ELFK之zookeeper+kafka
目录
kafka+zookeeper的系统架构
Zookeeper
一、zookeeper概述
二、zookeeper特点
三、zookeeper选举机制
四、应用场景
五、zookeeper实验实例
Kafka
一、概述
为什么需要消息队列(MQ)
使用消息队列的好处
消息队列的两种模式
Kafka 定义
二、Kafka 的特性
三、Kafka 系统架构
分区的原因
四、实例演示
kafka+zookeeper的系统架构
生产者要推送到kafka集群需要先通过zookeeper确定kafka的位置,消费者消费的数据到哪里也要根据数据在zookeeper上的offset确定offset偏移量记录上一条消费者消费的数据位置,以便在故障恢复后可以接着下一次继续消费。部署kafka集群要先部署zookeeper集群,在zookeeper集群基础上安装kafka应用,节点数量>=3的奇数台
几个kafka服务器就是几个broker,生成推送数据到topic,topic可以被分区多个partition,一个partition可以有多个replica(副本),replica可以是一个leader和多个follower,leader负责数据的读写,follower仅负责数据备份,消费者面向topic进行数据的消费
Zookeeper
一、zookeeper概述
定义:Zookeeper是一个开源的分布式的,为分布式框架提供协调服务的Apache项目。
zookeeper服务集群的条件:
zookeeper服务自身组成集群,2n+1个(奇数)主机,在集群中,允许n个主机宕机。
只要集群中有一半以上的机器可用,zookeeper集群就可用。
工作机制:Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。也就是说 Zookeeper = 文件系统 + 通知机制。
二、zookeeper特点
(1)Zookeeper:一个领导者(Leader),多个跟随者(Follower)组成的集群。
(2)Zookeepe集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。所以Zookeeper适合安装奇数台服务器。
(3)全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。
(4)更新请求顺序执行,来自同一个Client的更新请求按其发送顺序依次执行,即先进先出。
(5)数据更新原子性,一次数据更新要么成功,要么失败。
(6)实时性,在一定时间范围内,Client能读到最新数据。
三、zookeeper选举机制
第一次启动选举机制
(1)服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING;
(2)服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的myid比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING
(3)服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING;
(4)服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING;
(5)服务器5启动,同4一样当小弟。
非第一次启动选举机制
(1)当ZooKeeper 集群中的一台服务器出现以下两种情况之一时,就会开始进入Leader选举:
1)服务器初始化启动。
2)服务器运行期间无法和Leader保持连接。
(2)而当一台机器进入Leader选举流程时,当前集群也可能会处于以下两种状态:
1)集群中本来就已经存在一个Leader。
对于已经存在Leader的情况,机器试图去选举Leader时,会被告知当前服务器的Leader信息,对于该机器来说,仅仅需要和 Leader机器建立连接,并进行状态同步即可。
2)集群中确实不存在Leader。
假设ZooKeeper由5台服务器组成,SID分别为1、2、3、4、5,ZXID分别为8、8、8、7、7,并且此时SID为3的服务器是Leader。某一时刻,3和5服务器出现故障,因此开始进行Leader选举。
选举Leader规则:
1.EPOCH大的直接胜出
2.EPOCH相同,事务id大的胜出
3.事务id相同,服务器id大的胜出
ps:
SID:服务器ID。用来唯一标识一台ZooKeeper集群中的机器,每台机器不能重复,和myid一致。
ZXID:事务ID。ZXID是一个事务ID,用来标识一次服务器状态的变更。在某一时刻,集群中的每台机器的ZXID值不一定完全一致,这和ZooKeeper服务器对于客户端“更新请求”的处理逻辑速度有关。
Epoch:每个Leader任期的代号。没有Leader时同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加
四、应用场景
提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。
统一命名服务
在分布式环境下,经常需要对应用/服务进行统一命名,便于识别。例如:IP不容易记住,而域名容易记住。
统一配置管理
(1)分布式环境下,配置文件同步非常常见。一般要求一个集群中,所有节点的配置信息是一致的,比如Kafka集群。对配置文件修改后,希望能够快速同步到各个节点上。
(2)配置管理可交由ZooKeeper实现。可将配置信息写入ZooKeeper上的一个Znode。各个客户端服务器监听这个Znode。一旦 Znode中的数据被修改,ZooKeeper将通知各个客户端服务器。
统一集群管理
(1)分布式环境中,实时掌握每个节点的状态是必要的。可根据节点实时状态做出一些调整。
(2)ZooKeeper可以实现实时监控节点状态变化。可将节点信息写入ZooKeeper上的一个ZNode。监听这个ZNode可获取它的实时状态变化。
服务器动态上下线
客户端能实时洞察到服务器上下线的变化。
软负载均衡
在Zookeeper中记录每台服务器的访问数,让访问数最少的服务器去处理最新的客户端请求。
五、zookeeper实验实例
| ip地址 | 服务 | server | myid | |
| zookeeper1 | 192.168.11.14 | zookeeper | 1 | 1 |
| zookeeper2 | 192.168.11.15 | zookeeper | 2 | 2 |
| zookeeper3 | 192.168.11.10 | zookeeper | 3 | 3 |
代码示例:
---------------- 部署 Zookeeper 集群 ----------------
