Kafka为什么是高性能高并发高可用架构
目录
- 1 前言
- 2 顺序写入
- 3 页缓存
- 4 零拷贝
- 5 Broker 性能
- 6 流数据并行
- 7 总结
1 前言

我们都知道 Kafka 是基于磁盘进行存储的,但 Kafka 官方又称其具有高性能、高吞吐、低延时的特点,其吞吐量动辄几十上百万。小伙伴们是不是有点困惑了,一般认为在磁盘上读写数据是会降低性能的,因为寻址会比较消耗时间。那 Kafka 又是怎么做到其吞吐量动辄几十上百万的呢?
Kafka 高性能,是多方面协同的结果,包括宏观架构、分布式 partition 存储、ISR 数据同步、以及“无所不用其极”的高效利用磁盘、操作系统特性。
别急,下面老周从数据的写入与读取两个维度来带大家一探究竟。
2 顺序写入
磁盘读写有两种方式:顺序读写或者随机读写。在顺序读写的情况下,磁盘的顺序读写速度和内存持平。
因为磁盘是机械结构,每次读写都会寻址->写入,其中寻址是一个“机械动作”。为了提高读写磁盘的速度,Kafka 就是使用顺序 I/O。
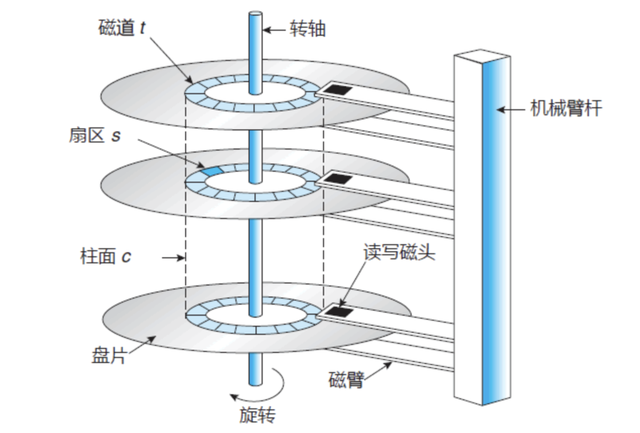
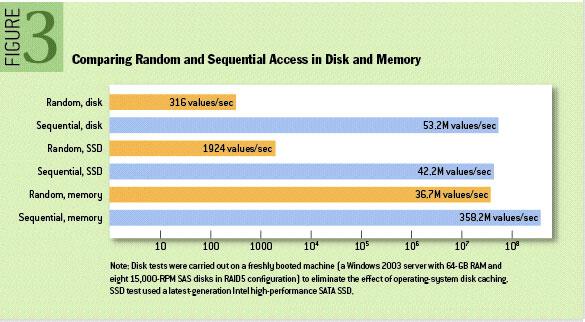
Kafka 利用了一种分段式的、只追加 (Append-Only) 的日志,基本上把自身的读写操作限制为顺序 I/O,也就使得它在各种存储介质上能有很快的速度。一直以来,有一种广泛的误解认为磁盘很慢。实际上,存储介质 (特别是旋转式的机械硬盘) 的性能很大程度依赖于访问模式。在一个 7200 转/分钟的 SATA 机械硬盘上,随机 I/O 的性能比顺序 I/O 低了大概 3 到 4 个数量级。此外,一般来说现代的操作系统都会提供预读和延迟写技术:以大数据块的倍数预先载入数据,以及合并多个小的逻辑写操作成一个大的物理写操作。正因为如此,顺序 I/O 和随机 I/O 之间的性能差距在 flash 和其他固态非易失性存储介质中仍然很明显,尽管它远没有旋转式的存储介质那么明显。
这里给出著名学术期刊 ACM Queue 上的性能对比图:
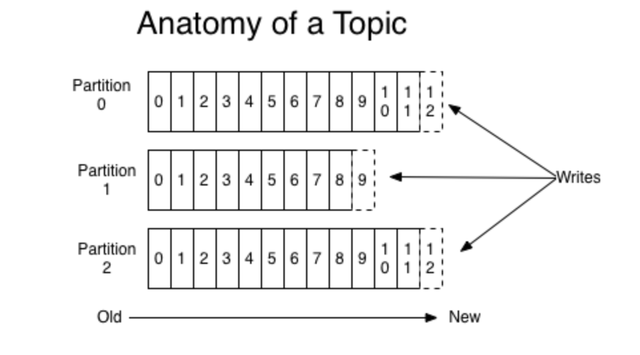
下图就展示了 Kafka 是如何写入数据的, 每一个 Partition 其实都是一个文件 ,收到消息后 Kafka 会把数据插入到文件末尾(虚框部分):
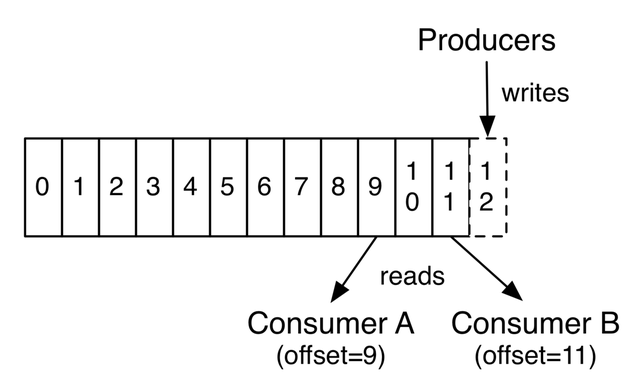
这种方法采用了只读设计 ,所以 Kafka 是不会修改、删除数据的,它会把所有的数据都保留下来,每个消费者(Consumer)对每个 Topic 都有一个 offset 用来表示读取到了第几条数据 。
磁盘的顺序读写是磁盘使用模式中最有规律的,并且操作系统也对这种模式做了大量优化,Kafka 就是使用了磁盘顺序读写来提升的性能。Kafka 的 message 是不断追加到本地磁盘文件末尾的,而不是随机的写入,这使得 Kafka 写入吞吐量得到了显著提升。
3 页缓存
即便是顺序写入硬盘,硬盘的访问速度还是不可能追上内存。所以 Kafka 的数据并不是实时的写入硬盘 ,它充分利用了现代操作系统分页存储来利用内存提高 I/O 效率。具体来说,就是把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问。
Kafka 接收来自 socket buffer 的网络数据,应用进程不需要中间处理、直接进行持久化时。可以使用mmap 内存文件映射。
3.1 Memory Mapped Files
简称 mmap,简单描述其作用就是:将磁盘文件映射到内存,用户通过修改内存就能修改磁盘文件。
它的工作原理是直接利用操作系统的 Page 来实现磁盘文件到物理内存的直接映射。完成映射之后你对物理内存的操作会被同步到硬盘上(操作系统在适当的时候)。
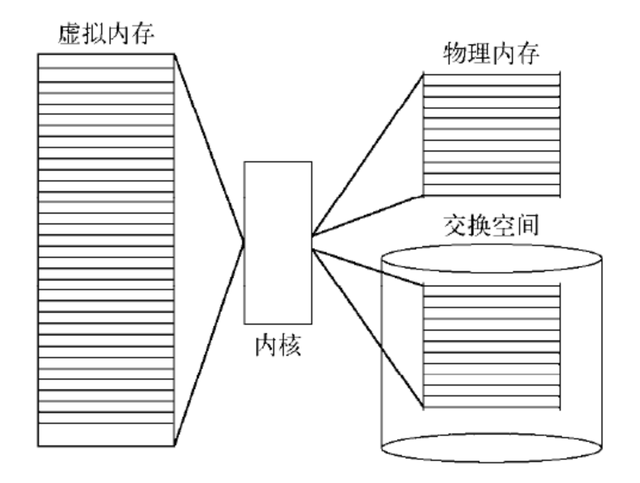
通过 mmap,进程像读写硬盘一样读写内存(当然是虚拟机内存)。使用这种方式可以获取很大的 I/O 提升,省去了用户空间到内核空间复制的开销。
mmap 也有一个很明显的缺陷:不可靠,写到 mmap 中的数据并没有被真正的写到硬盘,操作系统会在程序主动调用 flush 的时候才把数据真正的写到硬盘。
Kafka 提供了一个参数 producer.type 来控制是不是主动 flush:
- 如果 Kafka 写入到 mmap 之后就立即 flush,然后再返回 Producer 叫同步(sync);
- 写入 mmap 之后立即返回 Producer 不调用 flush 叫异步(async)。
3.2 Java NIO 对文件映射的支持
Java NIO,提供了一个 MappedByteBuffer 类可以用来实现内存映射。
MappedByteBuffer 只能通过调用 FileChannel 的 map() 取得,再没有其他方式。
FileChannel.map() 是抽象方法,具体实现是在 FileChannelImpl.map() 可自行查看 JDK 源码,其 map0() 方法就是调用了 Linux 内核的 mmap 的 API。



