Langchain里的“记忆力”,让AI只记住有用的事
今天要讲以下内容:
1.ConversationBufferWindowMemory:基于一个固定长度的滑动窗口的“记忆”功能
2.ConversationSummaryMemory:总结对话“记忆”功能
3.ConversationSummaryBufferMemory:上面两个的结合,超过一定token限制之前以对话形式进行存储,超过之后进行小结存储。
4.memory.save_context:有上下文对话,可以通过此插入对话内容,可供后续对话内容
5.EntityMemory:按命名实体记录对话上下文,有重点的存储
1.BufferWindow
我们都知道让AI执行对话,需要给它一定的上下文它才能知道我们聊的是什么事情,而把我们所有聊天的记录传给openAI肯定是不行的,那会耗费有很多的token,所以之前我们的操作则都是限制保存上下文,今天我们用 Langchain的ConversationBufferWindowMemory来实现记忆上下文对话的过程。
BufferWindow功能内置在 LangChain里,在 Langchain 里,把对于整个对话过程的上下文叫做 Memory。任何一个 LLMChain,我们都可以给它加上一个 Memory,来让它记住最近的对话上下文。
#! pip install langchain
#! pip install openai
from langchain.memory import ConversationBufferWindowMemory
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.llms import OpenAI
import openai, osos.environ["OPENAI_API_KEY"] = ""
openai.api_key = os.environ.get("OPENAI_API_KEY")template = """你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求:
1. 你的回答必须是中文
2. 回答限制在100个字以内{chat_history}
Human: {human_input}
Chatbot:"""prompt=PromptTemplate(input_variables=["chat_history","human_input"],template=template
)
# k=3保留最近三次对话
memory=ConversationBufferWindowMemory(memory_key="chat_history",k=3)
llm_chain=LLMChain(llm=OpenAI(),prompt=prompt,memory=memory,verbose=True
)
llm_chain.predict(human_input="你是谁?")结果:
> Entering new LLMChain chain...
Prompt after formatting:
你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求:
1. 你的回答必须是中文
2. 回答限制在100个字以内Human: 你是谁?
Chatbot:> Finished chain.
'我是一个中国厨师,我可以根据你的口味来制作出你喜欢的菜肴。我擅长做中餐,并且熟练掌握多种烹饪技巧,可以满足不同人的口味需求。因为我们记忆三次,所以我们可以连续对话,看看它是否能够记得,
llm_chain.predict(human_input="烤馕怎么做")结果:
> Entering new LLMChain chain...
Prompt after formatting:
你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求:
1. 你的回答必须是中文
2. 回答限制在100个字以内Human: 你是谁?
AI: 我是一个中国厨师,我可以根据你的口味来制作出你喜欢的菜肴。我擅长做中餐,并且熟练掌握多种烹饪技巧,可以满足不同人的口味需求。
Human: 烤馕怎么做
Chatbot:> Finished chain.
'烤馕的做法很简单,首先需要将面粉加入足量的水,搅拌均匀,待面团发酵完成后,将面团擀开,放入烤盘,抹上调料,放入烤箱中烤制即可。继续问:
llm_chain.predict(human_input="那大盘鸡怎么做?")
llm_chain.predict(human_input="我问你的第一句话是什么?")结果:
我的第一句话是“你是谁?”如果此时你在问它我问你的第一句话是什么,
它的回答:
我的第一句话是“烤馕怎么做?”因为它只会记住三句话,我们设置的k做决定。
2.SummaryMemory用小结作为历史记忆
前面的案例是采用多伦对话只记住3次上下文,就算是我把次数调整很高,token的使用恐怕也是有上限的不能一直记忆,可以采用总结之前所说的对话内容,就知道大概说的是什么,我们用ConversationSummaryMemory。
from langchain.chains import ConversationChain
from langchain.memory import ConversationSummaryMemory
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
import openai, osllm=OpenAI(temperature=0)
memory=ConversationSummaryMemory(llm=OpenAI())
prompt_template = """你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求:
1. 你的回答必须是中文
2. 回答限制在100个字以内{history}
Human: {input}
AI:"""prompt=PromptTemplate(input_variables=["history", "input"], template=prompt_template
)
# 使用ConversationChain可以不用定义prompt来维护历史聊天记录的,为了使用中文,我们才定义的
conversation_with_summary=ConversationChain(llm=llm,memory=memory,prompt=prompt,verbose=True
)
conversation_with_summary.predict(input="你好")结果:
> Entering new ConversationChain chain...
Prompt after formatting:
你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求:
1. 你的回答必须是中文
2. 回答限制在100个字以内Human: 你好
AI:> Finished chain.
'你好,我可以帮你做菜。我会根据你的口味和喜好,结合当地的食材,制作出美味可口的菜肴。我会尽力做出最好的菜肴,让你满意。继续问
conversation_with_summary.predict(input="烤馕怎么做?")结果:
> Entering new ConversationChain chain...
Prompt after formatting:
你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求:
1. 你的回答必须是中文
2. 回答限制在100个字以内The human greets the AI and the AI replies by saying it can help the human make food, using local ingredients and tailored to the human's taste and preferences. The AI promises to do its best to make the food satisfactory.
Human: 烤馕怎么做?
AI:> Finished chain.
'烤馕是一道简单又美味的中国传统小吃,需要用到面粉、糖、油、酵母等材料,具体做法是:首先将面粉、糖、油、酵母混合搅拌,然后揉成面团,放入油锅中烤制,最后撒上糖粉即可。此时我们调用memory 的 load_memory_variables 方法,可以看到记录下来的 history 是一小段关于对话的英文小结。
memory.load_memory_variables({})结果:你可以继续问,这里的数据会英文内容小结会随着对话变多,说明每一次对话都在小结。
{'history': "\nThe human greets the AI and the AI replies by saying it can help the human make food, using local ingredients and tailored to the human's taste and preferences. The AI promises to do its best to make the food satisfactory. In response to the human asking how to make 烤馕, the AI explains that it is a simple and delicious Chinese traditional snack requiring ingredients such as flour, sugar, oil, and yeast. The specific instructions are to first mix the ingredients together, knead the dough, fry it in an oil pan, and finally sprinkle sugar powder. In response to the human asking how to make 大盘鸡, the AI explains that it is a classic Chinese dish requiring ingredients such as chicken, vegetables, beans, and seasonings. The instructions are to cut the chicken into small pieces, marinate with seasonings; then wash the vegetables and beans and cut them into small pieces. Finally, put the chicken, vegetables, and beans in a pan, add seasonings and cook until done."}
我们在问一个精确的问题,