//准备 3 台服务器做 Zookeeper 集群
192.168.10.17
192.168.10.21
192.168.10.221.安装前准备
//关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
setenforce 0//安装 JDK
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel
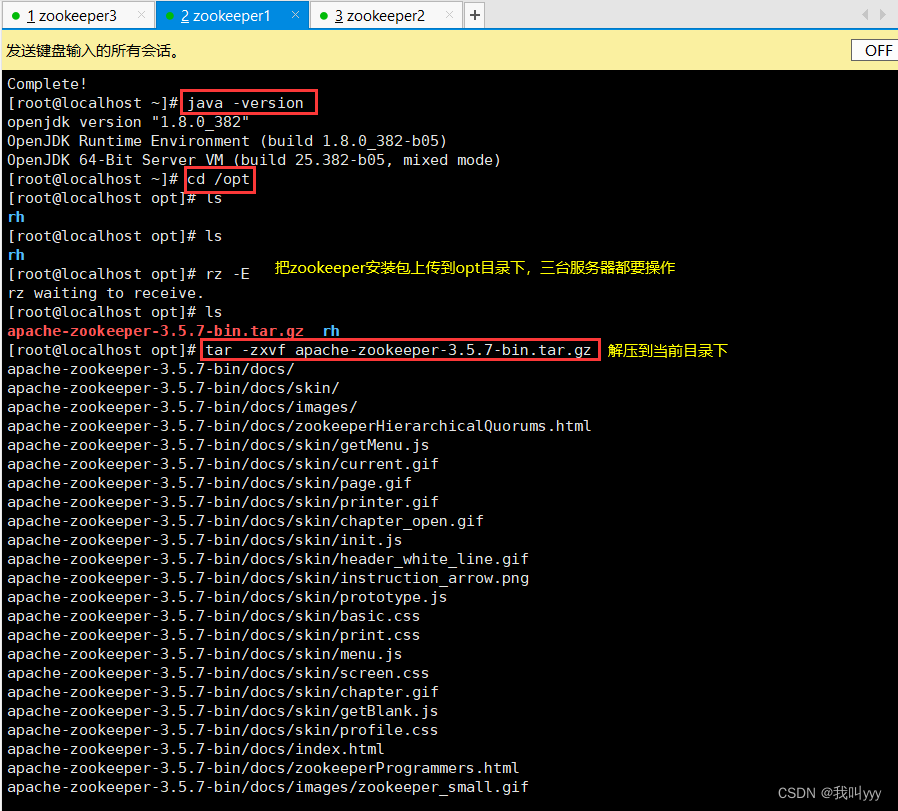
java -version//下载安装包
官方下载地址:https://archive.apache.org/dist/zookeeper/cd /opt
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/apache-zookeeper-3.5.7-bin.tar.gz2.安装 Zookeeper
cd /opt
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz
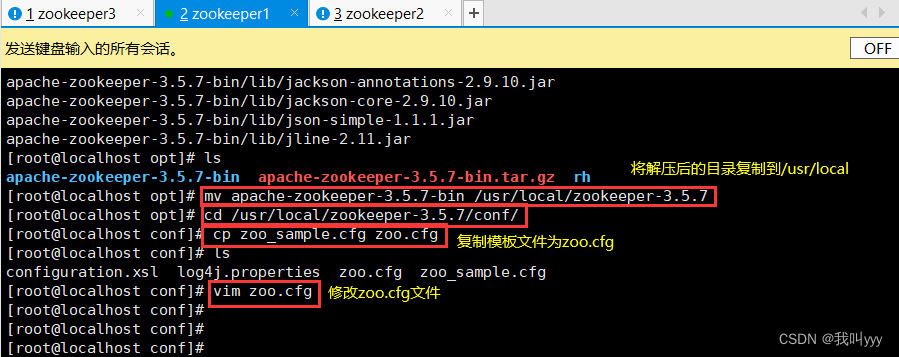
mv apache-zookeeper-3.5.7-bin /usr/local/zookeeper-3.5.7//修改配置文件
cd /usr/local/zookeeper-3.5.7/conf/
cp zoo_sample.cfg zoo.cfgvim zoo.cfg
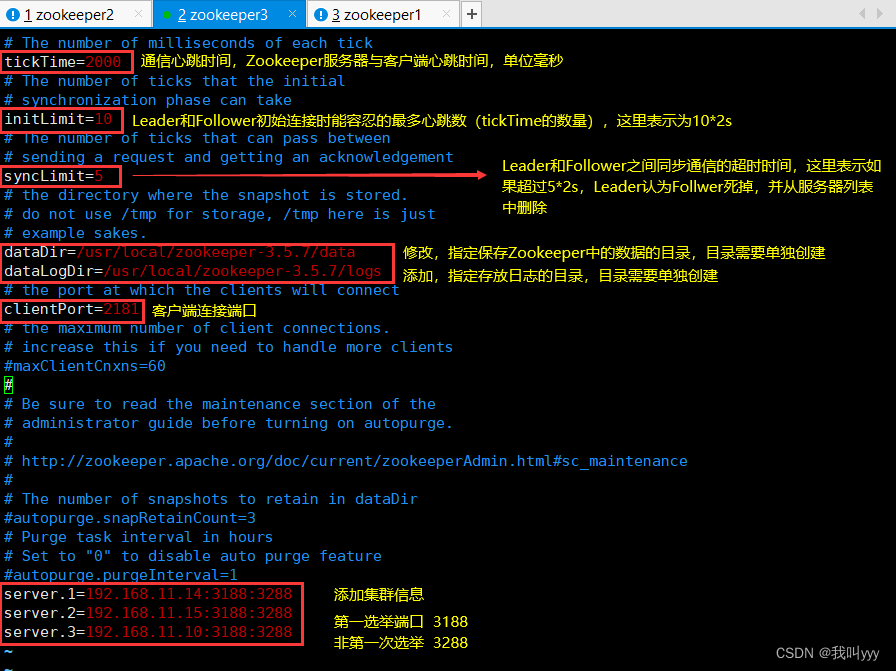
tickTime=2000 #通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
initLimit=10 #Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量),这里表示为10*2s
syncLimit=5 #Leader和Follower之间同步通信的超时时间,这里表示如果超过5*2s,Leader认为Follwer死掉,并从服务器列表中删除Follwer
dataDir=/usr/local/zookeeper-3.5.7/data ●修改,指定保存Zookeeper中的数据的目录,目录需要单独创建
dataLogDir=/usr/local/zookeeper-3.5.7/logs ●添加,指定存放日志的目录,目录需要单独创建
clientPort=2181 #客户端连:接端口
#添加集群信息
server.1=192.168.10.17:3188:3288
server.2=192.168.10.21:3188:3288
server.3=192.168.10.22:3188:3288-------------------------------------------------------------------------------------
server.A=B:C:D
●A是一个数字,表示这个是第几号服务器。集群模式下需要在zoo.cfg中dataDir指定的目录下创建一个文件myid,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
●B是这个服务器的地址。
●C是这个服务器Follower与集群中的Leader服务器交换信息的端口。
●D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
-------------------------------------------------------------------------------------//拷贝配置好的 Zookeeper 配置文件到其他机器上
scp /usr/local/zookeeper-3.5.7/conf/zoo.cfg 192.168.10.21:/usr/local/zookeeper-3.5.7/conf/
scp /usr/local/zookeeper-3.5.7/conf/zoo.cfg 192.168.10.22:/usr/local/zookeeper-3.5.7/conf///在每个节点上创建数据目录和日志目录
mkdir /usr/local/zookeeper-3.5.7/data
mkdir /usr/local/zookeeper-3.5.7/logs//在每个节点的dataDir指定的目录下创建一个 myid 的文件
echo 1 > /usr/local/zookeeper-3.5.7/data/myid
echo 2 > /usr/local/zookeeper-3.5.7/data/myid
echo 3 > /usr/local/zookeeper-3.5.7/data/myid//配置 Zookeeper 启动脚本
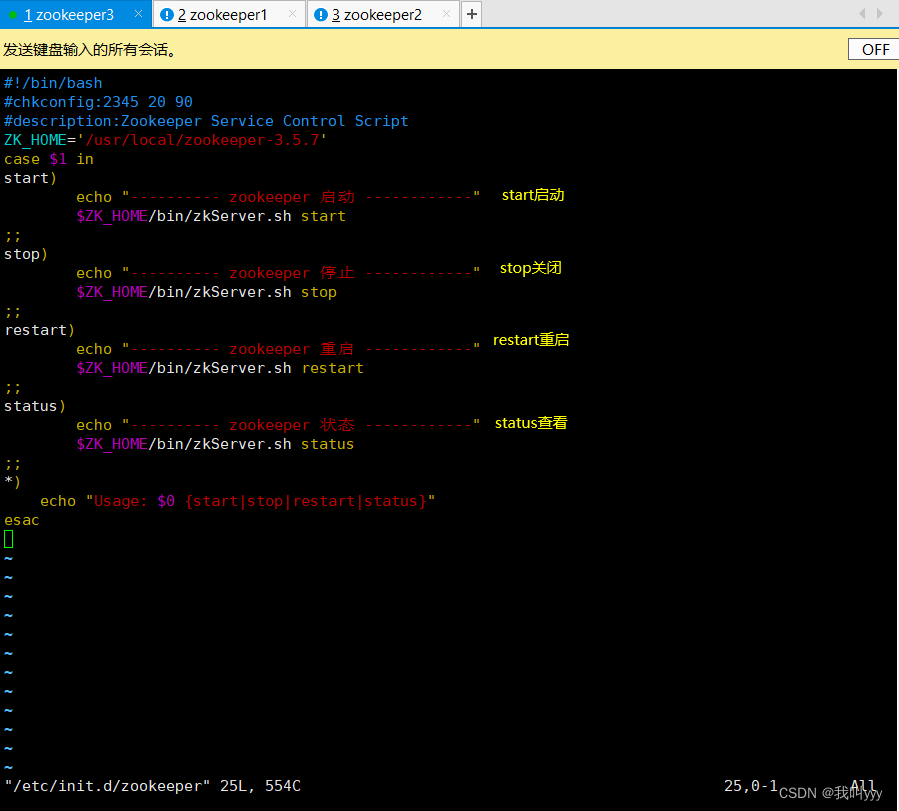
vim /etc/init.d/zookeeper
#!/bin/bash
#chkconfig:2345 20 90
#description:Zookeeper Service Control Script
ZK_HOME='/usr/local/zookeeper-3.5.7'
case $1 in
start)echo "---------- zookeeper 启动 ------------"$ZK_HOME/bin/zkServer.sh start
;;
stop)echo "---------- zookeeper 停止 ------------"$ZK_HOME/bin/zkServer.sh stop
;;
restart)echo "---------- zookeeper 重启 ------------"$ZK_HOME/bin/zkServer.sh restart
;;
status)echo "---------- zookeeper 状态 ------------"$ZK_HOME/bin/zkServer.sh status
;;
*)echo "Usage: $0 {start|stop|restart|status}"
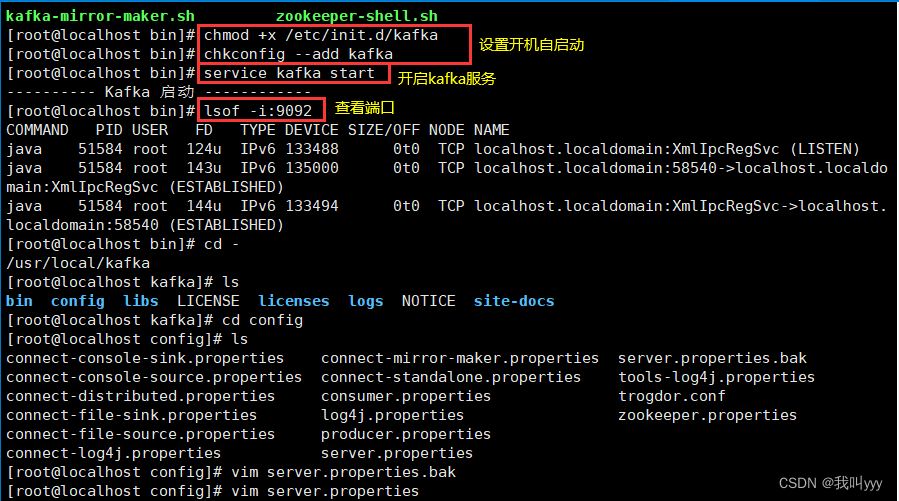
esac// 设置开机自启
chmod +x /etc/init.d/zookeeper
chkconfig --add zookeeper//分别启动 Zookeeper
service zookeeper start//查看当前状态
service zookeeper status
1.安装前准备,关闭防火墙,安装 JDK

