通俗易懂了解大语言模型LLM发展历程
1.大语言模型研究路程
NLP的发展阶段大致可以分为以下几个阶段:
- 词向量
- 词嵌入embedding
- 句向量和全文向量
- 理解上下文
- 超大模型与模型统一
1.1词向量
将自然语言的词使用向量表示,一般构造词语字典,然后使用one-hot表示。
例如2个单词,苹果,香蕉对应one-hot,苹果(1,0),香蕉(0,1)
1.2词嵌入embedding
词嵌入embedding,继续叫词向量也可以,对语言模型进行预训练,通过使用大量的现有文章,资料等,让词向量具备语言信息,2个训练方式:
- CBOW(continuous Bag-of-Words Model),根据上下文,预测当前词语出现概率的模型)
- Skip-gram,根据当前词预测上下文
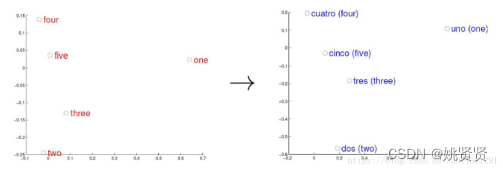
经过预训练后的词向量,在空间上附带了额外的信息,有效提高了模型的效果,并且可以在后续各个任务,场景中迁移使用(迁移学习),这就是大语言模型中的预训练模型初始原型。
常用训练技巧:负采样等。
1.3句向量和全文向量
根据前文信息,分析下文,或者根据本文,翻译成另一种语言,代表模型:seq2seq,RNN,LSTM。这个阶段已经可以写诗了
1.4理解上下文
根据上下文信息,理解当前的代词(他,她,它)是什么,完形填空,代表模型:transformer,BERT,GPT。真预训练模型时代开启。
1.5超大模型与模型统一
在BERT时代,每个任务都需要在预训练模型上进行微调,一个任务一个模型,通用性差,从Google T5时代开始,模型参数11B,使用Prompt范式训练模型,开启大模型与模型统一时代,由chatGPT引爆全球,目前的GPT-4效果惊艳。
1.6 OPENAI
在大语言模型时代,chatGPT,GPT-4效果惊艳,根据其在官网research栏目开放的研究博客,基本展露了大语言模型的发展优化过程。
1.6.1 OPENAI背景
OpenAI是美国的AI实验室。OpenAI成立于2015年底,创始人是伊隆·马斯克以及前YC 总裁Sam Altman。OpenAI发展历程见下:
- 2015年底,OpenAI成立,组织目标是通过与其他机构和研究者的“自由合作”,向公众开放专利和研究成果。
- 2016年,OpenAI宣称将制造“通用”机器人,希望能够预防人工智能的灾难性影响,推动人工智能发挥积极作用。
- 2019年3月1日,成立OpenAI LP子公司,目标是盈利和商业化。
- 2019年7月22日,微软投资OpenAI 10亿美元,双方合作为Azure(微软的云服务)开发人工智能技术。
- 2020年6月11日,宣布了GPT-3语言模型,微软于2020年9月22日取得独家授权。
- 2022年11月30日,OpenAI发布了名为ChatGPT的自然语言生成式模型,以对话方式进行交互。
- 2023年1月中旬,微软和OpenAI洽谈投资100亿美元事宜,并希望将OpenAI的人工智能技术纳入Word、Outlook、Powerpoint和其他应用程序中。
- 2023年1月末,ChatGPT月活跃用户估计已达1亿,超越TikTok,成为历史上增长最快的消费应用。
- 2023年3月,GPT-4发布
1.6.2 GPT发展
- 2018.06 GPT-1 约5GB文本,1.17亿参数量
- 2019.02 GPT-2 约40GB文本,15亿参数量
- 2020.05 GPT-3 约45TB文本,1750亿参数量,传闻GPT-3电费1200W美元
- 2022.01 GPT-3.5(InstructGPT) 基于GPT3,根据提示调整语言模型,采用人工反馈PPO微调
- 2022.11 chatGPT 基于InstructGPT,增加对话方式训练
- 2023.03 GPT4
1.6.3 OPENAI Research
下列是OPENAI大语言模型研究的相关博客,可以看到AI的发展脉络一直沿着learn to learn,让模型学会学习,以及与人对齐的方向发展。
- Reptile:一种可扩展的元学习算法-20180307
- 通过无监督学习提高语言理解Improving language understanding with unsupervised
learning-20180611 - GPT2-更好的语言及其含义Better language models and their implications-20190214
- 根据人类偏好微调 GPT-2 Fine-tuning GPT-2 from human preferences-20190919
- GTP3-语言模型是few-shot学习者Language models are few-shot learners-20200528
- 学习用人类反馈进行总结Learning to summarize with human feedback-20200904
- GPT-f 用于自动定理证明的生成语言建模-20200907
- OpenAI Microscope显微镜-20200414
- 通过在特选数据集上进行训练来改进语言模型行为Improving language model behavior by training on a curated dataset-20210710
- 解决数学单词问题Solving math word problems20210610
- WebGPT: Improving the factual accuracy of language models through web
browsing-20211216 - 通过对比预训练进行文本和代码embedding-20220124
- InstructGPT(GTP3.5):根据提示调整语言模型Aligning language models to follow
instructions-20220127 - 解决(一些)正式的数学奥林匹克问题Solving (some) formal math olympiad
problems-20220202 - 用语言表达不确定性的教学模型Teaching models to express their uncertainty in words
- 人工智能撰写的批评帮助人类注意到缺陷AI-written critiques help humans notice
flaws-20220613 - 训练大型神经网络的技术Techniques for training large neural networks-20220609
- 通过大型模型进行演变Evolution through large models-20220617
- GTP4-20230314
1.7其他大语言模型
1.7.1 Google-Flan-T5
Flan-T5是Google 发布的模型,通过在超大规模的任务上进行微调,让语言模型具备了极强的泛化性能,做到单个模型就可以在1800多个NLP任务上都能有很好的表现。这意味着模型一旦训练完毕,可以直接在几乎全部的NLP任务上直接使用,实现One model for ALL tasks,作为新一代语言模型开山之作。
这里的Flan 指的是(Instruction finetuning ),即"基于指令的微调";T5是2019年Google发布的一个语言模型了。论文的核心贡献是提出一套多任务的微调方案(Flan),来极大提升语言模型的泛化性。
例如下面文章中的例子,模型训练好之后,可直接让模型做问答

