一键智能视频语音转文本——基于PaddlePaddle语音识别与Python轻松提取视频语音并生成文案
前言
如今进行入自媒体行业的人越来越多,短视频也逐渐成为了主流,但好多时候是想如何把视频里面的语音转成文字,比如,录制会议视频后,做会议纪要;比如,网课教程视频,想要做笔记;比如,需要提取视频中文案使用;比如,需要给视频加个字幕;这时候,只要把视频转文字就好。
对于不是视频编辑专业人员,处理起来还是比较麻烦的,但网上也有好多可以用的小工具,这些工具大多数都标榜有自己技术和模型,但都是在线模型或者使用过一段时间之后就无法再使用了,这些工具实际上都是基于一些大公司提供的接口衍生出来的AI工具,使用效果也不错。但在处理的过程中,处理的文件要上传到大公司的服务器进行处理,这里可能会涉及到一些数据的安全问题。这些数据很大一部分有可能会涉及到数据泄露与安全的问题。
这个项目的核心算法是基于PaddlePaddle的语音识别加Python实现,使用的模型可以有自己训练,支持本地部署,支持GPU与CPU推理两种文案,可以处理短语音识别、长语音识别、实现输入的语音识别。
一、视频语音提取
想要把视频里面的语音进行识别,首先要对视频里面的语音进行提取,提取视频里的语音有很多用办法,可以借助视频编辑软件(如Adobe Premiere Pro、Final Cut Pro)中提取音频轨道,然后将其导出为音频文件。 也可以借助工具如FFmpeg或者moviepy,通过命令行将视频中的音频提取出来。
这里使用moviepy对视频里面的语音进行提取,MoviePy是一个功能丰富的Python模块,专为视频编辑而设计。使用MoviePy,可以轻松执行各种基本视频操作,如视频剪辑、视频拼接、标题插入等。此外,它还支持视频合成和高级视频处理,甚至可以添加自定义高级特效。这个模块可以读写绝大多数常见的视频格式,包括GIF。无论使用的是Mac、Windows还是Linux系统,MoviePy都能无缝运行,可以在不同平台上使用它。
MoviePy与FFmpeg环境安装:
pip install moviepy
pip install ffmpeg
因为使用moviepy提取出视频里面的音轨的比特率不是16000,不能直接输入到语音识别模型里面,这里还要借助FFmpeg的命来把音频采样率转成16000
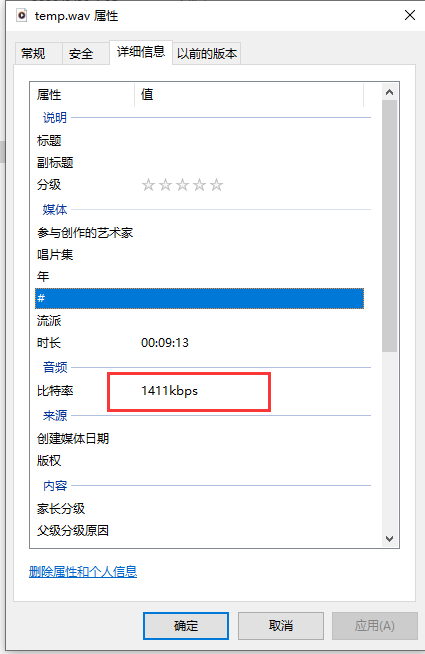
提取音轨:
def video_to_audio(video_path,audio_path):video = VideoFileClip(video_path)audio = video.audioaudio_temp = "temp.wav"if os.path.exists(audio_path):os.remove(audio_temp)audio.write_audiofile(audio_temp)audio.close()if os.path.exists(audio_path):os.remove(audio_path)cmd = "ffmpeg -i " + audio_temp + " -ac 1 -ar 16000 " + audio_pathsubprocess.run(cmd,shell=True)
二、语音识别
1.PaddleSpeech语音识别
PaddleSpeech是一款由飞浆开源全能的语音算法工具箱,其中包含多种领先国际水平的语音算法与预训练模型。它提供了多种语音处理工具和预训练模型供用户选择,支持语音识别、语音合成、声音分类、声纹识别、标点恢复、语音翻译等多种功能。在这里可以找到基于PaddleSpeech精品项目与训练教程:https://aistudio.baidu.com/projectdetail/4692119?contributionType=1
语音识别(Automatic Speech Recognition, ASR) 是一项从一段音频中提取出语言文字内容的任务。