2.安装 Zookeeper
修改配置文件
在每个节点上创建数据目录和日志目录

在每个节点的dataDir指定的目录下创建一个 myid 的文件


 配置 Zookeeper 启动脚本
配置 Zookeeper 启动脚本
设置开机自启
分别启动 Zookeeper!!!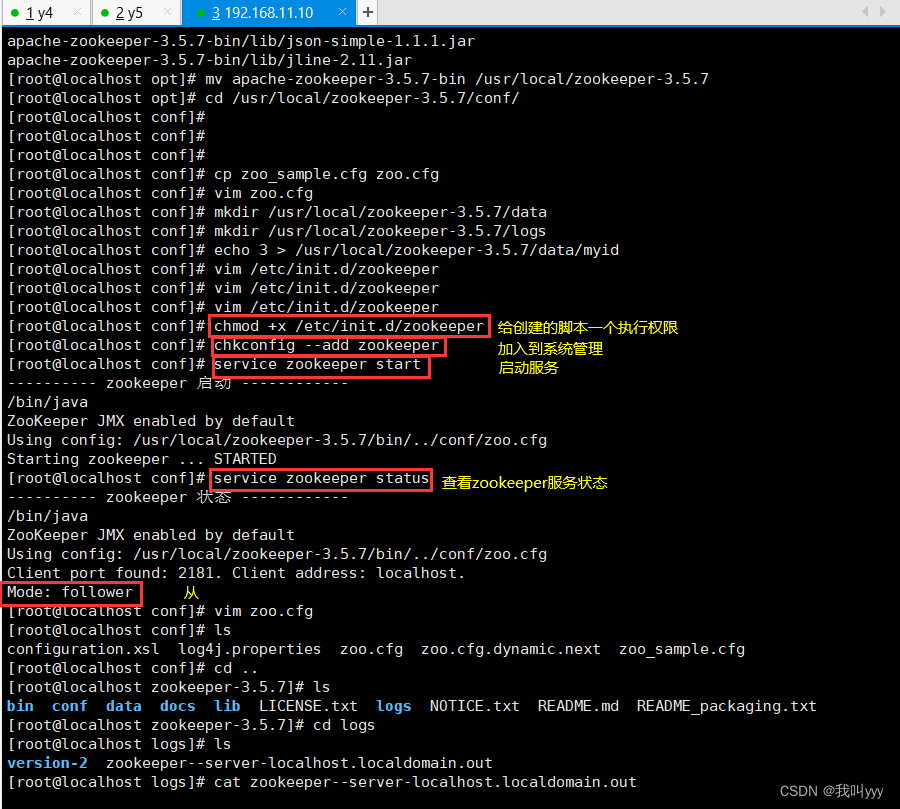
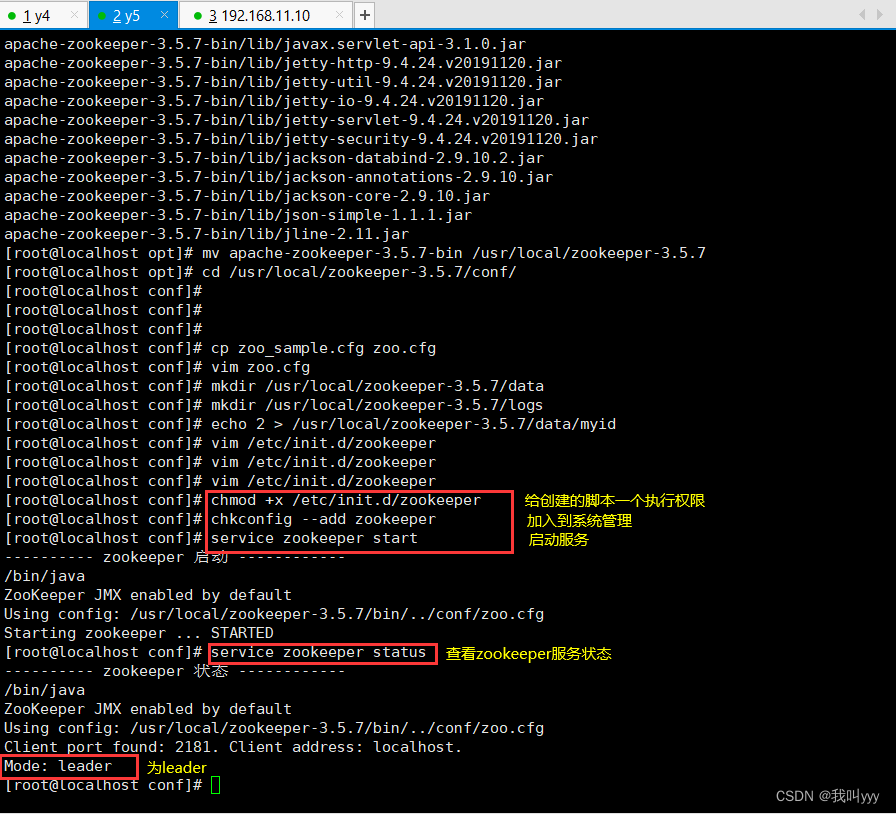
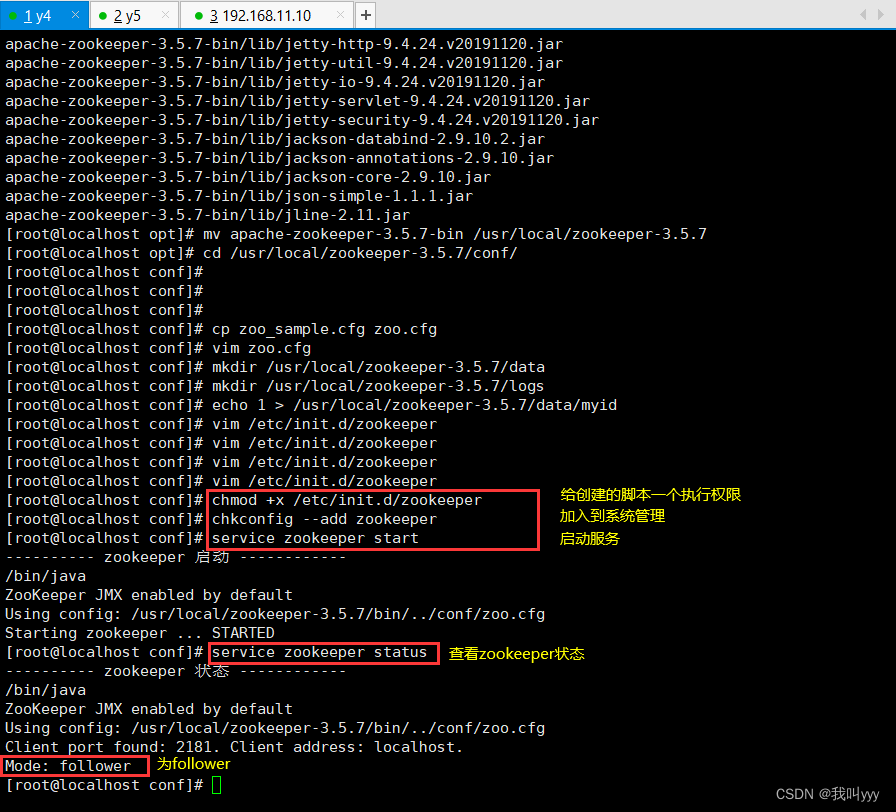
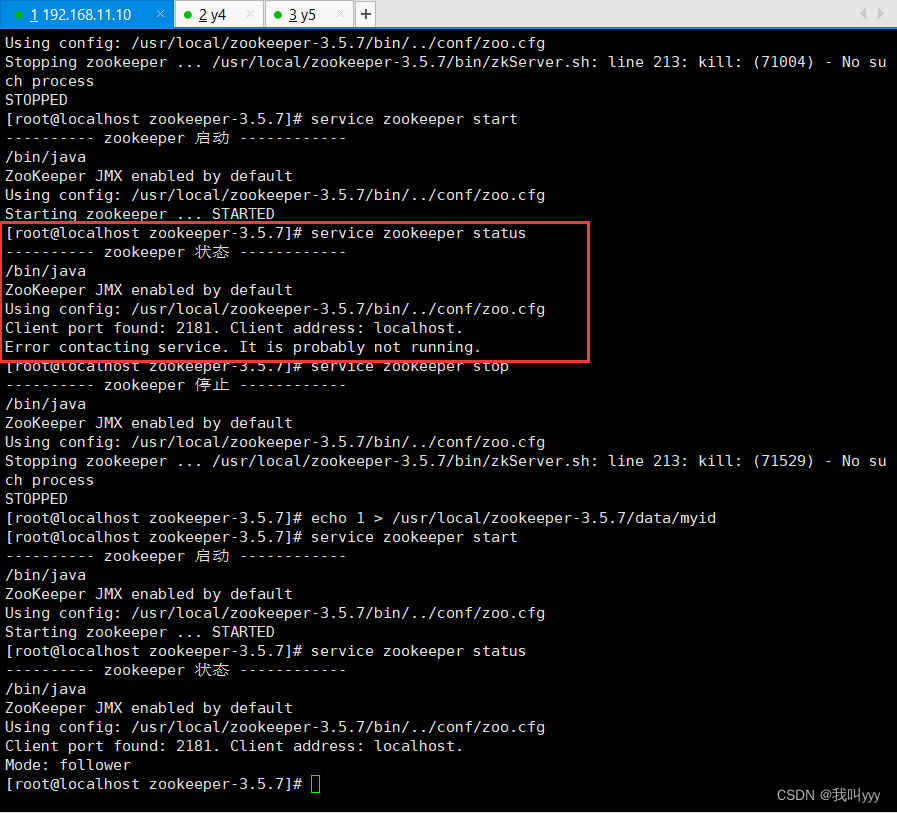
问题总结:如果出现error contacting service.It is probably not running 的状态,可能是你的zoo.cfg的配置文件中,server.1、server.2、server.3的顺序要和你输到myid里的序号id要对应!!!
比如server.1的myid序号就要为1
server.2的myid序号就要为2
server.3的myid序号就要为3
Kafka
一、概述
为什么需要消息队列(MQ)
主要原因是由于在高并发环境下,同步请求来不及处理,请求往往会发生阻塞。比如大量的请求并发访问数据库,导致行锁表锁,最后请求线程会堆积过多,从而触发 too many connection 错误,引发雪崩效应。
我们使用消息队列,通过异步处理请求,从而缓解系统的压力。消息队列常应用于异步处理,流量削峰,应用解耦,消息通讯等场景。
当前比较常见的 MQ 中间件有 ActiveMQ、RabbitMQ、RocketMQ、Kafka 等。
使用消息队列的好处
1)解耦
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
(2)可恢复性
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
(3)缓冲
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
(4)灵活性 & 峰值处理能力
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
(5)异步通信
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
消息队列的两种模式
(1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
消息生产者生产消息发送到消息队列中,然后消息消费者从消息队列中取出并且消费消息。消息被消费以后,消息队列中不再有存储,所以消息消费者不可能消费到已经被消费的消息。消息队列支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
(2)发布/订阅模式(一对多,又叫观察者模式,消费者消费数据之后不会清除消息)
消息生产者(发布)将消息发布到 topic 中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到 topic 的消息会被所有订阅者消费。
发布/订阅模式是定义对象间一种一对多的依赖关系,使得每当一个对象(目对标象)的状态发生改变,则所有依赖于它的对象(观察者对象)都会得到通知并自动更新。
Kafka 定义
Kafka 是一个分布式的基于发布/订阅模式的消息队列(MQ,Message Queue),主要应用于大数据实时处理领域。
基于 Zookeeper,Kafka 是最初由 Linkedin 公司开发,是一个分布式、支持分区的(partition)、多副本的(replicar 协调的分布式消息中间件系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景,比如基于 hadoop 的批处理系统、低延迟的实时系统、Spark/Flink 流式处理引擎,nginx 访问日志,消息服务等等,用 scala 语言编写,
Linkedin 于 2010 年贡献给了 Apache 基金会并成为顶级开源项目。
二、Kafka 的特性
(1)高吞吐量、低延迟
Kafka 每秒可以处理几十万条消息,它的延迟最低只有几毫秒。每个 topic 可以分多个 Partition,Consumer Group 对 Partition 进行消费操作,提高负载均衡能力和消费能力。
(2)可扩展性
kafka 集群支持热扩展
(3)持久性、可靠性
消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
(4)容错性
允许集群中节点失败(多副本情况下,若副本数量为 n,则允许 n-1 个节点失败)
(5)高并发
支持数千个客户端同时读写
三、Kafka 系统架构
(1)Broker 服务器
一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topic。
(2)Topic 主题
可以理解为一个队列,生产者和消费者面向的都是一个 topic。
类似于数据库的表名或者 ES 的 index
物理上不同 topic 的消息分开存储
(3)Partition 分区
