Java手写聚类算法
Java手写聚类算法
1. 算法思维导图
以下是聚类算法的实现原理的思维导图,使用Mermanid代码表示:
2. 该算法的手写必要性和市场调查
手写聚类算法的必要性在于深入理解聚类算法的原理和实现细节。通过手写实现聚类算法,可以加深对算法的理解,并且可以根据实际需求进行定制化的改进。
市场调查显示,聚类算法在数据挖掘、机器学习和人工智能领域有广泛的应用。聚类算法能够将相似的数据点归为一类,帮助人们发现数据中的模式和规律,从而为决策和分析提供支持。因此,掌握并理解聚类算法的实现原理和应用场景对于从事相关领域的人员来说是非常重要的。
3. 该算法手写实现的详细介绍和步骤
3.1 算法步骤
- 初始化数据集:将待聚类的数据集加载到内存中。
- 选择初始聚类中心:从数据集中随机选择K个样本作为初始聚类中心。
- 计算样本与聚类中心的距离:对于每个样本,计算其与各个聚类中心的距离,并将样本分配到距离最近的聚类中心。
- 更新样本的聚类标签:根据样本与聚类中心的距离,更新样本的聚类标签。
- 更新聚类中心:对于每个聚类,计算其所有样本的均值,并将该均值作为新的聚类中心。
- 重复步骤3至5,直到聚类中心不再改变。
3.2 代码实现
下面是Java中手写的K-means聚类算法的代码实现:
// 导入所需的库
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;public class KMeans {private int k; // 聚类数private List<double[]> data; // 数据集private List<double[]> centers; // 聚类中心public KMeans(int k, List<double[]> data) {this.k = k;this.data = data;this.centers = new ArrayList<>();}// 初始化聚类中心private void initCenters() {// 从数据集中随机选择k个样本作为初始聚类中心int n = data.size();List<Integer> indices = new ArrayList<>();for (int i = 0; i < n; i++) {indices.add(i);}Collections.shuffle(indices);for (int i = 0; i < k; i++) {centers.add(data.get(indices.get(i)));}}// 计算欧氏距离private double distance(double[] a, double[] b) {double sum = 0;for (int i = 0; i < a.length; i++) {sum += Math.pow(a[i] - b[i], 2);}return Math.sqrt(sum);}// 更新样本的聚类标签private void updateLabels() {for (double[] point : data) {double minDistance = Double.MAX_VALUE;int label = -1;for (int i = 0; i < k; i++) {double distance = distance(point, centers.get(i));if (distance < minDistance) {minDistance = distance;label = i;}}point[point.length - 1] = label;}}// 更新聚类中心private void updateCenters() {Map<Integer, List<double[]>> clusters = new HashMap<>();for (int i = 0; i < k; i++) {clusters.put(i, new ArrayList<>());}for (double[] point : data) {int label = (int) point[point.length - 1];clusters.get(label).add(point);}for (int i = 0; i < k; i++) {List<double[]> cluster = clusters.get(i);double[] center = new double[data.get(0).length - 1];for (double[] point : cluster) {for (int j = 0; j < center.length; j++) {center[j] += point[j];}}for (int j = 0; j < center.length; j++) {center[j] /= cluster.size();}centers.set(i, center);}}// 执行K-means聚类算法public void run() {initCenters();boolean converged = false;while (!converged) {updateLabels();List<double[]> oldCenters = new ArrayList<>(centers);updateCenters();converged = centers.equals(oldCenters);}}
}
4. 该算法的手写实现总结和思维拓展
通过手写实现K-means聚类算法,我们深入理解了算法的原理和实现细节。我们了解到,K-means算法通过迭代更新样本的聚类标签和聚类中心,直到聚类中心不再改变,从而实现聚类的目的。
思维拓展:K-means算法是一种基础的聚类算法,还有许多其他的聚类算法可以进一步学习和探索,例如DBSCAN、层次聚类等。此外,可以尝试使用不同的距离度量方法、聚类评估指标等来改进和扩展聚类算法。
5. 该算法的完整代码
下面是K-means聚类算法的完整代码,每行代码都有注释说明:
// 导入所需的库
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;public class KMeans {private int k; // 聚类数private List<double[]> data; // 数据集private List<double[]> centers; // 聚类中心public KMeans(int k, List<double[]> data) {this.k= k;this.data = data;this.centers = new ArrayList<>();}// 初始化聚类中心private void initCenters() {// 从数据集中随机选择k个样本作为初始聚类中心int n = data.size();List<Integer> indices = new ArrayList<>();for (int i = 0; i < n; i++) {indices.add(i);}Collections.shuffle(indices);for (int i = 0; i < k; i++) {centers.add(data.get(indices.get(i)));}}// 计算欧氏距离private double distance(double[] a, double[] b) {double sum = 0;for (int i = 0; i < a.length; i++) {sum += Math.pow(a[i] - b[i], 2);}return Math.sqrt(sum);}// 更新样本的聚类标签private void updateLabels() {for (double[] point : data) {double minDistance = Double.MAX_VALUE;int label = -1;for (int i = 0; i < k; i++) {double distance = distance(point, centers.get(i));if (distance < minDistance) {minDistance = distance;label = i;}}point[point.length - 1] = label;}}// 更新聚类中心private void updateCenters() {Map<Integer, List<double[]>> clusters = new HashMap<>();for (int i = 0; i < k; i++) {clusters.put(i, new ArrayList<>());}for (double[] point : data) {int label = (int) point[point.length - 1];clusters.get(label).add(point);}for (int i = 0; i < k; i++) {List<double[]> cluster = clusters.get(i);double[] center = new double[data.get(0).length - 1];for (double[] point : cluster) {for (int j = 0; j < center.length; j++) {center[j] += point[j];}}for (int j = 0; j < center.length; j++) {center[j] /= cluster.size();}centers.set(i, center);}}// 执行K-means聚类算法public void run() {initCenters();boolean converged = false;while (!converged) {updateLabels();List<double[]> oldCenters = new ArrayList<>(centers);updateCenters();converged = centers.equals(oldCenters);}}
}
手写总结
K-means聚类算法是一种基础的聚类算法,通过迭代更新样本的聚类标签和聚类中心来实现聚类的目的。算法的步骤如下:
- 初始化聚类中心:从数据集中随机选择k个样本作为初始聚类中心。
- 更新样本的聚类标签:计算每个样本与聚类中心的距离,将样本分配到距离最近的聚类中心对应的簇。
- 更新聚类中心:根据每个簇中的样本,计算新的聚类中心。
- 判断是否收敛:判断新的聚类中心与旧的聚类中心是否相等,如果相等则算法收敛,否则继续迭代。
- 重复步骤2-4,直到聚类中心不再改变。
K-means聚类算法的优点是简单、易于实现,并且在处理大规模数据集时具有较高的效率。然而,该算法对初始聚类中心的选择敏感,可能会陷入局部最优解。因此,可以采用多次运行算法并选择最优结果的方法来提高聚类的准确性。
通过手写实现K-means聚类算法,我们深入理解了算法的原理和实现细节。在实际应用中,可以根据具体问题的需求和特点,对算法进行改进和扩展,例如使用不同的距离度量方法、聚类评估指标等。此外,还可以进一步学习和探索其他聚类算法,如DBSCAN、层次聚类等,以应对更复杂的聚类任务。
相关文章:

