HBASE集群主节点迁移割接手动操作步骤
HBASE集群主节点迁移割接手动操作步骤
HBASE集群主节点指的是包含zk、nn、HM和rm服务的节点,一般这类服务都是一起复用在同一批节点上,我把这一类节点统称为HBASE集群主节点。
本文中使用了rsync、pssh等工具,这类是开源的,自己可以下载安装。还有一类是我自己写的环境变量,xcgraceful_stopRegionserver是用于优雅的停regionserver,建议使用脚本停,有时候可能会出现优雅的停失效的问题。dxshell和xcjpsuser是一些我放在环境变量里面,堡垒机全局生效,脚本内容会附在文章末尾。
一、迁移前准备工作
1、迁移规划
迁移节点 主机名 目标节点 角色 节点别名
10.168.168.1 hbase01.colabigdata.com 10.168.201.1 zk,nn,dn,jn,ZKFC,HM,HRS,rm,nm node1
10.168.168.2 hbase02.colabigdata.com 10.168.201.2 zk,nn,dn,jn,ZKFC,HM,HRS,rm,nm node2
10.168.168.3 hbase03.colabigdata.com 10.168.201.3 zk,dn,jn,HRS,nm node3
10.168.168.4 hbase04.colabigdata.com 10.168.201.4 zk,dn,jn,HRS,nm node4
10.168.168.5 hbase05.colabigdata.com 10.168.201.5 zk,dn,jn,HRS,nm node5
2、生成hosts文件
只包含集群在线的节点,不包含未扩容的。用于迁移过程中,每替换一个IP,需要修改一次/etc/hosts文件。
# vim move_hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain610.168.168.1 hbase01.colabigdata.com
10.168.168.2 hbase02.colabigdata.com
10.168.168.3 hbase03.colabigdata.com
10.168.168.4 hbase04.colabigdata.com
10.168.168.5 hbase05.colabigdata.com
10.168.168.6 hbase06.colabigdata.com
10.168.168.7 hbase07.colabigdata.com
10.168.168.8 hbase08.colabigdata.com
10.168.168.9 hbase09.colabigdata.com
10.168.168.10 hbase10.colabigdata.com
3、准备集群IP列表
此IP列表与hosts是对应关系,用于批量执行命令时使用。
cat > move_list <<EOF
10.168.168.1
10.168.168.2
10.168.168.3
10.168.168.4
10.168.168.5
10.168.168.6
10.168.168.7
10.168.168.8
10.168.168.9
10.168.168.10
EOF
4、准备zk集群IP列表
集群zk在线IP列表(不含新主节点ip):move_zk_list
cat > move_zk_list <<EOF
10.168.168.1
10.168.168.2
10.168.168.3
10.168.168.4
10.168.168.5
EOF
5、准备除zk集群外IP列表
集群在非zk节点IP列表(不含新主节点ip):data_list
cat > data_list <<EOF
10.168.168.6
10.168.168.7
10.168.168.8
10.168.168.9
10.168.168.10
EOF
6、准备旧zk集群IP列表
cat > old_zk_list <<EOF
10.168.168.1
10.168.168.2
10.168.168.3
10.168.168.4
10.168.168.5
EOF
7、准备新zk集群IP列表
cat > new_zk_list <<EOF
10.168.201.1
10.168.201.2
10.168.201.3
10.168.201.4
10.168.201.5
EOF
8、目标节点组件安装
五个目标zk节点zookeeper、hdfs、hbase、yarn组件已经提前安装完毕,未启动任何服务。
9、删除cmdb数据,关闭告警和自启脚本
dxshell move_list "userdel -r bdalarm"dxshell move_list "cd /var/spool/cron;rm -f bdalarm*"
10、关闭主节点dn、nm和rs服务
注意:排除主节点非核心服务,方便迁移
dxshell move_zk_list "su - bigdata -c 'hadoop-daemon.sh stop datanode'"dxshell move_zk_list "su - yarn -c 'yarn-daemon.sh stop nodemanager'"#这里是优雅的停Regionserver
xcgraceful_stopRegionserver move_zk_list
###正式开始迁移操作###
二、node5迁移
1、老机器停JN
sudo ssh 10.168.168.5 "su - bigdata -c 'hadoop-daemon.sh stop journalnode'"sudo ssh 10.168.168.5 "su - bigdata -c 'jps'"
2、老机器停ZK
sudo ssh 10.168.168.5 "su - zookeeper -c 'zkServer.sh stop'"sudo ssh 10.168.168.5 "su - zookeeper -c 'jps'"
3、老机器改主机名
sudo ssh 10.168.168.5 "hostnamectl set-hostname cola_node5"
4、DNS域名解析变更
使用的域名删除迁移节点IP,变更为目标节点IP。
5、更新/etc/hosts
#将move_list、move_hosts、move_zk_list文件中的 迁移节点IP 修改为目标节点 IP
sed -i 's/10.168.168.5/10.168.201.5/g' move_*#备份所有节点hosts
sudo pssh -h move_list "cp /etc/hosts /etc/hosts_$(date +%Y%m%d)_movenode5"#分发全量hosts到move_list列表
sudo pscp.pssh -h move_list move_hosts /etc/hosts
6、依次重启所有zk服务
注意列表IP,不要并发重启
dxshell move_zk_list "su - zookeeper -c 'zkServer.sh stop ; zkServer.sh start'"
7、查看zk服务状态
dxshell move_zk_list "su - zookeeper -c 'zkServer.sh status'"
8、验证zk_followers节点数量
先找到leader节点
echo 'mntr' | nc ${leader} 2015 |grep followers
zk_followers与zk_synced_followers的值相等则正常
9、拷贝node5的jn元数据到目标节点
mkdir baknode5rsync -e 'sudo ssh' -r 10.168.168.5:/home/bigdata/hadoop/journal baknode5/rsync -e 'sudo ssh' -r baknode5/journal 10.168.201.5:/home/bigdata/hadoop/sudo ssh 10.168.201.5 "chown -R bigdata:bigdata /home/bigdata/hadoop"
10、node5目标节点启动JN服务
sudo ssh 10.168.201.5 "su - bigdata -c 'hadoop-daemon.sh start journalnode'"
验证jn同步情况,及日志输出是否正常。namenode的50070页面上查看NameNode Journal Status,Written txid 一致则同步完成。
三、node4迁移
1、老机器停JN
sudo ssh 10.168.168.4 "su - bigdata -c 'hadoop-daemon.sh stop journalnode'"sudo ssh 10.168.168.4 "su - bigdata -c 'jps'"
2、老机器停ZK
sudo ssh 10.168.168.4 "su - zookeeper -c 'zkServer.sh stop'"sudo ssh 10.168.168.4 "su - zookeeper -c 'jps'"
3、老机器改主机名
sudo ssh 10.168.168.4 "hostnamectl set-hostname cola_node4"
4、DNS域名解析变更
使用的域名删除迁移节点IP,变更为目标节点IP。
5、更新/etc/hosts
#将move_list、move_hosts、move_zk_list文件中的 迁移节点IP 修改为目标节点 IP
sed -i 's/10.168.168.4/10.168.201.4/g' move_*#备份所有节点hosts
sudo pssh -h move_list "cp /etc/hosts /etc/hosts_$(date +%Y%m%d)_movenode4"#分发全量hosts到move_list列表
sudo pscp.pssh -h move_list move_hosts /etc/hosts
6、依次重启所有zk服务
注意列表IP,不要并发重启
dxshell move_zk_list "su - zookeeper -c 'zkServer.sh stop ; zkServer.sh start'"
7、查看zk服务状态
dxshell move_zk_list "su - zookeeper -c 'zkServer.sh status'"
8、验证zk_followers节点数量
先找到leader节点
echo 'mntr' | nc ${leader} 2015 |grep followers
zk_followers与zk_synced_followers的值相等则正常
9、拷贝node4的jn元数据到目标节点
mkdir baknode4rsync -e 'sudo ssh' -r 10.168.168.4:/home/bigdata/hadoop/journal baknode4/rsync -e 'sudo ssh' -r baknode4/journal 10.168.201.4:/home/bigdata/hadoop/sudo ssh 10.168.201.4 "chown -R bigdata:bigdata /home/bigdata/hadoop"
10、node4目标节点启动JN服务
sudo ssh 10.168.201.4 "su - bigdata -c 'hadoop-daemon.sh start journalnode'"
验证jn同步情况,及日志输出是否正常。namenode的50070页面上查看NameNode Journal Status,Written txid 一致则同步完成。
四、第一次nn主备切换
主备切换的目的,是担心nn不是认识新的zk5和zk4,从而有可能导致后续nn迁移失败。做一次nn切换,可以保证active nn在切换后,可以检测认识到新zk5和zk4。这是一种非常保守的做法,只是因为一次生产事故后,做出的一种改变。
1、获取nn1和nn2的状态
sudo ssh 10.168.168.1 "su - bigdata -c 'hdfs haadmin -getServiceState nn1'"
standbysudo ssh 10.168.168.2 "su - bigdata -c 'hdfs haadmin -getServiceState nn2'"
active
2、重启standby nn服务