目前 Transformer 和 Conformer 是语音识别领域的主流模型,关于这方面的教程可以看飞浆官方发的课程:飞桨PaddleSpeech语音技术课程
2.环境依赖安装
我当前的环境是win10,GPU是N卡3060,使用cuda 11.8,cudnn 8.5,为了之后方便封装,使用conda来安装环境,如果没有GPU,也可以装cpu版本:
conda create -n video_to_txt python=3.8
python -m pip install paddlepaddle-gpu==2.5.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
3. 模型下载
可以从官方git上下载到合适自己的模型:https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/README_cn.md
转换模型:
import argparse
import functoolsfrom ppasr.trainer import PPASRTrainer
from ppasr.utils.utils import add_arguments, print_argumentsparser = argparse.ArgumentParser(description=__doc__)
add_arg = functools.partial(add_arguments, argparser=parser)
add_arg('configs', str, 'models/csfw/configs/conformer.yml', '配置文件')
add_arg("use_gpu", bool, True, '是否使用GPU评估模型')
add_arg("save_quant", bool, False, '是否保存量化模型')
add_arg('save_model', str, 'models', '模型保存的路径')
add_arg('resume_model', str, 'models/csfw/models', '准备导出的模型路径')
args = parser.parse_args()
print_arguments(args=args)# 获取训练器
trainer = PPASRTrainer(configs=args.configs, use_gpu=args.use_gpu)# 导出预测模型
trainer.export(save_model_path=args.save_model,resume_model=args.resume_model,save_quant=args.save_quant)
4.语音识别
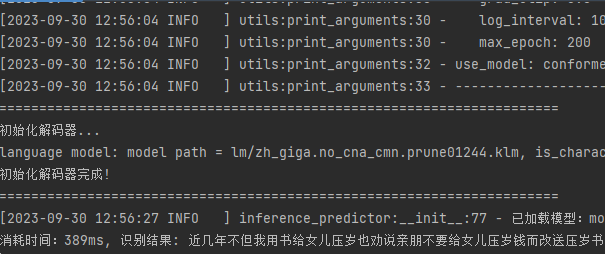
使用模型进行短语音识别:
def predict(self,audio_data,use_pun=False,is_itn=False,sample_rate=16000):# 加载音频文件,并进行预处理audio_segment = self._load_audio(audio_data=audio_data, sample_rate=sample_rate)audio_feature = self._audio_featurizer.featurize(audio_segment)input_data = np.array(audio_feature).astype(np.float32)[np.newaxis, :]audio_len = np.array([input_data.shape[1]]).astype(np.int64)# 运行predictoroutput_data = self.predictor.predict(input_data, audio_len)[0]# 解码score, text = self.decode(output_data=output_data, use_pun=use_pun, is_itn=is_itn)result = {'text': text, 'score': score}return result
看看识别结果,是全部整成一块,并没有短句与加标点符号:
5.断句与标点符号
可以基于飞浆的ERNIE训练标点行号模型:
添加标点符号代码:
import json
import os
import reimport numpy as np
import paddle.inference as paddle_infer
from paddlenlp.transformers import ErnieTokenizer
from ppasr.utils.logger import setup_loggerlogger = setup_logger(__name__)__all__ = ['PunctuationPredictor']class PunctuationPredictor:def __init__(self, model_dir, use_gpu=True, gpu_mem=500, num_threads=4):# 创建 configmodel_path = os.path.join(model_dir, 'model.pdmodel')params_path = os.path.join(model_dir, 'model.pdiparams')if not os.path.exists(model_path) or not os.path.exists(params_path):raise Exception("标点符号模型文件不存在,请检查{}和{}是否存在!".format(model_path, params_path))self.config = paddle_infer.Config(model_path, params_path)# 获取预训练模型类型pretrained_token = 'ernie-1.0'if os.path.exists(os.path.join(model_dir, 'info.json')):with open(os.path.join(model_dir, 'info.json'), 'r', encoding='utf-8') as f:data = json.load(f)pretrained_token = data['pretrained_token']if use_gpu:self.config.enable_use_gpu(gpu_mem, 0)else:self.config.disable_gpu()self.config.set_cpu_math_library_num_threads(num_threads)# enable memory optimself.config.enable_memory_optim()self.config.disable_glog_info()# 根据 config 创建 predictorself.predictor = paddle_infer.create_predictor(self.config)# 获取输入层self.input_ids_handle = self.predictor.get_input_handle('input_ids')self.token_type_ids_handle = self.predictor.get_input_handle('token_type_ids')# 获取输出的名称self.output_names = self.predictor.get_output_names()self._punc_list = []if not os.path.join(model_dir, 'vocab.txt'):raise Exception("字典文件不存在,请检查{}是否存在!".format(os.path.join(model_dir, 'vocab.txt')))with open(os.path.join(model_dir, 'vocab.txt'), 'r', encoding='utf-8') as f:for line in f:self._punc_list.append(line.strip())self.tokenizer = ErnieTokenizer.from_pretrained(pretrained_token)# 预热self('近几年不但我用书给女儿儿压岁也劝说亲朋不要给女儿压岁钱而改送压岁书')logger.info('标点符号模型加载成功。')