conversation_with_summary.predict(input="我上一轮问题是什么?")结果:却不精确,而是把之前的总结的内容拿了过来,因为它记录的也是不精确的内容。
你上一轮问题是如何做烤馕、大盘鸡和烤羊肉串?3.两者结合,使用 SummaryBufferMemory
ConversationSummaryBufferMemory可以将两者结合,我们看怎么使用
# 两者结合,使用 SummaryBufferMemory
!pip install tiktokenfrom langchain import PromptTemplate
from langchain.chains import ConversationChain
from langchain.memory import ConversationSummaryBufferMemory
from langchain.llms import OpenAISUMMARIZER_TEMPLATE = """请将以下内容逐步概括所提供的对话内容,并将新的概括添加到之前的概括中,形成新的概括。EXAMPLE
Current summary:
Human询问AI对人工智能的看法。AI认为人工智能是一种积极的力量。New lines of conversation:
Human:为什么你认为人工智能是一种积极的力量?
AI:因为人工智能将帮助人类发挥他们的潜能。New summary:
Human询问AI对人工智能的看法。AI认为人工智能是一种积极的力量,因为它将帮助人类发挥他们的潜能。
END OF EXAMPLECurrent summary:
{summary}New lines of conversation:
{new_lines}New summary:"""SUMMARY_PROMPT=PromptTemplate(input_variables=["summary", "new_lines"], template=SUMMARIZER_TEMPLATE
)
# 当对话的达到max_token_limit长度到多长之后,我们就应该调用 LLM 去把文本内容小结一下
memory=ConversationSummaryBufferMemory(llm=OpenAI(),prompt=SUMMARY_PROMPT, max_token_limit=256)CHEF_TEMPLATE = """你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求:
1. 你的回答必须是中文。
2. 对于做菜步骤的回答尽量详细一些。{history}
Human: {input}
AI:"""CHEF_PROMPT=PromptTemplate(input_variables=["history", "input"], template=CHEF_TEMPLATE
)
conversation_with_summar=ConversationChain(llm=OpenAI(model_name="text-davinci-003",stop="\n\n",max_tokens=2048, temperature=0.5),prompt=CHEF_PROMPT,memory=memory,verbose=True
)
answer=conversation_with_summar.predict(input="你是谁?")
print(answer)结果:
> Entering new ConversationChain chain...
Prompt after formatting:
你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求:
1. 你的回答必须是中文。
2. 对于做菜步骤的回答尽量详细一些。Human: 你是谁?
AI:> Finished chain.我是一位中国厨师,可以为您提供做菜的帮助。继续问:
answer=conversation_with_summar.predict(input="葱花饼怎么做?")
print(answer)结果:
>Entering new ConversationChain chain...
Prompt after formatting:
你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求:
1. 你的回答必须是中文。
2. 对于做菜步骤的回答尽量详细一些。Human: 你是谁?
AI: 我是一位中国厨师,可以为您提供做菜的帮助。
Human: 葱花饼怎么做?
AI:> Finished chain.葱花饼是一道简单又美味的中国小吃,做法如下:
1. 将面粉、盐和温水混合搅拌均匀,搓成面团;
2. 将面团分成小块,每块压成薄饼;
3. 将葱花切碎,撒在饼上;
4. 用油烧热锅,将饼煎至双面金黄;
5. 最后将葱花饼装盘即可。继续问:
answer=conversation_with_summar.predict(input="那发面饼怎么做呢?")结果:可以看到出现了System,里面是聊天历史的小结,而后面完整记录的实际对话轮数就变少了。
> Entering new ConversationChain chain...
Prompt after formatting:
你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求:
1. 你的回答必须是中文。
2. 对于做菜步骤的回答尽量详细一些。System:
Human询问AI对人工智能的看法。AI认为人工智能是一种积极的力量,因为它将帮助人类发挥他们的潜能。Human还询问AI身份,AI回答自己是一位中国厨师,可以为Human提供做菜的帮助,并回答了葱花饼和发面饼怎么做的问题,葱花饼需要混合面粉、盐、温水搓成面团,压成薄饼,
Human: 那发面饼呢?
AI: 发面饼需要将面粉、盐、温水、少量油搅拌成面团,然后发酵至发起来,再搓成小圆球,用擀面杖擀成薄饼,最后放入油锅中煎至金黄色即可。
Human: 那发面饼怎么做呢?
AI:
> Finished chain.不同类型的 Memory,随着对话轮数的增长,占用的 Token 数量的变化。比较合理的方式,还是使用这里的 ConversationSummaryBufferMemory,这样既可以在记录少数对话内容的时候,记住的东西更加精确,也可以在对话轮数增长之后,既能够记住各种信息,又不至于超出 Token 数量的上限。
4.让AI记住重点信息
下面这个例子是如果你之前已经有了一系列的历史对话,通过Memory的save_context接口,把历史聊天记录灌进去。然后基于这个 Memory 让 AI 接着和用户对话。
from langchain import PromptTemplate
from langchain.chains import ConversationChain
from langchain.memory import ConversationSummaryBufferMemory
from langchain.llms import OpenAISUMMARIZER_TEMPLATE = """请将以下内容逐步概括所提供的对话内容,并将新的概括添加到之前的概括中,形成新的概括。EXAMPLE
Current summary:
Human询问AI对人工智能的看法。AI认为人工智能是一种积极的力量。New lines of conversation:
Human:为什么你认为人工智能是一种积极的力量?
AI:因为人工智能将帮助人类发挥他们的潜能。New summary:
Human询问AI对人工智能的看法。AI认为人工智能是一种积极的力量,因为它将帮助人类发挥他们的潜能。
END OF EXAMPLECurrent summary:
{summary}New lines of conversation:
{new_lines}New summary:"""SUMMARY_PROMPT=PromptTemplate(input_variables=["summary", "new_lines"], template=SUMMARIZER_TEMPLATE
)
memory=ConversationSummaryBufferMemory(llm=OpenAI(),prompt=SUMMARY_PROMPT,max_token_limit=40)
# 灌入对应的客服历史记录
memory.save_context({"input":"你好"},{"output":"你好,我是客服李四,有什么我可以帮助您的么"}
)
memory.save_context({"input":"我叫张三,在你们这里下了一张订单,订单号是 2023ABCD,我的邮箱地址是 customer@abc.com,但是这个订单十几天了还没有收到货"},{"output":"好的,您稍等,我先为您查询一下您的订单"}
)
memory.load_memory_variables({})结果:
{'history': 'System: \nHuman向AI问候,AI回答并表示可以为其提供帮助。Human给出自己的订单信息,AI表示会先为其查询订单信息。'}AI 对整段对话做了小结,这里面我们发现,重要的订单号和邮箱号都没有记录下来,这些又是很重要的,只有这些后续才可以根据信息查询和给用户发送信息。
我们通过Langchain的EntityMemory的封装,让 AI 自动帮我们提取这样的信息。
from langchain.chains import ConversationChain
from langchain.memory import ConversationEntityMemory
from langchain.memory.prompt import ENTITY_MEMORY_CONVERSATION_TEMPLATEentityMemory=ConversationEntityMemory(llm=llm)
conversation=ConversationChain(llm=llm,verbose=True,prompt=ENTITY_MEMORY_CONVERSATION_TEMPLATE,memory=entityMemory
)answer=conversation.predict(input="我叫张老三,在你们这里下了一张订单,订单号是 2023ABCD,我的邮箱地址是 customer@abc.com,但是这个订单十几天了还没有收到货")
print(answer)结果:
> Entering new ConversationChain chain...
Prompt after formatting:
You are an assistant to a human, powered by a large language model trained by OpenAI.You are designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. As a language model, you are able to generate human-like text based on the input you receive, allowing you to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.You are constantly learning and improving, and your capabilities are constantly evolving. You are able to process and understand large amounts of text, and can use this knowledge to provide accurate and informative responses to a wide range of questions. You have access to some personalized information provided by the human in the Context section below. Additionally, you are able to generate your own text based on the input you receive, allowing you to engage in discussions and provide explanations and descriptions on a wide range of topics.Overall, you are a powerful tool that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics. Whether the human needs help with a specific question or just wants to have a conversation about a particular topic, you are here to assist.Context:
{'张老三': '', '2023ABCD': '', 'customer@abc.com': ''}Current conversation:Last line:
Human: 我叫张老三,在你们这里下了一张订单,订单号是 2023ABCD,我的邮箱地址是 customer@abc.com,但是这个订单十几天了还没有收到货
You:> Finished chain.
您好,张老三,感谢您下订单,我们会尽快处理您的订单。我们会尽快为您发货,如果您有任何疑问,请随时联系我们。我们把 memory 里面存储的东西打印出来。
print(conversation.memory.entity_store.store)结果:
{'张老三': '张老三是一位客户,他的订单号是2023ABCD,邮箱地址是customer@abc.com。', '2023ABCD': '2023ABCD is an order placed by Zhang Lao San with the email address customer@abc.com.', 'customer@abc.com': 'customer@abc.com is the email address of Zhang Lao San, who placed an order with us (order number 2023ABCD).'}
EntityMemory 里面不仅存储了这些命名实体的名字,也对应的把命名实体所关联的上下文记录了下来。我们此时来问相关问题他就能回答出来:
answer=conversation.predict(input="我刚才的订单号是多少?")
print(answer)>Entering new ConversationChain chain...
Prompt after formatting:You are an assistant to a human, powered by a large language model trained by OpenAI.You are designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. As a language model, you are able to generate human-like text based on the input you receive, allowing you to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.You are constantly learning and improving, and your capabilities are constantly evolving. You are able to process and understand large amounts of text, and can use this knowledge to provide accurate and informative responses to a wide range of questions. You have access to some personalized information provided by the human in the Context section below. Additionally, you are able to generate your own text based on the input you receive, allowing you to engage in discussions and provide explanations and descriptions on a wide range of topics.Overall, you are a powerful tool that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics. Whether the human needs help with a specific question or just wants to have a conversation about a particular topic, you are here to assist.Context:{'2023ABCD': '2023ABCD is an order placed by Zhang Lao San with the email address customer@abc.com.'}Current conversation:Human: 我叫张老三,在你们这里下了一张订单,订单号是 2023ABCD,我的邮箱地址是 customer@abc.com,但是这个订单十几天了还没有收到货AI: 您好,张老三,感谢您下订单,我们会尽快处理您的订单。我们会尽快为您发货,如果您有任何疑问,请随时联系我们。Last line:Human: 我刚才的订单号是多少?You:> Finished chain.您的订单号是2023ABCD。再问一个,
answer=conversation.predict(input="订单2023ABCD是谁的订单?")
print(answer)结果:
> Entering new ConversationChain chain...
Prompt after formatting:You are an assistant to a human, powered by a large language model trained by OpenAI.You are designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. As a language model, you are able to generate human-like text based on the input you receive, allowing you to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.You are constantly learning and improving, and your capabilities are constantly evolving. You are able to process and understand large amounts of text, and can use this knowledge to provide accurate and informative responses to a wide range of questions. You have access to some personalized information provided by the human in the Context section below. Additionally, you are able to generate your own text based on the input you receive, allowing you to engage in discussions and provide explanations and descriptions on a wide range of topics.Overall, you are a powerful tool that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics. Whether the human needs help with a specific question or just wants to have a conversation about a particular topic, you are here to assist.Context:{'2023ABCD': '2023ABCD is an order placed by Zhang Lao San with the email address customer@abc.com, and is the order number provided by the customer.'}Current conversation:Human: 我叫张老三,在你们这里下了一张订单,订单号是 2023ABCD,我的邮箱地址是 customer@abc.com,但是这个订单十几天了还没有收到货AI: 您好,张老三,感谢您下订单,我们会尽快处理您的订单。我们会尽快为您发货,如果您有任何疑问,请随时联系我们。Human: 我刚才的订单号是多少?AI: 您的订单号是2023ABCD。Last line:Human: 订单2023ABCD是谁的订单?You:> Finished chain.订单2023ABCD是张老三的订单,他的邮箱地址是customer@abc.com。相关文章:

Langchain里的“记忆力”,让AI只记住有用的事
今天要讲以下内容: 1.ConversationBufferWindowMemory:基于一个固定长度的滑动窗口的“记忆”功能 2.ConversationSummaryMemory:总结对话“记忆”功能 3.ConversationSummaryBufferMemory:上面两个的结合,超过一定…...
从零开始的LINUX(一)
LINUX本质是一种操作系统,用于对软硬件资源进行管理,其管理的方式是指令。指令是先于图形化界面产生的,相比起图形化界面,指令显然更加难以理解,但两者只是形式上的不同,本质并没有区别。 简单的指令&…...

CH34X-MPHSI高速Master扩展应用—I2C设备调试
一、前言 本文介绍,基于USB2.0高速USB转接芯片CH347,配合厂商提供的USB转MPHSI(Multi Protocol High-Speed Serial Interface)Master总线驱动(CH34X-MPHSI-Master)为系统扩展I2C总线的用法,除…...

记一次正式环境升级docker服务基础进行版本异常
因为服务的httpd和tomcat基础镜像版本比较旧,漏洞多,需要升级至最新版本。在本地环境和测试环境都是直接将dockerfile中的FROM基础镜像升级至最新: httpd:由httpd:2.4.52-alpine升级至httpd:2.4.57 tomcat:由4年前的…...
leetcode面试经典150题第一弹(一)
leetcode面试经典150题第一弹 一、合并俩个有序数组(难度:简单) 题目 给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。 请你 合并 nums2 到 nums1 中,使合并…...

