Hive 的函数介绍
目录
编辑
一、内置运算符
1.1 关系运算符
1.2算术运算符
1.3逻辑运算符
1.4复杂类型函数
1.5对复杂类型函数操作
二、内置函数
2.1数学函数
2.2收集函数
2.3类型转换函数
2.4日期函数
2.5条件函数
2.6字符函数
三、内置的聚合函数
四、内置表生成函数
五、自定义函数
5.1 自定义函数分类
5.2 自定义函数开发
5.2.1 开发UDF函数
5.2.1.1 开发流程步骤
5.2.1.1.1 继承Hive提供的类
5.2.1.1.2 实现类中的抽象方法
5.2.1.1.3 将jar包上传到虚拟机中
5.2.1.1.4 将jar包上传到hdfs集群中
5.2.1.2 实现UDF函数
5.2.1.2.1 创建Maven工程,导入依赖
5.2.1.2.2 创建函数类实现GenericUDF类
5.2.1.2.3 函数的使用
5.2.1.2.3.1 临时函数
5.2.1.2.3.2 永久函数
5.2.2 开发UDTF函数
5.2.2.1 开发流程
5.2.2.2 实现UDTF函数
5.2.2.2.1 创建Mvaen工程,导入依
5.2.2.2.2 创建函数类实现GenericUDTF类
5.2.2.2.3 函数的使用
一、内置运算符
1.1 关系运算符
| 运算符 | 类型 | 说明 |
| A = B | 所有原始类型 | 如果A与B相等,返回TRUE,否则返回FALSE |
| A == B | 无 | 失败,因为无效的语法。 SQL使用”=”,不使用”==” |
| A <> B | 所有原始类型 | 如果A不等于B返回TRUE,否则返回FALSE。如果A或B值为”NULL”,结果返回”NULL”。 |
| A < B | 所有原始类型 | 如果A小于B返回TRUE,否则返回FALSE。如果A或B值为”NULL”,结果返回”NULL”。 |
| A <= B | 所有原始类型 | 如果A小于等于B返回TRUE,否则返回FALSE。如果A或B值为”NULL”,结果返回”NULL”。 |
| A > B | 所有原始类型 | 如果A大于B返回TRUE,否则返回FALSE。如果A或B值为”NULL”,结果返回”NULL”。 |
| A >= B | 所有原始类型 | 如果A大于等于B返回TRUE,否则返回FALSE。如果A或B值为”NULL”,结果返回”NULL” |
| A IS NULL | 所有类型 | 如果A值为”NULL”,返回TRUE,否则返回FALSE |
| A IS NOT NULL | 所有类型 | 如果A值不为”NULL”,返回TRUE,否则返回FALSE |
| A LIKE B | 字符串 | 如 果A或B值为”NULL”,结果返回”NULL”。字符串A与B通过sql进行匹配,如果相符返回TRUE,不符返回FALSE。B字符串中 的”_”代表任一字符,”%”则代表多个任意字符。例如: (‘foobar’ like ‘foo’)返回FALSE,( ‘foobar’ like ‘foo_ _ _’或者 ‘foobar’ like ‘foo%’)则返回TURE |
| A RLIKE B | 字符串 | 如 果A或B值为”NULL”,结果返回”NULL”。字符串A与B通过java进行匹配,如果相符返回TRUE,不符返回FALSE。例如:( ‘foobar’ rlike ‘foo’)返回FALSE,(’foobar |
| A REGEXP B | 字符串 | 与RLIKE相同。 |
1.2算术运算符
| 运算符 | 类型 | 说明 |
| A + B | 所有数字类型 | A和B相加。结果的与操作数值有共同类型。例如每一个整数是一个浮点数,浮点数包含整数。所以,一个浮点数和一个整数相加结果也是一个浮点数。 |
| A – B | 所有数字类型 | A和B相减。结果的与操作数值有共同类型。 |
| A * B | 所有数字类型 | A和B相乘,结果的与操作数值有共同类型。需要说明的是,如果乘法造成溢出,将选择更高的类型。 |
| A / B | 所有数字类型 | A和B相除,结果是一个double(双精度)类型的结果。 |
| A % B | 所有数字类型 | A除以B余数与操作数值有共同类型。 |
| A & B | 所有数字类型 | 运算符查看两个参数的二进制表示法的值,并执行按位”与”操作。两个表达式的一位均为1时,则结果的该位为 1。否则,结果的该位为 0。 |
| A\|B | 所有数字类型 | 运算符查看两个参数的二进制表示法的值,并执行按位”或”操作。只要任一表达式的一位为 1,则结果的该位为 1。否则,结果的该位为 0。 |
| A ^ B | 所有数字类型 | 运算符查看两个参数的二进制表示法的值,并执行按位”异或”操作。当且仅当只有一个表达式的某位上为 1 时,结果的该位才为 1。否则结果的该位为 0。 |
1.3逻辑运算符
| 运算符 | 类型 | 说明 |
| A AND B | 布尔值 | A和B同时正确时,返回TRUE,否则FALSE。如果A或B值为NULL,返回NULL。 |
| A && B | 布尔值 | 与”A AND B”相同 |
| A OR B | 布尔值 | A或B正确,或两者同时正确返返回TRUE,否则FALSE。如果A和B值同时为NULL,返回NULL。 |
| A\| B | 布尔值 | 与”A OR B”相同 |
| NOT A | 布尔值 | 如果A为NULL或错误的时候返回TURE,否则返回FALSE。 |
| ! A | 布尔值 | 与”NOT A”相同 |
1.4复杂类型函数
| 函数 | 类型 | 说明 |
| map | (key1, value1, key2, value2, …) | 通过指定的键/值对,创建一个map。 |
| struct | (val1, val2, val3, …) | 通过指定的字段值,创建一个结构。结构字段名称将COL1,COL2,… |
| array | (val1, val2, …) | 通过指定的元素,创建一个数组。 |
1.5对复杂类型函数操作
| 函数 | 类型 | 说明 |
| A[n] | A是一个数组,n为int型 | 返回数组A的第n个元素,第一个元素的索引为0。如果A数组为['foo','bar'],则A[0]返回’foo’和A[1]返回”bar”。 |
| M[key] | M是Map<K, V>,关键K型 | 返回关键值对应的值,例如mapM为\{‘f’ -> ‘foo’, ‘b’ -> ‘bar’, ‘all’ -> ‘foobar’\},则M['all'] 返回’foobar’。 |
| S.x | S为struct | 返回结构x字符串在结构S中的存储位置。如 foobar\{int foo, int bar\} foobar.foo的领域中存储的整数。 |
二、内置函数
2.1数学函数
| 函数 | 返回类型 | 说明 |
| Tround(double a) | BIGIN | 四舍五入 |
| round(double a, int d) | DOUBLE | 小数部分d位之后数字四舍五入,例如round(21.263,2),返回21.26 |
| floor(double a) | BIGINT | 对给定数据进行向下舍入最接近的整数。例如floor(21.2),返回21。 |
| ceil(double a), ceiling(double a) | BIGINT | 将参数向上舍入为最接近的整数。例如ceil(21.2),返回23. |
| rand(), rand(int seed) | double | 返回大于或等于0且小于1的平均分布随机数(依重新计算而变) |
| exp(double a) | double | 返回e的n次方 |
| ln(double a) | double | 返回给定数值的自然对数 |
| log10(double a) | double | 返回给定数值的以10为底自然对数 |
| log2(double a) | double | 返回给定数值的以2为底自然对数 |
| log(double base, double a) | double | 返回给定底数及指数返回自然对数 |
| pow(double a, double p), power(double a, double p) | double | 返回某数的乘幂 |
| sqrt(double a) | double | 返回数值的平方根 |
| bin(BIGINT a) | string | 返回二进制格式 |
| hex(BIGINT a), hex(string a) | string | 将整数或字符转换为十六进制格式 |
| unhex(string a) | string | 十六进制字符转换由数字表示的字符。 |
| conv(BIGINT num, int from_base, int to_base) | string | 将 指定数值,由原来的度量体系转换为指定的数值体系。例如CONV(‘a’,16,2),返回。 |
| abs(double a) | double | 取绝对值 |
