NLP 项目:维基百科文章爬虫和分类 - 语料库阅读器

塞巴斯蒂安
一、说明
自然语言处理是机器学习和人工智能的一个迷人领域。这篇博客文章启动了一个具体的 NLP 项目,涉及使用维基百科文章进行聚类、分类和知识提取。灵感和一般方法源自《Applied Text Analysis with Python》一书。
在接下来的文章中,我将展示如何实现维基百科文章爬虫,如何将文章收集到语料库中,如何应用文本预处理、标记化、编码和矢量化,以及最后应用机器学习算法进行聚类和分类。
本文的技术背景是Python v3.11和几个附加库,其中最重要的nltk v3.8.1是 和wikipedia-api v0.6.0。所有示例也应该适用于较新的版本。
本文最初出现在我的博客admantium.com上。
二、项目概要
该项目的目标是下载、处理和应用维基百科文章上的机器学习算法。首先,下载并存储来自维基百科的选定文章。其次,生成一个语料库,即所有文本文档的总和。第三,对每个文档文本进行预处理,例如通过删除停用词和符号,然后进行标记化。第四,将标记化文本转换为向量以接收数字表示。最后,应用不同的机器学习算法。
在第一篇文章中,解释了步骤一和步骤二。
三、先决条件
我喜欢在Jupyter Notebook中工作并使用优秀的依赖管理器Poetry。在您选择的项目文件夹中运行以下命令以安装所有必需的依赖项并在浏览器中启动 Jupyter 笔记本。
# Complete the interactive project creation
poetry init# Add core dependencies
poetry add nltk@^3.8.1 jupyterlab@^4.0.0 scikit-learn@^1.2.2 wikipedia-api@^0.5.8 matplotlib@^3.7.1 numpy@^1.24.3 pandas@^2.0.1# Add NLTK dependencies
python3 -c "import nltk; \nltk.download('punkt'); \nltk.download('averaged_perceptron_tagger'); \nltk.download('reuters'); \nltk.download('stopwords');"# Start jupyterhub
poetry run jupyterlab浏览器中应该会打开一个新的 Jupyter Notebook。
四、Python 库
在这篇博文中,将使用以下 Python 库:
维基百科-API:
Page代表维基百科文章及其标题、文本、类别和相关页面的对象。
NLTK
PlaintextCorpusReader用于提供对文档的访问、提供标记化方法并计算有关所有文件的统计信息的可遍历对象sent_tokenizer并word_tokenizer用于生成令牌
五、(第 1 部分)维基百科文章爬虫
该项目从创建自定义维基百科爬虫开始。尽管我们可以使用来自各种来源的维基百科语料库数据集(例如 NLTK 中的内置语料库),但自定义爬虫提供了对文件格式、内容和内容现实的最佳控制。
下载和处理原始 HTML 可能非常耗时,尤其是当我们还需要从中确定相关链接和类别时。一个非常方便的图书馆可以帮助您。wikipedia -api为我们完成了所有这些繁重的工作。在此基础上,我们逐步开发核心功能。
首先,我们创建一个基类,定义它自己的 Wikipedia 对象并确定存储文章的位置。
import os
import re
import wikipediaapi as wiki_apiclass WikipediaReader():def __init__(self, dir = "articles"):self.pages = set()self.article_path = os.path.join("./", dir)self.wiki = wiki_api.Wikipedia(language = 'en',extract_format=wiki_api.ExtractFormat.WIKI)try:os.mkdir(self.article_path)except Exception as e:pass 这还定义了pages爬虫访问的一组页面对象。该page对象非常有用,因为它可以访问文章标题、文本、类别和其他页面的链接。
其次,我们需要接收文章名称的辅助方法,如果存在,它将page向集合中添加一个新对象。我们需要将调用包装在一个try except块中,因为某些包含特殊字符的文章无法正确处理,例如Add article 699/1000 Tomasz Imieliński. 此外,还有一些我们不需要存储的元文章。
def add_article(self, article):try:page = self.wiki.page(self._get_page_title(article))if page.exists():self.pages.add(page)return(page)except Exception as e:print(e)第三,我们要提取一篇文章的类别。每篇维基百科文章都在页面底部的两个可见部分(请参阅以下屏幕截图)以及未呈现为 HTML 的元数据中定义类别。因此,最初的类别列表可能听起来令人困惑。看一下这个例子:
wr = WikipediaReader()
wr.add_article("Machine Learning")
ml = wr.list().pop()print(ml.categories)
# {'Category:All articles with unsourced statements': Category:All articles with unsourced statements (id: ??, ns: 14),
# 'Category:Articles with GND identifiers': Category:Articles with GND identifiers (id: ??, ns: 14),
# 'Category:Articles with J9U identifiers': Category:Articles with J9U identifiers (id: ??, ns: 14),
# 'Category:Articles with LCCN identifiers': Category:Articles with LCCN identifiers (id: ??, ns: 14),
# 'Category:Articles with NDL identifiers': Category:Articles with NDL identifiers (id: ??, ns: 14),
# 'Category:Articles with NKC identifiers': Category:Articles with NKC identifiers (id: ??, ns: 14),
# 'Category:Articles with short description': Category:Articles with short description (id: ??, ns: 14),
# 'Category:Articles with unsourced statements from May 2022': Category:Articles with unsourced statements from May 2022 (id: ??, ns: 14),
# 'Category:Commons category link from Wikidata': Category:Commons category link from Wikidata (id: ??, ns: 14),
# 'Category:Cybernetics': Category:Cybernetics (id: ??, ns: 14),
# 'Category:Learning': Category:Learning (id: ??, ns: 14),
# 'Category:Machine learning': Category:Machine learning (id: ??, ns: 14),
# 'Category:Short description is different from Wikidata': Category:Short description is different from Wikidata (id: ??, ns: 14),
# 'Category:Webarchive template wayback links': Category:Webarchive template wayback links (id: ??, ns: 14)}因此,我们根本不通过应用多个正则表达式过滤器来存储这些特殊类别。