Java手写聚类算法
Java手写聚类算法 1. 算法思维导图 以下是聚类算法的实现原理的思维导图,使用Mermanid代码表示: #mermaid-svg-AK9EgYRS38PkRJI4 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-AK9EgYRS38…...
解密Java多线程中的锁机制:CAS与Synchronized的工作原理及优化策略
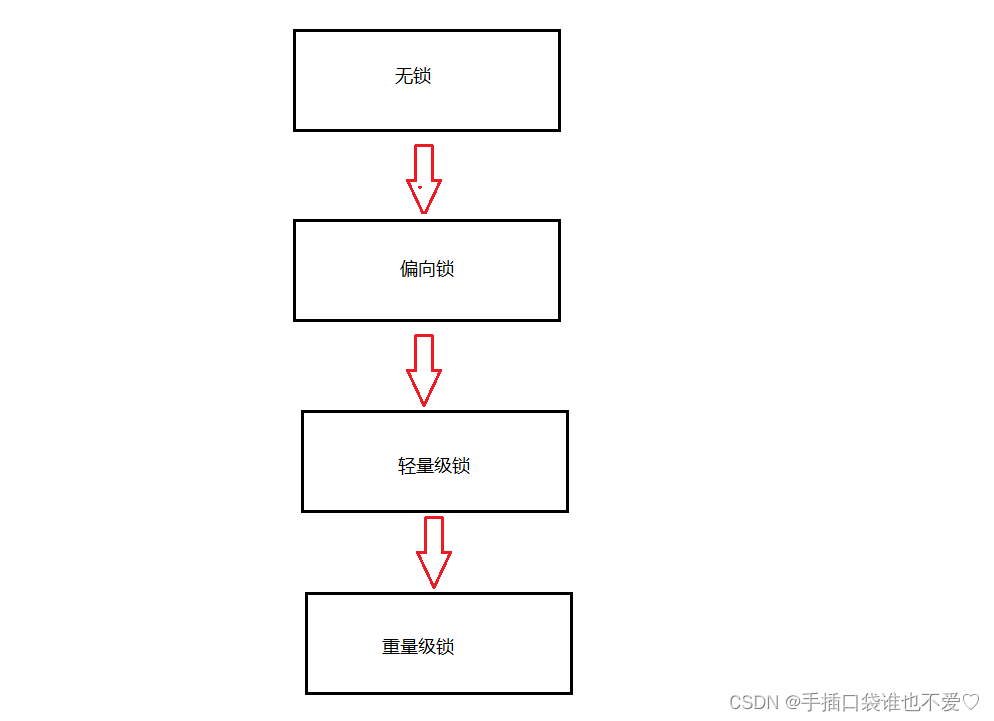
目录 CAS什么是CASCAS的应用ABA问题异常举例 Synchronized 原理基本特征加锁过程偏向锁轻量级锁重量级锁 其他优化操作锁消除锁粗化 CAS 什么是CAS CAS: 全称Compare and swap,字面意思:”比较并交换“,CAS涉及如下操作: 假设内存中的原数据…...

