计算机视觉与深度学习-图像分割-视觉识别任务02-目标检测-【北邮鲁鹏】
目录标题
- 参考
- 目标检测定义
- 深度学习对目标检测的作用
- 单目标检测
- 多任务框架
- 多任务损失
- 预训练模型
- 姿态估计
- 多目标检测
- 问题
- 滑动窗口(Sliding Window)
- 滑动窗口缺点
- AdaBoost(Adaptive Boosting)
- 参考
- 区域建议 selective search 思想
- 慢速R-CNN
- 慢速R-CNN思路
- 边界框回归(Bbox reg)
- 慢速R-CNN缺点
- Fast R-CNN
- 改进一:先提取特征后区域建议
- 改进二:全连接神经网络
- 改进三:裁剪+缩放特征(RoI Pool)
- 为什么需要RoI Pool?
- 区域裁剪
- Rol Pool
- Rol Align
- Fast R-CNN的问题
- Fast R-CNN vs 慢速R-CNN
- Faster R-CNN
- RPN(Region Proposal Network)
- 区域建议(Region Proposal Network)
- 运行分为两个阶段
- Faster R-CNN速度
- 目标检测: 影响精度的因素 ...
参考
【计算机视觉】计算机视觉与深度学习-07-目标检测-北邮鲁鹏老师课程笔记
计算机视觉与深度学习 北京邮电大学 鲁鹏 清晰版合集(完整版)
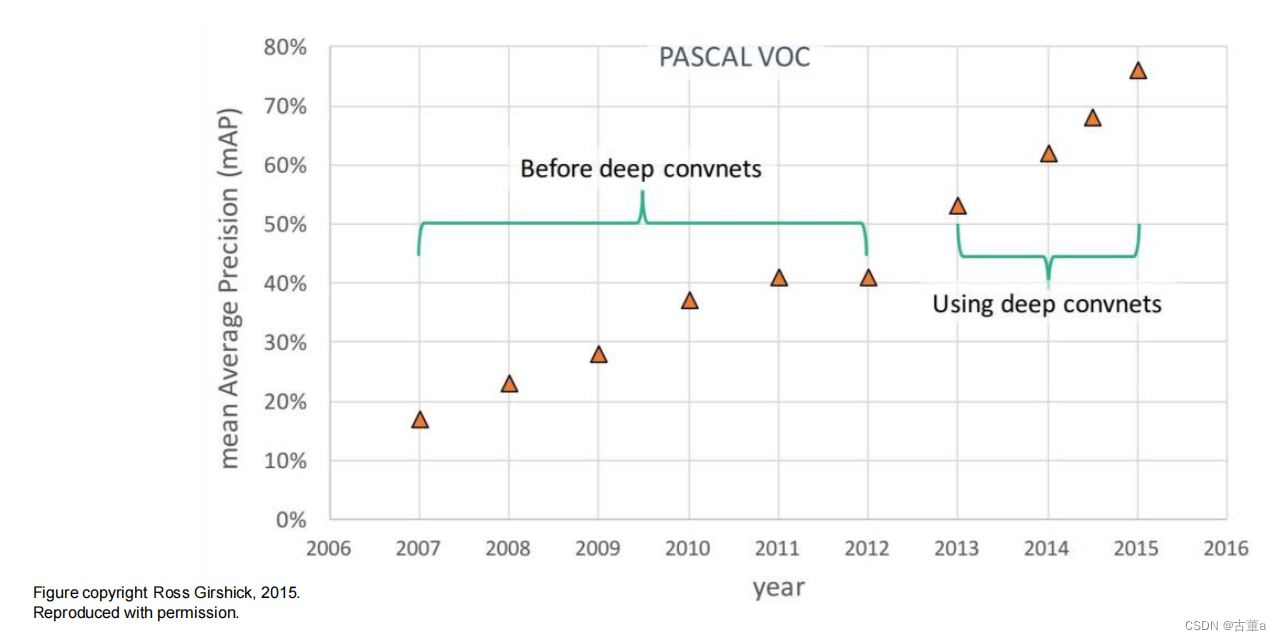
目标检测定义
目标检测的目标是确定图像中存在的目标的类别,并在图像中标记出它们的位置,通常使用边界框来表示目标的位置和大小。
单目标检测:分类+定位

深度学习对目标检测的作用
深度学习通过使用深层神经网络模型,可以从原始像素级别上学习和提取图像特征,从而实现目标检测。
单目标检测
将定位任务建模为回归问题!
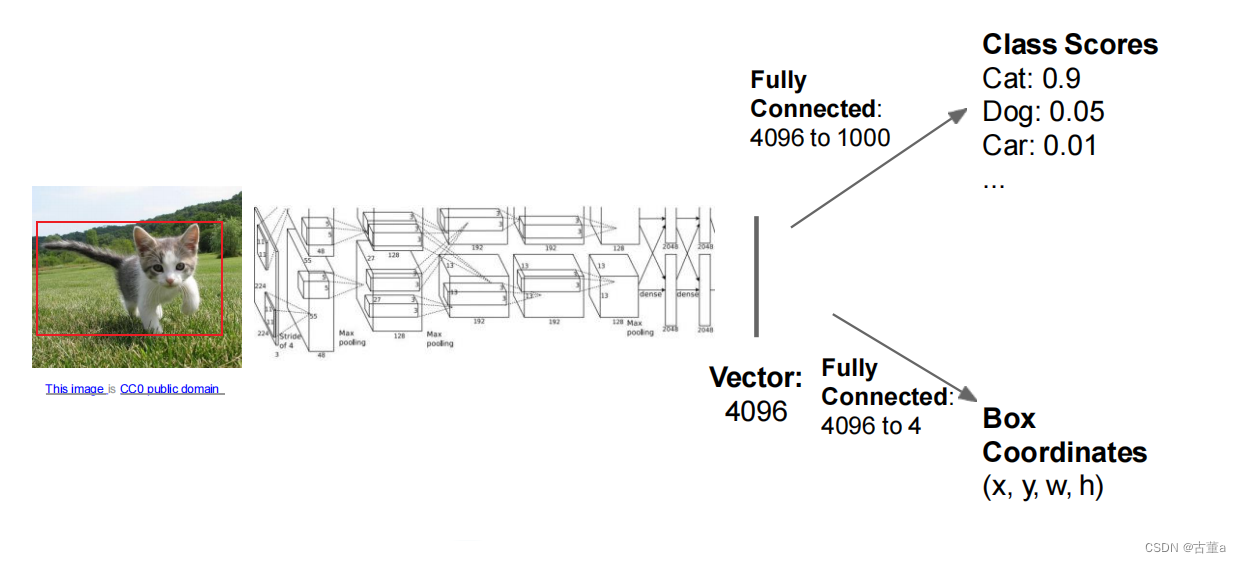
多任务框架
一个任务是:分类。
另一个任务是:定位。

