2023华为杯研究生数学建模竞赛CDEF题思路+模型代码
全程更新华为杯研赛CDEF题思路模型及代码,大家查看文末名片获取
华为杯C题思路分析
问题一 在每个评审阶段,作品通常都是随机分发的,每份作品需要多位评委独立评审。为了增加不同评审专家所给成绩之间的可比性,不同专家评审的作品集合之间应有一些交集。但有的交集大了,则必然有交集小了,则可比性变弱。请针对3000支参赛队和125位评审专家,每份作品由5位专家评审的情况,建立数学模型确定最优的“交叉分发”方案,并讨论该方案的有关指标(自己定义)和实施细节。
问题一主要是需要为3000支参赛队和125位评审专家建立一个最优的“交叉分发”方案。这里的关键是要保证每份作品由5位专家评审,并且不同专家评审的作品集合之间有一定的交集。这个问题可以看作是一个组合优化问题,我们可以使用图论模型,将其建模为图的顶点着色问题,并求解得到最优的“交叉分发”方案。
我们的变量为,定义二进制变量xij,当第i位专家评审第j份作品时为1,否则为0。
我们的目标函数是要最大化所有专家之间作品交集的大小,即最大化
![]()
我们给定约束条件,每份作品恰好被5位专家评审;每位专家评审的作品数量应均匀分布,防止某位专家评审任务过重或过轻。
这是一个NP-hard问题,我们可以应用遗传算法、模拟退火算法等启发式算法进行求解。这些算法适用于搜索大规模组合优化问题的解空间,能够在合理时间内找到满意解。
问题二 在评审中采用标准分(附件1)为基础的排序方法,其假设是不同评审专家评审的作品集合的学术水平分布相同。但在大规模创新类竞赛评审中,通常任意两位专家评审的作品只有小部分是共同的,绝大多数作品是不同的(见问题一),而且每位专家只看到作品集合的很小部分,因此标准分评审方案的假设可能不成立,需要探索新的评审方案。请选择两种或两种以上现有或自己设计的评审方案和题目附件数据,分析每位专家、每份作品原始成绩、调整之后(如取标准分)成绩的分布特点,按不同方案进行排序,并设法比较这些方案的优劣。进而针对大规模创新类竞赛的评审,设计新的标准分(公式)计算模型。另外,一般认为经多位专家协商一致的获奖论文具有最大的可信度,附件2提供的数据1,其第二评审阶段评选出的一等奖作品排序是经专家协商取得一致的,请利用这批数据,改进你们的标准分计算模型。
问题二涉及到对不同的评审方案进行比较和分析,以及基于给定的数据设计新的标准分计算模型。我们可以对现有的几种评审方案进行分析,利用描述性统计学和假设检验等方法来比较这些方案的优劣。,如均值、中位数、标准差等,来分析每位专家、每份作品原始成绩和调整后成绩的分布特点。对不同方案下的成绩分布我们做一些可视化的展示,来更直观地了解不同方案之间的差异。
为了判断不同方案之间的差异是否显著,我们可以使用假设检验方法。通过ANOVA(方差分析)来比较多个方案下成绩的均值是否存在显著差异。使用卡方检验或Fisher精确检验来比较不同方案下成绩的分布差异。
然后基于这些分析结果,设计新的标准分计算模型,这个问题可以考虑使用回归分析,除了使用回归分析,我们还可以构建一个优化模型来求解最优的标准分计算方法。这个模型的目标函数可以是最小化所有作品标准分的方差,以减少不同方案之间的差异。约束条件可以包括保持评分的公平性、保持一定的差异性。
问题三 “创新类”大赛的特点是“创新性”,即没有标准答案。由于这类竞赛的问题难度较大,一般需要通过创新才能在竞赛期间部分解决。而作品的创新到了什么程度,后续研究的前景如何,很难有一致看法,即使专家面对面的交流,都可能由于各持己见而无法统一。加上研究生的论文表达不到位,评审专家的视角不同,同一份作品的几位专家给出的成绩会有较大的差异(极差)。极差大是大规模创新类竞赛的特点,极差比较大的作品一般处于高分段或低分段。低分段属于淘汰范围,低分段极差大的原因是有专家对违规作品或有重大失误的作品给了很低的分数,或评审专家都认同该作品质量不高,只是其中某位(些)专家更不认同该作品。故这里极差虽大,但属于不获奖范畴,一般不需要调整极差。而高分段作品还要参加权威性较高的第二阶段评审(附件数据表格同一行代表同一个作品在两个阶段的成绩,没有第二阶段评审成绩的作品只参加了第一阶段的评审)。第二阶段评审仍然存在部分极差大的作品,因为是终审,误差可能影响获奖等级,因此对部分极差大的作品,需要复议调整极差(附件的数据中有记录,复议分就是该专家最后给的标准分,用来替换原来的标准分)。第二阶段(注意两个阶段每份作品评审专家人数不同)专家调整“大极差”的规律可以作为建立极差模型的借鉴。
请根据题目所给的模拟数据2.1和2.2,讨论两阶段的成绩整体的变化和两阶段极差整体的变化,分析两阶段评审方案相比不分阶段评审方案的优劣。注意到极差大和创新性强两大特点之间会有一定的关系,为了发掘创新论文,请建立“极差”模型(含分析、分类、调整等),并针对所给数据,尝试给出第一评审阶段程序化(不需要人工干预)处理非高且非低分段作品的 “大极差”的办法。
问题三我们要聚焦于两阶段评审方案与不分阶段评审方案的比较,以及“极差”模型的建立。需要去分析两阶段的成绩变化、极差变化,并探讨如何处理“大极差”。
