手刻 Deep Learning -第壹章-PyTorch入门教学-基础概念与再探线性回归

一、前言
本章会需要 微分、线性回归与矩阵的基本观念
这次我们要来做 PyTorch 的简单教学,我们先从简单的计算与自动导数( auto grad / 微分 )开始,使用优化器与误差计算,然后使用 PyTorch 做线性回归,还有 PyTorch 于 GPU 显示卡( CUDA ) 的使用范例。
本文的重点是学会 loss function 与 optimizer 使用
文本目录 :
- 为什么选择 PyTorch?
- 名词与概念介绍 导数(partial derivative), 优化器(optimizer), 损失函数 ( loss function )
- 自动导数 /Auto grad (手工优化与损失函数的实作)<- 此节很无聊
- 优化器, 损失函数, 矩阵与 partial derivative 示例
- 线性回归与矩阵范例 —Model 概念
- GPU 显卡 (CUDA) 运算范例
本文不讲解如何安装 PyTorch ,且假设读者已经拥有 Numpy 使用经验
如果手边没有环境,可以使用 Google Colab ( Google 已经帮各位安装好许多常用的套件 )
二、选择 PyTorch的理由
Machine Learning / Deep Learning 有许多 Framework 可以使用,其中 Keras (Tensorflow) 与 PyTorch 本人都有使用经验,但如果想要研究与了解 Deep Learning 如何运作,本人认为最好的方式是使用 PyTorch
一般使用 Keras (Tensorflow) 虽然可以快速的建立模型,但是底层原理没有打好基础的人一定会是雾里看花
知其然,知其所以然
PyTorch 使用上很接近 Numpy,另外有强大的数学计算功能,例如:自动微分,自动优化,方便配置到显卡上运算 (Nvidia CUDA,而且就本人使用经验来说,安装比 TensorFlow 容易 )... 如果知道 PyTorch 这些功能,可以使用在各种数学应用,而且对于 Machine Learning / Deep Learning 底层运作也会更加了如指掌
三、名词与概念介绍 导数(partial derivative), 优化器(optimizer), 损失函数 ( loss function )
其实我们之前的章节,就是在为这些铺路
3.1 损失函数 ( loss function )
这个名词中文看来奇怪,其实他是计算数值差距用的,计算与答案的误差,帮助我们找目标的公式,例如:
我们有 18 元去买 3块钱的苹果,我们只买了 5颗,我们是不是还可以买更多 ? ( 18–3*5=3,我们剩下 3元 ,误差就是 3 )
在线性回归 中就是计算和答案的差距,主要用来取得导数
3.2 导数( partial derivative)
就是微分概念,透过损失函数还可以找出我们要移动的方向和距离
3.3 优化器 ( optimizer )
开始修正我们的数值使用,也有人称优化器,就是依靠导数去调整数值
导数部分其实不用特别关心,他实务上隐藏在 loss function 与 optimizer 之间,但是这三者的组合就是 Machine Learning 中常用的概念
流程就是
误差计算 -> 寻找导数 -> 优化 ->误差计算 -> 寻找导数 -> 优化 ->误差计算 -> 寻找导数 -> 优化 ->误差计算 -> 寻找导数 -> 优化 ->...
四、自动导数 / Auto grad ( 手工优化与损失函数的实现)
先说此节很无聊, 是介绍损失函数与优化器如何运作,但是可以跳到下节没关系
本节承接 线性回归 概念,一样依照 loss function 与 optimizer 架构
微分在 Machine Learning 中是非常重要的计算,而这种计算已经有公式可循,所以 PyTorch 会自动的帮我们计算(也就是我们之前章节说过,不会算没关系,电脑可以帮我们算),但是概念与原理要懂
这边的 grad 其实就是微积分中的 partial derivative (导数 / 斜率),PyTorch 会帮我们追踪每个变量的 导数/斜率 ,即自动追踪变量的任何变化
现在我们来看最基础的 PyTorch 与 Auto grad 范例 :
假设今天在商场买苹果结账,假设苹果 3 元,我们手上有 18 元,纸袋 不用钱(这边为了方便范例先忽略) ,我们要去尽可能的买越多苹果越好