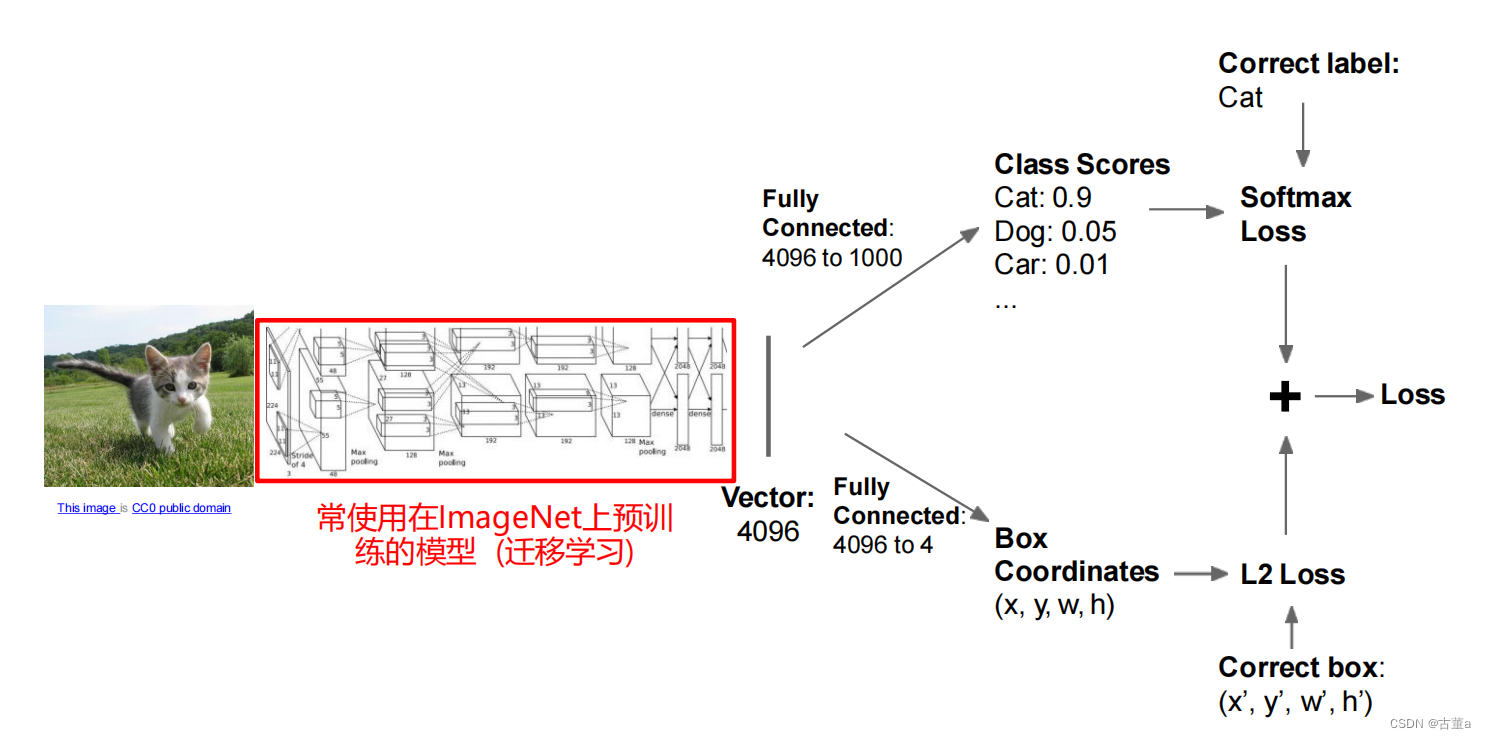
多任务损失
网络训练的目标是降低总损失,所以 softmax loss 和 L2 loss 将同时减小,也可以为 softmax loss 和 L2 loss 分别设置一个权重,通过改变权重,调整 softmax loss 和 L2 loss 在总损失中所占的比重。
预训练模型
目标检测中,一般不从头开始训练网络,而是使用ImageNet上预训练的模型。
一般分三个阶段:
1、分类训练阶段
在这个阶段,通常使用预训练的分类模型(如在ImageNet上预训练的模型)来进行训练。该模型已经在大规模图像分类任务上学习到了丰富的图像特征。然后,将最后的全连接层替换成适应目标检测任务的新的全连接层,并使用目标检测数据集进行训练。这个阶段的目标是学习分类任务所需的特征表示。
2、定位训练阶段
在这个阶段,固定预训练模型的大部分层,并仅仅调整输出层和一些顶层特征层。然后,使用目标检测数据集进行训练,让模型学习如何准确地定位目标。这个阶段的目标是学习目标的位置信息。
3、分类和定位一起训练阶段
在这个阶段,不仅训练分类任务,还同时训练目标的位置信息。在模型中同时使用分类和定位损失函数,并根据这两个任务的权重进行综合训练。这个阶段的目标是综合考虑分类和定位任务,使模型能够准确地检测并定位目标。
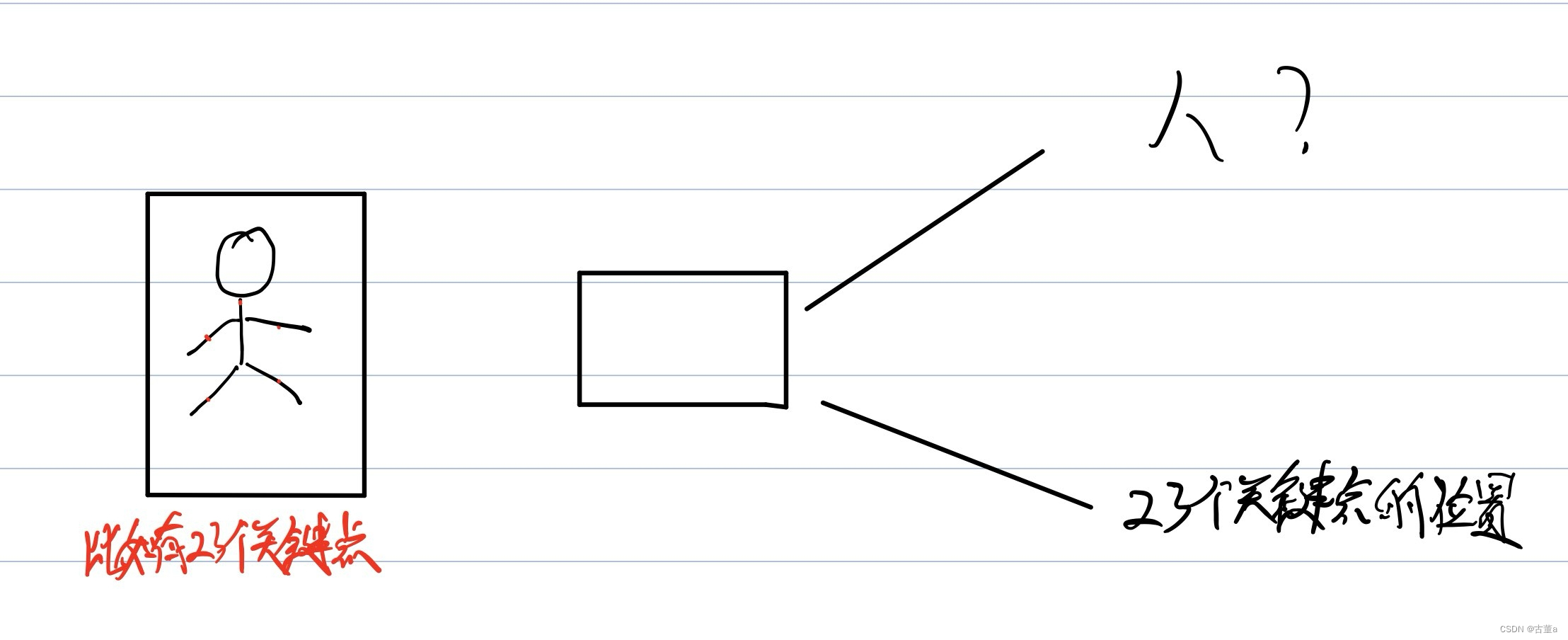
姿态估计
姿态估计(Pose Estimation)是计算机视觉中的一个重要任务,旨在从图像或视频中推断出人体、物体或其他目标的姿态信息,包括位置、方向和关节角度等。
单目标检测的思路,还应用于单人体姿态估计,与box coordinates不同的是,在人体上标注关键点,然后通过训练,与标答进行对比。
-
目标检测: 首先,使用目标检测算法来检测图像中的人体目标。目标检测算法可以是传统的方法(如基于特征的方法)或深度学习方法(如基于卷积神经网络的方法)。检测到的人体目标将作为后续姿态估计的输入。
-
关键点定位: 对于每个检测到的人体目标,需要进一步定位其关键点,例如人体姿态估计中的关节点。可以使用关键点检测算法(如姿态估计算法或关键点检测算法)来定位人体关键点。这些算法可以是传统的机器学习方法,也可以是基于深度学习的方法。
-
姿态估计: 一旦获得了人体关键点的位置,可以使用姿态估计算法来推断人体的姿态信息,如人体的位置、旋转和关节角度等。姿态估计算法可以基于几何模型、优化方法或深度学习方法。根据应用需求,可以选择合适的姿态表示形式,如关节角度、骨架模型或三维姿态等。
-
后处理与应用: 最后,可以对估计的姿态结果进行后处理,如滤波或平滑操作,以提高估计的准确性和稳定性。得到最终的姿态估计结果后,可以将其应用于各种应用领域,如动作识别、运动分析、虚拟现实、增强现实等。
多目标检测
问题
困境:每张图像期望输出的维度都不一样。
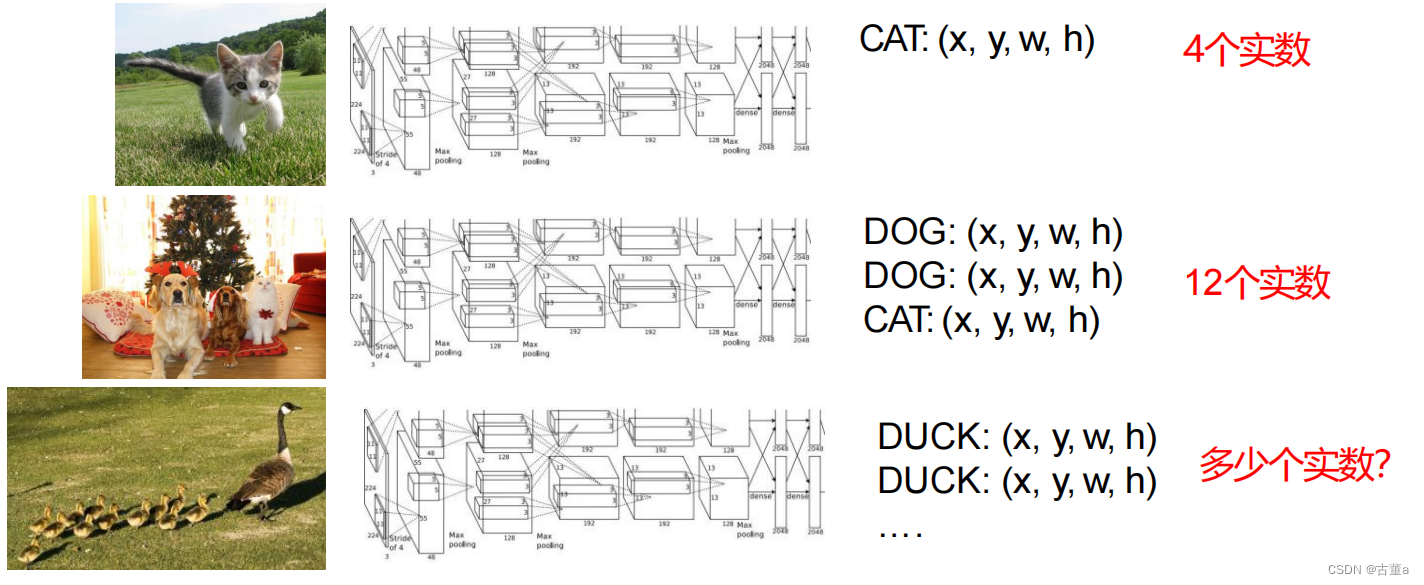
神经网络的标答是预先建立好的,因为多目标检测中目标数量并不确定,输出的维度不确定,就无法建立Correct box标答,如果使用单目标检测的训练方法,无法建立多目标检测的表达,训练将不能进行。
滑动窗口(Sliding Window)
在图像上以不同的尺度和位置滑动固定大小的窗口,然后在每个窗口上应用分类器或特征提取方法来判断窗口内是否存在目标。滑动窗口方法可以用于检测不同尺寸的目标,并且可以通过滑动步长控制检测的精度和速度。
将图像中所有可能的区域都给到分类器进行分类,只留下能正确分类的窗口。
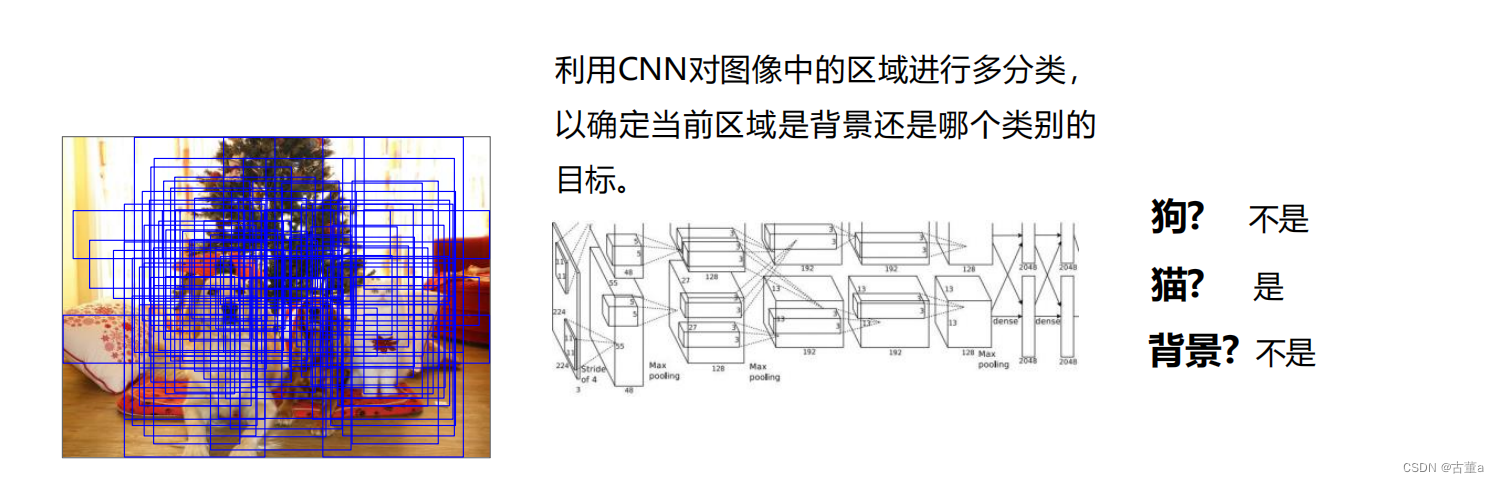
困境:CNN需要对图像中所有可能的区域(不同位置、尺寸、长宽比)进行分类,计算量巨大!
滑动窗口缺点
穷举图像中成千上万的区域进行分类,对于神经网络,计算量很大。
针对这个问题,提出了一种新的思想,先从图像中产生一些候选区域再进行分类,而不是穷举图像中所有区域。例如:selective search
AdaBoost(Adaptive Boosting)
AdaBoost是一个非常快的分类器,可以对图像上的区域进行穷举后分类。
参考
AdaBoost算法超详细讲解
AdaBoost 是一种集成学习算法,用于提高分类器的性能。它通过迭代训练一系列弱分类器(如决策树、支持向量机等),每次迭代都根据前一轮分类结果对样本进行调整,使得难以分类的样本获得更高的权重,从而加强对这些样本的分类能力。最终,通过组合多个弱分类器,AdaBoost 可以产生一个强大的分类器。
区域建议 selective search 思想
针对穷举图像所有区域神经网络分类计算量大这个问题,提出了一种新的思想,先从图像中产生一些候选区域再进行分类,而不是穷举图像中所有区域。例如:selective search。

