搭建Flink集群、集群HA高可用以及配置历史服务器
Flink集群搭建
- Flink集群搭建
- 集群规划
- 下载并解压安装包
- 修改集群配置
- 分发安装目录
- 启动集群
- 访问Web UI
- Flink集群HA高可用
- 概述
- 集群规划
- 配置flink
- 配置master、workers
- 配置ZK
- 分发安装目录
- 启动HA集群
- 测试
- Flink参数配置
- 配置历史服务器
- 概述
- 配置
- 启动、停止历史服务器
- 提交一个Job任务
- 查看历史Job信息
Flink集群搭建
集群规划
| 节点 | node01 | node02 | node03 |
|---|---|---|---|
| 角色 | JobManager TaskManager | TaskManager | TaskManager |
下载并解压安装包
wget https://repo.huaweicloud.com/apache/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz
在node01节点下载flink安装包,同时解压、重命名。
tar -zxvf flink-1.17.0-bin-scala_2.12.tgz
mv flink-1.17.0 flink
修改集群配置
进入flink的conf目录,修改集群配置
vim /usr/local/program/flink/conf/flink-conf.yaml
1.修改flink-conf.yaml文件
JobManager节点配置
# jobmanager.rpc.address: localhost
# jobmanager.bind-host: localhost
jobmanager.rpc.address: node01
jobmanager.bind-host: 0.0.0.0# rest.address: localhost
# rest.bind-address: localhost
rest.address: node01
rest.bind-address: 0.0.0.0
TaskManager节点配置
# taskmanager.host: localhost
# taskmanager.bind-host: localhosttaskmanager.host: node01
taskmanager.bind-host: 0.0.0.0
注意:需要在/etc/hosts文件中配置各个节点信息
172.29.234.1 node01 node01
172.29.234.2 node02 node02
172.29.234.3 node03 node03
2.修改workers文件
指定
node01、node02、node03等节点为TaskManager
# localhost
node01
node02
node03
3.修改masters文件
# localhost:8081
node01:8081
分发安装目录
在
node01节点安装、配置好后,将Flink安装目录分发给另外两个节点服务器。
[root@node01 program]# pwd
/usr/local/program
[root@node01 program]# ls
flink jdk8[root@node01 program]# scp -r flink node02:/usr/local/program/flink[root@node01 program]# scp -r flink node03:/usr/local/program/flink
在node02、node03节点,修改flink-conf.yaml 配置
1.node02节点
# taskmanager.host: localhosttaskmanager.host: node02
2.node03节点
# taskmanager.host: localhosttaskmanager.host: node03
启动集群
Flink附带了相关的bash脚本,可以用于启动、停止集群。
# 启动集群
./bin/start-cluster.sh# 停止集群
./bin/stop-cluster.sh
在node01节点服务器上执行start-cluster.sh脚本以启动Flink集群
[root@node01 bin]# cd /usr/local/program/flink/bin[root@node01 bin]# ./start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host node01.
Starting taskexecutor daemon on host node01.
Starting taskexecutor daemon on host node02.
Starting taskexecutor daemon on host node03.
查看进程情况
[root@node01 bin]# jps
6788 StandaloneSessionClusterEntrypoint
7256 Jps
7116 TaskManagerRunner
[root@node02 conf]# jps
16884 TaskManagerRunner
16959 Jps
[root@node03 conf]# jps
17139 TaskManagerRunner
17214 Jps
访问Web UI
当如上所示一样后,代表启动成功,此时可以访问http://node01:8081对flink集群和任务进行监控管理。
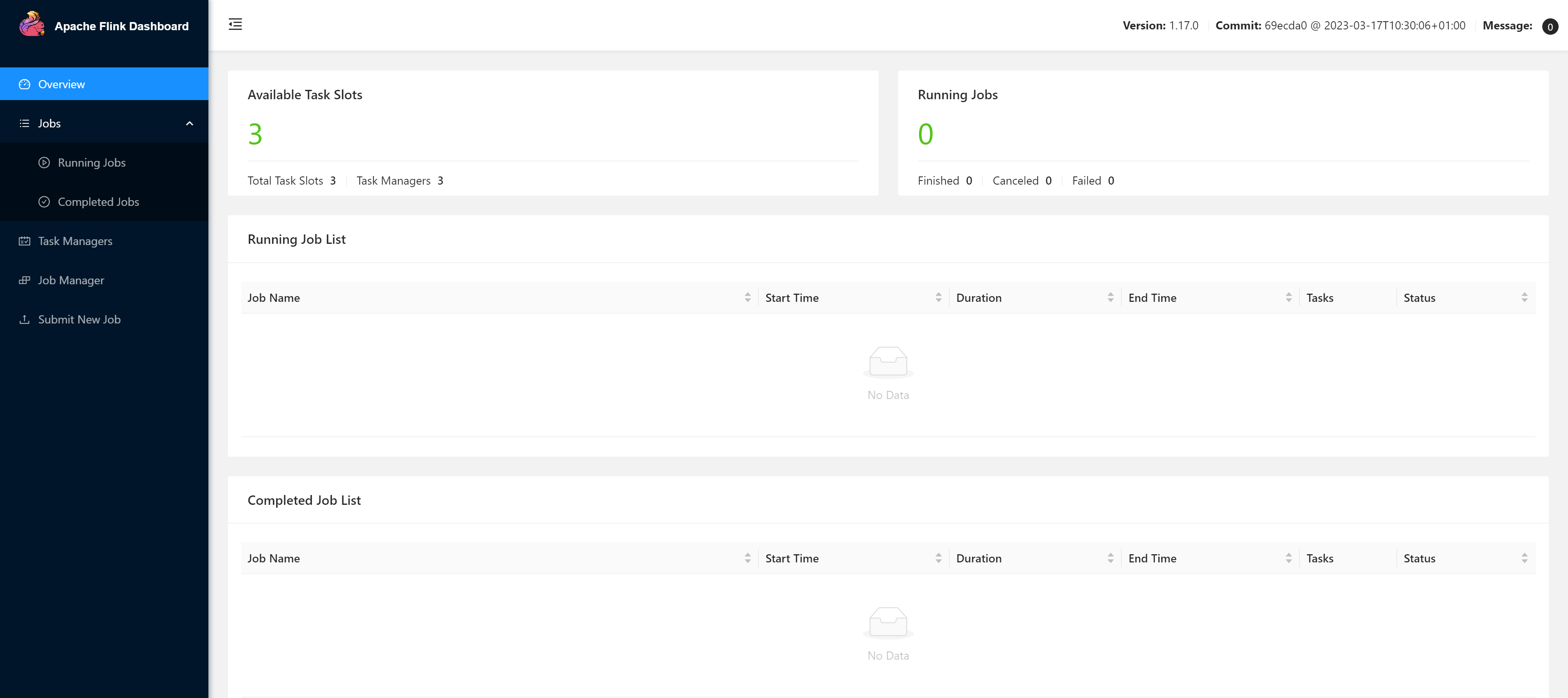
注意:关闭防火墙,否则可能无法访问,或者集群的TaskManager数量、Slot数量显示异常
systemctl stop firewalld
提交任务
[root@node01 bin]# flink run ../examples/streaming/WordCount.jar
查看运行结果
[root@node01 bin]# tail flink-*-taskexecutor-*.out
也可以通过Flink的 Web UI来监视集群的状态和正在运行的作业