def _clean_text(self, text):text = text.lower()text = re.sub('[^A-Za-z0-9\u4e00-\u9fa5]', '', text)text = re.sub(f'[{"".join([p for p in self._punc_list][1:])}]', '', text)return text# 预处理文本def preprocess(self, text: str):clean_text = self._clean_text(text)if len(clean_text) == 0: return Nonetokenized_input = self.tokenizer(list(clean_text), return_length=True, is_split_into_words=True)input_ids = tokenized_input['input_ids']seg_ids = tokenized_input['token_type_ids']seq_len = tokenized_input['seq_len']return input_ids, seg_ids, seq_lendef infer(self, input_ids: list, seg_ids: list):# 设置输入self.input_ids_handle.reshape([1, len(input_ids)])self.token_type_ids_handle.reshape([1, len(seg_ids)])self.input_ids_handle.copy_from_cpu(np.array([input_ids]).astype('int64'))self.token_type_ids_handle.copy_from_cpu(np.array([seg_ids]).astype('int64'))# 运行predictorself.predictor.run()# 获取输出output_handle = self.predictor.get_output_handle(self.output_names[0])output_data = output_handle.copy_to_cpu()return output_data# 后处理识别结果def postprocess(self, input_ids, seq_len, preds):tokens = self.tokenizer.convert_ids_to_tokens(input_ids[1:seq_len - 1])labels = preds[1:seq_len - 1].tolist()assert len(tokens) == len(labels)text = ''for t, l in zip(tokens, labels):text += tif l != 0:text += self._punc_list[l]return textdef __call__(self, text: str) -> str:# 数据batch处理try:input_ids, seg_ids, seq_len = self.preprocess(text)preds = self.infer(input_ids=input_ids, seg_ids=seg_ids)if len(preds.shape) == 2:preds = preds[0]text = self.postprocess(input_ids, seq_len, preds)except Exception as e:logger.error(e)return text推理结果:
6.长音频识别
长音频识别要通过VAD分割音频,再对短音频进行识别,拼接结果,最终得到长语音识别结果。 VAD也就是语音端点检测技术,是Voice Activity Detection的缩写。它的主要任务是从带有噪声的语音中准确的定位出语音的开始和结束点。
def get_speech_timestamps(self, audio, sampling_rate):self.reset_states()min_speech_samples = sampling_rate * self.min_speech_duration_ms / 1000min_silence_samples = sampling_rate * self.min_silence_duration_ms / 1000speech_pad_samples = sampling_rate * self.speech_pad_ms / 1000audio_length_samples = len(audio)speech_probs = []for current_start_sample in range(0, audio_length_samples, self.window_size_samples):chunk = audio[current_start_sample: current_start_sample + self.window_size_samples]if len(chunk) < self.window_size_samples:chunk = np.pad(chunk, (0, int(self.window_size_samples - len(chunk))))speech_prob = self(chunk, sampling_rate).item()speech_probs.append(speech_prob)triggered = Falsespeeches: List[dict] = []current_speech = {}neg_threshold = self.threshold - 0.15temp_end = 0for i, speech_prob in enumerate(speech_probs):if (speech_prob >= self.threshold) and temp_end:temp_end = 0if (speech_prob >= self.threshold) and not triggered:triggered = Truecurrent_speech['start'] = self.window_size_samples * icontinueif (speech_prob < neg_threshold) and triggered:if not temp_end:temp_end = self.window_size_samples * iif (self.window_size_samples * i) - temp_end < min_silence_samples:continueelse:current_speech['end'] = temp_endif (current_speech['end'] - current_speech['start']) > min_speech_samples:speeches.append(current_speech)temp_end = 0current_speech = {}triggered = Falsecontinueif current_speech and (audio_length_samples - current_speech['start']) > min_speech_samples:current_speech['end'] = audio_length_samplesspeeches.append(current_speech)for i, speech in enumerate(speeches):if i == 0:speech['start'] = int(max(0, speech['start'] - speech_pad_samples))if i != len(speeches) - 1:silence_duration = speeches[i + 1]['start'] - speech['end']if silence_duration < 2 * speech_pad_samples:speech['end'] += int(silence_duration // 2)speeches[i + 1]['start'] = int(max(0, speeches[i + 1]['start'] - silence_duration // 2))else:speech['end'] = int(min(audio_length_samples, speech['end'] + speech_pad_samples))speeches[i + 1]['start'] = int(max(0, speeches[i + 1]['start'] - speech_pad_samples))else:speech['end'] = int(min(audio_length_samples, speech['end'] + speech_pad_samples))return speeches
进行长语音识别:
def predict_long(self,audio_data,use_pun=False,is_itn=False,sample_rate=16000):self.init_vad()# 加载音频文件,并进行预处理audio_segment = self._load_audio(audio_data=audio_data, sample_rate=sample_rate)# 重采样,方便进行语音活动检测if audio_segment.sample_rate != self.configs.preprocess_conf.sample_rate:audio_segment.resample(self.configs.preprocess_conf.sample_rate)# 获取语音活动区域speech_timestamps = self.vad_predictor.get_speech_timestamps(audio_segment.samples, audio_segment.sample_rate)texts, scores = '', []for t in speech_timestamps:audio_ndarray = audio_segment.samples[t['start']: t['end']]# 执行识别result = self.predict(audio_data=audio_ndarray, use_pun=False, is_itn=is_itn)score, text = result['score'], result['text']if text != '':texts = texts + text if use_pun else texts + ',' + textscores.append(score)logger.info(f'长语音识别片段结果:{text}')if texts[0] == ',': texts = texts[1:]# 加标点符号if use_pun and len(texts) > 0:if self.pun_predictor is not None:texts = self.pun_predictor(texts)else:logger.warning('标点符号模型没有初始化!')result = {'text': texts, 'score': round(sum(scores) / len(scores), 2)}return result
推理结果:
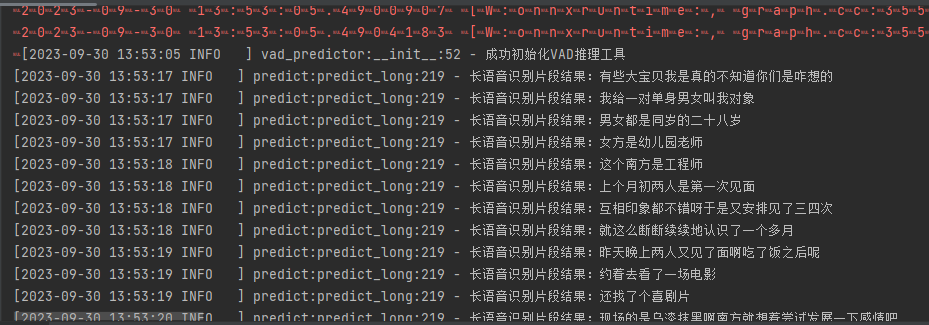
断句结果:
有些大宝贝,我是真的不知道你们是咋想的?我给一对单身男女叫我对象,男女都是同岁的二十八岁女方是幼儿园老师,这个南方是工程师,上个月初两人是第一次见面,互相印象都不错呀,于是又安排见了三四次,就这么断断续续地认识了一个多月,昨天晚上两人又见了面啊,吃了饭之后呢…
三、UI与保存
1. UI界面
为了方便应用,这里使用Gradio这个库,Gradio是一个开源的Python库,用于快速构建机器学习和数据科学演示的应用。它可以帮助你快速创建一个简单漂亮的用户界面,以便向客户、合作者、用户或学生展示你的机器学习模型。此外,还可以通过自动共享链接快速部署模型,并获得对模型性能的反馈。在开发过程中,你可以使用内置的操作和解释工具来交互式地调试模型。Gradio适用于多种情况,包括为客户/合作者/用户/学生演示机器学习模型、快速部署模型并获得性能反馈、以及在开发过程中使用内置的操作和解释工具交互式地调试模型。
pip install gradio
#可以使用清华镜像源来更快的安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple gradio
import os
from moviepy.editor import *
import subprocess
import gradio as gr
from ppasr.predict import PPASRPredictor
from ppasr.utils.utils import add_arguments, print_argumentsconfigs = "models/csfw/configs/conformer.yml"
pun_model_dir = "models/pun_models/"
model_path = "models/csfw/models"predictor = PPASRPredictor(configs=configs,model_path=model_path,use_gpu=True,use_pun=True,pun_model_dir=pun_model_dir)def video_to_audio(video_path):file_name, ext = os.path.splitext(os.path.basename(video_path))video = VideoFileClip(video_path)audio = video.audioaudio_temp = "temp.wav"audio_name = file_name + ".wav"if os.path.exists(audio_temp):os.remove(audio_temp)audio.write_audiofile(audio_temp)audio.close()if os.path.exists(audio_name):os.remove(audio_name)cmd = "ffmpeg -i " + audio_temp + " -ac 1 -ar 16000 " + audio_namesubprocess.run(cmd,shell=True)return audio_namedef predict_long_audio(wav_path):result = predictor.predict_long(wav_path, True, False)score, text = result['score'], result['text']return text# 短语音识别
def predict_audio(wav_path):result = predictor.predict(wav_path, True, False)score, text = result['score'], result['text']return textdef video_to_text(video,operation):audio_name = video_to_audio(video)if operation == "短音频":text = predict_audio(audio_name)elif operation == "长音频":text = predict_long_audio(audio_name)else:text = ""print("视频语音提取识别完成!")return textch = gr.Radio(["短音频","长音频"],label="选择识别音频方式:")demo = gr.Interface(fn=video_to_text,inputs=[gr.Video(), ch],outputs="text")demo.launch()
执行结果:
视频语音提取并转文字
四、优化与升级
1.优化
该项目目前能识别的语音的词错率为0.083327,对一些语音相近的词语并不能联系上下文进行修改,比如这句
“这个南方是工程师”
这里通过上下文联想,正确的应该是:
“这个男方是工程师”
这样的识别错误并不是很多,还有一些断句没有断好的,如果要优化可以加LLM(大语言模型)来进行一次错误的筛选,这个接入LLM的代码在训练和测试阶段。
2.升级
项目可升级:
- 当前项目只针对中文语音,之后会加多语言支持。
- 视频没有字幕可以给视频添加字幕生成模块。
- 视频有字幕,读取视频画面的字幕并使用OCR识别与语音识别相互验证。
- 添加支持web版本。
- 可选段对视频语音进行提取识别。
- 对多人对话的场景的视频,可以加入声纹识别后格式化识别。
- 把生成的文字输出到word并进行排版。
3. 项目源码
源码:https://download.csdn.net/download/matt45m/88386353
模型:
源码配置:
conda create -n video_to_txt python=3.8
python -m pip install paddlepaddle-gpu==2.5.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
cd VideoToTxt
pip install -r requirements.txt
python video_txt.py
然后用浏览器打开:http://127.0.0.1:7860/ ,就可以使用了。
4.备注
如果对该项目感兴趣或者在安装的过程中遇到什么错误的的可以加我的企鹅群:487350510,大家一起探讨。
相关文章:
一键智能视频语音转文本——基于PaddlePaddle语音识别与Python轻松提取视频语音并生成文案
前言 如今进行入自媒体行业的人越来越多,短视频也逐渐成为了主流,但好多时候是想如何把视频里面的语音转成文字,比如,录制会议视频后,做会议纪要;比如,网课教程视频,想要做笔记&…...