选择性搜索(Selective Search):选择性搜索是一种经典的区域建议算法。它基于图像的颜色、纹理、边缘等信息,在不同尺度和层次上进行区域合并和分割,生成一系列候选区域。
selective search思想是在R-CNN的论文中提出的。
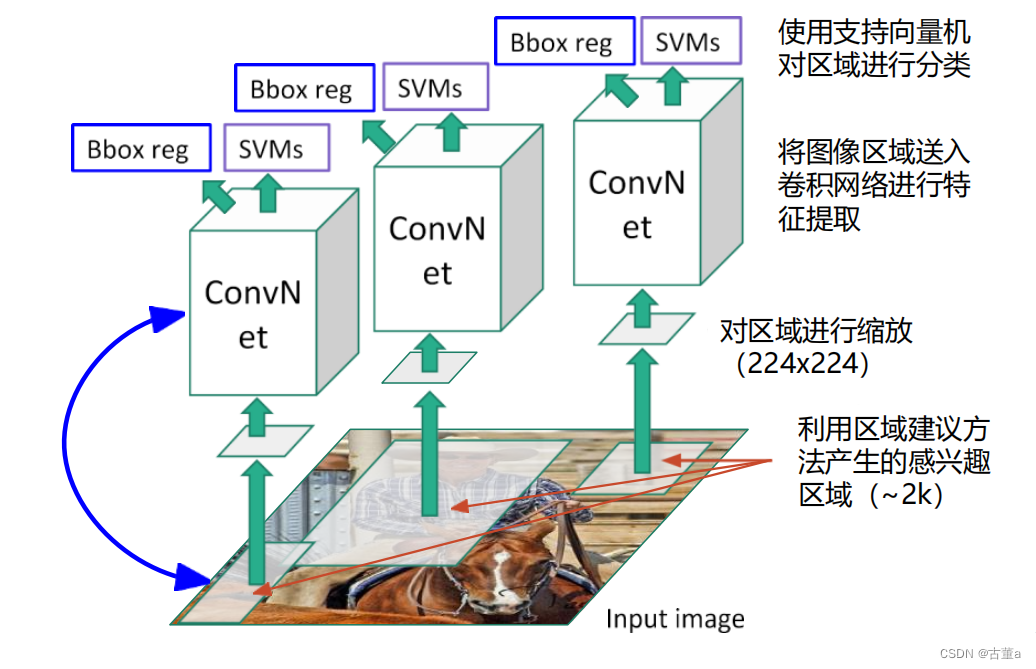
慢速R-CNN
基于区域的目标检测算法。
慢速R-CNN思路
1 利用区域建议产生感兴趣的区域。(存入硬盘)
2 对区域进行缩放。
3 将图像区域送入卷积网络进行特征提取。(存入硬盘)
4 使用支持向量机对区域进行分类,同时进行边界框回归(修正学习)。
边界框回归(Bbox reg)
区域建议生成的区域,可能有损失,效果不好,进行边界框回归,就是为了修正区域建议生成的区域与真实区域的偏差。
边框回归(Bounding Box Regression)详解

对于上图,绿色的框表示Ground Truth, 红色的框为Selective Search提取的Region Proposal。那么即便红色的框被分类器识别为飞机,但是由于红色的框定位不准(IoU<0.5), 那么这张图相当于没有正确的检测出飞机。 如果我们能对红色的框进行微调, 使得经过微调后的窗口跟Ground Truth 更接近, 这样岂不是定位会更准确。 确实,Bounding-box regression 就是用来微调这个窗口的。
慢速R-CNN缺点
问题:计算效率低下,每张图像大约有2k个区域需要卷积网络进行特征提取,重叠区域反复计算。
Fast R-CNN
在Fast R-CNN中,首先通过卷积神经网络(CNN)提取整个图像的特征图。然后,针对每个感兴趣区域(Region of Interest,RoI),通过RoI池化层将其映射为固定大小的特征图。这样可以避免在每个RoI上进行独立的卷积操作,从而大大减少了计算量。
接下来,将RoI映射后的特征图输入到全连接层中,进行目标分类和边界框回归。分类部分使用softmax函数对RoI进行多类别分类,而边界框回归则用于预测目标的位置和大小。
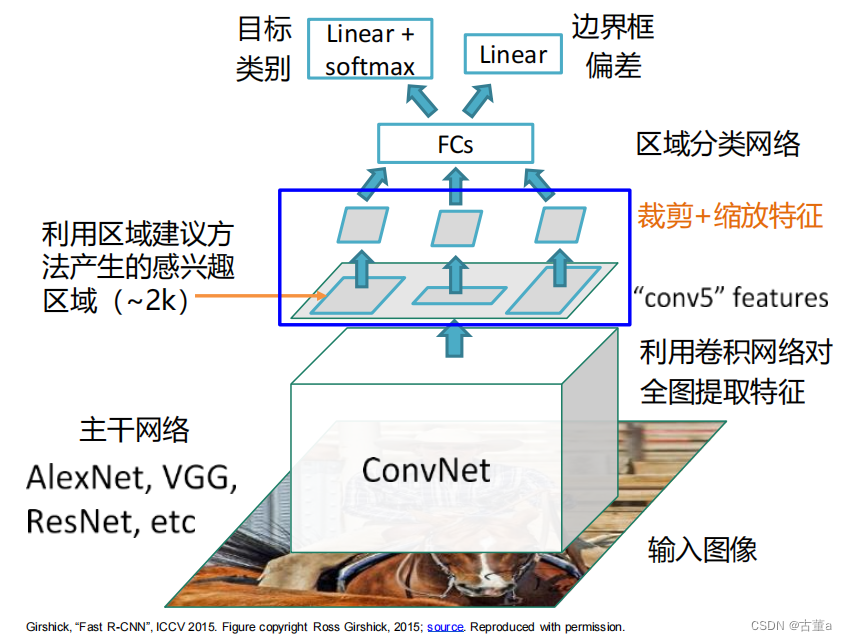
Fast R-CNN的训练是端到端的,可以通过反向传播同时优化特征提取网络和分类/回归网络。这种端到端的训练方式比R-CNN中的多阶段训练更加高效。
改进一:先提取特征后区域建议
如果先进行区域建议后进行特征提取,计算量比较大。因此先对整个图片进行卷积提取特征后,在特征图上进行区域扣取。
改进二:全连接神经网络
改进三:裁剪+缩放特征(RoI Pool)
为什么需要RoI Pool?
先来看一个问题:对于传统的CNN(如AlexNet和VGG),当网络训练好后输入的图像尺寸必须是固定值,同时网络输出也是固定大小的vector or matrix。如果输入图像大小不定,这个问题就变得比较麻烦。有2种解决办法:
- 从图像中crop一部分传入网络。
- 将图像warp成需要的大小后传入网络。