Flink集群HA高可用
概述
集群实际上只有一个JobManager,是存在单点故障的,官方提供了Standalone Cluster HA模式来实现集群高可用。
集群可以有多个JobManager,但只有一个处于active状态,其余的则处于备用状态,Flink使用 ZooKeeper来选举出Active JobManager,并依赖其来提供一致性协调服务,所以需要预先安装 ZooKeeper 。
Flink本身提供了内置ZooKeeper插件,可以直接修改
conf/zoo.cfg,并且使用/bin/start-zookeeper-quorum.sh直接启动。
集群规划
| 节点 | node01 | node02 | node03 |
|---|---|---|---|
| 角色 | JobManager TaskManager | JobManager TaskManager | TaskManager |
配置flink
基于Flink集群的node01节点配置的情况下,修改conf/flink-conf.yaml文件,增加如下配置:
# 配置使用zookeeper来开启高可用模式
high-availability.type: zookeeper# 配置zookeeper的地址,采用zookeeper集群时,可以使用逗号来分隔多个节点地址
high-availability.zookeeper.quorum: node01:2181,node02:2181,node03:2181# 在zookeeper上存储flink集群元信息的路径
high-availability.zookeeper.path.root: /flink# 集群id 放置集群的所有必需协调数据
high-availability.cluster-id: /cluster_one# 持久化存储JobManager元数据的地址,zookeeper上存储的只是指向该元数据的指针信息
high-availability.storageDir: hdfs://node01:9000/flink/recovery
配置master、workers
修改conf/masters文件,配置master节点
node01:8081
node02:8081
修改conf/workers文件,配置worker节点
node01
node02
node03
配置ZK
编辑vim zoo.cfg文件
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
分发安装目录
在
node01节点安装、配置好后,将Flink安装目录分发给另外两个节点服务器。
[root@node01 program]# pwd
/usr/local/program
[root@node01 program]# ls
flink jdk8[root@node01 program]# scp -r flink node02:/usr/local/program/flink[root@node01 program]# scp -r flink node03:/usr/local/program/flink
在node02、node03节点,修改flink-conf.yaml 配置
1.node02节点
jobmanager.rpc.address: node02taskmanager.host: node02
2.node03节点
taskmanager.host: node03
启动HA集群
分发Flink相关配置到其他节点,然后确保Hadoop和ZooKeeper已经启动后,使用以下命令来启动集群:
[root@node01 flink]# bin/start-cluster.sh
Starting HA cluster with 2 masters.
Starting standalonesession daemon on host node01.
Starting standalonesession daemon on host node02.
Starting taskexecutor daemon on host node01.
Starting taskexecutor daemon on host node02.
Starting taskexecutor daemon on host node03.
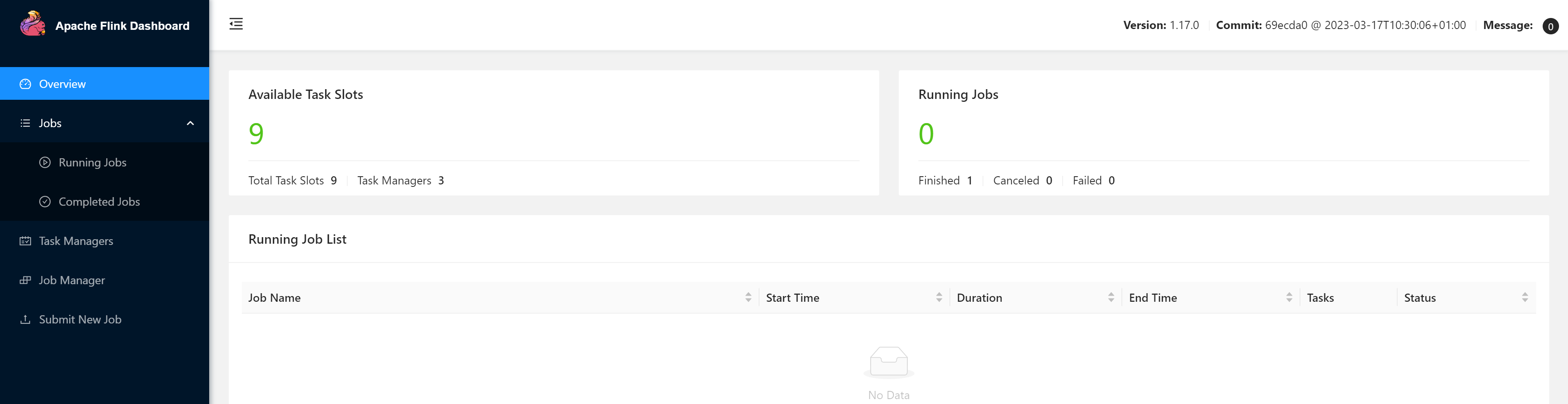
访问http://node01:8081
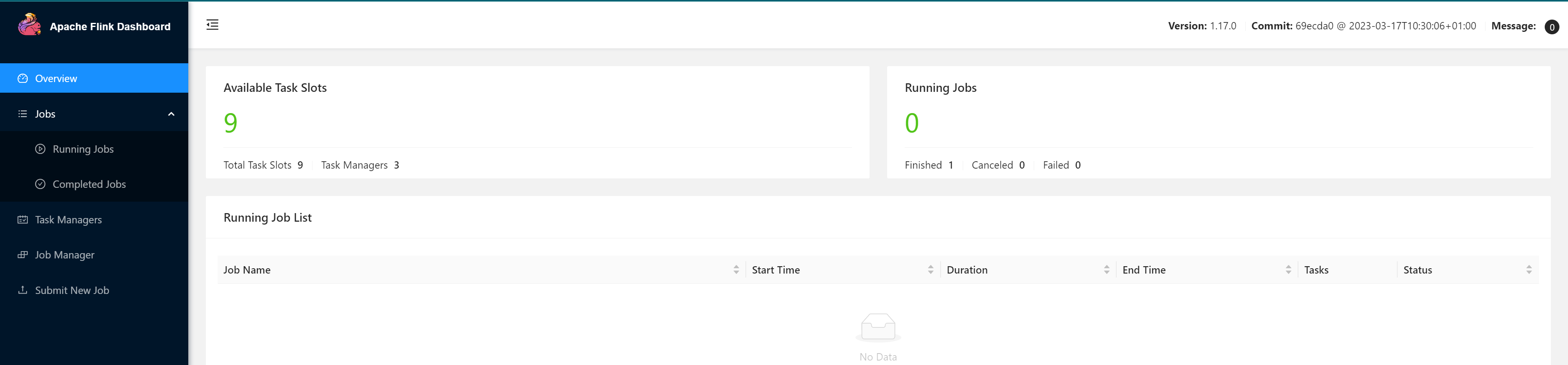
访问http://node02:8081
测试
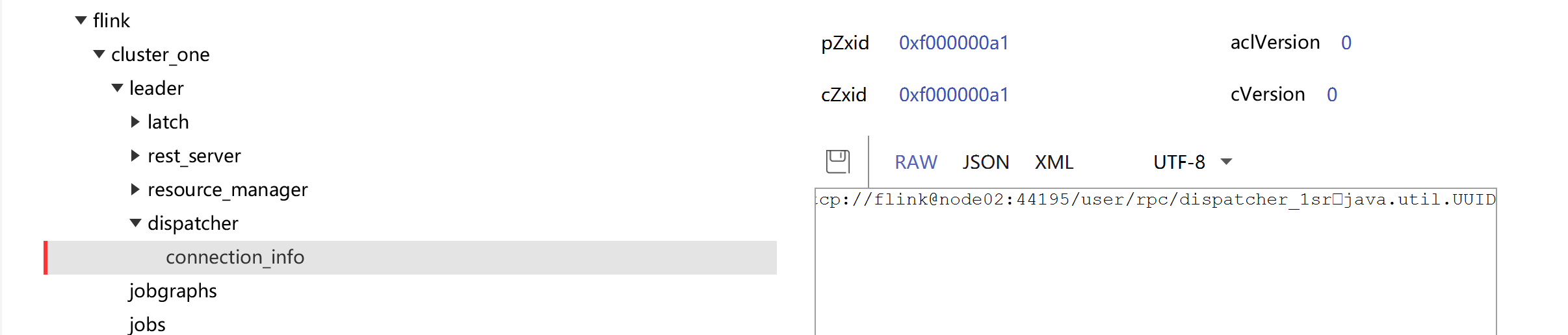
查看ZK:JobManager节点信息
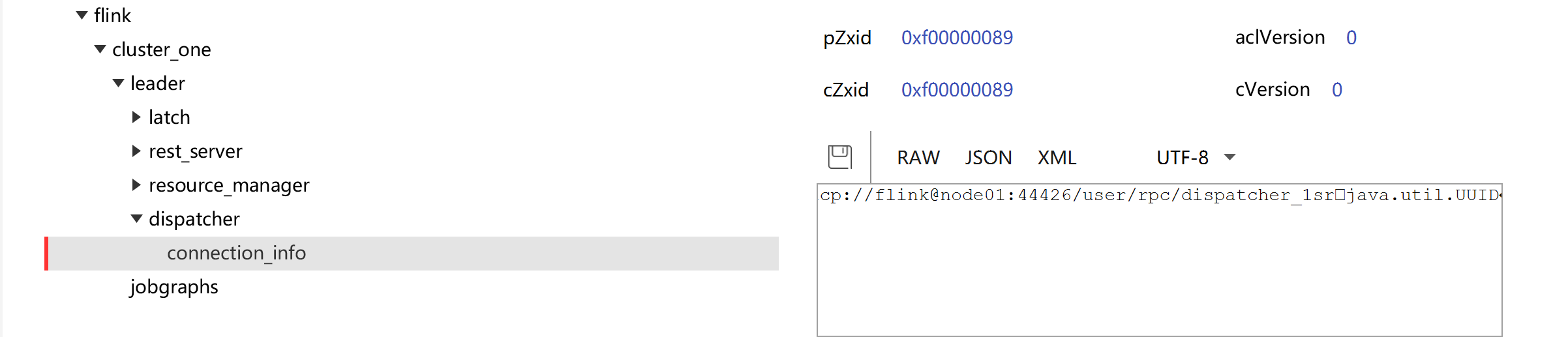
kill node01节点上的JobManager进程
[root@node01 flink]# jps
2564 DataNode
3508 NodeManager
18741 Jps
7784 QuorumPeerMain
16666 TaskManagerRunner
2363 NameNode
16300 StandaloneSessionClusterEntrypoint
3117 ResourceManager
[root@node01 flink]# kill -9 16300
查看Active JobManager是否变化
Flink参数配置
flink-conf.yaml文件中有大量的配置参数,基本常见参数如下:
# jobmanager地址
jobmanager.rpc.address: node01# JobManager 的 JVM 堆内存大小,默认为 1024m
jobmanager.heap.size: 1024m# rpc通信端口
jobmanager.rpc.port: 6123# 进程使用的全部内存大小,可以根据集群规模进行适当调整
jobmanager.memory.process.size:1600m# Taskmanager 的 JVM 堆内存大小,默认为 1024m
taskmanager.heap.size: 1024m# 进程使用的全部内存大小,可以根据集群规模进行适当调整
taskmanager.memory.process.size: 1728m# 每个TaskManager能够分配的Slot数量进行配置,默认为1
# 通常设置为 CPU 核心的数量,或其一半
# Slot就是TaskManager中具体运行一个任务所分配的计算资源
taskmanager.numberOfTaskSlots: 1# flink任务执行的并行度,默认为1
# 优先级低于代码中进行的并行度配置和任务提交时使用参数指定的并行度数量
parallelism.default: 1# 重启策略
jobmanager.execution.failover-strategy: region# 存储临时文件的路径,如果没有配置,则默认采用服务器的临时目录,如 LInux 的 /tmp 目录
io.tmp.dirs: /tmp
参考Flink的官方手册:更多配置
配置历史服务器
概述
