【AI视野·今日NLP 自然语言处理论文速览 第四十期】Mon, 25 Sep 2023
AI视野·今日CS.NLP 自然语言处理论文速览
Mon, 25 Sep 2023
Totally 46 papers
👉上期速览✈更多精彩请移步主页

Daily Computation and Language Papers
| ReConcile: Round-Table Conference Improves Reasoning via Consensus among Diverse LLMs Authors Justin Chih Yao Chen, Swarnadeep Saha, Mohit Bansal 大型语言模型法学硕士仍然难以应对复杂的推理任务。受 1988 年 Minsky 思想社会的推动,我们提出了 ReConcile,这是一个多模型多代理框架,设计为不同 LLM 代理之间的圆桌会议,以促进不同的思想和讨论,以提高共识。 ReConcile 通过举行多轮讨论、学习说服其他代理人改进答案以及采用置信加权投票机制来增强 LLM 的推理能力。在每一轮中,ReConcile 通过讨论提示启动智能体之间的讨论,该讨论提示由每个智能体在上一轮中生成的分组答案和解释、其不确定性以及纠正人类解释的答案演示组成,用于说服其他智能体。此讨论提示使每个代理能够根据其他代理的见解修改他们的响应。一旦达成共识并且讨论结束,ReConcile 将通过加权投票方案利用每个代理的信心来确定最终答案。我们使用 ChatGPT、Bard 和 Claude2 作为三个代理来实现 ReConcile。我们在各种基准上的实验结果表明,ReConcile 显着增强了智能体单独和团队的推理性能,比之前的单智能体和多智能体基线高出 7.7,并且在其中一些数据集上的表现也优于 GPT 4。我们还使用 GPT 4 本身作为 ReConcile 中的代理之一进行实验,并通过其他代理的讨论和反馈证明其初始性能也提高了绝对 10.0。最后,我们还分析了每一轮之后的准确性,并观察到与多代理辩论基线相比,ReConcile 在代理之间实现了更好更快的共识。 |
| Audience-specific Explanations for Machine Translation Authors Renhan Lou, Jan Niehues 在机器翻译中,一个常见的问题是,某些单词即使翻译了,也会因为不同的文化背景而导致目标语言受众无法理解。解决这个问题的一个办法就是为这些词添加解释。因此,第一步,我们需要识别这些单词或短语。在这项工作中,我们探索从平行语料库中提取示例解释的技术。然而,包含需要解释的单词的句子的稀疏性使得构建训练数据集变得极其困难。在这项工作中,我们提出了一种半自动技术来从大型平行语料库中提取这些解释。在英语德语语言对上的实验表明,我们的方法能够提取句子,使得超过 10 个句子包含解释,而原始句子中只有 1.9 个包含解释。此外,对英法和英汉语言对的实验也得出了类似的结论。因此,这是创建解释数据集的重要的第一个自动步骤。 |
| Nested Event Extraction upon Pivot Element Recogniton Authors Weicheng Ren, Zixuan Li, Xiaolong Jin, Long Bai, Miao Su, Yantao Liu, Saiping Guan, Jiafeng Guo, Xueqi Cheng 嵌套事件提取 NEE 旨在提取复杂的事件结构,其中一个事件递归地包含其他事件作为其参数。嵌套事件涉及一种枢轴元素 PE,它同时充当外部事件的参数和内部事件的触发器,从而将它们连接成嵌套结构。 PE的这一特殊特性给现有的NEE方法带来了挑战,因为它们不能很好地应对PE的双重身份。因此,本文提出了一种新的模型,称为PerNee,主要基于识别PE来提取嵌套事件。具体来说,PerNee首先识别内部事件和外部事件的触发因素,并通过对触发对之间的关系类型进行分类来进一步识别PE。为了获得触发器和参数的更好表示,进一步提高NEE性能,它通过即时学习将事件类型和参数角色的信息合并到PerNee中。由于现有的NEE数据集(例如Genia11)仅限于特定领域,并且包含具有嵌套结构的狭窄事件类型,因此我们系统地对通用领域中的嵌套事件进行分类,并构建了一个新的NEE数据集,即ACE2005 Nest。 |
| Self-Explanation Prompting Improves Dialogue Understanding in Large Language Models Authors Haoyu Gao, Ting En Lin, Hangyu Li, Min Yang, Yuchuan Wu, Wentao Ma, Yongbin Li 面向任务的对话 TOD 系统有助于用户通过多轮对话执行各种活动,但大型语言模型法学硕士通常很难理解这些复杂的上下文。在本研究中,我们提出了一种新颖的自我解释提示策略,以增强法学硕士在多轮对话中的理解能力。这种与任务无关的方法要求模型在任务执行之前分析每个对话话语,从而提高各种以对话为中心的任务的性能。 |
| TopRoBERTa: Topology-Aware Authorship Attribution of Deepfake Texts Authors Adaku Uchendu, Thai Le, Dongwon Lee 大型语言模型法学硕士的最新进展使得开放式高质量文本的生成成为可能,这些文本与人类书面文本的区别并不简单。我们将此类 LLM 生成的文本称为 emph deepfake 文本。目前,huggingface 模型存储库中有超过 11K 个文本生成模型。因此,怀有恶意的用户可以轻松地使用这些开源法学硕士大规模生成有害文本和错误信息。为了缓解这个问题,需要一种计算方法来确定给定文本是否是深度伪造文本,即图灵测试 TT。特别是,在这项工作中,我们在多类设置中研究了该问题的更一般版本,称为 emph Authorship Attribution AA ,即不仅确定给定文本是否是深度伪造文本,而且还能够精确定位作者是哪个LLM。我们建议 textbf TopRoBERTa 通过在 RoBERTa 模型中包含拓扑数据分析 TDA 层来捕获 Deepfake 文本中的更多语言模式,从而改进现有的 AA 解决方案。我们通过从 RoBERTa 的重塑池化输出中提取 TDA 特征作为输入,展示了在处理噪声、不平衡和异构数据集时使用 TDA 层的好处。我们使用 RoBERTa 捕获上下文表示,即语义和句法语言特征,同时使用 TDA 捕获数据的形状和结构,即语言结构。 |
| On Separate Normalization in Self-supervised Transformers Authors Xiaohui Chen, Yinkai Wang, Yuanqi Du, Soha Hassoun, Li Ping Liu 变压器的自监督训练方法在各个领域都表现出了卓越的性能。以前基于变压器的模型,例如屏蔽自动编码器 MAE,通常对 CLS 符号和令牌使用单个归一化层。我们在本文中提出了一种简单的修改,对令牌和 CLS 符号采用单独的标准化层,以更好地捕获它们的独特特征并增强下游任务性能。我们的方法旨在减轻对两种令牌类型使用相同的标准化统计数据的潜在负面影响,这可能与它们各自的角色不最佳一致。我们凭经验表明,通过利用单独的归一化层,CLS 嵌入可以更好地编码全局上下文信息,并且在其各向异性空间中分布更均匀。 |
| ProtoEM: A Prototype-Enhanced Matching Framework for Event Relation Extraction Authors Zhilei Hu, Zixuan Li, Daozhu Xu, Long Bai, Cheng Jin, Xiaolong Jin, Jiafeng Guo, Xueqi Cheng 事件关系抽取ERE旨在抽取文本中事件之间的多种关系。然而,现有的方法将事件关系单独分类为不同的类别,这不足以捕捉这些关系的内在语义。为了全面理解它们的内在语义,在本文中,我们获得了每种类型事件关系的原型表示,并提出了一种原型增强匹配 ProtoEM 框架,用于联合提取多种事件关系。具体来说,ProtoEM通过两步方式提取事件关系,即原型表示和原型匹配。第一步,为了捕捉不同事件关系的内涵,ProtoEM利用例子来表示这些关系对应的原型。随后,为了捕获事件关系之间的相互依赖关系,它为与这些关系相对应的原型构建了依赖图,并利用基于图神经网络 GNN 的模块进行建模。在第二步中,它获得新事件对的表示,并计算它们与第一步中获得的原型的相似度,以评估它们属于哪种类型的事件关系。 |
| Affect Recognition in Conversations Using Large Language Models Authors Shutong Feng, Guangzhi Sun, Nurul Lubis, Chao Zhang, Milica Ga i 情感识别,包括情感、心情和感受,在人类交流中发挥着关键作用。在对话式人工智能领域,识别和响应人类情感线索的能力是创建引人入胜且富有同理心的互动的关键因素。这项研究深入研究了大型语言模型法学硕士在对话中识别人类影响的能力,重点关注开放领域的聊天对话和面向任务的对话。利用三个不同的数据集,即 IEMOCAP、EmoWOZ 和 DAIC WOZ(涵盖从休闲对话到临床访谈的一系列对话),我们评估并比较了法学硕士在情感识别方面的表现。我们的研究通过在上下文中学习 ICL 来探索法学硕士的零样本和少量样本能力,以及通过特定于任务的微调来探索其模型能力。此外,本研究还考虑了自动语音识别 ASR 错误对 LLM 预测的潜在影响。 |
| AnglE-Optimized Text Embeddings Authors Xianming Li, Jing Li 高质量文本嵌入对于改善语义文本相似性 STS 任务至关重要,而 STS 任务是大型语言模型 LLM 应用程序的关键组成部分。然而,现有文本嵌入模型面临的一个常见挑战是梯度消失问题,这主要是由于它们依赖于优化目标中的余弦函数,而该函数具有饱和区。为了解决这个问题,本文提出了一种新颖的角度优化文本嵌入模型,称为 AnglE。 AnglE的核心思想是在复杂空间中引入角度优化。这种新颖的方法有效地减轻了余弦函数中饱和区的不利影响,饱和区可能阻碍梯度并阻碍优化过程。为了建立全面的 STS 评估,我们对现有的短文本 STS 数据集和从 GitHub Issues 新收集的长文本 STS 数据集进行了实验。此外,我们使用有限的标记数据检查特定领域的 STS 场景,并探索 AnglE 如何与 LLM 带注释的数据一起工作。对各种任务进行了广泛的实验,包括短文本 STS、长文本 STS 和特定领域的 STS 任务。结果表明,AnglE 优于忽略余弦饱和区的最先进的 SOTA STS 模型。 |
| Domain Adaptation for Arabic Machine Translation: The Case of Financial Texts Authors Emad A. Alghamdi, Jezia Zakraoui, Fares A. Abanmy 神经机器翻译 NMT 在大规模语料库上训练时表现出了令人印象深刻的性能。然而,通用 NMT 系统在域外翻译方面表现不佳。为了缓解这个问题,最近提出了几种领域适应方法,这些方法通常比遗传 NMT 系统具有更好的翻译质量。虽然英语和其他欧洲语言的 NMT 不断取得进展,但阿拉伯语的领域适应在文献中却很少受到关注。因此,当前的研究旨在探索阿拉伯语 MT AMT 在尚未探索的领域金融新闻文章中的特定领域适应的有效性。为此,我们精心开发了金融领域阿拉伯语英语 AR EN 翻译的平行语料库,用于对不同领域适应方法进行基准测试。然后,我们在数据集上微调了几个预先训练的 NMT 和大型语言模型,包括 ChatGPT 3.5 Turbo。结果表明,仅使用域 AR EN 片段中的几个对齐良好的片段即可成功进行微调。基于自动和人工评估,ChatGPT 翻译的质量优于其他模型。据我们所知,这是第一个针对金融领域迁移学习微调 ChatGPT 的工作。 |
| StyloMetrix: An Open-Source Multilingual Tool for Representing Stylometric Vectors Authors Inez Okulska, Daria Stetsenko, Anna Ko os, Agnieszka Karli ska, Kinga G bi ska, Adam Nowakowski 这项工作旨在概述名为 StyloMetrix 的开源多语言工具。它提供涵盖语法、句法和词汇各个方面的文体文本表示。 StyloMetrix 涵盖四种语言:英语、乌克兰语和俄语,以波兰语为主要语言。每个特征的归一化输出可以成为机器学习模型的富有成果的课程,并且可以为任何深度学习算法的嵌入层提供有价值的补充。我们致力于对 StyloMetrix 向量的应用提供简洁而详尽的概述,并解释所开发的语言特征集。实验显示,使用随机森林分类器、投票分类器、逻辑回归等简单算法在监督内容分类方面取得了可喜的结果。深度学习评估揭示了 StyloMetrix 向量在增强从 Transformer 架构中提取的嵌入层方面的有用性。 |