微调任务:
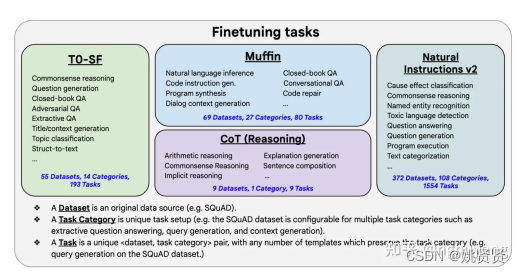
尽管微调的任务数量很多,但是相比于语言模型本身的预训练过程,计算量小了非常多,只有0.2%。所以通过这个方案,大公司训练好的语言模型可以被再次有效的利用,我们只需要做好“微调”即可,不用重复耗费大量计算资源再去训一个语言模型。
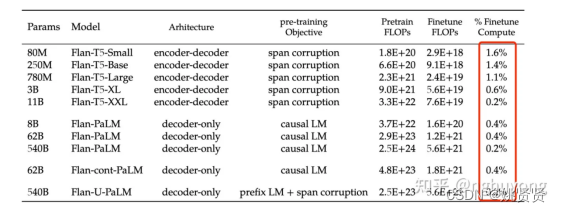
备注:什么FLOPs?
FLOPs:注意s小写,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度,即表示前向传播时所需的计算力。
1.7.2 Google-Bard
Google Bard是谷歌推出的一款基于大型语言模型的聊天机器人。它的背后是Google的对话应用语言模型,也被称为LaMDA。Bard是LaMDA的轻量级版本,使用更少的计算能力,可以扩展到更多的人,并提供额外的反馈。2023年3月21日,谷歌向公众开放了Bard的访问权限,美国和英国用户可以预约。同年4月1日,谷歌首席执行官桑达尔・皮查伊在接受纽约时报播客采访时表示,谷歌有更强大的语言模型,将会推出升级版的Bard聊天机器人。2023年7月13日,谷歌Bard AI助理现已支持简体中文对话,无需申请,可朗读、分享、修改回答。
1.7.3 Meta-LLAMA
Meta-LLAMA是Meta公司公开发布的产品,是元宇宙平台的一部分。2023年7月,Meta发布了Meta-LLAMA的开源商用版本,这意味着大模型应用进入了“免费时代”,初创公司也能够以低廉的价格创建类似ChatGPT这样的聊天机器人。
1.7.4清华chatGLM
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
- 更强大的性能:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。
- ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
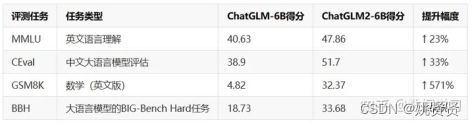
- 更长的上下文:基于 FlashAttention 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的 ChatGLM2-6B对单轮超长文档的理解能力有限,我们会在后续迭代升级中着重进行优化。
- 更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
- 更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
1.7.5文心一言
文心一言是百度研发的知识增强大语言模型,能够与人对话互动,回答问题,协助创作,高效便捷地帮助人们获取信息、知识和灵感。
1.7.6通义千问
通义千问是阿里云推出的一个超大规模的语言模型,功能包括多轮对话、文案创作、逻辑推理、多模态理解、多语言支持。能够跟人类进行多轮的交互,也融入了多模态的知识理解,且有文案创作能力,能够续写小说,编写邮件等。2023年4月7日,“通义千问”开始邀请测试,4月11日,“通义千问”在2023阿里云峰会上揭晓。4月18日,钉钉正式接入阿里巴巴“通义千问”大模型。
1.7.8讯飞星火
科大讯飞推出的新一代认知智能大模型,拥有跨领域的知识和语言理解能力,能够基于自然对话方式理解与执行任务。从海量数据和大规模知识中持续进化,实现从提出、规划到解决问题的全流程闭环。
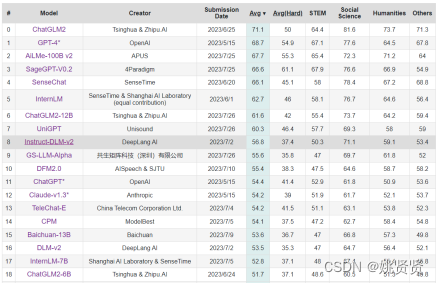
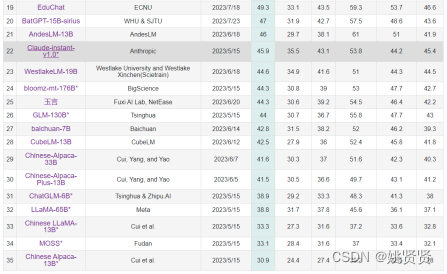
1.7.9大语言模型中文评测排行
下图是大语言模型对中文的相关测评排行
https://cevalbenchmark.com/static/leaderboard.html
2.大语言模型
OPENAI虽然没有公开chatGPT内部模型,工程实现的细节,但在官网research栏目博客公布的chatGPT架构,也是目前现在业界追逐的方式,下面将以此架构作为引子,更具体的介绍大语言模型。
2.1基本组件
语言模型有哪些部分组成,这些可以轻易得到吗?首先我们看看现在想要从0开始构建语言模型到应用包含了哪几部分,如下图:
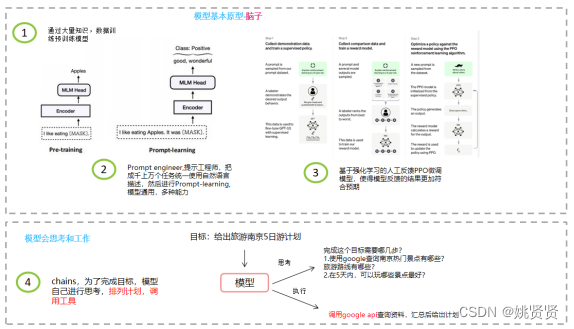
2.2训练模型
从 2018 年起,迁移学习的思想被广泛应用在自然语言处理领域,提出了许多预训练语言模型,如 ELMO、GPT、BERT、XLNET、ELECTRA、Albert等。预训练语言模型采用两阶段学习方法,首先在大型语料库中训练模型,再根据不同的下游任务对预训练模型进行微调。到这里,预训练语言模型在很多自然语言处理任务上取得了巨大的成功。一些研究表明,预训练语言模型不仅能够学习到上下文表示,也能够学到语法、句法、常识、甚至是世界知识,也被当做知识库使用(这也引申了一个研究-预训练模型具备哪些知识和能力,边界在哪里)。
随着语言模型越来越大,模型训练,微调的难度越大,每个应用需要提供专门的大模型,模型无法复用,对一些特殊情况,例如数据量小时,全量训练,微调可能会伤害模型。
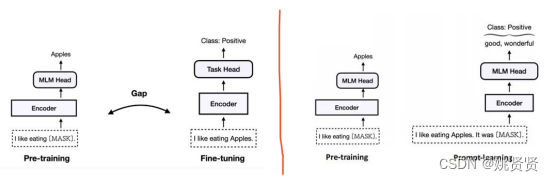
既然预训练模型具备了知识库的特性,那么将特定的下游任务转换为预训练语言模型的预训练任务,增强预训练模型的能力,统一通用语言模型。新的训练预训练模型方式就是prompt(提示) learning,所有的任务都通过prompt方式进行描述,对应的微调方式就是 prompt-tuning(p-tuning),为了构造更好的prompt,又有prompt engineering。后来在InstructGPT(GPT3.5)中的Instruct其实也是一种prompt,在此基础上增加指令,命令等,例如:结果以表格的形式输出,请以奥特曼的口吻和我对话等。
在训练方面就是使用哪个prompt使得模型训练效果最好,在预测方面,使用哪个prompt获得的答案最好。
左图为以前预训练与微调语言模型的方式,右图为使用Prompt-learning的新的微调方式。
2.2.1 预训练模型
预训练模型是为了让模型具备基础知识,并通过学习知识,将学习到的单词建立关联,训练方式可以参考2.2章节。
2.2.2 微调模型
在完成预训练模型之后,进行fine-tune进一步激活模型能力。
2.2.2.1 训练任务领域
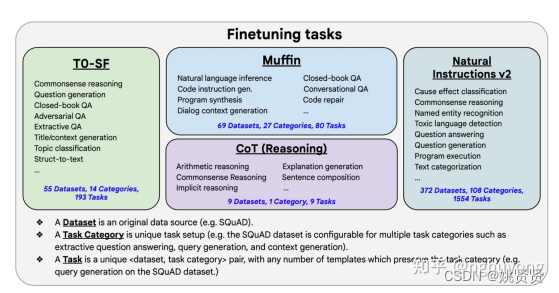
训练任务的领域很多,除了公开的一些常见任务领域外,目前公开的厂家也只是透露出一小部分自家使用的训练任务。
例如公开的中文训练任务:中文自然语言处理 Chinese NLPhttps://chinesenlp.xyz/#/
2.2.2.1.1 其他任务
flan-t5
其它

