如何查看mysql的存储引擎
要查看MySQL中的存储引擎,可以使用以下两种方法:
1. 使用 SQL 查询:
您可以使用SQL查询来查看MySQL中的存储引擎。打开MySQL客户端,并连接到您的MySQL服务器,然后运行以下SQL查询:
SHOW TABLE STATUS;
这将列出所有数据库中的表以及与每个表相关的信息,包括存储引擎。在结果中,可以查看"Engine"列,该列显示了每个表所使用的存储引擎。
示例结果:
+--------------+--------+---------+------------+-------+----------------+-------------+-----------------+--------------+
| Name | Engine | Version | Row_format | Rows | Avg_row_length | Data_length | Max_data_length | Index_length |
+--------------+--------+---------+------------+-------+----------------+-------------+-----------------+--------------+
| my_table1 | InnoDB | 10 | Dynamic | 10000 | 1024 | 10240000 | 0 | 8192000 |
| my_table2 | MyISAM | 10 | Dynamic | 20000 | 512 | 10240000 | 0 | 6144000 |
| my_table3 | InnoDB | 10 | Dynamic | 15000 | 768 | 12288000 | 0 | 7168000 |
+--------------+--------+---------+------------+-------+----------------+-------------+-----------------+--------------+
在这个示例中,您可以看到每个表使用的存储引擎("Engine"列中的值),例如InnoDB或MyISAM。
2. 使用命令行工具:
另一种查看MySQL存储引擎的方法是使用MySQL的命令行工具。打开终端或命令提示符,然后执行以下命令:
-
连接到MySQL服务器:首先,使用MySQL客户端连接到MySQL服务器。您可以在终端中运行以下命令,然后输入MySQL服务器的用户名和密码:
mysql -u your_username -p替换
your_username为您的用户名,然后按提示输入密码。 -
选择数据库:如果您要查看特定数据库的表的存储引擎,可以选择该数据库。例如,要选择名为
your_database的数据库,可以运行:USE your_database; -
查看表的存储引擎:要查看表的存储引擎,可以使用
SHOW TABLE STATUS命令,然后过滤您感兴趣的表。以下是一个示例:SHOW TABLE STATUS LIKE 'your_table';替换
your_table为您要查看的表名。如果要查看数据库中所有表的存储引擎,可以省略LIKE子句:SHOW TABLE STATUS; -
分析结果:执行上述命令后,您将获得一个包含表信息的结果集。在结果集中,可以查看
Engine列,该列将显示表的存储引擎类型。
例如,以下是一个示例结果集:
+--------------+--------+---------+------------+------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+---------------------+------------+-------------------+----------+----------------+---------+
| Name | Engine | Version | Row_format | Rows | Avg_row_length | Data_length | Max_data_length | Index_length | Data_free | Create_time | Update_time | Check_time | Collation | Checksum | Create_options | Comment | Max_index_length | Temporary |
+--------------+--------+---------+------------+------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+---------------------+------------+-------------------+----------+----------------+---------+
| your_table | InnoDB | 10 | Compact | 3 | 5461 | 16384 | 0 | 16384 | 52428800 | 2022-01-01 ... | 2022-01-01 ... | 2022-01-01 ... | utf8mb4_...| 1234567890 | | | 768 | N |
+--------------+--------+---------+------------+------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+---------------------+------------+-------------------+----------+----------------+---------+
在此示例中,your_table 表的存储引擎是 InnoDB。
存储引擎类型
MySQL支持多种存储引擎类型,每种引擎都有其特定的特性和用途。以下是一些常见的MySQL存储引擎类型:
-
InnoDB: InnoDB是MySQL的默认存储引擎,它支持事务处理(ACID兼容)、行级锁定、外键约束等高级特性。InnoDB适用于大多数应用,特别是需要事务支持和数据完整性的应用。
-
MyISAM: MyISAM是一种较早的存储引擎,不支持事务处理和外键约束,但在一些特定情况下具有高性能。MyISAM适用于只读或很少更新的应用,如数据仓库或日志文件。
-
MEMORY(或HEAP): MEMORY引擎将表数据存储在内存中,因此读写速度非常快,但数据在服务器重启时会丢失。它适用于需要快速临时存储数据的情况,如缓存表。
-
CSV: CSV引擎用于存储CSV格式的数据文件,支持读写CSV文件,但不支持索引和事务处理。
-
ARCHIVE: ARCHIVE引擎用于存储大量历史数据,它对数据的压缩率很高,但只支持INSERT和SELECT操作,不支持UPDATE和DELETE。
-
BLACKHOLE: BLACKHOLE引擎接收数据但不将其存储,用于复制数据到其他MySQL服务器。
-
Federated(联合): FEDERATED引擎用于在多个MySQL服务器之间建立联合表,允许在不同服务器上查询和操作数据。
-
NDB Cluster(NDB): NDB Cluster引擎用于MySQL集群(MySQL Cluster),它提供了高可用性和分布式存储功能,适用于需要实时数据复制和故障切换的应用。
-
TokuDB: TokuDB引擎是一个高性能的存储引擎,特别适用于大规模的写入操作,如日志处理和分析。
-
RocksDB: RocksDB是一个开源的存储引擎,基于Google的RocksDB项目,具有高性能和可扩展性,适用于大规模数据存储和分析。
-
Spider: Spider引擎用于分布式查询,允许将数据分布在多个MySQL服务器上,并以透明方式进行查询。
要选择合适的存储引擎,需要考虑应用的性能需求、数据完整性、事务处理要求以及数据访问模式等因素。不同的存储引擎适用于不同的用例,因此选择合适的引擎非常重要。可以根据具体的应用需求,在创建表时选择适当的存储引擎。
相关文章:

如何查看mysql的存储引擎
要查看MySQL中的存储引擎,可以使用以下两种方法: 1. 使用 SQL 查询: 您可以使用SQL查询来查看MySQL中的存储引擎。打开MySQL客户端,并连接到您的MySQL服务器,然后运行以下SQL查询: SHOW TABLE STATUS;这…...

FPGA project : dht11 温湿度传感器
没有硬件,过几天上板测试。 module dht11(input wire sys_clk ,input wire sys_rst_n ,input wire key ,inout wire dht11 ,output wire ds ,output wire …...

std::string和QString的区别以及互转
一 区别 1.字符编码支持 std::string:默认情况下,使用 ASCII 或 UTF-8 编码。不直接提供对多字节字符的内置支持。 QString:提供对多种字符编码的支持,包括 ASCII、UTF-8、UTF-16 等。它更适合处理国际化和本地化的字符串。 2.…...
python+vue理发店管理系统
理发店管理系统主要实现角色有管理员和会员,管理员在后台管理用户表模块、token表模块、收藏表模块、商品分类模块、热卖商品模块、活动公告模块、留言反馈模块、理发师模块、会员卡模块、会员充值模块、会员模块、服务预约模块、服务项目模块、服务类别模块、热卖商品评论表模…...
基于微信小程序的个人健康管理系统的设计与实现(源码+lw+部署文档+讲解等)
前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计划导师、全栈领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java、小程序技术领域和毕业项目实战✌💗 👇🏻…...

共聚焦显微镜在化学机械抛光课题研究中的应用
两个物体表面相互接触即会产生相互作用力,研究具有相对运动的相互作用表面间的摩擦、润滑与磨损及其三者之间关系即为摩擦学,目前摩擦学已涵盖了化学机械抛光、生物摩擦、流体摩擦等多个细分研究方向,其研究的数值量级也涵盖了亚纳米到百微米…...
本地Linux 部署 Dashy 并远程访问
文章目录 简介1. 安装Dashy2. 安装cpolar3.配置公网访问地址4. 固定域名访问 转载自cpolar极点云文章:本地Linux 部署 Dashy 并远程访问 简介 Dashy 是一个开源的自托管的导航页配置服务,具有易于使用的可视化编辑器、状态检查、小工具和主题等功能。你…...
)
互联网摸鱼日报(2023-09-18)
互联网摸鱼日报(2023-09-18) 36氪新闻 最前线 | 号外电摩12.68万元起订,配16.9度一体压铸电池包 本周双碳大事:CCER交易管理办法获生态环境部原则通过;明阳斥资100亿元加码光伏项目;“全路程”获2亿元D轮融资 200亿,…...

