Scrapy+Selenium自动化获取个人CSDN文章质量分
前言
本文将介绍如何使用Scrapy和Selenium这两个强大的Python工具来自动获取个人CSDN文章的质量分数。我们将详细讨论Scrapy爬虫框架的使用,以及如何结合Selenium浏览器自动化工具来实现这一目标。无需手动浏览每篇文章,我们可以轻松地获取并记录文章的质量分数,从而更好地了解我们的博客表现。
CSDN文章质量分查询链接
Scrapy相关基础知识:
爬虫框架Scrapy学习笔记-1
爬虫框架Scrapy学习笔记-2
文章目录
- 前言
- 1. Scrapy的安装
- 2. Scrapy的工作流程
- 2.1 创建项目
- 2.2 进入项目目录
- 2.3 生成Spider
- 2.4 调整Spider
- 2.5 调整Settings配置
- 2.6 运行Scrapy程序
- 2.7 找URL
- 2.8 查看处理 response,交给管道
- 3. 使用Selenium获取质量分数
- 总结
1. Scrapy的安装
首先,我们需要安装Scrapy。建议在单独的虚拟环境中进行安装,你可以使用Virtualenv环境或Conda环境。执行以下命令来安装Scrapy:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy==2.5.1
pip install pyopenssl==22.0.0
pip install cryptography==36.0.2
scrapy version
scrapy version --verbose
2. Scrapy的工作流程
Scrapy是一个强大的Python爬虫框架,我们可以按照以下步骤来使用它:
2.1 创建项目
使用以下命令创建一个Scrapy项目:
scrapy startproject csdn
2.2 进入项目目录
cd csdn
2.3 生成Spider