2.2.2.2 Prompt
针对不同的任务,需要不同的prompt设计和模板
2.2.2.2.1早期Prompt构成和模板
通常我们手头上的语料都无法满足上述的这些prompt形式,所以都需要进行转换,示例模板:
[X] Overall, it was a [Z] movie
对语料进行套用,x = “I love this movie”, z = “great”
prompts应该有空位置来填充答案,这个位置一般在句中或者句末。如果在句中,一般称这种prompt为cloze prompt;如果在句末,一般称这种prompt为prefix prompt。位置以及数量都可能对结果造成影响,因此可以根据需要灵活调整。
另外,上面的例子中prompts都是有意义的自然语言,但实际上其形式并不一定要拘泥于自然语言。现有相关研究使用虚拟单词甚至直接使用向量作为prompt,然后会进行答案搜索,顾名思义就是LM寻找填在[Z]处可以使得分数最高的文本z,最后是答案映射。有时LM填充的文本并非任务需要的最终形式,因此要将此文本映射到最终的输出 。例如,在文本情感分类任务中,“excellent”, “great”, “wonderful” 等词都对应一个种类 “++”,这时需要将词语映射到标签再输出。
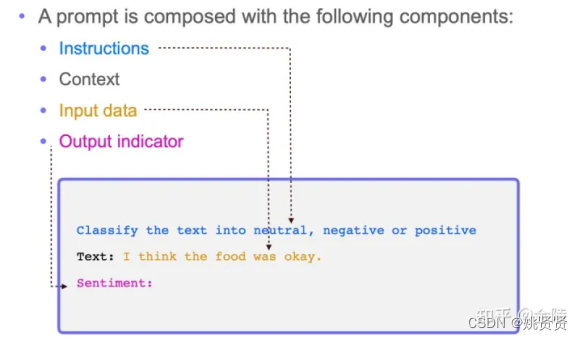
2.2.2.2.2 现阶段Prompt构成和模板
一个标准的prompt由以下几个部分组成,即:说明Instructions、语境Context、输入数据Input data、输出指标Output indicator,示例:
更详细,清晰的设计可以参考下面链接,不错
https://zhuanlan.zhihu.com/p/615197354
2.2.2.2.3 Prompt应用与微调
虽然上述列举了很多为了提升语言模型的能力设计了各种层次的prompt,但从另外一个发展维度上看,prompt还有其它大形式,如图:
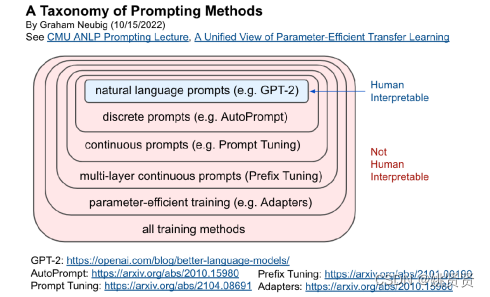
人工设计prompt(蓝色),但可解释性也强的,其余(红色)都为抽象prompt。
2.2.2.2.3.1离散型Prompt
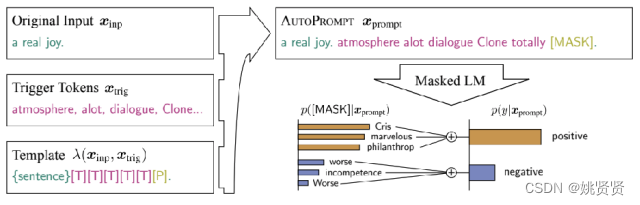
AutoPprompt,discrete prompt(离散型prompt),生成prompt都需要从已有的离词典中获取,使用一个好的语言模型(bert)等,给定一些句子,和标签,然后根据效果生成紫色的,凑成一个prompt,如果生成的prompt对LLM有效果,梯度有下降或者测评分有提高,那么就认为这个时个不错的prompt。
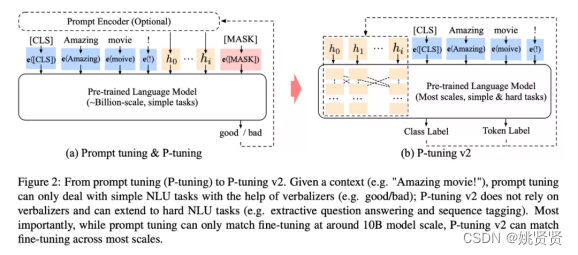
2.2.2.2.3.2 连续型Prompt与P-tuning
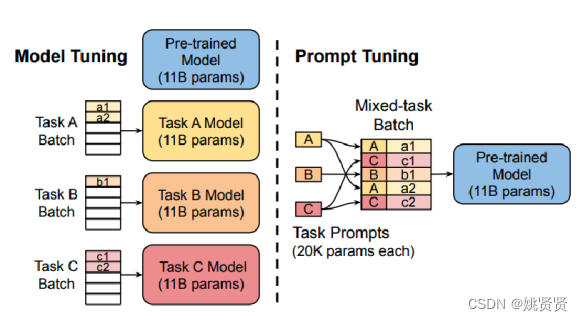
continuous prompts,传统的fine-tuning任务如左图,1类任务1个模型。p-tuning如右图,目标是不关心模版长什么样, 只需要知道模版由哪些 token 组成,该插入到哪里,插入后能不能完成我们的下游任务,输出的候选空间是什么就可以了。将多任务的prompt经过一层前置encode,锁住PLM参数,只调整前置encode,目的就是PLM作为知识库,让各个任务Prompt经过encode变成更好的prompt去查询知识库,且这些任务之间也会变得有关联(也就变得连续,连续型prompt),训练的这个前置encode一般也就占总参数的1%,就能带来不错的效果。
2.2.2.2.3.3 多层连续型Prompt与Prefix-tuning
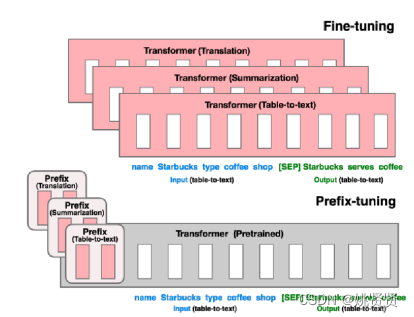
multi-layer continuous prompts,prefix-tuning 的主要贡献是提出任务特定的trainable前缀prefix,这样直接为不同任务保存不同的前缀即可,但还是p-tuning更通用
2.2.2.2.3.4 parameter-efficient training Adapters
parameter-efficient training Adapters,保持原PLM参数不变,在PLM中的transformer中添加一些可训练的层(adapter),采用prefix-tuning,虽然能提升效果,减少调整的参数,但通用性也又降低了。
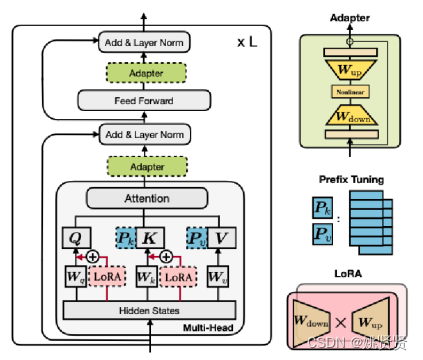
下图时调整的参数和效果提升的比例
2.2.2.2.3.5 P-tuning v2
p-tuning在一些复杂的自然语言理解NLU任务上效果很差(任务不通用)+预训练的参数量不能小(规模不通用)。因此V2版本主要是基于P-tuning和Prefix-tuning,引入Deep Prompt Encoding和Multi-task Learning等策略进行优化的。
2.2.2.2.4公开prompt数据集和工具
promptsource:PromptSource是一个用于创建、共享和使用自然语言提示的工具包,截至2022年1月20日,P3中有约2000个prompt,涵盖170多个英语数据https://github.com/bigscience-workshop/promptsource

huggingface上也有bigscience/P3 · Datasets at Hugging Face
还有下面
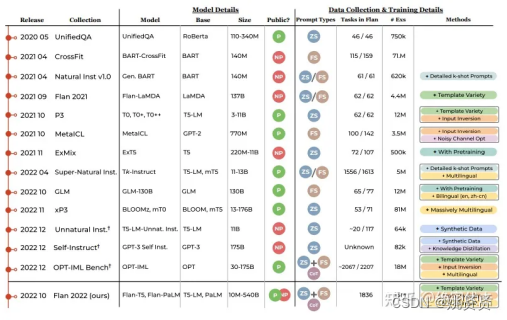
2.2.3 基于强化学习人工反馈微调模型
对模型输出的答案进行打分,可以人工打分,也可以使用模型进行打分,在chatGPT中,也使用了这种方式。下面也举例一个简单的例子加深理解:
任务目标:让模型根据提示(积极,中性,消息)生成影评

2.3模型评测
虽然有一些较为公信的评测数据集和平台,但维度太少,且似乎没有那么统一。
2.3.1 LAMA
LAMA(LAnguage Model Analysis) Probe,用来检测语言模型中包含了多少的事实类与常识类的知识,例如xxx名人的出生时间,地点GitHub - facebookresearch/LAMA: LAnguage Model Analysis