| pmod(int a, int b), pmod(double a, double b) | int, double | 返回a除b的余数的绝对值 |
| sin(double a) | double | 返回给定角度的正弦值 |
| asin(double a) | double | 返回x的反正弦,即是X。如果X是在-1到1的正弦值,返回NULL。 |
| cos(double a) | double | 返回余弦 |
| acos(double a) | double | 返回X的反余弦,即余弦是X,,如果-1<= A <= 1,否则返回null. |
| positive(int a), positive(double a) | int, double | 返回A的值,例如positive(2),返回2。 |
| negative(int a), negative(double a) | int, double | 返回A的相反数,例如negative(2),返回-2。 |
2.2收集函数
| 函数 | 返回类型 | 说明 |
| size(Map<K.V>) | int | 返回的map类型的元素的数量 |
| size(Array<T>) | int | 返回数组类型的元素数量 |
2.3类型转换函数
| 函数 | 返回类型 | 说明 |
| cast(expr as<type>) | 指定 “type” | 类型转换。例如将字符”1″转换为整数:cast(’1′ as bigint),如果转换失败返回NULL。 |
2.4日期函数
| 函数 | 返回类型 | 说明 |
| from_unixtime(bigint unixtime[, string format]) | string | UNIX_TIMESTAMP参数表示返回一个值’YYYY- MM – DD HH:MM:SS’或YYYYMMDDHHMMSS.uuuuuu格式,这取决于是否是在一个字符串或数字语境中使用的功能。该值表示在当前的时区。 |
| unix_timestamp() | bigint | 如果不带参数的调用,返回一个Unix时间戳(从’1970- 01 – 0100:00:00′到现在的UTC秒数)为无符号整数。 |
| unix_timestamp(string date) | bigint | 指定日期参数调用UNIX_TIMESTAMP(),它返回参数值’1970- 01 – 0100:00:00′到指定日期的秒数。 |
| unix_timestamp(string date, string pattern) | bigint | 指定时间输入格式,返回到1970年秒数:unix_timestamp(’2009-03-20′, ‘yyyy-MM-dd’) = 1237532400 |
| to_date(string timestamp) | string | 返回时间中的年月日: to_date(“1970-01-01 00:00:00″) = “1970-01-01″ |
| to_dates(string date) | string | 给定一个日期date,返回一个天数(0年以来的天数) |
| year(string date) | int | 返回指定时间的年份,范围在1000到9999,或为”零”日期的0。 |
| month(string date) | int | 返回指定时间的月份,范围为1至12月,或0一个月的一部分,如’0000-00-00′或’2008-00-00′的日期。 |
| day(string date) dayofmonth(date) | int | 返回指定时间的日期 |
| hour(string date) | int | 返回指定时间的小时,范围为0到23。 |
| minute(string date) | int | 返回指定时间的分钟,范围为0到59。 |
| second(string date) | int | 返回指定时间的秒,范围为0到59。 |
| weekofyear(string date) | int | 返回指定日期所在一年中的星期号,范围为0到53。 |
| datediff(string enddate, string startdate) | int | 两个时间参数的日期之差。 |
| date_add(string startdate, int days) | int | 给定时间,在此基础上加上指定的时间段。 |
| date_sub(string startdate, int days) | int | 给定时间,在此基础上减去指定的时间段。 |
2.5条件函数
| 函数 | 返回类型 | 说明 |
| if(boolean testCondition, T valueTrue, T valueFalseOrNull) | T | 判断是否满足条件,如果满足返回一个值,如果不满足则返回另一个值。 |
| COALESCE(T v1, T v2, …) | T | 返回一组数据中,第一个不为NULL的值,如果均为NULL,返回NULL。 |
| CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END | T | 当a=b时,返回c;当a=d时,返回e,否则返回f。 |
| CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END | T | 当值为a时返回b,当值为c时返回d。否则返回e。 |
2.6字符函数
| 函数 | 返回类型 | 说明 |
| length(string A) | int | 返回字符串的长度 |
| reverse(string A) | string | 返回倒序字符串 |
| concat(string A, string B…) | string | 连接多个字符串,合并为一个字符串,可以接受任意数量的输入字符串 |
| concat_ws(string SEP, string A, string B…) | string | 链接多个字符串,字符串之间以指定的分隔符分开。 |
| substr(string A, int start), substring(string A, int start) | string | 从文本字符串中指定的起始位置后的字符。 |
| substr(string A, int start, int len), substring(string A, int start, int len) | string | 从文本字符串中指定的位置指定长度的字符。 |
| upper(string A) ucase(string A) | string | 将文本字符串转换成字母全部大写形式 |
| lower(string A) lcase(string A) | string | 将文本字符串转换成字母全部小写形式 |
| trim(string A) | string | 删除字符串两端的空格,字符之间的空格保留 |
| ltrim(string A) | string | 删除字符串左边的空格,其他的空格保留 |
| rtrim(string A) | string | 删除字符串右边的空格,其他的空格保 |
| regexp_replace(string A, string B, string C) | string | 字符串A中的B字符被C字符替代 |
| regexp_extract(string subject, string pattern, int index) | string | 通过下标返回正则表达式指定的部分。regexp_extract(‘foothebar’, ‘foo(.*?)(bar)’, 2) returns ‘bar.’ |
| parse_url(string urlString, string partToExtract [, string keyToExtract]) | string | 返回URL指定的部分。parse_url(‘http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1′, ‘HOST’) 返回:’facebook.com’ |
| get_json_object(string json_string, string path) | string | select a.timestamp, get_json_object(a.appevents, ‘$.eventid’), get_json_object(a.appenvets, ‘$.eventname’) from log a; |
| space(int n) | string | 返回指定数量的空格 |
| repeat(string str, int n) | string | 重复N次字符串 |
| ascii(string str) | int | 返回字符串中首字符的数字值 |