def get_categories(self, title):page = self.add_article(title)if page:if (list(page.categories.keys())) and (len(list(page.categories.keys())) > 0):categories = [c.replace('Category:','').lower() for c in list(page.categories.keys())if c.lower().find('articles') == -1and c.lower().find('pages') == -1and c.lower().find('wikipedia') == -1and c.lower().find('cs1') == -1and c.lower().find('webarchive') == -1and c.lower().find('dmy dates') == -1and c.lower().find('short description') == -1and c.lower().find('commons category') == -1]return dict.fromkeys(categories, 1)return {}第四,我们现在定义抓取方法。这是一种可定制的广度优先搜索,从一篇文章开始,获取所有相关页面,将这些页面广告到页面对象,然后再次处理它们,直到文章总数耗尽或达到深度级别。说实话:我只用它爬过 1000 篇文章。
def crawl_pages(self, article, depth = 3, total_number = 1000):print(f'Crawl {total_number} :: {article}')page = self.add_article(article)childs = set()if page:for child in page.links.keys():if len(self.pages) < total_number:print(f'Add article {len(self.pages)}/{total_number} {child}')self.add_article(child)childs.add(child)depth -= 1if depth > 0:for child in sorted(childs):if len(self.pages) < total_number:self.crawl_pages(child, depth, len(self.pages))让我们开始爬取机器学习文章:
reader = WikipediaReader()
reader.crawl_pages("Machine Learning")print(reader.list())
# Crawl 1000 :: Machine Learning
# Add article 1/1000 AAAI Conference on Artificial Intelligence
# Add article 2/1000 ACM Computing Classification System
# Add article 3/1000 ACM Computing Surveys
# Add article 4/1000 ADALINE
# Add article 5/1000 AI boom
# Add article 6/1000 AI control problem
# Add article 7/1000 AI safety
# Add article 8/1000 AI takeover
# Add article 9/1000 AI winter 最后,当一组page对象可用时,我们提取它们的文本内容并将它们存储在文件中,其中文件名代表其标题的清理版本。需要注意的是:文件名需要保留其文章名称的投降,否则我们无法再次获取页面对象,因为使用小写文章名称的搜索不会返回结果。
def process(self, update=False):for page in self.pages:filename = re.sub('\s+', '_', f'{page.title}')filename = re.sub(r'[\(\):]','', filename)file_path = os.path.join(self.article_path, f'{filename}.txt')if update or not os.path.exists(file_path):print(f'Downloading {page.title} ...')content = page.textwith open(file_path, 'w') as file:file.write(content)else:print(f'Not updating {page.title} ...')这是该类的完整源代码WikipediaReader。
import os
import re
import wikipediaapi as wiki_apiclass WikipediaReader():def __init__(self, dir = "articles"):self.pages = set()self.article_path = os.path.join("./", dir)self.wiki = wiki_api.Wikipedia(language = 'en',extract_format=wiki_api.ExtractFormat.WIKI)try:os.mkdir(self.article_path)except Exception as e:passdef _get_page_title(self, article):return re.sub(r'\s+','_', article)def add_article(self, article):try:page = self.wiki.page(self._get_page_title(article))if page.exists():self.pages.add(page)return(page)except Exception as e:print(e)def list(self):return self.pagesdef process(self, update=False):for page in self.pages:filename = re.sub('\s+', '_', f'{page.title}')filename = re.sub(r'[\(\):]','', filename)file_path = os.path.join(self.article_path, f'{filename}.txt')if update or not os.path.exists(file_path):print(f'Downloading {page.title} ...')content = page.textwith open(file_path, 'w') as file:file.write(content)else:print(f'Not updating {page.title} ...')def crawl_pages(self, article, depth = 3, total_number = 1000):print(f'Crawl {total_number} :: {article}')page = self.add_article(article)childs = set()if page:for child in page.links.keys():if len(self.pages) < total_number:print(f'Add article {len(self.pages)}/{total_number} {child}')self.add_article(child)childs.add(child)depth -= 1if depth > 0:for child in sorted(childs):if len(self.pages) < total_number:self.crawl_pages(child, depth, len(self.pages))def get_categories(self, title):page = self.add_article(title)if page:if (list(page.categories.keys())) and (len(list(page.categories.keys())) > 0):categories = [c.replace('Category:','').lower() for c in list(page.categories.keys())if c.lower().find('articles') == -1and c.lower().find('pages') == -1and c.lower().find('wikipedia') == -1and c.lower().find('cs1') == -1and c.lower().find('webarchive') == -1and c.lower().find('dmy dates') == -1and c.lower().find('short description') == -1and c.lower().find('commons category') == -1]return dict.fromkeys(categories, 1)return {}让我们使用维基百科爬虫来下载与机器学习相关的文章。