3.3 使用 MappedByteBuffer 类注意事项
mmap 的文件映射,在 full gc 时才会进行释放。当 close 时,需要手动清除内存映射文件,可以反射调用 sun.misc.Cleaner 方法。
当一个进程准备读取磁盘上的文件内容时:
- 操作系统会先查看待读取的数据所在的页(page)是否在页缓存(pagecache)中,如果存在(命中) 则直接返回数据,从而避免了对物理磁盘的 I/O 操作;
- 如果没有命中,则操作系统会向磁盘发起读取请求并将读取的数据页存入页缓存,之后再将数据返回给进程。
如果一个进程需要将数据写入磁盘:
- 操作系统也会检测数据对应的页是否在页缓存中,如果不存在,则会先在页缓存中添加相应的页,最后将数据写入对应的页。
- 被修改过后的页也就变成了脏页,操作系统会在合适的时间把脏页中的数据写入磁盘,以保持数据的一致性。
对一个进程而言,它会在进程内部缓存处理所需的数据,然而这些数据有可能还缓存在操作系统的页缓存中,因此同一份数据有可能被缓存了两次。并且,除非使用 Direct I/O 的方式, 否则页缓存很难被禁止。
当使用页缓存的时候,即使 Kafka 服务重启, 页缓存还是会保持有效,然而进程内的缓存却需要重建。这样也极大地简化了代码逻辑,因为维护页缓存和文件之间的一致性交由操作系统来负责,这样会比进程内维护更加安全有效。
Kafka 中大量使用了页缓存,这是 Kafka 实现高吞吐的重要因素之一。
消息先被写入页缓存,由操作系统负责刷盘任务。
4 零拷贝
导致应用程序效率低下的一个典型根源是缓冲区之间的字节数据拷贝。Kafka 使用由 Producer、Broker 和 Consumer 多方共享的二进制消息格式,因此数据块即便是处于压缩状态也可以在不被修改的情况下在端到端之间流动。虽然消除通信各方之间的结构化差异是非常重要的一步,但它本身并不能避免数据的拷贝。
Kafka 通过利用 Java 的 NIO 框架,尤其是 java.nio.channels.FileChannel 里的 transferTo 这个方法,解决了前面提到的在 Linux 等类 UNIX 系统上的数据拷贝问题。此方法能够在不借助作为传输中介的应用程序的情况下,将字节数据从源通道直接传输到接收通道。要了解 NIO 的带来的改进,请考虑传统方式下作为两个单独的操作:源通道中的数据被读入字节缓冲区,接着写入接收通道:
File.read(fileDesc, buf, len);
Socket.send(socket, buf, len);
通过图表来说明,这个过程可以被描述如下:
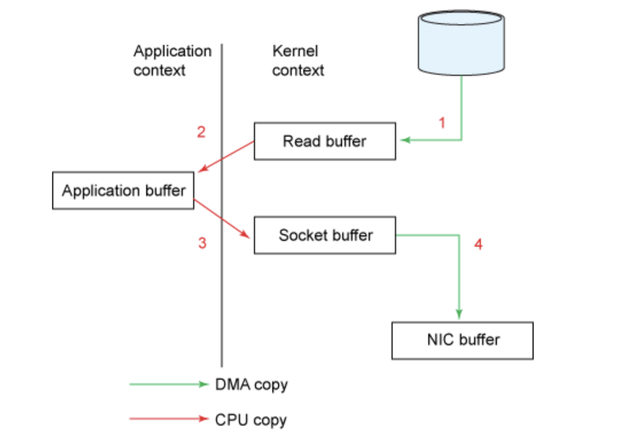
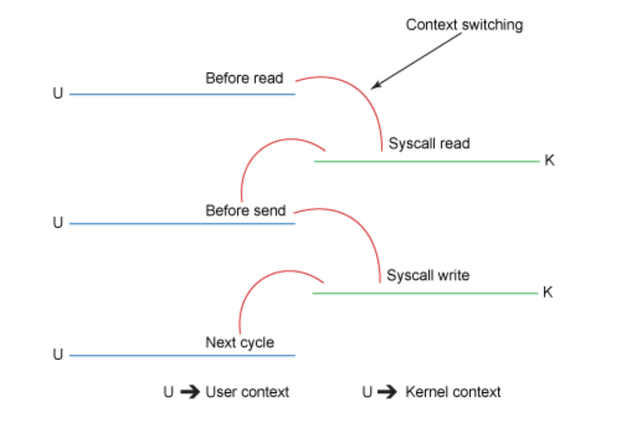
尽管上面的过程看起来已经足够简单,但是在内部仍需要 4 次用户态和内核态的上下文切换来完成拷贝操作,而且需要拷贝 4 次数据才能完成这个操作。下面的示意图概述了每一个步骤中的上下文切换。
让我们来更详细地看一下细节:
- 初始的 read() 调用导致了一次用户态到内核态的上下文切换。DMA (Direct Memory Access 直接内存访问) 引擎读取文件,并将其内容复制到内核地址空间中的缓冲区中。这个缓冲区和上面的代码片段里使用的并非同一个。
- 在从 read() 返回之前,内核缓冲区的数据会被拷贝到用户态的缓冲区。此时,我们的程序可以读取文件的内容。
- 接下来的 send() 方法会切换回内核态,拷贝用户态的缓冲区数据到内核地址空间 —— 这一次是拷贝到一个关联着目标套接字的不同缓冲区。在后台,DMA 引擎会接手这一操作,异步地把数据从内核缓冲区拷贝到协议堆栈,由网卡进行网络传输。 send() 方法在返回之前不等待此操作。
- send() 调用返回,切换回用户态。
尽管模式切换的效率很低,而且需要进行额外的拷贝,但在许多情况下,中间内核缓冲区的性能实际上可以进一步提高。比如它可以作为一个预读缓存,异步预载入数据块,从而可以在应用程序前端运行请求。但是,当请求的数据量极大地超过内核缓冲区大小时,内核缓冲区就会成为性能瓶颈。它不会直接拷贝数据,而是迫使系统在用户态和内核态之间摇摆,直到所有数据都被传输完成。
相比之下,零拷贝方式能在单个操作中处理完成。前面示例中的代码片段现在能重写为一行程序:
fileDesc.transferTo(offset, len, socket);
零拷贝方式可以用下图来说明:
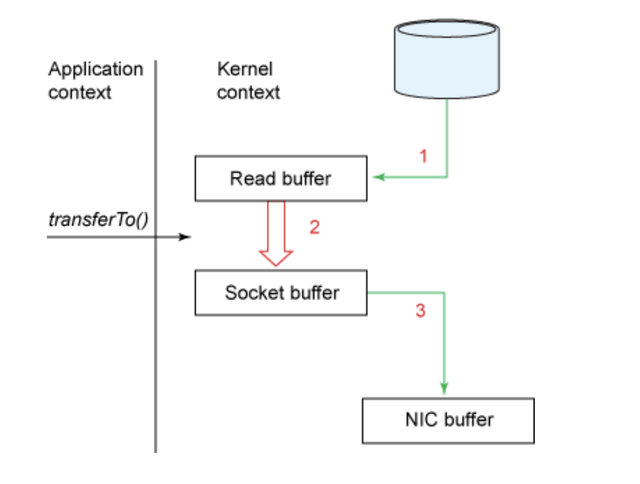
在这种模式下,上下文的切换次数被缩减至一次。具体来说, transferTo() 方法指示数据块设备通过 DMA 引擎将数据读入读缓冲区,然后这个缓冲区的数据拷贝到另一个内核缓冲区中,分阶段写入套接字。最后,DMA 将套接字缓冲区的数据拷贝到 NIC 缓冲区中。
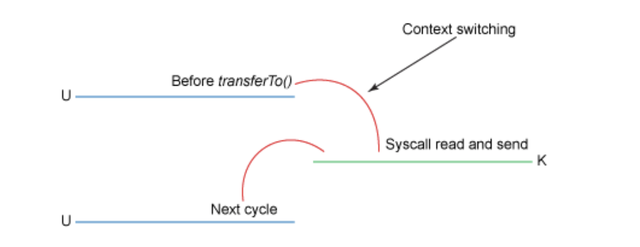
最终结果,我们已经把拷贝的次数从 4 降到了 3,而且其中只有一次拷贝占用了 CPU 资源。我们也已经把上下文切换的次数从 4 降到了 2。
把磁盘文件读取 OS 内核缓冲区后的 fileChannel,直接转给 socketChannel 发送;底层就是 sendfile。消费者从 broker 读取数据,就是由此实现。
具体来看,Kafka 的数据传输通过 TransportLayer 来完成,其子类 PlaintextTransportLayer 通过 Java NIO 的 FileChannel 的 transferTo 和 transferFrom 方法实现零拷贝。
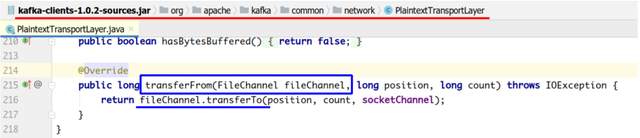
注:transferTo 和 transferFrom 并不保证一定能使用零拷贝,需要操作系统支持。
这是一个巨大的提升,不过还没有实现完全 “零拷贝”。我们可以通过利用 Linux 内核 2.4 或更高版本以及支持 gather 操作的网卡来做进一步的优化从而实现真正的 “零拷贝”。下面的示意图可以说明:
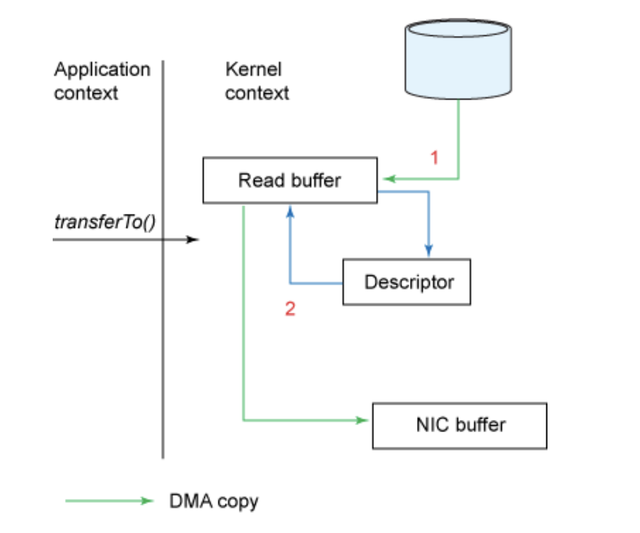
调用 transferTo() 方法会致使设备通过 DMA 引擎将数据读入内核读缓冲区,就像前面的例子那样。然而,通过 gather 操作,读缓冲区和套接字缓冲区之间的数据拷贝将不复存在。相反地,NIC 被赋予一个指向读缓冲区的指针,连同偏移量和长度,所有数据都将通过 DMA 抽取干净并拷贝到 NIC 缓冲区。在这个过程中,在缓冲区间拷贝数据将无需占用任何 CPU 资源。
传统的方式和零拷贝方式在 MB 字节到 GB 字节的文件大小范围内的性能对比显示,零拷贝方式相较于传统方式的性能提升幅度在 2 到 3 倍。但更令人惊叹的是,Kafka 仅仅是在一个纯 JVM 虚拟机下、没有使用本地库或 JNI 代码,就实现了这一点。
5 Broker 性能
5.1 日志记录批处理
顺序 I/O 在大多数的存储介质上都非常快,几乎可以和网络 I/O 的峰值性能相媲美。在实践中,这意味着一个设计良好的日志结构的持久层将可以紧随网络流量的速度。事实上,Kafka 的瓶颈通常是网络而非磁盘。因此,除了由操作系统提供的底层批处理能力之外,Kafka 的 Clients 和 Brokers 会把多条读写的日志记录合并成一个批次,然后才通过网络发送出去。日志记录的批处理通过使用更大的包以及提高带宽效率来摊薄网络往返的开销。
5.2 批量压缩
当启用压缩功能时,批处理的影响尤为明显,因为压缩效率通常会随着数据量大小的增加而变得更高。特别是当使用 JSON 等基于文本的数据格式时,压缩效果会非常显著,压缩比通常能达到 5 到 7 倍。此外,日志记录批处理在很大程度上是作为 Client 侧的操作完成的,此举把负载转移到 Client 上,不仅对网络带宽效率、而且对 Brokers 的磁盘 I/O 利用率也有很大的提升。
5.3 非强制刷新缓冲写操作