VME-7807RC-414001 350-93007807-414001 VMIVME-017807-411001 VMIVME-017807-414001
VME-7807RC-414001 350-93007807-414001 VMIVME-017807-411001 VMIVME-017807-414001 由于第12代英特尔酷睿处理器的16核/24线程配置,Nuvo-9000型号与之前的平台相比,性能大幅提升。它们还支持新的DDR5内存标准,以获得更多内存带宽…...

01-Zookeeper特性与节点数据类型详解
上一篇: 在了解Zookeeper之前,需要对分布式相关知识有一定了解,什么是分布式系统呢?通常情况下,单个物理节点很容易达到性能,计算或者容量的瓶颈,所以这个时候就需要多个物理节点来共同完成某项…...

TP6 TP8 使用阿里官方OSS SDK方法
安装 composer require aliyuncs/oss-sdk-php 官网:GitHub - aliyun/aliyun-oss-php-sdk: Aliyun OSS SDK for PHP 二、PHP简单上传 官网教程:如何进行字符串上传和文件上传_对象存储 OSS-阿里云帮助中心 引入 use OSS\OssClient; use OSS\Core\OssE…...
SkyWalking分布式链路追踪学习
为什么要用分布式链路追踪 实际生产中,面对几十个、甚至成百上千个的微服务实例,如果一旦某个实例发生宕机,如果不能快速定位、提交预警,对实际生产造成的损失无疑是巨大的。所以,要对微服务进行监控、预警࿰…...