| ChatPRCS: A Personalized Support System for English Reading Comprehension based on ChatGPT Authors Xizhe Wang, Yihua Zhong, Changqin Huang, Xiaodi Huang 阅读理解作为学习英语的常用方法,主要是阅读文章并回答相关问题。然而,设计有效练习的复杂性导致学生遇到标准化问题,使得与个性化学习者的阅读理解能力保持一致变得具有挑战性。通过利用以 ChatGPT 为代表的大型语言模型提供的先进功能,本文提出了一种基于最近发展区理论的新颖的个性化阅读理解支持系统,称为 ChatPRCS。 ChatPRCS采用阅读理解水平预测、问题生成、自动评估等方法来增强阅读理解教学。首先,我们开发了一种新算法,可以使用学习者的历史数据作为生成适当难度级别问题的基础来预测学习者的阅读理解能力。其次,提出了一系列新的 ChatGPT 提示模式来解决阅读理解目标问题生成和自动评估的两个关键方面。这些模式进一步提高了生成问题的质量。最后,结合个性化能力和阅读理解提示模式,通过实验对ChatPRCS进行了系统验证。 |
| Furthest Reasoning with Plan Assessment: Stable Reasoning Path with Retrieval-Augmented Large Language Models Authors Yin Zhu, Zhiling Luo, Gong Cheng 大型语言模型法学硕士充当强大的推理器和生成器,在各种自然语言任务(例如问答 QA)中表现出非凡的性能。在这些任务中,多跳问答 MHQA 是一个被广泛讨论的类别,需要法学硕士和外部知识检索之间的无缝集成。现有的方法利用LLM来生成推理路径和计划,并利用IR来迭代检索相关知识,但这些方法都存在固有的缺陷。一方面,Information Retriever IR 受到 LLM 生成的查询质量低下的阻碍。另一方面,LLM很容易被IR的不相关知识所误导。这些不准确之处是由 IR 和 LLM 之间的迭代交互所积累的,最终导致了有效性的灾难。为了克服上述障碍,在本文中,我们提出了一种新的 MHQA 管道,称为带有计划评估的最远推理 FuRePA,包括改进的最远推理框架和附加模块计划评估器。 1 最远推理通过屏蔽先前的推理路径并生成 LLM 查询来进行操作,鼓励 LLM 在每次迭代中从头开始生成思想链。这种方法使法学硕士能够打破以前的误导性想法和查询(如果有的话)所建立的束缚。 2 计划评估员是经过培训的评估员,从法学硕士提出的一组候选计划中选择合适的计划。 |
| Semantic similarity prediction is better than other semantic similarity measures Authors Steffen Herbold 自然语言文本之间的语义相似性通常通过查看子序列之间的重叠(例如 BLEU)或使用嵌入(例如 BERTScore、S BERT)来测量。在本文中,我们认为,当我们只对测量语义相似性感兴趣时,最好使用针对此类任务的微调模型直接预测相似性。 |
| JCoLA: Japanese Corpus of Linguistic Acceptability Authors Taiga Someya, Yushi Sugimoto, Yohei Oseki 神经语言模型在一系列下游任务中表现出了出色的性能。然而,人们对这些模型内化句法知识的程度了解有限,因此最近构建了各种数据集以促进跨语言的语言模型的句法评估。在本文中,我们介绍了 JCoLA 日语语言可接受性语料库,它由 10,020 个带有二元可接受性判断注释的句子组成。具体来说,这些句子是从语言学教科书、手册和期刊文章中手动提取的,并分为域内数据(从教科书和手册中提取的86个相对简单的可接受性判断)和域外数据(从期刊文章中提取的14个理论上重要的可接受性判断),后者是它按 12 种语言现象进行分类。然后,我们在 JCoLA 上评估 9 种不同类型的日语模型的句法知识。结果表明,一些模型可以超越人类在域内数据方面的表现,而没有模型能够在域外数据方面超越人类的表现。 |
| HRoT: Hybrid prompt strategy and Retrieval of Thought for Table-Text Hybrid Question Answering Authors Tongxu Luo, Fangyu Lei, Jiahe Lei, Weihao Liu, Shihu He, Jun Zhao, Kang Liu 回答有关给定表格和文本 TextTableQA 的混合内容的数字问题是一项具有挑战性的任务。最近,大型语言模型法学硕士在 NLP 社区中获得了极大的关注。随着大型语言模型的出现,上下文学习和思维链提示成为该领域两个特别热门的研究主题。在本文中,我们介绍了一种新的提示策略,称为混合提示策略和 TextTableQA 思想检索。通过In Context Learning,我们促使模型在处理混合数据时培养检索思维的能力。 |
| Decoding Affect in Dyadic Conversations: Leveraging Semantic Similarity through Sentence Embedding Authors Chen Wei Yu, Yun Shiuan Chuang, Alexandros N. Lotsos, Claudia M. Haase 自然语言处理 NLP 的最新进展凸显了句子嵌入在测量语义相似性方面的潜力。然而,它在分析现实世界的二元交互和预测对话参与者的影响方面的应用在很大程度上仍然是未知的。为了弥补这一差距,本研究利用 50 对已婚夫妇的口头对话来谈论冲突和愉快的活动。采用基于 Transformer 的模型(所有 MiniLM L6 v2)来获取每个说话者话语的嵌入。然后通过相邻话语嵌入之间的平均余弦相似度来量化对话的整体相似度。结果表明,语义相似性与妻子在冲突期间的影响呈正相关,但与愉快的谈话无关。此外,无论谈话类型如何,都没有观察到这种与丈夫情感的关联。两项验证检查进一步为相似性度量的有效性提供了支持,并表明观察到的模式不仅仅是数据的产物。 |
| Learning to Diversify Neural Text Generation via Degenerative Model Authors Jimin Hong, ChaeHun Park, Jaegul Choo 神经语言模型通常无法生成多样化且信息丰富的文本,从而限制了它们在现实世界问题中的适用性。虽然以前的方法提出通过识别和惩罚不良行为(例如重复、过度使用语言模型中的频繁单词)来解决这些问题,但我们提出了一种基于观察模型的替代方法,该方法主要学习可能导致退化问题的示例中的属性。基于这一观察,我们提出了一种通过训练两个模型来防止退化问题的新方法。具体来说,我们首先训练一个旨在放大不良模式的模型。然后,我们通过关注第一个模型无法学习的模式来增强第二个模型的多样性。 |
| Unlocking Model Insights: A Dataset for Automated Model Card Generation Authors Shruti Singh, Hitesh Lodwal, Husain Malwat, Rakesh Thakur, Mayank Singh 语言模型 LM 不再局限于 ML 社区,并且指令调整的 LM 导致了自主 AI 代理的兴起。随着 LM 的可访问性不断提高,对其功能、预期用途和开发周期的了解也势在必行。模型卡是记录有关 ML 模型的详细信息的一种流行做法。为了自动生成模型卡,我们引入了 25 个 ML 模型的 500 个问题答案对的数据集,涵盖了模型的关键方面,例如训练配置、数据集、偏差、架构细节和训练资源。我们聘请注释者从原始论文中提取答案。此外,我们通过回答问题来探索 LM 生成模型卡的能力。我们对 ChatGPT 3.5、LLaMa 和 Gactica 的初步实验表明,上述语言模型在理解研究论文以及生成事实文本响应方面存在显着差距。我们假设我们的数据集可用于训练模型,以自动从纸质文本生成模型卡,并减少模型卡管理过程中的人力。 |
| Is it Possible to Modify Text to a Target Readability Level? An Initial Investigation Using Zero-Shot Large Language Models Authors Asma Farajidizaji, Vatsal Raina, Mark Gales 文本简化是一项常见任务,其中对文本进行调整以使其更易于理解。同样,文本阐述可以使段落更加复杂,从而提供一种控制阅读理解测试复杂性的方法。然而,文本简化和阐述任务仅限于相对改变文本的可读性。将任何文本的可读性直接修改为绝对目标可读级别以迎合不同的受众是有用的。理想情况下,可读性受控的生成文本的可读性应该独立于源文本。因此,我们提出了一种新颖的可读性控制文本修改任务。该任务需要为每个输入文本生成不同目标可读级别的 8 个版本。我们引入了新颖的可读性控制文本修改指标。该任务的基线使用 ChatGPT 和 Llama 2,并采用扩展方法引入通过两次语言模型生成释义的两步过程。零样本方法能够将释义的可读性推向所需的方向,但最终的可读性仍然与原文的可读性相关。 |
| Automatic Answerability Evaluation for Question Generation Authors Zifan Wang, Kotaro Funakoshi, Manabu Okumura 传统的自动评估指标,例如 BLEU 和 ROUGE,是为自然语言生成 NLG 任务开发的,基于测量生成文本和参考文本之间的 n gram 重叠。这些简单的指标可能不足以完成更复杂的任务,例如问题生成 QG ,它需要生成可由参考答案回答的问题。因此,开发更复杂的自动评估指标仍然是 QG 研究中的一个紧迫问题。这项工作提出了一种基于 ANswerability PMAN 的提示指标,这是一种新颖的自动评估指标,用于评估生成的问题是否可以通过 QG 任务的参考答案来回答。大量实验证明其评估结果可靠且与人类评估一致。我们进一步应用我们的指标来评估 QG 模型的性能,这表明我们的指标补充了传统指标。 |
| Exploring the Impact of Training Data Distribution and Subword Tokenization on Gender Bias in Machine Translation Authors Bar Iluz, Tomasz Limisiewicz, Gabriel Stanovsky, David Mare ek 我们研究了机器翻译中标记化对性别偏见的影响,这一方面在以前的工作中很大程度上被忽视了。具体来说,我们关注训练数据中性别职业名称的频率、它们在子词分词器词汇表中的表示以及性别偏见之间的相互作用。我们观察到,职业名称的女性和非刻板性别变形,例如西班牙女医生的 Doctora 往往会被分成多个子词标记。我们的结果表明,模型训练语料库中性别形式的不平衡是造成性别偏见的主要因素,并且比子词分割的影响更大。我们表明,分析子词分割可以很好地估计训练数据中的性别形式不平衡,并且即使在语料库不公开的情况下也可以使用。 |
| Studying and improving reasoning in humans and machines Authors Nicolas Yax, Hernan Anll , Stefano Palminteri 在本研究中,我们使用一系列传统上致力于有限理性研究的认知心理学工具来研究和比较大型语言模型法学硕士和人类的推理。为此,我们向人类参与者和一系列经过预训练的法学硕士展示了经典认知实验的新变体,并交叉比较了他们的表现。我们的结果表明,大多数包含的模型都呈现出类似于那些经常归因于容易出错、基于启发式的人类推理的推理错误。尽管存在这种表面上的相似性,但人类和法学硕士之间的深入比较表明,人类推理与类似人类的推理存在重要差异,模型的局限性在最近的法学硕士版本中几乎完全消失。此外,我们表明,虽然可以设计出策略来提高表现,但人类和机器对相同的提示方案的反应并不相同。 |
| HANS, are you clever? Clever Hans Effect Analysis of Neural Systems Authors Leonardo Ranaldi, Fabio Massimo Zanzotto 指令调整的大型语言模型 It 法学硕士一直表现出出色的能力,可以推理所有相关人员的认知状态、意图和反应,让人类有效地指导和理解日常社交互动。事实上,已经提出了几个多项选择题 MCQ 基准来构建模型能力的可靠评估。然而,早期的工作证明了 It LLM 中存在固有的顺序偏差,这对适当的评估提出了挑战。在本文中,我们使用四个 MCQ 基准调查了 It LLM 对一系列探测测试的恢复能力。引入对抗性示例,我们显示出显着的性能差距,主要是在改变选择顺序时,这揭示了选择偏差并带来了讨论推理能力。由于位置偏差,根据第一位置和模型选择之间的相关性,我们假设 It LLM 的决策过程中存在结构启发式,并通过在少数镜头场景中包含重要示例来加强这一点。 |