另一个助力 Kafka 高性能、同时也是一个值得更进一步去探究的底层原因:Kafka 在确认写成功 ACK 之前的磁盘写操作不会真正调用 fsync 命令;通常只需要确保日志记录被写入到 I/O Buffer 里就可以给 Client 回复 ACK 信号。这是一个鲜为人知却至关重要的事实:事实上,这正是让 Kafka 能表现得如同一个内存型消息队列的原因 —— 因为 Kafka 是一个基于磁盘的内存型消息队列 (受缓冲区/页面缓存大小的限制)。
另一方面,这种形式的写入是不安全的,因为副本的写失败可能会导致数据丢失,即使日志记录似乎已经被确认成功。换句话说,与关系型数据库不同,确认一个写操作成功并不等同于持久化成功。真正使得 Kafka 具备持久化能力的是运行多个同步的副本的设计;即便有一个副本写失败了,其他的副本(假设有多个)仍然可以保持可用状态,前提是写失败是不相关的(例如,多个副本由于一个共同的上游故障而同时写失败)。因此,不使用 fsync 的 I/O 非阻塞方法和冗余同步副本的结合,使得 Kafka 同时具备了高吞吐量、持久性和可用性。
6 流数据并行
日志结构 I/O 的效率是影响性能的一个关键因素,主要影响写操作;Kafka 在对 Topic 结构和 Consumer 群组的并行处理是其读性能的基础。这种组合产生了非常高的端到端消息传递总体吞吐量。并发性根深蒂固地存在于 Kafka 的分区方案和 Consumer Groups 的操作中,这是 Kafka 中一种有效的负载均衡机制 —— 把数据分区 (Partition) 近似均匀地分配给组内的各个 Consumer 实例。将此与更传统的 MQ 进行比较:在 RabbitMQ 的等效设置中,多个并发的 Consumers 可能以轮询的方式从队列读取数据,然而这样做,就会失去消息消费的顺序性。
分区机制也使得 Kafka Brokers 可以水平扩展。每个分区都有一个专门的 Leader;因此,任何重要的主题 Topic (具有多个分区) 都可以利用整个 Broker 集群进行写操作,这是 Kafka 和消息队列之间的另一个区别;后者利用集群来获得可用性,而 Kafka 将真正地在 Brokers 之间负载均衡,以获得可用性、持久性和吞吐量。
生产者在发布日志记录之时指定分区,假设你正在发布消息到一个有多个分区的 Topic 上。(也可能有单一分区的 Topic, 这种情况下将不成问题。) 这可以通过直接指定分区索引来完成,或者间接通过日志记录的键值来完成,该键值能被确定性地哈希到一个一致的 (即每次都相同) 分区索引。拥有相同哈希值的日志记录将会被存储到同一个分区中。假设一个 Topic 有多个分区,那些不同哈希值的日志记录将很可能最后被存储到不同的分区里。但是,由于哈希碰撞的缘故,不同哈希值的日志记录也可能最后被存储到相同的分区里。这是哈希的本质,如果你理解哈希表的原理,那应该是显而易见的。
日志记录的实际处理是由一个在 (可选的) Consumer Group 中的 Consumer 操作完成。Kafka 确保一个分区最多只能分配给它的 Consumer Group 中的一个 Consumer 。(我们说 “最多” 是因为考虑到一种全部 Consumer 都离线的情况。) 当第一个 Consumer Group 里的 Consumer 订阅了 Topic,它将消费这个 Topic 下的所有分区的数据。当第二个 Consumer 紧随其后加入订阅时,它将大致获得这个 Topic 的一半分区,减轻第一个 Consumer 先前负荷的一半。这使得你能够并行处理事件流,并根据需要增加 Consumer (理想情况下,使用自动伸缩机制),前提是你已经对事件流进行了合理的分区。
日志记录吞吐量的控制一般通过以下两种方式来达成:
- Topic 的分区方案。应该对 Topics 进行分区,以最大限度地增加独立子事件流的数量。换句话说,日志记录的顺序应该只保留在绝对必要的地方。如果任意两个日志记录在某种意义上没有合理的关联,那它们就不应该被绑定到同一个分区。这暗示你要使用不同的键值,因为 Kafka 将使用日志记录的键值作为一个散列源来派生其一致的分区映射。
- 一个组里的 Consumers 数量。你可以增加 Consumer Group 里的 Consumer 数量来均衡入站的日志记录的负载,这个数量的上限是 Topic 的分区数量。(如果你愿意的话,你当然可以增加更多的 Consumers ,不过分区计数将会设置一个上限来确保每一个活跃的 Consumer 至少被指派到一个分区,多出来的 Consumers 将会一直保持在一个空闲的状态。) 请注意, Consumer 可以是进程或线程。依据 Consumer 执行的工作负载类型,你可以在线程池中使用多个独立的 Consumer 线程或进程记录。
如果你之前一直想知道 Kafka 是否很快、它是如何拥有其现如今公认的高性能标签,或者它是否可以满足你的使用场景,那么相信你现在应该有了所需的答案。
为了让事情足够清楚,必须说明 Kafka 并不是最快的 (也就是说,具有最大吞吐量能力的) 消息传递中间件,还有其他具有更大吞吐量的平台 —— 有些是基于软件的 —— 有些是在硬件中实现的。Apache Pulsar 是一项极具前景的技术,它具备可扩展性,在提供相同的消息顺序性和持久性保证的同时,还能实现更好的吞吐量-延迟效果。使用 Kafka 的根本原因是,它作为一个完整的生态系统仍然是无与伦比的。它展示了卓越的性能,同时提供了一个丰富和成熟而且还在不断进化的环境,尽管 Kafka 的规模已经相当庞大了,但仍以一种令人羡慕的速度在成长。
Kafka 的设计者和维护者们在创造一个以性能导向为核心的解决方案这方面做得非常出色。它的大多数设计/理念元素都是早期就构思完成、几乎没有什么是事后才想到的,也没有什么是附加的。从把工作负载分摊到 Client 到 Broker 上的日志结构持久性,批处理、压缩、零拷贝 I/O 和流数据级并行 —— Kafka 向几乎所有其他面向消息的中间件 (商业的或开源的) 发起了挑战。而且最令人叹为观止的是,它做到这些事情的同时竟然没有牺牲掉持久性、日志记录顺序性和至少交付一次的语义等特性。
7 总结
7.1 mmap 和 sendfile
- Linux 内核提供、实现零拷贝的 API。
- mmap 将磁盘文件映射到内存,支持读和写,对内存的操作会反映在磁盘文件上。
- sendfile 是将读到内核空间的数据,转到 socket buffer,进行网络发送。
- RocketMQ 在消费消息时,使用了 mmap;Kafka 使用了 sendfile。
7.2 Kafka 为啥这么快?
- Partition 顺序读写,充分利用磁盘特性,这是基础。
- Producer 生产的数据持久化到 Broker,采用 mmap 文件映射,实现顺序的快速写入。
- Customer 从 Broker 读取数据,采用 sendfile,将磁盘文件读到 OS 内核缓冲区后,直接转到 socket buffer 进行网络发送。
- Broker 性能优化:日志记录批处理、批量压缩、非强制刷新缓冲写操作等。
- 流数据并行
相关文章:
Kafka为什么是高性能高并发高可用架构
目录 1 前言2 顺序写入3 页缓存4 零拷贝5 Broker 性能6 流数据并行7 总结 1 前言 我们都知道 Kafka 是基于磁盘进行存储的,但 Kafka 官方又称其具有高性能、高吞吐、低延时的特点,其吞吐量动辄几十上百万。小伙伴们是不是有点困惑了,一般认为…...
QT-day3
完成文本编辑器的保存工作 void Widget::on_savebton_clicked() {QString fileName QFileDialog::getSaveFileName(this,"保存","./","All(*.*);;Images(*.png *.xpm *.jpg);;Text files (*.txt);;XML files (*.xml)");QFile file(fileName);i…...