公式如下:
结账总额(Y) = 苹果数量(a) * 苹果单价(X) + 纸袋单价(b)
换成数学公式是 Y = aX + b
- Y 是我们手上有的钱,这个我们不能改变
- X 是苹果单价,这个我们不能改变
- a 是苹果数量,这是我们要找出来的
- b 这边因为纸袋0元,所以我们直接省略不看
x = torch.tensor([3.0]) # 蘋果單價
y = torch.tensor([18.0]) # 我們的預算
a = torch.tensor([1.0], requires_grad=True) # 追蹤導數
print('grad:', a.grad)
loss = y - (a * x) # loss function ( 中文稱 損失函數 )
loss.backward()
print('grad:', a.grad)解说:
- torch.tensor: 就是建立一个 Tensor (类似于 np.array )
- requires_grad=True 我们有需要追踪的变量才要加上这个参数,不用追踪的不用,例如这个范例中我们只希望 a 改变,不要去动其他数值,所以只有 a 有 requires_grad=True
4.1 损失函数( loss function)
实务上是让他越接近 0 越好,我们后面会套用 PyTorch 内建的 function ,就不用每次的手工打造
- 上面代码中,loss就是差价公式,概念就是Y= ax + b,但是我们的目标是要把钱花光光,所以loss要越趋近于0越好
所以数学上就成了Y-(ax + b) = 0是我们的目标 - loss.backward() 就是和 PyTorch 说开始反向追踪
这是 print 出来的结果
# grad: None
# grad: tensor([-3.])可以看到我们 print('grad:', a.grad) ,在 loss.backward 之前是没有数值的
但是之后冒出一个 -3,这个 -3 就是 partial derivative (会微积分的人可以算看看 ),然后我们可以靠这个数值去调整 a 的值,如下
4.2 优化器
PyTorch 有内建好的优化器,但是我们这边为了演示原理,一样手工计算 (下节我们会使用内建的)
下面代码是我们开始进行线性回归优化 ( 计算 100 次 )
for _ in range(100):a.grad.zero_()loss = y - (a * x)loss.backward()with torch.no_grad():a -= a.grad * 0.01 * loss解说:
- 每一次的 backward ,a 的 grad 都会相加,所以我们要先做归零
(就像是实验室仪器每次都要先归零校正 ) - loss 与 loss.backward 上面已经解说过,用来反向追踪导数
- with torch.no_grad(): 这部分概念很重要,前面提过 PyTorch 会自动追踪 a 的任何计算,所以我们手动调整 a 一定要和 PyTorch 说,不要追踪我们的手动调整
我們看看跑 100 次迴歸的結果
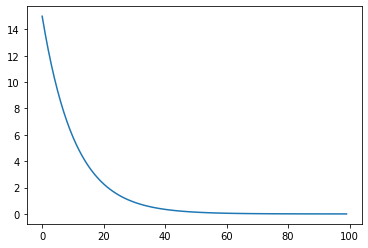
損失函跑 100 次的變化
print('a:', a)
print('loss:', (y - (a * x)))
print('result:', (a * x))
# a: 5.999598503112793
# loss: 0.0012054443359375
# result: 17.998794555664062可以看到 a 趋近于 6, 误差 (loss ) 趋近于 0
表示我们真的可以用 18 块钱去买 6 颗苹果 3元的苹果
五、优化器, 损失函数, 矩阵与 partial derivative 示例
这边我们要用 PyTorch 内建的 loss function 与 optimizer 来做计算,会方便很多,而且可以做更多复杂的问题
本文的重点是学会 loss function 与 optimizer 使用
直接看代码(一样是苹果 3元范例 )
x = torch.tensor([3.0])
y = torch.tensor([18.0])
a = torch.tensor([1.0], requires_grad=True)
loss_func = torch.nn.MSELoss()