solid works草图绘制与设置零件特征的使用说明
(1)草图绘制 • 草图块 在 FeatureManager 设计树中,您可以隐藏和显示草图的单个块。您还可以查看块是欠定义 (-)、过定义 () 还是完全定义。 要隐藏和显示草图的单个块,请在 FeatureManager 设计树中右键单击草图块,…...
页面跳转后,该页面不刷新问题)
vue3使用router.push()页面跳转后,该页面不刷新问题
文章目录 原因分析最优解决 原因分析 这是一个常见问题,当使用push的时候,会向history栈添加一个新记录,这个时候,再添加一个完全相同的路由时,就不会再次刷新了 最优解决 在页面跳转时加上params参数时间 router.…...

如何理解数字工厂管理系统的本质
随着科技的飞速发展和数字化转型的推动,数字工厂管理系统逐渐成为工业4.0时代的重要工具。数字工厂系统旨在整合和优化工厂运营的各个环节,通过实时数据分析和处理,提升生产效率,降低成本,并增强企业的整体竞争力。为了…...
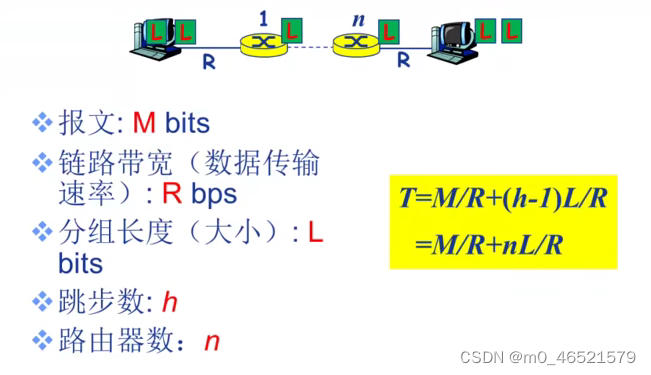
笔记1.3 数据交换
如何实现数据通过网络核心从源主机到达目的主机? 数据交换 交换网络: 动态转接动态分配传输资源 数据交换类型: (1)电路交换 (2)报文交换 (3)分组交换 电路交换的特…...
实时车辆行人多目标检测与跟踪系统(含UI界面,Python代码)
算法架构: 目标检测:yolov5 目标跟踪:OCSort其中, Yolov5 带有详细的训练步骤,可以根据训练文档,训练自己的数据集,及其方便。 另外后续 目标检测会添加 yolov7 、yolox,目标跟踪会…...

