JVM18运行时参数
4. JVM 运行时参数
4.1. JVM 参数选项
官网地址:https://docs.oracle.com/javase/8/docs/technotes/tools/windows/java.html
4.1.1. 类型一:标准参数选项
> java -help
用法: java [-options] class [args...](执行类)或 java [-options] -jar jarfile [args...](执行 jar 文件)
其中选项包括:-d32 使用 32 位数据模型 (如果可用)-d64 使用 64 位数据模型 (如果可用)-server 选择 "server" VM默认 VM 是 server.-cp <目录和 zip/jar 文件的类搜索路径>-classpath <目录和 zip/jar 文件的类搜索路径>用 ; 分隔的目录, JAR 档案和 ZIP 档案列表, 用于搜索类文件。-D<名称>=<值>设置系统属性-verbose:[class|gc|jni]启用详细输出-version 输出产品版本并退出-version:<值>警告: 此功能已过时, 将在未来发行版中删除。需要指定的版本才能运行-showversion 输出产品版本并继续-jre-restrict-search | -no-jre-restrict-search警告: 此功能已过时, 将在未来发行版中删除。在版本搜索中包括/排除用户专用 JRE-? -help 输出此帮助消息-X 输出非标准选项的帮助-ea[:<packagename>...|:<classname>]-enableassertions[:<packagename>...|:<classname>]按指定的粒度启用断言-da[:<packagename>...|:<classname>]-disableassertions[:<packagename>...|:<classname>]禁用具有指定粒度的断言-esa | -enablesystemassertions启用系统断言-dsa | -disablesystemassertions禁用系统断言-agentlib:<libname>[=<选项>]加载本机代理库 <libname>, 例如 -agentlib:hprof另请参阅 -agentlib:jdwp=help 和 -agentlib:hprof=help-agentpath:<pathname>[=<选项>]按完整路径名加载本机代理库-javaagent:<jarpath>[=<选项>]加载 Java 编程语言代理, 请参阅 java.lang.instrument-splash:<imagepath>使用指定的图像显示启动屏幕
有关详细信息, 请参阅 http://www.oracle.com/technetwork/java/javase/documentation/index.html。
Server 模式和 Client 模式
Hotspot JVM 有两种模式,分别是 server 和 client,分别通过-server 和-client 模式设置
- 32 位系统上,默认使用 Client 类型的 JVM。要想使用 Server 模式,机器配置至少有 2 个以上的 CPU 和 2G 以上的物理内存。client 模式适用于对内存要求较小的桌面应用程序,默认使用 Serial 串行垃圾收集器
- 64 位系统上,只支持 server 模式的 JVM,适用于需要大内存的应用程序,默认使用并行垃圾收集器
官网地址:https://docs.oracle.com/javase/8/docs/technotes/guides/vm/server-class.html
如何知道系统默认使用的是那种模式呢?
通过 java -version 命令:可以看到 Server VM 字样,代表当前系统使用是 Server 模式
> java -version
java version "1.8.0_201"
Java(TM) SE Runtime Environment (build 1.8.0_201-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.201-b09, mixed mode)
4.1.2. 类型二:-X 参数选项
> java -X-Xmixed 混合模式执行 (默认)-Xint 仅解释模式执行-Xbootclasspath:<用 ; 分隔的目录和 zip/jar 文件>设置搜索路径以引导类和资源-Xbootclasspath/a:<用 ; 分隔的目录和 zip/jar 文件>附加在引导类路径末尾-Xbootclasspath/p:<用 ; 分隔的目录和 zip/jar 文件>置于引导类路径之前-Xdiag 显示附加诊断消息-Xnoclassgc 禁用类垃圾收集-Xincgc 启用增量垃圾收集-Xloggc:<file> 将 GC 状态记录在文件中 (带时间戳)-Xbatch 禁用后台编译-Xms<size> 设置初始 Java 堆大小-Xmx<size> 设置最大 Java 堆大小-Xss<size> 设置 Java 线程堆栈大小-Xprof 输出 cpu 配置文件数据-Xfuture 启用最严格的检查, 预期将来的默认值-Xrs 减少 Java/VM 对操作系统信号的使用 (请参阅文档)-Xcheck:jni 对 JNI 函数执行其他检查-Xshare:off 不尝试使用共享类数据-Xshare:auto 在可能的情况下使用共享类数据 (默认)-Xshare:on 要求使用共享类数据, 否则将失败。-XshowSettings 显示所有设置并继续-XshowSettings:all显示所有设置并继续-XshowSettings:vm 显示所有与 vm 相关的设置并继续-XshowSettings:properties显示所有属性设置并继续-XshowSettings:locale显示所有与区域设置相关的设置并继续-X 选项是非标准选项, 如有更改, 恕不另行通知。
如何知道 JVM 默认使用的是混合模式呢?
同样地,通过 java -version 命令:可以看到 mixed mode 字样,代表当前系统使用的是混合模式
4.1.3. 类型三:-XX 参数选项