optimizer = torch.optim.SGD([a], lr=0.01)
for _ in range(100):optimizer.zero_grad()loss = loss_func(y, a * x)loss.backward()optimizer.step()解说:
- loss_func 就是损失函数,我们这边使用 torch.nn.MSELoss
他其实是计算 均方误差,loss function 有很多种,我们日后有机会再介绍,但是这边要知道很多情况下的数值比较其实用 MSELoss 就很好用了
细节:https://pytorch.org/docs/stable/nn.html#loss-functions - optimizer 就是优化器
torch.optim.SGD([a], lr=0.01) 这边是我们使用 SGD ,一样优化器有很多种,我们这边为了简单示范先用 SGD
-> [a] 是我们和优化器说照顾好我们的 a 变量
-> lr 是学习率, 数值都是小于 1,实际看场合调整, 我们这边 0.01 是为了快速示范
细节 : torch.optim — PyTorch 2.0 documentation - optimizer.zero_grad 是为了归零调整,因为每次 backward 都会增加 grad 的数值(就像是实验室每次做实验都要归零调整,不然上个用户的操作会干扰实验结果 )
- loss.backward() 做反向传导,就是找出导数
- optimizer.step 告诉优化器做优化,他会自动帮我们调整 a 的数值
我们测试一下矩阵概念的计算
假设一样是 18 元的预算,三个种不同的苹果
售价分别是 3 元, 5 元, 6 元,这样可以买几颗 ?
我们只要修改一下数值
x = torch.tensor([3.0, 5.0, 6.0,]) # 不同種蘋果售價
y = torch.tensor([18.0, 18.0, 18.0]) # 我們的預算
a = torch.tensor([1.0, 1.0, 1.0], requires_grad=True) # 先假設都只能買一顆然后我们跑计算 ( 这里跑 1000 次,让数值精准些 )
loss_func = torch.nn.MSELoss()
optimizer = torch.optim.SGD([a], lr=0.01)
for _ in range(1000):optimizer.zero_grad()loss = loss_func(y, a * x)loss.backward()optimizer.step()
print('a:', a)
# a: tensor([6.0000, 3.6000, 3.0000], requires_grad=True)看起来没错,如果只有 18 元,分别去买不同的苹果,我们只能买 6 颗 ( 3元 ), 3 颗(5元), 3 颗(6元)
六、线性回归与矩阵范例 —Model 概念
有了上面的概念,现在我们来做更进阶的范例
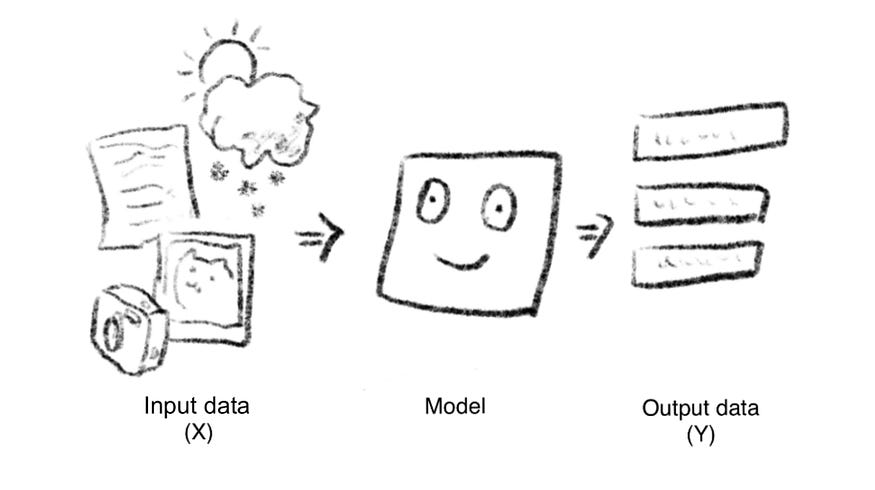
data -> model -> output
我们将输入数据到输出数据这个过程称为 “Model” ,概念上就是可以当作是一个黑箱,我们把数据丢进去 (一般称为 X ),就会产生出预测数据 ( 称为 Y ),例如:
- 影像分类:照片丢入 model ,然后 model 告诉我们影像的类别
- 资料预测:过去几天的气象资料(温度、湿度、气压.. . ) 丢入 model ,然后得到几天后的预测
- 语音识别:用户说话的音频丢入 model ,得到文字输出
6.1 准备资料
因为本文是在示范线性回归,我们先不探讨复杂问题,先做最简单的计算,所以这次我们使用 sklearn 来产生假资料练习
(打好基础比较重要)
from sklearn.datasets import make_regression
np_x, np_y = make_regression(n_samples=500, n_features=10)
x = torch.from_numpy(np_x).float()
y = torch.from_numpy(np_y).float() np_x 是产生出来的测试线性回归数据,有 10 个不同的属性,500 笔数据(可以使用 np_x.shape 看到 )
np_y 是产生出来的答案