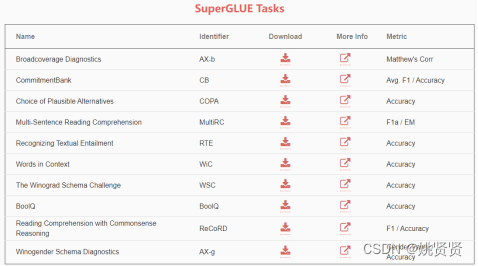
2.3.2 SuperGLUE
SuperGLUE,一个以GLUE为风格的新基准,它有一套新的更难的语言理解任务、一个软件工具箱和一个公共排行榜。SuperGLUE可以在http://super.gluebenchmark.com上找到附录图。
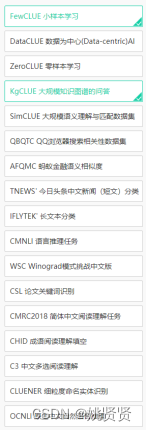
2.3.3 中文语言理解测评基准(CLUE)
2.3.4 oLMpics

2.3.5 其他评测
| 名称 | 内容 |
|---|---|
| MMLU | 英文语言理解 |
| CEval | 中文大语言模型评估 |
| GSM8K | 数学(英文) |
| BBH | 大语言模型的BIG-Bench Hard任务 |
2.3.6评估技术
2.3.6.1传统评估技术
NLP文本生成任务的评价指标有哪些?怎么判断模型好坏呢?如何解读指标的意义?
除了人工评估外,常见传统评估技术如:BLEU,ROUGE,METEOR,CIDEr。但其缺点也很明显,评估指标主要是基于单词或短语匹配的程度来评估文本的相似度,因此在某些情况下可能会出现评估结果与实际语义相似度不符的情况。
例如:
模型输出:a cat is on the table
参考(标签):there is a cat on the table
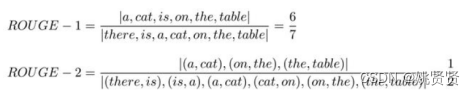
2.3.6.2新评估技术
大语言模型(LLM)的能力似乎在GPT-3和GPT-4上产生了质的飞跃,那么将其作为评估指标,“大模型评价小模型”就听起来越来越有可行性了。提出了一种利用chain-of-thought(CoT)来提升LLM打分模型的机制,主要工作流程如下:将任务的定义和评估维度的定义输入LLM,先生成评估的步骤,然后把这些文本再加上需要评估的输入和输出,用一种填表的方式再次输入LLM得到分数。最后,用1~5的分数乘上对应概率得到一个更细粒度的分数。
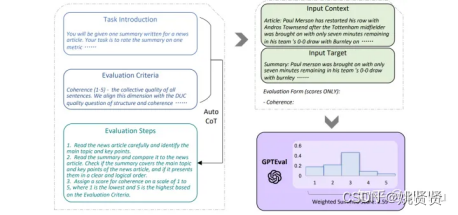
2.4语言模型token&Vocabulary
在大型语言模型中,“token”是指文本中的一个最小单位。通常,一个token可以是一个单词、一个标点符号、一个数字、一个符号等。在自然语言处理中,tokenization是将一个句子或文本分成tokens的过程。在大型语言模型的训练和应用中,模型接收一串tokens作为输入,并尝试预测下一个最可能的token。对于很多模型来说,tokens还可以通过embedding操作转换为向量表示,以便在神经网络中进行处理。由于大型语言模型处理的文本非常大,因此对于处理速度和内存占用等方面的考虑,通常会使用特定的tokenization方法,例如基于字节对编码(byte-pair encoding,BPE)或者WordPiece等算法。
业界大语言模型一般使用token说明有两种场景
(1)表示训练的数据量,除了使用多少T文本以外,也可能会表示使用了多少tokens。
使用的tokens数量可以有很大的变化,因为模型的规模和用途不同,会导致tokens数量有所差异。以下是一些典型的tokens数量范围:
- BERT-large-340B,BERT-large是一个较大规模的预训练模型,tokens数量在数千万级别。
- RoBERTa -355B,RoBERTa是改进的BERT模型,tokens数量与BERT-large类似,也在数千万级别。
- GPT-2 (1.5B),tokens数量在数亿级别。
- T5-11B,tokens数量在数十亿级别。
- GPT-3 (175B),tokens数量在数万亿级别。
- chatGLM2-6B,1.4万亿中英文token。
(2)Vocabulary Size,词典
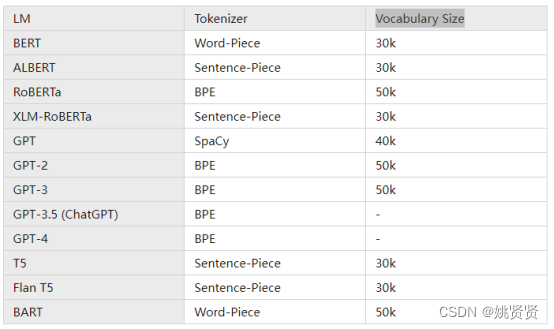
chatGLM的Vocabulary Size为150344约为150K。
2.5模型内存/显存占用
模型的内存占用和下面几个因素有关:
(1)模型层model layer,保存着每个样本在网络中每一层的向量,这一层的参数还要*上batch_size
(2)模型参数权重model params
(3)优化器类型,例如adam就需要保存4份上述(1)(2)的占用
例如在CV典型模型VGG16的计算方式(暂且没有找到transforer更清晰的统计方式):