运行Flink job的集群一旦停止,只能去yarn或本地磁盘上查看日志,对于Job任务信息的查看、异常问题的排查非常不友好。
Flink提供了历史服务器,用来在相应的Flink集群关闭后查询已完成作业的统计信息。通过History Server可以查询这些已完成作业的统计信息,无论是正常退出还是异常退出。
Flink任务停止后,JobManager会将已经完成任务的统计信息进行存档,History Server进程则在任务停止后可以对任务统计信息进行查询。
配置
创建存储目录
[root@node01 flink]# hadoop fs -mkdir -p /logs/flink-job
在flink-config.yaml中添加如下配置
#==============================================================================
# HistoryServer
#==============================================================================# The HistoryServer is started and stopped via bin/historyserver.sh (start|stop)# Directory to upload completed jobs to. Add this directory to the list of
# monitored directories of the HistoryServer as well (see below).
#jobmanager.archive.fs.dir: hdfs:///completed-jobs/
jobmanager.archive.fs.dir: hdfs://node01:9000/logs/flink-job# The address under which the web-based HistoryServer listens.
#historyserver.web.address: 0.0.0.0
historyserver.web.address: node01# The port under which the web-based HistoryServer listens.
#historyserver.web.port: 8082
historyserver.web.port: 8082# Comma separated list of directories to monitor for completed jobs.
#historyserver.archive.fs.dir: hdfs:///completed-jobs/
historyserver.archive.fs.dir: hdfs://node01:9000/logs/flink-job# Interval in milliseconds for refreshing the monitored directories.
#historyserver.archive.fs.refresh-interval: 10000
historyserver.archive.fs.refresh-interval: 5000
启动、停止历史服务器
启动历史服务器
[root@node01 flink]# bin/historyserver.sh start
Starting historyserver daemon on host node01.
停止历史服务器
[root@node01 flink]# bin/historyserver.sh stop
Stopping historyserver daemon (pid: 30749) on host node01.
提交一个Job任务
[root@node01 flink]# bin/flink run -t yarn-per-job -c com.atguigu.wc.WordCountStreamUnboundedDemo /root/FlinkTutorial-1.17-1.0-SNAPSHOT.jar2023-06-12 23:41:00,719 INFO org.apache.hadoop.hdfs.protocol.datatransfer.sasl.SaslDataTransferClient [] - SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2023-06-12 23:41:00,742 INFO org.apache.hadoop.hdfs.protocol.datatransfer.sasl.SaslDataTransferClient [] - SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2023-06-12 23:41:00,761 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cannot use kerberos delegation token manager, no valid kerberos credentials provided.
2023-06-12 23:41:00,766 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Submitting application master application_1686577483648_0012
2023-06-12 23:41:00,792 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl [] - Submitted application application_1686577483648_0012
2023-06-12 23:41:00,792 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Waiting for the cluster to be allocated
2023-06-12 23:41:00,793 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deploying cluster, current state ACCEPTED
2023-06-12 23:41:04,565 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully.
2023-06-12 23:41:04,565 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface node02:38887 of application 'application_1686577483648_0012'.
Job has been submitted with JobID cd41d983c93d8eb906c9aa899dcdefd0
访问http://node01:8088/cluster查看Hadoop