| lpad(string str, int len, string pad) | string | 返回指定长度的字符串,给定字符串长度小于指定长度时,由指定字符从左侧填补。 |
| rpad(string str, int len, string pad) | string | 返回指定长度的字符串,给定字符串长度小于指定长度时,由指定字符从右侧填补。 |
| split(string str, string pat) | array | 将字符串转换为数组。 |
| find_in_set(string str, string strList) | int | 返回字符串str第一次在strlist出现的位置。如果任一参数为NULL,返回NULL;如果第一个参数包含逗号,返回0。 |
| sentences(string str, string lang, string locale) | array<array<string>> | 将字符串中内容按语句分组,每个单词间以逗号分隔,最后返回数组。 例如sentences(‘Hello there! How are you?’) 返回:( (“Hello”, “there”), (“How”, “are”, “you”) ) |
| ngrams(array<array<string>>, int N, int K, int pf) | array<struct<string,double>> | SELECT ngrams(sentences(lower(tweet)), 2, 100 [, 1000]) FROM twitter; |
| context_ngrams(array<array<string>>, array<string>, int K, int pf) | array<struct<string,double>> | SELECT context_ngrams(sentences(lower(tweet)), array(null,null), 100, [, 1000]) FROM twitter; |
三、内置的聚合函数
| 函数 | 返回类型 | 说明 |
| count(*) , count(expr), count(DISTINCT expr[, expr_., expr_.]) | bigint | 返回记录条数。 |
| sum(col), sum(DISTINCT col) | double | 求和 |
| avg(col), avg(DISTINCT col) | double | 求平均值 |
| min(col) | double | 返回指定列中最小值 |
| max(col) | double | 返回指定列中最大值 |
| var_pop(col) | double | 返回指定列的方差 |
| var_samp(col) | double | 返回指定列的样本方差 |
| stddev_pop(col) | double | 返回指定列的偏差 |
| stddev_samp(col) | double | 返回指定列的样本偏差 |
| covar_pop(col1, col2) | double | 两列数值协方差 |
| covar_samp(col1, col2) | double | 两列数值样本协方差 |
| corr(col1, col2) | double | 返回两列数值的相关系数 |
| percentile(col, p) | double | 返回数值区域的百分比数值点。0<=P<=1,否则返回NULL,不支持浮点型数值。 |
| percentile(col, array(p~1,,\ [, p,,2,,]…)) | array<double> | 返回数值区域的一组百分比值分别对应的数值点。0<=P<=1,否则返回NULL,不支持浮点型数值。 |
| percentile_approx(col, p[, B]) | double | Returns an approximate p^th^ percentile of a numeric column (including floating point types) in the group. The B parameter controls approximation accuracy at the cost of memory. Higher values yield better approximations, and the default is 10,000. When the number of distinct values in col is smaller than B, this gives an exact percentile value. |
| percentile_approx(col, array(p~1,, [, p,,2_]…) [, B]) | array<double> | Same as above, but accepts and returns an array of percentile values instead of a single one. |
| histogram_numeric(col, b) | array<struct\{‘x’,'y’\}> | Computes a histogram of a numeric column in the group using b non-uniformly spaced bins. The output is an array of size b of double-valued (x,y) coordinates that represent the bin centers and heights |
| collect_set(col) | array | 返回无重复记录 |
四、内置表生成函数
| 函数 | 返回类型 | 说明 |
| explode(array<TYPE> a) | 数组 | 数组一条记录中有多个参数,将参数拆分,每个参数生成一列。 |
五、自定义函数
5.1 自定义函数分类
自定义函数包括三种UDF、UDAF、UDTF
UDF(User-Defined-Function) :一进一出
UDAF(User- Defined Aggregation Funcation) :用户自定义聚合函数,多进一出。Count/max/min
UDTF(User-Defined Table-Generating Functions) :用户自定义表生成函数,一进多出,如explore()
聚合函数 UDAF 能够满足我们使用的基本都已经内置了,本文就重点介绍一下UDF和UDTF函数的实现。
5.2 自定义函数开发
5.2.1 开发UDF函数
5.2.1.1 开发流程步骤
5.2.1.1.1 继承Hive提供的类
org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
5.2.1.1.2 实现类中的抽象方法
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {}public Object evaluate(DeferredObject[] arguments) throws HiveException {}public String getDisplayString(String[] children) {}5.2.1.1.3 将jar包上传到虚拟机中
a)把程序打包放到目标机器上去;
b)进入hive客户端,添加jar包:hive>add jar /run/jar/udf_test.jar;
c)创建临时函数:hive>CREATE TEMPORARY FUNCTION add_example AS 'hive.udf.Add';
d)查询HQL语句:
SELECT add_example(xx, xx) FROM scores;
e)销毁临时函数:hive> DROP TEMPORARY FUNCTION add_example;
注意:此种方式创建的函数属于临时函数,当关闭了当前会话之后,函数会无法使用,因为jar的引用没有了,无法找到对应的java文件进行处理,因此不推荐使用。
5.2.1.1.4 将jar包上传到hdfs集群中
a)把程序打包上传到hdfs的某个目录下
b)创建函数:hive>CREATE FUNCTION add_example AS 'hive.udf.Add' using jar "hdfs://mycluster/jar/udf_test.jar";
d)查询HQL语句:
SELECT add_example(xx, xx) FROM scores;
e)销毁临时函数:hive> DROP FUNCTION add_example;
5.2.1.2 实现UDF函数
自定义一个UDF实现计算给定基本数据类型的长度,例如:
select my_len("abcd");
5.2.1.2.1 创建Maven工程,导入依赖