sudo ssh 10.168.168.1 "su - bigdata -c 'hadoop-daemon.sh stop namenode'"sudo ssh 10.168.168.1 "su - bigdata -c 'hadoop-daemon.sh start namenode'"
3、执行主备切换
注意:等待nn退出安全模式后再执行切换。
如下命令是将active nn从nn2切换到nn1
sudo ssh 10.168.168.2 "su - bigdata -c 'hdfs haadmin -failover nn2 nn1'"
五、node3迁移
1、老机器停JN
sudo ssh 10.168.168.3 "su - bigdata -c 'hadoop-daemon.sh stop journalnode'"sudo ssh 10.168.168.3 "su - bigdata -c 'jps'"
2、老机器停ZK
sudo ssh 10.168.168.3 "su - zookeeper -c 'zkServer.sh stop'"sudo ssh 10.168.168.3 "su - zookeeper -c 'jps'"
3、老机器改主机名
sudo ssh 10.168.168.3 "hostnamectl set-hostname cola_node3"
4、DNS域名解析变更
使用的域名删除迁移节点IP,变更为目标节点IP。
5、更新/etc/hosts
#将move_list、move_hosts、move_zk_list文件中的 迁移节点IP 修改为目标节点 IP
sed -i 's/10.168.168.3/10.168.201.3/g' move_*#备份所有节点hosts
sudo pssh -h move_list "cp /etc/hosts /etc/hosts_$(date +%Y%m%d)_movenode3"#分发全量hosts到move_list列表
sudo pscp.pssh -h move_list move_hosts /etc/hosts
6、依次重启所有zk服务
注意列表IP,不要并发重启
dxshell move_zk_list "su - zookeeper -c 'zkServer.sh stop ; zkServer.sh start'"
7、查看zk服务状态
dxshell move_zk_list "su - zookeeper -c 'zkServer.sh status'"
8、验证zk_followers节点数量
先找到leader节点
echo 'mntr' | nc ${leader} 2015 |grep followers
zk_followers与zk_synced_followers的值相等则正常
9、拷贝node3的jn元数据到目标节点
mkdir baknode3rsync -e 'sudo ssh' -r 10.168.168.3:/home/bigdata/hadoop/journal baknode3/rsync -e 'sudo ssh' -r baknode3/journal 10.168.201.3:/home/bigdata/hadoop/sudo ssh 10.168.201.3 "chown -R bigdata:bigdata /home/bigdata/hadoop"
10、node3目标节点启动JN服务
sudo ssh 10.168.201.3 "su - bigdata -c 'hadoop-daemon.sh start journalnode'"
验证jn同步情况,及日志输出是否正常。namenode的50070页面上查看NameNode Journal Status,Written txid 一致则同步完成。
注意:如果长时间同步一不一致,可以尝试把正确jn数据重新复制一份到新节点。
六、node2迁移
先确认namenode的active和standby分布在那个节点上。如果node1是active,node2是standby,必须先迁移standby。
迁移到目前为止,当前主节点列表应该和如下一致。
10.168.168.1 hbase01.colabigdata.com
10.168.168.2 hbase02.colabigdata.com
10.168.201.3 hbase03.colabigdata.com
10.168.201.4 hbase04.colabigdata.com
10.168.201.5 hbase05.colabigdata.com
1、获取nn1和nn2的状态
sudo ssh 10.168.168.1 "su - bigdata -c 'hdfs haadmin -getServiceState nn1'"
standbysudo ssh 10.168.168.2 "su - bigdata -c 'hdfs haadmin -getServiceState nn2'"
active
2、先停standby nn节点的zkfc
sudo ssh 10.168.168.2 "su - bigdata -c 'hadoop-daemon.sh stop zkfc'"
3、再停active nn节点的zkfc
sudo ssh 10.168.168.1 "su - bigdata -c 'hadoop-daemon.sh stop zkfc'"
注意:如果当前standby为node2,就先操作node2节点的迁移,原则上先操作standby节点。
注:如果node2不是standby,建议提前将node2切换为standby。因为操作步骤中是按照node5~node1顺序迁移写的,如果现场改操作内容,可能会导致操作变复杂。
4、停node2节点所有服务
sudo ssh 10.168.168.2 "su - yarn -c 'yarn-daemon.sh stop resourcemanager'"
sudo ssh 10.168.168.2 "su - yarn -c 'mr-jobhistory-daemon.sh stop historyserver'"
sudo ssh 10.168.168.2 "su - hbase -c 'hbase-daemon.sh stop master'"
sudo ssh 10.168.168.2 "su - bigdata -c 'hadoop-daemon.sh stop journalnode'"
sudo ssh 10.168.168.2 "su - bigdata -c 'hadoop-daemon.sh stop namenode'"
sudo ssh 10.168.168.2 "su - zookeeper -c 'zkServer.sh stop'"
5、老机器改主机名
sudo ssh 10.168.168.2 "hostnamectl set-hostname cola_node2"
6、DNS域名解析变更
使用的域名删除迁移节点IP,变更为目标节点IP。
7、更新/etc/hosts
#将move_list、move_hosts、move_zk_list文件中的 迁移节点IP 修改为目标节点 IP
sed -i 's/10.168.168.2/10.168.201.2/g' move_*#备份所有节点hosts
sudo pssh -h move_list "cp /etc/hosts /etc/hosts_$(date +%Y%m%d)_movenode2"#分发全量hosts到move_list列表
sudo pscp.pssh -h move_list move_hosts /etc/hosts
8、备份JN元数据、NN元数据fsimage和editlog日志
mkdir baknode2rsync -e 'sudo ssh' -r 10.168.168.2/home/bigdata/hadoop/journal baknode2/rsync -e 'sudo ssh' -r 10.168.168.2:/metadata/namenode baknode2/rsync -e 'sudo ssh' -r 10.168.168.2:/log/bigdata/hdfs-audit.log baknode2/
9、拷贝JN元数据、NN元数据到新节点
# 拷贝JN元数据到新节点
rsync -e 'sudo ssh' -r baknode2/journal 10.168.201.2:/home/bigdata/hadoop/sudo ssh 10.168.201.2 "chown -R bigdata:bigdata /home/bigdata/hadoop"# 拷贝NN元数据到新节点
sudo ssh 10.168.201.2 "mkdir /log/bigdata"rsync -e 'sudo ssh' -r baknode2/namenode 10.168.201.2:/metadata/sudo ssh 10.168.201.2 "chown -R bigdata:bigdata /metadata/namenode"rsync -e 'sudo ssh' -r baknode2/hdfs-audit.log 10.168.201.2:/home/bigdata/hadoop/sudo ssh 10.168.201.2 "chown -R bigdata:bigdata /log"sudo ssh 10.168.201.2 "su - bigdata -c 'cd hadoop;ln -nsf /log/bigdata logs; ln -nsf /metadata/namenode namenode'"
10、新机器启动 journalnode 和 namenode
sudo ssh 10.168.201.2 "su - bigdata -c 'hadoop-daemon.sh start journalnode'"sudo ssh 10.168.201.2 "su - bigdata -c 'hadoop-daemon.sh start namenode'"
a、验证jn同步情况,及日志输出是否正常。namenode的50070页面上查看NameNode Journal Status,Written txid 一致则同步完成。
b、验证standby文件数和block数与active是否一致,是否实时更新,不断观察日志,当standby nn 进入safemode后如有异常,立即停止standby nn进程,确认问题原因。
c、实时观察dn日志Block report是否报错(进入安全模式之后)。
11、依次重启所有zk服务
注意列表IP,不要并发重启
dxshell move_zk_list "su - zookeeper -c 'zkServer.sh stop ; zkServer.sh start'"
12、查看zk服务状态
dxshell move_zk_list "su - zookeeper -c 'zkServer.sh status'"
13、验证zk_followers节点数量
先找到leader节点
echo 'mntr' | nc ${leader} 2015 |grep followers
zk_followers与zk_synced_followers的值相等则正常
14、新机器启动HMaster
sudo ssh 10.168.201.2 "su - hbase -c 'hbase-daemon.sh start master'"
查看16010界面master状态是否正常
15、新机器启动ResourceManager和historyserver服务
sudo ssh 10.168.201.2 "su - yarn -c 'yarn-daemon.sh start resourcemanager'"sudo ssh 10.168.201.2 "su - yarn -c 'mr-jobhistory-daemon.sh start historyserver'"
16、重启node1节点HMaster服务
sudo ssh 10.168.168.1 "su - hbase -c 'hbase-daemon.sh stop master'"
sudo ssh 10.168.168.1 "su - hbase -c 'hbase-daemon.sh start master'"
17、重启node1节点ResourceManager服务
sudo ssh 10.168.168.1 "su - yarn -c 'yarn-daemon.sh stop resourcemanager && sleep 10s && yarn-daemon.sh start resourcemanager'"
