Spark SQL
Spark SQL
- 一、Spark SQL概述
- 二、准备Spark SQL的编程环境
- 三、Spark SQL程序编程的入口
- 四、DataFrame的创建
- 五、DataFrame的编程风格
- 六、DataSet的创建和使用
- 七、Spark SQL的函数操作
一、Spark SQL概述
Spark SQL属于Spark计算框架的一部分,是专门负责结构化数据的处理计算框架,Spark SQL提供了两种数据抽象:DataFrame、Dataset,都是基于RDD之上的一种高级数据抽象,在RDD基础之上增加了一个schema表结构。
DataFrame是以前旧版本的数据抽象(untyped类型的数据抽象),Dataset是新版本的数据抽象(typed有类型的数据抽象),新版本当中DataFrame底层就是Dataset[Row]。
Spark SQL特点
- 易整合
- 统一的数据访问方式
- 兼容Hive
- 标准的数据库连接
二、准备Spark SQL的编程环境
1、创建Spark SQL的编程项目,scala语言支持的
2、引入编程依赖
spark-core_2.12
hadoop-hdfs
spark-sql_2.12
spark-hive_2.12
hadoop的有一个依赖jackson版本和scala2.12版本冲突了,Spark依赖中也有这个依赖,但是默认使用的是pom.xml先引入的那个依赖,把hadoop中jackson依赖排除了即可。
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.kang</groupId><artifactId>spark-sql-study</artifactId><version>1.0-SNAPSHOT</version><packaging>jar</packaging><name>spark-sql-study</name><url>http://maven.apache.org</url><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>3.1.4</version><exclusions><exclusion><groupId>com.fasterxml.jackson.module</groupId><artifactId>*</artifactId></exclusion><exclusion><groupId>com.fasterxml.jackson.core</groupId><artifactId>*</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.1.1</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><version>3.1.1</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.18</version></dependency>
<!-- spark sql on hive--><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.12</artifactId><version>3.1.1</version></dependency></dependencies>
</project>
三、Spark SQL程序编程的入口
1、SQLContext:只能做SQL编程,无法操作Hive以及使用HQL操作。
2、HiveContext:专门提供用来操作和Hive相关的编程。
3、SparkSession:全新的Spark SQL程序执行入口,把SQLContext和HiveContext功能全部整合了,SparkSession底层封装了一个SparkContext,而且SparkSession可以开启Hive的支持。
package studyimport org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
/*** Spark SQL的基本案例执行*/
object Demo01 {def main(args: Array[String]): Unit = {/*** 1、创建Spark SQL的程序编程入口*/val sparkConf:SparkConf = new SparkConf()val sc:SparkSession = SparkSession.builder().appName("test").master("local[*]").config(sparkConf).getOrCreate()import sc.implicits._/*** 2、创建DataFrame或者Dataset数据抽象*/val rdd:RDD[(String,Int)] = sc.sparkContext.makeRDD(Array(("zs",20),("ls",30)))val df:DataFrame = rdd.toDF("name","age")df.printSchema()df.show()sc.stop()}
}
四、DataFrame的创建
-
1、使用隐式转换函数从RDD、Scala集合创建DataFrame
toDF() toDF(columnName*)-
机制:如果集合或者RDD的类型不是Bean,而且再toDF没有传入任何的列名,那么Spark会默认按照列的个数给生成随机的列名,但是如果类型是一个Bean类型,那么toDF产生的随机列名就是bean的属性名。
-
package create.methon1import org.apache.spark.SparkConf import org.apache.spark.sql.{DataFrame, SparkSession} /*** 1、通过隐式转换函数从Scala集合创建DataFrame* 如果使用隐式转换函数 那么必须引入spark定义的隐式转换函数代码* sparksession的对象名.implicits._*/ object Demo01 {def main(args: Array[String]): Unit = {val sparkConf:SparkConf = new SparkConf()val ss:SparkSession = SparkSession.builder().appName("seq to df").master("local[*]").config(sparkConf).getOrCreate()//隐式转换必须导入隐式转换函数类import ss.implicits._/*** 从集合创建DataFrame* 集合一般都是T类型的 T类型如果是Scala自带类型,toDF后面需要跟列名,不跟列名也可以* 集合必须是Seq类型的 而且必须显示的声明为Seq类型*/val array:Seq[(String,Int)] = Array(("zs",20),("ls",30))val df:DataFrame = array.toDF("name","age")df.printSchema()df.show()val array1:Seq[Student] = Array(Student("zs",21),Student("ls",25))val df1:DataFrame = array1.toDF()df1.printSchema()df1.show()ss.stop()} } -