两种办法的示意图如图,可以看到无论采取那种办法都不好,要么crop后破坏了图像的完整结构,要么warp破坏了图像原始形状信息。
回忆RPN网络生成的proposals的方法:对positive anchors进行bounding box regression,那么这样获得的proposals也是大小形状各不相同,即也存在上述问题。所以Faster R-CNN中提出了RoI Pooling解决这个问题。不过RoI Pooling确实是从Spatial Pyramid Pooling发展而来。
通过RoI Pooling,即使大小不同的proposal输出结果都是固定大小,实现了固定长度输出。
参考:一文读懂Faster RCNN
区域裁剪
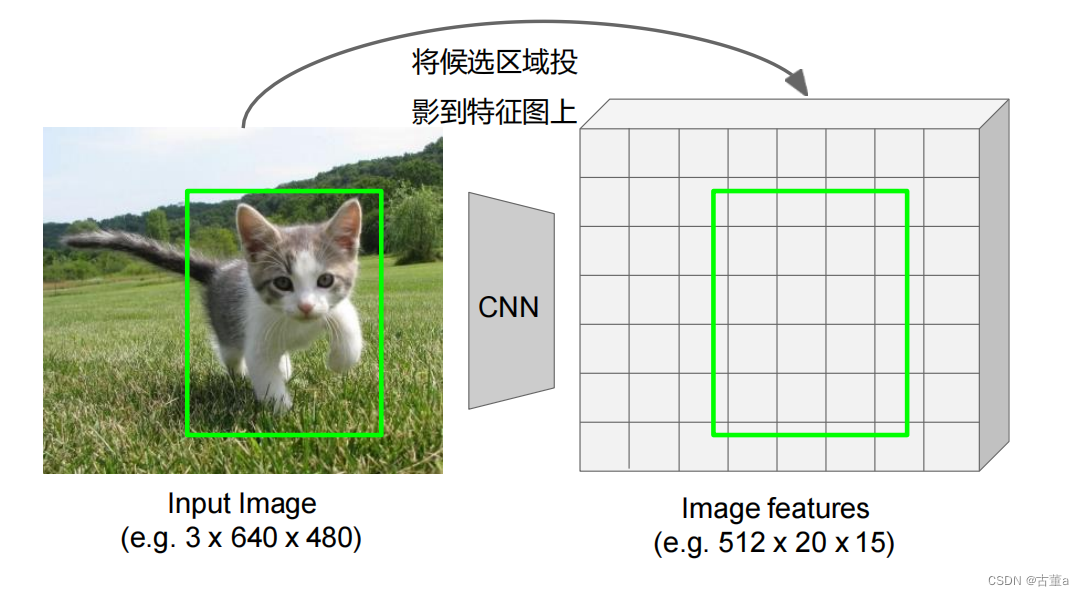
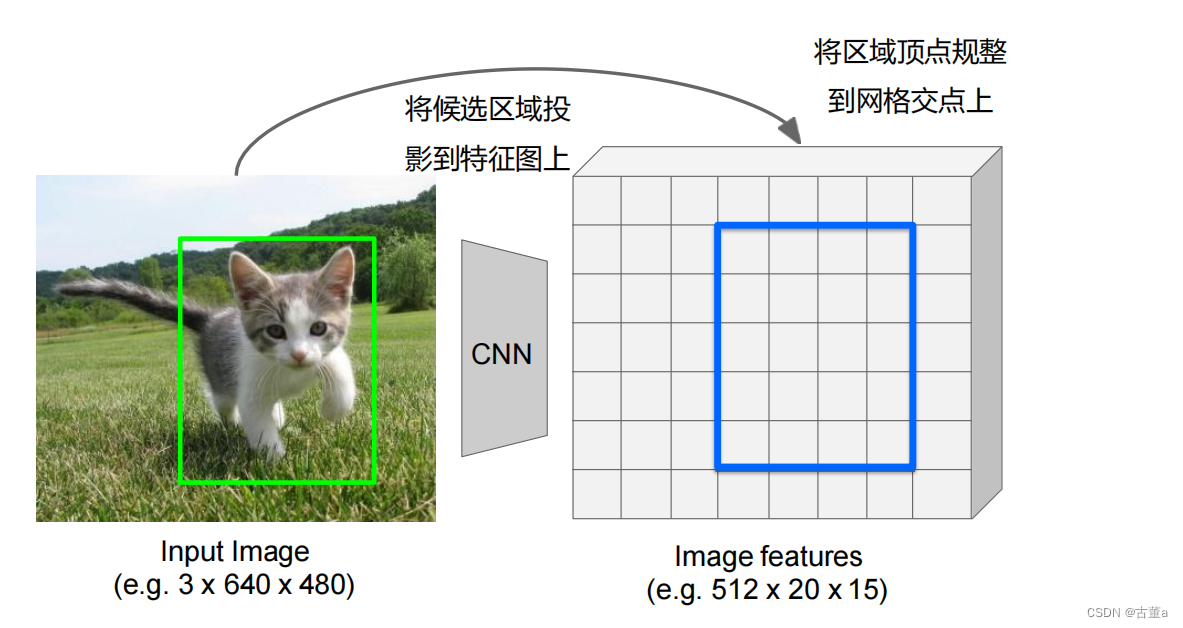
Rol Pool
区域顶点规整到网格交点上(有偏移)
然后进行处理
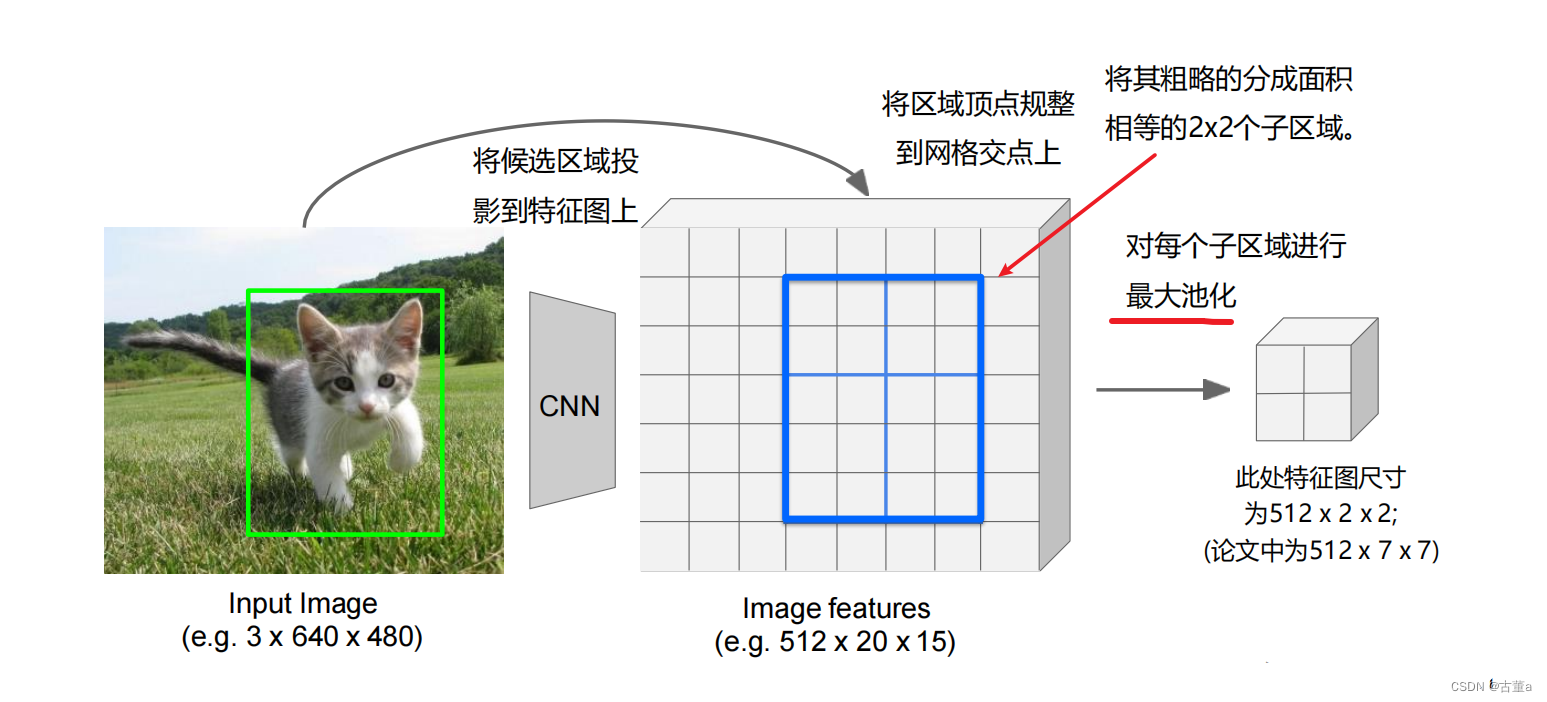
Rol Pool处理前不同的区域特征的空间尺寸可能不一致,但是处理后的所有区域特征尺寸都是一样的。
问题: 处理后的区域特征会有轻微的对不齐!
Rol Align
区域顶点不规整到网格交点上(无偏移)
在每个区域中选择几个关键点,关键点个数是可自定义的,是超参数。
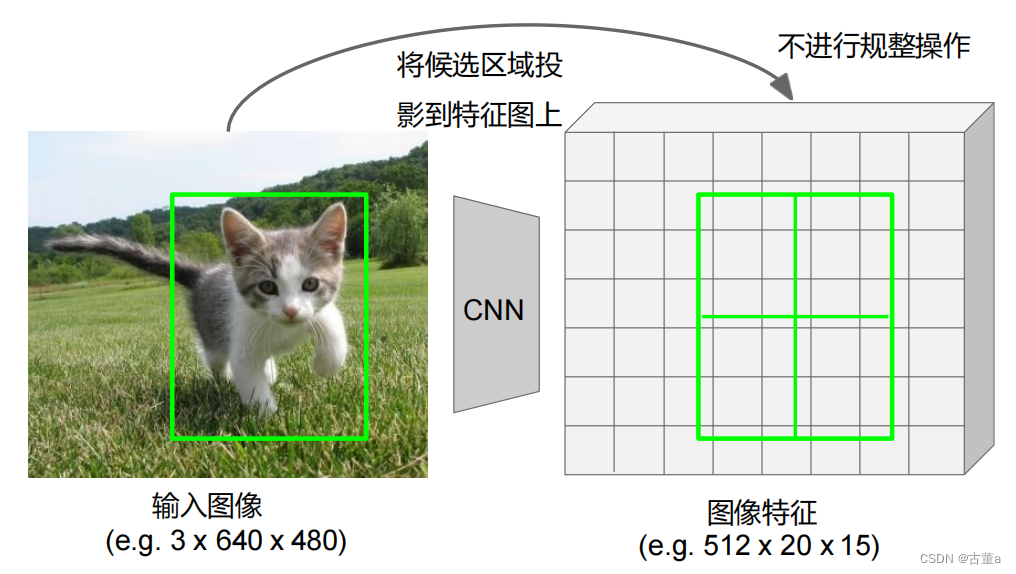
RoI Align 解决了传统 RoI Pooling 中的精度损失和空间错位问题。它通过使用双线性插值的方式,精确地计算感兴趣区域内每个位置的特征值。具体而言,RoI Align 将感兴趣区域划分为更细的小格,然后在每个小格内使用双线性插值计算对应位置的特征值。最后,这些特征值通过平均池化得到感兴趣区域的特征表示。
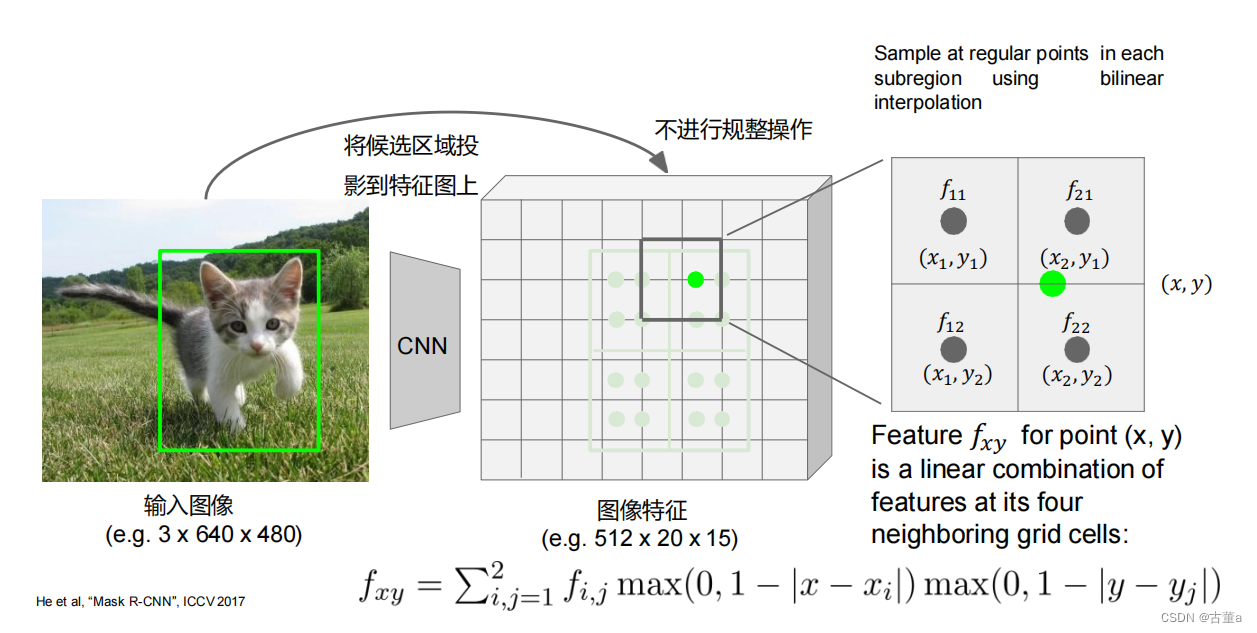
双线性插值: 在每个小格内使用双线性插值来计算对应位置的特征值。双线性插值利用小格内的四个相邻像素的特征值,通过加权平均来估计目标位置的特征值。
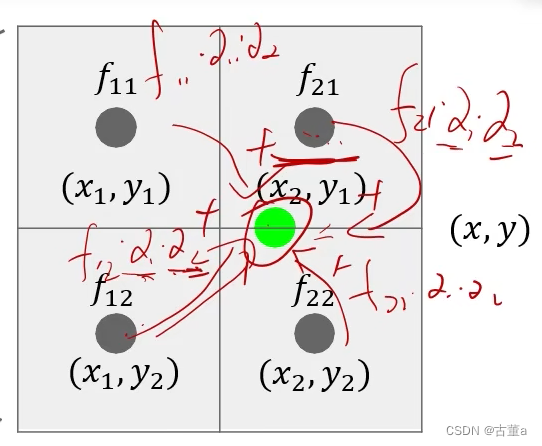
双线性插值通过使用周围四个最近的数据点来估计目标位置的值。假设我们要在一个二维网格上进行插值,其中四个最近的数据点的坐标为 (x1, y1)、(x1, y2)、(x2, y1) 和 (x2, y2),目标位置的坐标为 (x, y)。双线性插值的计算步骤如下:
- 计算水平方向上的插值:
a. 在 x 轴上,对数据点 (x1, y1) 和 (x2, y1) 进行线性插值,得到两个插值结果:
f 1 = f ( x 1 ) + ( x − x 1 ) ∗ ( f ( x 2 ) − f ( x 1 ) ) / ( x 2 − x 1 ) f_1 = f(x1) + (x - x1) * (f(x2) - f(x1)) / (x2 - x1) f1=f(x1)+(x−x1)∗(f(x2)−f(x1))/(x2−x1)
f 2 = f ( x 1 ) + ( x − x 1 ) ∗ ( f ( x 2 ) − f ( x 1 ) ) / ( x 2 − x 1 ) f_2 = f(x1) + (x - x1) * (f(x2) - f(x1)) / (x2 - x1) f2=f(x1)+(x−x1)∗(f(x2)−f(x1))/(x2−x1)。
b. 在 x 轴上,对数据点 (x1, y2) 和 (x2, y2) 进行线性插值,得到两个插值结果:
f 3 = f ( x 1 ) + ( x − x 1 ) ∗ ( f ( x 2 ) − f ( x 1 ) ) / ( x 2 − x 1 ) f_3 = f(x1) + (x - x1) * (f(x2) - f(x1)) / (x2 - x1) f3=f(x1)+(x−x1)∗(f(x2)−f(x1))/(x2−x1)
f 4 = f ( x 1 ) + ( x − x 1 ) ∗ ( f ( x 2 ) − f ( x 1 ) ) / ( x 2 − x 1 ) f_4 = f(x1) + (x - x1) * (f(x2) - f(x1)) / (x2 - x1) f4=f(x1)+(x−x1)∗(f(x2)−f(x1))/(x2−x1)。
- 计算垂直方向上的插值:
a. 在 y 轴上,对插值结果 f1 和 f2 进行线性插值,得到结果: f 12 = f 1 + ( y − y 1 ) ∗ ( f 2 − f 1 ) / ( y 2 − y 1 ) f_{12} = f_1 + (y - y_1) * (f_2 - f_1) / (y_2 - y_1) f12=f1+(y−y1)∗(f2−f1)/(y2−y1)。