谷歌AI机器人Bard发布强大更新,支持插件功能并增强事实核查;全面整理高质量的人工智能、机器学习、大数据等技术资料
🦉 AI新闻 🚀 谷歌AI机器人Bard发布强大更新,支持插件功能并增强事实核查 摘要:谷歌的人工智能聊天机器人Bard发布了一项重大更新,增加了对谷歌应用的插件支持,包括 Gmail、Docs、Drive 等,并…...

NI SCXI-1125 数字量控制模块
NI SCXI-1125 是 NI(National Instruments)生产的数字量控制模块,通常用于工业自动化和控制系统中,以进行数字输入和输出控制。以下是该模块的一些主要产品特点: 数字量输入:SCXI-1125 模块通常具有多个数字…...
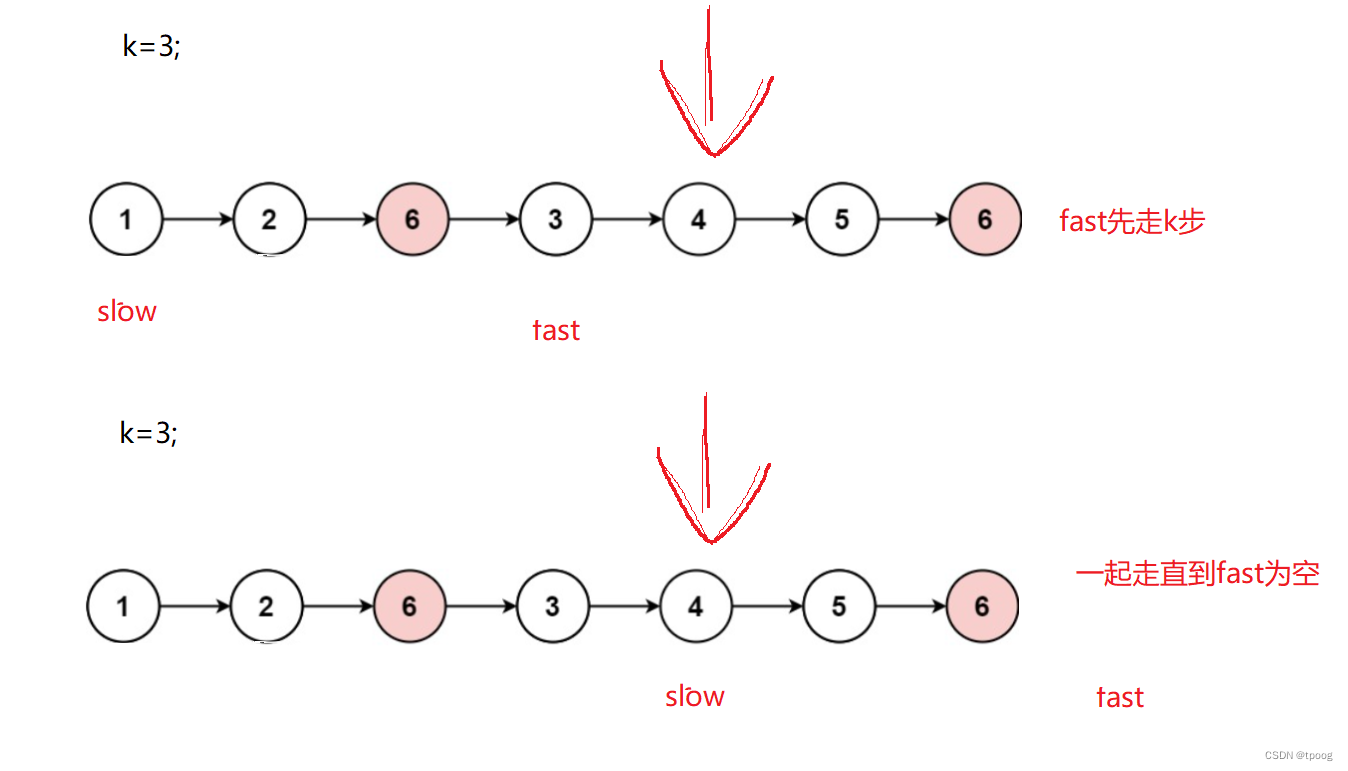
链表oj题1(Leetcode)——移除链表元素,反转链表,链表的中间节点,
链表OJ 一,移除链表元素1.1分析1.2代码 二,找到链表的中间节点2.1分析2.2代码 三,反转链表3.1分析3.2代码 四,找到链表中倒数第k个节点4.1分析4.2代码 一,移除链表元素 移除链表元素 1.1分析 这里的删除要分成两种…...
【libuv】与uvgrtrp的_SSIZE_T_定义不同
libuv的 #if !defined(_SSIZE_T_) && !defined(_SSIZE_T_DEFINED) typedef intptr_t ssize_t;...

