); // 解…...

docker 已经配置了国内镜像源,但是拉取镜像速度还是很慢(gcr.io、quay.io、ghcr.io)
前言 国内用户在使用 docker 时,想必都遇到过镜像拉取慢的问题,那是因为 docker 默认指向的镜像下载地址是 https://hub.docker.com,服务器在国外。 网上有关配置 docker 国内镜像源的教程很多,像 腾讯、阿里、网易 等等都会提供…...
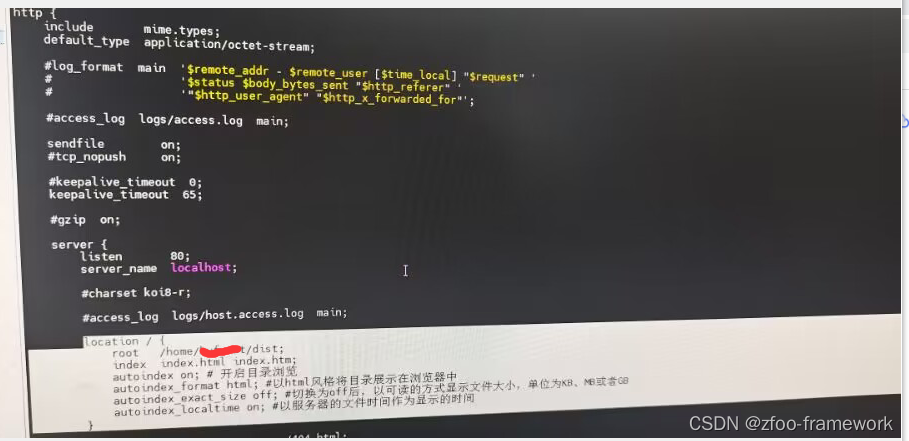
[linux(静态文件服务)] 部署vue发布后的dist网页到nginx
所以说: 1.windows下把开发好的vue工程打包为dist文件然后配置下nginx目录即可。 2.linux上不需要安装node.js环境。 3.这样子默认访问服务器ip地址,就可以打开,毕竟默认就是:80端口。...

智华计算机终端保护检查系统使用笔记
使用说明 【智华保密检查右键管理员运行后粘贴密码】—— 点击脚本更改系统时间【智华计算机终端保护检查系统】—— 打开检测软件进行保密检查 检测文件格式 .pdf .doc .docx .xls .pptx 检测时间日志 2023年9月14日A:【34:03秒】2023年9月14日B:【…...
)
前端面试话术集锦第 15 篇:高频考点(React常考进阶知识点)
这是记录前端面试的话术集锦第十五篇博文——高频考点(React常考进阶知识点),我会不断更新该博文。❗❗❗ 1. HOC 是什么?相比 mixins 有什么优点? 很多人看到高阶组件(HOC)这个概念就被吓到了,认为这东西很难,其实这东西概念真的很简单,我们先来看一个例子: func…...

汽车电子——产品标准规范汇总和梳理(适应可靠性)
文章目录 前言 一、电气性能要求 二、机械性能要求 三、气候性能要求 四、材料性能要求 五、耐久性能要求 六、防护性能要求 总结 前言 见《汽车电子——产品标准规范汇总和梳理》 一、电气性能要求 《GB/T 28046.2-2019(ISO 16750-2:2012&#…...
计算机是如何工作的(上篇)
计算机发展史 世界上很多的高科技发明,来自于军事领域 计算机最初是用来计算弹道导弹轨迹的 弹道导弹 ~~国之重器,非常重要 两弹一星 原子弹,氢弹,卫星(背后的火箭发射技术) 计算弹道导弹轨迹的计算过程非常复杂,计算量也很大 ~~ 但是可以手动计算出来的(当年我国研究两弹一…...

数学建模| 优化入门+多目标规划
优化入门多目标规划 优化入门知识什么是优化问题如何判断是不是优化问题优化模型建模求解器优化问题的分类 多目标规划 优化入门知识 什么是优化问题 优化问题:求最优,例如获利最大、最少损失、最短路径、最小化风险等等。 例如:之前文章提…...

SSM整合Thymeleaf时,抽取公共页面并向其传递参数
第一步 创建一个名为 header.html 的公共头部页面模板,放在 WEB-INF 目录下的 common 文件夹中。在 header.html 中可以编写头部页面的HTML代码,并通过Thymeleaf的语法来接收参数,如下所示: <!DOCTYPE html> <html xml…...

接口测试 —— requests 的基本了解
● requests介绍及安装 ● requests原理及源码介绍 ● 使用requests发送请求 ● 使用requests处理响应 ● get请求参数 ● 发送post请求参数 ● 请求header设置 ● cookie的处理 ● https证书的处理 ● 文件上传、下载 requests介绍 ● requests是python第三方的HTT…...