b. 在 y 轴上,对插值结果 f3 和 f4 进行线性插值,得到结果: f 34 = f 3 + ( y − y 1 ) ∗ ( f 4 − f 3 ) / ( y 2 − y 1 ) f_{34} = f_3 + (y - y_1) * (f_4 - f_3) / (y_2 - y_1) f34=f3+(y−y1)∗(f4−f3)/(y2−y1)。
最终的插值结果为在垂直方向上插值得到的 f 12 f_{12} f12和 f 34 f_{34} f34的线性插值结果: f = f 12 + ( y − y 1 ) ∗ ( f 34 − f 12 ) / ( y 2 − y 1 ) f = f_{12} + (y - y_1) * (f_{34} - f_{12}) / (y_2 - y_1) f=f12+(y−y1)∗(f34−f12)/(y2−y1)。
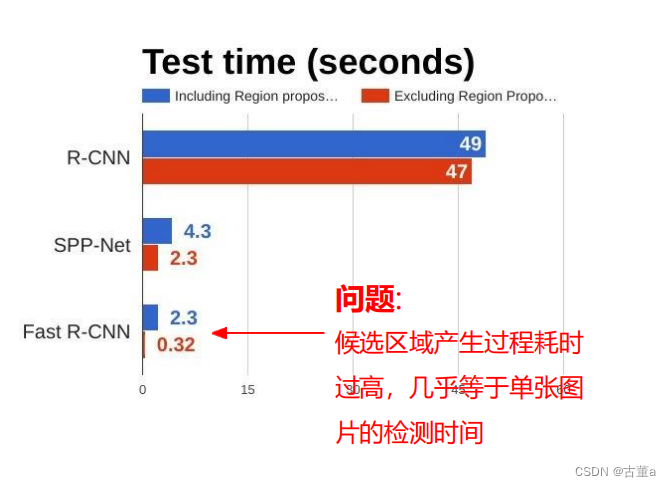
Fast R-CNN的问题
selective search 区域建议 耗时过高,几乎等于单张图片的检测时间。
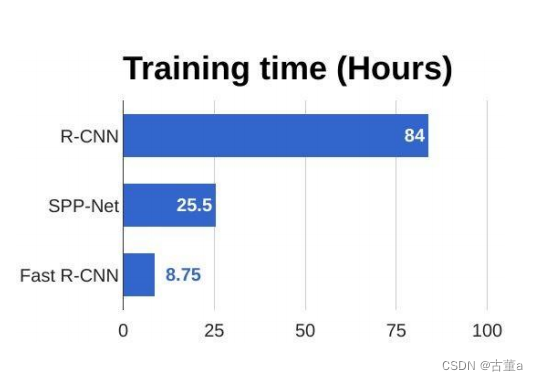
Fast R-CNN vs 慢速R-CNN
Fast R-CNN 相对于慢速 R-CNN 有几个改进点:
- 特征共享:Fast R-CNN 在整个图像上只进行一次卷积运算,而慢速 R-CNN 需要为每个候选区域分别进行卷积运算。这意味着 Fast R-CNN 可以共享卷积层的计算,从而更高效地提取特征。
- 单次前向传播:Fast R-CNN 可以通过单次前向传播同时计算所有候选区域的特征和分类结果,而慢速 R-CNN 需要为每个候选区域独立地进行前向传播,效率较低。
- 损失函数:Fast R-CNN 引入了多任务损失函数,同时优化目标分类和边界框回归,而慢速 R-CNN 仅使用分类损失函数。
Faster R-CNN
参考:一文读懂Faster RCNN
在结构上,在中间特征层后加入区域建议网络RPN(Region Proposal Network) 产生候选区域,其他部分保持与Fast R-CNN一致,即扣取每个候选区域的特征,然后对其进行分类。
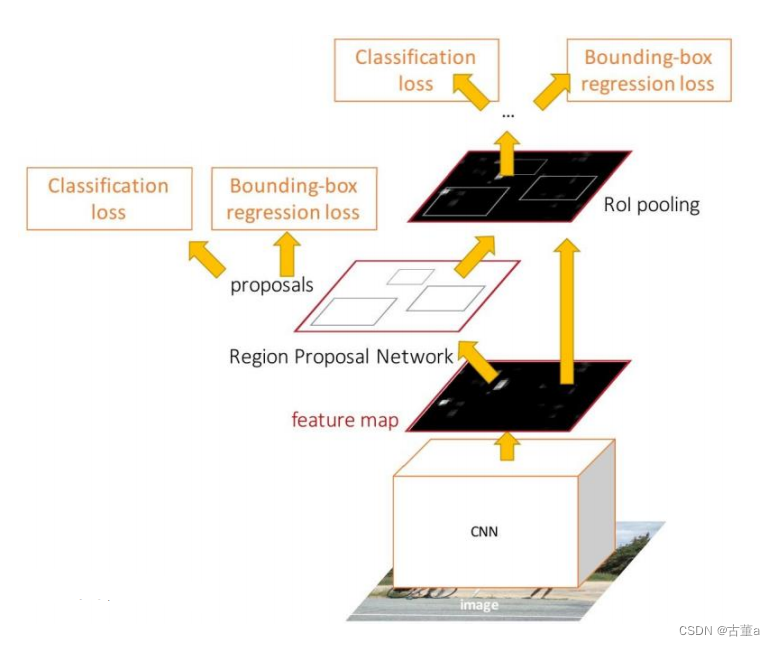
RPN(Region Proposal Network)
在目标检测任务中,RPN的作用是在输入图像上提出可能包含目标的候选框(或称为候选区域)。RPN是一个小型的神经网络,它以滑动窗口的方式在特征图上滑动,并为每个位置生成多个不同尺度和长宽比的候选框。
RPN的输入是经过卷积神经网络(如VGG、ResNet等)提取的特征图。特征图具有丰富的语义信息,可以帮助RPN更好地定位目标。RPN在特征图上应用一个小型的卷积滑动窗口,并对每个窗口位置生成多个anchors。
对于每个anchor,RPN会通过卷积和全连接层进行处理,并输出两个值:
1)表示该anchor是否包含目标的概率(通常是二分类问题);
2)对应目标边界框的修正信息,用于调整候选框的位置和形状。
通过这个过程,RPN能够生成大量的候选框,并为每个候选框提供目标概率和边界框的修正信息。然后,根据这些概率和修正信息,可以对候选框进行筛选和精细调整,选出最具有潜力的候选区域。
RPN所生成的候选区域随后被传递给后续的分类器和边界框回归器,进行目标分类和精确定位。
区域建议(Region Proposal Network)
实际使用中,对于每个特征图上的每个位置,我们通常会采用k个不同尺寸和分辨率的锚点区域(anchor boxes)
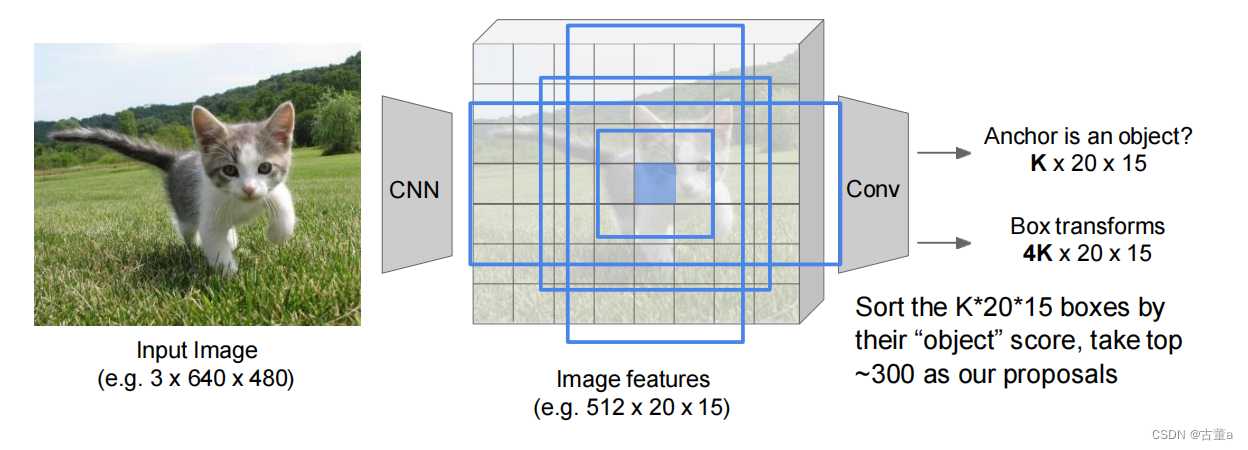
四种损失联合训练:
• RPN分类损失(目标/非目标)
• RPN边界框坐标回归损失
• 候选区域分类损失
• 最终边界框坐标回归损失
运行分为两个阶段
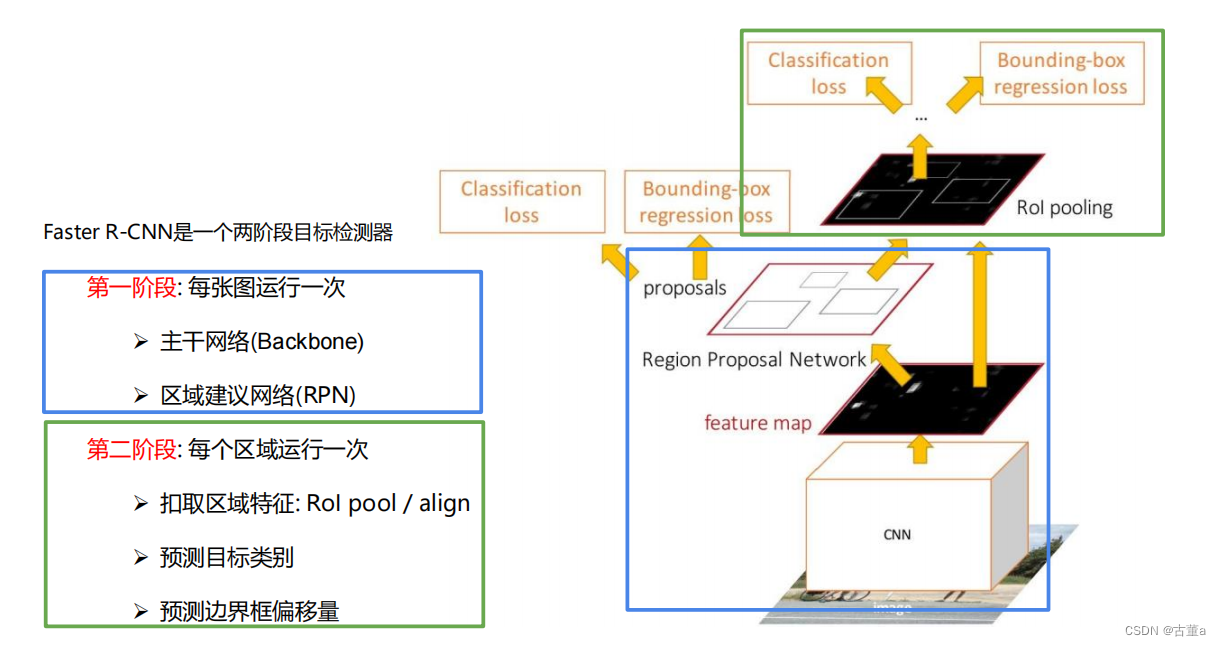
第一阶段:候选区域生成
在第一阶段,Faster R-CNN使用Region Proposal Network (RPN) 来生成候选区域。
RPN通过在输入图像上滑动窗口,并在不同位置和尺度上生成一系列的候选框(也称为锚框或anchors),这些候选框可能包含目标。对于每个候选框,RPN预测其包含目标的概率以及对应目标边界框的修正信息。
第二阶段:目标分类和边界框回归
在第二阶段,Faster R-CNN使用先前生成的候选区域作为输入,对这些候选区域进行目标分类和边界框回归。通常,这个阶段包括一个用于特征提取的卷积神经网络(如VGG、ResNet等),以及用于目标分类和边界框回归的全连接层。这些层将从候选区域中提取的特征映射与目标类别进行关联,并对边界框进行微调,以更准确地定位目标。
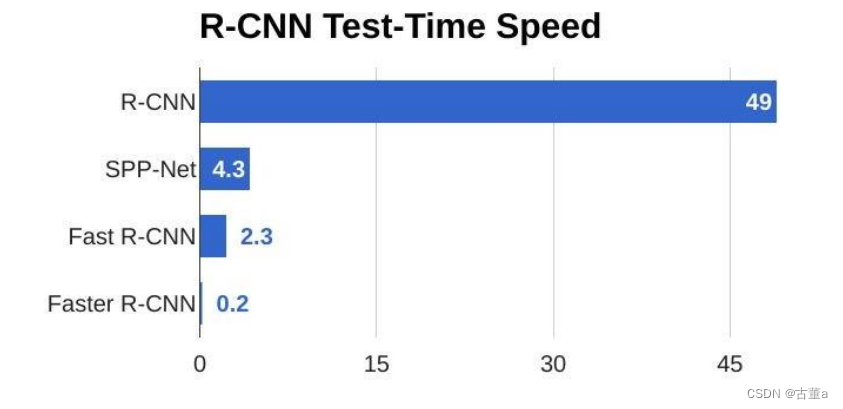
Faster R-CNN速度
目标检测: 影响精度的因素 …