比较两阶段评审方案和不分阶段评审方案,可以通过方差分析(ANOVA)来比较两阶段评审方案和不分阶段评审方案的成绩差异,检验不同方案下成绩的均值是否有显著差异,以及这些差异是否可以归因于使用的评审方案
然后去计算它们的均值、标准差、四分位数差等描述性统计量,可以更详细地了解两种方案在成绩分布上的差异。以及通过可视化工具如箱线图、直方图等可以去展现这些差异。
建立极差模型的话,用分类和聚类都可以,先是分类模型,我们来来预测作品的极差大小。通过输入作品的各种特征(如各位专家的初步评分、作品类型等),分类模型可以预测该作品的极差是否会超过某个阈值。算法的话,可以用决策树、随机森林、支持向量机等。最后通过交叉验证来选择最佳的模型和参数。
聚类分析的话,我们可以将具有相似极差特性的作品分为同一类。可以让我们了解哪些作品更容易产生大的极差,聚类算法可以用K-means聚类或者层次聚类。
华为杯D题思路分析
问题一:区域碳排放量以及经济、人口、能源消费量的现状分析
(1)建立指标与指标体系
要求1:指标能够描述某区域经济、人口、能源消费量和碳排放量的状况;
要求2:指标能够描述各部门(能源供应部门、工业消费部门、建筑消费部门、交通消费部门、居民生活消费、农林消费部门)的碳排放状况;
要求3:指标体系能够描述各主要指标之间的相互关系;
要求4、部分指标的变化(同比或环比)可以成为碳排放量预测的基础。
指标选择我们可以考虑如下:
经济指标:选择GDP增长率作为衡量区域经济状况的主要指标,它能够综合反映一个区域的经济发展水平和经济活动的活跃程度。
人口指标:人口总量和人口增长率是评价人口状况的重要指标,它们可以反映区域人口的规模和增长速度,对能源消费和碳排放有直接影响。
能源消费指标:能源消费总量和能源消费结构(化石能源与非化石能源比例)是衡量能源消费状况的关键指标,它们直接影响碳排放量的大小和结构。
碳排放指标:总碳排放量、单位GDP碳排放量和各部门碳排放量是评估碳排放状况的主要指标,它们能够全面描述一个区域的碳排放水平和结构。
部门划分:将整个区域划分为能源供应部门、工业消费部门、建筑消费部门、交通消费部门、居民生活消费和农林消费部门,对每个部门的能源消费和碳排放进行独立分析。
在选定指标后,需要建立这些指标之间的关系模型。这里可以采用多元线性回归模型,将碳排放量作为因变量,其余指标作为自变量,建立它们之间的数学关系。例如,可以探究GDP增长率、人口增长率和能源消费结构对碳排放量的影响程度,分析它们之间的敏感性和弹性。对于选定的指标,计算它们的同比和环比变化,这些变化可以作为碳排放量预测的基础。如果某一年的能源消费量出现显著增加,那么这一年的碳排放量很可能也会增加。通过分析这些变化,我们可以更好地理解各个指标对碳排放的影响。
(2)分析区域碳排放量以及经济、人口、能源消费量的现状
要求1:以2010年为基期,分析某区域十二五(2011-2015年)和十三五
(2016-2020年)期间的碳排放量状况(如总量、变化趋势等);
要求2:分析对该区域碳排放量产生影响的各因素及其贡献;
要求3:研判该区域实现碳达峰与碳中和需要面对的主要挑战,为该区域双碳(碳达峰与碳中和)路径规划中差异化的路径选择提供依据。
利用已有的历史数据,我们可以分析2010年至2020年间区域的碳排放量、经济增长、人口增长和能源消费量的变化趋势和状况。通过作图、计算增长率等方法,我们可以清晰地看到这些指标的发展轨迹,从而初步了解这个区域的碳排放现状。然后再去分析各个指标的变化对碳排放的影响,找出碳排放增长的主要驱动因素。
模型的话可以使用相关性分析、回归分析等统计方法,去量化各因素对碳排放量的贡献。我们可以分析经济增长对碳排放的贡献程度,判断经济发展是否是碳排放增长的主要原因。
当然还有一些其他的外部因素,如政府政策、技术进步等,这些因素也会影响碳排放量的变化。基于对现状的分析和对影响因素的理解,我们可以预判该区域实现碳达峰和碳中和的主要挑战。包括像能源结构调整的困难、非化石能源开发的限制、经济发展和碳排放减少的矛盾等等。
(3)区域碳排放量以及经济、人口、能源消费量各指标及其关联模型
要求1:分析相关指标的变化(环比与同比);
要求2:建立各项指标间的关联关系模型;
要求3:基于相关指标的变化,结合双碳政策与技术进步等多重效应,确定碳排放预测模型参数(如能源利用效率提升和非化石能源消费比重等)取值。
在分析了各指标的现状和影响因素后,我们需要建立各项指标间的关联模型。这里可以采用多元线性回归、主成分分析等方法,根据历史数据拟合出各指标间的数学关系。
我们将碳排放量作为因变量,将GDP、人口、能源消费量等作为自变量,通过回归分析建立它们之间的线性和非线性模型。可以帮助我们了解各指标间的相互影响。建立了关联模型后,我们需要确定模型中的参数。这些参数包括能源利用效率、非化石能源消费比重等,它们是模型的核心组成部分,直接影响模型的预测效果。
问题二:区域碳排放量以及经济、人口、能源消费量的预测模型
(1)基于人口和经济变化的能源消费量预测模型
要求1:以2020年为基期,结合中国式现代化的两个时间节点(2035和2050),预测某区域十四五(2021-2025年)至二十一五(2056-2060年)期间人口、经济(GDP)和能源消费量变化。