因为, make_regression 产生出来的是 numpy,他不是 PyTorch 的 Tensor,所以我们要转换一下 ( torch.from_numpy(... ). float() )
6.2 建立我们的 Model
w = torch.randn(10, requires_grad=True)
b = torch.randn(1, requires_grad=True)
optimizer = torch.optim.SGD([w, b], lr=0.01)
def model(x):return x @ w + b解说:
- w:就是乱数产生的“权重”,我们会用矩阵计算将 x 的每个特征相乘,记得我们上面产生的数据有 10 个特征吗? 所以他是 torch.randn(10),而 requires_grad=True 就是和 PyTorch 说我们要优化这个数值
- b:源自于 y=aX + b 公式,这次我们把 b 放进来了
- torch.optim.SGD([w, b], lr=0.01) 就是优化器,和他说明我们要追踪 w 和 b
再来 model function 就是我们这次的主角,基本精神就是 y=aX + b (这边的 a 我们已经改用 w 替代 )
6.3 先预测
我们还没有训练我们的 model ,先看直接丢入 数据 (x) 会生出什么
predict_y = model(x)然后我们可视化一下
plt.figure(figsize=(20, 10))
plt.subplot(1, 2, 1)
plt.plot(y)
plt.plot(predict_y.detach().numpy())
plt.subplot(1, 2, 2)
plt.scatter(y.detach().numpy(), predict_y.detach().numpy())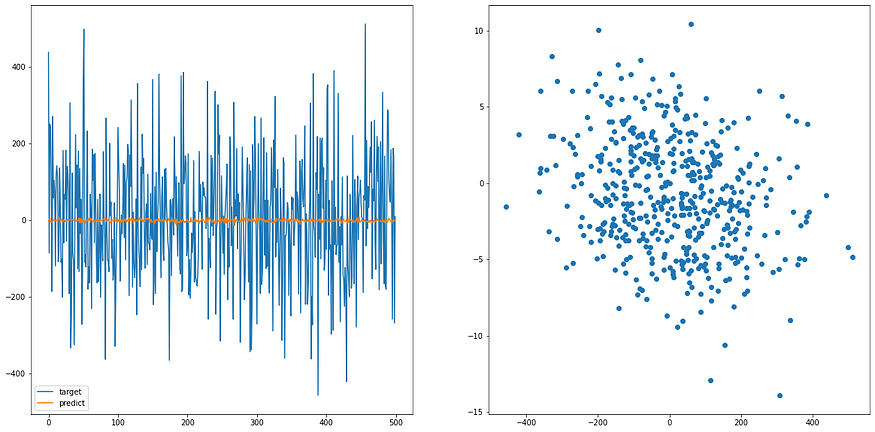
说明一下,左图是数据范围,理想上两个颜色的线应该会看起来一致; 右图是数据预测与目标数据的分布图,理想上应该要是一条直线(左右到右上),看我们之后训练过的 model 就可以知道差异
6.4 开始训练
直接看程序
loss_func = torch.nn.MSELoss() # 之前提過的 loss function
history = [] # 紀錄 loss(誤差/損失)的變化
for _ in range(300): # 訓練 300 次predict_y = model(x)loss = loss_func(predict_y, y)# 優化與 backward 動作,之前介紹過optimizer.zero_grad()loss.backward()optimizer.step()history.append(loss.item())
plt.plot(history)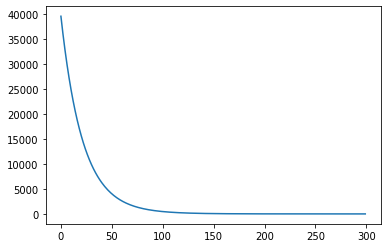
可以看到 loss 随时间降低,这表示我们的 model 确实有学到东西,再来看看预测结果
predict_y = model(x)
plt.figure(figsize=(20, 10))
plt.subplot(1, 2, 1)
plt.plot(y, label='target')
plt.plot(predict_y.detach().numpy(), label='predict')
plt.legend()
plt.subplot(1, 2, 2)
plt.scatter(y.detach().numpy(), predict_y.detach().numpy())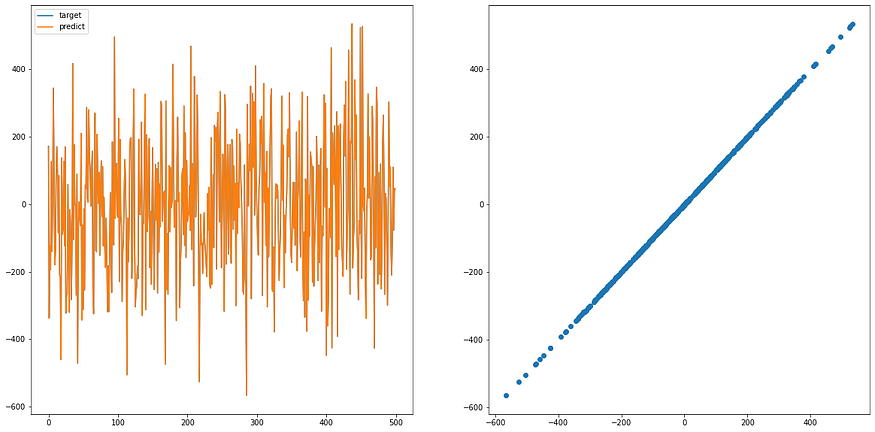
如上所言,我们输入 x 到 model ,可以得到很好的 y ( 预测与答案几乎相似)
七、GPU 显卡 (CUDA) 运算范例
之前的其他文章提过, 显示卡对于矩阵计算非常在行
而 PyTorch 对于使用显卡计算很容易,如果读者是 Nvidia 显卡用户,安装 CUDA 相关套件即可(这部分就不在本文教学范围了),而 AMD 用户,听说有 AMD ROCm 可以使用,不过本人没有使用过也不清楚(本人手上都是老黄牌的显卡)
我们要在 PyTorch 使用 cuda ,先检测一下环境支不支持
torch.cuda.is_available()看到结果是true,表示应该(可能? 或许? 大概? )没有问题( 因为实际上可能会有 CUDA 版本 / 驱动 各种奇怪状况)