为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分割为一个或多个 partition,每个 partition 是一个有序的队列。Kafka 只保证 partition 内的记录是有序的,而不保证 topic 中不同 partition 的顺序。
每个 topic 至少有一个 partition,当生产者产生数据的时候,会根据分配策略选择分区,然后将消息追加到指定的分区的队列末尾。
##Partation 数据路由规则:
1.指定了 patition,则直接使用;
2.未指定 patition 但指定 key(相当于消息中某个属性),通过对 key 的 value 进行 hash 取模,选出一个 patition;
3.patition 和 key 都未指定,使用轮询选出一个 patition。
每条消息都会有一个自增的编号,用于标识消息的偏移量,标识顺序从 0 开始。
每个 partition 中的数据使用多个 segment 文件存储。
如果 topic 有多个 partition,消费数据时就不能保证数据的顺序。严格保证消息的消费顺序的场景下(例如商品秒杀、 抢红包),需要将 partition 数目设为 1。
broker 存储 topic 的数据。如果某 topic 有 N 个 partition,集群有 N 个 broker,那么每个 broker 存储该 topic 的一个 partition。
如果某 topic 有 N 个 partition,集群有 (N+M) 个 broker,那么其中有 N 个 broker 存储 topic 的一个 partition, 剩下的 M 个 broker 不存储该 topic 的 partition 数据。
如果某 topic 有 N 个 partition,集群中 broker 数目少于 N 个,那么一个 broker 存储该 topic 的一个或多个 partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致 Kafka 集群数据不均衡。
分区的原因
方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了;
可以提高并发,因为可以以Partition为单位读写了。
(1)Replica
副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower。
(2)Leader
每个 partition 有多个副本,其中有且仅有一个作为 Leader,Leader 是当前负责数据的读写的 partition。
(3)Follower
Follower 跟随 Leader,所有写请求都通过 Leader 路由,数据变更会广播给所有 Follower,Follower 与 Leader 保持数据同步。Follower 只负责备份,不负责数据的读写。
如果 Leader 故障,则从 Follower 中选举出一个新的 Leader。
当 Follower 挂掉、卡住或者同步太慢,Leader 会把这个 Follower 从 ISR(Leader 维护的一个和 Leader 保持同步的 Follower 集合) 列表中删除,重新创建一个 Follower。
(4) producer
生产者即数据的发布者,该角色将消息 push 发布到 Kafka 的 topic 中。
broker 接收到生产者发送的消息后,broker 将该消息追加到当前用于追加数据的 segment 文件中。
生产者发送的消息,存储到一个 partition 中,生产者也可以指定数据存储的 partition。
(5)Consumer
消费者可以从 broker 中 pull 拉取数据。消费者可以消费多个 topic 中的数据。
(6)Consumer Group(CG)
消费者组,由多个 consumer 组成。
所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。可为每个消费者指定组名,若不指定组名则属于默认的组。
将多个消费者集中到一起去处理某一个 Topic 的数据,可以更快的提高数据的消费能力。
消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费,防止数据被重复读取。
消费者组之间互不影响。
(7)offset 偏移量
可以唯一的标识一条消息。
偏移量决定读取数据的位置,不会有线程安全的问题,消费者通过偏移量来决定下次读取的消息(即消费位置)。
消息被消费之后,并不被马上删除,这样多个业务就可以重复使用 Kafka 的消息。
某一个业务也可以通过修改偏移量达到重新读取消息的目的,偏移量由用户控制。
消息最终是会还被删除的,默认生命周期为 1 周(7*24小时)。
(8)Zookeeper
Kafka 通过 Zookeeper 来存储集群的 meta 信息。
由于 consumer 在消费过程中可能会出现断电宕机等故障,consumer 恢复后,需要从故障前的位置的继续消费,所以 consumer 需要实时记录自己消费到了哪个 offset,以便故障恢复后继续消费。