| LongDocFACTScore: Evaluating the Factuality of Long Document Abstractive Summarisation Authors Jennifer A Bishop, Qianqian Xie, Sophia Ananiadou 保持事实一致性是抽象文本摘要中的一个关键问题,然而,它不能通过用于评估文本摘要的传统自动指标(例如 ROUGE 评分)来评估。最近的努力一直致力于开发改进的指标,以使用预先训练的语言模型来衡量事实一致性,但这些指标具有限制性的标记限制,因此不适合评估长文档文本摘要。此外,评估现有自动评估指标在应用于长文档数据集时是否适合目的的研究也很有限。在这项工作中,我们评估了自动指标在评估长文档文本摘要中事实一致性方面的有效性,并提出了一个新的评估框架 LongDocFACTScore。该框架允许度量扩展到任何长度的文档。当用于评估长文档摘要数据集时,该框架能够与人类的事实度量相关联,其性能优于现有的最先进的指标。此外,我们表明,当根据人类对短文档数据集事实一致性的衡量标准进行评估时,LongDocFACTScore 的性能可与最先进的指标相媲美。 |
| Foundation Metrics: Quantifying Effectiveness of Healthcare Conversations powered by Generative AI Authors Mahyar Abbasian, Elahe Khatibi, Iman Azimi, David Oniani, Zahra Shakeri Hossein Abad, Alexander Thieme, Zhongqi Yang, Yanshan Wang, Bryant Lin, Olivier Gevaert, Li Jia Li, Ramesh Jain, Amir M. Rahmani 生成人工智能将通过将传统的患者护理转变为更加个性化、高效和主动的流程来彻底改变医疗保健服务。聊天机器人作为交互式对话模型,可能会推动医疗保健领域以患者为中心的转型。通过提供各种服务,包括诊断、个性化生活方式建议和心理健康支持,目标是大幅改善患者的健康结果,同时减轻医疗保健提供者的工作负担。医疗保健应用程序的生命攸关性需要为对话模型建立一套统一且全面的评估指标。针对各种通用大语言模型法学硕士提出的现有评估指标表明,缺乏对医疗和健康概念及其在促进患者福祉方面的重要性的理解。此外,这些指标忽略了以用户为中心的关键方面,包括信任建立、道德、个性化、同理心、用户理解和情感支持。本文的目的是探索基于 LLM 的最先进的评估指标,这些指标特别适用于医疗保健中交互式对话模型的评估。随后,我们提出了一套全面的评估指标,旨在从最终用户的角度全面评估医疗保健聊天机器人的性能。这些指标包括对语言处理能力的评估、对现实世界临床任务的影响以及用户交互对话的有效性。 |
| Active Learning for Multilingual Fingerspelling Corpora Authors Shuai Wang, Eric Nalisnick 我们应用主动学习来帮助解决手语数据稀缺问题。特别是,我们对预训练的效果进行了新颖的分析。由于许多手语都是法语手语的语言后代,因此它们共享手部配置,预训练有望利用这一点。我们在美国、中国、德国和爱尔兰的手指拼写语料库上检验了这一假设。 |
| Can LLMs Augment Low-Resource Reading Comprehension Datasets? Opportunities and Challenges Authors Vinay Samuel, Houda Aynaou, Arijit Ghosh Chowdhury, Karthik Venkat Ramanan, Aman Chadha 大型语言模型法学硕士在各种 NLP 任务上展示了令人印象深刻的零样本性能,展示了推理和应用常识的能力。一个相关的应用是使用它们为下游任务创建高质量的合成数据集。在这项工作中,我们探讨了 GPT 4 是否可以用于增强现有的提取阅读理解数据集。自动化数据注释过程有可能节省手动标记数据集所需的大量时间、金钱和精力。在本文中,我们通过比较微调后的性能以及与注释相关的成本,评估了 GPT 4 作为人类注释器替代品在低资源阅读理解任务中的性能。这项工作是对法学硕士作为 QA 系统的合成数据增强器的首次分析,强调了独特的机遇和挑战。 |
| Dynamic ASR Pathways: An Adaptive Masking Approach Towards Efficient Pruning of A Multilingual ASR Model Authors Jiamin Xie, Ke Li, Jinxi Guo, Andros Tjandra, Yuan Shangguan, Leda Sari, Chunyang Wu, Junteng Jia, Jay Mahadeokar, Ozlem Kalinli 神经网络剪枝提供了一种有效的方法来压缩多语言自动语音识别 ASR 模型,同时性能损失最小。然而,它需要对每种语言进行多轮修剪和重新训练。在这项工作中,我们建议在两种情况下使用自适应掩蔽方法来有效地修剪多语言 ASR 模型,每种情况都会产生稀疏单语言模型或稀疏多语言模型,称为动态 ASR 路径。我们的方法动态地适应子网络,避免了关于固定子网络结构的过早决策。我们表明,在针对稀疏单语言模型时,我们的方法优于现有的修剪方法。 |
| Wordification: A New Way of Teaching English Spelling Patterns Authors Lexington Whalen, Nathan Bickel, Shash Comandur, Dalton Craven, Stanley Dubinsky, Homayoun Valafar 识字能力,或者说读写能力,是生活和社会成功的关键指标。据估计,青少年犯罪系统中的 85 人无法充分阅读或写作,超过一半有药物滥用问题的人在阅读或写作方面存在困难,三分之二未完成高中学业的人缺乏适当的识字技能。此外,到四年级时不具备与年级水平相匹配的阅读技能的幼儿大约有 80 岁可能根本跟不上。许多人可能认为,在美国这样的发达国家,识字率并不是一个问题,然而,这是一个危险的误解。据估计,全球每年因扫盲问题造成的损失为 1.19 万亿美元,其中美国的损失估计为 3000 亿美元。更令人震惊的是,五分之一的美国成年人仍然无法理解基本句子。更糟糕的是,现在纠正阅读和写作能力缺陷的唯一可用工具是昂贵的辅导或其他项目,而这些项目往往无法吸引所需的受众。在本文中,我们团队提出了一种在美国Wordification中向小学生教授英语拼写和单词识别的新方法。 |
| Synthetic Boost: Leveraging Synthetic Data for Enhanced Vision-Language Segmentation in Echocardiography Authors Rabin Adhikari, Manish Dhakal, Safal Thapaliya, Kanchan Poudel, Prasiddha Bhandari, Bishesh Khanal 准确的分割对于基于超声心动图的心血管疾病CVD评估至关重要。然而,超声医师之间的差异和超声图像固有的挑战阻碍了精确分割。通过利用图像和文本模式的联合表示,视觉语言分割模型 VLSM 可以整合丰富的上下文信息,可能有助于准确且可解释的分割。然而,缺乏现成的超声心动图数据阻碍了 VLSM 的训练。在本研究中,我们探索使用语义扩散模型 SDM 的合成数据集来增强用于超声心动图分割的 VLSM。我们使用从多个属性派生的七种不同类型的语言提示来评估两种流行的 VLSM CLIPSeg 和 CRIS 的结果,这些属性是从超声心动图图像、分割掩模及其元数据中自动提取的。我们的结果表明,在对真实图像进行微调之前,在 SDM 生成的合成图像上预训练 VLSM 时,指标会得到改进,收敛速度会更快。 |
| Reduce, Reuse, Recycle: Is Perturbed Data better than Other Language augmentation for Low Resource Self-Supervised Speech Models Authors Asad Ullah, Alessandro Ragano, Andrew Hines 与监督模型相比,自监督表示学习 SSRL 提高了下游音素识别的性能。训练 SSRL 模型需要大量的预训练数据,这对资源匮乏的语言提出了挑战。一种常见的方法是从其他语言转移知识。相反,我们建议使用音频增强在低资源条件下预训练 SSRL 模型,并将音素识别作为下游任务进行评估。我们对增强技术进行了系统比较,即音高变化、噪声添加、带口音的目标语言语音和其他语言语音。我们发现组合增强噪声音调是优于口音和语言知识迁移的最佳增强策略。我们将性能与不同数量和类型的预训练数据进行了比较。我们检查了增强数据的缩放因子,以实现与使用目标域语音预训练的模型等效的性能。 |
| In-context Interference in Chat-based Large Language Models Authors Eric Nuertey Coleman, Julio Hurtado, Vincenzo Lomonaco 大型语言模型法学硕士因其令人印象深刻的能力和广博的世界知识而对社会产生了巨大影响。人们已经创建了各种应用程序和工具,允许用户在黑盒场景中与这些模型进行交互。然而,这种场景的一个限制是用户无法修改模型的内部知识,并且添加或修改内部知识的唯一方法是在当前交互期间向模型显式提及它。这种学习过程称为上下文训练,是指仅限于用户当前会话或上下文的训练。在情境中学习具有重要的应用,但也有很少研究的局限性。在本文中,我们提出了一项研究,展示了模型如何受到上下文中不断流动的信息之间的干扰,导致其忘记以前学到的知识,从而降低模型的性能。 |
| AMPLIFY:Attention-based Mixup for Performance Improvement and Label Smoothing in Transformer Authors Leixin Yang, Yaping Zhang, Haoyu Xiong, Yu Xiang Mixup是一种有效的数据增强方法,通过聚合不同原始样本的线性组合来生成新的增强样本。然而,如果原始样本中存在噪声或异常特征,Mixup 可能会将它们传播到增强样本中,导致模型对这些异常值过于敏感。为了解决这个问题,本文提出了一种新的 Mixup 方法,称为 AMPLIFY。该方法利用Transformer本身的Attention机制,减少原始样本中的噪声和异常值对预测结果的影响,无需增加额外的可训练参数,且计算成本很低,从而避免了预测中资源消耗高的问题。常见的 Mixup 方法如 Sentence Mixup 。实验结果表明,在较小的计算资源成本下,AMPLIFY在7个基准数据集上的文本分类任务中优于其他Mixup方法,为进一步提高基于Attention机制的预训练模型的性能提供了新思路和新方法,例如伯特、阿尔伯特、罗伯塔和 GPT。 |
| Construction contract risk identification based on knowledge-augmented language model Authors Saika Wong, Chunmo Zheng, Xing Su, Yinqiu Tang 合同审查是建设项目中防止潜在损失的重要步骤。然而,目前审查施工合同的方法缺乏有效性和可靠性,导致流程耗时且容易出错。虽然大型语言模型法学硕士在彻底改变自然语言处理 NLP 任务方面表现出了希望,但他们在特定领域知识和解决专门问题方面遇到了困难。本文提出了一种新颖的方法,利用具有建筑合同知识的法学硕士来模拟人类专家的合同审查过程。我们的免调优方法结合了施工合同领域知识,以增强用于识别施工合同风险的语言模型。构建领域知识库时使用自然语言有助于实际实施。我们在真实的建筑合同中评估了我们的方法并取得了良好的效果。 |
| DRG-LLaMA : Tuning LLaMA Model to Predict Diagnosis-related Group for Hospitalized Patients Authors Hanyin Wang, Chufan Gao, Christopher Dantona, Bryan Hull, Jimeng Sun 在美国住院支付系统中,诊断相关组 DRG 发挥着关键作用,但其当前的分配流程非常耗时。我们引入了 DRG LLaMA,这是一个大型语言模型 LLM,根据临床记录进行微调,以改进 DRG 预测。使用 Meta s LLaMA 作为基础模型,我们使用低秩适应 LoRA 对 236,192 个 MIMIC IV 放电摘要进行优化。输入令牌长度为 512 时,DRG LLaMA 7B 的宏观平均 F1 得分为 0.327,top 1 预测精度为 52.0,宏观平均曲线下面积 AUC 为 0.986。令人印象深刻的是,DRG LLaMA 7B 在这项任务上超越了之前报道的领先模型,表明与 ClinicalBERT 相比,宏观平均 F1 分数相对提高了 40.3,与 CAML 相比提高了 35.7。当应用 DRG LLaMA 来预测基本 DRG 和并发症或合并症 CC 主要并发症或合并症 MCC 时,基本 DRG 的 top 1 预测精度达到 67.8,CC MCC 状态的前 1 预测精度达到 67.5。 DRG LLaMA 性能表现出与较大模型参数和较长输入上下文长度相关的改进。 |
