golang工程——protobuf使用及原理
相关文档
源码:https://github.com/grpc/grpc-go
官方文档:https://www.grpc.io/docs/what-is-grpc/introduction/
protobuf编译器源码:https://github.com/protocolbuffers/protobuf
proto3文档:https://protobuf.dev/programming-guides/proto3/
protobuf使用
protoc下载
用于编译.proto文件,生成对应语言的模板文件
#下载地址
https://github.com/protocolbuffers/protobuf/releases/
windows的话选择对应版本,下载解压后配置对应环境变量
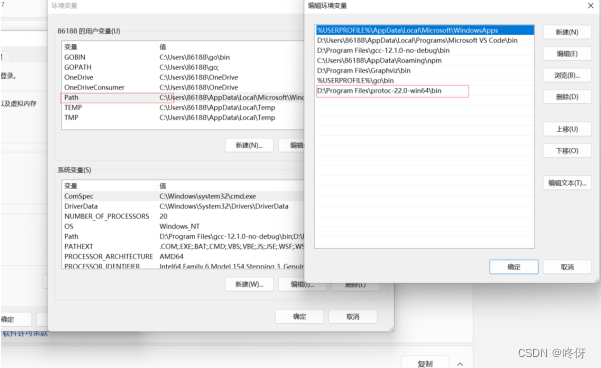
protoc 插件安装
go install google.golang.org/protobuf/cmd/protoc-gen-go@v1.28 go install google.golang.org/grpc/cmd/protoc-gen-go-grpc@v1.2
protoc 编译
protoc --go_out=. --go_opt=paths=source_relative --go-grpc_out=. --go- grpc_opt=paths=source_relative .\echo\echo.proto
- –proto_path 或者 -I :指定 import 路径,可以指定多个参数,编译时按顺序查找,不指定时默 认查找
当前目录。(.proto 文件中也可以引入其他 .proto 文件,这里主要用于指定被引入文件的 位置) - –go_out :golang编译支持,指定输出文件路径;
- –-go_opt :指定参数,比如 --go_opt=paths=source_relative 就是表明生成文件输出使用相对 路径。
- path/to/file.proto :被编译的 .proto 文件放在最后面
protobuf原理
protobuf字段
定义一个搜索相关的proto 消息,请求有 查询字符串,有分页页数,和每页的数量。例子如下
message SearchRequest {string query = 1; // 查询字符串optional int32 page_number = 2; // 第几页optional int32 result_per_page = 3; // 每页的结果数
}
- 每个消息应该有类型和字段编号
- optional: message 可以包含该字段零次或一次(不超过一次)。
- repeated: 该字段可以在消息中重复任意多次(包括零)。其中重复值的顺序会被保留。在开发语言中就是数组和列表
字段类型
字段有很多数据类型,看个例子
syntax = "proto3";
option go_package = "protos/pbs";
enum Status{Status1=0;Status2=1;Status3=2;
}message Source{//金条int64 Gold =1;//血条int64 Blood=2;
}
message Role {//idint64 Id =1; //有符号整型//姓名string Name=2;//字符串类型//属性map<int64,int64> Attr=3; //map 类型//状态Status typ =4; //枚举类型//是不是vipbool IsVip =5; //bool 类型//资源Source source=6; //复合类型
}字段编号
- 每个字段有唯一的编号,proto编码的时候是不管字段名的,仅根据编号来确定是哪个字段
- 消息被使用了,字段就不能改了,改了会造成数据错乱(常见坑),服务器和客户端很多bug,是proto buffer 文件更改,未使用更改后的协议导致。
- 1 到 15 范围内的字段编号需要一个字节进行编码,编码结果将同时包含编号和类型
- 16 到 2047 范围内的字段编号占用两个字节。因此,非常频繁出现的 message 元素保留字段编号 1 到 15。
- 字段最小数字为1,最大字段数为2^29 - 1。(原因在编码原理那章讲解过,字段数字会作为key,key最后三位是类型)
- 19000 through 19999 (FieldDescriptor::kFirstReservedNumber through FieldDescriptor::kLastReservedNumber这些数字不能用,这些是保留字段,如果使用会编译器会报错
syntax = "proto3";
option go_package = "protos/pbs";message Role {int64 Id =19527;
}
编译会报下面的错
protoc --go_out=. ./*.proto
intro.proto:5:14: Field numbers 19000 through 19999 are reserved for the protocol buffer library implementation.
- 保留字段指 reserved 关键字指定的字段
protobuf 数据类型
变量类型
| protoYype | notes | GO type |
|---|---|---|
| double | *float64 | |
| float | *float32 | |
| int32 | 可变长编码,负数编码效率低,要经过zigzag | *int32 |
| int64 | 可变长编码,负数编码效率低,要经过zigzag | *int64 |
| uint32 | 可变长编码 | *uint32 |
| uint64 | 可变长编码 | *uint64 |
| sint32 | 可变长编码,比int32效率高 | *int32 |
| sint64 | 可变长编码,比int64效率高 | *int64 |
| fixed32 | 总是4字节,如果经常比228大,那比uint32效率更高 | *uint32 |
| fixed64 | 总是4字节,如果经常比256大,那比uint32效率更高 | *uint64 |
| sfixed32 | 总是4字节 | *int32 |
| sfixed64 | 总是8字节 | *int64 |
| bool | *bool | |
| string | utf8或7-bit ASCII文本编码 | *string |
| bytes | 任意序列字节 | []byte |
- java中,无符号32 位和64位使用其有符号类型表示。最高位是符号位
- 所有场景中,给字段赋值都会给类型检查确保它是有效的
- 64 位或无符号 32 位整数在解码时始终表示为 long,但如果在设置字段时给出 int,则可以为int
默认值
解析消息的时候,编码的消息字段没有赋值,将会设置默认值
- 字符串类型默认值是" "
- bytes 默认值是空字节
- bool 默认值是false
- 数字类型默认是0
- 枚举值默认是0,详情看下面枚举类型
- 空列表在合适的语言会转换成合适的数据类型空列表
枚举
当我们想定义一个消息类型,只使用定义好的一系列值的一个,我们就可以使用枚举
message SearchRequest {string query = 1;int32 page_number = 2;int32 result_per_page = 3;enum Corpus { //定义枚举UNIVERSAL = 0;WEB = 1;IMAGES = 2;LOCAL = 3;NEWS = 4;PRODUCTS = 5;VIDEO = 6;}Corpus corpus = 4; //使用枚举
}
注意:
枚举第一个字段必须是0,像上面UNIVERSAL = 0,而且不能省略,原因有两点:
- 当该枚举类型字段没有赋值的时候,我们使用0这个定义作为默认值
- 兼容proto2 第一个字段总是默认值
如何给枚举定义别名? 当我们希望两个枚举值一样,但是变量名不一样的时候,我们可以添加allow_alias option,并设置值为true,类似于下面这个样式,要不然编译器会报错。
message MyMessage1 {enum EnumAllowingAlias {option allow_alias = true;UNKNOWN = 0;STARTED = 1;RUNNING = 1;}
}