生成一个Spider来定义爬取规则:
scrapy genspider cs csdn.net
这将会生成一个Spider文件,你可以在其中定义你的爬取规则。
2.4 调整Spider
在生成的Spider文件中,你需要定义起始URL(start_urls)和如何解析数据的方法(通常是parse函数)。
例如:
import scrapyclass ExampleSpider(scrapy.Spider):name = 'cs'allowed_domains = ['csdn.net']start_urls = ['http://csdn.net/']def parse(self, response):pass
2.5 调整Settings配置
在项目目录中的settings.py文件中,你可以调整各种配置选项。
以下是一些需要调整的配置选项:
- LOG_LEVEL:设置日志级别,你可以将其设置为"WARNING"以减少日志输出。
LOG_LEVEL = "WARNING"
- ROBOTSTXT_OBEY:设置是否遵守Robots协议,如果你不希望爬虫遵守Robots协议,可以将其设置为False。
ROBOTSTXT_OBEY = False
- ITEM_PIPELINES:打开管道以处理爬取的数据,你可以配置不同的管道来处理不同类型的数据。
ITEM_PIPELINES = {'csdn.pipelines.CsdnPipeline': 300,
}
2.6 运行Scrapy程序
使用以下命令来运行Scrapy程序:
scrapy crawl csdn
2.7 找URL
在这一步,我们需要找到用于获取文章数据的URL。可以通过以下步骤来找到URL:
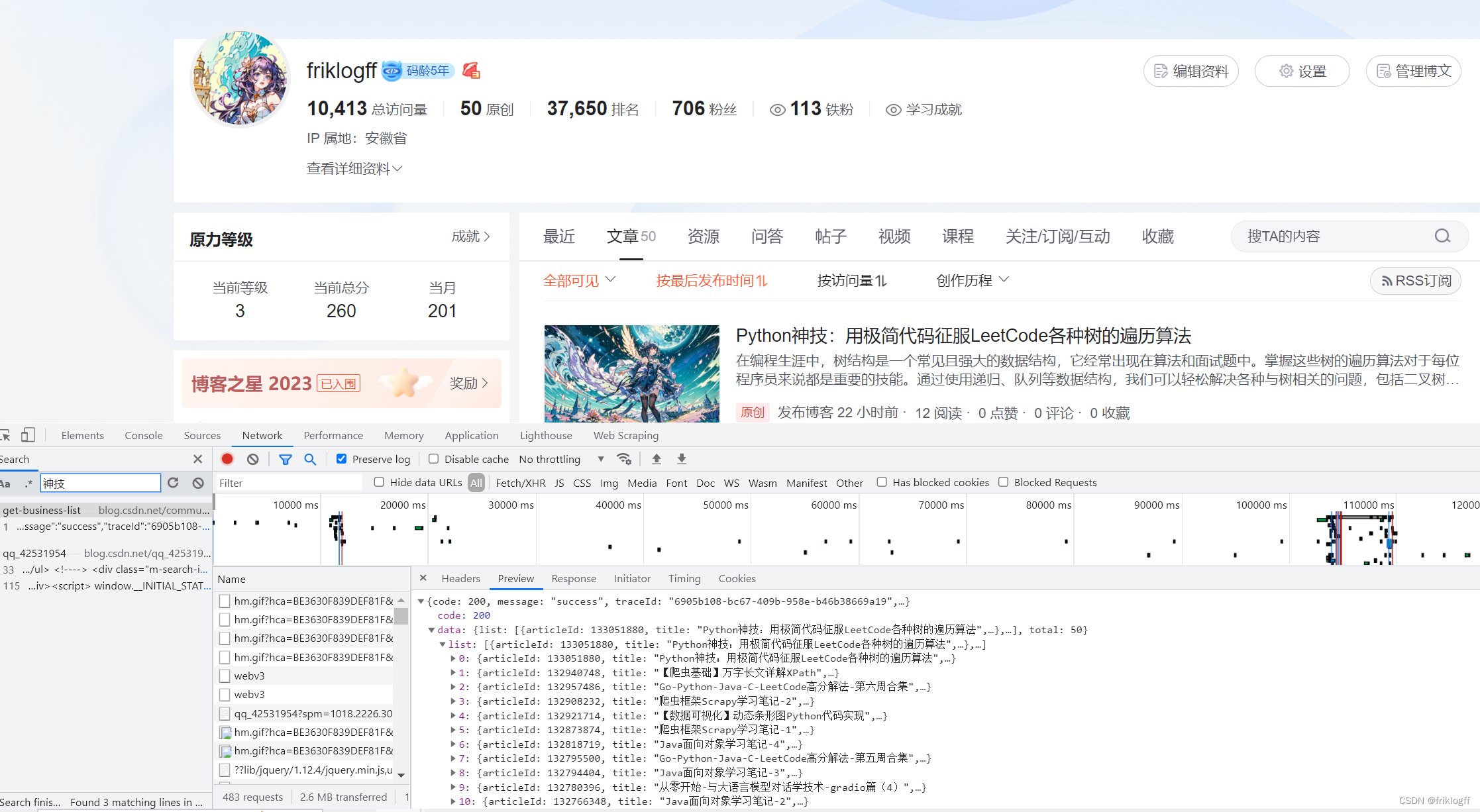
我们可以先点开搜索按钮预设一个搜索值
然后在Fetch/XHR或JS中逐个点,加载出来就会在左侧被搜索到