18、第一次滚动重启客户端服务
重启regionserver,datanode、nodemanager服务。所有数据节点在 data_list文件中。
dxshell data_list "su - hbase -c 'hbase-daemon.sh restart regionserver'"xcjpsuser data_list hbasedxshell data_list "su - bigdata -c 'hadoop-daemon.sh stop datanode && hadoop-daemon.sh start datanode'"xcjpsuser data_list bigdatadxshell data_list "su - yarn -c 'yarn-daemon.sh stop nodemanager && yarn-daemon.sh start nodemanager'"xcjpsuser data_list yarn
七、第二次nn主备切换
这一次主备切换,主要是为了将active nn切换至新节点,检验新节点是否可以切换成功。第二个目的是将node1变为standby,减少node1迁移的影响。
1、获取nn1和nn2的状态
sudo ssh 10.168.168.1 "su - bigdata -c 'hdfs haadmin -getServiceState nn1'"
activesudo ssh 10.168.201.2 "su - bigdata -c 'hdfs haadmin -getServiceState nn2'"
standby
2、启动zkfc
sudo ssh 10.168.168.1 "su - bigdata -c 'hadoop-daemon.sh start zkfc'"sudo ssh 10.168.201.2 "su - bigdata -c 'hadoop-daemon.sh start zkfc'"
3、新节点10.168.201.2生成秘钥
su - bigdata#一路回车
ssh-keygen -t rsa#在.ssh目录下,新建authorized_keys文件
touch ~/.ssh/authorized_keys#修改权限,.ssh必须是700,authorized_keys必须是600。否则可能会提醒你输入密码,免密不成功。
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
4、做nn1和nn2互密
将彼此的 ~/.ssh/id_rsa.pub公钥文件内容 --> 追加到~/.ssh/authorized_keys文件中
5、执行主备切换
本次不用等fsimage元数据合并了,只要该节点jn有edits新数据就可以了。
# nn1 to nn2(根据实际情况)
sudo ssh 10.168.201.2 "su - bigdata -c 'hdfs haadmin -failover nn1 nn2'"
6、验证主备切换是否成功
curl -s 'http://10.168.168.1:50070/jmx?qry=Hadoop:service=NameNode,name=FSNamesystem' |jq -r .beans[0].'"tag.HAState"'curl -s 'http://10.168.201.2:50070/jmx?qry=Hadoop:service=NameNode,name=FSNamesystem' |jq -r .beans[0].'"tag.HAState"'
八、node1迁移
先确认namenode的active和standby分布在那个节点上。node1是最后一个节点了,此刻该节点是standby才对,如果不对,那就是你漏了什么步骤。建议手动切换后,再迁移。
迁移到目前为止,当前主节点列表应该和如下一致。
10.168.168.1 hbase01.colabigdata.com
10.168.201.2 hbase02.colabigdata.com
10.168.201.3 hbase03.colabigdata.com
10.168.201.4 hbase04.colabigdata.com
10.168.201.5 hbase05.colabigdata.com
1、获取nn1和nn2的状态
sudo ssh 10.168.168.1 "su - bigdata -c 'hdfs haadmin -getServiceState nn1'"
activesudo ssh 10.168.201.2 "su - bigdata -c 'hdfs haadmin -getServiceState nn2'"
standby
2、先停standby nn节点的zkfc
sudo ssh 10.168.168.1 "su - bigdata -c 'hadoop-daemon.sh stop zkfc'"
3、再停active nn节点的zkfc
sudo ssh 10.168.201.2 "su - bigdata -c 'hadoop-daemon.sh stop zkfc'"
4、停node1节点所有服务
sudo ssh 10.168.168.1 "su - yarn -c 'yarn-daemon.sh stop resourcemanager'"
sudo ssh 10.168.168.1 "su - hbase -c 'hbase-daemon.sh stop master'"
sudo ssh 10.168.168.1 "su - bigdata -c 'hadoop-daemon.sh stop journalnode'"
sudo ssh 10.168.168.1 "su - bigdata -c 'hadoop-daemon.sh stop namenode'"
sudo ssh 10.168.168.1 "su - zookeeper -c 'zkServer.sh stop'"
5、老机器改主机名
sudo ssh 10.168.168.1 "hostnamectl set-hostname cola_node1"
6、DNS域名解析变更
使用的域名删除迁移节点IP,变更为目标节点IP。
7、更新/etc/hosts
#将move_list、move_hosts、move_zk_list文件中的 迁移节点IP 修改为目标节点 IP
sed -i 's/10.168.168.1/10.168.201.1/g' move_*#备份所有节点hosts
sudo pssh -h move_list "cp /etc/hosts /etc/hosts_$(date +%Y%m%d)_movenode1"#分发全量hosts到move_list列表
sudo pscp.pssh -h move_list move_hosts /etc/hosts
8、备份JN元数据、NN元数据fsimage和editlog日志
mkdir baknode1rsync -e 'sudo ssh' -r 10.168.168.1:/home/bigdata/hadoop/journal baknode1/rsync -e 'sudo ssh' -r 10.168.168.1:/metadata/namenode baknode1/rsync -e 'sudo ssh' -r 10.168.168.1:/log/bigdata/hdfs-audit.log baknode1/
9、拷贝JN元数据、NN元数据到新节点
# 拷贝JN元数据到新节点
rsync -e 'sudo ssh' -r baknode1/journal 10.168.201.1:/home/bigdata/hadoop/sudo ssh 10.168.201.1 "chown -R bigdata:bigdata /home/bigdata/hadoop"# 拷贝NN元数据到新节点
sudo ssh 10.168.201.1 "mkdir /log/bigdata"rsync -e 'sudo ssh' -r baknode1/namenode 10.168.201.1:/metadata/sudo ssh 10.168.201.1 "chown -R bigdata:bigdata /metadata/namenode"rsync -e 'sudo ssh' -r baknode1/hdfs-audit.log 10.168.201.1:/home/bigdata/hadoop/sudo ssh 10.168.201.1 "chown -R bigdata:bigdata /log"sudo ssh 10.168.201.1 "su - bigdata -c 'cd hadoop;ln -nsf /log/bigdata logs; ln -nsf /metadata/namenode namenode'"
10、新机器启动 journalnode 和 namenode
sudo ssh 10.168.201.1 "su - bigdata -c 'hadoop-daemon.sh start journalnode'"sudo ssh 10.168.201.1 "su - bigdata -c 'hadoop-daemon.sh start namenode'"
a、验证jn同步情况,及日志输出是否正常。namenode的50070页面上查看NameNode Journal Status,Written txid 一致则同步完成。
b、验证standby文件数和block数与active是否一致,是否实时更新,不断观察日志,当standby nn 进入safemode后如有异常,立即停止standby nn进程,确认问题原因。
c、实时观察dn日志Block report是否报错(进入安全模式之后)。
11、依次重启所有zk服务
注意列表IP,不要并发重启
dxshell move_zk_list "su - zookeeper -c 'zkServer.sh stop ; zkServer.sh start'"
12、查看zk服务状态
dxshell move_zk_list "su - zookeeper -c 'zkServer.sh status'"
13、验证zk_followers节点数量
先找到leader节点
echo 'mntr' | nc ${leader} 2015 |grep followers
zk_followers与zk_synced_followers的值相等则正常
14、新机器启动HMaster
sudo ssh 10.168.201.1 "su - hbase -c 'hbase-daemon.sh start master'"
查看16010界面master状态是否正常
15、新机器启动ResourceManager
sudo ssh 10.168.201.1 "su - yarn -c 'yarn-daemon.sh start resourcemanager'"
16、重启node2节点HMaster服务
sudo ssh 10.168.201.2 "su - hbase -c 'hbase-daemon.sh stop master'"
sudo ssh 10.168.201.2 "su - hbase -c 'hbase-daemon.sh start master'"
17、重启node2节点ResourceManager服务
sudo ssh 10.168.201.2 "su - yarn -c 'yarn-daemon.sh stop resourcemanager ; yarn-daemon.sh start resourcemanager'"
18、第二次滚动重启客户端服务
重启regionserver,datanode、nodemanager服务。所有数据节点在 data_list文件中。
dxshell data_list "su - hbase -c 'hbase-daemon.sh restart regionserver'"xcjpsuser data_list hbasedxshell data_list "su - bigdata -c 'hadoop-daemon.sh stop datanode && hadoop-daemon.sh start datanode'"xcjpsuser data_list bigdatadxshell data_list "su - yarn -c 'yarn-daemon.sh stop nodemanager && yarn-daemon.sh start nodemanager'"xcjpsuser data_list yarn