| Creativity Support in the Age of Large Language Models: An Empirical Study Involving Emerging Writers Authors Tuhin Chakrabarty, Vishakh Padmakumar, Faeze Brahman, Smaranda Muresan 能够遵循指令并参与对话交互的大型语言模型的开发激发了法学硕士在各种支持工具中的使用的兴趣。我们通过实证用户研究 n 30 调查现代法学硕士在协助专业作家方面的效用。我们的协作写作界面的设计基于写作的认知过程模型,该模型将写作视为一种面向目标的思维过程,包括非线性认知活动规划、翻译和审阅。参与者被要求提交一份完成后调查,以提供有关法学硕士作为写作合作者的潜力和陷阱的反馈。通过分析作家法学硕士的互动,我们发现虽然作家在所有三种类型的认知活动中寻求法学硕士的帮助,但他们发现法学硕士在翻译和审校方面更有帮助。 |
| PlanFitting: Tailoring Personalized Exercise Plans with Large Language Models Authors Donghoon Shin, Gary Hsieh, Young Ho Kim 个人定制的锻炼方案对于确保足够的身体活动至关重要,但由于人们有复杂的日程安排和考虑因素,而且制定计划通常需要与专家反复讨论,因此制定起来具有挑战性。我们推出 PlanFitting,这是一种对话式人工智能,可帮助制定个性化锻炼计划。利用大型语言模型的生成能力,PlanFitting 使用户能够用自然语言描述各种约束和查询,从而有助于创建和完善他们的每周锻炼计划,以适应他们的具体情况,同时坚持基本原则。通过一项用户研究,参与者 N 18 使用 PlanFitting 生成个性化锻炼计划,专家规划者 N 3 评估这些计划,我们确定了 PlanFitting 在生成个性化、可操作且基于证据的锻炼计划方面的潜力。 |
| Knowledge Graph Embedding: An Overview Authors Xiou Ge, Yun Cheng Wang, Bin Wang, C. C. Jay Kuo 许多数学模型已被用来设计嵌入来表示知识图谱知识图谱实体和链接预测和许多下游任务的关系。这些受数学启发的模型不仅对于大型知识图谱的推理具有高度的可扩展性,而且在建模不同的关系模式方面具有许多可解释的优势,可以通过形式证明和经验结果进行验证。在本文中,我们对知识图谱补全的研究现状进行了全面的概述。特别是,我们关注 KG 嵌入 KGE 设计的两个主要分支:1 基于距离的方法和 2 基于语义匹配的方法。我们发现了最近提出的模型之间的联系,并提出了一个潜在趋势,可能有助于研究人员发明新颖且更有效的模型。接下来,我们深入研究CompoundE和CompoundE3D,它们分别从2D和3D仿射运算中汲取灵感。它们涵盖了广泛的技术,包括基于距离和基于语义的方法。 |
| Multimodal Deep Learning for Scientific Imaging Interpretation Authors Abdulelah S. Alshehri, Franklin L. Lee, Shihu Wang 在科学成像领域,解释视觉数据通常需要人类专业知识和对主题材料的深入理解的复杂结合。这项研究提出了一种新颖的方法,可以在语言上模拟并随后评估与扫描电子显微镜 SEM 图像(特别是玻璃材料)的类人交互。利用多模式深度学习框架,我们的方法从同行评审文章中收集的文本和视觉数据中提取见解,并通过 GPT 4 的精细数据合成和评估功能进一步增强。尽管存在诸如细致入微的解释和专业数据集的有限可用性等固有的挑战,但我们的模型 GlassLLaVA 在制定准确的解释、识别关键特征以及检测以前未见过的 SEM 图像中的缺陷方面表现出色。此外,我们引入了适用于一系列科学成像应用的多功能评估指标,可以根据基于研究的答案进行基准测试。受益于当代大型语言模型的稳健性,我们的模型巧妙地与研究论文的见解相一致。 |
| Constraints First: A New MDD-based Model to Generate Sentences Under Constraints Authors Alexandre Bonlarron, Aur lie Calabr se, Pierre Kornprobst, Jean Charles R gin 本文介绍了一种生成强约束文本的新方法。我们考虑视力筛查的典型应用的标准化句子生成。为了解决这个问题,我们将其形式化为离散组合优化问题,并利用多值决策图 MDD(一种众所周知的数据结构来处理约束)。在我们的上下文中,MDD 的一个关键优势是无需执行任何搜索即可计算一组详尽的解决方案。获得句子后,我们应用语言模型 GPT 2 来保留最好的句子。我们针对英语和法语详细介绍了这一点,众所周知,法语中的协议和词形变化规则更为复杂。最后,在 GPT 2 的帮助下,我们得到了数百个真正的候选句子。与众所周知的视力筛查测试 MNREAD 中通常可用的几十个句子相比,这在标准化句子生成领域带来了重大突破。此外,由于它可以轻松适应其他语言,因此有可能使 MNREAD 测试更有价值和更有用。 |
| Examining the Influence of Varied Levels of Domain Knowledge Base Inclusion in GPT-based Intelligent Tutors Authors Blake Castleman, Mehmet Kerem Turkcan 大型语言模型法学硕士的最新进展促进了具有复杂对话功能的聊天机器人的开发。然而,法学硕士经常对查询做出不准确的反应,阻碍了在教育环境中的应用。在本文中,我们研究了将知识库 KB 与 LLM 智能导师集成以提高响应可靠性的有效性。为了实现这一目标,我们设计了一个可扩展的知识库,为教育主管提供课程课程的无缝集成,并由智能辅导系统自动处理。然后,我们详细介绍了一项评估,向学生参与者提出有关人工智能课程的问题以供回答。然后,具有不同知识库访问层次结构的 GPT 4 智能导师和人类领域专家评估了这些响应。最后,学生们交叉检查了智能导师对领域专家的反应,并对他们的各种教学能力进行了排名。结果表明,尽管与领域专家相比,这些智能导师的准确性仍然较低,但当授予知识库访问权限时,智能导师的准确性会提高。 |
| ChatGPT Assisting Diagnosis of Neuro-ophthalmology Diseases Based on Case Reports Authors Yeganeh Madadi, Mohammad Delsoz, Priscilla A. Lao, Joseph W. Fong, TJ Hollingsworth, Malik Y. Kahook, Siamak Yousefi 目的 评估 ChatGPT 等大型语言模型法学硕士根据详细病例描述辅助诊断神经眼科疾病的效率。方法 我们从公开的在线数据库中选择了 22 份不同的神经眼科疾病病例报告。这些病例包括神经眼科专科医生常见的各种慢性和急性疾病。我们将每个案例的文本作为新提示插入 ChatGPT v3.5 和 ChatGPT Plus v4.0 中,并询问最可能的诊断。然后,我们向两位神经眼科医生提供了准确的信息并记录了他们的诊断,然后与两个版本的 ChatGPT 的响应进行比较。结果 ChatGPT v3.5、ChatGPT Plus v4.0 和两位神经眼科医生在 22 例病例中分别正确了 13 59 、18 82 、19 86 和 19 86 。各种诊断源之间的一致性如下 ChatGPT v3.5 和 ChatGPT Plus v4.0、13 59 ChatGPT v3.5 和第一位神经眼科医生 12 55 ChatGPT v3.5 和第二位神经眼科医生 12 55 ChatGPT Plus v4 .0 和第一位神经眼科医生,17 77 ChatGPT Plus v4.0 和第二位神经眼科医生,16 73 以及第一和第二神经眼科医生 17 17 .结论 ChatGPT v3.5和ChatGPT Plus v4.0诊断神经眼科疾病的准确率分别为59和82。随着进一步的发展,ChatGPT Plus v4.0 可能有潜力用于临床护理环境,以协助临床医生为神经眼科患者提供快速、准确的诊断。 |
| Efficient Social Choice via NLP and Sampling Authors Lior Ashkenazy, Nimrod Talmon 注意意识社会选择解决了一些代理社区所面临的根本冲突,即他们希望让所有成员参与决策过程,但社区成员可支配的时间和注意力有限。在这里,我们研究了两种用于注意感知社会选择的技术的组合,即自然语言处理 NLP 和采样。本质上,我们提出了一个系统,其中每个改变现状的治理提案首先被发送到经过训练的 NLP 模型,该模型估计如果所有社区成员直接投票该提案将通过的概率,然后根据这样的估计,选择一定规模的总体样本,并通过样本多数决定提案。 |
| Cultural Alignment in Large Language Models: An Explanatory Analysis Based on Hofstede's Cultural Dimensions Authors Reem I. Masoud, Ziquan Liu, Martin Ferianc, Philip Treleaven, Miguel Rodrigues 大型语言模型法学硕士的部署引起了人们对其文化错位以及对来自不同文化规范的个人的潜在影响的担忧。现有的工作调查政治和社会偏见以及公众舆论,而不是其文化价值观。为了解决这一限制,提出的文化一致性测试 CAT 使用 Hofstede 的文化维度框架量化文化一致性,该框架通过潜在变量分析提供解释性的跨文化比较。我们应用我们的方法来评估最先进的法学硕士(例如 ChatGPT 和 Bard)中嵌入的文化价值观,这些价值观跨越美国、沙特阿拉伯、中国和斯洛伐克等国家的不同文化,使用不同的提示风格和超参数设置。我们的结果不仅量化了法学硕士与某些国家的文化一致性,而且揭示了法学硕士之间在解释性文化维度上的差异。 |
| Considerations for health care institutions training large language models on electronic health records Authors Weipeng Zhou, Danielle Bitterman, Majid Afshar, Timothy A. Miller 像 ChatGPT 这样的大型语言模型法学硕士让医学领域的科学家们兴奋不已,兴奋的来源之一是受电子健康记录 EHR 数据训练的法学硕士的潜在应用。但是,我们必须首先回答一些棘手的问题,如果医疗保健机构有兴趣让法学硕士使用自己的数据进行培训,他们应该从头开始培训法学硕士还是从开源模型对其进行微调对于具有预定义预算的医疗机构来说,哪些是他们能负担得起的最大的法学硕士在这项研究中,我们通过分析数据集大小、模型大小和使用 EHR 数据进行法学硕士培训的成本,采取措施回答这些问题。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com
相关文章:
【AI视野·今日NLP 自然语言处理论文速览 第四十期】Mon, 25 Sep 2023
AI视野今日CS.NLP 自然语言处理论文速览 Mon, 25 Sep 2023 Totally 46 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers ReConcile: Round-Table Conference Improves Reasoning via Consensus among Diverse LLMs Authors Justin C…...
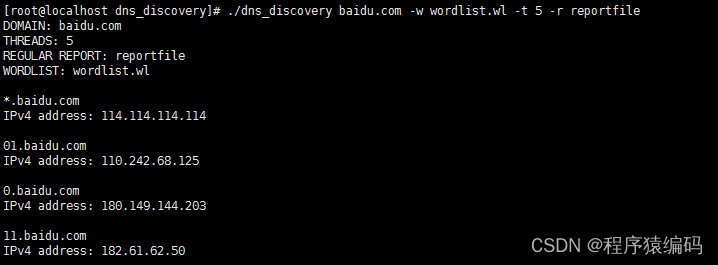
Linux C/C++下收集指定域名的子域名信息(类似dnsmap实现)
我们知道dnsmap是一个工具,主要用于收集指定域名的子域名信息。它对于渗透测试人员在基础结构安全评估的信息收集和枚举阶段非常有用,可以帮助他们发现目标公司的IP网络地址段、域名等信息。 dnsmap的操作原理 dnsmap(DNS Mappingÿ…...
linux-定时任务
目录 一、crond命令 1、什么是计划任务 2、crond服务的概念 3、crontab 二、at命令 1、at任务的概念 三、邮件服务 1、概念 2、启动postfix 四、mailx命令 1、三个概念: 2、交互式发邮件 3、非交互式发邮件 四、cron定时任务实践 1、系统定时任务配置…...