相关文章:
计算机视觉与深度学习-图像分割-视觉识别任务02-目标检测-【北邮鲁鹏】
目录标题 参考目标检测定义深度学习对目标检测的作用单目标检测多任务框架多任务损失预训练模型姿态估计 多目标检测问题滑动窗口(Sliding Window)滑动窗口缺点 AdaBoost(Adaptive Boosting)参考 区域建议 selective search 思想慢…...

Flink——Flink检查点(checkpoint)、保存点(savepoint)的区别与联系
Flink checkpoint Checkpoint是Flink实现容错机制最核心的功能,能够根据配置周期性地基于Stream中各个Operator的状态来生成Snapshot,从而将这些状态数据定期持久化存储下来,从而将这些状态数据定期持久化存储下来,当Flink程序一…...
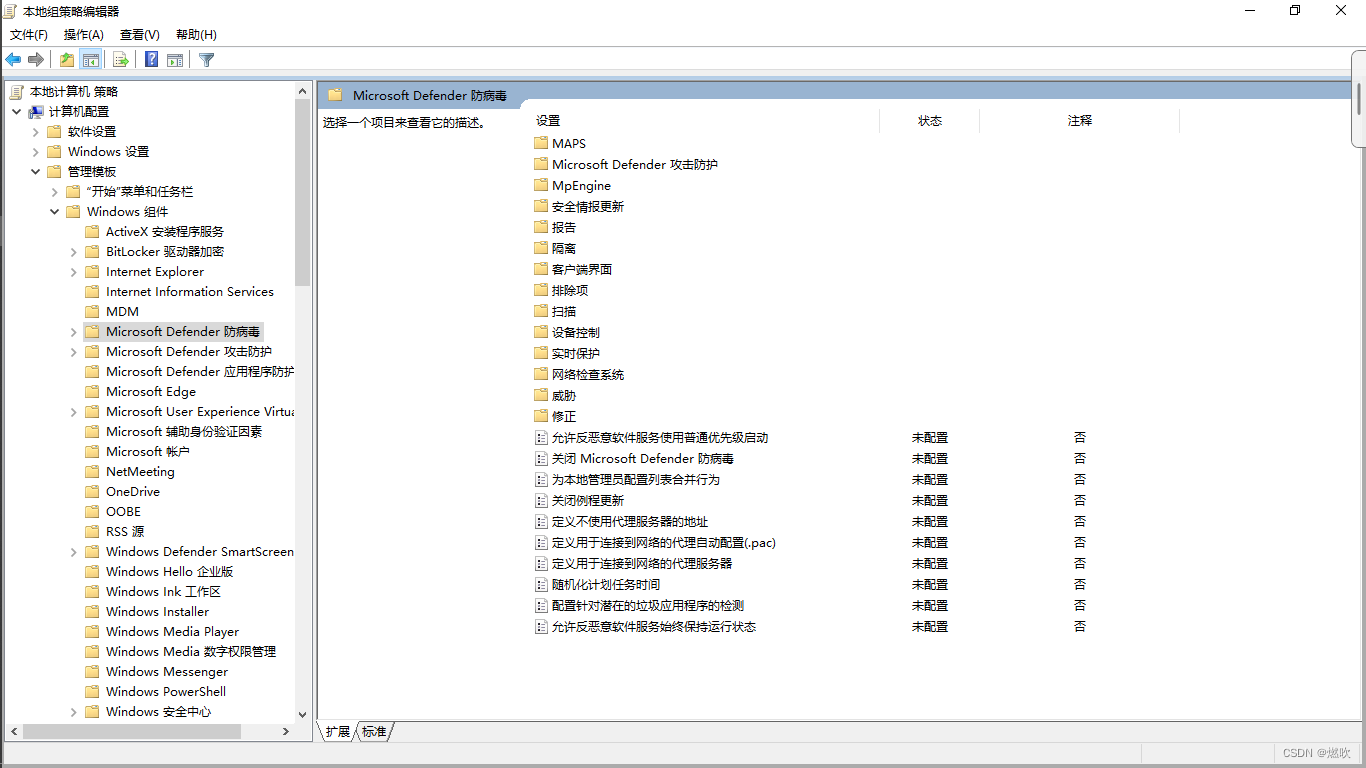
[篇五章五]-如何禁用 Windows Defender-我的创作纪念日
################################################## 目录 禁用掉烦人的 Windows Defender 在本地组策略编辑器中禁用 Windows Defende 关闭 Microsoft Defender 防病毒 禁止 Defender 开机自动运行 重新激活 Windows Defender #######################################…...
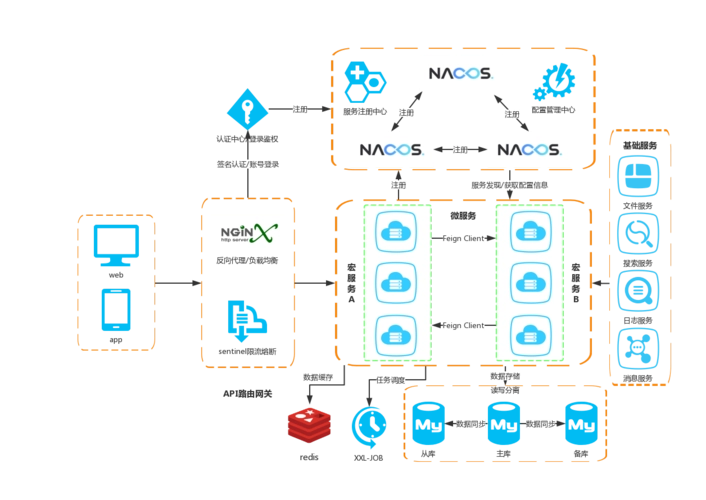
什么情况下使用微服务?
单体架构图参考网络: 1. 什么是单体应用 单体应用就是将应用程序的所有功能都打包成一个独立的单元,最终以一个WAR包或JAR包存在,没有外部的任何依赖,里面包含DAO、Service、UI等所有的逻辑。 优点: 1&…...
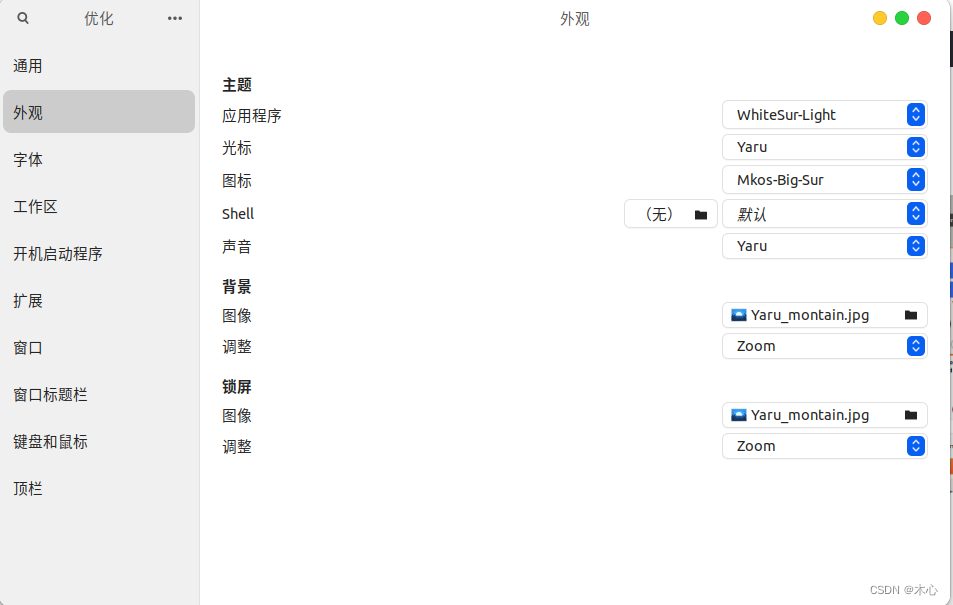
【Linux】Ubuntu美化主题【教程】
【Linux】Ubuntu美化主题【教程】 文章目录 【Linux】Ubuntu美化主题【教程】1. 安装优化工具Tweak2.下载自己喜欢的主题3. 下载自己喜欢的iconReference 1. 安装优化工具Tweak 首先安装优化工具Tweak sudo apt-get install gnome-tweak-tool安装完毕后在菜单中打开Tweak 然后…...

