数据预处理方式合集
删除空行
#del all None value
data_all.dropna(axis=1, how='all', inplace=True)删除空列
#del all None value
data_all.dropna(axis=0, how='all', inplace=True)缺失值处理
观测缺失值
观测数据缺失值有一个比较好用的工具包——missingno,直接传入DataFrame,会将所有的列缺失比例可视化,是一个比较方便的工具。
将观测的缺失值数据统计成为一个数据表,并将数据表可视化,
# 统计缺失值数量
missing=data_all.isnull().sum().reset_index().rename(columns={0:'missNum'})
# 计算缺失比例
missing['missRate']=missing['missNum']/data_all.shape[0]
# 按照缺失率排序显示
miss_analy=missing[missing.missRate>0].sort_values(by='missRate',ascending=False)
# miss_analy 存储的是每个变量缺失情况的数据框然后将缺失值数据miss_analy可视化
import matplotlib.pyplot as plt
import pylab as pl
fig = plt.figure(figsize=(18,6))
plt.bar(np.arange(miss_analy.shape[0]), list(miss_analy.missRate.values), align = 'center',color=['red','green','yellow','steelblue'])
plt.title('Histogram of missing value of variables')
plt.xlabel('variables names')
plt.ylabel('missing rate')# 添加x轴标签,并旋转90度
plt.xticks(np.arange(miss_analy.shape[0]),list(miss_analy['index']))
plt.xticks(rotation=90)
# 添加数值显示
for x,y in enumerate(list(miss_analy.missRate.values)): plt.text(x,y+0.12,'{:.2%}'.format(y),ha='center',rotation=90) plt.ylim([0,1.2])
plt.show()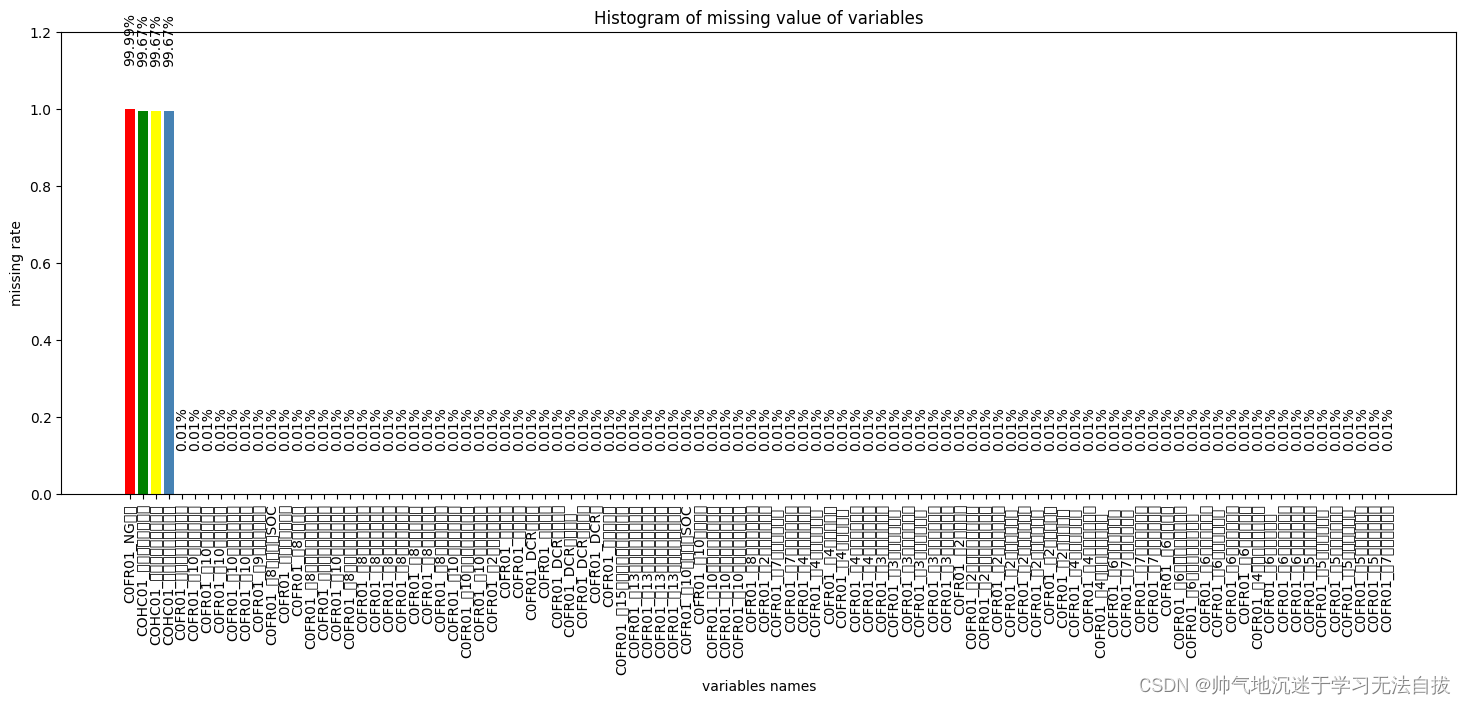
当然有些画图的技巧,需要每个人根据各自的需求去探索,笔者画图功底也比较差,可以参考Sklearn里面的sample,也可以查阅Seaborn中的技术文档。以上数据可视化后可以看到每一列的缺失值比例,然后可以自己设定缺失值阈值α,如果缺失值比例大于α则删除该列,或者其他却缺失值处理策略。当然笔者任务是建立高精度的预测模型,而且,数据量还可以。所以就没有用填充策略。
删除缺失严重特征
alpha = 0.2
need_delete_cols = []
for index,row in miss_analy.iterrows():if row['missRate'] > alpha:need_delete_cols.append(row['index'])#delete most empty col
data_all = data_all.drop(columns=need_delete_cols, axis=0, inplace=True)有的人可能觉得这种方法比较麻烦,又要可视化又要单独删除,如果不需要可视化或者探索缺失值的具体情况,我这里也提供一个非常简单粗暴的缺失值删除办法
data_all=data_all.dropna(thresh=len(data_all)*alpha, axis=1)以上一行代码完成了,前述的所有删除工作。
删除单值特征
单值特征是指某一列只有一个值,不存在变化的情况,这种特征是没有任何意义的,需要直接删除
desc = data_all.astype('str').describe()
mask = desc.loc['unique',:] == 1
data_all.drop(labels=desc.columns[mask],axis=1,inplace=True)异常数据处理
这里我说的异常数据一般是指每个特征中的离群数据,因为我的任务是建立一个通用的,泛化能力较强的模型,所以这里对每个特征的离群数据进行删除操作,避免后续模型为了拟合离群点,导致过拟合的现象。那如何判断某个数据点是否离群或者异常呢?这里提供两种方法,每个方法都有优劣势,后续我再细说。
3σ方式
用传统意义上的统计方法实现,3σ我就不细说了,正态分布3σ之外的数据为异常