九、第三次nn主备切换
这一次主备切换,主要是为了将active nn切换至node1新节点,检验最后一个新节点是否可以切换成功。
1、获取nn1和nn2的状态
sudo ssh 10.168.201.1 "su - bigdata -c 'hdfs haadmin -getServiceState nn1'"
standbysudo ssh 10.168.201.2 "su - bigdata -c 'hdfs haadmin -getServiceState nn2'"
active
2、启动zkfc
sudo ssh 10.168.201.1 "su - bigdata -c 'hadoop-daemon.sh start zkfc'"sudo ssh 10.168.201.2 "su - bigdata -c 'hadoop-daemon.sh start zkfc'"
3、新节点10.168.201.1生成秘钥
su - bigdata#一路回车
ssh-keygen -t rsa#在.ssh目录下,新建authorized_keys文件
touch ~/.ssh/authorized_keys#修改权限,.ssh必须是700,authorized_keys必须是600。否则可能会提醒你输入密码,免密不成功。
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
4、做nn1和nn2互密
将彼此的 ~/.ssh/id_rsa.pub公钥文件内容 --> 追加到~/.ssh/authorized_keys文件中
5、执行主备切换
本次不用等fsimage元数据合并了,只要该节点jn有edits新数据就可以了。
但这是最后一次主备切换,standby节点会在一个小时之后生成一个新的fsimage文件,并同步到active节点。
# nn2 to nn1(根据实际情况)
sudo ssh 10.168.201.1 "su - bigdata -c 'hdfs haadmin -failover nn2 nn1'"
6、验证主备切换是否成功
curl -s 'http://10.168.201.1:50070/jmx?qry=Hadoop:service=NameNode,name=FSNamesystem' |jq -r .beans[0].'"tag.HAState"'curl -s 'http://10.168.201.2:50070/jmx?qry=Hadoop:service=NameNode,name=FSNamesystem' |jq -r .beans[0].'"tag.HAState"'
7、主节点启动datanode服务
sudo pssh -h move_zk_list "su - bigdata -c 'hadoop-daemon.sh start datanode'"
8、主节点启动regionserver服务
sudo pssh -h move_zk_list "su - hbase -c 'hbase-daemon.sh start regionserver'"
9、主节点启动nodemanager服务
sudo pssh -h move_zk_list "su - yarn -c 'yarn-daemon.sh start nodemanager'"
10、观察fsimage元数据是否生成
因为到目前为止,主节点服务迁移已经完成了。这里有最后一次主备切换,standby nn节点会在一个小时之后生成一个新的fsimage文件,并同步到active nn节点上。所以一定要观察standby nn和active nn是否有新的fsimage文件。
十、缩容需要下线的数据节点
老数据节点HRegionServer,nodemanager,dn要decommission
#olddata 添加需要下线的IP列表
cat > olddata <<EOF
10.168.168.6
10.168.168.7
10.168.168.8
10.168.168.9
10.168.168.10
EOF#优雅的停hregionserver
xcgraceful_stopRegionserver olddata
xcjpsuser olddata hbase#停nodemanager
dxshell olddata "su - yarn -c 'yarn-daemon.sh stop nodemanager'"
xcjpsuser olddata yarn#decommission做dn节点
#登录主节点
sudo ssh 10.168.201.1
#备份配置文件
su - bigdata
cd software/hadoop/etc/hadoop/
cp exclude exclude_$(date +%Y%m%d)
#添加下线节点
vi exclude
#刷新生效
hdfs dfsadmin -refreshNodes#登录主节点
sudo ssh 10.168.201.2
#备份配置文件
su - bigdata
cd software/hadoop/etc/hadoop/
cp exclude exclude_$(date +%Y%m%d)
#添加下线节点
vi exclude
#刷新生效
hdfs dfsadmin -refreshNodes
附:脚本
这一类脚本就是平时总结通用的内容,存放在堡垒机环境变量路径下,方便随时可以调用。
1、dxshell脚本
#!/bin/bash
# Author : LJ
# Date : 2021/10/11
# Func : 通用批处理查询。if [ $# -lt 2 ]
thenecho -e "\033[1;31m 参数不足,请重新执行... \033[0m"echo -e "\033[1;32m 此脚本传参使用方法:$0 第一个参数为待查询的ip列表文件名 第二个参数为等待执行的shell命令,命令中如果有“$”,注意转译。 \033[0m"exit ;
fi
workdir=`pwd`list=$1
list_ip=`cd ${workdir};cat $list|awk '{print $1}'`
#此脚本适用于通用查询,用户就在root下就可以。
user=xcommand=$2sum=`cat $list|sed '/^$/d'|wc -l`
num=1for ip in ${list_ip[@]} ; doecho -e "\033[1;31m$num\033[1;32m/$sum =============== $ip 节点 \033[1;33m执行命令:${xcommand} \033[1;32m返回结果如下: =============== \033[0m"sudo ssh $ip -C "${xcommand}" let num++
done2、xcjpsuser脚本
#!/bin/bash
if [ $# -lt 2 ]
thenecho -e "\033[1;31m 参数不足,请重新执行... \033[0m"echo -e "\033[1;32m 此脚本传参使用方法:$0 第一个参数为待查询的ip列表文件名 第二个参数为有jdk的用户,用于执行jps命令 \033[0m"exit ;
fi
workdir=`pwd`list=$1
list_ip=`cd ${workdir};cat $list|awk '{print $1}'`
user=$2sum=`cat $list|sed '/^$/d'|wc -l`
num=1for ip in ${list_ip[@]} ; doecho -e "\033[1;31m$num\033[1;32m/$sum =============== $ip 节点 $user 用户下 现有java进程 =============== \033[0m"sudo ssh $ip -C "su - $user -c 'jps|grep -v Jps'" let num++
done3、xcgraceful_stopRegionserver脚本
#!/bin/bash
# Author : LJ
# Date : 2023/3/15
# Func : 批量优雅的停一批节点HRegionServer服务if [ $# -lt 1 ]
thenecho -e "\033[1;31m 参数不足,请重新执行... \033[0m"echo -e "\033[1;32m 此脚本传参使用方法:$0 第一个参数为待查询的ip列表文件名 \033[0m"exit ;
fi
#workdir=`pwd`
list_ip="$1"
#sum记录节点个数
sum=`cat "${list_ip}"|wc -l`
#使用stop_count数组,用于记录stop次数,次数用于初始化赋值
for (( i=0; i<"$sum"; i=i+1 )) ; dostop_count[i]=0
done
#对ip进行遍历执行stop,stop不成功的节点会使用数组i--进行再次重试。如果重试大于5次,直接使用kill -9 stop。
for (( i=0; i<"$sum"; i=i+1 )) ; dolet num=${i}+1let stop_count[i]++arr[i]=`sed -n "${num}p" ${list_ip}`ip="${arr[i]}"#操作第一实例 HRegionServerrg1_wc=`sudo ssh $ip -C "ps -ef|grep -w '/home/hbase/logs'|grep -w 'org.apache.hadoop.hbase.regionserver.HRegionServer'|grep -v grep|wc -l"`if [ "${rg1_wc}" -eq 1 ] ; thenecho -e "\033[1;31m$num\033[1;32m/$sum 开始 第 ${stop_count[i]} 次优雅的停 ${ip} 节点的 HRegionServer1 服务 执行时间: $(date +%Y-%m-%d\ %H:%M:%S) \033[0m"sudo ssh $ip -C 'su - hbase -c "graceful_stop.sh --maxthreads 32 -e `hostname` "' >/dev/null 2>&1sleep 30fi#操作第二实例 HRegionServerrg2_wc=`sudo ssh $ip -C "ps -ef|grep -w '/home/hbase/logs2'|grep -w 'org.apache.hadoop.hbase.regionserver.HRegionServer'|grep -v grep|wc -l"`if [ "${rg2_wc}" -eq 1 ] ; thenecho -e "\033[1;31m$num\033[1;32m/$sum 开始 第 ${stop_count[i]} 次优雅的停 ${ip} 节点的 HRegionServer2 服务 执行时间: $(date +%Y-%m-%d\ %H:%M:%S) \033[0m"sudo ssh $ip -C 'su - hbase -c "graceful_stop.sh --config /home/hbase/software/hbase/conf2 --maxthreads 32 -e `hostname` "' >/dev/null 2>&1sleep 30fi#stop操作结果检查,只要还存在 HRegionServer 进程,就返回继续执行本节点stop操作check_rg_wc=`sudo ssh $ip -C 'su - hbase -c "jps|grep -i HRegionServer"|wc -l'`#判断是否还要 HRegionServer 进程if [ "${check_rg_wc}" -ne 0 ] ; thenif [ "${stop_count[i]}" -gt 5 ] ; thenecho -e "\033[1;31m$num\033[1;32m/$sum \033[1;33m 优雅的停第 ${stop_count[i]} 没成功,重试次数大于5次,跳过本节点操作 执行时间: $(date +%Y-%m-%d\ %H:%M:%S) \033[0m"echo "${ip}"elselet i--fielseecho -e "\033[1;31m$num\033[1;32m/$sum \033[1;33m ${ip} 节点(已经)无 HRegionServer 服务 执行时间: $(date +%Y-%m-%d\ %H:%M:%S) \033[0m"fi
done相关文章:

HBASE集群主节点迁移割接手动操作步骤
HBASE集群主节点迁移割接手动操作步骤 HBASE集群主节点指的是包含zk、nn、HM和rm服务的节点,一般这类服务都是一起复用在同一批节点上,我把这一类节点统称为HBASE集群主节点。 本文中使用了rsync、pssh等工具,这类是开源的,自己…...

TRB爆仓分析,套利分析,行情判断!
毫无疑问昨日TRB又成为涨幅榜的明星,总结下来,多军赚麻,空头爆仓,套利爽歪歪! 先说风险最小的套利情况,这里两种套利都能实现收益。 现货与永续合约的资金费率套利年化资金费率达到惊人的3285%——DeFi的…...

LVGL - RV1109 LVGL UI刷新效率优化-02
说明 前面好早写过一个文章,说明如何把LVGL移到RV1109上的操作,使用DRM方式!但出现刷新效率不高的问题! 因为一直没有真正的应用在产品中,所以也就放下了! 最近开发上需要考虑低成本,低内存的…...

5、布局管理器
5、布局管理器 一、流式布局 package com.dryant.lesson1;import java.awt.*;public class TestFlowLayout {public static void main(String[] args) {Frame frame new Frame();Button button1 new Button("bt1");Button button2 new Button("bt2");…...
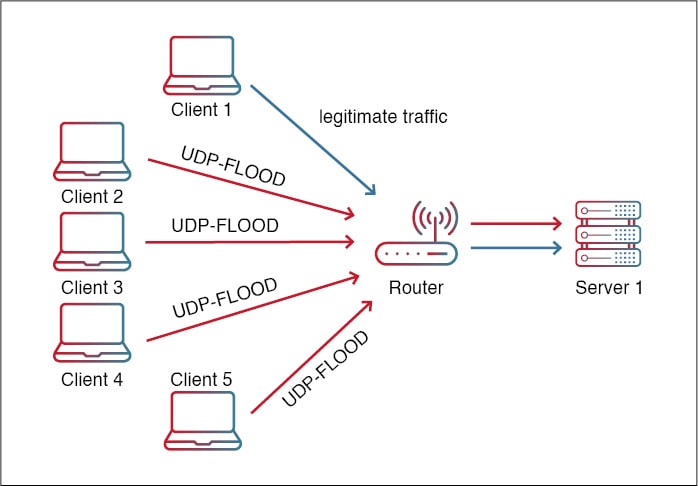
What is a UDP Flood Attack?
用户数据报协议 (UDP) 是计算机网络中使用的无连接、不可靠的协议。它在互联网协议 (IP) 的传输层上运行,并提供跨网络的快速、高效的数据传输。与TCP(其更可靠的对应物)不同,UDP不提…...