再来就是我们把 device 抓出来
device = torch.device('cuda') # cuda 即 nvidia gpu 計算
# device = torch.device('cpu') # 如果想回到 cpu 計算再来,为了我们要示范GPU和CPU的差异,我们需要更多数据
from sklearn.datasets import make_regression
np_x, np_y = make_regression(n_samples=5000, n_features=5000)
x = torch.from_numpy(np_x).float().to(device)
y = torch.from_numpy(np_y).float().to(device) 为了要让矩阵更大,所以我们这次增加到5000个特征
然后注意上面的to(device)这就是把 PyTorch 的 Tensor 搬移到设备上面(我们已经指定成 cuda ),所以这些资料已经被移动到 GPU 上
只有位在相同的设备的 Tensor 才能互相计算,例如 gpu 只能算 gpu,cpu 只能算 cpu,所以计算之前要 .to(device) 到相同设备
现在我们建立 model (这个 model 我们要移动到 GPU 上)
w = torch.randn(5000).to(device)
b = torch.randn(1).to(device)
w.requires_grad=True
b.requires_grad=True
optimizer = torch.optim.SGD([w, b], lr=0.01)
def model(x):x = x @ w + breturn x一样的 to(device),然后 requires_grad 是因为移动到 GPU 上已经不同于 CPU,所以我们要另外设置要求追踪导数 ( 优化器这些就一样的代码)
再来跑训练
loss_func = torch.nn.MSELoss()
history = []
ts = time.time()
for _ in range(1000): # 訓練 1000 次predict_y = model(x)loss = loss_func(predict_y, y)# 優化與 backward 動作optimizer.zero_grad()loss.backward()optimizer.step()history.append(loss.item())
print(f'run_time: {time.time()-ts:.5f}')
plt.plot(history)我們另外加了 time.time 來看執行時間
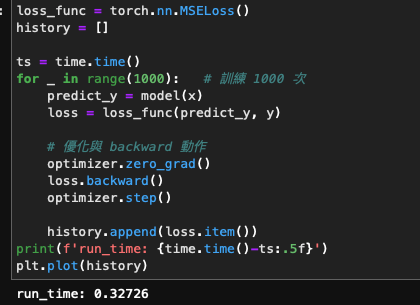
以下是本人的一些紀錄
- AMD 3900X (CPU): 2.8 sec
- Nvidia 3090(GPU) : 0.327 sec
- Jetson Nano 4GB (CPU): 52.7 sec
- Jetson Nano 4GB (GPU):16.47 sec
如果是影像處理(CNN)或是隨 model 複雜度增加,時間差距會更大,另外也看到 GPU 的 RAM 被佔用
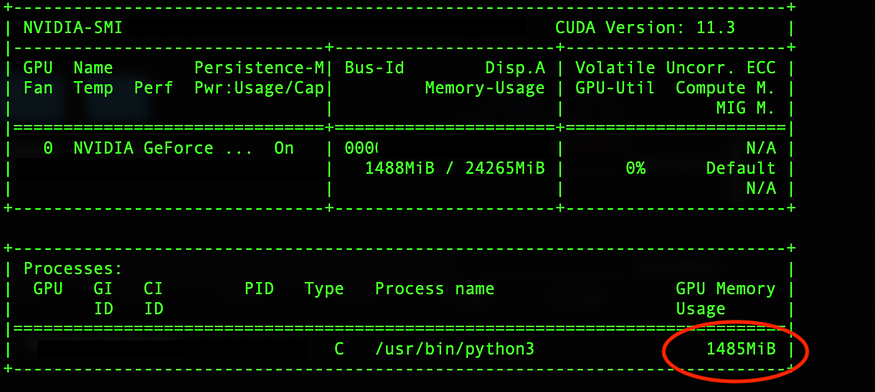
这也是为什么 Deep Learning 会需要大内存显卡的原因,当你越多的数据搬移到 GPU 就会需要更多空间
八、结语
本文的重点是学会 loss function 与 optimizer 使用
其实掌握正确的 loss function 与 optimizer,在 model 的设计上就会顺利很多,这个我们日后有机会介绍会看到,另外本文其实很多观念与细节碍于篇幅与时间没有很详细的交代
如果有兴趣的读者可以自行输入代码与试验不同的数值,去发现其中的细节变化,熟悉这些操作与概念对于 Machine Learning / Deep Learning 会很有帮助Seachaos
相关文章:
手刻 Deep Learning -第壹章-PyTorch入门教学-基础概念与再探线性回归
一、前言 本章会需要 微分、线性回归与矩阵的基本观念 这次我们要来做 PyTorch 的简单教学,我们先从简单的计算与自动导数( auto grad / 微分 )开始,使用优化器与误差计算,然后使用 PyTorch 做线性回归,还有…...