reader = WikipediaReader()
reader.crawl_pages("Machine Learning")print(reader.list())
# Downloading The Register ...
# Not updating Bank ...
# Not updating Boosting (machine learning) ...
# Not updating Ian Goodfellow ...
# Downloading Statistical model ...
# Not updating Self-driving car ...
# Not updating Behaviorism ...
# Not updating Statistical classification ...
# Downloading Search algorithm ...
# Downloading Support vector machine ...
# Not updating Deep learning speech synthesis ...
# Not updating Expert system ...六、(第 2 部分)维基百科语料库
所有文章均以文本文件形式下载到article文件夹中。为了提供所有这些单独文件的抽象,NLTK 库提供了不同的语料库阅读器对象。该对象不仅提供对单个文件的快速访问,还可以生成统计信息,例如词汇量、单个标记的总数或单词量最多的文档。
让我们使用该类PlaintextCorpusReader作为起点,然后初始化它,使其指向文章:
import nltk
from nltk.corpus.reader.plaintext import PlaintextCorpusReader
from time import timeclass WikipediaCorpus(PlaintextCorpusReader):passcorpus = WikipediaCorpus('articles', r'[^\.ipynb].*', cat_pattern=r'[.*]')
print(corpus.fileids())
# ['2001_A_Space_Odyssey.txt',
# '2001_A_Space_Odyssey_film.txt',
# '2001_A_Space_Odyssey_novel.txt',
# '3D_optical_data_storage.txt',
# 'A*_search_algorithm.txt',
# 'A.I._Artificial_Intelligence.txt',
# 'AAAI_Conference_on_Artificial_Intelligence.txt',
# 'ACM_Computing_Classification_System.txt', 好的,这已经足够好了。让我们用两种方法来扩展它来计算词汇量和最大单词数。对于词汇,我们将使用 NLTK 辅助类FreqDist,它是一个包含所有单词出现的字典对象,此方法使用简单辅助类消耗所有文本corpus.words(),从中删除非文本和非数字。
def vocab(self):return nltk.FreqDist(re.sub('[^A-Za-z0-9,;\.]+', ' ', word).lower() for word in corpus.words()) 为了得到最大单词数,我们遍历所有带有 的文档fileids(),然后确定 的长度words(doc),并记录最高值
def max_words(self):max = 0for doc in self.fileids():l = len(self.words(doc))max = l if l > max else maxreturn max 最后,我们添加一个describe生成统计信息的方法(这个想法也源于上面提到的《Applied Text Analysis with Python》一书)。
该方法启动一个计时器来记录校园处理持续了多长时间,然后使用语料库阅读器对象的内置方法和刚刚创建的方法来计算文件数、段落数、句子数、单词数、词汇量和文档中的最大字数。
def describe(self, fileids=None, categories=None):started = time()return {'files': len(self.fileids()),'paras': len(self.paras()),'sents': len(self.sents()),'words': len(self.words()),'vocab': len(self.vocab()),'max_words': self.max_words(),'time': time()-started}pass 这是最后一WikipediaCorpus堂课:
import nltk
from nltk.corpus.reader.plaintext import PlaintextCorpusReader
from time import timeclass WikipediaCorpus(PlaintextCorpusReader):def vocab(self):return nltk.FreqDist(re.sub('[^A-Za-z0-9,;\.]+', ' ', word).lower() for word in corpus.words())def max_words(self):max = 0for doc in self.fileids():l = len(self.words(doc))max = l if l > max else maxreturn maxdef describe(self, fileids=None, categories=None):started = time()return {'files': len(self.fileids()),'paras': len(self.paras()),'sents': len(self.sents()),'words': len(self.words()),'vocab': len(self.vocab()),'max_words': self.max_words(),'time': time()-started}pass在撰写本文时,爬取维基百科有关人工智能和机器学习的文章后,可以获得以下统计数据:
corpus = WikipediaCorpus('articles', r'[^\.ipynb].*', cat_pattern=r'[.*]')corpus.describe()
{'files': 1163,'paras': 96049,'sents': 238961,'words': 4665118,'vocab': 92367,'max_words': 46528,'time': 32.60307598114014}七、结论
本文是 NLP 项目在维基百科文章上下载、处理和应用机器学习算法的起点。本文涵盖了两个方面。首先,创建WikipediaReader通过名称查找文章的类,并可以提取其标题、内容、类别和提到的链接。爬虫由两个变量控制:爬取的文章总数和爬取的深度。其次,WikipediaCorpusNLTK 的扩展PlaintextCorpusReader。该对象可以方便地访问单个文件、句子和单词,以及总语料库数据,例如文件数量或词汇、唯一标记的数量。下一篇文章将继续构建文本处理管道。
相关文章:
NLP 项目:维基百科文章爬虫和分类 - 语料库阅读器
塞巴斯蒂安 一、说明 自然语言处理是机器学习和人工智能的一个迷人领域。这篇博客文章启动了一个具体的 NLP 项目,涉及使用维基百科文章进行聚类、分类和知识提取。灵感和一般方法源自《Applied Text Analysis with Python》一书。 在接下来的文章中,我将…...
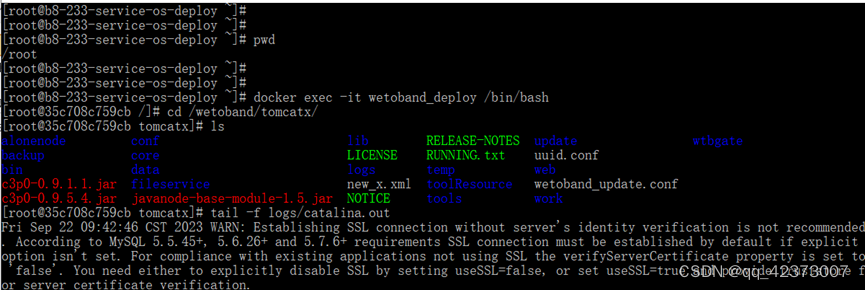
查看吾托帮88.47的docker里的tomcat日志
步骤如下 (1)ssh (2)ssh root192.168.88.47 等待输入密码:fytest (3)pwd #注释:输出/root (4)docker exec -it wetoband_deploy /bin/bash #注释࿱…...