message MyMessage2 {enum EnumNotAllowingAlias {UNKNOWN = 0;STARTED = 1; //直接使用会报错,因为这两个值一样了// RUNNING = 1; // Uncommenting this line will cause a compile error inside Google and a warning message outside.}
}
枚举值范围是32位范围内的整数,这是因为是是varint encoding 编码的。对于没有定义的枚举值,在go 和c++中会识别成数字
枚举保留字段
枚举更新的安全性,官方新增了个枚举保留字段,使用方法如下
enum Foo {reserved 2, 15, 9 to 11, 40 to max;reserved "FOO", "BAR";
}
如果删除枚举定义或者注释来更新枚举类型,将来用户可能不注意去重用该类型的值,如果以后proto buffer 版本更新了,再加载到旧版本,那么可能导致严重问题,包括数据损坏、隐私漏洞等。
官方提供了保留字段,可以保留枚举字段名和枚举字段值,如下,使用保留的字段会报错,超过max 也会报错。
例如下面这个例子
enum TestType {Hello1=0;Hello2=1;Hello3=2;Hello4=3;FOO=4; # 使用保留字段BAR=5;foo=6;Bar=7;Foo1=8;Hello6=39;Hello6=40;Hello5=99; # 超过最大值reserved 2,3, 15, 9 to 11, 40 to max;reserved "FOO", "BAR";
}
消息嵌套和导入其他proto
消息引用
当使用其他消息的时候,如果在本文件,直接使用就可以了。Result代表自定义消息类型
message SearchResponse {repeated Result results = 1;
}message Result {string url = 1;string title = 2;repeated string snippets = 3;
}
消息嵌套
如何在消息里面再定义消息了?例子如下,在SearchResponse定义了个内部消息Result,然后直接引用就可以了。
message SearchResponse {message Result {string url = 1;string title = 2;repeated string snippets = 3;}repeated Result results = 1;
}
如果其他消息引用消息内部的消息呢?语法为_Parent_.Type
message SomeOtherMessage {SearchResponse.Result result = 1;
}
导入其他文件proto
在项目开发中,我们有这种需要,将相同的结构放在一个公共文件夹,将请求响应的业务消息放一个文件夹,然后请求响应的proto 会引用通文件夹。我们来写一个例子,文件结构如下。
- bussiness 代表业务文件夹,里面存放业务逻辑
- share 存放公共结构文件夹
user_business.proto
syntax = "proto3";
option go_package = "protos/pbs";
import "share/user.proto";
//获取角色信息请求
message GetUserRequest {}
//获取角色信息响应
message GetUserResponse {User user=1;
}user.proto
syntax = "proto3";
option go_package = "protos/pbs";//用户定义
message User {string Id=1;string Name=2;string Age=3;
}
protoc --go_out=. ./business/*.proto ./share/*.proto
Any
官方说作用是集成proto 没有定义的类型,其实可以理解为go 语言接口类型,可以存任何类型的值,但是跨语言只能通过字节流代表任意类型,所以any 内部实现包含字节流,和标识字节流的唯一url。
用这个关键字,官方说要导入官方proto,类似下面,相信如果直接编译肯定会有坑,编译不过,因为没有any.proto这个文件
import "google/protobuf/any.proto";message ErrorStatus {string message = 1;repeated google.protobuf.Any details = 2;
}
- 去官方下载这个文件
- 安装protobuf的时候有个proto目录,拷贝过来
最后序列化出来的any 结构包含下面两个字段:
TypeUrl string `protobuf:"bytes,1,opt,name=type_url,json=typeUrl,proto3" json:"type_url,omitempty"`
// Must be a valid serialized protocol buffer of the above specified type.
Value []byte `protobuf:"bytes,2,opt,name=value,proto3" json:"value,omitempty"`
- 一个是序列化成bytes 的属性value
- 一个是标识这个属性全局唯一的标识TypeUrl
Oneof
如果在平时在一个消息有许多字段,但是最多设置一个字段,我们可以使用oneof 来执行并节省内存。
Oneof 字段类似于常规字段,除了Oneof共享内存的所有字段之外,最多可以同时设置一个字段。设置Oneof 的任何成员都会自动清除所有其他成员。您可以使用case()或WhichOneof()方法检查Oneof 中的哪个值被设置(如果有的话),具体取决于选择的语言。
syntax = "proto3";
option go_package = "protos/pbs";message SubMessage {int32 Id=1;string Age2=2;}
message SampleMessage {oneof test_oneof {string name = 4;SubMessage sub_message = 9;}
}
oneof 可以添加任何字段,除了repeated字段
oneof功能
- oneof 设置一个字段会清除其他字段,如果设置了几个字段,自会保留最后一个设置的字段,可以看到在go中是通过一个接口类型来做到oneof的,只能给这个字段赋值为定义的字段结构体
package mainimport ("fmt""grpcdemo/protobuf/any/protos/pbs"
)func main() {p:=&pbs.SampleMessage{TestOneof: &pbs.SampleMessage_Name{Name: "hello"},}fmt.Println(p)fmt.Println(p.GetTestOneof())p.TestOneof=&pbs.SampleMessage_SubMessage{SubMessage: &pbs.SubMessage{Id: 1}}fmt.Println(p)fmt.Println(p.GetTestOneof())
}
- oneof 不能被repeated
- 反射作用于oneof的字段
兼容性问题
添加或删除其中一个字段时要小心。如果检查 oneof 的值返回 None/NOT_SET,则可能意味着 oneof 尚未设置或已设置为 oneof 的另一个字段。这种情况是无法区分的,因为无法知道未知字段是否是 oneof 成员。
标签重用问题
- 将 optional 可选字段移入或移出 oneof:在序列化和解析 message 后,你可能会丢失一些信息(某些字段将被清除)。但是,你可以安全地将单个字段移动到新的 oneof 中,并且如果已知只有一个字段被设置,则可以移动多个字段。
- 删除 oneof 字段并将其重新添加回去:在序列化和解析 message 后,这可能会清除当前设置的 oneof 字段。
- 拆分或合并 oneof:这与移动常规的 optional 字段有类似的问题。
maps
在数据定义创建map,语法格式为
map<key_type, value_type> map_field = N;
例如,创建一个项目,key 是string,value 是Project
map<string, Project> projects = 3;
PS:
- map 类型不能加repeated,简单来说map 是不支持map 数组的
- map是无序的,不能依赖map 的特定顺序
总的来说,map 语法等价于下面的语法,所以protocol buffers 的实现在不支持map 的语言上也能处理数据
message MapFieldEntry {key_type key = 1;value_type value = 2;
}repeated MapFieldEntry map_field = N;
packages
package提供命名空间,防冲突
package foo.bar;
message Open { ... }
在其他地方引用
message Foo {...foo.bar.Open open = 1;...
}
options
- 可用的选项列表在google/protobuf/descriptor.proto
- 其它选项官方有,是其它语言相关的,这里就不细讲了,看官方文档Options。
- deprecated选项: 设为true 代表字段被废弃,在新代码不应该被使用,在大多数语言都没有实际的效果,在java 变成@Deprecated注解。 在未来,可能产生废弃的注解在方法字段的入口。并且将会引起警告当编译这个字段的时候。如果这个字段没人使用,可以将字段的声明改为保留字段,上面已经讲解
int32 old_field = 6 [deprecated = true];
custom options
proto buffer 提供大多人都不会使用的高级功能-自定义选项。
由于选项是由 google/protobuf/descriptor.proto(如 FileOptions 或 FieldOptions)中定义的消息定义的,因此定义你自己的选项只需要扩展这些消息
import "google/protobuf/descriptor.proto";extend google.protobuf.MessageOptions {optional string my_option = 51234;
}message MyMessage {option (my_option) = "Hello world!";
}
获取选项
package mainimport ("fmt""grpcdemo/protobuf/any/protos/pbs"
)func main() {p:=&pbs.MyMessage{}fmt.Println(p.ProtoReflect().Descriptor().Options())//[my_option]:"Hello world!"
}
Protocol Buffers可以为每种类型提供选项
import "google/protobuf/descriptor.proto";extend google.protobuf.FileOptions {optional string my_file_option = 50000;
}
extend google.protobuf.MessageOptions {optional int32 my_message_option = 50001;
}
extend google.protobuf.FieldOptions {optional float my_field_option = 50002;
}
extend google.protobuf.OneofOptions {optional int64 my_oneof_option = 50003;
}
extend google.protobuf.EnumOptions {optional bool my_enum_option = 50004;
}
extend google.protobuf.EnumValueOptions {optional uint32 my_enum_value_option = 50005;
}
extend google.protobuf.ServiceOptions {optional MyEnum my_service_option = 50006;
}
extend google.protobuf.MethodOptions {optional MyMessage my_method_option = 50007;
}option (my_file_option) = "Hello world!";message MyMessage {option (my_message_option) = 1234;optional int32 foo = 1 [(my_field_option) = 4.5];optional string bar = 2;oneof qux {option (my_oneof_option) = 42;string quux = 3;}
}enum MyEnum {option (my_enum_option) = true;FOO = 1 [(my_enum_value_option) = 321];BAR = 2;
}message RequestType {}
message ResponseType {}service MyService {option (my_service_option) = FOO;rpc MyMethod(RequestType) returns(ResponseType) {// Note: my_method_option has type MyMessage. We can set each field// within it using a separate "option" line.option (my_method_option).foo = 567;option (my_method_option).bar = "Some string";}
}
引用其他包的选项需要加上包名
// foo.proto
import "google/protobuf/descriptor.proto";
package foo;
extend google.protobuf.MessageOptions {optional string my_option = 51234;
}
// bar.proto
import "foo.proto";
package bar;
message MyMessage {option (foo.my_option) = "Hello world!";
}
- 自定义选项是扩展名,必须分配字段号,像上面的例子一样。在上面的示例中,使用了 50000-99999 范围内的字段编号。这个字段范围供个人组织使用,所以可以内部用。
- 在公共应用使用的话,要保持全球唯一数字,需要申请,申请地址为: protobuf global extension registry
- 通常只需要一个扩展号,可以多个选项放在子消息中来实现一个扩展号声明多个选项
message FooOptions {optional int32 opt1 = 1;optional string opt2 = 2;
}extend google.protobuf.FieldOptions {optional FooOptions foo_options = 1234;
}// usage:
message Bar {optional int32 a = 1 [(foo_options).opt1 = 123, (foo_options).opt2 = "baz"];// alternative aggregate syntax (uses TextFormat):optional int32 b = 2 [(foo_options) = { opt1: 123 opt2: "baz" }];
}
每种选项类型(文件级别,消息级别,字段级别等)都有自己的数字空间,例如:可以使用相同的数字声明 FieldOptions 和 MessageOptions 的扩展名。
编解码原理
Base 128 Varints
可变字节长度编码,用一个字节或者多个字节表示整数类型,更小的数占用更小的字节。
编码的理念是:越小的数字花费越少的字节
来看看下面的例子:
00000000 00000000 00000000 00000001 //int32
- 假设值为1 ,类型为int32 在网络传输,其实有效位就一个,其他的位都是无效的,Base 128 Varints的出现就是为了解决这个问题
Base 128 Varints 原理
Base128 Varints 采用的是小端序, 即数字的低位存放在高地址。
比如数字 666, 其以标准的整型存储, 其二进制表示为