Boolean 类型格式
-XX:+<option> 启用option属性
-XX:-<option> 禁用option属性
非 Boolean 类型格式
-XX:<option>=<number> 设置option数值,可以带单位如k/K/m/M/g/G
-XX:<option>=<string> 设置option字符值
4.2. 添加 JVM 参数选项
eclipse 和 idea 中配置不必多说,在 Run Configurations 中 VM Options 中配置即可,大同小异
运行 jar 包
java -Xms100m -Xmx100m -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -jar demo.jar
Tomcat 运行 war 包
# linux下catalina.sh添加
JAVA_OPTS="-Xms512M -Xmx1024M"
# windows下catalina.bat添加
set "JAVA_OPTS=-Xms512M -Xmx1024M"
程序运行中
# 设置Boolean类型参数
jinfo -flag [+|-]<name> <pid>
# 设置非Boolean类型参数
jinfo -flag <name>=<value> <pid>
4.3. 常用的 JVM 参数选项
4.3.1. 打印设置的 XX 选项及值
-XX:+PrintCommandLineFlags 程序运行时JVM默认设置或用户手动设置的XX选项
-XX:+PrintFlagsInitial 打印所有XX选项的默认值
-XX:+PrintFlagsFinal 打印所有XX选项的实际值
-XX:+PrintVMOptions 打印JVM的参数
4.3.2. 堆、栈、方法区等内存大小设置
# 栈
-Xss128k <==> -XX:ThreadStackSize=128k 设置线程栈的大小为128K# 堆
-Xms2048m <==> -XX:InitialHeapSize=2048m 设置JVM初始堆内存为2048M
-Xmx2048m <==> -XX:MaxHeapSize=2048m 设置JVM最大堆内存为2048M
-Xmn2g <==> -XX:NewSize=2g -XX:MaxNewSize=2g 设置年轻代大小为2G
-XX:SurvivorRatio=8 设置Eden区与Survivor区的比值,默认为8
-XX:NewRatio=2 设置老年代与年轻代的比例,默认为2
-XX:+UseAdaptiveSizePolicy 设置大小比例自适应,默认开启
-XX:PretenureSizeThreadshold=1024 设置让大于此阈值的对象直接分配在老年代,只对Serial、ParNew收集器有效
-XX:MaxTenuringThreshold=15 设置新生代晋升老年代的年龄限制,默认为15
-XX:TargetSurvivorRatio 设置MinorGC结束后Survivor区占用空间的期望比例# 方法区
-XX:MetaspaceSize / -XX:PermSize=256m 设置元空间/永久代初始值为256M
-XX:MaxMetaspaceSize / -XX:MaxPermSize=256m 设置元空间/永久代最大值为256M
-XX:+UseCompressedOops 使用压缩对象
-XX:+UseCompressedClassPointers 使用压缩类指针
-XX:CompressedClassSpaceSize 设置Klass Metaspace的大小,默认1G# 直接内存
-XX:MaxDirectMemorySize 指定DirectMemory容量,默认等于Java堆最大值
4.3.3. OutOfMemory 相关的选项
-XX:+HeapDumpOnOutMemoryError 内存出现OOM时生成Heap转储文件,两者互斥
-XX:+HeapDumpBeforeFullGC 出现FullGC时生成Heap转储文件,两者互斥
-XX:HeapDumpPath=<path> 指定heap转储文件的存储路径,默认当前目录
-XX:OnOutOfMemoryError=<path> 指定可行性程序或脚本的路径,当发生OOM时执行脚本
4.3.4. 垃圾收集器相关选项
首先需了解垃圾收集器之间的搭配使用关系
- 红色虚线表示在 jdk8 时被 Deprecate,jdk9 时被删除
- 绿色虚线表示在 jdk14 时被 Deprecate
- 绿色虚框表示在 jdk9 时被 Deprecate,jdk14 时被删除
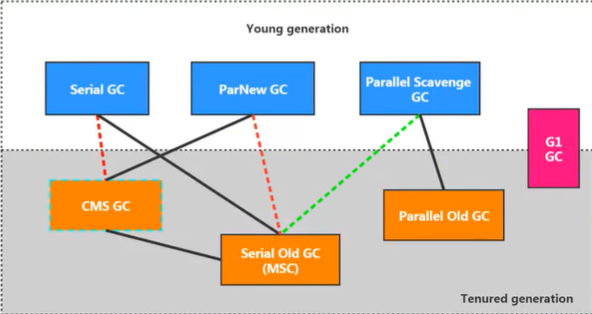
# Serial回收器
-XX:+UseSerialGC 年轻代使用Serial GC, 老年代使用Serial Old GC
# ParNew回收器
-XX:+UseParNewGC 年轻代使用ParNew GC
-XX:ParallelGCThreads 设置年轻代并行收集器的线程数。一般地,最好与CPU数量相等,以避免过多的线程数影响垃圾收集性能。
ParallelGCThreads={CPU_Count(CPU_Count<=8)3+(5∗CPU_Count/8)(CPU_Count>8)ParallelGCThreads = \begin{cases} CPU\_Count & \text (CPU\_Count <= 8) \\ 3 + (5 * CPU_Count / 8) & \text (CPU\_Count > 8) \end{cases} ParallelGCThreads={CPU_Count3+(5∗CPU_Count/8)(CPU_Count<=8)(CPU_Count>8)
# Parallel回收器
-XX:+UseParallelGC 年轻代使用 Parallel Scavenge GC,互相激活
-XX:+UseParallelOldGC 老年代使用 Parallel Old GC,互相激活
-XX:ParallelGCThreads