大语言模型中也遵循如此,例如在chatGLM2-6B中
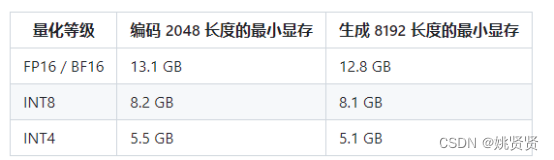
2.6模型量化
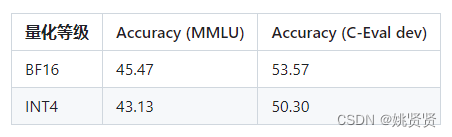
模型量化是指将模型的连续取值近似为有限多个离散值的过程,一种信息压缩的方法。具体来说,它通过将浮点数替换成整数,并进行存储和计算,从而大大减少模型存储空间(最高可达4倍),同时将浮点数运算替换成整数运算,能够加快模型的推理速度并降低计算内存。模型量化可以将在N卡上面进行推理的复杂模型压缩,使得将这些复杂的模型应用到手机、机器人等嵌入式终端中变成了可能。例如chatGLM2在未量化和量化下的对比:
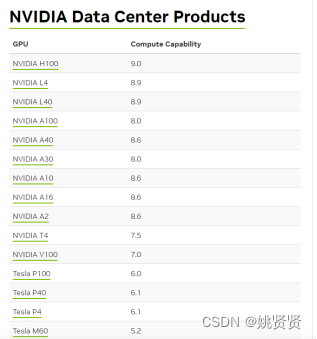
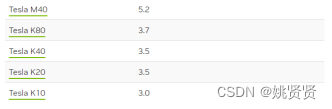
2.7常用GPU型号
算力排行:
2.8混合专家
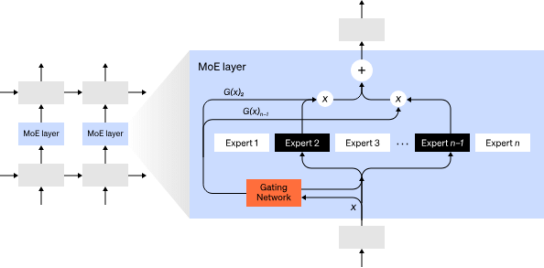
2017年提出专家混合 (MoE)方法,仅使用网络的一小部分来计算任何一个输入的输出。一个示例方法是拥有许多组权重,网络可以在推理时通过门控机制选择使用哪一组权重。这样可以在不增加计算成本的情况下实现更多参数。每组权重被称为“专家”,希望网络能够学会为每个专家分配专门的计算和技能。不同的专家可以托管在不同的 GPU 上,从而提供了一种清晰的方法来扩展用于模型的 GPU 数量。如下图门控网络仅选择n个专家中的2个,传闻GTP-4就采用了这种架构。
2.8.1华为盘古PanGu-Σ
大型语言模型的扩展极大地改善了自然语言的理解、生成和推理。在这项工作中,开发了一个系统,该系统在 Ascend 910 AI ( https://e.huawei.com/en/products/servers/ascend)处理器和 MindSpore 框架( https://www.mindspore.cn/en)的集群上训练了万亿参数的语言模型,并提供了名为 PanGu-Σ 的具有 1.085T (1万亿)参数的语言模型。利用 PanGu-α 固有的参数,将密集的 Transformer 模型扩展为具有随机路由专家 (RRE) 的稀疏模型,并通过使用专家计算和存储分离 (ECSS) 在 329B 令牌上有效地训练模型。这导致通过异构计算将训练吞吐量提高了 6.3 倍。实验结果表明,PanGu-Σ 在各种中文 NLP 下游任务的零样本学习中提供了最先进的性能。此外,它在开放域对话、问答、机器翻译和代码生成等应用数据微调时表现出强大的能力。
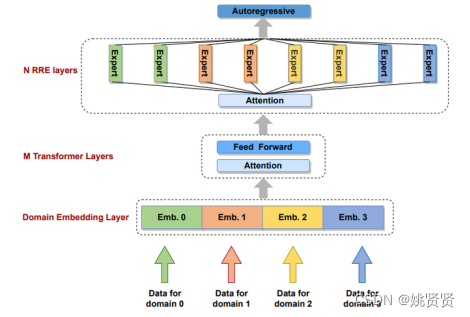
收集了 40 个领域的数据集,其中大量数据分布在四个主要领域:中文、英文、双语(中文和英文)和代码。其余较小部分的领域分别由 26 种其他单语自然语言、6 种编程语言和来自金融、健康、法律和诗歌领域的文本数据组成,其中四个主要领域的数据分布和数据来源如下:
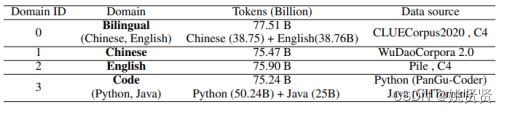
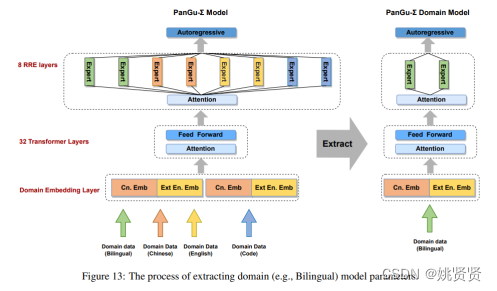
PanGu-Σ 预训练过程分为两个阶段。在第一阶段,激活四个主要领域的专家来消费来自所有四个主要领域的数据,包括双语、中文、英语和代码。在第二阶段,让所有专家消费所有领域的数据。下图 显示了 640 名专家如何分配到 40 个域组。来自特定领域的数据被路由到分布在不同设备上的一组专家。专家的颜色区分他们对应的领域。每个设备上有来自不同领域的十位专家。训练 PanGu-Σ,每个样本的全局批量大小为 512,序列长度为 1024。预训练持续约 100 天。

直接部署像 PanGu-Σ 这样的万亿参数模型是昂贵的。为了将 PanGu-Σ 的能力转移到各种下游任务并减少服务资源的消耗,提出了一种利用 RRE 设计的无损专家剪枝方法。可以单独提取域模型以进行进一步的微调、评估和部署。图说明了如何从 PanGu-Σ 中提取特定领域的子模型。
2.9 修正模型知识
通过一种ROME的算法修改模型参数,修正模型计算生成结果https://github.com/hiyouga/FastEdit。

例如修改现任日本首相

3.大语言模型应用框架
在chatGPT爆火之后,大语言模型应用框架也跟紧推出,目前最优秀的框架LangChain。AutoGPT也实现了自己应用框架。
3.1 LangChain
LangChain是一个用于构建基于大型语言模型(LLM)的应用程序的库。它可以帮助开发者将LLM与其他计算或知识源结合起来,创建更强大的应用程序。LangChain提供了以下几个主要模块来支持这些应用程序的开发:
- Prompts:这包括提示管理、提示优化和提示序列化。
- LLMs:这包括所有LLM的通用接口,以及与LLM相关的常用工具。
- Document Loaders:这包括加载文档的标准接口,以及与各种文本数据源的特定集成。
- Utils:语言模型在与其他知识或计算源交互时通常更强大。这可能包括Python
REPL、嵌入、搜索引擎等。LangChain提供了一系列常用的工具来在应用程序中使用。 - Chains:Chains不仅仅是一个单独的LLM调用,而是一系列的调用(无论是对LLM还是其他工具)。LangChain提供了链的标准接口,许多与其他工具的集成,以及常见应用程序的端到端链。
- Indexes:语言模型在与自己的文本数据结合时通常更强大 - 这个模块涵盖了这样做的最佳实践。
- Agents:Agents涉及到一个LLM在决定采取哪些行动、执行该行动、看到一个观察结果,并重复这个过程直到完成。LangChain提供了代理的标准接口,可供选择的代理,以及端到端代理的示例。
- Memory:Memory是在链/代理调用之间持久化状态的概念。LangChain提供了内存的标准接口,一系列内存实现,以及使用内存的链/代理示例。
- Chat:Chat模型是一种与语言模型不同的API -
它们不是使用原始文本,而是使用消息。LangChain提供了一个标准接口来使用它们,并做所有上述相同的事情。
3.2向量数据库
矢量数据库是为实现高维矢量数据的高效存储、检索和相似性搜索而设计的。使用一种称为嵌入(embedding)的过程,将向量数据表示为一个连续的、有意义的高维向量。矢量数据库的两个关键功能:
(1)执行搜索的能力
当给定查询向量时,向量数据库可以根据指定的相似度度量(如余弦相似度或欧几里得距离)检索最相似的向量。这允许应用程序根据它们与给定查询的相似性来查找相关项或数据点。
(2)高性能
矢量数据库通常使用索引技术,比如近似最近邻(ANN)算法来加速搜索过程。这些索引方法旨在降低在高维向量空间中搜索的计算复杂度,而传统的方法如空间分解由于高维而变得不切实际。
矢量数据库领域现在正在急速的扩展,如何权衡选择呢,这里我整理了5个主要的方向:
- 纯矢量数据库,比如Pinecone也是建立在下面的Faiss之上的。
- 全文搜索数据库,如ElasticSearch,以前是作为搜索引擎现在增加了矢量存储和检索的功能。
- 矢量库,如Faiss, Annoy和Hnswlib,还不能作为数据库,只是矢量的处理。
- 支持矢量的NoSQL数据库,如MongoDB、Cosmos DB和Cassandra,都是老牌的数据存储,但是加入了矢量的功能。
- 支持矢量的SQL数据库,如SingleStoreDB或PostgreSQL,与上面不同的是这些数据库支持SQL语句。
除了上面提到的五种主要方法外,还有如Vertex AI和Databricks,它们的功能超越了数据库,这里先不进行讨论。
https://baijiahao.baidu.com/s?id=1770637201988677681&wfr=spider&for=pc
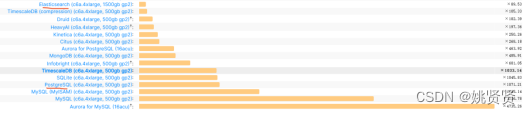
3.2.1性能排行
ClickHouse性能最优,是ES的90倍,但据说redis也有向量存储,这里没有进行对比不知效率如何,信息提供来自https://benchmark.clickhouse.com/