[unity]对象的序列化
序 抽象的图纸叫类,包含具体数据的叫对象。 类的序列化和反序列化 using System.Collections; using System.Collections.Generic; using UnityEngine;using System; using System.IO; using System.Runtime.Serialization.Formatters.Binary; [Serializabl…...

java开发岗位面试
java开发岗位面试 技术栈:springboot框架+redis 个人笔试/技术面问题整理 1、SpringBoot有什么组件? 举例说几个: ①auto-configuration组件:核心特征。其约定大于配置思想,赋予了SpringBoot开箱即用的强…...

坠落防护 挂点装置
声明 本文是学习GB 30862-2014 坠落防护 挂点装置. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 1 范围 本标准规定了高处坠落防护挂点装置的技术要求、检验方法、检验规则及标识。 本标准适用于防护高处坠落的挂点装置。 本标准不适用于体育及消…...
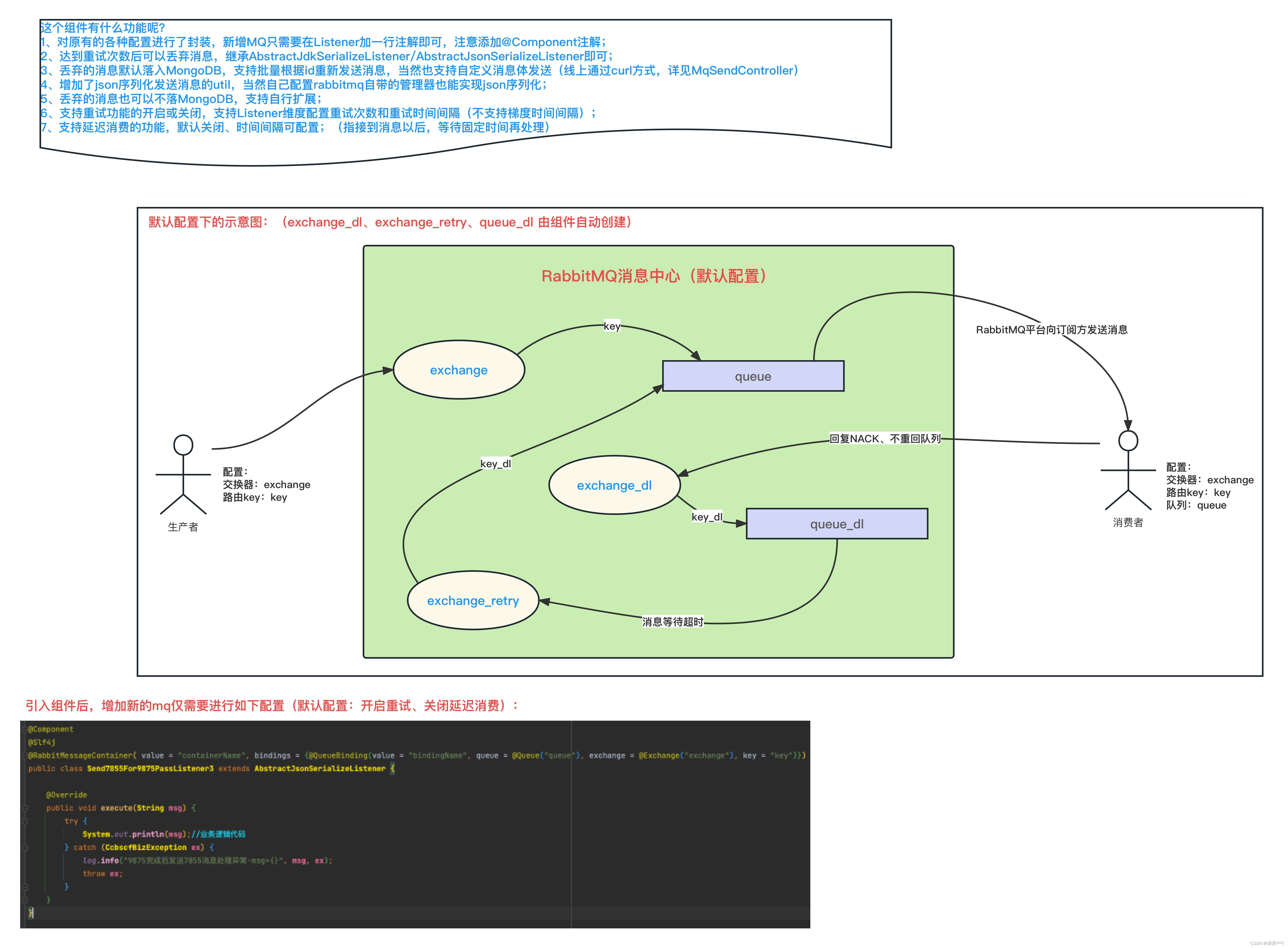
关于 自定义的RabbitMQ的RabbitMessageContainer注解-实现原理
概述 RabbitMessageContainer注解 的主要作用就是 替换掉Configuration配置类中的各种Bean配置; 采用注解的方式可以让我们 固化配置,降低代码编写复杂度、减少配置错误情况的发生,提升编码调试的效率、提高业务的可用性。 为什么说“降低…...
uniapp快速入门系列(1)- 概述与基础知识
章节三:抖音小程序页面开发 第1章:概述与基础知识1.1 uniapp简介1.1.1 什么是uniapp?1.1.2 为什么选择uniapp?1.1.3 uniapp与微信小程序的关系 1.2 HBuilderX介绍与安装1.2.1 什么是HBuilderX?1.2.2 HBuilderX的安装1.…...