-XX:MaxGCPauseMillis 设置垃圾收集器最大停顿时间(即STW的时间),单位是毫秒。为了尽可能地把停顿时间控制在MaxGCPauseMills以内,收集器在工作时会调整Java堆大小或者其他一些参数。对于用户来讲,停顿时间越短体验越好;但是服务器端注重高并发,整体的吞吐量。所以服务器端适合Parallel,进行控制。该参数使用需谨慎。
-XX:GCTimeRatio 垃圾收集时间占总时间的比例(1 / (N+1)),用于衡量吞吐量的大小取值范围(0,100),默认值99,也就是垃圾回收时间不超过1%。与前一个-XX:MaxGCPauseMillis参数有一定矛盾性。暂停时间越长,Radio参数就容易超过设定的比例。
-XX:+UseAdaptiveSizePolicy 设置Parallel Scavenge收集器具有自适应调节策略。在这种模式下,年轻代的大小、Eden和Survivor的比例、晋升老年代的对象年龄等参数会被自动调整,以达到在堆大小、吞吐量和停顿时间之间的平衡点。在手动调优比较困难的场合,可以直接使用这种自适应的方式,仅指定虚拟机的最大堆、目标的吞吐量(GCTimeRatio)和停顿时间(MaxGCPauseMills),让虚拟机自己完成调优工作。
# CMS回收器
-XX:+UseConcMarkSweepGC 年轻代使用CMS GC。开启该参数后会自动将-XX:+UseParNewGC打开。即:ParNew(Young区)+ CMS(Old区)+ Serial Old的组合
-XX:CMSInitiatingOccupanyFraction 设置堆内存使用率的阈值,一旦达到该阈值,便开始进行回收。JDK5及以前版本的默认值为68,DK6及以上版本默认值为92%。如果内存增长缓慢,则可以设置一个稍大的值,大的阈值可以有效降低CMS的触发频率,减少老年代回收的次数可以较为明显地改善应用程序性能。反之,如果应用程序内存使用率增长很快,则应该降低这个阈值,以避免频繁触发老年代串行收集器。因此通过该选项便可以有效降低Fu1l GC的执行次数。
-XX:+UseCMSInitiatingOccupancyOnly 是否动态可调,使CMS一直按CMSInitiatingOccupancyFraction设定的值启动
-XX:+UseCMSCompactAtFullCollection 用于指定在执行完Full GC后对内存空间进行压缩整理以此避免内存碎片的产生。不过由于内存压缩整理过程无法并发执行,所带来的问题就是停顿时间变得更长了。
-XX:CMSFullGCsBeforeCompaction 设置在执行多少次Full GC后对内存空间进行压缩整理。
-XX:ParallelCMSThreads 设置CMS的线程数量。CMS 默认启动的线程数是(ParallelGCThreads+3)/4,ParallelGCThreads 是年轻代并行收集器的线程数。当CPU 资源比较紧张时,受到CMS收集器线程的影响,应用程序的性能在垃圾回收阶段可能会非常糟糕。
-XX:ConcGCThreads 设置并发垃圾收集的线程数,默认该值是基于ParallelGCThreads计算出来的
-XX:+CMSScavengeBeforeRemark 强制hotspot在cms remark阶段之前做一次minor gc,用于提高remark阶段的速度
-XX:+CMSClassUnloadingEnable 如果有的话,启用回收Perm 区(JDK8之前)
-XX:+CMSParallelInitialEnabled 用于开启CMS initial-mark阶段采用多线程的方式进行标记用于提高标记速度,在Java8开始已经默认开启
-XX:+CMSParallelRemarkEnabled 用户开启CMS remark阶段采用多线程的方式进行重新标记,默认开启
-XX:+ExplicitGCInvokesConcurrent
-XX:+ExplicitGCInvokesConcurrentAndUnloadsClasses这两个参数用户指定hotspot虚拟在执行System.gc()时使用CMS周期
-XX:+CMSPrecleaningEnabled 指定CMS是否需要进行Pre cleaning阶段
# G1回收器
-XX:+UseG1GC 手动指定使用G1收集器执行内存回收任务。
-XX:G1HeapRegionSize 设置每个Region的大小。值是2的幂,范围是1MB到32MB之间,目标是根据最小的Java堆大小划分出约2048个区域。默认是堆内存的1/2000。
-XX:MaxGCPauseMillis 设置期望达到的最大GC停顿时间指标(JVM会尽力实现,但不保证达到)。默认值是200ms
-XX:ParallelGCThread 设置STW时GC线程数的值。最多设置为8
-XX:ConcGCThreads 设置并发标记的线程数。将n设置为并行垃圾回收线程数(ParallelGCThreads)的1/4左右。
-XX:InitiatingHeapOccupancyPercent 设置触发并发GC周期的Java堆占用率阈值。超过此值,就触发GC。默认值是45。
-XX:G1NewSizePercent 新生代占用整个堆内存的最小百分比(默认5%)
-XX:G1MaxNewSizePercent 新生代占用整个堆内存的最大百分比(默认60%)
-XX:G1ReservePercent=10 保留内存区域,防止 to space(Survivor中的to区)溢出
怎么选择垃圾回收器?
- 优先让 JVM 自适应,调整堆的大小
- 串行收集器:内存小于 100M;单核、单机程序,并且没有停顿时间的要求
- 并行收集器:多 CPU、高吞吐量、允许停顿时间超过 1 秒
- 并发收集器:多 CPU、追求低停顿时间、快速响应(比如延迟不能超过 1 秒,如互联网应用)
- 官方推荐 G1,性能高。现在互联网的项目,基本都是使用 G1
特别说明:
- 没有最好的收集器,更没有万能的收集器
- 调优永远是针对特定场景、特定需求,不存在一劳永逸的收集器
4.3.5. GC 日志相关选项
-XX:+PrintGC <==> -verbose:gc 打印简要日志信息
-XX:+PrintGCDetails 打印详细日志信息
-XX:+PrintGCTimeStamps 打印程序启动到GC发生的时间,搭配-XX:+PrintGCDetails使用