而采用 Varints 编码, 其二进制形式为

可以尝试来复原一下上面这个 Base128 Varints 编码的二进制串, 首先看最高有效位

接下来我们移除标识位, 由于 Base128 Varints 采用小端字节序, 因此数字的高位存放于低地址上

移除标志位并交换字节序, 便得到原本的数值 1010011010, 即数字 666

可变长整型编码对于不同大小的数字, 其所占用的存储空间是不同的, 编码思想与 CPU 的间接寻址原理相似, 都是用一比特来标识是否走到末尾, 但采用这种方式存储数字, 也有一个相对不好的点便是, 无法对一个序列的数值进行随机查找, 因为每个数字所占用的存储空间不是等长的, 因此若要获得序列中的第 N 个数字, 无法像等长存储那样在查找之前直接计算出 Offset, 只能从头开始顺序查找
zigzag 编码
Varints 编码的实质在于去掉数字开头的 0, 因此可缩短数字所占的存储字节数, 在上面的例子中, 我们只举例说明了正数的 Varints 编码, 但如果数字为负数, 则采用 Varints 编码会恒定占用 10 个字节, 原因在于负数的符号位为 1, 对于负数其从符号位开始的高位均为 1, 在 Protobuf 的具体实现中, 会将此视为一个很大的无符号数, 以 Go 语言的实现为例, 对于 int32 类型的 pb 字段, 对于如下定义的 proto
syntax = "proto3";
package pbTest;message Request {int32 a = 1;
}
Request 中包含类型为 int32 类型的字段, 当 a 为负数时, 其序列化之后将恒定占用 10 个字节, 我们可以使用如下的测试代码
func main() {a := pbTest.Request{A: -5,}bytes, err := proto.Marshal(&a)if err != nil {fmt.Println(err)return}fmt.Println(fmt.Sprintf("%08b", bytes))
}
对于 int32 类型的数字 -5, 其序列化之后的二进制为
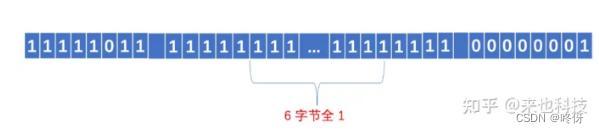
究其原因在于 Protobuf 的内部将 int32 类型的负数转换为 uint64 来处理, 转换后的 uint64 数值的高位全为 1, 相当于是一个 8 字节的很大的无符号数, 因此采用 Base128 Varints 编码后将恒定占用 10 个字节的空间, 可见 Varints 编码对于表示负数毫无优势, 甚至比普通的固定 32 位存储还要多占 4 个字节。Varints 编码的实质在于设法移除数字开头的 0 比特, 而对于负数, 由于其数字高位都是 1, 因此 Varints 编码在此场景下失效
Zigzag 编码便是为了解决这个问题, Zigzag 编码的大致思想是首先对负数做一次变换, 将其映射为一个正数, 变换以后便可以使用 Varints 编码进行压缩, 这里关键的一点在于变换的算法, 首先算法必须是可逆的, 即可以根据变换后的值计算出原始值, 否则就无法解码, 同时要求变换算法要尽可能简单, 以避免影响 Protobuf 编码、解码的速度, 我们假设 n 是一个 32 位类型的数字, 则 Zigzag 编码的计算方式为
(n << 1) ^ (n >> 31)

首先对其进行一次逻辑左移, 移位后空出的比特位由 0 填充

然后对原数字进行 15 次算术右移, 得到 16 位全为原符号位(即 1)的数字

然后对逻辑移位和算术移位的结果按位异或, 便得到最终的 Zigzag 编码

可以看到, 对负数使用 Zigzag 编码以后, 其高位的 1 全部变成了 0, 这样以来我们便可以使用 Varints 编码进行进一步地压缩, 再来看正数的情形, 对于 16 位的正数 5。后面就可以用varints编码了
可以看到, 对负数使用 Zigzag 编码以后, 其高位的 1 全部变成了 0, 这样以来我们便可以使用 Varints 编码进行进一步地压缩, 再来看正数的情形, 对于 16 位的正数 5, 其在内存中的存储形式为