def del_outlier(dataset):temp = dataset.copy()for each in temp.columns:std = np.std(temp[each])mean = np.mean(temp[each])sigma = 4 * stdlimit_up = mean + sigma limit_bottom = mean - sigma temp = temp.query('({} > {}) and ({} <{})'.format(each,limit_bottom,each,limit_up))print(limit_up,limit_bottom)print(each,temp.shape)return temp这个方式比较通用,最适合看起来服从正太分布的特征。
分位数方式
首先我放个连接(https://www.itl.nist.gov/div898/handbook/prc/section1/prc16.htm),里面描述了什么是离群点。
def del_outlier(dataset):temp = dataset.copy()for each in temp.columns: first_quartile = temp[each].describe()['25%']third_quartile = temp[each].describe()['75%']iqr = third_quartile - first_quartilelimit_up = third_quartile + 3 * iqrlimit_bottom = first_quartile - 3 * iqr temp = temp.query('({} > {}) and ({}<{})'.format(each,limit_bottom,each,limit_up))print(limit_up,limit_bottom)print(each,temp.shape)return temp分位数方式存在一个问题,如果离群点非常少,导致3/4和1/4分位数相等,就无法执行下去。
个人还是比较推荐σ的方法。
特征信息量
特诊信息量是描述的某一特征的数据是否有足够的信息熵去辅助建模,如果一个特诊的信息熵很低,那说明该特诊基本上不存在什么波动,蕴含的信息量极少(当然可能要做完归一化后观测起来会比较明显),那该特诊就可以直接删除。
以下为计算信息熵的Python代码:
from scipy.stats import entropy
from math import log, e
import pandas as pd ##""" Usage: pandas_entropy(df['column1']) """def pandas_entropy(column, base=None):vc = pd.Series(column).value_counts(normalize=True, sort=False)base = e if base is None else basereturn -(vc * np.log(vc)/np.log(base)).sum()执行删除信息熵小的特诊:
for each in feature_list:
# print(each,pandas_entropy(data_all[each]))if pandas_entropy(data_all[each]) < 1:print(each,pandas_entropy(data_all[each]))data_all.drop(columns=[each],axis=1,inplace=True)处理不同数据类型特诊(时间特征为例)
DataFrame数据类型通常包含Object,int64,float64,,对于后两者我们没必要可以去改变,但是对于Object类型的数据,不同含义的Object数据做不同处理。笔者这里举例时间格式的Object数据处理。
数据类型查看与统计
data_all.dtypes.values_counts()将时间的Object数据进行转换。
data_all[key] = pd.to_datetime(data_all[key])
如果存在类似开始时间-结束时间的时间对数据,可以将两者相减,得到时间片段数据,例如:
data_all[time_gap] = pd.to_datetime(data_all['end']) - pd.to_datetime(data_all['start'])然后将时间段数据转为小时,或者分钟,或者秒:
data_all[key] = data_all[key].apply(lambda x: x.total_seconds() / 60 / 60)以上为个人通常来讲的数据预处理过程,建议在每执行一步后数据重新命名,并保存一份备份。
以上。
如有什么建议或者错误,大家随时拍砖。
相关文章:
数据预处理方式合集
删除空行 #del all None value data_all.dropna(axis1, howall, inplaceTrue) 删除空列 #del all None value data_all.dropna(axis0, howall, inplaceTrue) 缺失值处理 观测缺失值 观测数据缺失值有一个比较好用的工具包——missingno,直接传入DataFrame&…...