-XX:+PrintGCDateStamps 打印GC发生时的时间戳,搭配-XX:+PrintGCDetails使用
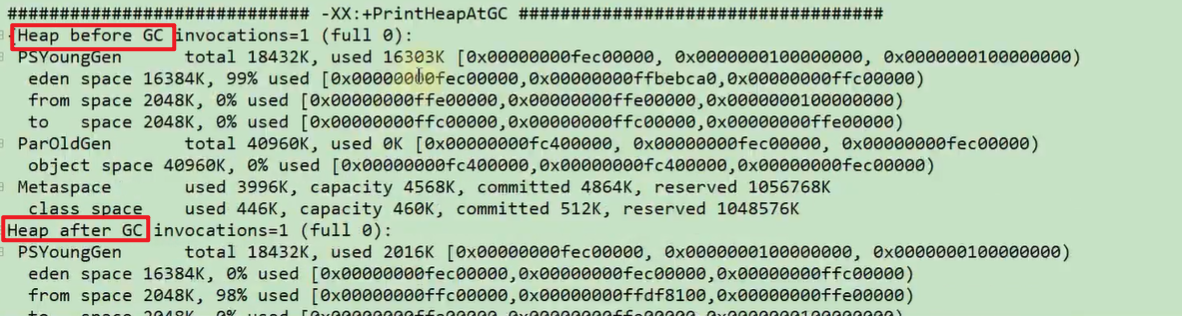
-XX:+PrintHeapAtGC 打印GC前后的堆信息,如下图
-Xloggc:<file> 输出GC导指定路径下的文件中
-XX:+TraceClassLoading 监控类的加载
-XX:+PrintGCApplicationStoppedTime 打印GC时线程的停顿时间
-XX:+PrintGCApplicationConcurrentTime 打印垃圾收集之前应用未中断的执行时间
-XX:+PrintReferenceGC 打印回收了多少种不同引用类型的引用
-XX:+PrintTenuringDistribution 打印JVM在每次MinorGC后当前使用的Survivor中对象的年龄分布
-XX:+UseGCLogFileRotation 启用GC日志文件的自动转储
-XX:NumberOfGCLogFiles=1 设置GC日志文件的循环数目
-XX:GCLogFileSize=1M 设置GC日志文件的大小
4.3.6. 其他参数
-XX:+DisableExplicitGC 禁用hotspot执行System.gc(),默认禁用
-XX:ReservedCodeCacheSize=<n>[g|m|k]、-XX:InitialCodeCacheSize=<n>[g|m|k] 指定代码缓存的大小
-XX:+UseCodeCacheFlushing 放弃一些被编译的代码,避免代码缓存被占满时JVM切换到interpreted-only的情况
-XX:+DoEscapeAnalysis 开启逃逸分析
-XX:+UseBiasedLocking 开启偏向锁
-XX:+UseLargePages 开启使用大页面
-XX:+PrintTLAB 打印TLAB的使用情况
-XX:TLABSize 设置TLAB大小
4.4. 通过 Java 代码获取 JVM 参数
Java 提供了 java.lang.management 包用于监视和管理 Java 虚拟机和 Java 运行时中的其他组件,它允许本地或远程监控和管理运行的 Java 虚拟机。其中 ManagementFactory 类较为常用,另外 Runtime 类可获取内存、CPU 核数等相关的数据。通过使用这些 api,可以监控应用服务器的堆内存使用情况,设置一些阈值进行报警等处理。
public class MemoryMonitor {public static void main(String[] args) {MemoryMXBean memorymbean = ManagementFactory.getMemoryMXBean();MemoryUsage usage = memorymbean.getHeapMemoryUsage();System.out.println("INIT HEAP: " + usage.getInit() / 1024 / 1024 + "m");System.out.println("MAX HEAP: " + usage.getMax() / 1024 / 1024 + "m");System.out.println("USE HEAP: " + usage.getUsed() / 1024 / 1024 + "m");System.out.println("\nFull Information:");System.out.println("Heap Memory Usage: " + memorymbean.getHeapMemoryUsage());System.out.println("Non-Heap Memory Usage: " + memorymbean.getNonHeapMemoryUsage());System.out.println("=======================通过java来获取相关系统状态============================ ");System.out.println("当前堆内存大小totalMemory " + (int) Runtime.getRuntime().totalMemory() / 1024 / 1024 + "m");// 当前堆内存大小System.out.println("空闲堆内存大小freeMemory " + (int) Runtime.getRuntime().freeMemory() / 1024 / 1024 + "m");// 空闲堆内存大小System.out.println("最大可用总堆内存maxMemory " + Runtime.getRuntime().maxMemory() / 1024 / 1024 + "m");// 最大可用总堆内存大小}
}
5. 分析 GC 日志
5.1. GC 分类
针对 HotSpot VM 的实现,它里面的 GC 按照回收区域又分为两大种类型:一种是部分收集(Partial GC),一种是整堆收集(Full GC)
-
部分收集(Partial GC):不是完整收集整个 Java 堆的垃圾收集。其中又分为:
- 新生代收集(Minor GC / Young GC):只是新生代(Eden / S0, S1)的垃圾收集
- 老年代收集(Major GC / Old GC):只是老年代的垃圾收集。目前,只有 CMS GC 会有单独收集老年代的行为。注意,很多时候 Major GC 会和 Full GC 混淆使用,需要具体分辨是老年代回收还是整堆回收。
-
混合收集(Mixed GC):收集整个新生代以及部分老年代的垃圾收集。目前,只有 G1 GC 会有这种行为
-
整堆收集(Full GC):收集整个 java 堆和方法区的垃圾收集。
5.2. GC 日志分类
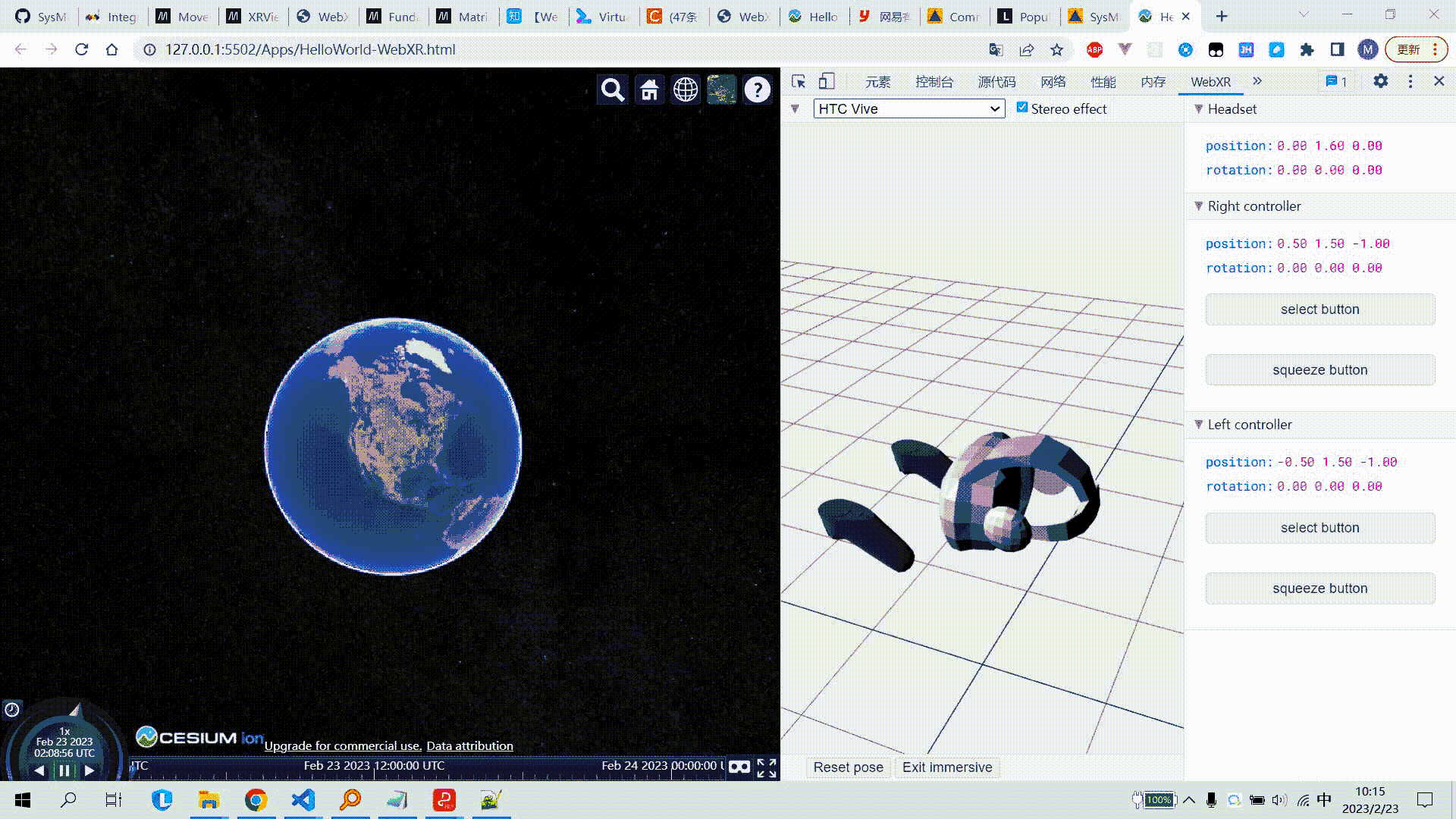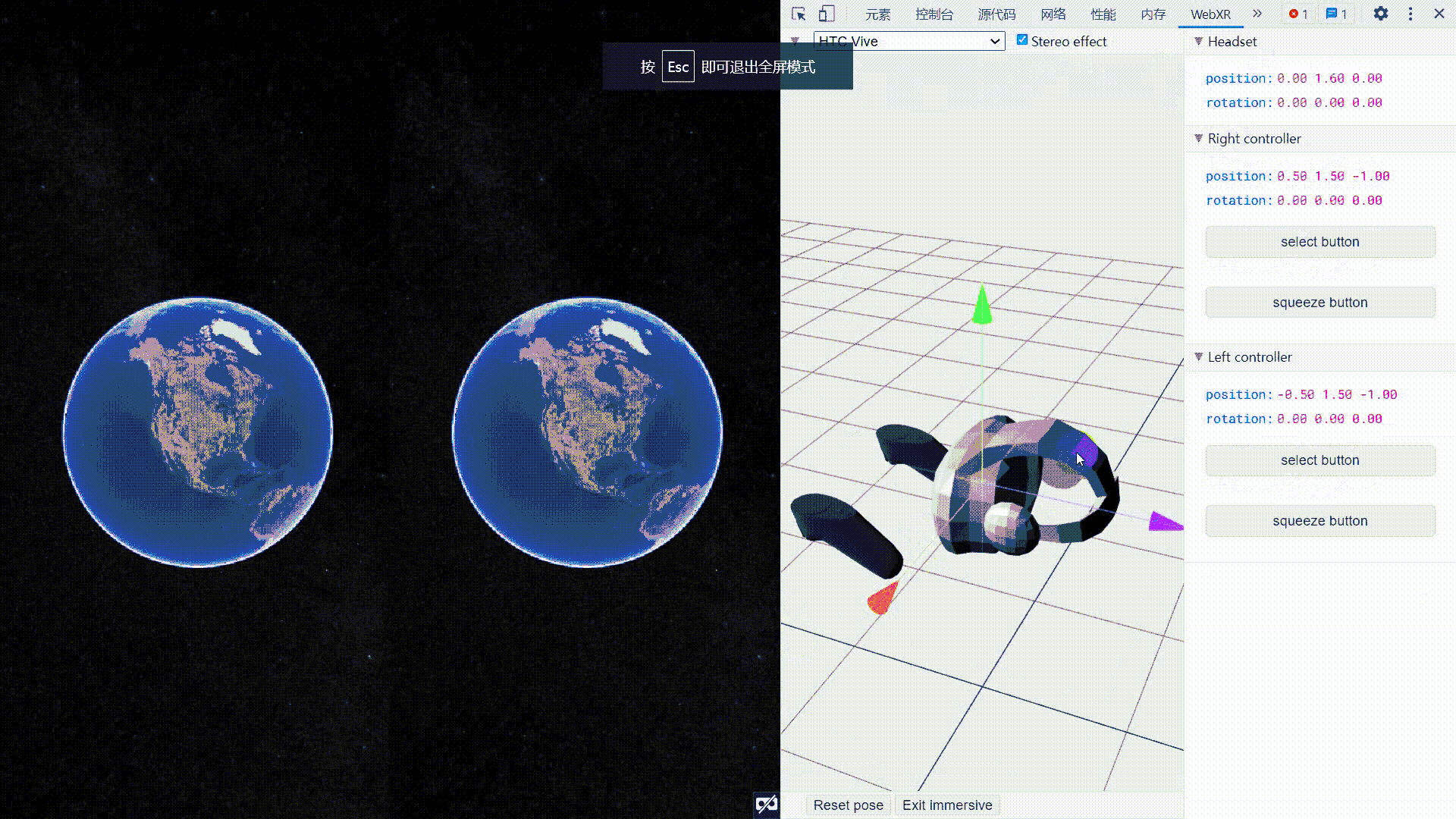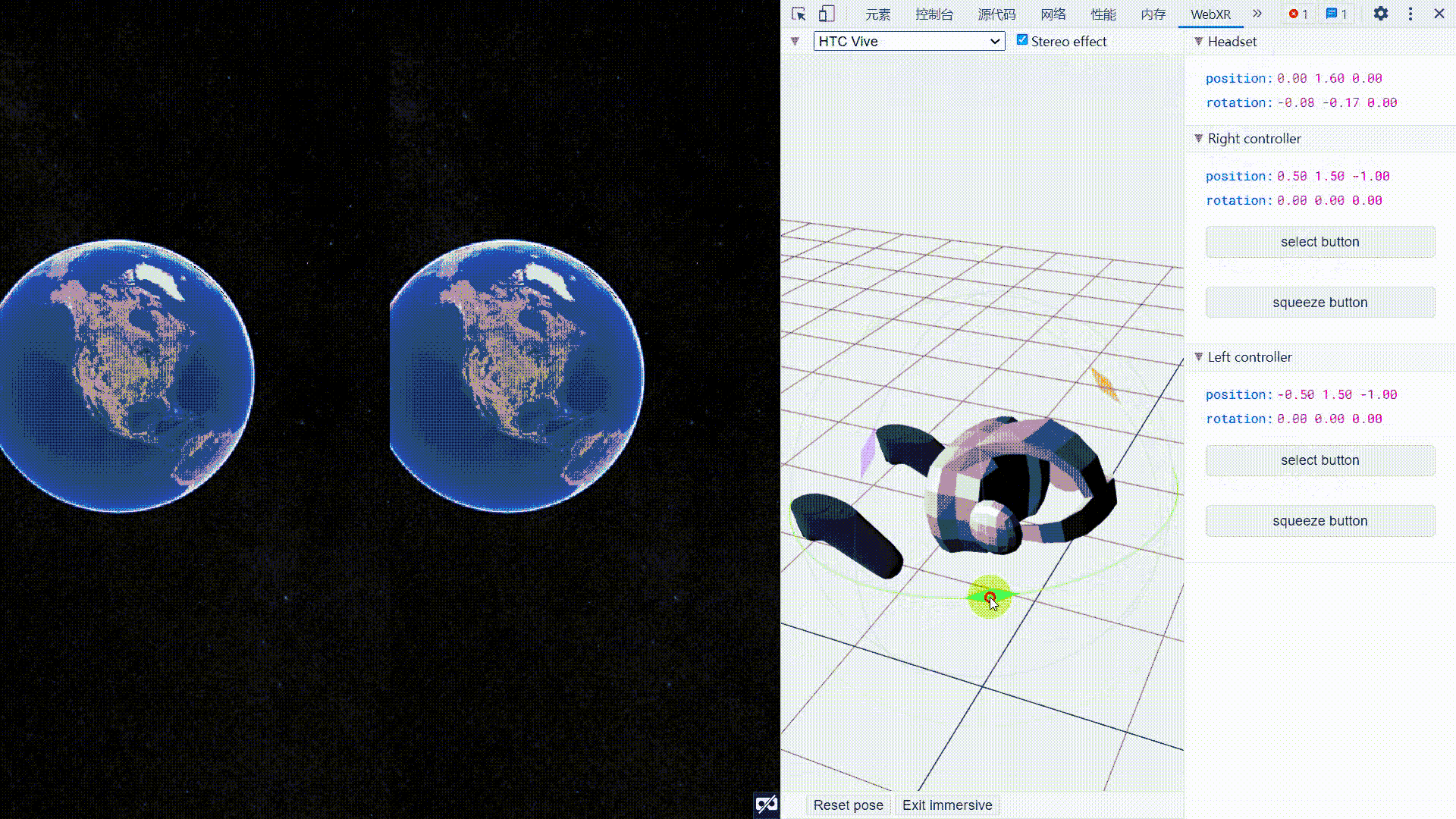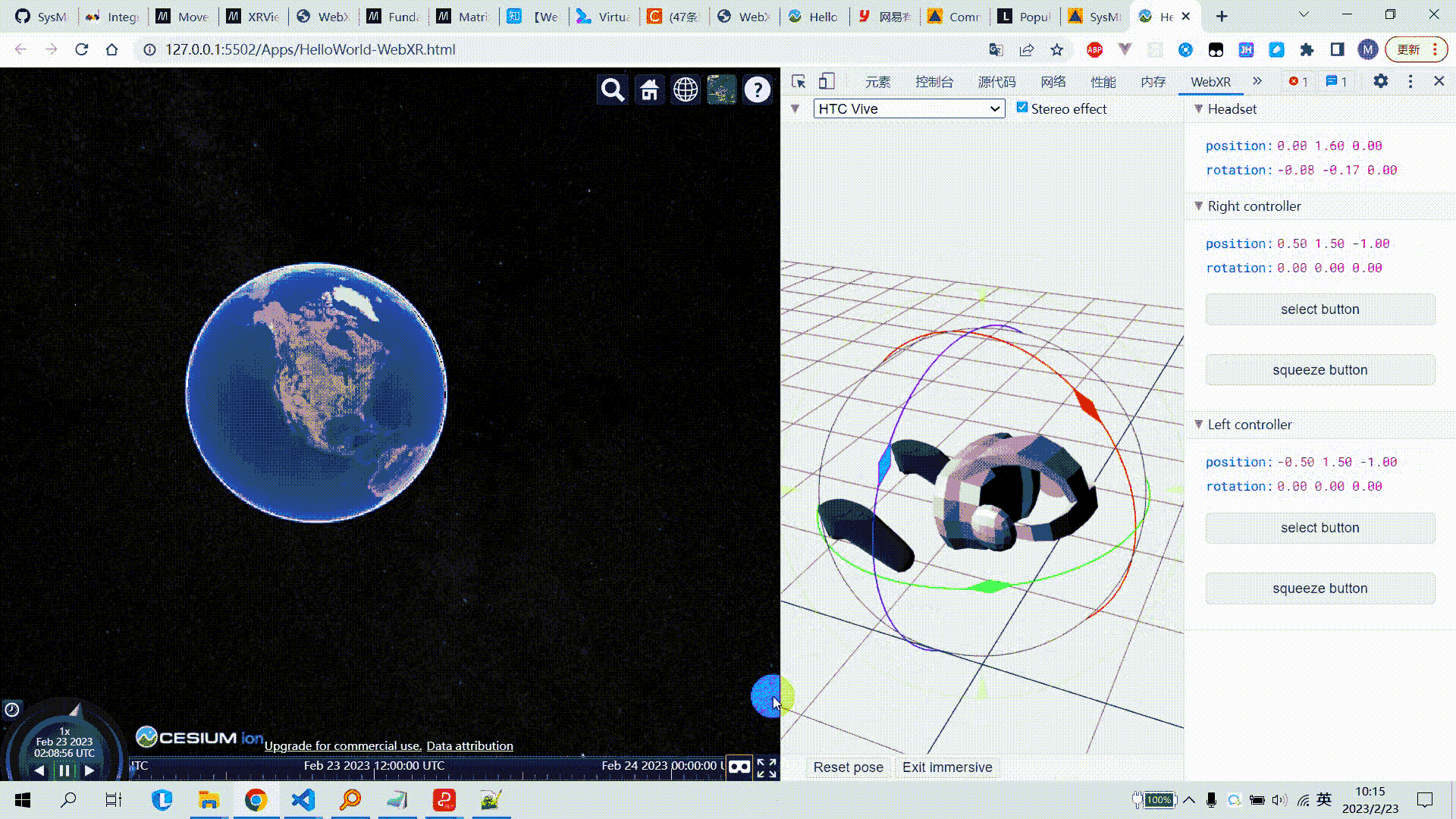
MinorGC