Kotlin中函数的基本用法以及函数类型
函数的基本用法 1、函数的基本格式 2、函数的缺省值 可以为函数设置指定的初始值,而不必要传入值 private fun fix(name: String,age: Int 2){println(name age) }fun main(args: Array<String>) {fix("张三") }输出结果为:张三2 …...

在macOS使用VMware踩过的坑
目录 MAC提示将对您的电脑造成伤害/MAC OS 升级到10.15.3后vmware虚拟机黑屏 mac系统下,vm虚拟机提示打不开/dev/vmmon mac VMware Workstation 在此主机上不支持嵌套虚拟化 mac VMware清理虚拟机空间 MAC提示将对您的电脑造成伤害/MAC OS 升级到…...

构建健壮的Spring MVC应用:JSON响应与异常处理
目录 1. 引言 2. JSON 1. 轻量级和可读性 2. 易于编写和解析 3. 自描述性 4. 支持多种数据类型 5. 平台无关性 6. 易于集成 7. 社区支持和标准化 3. 高效处理异常 综合案例 异常处理方式一 异常处理方式二 异常处理方式三 1. 引言 探讨Spring MVC中关键的JSON数据…...

那些配置服务器踩的坑
最近在配置内网,无外网的服务器,纯纯记录一下踩得坑,希望看到的人不要再走这条弯路。 ------------------------------------------------------------------------------------------------------------------------------- 任务ÿ…...