访问Web UI查看提交任务信息

查看历史Job信息
在浏览器地址栏输入:http://node01:8082 查看已经停止的 job 的统计信息

停止提交任务
[root@node01 flink]# bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_1686577483648_0012 cd41d983c93d8eb906c9aa899dcdefd0
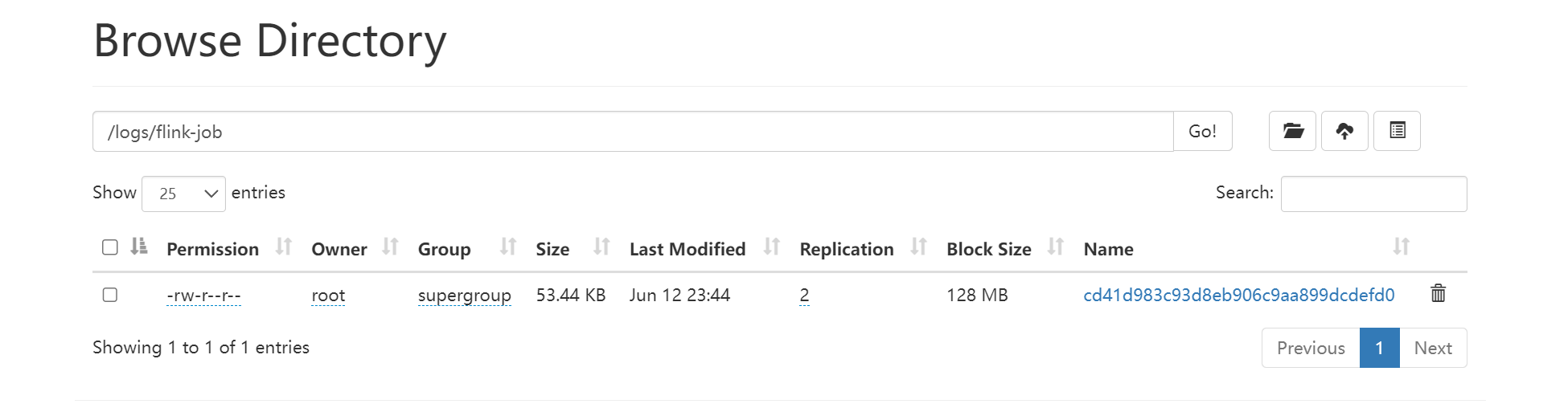
访问http://node01:9870/explorer.html#/logs/flink-job查看HDFS中的归档文件
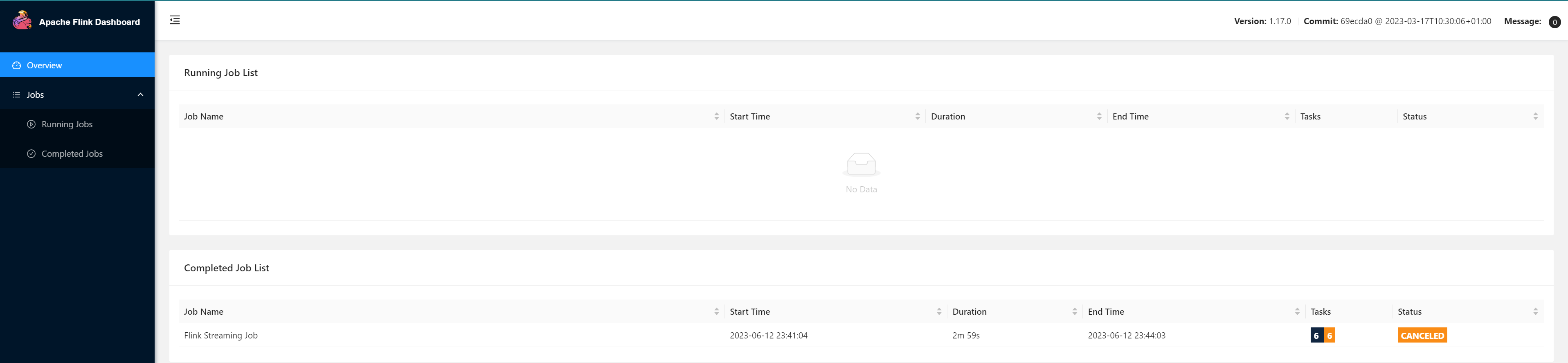
等一段时间,几分钟后查看历史服务器
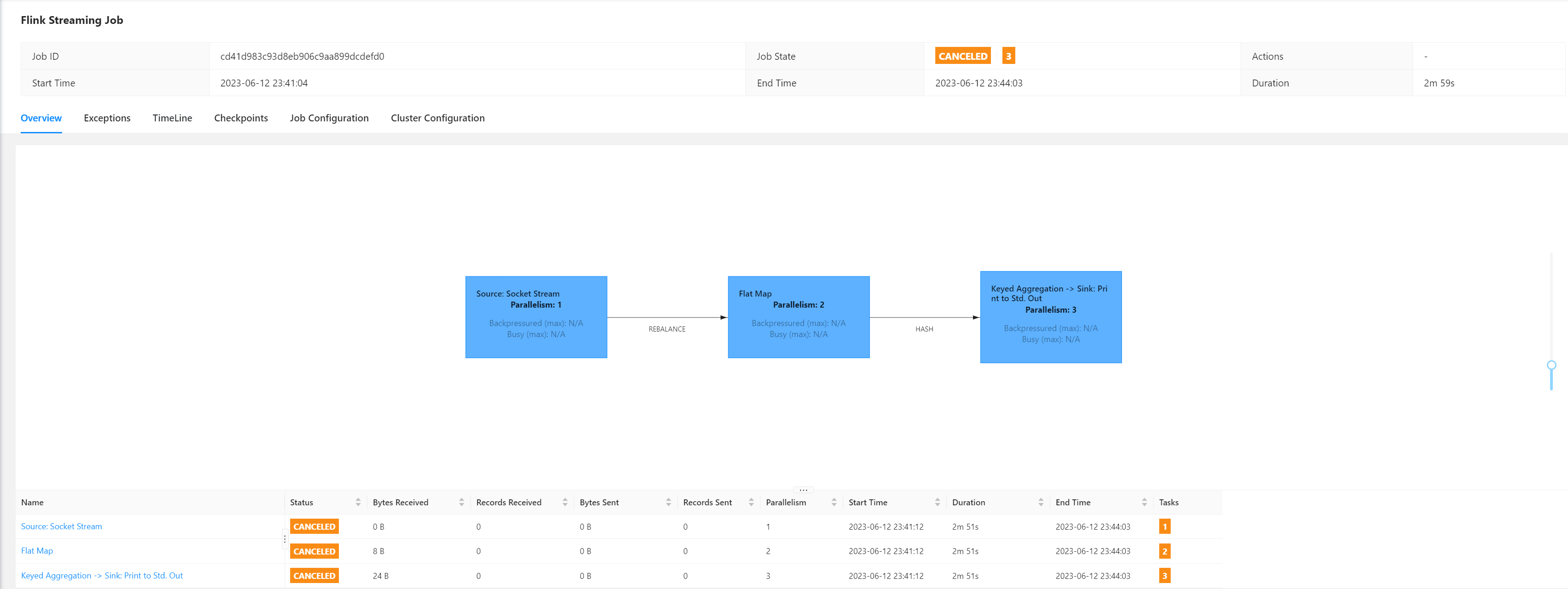
查看Job具体信息
相关文章:
搭建Flink集群、集群HA高可用以及配置历史服务器