spring-boot2.x,使用EnableWebMvc注解导致的自定义HttpMessageConverters不可用
在json对象转换方面,springboot默认使用的是MappingJackson2HttpMessageConverter。常规需求,在工程中使用阿里的FastJson作为json对象的转换器。 FastJson SerializerFeatures WriteNullListAsEmpty :List字段如果为null,输出为[],而非nu…...

2023-09-20 Android CheckBox 让文字显示在选择框的左边
一、CheckBox 让文字在选择框的左边 ,在布局文件里面添加下面一行就可以。 android:layoutDirection"rtl" 即可实现 android:paddingStart"10dp" 设置框文间的间距 二、使用的是left to right <attr name"layoutDirection">&…...

目标检测YOLO实战应用案例100讲-基于改进YOLOv5的口罩人脸检测
目录 前言 国内外研究现状 目标检测研究发展 国内外口罩人脸检测研究现状...
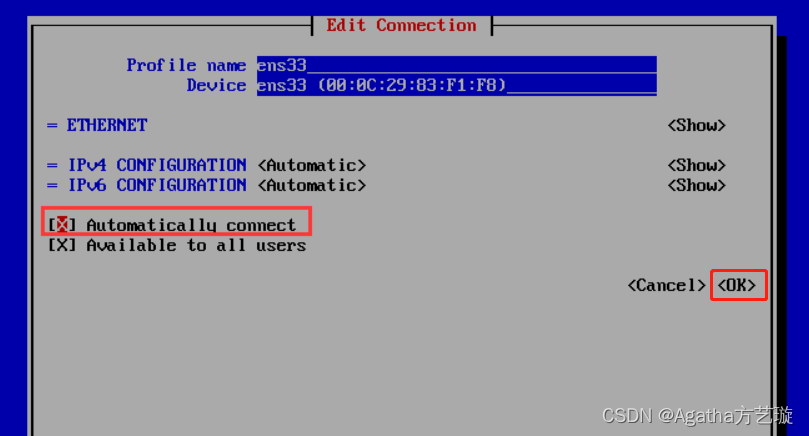
CentOS7 yum安装报错:“Could not resolve host: mirrorlist.centos.org; Unknown error“
虚拟机通过yum安装东西的时候弹出这个错误: 1、查看安装在本机的网卡 网卡ens33处于disconnected的状态 nmcli d2、输入命令: nmtui3、选择网卡,然后点击edit 4、移动到Automatically connect按空格键选择,然后移动到OK键按空格…...

关于token续签
通常我们会对token设置一个有效期,于是,就有了token续签的问题。由于token并没有续时机制,如果不能及时的替换掉过期的token,可能会拦截用户正常的请求,用户只能重新登录,如果提交的信息量很大,…...
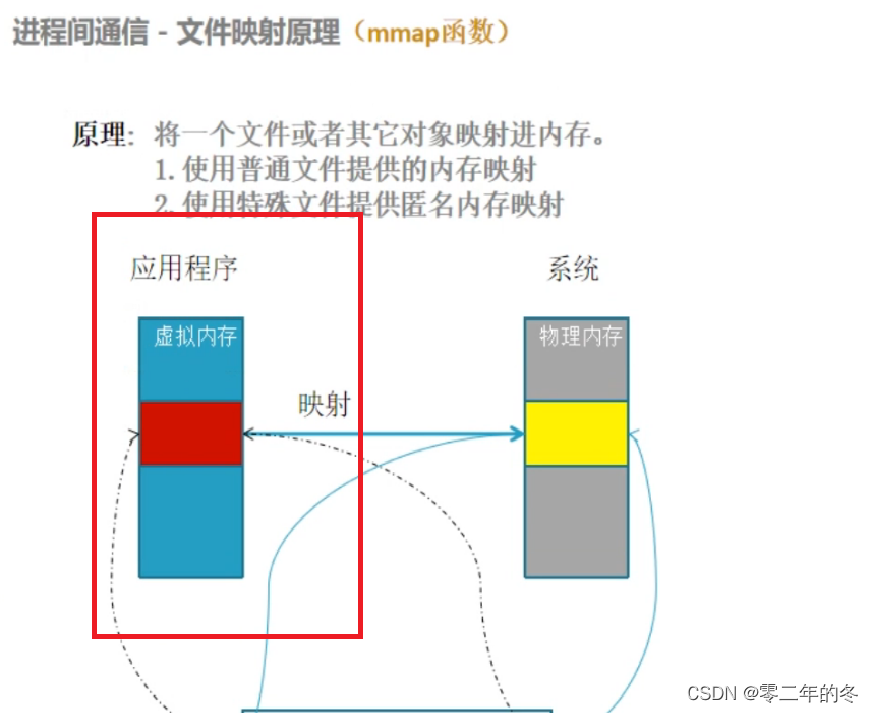
淘宝分布式文件存储系统( 二 ) -TFS
淘宝分布式文件存储系统( 二 ) ->>TFS 目录 : 大文件存储结构哈希链表的结构文件映射原理及对应的API文件映射头文件的定义 大文件存储结构 : 采用块(block)文件的形式对数据进行存储 , 分成索引块,主块 , 扩展块 。所有的小文件都是存放到主块中的 ,扩展块…...