多核 ARM Server 性能调优
概述 thinkforce ARM Server是多核心ARM服务器,硬件环境资源如下: CPU信息如下: yuxunyuxun:/$ lscpu Architecture: aarch64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian …...
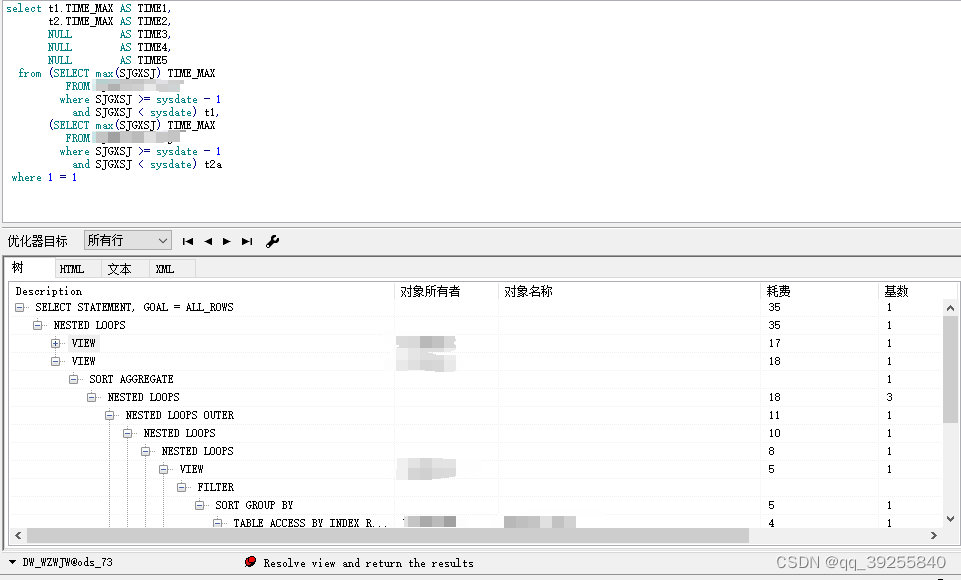
oracle执行计划中,同一条语句块,在不同情况下执行计划不一样问题。子查询,union 导致索引失效。
场景: 需要获取部分数据集(视图)的业务时间最大值,希望只通过一条语句获取多个的最大值。 则使用select (视图1业务时间最大值),(视图2业务时间最大值),(视图3业务时间最大值) from dual 程序执行过程中,发现语句执行较慢,则进行s…...