【前端】jquery获取data-*的属性值
通过jquery获取下面data-id的值 <div id"getId" data-id"122" >获取id</div> 方法一:dataset()方法 //data-前缀属性可以在JS中通过dataset取值,更加方便 console.log(getId.dataset.id);//112//赋值 getId.dataset.…...
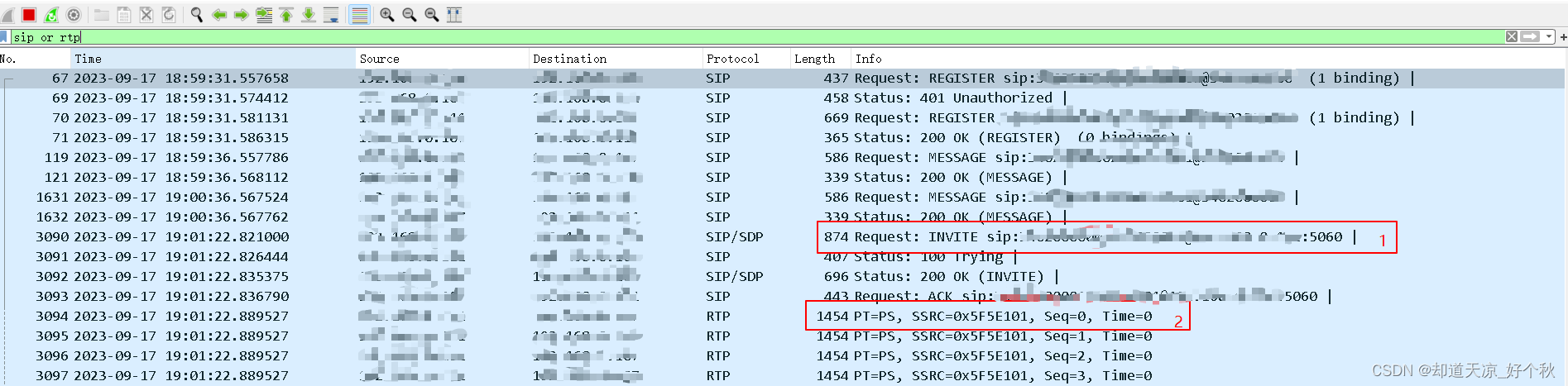
GB28181学习(五)——实时视音频点播(信令传输部分)
要求 实时视音频点播的SIP消息应通过本域或其他域的SIP服务器进行路由、转发,目标设备的实时视音频流宜通过本域的媒体服务器进行转发;采用INVITE方法实现会话连接,采用RTP/RTCP协议实现媒体传输;信令流程分为客户端主动发起和第…...