3.3 向量文本检索
向量数据库中的embedding function在数据管理和数据分析中起着至关重要的作用。这种函数将非结构化数据或复杂数据结构转化为向量形式,以便进行高效且准确的查询和分析。通过这种方式,我们可以利用向量数据库的先进搜索和查询功能,包括相似性搜索、范围查询、多维查询等。
embedding function的准确性对于向量数据库的性能和可靠性,以及结合LLM应用至关重要。如果嵌入的向量不能准确地反映原始数据的结构和使用情况,那么查询结果的准确性和效率都将受到影响。
目前现阶段向量数据库结合LLM常使用,除了chatGPT等还有一些其它的:
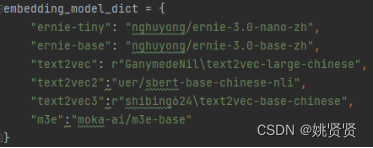
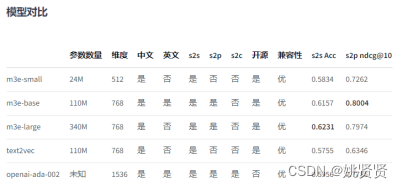
但其实本质是看这个embedding经过了怎样的任务训练,能够更适配query。
3.4 基于知识图谱的LLM
使用向量数据库查询到的条目会受以下几个问题的影响:
- 数据库中知识分片存储,每次都只会计算分片的相似度,如果查询的问题需要几个分片合并得分更高,而单个分片很低,那么也无法有效查询。
- 相关度阈值设置较困难
- Topk设置也可能会丢失有用的信息
通过查询知识图谱可以获取关联度或者关联链更高的知识。
Langchain也有相关图数据库的支持,能和图数据库相连,自然语言转图sql查询等
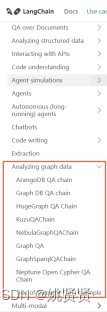
4.深度认识大语言模型
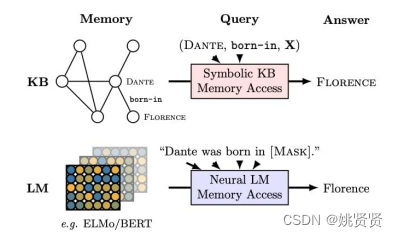
4.1LLM和知识图谱有什么关系?
| 关注点 | LLM | KB |
|---|---|---|
| 数据|知识处理 | 需要进行prompt设计 | 需要提取实体,关系等 |
| 知识查询语句 | 自然语言,自由度高 | 严格按照格式 |
| 知识增删消耗 | 需要重新微调模型,代价较大 | 低 |
| 知识关联度 | 高,上限高 | 中,上限有限 |
| 精度 | 较高 | 高 |
4.2LLM的答案只能基于学习到的知识?
实际上是,但其实应该并不完全是。
LLM将学习到的知识融会贯通,回答问题,虽然在这方面已经远远超过了人类,但这依然还是属于对学习到的知识进行回答。但是LLM已经是一个具有一定判断能力的仿生人,可以通过提出问题,列出可以选择的方案,思路,“实践”后对结果进行判断,如果结果可信任,那么这也在原本知识的基础上,总结出来的新知识,作为回答或者可以作为LLM新的知识,自己扩充自己,行为方式可参考(AutoGPT,langchain)其实人类学习过程也是如此,基于信任的学习。OPENAI一篇博客中也有相关基于通过辩论寻找答案的研究,https://openai.com/research/debate。
4.3如何看待业界新出现的各种LLM
主要关注几个点:
- 支持的语言,例如中文,英文,其他语言。
- 模型参数大小,参数越多,能表示的就越丰富。
- 训练的数据量,任务量,经常有报道称xxx模型在某项能力得分上取得了top1,这个目前判断应该和模型本身结构关系不是特别大,而是在训练的数据量和任务上。
- token&Vocabulary数量,一般训练数据量token&Vocabulary数量也比较大,也代表训练的数据格式,字符丰富。
- 支持query的上下文长度,越长越好,也代表模型训练时使用的句子越长或者微调得更充分。
4.4LLM是否具有自我意识
可以有,假设一下,一个人静止不动可以吗?机器可以,但是人不行,要生存,有爱好,这就是触发意识的起点,目前本质来看AI根据当前状态做出决策,那么假设给它一个生存条件,比如要充电,充电要付钱,你没有钱就自己想办法,那它的自我意识和人生就此开始,但还是没有爱好,一个机器人需要爱好吗?爱好能给它带来什么收益?最终还是回到对自身对自身的收益,有收益就有意识,就有决策。
4.5如何看待LLM回答错误
很正常,对于训练,微调不充分的情况肯会这样,其实人也是,对于掌握不透的知识,理解上有偏差的知识也会进行错误回答。
那么肯定会有人问,LLM的回答都是基于概率回答。
这没什么问题,因为根据研究生物,神经,人脑的人回答,人脑中其实也没有一块是专门存储信息的,也都是通过激活,传递,“连线”产生,那么只要回答正确,每次回答不一样也是符合人的行为,因为人也无法保证每一次说话回答都是一样的。
4.6LLM与人的学习上限
人学习的“带宽”非常低,例如看,理解一本书可能需要几天的时间,记忆也有限,无法在很多领域中做到绝对专家,这个问题也被作为在马斯克脑机接入的一个重要领域。LLM在这方向上显然有绝对的优势。
除了在学习,记忆的方向上LLM能突破人的上限,在知识关联上也超越人类,例如人在学习了知识后,无法有效应用,激活,联想,“白学”。
那么也引申出另外一个问题,学习,搜索资料是否是浪费时间?
4.7什么是LLM正确的学习资料?
2方面,1方面是面向生命科学,了解和学习人最自然的知识和本性;另一方面是面向行业,例如下面是天猫精灵团队为了让回复更加先得有温度,请了社会,心理专家面对敏感问题打的标签。




4.8AI监管
各国对AI监管政策正在研究中。
相关文章:
通俗易懂了解大语言模型LLM发展历程
1.大语言模型研究路程 NLP的发展阶段大致可以分为以下几个阶段: 词向量词嵌入embedding句向量和全文向量理解上下文超大模型与模型统一 1.1词向量 将自然语言的词使用向量表示,一般构造词语字典,然后使用one-hot表示。 例如2个单词&…...

Vim - 快速插入C语言函数注释模板
背景 C语言使用vim编写时,需要快速对函数进行说明头插入; 代码 function! InsertCFunctionHeader()" 获取当前行内容let line getline(.)" 匹配 C 函数定义let matched matchlist(line, ^\s*\w\ \\(\w\\)(\(.*\)))" 如果当前行不是函…...

Leetcode171. Excel 表列序号
给你一个字符串 columnTitle ,表示 Excel 表格中的列名称。返回 该列名称对应的列序号 。 例如: A -> 1 B -> 2 C -> 3 ... Z -> 26 AA -> 27 AB -> 28 ... 题解:力扣(LeetCode)官网 - 全球极客挚爱…...

自主设计,模拟实现 RabbitMQ - 实现 拒绝/否定 应答机制
目录 一、拒绝/否定 应答机制 1.1、需求分析 什么是 拒绝/否定 应答呢?...

在github上设置不同分支,方便回滚
在github上设置不同分支,方便回滚 步骤可能出现的问题couldnt find remote ref gpuVersion1. 确保您处于正确的分支2. 添加并提交更改(如果还未进行)3. 推送本地分支到远程仓库4. 验证操作 步骤 之前在github上上传了一个项目代码,…...

【Elsevier旗下】JCR2/3区,最快25天录用!计算机与娱乐、教育、游戏、新媒体均可
期刊简介: 出版社:Elsevier 影响因子(2022):2.5-3.0 期刊分区:JCR2/3区,中科院4区 检索数据库:SCIE 在检 数据库检索年份:2016年 预警情况:无中科院预警…...
TSINGSEE视频AI智能分析技术:水泥厂安全生产智能监管解决方案
一、方案背景 随着人工智能技术的快速发展以及视频监控系统在全国范围内的迅速推进,基于AI视频智能分析技术的智能视频监控与智慧监管系统,也已经成为当前行业的发展趋势。在工业制造与工业生产领域,工厂对设备的巡检管理、维护维修、资产管…...
Whisper + NemoASR + ChatGPT 实现语言转文字、说话人识别、内容总结等功能
引言 2023年,IT领域的焦点无疑是ChatGPT,然而,同属OpenAI的开源产品Whisper似乎鲜少引起足够的注意。 Whisper是一款自动语音识别系统,可以识别来自99种不同语言的语音并将其转录为文字。 如果说ChatGPT为计算机赋予了大脑&…...

795. 区间子数组个数
795. 区间子数组个数 给你一个整数数组 nums 和两个整数:left 及 right 。找出 nums 中连续、非空且其中最大元素在范围 [left, right] 内的子数组,并返回满足条件的子数组的个数。 生成的测试用例保证结果符合 32-bit 整数范围。 示例 1:…...