Kafka 0.9 版本之前,consumer 默认将 offset 保存在 Zookeeper 中;从 0.9 版本开始,consumer 默认将 offset 保存在 Kafka 一个内置的 topic 中,该 topic 为 __consumer_offsets。
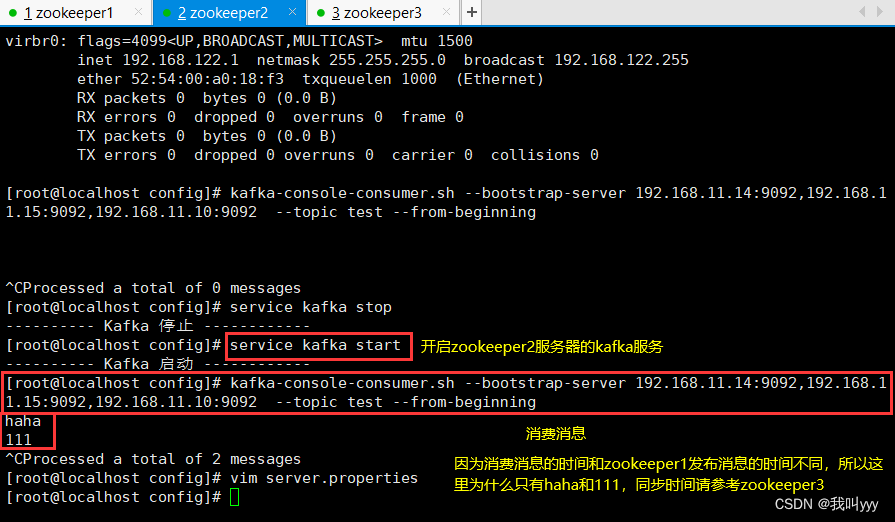
也就是说,zookeeper的作用就是,生产者push数据到kafka集群,就必须要找到kafka集群的节点在哪里,这些都是通过zookeeper去寻找的。消费者消费哪一条数据,也需要zookeeper的支持,从zookeeper获得offset,offset记录上一次消费的数据消费到哪里,这样就可以接着下一条数据进行消费。
四、实例演示
| 服务器名 | ip地址 | 服务 | server | myid | broker_id |
| zookeeper1 | 192.168.11.14 | zookeeper+kafka | 1 | 1 | 0 |
| zookeeper2 | 192.168.11.15 | zookeeper+kafka | 2 | 2 | 1 |
| zookeeper3 | 192.168.11.10 | zookeeper+kafka | 3 | 3 | 2 |
代码示例:
---------------- 部署 kafka 集群 ----------------
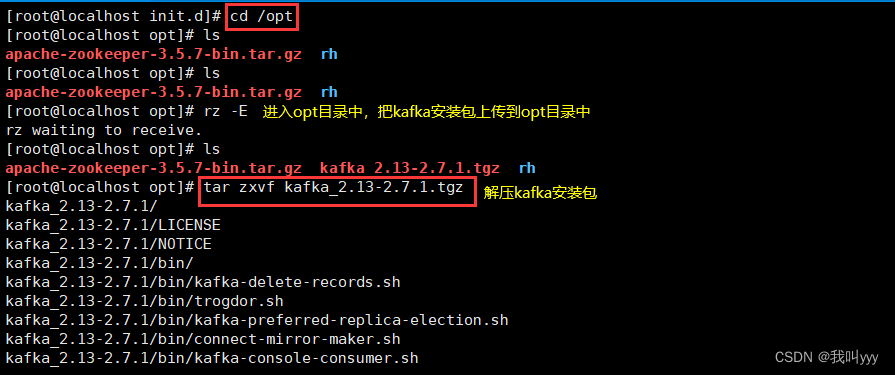
1.下载安装包
官方下载地址:http://kafka.apache.org/downloads.htmlcd /opt
wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.7.1/kafka_2.13-2.7.1.tgz2.安装 Kafka
cd /opt/
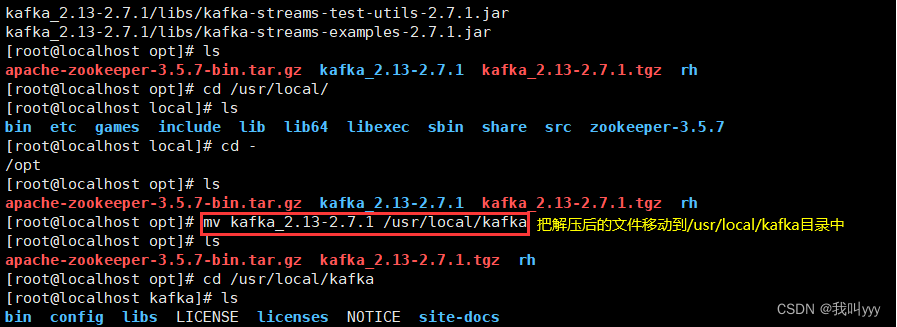
tar zxvf kafka_2.13-2.7.1.tgz
mv kafka_2.13-2.7.1 /usr/local/kafka//修改配置文件
cd /usr/local/kafka/config/
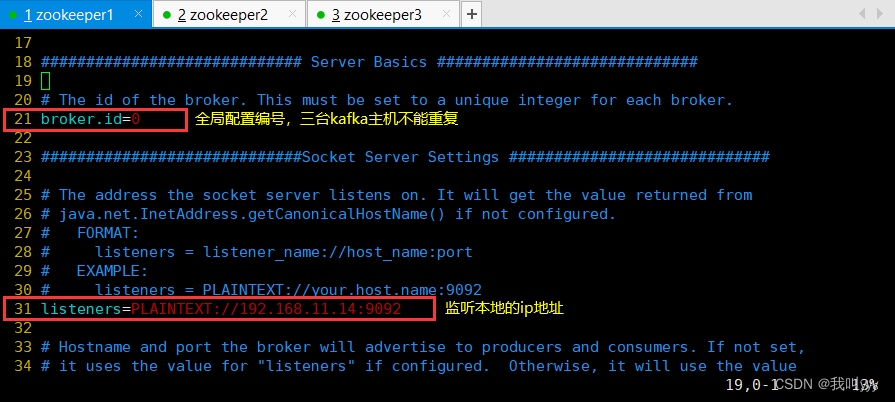
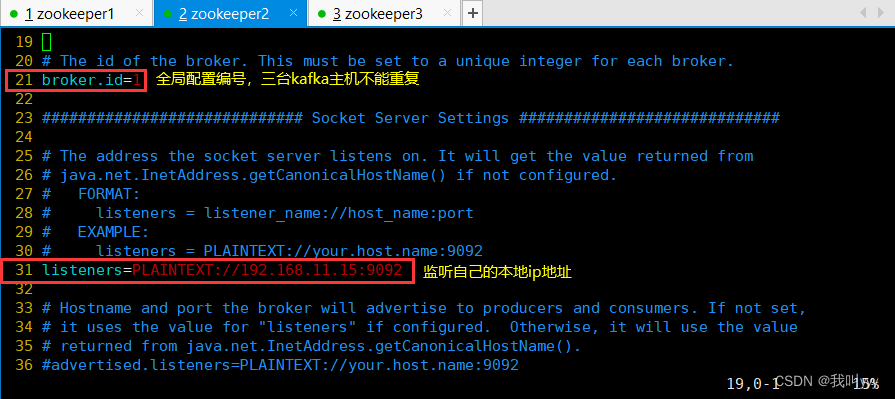
cp server.properties{,.bak}vim server.properties
broker.id=0 ●21行,broker的全局唯一编号,每个broker不能重复,因此要在其他机器上配置 broker.id=1、broker.id=2
listeners=PLAINTEXT://192.168.10.17:9092 ●31行,指定监听的IP和端口,如果修改每个broker的IP需区分开来,也可保持默认配置不用修改
num.network.threads=3 #42行,broker 处理网络请求的线程数量,一般情况下不需要去修改
num.io.threads=8 #45行,用来处理磁盘IO的线程数量,数值应该大于硬盘数
socket.send.buffer.bytes=102400 #48行,发送套接字的缓冲区大小
socket.receive.buffer.bytes=102400 #51行,接收套接字的缓冲区大小
socket.request.max.bytes=104857600 #54行,请求套接字的缓冲区大小
log.dirs=/usr/local/kafka/logs #60行,kafka运行日志存放的路径,也是数据存放的路径
num.partitions=1 #65行,topic在当前broker上的默认分区个数,会被topic创建时的指定参数覆盖
num.recovery.threads.per.data.dir=1 #69行,用来恢复和清理data下数据的线程数量
log.retention.hours=168 #103行,segment文件(数据文件)保留的最长时间,单位为小时,默认为7天,超时将被删除
log.segment.bytes=1073741824 #110行,一个segment文件最大的大小,默认为 1G,超出将新建一个新的segment文件
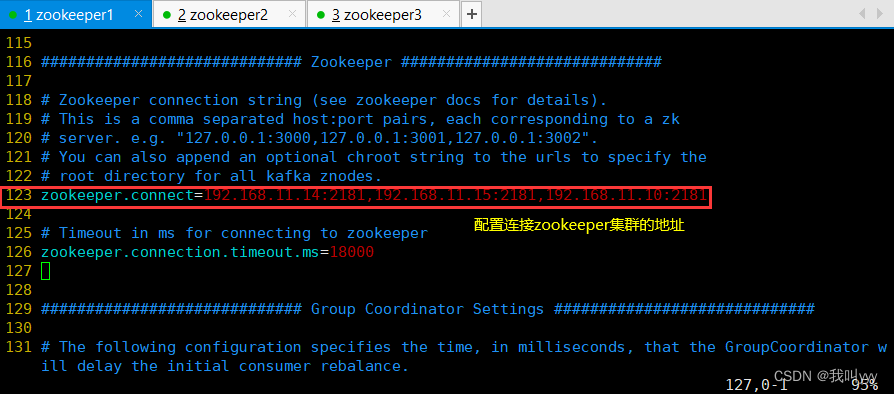
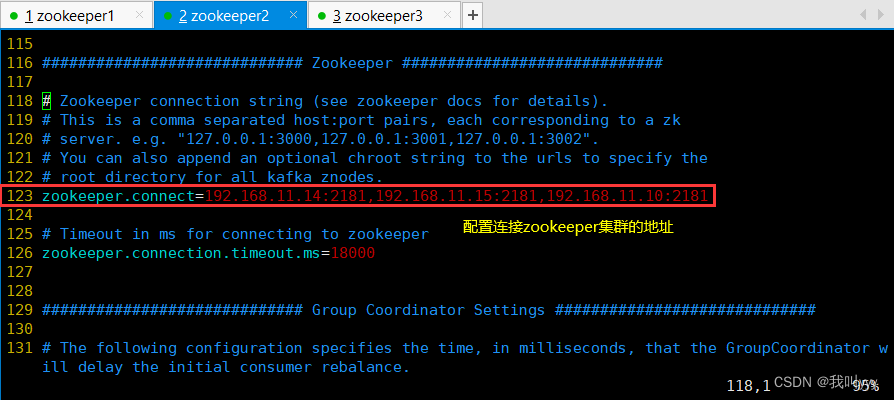
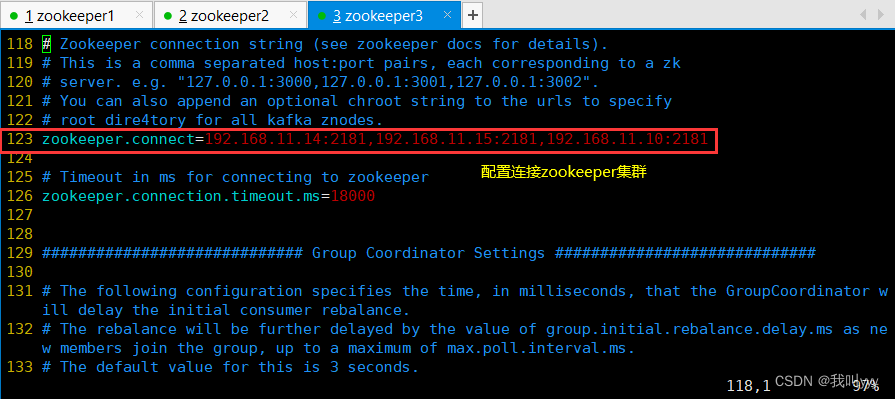
zookeeper.connect=192.168.10.17:2181,192.168.10.21:2181,192.168.10.22:2181 ●123行,配置连接Zookeeper集群地址//修改环境变量
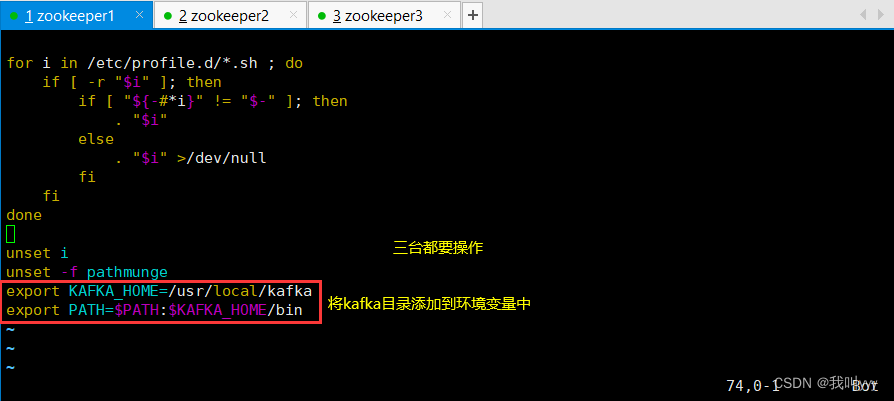
vim /etc/profile
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/binsource /etc/profile//配置 Zookeeper 启动脚本
vim /etc/init.d/kafka
#!/bin/bash
#chkconfig:2345 22 88
#description:Kafka Service Control Script