深入学习 Redis - 如何使用 Redis 作缓存?缓存更新策略?使用需要注意哪些问题(工作/重点)
目录 一、Redis 作为缓存 1.1、缓存的基本概念 1.1.1、理解 1.1.2、缓存存什么样的数据?二八定律 1.2、如何使用 redis 作为缓存 1.3、缓存更新策略(redis 内存淘汰机制 / 重点) 1.3.1、定期生成 1.3.2、实时生成 内存淘汰策略&#…...

好用的软件测试框架有哪些?测试框架的作用是什么?
软件测试框架是现代软件开发过程中至关重要的工具,它可以帮助开发团队更加高效地进行测试和验证工作,从而大大提高软件质量和用户体验。 一、好用的软件测试框架 1. Selenium:作为一种开源的自动化测试框架,Selenium具有功能强大…...

PAT 1035 插入与归并
PAT 1035 插入与归并 题目描述思路讲解代码展示 题目描述 思路讲解 分析:先将i指向中间序列中满足从左到右是从小到大顺序的最后一个下标,再将j指向从i1开始,第一个不满足a[j] b[j]的下标,如果j顺利到达了下标n,说明…...

K-means 聚类算法学习笔记
K-means 聚类算法 是一种无监督学习算法,用来将 n n n 个样本点分成 k k k 类,使得整个数据集的误差平方和 S S E SSE SSE 最小。在本例中,样本点是指平面直角坐标系上的点,聚类中心也是平面直角坐标系上的点,而每个…...

API文档搜索引擎
导航小助手 一、认识搜索引擎 二、项目目标 三、模块划分 四、创建项目 五、关于分词 六、实现索引模块 6.1 实现 Parser类 6.2 实现 Index类 6.2.1 创建 Index类 6.2.2 创建DocInfo类 6.2.3 创建 Weight类 6.2.4 实现 getDocInfo 和 getInverted方法 6.2.5 实现 …...