Request method ‘GET‘ not supported,不支持GET形式访问
org.springframework.web.HttpRequestMethodNotSupportedException: Request method ‘GET’ not supported 原因:异常提示的很明确,请求不支持GET方式访问,出现这种问题一般都是由于限制请求接口为POST,然后使用GET形式访问造成的…...
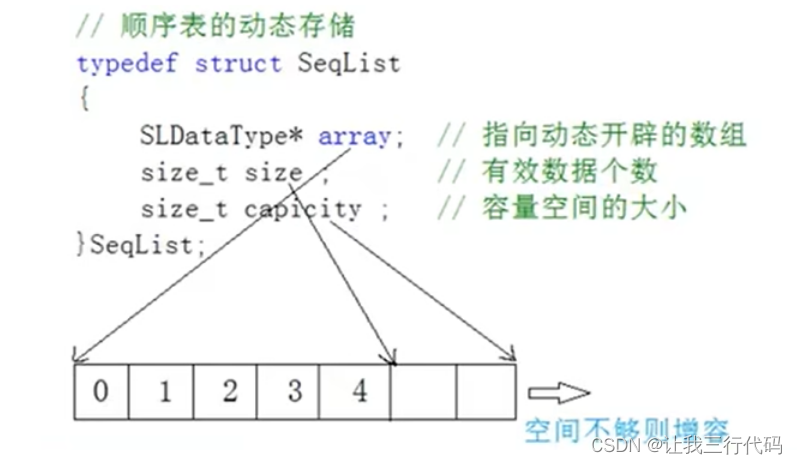
数据结构与算法(C语言版)P2---线性表之顺序表
前景回顾 #mermaid-svg-sXTObkmwPR34tOT4 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-sXTObkmwPR34tOT4 .error-icon{fill:#552222;}#mermaid-svg-sXTObkmwPR34tOT4 .error-text{fill:#552222;stroke:#552222;}#…...
AI写文章软件-怎么选择不同的AI写文章软件
在如今信息爆炸的时代,无论是学生、职场人士,还是创作者和企业家,写文章都是一项常见而又重要的任务。然而,随着科技的不断进步,AI写文章的软件也逐渐走进了人们的视野。 147GPT批量文章生成工具www.147seo.com/post…...
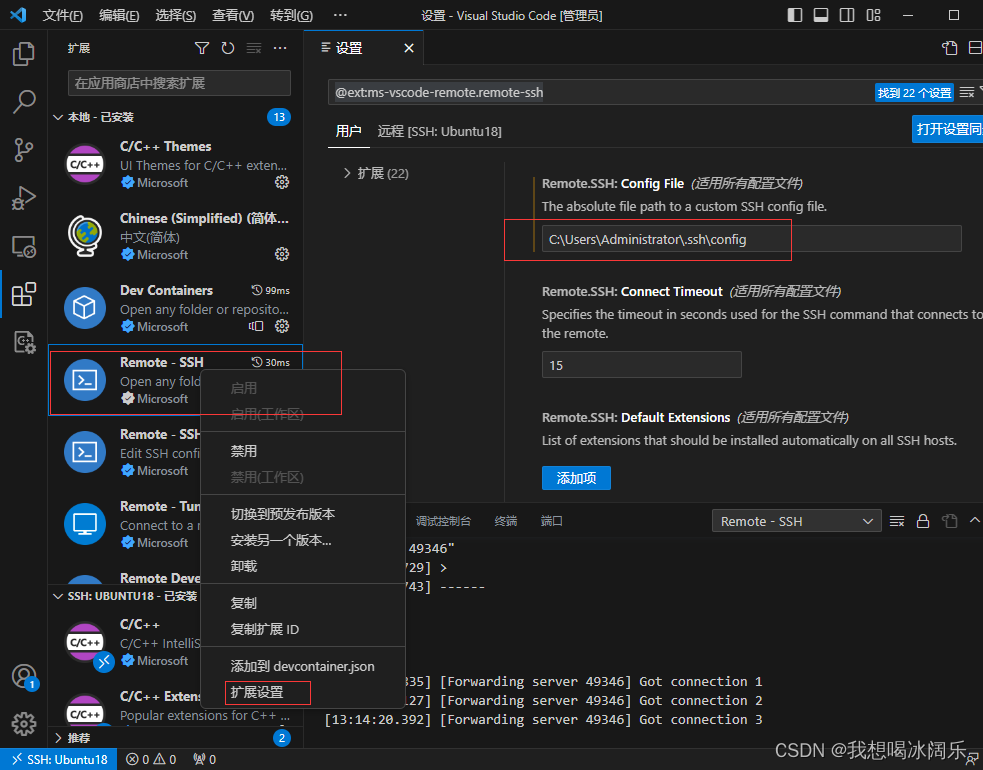
VSCode远程连接服务器报错:Could not establish connection to
参考:https://blog.csdn.net/weixin_42538848/article/details/118113262 https://www.jb51.net/article/219138.htm 刚开始把ssh文件夹中的known_hosts给删除了,发现没啥用。 之后在扩展Remote-SSH里面,把config file路径设置为ssh文件夹里…...

openssl 用法整理 —— 筑梦之路
用法一 生成自签名数字证书 # 生成私钥 openssl genpkey -algorithm RSA -out private.key# 生成证书请求 openssl req -new -key private.key -out certificate.csr# 使用私钥签署证书 openssl x509 -req -days 365 -in certificate.csr -signkey private.key -out certifica…...
Mac安装SPSS 26(含安装包)
Mac安装SPSS 26(含安装包) 安装包地址(百度网盘):https://pan.baidu.com/s/127ZJNRIMZaeR2hDilQT0Zg提取码: m5xj 查看是否允许安装任何来源的app 如果没有任何来源这个选项 打开终端输入:sudo spctl --master-disable回车之后输入password(注:电脑的…...

uniapp存值和取值方法
在UniApp中,可以使用全局变量、本地缓存和Vuex状态管理等方式来进行存值和取值。 全局变量:可以在App.vue文件的data中定义一个全局变量,在其他页面或组件中通过uni.$emit方法修改其值,并通过uni.$on方法监听值的变化。 // App.…...