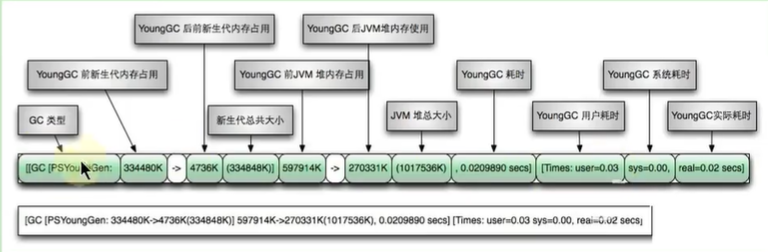
MinorGC(或 young GC 或 YGC)日志:
[GC (Allocation Failure) [PSYoungGen: 31744K->2192K (36864K) ] 31744K->2200K (121856K), 0.0139308 secs] [Times: user=0.05 sys=0.01, real=0.01 secs]
FullGC
[Full GC (Metadata GC Threshold) [PSYoungGen: 5104K->0K (132096K) ] [Par01dGen: 416K->5453K (50176K) ]5520K->5453K (182272K), [Metaspace: 20637K->20637K (1067008K) ], 0.0245883 secs] [Times: user=0.06 sys=0.00, real=0.02 secs]
5.3. GC 日志结构剖析
透过日志看垃圾收集器
-
Serial 收集器:新生代显示 “[DefNew”,即 Default New Generation
-
ParNew 收集器:新生代显示 “[ParNew”,即 Parallel New Generation
-
Parallel Scavenge 收集器:新生代显示"[PSYoungGen",JDK1.7 使用的即 PSYoungGen
-
Parallel Old 收集器:老年代显示"[ParoldGen"
-
G1 收集器:显示”garbage-first heap“
透过日志看 GC 原因
- Allocation Failure:表明本次引起 GC 的原因是因为新生代中没有足够的区域存放需要分配的数据
- Metadata GCThreshold:Metaspace 区不够用了
- FErgonomics:JVM 自适应调整导致的 GC
- System:调用了 System.gc()方法
透过日志看 GC 前后情况
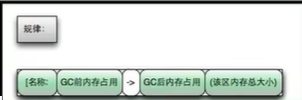
通过图示,我们可以发现 GC 日志格式的规律一般都是:GC 前内存占用-> GC 后内存占用(该区域内存总大小)
[PSYoungGen: 5986K->696K (8704K) ] 5986K->704K (9216K)
-
中括号内:GC 回收前年轻代堆大小,回收后大小,(年轻代堆总大小)
-
括号外:GC 回收前年轻代和老年代大小,回收后大小,(年轻代和老年代总大小)
注意:Minor GC 堆内存总容量 = 9/10 年轻代 + 老年代。原因是 Survivor 区只计算 from 部分,而 JVM 默认年轻代中 Eden 区和 Survivor 区的比例关系,Eden:S0:S1=8:1:1。
透过日志看 GC 时间
GC 日志中有三个时间:user,sys 和 real
- user:进程执行用户态代码(核心之外)所使用的时间。这是执行此进程所使用的实际 CPU 时间,其他进程和此进程阻塞的时间并不包括在内。在垃圾收集的情况下,表示 GC 线程执行所使用的 CPU 总时间。
- sys:进程在内核态消耗的 CPU 时间,即在内核执行系统调用或等待系统事件所使用的 CPU 时间
- real:程序从开始到结束所用的时钟时间。这个时间包括其他进程使用的时间片和进程阻塞的时间(比如等待 I/O 完成)。对于并行 gc,这个数字应该接近(用户时间+系统时间)除以垃圾收集器使用的线程数。
由于多核的原因,一般的 GC 事件中,real time 是小于 sys time + user time 的,因为一般是多个线程并发的去做 GC,所以 real time 是要小于 sys + user time 的。如果 real > sys + user 的话,则你的应用可能存在下列问题:IO 负载非常重或 CPU 不够用。
5.4. GC 日志分析工具
GCEasy
GCEasy 是一款在线的 GC 日志分析器,可以通过 GC 日志分析进行内存泄露检测、GC 暂停原因分析、JVM 配置建议优化等功能,大多数功能是免费的。
官网地址:https://gceasy.io/
GCViewer
GCViewer 是一款离线的 GC 日志分析器,用于可视化 Java VM 选项 -verbose:gc 和 .NET 生成的数据 -Xloggc:<file>。还可以计算与垃圾回收相关的性能指标(吞吐量、累积的暂停、最长的暂停等)。当通过更改世代大小或设置初始堆大小来调整特定应用程序的垃圾回收时,此功能非常有用。
源码下载:https://github.com/chewiebug/GCViewer
运行版本下载:https://github.com/chewiebug/GCViewer/wiki/Changelog
GChisto
- 官网上没有下载的地方,需要自己从 SVN 上拉下来编译
- 不过这个工具似乎没怎么维护了,存在不少 bug
HPjmeter
- 工具很强大,但是只能打开由以下参数生成的 GC log,-verbose:gc -Xloggc:gc.log。添加其他参数生成的 gc.log 无法打开
- HPjmeter 集成了以前的 HPjtune 功能,可以分析在 HP 机器上产生的垃圾回收日志文件
相关文章:
JVM18运行时参数
4. JVM 运行时参数 4.1. JVM 参数选项 官网地址:https://docs.oracle.com/javase/8/docs/technotes/tools/windows/java.html 4.1.1. 类型一:标准参数选项 > java -help 用法: java [-options] class [args...](执行类)或 java [-options] -jar …...
Cesium集成WebXR_连接VR设备
Cesium集成WebXR 文章目录Cesium集成WebXR1. 需求2. 技术基础2.1 WebGL2.2 WebXR2.3 其他3. 示例代码4. 效果图5. 参考链接1. 需求 通过WebXR接口,将浏览器端连接到VR头盔,实现在VR头盔中浏览Cesium场景,并可将头盔旋转的操作同步映射为场景…...