我们按照与负数相同的处理方法, 可以得到其 Zigzag 编码为

从上面的结果来看, 无论是正数还是负数, 经过 Zigzag 编码以后, 数字高位都是 0, 这样以来, 便可以进一步使用 Varints 编码进行数据压缩, 即 Zigzag 编码在 Protobuf 中并不单独使用, 而是配合 Varints 编码共同来进行数据压缩
消息编码
protocol buffer消息是由一些key-value 组成的,其中key 代表字段后面的数字,变量名和变量类型仅仅决定编码的最终截止位置。
消息编码的时候,key 和value 都会被编码进字节流。当解码器解码时,需要跳过不能识别的字段,因为新添加字段不会对原来造成影响。每个key 由两部分组成,1个是定义在proto消息字段后面的数字,后面跟的是wire type (消息类型)。通过消息类型能够找到后面值的长度。
可用的wire type
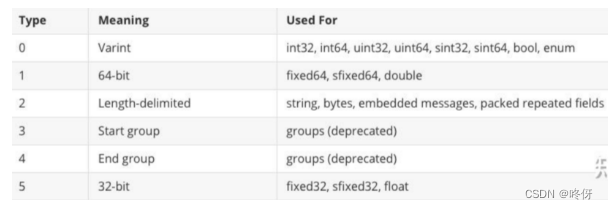
每个key 在消息流里面都是这样的结构,(field_number << 3) | wire_type,最后三位存储wire_type,直白来说,wire_type类似语言中的数据类型,标识存储数据的长度
解码例子
假设有下面这种消息类型Test1
message Test1 {optional int32 a = 1;
}
当我们定义上面的消息,并赋值a=150,我们将得到下面序列化结构,总共三个字节
08 96 01
解码步骤
1、数据流第一个数字是 varint key,这里是08,二进制数据为000 1000
- 最后三位000是wire_type(0),右移三位得到000 1(1),所以知道了字段1和后面的值是varint 类型
- 将96 01 通过上面的Base 128 Varints解码方法得到数字150
96 01 = 1001 0110 0000 0001→ 000 0001 ++ 001 0110 (drop the msb and reverse the groups of 7 bits)→ 10010110→ 128 + 16 + 4 + 2 = 150
Non-varint 数字
- double and fixed64 用的wire type 是1,编译器解析时会认为是64位的块数据。直接取64位解析,没有varint 编解码过程。
- float and fixed32使用wire type 5,告诉编译器是32位的数据
- 该数字都被排成小端字节序了
字符串编码
字符串的wire_type 是2,代表值是可变的,长度会被编码进字节流里面。
如下例子:
message Test2 {optional string b = 2;
}
将b 赋值为"testing" ,得到下面的结果
12 07 [74 65 73 74 69 6e 67]
- key 是0x12,最后三位代表wire_type 结果为2(length-delimited),key 为2
- []里面的内容是UTF8 的 “testing”
0x12
→ 0001 0010 (binary representation)
→ 00010 010 (regroup bits)
→ field_number = 2, wire_type = 2
- 长度是07,代表后面的7个字节为字符串内容
复合结构消息
message Test1 {optional int32 a = 1;
}
message Test3 {optional Test1 c = 3;
}
Test1’s a 字段依然是150:
1a 03 08 96 01
- 后面08 96 01就不说了,前面解析过了
- 1a 二进制为00011010,后三位代表wire_type 为2,前面代表key 为数字3。所以Test1结果被当作字符串对待了
- 03 为长度,代表Test3里面内容长度为3 个字节
optional and repoeated
- 在proto2 里面,消息字段定义为repeated没有在后面加选项packed=true,编码的消息可能有零个或者多个key-value 键值对,这些键值对也不是连续的,可能中间插入了其他字段,意思是和其他字段交替出现。
- 任何不是repeated字段在proto3 里面或者optional 字段在proto2,编码消息可能有也可能没有那个字段形成的key value键值对。
- 通常编码消息对于不是repeated字段永远不可能出现超过1个的键值对,解析器期望去处理这种情况。对于数字类型和字符串类型,如果同一个字段出现多次,解析器会使用最后看见的一个值。对于复合类型字段,解析器合并多个实例到同一个字段,就像Message::MergeFrom方法一样。同个嵌套类型,如果出现了多个键值对,解析器会采取合并策略。
MyMessage message;
message.ParseFromString(str1 + str2);
和下面的结果是一样的
MyMessage message, message2;
message.ParseFromString(str1);
message2.ParseFromString(str2);
message.MergeFrom(message2);
packed repoeated fields
- proto3默认使用packed编码repeated数字字段
- 这些函数类似于重复字段,但是编码方式不同,包含零元素的压缩重复字段不会出现在编码消息中,要不然,该字段的所有元素会打包到wire_type 为2 的键值对中。每个元素的编码方式于正常情况相同,只是前面没有键
例如下面的类型
message Test4 {repeated int32 d = 4 [packed=true];
}
Test4 的repeated 有三个值,3、270、86942 。编码结果将会如下面所示
22 // key (field number 4, wire type 2)
06 // payload size (6 bytes)
03 // first element (varint 3)
8E 02 // second element (varint 270)
9E A7 05 // third element (varint 86942)
- 只有varint, 32-bit, or 64-bit wire types可以使用packed
- 虽然通常情况下没有必要为编码repeated字段使用多个键值对,但是解析器也必须做这样的编码,每对包含完整的信息。
- Protocol buffer必须能解析编译为packed的字段跟没有使用packed一样。在兼容性上就可以向前向后兼容使用[packed=true]
filed oder
字段数字顺序可以任何顺序出现在proto里面。顺序对消息序列化没有任何影响。
当消息被序列化时,是无法保证已知字段和未知字段被写入,序列化是一个实现细节,任何特定实现的细节在将来都会被改变,因此protocol buffer 必须能够解析字段在任何顺序。
未知字段
- 未知字段是protocol buffer无法识别的字段,通常发送在旧二进制文件去解析新二进制发送的数据时,这些新字段就是未知字段
- 最初,proto3消息在解析期间总是丢弃未知字段,但在3.5版本中,将未知字段保存以匹配proto2行为。 在版本3.5及更高版本中,未知字段在解析期间保留并包含在序列化输出中。
【侵权删】
相关文章:
golang工程——protobuf使用及原理
相关文档 源码:https://github.com/grpc/grpc-go 官方文档:https://www.grpc.io/docs/what-is-grpc/introduction/ protobuf编译器源码:https://github.com/protocolbuffers/protobuf proto3文档:https://protobuf.dev/programmin…...