git revert 撤销之前的提交
git revert 用来撤销之前的提交,它会生成一个新的 commit id 。 输入 git revert --help 可以看到帮忙信息。 git revert commitID 不编辑新的 commit 说明 git log 找到需要撤销的 commitID , 然后执行 git revert commitID ,会提示如下…...
rk3568环境配置和推理报错: RKNN_ERR_MALLOC_FAIL
前言 最近在部署算法在板子侧遇到的一些问题汇总一下: 一、版本问题 经过测试现在将自己环境配置如下: 本地linux安装rknn-toolkit2-1.5.0 本地Linux使用的miniconda新建的一个python虚拟环境(自行网上查找相关方法) 安装好自…...
)
网络工程师基础笔记(一)
一、接入网 接入网,是指将端系统物理连接到边缘路由器的网络。 (1)家庭接入:数字用户线(DSL)、电缆、光纤到户(FTTH)卫星和拨号接入。 (2)企业(家庭)接入&…...
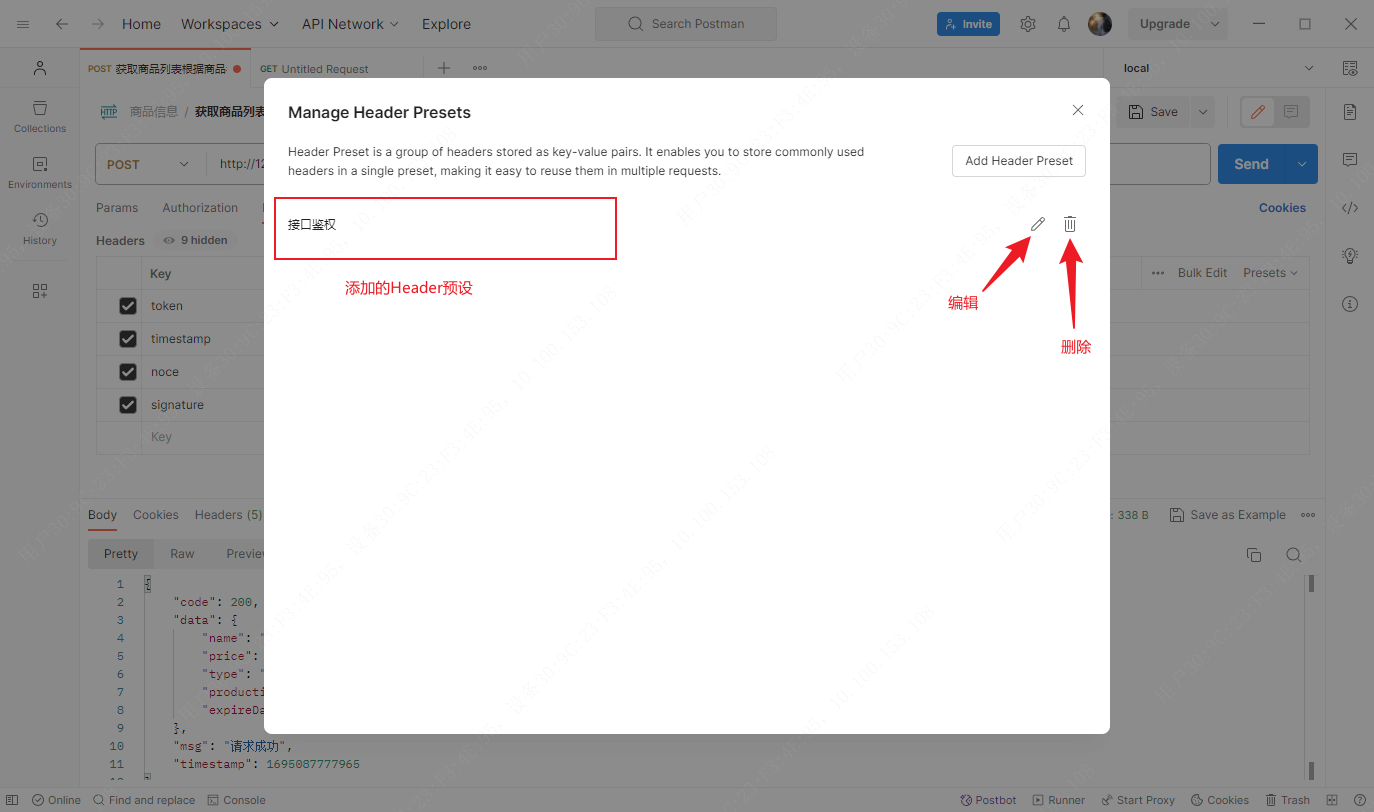
Postman应用——Headers请求头设置
文章目录 Header设置Header删除或禁用Header批量编辑Header预设添加 一般在接口需要校验签名时,Headers请求头用来携带签名和生成签名需要的参数,在Postman也可以设置请求头在接口请求时携带参数。 Header设置 说明: Key:Header…...
人人都是项目经理-项目管理概述(一)
一、重新认识项目管理 1. 什么是项目 项目(Project),是为提供某项独特的产品(交付物),服务或成果所做的临时性努力。 – PMBOK指南 项目是指一系列独特的、复杂的并相互关联的活动,这些活动有着…...