衷心 祝愿
达之云衷心祝愿您,中秋国庆双节快乐,阖家幸福!感谢您们一直以来对达之云的关注与支持。 双节来临之际,达之云发布全新产品——达之云CDP客户数据平台(Dazdata CDP),致力于为中小企业提供互联网营…...

表单中某一项点击添加和删除
<!-- 特殊表单 --><div v-for"(item, index) in form.fwzb" :key"indexfwzb" style"height: 102px"><el-form-item label"经度:" class"form-style":prop"fwzb. index .lon":rules&q…...
深信服安全GPT 2.0升级,开启安全运营“智能驾驶”旅程
9月22日,深信服对外展示安全GPT落地成果与2.0升级能力。来自各行业权威嘉宾代表:美的集团首席信息安全官(CISO)兼软件工程院院长、欧洲科学院院士(MAE)、IEEE Fellow、IET Fellow、ACM杰出科学家、AAIA Fel…...

【C++】STL之list深度剖析及模拟实现
目录 前言 一、list 的使用 1、构造函数 2、迭代器 3、增删查改 4、其他函数使用 二、list 的模拟实现 1、节点的创建 2、push_back 和 push_front 3、普通迭代器 4、const 迭代器 5、增删查改(insert、erase、pop_back、pop_front) 6、构造函数和析构函数 6.1、默认构造…...
解释器风格架构C# 代码
/*解释器风格架构是一种基于组件的设计架构,它将应用程序分解为一系列组件,每个组件负责处理特定的任务。这种架构有助于提高代码的可维护性和可扩展性。以下是如何使用C#实现解释器风格架构的步骤:定义组件:首先,定义…...