KAFKA_HOME='/usr/local/kafka'
case $1 in
start)echo "---------- Kafka 启动 ------------"${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties
;;
stop)echo "---------- Kafka 停止 ------------"${KAFKA_HOME}/bin/kafka-server-stop.sh
;;
restart)$0 stop$0 start
;;
status)echo "---------- Kafka 状态 ------------"count=$(ps -ef | grep kafka | egrep -cv "grep|$$")if [ "$count" -eq 0 ];thenecho "kafka is not running"elseecho "kafka is running"fi
;;
*)echo "Usage: $0 {start|stop|restart|status}"
esac//设置开机自启
chmod +x /etc/init.d/kafka
chkconfig --add kafka//分别启动 Kafka
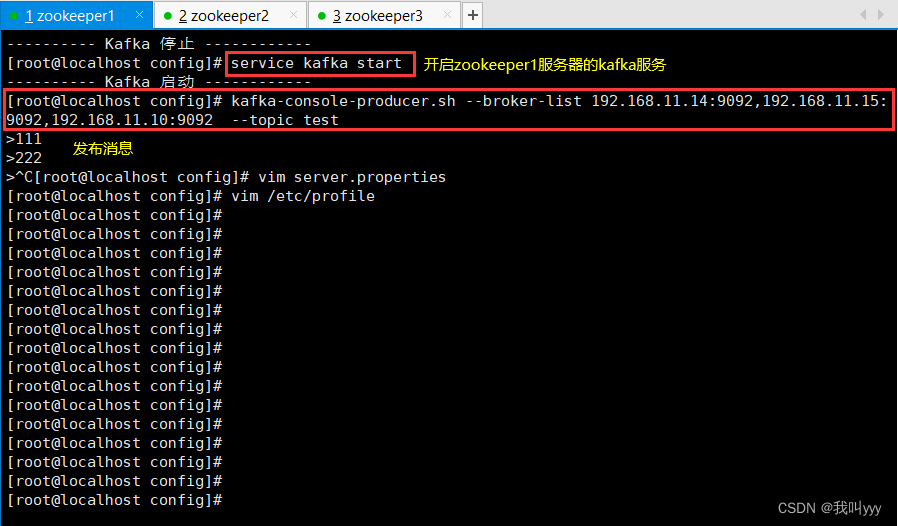
service kafka start3.Kafka 命令行操作
//创建topic
kafka-topics.sh --create --zookeeper 192.168.10.17:2181,192.168.10.21:2181,192.168.10.22:2181 --replication-factor 2 --partitions 3 --topic testkafka-topics.sh --create --zookeeper 192.168.10.17:2181,192.168.10.20:2181,192.168.10.21:2181 --replication-factor 2 --partitions 3 --topic test
-------------------------------------------------------------------------------------
--zookeeper:定义 zookeeper 集群服务器地址,如果有多个 IP 地址使用逗号分割,一般使用一个 IP 即可
--replication-factor:定义分区副本数,1 代表单副本,建议为 2
--partitions:定义分区数
--topic:定义 topic 名称
-------------------------------------------------------------------------------------//查看当前服务器中的所有 topic
kafka-topics.sh --list --zookeeper 192.168.10.17:2181,192.168.10.21:2181,192.168.10.22:2181//查看某个 topic 的详情
kafka-topics.sh --describe --zookeeper 192.168.10.17:2181,192.168.10.21:2181,192.168.10.22:2181//发布消息
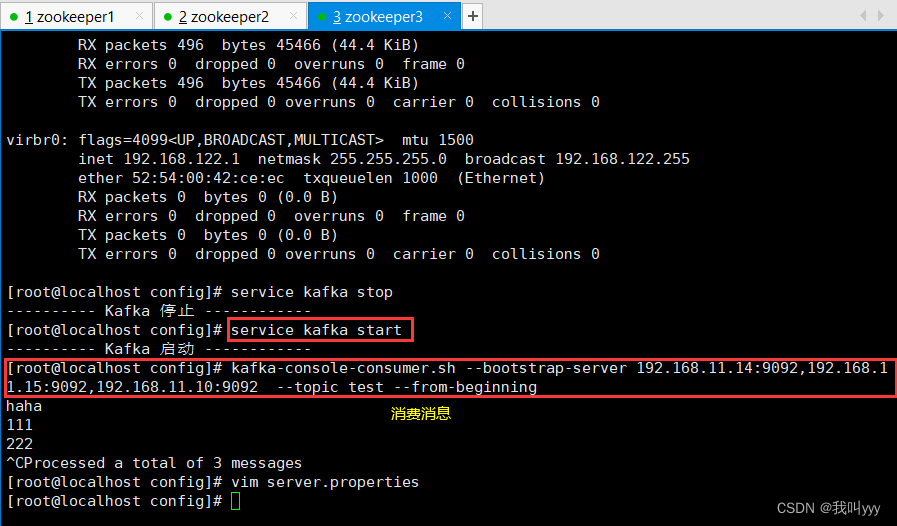
kafka-console-producer.sh --broker-list 192.168.10.17:9092,192.168.10.21:9092,192.168.10.22:9092 --topic test//消费消息
kafka-console-consumer.sh --bootstrap-server 192.168.10.17:9092,192.168.10.21:9092,192.168.10.22:9092 --topic test --from-beginning-------------------------------------------------------------------------------------
--from-beginning:会把主题中以往所有的数据都读取出来
-------------------------------------------------------------------------------------//修改分区数
kafka-topics.sh --zookeeper 192.168.10.17:2181,192.168.10.21:2181,192.168.10.22:2181 --alter --topic test --partitions 6//删除 topic
kafka-topics.sh --delete --zookeeper 192.168.10.17:2181,192.168.10.21:2181,192.168.10.22:2181 --topic test
三台服务器都需要操作!!!!
 此时,每个服务i器都需要单独操作!!!
此时,每个服务i器都需要单独操作!!!