2023年华为杯数学建模研赛D题思路解析+代码+论文
下文包含:2023华为杯研究生数学建模竞赛(研赛)D题思路解析代码参考论文等及如何准备数学建模竞赛(22号比赛开始后逐步更新) C君将会第一时间发布选题建议、所有题目的思路解析、相关代码、参考文献、参考论文等多项资…...
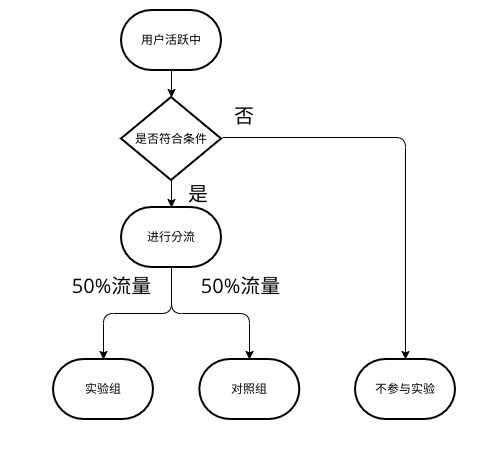
AB试验(三)一次试验的规范流程
AB试验(三)一次试验的规范流程 一次完整且规范的A/B试验可参考下图: 确定目标和假设 核心:A/B测试是因果推断,所以我们首先要确定原因和结果。目标决定了结果,而假设又决定了原因。 如何确定 分析问题&am…...

MFC内存泄露
1、泄露代码示例 void X::SetApplicationBtn() {CMFCRibbonApplicationButton* pBtn GetApplicationButton();// 获取 Ribbon Bar 指针// 创建自定义按钮CCustomRibbonAppButton* pCustomButton new CCustomRibbonAppButton();pCustomButton->SetImage(IDB_BITMAP_Jdp26)…...

Nuxt.js 中的路由配置详解
Nuxt.js 通过其内置的路由系统简化了应用的路由配置,使得开发者可以轻松地管理页面导航和 URL 结构。路由配置主要涉及页面组件的组织、动态路由的设置以及路由元信息的配置。 自动路由生成 Nuxt.js 会根据 pages 目录下的文件结构自动生成路由配置。每个文件都会对…...

P3 QT项目----记事本(3.8)
3.8 记事本项目总结 项目源码 1.main.cpp #include "widget.h" #include <QApplication> int main(int argc, char *argv[]) {QApplication a(argc, argv);Widget w;w.show();return a.exec(); } 2.widget.cpp #include "widget.h" #include &q…...