package create.methon1import org.apache.spark.SparkConf import org.apache.spark.rdd.RDD import org.apache.spark.sql.{DataFrame, SparkSession} /*** 1、通过隐式转换函数从RDD创建DataFrame* 如果使用隐式转换函数 那么必须引入spark定义的隐式转换函数代码* sparksession的对象名.implicits._*/ object Demo02 {def main(args: Array[String]): Unit = {val sparkConf:SparkConf = new SparkConf()val ss:SparkSession = SparkSession.builder().appName("seq to df").master("local[*]").config(sparkConf).getOrCreate()//隐式转换必须导入隐式转换函数类import ss.implicits._/*** 从RDD创建DataFrame*/val array:Seq[(String,Int)] = Array(("zs",20),("ls",30))val rdd:RDD[(String,Int)] = ss.sparkContext.makeRDD(array)val df:DataFrame = rdd.toDF()df.printSchema()df.show()val array1:Seq[Student] = Array(Student("zs",21),Student("ls",25))val rdd1:RDD[Student] = ss.sparkContext.makeRDD(array1)val df1:DataFrame = rdd1.toDF()df1.printSchema()df1.show()ss.stop()} } -
package create.methon1case class Student(name:String,age:Int)
-
-
2、通过SparkSession自带的createDataFrame函数从集合或者RDD中创建DataFrame—使用并不多
-
package create.methon2import org.apache.spark.SparkConf import org.apache.spark.sql.types.{DataType, DataTypes, StructField, StructType} import org.apache.spark.sql.{DataFrame, Row, SparkSession} /*** createDataFrame函数从集合中创建DataFrame*/ object Demo01 {def main(args: Array[String]): Unit = {val sparkConf: SparkConf = new SparkConf()val ss: SparkSession = SparkSession.builder().appName("seq to df").master("local[*]").config(sparkConf).getOrCreate()/*** 1、通过Scala的seq集合创建DataFrame 列名是自动生成的*/val array:Seq[(String,Int)] = Array(("zs",20),("ls",30))val df:DataFrame = ss.createDataFrame(array)df.printSchema()df.show()val array1:Seq[Student] = Array(Student("zs",20),Student("ls",30))val df1:DataFrame = ss.createDataFrame(array1)df1.printSchema()df1.show()/*** 2、从java集合中创建DataFrame,如果是Java集合,必须传入一个BeanClass* 同时如果Java集合中存放的数据类型是Row类型,那么必须传入StructType指定row的结构** java集合中如果使用BeanClass构建DaraFrame,要求Java集合中存放的数据类型也必须是Bean的类型* BeanClass必须有getter和setter方法*/val list: java.util.List[Student] = java.util.Arrays.asList(Student("ls",20),Student("zs",30))val df2 = ss.createDataFrame(list,classOf[Student])df2.printSchema()df2.show()/*** 3、java集合的类型为row类型*/val list1: java.util.List[Row] = java.util.Arrays.asList(Row("ls",20),Row("zs",30))val df3 = ss.createDataFrame(list1,StructType(java.util.Arrays.asList(StructField("name",DataTypes.StringType),StructField("age",DataTypes.IntegerType))))df3.printSchema()df3.show()ss.stop()} } -
package create.method2import create.methon2.Student import org.apache.spark.SparkConf import org.apache.spark.rdd.RDD import org.apache.spark.sql.types.{DataTypes, StructField, StructType} import org.apache.spark.sql.