Flink集群搭建 Flink集群搭建集群规划下载并解压安装包修改集群配置分发安装目录启动集群访问Web UI Flink集群HA高可用概述集群规划配置flink配置master、workers配置ZK分发安装目录启动HA集群测试 Flink参数配置配置历史服务器概述配置启动、停止历史服务器提交一个Job任务查…...
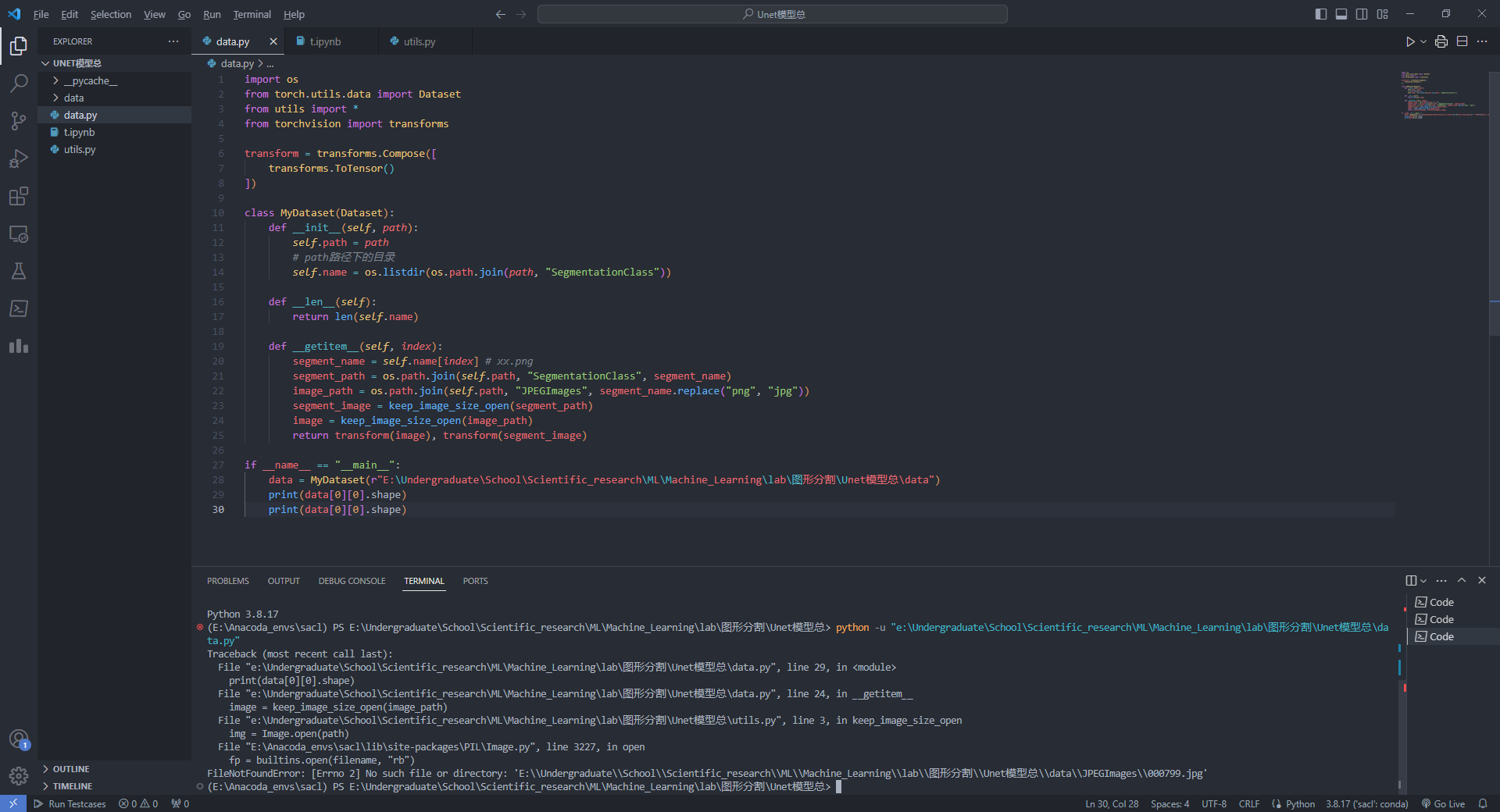
vscode终端中打不开conda虚拟包管理
今天,想着将之前鸽的Unet网络模型给实现一下,结果发现,在vscode中运行python脚本,显示没有这包,没有那包。但是在其他的ipynb中是有的,感觉很奇怪。我检查了一下python版本,发现不是我深度学习的…...

【音视频】MP4封装格式
基本概念 使用MP4box.js查看MP4内部组成结构 整体结构 数据索引(moov)数据流包(mdat) 各个包的位置,大小,信息,时间戳,编码方式等全在数据索引 数据流包只有纯二进制码流数据 数据…...