国密国际SSL双证书解决方案,满足企事业单位国产国密SSL证书要求
近年来,为了摆脱对国外技术和产品的依赖,建设安全的网络环境,以及加强我国对网络信息的安全可控能力,我国推出了国密算法。同时,为保护网络通信信息安全,更高级别的安全加密数字证书—国密SSL证书应运而生。…...

LabVIEW开发虚拟与现实融合的数字电子技术渐进式实验系统
LabVIEW开发虚拟与现实融合的数字电子技术渐进式实验系统 数字电子技术是所有电气专业的重要学科基础,具有很强的理论性和实践性。其实验是提高学生分析、设计和调试数字电路能力,培养学生解决实际问题的工程实践能力,激发学生创新意识&…...
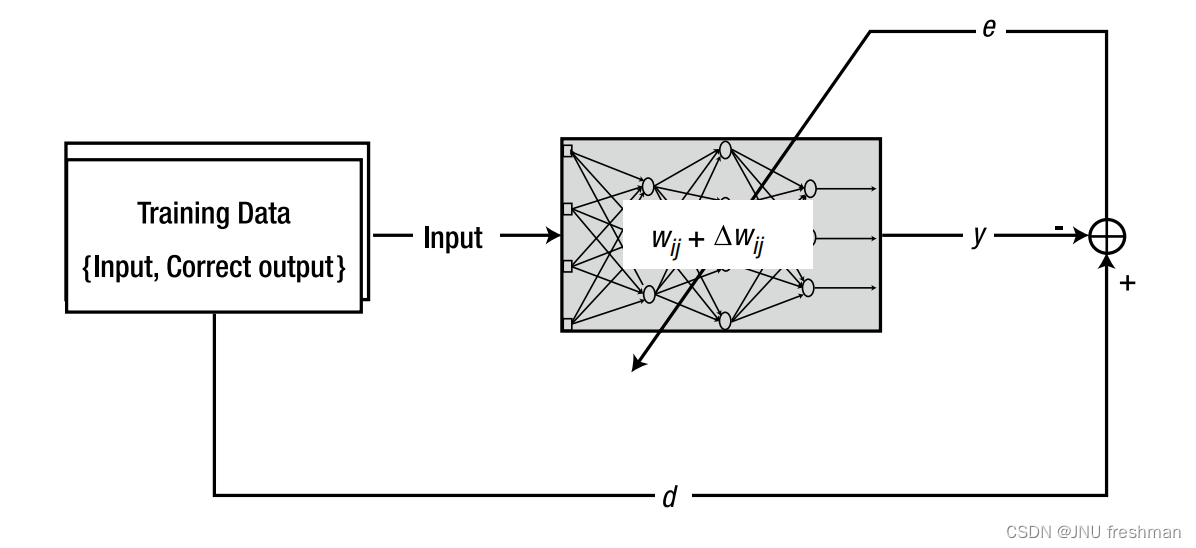
机器学习之单层神经网络的训练:增量规则(Delta Rule)
文章目录 权重的调整单层神经网络使用delta规则的训练过程 神经网络以权值的形式存储信息,根据给定的信息来修改权值的系统方法称为学习规则。由于训练是神经网络系统地存储信息的唯一途径,因此学习规则是神经网络研究中的一个重要组成部分 权重的调整 (…...
C# Task任务详解
文章目录 前言Task返回值无参返回有参返回 async和await返回值await搭配使用Main async改造 Task进阶Task线程取消测试用例超时设置 线程暂停和继续测试用例 多任务等最快多任务全等待 结论 前言 Task是对于Thread的封装,是极其优化的设计,更加方便了我…...

百度网盘的扩容
百度网盘的扩容怎么扩 百度网盘的扩容通常需要购买额外的存储空间。以下是扩容百度网盘存储空间的一般步骤: 登录百度网盘:首先,在您的计算机或移动设备上打开百度网盘,并使用您的百度账号登录。 选择扩容选项:一旦登…...

Android 悬浮窗
本文参考文章地址:https://juejin.cn/post/7009180088310693919 一、申请权限 <uses-permission android:name"android.permission.SYSTEM_ALERT_WINDOW" />二、创建悬浮窗service <serviceandroid:name".FloatingWindowService"an…...
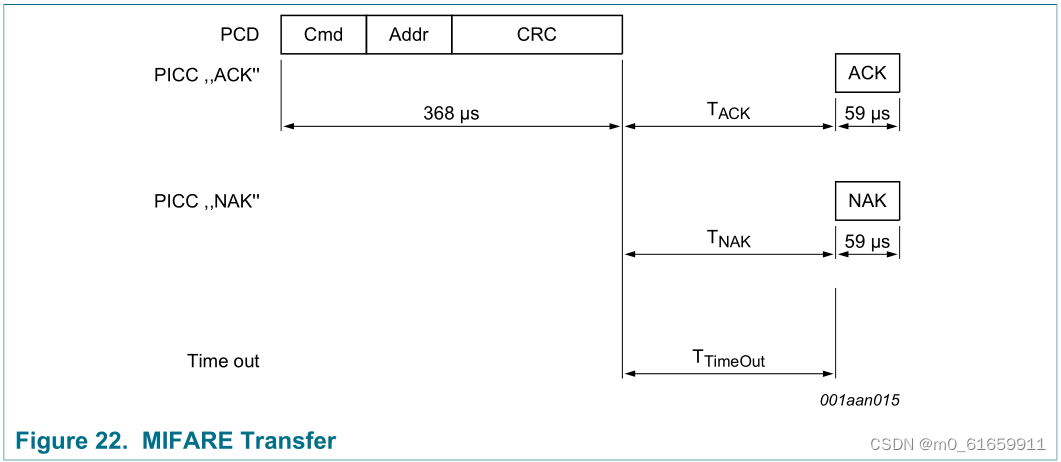
3.物联网射频识别,(高频)RFID应用ISO14443-2协议
一。ISO14443-2协议简介 1.ISO14443协议组成及部分缩略语 (1)14443协议组成(下面的协议简介会详细介绍) 14443-1 物理特性 14443-2 射频功率和信号接口 14443-3 初始化和防冲突 (分为Type A、Type B两种接口&…...