交换机端口镜像详解
交换机端口镜像是一种网络监控技术,它允许将一个或多个交换机端口的网络流量复制并重定向到另一个端口上,以便进行流量监测、分析和记录。通过端口镜像,管理员可以实时查看特定端口上的流量,以进行网络故障排查、安全审计和性能优…...
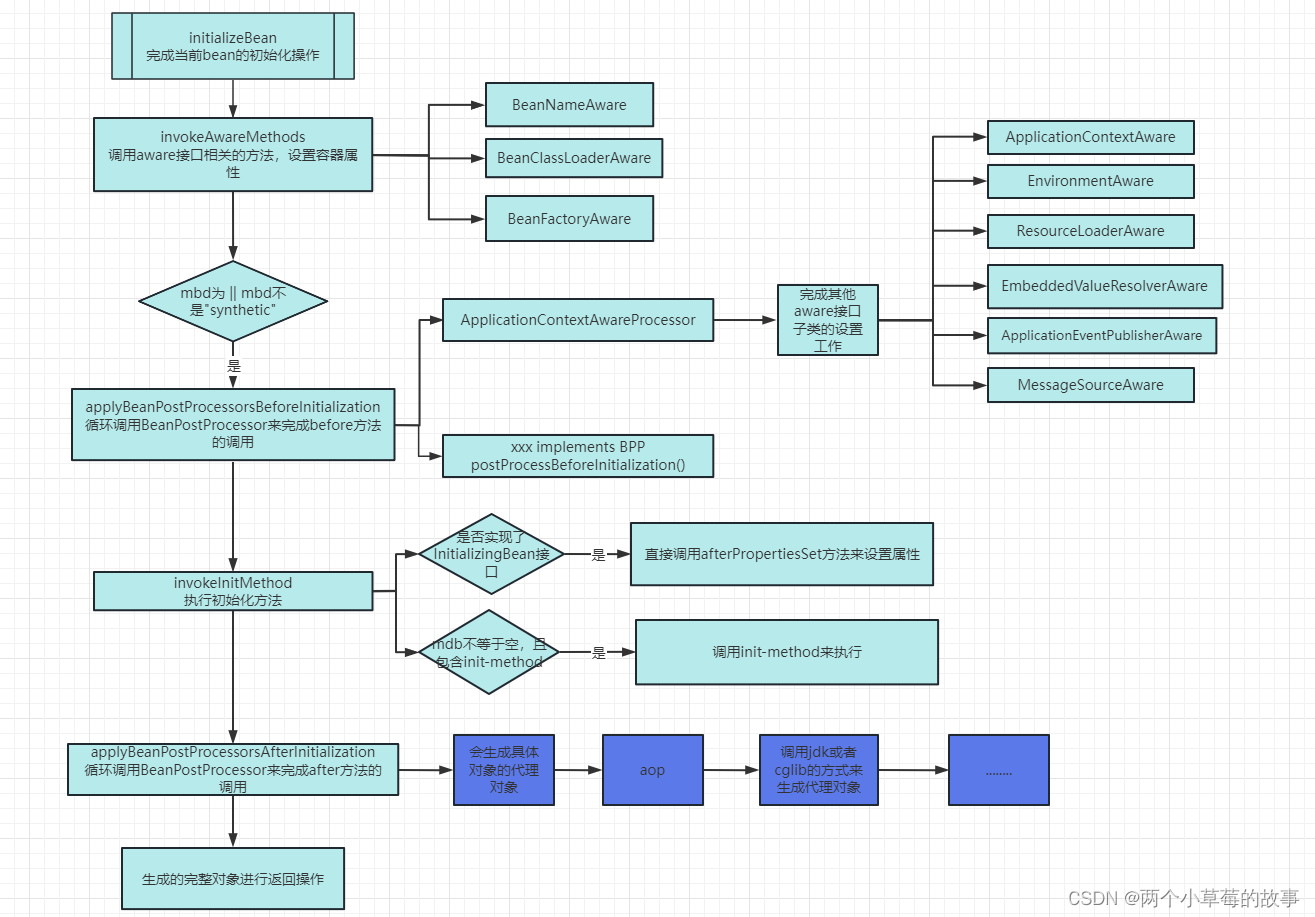
Spring源码分析(三) IOC 之 createBean()和doCreateBean()
a、在createBean中又是主要做了什么事情? 完成bean得创建,填充属性、循环依赖 、aop等一系列过程 1、createBean() 在createBean中主要干了3件事情 1、解析class -> resolveBeanClass() 2、验证及准备覆盖的方法,lookup-method replace-method -> …...
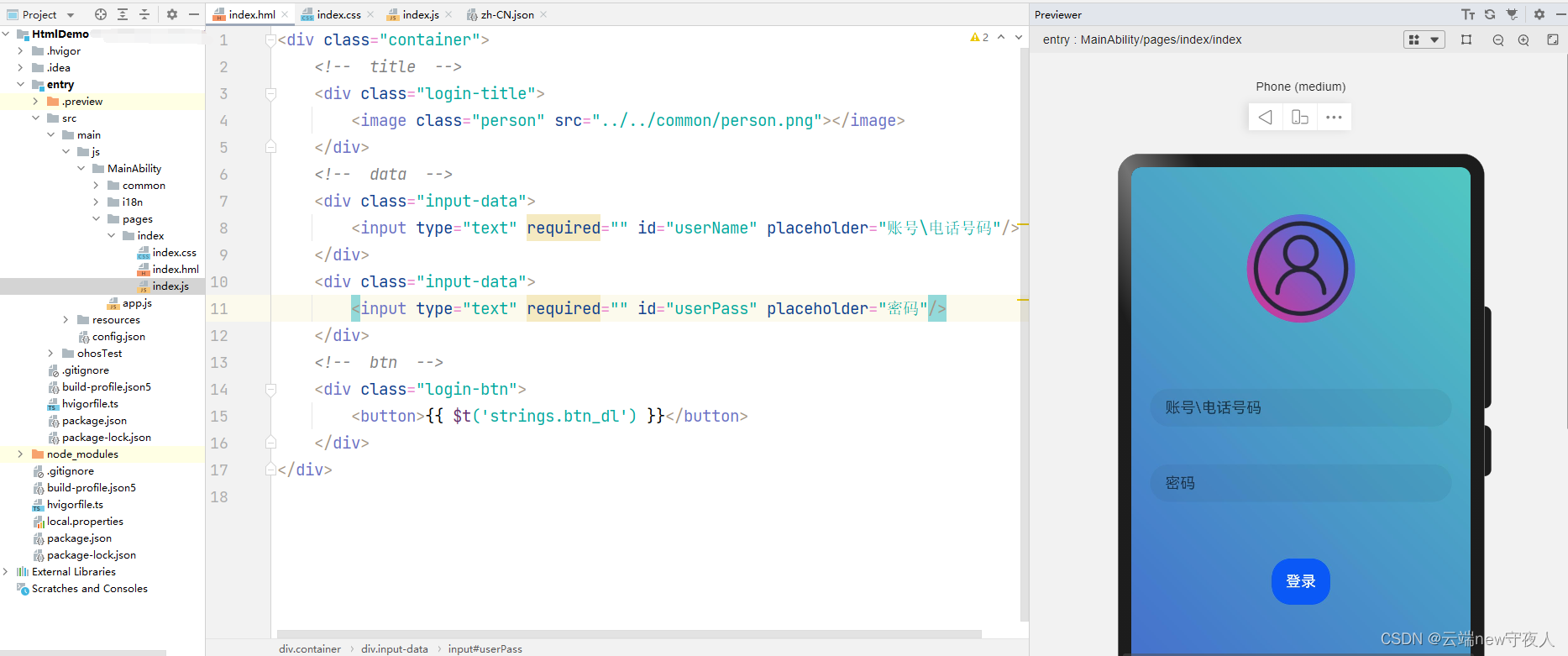
【鸿蒙(HarmonyOS)】UI开发的两种范式:ArkTS、JS(以登录界面开发为例进行对比)
文章目录 一、引言1、开发环境2、整体架构图 二、认识ArkUI1、基本概念2、开发范式(附:案例)(1)ArkTS(2)JS 三、附件 一、引言 1、开发环境 之后关于HarmonyOS技术的分享,将会持续使…...