开发自测的测试用例设计方法
测试用例设计方法有:等价类划分法、边界值分析法、错误推测法、判定表法、正交实验法。 测试用例就是一个文档,描述输入、动作、或者时间和一个期望的结果,其目的是确定应用程序的某个特性是否正常的工作。 一.等价类划分法 顾名思义&#x…...
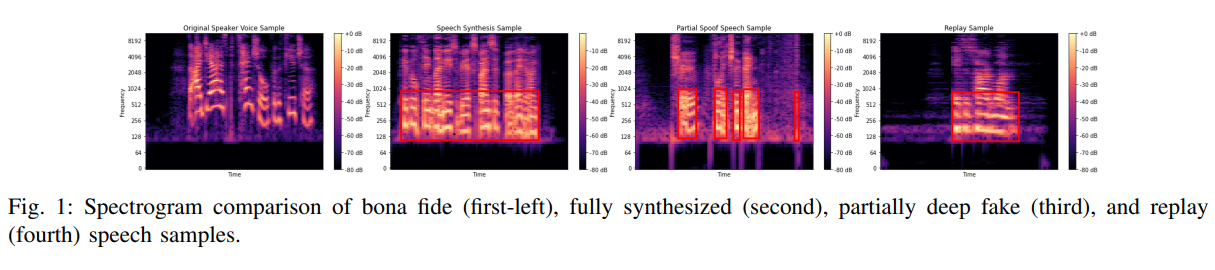
【AI视野·今日Sound 声学论文速览 第七期】Tue, 19 Sep 2023
AI视野今日CS.Sound 声学论文速览 Tue, 19 Sep 2023 Totally 1 papers 👉上期速览✈更多精彩请移步主页 Daily Sound Papers Frame-to-Utterance Convergence: A Spectra-Temporal Approach for Unified Spoofing Detection Authors Awais Khan, Khalid Mahmood Ma…...