要求2:能源消费量与人口预测相关联。
要求3:能源消费量与经济(GDP)预测相关联;
可以选择黄福涛模型来预测未来人口数量。该模型考虑了出生率、死亡率等因素的影响。
Pt+1 = Pt + Bt - Dt + It - Et
我们也可以采用人口预测模型如对数线性模型或Logistic模型,结合区域历史人口数据,预测未来人口变化趋势。当然我们需要去考虑的包括生育率、死亡率、迁移率等可能会影响的因素。在预测过程中,要不断地去调整模型参数,来确保预测结果的准确性。
经济(GDP)预测可以采用时间序列分析、多元回归分析等方法,结合国家宏观经济政策、全球经济形势等,预测区域未来经济发展趋势。
G(t) = G0 / [1 + ae^(-bt)]
能源消费量预测要去结合预测得到的人口和经济数据,使用协整分析、因果模型等方法,预测未来能源消费量。
E(t) = c1P(t) + c2G(t) - c3*E'(t)
(2)区域碳排放量预测模型
要求1:碳排放量与人口、GDP和能源消费量预测相关联;
要求2:碳排放量与各能源消费部门(工业消费部门、建筑消费部门、交通
消费部门、居民生活消费、农林消费部门)以及能源供应部门的能源消费量相关联(如反映能效提升对总能耗在上述能源消费部门分布的影响);
要求3:碳排放量与各能源消费部门(同上)的能源消费品种(一次能源中
化石能源消费与非化石能源消费以及二次能源(电或热)消费)以及能源供应部门的能源消费品种(化石能源发电与非化石能源发电)相关联(如反映非化石能源消费比重提升对各部门能源消费品种或碳排放因子的影响)。
我们要先去建立碳排放量与人口、GDP和能源消费量的关联模型。这里大家可以考虑采用多元回归分析,将碳排放量作为因变量,人口、GDP和能源消费量作为自变量,去拟合它们之间的关系。然后我们可以量化人口、经济和能源消费对碳排放量的影响,来预测未来碳排放量的变化。
还要对各个能源消费部门(如工业、建筑、交通等)分别建立碳排放量预测模型,考虑各部门能源消费量、能源消费结构等因素的影响。
分析非化石能源消费比重的提升对各部门能源消费品种或碳排放因子的影响。这个需要我们深入研究非化石能源的碳排放特性,以及其在不同部门的应用情况。来评估提高非化石能源消费比重的减排效果。
最后,我们还要对模型进行验证,来检验模型的预测能力和准确性。如果模型预测的结果与实际数据相符,说明模型是有效的;不行的话就需要对模型进行调整。
E题思路分析
- 血肿扩张风险相关因素探索建模。
请根据“表1”(字段:入院首次影像检查流水号,发病到首次影像检查时间间隔),“表2”(字段:各时间点流水号及对应的HM_volume),判断患者sub001至sub100发病后48小时内是否发生血肿扩张事件。
结果填写规范:1是0否,填写位置:“表4”C字段(是否发生血肿扩张)。
如发生血肿扩张事件,请同时记录血肿扩张发生时间。
结果填写规范:如10.33小时,填写位置:“表4”D字段(血肿扩张时间)。
是否发生血肿扩张可根据血肿体积前后变化,具体定义为:后续检查比首次检查绝对体积增加≥6 mL或相对体积增加≥33%。
注:可通过流水号至“附表1-检索表格-流水号vs时间”中查询相应影像检查时间点,结合发病到首次影像时间间隔和后续影像检查时间间隔,判断当前影像检查是否在发病48小时内。
从“表1”中提取“入院首次影像检查流水号”以及“发病到首次影像检查时间间隔”。
从“表2”中提取各时间点的“流水号”和对应的“HM_volume”。使用“附表1-检索表格-流水号vs时间”来查询每个流水号对应的影像检查时间点。
对于每个患者,找出发病后48小时内的所有影像检查。比较这些影像检查的“HM_volume”与首次影像检查的“HM_volume”,判断是否满足血肿扩张的条件(绝对体积增加≥6 mL或相对体积增加≥33%)。如果发生血肿扩张,记录发生时间;否则,标记为未发生血肿扩张。
请以是否发生血肿扩张事件为目标变量,基于“表1” 前100例患者(sub001至sub100)的个人史,疾病史,发病相关(字段E至W)、“表2”中其影像检查结果(字段C至X)及“表3”其影像检查结果(字段C至AG,注:只可包含对应患者首次影像检查记录)等变量,构建模型预测所有患者(sub001至sub160)发生血肿扩张的概率。
注:该问只可纳入患者首次影像检查信息。
结果填写规范:记录预测事件发生概率(取值范围0-1,小数点后保留4位数);填写位置:“表4”E字段(血肿扩张预测概率)。
我们先进行特征选择,从“表1”中选择患者个人史、疾病史、发病相关特征。从“表2”和“表3”中选择首次影像检查的相关特征。
然后可以可以使用机器学习的方法来进行分类,这里有很多模型可以使用,比如逻辑回归、支持向量机、随机森林、梯度提升等等,我们用这些模型做一个交叉验证和参数调优,来选择最优模型和参数。
用前100个患者的数据作为训练集进行模型训练。使用交叉验证的方法,评估模型在训练集上的表现,考察模型的准确率、召回率、F1分数等。最后来预测所有患者(sub001至sub160)发生血肿扩张的概率。
- 血肿周围水肿的发生及进展建模,并探索治疗干预和水肿进展的关联关系。