环境-使用vagrant快速创建linux虚拟机
1.下载软件 虚拟机 Oracle VM VirtualBox 镜像 Vagrant by HashiCorp (vagrantup.com) 如果下载慢,可以复制下载链接,使用迅雷下载 2.安装 根据提示点击下一步即可,建议安装到空间较大的非系统盘。 打开 window cmd 窗口,…...
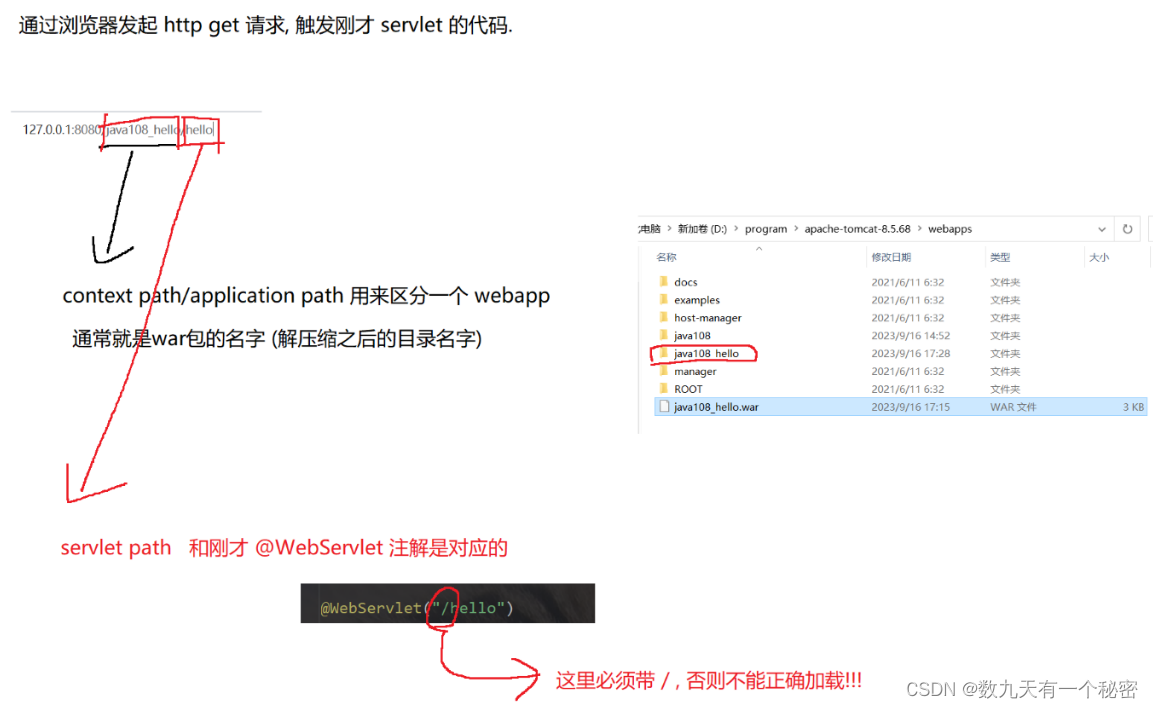
10.1网站编写(Tomcat和servlet基础)
一.Tomcat: 1.Tomcat是java写的,运行时需要依赖jre,所以要装jdk. 2.建议配置好环境变量. 3.默认端口号8080(业务端口)可能会被占用,建议改一下(本人改成了9999). 4.另一个默认端口是8005(管理端口). 二Servlet基础(编写一个hello world代码): 整体分为7个步骤,分别是创建…...
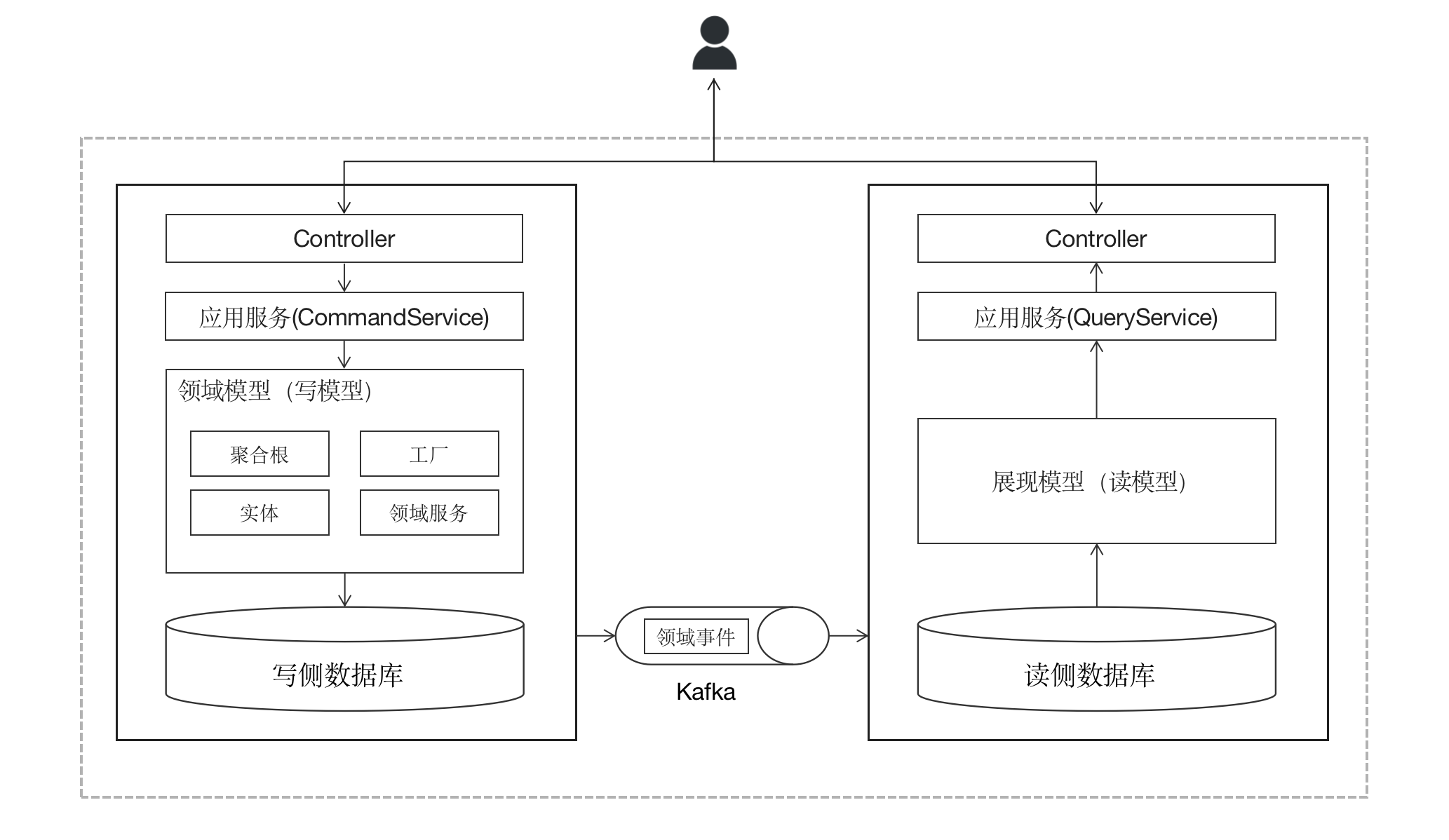
10CQRS
本系列包含以下文章: DDD入门DDD概念大白话战略设计代码工程结构请求处理流程聚合根与资源库实体与值对象应用服务与领域服务领域事件CQRS(本文) 案例项目介绍 # 既然DDD是“领域”驱动,那么我们便不能抛开业务而只讲技术&…...