CocosCreator3.8研究笔记(二十三)CocosCreator 动画系统-动画编辑器相关功能面板说明
国庆假期,闲着没事,在家研究技术~ 上一篇,我们介绍了动画剪辑、动画组件以及基本的使用流程,感兴趣的朋友可以前往阅读: CocosCreator 动画系统-动画剪辑和动画组件介绍。 今天,主要介绍动画编辑器相关功能…...

免费 AI 代码生成器 Amazon CodeWhisperer 初体验
文章作者:浪里行舟 简介 随着 ChatGPT 的到来,不由让很多程序员感到恐慌。虽然我们阻止不了 AI 时代到来,但是我们可以跟随 AI 的脚步,近期我发现了一个神仙 AI 代码生产工具 CodeWhisperer ,它是一项基于机器学习的服…...

谷歌扩展下载
Chrome 扩展下载安装网站推荐 # 1. 极简插件优质crx应用 ●地址:https://chrome.zzzmh.cn ●推荐:★★★★★ 一个非常良心 & 干净 & 简洁的 Chrome 扩展下载网站,体验非常不错! 侧边栏可以通过类型对扩展进行筛选和排序&…...
Mac上如何修复损坏的音频?试试iZotope RX 10,对音频进行处理,提高音频质量!
iZotope RX 10是一款由iZotope公司开发的音频修复和编辑软件。它被广泛用于电影、电视、音乐和游戏等行业的音频后期制作,以及声音设计和修复工作。 在RX 10中,iZotope从头开始重新设计了全新的Repair Assistant修复助手,并且推出了相应的修…...
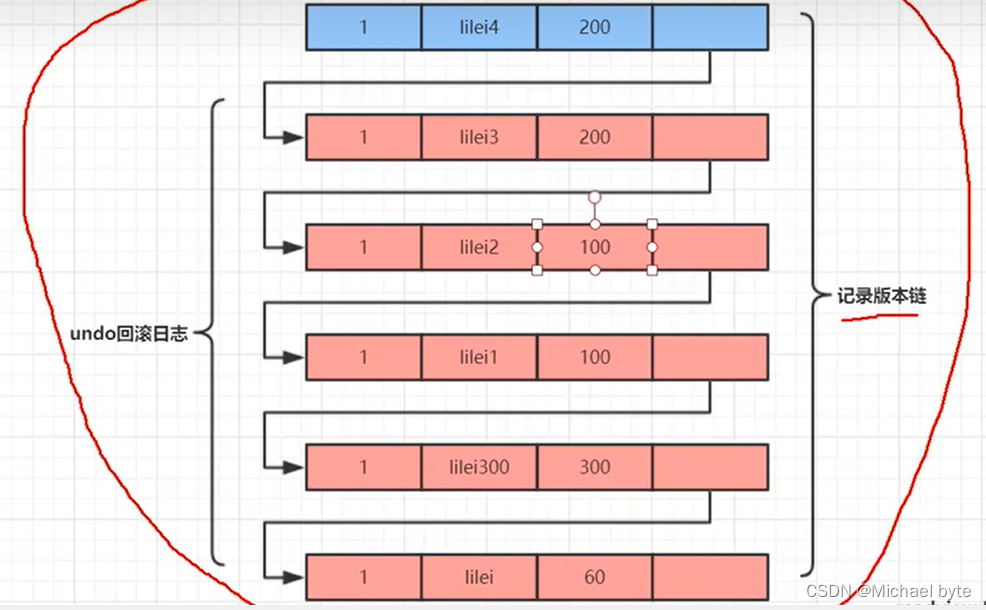
Mysql各种锁
一.不同存储引擎支持的锁机制 Mysql数据库有多种数据存储引擎,Mysql中不同的存储引擎支持不同的锁机制 MyISAM和MEMORY存储引擎采用的表级锁 InnoDB存储引擎支持行级锁,也支持表级锁,默认情况下采用行级锁 二.锁类型的划分 按照数据操作…...
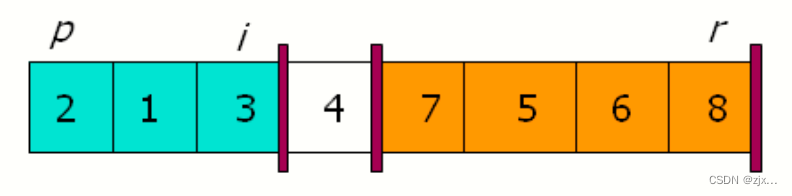
【算法导论】快速排序
文章目录 1. 快速排序的描述 1.1基本描述1.2 PARTITOION函数1.3 快速排序C完整代码 2. 快速排序的性能2.1 最坏时间复杂度2.2 平均时间复杂度 1. 快速排序的描述 1.1基本描述 快速排序是一种时间复杂度为 O(n^2) 的排序算法。虽然最坏情况时间复杂度很差,但他的平…...