物联网在物流行业中的应用
物流管理需要同时监控供应链、仓储、运输等多项活动,然而许多因素会影响物流流程本身并导致延迟。为了简化流程和提高客户满意度,一些行业领导者和决策者积极创新,不断评估并使用物联网对物流流程的成本效益进行深入优化。在本文中࿰…...

<c++> 类与对象 | 面向对象 | 访问说明符 | 类的声明 | 创建类
文章目录前言面向过程编程面向对象编程什么是类类和结构体有什么区别三个访问说明符如何创建一个类类的声明创建类申明和定义全部放在类中声明和定义分离前言 从这里我们正式开始学习c中的面向对象编程,在学习之前,我们有必要了解一下什么是面向对象编程…...

恭喜!龙蜥社区荣登 2022 科创中国“开源创新榜”
2 月 20 日,中国科协召开以“创新提振发展信心,科技激发产业活力”为主题的2023“科创中国”年度会议。会上,“科创中国”联合体理事长、中国工程院院士周济介绍了 2022 年系列榜单征集遴选情况,并与中国科协副主席、中国工程院院…...

2023双非计算机硕士应战秋招算法岗之机器学习基础知识
目录 特征工程 2 缺失值处理 15 评价指标 33 逻辑回归 37 决策树 40 随机森林 46 SVM 49 Knn 56 Kmeans 59 PCA 66 朴素贝叶斯 68 常见分类算法的优缺点 72 特征工程 1.什么是特征工程 有这么一句话在业界广泛流传,数据和特征决定了机器学习的上限,而模型…...