DAZ To UMA⭐一.DAZ简单使用教程
文章目录 🟥 DAZ快捷键🟧 DAZ界面介绍 🟥 DAZ快捷键 移动物体:ctrlalt鼠标左键 旋转物体:ctrlalt鼠标右键 导入模型:双击左侧模型UI 🟧 DAZ界面介绍 Files:显示全部文件 Products:显示全部产品 Figures:安装的全部人物 Wardrobe…...
)
面试题 —— Java集合篇(23题)
文章目录 1.Java中常见集合有哪些 ?2. 说说你对Java集合是怎么理解的?3.请你说一下List,Set,Map三者的特点是 ?4.在实际开发过程中如何更好的选择集合 ?5. ArrayList和Vector区别 ?6. ArrayList…...

SpringBoot2.7.14整合Swagger3.0的详细步骤及容易踩坑的地方
🧑💻作者名称:DaenCode 🎤作者简介:啥技术都喜欢捣鼓捣鼓,喜欢分享技术、经验、生活。 😎人生感悟:尝尽人生百味,方知世间冷暖。 📖所属专栏:Sp…...

题解:ABC321D - Set Menu
题解:ABC321D - Set Menu 题目 链接:Atcoder。 链接:洛谷。 难度 算法难度:B。 思维难度:C。 调码难度:B。 综合评价:见洛谷链接。 算法 枚举二分查找。 思路 先对b升序排序&#x…...

什么是Progressive Web App(PWA)?它们有哪些特点?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 渐进式Web App简介⭐ PWAs的主要特点⭐ 总结⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 欢迎来到前端入门之旅!感兴趣的可以订阅本专栏哦!这个专栏是为那些对Web开发感兴趣、刚刚踏入…...
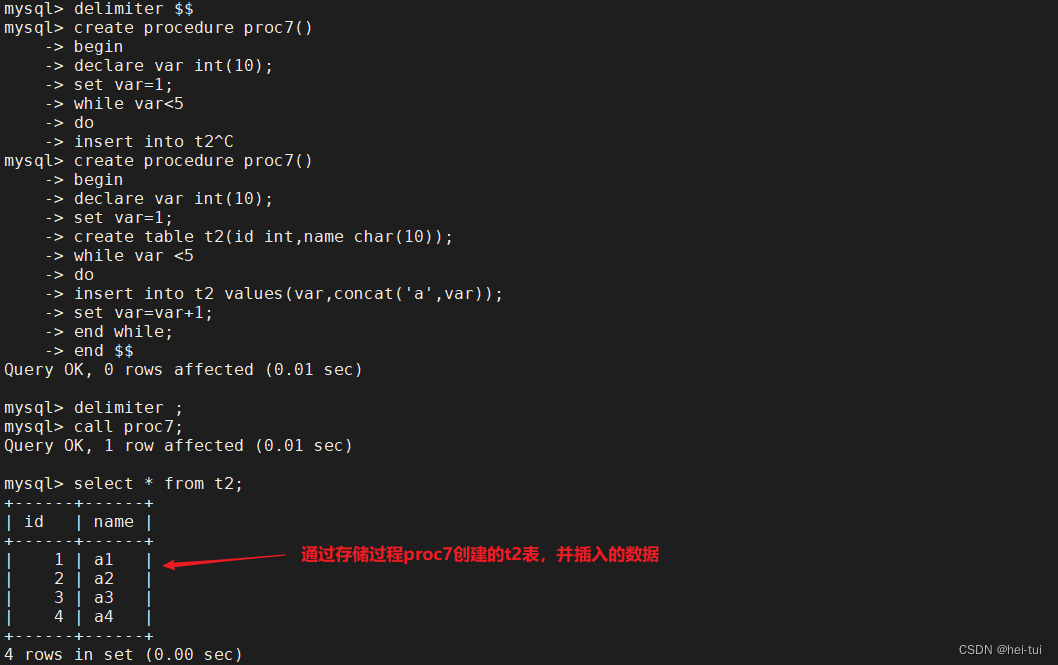
MySQL的高级SQL语句
目录 一、高级SQL语句 1、select 查询表中一个或多个字段的数据 2、distinct 不显示重复的数据记录 3、where 有条件查询 4、and与or 且与或 5、in 显示在某个范围值内 的字段的信息 6、between 显示两个值范围内的数据记录 7、order by 对字…...

基于人脸5个关键点的人脸对齐(人脸纠正)
摘要:人脸检测模型输出人脸目标框坐标和5个人脸关键点,在进行人脸比对前,需要对检测得到的人脸框进行对齐(纠正),本文将通过5个人脸关键点信息对人脸就行对齐(纠正)。 一、输入图像…...