在Spring Boot项目中使用Redisson
在Spring Boot项目中使用Redisson Redisson简介 Redisson官网仓库 Redisson中文文档 Redission是一个基于Java的分布式缓存和分布式任务调度框架,用于处理分布式系统中的缓存和任务队列。它是一个开源项目,旨在简化分布式系统的开发和管理。 以下是…...
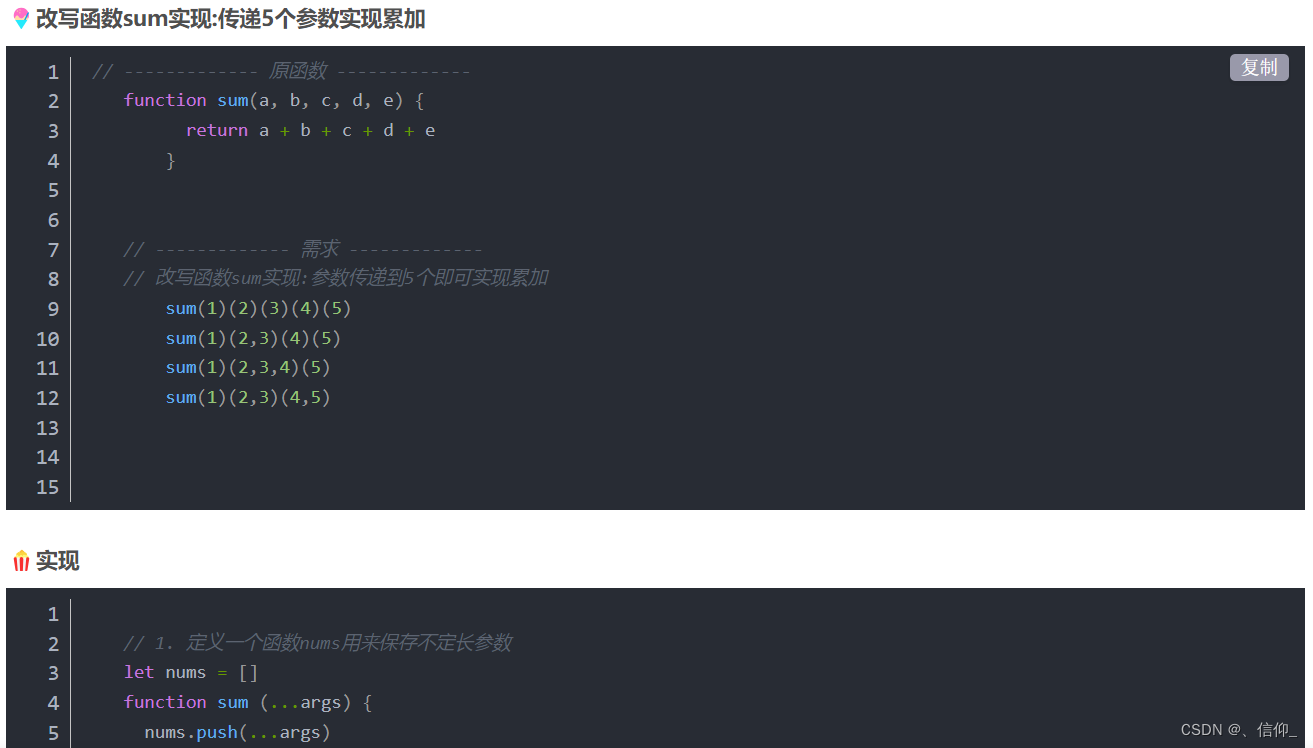
JavaScript 函数柯里化
🎶什么是柯里化 柯里化(Currying)是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数且返回结果的新函数的技术。 🎡简单的函数柯里化的实现 // ------------- 原函数…...
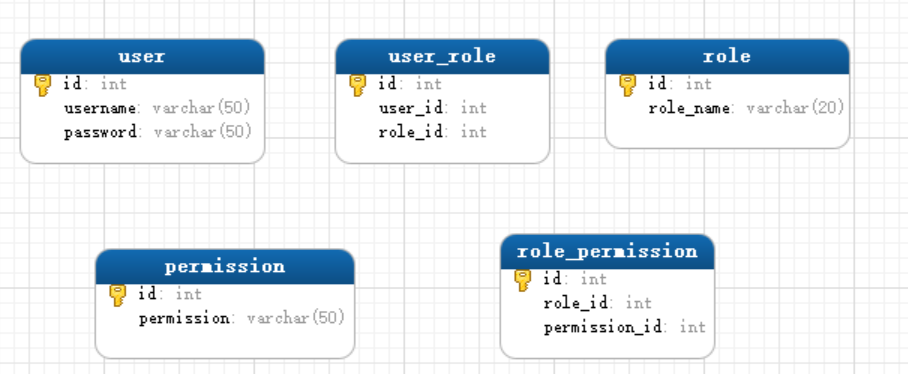
springboot实现ACL+RBAC权限体系
本文基于web系统的权限控制非常重要的前提下,从ALC和RBAC权限控制两个方面,介绍如何在springboot项目中实现一个完整的权限体系。 源码下载 :https://gitee.com/skyblue0678/springboot-demo 序章 一个后台管理系统,基本都有一套…...