这里我们最终在header中找到这个连接,我们会发现其实链接是通用的,你可以跳过上一步直接使用这个连接,只需要替换你的username
https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog&orderby=&noMore=false&year=&month=&username=qq_42531954
另外,这里page=1&size=20,当你的文章大于20篇,你可以调整size,这里我刚好有50篇,于是我调整size=50
2.8 查看处理 response,交给管道
import scrapyclass CsSpider(scrapy.Spider):name = 'cs'allowed_domains = ['csdn.net']start_urls = ['https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=50&businessType=blog&orderby=&noMore=false&year=&month=&username=qq_42531954']def parse(self, response):print(response.text)
分析response.text,发现返回值为字典
稍作处理后传递给管道
import scrapyclass CsSpider(scrapy.Spider):name = 'cs'allowed_domains = ['csdn.net']start_urls = ['https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=50&businessType=blog&orderby=&noMore=false&year=&month=&username=qq_42531954']def parse(self, response):# print(response.text)data_list = response.json()["data"]["list"]for data in data_list:url = data["url"]title = data["title"]yield { # 宁典可以充当item -> dict"url": url,"title": title}csdn/csdn/pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapterclass CsdnPipeline:def process_item(self, item, spider):print("我是管道,我看到的东西是", item)with open("data.csv", mode="a", encoding="utf-8") as f:f.write(f"{item['url']},{item['title']}\n")return item3. 使用Selenium获取质量分数
如果你的chromedriver出现问题,你可以从这里找到解决方案
自动化管理chromedriver-完美解决版本不匹配问题
以下是使用Selenium的代码示例:
import csv
import time
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.chrome.options import Optionsoption = Options()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_argument('--disable-blink-features=AutomationControlled')
option.add_argument('--headless') # 启用无头模式driver = webdriver.Chrome(options=option)
# 用于存储CSV数据的列表
data = []
#
# 打开CSV文件并读取内容
with open('data.csv','r', encoding='utf-8') as csvfile:reader = csv.reader(csvfile)for row in reader:# 每行包括两个字段:链接和标题link, title = row# 将链接和标题作为元组添加到数据列表中data.append((link, title))# 使用浏览器访问网页
driver.get("https://www.csdn.net/qc")
for link,title in data:driver.find_element(By.CSS_SELECTOR, ".el-input__inner").send_keys(f"{link}",link)driver.find_element(By.CSS_SELECTOR, ".trends-input-box-btn").click()time.sleep(0.5)soc = driver.find_element(By.XPATH, '//*[@id="floor-csdn-index_850"]/div/div[1]/div/div[2]/p[1]').textprint(title,soc)time.sleep(1)
driver.quit()这段代码是一个Python脚本,使用了CSV模块和Selenium库来自动化获取CSDN文章的质量分数。下面我将逐行详细解释这段代码的功能和作用:
- 导入必要的库:
import csv
import time
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
这里导入了CSV模块(用于读取CSV文件)、time模块(用于添加延迟等待)、以及Selenium相关的模块和类。
- 配置Selenium选项:
option = Options()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_argument('--disable-blink-features=AutomationControlled')
option.add_argument('--headless') # 启用无头模式
这部分代码配置了Selenium的选项。其中,Options是用于配置Chrome浏览器的选项,add_experimental_option用于设置Chrome的实验性选项,以避免被检测为自动化程序。--disable-blink-features=AutomationControlled用于禁用某些自动化特性,而--headless则启用了无头模式,使得浏览器在后台运行,不会显示界面。
- 创建Chrome WebDriver实例:
driver = webdriver.Chrome(options=option)
这里创建了一个Chrome WebDriver实例,使用了上述配置选项。WebDriver将用于模拟浏览器操作。
- 创建一个空列表用于存储数据:
data = []
这个列表将用于存储从CSV文件中读取的数据。
- 打开CSV文件并读取内容:
with open('data.csv', 'r', encoding='utf-8') as csvfile:reader = csv.reader(csvfile)for row in reader:link, title = rowdata.append((link, title))
这部分代码使用open函数打开名为"data.csv"的CSV文件,并使用csv.reader来读取文件的内容。每一行都包括两个字段:链接和标题,这些数据被添加到之前创建的data列表中。
- 使用浏览器访问网页:
driver.get("https://www.csdn.net/qc")
这行代码使用WebDriver打开了CSDN网站的首页,准备开始搜索文章的质量分数。
- 迭代处理CSV文件中的每一行数据:
for link, title in data:driver.find_element(By.CSS_SELECTOR, ".el-input__inner").send_keys(f"{link}", link)driver.find_element(By.CSS_SELECTOR, ".trends-input-box-btn").click()time.sleep(0.5)soc = driver.find_element(By.XPATH, '//*[@id="floor-csdn-index_850"]/div/div[1]/div/div[2]/p[1]').textprint(title, soc)time.sleep(1)
在这个循环中,我们对CSV文件中的每一行数据执行以下操作:
- 使用
driver.find_element通过CSS选择器定位搜索框,并在搜索框中输入文章链接。 - 使用
driver.find_element定位搜索按钮,并模拟点击搜索按钮。 - 延迟0.5秒以等待页面加载完毕。
- 使用XPath表达式定位质量分数元素,并提取其文本内容。
- 打印文章标题和质量分数。
- 延迟1秒以确保不会频繁访问网站。
- 最后,使用
driver.quit()关闭浏览器窗口,释放资源。
这段代码的主要作用是自动化地访问CSDN网站,搜索文章链接,提取文章的质量分数,并将结果打印出来。这对于批量获取文章质量分数非常有用,而无需手动一个个查看。
当然,我将为你添加前言、摘要和总结来完善这篇文章。
总结
通过本文的学习,你将掌握使用Scrapy和Selenium自动获取个人CSDN文章质量分数的技能。这将帮助你更好地了解你的博客表现,以及哪些文章受到了更多的关注和评价。
同时,你也学到了如何设置Scrapy爬虫项目,配置爬虫规则,以及如何处理数据。这些技能对于进行各种网络数据采集任务都是非常有用的。
希望本文对你的网络数据采集和分析工作有所帮助,让你能够更好地理解你的读者和观众。如果你有任何问题或疑问,欢迎提出,我们将竭诚为你提供帮助。
相关文章:
Scrapy+Selenium自动化获取个人CSDN文章质量分
前言 本文将介绍如何使用Scrapy和Selenium这两个强大的Python工具来自动获取个人CSDN文章的质量分数。我们将详细讨论Scrapy爬虫框架的使用,以及如何结合Selenium浏览器自动化工具来实现这一目标。无需手动浏览每篇文章,我们可以轻松地获取并记录文章的…...