- 请根据“表2”前100个患者(sub001至sub100)的水肿体积(ED_volume)和重复检查时间点,构建一条全体患者水肿体积随时间进展曲线(x轴:发病至影像检查时间,y轴:水肿体积,y=f(x)),计算前100个患者(sub001至sub100)真实值和所拟合曲线之间存在的残差。
结果填写规范:记录残差,填写位置“表4”F字段(残差(全体))。
从“表2”中提取前100个患者的水肿体积(ED_volume)和重复检查时间点。用这些数据点来表示水肿体积随时间的变化,即y轴为水肿体积,x轴为发病至影像检查时间。
我们可以选择合适的回归模型,例如多项式回归、非线性回归等,来拟合水肿体积随时间的变化。再使用最小二乘法等方法优化模型参数,使模型能够较好地拟合训练数据。
对每个患者,使用拟合的模型预测其水肿体积,并与实际水肿体积进行比较,计算残差。记录每个患者的残差,并分析残差的分布,最终来评估模型的拟合效果。
-
- 请探索患者水肿体积随时间进展模式的个体差异,构建不同人群(分亚组:3-5个)的水肿体积随时间进展曲线,并计算前100个患者(sub001至sub100)真实值和曲线间的残差。
结果填写规范:记录残差,填写位置“表4”G字段(残差(亚组)),同时将所属亚组填写在H段(所属亚组)。
将人群进行分组,明显是一个聚类问题,我们需要选择一组特征,这些特征能够反映患者之间的差异,从而有助于我们对患者进行亚组划分。这些特征可能包括临床信息(如年龄、性别、病史等)、治疗方式、初次检查时的影像特征等。对选定的特征进行标准化或归一化,然后开始进行聚类,这里可以使用kmeans聚类,划分3-5个簇根据轮廓系数、Davies–Bouldin index等指标评估聚类效果。
还需要用主成分来降维,通过PCA,我们可以发现数据中的主要变异方向,这些方向可能代表了患者之间的主要差异。根据主成分得分,可以将患者划分为不同的亚组。对每个亚组的患者,分别进行曲线拟合,根据水肿体积随时间的变化特性,选择合适的回归模型,水肿体积的变化应该是非线性的,多项式回归和核回归可能是较好的选择。
还要进行残差计算,对于每个患者,计算其真实水肿体积与模型预测水肿体积之间的残差。分析残差的分布,检查模型的假设是否成立,比如残差是否呈正态分布,是否存在异方差性等。
-
- 请分析不同治疗方法(“表1”字段Q至W)对水肿体积进展模式的影响。
在本题,我们可以将不同治疗方法作为组别,水肿体积作为因变量进行ANOVA。
如果ANOVA结果显示组间差异显著,我们可以进行进一步的多重比较,例如Tukey HSD,来查看哪些组别之间存在显著差异。
如果存在可能影响水肿体积的其他变量(例如患者年龄、性别等),我们可以将这些变量作为协变量纳入ANCOVA模型。通过计算相关系数,可以使用皮尔逊相关系数或斯皮尔曼等级相关系数,来评估治疗方法与水肿体积变化之间的线性或非线性关联。
建立回归模型,以治疗方法为自变量,水肿体积为因变量,来看看两者之间的因果关系
-
- 请分析血肿体积、水肿体积及治疗方法(“表1”字段Q至W)三者之间的关系。
这道题我们可以用先去计算血肿体积、水肿体积和治疗方法之间的两两相关性,比如使用点双列相关系数,斯皮尔曼相关系数等,相关系数的绝对值大小可表示变量之间的关联强度,正负号表示关联方向。
然后再去构建多因素回归模型,以血肿体积和水肿体积为因变量,治疗方法为自变量,探索治疗方法对血肿和水肿体积的影响。
检查模型的合适性,包括模型的整体显著性、各自变量的显著性、模型的解释力(例如R²)等。
F题思路分析
1.如何有效应用双偏振变量改进强对流预报,仍是目前气象预报的重点难点问题。请利用题目提供的数据,建立可提取用于强对流临近预报双偏振雷达资料中微物理特征信息的数学模型。临近预报的输入为前面一小时(10帧)的雷达观测量(ZH 、ZDR、KDP),输出为后续一小时(10帧)的ZH预报。
这个问题我们可以考虑使用深度学习模型,特别是时间序列模型如LSTM或GRU,来处理雷达观测数据序列。输入可以是过去一小时的雷达观测量(ZH、ZDR、KDP),输出则是未来一小时的ZH预报。模型可以设计成多层的RNN结构,每一层学习不同层次的特征,最终输出预测的ZH值。
2.当前一些数据驱动的算法在进行强对流预报时,倾向于生成接近于平均值的预报,即存在“回归到平均(Regression to the mean)”问题,因此预报总是趋于模糊。在问题1的基础上,请设计数学模型以缓解预报的模糊效应,使预报出的雷达回波细节更充分、更真实。
为了缓解“回归到平均”的问题,可以考虑在模型训练时引入一些正则化技术,如Dropout,来防止模型过拟合。另外,可以加入对模型预测结果的不确定性估计,比如使用贝叶斯神经网络。模型不仅仅给出一个预测值,还会给出这个预测值的不确定性,去准确评估预报的可靠性。
3.请利用题目提供的ZH、ZDR和降水量数据,设计适当的数学模型,利用ZH及ZDR进行定量降水估计。模型输入为ZH和ZDR,输出为降水量。(注意:算法不可使用KDP变量。)
我们可以使用线性回归模型来估计降水量,其中输入特征为ZH和ZDR。模型的形式可以是:

更多思路,查看下方名片
相关文章:
2023华为杯研究生数学建模竞赛CDEF题思路+模型代码
全程更新华为杯研赛CDEF题思路模型及代码,大家查看文末名片获取 华为杯C题思路分析 问题一 在每个评审阶段,作品通常都是随机分发的,每份作品需要多位评委独立评审。为了增加不同评审专家所给成绩之间的可比性,不同专家评审的作…...

FP独立站之黑科技:AB站收款、斗篷CLOAK
最近一段时间经常有不少小伙伴来咨询我独立站的相关的业务,因为很多独立站卖家觉得独立站不好做,再加上跨境平台禁止特货类产品的销售(如FP产品、成人用品、电子烟、灰黑类产品等等),但这类产品市场需求大,…...
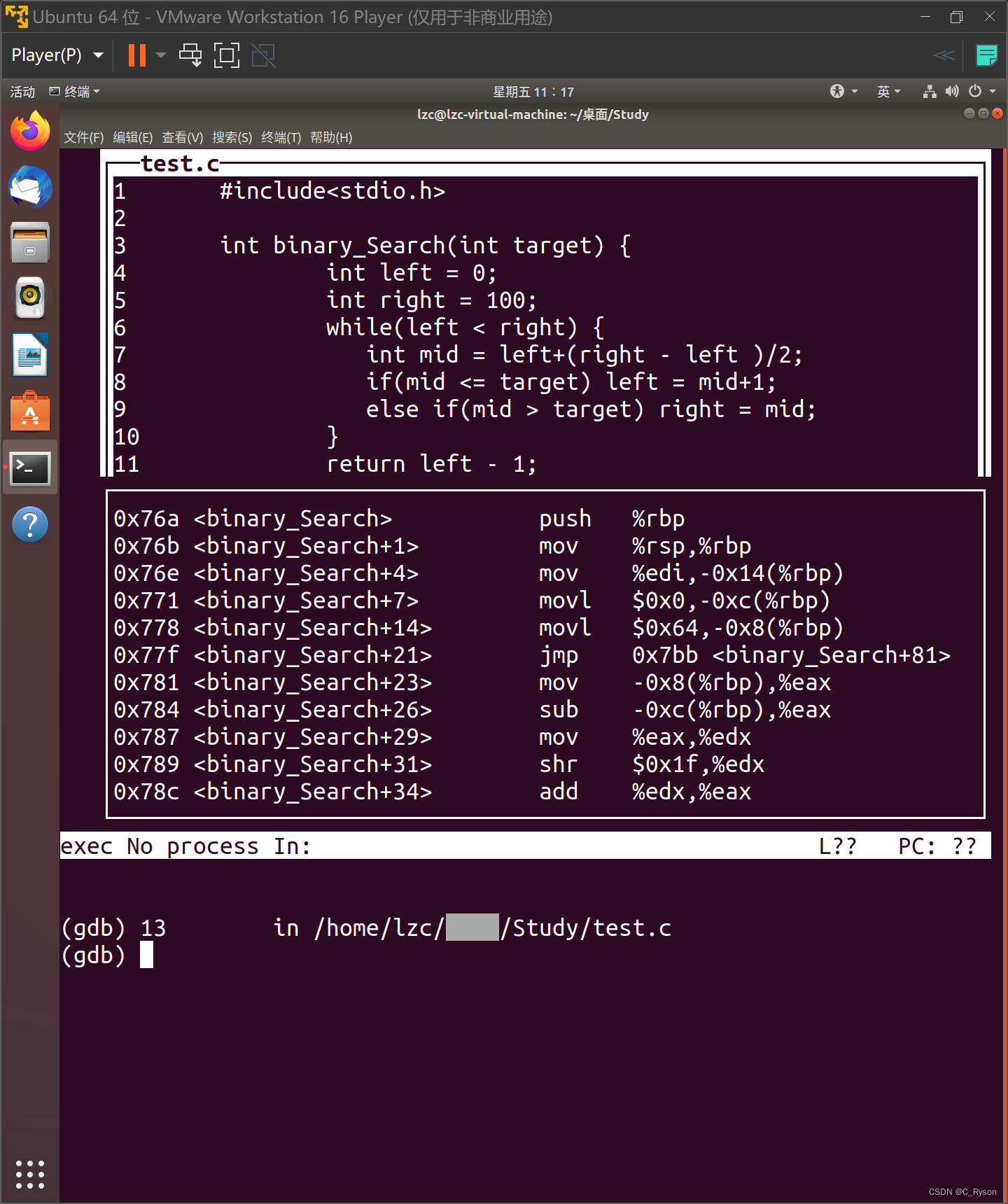
【Linux网络编程】gdb调试技巧
这篇博客主要要记录一下自己在Linux操作系统Ubuntu下使用gbd调试程序的一些指令,以及使用过程中的一些心得。 使用方法 可以使用如下代码 gcc -g test.c -o test 或者 gcc test.c -o test -g的选项最好添加,如果不添加,l指令无法被识别 …...
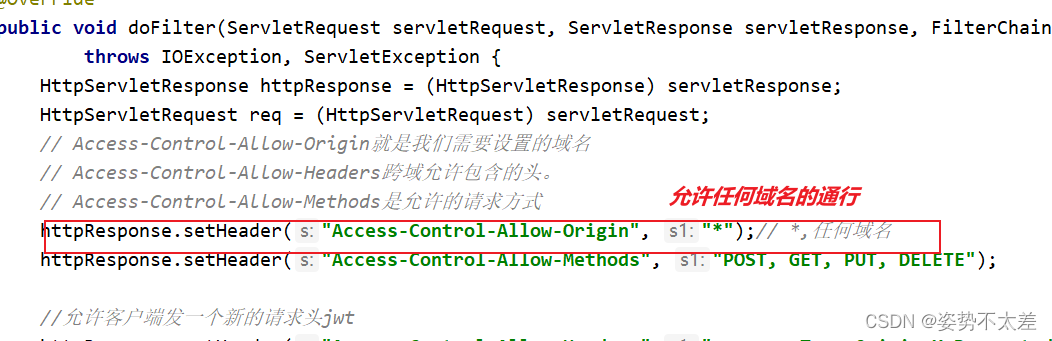
ElementUI之登录与注册
目录 一.前言 二.ElementUI的简介 三.登录注册前端界面的开发 三.vue axios前后端交互--- Get请求 四.vue axios前后端交互--- Post请求 五.跨域问题 一.前言 这一篇的知识点在前面两篇的博客中就已经详细详解啦,包括如何环境搭建和如何建一个spa项目等等知识…...