C++20协程示例
C20协程示例 认识协程 在C中,协程就是一个可以暂停和恢复的函数。 包含co_wait、co_yield、co_return关键字的都可以叫协程。 看一个例子: MyCoroGenerator<int> testFunc(int n) {std::cout << "Begin testFunc" << s…...
【Verilog 教程】6.2Verilog任务
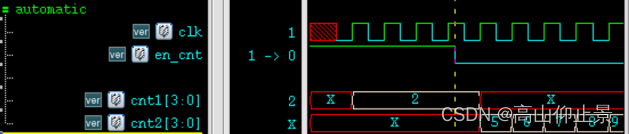
关键词:任务 任务与函数的区别 和函数一样,任务(task)可以用来描述共同的代码段,并在模块内任意位置被调用,让代码更加的直观易读。函数一般用于组合逻辑的各种转换和计算,而任务更像一个过程&a…...
Spring修炼之路(1)基础入门
一、简介 1.1Spring概述 Spring框架是一个轻量级的Java开发框架,它提供了一系列底层容器和基础设施,并可以和大量常用的开源框架无缝集成,可以说是开发Java EE应用程序的必备。Spring是一个轻量级的控制反转(IoC)和面向切面(AOP)的容器&…...

GANs学习记录
GAN 基于GAN的研究识别相关不同背景目标图像 可以用Augmentation2021.3.15 基于GAN的研究 是通过GAN 进行图像重建,恢复细节,去模糊,提高图像质量,图像还原,去噪等等。 识别相关 一种基于生成对抗网络的训练样本扩充…...