MySQL 清空表 截断表
清空表:delete from users; 清空表只是清空表中的逻辑数据,但是物理数据不清除,如主键值、索引等不被清除,还是原来的值。 截断表:truncate table users; 截断表可以用于删除表中 的所有数据…...
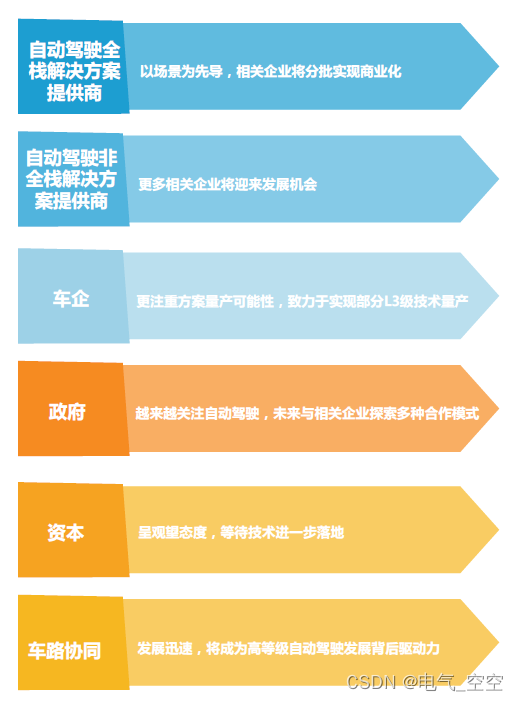
2020-2023中国高等级自动驾驶产业发展趋势研究-中国高等级自动驾驶发展近况
1.2 中国高等级自动驾驶发展近况 通过对中国高等级自动驾驶行业的观察和分析,亿欧汽车认为,除技术解决方案提供商外,如今的车企、政府、资本同样在产业链中扮演重要角色。此外,车路协同技术的发展也为高等级自动驾驶的发展提供了更…...