报错处理:Error: Redis server is running but Redis CLI cannot connect
嗨,读者朋友们!今天我来跟大家分享一个我在运维过程中遇到的一个关于Linux上运行Redis服务时的报错及解决方法。 报错信息如下: Error: Redis server is running but Redis CLI cannot connect 这个报错信息表明Redis服务器已经运行ÿ…...

RocketMQ 源码分析——Producer
文章目录 消息发送代码实现消息发送者启动流程检查配置获得MQ客户端实例启动实例定时任务 Producer 消息发送流程选择队列默认选择队列策略故障延迟机制策略*两种策略的选择 技术亮点:ThreadLocal 消息发送代码实现 下面是一个生产者发送消息的demo(同步发送&#…...

ISTQB术语表
此术语表为国际软件测试认证委员会(ISTQB)发布的标准术语表。此表历经数次修改、完善,集纳了计算机行业界、商业界及政府相关机构的见解及意见,在国际化的层面上达到了罕有的统一性及一致性。参与编制此表的国际团体包括澳大利亚、…...
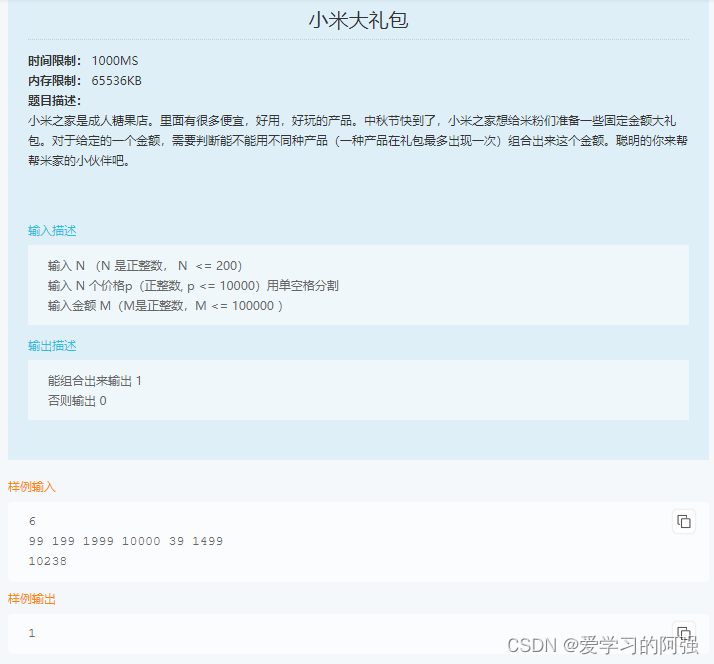
小米笔试题——01背包问题变种
这段代码的主要思路是使用动态规划来构建一个二维数组 dp,其中 dp[i][j] 表示前 i 个产品是否可以组合出金额 j。通过遍历产品列表和可能的目标金额,不断更新 dp 数组中的值,最终返回 dp[N][M] 来判断是否可以组合出目标金额 M。如果 dp[N][M…...