单例模式(饿汉模式 懒汉模式)与一些特殊类设计
文章目录 一、不能被拷贝的类 二、只能在堆上创建类对象 三、只能在栈上创建类对象 四、不能被继承的类 五、单例模式 5、1 什么是单例模式 5、2 什么是设计模式 5、3 单例模式的实现 5、3、1 饿汉模式 5、3、1 懒汉模式 🙋♂️ 作者:Ggggggtm &#x…...
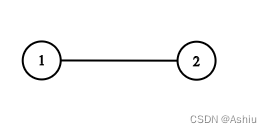
133. 克隆图
133. 克隆图 题目-中等难度示例1. bfs 题目-中等难度 给你无向 连通 图中一个节点的引用,请你返回该图的 深拷贝(克隆)。 图中的每个节点都包含它的值 val(int) 和其邻居的列表(list[Node])。…...

交流耐压试验目的
试验目的 交流耐压试验是鉴定电力设备绝缘强度最有效和最直接的方法。 电力设备在运行中, 绝缘长期受着电场、 温度和机械振动的作用会逐渐发生劣化, 其中包括整体劣化和部分劣化,形成缺陷, 例如由于局部地方电场比较集中或者局部…...
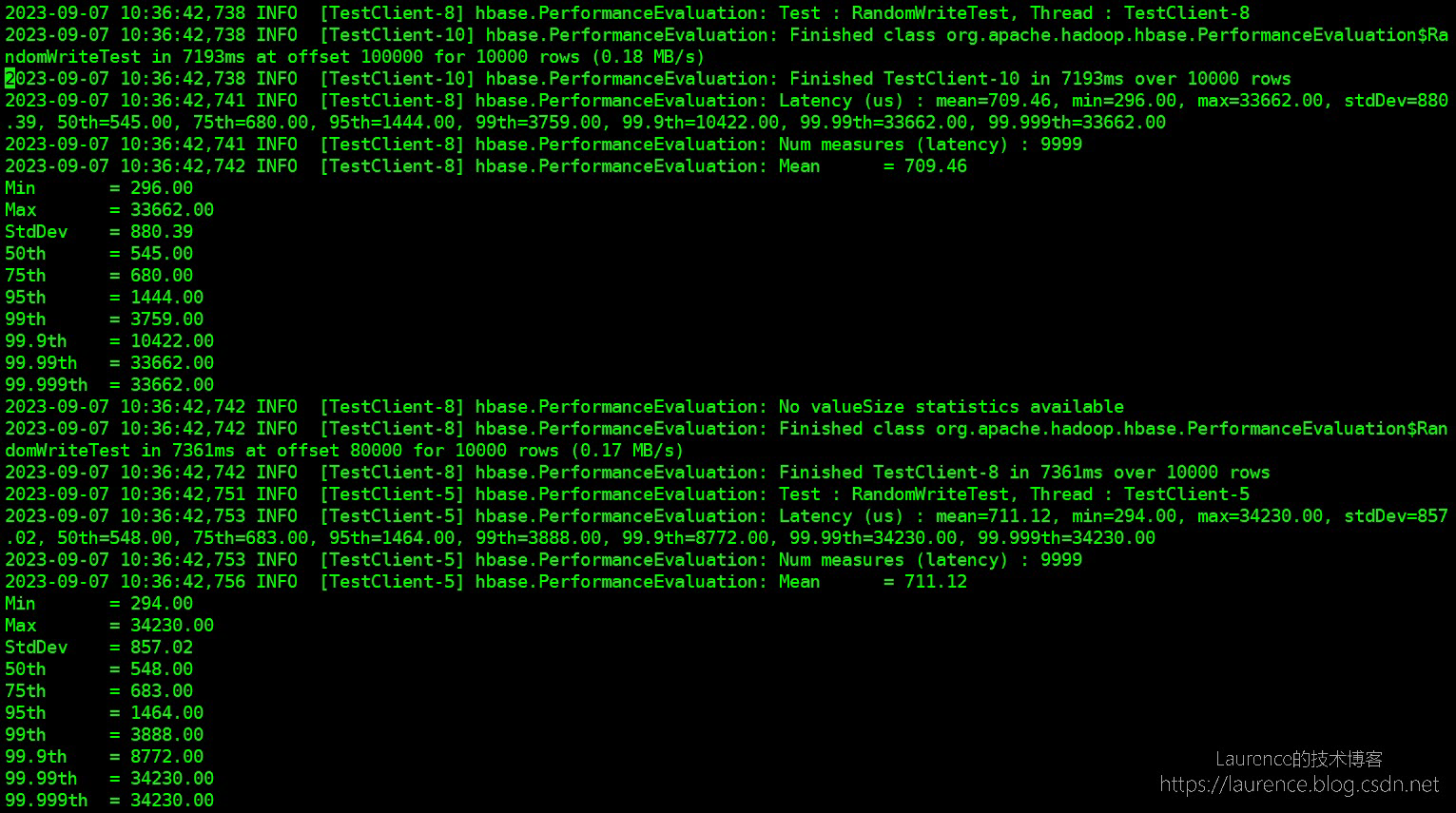
使用 YCSB 和 PE 进行 HBase 性能压力测试
HBase主要性能压力测试有两个,一个是 HBase 自带的 PE,另一个是 YCSB,先简单说一个两者的区别。PE 是 HBase 自带的工具,开箱即用,使用起来非常简单,但是 PE 只能按单个线程统计压测结果,不能汇…...

