性能优化实战使用CountDownLatch
1.分析问题
原程序是分页查询EventAffinityScoreDO表的数据,每次获取2000条在一个个遍历去更新EventAffinityScoreDO表的数据。但是这样耗时比较慢,测试过30万的数据需要2小时
private void eventSubjectHandle(String tenantId, String eventSubject) {// 查询eventAffinityScoreDO表,更新时间小于今天的(今天更新过的不更新)final Integer pageSize = 2000;PageResult<EventAffinityScoreDO> groupPag =eventAffinityScoreDbService.findByTenantIdAndTimePage(tenantId, eventSubject, 1, pageSize);Integer pages = groupPag.getPages();Integer pageNum = groupPag.getPageNum();while (pages >= pageNum) {if (pageNum > 1) {groupPag =eventAffinityScoreDbService.findByTenantIdAndTimePage(tenantId, eventSubject, 1, pageSize);}List<EventAffinityScoreDO> list = groupPag.getList();forEventAffinityScore(tenantId, eventSubject, list);if (list.size() < pageSize) {break;}pageNum++;}}private void forEventAffinityScore(String tenantId, String eventSubject, List<EventAffinityScoreDO> eventAffinityScoreDOS) {eventAffinityScoreDOS.forEach((eventAffinityScoreDO) -> {//更新EventAffinityScoreDO表数据updateOrAddAffinity(tenantId,eventAffinityScoreDO.getChatLabsId(),eventAffinityScoreDO.getEconomyId(),eventAffinityScoreDO.getAttributeValue(),eventSubject,eventAffinityScoreDO.getAttributeName());});}
单个线程一个个遍历去更新表数据太慢了,我想把2000的数据分成多份,每份200条,可以分成10份。每份用一个线程去跑。这样跑2000的时间就大大缩短。大概等于跑200个数据的时间。
这里想到使用CountDownLatch
2.知识点CountDownLatch
CountDownLatch 是 Java 中的一个并发工具类,用于在多线程环境中控制线程的执行顺序。它允许一个或多个线程等待其他线程完成操作后再继续执行。
CountDownLatch 的构造方法接受一个整数作为参数,表示需要等待的线程数量。当一个线程完成了自己的任务后,可以调用 countDown() 方法来将计数器减1。当计数器的值变为0时,所有等待的线程都会被释放,可以继续执行。
3.解决问题
我们使用Lists.partition,把2000的集合拆分成每份200的小份,共10分。
CountDownLatch countDownLatch = new CountDownLatch(partition.size())设置CountDownLatch需要等待的线程数为拆分后的份数partition.size(),也就是10份
countDownLatch.countDown(); 每跑完一份计数器减一
countDownLatch.await();计数器减完主程序开始执行,继续循环后面的2000份
private void eventSubjectHandle(String tenantId, String eventSubject)throws InterruptedException {// 查询eventAffinityScoreDO表,更新时间小于今天的(今天更新过的不更新)final Integer pageSize = 2000;PageResult<EventAffinityScoreDO> groupPag =eventAffinityScoreDbService.findByTenantIdAndTimePage(tenantId, eventSubject, 1,pageSize);Integer pages = groupPag.getPages();Integer pageNum = groupPag.getPageNum();while (pages >= pageNum) {if (pageNum > 1) {groupPag =eventAffinityScoreDbService.findByTenantIdAndTimePage(tenantId, eventSubject, 1, pageSize);}List<EventAffinityScoreDO> list = groupPag.getList();//Lists.partition把list进行拆分,没份200个List<List<EventAffinityScoreDO>> partition = Lists.partition(list, 200);//设置需要等待的线程数量,就是我们的集合大小CountDownLatch countDownLatch = new CountDownLatch(partition.size());for (List<EventAffinityScoreDO> eventAffinityScoreDOS : partition) {eventSubjectExecutorPool.execute(() -> {try {forEventAffinityScore(tenantId, eventSubject, eventAffinityScoreDOS);} catch (Exception e) {log.info("AutoAffinityJob updateAffinityByEventSubject error tenantId:{},eventSubject:{}",tenantId,eventSubject,e);}//每处理完200份计数器减一countDownLatch.countDown();});}//计数器减完主程序开始执行,继续循环后面的2000份countDownLatch.await();if (list.size() < pageSize) {break;}pageNum++;}}private void forEventAffinityScore(String tenantId, String eventSubject, List<EventAffinityScoreDO> eventAffinityScoreDOS) {eventAffinityScoreDOS.forEach((eventAffinityScoreDO) -> {// 根据生态中事件属性属性值更新or新增影响到的内容亲和力updateOrAddAffinity(tenantId,eventAffinityScoreDO.getChatLabsId(),eventAffinityScoreDO.getEconomyId(),eventAffinityScoreDO.getAttributeValue(),eventSubject,eventAffinityScoreDO.getAttributeName());});}
这里需要注意的是如果线程池设置的太小,会导致触发拒绝策略。如果触发了拒绝策略countDownLatch.countDown()就不会执行了。就会导致countDownLatch.await()一直等待。所以这里我把线程池的队列设置的很大Integer.MAX_VALUE,这样不会触发拒绝策略。因为我们最多就10个线程,也不会导致出现OOM
@Configuration
@Slf4j
public class CalculateAffinityThreadPool {@Bean(name = "eventSubjectExecutorPool")public ExecutorService eventSubjectExecutorPool() {int poolSize = ThreadExecutorUtils.getNormalCoreSize();return ThreadExecutorUtils.createNormalThreadPool(poolSize,poolSize,0L,TimeUnit.MILLISECONDS,Integer.MAX_VALUE,"eventSubject-pool",false);}}经过测试跑30万的数据只需要20分钟了。
相关文章:

性能优化实战使用CountDownLatch
1.分析问题 原程序是分页查询EventAffinityScoreDO表的数据,每次获取2000条在一个个遍历去更新EventAffinityScoreDO表的数据。但是这样耗时比较慢,测试过30万的数据需要2小时 private void eventSubjectHandle(String tenantId, String eventSubject) …...
基于视频技术与AI检测算法的体育场馆远程视频智能化监控方案
一、方案背景 近年来,随着居民体育运动意识的增强,体育场馆成为居民体育锻炼的重要场所。但使用场馆内的器材时,可能发生受伤意外,甚至牵扯责任赔偿纠纷问题。同时,物品丢失、人力巡逻成本问题突出,体育场…...
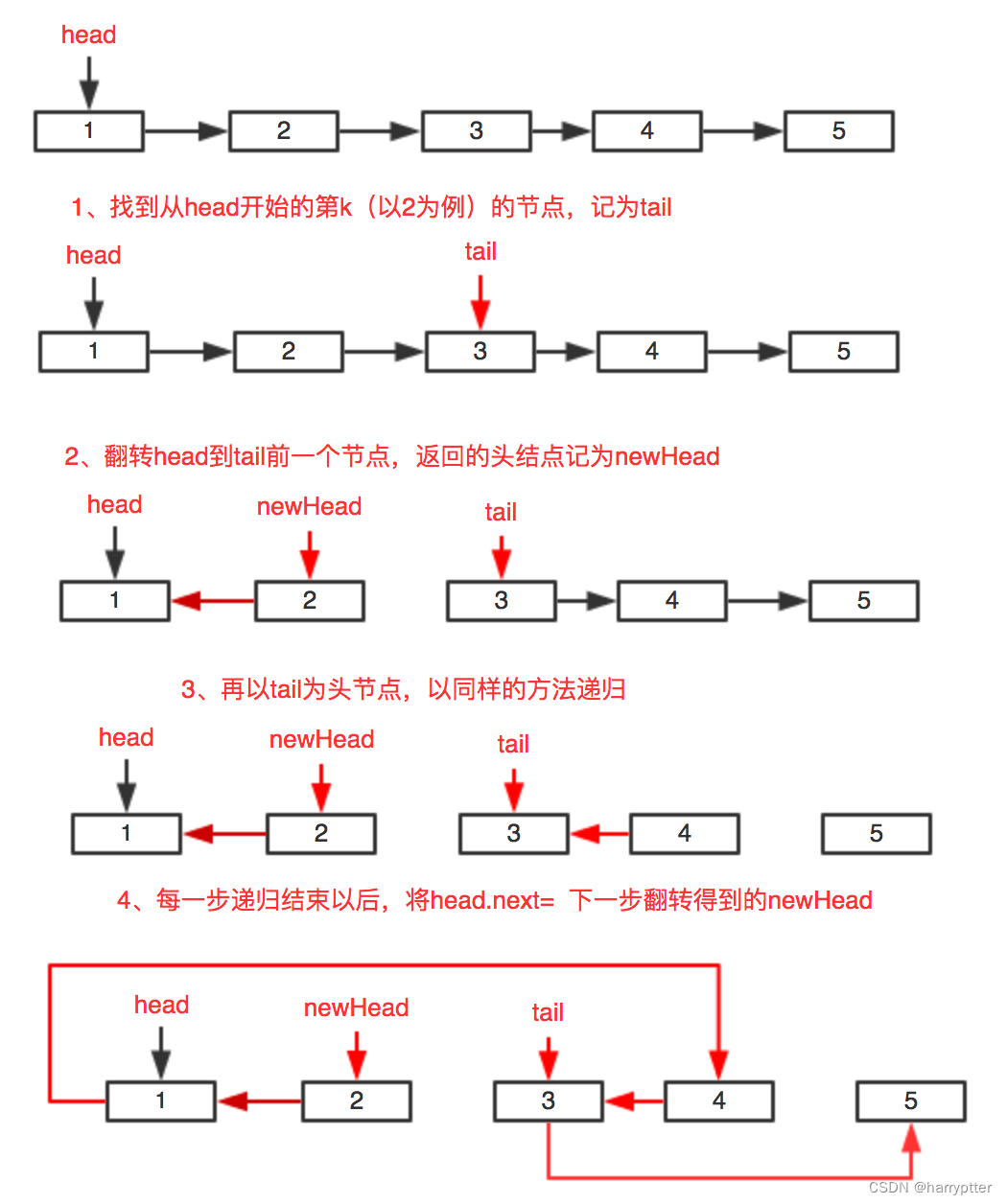
leetcodetop100(29) K 个一组翻转链表
K 个一组翻转链表 给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。 k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。 你不能只是单纯的改…...
最新影视视频微信小程序源码-带支付和采集功能/微信小程序影视源码PHP(更新)
源码简介: 这个影视视频微信小程序源码,新更新的,它还带支付和采集功能,作为微信小程序影视源码,它可以为用户 提供丰富的影视资源,包括电影、电视剧、综艺节目等。 这个小程序影视源码,还带有…...