Java中synchronized:特性、使用、锁机制与策略简析
目录 synchronized的特性互斥性可见性可重入性 synchronized的使用方法synchronized的锁机制常见锁策略乐观锁与悲观锁重量级锁与轻量级锁公平锁与非公平锁可重入锁与不可重入锁自旋锁读写锁 synchronized的特性 互斥性 synchronized确保同一时间只有一个线程可以进入同步块或…...

记一次clickhouse手动更改分片数异常
背景:clickhouse中之前是1分片1副本,随着数据量增多,想将分片数增多,于是驻场人员手动添加了分片数的节点信息 <clickhouse><!-- 集群配置 --><clickhouse_remote_servers><feihuang_ck_cluster><sha…...

深度学习论文: ISTDU-Net:Infrared Small-Target Detection U-Net及其PyTorch实现
深度学习论文: ISTDU-Net:Infrared Small-Target Detection U-Net及其PyTorch实现 ISTDU-Net:Infrared Small-Target Detection U-Net PDF: https://doi.org/10.1109/LGRS.2022.3141584 PyTorch代码: https://github.com/shanglianlm0525/CvPytorch PyTo…...
图像识别-YOLO V8安装部署-window-CPU-Pycharm
前言 安装过程中发现,YOLO V8一直在更新,现在是2023-9-20的版本,已经和1月份刚发布的不一样了。 eg: 目录已经变了,旧版预测:在ultralytics/yolo/v8/下detect 新版:ultralytics/models/yolo/detect/predict.py 1.安…...

js禁用F1至F12、禁止缩放、取消选中并且取消右键操作、打印、拖拽、鼠标点击弹出自定义信息、禁用开发者工具js
禁用js //禁止缩放 //luwenjie hualun window.addEventListener(mousewheel, function (event) {if (event.ctrlKey true || event.metaKey) {event.preventDefault();} }, {passive: false});//firefox window.addEventListener(DOMMouseScroll, function (event) {if (even…...
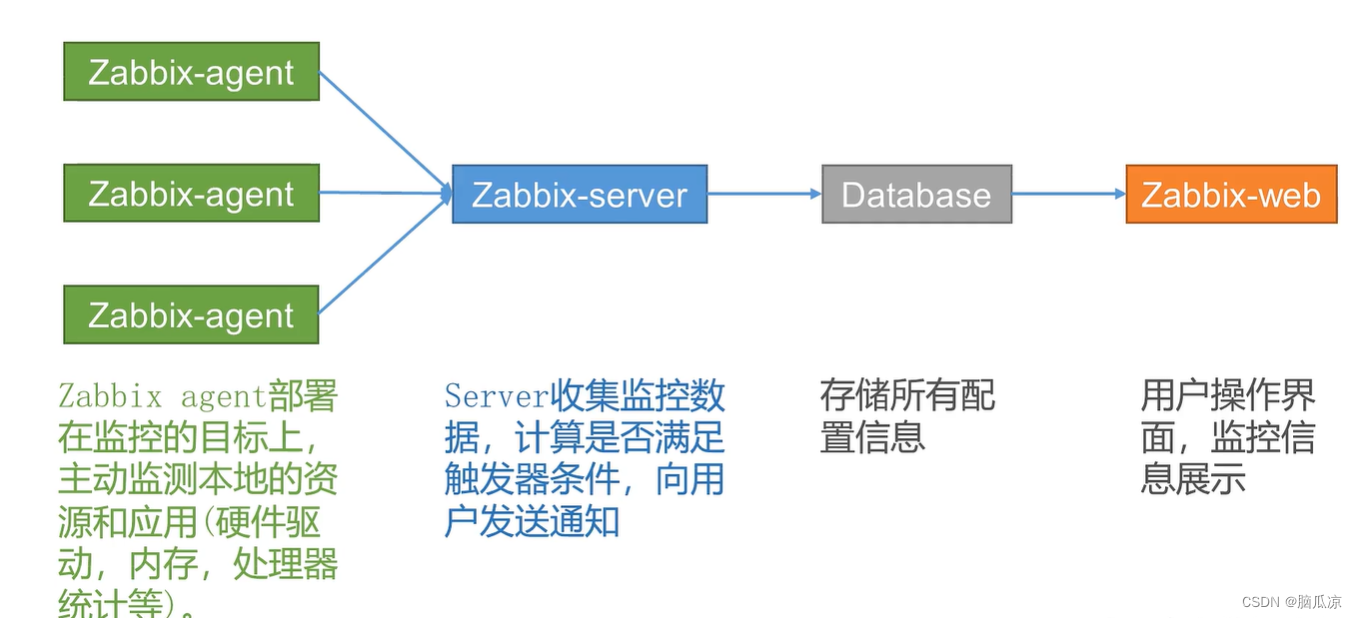
Zabbix5.0_介绍_组成架构_以及和prometheus的对比_大数据环境下的监控_网络_软件_设备监控_Zabbix工作笔记
z 这里Zabbix可以实现采集 存储 展示 报警 但是 zabbix自带的,展示 和报警 没那么好看,我们可以用 grafana进行展示,然后我们用一个叫睿象云的来做告警展示, 会更丰富一点. 可以看到 看一下zabbix的介绍. 对zabbix的介绍,这个zabbix比较适合对服务器进行监控 这个是zabbix的…...

百度SEO优化TDK介绍(分析下降原因并总结百度优化SEO策略)
TDK是SEO优化中很重要的部分,包括标题(Title)、描述(Description)和关键词(Keyword),为百度提供网页内容信息。其中标题是最重要的,应尽量突出关键词,同时描述…...
搭建自动化 Web 页面性能检测系统 —— 设计篇
页面性能对于用户体验、用户留存有着重要影响,当页面加载时间过长时,往往会伴随着一部分用户的流失,也会带来一些用户差评。性能的优劣往往是同类产品中胜出的影响因素,也是一个网站口碑的重要评判标准。 一、名称解释 前端监控…...
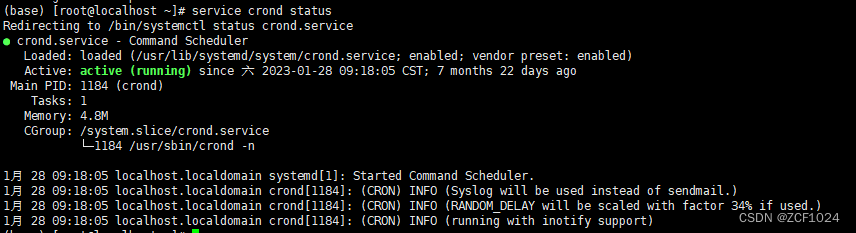
记一次 mysql 数据库定时备份
环境:Centos 7.9 数据库:mysql 8.0.30 需求:生产环境 mysql 数据(约670MB)备份。其中存在大字段、longblob字段 参考博客:Linux环境下使用crontab实现mysql定时备份 - 知乎 一、数据库备份 1. 备份脚本。创…...

跨平台媒体播放新标杆:开源播放器Screenbox技术解析与实践指南
跨平台媒体播放新标杆:开源播放器Screenbox技术解析与实践指南 【免费下载链接】Screenbox LibVLC-based media player for the Universal Windows Platform 项目地址: https://gitcode.com/gh_mirrors/sc/Screenbox 在数字媒体爆炸的今天,用户面…...

FastAPI+Diffusers架构解析:造相-Z-Image-Turbo Web服务多LoRA热切换实现原理
FastAPIDiffusers架构解析:造相-Z-Image-Turbo Web服务多LoRA热切换实现原理 1. 引言:当AI绘画遇上Web服务 想象一下,你正在为一个电商项目设计产品海报,需要生成一批具有统一“亚洲美学”风格的模特图片。传统方法要么是找设计…...

从爱因斯坦肖像到医学影像:手把手教你用SSIM Loss训练自己的图像生成模型
从爱因斯坦肖像到医学影像:基于SSIM Loss的图像生成实战指南 当一张随机噪声图像逐渐演化成爱因斯坦的经典肖像时,我们看到的不仅是机器学习的魔力,更是一种衡量图像相似度的强大工具——结构相似性指数(SSIM)在发挥作…...

杰理之改为spin_lock的方式,锁住多核调度【篇】
保护iis_in->wait_resume变量。 并增加cbuf写满->触发主动resume一次音频流。...

告别平庸配图!用Nunchaku FLUX.1 CustomV3轻松制作社交媒体爆款图片
告别平庸配图!用Nunchaku FLUX.1 CustomV3轻松制作社交媒体爆款图片 你是不是也遇到过这样的烦恼?写好了精彩的社交媒体文案,却找不到一张能与之匹配、足够吸引眼球的配图。网上的图片要么版权不明,要么千篇一律,要么…...

SpringBoot+Vue2+Element-UI搭建AI-Agent平台:从零部署到对话接口调用全流程
SpringBootVue2Element-UI构建智能对话平台实战指南 在数字化转型浪潮中,AI-Agent技术正逐步改变人机交互方式。本文将带您从零开始构建一个具备多轮对话、工具调用和记忆功能的智能平台,采用SpringBootVue2Element-UI技术栈,结合LangChain设…...

DeepSeek-OCR-2惊艳效果:91.09%准确率真实测试展示
DeepSeek-OCR-2惊艳效果:91.09%准确率真实测试展示 1. 突破性的OCR识别技术 DeepSeek-OCR-2代表了当前OCR技术的最前沿水平。这款由DeepSeek团队开发的第二代光学字符识别模型,在2026年1月发布后立即引起了广泛关注。它最引人注目的特点是在OmniDocBen…...

B6充电器模式详解:从平衡充到储存模式的实战指南
1. B6充电器基础入门:认识你的智能充电伙伴 第一次拿到B6充电器时,我盯着面板上密密麻麻的英文缩写发懵。这玩意儿比手机充电器复杂十倍,但用顺手后发现它简直是锂电池的"智能保姆"。B6充电器本质上是个多功能充放电设备࿰…...
)
Java开发者必看:斑马打印机DLL文件配置全攻略(含32/64位JDK适配指南)
Java开发者必看:斑马打印机DLL文件配置全攻略(含32/64位JDK适配指南) 1. 环境准备与基础概念 斑马打印机在物流、零售等行业的标签打印场景中占据重要地位。Java开发者通过官方提供的zebraAPI进行打印机控制时,DLL文件的正确配置往…...

低查重AI教材生成指南,利用AI工具,轻松搞定教材编写!
在教材制作的过程中,保持原创性与合规性之间的平衡是一个关键的挑战。许多创作者在借鉴优秀教材内容时,常常担心其查重率会超出标准;而在进行自主创新时,又可能会面临逻辑不够严谨或内容不准确的问题。当引用他人的研究成果时&…...