正则表达式相关概念及不可见高度页面的获取
12.正则 概念:匹配有规律的字符串,匹配上则正确 1.正则的创建方式 构造函数创建 // 修饰符 igm// i 忽视 ignore// g global 全球 全局// m 换行 var regnew RegExp("匹配的内容","修饰符")var str "this is a Box";var reg new RegExp(&qu…...

深入学习 Redis - 分布式锁底层实现原理,以及实际应用
目录 一、Redis 分布式锁 1.1、什么是分布式锁 1.2、分布式锁的基础实现 1.2.1、引入场景 1.2.2、基础实现思想 1.2.3、引入 setnx 1.3、引入过期时间 1.4、引入校验 id 1.5、引入 lua 脚本 1.5.1、引入 lua 脚本的原因 1.5.2、lua 脚本介绍 1.6、过期时间续约问题&…...
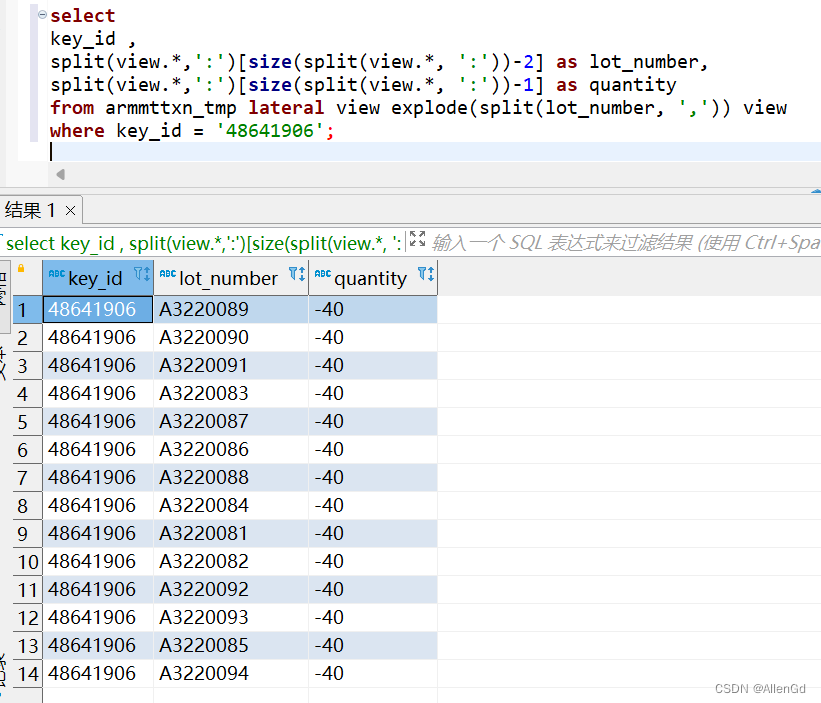
Hive行转列[一行拆分成多行/一列拆分成多列]
场景: hive有张表armmttxn_tmp,其中有一个字段lot_number,该字段以逗号分隔开多个值,每个值又以冒号来分割料号和数量,如:A3220089:-40,A3220090:-40,A3220091:-40,A3220083:-40,A3220087:-40,A3220086:-4…...