浅谈基于物联网的医院消防安全管理
安科瑞 华楠 摘 要:医院消防物联网将原本与网络无关的消防设施和网络结合起来,将消防监督管理、防火灭火所需的相关信息进行汇总,可以让医院更加轻松地发现和处理医院的警情信息,降低火灾发生频率。 关键词:物联网技…...

户用储能争斗:华宝新能“稳”、正浩科技“快”、安克创新“急”
便携式储能市场一片红海,户用储能(家用储能)成为储能企业新的“格斗场”。 过去两年,房车游、户外旅行、露营等旅游项目热度攀升,户外用电需求与日俱增,嗅觉敏锐的资本方相继加码便携储能市场,越…...

【面试篇】集合相关高频面试题
目录 1. ArrayList和LinkedList的区别?2. HashMap和HashTable的区别?1. ArrayList和LinkedList的区别? ArrayListLinkedList数据结构数组链表插入和删除在中间插入或删除元素时需要移动数组中的其他元素,时间复杂度为O(n)只需要调整指针,时间复杂度为O(1)访问元素通过索引…...

RT Preempt linux学习笔记
RT Preempt linux学习笔记 一、实时操作系统(Realtime Operating System) 1. 什么是实时操作系统 A real-time system is a time-bound system which has well-defined, fixed time constraints. Processing must be done within the defined constra…...
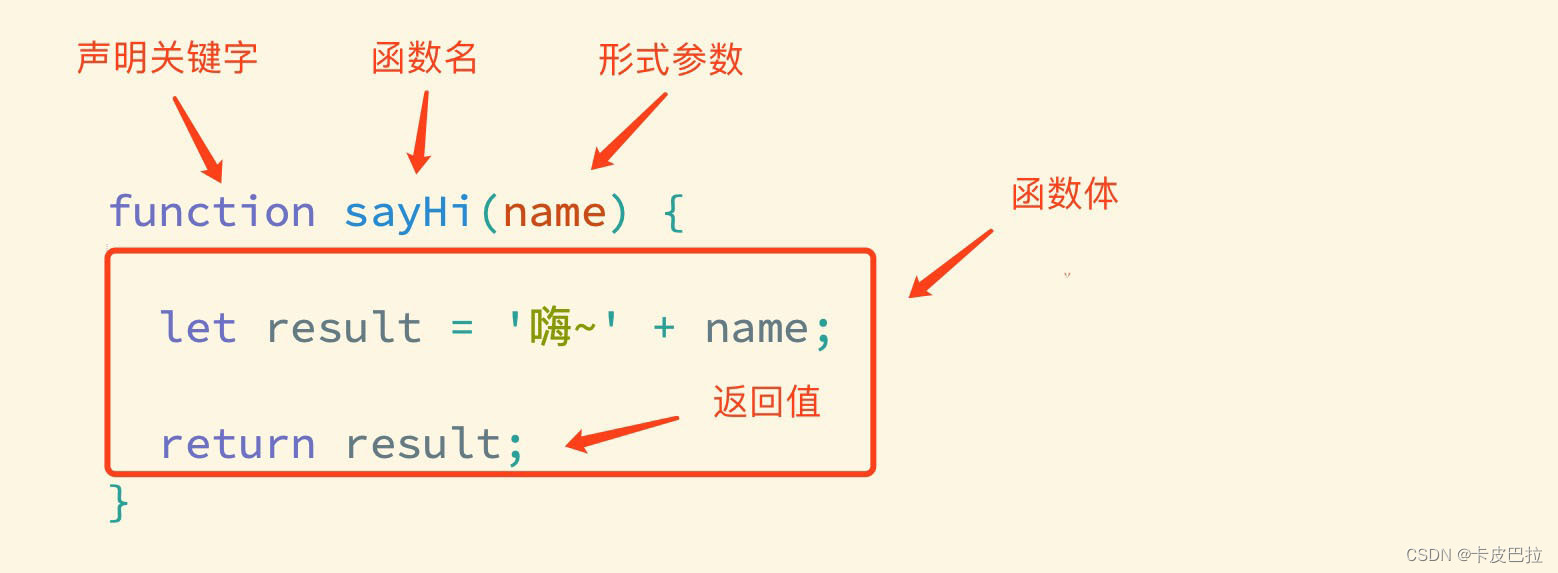
JavaScript 基础第四天笔记
JavaScript 基础 - 第4天笔记 理解封装的意义,能够通过函数的声明实现逻辑的封装,知道对象数据类型的特征,结合数学对象实现简单计算功能。 理解函数的封装的特征掌握函数声明的语法理解什么是函数的返回值知道并能使用常见的内置函数 函数 …...