【Android Framework系列】第15章 Fragment+ViewPager与Viewpager2相关原理
1 前言 上一章节【Android Framework系列】第14章 Fragment核心原理(AndroidX版本)我们学习了Fragment的核心原理,本章节学习常用的FragmentViewPager以及FragmentViewPager2的相关使用和一些基本的源码分析。 2 FragmentViewPager 我们常用的两个Page…...

typeof的作用
typeof 是 JavaScript 中的一种运算符,用于获取给定值的数据类型。 它的作用是返回一个字符串,表示目标值的数据类型。通过使用 typeof 运算符,我们可以在运行时确定一个值的类型,从而进行相应的处理或逻辑判断。 常见的数据类型…...

性能测试 —— Tomcat监控与调优:status页监控
Tomcat服务器是一个免费的开放源代码的Web 应用服务器,Tomcat是Apache 软件基金会(Apache Software Foundation)Jakarta 项目中的一个核心项目,由Apache、Sun 和其他一些公司及个人共同开发而成。 Tomcat是一个轻量级应用服务器,在中小型系统…...

Ubuntu 安装 CUDA 与 CUDNN GPU加速引擎
一、NVIDIA(英伟达)显卡驱动安装 NVIDIA显卡驱动可以通过指令sudo apt purge nvidia*删除以前安装的NVIDIA驱动版本,重新安装。 1.1. 关闭系统自带驱动nouveau 注意!在安装NVIDIA驱动以前需要禁止系统自带显卡驱动nouveau…...
pdf文件太大如何处理?教你pdf压缩简单方法
PDF文件过大,是很多人在使用PDF文件时都遇到过的一个常见问题,过大的PDF文件不仅会占用大量的存储空间,还会影响文件传输和处理效率,下面给大家总结了几个方法,帮助大家解决PDF文件过大的问题。 方法一:嗨格…...
——nacos注册中心(1))
Nacos使用教程(二)——nacos注册中心(1)
文章目录 Nacos vs Eureka介绍架构设计Nacos架构Eureka架构 功能特性服务注册与发现配置管理健康检查 生态系统支持可用性与稳定性总结 Nacos中的CAP原则介绍CAP原则一致性(Consistency)可用性(Availability)分区容错性࿰…...