安卓ROM定制 修改必备常识-----初步了解system系统分区文件夹的基本含义 【二】
安卓修改rom 固件 修改GSI 移植rom 必备常识 lib--**so文件基本解析 一起来了解system目录相应文件的用途吧。(rom版本不同里面的app也会不一样) 简单打开img格式后缀文件 给大家说下最简单的方法提取img里面的文件,对于后缀img格式的文件可…...

GPT会统治人类吗
一 前言 花了大概两天时间看完《这就是ChatGPT》,触动还是挺大的,让我静下来,认真地想一想,是否真正理解了ChatGPT,又能给我们以什么样的启发。 二 思考 在工作和生活中,使用ChatGPT或文心一言,…...
win系统环境搭建(六)——Windows安装nginx
windows环境搭建专栏🔗点击跳转 win系统环境搭建(六)——Windows安装nginx 本系列windows环境搭建开始讲解如何给win系统搭建环境,本人所用系统是腾讯云服务器的Windows Server 2022,你可以理解成就是你用的windows10…...

Java中使用BigDecimal类相除保留两位小数
问题 遇到2个数相除,需要保留2位小数的结果。 解决 BigDecimal sum ...; BigDecimal yearValue ...;MathContext mathContext new MathContext(2, RoundingMode.DOWN); yearValue.divide(sum, mathContext);...
激光雷达在ADAS测试中的应用与方案
在科技高速发展的今天,汽车智能化已是必然的趋势,且自动驾驶汽车的研究也在世界范围内进行得如火如荼。而在ADAS测试与开发中,激光雷达以其高性能和高精度占据着非常重要的地位,它是ADAS测试与开发中不可缺少的组成。 一 激光雷达…...

malloc与free
目录 前提须知: malloc: 大意: 头文件: 申请空间: 判断是否申请成功: 使用空间: 结果: 整体代码: malloc申请的空间怎么回收呢? 注意事项: free:…...

计算周包材,日包材用来发送给外围系统
文章目录 1 Introduction2 code 1 Introduction In this example We get data from BOM and RESB . and calculate it . 2 code TYPES: BEGIN OF TY_ZPPT_0015_W,AUFNR TYPE ZPPT_0015-AUFNR,ZXH TYPE ZPPT_0015-ZXH,ZZJHID TYPE ZPPT_0015-ZZJHID,ZRJHID TYPE Z…...
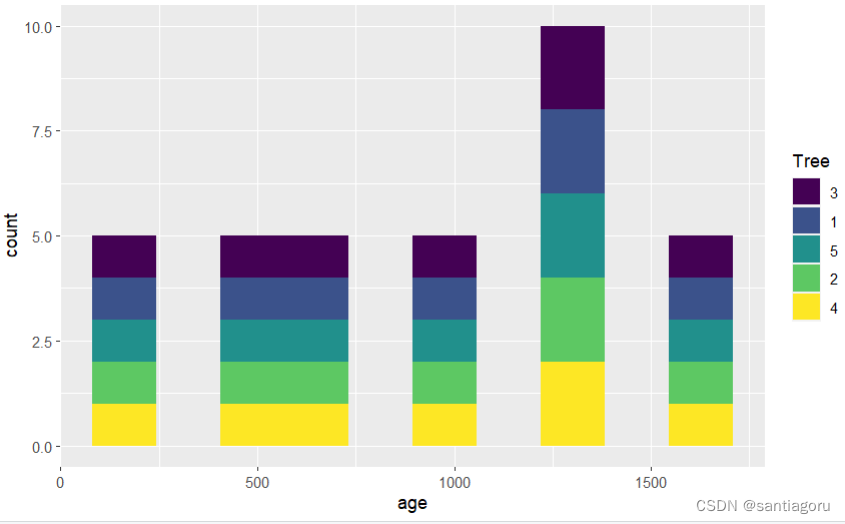
R语言柱状图直方图 histogram
柱状图简介 柱状图也叫直方图,是展示连续性数值的分布状况。在x轴上将连续型数值分为一定数量的组,y轴显示对应值的频数。 R基本的柱状图 hist 我们用R自带的Orange数据来画图。 > head(Orange)Tree age circumference(圆周长) 1 1 118 …...