TypeScript系列之类型 string
文章の目录 背景写在最后 背景 与JavaScript不同的是,TypeScript使用的是静态类型,比如说它指定了变量可以保存的数据类型。如下面代码所示,如果在JavaScript中,指定变量可以保存的数据类型,会报错:类型注…...
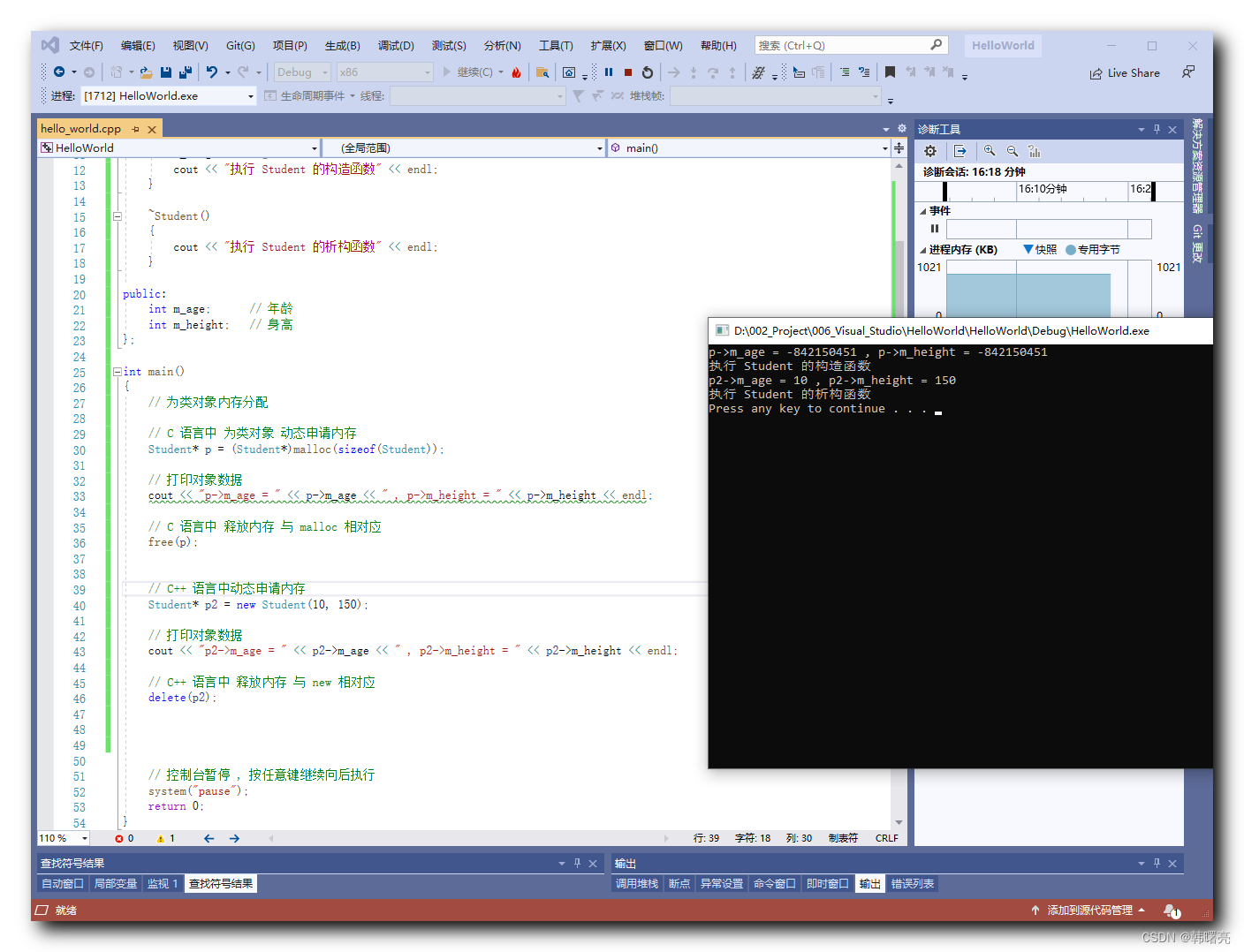
【C++】动态内存管理 ③ ( C++ 对象的动态创建和释放 | new 运算符 为类对象 分配内存 | delete 运算符 释放对象内存 )
文章目录 一、C 对象的动态创建和释放1、C 语言 对象的动态创建和释放 的方式2、C 语言 对象的动态创建和释放 的方式 二、代码示例 - 对象的动态创建和释放 一、C 对象的动态创建和释放 使用 C 语言中的 malloc 函数 可以为 类对象 分配内存 ; 使用 free 函数可以释放上述分配…...