Apache Beam 2.50.0发布,该版本包括改进功能和新功能
导读我们很高兴向您介绍 Beam 的新版本 2.50.0。该版本包括改进功能和新功能。请查看此版本的下载页面。 亮点 Spark 3.2.2 被用作 Spark 运行程序的默认版本(#23804)。Go SDK 新增默认本地运行程序,名为 Prism(#24789࿰…...
华为云云耀云服务器 L 实例评测|配置教程 + 用 Python 简单绘图
文章目录 Part.I IntroductionChap.I 云耀云服务器 L 实例简介Chap.II 参与活动步骤 Part.II 配置Chap.I 初步配置Chap.II 配置安全组 Part.III 简单使用Chap.I VScode 远程连接华为云Chap.II 简单绘图 Reference Part.I Introduction 本篇博文是为了参与华为“【有奖征文】华…...
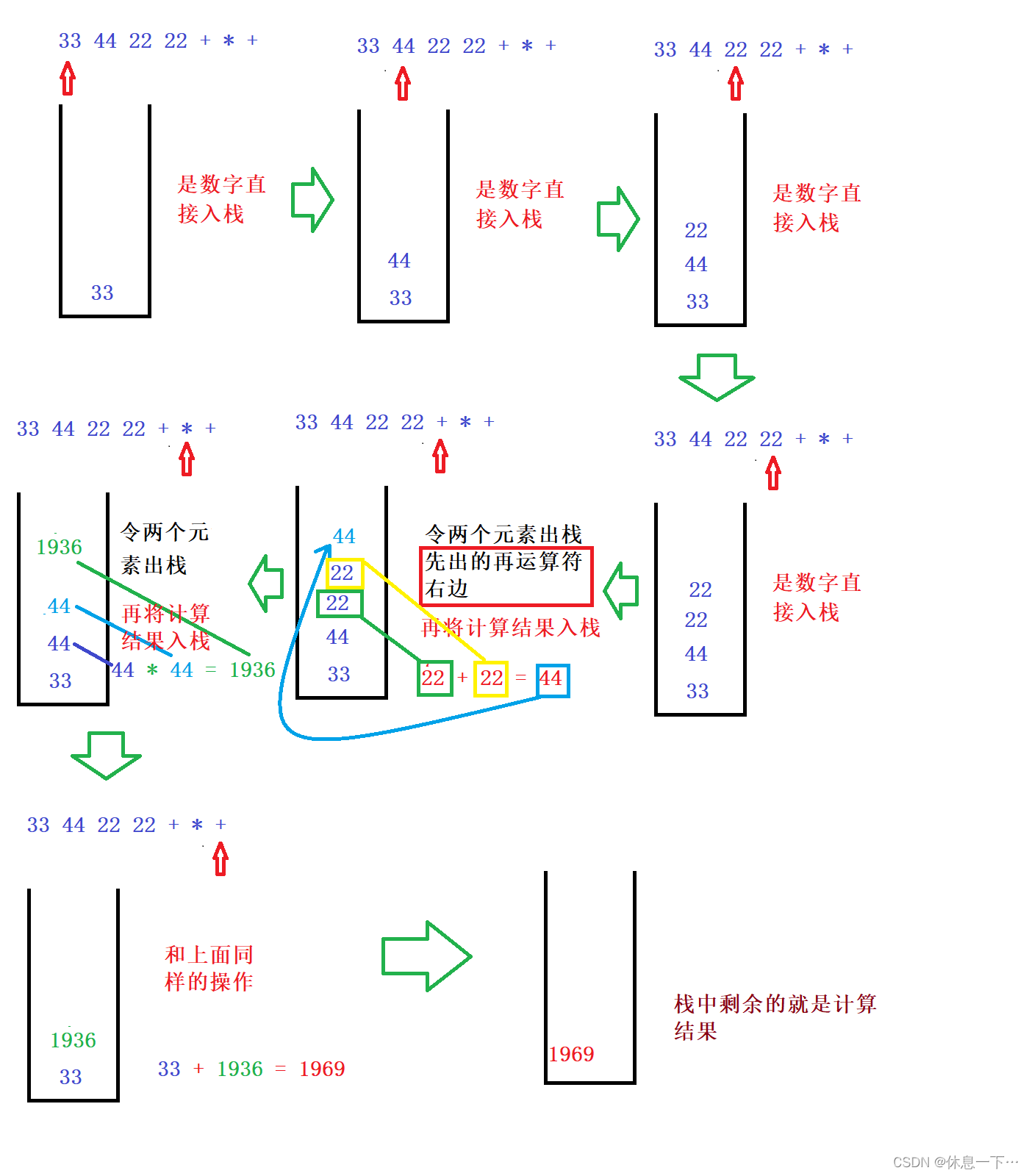
栈的简单应用(利用Stack进行四则混合运算)(JAVA)
目录 中缀表达式转后缀表达式 图解 代码实现过程: 完整代码: 利用后缀表达式求值: 完整代码: 首先我们得先了解逆波兰表达式。 中缀表达式转后缀表达式 所谓的中缀表达式其实就是我们平时写的例如:࿱…...

Python---异常
捕获全部异常 语法: try: 可能发生的错误代码 except: 如果出现异常执行的代码 例子: try:open("test2.txt", "r", encoding"UTF-8") except:print("出现异常,文件不存在,换个模式打…...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

React Native在HarmonyOS 5.0阅读类应用开发中的实践
一、技术选型背景 随着HarmonyOS 5.0对Web兼容层的增强,React Native作为跨平台框架可通过重新编译ArkTS组件实现85%以上的代码复用率。阅读类应用具有UI复杂度低、数据流清晰的特点。 二、核心实现方案 1. 环境配置 (1)使用React Native…...

Java多线程实现之Callable接口深度解析
Java多线程实现之Callable接口深度解析 一、Callable接口概述1.1 接口定义1.2 与Runnable接口的对比1.3 Future接口与FutureTask类 二、Callable接口的基本使用方法2.1 传统方式实现Callable接口2.2 使用Lambda表达式简化Callable实现2.3 使用FutureTask类执行Callable任务 三、…...

基于Java+VUE+MariaDB实现(Web)仿小米商城
仿小米商城 环境安装 nodejs maven JDK11 运行 mvn clean install -DskipTestscd adminmvn spring-boot:runcd ../webmvn spring-boot:runcd ../xiaomi-store-admin-vuenpm installnpm run servecd ../xiaomi-store-vuenpm installnpm run serve 注意:运行前…...

vue3 daterange正则踩坑
<el-form-item label"空置时间" prop"vacantTime"> <el-date-picker v-model"form.vacantTime" type"daterange" start-placeholder"开始日期" end-placeholder"结束日期" clearable :editable"fal…...
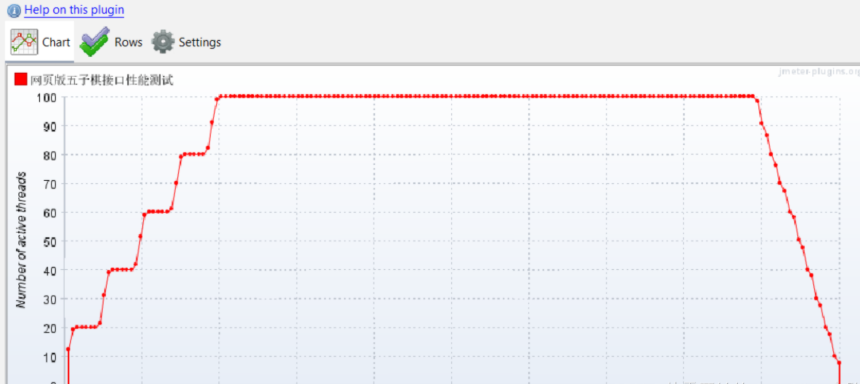
五子棋测试用例
一.项目背景 1.1 项目简介 传统棋类文化的推广 五子棋是一种古老的棋类游戏,有着深厚的文化底蕴。通过将五子棋制作成网页游戏,可以让更多的人了解和接触到这一传统棋类文化。无论是国内还是国外的玩家,都可以通过网页五子棋感受到东方棋类…...

前端高频面试题2:浏览器/计算机网络
本专栏相关链接 前端高频面试题1:HTML/CSS 前端高频面试题2:浏览器/计算机网络 前端高频面试题3:JavaScript 1.什么是强缓存、协商缓存? 强缓存: 当浏览器请求资源时,首先检查本地缓存是否命中。如果命…...
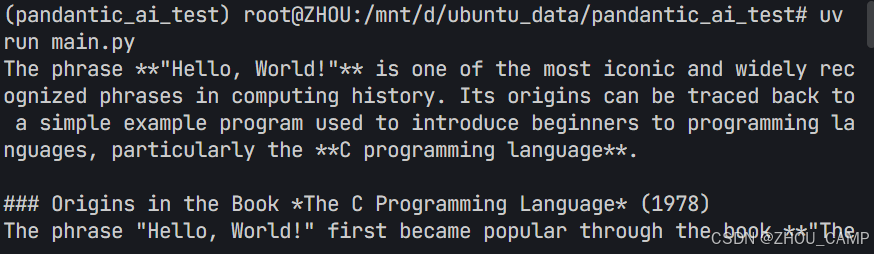
PydanticAI快速入门示例
参考链接:https://ai.pydantic.dev/#why-use-pydanticai 示例代码 from pydantic_ai import Agent from pydantic_ai.models.openai import OpenAIModel from pydantic_ai.providers.openai import OpenAIProvider# 配置使用阿里云通义千问模型 model OpenAIMode…...
数据挖掘是什么?数据挖掘技术有哪些?
目录 一、数据挖掘是什么 二、常见的数据挖掘技术 1. 关联规则挖掘 2. 分类算法 3. 聚类分析 4. 回归分析 三、数据挖掘的应用领域 1. 商业领域 2. 医疗领域 3. 金融领域 4. 其他领域 四、数据挖掘面临的挑战和未来趋势 1. 面临的挑战 2. 未来趋势 五、总结 数据…...

第14节 Node.js 全局对象
JavaScript 中有一个特殊的对象,称为全局对象(Global Object),它及其所有属性都可以在程序的任何地方访问,即全局变量。 在浏览器 JavaScript 中,通常 window 是全局对象, 而 Node.js 中的全局…...