 三台服务器都需要操作!!!!
三台服务器都需要操作!!!!
![]()
![]()
![]()

此时,每个服务器都需要单独操作!!!

单独在一台服务器中测试命令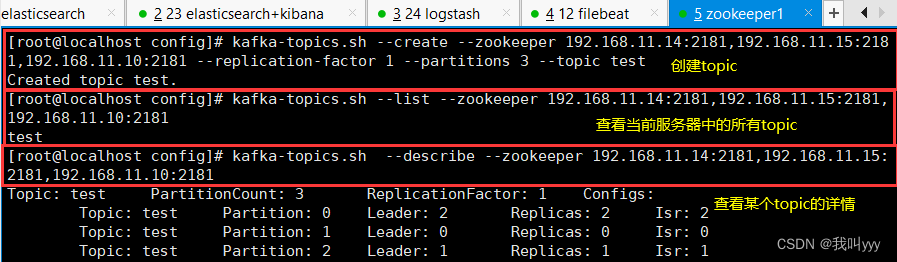
此时,每个服务器都需要单独操作!!!
相关文章:
ELFK之zookeeper+kafka
目录 kafkazookeeper的系统架构 Zookeeper 一、zookeeper概述 二、zookeeper特点 三、zookeeper选举机制 四、应用场景 五、zookeeper实验实例 Kafka 一、概述 为什么需要消息队列(MQ) 使用消息队列的好处 消息队列的两种模式 Kafka 定义 二、Kafka 的特性 三、Ka…...
ECharts
ECharts是一款基于JavaScript的数据可视化图表库,提供直观,生动,可交互,可个性化定制的数据可视化图表。ECharts 提供了常规的折线图、柱状图、散点图、饼图、K线图,用于统计的盒形图,用于地理数据可视化的…...

jsoup框架技术文档--java爬虫--架构体系
阿丹: 在学习以及认知使用一个新技术之前一定要搞清楚有关框架的架构体系。了解一下该技术的底层会对后面编写代码以及寻找报错都是很有用处的,前期做的铺垫多一点,后期开发的时候就很方便。 jsoup框架的关键组件 JSoup框架的关键组件主要包…...
OpenStack创建云主机并连接CRT
文章目录 OpenStackT版创建云主机并连接CRT命令行操作(1)创建镜像(2)创建实例(3)创建网络创建内网创建外网 (4)创建安全组(5)创建路由(6ÿ…...

linux-sed命令
目录 1.linux-shell sed获取某一段字符串 2.linux-shell shell脚本中 sed -n取出某一行赋给一个变量 3.linux-shell sed查询某一行 1.linux-shell sed获取某一段字符串 如果要获取的是某一段字符串,可以在 sed 命令中使用正则表达式来指定需要获取的字符串。例如…...
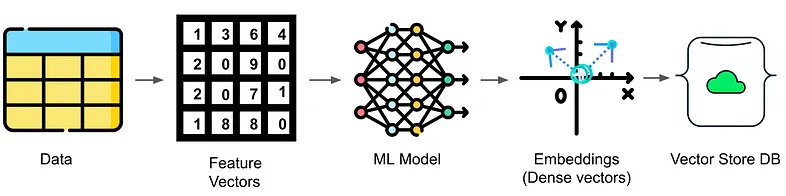
Elasticsearch:什么是向量和向量存储数据库,我们为什么关心?
Elasticsearch 从 7.3 版本开始支持向量搜索。从 8.0 开始支持带有 HNSW 的 ANN 向量搜索。目前 Elasticsearch 已经是全球下载量最多的向量数据库。它允许使用密集向量和向量比较来搜索文档。 矢量搜索在人工智能和机器学习领域有许多重要的应用。 有效存储和检索向量的数据库…...