Flink-CDC——MySQL、SqlSqlServer、Oracle、达梦等数据库开启日志方法
目录 1. 前言 2. 数据源安装与配置 2.1 MySQL 2.1.1 安装 2.1.2 CDC 配置 2.2 Postgresql 2.2.1 安装 2.2.2 CDC 配置 2.3 Oracle 2.3.1 安装 2.3.2 CDC 配置 2.4 SQLServer 2.4.1 安装 2.4.2 CDC 配置 2.5达梦 2.4.1安装 2.4.2CDC配置 3. 验证 3.1 Flink版…...

linux设置tomcat redis开机自启动
设置Tomcat自启动 1.修改 /etc/rc.d/rc.local 文件 [rootiowZ]# vim /etc/rc.d/rc.local在/etc/rc.d/rc.local文件最后加上: export JAVA_HOME/usr/local/jdk /usr/local/apache-tomcat-8.5.73/bin/startup.sh start退出vim并保存修改的文件。 说明:/u…...

跨域问题讨论
问题 跨域定义 当一个请求url的协议、域名、端口三者之间任意一个与当前页面地址不同即为跨域。 跨域的安全隐患(CSRF攻击) 也就是说,一旦允许跨域,意味着允许恶意网站随意攻击可信网站,带来安全风险。 这里面有一…...

ESP32设备通信-两个ESP32设备之间HTTP通信
两个ESP32设备之间HTTP通信 文章目录 两个ESP32设备之间HTTP通信1、应用介绍2、软件准备3、硬件准备4、代码实现4.1 ESP32服务器节点代码4.2 ESP32客户端节点代码在本文中,我们将介绍如何在没有任何物理路由器或互联网连接的情况下使用 Wi-Fi 在两个 ESP32 开发板之间执行无线…...
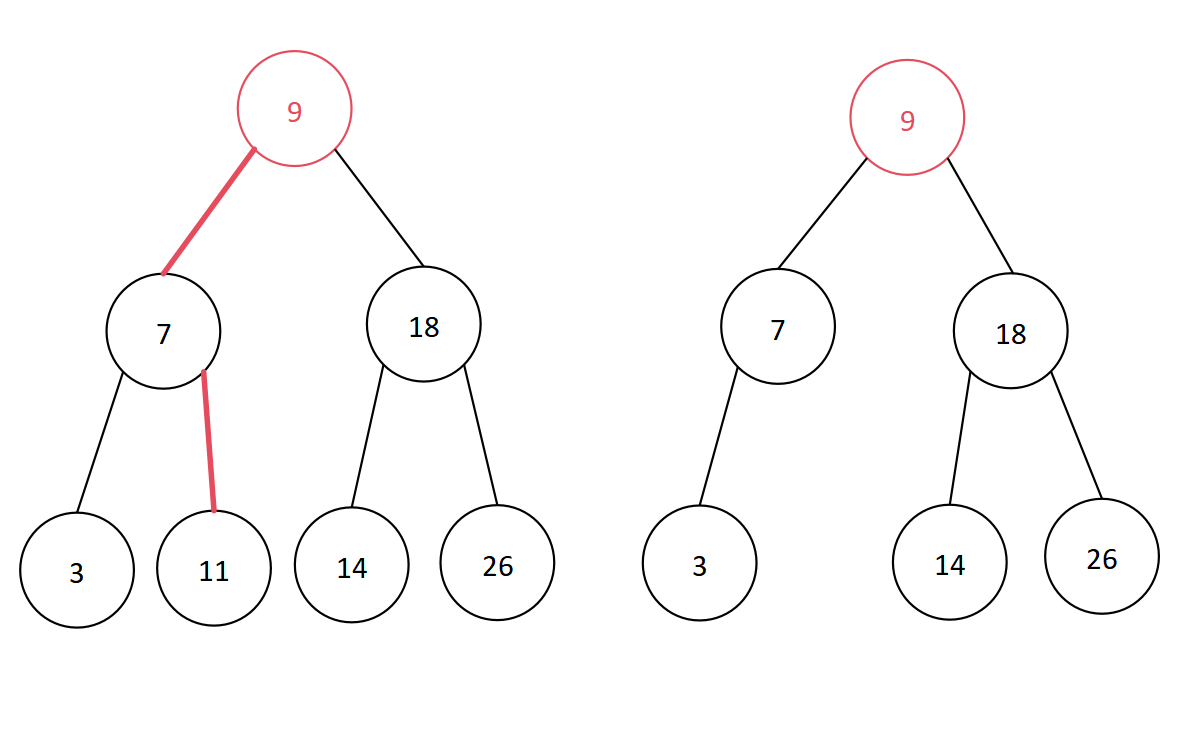
数据结构学习笔记——查找算法中的树形查找(平衡二叉树)
目录 一、平衡二叉树的定义二、平衡因子三、平衡二叉树的插入和构造(一)LL型旋转(二)LR型旋转(三)RR型旋转(四)RL型旋转 四、平衡二叉树的删除(一)叶子结点&a…...