QT之QScriptEngine的用法介绍
QT之QScriptEngine的用法介绍 成员函数用法举例 成员函数 1)QScriptEngine::evaluate(const QString &program, const QString &fileName QString(), int lineNumber 1) 执行 JavaScript 代码并返回结果。 2)QScriptEngine::evaluate(const…...

vim 工具的使用
注:以下操作都在普通模式下进行 光标的移动操作 gg 定位到代码的第一行 shiftg 定位到代码的最后一行 nshiftg 定位到第n行 shift6: 特定一行的开始 shift4 特定一行的结尾 上下左右的移动光标 h: 向左移动光标 j: 向下移动光标 k: 向上移动光标 l: 向右移动光标 …...

RPA有什么优势?RPA的8大优势!建议学习!
随着科技的不断发展,越来越多的企业开始寻求数字化转型,以提高生产力和效率。在这个过程中,RPA(Robotic Process Automation)机器人流程自动化技术逐渐成为企业数字化转型的重要工具之一。本文将从八个方面阐述RPA的优…...
初级篇—第二章SELECT查询语句
文章目录 什么是SQLSQL 分类SQL语言的规则与规范阿里巴巴MySQL命名规范数据导入指令 显示表结构 DESC基本的SELECT语句SELECTSELECT ... FROM列的别名 AS去除重复行 DISTINCT空值参与运算着重号查询常数过滤数据 WHERE练习 运算符算术运算符加减符号乘除符号取模符号 符号比较运…...

PostMan的学习
PostMan的学习 目录 环境变量和全局变量接口关联内置动态参数以及自定义动态参数实现业务闭环Postman断言批量运行collection数据驱动之CSV文件和JSON文件测试必须带请求头的接口Mock Serviers 服务器Cookie鉴权NewmanPostManNewManjenkins实现接口测试持续集成 参考资料&am…...

配置OSPF路由
OSPF路由 1.OSPF路由 1.1 OSPF简介 OSPF(Open Shortest Path First,开放式最短路径优先)路由协议是另一个比较常用的路由协议之一,它通过路由器之间通告网络接口的状态,使用最短路径算法建立路由表。在生成路由表时,…...

CCF CSP认证 历年题目自练Day17
CCF CSP认证 历年题目自练Day17 题目一 试题编号: 201803-1 试题名称: 跳一跳 时间限制: 1.0s 内存限制: 256.0MB 问题描述: 问题描述 近来,跳一跳这款小游戏风靡全国,受到不少玩家的喜爱…...
)
基于Matlab实现多因子选股模型(附上源码+数据)
本文将介绍如何使用MATLAB实现多因子选股模型。我们将使用市盈率和市净率两个因子来进行选股,并通过简单的代码案例来演示该过程。 文章目录 引言简单案例总结源码数据下载 引言 多因子选股模型是一种常用的股票选股方法,通过综合考虑多个因子的信息来…...

【中秋国庆不断更】OpenHarmony多态样式stateStyles使用场景
Styles和Extend仅仅应用于静态页面的样式复用,stateStyles可以依据组件的内部状态的不同,快速设置不同样式。这就是我们本章要介绍的内容stateStyles(又称为:多态样式)。 概述 stateStyles是属性方法,可以根…...
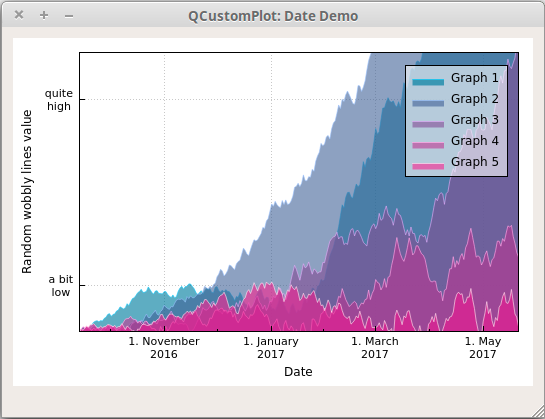
Qt扩展-QCustomPlot绘图基础概述
QCustomPlot绘图基础概述 一、概述二、改变外观1. Graph 类型2. Axis 坐标轴3. 网格 三、案例1. 简单布局两个图2. 绘图与多个轴和更先进的样式3. 绘制日期和时间数据 四、其他Graph:曲线,条形图,统计框图,… 一、概述 本教程使用…...
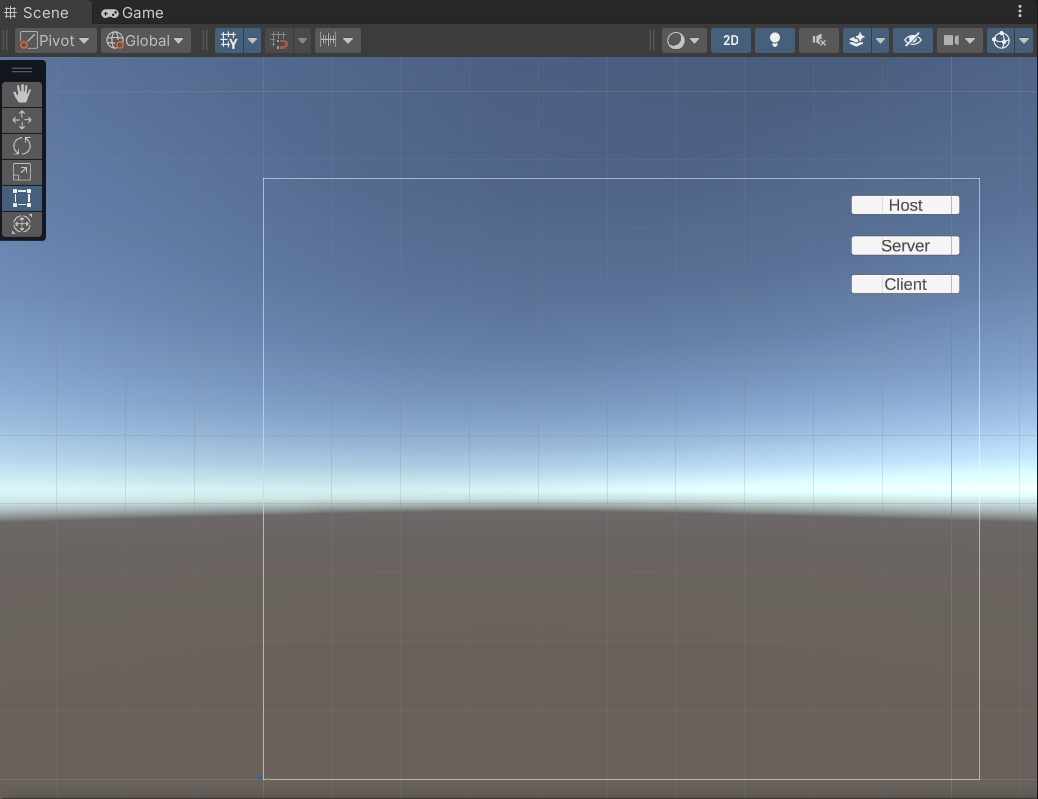
二、局域网联机
目录 1.下载资源包 2.配置NetworkManager 3.编写测试UI 1.下载资源包 2.配置NetworkManager (1)在Assets/Prefabs下创建Network Prefabs List 相应设置如下: (2) 创建空物体“NetworkManager”并挂载NetworkMan…...