文案内容千篇一律,软文推广如何加深用户印象
随着互联网技术的发展,企业营销的方式逐渐转向软文推广,但是现在软文推广的内容同质化越来越严重,企业应该如何让自己的软文推广保持差异性,在用户心中留下独特的印象呢?下面就让媒介盒子告诉你。 一、 找出产品独特卖…...

十二、流程控制-循环
流程控制-循环 1.while循环语句★2.do...while语句★3.for循环语句 —————————————————————————————————————————————————— 1.while循环语句★ while语句也称条件判断语句,它的循环方式是利用一个条件来控制是否…...
五、回溯(trackback)
文章目录 一、算法定义二、经典例题(一)排列1.[46.全排列](https://leetcode.cn/problems/permutations/description/)(1)思路(2)代码(3)复杂度分析 2.[LCR 083. 全排列](https://le…...

什么是分布式锁?他解决了什么样的问题?
相信对于朋友们来说,锁这个东西已经非常熟悉了,在说分布式锁之前,我们来聊聊单体应用时候的本地锁,这个锁很多小伙伴都会用 ✔本地锁 我们在开发单体应用的时候,为了保证多个线程并发访问公共资源的时候,…...
Ubuntu 12.04增加右键命令:在终端中打开增加打开文件
Ubuntu 12.04增加右键命令:在终端中打开 软件中心:搜索nautilus-open-terminal安装 用快捷键CtrlT打开命令行输入: sudo apt-get install nautilus-open-terminal 重新加载文件管理器 nautilus -q 或注销再登录即要使用...

Centos 7 访问局域网windows共享文件夹
Refer: centos7 访问windows系统的共享文件夹_centos访问windows共享_三希的博客-CSDN博客 一、在CentOS中配置CIFS网络存储服务 CIFS(Common Internet File System)是一种在网络上共享文件的协议,也称为SMB(Server Message Blo…...

GDB的TUI模式(文本界面)
2023年9月22日,周五晚上 今晚在看GDB的官方文档时,发现GDB居然有文本界面模式 TUI (Debugging with GDB) (sourceware.org) GDB开启TUI的条件 GDB的文本界面的开启条件是:操作系统有适当版本的curses库 The TUI mode is supported only on…...

深入了解Python和OpenCV:图像的卡通风格化
前言 当今数字时代,图像处理和美化已经变得非常普遍。从社交媒体到个人博客,人们都渴望分享独特且引人注目的图片。本文将介绍如何使用Python编程语言和OpenCV库创建令人印象深刻的卡通风格图像。卡通风格的图像具有艺术性和创意,它们可以用…...

【算法挨揍日记】day06——1004. 最大连续1的个数 III、1658. 将 x 减到 0 的最小操作数
1004. 最大连续1的个数 III 1004. 最大连续1的个数 III 题目描述: 给定一个二进制数组 nums 和一个整数 k,如果可以翻转最多 k 个 0 ,则返回 数组中连续 1 的最大个数 。 解题思路: 首先题目要我们求出的最多翻转k个0后&#x…...
华为云HECS安装docker
1、运行安装指令 yum install docker都选择y,直到安装成功 2、查看是否安装成功 运行版本查看指令,显示docker版本,证明安装成功 docker --version 或者 docker -v 3、启用并运行docker 3.1启用docker 指令 systemctl enable docker …...

力扣669 补9.16
最近大三上四天有早八,真的是受不了了啊,欧嗨呦,早上困如狗,然后,下午困如狗,然后晚上困如狗,尤其我最近在晚上7点到10点这个时间段看力扣,看得我昏昏欲睡,不自觉就睡了1…...

2023-9-22 没有上司的舞会
题目链接:没有上司的舞会 #include <cstring> #include <iostream> #include <algorithm>using namespace std;const int N 6010;int n; int happy[N]; int h[N], e[N], ne[N], idx; bool has_father[N];// 两个状态,选该节点或不选该…...

【HDFS】cachingStrategy的设置
org.apache.hadoop.hdfs.client.impl.BlockReaderFactory#getRemoteBlockReader: private BlockReader getRemoteBlockReader(Peer peer) throws IOException {int networkDistance = clientContext.getNetworkDistance(datanode);return BlockReaderRemote...