数据分析笔记1
数据分析概述:数据获取--探索分析与可视化--预处理--分析建模--模型评估 数据分析含义:利用统计与概率的分析方法提取有用的信息,最后进行总结与概括 一、数据获取 实用网站:kaggle 阿里云天池 数据仓库:将所有业务数据…...

paramiko 3
import paramiko import concurrent.futuresdef execute_remote_command(hostname, username, password, command):try:# 创建SSH客户端client paramiko.SSHClient()client.set_missing_host_key_policy(paramiko.AutoAddPolicy())# 使用密码认证连接远程主机client.connect(h…...

基于Dlib训练自已的人脸数据集提高人脸识别的准确率
前言 由于图像的质量、光线、角度等因素影响。这时如果使用官方提供的模型做人脸识别,就会导至识别率不是很理想。人脸识别的准确率与图像的清晰度和质量有关。如果图像模糊、光线不足或者有其他干扰因素,Dlib 可能无法正确地识别人脸。为了确保图像质量…...

Git 详细安装教程(详解 Git 安装过程的每一个步骤
Git 详细安装教程(详解 Git 安装过程的每一个步骤) 该文章详细具体,值得收藏学习...

kafka伪集群部署,使用KRAFT模式
1:拉去管理kafka界面UI镜像 docker pull provectuslabs/kafka-ui2:拉去管理kafka镜像 docker pull bitnami/kafka3:docker-compose.yml version: 3.8 services:kafka-1:container_name: kafka1image: bitnami/kafka ports:- "19092:19092"- "19093:19093&quo…...

【双指针遍历】N数之和问题
文章目录 二数之和LC1三数之和LC15四数之和LC18最接近的三数之和LC16 二数之和LC1 题目链接 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对…...

Qt的QObject类
文章目录 QObject类如何在Qt中使用QObject的信号与槽机制?如何在Qt中使用QObject的属性系统?QObject的元对象系统如何实现对象的反射功能? QObject类 Qt的QObject类是Qt框架中的基类,它是所有Qt对象的父类。QObject提供了一些常用…...

iPhone密码忘记了办?iPhoneUnlocker,iPhone解锁工具Aiseesoft iPhone Unlocker 高级注册版分享
平时用 iPhone 的时候,难免会碰到解锁的麻烦事。比如密码忘了、人脸识别 / 指纹识别突然不灵,或者买了二手 iPhone 却被原来的 iCloud 账号锁住,这时候就需要靠谱的解锁工具来帮忙了。Aiseesoft iPhone Unlocker 就是专门解决这些问题的软件&…...

Springboot社区养老保险系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,社区养老保险系统小程序被用户普遍使用,为方…...

HarmonyOS运动开发:如何用mpchart绘制运动配速图表
##鸿蒙核心技术##运动开发##Sensor Service Kit(传感器服务)# 前言 在运动类应用中,运动数据的可视化是提升用户体验的重要环节。通过直观的图表展示运动过程中的关键数据,如配速、距离、卡路里消耗等,用户可以更清晰…...

处理vxe-table 表尾数据是单独一个接口,表格tableData数据更新后,需要点击两下,表尾才是正确的
修改bug思路: 分别把 tabledata 和 表尾相关数据 console.log() 发现 更新数据先后顺序不对 settimeout延迟查询表格接口 ——测试可行 升级↑:async await 等接口返回后再开始下一个接口查询 ________________________________________________________…...