C++:vector 定义,用法,作用,注意点
C 中的 vector 是标准模板库(STL)提供的一种动态数组容器,它提供了一组强大的方法来管理和操作可变大小的数组。以下是关于 vector 的定义、用法、作用以及一些注意点: 定义: 要使用 vector,首先需要包含 …...
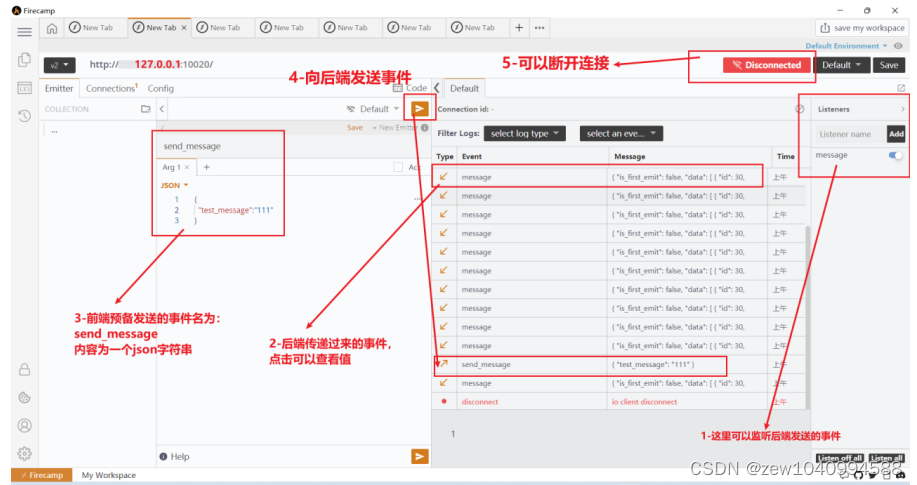
Firecamp2.7.1exe安装与工具调试向后端发送SocketIO请求
背景: 笔者在python使用socket-io包时需要一个测试工具,选择了firecamp这个测试工具来发送请求。 参考视频与exe资源包: Firecamp2.7.1exe安装包以及基本使用说明文档(以SocketIO为例).zip资源-CSDN文库 15_send方法…...
MySQL到TiDB:Hive Metastore横向扩展之路
作者:vivo 互联网大数据团队 - Wang Zhiwen 本文介绍了vivo在大数据元数据服务横向扩展道路上的探索历程,由实际面临的问题出发,对当前主流的横向扩展方案进行了调研及对比测试,通过多方面对比数据择优选择TiDB方案。其次分享了整…...