vue3中两个el-select下拉框选项相互影响
vue3中两个el-select下拉框选项相互影响 1、开发需求2、代码2.1 定义hooks文件2.2 在组件中使用 1、开发需求 如图所示,在项目开发过程中,遇到这样一个需求,常规时段中选中的月份在高峰时段中是禁止选择的状态,反之亦然。 2、代…...
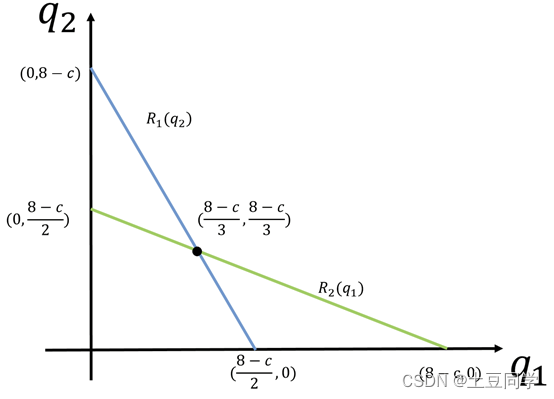
博弈论——反应函数
反应函数 1 引言 谢老师的《经济博弈论》书中对反应函数并没有给出一般笼统的定义,而是将其应用与古诺模型并给出了相关解释:反应函数是指在无限策略的古诺博弈模型中,博弈方的策略有无限多种,因此各个博弈方的最佳对策也有无限…...
UE5读取json文件
一、下载插件 在工程中启用 二、定义读取外部json文件的函数,参考我之前的文章 ue5读取外部文件_艺菲的博客-CSDN博客 三、读取文件并解析为json对象 这里Load Text就是自己定义的函数,ResourceBundle为一个字符串常量,通常是读取的文件夹…...
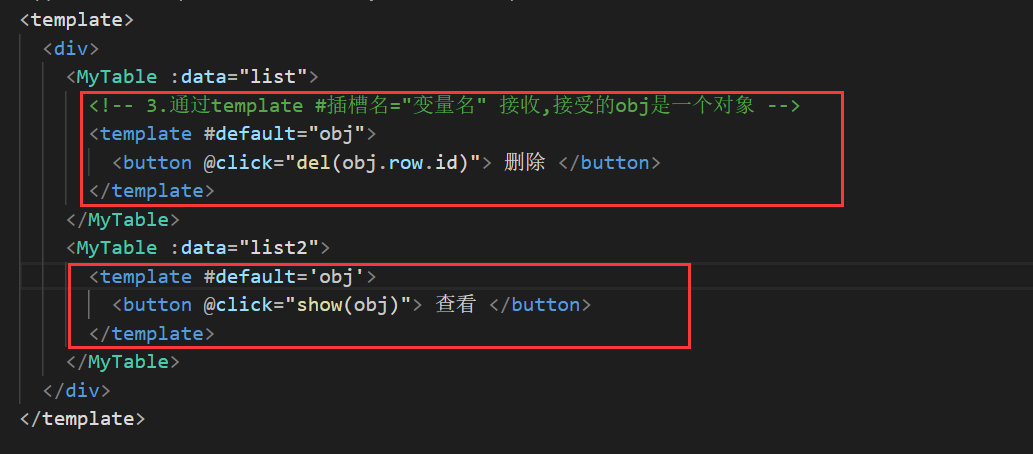
Vue中的插槽--组件复用,内容自定义
插槽 文章目录 插槽插槽-默认插槽插槽-后备内容(设置默认值)插槽-具名插槽插槽–作用域插槽 插槽-默认插槽 作用:让组件内部的一些结构支持自定义 需求:要在页面中显示一个对话框,封装成一个组件(对话框有很多功能是类…...

完全指南:mv命令用法、示例和注意事项 | Linux文件移动与重命名
文章目录 mv命令使用指南1. 简介什么是mv命令?mv命令的作用和功能是什么? 2. 基本用法基本语法格式如何移动文件?如何重命名文件?如何移动和重命名目录? 3. 高级用法使用通配符进行批量移动和重命名使用选项进行文件移…...
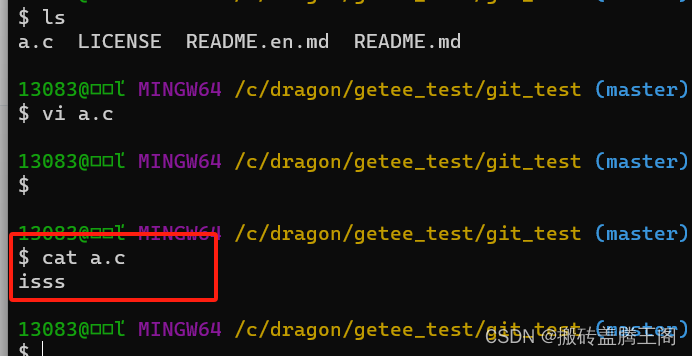
gitee生成公钥和远程仓库与本地仓库使用验证
参考文档: https://help.gitee.com/base/account/SSH%E5%85%AC%E9%92%A5%E8%AE%BE%E7%BD%AE(1)通过命令ssh-keygen 生成SSH key -t key类型 -c注释 ssh-keygen -t ed25519 -C "Gitee SSH Key" (2)按三次回车 (3)查看生成的 SSH 公钥和私钥: …...

请求后端接口413
当在进行HTTP请求时出现"413 Request Entity Too Large"错误时,通常是因为请求体的大小超过了服务器的配置限制。这个错误提示表明服务器拒绝接受过大的请求。 此时一般还未到后端服务,是被后端的ngnix代理服务器拦截的,所以可以检…...

docker详细操作--未完待续
docker介绍 docker官网: Docker:加速容器应用程序开发 harbor官网:Harbor - Harbor 中文 使用docker加速器: Docker镜像极速下载服务 - 毫秒镜像 是什么 Docker 是一种开源的容器化平台,用于将应用程序及其依赖项(如库、运行时环…...

Zustand 状态管理库:极简而强大的解决方案
Zustand 是一个轻量级、快速和可扩展的状态管理库,特别适合 React 应用。它以简洁的 API 和高效的性能解决了 Redux 等状态管理方案中的繁琐问题。 核心优势对比 基本使用指南 1. 创建 Store // store.js import create from zustandconst useStore create((set)…...

【WiFi帧结构】
文章目录 帧结构MAC头部管理帧 帧结构 Wi-Fi的帧分为三部分组成:MAC头部frame bodyFCS,其中MAC是固定格式的,frame body是可变长度。 MAC头部有frame control,duration,address1,address2,addre…...

前端开发面试题总结-JavaScript篇(一)
文章目录 JavaScript高频问答一、作用域与闭包1.什么是闭包(Closure)?闭包有什么应用场景和潜在问题?2.解释 JavaScript 的作用域链(Scope Chain) 二、原型与继承3.原型链是什么?如何实现继承&a…...

CMake 从 GitHub 下载第三方库并使用
有时我们希望直接使用 GitHub 上的开源库,而不想手动下载、编译和安装。 可以利用 CMake 提供的 FetchContent 模块来实现自动下载、构建和链接第三方库。 FetchContent 命令官方文档✅ 示例代码 我们将以 fmt 这个流行的格式化库为例,演示如何: 使用 FetchContent 从 GitH…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...

Map相关知识
数据结构 二叉树 二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子 节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只 有左子节点,有的节点只有…...

Java多线程实现之Thread类深度解析
Java多线程实现之Thread类深度解析 一、多线程基础概念1.1 什么是线程1.2 多线程的优势1.3 Java多线程模型 二、Thread类的基本结构与构造函数2.1 Thread类的继承关系2.2 构造函数 三、创建和启动线程3.1 继承Thread类创建线程3.2 实现Runnable接口创建线程 四、Thread类的核心…...

管理学院权限管理系统开发总结
文章目录 🎓 管理学院权限管理系统开发总结 - 现代化Web应用实践之路📝 项目概述🏗️ 技术架构设计后端技术栈前端技术栈 💡 核心功能特性1. 用户管理模块2. 权限管理系统3. 统计报表功能4. 用户体验优化 🗄️ 数据库设…...

离线语音识别方案分析
随着人工智能技术的不断发展,语音识别技术也得到了广泛的应用,从智能家居到车载系统,语音识别正在改变我们与设备的交互方式。尤其是离线语音识别,由于其在没有网络连接的情况下仍然能提供稳定、准确的语音处理能力,广…...