Linux磁盘管理:最佳实践
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

QPainter避坑指南:绘制高清矢量图时容易踩的5个性能陷阱
QPainter性能优化实战:避开高清矢量图绘制的五大陷阱 在移动端和跨平台开发中,Qt的QPainter作为核心绘图引擎,其性能表现直接影响应用流畅度。本文将深入分析Retina屏幕适配、大尺寸路径渲染等场景下的性能瓶颈,并提供经过验证的…...
PP-DocLayoutV3技术解析:其视觉Transformer骨干网络设计
PP-DocLayoutV3技术解析:其视觉Transformer骨干网络设计 文档智能处理,比如从一张扫描的合同或报告里自动识别出标题、段落、表格和图片,听起来简单,做起来却不容易。传统的模型在处理复杂的版面,尤其是那些元素之间距…...

Mirage Flow 在计算机网络教学中的应用:模拟协议交互与故障排查
Mirage Flow 在计算机网络教学中的应用:模拟协议交互与故障排查 计算机网络这门课,教起来挺费劲的。我见过不少学生,对着课本上TCP三次握手的示意图,眉头紧锁,嘴里念叨着“SYN, SYN-ACK, ACK”…...

UNIT-00:Berserk Interface辅助LaTeX学术论文写作与排版
UNIT-00:Berserk Interface辅助LaTeX学术论文写作与排版 写论文,尤其是用LaTeX写,对很多科研人员和学生来说,是个又爱又恨的活儿。爱的是它排版出来的那份专业和精致,恨的是那些层出不穷的编译错误、复杂的宏包语法&a…...

微信聊天记录的数据管理与隐私保护:本地化存储解决方案
微信聊天记录的数据管理与隐私保护:本地化存储解决方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeCh…...

零基础玩转OpenClaw:GLM-4.7-Flash镜像云端体验指南
零基础玩转OpenClaw:GLM-4.7-Flash镜像云端体验指南 1. 为什么选择云端沙盒体验OpenClaw 作为一个长期关注AI自动化工具的技术爱好者,我一直在寻找一种既安全又便捷的方式来体验OpenClaw。直到发现星图平台提供的预装镜像方案,才真正解决了…...

小程序毕业设计基于微信小程序的校园快递系统weixin414
前言 传统校园快递平台系统存在信息管理难度大、容错率低、管理人员处理数据费工费时等问题。为了解决这些难题,专门开发了Spring Boot基于微信小程序的校园快递系统。该系统旨在提高校园快递平台系统信息管理问题的解决效率,优化信息处理流程࿰…...

探索AI原生应用在业务流程增强中的最佳实践
AI原生应用增强业务流程:从0到1落地指南与实战最佳实践 摘要/引言:为什么你的业务流程需要“AI原生”重构? 凌晨1点,某电商售后客服小张还在处理今天的第127个退货申请——他需要手动核对用户上传的商品图片、查订单系统的购买记录、翻用户历史退货次数,最后才能点击“审…...

计算机毕业设计springboot同城喂溜宠物预约系统 基于SpringBoot的同城宠物上门照护预约平台 SpringBoot驱动的城市宠物代遛代喂一键预约系统
计算机毕业设计springboot同城喂溜宠物预约系统087g11n0 (配套有源码 程序 mysql数据库 论文) 本套源码可以在文本联xi,先看具体系统功能演示视频领取,可分享源码参考。 随着现代生活节奏加快,城市养宠人群面临"想养不敢养&q…...

计算机毕业设计springboot基于超市管理系统的设计与实现 基于SpringBoot框架的零售门店智能运营平台设计与实现 SpringBoot驱动的超市进销存一体化管理系统开发与实践
计算机毕业设计springboot基于超市管理系统的设计与实现(配套有源码 程序 mysql数据库 论文) 本套源码可以在文本联xi,先看具体系统功能演示视频领取,可分享源码参考。随着信息技术的飞速发展和零售行业数字化转型的深入推进,传统…...