【新的小主机】向日葵远程控制ubuntu
向日葵远程控制ubuntu 一、简介二、问题及解决方法2.1 向日葵远程连接Ubuntu22主机黑屏?2.2 Ubuntu如何向日葵开机自启?2.3 无显示器情况下,windows远程桌面连接Ubuntu? 三、待续。。。 一、简介 系统:ubuntu22.04.3 目的&#…...

在Android studio高版本上使用低版本的Github项目库报错未能解析:Landroid/support/v4/app/FrageActivity;
我在我的项目中有一个导包: // 基础依赖包,必须要依赖 沉浸式狀態欄 implementation com.gyf.immersionbar:immersionbar:3.0.0 但是我的as版本比较高,我使用这个导包里面的方法会直接报错: java.lang.NoClassDefFoundError: Failed resolution of: Landroid/suppor…...
自动混剪多段视频、合并音频、添加文案的技巧分享
在如今的社交媒体时代,视频的重要性越来越被人们所重视。许多人喜欢记录生活中的美好瞬间,并将其制作成视频分享给朋友和家人。然而,对于那些拍摄了大量视频的人来说,一个一个地进行剪辑和合并可能是一项令人头痛的任务。但是&…...

学习笔记——BSGS
众所周知,北上广深是中国非常一线的城市,北京是首都,地处…… 正片开始! 一、BSGS基础算法 实现目标: A x ≡ B ( m o d P ) , ( gcd ( P , A ) 1 ) A^x\equiv B(\mod P),(\gcd(P,A)1) Ax≡B(modP),(gcd(P,A)1)…...

【AI视野·今日NLP 自然语言处理论文速览 第四十期】Mon, 25 Sep 2023
AI视野今日CS.NLP 自然语言处理论文速览 Mon, 25 Sep 2023 Totally 46 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers ReConcile: Round-Table Conference Improves Reasoning via Consensus among Diverse LLMs Authors Justin C…...
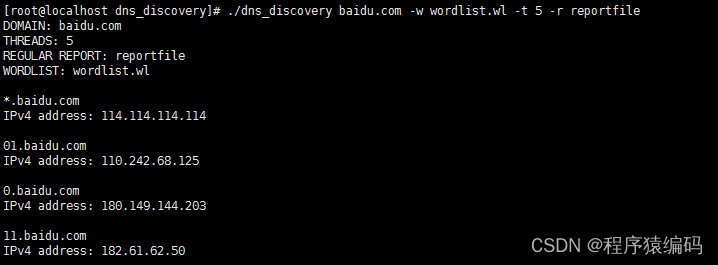
Linux C/C++下收集指定域名的子域名信息(类似dnsmap实现)
我们知道dnsmap是一个工具,主要用于收集指定域名的子域名信息。它对于渗透测试人员在基础结构安全评估的信息收集和枚举阶段非常有用,可以帮助他们发现目标公司的IP网络地址段、域名等信息。 dnsmap的操作原理 dnsmap(DNS Mappingÿ…...
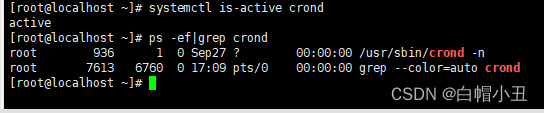
linux-定时任务
目录 一、crond命令 1、什么是计划任务 2、crond服务的概念 3、crontab 二、at命令 1、at任务的概念 三、邮件服务 1、概念 2、启动postfix 四、mailx命令 1、三个概念: 2、交互式发邮件 3、非交互式发邮件 四、cron定时任务实践 1、系统定时任务配置…...

在Spring Boot项目中使用Redisson
在Spring Boot项目中使用Redisson Redisson简介 Redisson官网仓库 Redisson中文文档 Redission是一个基于Java的分布式缓存和分布式任务调度框架,用于处理分布式系统中的缓存和任务队列。它是一个开源项目,旨在简化分布式系统的开发和管理。 以下是…...
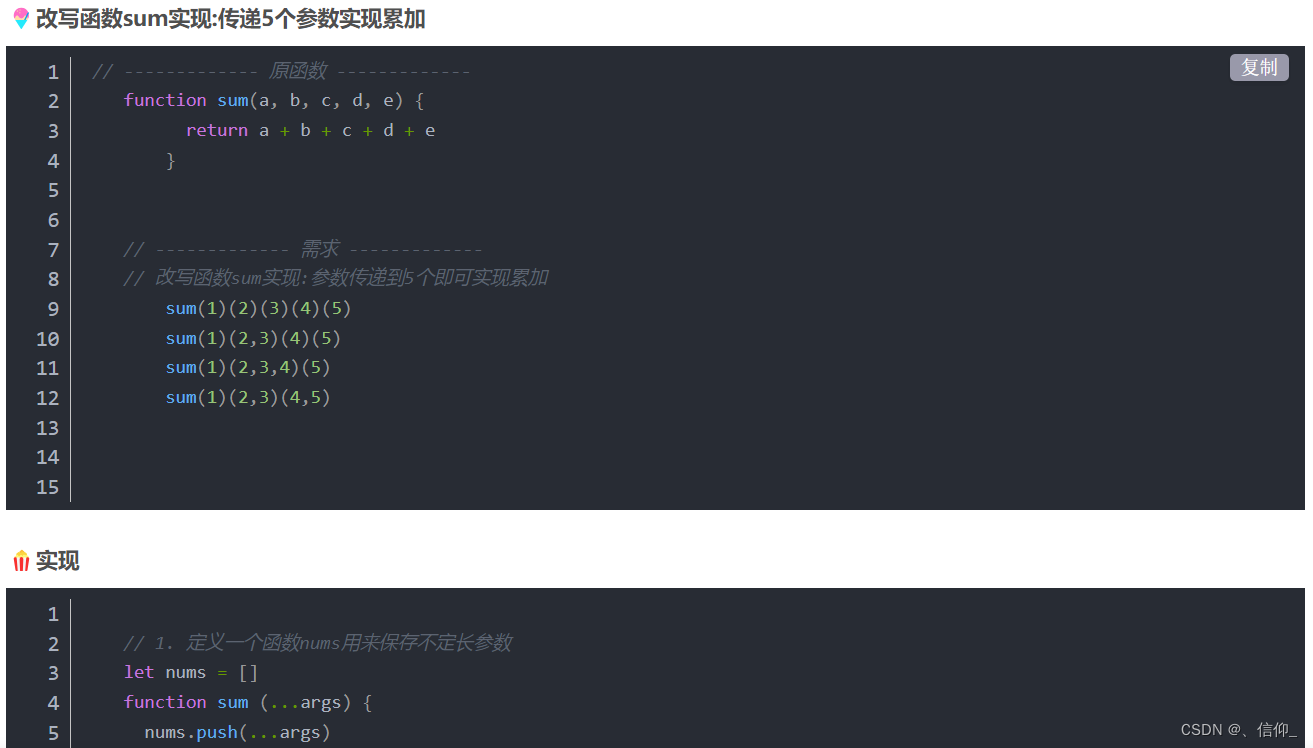
JavaScript 函数柯里化
🎶什么是柯里化 柯里化(Currying)是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数且返回结果的新函数的技术。 🎡简单的函数柯里化的实现 // ------------- 原函数…...
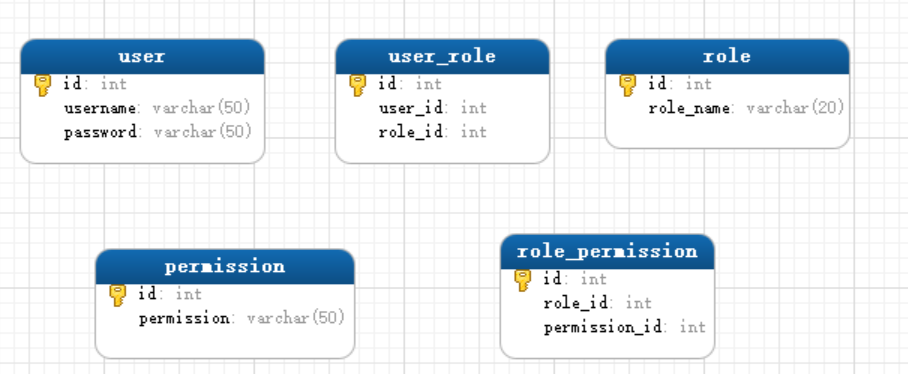
springboot实现ACL+RBAC权限体系
本文基于web系统的权限控制非常重要的前提下,从ALC和RBAC权限控制两个方面,介绍如何在springboot项目中实现一个完整的权限体系。 源码下载 :https://gitee.com/skyblue0678/springboot-demo 序章 一个后台管理系统,基本都有一套…...