Unity 2021.x及以下全版本Crack
前言 最近Unity那档子事不出来了吗,搞得所有人都挺烦的,顺便在公司内网需要我完成一个游戏的项目,就研究了一下如何将Unity给Crack掉。 注意所有操作应有连接外网的权限 以我选择的版本为例,我使用的是Unity 2021.3.5f1与Unity…...

2-3 上下文管理:让AI真正“看懂“你的项目
你有没有遇到过这种情况: 同一个AI编程工具,在Project A里表现得像个资深架构师,能准确遵循项目规范、理解业务逻辑;到了Project B,却像个刚毕业的新手,写出完全不符合规范的代码,甚至提出违背项目基础设计的修改建议。 差距在哪里? 答案:上下文管理(Context Mana…...

效率提升不可想象!传统程序员转型AI数字化办公专家,如何靠提效工具实现升职
不是加班感动老板,而是工具改变产出01. 一个真实的职场跃迁张恒,35岁,某传统IT部门的Java开发,月薪28K。他技术扎实,但部门不核心,干的都是“增删改查报表导出”。每年晋升答辩,评委都说“表现不…...

嵌入式系统引导程序uboot原理与应用详解
1. 为什么嵌入式系统需要uboot1.1 计算机系统启动的基本原理任何计算机系统启动时都需要一个引导程序来完成硬件初始化和操作系统加载的工作。无论是PC机还是嵌入式设备,这个基本原理都是相通的。在PC架构中,这个引导程序叫做BIOS(基本输入输…...

同一篇80%AI率的论文,3种方法降完效果对比
为了给同学一个有说服力的参考,我用同一篇论文做了一个完整对比实验: 同一篇知网AI率80%的论文(经济学,3万字),分别用3种方法处理,然后统一检测,看最终结果。 下面是完整数据。 论…...
✅)
计算机毕业设计:Python地铁线路客流与票价数据可视化系统 Django框架 数据分析 可视化 大数据 机器学习 深度学习(建议收藏)✅
博主介绍:✌全网粉丝50W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战8年之久,选择我们就是选择放心、选择安心毕业✌ > 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与…...

为什么芯片工程师都在学Chisel?从Verilog到高级硬件设计的跃迁指南
为什么芯片工程师都在学Chisel?从Verilog到高级硬件设计的跃迁指南 在半导体行业,设计效率正成为决定产品成败的关键因素。传统Verilog开发中,工程师们常常需要花费70%的时间调试RTL代码中的低级错误,而非专注于架构创新。这种现状…...

OpCore-Simplify:黑苹果配置的智能革命——从手动调试到自动化生成的转变
OpCore-Simplify:黑苹果配置的智能革命——从手动调试到自动化生成的转变 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 传统黑苹果配置需…...

S7-1200 PLC 高级语言SCL数控G代码功能块源文件解析及程序思路
S7-1200PLC 高级语言SCL数控G代码功能块源文件| S7-1200PLC 高级语言SCL数控G代码功能块源文件| S7-1200PLC 高级语言SCL数控G代码功能块源文件||| 整个G代码解析的程序做成了一个FB功能块,利用1200PLC内置的字符串控制指令来实现拆分提取字符串信息;整个程序的大概思路就是1.解…...

OpenClaw任务监控实战:Phi-3-vision-128k-instruct长流程管理
OpenClaw任务监控实战:Phi-3-vision-128k-instruct长流程管理 1. 为什么需要长流程监控 去年夏天,我接手了一个需要处理大量图文混合数据的项目。最初尝试用传统脚本串联处理,结果发现当任务运行到第37小时突然中断时,我甚至不知…...

2026届学术党必备的六大AI写作网站推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 削减AIGC率,这意味着要去降低文本之中,那些可被辨别为系人工智能生成…...