Flink中的批和流
批处理的特点是有界、持久、大量,非常适合需要访问全部记录才能完成的计算工作,一般用于离线统计。 流处理的特点是无界、实时, 无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。 而在Flin…...
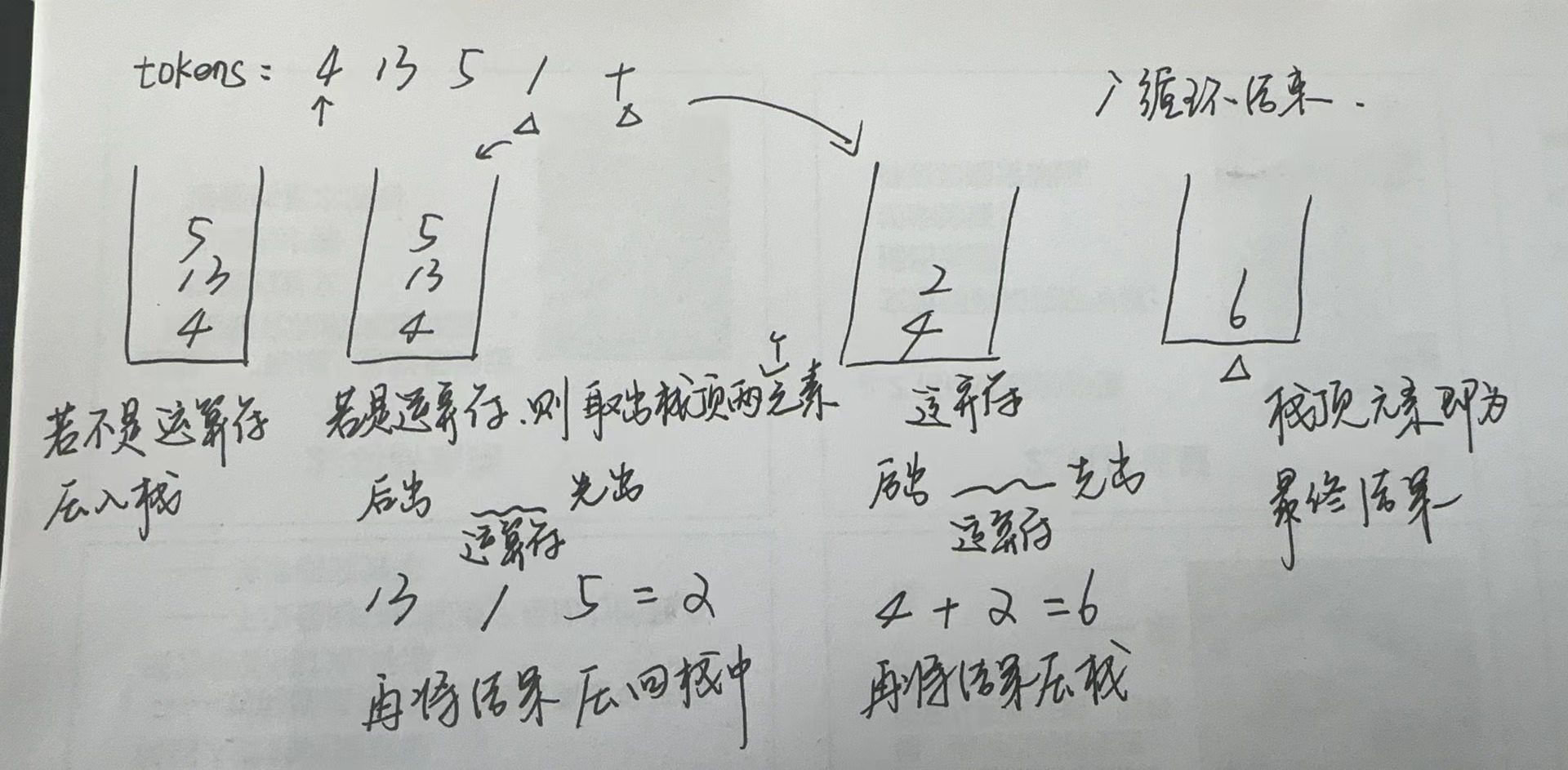
【LeetCode-中等题】150. 逆波兰表达式求值
文章目录 题目方法一:栈 题目 方法一:栈 class Solution {public int evalRPN(String[] tokens) {Deque<Integer> deque new LinkedList<>();String rpn "-*/";//符号集 用来判断扫描的是否为运算符int sum 0;for(int i 0 ; i…...
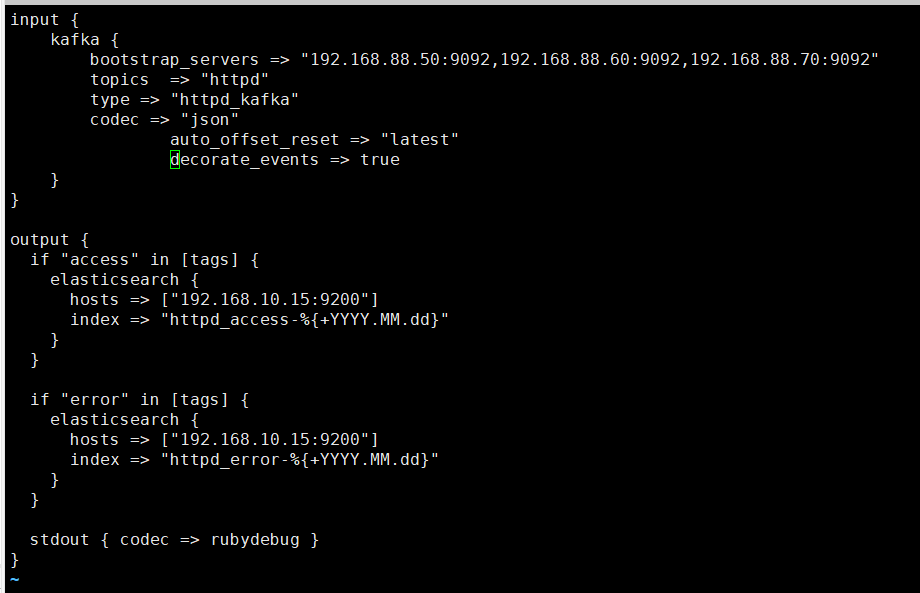
搭建ELK+Filebead+zookeeper+kafka实验
部署 Zookeeper 集群 准备 3 台服务器做 Zookeeper 集群 192.168.10.17 192.168.10.21 192.168.10.22 1.安装前准备 关闭防火墙 systemctl stop firewalld systemctl disable firewalld setenforce 0 安装 JDK yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-…...
)
java专题练习(抢红包)
package 专题练习;import java.util.Random;public class grab_red_packet {/* 需求:直播抽奖,分别由{2,588,888,1000,10000}五个奖金,请用代码模拟抽奖,奖项出现顺序要随机且不重复打印效果:588元的奖金被抽出*///思路://1. 先用数组把奖金定义好//2. 用random方法给出随机数索…...