AMS爆炸来袭,上线即巅峰
1.关于首发项目Antmons(AMS)空投结果 Gate.io Startup 首发项目Antmons代币AMS于Aug15th,AM 07:00开始下单,24小时内下单同等对待总共有15,950人下单,下单总价值超过1,000万美金分发系数约为0.001640495298341。根据上线规则AMS项目认购成功,…...
是面试官放水,还是公司实在是太缺人?这都没挂,华为原来这么容易进...
华为是大企业,是不是很难进去啊?” “在华为做软件测试,能得到很好的发展吗? 一进去就有9.5K,其实也没有想的那么难” 直到现在,心情都还是无比激动! 本人211非科班,之前在字节和腾…...
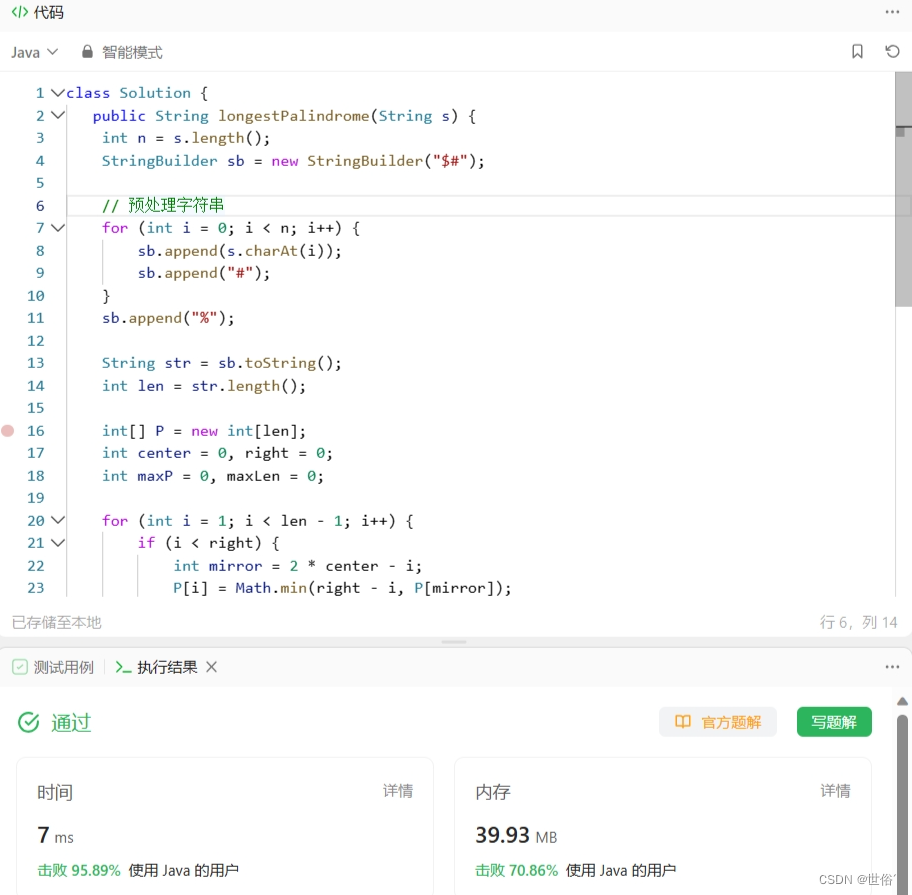
怒刷LeetCode的第2天(Java版)
目录 第一题 题目来源 题目内容 解决方法 方法一:滑动窗口 方法二:双指针加哈希表 第二题 题目来源 题目内容 解决方法 方法一:二分查找 方法二:归并排序 方法三:分治法 第三题 题目来源 题目内容 解…...
)
AUTOSAR汽车电子嵌入式编程精讲300篇-车载CAN总线网络的异常检测(续)
目录 车载 CAN 总线网络异常检测技术 3.1 车载 CAN 总线网络异常检测技术概述 3.1.1基于统计的异...
mojo安装
docker安装mojo 官网 https://developer.modular.com/login 很奇怪登录页面不显示 类似于网站劫持 docker 安装mojo带jupyterlab的方式 https://hub.docker.com/r/lmq886/mojojupyterlab 拉取镜像 docker pull lmq886/mojojupyterlab docker pull lmq886/mojojupyterlab:1.2 启…...