第七天:gec6818开发板QT和Ubuntu中QT安装连接sqlite3数据库驱动环境保姆教程
sqlite3数据库简介 帮助文档 SQL Programming 大多数关系型数的操作步骤:1)连接数据库 多数关系型数据库都是C/S模型 (Client/Server)sqlite3是一个本地的单文件关系型数据库,同样也有“连接”的过程 2)操作数据库 作为程序员&am…...
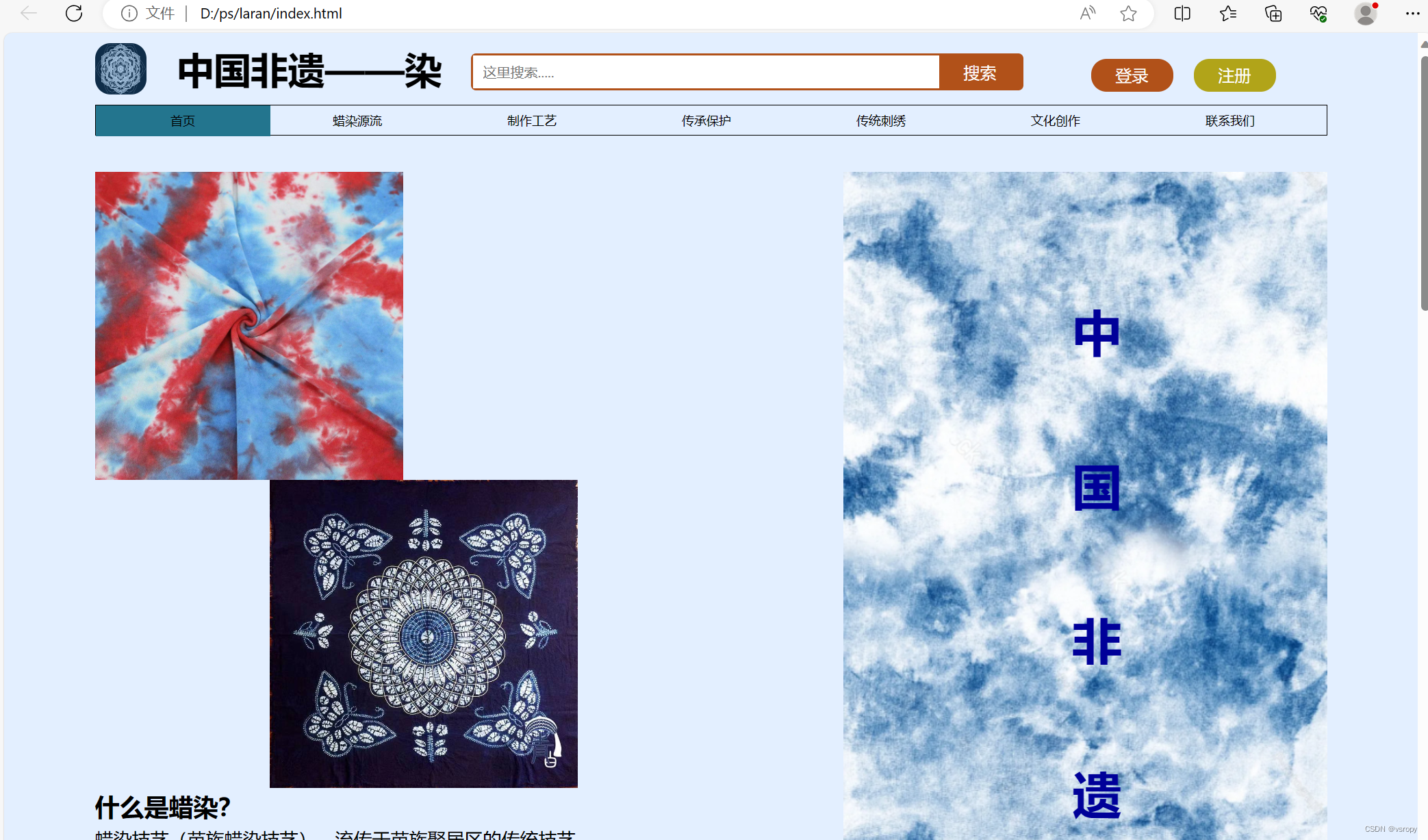
自制网页。
文章目录 注:代码中图片等素材均来自网络,侵删 20230920_213831 index.html <!DOCTYPE html> <html lang="en"> <head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-…...

MySQL单表查询和多表查询
一、单表查询 素材: 表名:worker-- 表中字段均为中文,比如 部门号 工资 职工号 参加工作等 CREATE TABLE worker (部门号 int(11) NOT NULL,职工号 int(11) NOT NULL,工作时间 date NOT NULL,工资 float(8,2) NOT NULL,政治面貌 varchar(10)…...

蓝桥等考Python组别四级006
第一部分:选择题 1、Python L4 (15分) 在Python中,符号“\n”代表( )。 换行空格退格注释正确答案:A 2、Python L4 (15分) 已知大写字母A的ASCII码值为…...