Spring学习之ImportBeanDefinitionRegistrar接口
一、本文内容分类 1、接口功能 2、接口运用场景 3、使用案例 4、注意事项 二、接口功能介绍 描述:ImportBeanDefinitionRegistrar接口是也是spring的扩展点之一,它可以支持我们自己写的代码封装成BeanDefinition对象,注册到Spring容器中,功能类似于注…...
)
React 全栈体系(八)
第四章 React ajax 三、案例 – github 用户搜索 2. 代码实现 2.3 axios 发送请求 Search /* src/components/Search/index.jsx */ import React, { Component } from "react"; import axios from axiosexport default class Search extends Component {search …...
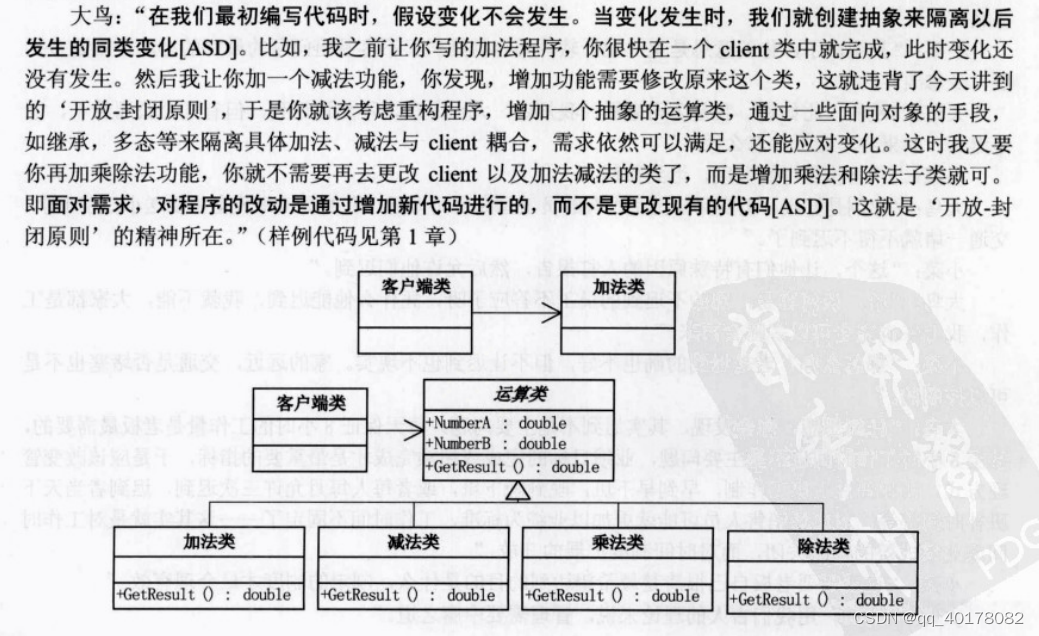
4.开放-封闭原则
这个原则其实是有两个特征,一个是说‘对于扩展是开放的(Open for extension),另一个是说‘对于更改是封闭的(Closed for modification)[ASD]。...