<dependencies><dependency><groupId>org.apache.hive</groupId>、<artifactId>hive-exec</artifactId><version>3.1.3</version></dependency></dependencies>5.2.1.2.2 创建函数类实现GenericUDF类
package com.atguigu;import org.apache.hadoop.hive.ql.exec.UDFArgumentException;import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;import org.apache.hadoop.hive.ql.metadata.HiveException;import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;public class LengthUDFTest extends GenericUDF {//initialize方法,全局执行一次(一般做一些校验)@Overridepublic ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {// 判断输入参数的个数if (arguments.length != 1) {throw new UDFArgumentException("输入参数长度异常,只允许输入1个参数");}// 判断输入参数的类型(是否是基本类型)// Category 共定义了5种类型:基本类型(Primitive),集合(List),键值对映射(Map),结构体(Struct),联合体(Union)if(!arguments[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE)){throw new UDFArgumentTypeException(0,"输入参数类型异常");}// 函数本身返回值为 int,需要返回 int 类型的鉴别器对象return PrimitiveObjectInspectorFactory.javaIntObjectInspector;}//evaluate方法,函数的逻辑处理方法,进来一条执行一次@Overridepublic Object evaluate(DeferredObject[] arguments) throws HiveException {if (arguments[0].get() == null) {return 0;} else {return arguments[0].get().toString().length();}}//getDisplayString 方法,在使用explain 查看SQL执行计划时,会显示(一般直接返回null即可)@Overridepublic String getDisplayString(String[] strings) {return null;}}5.2.1.2.3 函数的使用
5.2.1.2.3.1 临时函数
1)打成jar包上传到服务器/hive/datas/myudf.jar。
2)将jar包添加到hive的classpath,临时生效。
add jar /hive/datas/myudf.jar;
3)创建临时函数与开发好的java class关联。
create temporary function my_len as "com.atguigu.LengthUDFTest";
4)即可在hql中使用自定义的临时函数
select ename, my_len(ename) ename_lenfrom emp;
5)删除临时函数
drop temporary function my_len;
提示:临时函数只跟会话有关系,跟库没有关系。只要创建临时函数的会话不断,在当前会话下,任意一个库都可以使用,其他会话全都不能使用。
5.2.1.2.3.2 永久函数
1)创建永久函数
create function my_len2 as "hive.udf.MyUDF" using jar "hdfs://hadoop:8020/udf/myudf.jar";
提示:
因为add jar本身也是临时生效,所以在创建永久函数的时候,需要制定路径(并且因为元数据的原因,这个路径还得是HDFS上的路径)。
2)即可在hql中使用自定义的永久函数。
select ename, my_len2(ename) ename_lenfrom emp;
3)删除永久函数
drop function my_len2;
提示:
永久函数跟会话没有关系,创建函数的会话断了以后,其他会话也可以使用。
永久函数创建的时候,在函数名之前需要自己加上库名,如果不指定库名的话,会默认把当前库的库名给加上。
永久函数使用的时候,需要在指定的库里面操作,或者在其他库里面使用的话加上,库名.函数名。
5.2.2 开发UDTF函数
5.2.2.1 开发流程
和开发UDF函数流程差不多,不同的是,需要继承
org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
同时,需要实现的方法为:
@Overridepublic StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {}public void process(Object[] args) throws HiveException {}public void close() throws HiveException {}5.2.2.2 实现UDTF函数
5.2.2.2.1 创建Mvaen工程,导入依
<dependencies><dependency><groupId>org.apache.hive</groupId>、<artifactId>hive-exec</artifactId><version>3.1.3</version></dependency></dependencies>5.2.2.2.2 创建函数类实现GenericUDTF类
package com.atguigu;import org.apache.hadoop.hive.ql.exec.UDFArgumentException;import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;import org.apache.hadoop.hive.ql.metadata.HiveException;import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
public class SplitUDTFTest extends GenericUDF {//initialize方法,全局执行一次(一般做一些校验)@Overridepublic ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {// 判断输入参数的个数if (arguments.length != 1) {throw new UDFArgumentException("输入参数长度异常,只允许输入1个参数");}// 判断输入参数的类型(是否是基本类型)// Category 共定义了5种类型:基本类型(Primitive),集合(List),键值对映射(Map),结构体(Struct),联合体(Union)if(!arguments[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE)){throw new UDFArgumentTypeException(0,"输入参数类型异常");}// 函数本身返回值为 int,需要返回 int 类型的鉴别器对象return PrimitiveObjectInspectorFactory.javaIntObjectInspector;}//evaluate方法,函数的逻辑处理方法,进来一条执行一次@Overridepublic Object evaluate(DeferredObject[] arguments) throws HiveException {if (arguments[0].get() == null) {return 0;} else {return arguments[0].get().toString().length();}}//getDisplayString 方法,在使用explain 查看SQL执行计划时,会显示(一般直接返回null即可)@Overridepublic String getDisplayString(String[] strings) {return null;}}5.2.2.2.3 函数的使用
和UDF函数的使用一致,也分临时函数和永久函数,具体可参考UDF函数的使用,这里不做重复说明。
好了,今天Hive函数的相关内容就分享到这里,如果帮助到大家,欢迎大家点赞+关注+收藏,有疑问也欢迎大家评论留言!
相关文章:

Hive 的函数介绍
目录 编辑 一、内置运算符 1.1 关系运算符 1.2算术运算符 1.3逻辑运算符 1.4复杂类型函数 1.5对复杂类型函数操作 二、内置函数 2.1数学函数 2.2收集函数 2.3类型转换函数 2.4日期函数 2.5条件函数 2.6字符函数 三、内置的聚合函数 四、内置表生成函数 五、…...

【Linux基础】第31讲 Linux用户和用户组权限控制命令(三)
用户组管理命令 每个用户都有一个用户组,系统可以对一个用户组中的所有用户进行集中管理。不同Linux系统对用户组的规定有所不同。如Linux下的用户属于与它同名的用户组,这个用户组在创建用户时同时创建。用户组的管理涉及用户组的添加、删除和修改。组…...
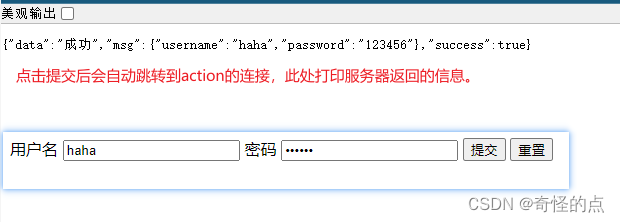
html form表单高级用法
场景:想单纯使用表单内置的api完成提交,不使用js代码 代码如下: <form name"myForm" action"http://localhost:13734/form" method"post"><label>用户名<input type"text" name&qu…...