【探索Linux】—— 强大的命令行工具 P.8(进程地址空间)
阅读导航 前言一、内存空间分布二、什么是进程地址空间1. 概念2. 进程地址空间的组成 三、进程地址空间的设计原理1. 基本原理2. 虚拟地址空间 概念 大小和范围 作用 虚拟地址空间的优点 3. 页表 四、为什么要有地址空间五、总结温馨提示 前言 前面我们讲了C语言的基础知识&am…...
vue3 - Element Plus 切换主题色及el-button hover颜色不生效的解决方法
GitHub Demo 地址 在线预览 Element Plus 自定义主题官方文档 如果您想要通过 js 控制 css 变量,可以这样做: // document.documentElement 是全局变量时 const el document.documentElement // const el document.getElementById(xxx)// 获取 css 变…...

【C++面向对象侯捷】1.C++编程简介
文章目录 视频来源:我的百度网盘...
)
ElevenLabs葡语语音私密训练技巧(仅限白名单客户使用的SSML扩展语法+方言权重微调指令集)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs葡语语音私密训练的核心价值与白名单准入机制 ElevenLabs 的葡语语音私密训练(Private Voice Fine-tuning for Portuguese)专为高合规性场景设计,面向金融…...
Pixel Framebuf库:图形化编程驱动LED矩阵,告别底层坐标换算
1. 项目概述:告别点灯,拥抱图形化LED矩阵编程如果你玩过Arduino或者树莓派,大概率接触过WS2812B这类可寻址LED,也就是大家常说的NeoPixel。单个灯珠的控制很简单,setPixelColor一下就能亮。但当你面对一个8x8、16x16甚…...

MATLAB/Simulink模型化设计驱动树莓派:从LED闪烁到快速原型开发
1. 项目概述:当MATLAB/Simulink遇见树莓派 如果你是一名算法工程师、控制工程师,或者正在学习嵌入式系统,那么“模型化设计”和“快速原型开发”这两个词对你来说一定不陌生。它们听起来很高大上,但核心目标其实很朴素࿱…...

FPGA与GPU在OSOS-ELM算法中的性能对比与优化
1. 项目概述在边缘计算和实时信号处理领域,极端学习机(ELM)因其独特的训练机制和高效的计算性能而备受关注。OSOS-ELM作为ELM的一种变体,通过在线顺序学习机制进一步提升了算法的实用性。这项研究聚焦于FPGA和GPU两种硬件平台在执行OSOS-ELM算法时的性能…...

开源UI组件库深度解析:从设计系统到工程实践
1. 项目概述:一个开源UI组件库的诞生与价值如果你是一名前端开发者,或者正在负责一个需要快速搭建现代化界面的项目,那么你大概率听说过或者用过一些知名的UI组件库。今天我想深入聊聊一个在GitHub上拥有超过1.5万星标,被许多开发…...

边缘计算赋能工业智能化:重大危险源监测+产线控制+视觉分析一体化解决方案
在工业 4.0 与智能制造深度融合的今天,工业现场产生的数据量呈指数级增长。传统的 "云端集中式" 数据处理架构在面对毫秒级实时控制、海量视觉数据传输、高危场景 724 小时不间断监测等需求时,逐渐暴露出延迟高、带宽成本大、网络依赖强、数据…...

基于Blazor与LLamaSharp构建本地大模型ChatGPT式Web应用
1. 项目概述与核心价值最近在折腾一个内部工具,想把本地大模型的能力和类似ChatGPT的对话体验结合起来,部署成一个Web应用。找了一圈,发现一个挺有意思的项目叫“BLlamaSharp.ChatGpt.Blazor”。光看这个名字,信息量就很大了&…...

Linux驱动开发:原子操作实现LED设备互斥访问
1. 项目概述:用原子操作给LED驱动加把“锁”在嵌入式Linux开发里,驱动开发是绕不开的一环。很多时候,一个硬件设备,比如一个简单的LED灯,可能会被多个用户空间的应用程序同时访问。想象一下,一个APP想开灯&…...

学生综合素质评价系统设计实现【附程序】
✨ 长期致力于综合素质评价、AHP层次分析、BP神经网络、遗传算法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)三层指标体系构建与AHP动态权重分配&…...

从零到一:基于Ultralytics框架与自定义数据集实战RT-DETR模型训练
1. RT-DETR与Ultralytics框架初探 第一次接触RT-DETR时,我被它的"实时检测Transformer"组合惊艳到了。这个由百度开发的检测器,完美解决了传统Transformer模型在实时场景下的性能瓶颈。不同于YOLO系列的锚框机制,RT-DETR采用端到端…...