{DataFrame, Row, SparkSession}import java.util/*** createDataFrame函数从RDD中创建DataFrame(操作手法完全一致的)*/ object Demo02 {def main(args: Array[String]): Unit = {val sparkConf: SparkConf = new SparkConf()val ss: SparkSession = SparkSession.builder().config(sparkConf).appName("seq to df").master("local[*]").getOrCreate()/*** 1、通过Scala的seq集合创建DataFrame 列名是自动生成的*/val array:Seq[(String,Int)] = Array(("zs",20),("ls",30))val rdd:RDD[(String,Int)] = ss.sparkContext.makeRDD(array)val df:DataFrame = ss.createDataFrame(rdd)df.printSchema()df.show()val array1: Seq[Student] = Array(Student("zs",20))val rdd1:RDD[Student] = ss.sparkContext.makeRDD(array1)val df1: DataFrame = ss.createDataFrame(rdd1,classOf[Student])df1.printSchema()df1.show()/*** 3、java集合的类型为row类型*/val array2:Array[Row] = Array(Row("zs",20),Row("ww",30))val rdd2:RDD[Row] = ss.sparkContext.makeRDD(array2)val df3 = ss.createDataFrame(rdd2, StructType(Array(StructField("name", DataTypes.StringType), StructField("age", DataTypes.IntegerType))))df3.printSchema()df3.show()ss.stop()} } -
package create.methon2import scala.beans.BeanPropertycase class Student(@BeanProperty var name:String, @BeanProperty var age:Int)
-
-
3、从Spark SQL支持的数据源创建DataFrame(HDFS、Hive、JSON文件、CSV文件等等):使用频率最高的
-
外部存储HDFS中读取数据成为DataFrame
- ss.read.format(“jsonxx”).load(“path”) 不太好用
- ss.read.option(key,value).option(…).csv/json(path)
-
从jdbc支持的数据库创建DataFrame
- ss.read.jdbc(url,table,properties)
package create.methon3import org.apache.spark.SparkConf import org.apache.spark.sql.{DataFrame, SparkSession}import java.util.Properties/*** 从外部存储读取数据成为DataFrame*/ object Demo01 {def main(args: Array[String]): Unit = {val sparkConf:SparkConf = new SparkConf()val ss:SparkSession = SparkSession.builder().appName("storage to df").master("local[*]").getOrCreate()/*** 从csv文件读取数据成为DataFrame*/val df:DataFrame = ss.read.option("header","true").format("csv").load("file:///D://Desktop/Student.csv")df.printSchema()df.show()/*** 读取模式有三种:* permissive:默认的* dropMalformed* failfast*/val df1:DataFrame = ss.read.option("header","true").format("csv").option("mode","permissive").csv("file:///D://Desktop/Student.csv")df1.printSchema()df1.show()/*** 从json文件创建DataFrame* json文件中要求一个json对象独占一行*/val df2:DataFrame = ss.read.option("mode","dropMalformed").json("file:///D://Desktop/Student.json")df2.printSchema()df2.show()/*** 从普通的文本文档创建DataFrame---不太实用*/val df3 = ss.read.text("file:///D://Desktop/Student.csv")df3.printSchema()df3.show()/*** 从JDBC可以连接的数据库(rdbms、Hive)创建DataFrame*/val prop:Properties = new Properties()prop.setProperty("user","root")prop.setProperty("password","root")val df4 = ss.read.jdbc("jdbc:mysql://localhost:3306/spark?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8","student",prop)df4.printSchema()df4.show()ss.stop()} } -
读取Hive数据成为DataFrame
-
1、通过SparkSession开启Hive的支持
-
2、引入spark-hive的编程依赖
-
3、通过ss.sql()
-
package create.methon3import org.apache.spark.SparkConf import org.apache.spark.sql.{DataFrame, SparkSession}/*** 连接Hive创建DataFrame:* 1、jdbc方式(基本的操作只能查询表中的所有字段 所有数据)* 2、Spark SQL On Hive:用Hive作为数据存储,用Spark直连Hive 操作Hive中的数据* 不是使用JDBC的方式,而是使用的Hive的元数据库来完成的* 两步操作:(1)需要把Hive的配置文件放到项目的resources目录下,如果在集群环境下,我们需要把hive的配置文件放到spark的conf目录下,(2)需要开启SparkSession的hive支持*/ object Demo02 {def main(args: Array[String]): Unit = {val sparkConf:SparkConf = new SparkConf()val sparkSession:SparkSession = SparkSession.builder().appName("spark sql on hive").master("local[*]").config(sparkConf).enableHiveSupport().getOrCreate()/*** 从Hive中读取数据创建DataFrame*/val df:DataFrame = sparkSession.sql("select * from project.ods_user_behavior_origin")df.printSchema()df.show()//新建数据表sparkSession.sql("create table test (name string,age int,sex string) row format delimited fields terminated by '*'")sparkSession.stop()} }