Golang——6、指针和结构体
指针和结构体 1、指针1.1、指针地址和指针类型1.2、指针取值1.3、new和make 2、结构体2.1、type关键字的使用2.2、结构体的定义和初始化2.3、结构体方法和接收者2.4、给任意类型添加方法2.5、结构体的匿名字段2.6、嵌套结构体2.7、嵌套匿名结构体2.8、结构体的继承 3、结构体与…...
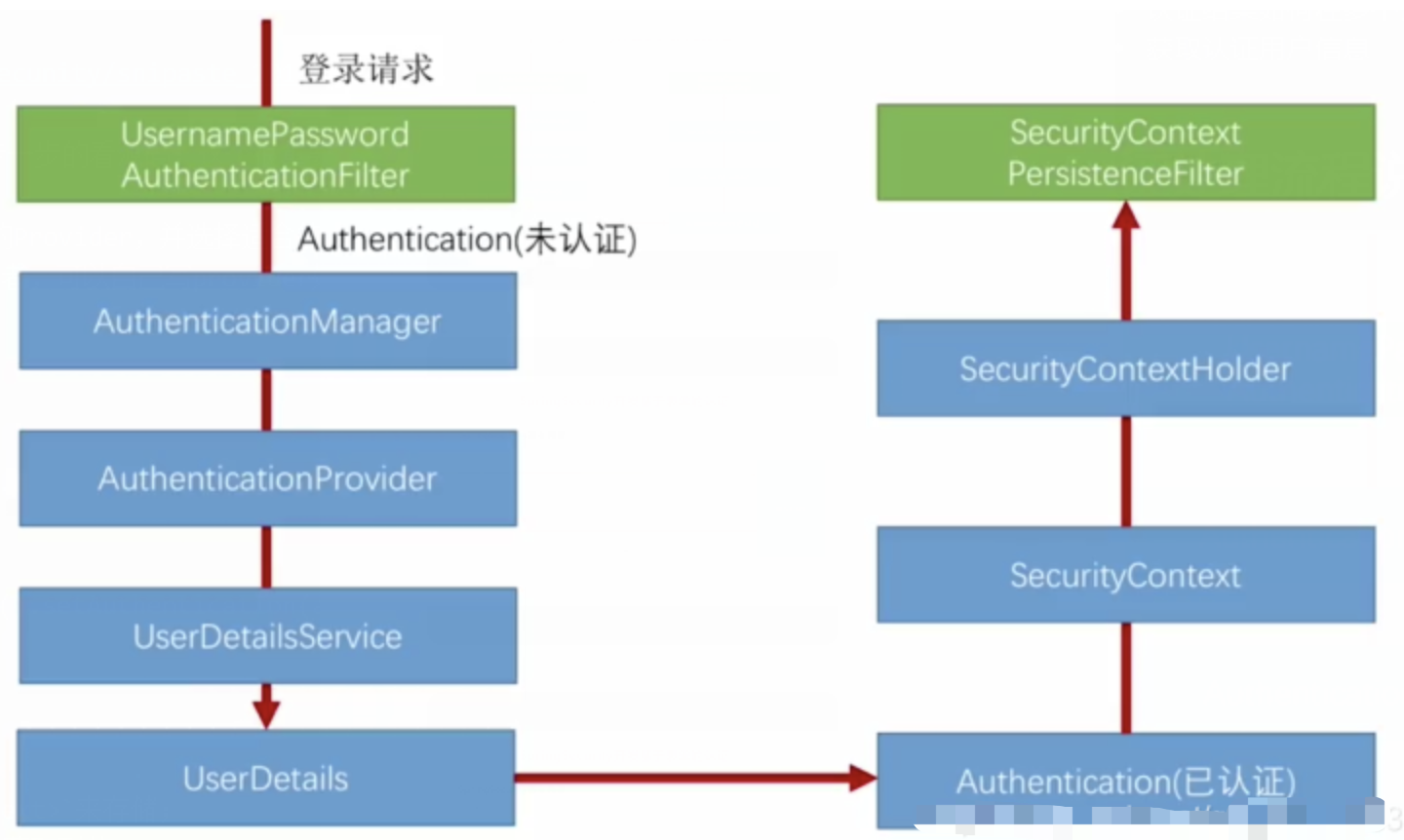
spring Security对RBAC及其ABAC的支持使用
RBAC (基于角色的访问控制) RBAC (Role-Based Access Control) 是 Spring Security 中最常用的权限模型,它将权限分配给角色,再将角色分配给用户。 RBAC 核心实现 1. 数据库设计 users roles permissions ------- ------…...

跨平台商品数据接口的标准化与规范化发展路径:淘宝京东拼多多的最新实践
在电商行业蓬勃发展的当下,多平台运营已成为众多商家的必然选择。然而,不同电商平台在商品数据接口方面存在差异,导致商家在跨平台运营时面临诸多挑战,如数据对接困难、运营效率低下、用户体验不一致等。跨平台商品数据接口的标准…...
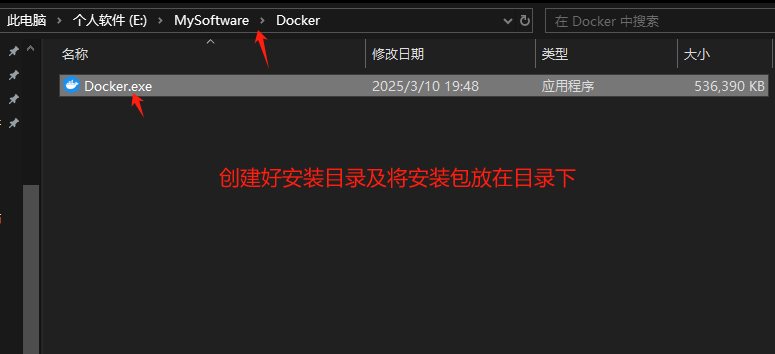
大模型——基于Docker+DeepSeek+Dify :搭建企业级本地私有化知识库超详细教程
基于Docker+DeepSeek+Dify :搭建企业级本地私有化知识库超详细教程 下载安装Docker Docker官网:https://www.docker.com/ 自定义Docker安装路径 Docker默认安装在C盘,大小大概2.9G,做这行最忌讳的就是安装软件全装C盘,所以我调整了下安装路径。 新建安装目录:E:\MyS…...
加密芯片与MCU协同工作的典型流程)
SE(Secure Element)加密芯片与MCU协同工作的典型流程
以下是SE(Secure Element)加密芯片与MCU协同工作的典型流程,综合安全认证、数据保护及防篡改机制: 一、基础认证流程(参数保护方案) 密钥预置 SE芯片与MCU分别预置相同的3DES密钥(Key1、Key2…...