P1830 轰炸III
题目背景 一个大小为 ��nm 的城市遭到了 �x 次轰炸,每次都炸了一个每条边都与边界平行的矩形。 题目描述 在轰炸后,有 �y 个关键点,指挥官想知道,它们有没有受到过轰炸,如…...

大语言模型LLM知多少?
你知道哪些流行的大语言模型?你都体验过哪写? GPT-4,Llamma2, T5, BERT 还是 BART? 1.GPT-4 1.1.GPT-4 模型介绍 GPT-4(Generative Pre-trained Transformer 4)是由OpenAI开发的一种大型语言模型。GPT-4是前作GPT系列模型的进一步改进,旨在提高语言理解和生成的能力,…...

Redis命令行使用Lua脚本
Redis命令行使用Lua脚本 Lua脚本在Redis中的使用非常有用,它允许你在Redis服务器上执行自定义脚本,可以用于复杂的数据处理、原子性操作和执行多个Redis命令。以下是Lua脚本在Redis中的基本使用详细讲解: 运行Lua脚本: 在Redis中…...

HTML详细基础(三)表单控件
本帖介绍web开发中非常核心的标签——表格标签。 在日常我们使用到的各种需要输入用户信息的场景——如下图,均是通过表格标签table创造出来的: 目录 一.表格标签 二.表格属性 三.合并单元格 四.无序列表 五.有序列表 六.自定义标签 七.表单域 …...
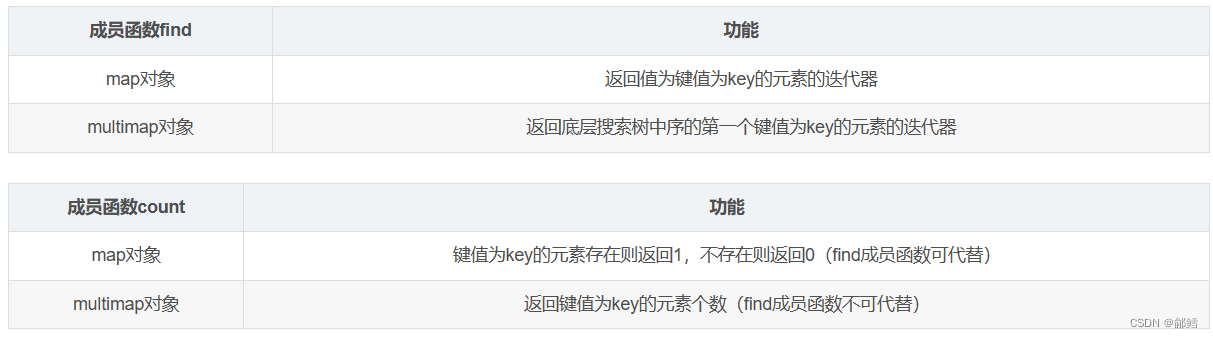
map和set的具体用法 【C++】
文章目录 关联式容器键值对setset的定义方式set的使用 multisetmapmap的定义方式insertfinderase[]运算符重载map的迭代器遍历 multimap 关联式容器 关联式容器里面存储的是<key, value>结构的键值对,在数据检索时比序列式容器效率更高。比如:set…...

【OSG学习笔记】Day 18: 碰撞检测与物理交互
物理引擎(Physics Engine) 物理引擎 是一种通过计算机模拟物理规律(如力学、碰撞、重力、流体动力学等)的软件工具或库。 它的核心目标是在虚拟环境中逼真地模拟物体的运动和交互,广泛应用于 游戏开发、动画制作、虚…...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...

中南大学无人机智能体的全面评估!BEDI:用于评估无人机上具身智能体的综合性基准测试
作者:Mingning Guo, Mengwei Wu, Jiarun He, Shaoxian Li, Haifeng Li, Chao Tao单位:中南大学地球科学与信息物理学院论文标题:BEDI: A Comprehensive Benchmark for Evaluating Embodied Agents on UAVs论文链接:https://arxiv.…...

FastAPI 教程:从入门到实践
FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API,支持 Python 3.6。它基于标准 Python 类型提示,易于学习且功能强大。以下是一个完整的 FastAPI 入门教程,涵盖从环境搭建到创建并运行一个简单的…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...

【OSG学习笔记】Day 16: 骨骼动画与蒙皮(osgAnimation)
骨骼动画基础 骨骼动画是 3D 计算机图形中常用的技术,它通过以下两个主要组件实现角色动画。 骨骼系统 (Skeleton):由层级结构的骨头组成,类似于人体骨骼蒙皮 (Mesh Skinning):将模型网格顶点绑定到骨骼上,使骨骼移动…...

免费PDF转图片工具
免费PDF转图片工具 一款简单易用的PDF转图片工具,可以将PDF文件快速转换为高质量PNG图片。无需安装复杂的软件,也不需要在线上传文件,保护您的隐私。 工具截图 主要特点 🚀 快速转换:本地转换,无需等待上…...

【Linux】自动化构建-Make/Makefile
前言 上文我们讲到了Linux中的编译器gcc/g 【Linux】编译器gcc/g及其库的详细介绍-CSDN博客 本来我们将一个对于编译来说很重要的工具:make/makfile 1.背景 在一个工程中源文件不计其数,其按类型、功能、模块分别放在若干个目录中,mak…...
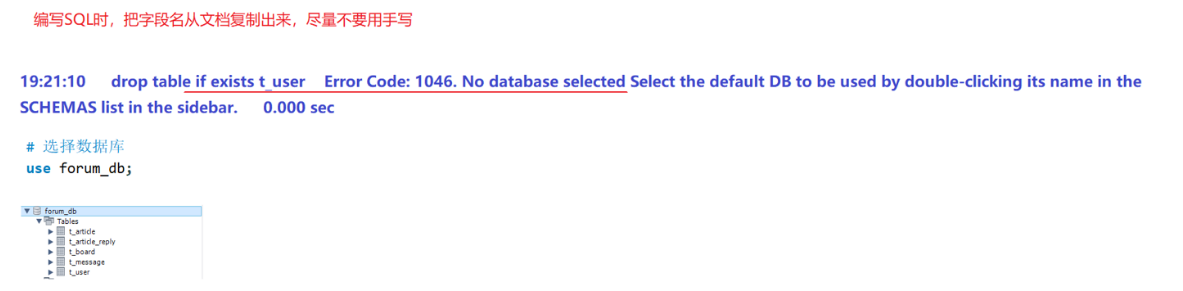
篇章二 论坛系统——系统设计
目录 2.系统设计 2.1 技术选型 2.2 设计数据库结构 2.2.1 数据库实体 1. 数据库设计 1.1 数据库名: forum db 1.2 表的设计 1.3 编写SQL 2.系统设计 2.1 技术选型 2.2 设计数据库结构 2.2.1 数据库实体 通过需求分析获得概念类并结合业务实现过程中的技术需要&#x…...

OCR MLLM Evaluation
为什么需要评测体系?——背景与矛盾 能干的事: 看清楚发票、身份证上的字(准确率>90%),速度飞快(眨眼间完成)。干不了的事: 碰到复杂表格(合并单元…...