蓝桥杯2023年第十四届省赛真题-买瓜--C语言题解
目录 蓝桥杯2023年第十四届省赛真题-买瓜 题目描述 输入格式 输出格式 样例输入 样例输出 提示 【思路解析】 【代码实现】 蓝桥杯2023年第十四届省赛真题-买瓜 时间限制: 3s 内存限制: 320MB 提交: 796 解决: 69 题目描述 小蓝正在一个瓜摊上买瓜。瓜摊上共有 n 个…...
R语言进行孟德尔随机化+meta分析(1)---meta分析基础
目前不少文章用到了孟德尔随机化meta分析,今天咱们也来介绍一下,孟德尔随机化meta其实主要就是meta分析的过程,提取了孟德尔随机化文章的结果,实质上就是个meta分析,不过多个孟德尔随机化随机化的结果合并更加加强了结…...
网络安全第一次作业
1、什么是防火墙 防火墙是一种网络安全系统,它根据预先确定的安全规则监视和控制传入和传出的网络流量。其主要目的是阻止对计算机或网络的未经授权的访问,同时允许合法通信通过。 防火墙可以在硬件、软件或两者的组合中实现,并且可以配置为根…...
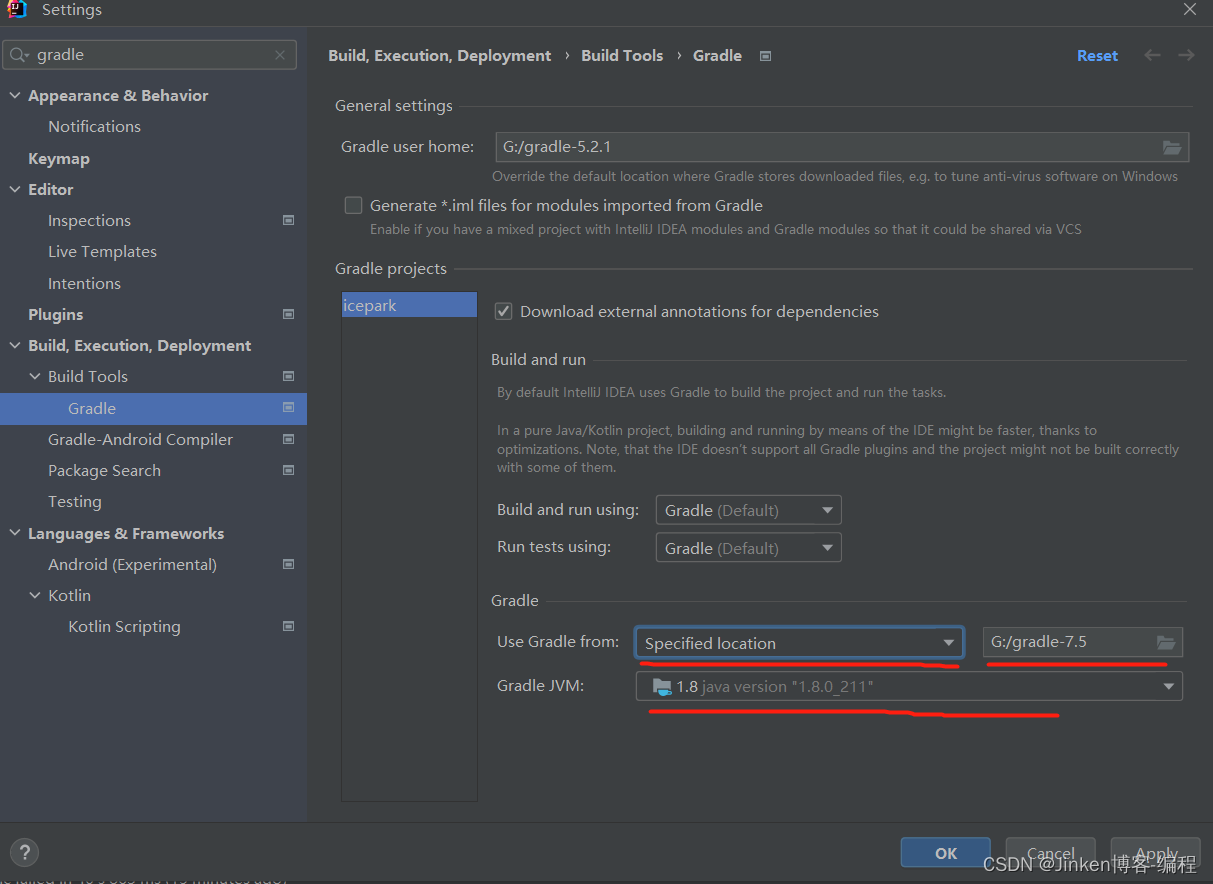
idea设置gradle
1、不选中 2、下面选specified location 指定gradle目录...
基于Elasticsearch的多文档检索 比如 商品(goods)、案例(cases)
概述 Elasticsearch多文档聚合检索 详细 记得把这几点描述好咯:需求(要做什么) 代码实现过程 项目文件结构截图 演示效果 应用场景 我们需要在五种不同的文档中检索数据。 比如 商品(goods)、案例(ca…...