第3章-指标体系与数据可视化-3.2-描述性统计分析与绘图
目录 3.2.1 描述性统计进行数据探索 1. 变量度量类型与分布类型 度量类型 分布类型...
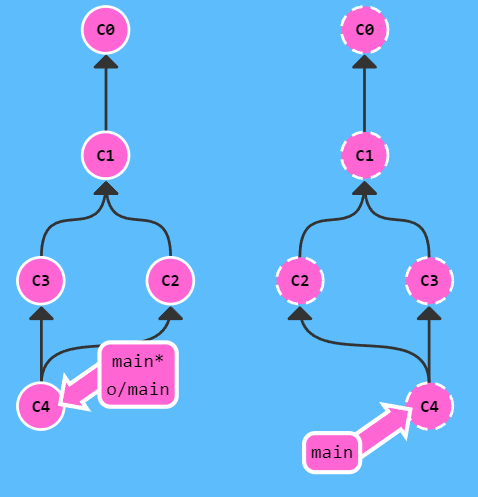
更直观地学习 Git 命令
前言 本文参考于 Learn Git Branching 这个有趣的 Git 学习网站。 在该网站,可以使用 show command 命令展示所有可用命令。 直接访问网站的sandbox。 本地篇 基础篇 git commit git commit将暂存区的修改提交到本地版本库并创建一个新的提交,新提…...
)
在 Vue 项目中添加字典翻译工具(二)
封装字段翻译组件,可以格式化字典、枚举、字段 优点: 使用简单,一次配置多次使用,缓存降低后端请求次数,扩展性强 没有缓存时造成单页面多次请求解决方法:axios添加缓存请求,防止多次请求&#…...
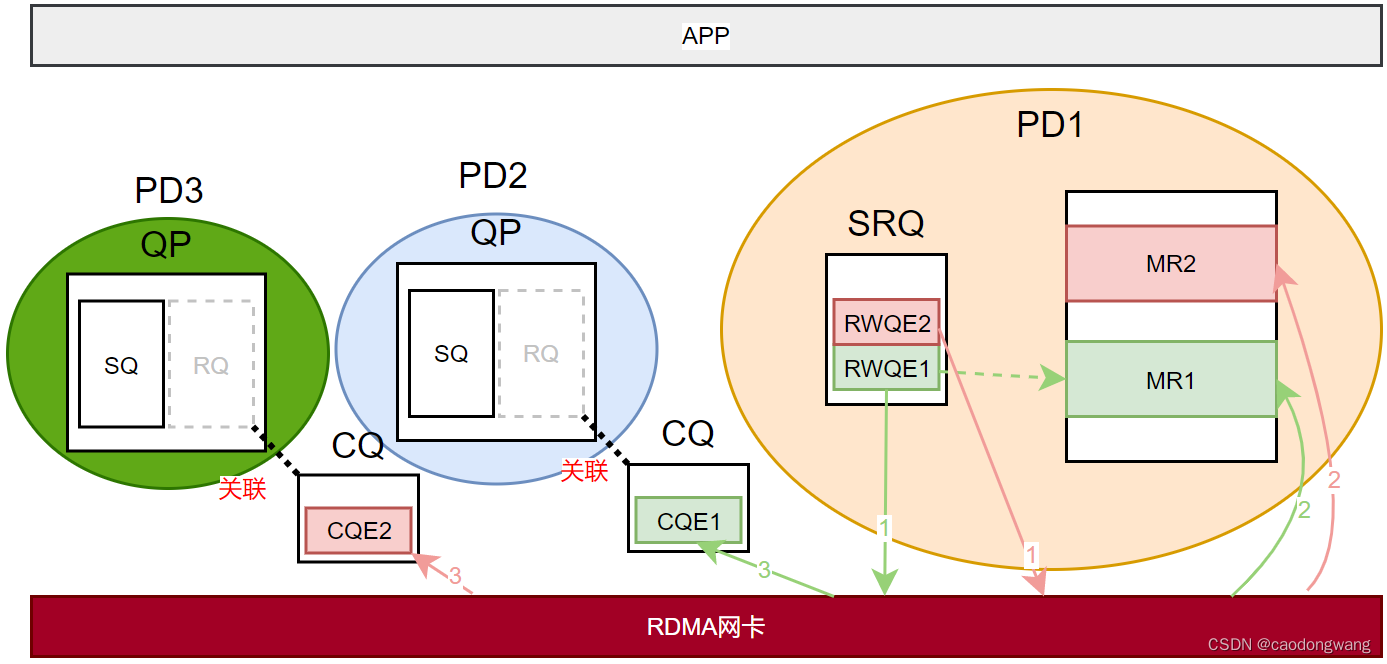
RDMA Shared Receive Queue(四)
参考知乎文章《RDMA之Shared Receive Queue》:https://zhuanlan.zhihu.com/p/279904125 SRQ SRQ全称为Shared Receive Queue,即共享接受队列。在QP中,SQ用于下发SEND/WRITE/READ等操作,而RQ只用于下发RECV操作,对于本…...