决策树剪枝:解决模型过拟合【决策树、机器学习】
如何通过剪枝解决决策树的过拟合问题 决策树是一种强大的机器学习算法,用于解决分类和回归问题。决策树模型通过树状结构的决策规则来进行预测,但在构建决策树时,常常会出现过拟合的问题,即模型在训练数据上表现出色,…...

Ubuntu部署运行ORB-SLAM2
ORB-SLAM2是特征点法的视觉SLAM集大成者,不夸张地说是必学代码。博主已经多次部署运行与ORB-SLAM2相关的代码,所以对环境和依赖很熟悉,对整个系统也是学习了几个月,一行行代码理解。本次在工控机上部署记录下完整的流程。 ORB-SLA…...
)
Spring Boot 实现流式响应(兼容 2.7.x)
在实际开发中,我们可能会遇到一些流式数据处理的场景,比如接收来自上游接口的 Server-Sent Events(SSE) 或 流式 JSON 内容,并将其原样中转给前端页面或客户端。这种情况下,传统的 RestTemplate 缓存机制会…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

MVC 数据库
MVC 数据库 引言 在软件开发领域,Model-View-Controller(MVC)是一种流行的软件架构模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种模式有助于提高代码的可维护性和可扩展性。本文将深入探讨MVC架构与数据库之间的关系,以…...

如何在看板中有效管理突发紧急任务
在看板中有效管理突发紧急任务需要:设立专门的紧急任务通道、重新调整任务优先级、保持适度的WIP(Work-in-Progress)弹性、优化任务处理流程、提高团队应对突发情况的敏捷性。其中,设立专门的紧急任务通道尤为重要,这能…...

Matlab | matlab常用命令总结
常用命令 一、 基础操作与环境二、 矩阵与数组操作(核心)三、 绘图与可视化四、 编程与控制流五、 符号计算 (Symbolic Math Toolbox)六、 文件与数据 I/O七、 常用函数类别重要提示这是一份 MATLAB 常用命令和功能的总结,涵盖了基础操作、矩阵运算、绘图、编程和文件处理等…...

【JavaSE】绘图与事件入门学习笔记
-Java绘图坐标体系 坐标体系-介绍 坐标原点位于左上角,以像素为单位。 在Java坐标系中,第一个是x坐标,表示当前位置为水平方向,距离坐标原点x个像素;第二个是y坐标,表示当前位置为垂直方向,距离坐标原点y个像素。 坐标体系-像素 …...

在WSL2的Ubuntu镜像中安装Docker
Docker官网链接: https://docs.docker.com/engine/install/ubuntu/ 1、运行以下命令卸载所有冲突的软件包: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done2、设置Docker…...

Java 二维码
Java 二维码 **技术:**谷歌 ZXing 实现 首先添加依赖 <!-- 二维码依赖 --><dependency><groupId>com.google.zxing</groupId><artifactId>core</artifactId><version>3.5.1</version></dependency><de…...

使用Matplotlib创建炫酷的3D散点图:数据可视化的新维度
文章目录 基础实现代码代码解析进阶技巧1. 自定义点的大小和颜色2. 添加图例和样式美化3. 真实数据应用示例实用技巧与注意事项完整示例(带样式)应用场景在数据科学和可视化领域,三维图形能为我们提供更丰富的数据洞察。本文将手把手教你如何使用Python的Matplotlib库创建引…...

HarmonyOS运动开发:如何用mpchart绘制运动配速图表
##鸿蒙核心技术##运动开发##Sensor Service Kit(传感器服务)# 前言 在运动类应用中,运动数据的可视化是提升用户体验的重要环节。通过直观的图表展示运动过程中的关键数据,如配速、距离、卡路里消耗等,用户可以更清晰…...