SkyWalking内置MQE语法
此文档出自SkyWalking官方git https://github.com/apache/skywalking docs/en/api/metrics-query-expression.md Metrics Query Expression(MQE) Syntax MQE is a string that consists of one or more expressions. Each expression could be a combination of one or more …...
Springboot2 Pandas Pyecharts 量子科技专利课程设计大作业
数据集介绍 1.背景 根据《中国科学:信息科学》期刊上的一篇文章,量子通信包括多种协议与应用类型: 基于量子隐形传态与量子存储中继等技术,可实现量子态信息传输,进而构建量子信息网络,已成为当前科研热点&…...

RabbitMQ里的几个重要概念
RabbitMQ中的一些角色: publisher:生产者consumer:消费者exchange个:交换机,负责消息路由,接受生产者发送的消息,把消息发送到一个或多个队列里queue:队列,存储消息virt…...

23. 图论 - 图的由来和构成
文章目录 图的由来图的构成Hi, 你好。我是茶桁。 从第一节课上到现在,我基本上把和人工智能相关的一些数学知识都教给大家了,终于来到我们人工智能数学的最后一个部分了,让我们从今天开始进入「图论」。 图论其实是一个比较有趣的领域,因为微积分其实更多的是对应连续型的…...
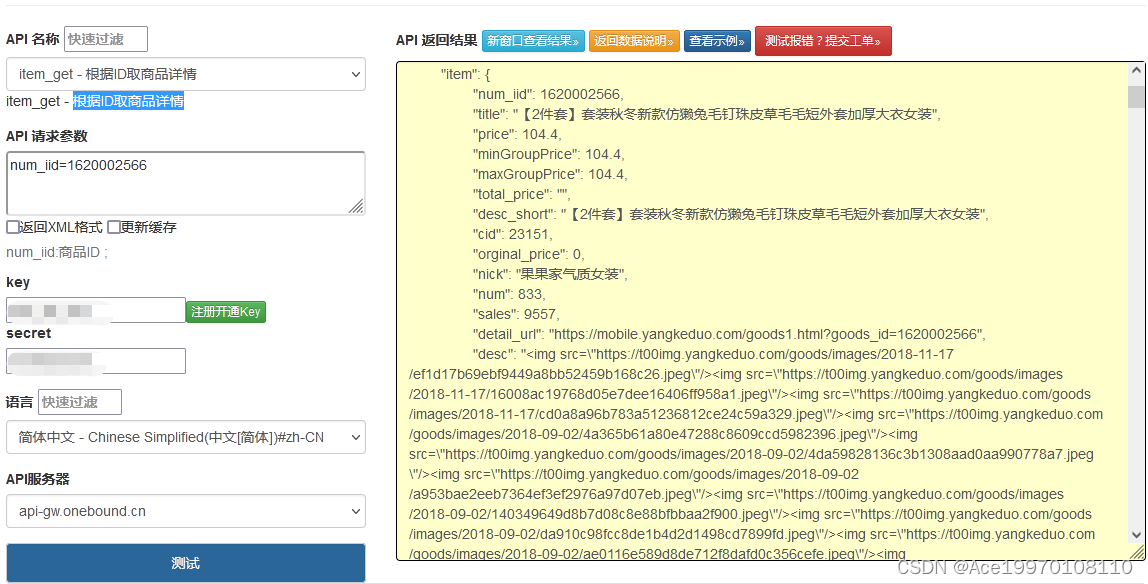
拼多多API接口解析,实现根据ID取商品详情
拼多多是一个流行的电商平台,它提供了API接口供开发者使用。要根据ID获取商品详情,您需要使用拼多多API接口并进行相应的请求。 以下是使用拼多多API接口根据ID获取商品详情的示例代码(使用Python编写): import requ…...

【JavaScript】解构
解构(Destructuring)是 JavaScript 中一种强大的语法特性,它允许你从数组或对象中提取值并赋值给变量,使代码更加简洁和易读。JavaScript 中有两种主要的解构语法:数组解构和对象解构。 数组解构 数组解构用于从数组…...

现代卷积网络实战系列2:训练函数、PyTorch构建LeNet网络
4、训练函数 4.1 调用训练函数 train(epochs, net, train_loader, device, optimizer, test_loader, true_value)因为每一个epoch训练结束后,我们需要测试一下这个网络的性能,所有会在训练函数中频繁调用测试函数,所有测试函数中所有需要的…...