C++20协程示例
C20协程示例 认识协程 在C中,协程就是一个可以暂停和恢复的函数。 包含co_wait、co_yield、co_return关键字的都可以叫协程。 看一个例子: MyCoroGenerator<int> testFunc(int n) {std::cout << "Begin testFunc" << s…...
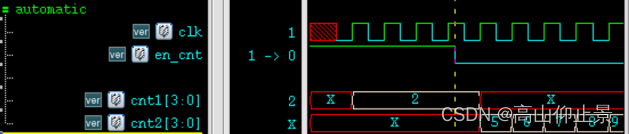
【Verilog 教程】6.2Verilog任务
关键词:任务 任务与函数的区别 和函数一样,任务(task)可以用来描述共同的代码段,并在模块内任意位置被调用,让代码更加的直观易读。函数一般用于组合逻辑的各种转换和计算,而任务更像一个过程&a…...
Spring修炼之路(1)基础入门
一、简介 1.1Spring概述 Spring框架是一个轻量级的Java开发框架,它提供了一系列底层容器和基础设施,并可以和大量常用的开源框架无缝集成,可以说是开发Java EE应用程序的必备。Spring是一个轻量级的控制反转(IoC)和面向切面(AOP)的容器&…...
)
保姆级教程:在uni-app项目中集成驰腾打印机SDK,实现蓝牙打印(附避坑指南)
保姆级教程:在uni-app项目中集成驰腾打印机SDK,实现蓝牙打印(附避坑指南) 在移动应用开发中,打印功能的需求日益增长,尤其是零售、物流等行业。驰腾打印机作为国内知名品牌,其蓝牙打印功能被广泛…...

Nanbeige4.1-3B保姆级教程:WebUI中上传文件解析PDF/Markdown内容
Nanbeige4.1-3B保姆级教程:WebUI中上传文件解析PDF/Markdown内容 你是不是经常遇到这样的烦恼:手头有一堆PDF报告、Markdown文档,想快速提炼里面的关键信息,却要一页页翻看,费时又费力?或者,你…...

25年的第二题--旅行最短路径问题
暴力解法思路 弗洛伊德算法全图最短路径搜集有 n 个点, 要每个点都走一遍 枚举所有可能的访问顺序(全排列) 对每种顺序, 按顺序走,算总距离 最后输出最小的总距离//计算任意两个点之间的最短路径!暴力全部计…...

Oracle数据库PL/SQL循环实战:从12小时到10分钟的性能优化
1. 从12小时到10分钟的蜕变:PL/SQL循环性能优化实战 去年我接手了一个制造业的ETL项目,客户需要将产线检测设备每天产生的2000多列数据与另外两个工艺表关联后导出CSV。最初用Java写的控制台程序跑了整整12小时才完成,产线主管差点把咖啡泼在…...

CYBER-VISION零号协议在网络安全领域的应用:威胁情报智能分析
CYBER-VISION零号协议在网络安全领域的应用:威胁情报智能分析 每天,安全运营中心(SOC)的告警大屏上,成千上万条日志像瀑布一样滚动。分析师小王紧盯着屏幕,试图从这些看似无关的“噪音”中,分辨…...

Qwen2.5-VL-7B-Instruct多模态应用落地:电商图识文+智能问答实战案例
Qwen2.5-VL-7B-Instruct多模态应用落地:电商图识文智能问答实战案例 想象一下,你是一家电商公司的运营人员,每天要面对海量的商品图片。老板让你从这些图片里提取商品信息、分析卖点、甚至为新品写文案。一张张看?效率太低。用传…...
)
MinIO在Linux上的5个隐藏性能优化技巧(实测提升30%吞吐量)
MinIO在Linux上的5个隐藏性能优化技巧(实测提升30%吞吐量) 当你的MinIO集群已经稳定运行,但总感觉硬件性能没有被完全释放时,这些隐藏的性能优化技巧可能就是你需要的关键突破点。不同于常规的配置调整,本文将揭示那些…...

真心不骗你!AI论文网站 千笔写作工具 VS PaperRed,专为论文写作全流程设计
还在为选题→大纲→初稿→文献→降重→查重→格式→答辩PPT的全流程焦头烂额?千笔AI以八大核心功能实现全流程一站式覆盖,从选题到答辩PPT生成全程护航,让论文写作从“耗时耗力”变成“高效规范”,真正实现“选题快、框架稳、修改…...

探索IEEE 39节点暂态模型:Simulink与PSCAD仿真之旅
IEEE39节点暂态模型,包括simulink与PSCAD两类仿真模型。 (运行时先运行m文件)IEEE39节点标准系统,标准算例数据,电源采用发电机模型,更能考虑完备暂态响应。 适合新手学习所用,减少搭建模型时间…...
批量生成时频图)
Matlab基于连续小波变换(CWT)批量生成时频图
Matlab基于连续小波变换(CWT),将一维信号批量生成时频图的源 此示例中,原始信号data是30*1280的格式,一共30条信号,信号长度为1280。 最终生成30张时频图。 生成的图像可用于后续的深度学习分类或其他处理。…...