openssl升级
参考 https://www.cnblogs.com/shareHistory/p/15850707.html 下载并安装依赖 wget https://www.openssl.org/source/openssl-3.0.5.tar.gz yum -y install perl-IPC-Cmd编译安装 ./config -Wl,-rpath/usr/local/openssl/lib -fPIC --prefix/usr/local/openssl --openssldir…...
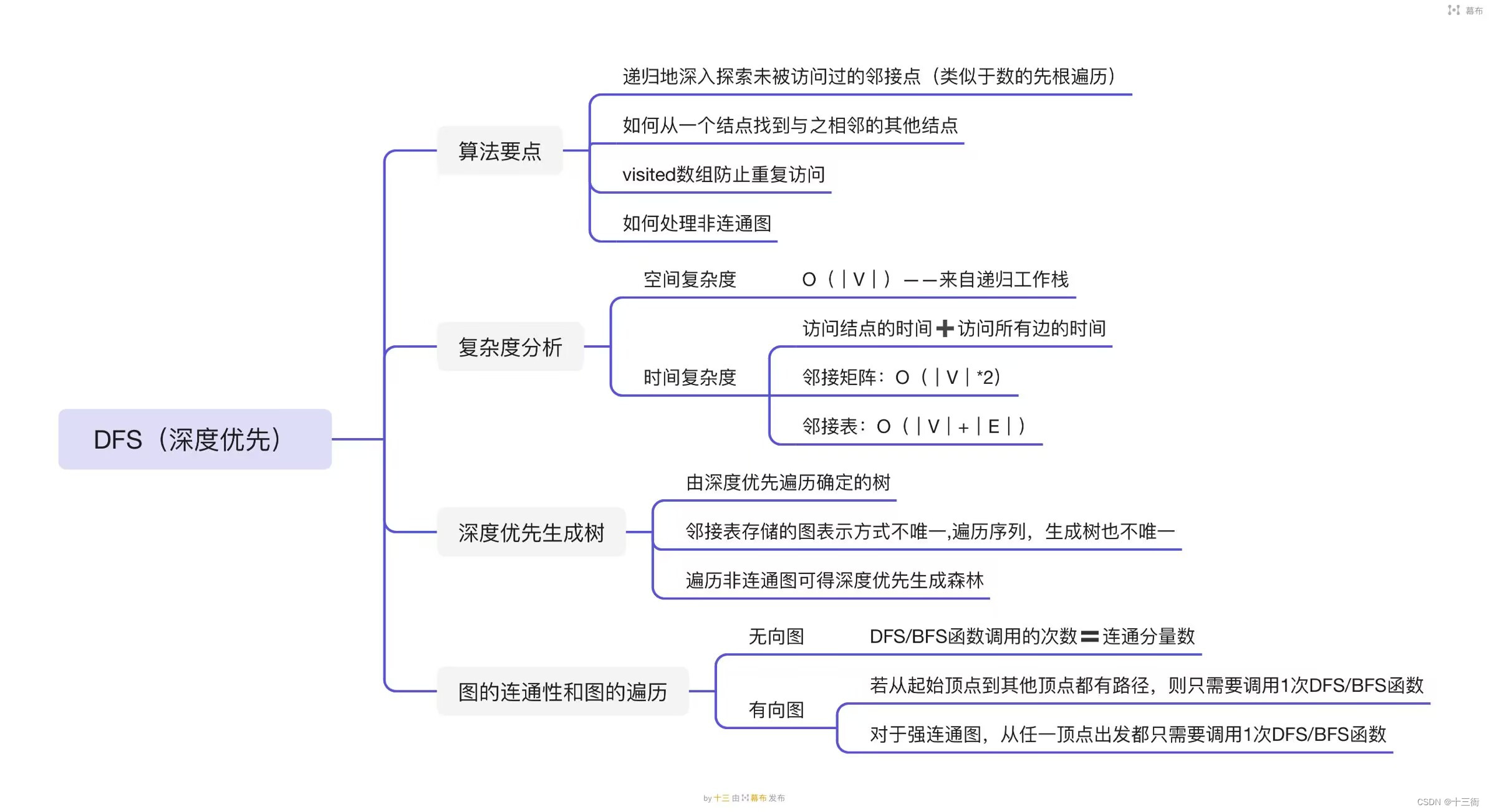
【数据结构】图的遍历:广度优先(BFS),深度优先(DFS)
目录 1、广度优先(BFS) 算法思想 广度优先生成树 知识树 代码实现 2、深度优先(DFS) 算法思想 深度优先生成树 知识树 代码实现 1、广度优先(BFS) 算法思想 图的广度优先遍历࿰…...
—— Mysql 库表容量统计)
Mysql 学习总结(89)—— Mysql 库表容量统计
前言 统计每个库每个表的大小是数据治理中最简单的一个要求,下面从抽样统计结果及精确统计结果两方面来统计MySQL的每个库每个表的数据量情况。mysql 数据字典库 information_schema 里记录了统计的预估数据量(innodb 引擎表不准确,MyISAM 引擎表准确)及数据大小、索引大小及…...