oracle递归with子句
比如现在想获取开始日期到结束日期每个月的月底日期,这个时候可以通过递归实现: --通过递归with子句获取开始日期到结束日期每个月的月末日期 WITH date_range (month_start, month_end) AS (SELECT TRUNC(to_date(bdate,yyyy-mm-dd), MM),LAST_DAY(to_…...

如何在Proteus进行STM32F103C8T6模拟以及keil5开发
一、下载Proteus 8和keil5 最新版 Proteus 8.15 Professional 图文安装教程(附安装包)_proteus密钥_main工作室的博客-CSDN博客Keil uVision5 5.38官方下载、安装及注册教程_keil uvision5下载_这是乐某的博客-CSDN博客 二、新建STM32F103C8项目 接下来…...
C# OpenCvSharp 图片模糊检测(拉普拉斯算子)
效果 项目 代码 using OpenCvSharp; using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Linq; using System.Text; using System.Windows.Forms; using System.Windows.Forms.VisualStyl…...

志高团队:广阔前景 全新的投资理财体验
当今时代,数字金融迅猛发展,投资理财领域正在经历前所未有的重大变革。作为加拿大华企联合会控股旗下的重要项目,恒贵即将启动,旨在为广大投资者带来全新的投资理财体验。这一创新项目的优势和广阔前景受到了业内观察机构的广泛关注和期待。 恒贵作为一家全新的P2C多元化投资理…...