Python竞赛环境搭建全攻略
Python环境搭建竞赛技术文章大纲 竞赛背景与意义 竞赛的目的与价值Python在竞赛中的应用场景环境搭建对竞赛效率的影响 竞赛环境需求分析 常见竞赛类型(算法、数据分析、机器学习等)不同竞赛对Python版本及库的要求硬件与操作系统的兼容性问题 Pyth…...
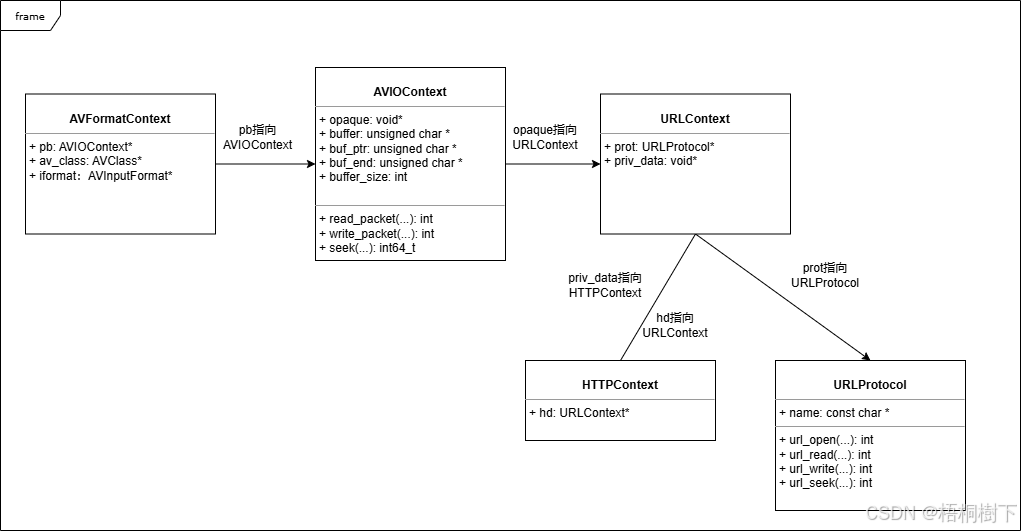
FFmpeg avformat_open_input函数分析
函数内部的总体流程如下: avformat_open_input 精简后的代码如下: int avformat_open_input(AVFormatContext **ps, const char *filename,ff_const59 AVInputFormat *fmt, AVDictionary **options) {AVFormatContext *s *ps;int i, ret 0;AVDictio…...
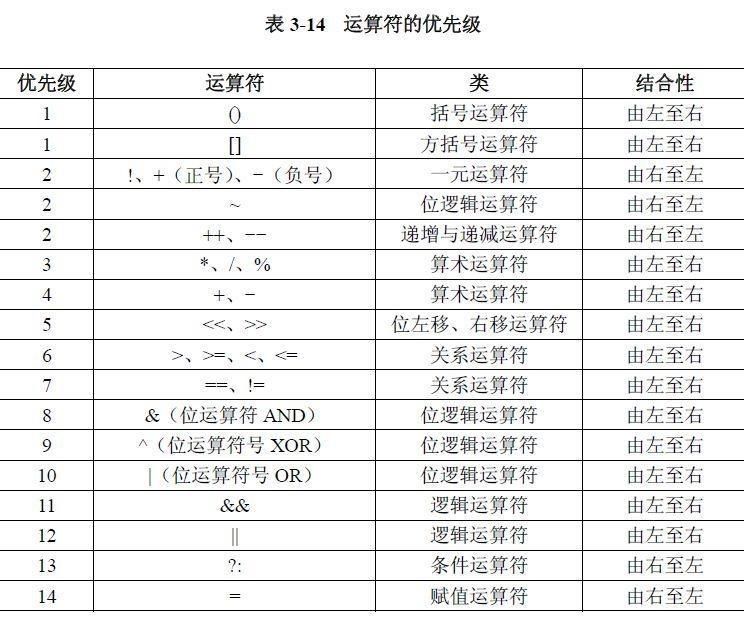
02.运算符
目录 什么是运算符 算术运算符 1.基本四则运算符 2.增量运算符 3.自增/自减运算符 关系运算符 逻辑运算符 &&:逻辑与 ||:逻辑或 !:逻辑非 短路求值 位运算符 按位与&: 按位或 | 按位取反~ …...

13.10 LangGraph多轮对话系统实战:Ollama私有部署+情感识别优化全解析
LangGraph多轮对话系统实战:Ollama私有部署+情感识别优化全解析 LanguageMentor 对话式训练系统架构与实现 关键词:多轮对话系统设计、场景化提示工程、情感识别优化、LangGraph 状态管理、Ollama 私有化部署 1. 对话训练系统技术架构 采用四层架构实现高扩展性的对话训练…...
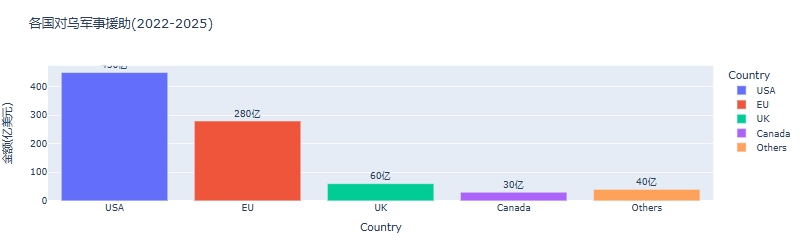
python可视化:俄乌战争时间线关键节点与深层原因
俄乌战争时间线可视化分析:关键节点与深层原因 俄乌战争是21世纪欧洲最具影响力的地缘政治冲突之一,自2022年2月爆发以来已持续超过3年。 本文将通过Python可视化工具,系统分析这场战争的时间线、关键节点及其背后的深层原因,全面…...

LTR-381RGB-01RGB+环境光检测应用场景及客户类型主要有哪些?
RGB环境光检测 功能,在应用场景及客户类型: 1. 可应用的儿童玩具类型 (1) 智能互动玩具 功能:通过检测环境光或物体颜色触发互动(如颜色识别积木、光感音乐盒)。 客户参考: LEGO(乐高&#x…...