NLP常用工具包
✨做一次按NLP项目常见工具的使用拆解 1. tokenizer from torchtext.data.utils import get_tokenizertokenizer get_tokenizer(basic_english) text_sample "Were going on an adventure! The weather is really nice today." tokens tokenizer(text_sample) p…...
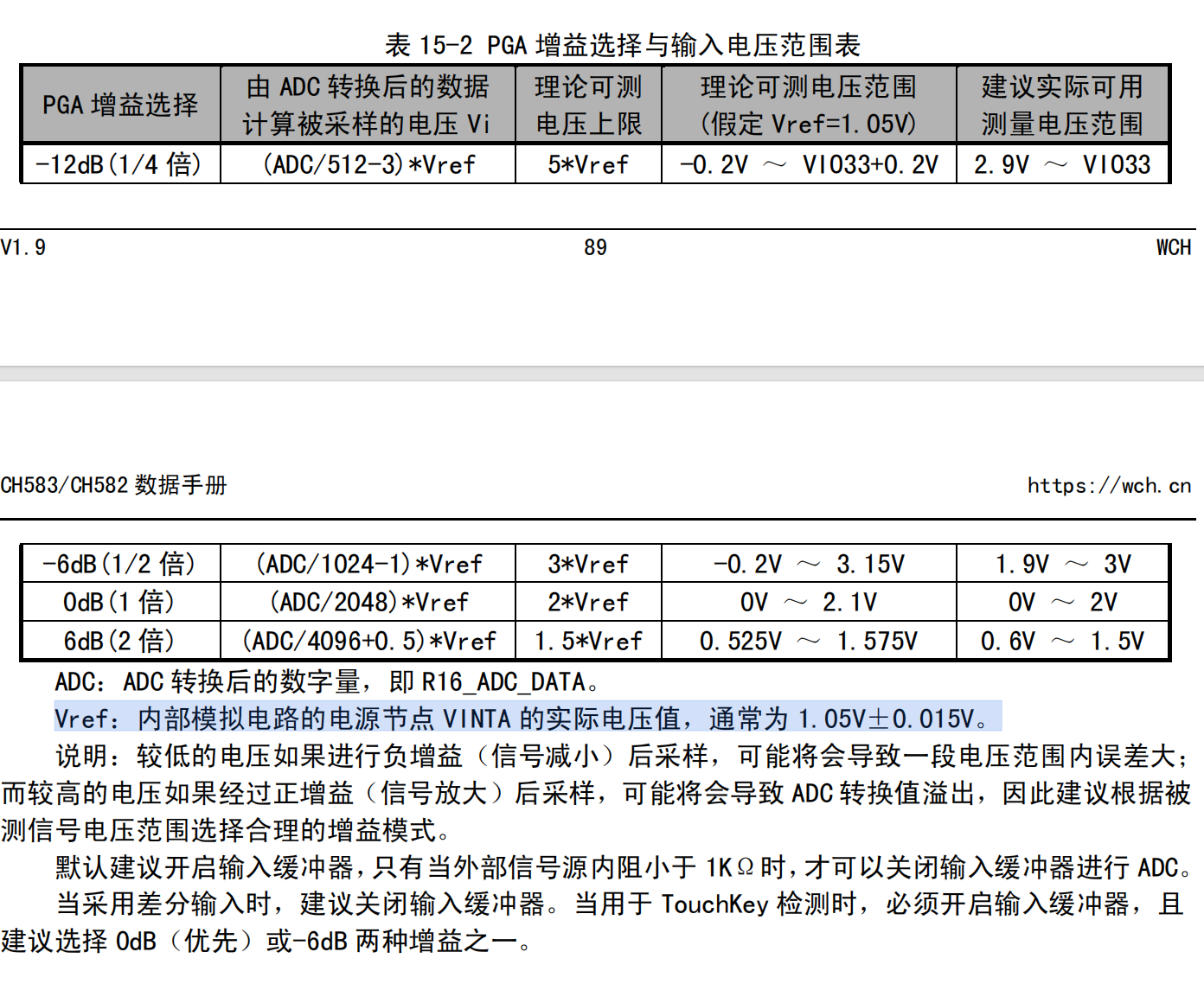
使用MounRiver Studio Ⅱ软件写一个CH592F芯片的ADC采集程序,碰到的问题
MounRiver Studio Ⅱ 默认是不开启浮点计算的,所以有些浮点功能不能用,碰到问题是 while (1) {DelayMs (100);tmp Read_Temperature (0);sprintf (tempBuffer, "temp:%.2f\r\n", tmp); // 格式化温度值到字符串。使用%f要开启相应的…...