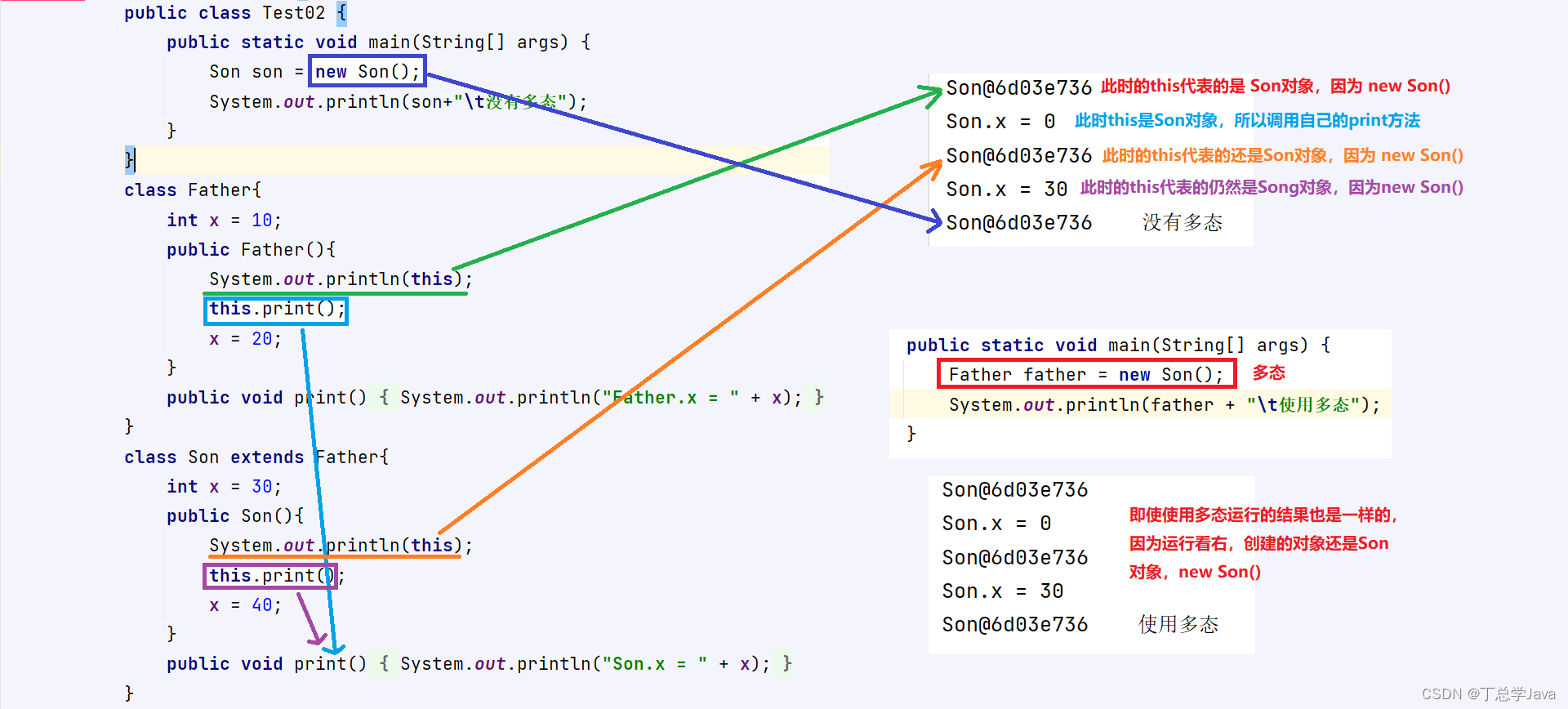
this关键字
作用:出现在成员方法,构造器中代表当前对象的地址,用于访问当前对象的成员变量、成员方法。this出现在 有参数构造器 中的用法 (this.成员变量 局部变量)this出现在 成员方法 中的用法 (this…...
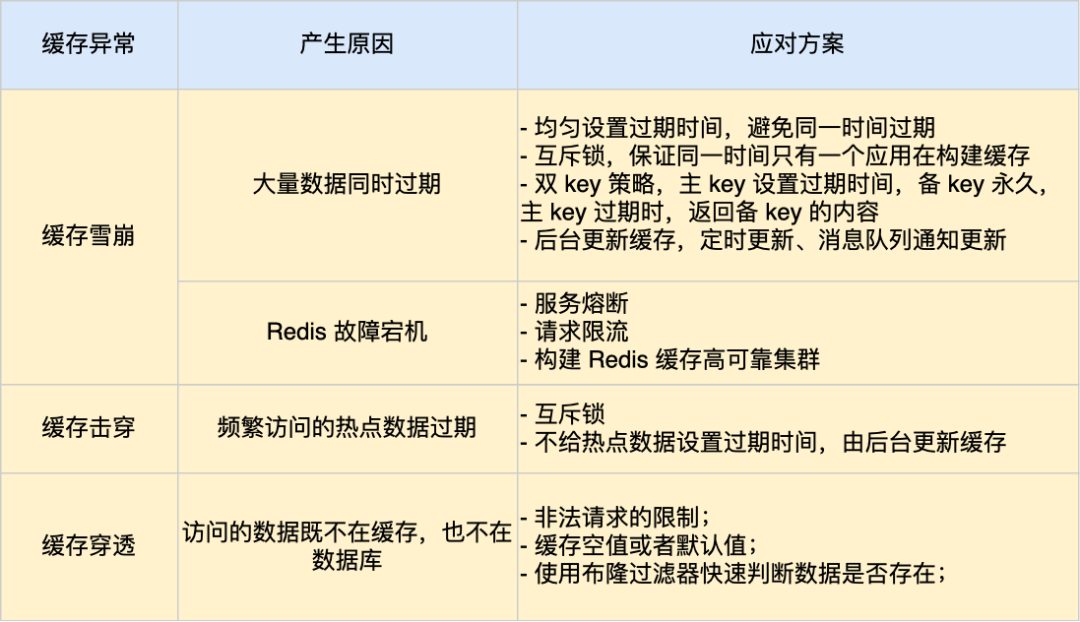
缓存雪崩、缓存击穿、缓存穿透
缓存雪崩 当缓存中大量的键值对同时过期或者Redis宕机了,大量的请求就会直接打到数据库,这种现象就是缓存雪崩 应对策略 有四种,分别是“均匀设置过期时间”、“互斥锁”、“双key策略”、“设置逻辑过期时间,异步更新缓存” …...
Bigemap如何查看历史影像
工具 Bigemap gis office地图软件 BIGEMAP GIS Office-全能版 Bigemap APP_卫星地图APP_高清卫星地图APP 很多人都在寻找历史影像图,这块的需求是非常大,历史影像一般可以用于历史地貌的变迁分析,还原以前的生态场景,对范围面积…...
如何离线安装和使用pymysql操作mysql数据库
一、应用背景 在企业内部网络要使用python操作mysql数据库。然而,python未自带访问MySQL数据库的函数库pymysql,需要另外安装。网上有很多安装pymysql都需要互联网支持。本文主要阐述如何离线安装pymysql,并简要介绍pymysql如何进行mysql操作。 pymysq…...