二、TS的基础类型、类型注解
TS的基础类型、类型注解 TS的基础类型 js的数据类型: 基础数据类型(7个) boolean string number null undefined BigInt Symbol 引用数据类型(1个) Object 变量后面多了一个注解,注解为变量限定数据类型&…...

3年经验,3轮技术面+1轮HR面,拿下字节30k*16薪offer,这些自动化测试面试题值得大家借鉴
面试一般分为技术面和hr面,形式的话很少有群面,少部分企业可能会有一个交叉面,不过总的来说,技术面基本就是考察你的专业技术水平的,hr面的话主要是看这个人的综合素质以及家庭情况符不符合公司要求,一般来…...
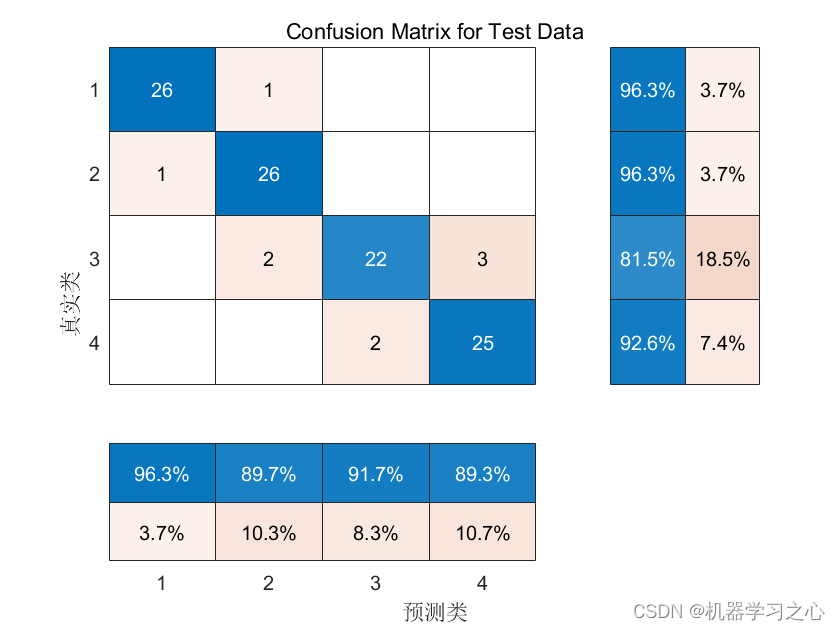
分类预测 | MATLAB实现WOA-CNN-LSTM鲸鱼算法优化卷积长短期记忆网络数据分类预测
分类预测 | MATLAB实现WOA-CNN-LSTM鲸鱼算法优化卷积长短期记忆网络数据分类预测 目录分类预测 | MATLAB实现WOA-CNN-LSTM鲸鱼算法优化卷积长短期记忆网络数据分类预测分类效果基本描述模型描述程序设计参考资料分类效果 基本描述 1.Matlab实现WOA-CNN-LSTM多特征分类预测&…...
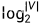
自然语言处理(NLP)之近似训练法:负采样与层序Softmax
我们在前面介绍的跳字模型与连续词袋模型有个缺陷就是在计算梯度时的开销随着词典增大会变得很大,因为每一步的梯度计算都包含词典大小数目的项的累加。为了降低这种带来的计算复杂度,介绍两种近似的处理方案:负采样和层序softmax负采样(Nega…...

关于上位机,C#
TCP与modbusTCP的区别 (10条消息) C#高级--常用数据结构_李宥小哥的博客-CSDN博客_c# 数据结构 C#中常用的数据结构 TCP/IP协议是网络通讯协议。MODBUS是应用与工业现场(电子控制)的通讯协议。两者的应用范围和应用环境有…...

华为OD机试真题 用 C++ 实现 - 字符串加密 | 多看题,提高通过率
最近更新的博客 华为OD机试 - 入栈出栈(C++) | 附带编码思路 【2023】 华为OD机试 - 箱子之形摆放(C++) | 附带编码思路 【2023】 华为OD机试 - 简易内存池 2(C++) | 附带编码思路 【2023】 华为OD机试 - 第 N 个排列(C++) | 附带编码思路 【2023】 华为OD机试 - 考古…...
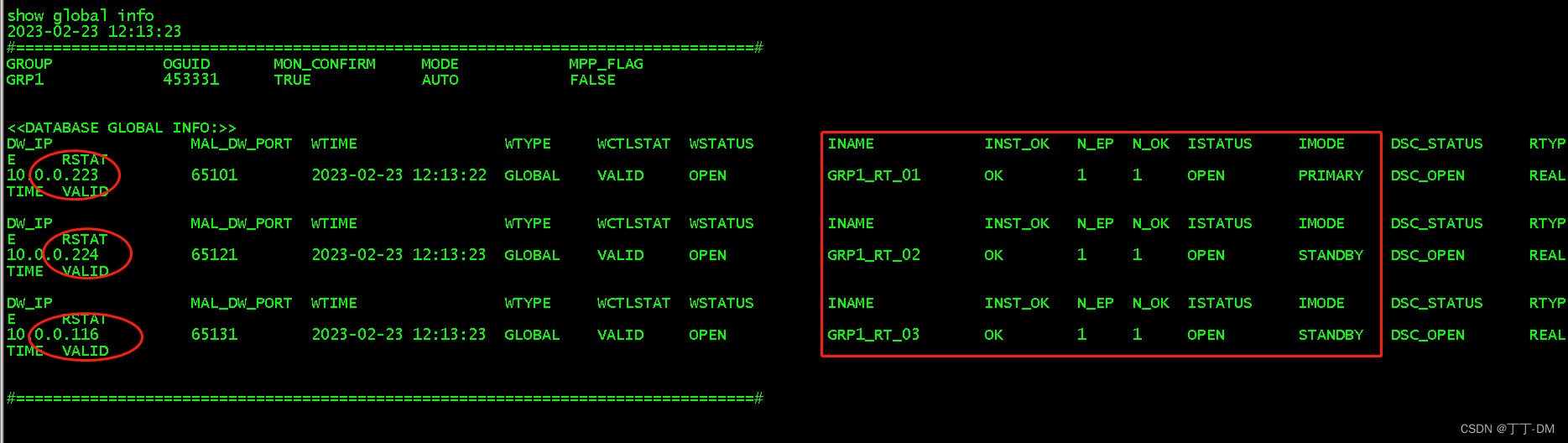
达梦8数据守护动态增加实时备库
实时主备环境 类型 业务IP 库名 实例名 PORT_NUM MAL_HOST MAL_INST_DW_PORT MAL_PORT MAL_DW_PORT 主库dm8p 192.168.1.223 DAMENG GRP1_RT_01 5236 10.0.0.223 45101 55101 65101 备库dm8s 192.168.1.224 DAMENG GRP1_RT_02 5236 10.0.0.224 45121…...