virtualBox安装配置使用
virtualBox下载 //官网下载地址 https://www.virtualbox.org/wiki/Downloads //ubuntu下载地址 https://cn.ubuntu.com/download/server/step1 virtualBox使用 导入现有镜像 (如果报错可以降低系统配置,因为有些主机可能不支持高配置,例如…...
北斗导航 | RTD、RTK完好性之B值、VPL与HPL计算(附B值计算matlab源代码)
===================================================== github:https://github.com/MichaelBeechan CSDN:https://blog.csdn.net/u011344545 ===================================================== 1、S矩阵获取 为第i颗卫星测距标准差:...

more often than not 的含义
今天听https://www.bilibili.com/video/BV1w94y12727/?p2&spm_id_frompageDriver more often than not 连读:mor ofen than au 想了半天不动什么意思. 查了一下表示大部分情况下. 还是不理解为什么, 就查了必应里面的词典. 表示超过一半的情况下. 又自己想了想突然懂了.…...
【Linux】Linux环境配置安装
目录 一、双系统(特别不推荐) 安装双系统的缺点: 安装双系统优点(仅限老手): 二、虚拟机centos7镜像(较为推荐推荐) 虚拟机的优点: 虚拟机的缺点: …...

从零学习开发一个RISC-V操作系统(二)丨GCC编译器和ELF格式
本篇文章的内容 一、GCC(GUN Compiler Collection)1.1 GCC的命令格式1.2 GCC的主要执行步骤1.3 GCC涉及的文件类型 二、ELF简介2.1 ELF文件格式图2.2 ELF文件处理的相关工具2.3 练习 本系列是博主参考B站课程学习开发一个RISC-V的操作系统的学习笔记&…...
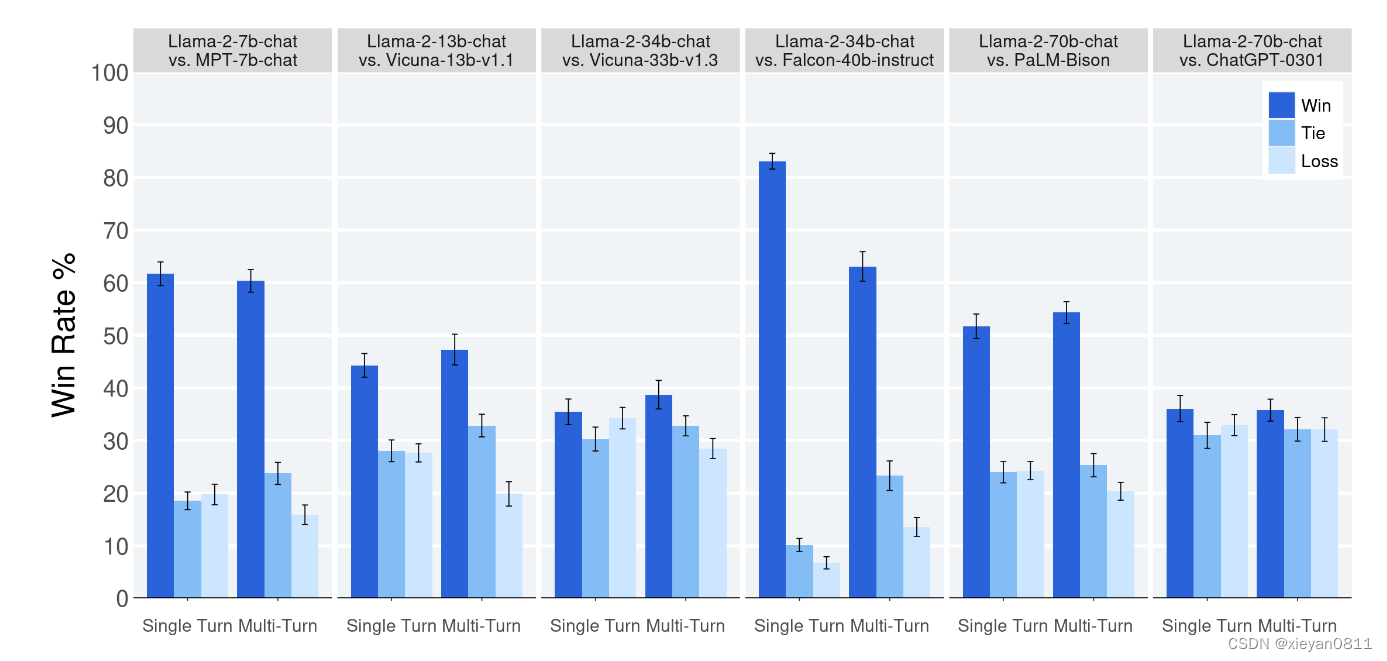
论文阅读_大语言模型_Llama2
英文名称: Llama 2: Open Foundation and Fine-Tuned Chat Models 中文名称: Llama 2:开源的基础模型和微调的聊天模型 文章: http://arxiv.org/abs/2307.09288 代码: https://github.com/facebookresearch/llama 作者: Hugo Touvron 日期: 2023-07-19 引用次数: 11…...
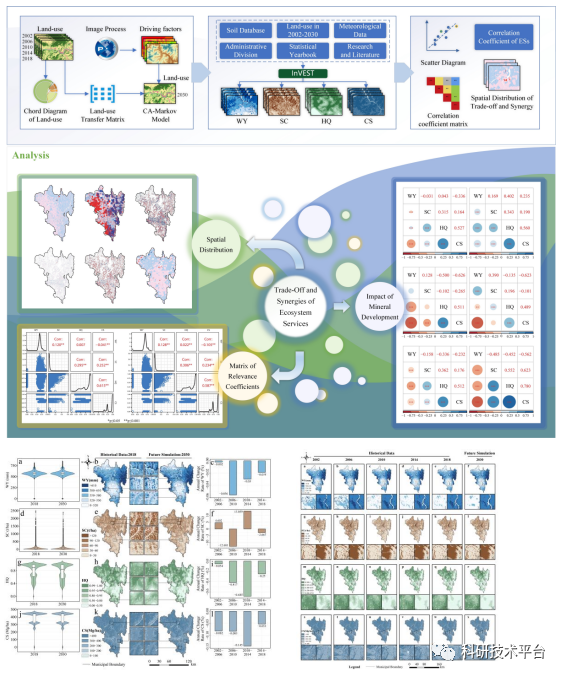
当量因子法、InVEST、SolVES模型等多技术融合在生态系统服务功能社会价值评估中的应用及论文写作、拓展分析
生态系统服务是人类从自然界中获得的直接或间接惠益,可分为供给服务、文化服务、调节服务和支持服务4类,对提升人类福祉具有重大意义,且被视为连接社会与生态系统的桥梁。自从启动千年生态系统评估项目(Millennium Ecosystem Asse…...

k8s Limits 限制内存
Limits 限制内存 在 Kubernetes (K8s) 中,可以使用 Limits(资源限制)来限制 Pod(容器)使用的内存数量。此处的 Limits 表示 Pod 在 K8s 集群中可用的最大内存量。一旦 Pod 内存使用超过这个限制,可能会触发…...
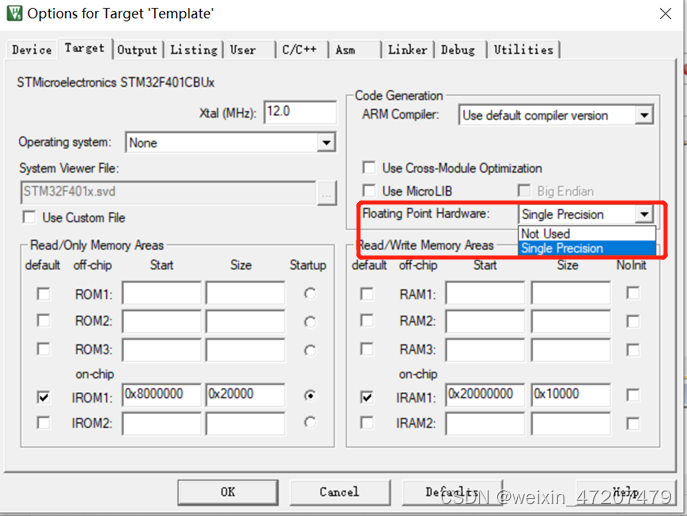
单片机第三季-第三课:STM32开发板原理图、配置、浮点运算单元
目录 1,开发板原理图 2,浮点运算单元(FPU) 1,开发板原理图 课程视频比较早,介绍了三款开发板。观看视频时用的开发板说和51单片机共板的STM32核心板,将51单片机从底座拆下来后,安…...
)
观察者模式 发布-订阅模式(设计模式与开发实践 P8)
文章目录 观察者模式运用实现 观察者模式 定义:他用来定义对象之间一种一对多的依赖关系,当一个对象状态发生改变时,所有依赖他的对象都会得到通知 运用 如果我们使用过 DOM 上的事件函数,那就接触过观察者模式 document.body…...