9月18日,每日信息差
今天是2023年09月19日,以下是为您准备的11条信息差 第一、江苏无锡首次获得6000年前古人类DNA 第二、全球天然钻石价格暴跌。数据显示,国际钻石交易所钻石价格指数在2022年3月达到158的历史峰值,之后一路下跌到目前的110左右,创…...
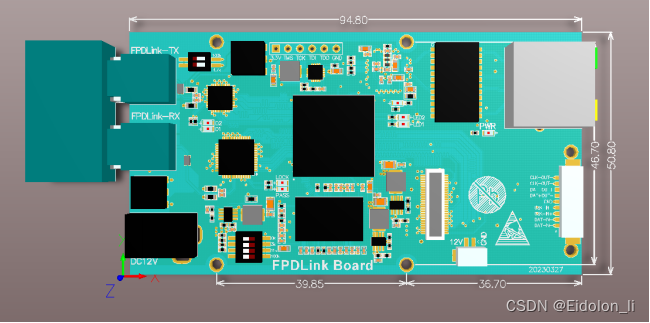
基于FPGA实现FPDLINK III
功能概述 本模块主要包含FPDLINKIII/CML收发信号与HDMI/SDI/USB信号、千兆网络信号,支持客户按照按照指定功能定制 当前默认功能为FPD LINK III/CML转为HDMI/SDI/UVC信号 性能参数 名称 描述 供电接口 DC12V FPD LINK RX GM8914 FPD LINK TX GM8913 千兆网…...

[补题记录] Atcoder Beginner Contest 309(E)
URL:https://atcoder.jp/contests/abc309 目录 E Problem/题意 Thought/思路 解法一: 解法二: Code/代码 E Problem/题意 一个家庭有 N 个人,根节点为 1,给出 2 ~ N 的父节点。一共购买 M 次保险,每…...
【HarmonyOS】解决API6 WebView跳转外部浏览器问题、本地模拟器启动黑屏
【问题描述1】 HarmonyOS API6 Java开发中使用WebView组件,如果网页中有跳转链接,点击会跳转到手机系统浏览器。 【解决方案】 解决这个问题的方法就是给WebView这种自定义的WebAgent对象。具体代码如下: WebConfig webConfigthis.webView…...

给出三个整数,判断大小
7-2 比较大小 给出三个整数,判断大小。 输入格式: 给出三个整数a,b,c 输出格式: 在一行中依次从小到大的顺序输出,两数之间有一个空格,无多余空格。 输入样例: 在这里给出一组输入。例如: 2 1 5 输出样例: 在这里给出相应的输…...