rust特性
特性,也叫特质,英文是trait。 trait是一种特殊的类型,用于抽象某些方法。trait类似于其他编程语言中的接口,但又有所不同。 trait定义了一组方法,其他类型可以各自实现这个trait的方法,从而形成多态。 一、…...
TouchGFX之画布控件
TouchGFX的画布控件,在使用相对较小的存储空间的同时保持高性能,可提供平滑、抗锯齿效果良好的几何图形绘制。 TouchGFX 设计器中可用的画布控件: LineCircleShapeLine Progress圆形进度条 存储空间分配和使用 为了生成反锯齿效果良好的…...
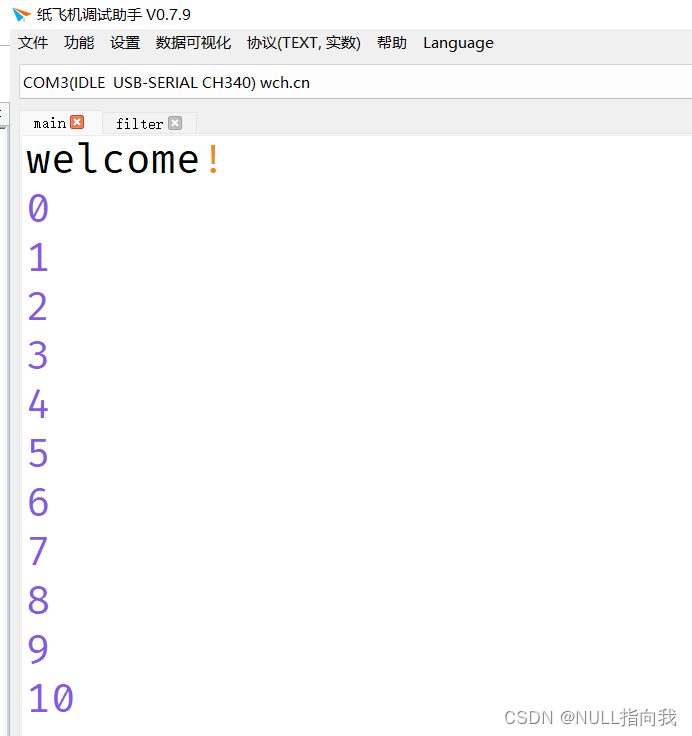
STM32F103RCT6学习笔记2:串口通信
今日开始快速掌握这款STM32F103RCT6芯片的环境与编程开发,有关基础知识的部分不会多唠,直接实践与运用!文章贴出代码测试工程与测试效果图: 目录 串口通信实验计划: 串口通信配置代码: 测试效果图&#…...

Opencv-图像噪声(均值滤波、高斯滤波、中值滤波)
图像的噪声 图像的平滑 均值滤波 均值滤波代码实现 import cv2 as cv import numpy as np import matplotlib.pyplot as plt from pylab import mplmpl.rcParams[font.sans-serif] [SimHei]img cv.imread("dog.png")#均值滤波cv.blur(img, (5, 5))将对图像img进行…...
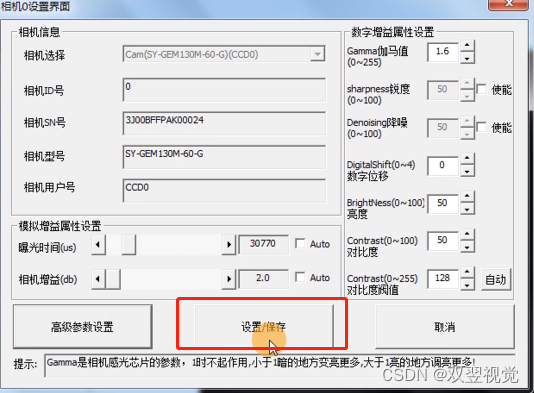
MasterAlign相机参数设置-增益调节
相机参数设置-曝光时间调节操作说明 相机参数的设置对于获取清晰、准确的图像至关重要。曝光时间是其中一个关键参数,它直接影响图像的亮度和清晰度。以下是关于曝光时间调节的详细操作步骤,以帮助您轻松进行设置。 步骤一:登录系统 首先&…...

XML Group端口详解
在XML数据映射过程中,经常需要对数据进行分组聚合操作。例如,当处理包含多个物料明细的XML文件时,可能需要将相同物料号的明细归为一组,或对相同物料号的数量进行求和计算。传统实现方式通常需要编写脚本代码,增加了开…...

网络六边形受到攻击
大家读完觉得有帮助记得关注和点赞!!! 抽象 现代智能交通系统 (ITS) 的一个关键要求是能够以安全、可靠和匿名的方式从互联车辆和移动设备收集地理参考数据。Nexagon 协议建立在 IETF 定位器/ID 分离协议 (…...

【kafka】Golang实现分布式Masscan任务调度系统
要求: 输出两个程序,一个命令行程序(命令行参数用flag)和一个服务端程序。 命令行程序支持通过命令行参数配置下发IP或IP段、端口、扫描带宽,然后将消息推送到kafka里面。 服务端程序: 从kafka消费者接收…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...

从零实现STL哈希容器:unordered_map/unordered_set封装详解
本篇文章是对C学习的STL哈希容器自主实现部分的学习分享 希望也能为你带来些帮助~ 那咱们废话不多说,直接开始吧! 一、源码结构分析 1. SGISTL30实现剖析 // hash_set核心结构 template <class Value, class HashFcn, ...> class hash_set {ty…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

SAP学习笔记 - 开发26 - 前端Fiori开发 OData V2 和 V4 的差异 (Deepseek整理)
上一章用到了V2 的概念,其实 Fiori当中还有 V4,咱们这一章来总结一下 V2 和 V4。 SAP学习笔记 - 开发25 - 前端Fiori开发 Remote OData Service(使用远端Odata服务),代理中间件(ui5-middleware-simpleproxy)-CSDN博客…...