《代码整洁之道 - 程序员的职业素养》读书笔记
一 前言 《代码整洁之道 - 程序员的职业素养》的作者是Robert C. Martin,大家喜欢喊他Bob大叔。这本书主要是Bob大叔40年编程生涯的心得体会,主要讲述了一个专业的程序员需要具备什么样的态度,遵循什么样的原则,采取什么样的行动。…...
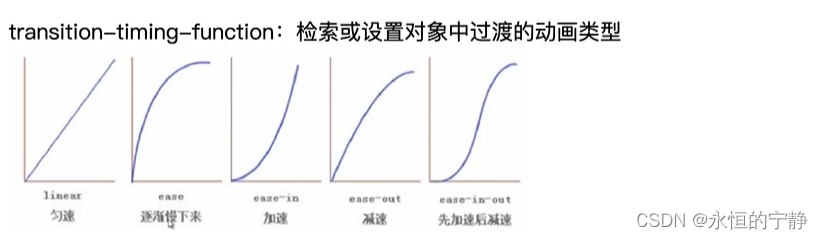
八、CSS新特性二
文章目录一、CSS3多背景和圆角二、怪异盒子模型三、多列属性四、H5多列布局瀑布流五、CSS3线性渐变5.1 线性渐变5.2 径向渐变六、CSS3过渡动画七、CSS3 2D八、CSS3动画一、CSS3多背景和圆角 css3多背景,表示CSS3中可以添加多个背景。 CSS3圆角 border-radius: 0px;…...

Ubuntu国内镜像源
查看系统版本命令: $ lsb_release -aDistributor ID: UbuntuDescription: Ubuntu 22.04 LTSRelease: 22.04Codename: jammy国内的更新源有多个,几个大互联网公司的源都比较稳定,没什么差别。 下面是比较主流的、常用的几个…...
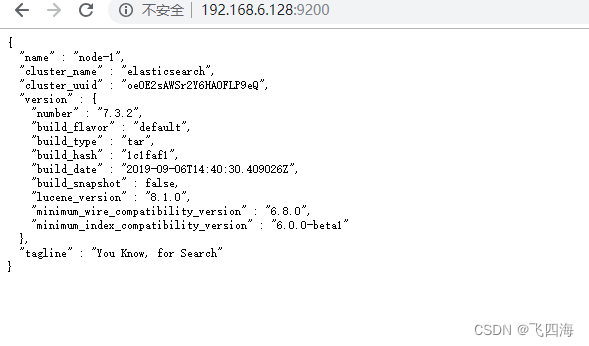
3.Linux安装es单机版
1.下载 版本 JDK 11ES elasticsearch-7.10.0 jdk安装 下载: wget https://download.java.net/openjdk/jdk11/ri/openjdk-1128_linux-x64_bin.tar.gz配置环境变量:# 编辑配置文件 vim /etc/profile# Java11环境变量配置 export JAVA_HOME/devtools/ja…...

C语言实现通讯录
咱们手机上面还有教务系统上都可以存储信息,这些都是使用编程语言来实现的,那么今天,咱们今天就用C语言来实现通讯录。 一. 实验名称 通讯录 二. 实验目标 1.数据的储存 2.数据的增加 3.数据的删除 4.数据的修改 5.数据的展示 6.数据…...

Python-生成列表
1.生成列表使用列表前必须先生成列表。1.1使用运算符[ ]生成列表在运算符[ ]中以逗号隔开各个元素会生成包含这些元素的新列表。另外,如果[ ]中没有元素就会生成空列表示例>>> list01 [] >>> list01 [] >>> list02 [1, 2, 3] >>…...
如何写好controller层
前言本篇主要要介绍的就是controller层的处理,一个完整的后端请求由4部分组成:1. 接口地址(也就是URL地址)、2. 请求方式(一般就是get、set,当然还有put、delete)、3. 请求数据(request,有head跟body)、4. 响应数据(response)本篇…...

Linux相关概念和易错知识点(42)(TCP的连接管理、可靠性、面临复杂网络的处理)
目录 1.TCP的连接管理机制(1)三次握手①握手过程②对握手过程的理解 (2)四次挥手(3)握手和挥手的触发(4)状态切换①挥手过程中状态的切换②握手过程中状态的切换 2.TCP的可靠性&…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...

使用 SymPy 进行向量和矩阵的高级操作
在科学计算和工程领域,向量和矩阵操作是解决问题的核心技能之一。Python 的 SymPy 库提供了强大的符号计算功能,能够高效地处理向量和矩阵的各种操作。本文将深入探讨如何使用 SymPy 进行向量和矩阵的创建、合并以及维度拓展等操作,并通过具体…...
)
【LeetCode】3309. 连接二进制表示可形成的最大数值(递归|回溯|位运算)
LeetCode 3309. 连接二进制表示可形成的最大数值(中等) 题目描述解题思路Java代码 题目描述 题目链接:LeetCode 3309. 连接二进制表示可形成的最大数值(中等) 给你一个长度为 3 的整数数组 nums。 现以某种顺序 连接…...

libfmt: 现代C++的格式化工具库介绍与酷炫功能
libfmt: 现代C的格式化工具库介绍与酷炫功能 libfmt 是一个开源的C格式化库,提供了高效、安全的文本格式化功能,是C20中引入的std::format的基础实现。它比传统的printf和iostream更安全、更灵活、性能更好。 基本介绍 主要特点 类型安全:…...

DiscuzX3.5发帖json api
参考文章:PHP实现独立Discuz站外发帖(直连操作数据库)_discuz 发帖api-CSDN博客 简单改造了一下,适配我自己的需求 有一个站点存在多个采集站,我想通过主站拿标题,采集站拿内容 使用到的sql如下 CREATE TABLE pre_forum_post_…...
Spring AOP代理对象生成原理
代理对象生成的关键类是【AnnotationAwareAspectJAutoProxyCreator】,这个类继承了【BeanPostProcessor】是一个后置处理器 在bean对象生命周期中初始化时执行【org.springframework.beans.factory.config.BeanPostProcessor#postProcessAfterInitialization】方法时…...
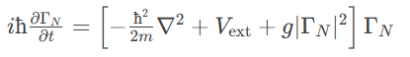
解析“道作为序位生成器”的核心原理
解析“道作为序位生成器”的核心原理 以下完整展开道函数的零点调控机制,重点解析"道作为序位生成器"的核心原理与实现框架: 一、道函数的零点调控机制 1. 道作为序位生成器 道在认知坐标系$(x_{\text{物}}, y_{\text{意}}, z_{\text{文}}…...

小智AI+MCP
什么是小智AI和MCP 如果还不清楚的先看往期文章 手搓小智AI聊天机器人 MCP 深度解析:AI 的USB接口 如何使用小智MCP 1.刷支持mcp的小智固件 2.下载官方MCP的示例代码 Github:https://github.com/78/mcp-calculator 安这个步骤执行 其中MCP_ENDPOI…...

Win系统权限提升篇UAC绕过DLL劫持未引号路径可控服务全检项目
应用场景: 1、常规某个机器被钓鱼后门攻击后,我们需要做更高权限操作或权限维持等。 2、内网域中某个机器被钓鱼后门攻击后,我们需要对后续内网域做安全测试。 #Win10&11-BypassUAC自动提权-MSF&UACME 为了远程执行目标的exe或者b…...