算法通关村-----寻找祖先问题
最近公共祖先 问题描述 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一…...
Sentinel结合Nacos实现配置持久化(全面)
1、前言 我们在进行分布式系统的开发中,无论是在开发环境还是发布环境,配置一定不能是内存形式的,因为系统可能会在中途宕机或者重启,所以如果放在内存中,那么配置在服务停到就是就会消失,那么此时就需要重…...

Verilog中什么是断言?
断言就是在我们的程序中插入一句代码,这句代码只有仿真的时候才会生效,这段代码的作用是帮助我们判断某个条件是否满足(例如某个数据是否超出了范围),如果条件不满足(数据超出了范围)࿰…...

Oracle分区的使用详解:创建、修改和删除分区,处理分区已满或不存在的插入数据,以及分区历史数据与近期数据的操作指南
一、前言 什么是表分区: Oracle的分区是一种将表或索引数据分割为更小、更易管理的部分的技术。它可以提高查询性能、简化维护操作,并提供更好的数据组织和管理。 表分区和表空间的区别和联系: 在Oracle数据库中,表空间(Tablespace)是用于存储表、索引和其他数据库对…...
SLAM从入门到精通(amcl定位使用)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 学习slam,一般就是所谓的边定位、边制图的知识。然而在实际生产过程中,比如扫地机器人、agv、巡检机器人、农业机器人&…...
【C/C++】C/C++面试八股
C/C面试八股 C和C语言的区别简单介绍一下三大特性多态的实现原理虚函数的构成原理虚函数的调用原理虚表指针在什么地方进行初始化的?构造函数为什么不能是虚函数虚函数和纯虚函数的区别抽象类类对象的对象模型内存对齐是什么?为什么要内存对齐static关键…...

Scala第八章节
Scala第八章节 scala总目录 章节目标 能够使用trait独立完成适配器, 模板方法, 职责链设计模式能够独立叙述trait的构造机制能够了解trait继承class的写法能够独立完成程序员案例 1. 特质入门 1.1 概述 有些时候, 我们会遇到一些特定的需求, 即: 在不影响当前继承体系的情…...

k8s-实战——kubeadm二进制编译
文章目录 源码编译获取源码修改证书有效期修改 CA 有效期为 100 年(默认为 10 年)修改证书有效期为 100 年(默认为 1 年)CentOS7.9环境准备centos脚本安装执行脚本脚本内容手动安装验证编译查看编译后的版本信息参考链接脚本修改源码编译 源码编译kubeadm文件、修改证书的默…...

vite 和 webpack 的区别
1. 构建原理: Webpack 是一个静态模块打包器,通过对项目中的JavaScript、css、Image 等文件进行分析,生成对应的静态资源,并且通过一些插件和加载器来实现各种功能。 Vite 是一种基于浏览器元素 ES 模块解析构建工具,…...

传统遗产与技术相遇,古彝文的数字化与保护
古彝文是中国彝族的传统文字,具有悠久的历史和文化价值。然而,由于古彝文的形状复杂且没有标准化的字符集,对其进行文字识别一直是一项具有挑战性的任务。本文介绍了古彝文合合信息的文字识别技术,旨在提高古彝文的自动识别准确性…...