优化软件系统,解决死锁问题,提升稳定性与性能 redis排队下单
项目背景: 随着用户数量的不断增加,我们的速卖通小管家软件系统面临了一个日益严重的问题:在从存储区提供程序的数据读取器中进行读取时,频繁出现错误。系统报告了一个内部异常: 异常信息如下: 从存储区提供程序的数…...
MyBatisPlus 底层用 json 存储,Java 仍然使用 对象操作
PO 类的字段定义为一个对象,然后使用以下注解修饰 TableField(typeHandler JacksonTypeHandler.class) 当然 jsonTypeHandler 有多种可以选择...

发送验证码倒计时 防刷新重置!!!
需求:发送验证码,每60s可点击发送一次,倒计时中按钮不可点击,且刷新页面倒计时不会重置 可用以下方式避免刷新页面时,倒计时重置 localStorage本地缓存方式 思路: 1.记录倒计时的时间 2.页面加载时&…...

【网络】每天掌握一个Linux命令 - iftop
在Linux系统中,iftop是网络管理的得力助手,能实时监控网络流量、连接情况等,帮助排查网络异常。接下来从多方面详细介绍它。 目录 【网络】每天掌握一个Linux命令 - iftop工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景…...

蓝牙 BLE 扫描面试题大全(2):进阶面试题与实战演练
前文覆盖了 BLE 扫描的基础概念与经典问题蓝牙 BLE 扫描面试题大全(1):从基础到实战的深度解析-CSDN博客,但实际面试中,企业更关注候选人对复杂场景的应对能力(如多设备并发扫描、低功耗与高发现率的平衡)和前沿技术的…...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...

聊一聊接口测试的意义有哪些?
目录 一、隔离性 & 早期测试 二、保障系统集成质量 三、验证业务逻辑的核心层 四、提升测试效率与覆盖度 五、系统稳定性的守护者 六、驱动团队协作与契约管理 七、性能与扩展性的前置评估 八、持续交付的核心支撑 接口测试的意义可以从四个维度展开,首…...

九天毕昇深度学习平台 | 如何安装库?
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple --user 举个例子: 报错 ModuleNotFoundError: No module named torch 那么我需要安装 torch pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple --user pip install 库名&#x…...

高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数
高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数 在软件开发中,单例模式(Singleton Pattern)是一种常见的设计模式,确保一个类仅有一个实例,并提供一个全局访问点。在多线程环境下,实现单例模式时需要注意线程安全问题,以防止多个线程同时创建实例,导致…...

蓝桥杯 冶炼金属
原题目链接 🔧 冶炼金属转换率推测题解 📜 原题描述 小蓝有一个神奇的炉子用于将普通金属 O O O 冶炼成为一种特殊金属 X X X。这个炉子有一个属性叫转换率 V V V,是一个正整数,表示每 V V V 个普通金属 O O O 可以冶炼出 …...

初探Service服务发现机制
1.Service简介 Service是将运行在一组Pod上的应用程序发布为网络服务的抽象方法。 主要功能:服务发现和负载均衡。 Service类型的包括ClusterIP类型、NodePort类型、LoadBalancer类型、ExternalName类型 2.Endpoints简介 Endpoints是一种Kubernetes资源…...

【Linux】Linux 系统默认的目录及作用说明
博主介绍:✌全网粉丝23W,CSDN博客专家、Java领域优质创作者,掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域✌ 技术范围:SpringBoot、SpringCloud、Vue、SSM、HTML、Nodejs、Python、MySQL、PostgreSQL、大数据、物…...

Bean 作用域有哪些?如何答出技术深度?
导语: Spring 面试绕不开 Bean 的作用域问题,这是面试官考察候选人对 Spring 框架理解深度的常见方式。本文将围绕“Spring 中的 Bean 作用域”展开,结合典型面试题及实战场景,帮你厘清重点,打破模板式回答,…...