【日常业务开发】Java实现异步编程
【日常业务开发】Java实现异步编程 Java实现异步编程什么是异步异步的八种实现方式异步编程线程异步Future异步CompletableFuture实现异步Spring的Async异步Spring ApplicationEvent事件实现异步消息队列ThreadUtil异步工具类Guava异步 CompletableFuture异步编排工具类创建异步…...
学习笔记|模数转换器|ADC原理|STC32G单片机视频开发教程(冲哥)|第十七集:ADC采集
文章目录 1.模数转换器(ADC)是什么?手册说明: 2.STC32G单片机ADC使用原理19.1.1 ADC控制寄存器(ADC_CONTR)19.1.2 ADC配置寄存器(ADCCFG)19.1.4ADC时序控制寄存器(ADCTIM)19.3 ADC相…...

OpenCV实现“蓝线挑战“特效
原理 算法原理可以分为三个流程: 1、将视频(图像)从(顶->底)或(左->右)逐行(列)扫描图像。 2、将扫描完成的行(列)像素重新生成定格图像…...
容器管理工具 Docker生态架构及部署
目录 一、Docker生态架构 1.1 Docker Containers Are Everywhere 1.2 生态架构 1.2.1 Docker Host 1.2.2 Docker daemon 1.2.3 Registry 1.2.4 Docker client 1.2.5 Image 1.2.6 Container 1.2.7 Docker Dashboard 1.3 Docker版本 二、Docker部署 2.1 使用YUM源部署…...

简易版抽奖活动的设计技术方案
1.前言 本技术方案旨在设计一套完整且可靠的抽奖活动逻辑,确保抽奖活动能够公平、公正、公开地进行,同时满足高并发访问、数据安全存储与高效处理等需求,为用户提供流畅的抽奖体验,助力业务顺利开展。本方案将涵盖抽奖活动的整体架构设计、核心流程逻辑、关键功能实现以及…...

CMake基础:构建流程详解
目录 1.CMake构建过程的基本流程 2.CMake构建的具体步骤 2.1.创建构建目录 2.2.使用 CMake 生成构建文件 2.3.编译和构建 2.4.清理构建文件 2.5.重新配置和构建 3.跨平台构建示例 4.工具链与交叉编译 5.CMake构建后的项目结构解析 5.1.CMake构建后的目录结构 5.2.构…...

抖音增长新引擎:品融电商,一站式全案代运营领跑者
抖音增长新引擎:品融电商,一站式全案代运营领跑者 在抖音这个日活超7亿的流量汪洋中,品牌如何破浪前行?自建团队成本高、效果难控;碎片化运营又难成合力——这正是许多企业面临的增长困局。品融电商以「抖音全案代运营…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

ArcGIS Pro制作水平横向图例+多级标注
今天介绍下载ArcGIS Pro中如何设置水平横向图例。 之前我们介绍了ArcGIS的横向图例制作:ArcGIS横向、多列图例、顺序重排、符号居中、批量更改图例符号等等(ArcGIS出图图例8大技巧),那这次我们看看ArcGIS Pro如何更加快捷的操作。…...

HDFS分布式存储 zookeeper
hadoop介绍 狭义上hadoop是指apache的一款开源软件 用java语言实现开源框架,允许使用简单的变成模型跨计算机对大型集群进行分布式处理(1.海量的数据存储 2.海量数据的计算)Hadoop核心组件 hdfs(分布式文件存储系统)&a…...

【Go语言基础【13】】函数、闭包、方法
文章目录 零、概述一、函数基础1、函数基础概念2、参数传递机制3、返回值特性3.1. 多返回值3.2. 命名返回值3.3. 错误处理 二、函数类型与高阶函数1. 函数类型定义2. 高阶函数(函数作为参数、返回值) 三、匿名函数与闭包1. 匿名函数(Lambda函…...

Java数值运算常见陷阱与规避方法
整数除法中的舍入问题 问题现象 当开发者预期进行浮点除法却误用整数除法时,会出现小数部分被截断的情况。典型错误模式如下: void process(int value) {double half = value / 2; // 整数除法导致截断// 使用half变量 }此时...
宇树科技,改名了!
提到国内具身智能和机器人领域的代表企业,那宇树科技(Unitree)必须名列其榜。 最近,宇树科技的一项新变动消息在业界引发了不少关注和讨论,即: 宇树向其合作伙伴发布了一封公司名称变更函称,因…...

pikachu靶场通关笔记19 SQL注入02-字符型注入(GET)
目录 一、SQL注入 二、字符型SQL注入 三、字符型注入与数字型注入 四、源码分析 五、渗透实战 1、渗透准备 2、SQL注入探测 (1)输入单引号 (2)万能注入语句 3、获取回显列orderby 4、获取数据库名database 5、获取表名…...