多维时序 | MATLAB实现WOA-CNN-GRU-Attention多变量时间序列预测(SE注意力机制)
多维时序 | MATLAB实现WOA-CNN-GRU-Attention多变量时间序列预测(SE注意力机制) 目录 多维时序 | MATLAB实现WOA-CNN-GRU-Attention多变量时间序列预测(SE注意力机制)预测效果基本描述模型描述程序设计参考资料 预测效果 基本描述…...

1042 字符统计
description 请编写程序,找出一段给定文字中出现最频繁的那个英文字母。 输入格式: 输入在一行中给出一个长度不超过 1000 的字符串。字符串由 ASCII 码表中任意可见字符及空格组成,至少包含 1 个英文字母,以回车结束ÿ…...

3 OpenCV两张图片实现稀疏点云的生成
前文: 1 基于SIFT图像特征识别的匹配方法比较与实现 2 OpenCV实现的F矩阵RANSAC原理与实践 1 E矩阵 1.1 由F到E E K T ∗ F ∗ K E K^T * F * K EKT∗F∗K E 矩阵可以直接通过之前算好的 F 矩阵与相机内参 K 矩阵获得 Mat E K.t() * F * K;相机内参获得的方式…...

【大模型RAG】拍照搜题技术架构速览:三层管道、两级检索、兜底大模型
摘要 拍照搜题系统采用“三层管道(多模态 OCR → 语义检索 → 答案渲染)、两级检索(倒排 BM25 向量 HNSW)并以大语言模型兜底”的整体框架: 多模态 OCR 层 将题目图片经过超分、去噪、倾斜校正后,分别用…...

练习(含atoi的模拟实现,自定义类型等练习)
一、结构体大小的计算及位段 (结构体大小计算及位段 详解请看:自定义类型:结构体进阶-CSDN博客) 1.在32位系统环境,编译选项为4字节对齐,那么sizeof(A)和sizeof(B)是多少? #pragma pack(4)st…...
)
【位运算】消失的两个数字(hard)
消失的两个数字(hard) 题⽬描述:解法(位运算):Java 算法代码:更简便代码 题⽬链接:⾯试题 17.19. 消失的两个数字 题⽬描述: 给定⼀个数组,包含从 1 到 N 所有…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

鱼香ros docker配置镜像报错:https://registry-1.docker.io/v2/
使用鱼香ros一件安装docker时的https://registry-1.docker.io/v2/问题 一键安装指令 wget http://fishros.com/install -O fishros && . fishros出现问题:docker pull 失败 网络不同,需要使用镜像源 按照如下步骤操作 sudo vi /etc/docker/dae…...

零基础设计模式——行为型模式 - 责任链模式
第四部分:行为型模式 - 责任链模式 (Chain of Responsibility Pattern) 欢迎来到行为型模式的学习!行为型模式关注对象之间的职责分配、算法封装和对象间的交互。我们将学习的第一个行为型模式是责任链模式。 核心思想:使多个对象都有机会处…...

Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习)
Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习) 一、Aspose.PDF 简介二、说明(⚠️仅供学习与研究使用)三、技术流程总览四、准备工作1. 下载 Jar 包2. Maven 项目依赖配置 五、字节码修改实现代码&#…...

【笔记】WSL 中 Rust 安装与测试完整记录
#工作记录 WSL 中 Rust 安装与测试完整记录 1. 运行环境 系统:Ubuntu 24.04 LTS (WSL2)架构:x86_64 (GNU/Linux)Rust 版本:rustc 1.87.0 (2025-05-09)Cargo 版本:cargo 1.87.0 (2025-05-06) 2. 安装 Rust 2.1 使用 Rust 官方安…...

云原生安全实战:API网关Kong的鉴权与限流详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 1. API网关(API Gateway) API网关是微服务架构中的核心组件,负责统一管理所有API的流量入口。它像一座…...

Linux nano命令的基本使用
参考资料 GNU nanoを使いこなすnano基础 目录 一. 简介二. 文件打开2.1 普通方式打开文件2.2 只读方式打开文件 三. 文件查看3.1 打开文件时,显示行号3.2 翻页查看 四. 文件编辑4.1 Ctrl K 复制 和 Ctrl U 粘贴4.2 Alt/Esc U 撤回 五. 文件保存与退出5.1 Ctrl …...