AVR 单片机 调试环境 JTAG MKII
注意 驱动 的厂家: 如果驱动备改变为其他厂家的驱动 就与 AVR Studio7不兼容 保证驱动选择正确是 能够使用硬件调试的关键 如果驱动不对,使用 USB驱动修改工具 修改 比如 UsbDriverTool.exe...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...

鱼香ros docker配置镜像报错:https://registry-1.docker.io/v2/
使用鱼香ros一件安装docker时的https://registry-1.docker.io/v2/问题 一键安装指令 wget http://fishros.com/install -O fishros && . fishros出现问题:docker pull 失败 网络不同,需要使用镜像源 按照如下步骤操作 sudo vi /etc/docker/dae…...

【OSG学习笔记】Day 16: 骨骼动画与蒙皮(osgAnimation)
骨骼动画基础 骨骼动画是 3D 计算机图形中常用的技术,它通过以下两个主要组件实现角色动画。 骨骼系统 (Skeleton):由层级结构的骨头组成,类似于人体骨骼蒙皮 (Mesh Skinning):将模型网格顶点绑定到骨骼上,使骨骼移动…...

技术栈RabbitMq的介绍和使用
目录 1. 什么是消息队列?2. 消息队列的优点3. RabbitMQ 消息队列概述4. RabbitMQ 安装5. Exchange 四种类型5.1 direct 精准匹配5.2 fanout 广播5.3 topic 正则匹配 6. RabbitMQ 队列模式6.1 简单队列模式6.2 工作队列模式6.3 发布/订阅模式6.4 路由模式6.5 主题模式…...

安全突围:重塑内生安全体系:齐向东在2025年BCS大会的演讲
文章目录 前言第一部分:体系力量是突围之钥第一重困境是体系思想落地不畅。第二重困境是大小体系融合瓶颈。第三重困境是“小体系”运营梗阻。 第二部分:体系矛盾是突围之障一是数据孤岛的障碍。二是投入不足的障碍。三是新旧兼容难的障碍。 第三部分&am…...
免费数学几何作图web平台
光锐软件免费数学工具,maths,数学制图,数学作图,几何作图,几何,AR开发,AR教育,增强现实,软件公司,XR,MR,VR,虚拟仿真,虚拟现实,混合现实,教育科技产品,职业模拟培训,高保真VR场景,结构互动课件,元宇宙http://xaglare.c…...