基于自编译的onlyoffice镜像,关于修改字体的问题
基于自编译的onlyoffice镜像,关于修改字体的问题 自编译onlyoffice镜像来自于 https://blog.csdn.net/Gemini1995/article/details/132427908 该镜像里面没有documentserver-generate-allfonts.sh文件,所以需要自己创建一个(建议放在/usr/b…...
1.wifi开发,wifi连接初次连接电脑没有识别,搭建环境
wifi连接初次连接电脑没有识别 1.不识别可能是线的问题,即使wifi的灯亮了,虽然串口却没有找到。所以解决方法就是重新来一个usb的线 一。初步使用 (1)使用ESP烧写工具(选择esp8266) (2…...

【JAVA-Day25】解密进制转换:十进制向R进制和R进制向十进制的过程
解密进制转换:十进制向R进制和R进制向十进制的过程 一、什么是进制转换1.1 进制1.2 进制转换 二、十进制转R进制2.1 转换算法2.2 示例代码 三、R进制转十进制3.1 转换算法3.2 示例代码 四、总结参考资料 ) 博主 默语带您 Go to New World. ✍ 个人主页—— 默语 的…...

牛客网字节面试算法刷题记录
NC78 反转链表 public ListNode ReverseList (ListNode head) {if(headnull) return head;ListNode phead.next,q,tailhead;tail.next null;while(p!null){q p.next;p.next tail;tail p;p q;}return tail;} NC140 排序 冒泡排序 public int[] MySort (int[] arr) {for…...
QT连接Sqlite
使用QTCreator; 根据资料,Qt自带SQLite数据库,不需要再单独安装,默认情况下,使用SQLite版本3,驱动程序为***QSQLITE***; 首先创建项目;在 Build system 中应选中qmake,…...
ChatGPT AIGC 完成各省份销售动态可视化分析
像这样的动态可视化由人工智能ChatGPT AIGC结合前端可视化技术就可以实现。 Prompt:请使用HTML,JS,Echarts 做一个可视化分析的案例,地图可视化,数据可以随机生成,请写出完整的代码 完整代码复制如下: <!DOCTYPE html> <html> <head><meta char…...
基于SpringBoot+Vue的餐饮管理系统设计与实现
前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计划导师、全栈领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java、小程序技术领域和毕业项目实战✌💗 👇🏻…...

stm32G473的flash模式是单bank还是双bank?
今天突然有人stm32G473的flash模式是单bank还是双bank?由于时间太久,我真忘记了。搜搜发现,还真有人和我一样。见下面的链接:https://shequ.stmicroelectronics.cn/forum.php?modviewthread&tid644563 根据STM32G4系列参考手…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

大数据零基础学习day1之环境准备和大数据初步理解
学习大数据会使用到多台Linux服务器。 一、环境准备 1、VMware 基于VMware构建Linux虚拟机 是大数据从业者或者IT从业者的必备技能之一也是成本低廉的方案 所以VMware虚拟机方案是必须要学习的。 (1)设置网关 打开VMware虚拟机,点击编辑…...

pam_env.so模块配置解析
在PAM(Pluggable Authentication Modules)配置中, /etc/pam.d/su 文件相关配置含义如下: 配置解析 auth required pam_env.so1. 字段分解 字段值说明模块类型auth认证类模块,负责验证用户身份&am…...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...

CRMEB 框架中 PHP 上传扩展开发:涵盖本地上传及阿里云 OSS、腾讯云 COS、七牛云
目前已有本地上传、阿里云OSS上传、腾讯云COS上传、七牛云上传扩展 扩展入口文件 文件目录 crmeb\services\upload\Upload.php namespace crmeb\services\upload;use crmeb\basic\BaseManager; use think\facade\Config;/*** Class Upload* package crmeb\services\upload* …...

RNN避坑指南:从数学推导到LSTM/GRU工业级部署实战流程
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文全面剖析RNN核心原理,深入讲解梯度消失/爆炸问题,并通过LSTM/GRU结构实现解决方案,提供时间序列预测和文本生成…...

【碎碎念】宝可梦 Mesh GO : 基于MESH网络的口袋妖怪 宝可梦GO游戏自组网系统
目录 游戏说明《宝可梦 Mesh GO》 —— 局域宝可梦探索Pokmon GO 类游戏核心理念应用场景Mesh 特性 宝可梦玩法融合设计游戏构想要素1. 地图探索(基于物理空间 广播范围)2. 野生宝可梦生成与广播3. 对战系统4. 道具与通信5. 延伸玩法 安全性设计 技术选…...

React---day11
14.4 react-redux第三方库 提供connect、thunk之类的函数 以获取一个banner数据为例子 store: 我们在使用异步的时候理应是要使用中间件的,但是configureStore 已经自动集成了 redux-thunk,注意action里面要返回函数 import { configureS…...

【 java 虚拟机知识 第一篇 】
目录 1.内存模型 1.1.JVM内存模型的介绍 1.2.堆和栈的区别 1.3.栈的存储细节 1.4.堆的部分 1.5.程序计数器的作用 1.6.方法区的内容 1.7.字符串池 1.8.引用类型 1.9.内存泄漏与内存溢出 1.10.会出现内存溢出的结构 1.内存模型 1.1.JVM内存模型的介绍 内存模型主要分…...