JOSEF约瑟 剩余电流继电器PFR-5 PFE-W-20 国产化改造ZLR-G81 ZCT-45
系列型号: PFR-003剩余电流继电器 PFR-03剩余电流继电器 PFR-5剩余电流继电器 PFR-W-105互感器 PFR-W-140互感器 PFR-W-20互感器 PFR-W-210互感器 PFR-W-30互感器 PFR-W-35互感器 PFR-W-70互感器 一、用途 PFR剩余电流继电器(以下简称继电器…...

分别用Python和Go实现对文件夹及其子文件夹里的文件进行批量重命名
文章目录 问题阐述上代码结果如何 问题阐述 最近在继续提高自己的go技术时,从网上一些平台获取到了一些学习资料,然后下载到本地后,文件的命名是真的像衣托答辩: 除了上述的文件,还有一mol多神奇的命名,害…...

redis深度历险 千帆竞发 —— 分布式锁
分布式应用进行逻辑处理时经常会遇到并发问题。 比如一个操作要修改用户的状态,修改状态需要先读出用户的状态,在内存里进行修改,改完了再存回去。如果这样的操作同时进行了,就会出现并发问题,因为读取和保存状态这两个…...

C#根据中文首字母排序
第一种方式: 这种方式会受制于服务器的区域和语言设置。 1.首先添加一个排序类ChineseNameComparer public class ChineseNameComparer : IComparer<string> {public int Compare(string x, string y){if (x null || y null)return 0;var xFirstChar x.Su…...
仪表基础知识培训
压力传感器:E+H PMX5x/FMX5x 一、安装:安装注意事项: 1、水平安装时仪表的呼吸孔(1)需要向下安装,并远离污染物。 2、请勿用坚硬的物体擦拭或接触膜片。 3、请勿安装在水泵的入口和搅拌叶附近 二、供电、接线、信号、:二线制,仪表输出4-20mA 三、量程:设置最大最小量程…...

无涯教程-JavaScript - PI函数
描述 PI函数返回数字3.14159265358979,数学常数pi,精确到15位数字。 语法 PI ()争论 PI函数语法没有参数。 适用性 Excel 2007,Excel 2010,Excel 2013,Excel 2016 Example JavaScript 中的 PI函数 - 无涯教程网无涯教程网提供描述PI函数返回数字3.14159265358979,数学常…...

前端防抖和节流
前端防抖和节流 概述 防抖: 防止抖动,个人字面理解此处防的不是页面的抖动,而是用户手抖。为了防止用户快速且频繁的触发事件而导致多次执行事件函数,这样的场景有很多,比如监听滚动、鼠标移动事件onmousemove、频繁…...
[pai-diffusion]pai的easynlp的clip模型训练
EasyNLP带你玩转CLIP图文检索 - 知乎作者:熊兮、章捷、岑鸣、临在导读随着自媒体的不断发展,多种模态数据例如图像、文本、语音、视频等不断增长,创造了互联网上丰富多彩的世界。为了准确建模用户的多模态内容,跨模态检索是跨模态…...
期权如何交易?期权如何做模拟交易?
买卖期权的第一步就是要有期权账户,国内的期权品种有商品期权和ETF期权以及股指期权,每种的开户方式和要求都不同,下文为大家介绍期权如何交易?期权如何做模拟交易? 一、期权交易需要开立一个期权账户,可以…...

【新书推荐】大模型赛道如何实现华丽的弯道超车 —— 《分布式统一大数据虚拟文件系统 Alluxio原理、技术与实践》
文章目录 大模型赛道如何实现华丽的弯道超车 —— AI/ML训练赋能解决方案01 具备对海量小文件的频繁数据访问的 I/O 效率02 提高 GPU 利用率,降低成本并提高投资回报率03 支持各种存储系统的原生接口04 支持单云、混合云和多云部署01 通过数据抽象化统一数据孤岛02 …...

Calendar对象获取当前周的bug
项目场景: 双周项目管理,需要获取当前周为一年之中的第几周,原先的代码是用Calendar对象,先用setTime()把当前时间传入,再用get(3)获取一年中的第几周 问题描述 实际发…...

嵌入式环境buildroot的espeak配置与编译
1、在buildroot目录下输入make menuconfig 2、选择Target packages 3、选择Audio and video applications 4、选择espeak、选择alsa via portaudio (新版嵌入式linux一般都是用alsa音频驱动) 5、配置portaudio 选择Library 6、选择Audio/Sound 7、选择…...

物理机环境搭建-linux部署nginx
1、安装nginx部署所需依赖 yum install -y gcc-c pcre pcre-devel zlib zlib-devel openssl openssl-devel2、安装nginx包 wget http://nginx.org/download/nginx-1.8.0.tar.gz 如果没有wget可以安装一下 yum install -y wget下载完成后可以在/usr/local/下放置tar包…...
删除安装Google Chrome浏览器时捆绑安装的Google 文档、表格、幻灯片、Gmail、Google 云端硬盘、YouTube网址链接(Mac)
删除安装Google Chrome浏览器时捆绑安装的Google 文档、表格、幻灯片、Gmail、Google 云端硬盘、YouTube网址链接(Mac) Mac mini操作系统,安装完 Google Chrome 浏览器以后,单击 启动台 桌面左下角的“显示应用程序”,我们发现捆绑安装了 Goo…...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...

DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

家政维修平台实战20:权限设计
目录 1 获取工人信息2 搭建工人入口3 权限判断总结 目前我们已经搭建好了基础的用户体系,主要是分成几个表,用户表我们是记录用户的基础信息,包括手机、昵称、头像。而工人和员工各有各的表。那么就有一个问题,不同的角色…...

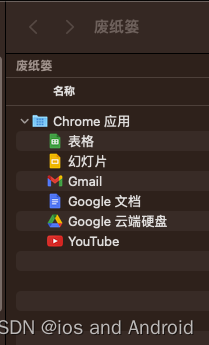
【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

20个超级好用的 CSS 动画库
分享 20 个最佳 CSS 动画库。 它们中的大多数将生成纯 CSS 代码,而不需要任何外部库。 1.Animate.css 一个开箱即用型的跨浏览器动画库,可供你在项目中使用。 2.Magic Animations CSS3 一组简单的动画,可以包含在你的网页或应用项目中。 3.An…...
CSS | transition 和 transform的用处和区别
省流总结: transform用于变换/变形,transition是动画控制器 transform 用来对元素进行变形,常见的操作如下,它是立即生效的样式变形属性。 旋转 rotate(角度deg)、平移 translateX(像素px)、缩放 scale(倍数)、倾斜 skewX(角度…...

Windows安装Miniconda
一、下载 https://www.anaconda.com/download/success 二、安装 三、配置镜像源 Anaconda/Miniconda pip 配置清华镜像源_anaconda配置清华源-CSDN博客 四、常用操作命令 Anaconda/Miniconda 基本操作命令_miniconda创建环境命令-CSDN博客...
篇章二 论坛系统——系统设计
目录 2.系统设计 2.1 技术选型 2.2 设计数据库结构 2.2.1 数据库实体 1. 数据库设计 1.1 数据库名: forum db 1.2 表的设计 1.3 编写SQL 2.系统设计 2.1 技术选型 2.2 设计数据库结构 2.2.1 数据库实体 通过需求分析获得概念类并结合业务实现过程中的技术需要&#x…...