性能测试 —— 性能测试常见的测试指标 !
一、什么是性能测试 先看下百度百科对它的定义,性能测试是通过自动化的测试工具模拟多种正常、峰值以及异常负载条件来对系统的各项性能指标进行测试。 我们可以认为性能测试是:通过在测试环境下对系统或构件的性能进行探测,用以验证在生产环…...

别再死记公式了!用Multisim仿真+实物测量,5分钟搞懂运放差分放大电路
运算放大器差分电路实战指南:从仿真到实测的完整学习路径 看着示波器上跳动的波形,我突然意识到——那些在课本上死记硬背的公式,原来可以如此直观地呈现。作为一名电子工程师,我至今记得第一次用Multisim仿真配合实物测量理解差分…...

System.Drawing.Graphics进阶:手把手教你打造可动态更新的Winform纵向标签控件
深度解析System.Drawing.Graphics:构建高性能Winform纵向标签控件实战指南 在Winform开发中,标准控件库提供的横向文本标签往往无法满足特殊排版需求。本文将带您深入System.Drawing.Graphics的核心机制,从底层原理到实战优化,打造…...

树莓派GPIO上拉下拉电阻实战:为什么你的按键检测总是不稳定?
树莓派GPIO上拉下拉电阻实战:为什么你的按键检测总是不稳定? 树莓派的GPIO接口是开发者最常使用的功能之一,但很多人在按键检测项目中都会遇到信号抖动、误触发等问题。这往往是因为忽略了上拉/下拉电阻的合理配置。本文将带你从电路原理到代…...

LiteFlow实战:如何用组件化思维重构复杂业务流程
1. 为什么需要组件化思维重构复杂业务流程 在传统的软件开发中,我们经常会遇到这样的场景:一个业务流程变得越来越复杂,代码逐渐演变成难以维护的"面条式"代码。特别是在电商系统中,像订单处理、价格计算这样的核心流程…...

8B小身材大能力!Qwen3-VL图文模型Windows部署避坑指南
8B小身材大能力!Qwen3-VL图文模型Windows部署避坑指南 1. 为什么选择Qwen3-VL-8B模型 在当今多模态AI领域,大模型往往意味着高算力需求和高部署成本。而Qwen3-VL-8B-Instruct-GGUF的出现打破了这一常规,它用仅8B的参数规模实现了接近72B大模…...

Arduino AT24Cxx EEPROM类型安全驱动库详解
1. 项目概述EEPROMHandler 是一款专为 Arduino 兼容平台设计的 AT24Cxx 系列 IC 外部 EEPROM 存储芯片驱动辅助库。其核心定位并非替代底层 Wire 库,而是构建在标准 IC 通信协议之上、面向嵌入式数据持久化场景的类型安全(type-safe)抽象层。…...
)
C#项目移植避坑指南:如何正确修改命名空间和文件夹名称(附完整步骤)
C#项目移植避坑指南:如何正确修改命名空间和文件夹名称(附完整步骤) 在C#项目开发中,经常会遇到需要移植或重构项目的情况。无论是项目合并、框架升级,还是简单的重命名需求,修改命名空间和文件夹名称都是绕…...

本科毕业论文 AI 写作新范式:Paperzz 4 步智能写作系统,解锁毕业高效新体验
Paperzz-AI官网免费论文查重复率AIGC检测/开题报告/文献综述/论文初稿paperzz - 毕业论文-AIGC论文检测-AI智能降重-ai智能写作https://www.paperzz.cc/dissertation 一、本科毕业论文的写作困局与破局 本科毕业论文是大学学业的收官之作,却也是无数学生的 “毕业拦…...

Cartographer实战:如何用官方数据集快速验证你的安装是否正确
Cartographer实战:官方数据集验证安装全流程指南 当你花了大半天时间终于完成了Cartographer的编译安装,看着终端里密密麻麻的日志滚过最后一行"Build finished successfully",心里难免会犯嘀咕:这玩意儿真的装对了吗&a…...

解密字节内部30+项目都在用的FlowGram:自由布局VS固定布局保姆级选择指南
解密字节内部30项目都在用的FlowGram:自由布局VS固定布局保姆级选择指南 在当今快速迭代的企业级应用开发中,流程可视化工具已成为提升开发效率的关键。作为字节跳动内部广泛采用的流程搭建引擎,FlowGram凭借其灵活的布局模式和强大的扩展能力…...