Prometheus-监控Mysql进阶用法(1)(安装配置)
阿丹: 在开发和生产环境中有可能会出现慢mysql等问题,那么这里就需要我们优秀的程序员来进行监控和解决,那么如何借助云原生的监控系统来完成这个操作呢? 环境描述: 使用一台空白的阿里云服务器2核4G。 服务器基本安装…...

美军“转正”美科技公司AI系统,专家解读
来源:环球时报【环球时报报道 记者 刘扬】据路透社等外媒近日报道,五角大楼将把美国科技公司Palantir的人工智能(AI)系统Maven列为“正式在编项目”,使美军多军种将该公司的相关技术用于军事领域。五角大楼强调&#x…...

ChezScheme测试性能优化:从53分钟到8分钟的效率跃迁
ChezScheme测试性能优化:从53分钟到8分钟的效率跃迁 【免费下载链接】ChezScheme Chez Scheme 项目地址: https://gitcode.com/gh_mirrors/ch/ChezScheme 一、痛点分析:串行测试的性能瓶颈 识别测试效率问题 在软件开发迭代过程中,…...

2026年AI大爆发:DeepSeek、Claude、Gemini三强鼎立,智能体应用成为新战场
进入2026年,AI领域迎来前所未有的激烈竞争格局。DeepSeek凭借极低的训练成本和开源策略强势出圈,R1模型在推理能力上直追GPT-o1,引发全球AI圈震动;Anthropic的Claude 3.7 Sonnet推出了扩展思考模式,在代码和复杂推理任…...

非隔离双向 DC/DC 变换器 buck - boost 变换器仿真探索
非隔离双向DC/DC变换器 buck-boost变换器仿真 输入侧为直流电压源,输出侧接蓄电池 模型采用电压外环电流内环的双闭环控制方式 可实现恒流充放电,且具备充放电保护装置防止过充和过放。 蓄电池充放电模式可切换 Matlab/Simulink模型在电力电子领域&#…...

AI原生应用:解决幻觉难题的有效途径
AI原生应用:解决幻觉难题的有效途径 关键词:AI原生应用、大模型幻觉、检索增强生成(RAG)、验证模块、智能系统架构 摘要:大语言模型(LLM)的“幻觉”(Hallucination)问题——生成与事实不符的内容,正成为AI应用落地的最大障碍。本文将从“AI原生应用”的视角出发,用通…...

纺织抗菌,选对材料才关键
在纺织行业中,抗菌消臭性能是提升产品附加值的核心抓手,其中贴身衣物、家纺等贴身类产品,因长期接触人体或所处环境特性,细菌滋生、异味残留等问题尤为突出。DN128抗菌消臭剂作为高效无机消臭材料,可广泛用作面料及家纺…...

Steam致命错误failed to load steamui.dll?小白必看的6种实用修复方案
软件获取地址 https://pan.quark.cn/s/4cc6a4c0e881 打开Steam时突然弹出“failed to load steamui.dll”提示,无法进入平台甚至启动Y戏?这是Steam最常见的致命错误之一,在failed to load类问题中占比超4成,很多小白不清楚dll文件…...

Linux内核观测与跟踪的利器BPF环境测试
内核观测工具BPF实例BPF介绍BPF实例使用 BCC 工具集(最简单)使用 libbpf BPF 骨架(更接近生产环境)使用 bpftool 直接加载(适合调试)总结BPF介绍 BPF 最初诞生于 1992 年,是一种用于网络数据包…...

QMCDecode:解锁QQ音乐加密文件的macOS终极解决方案
QMCDecode:解锁QQ音乐加密文件的macOS终极解决方案 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认转换…...

ORA-19909: datafile 1 belongs to an orphan incarnation
某项目备用库执行数据库恢复 ORA-00283: recovery session canceled due to errors ORA-19909: datafile 1 belongs to an orphan incarnation ORA-01110: data file 1: /ccdata/cc/system01.dbf RMAN> list incarnation; List of Database Incarnations DB Key Inc Key DB…...