-
-
-
4、从其他的DataFrame转换的来
五、DataFrame的编程风格
-
通过代码来操作计算DataFrame中数据
-
DSL编程风格
-
DataFrame和Dataset提供了一系列的API操作,API说白了就是Spark SQL中算子操作,可以通过算子操作来获取DataFrame或者Dataset中的数据。
-
转换算子
- RDD具备的算子DataFrame基本上都可以使用。
- DataFrame还增加了一些和SQL操作有关的算子:
selectExpr、where/filter、groupBy、orderBy/sort、limit、join
操作算子 算子概念 limit 获得指定前n行数据并形成新的 dataframe where、filter 条件过滤 select 根据传入的 string 类型字段名,获取指定字段的值,以 DataFrame 类型返回 join 按指定的列进行合并两个dataframe groupBy 按指定字段进行分组,后面可加聚合函数对分组后的数据进行操作 orderBy、sort 按指定字段排序 selectExpr 对指定字段进行特殊处理,可以对指定字段调用 UDF 函数或者指定别名;selectExpr 传入 string 类型的参数,返回 DataFrame 对象。 -
行动算子
-
RDD具备的行动算子DataFrame和Dataset也都具备一些
-
collect/collectAsList:不建议使用,尤其是数据量特别庞大的情况下
-
foreach/foreachPartition
-
获取结果集的一部分数据
- first/take(n)/head(n)/takeAsList(n)/tail(n)
- 获取的返回值类型就是Dataset存储的数据类型
-
printSchema:获取DataFrame或者Dataset的表结构的
-
show()/show(num,truncate:boolean)/show(num,truncate:Int)/show(num,truncate:Int,ver:boolean)
-
保存输出的算子
-
文件系统
- df/ds.write.mode(SaveMode).csv/json/parquet/orc/text(path–目录)
- text纯文本文档要求DataFrame和Dataset的结果集只有一列 而且列必须是String类型
-
JDBC支持的数据库
-
df/ds.write.mode().jdbc
-
foreach|foreachPartition
-
package opratorimport org.apache.spark.SparkConf import org.apache.spark.sql.{Dataset, SaveMode, SparkSession}import java.util.Propertiesobject Demo03 {def main(args: Array[String]): Unit = {val sparkConf: SparkConf = new SparkConf()val ss: SparkSession = SparkSession.builder().appName("action").master("local[*]").config(sparkConf).enableHiveSupport().getOrCreate()import ss.implicits._/*** 创建DataFrame*/val array:Seq[(String,Int,String)] = Array(("zs",20,"man"),("ls",30,"woman"),("ww",40,"man"),("ml",50,"woman"))val dataset:Dataset[(String,Int,String)] = array.toDS() // dataset.show()/*** 保存到MySQL当中 JDBC连接保存*/val prop = new Properties()prop.setProperty("user","root")prop.setProperty("password","root")dataset.write.mode(SaveMode.Overwrite).jdbc("jdbc:mysql://localhost:3306/spark?serverTimezone=Asia/Shanghai","Student",prop)ss.stop()} } -
执行前
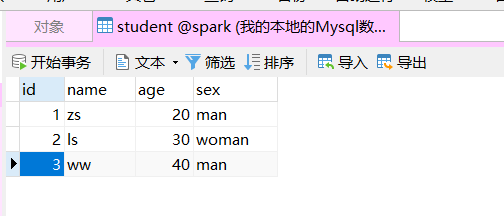
- 执行后

-
-
Hive
-
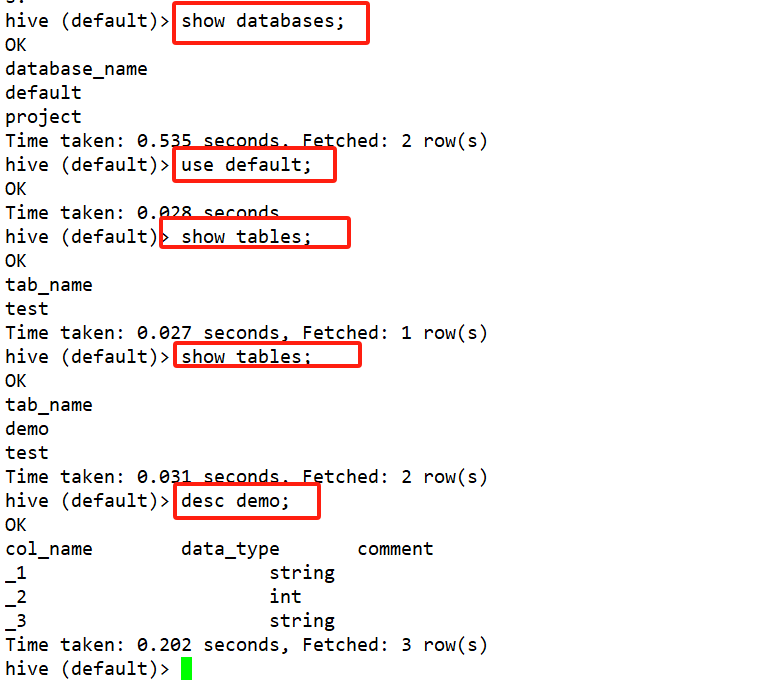
df/ds.write.mode().saveAsTable(“库名.表名”)
-
1、保证hive支持开启的
-
2、保存的数据底层在HDFS上以parquet文件格式保存的
-
dataset.write.mode(SaveMode.Append).saveAsTable("default.demo") -
-
-
-
-
-
SQL编程风格
- 1、将创建的DataFrame加载为一个临时表格
- 2、然后通过ss.sql(sql语句)进行数据的查询
package opratorimport org.apache.spark.SparkConf import org.apache.spark.sql.{DataFrame, SparkSession}object Demo01 {def main(args: Array[String]): Unit = {val sparkConf:SparkConf = new SparkConf()val ss:SparkSession = SparkSession.builder().appName("spark sql on hive").enableHiveSupport().master("local[*]").getOrCreate()/*** 从Hive中读取数据创建DataFrame*/val df:DataFrame = ss.sql("select * from project.ods_user_behavior_origin")df.createTempView("test_spark_sql")val df1 = ss.sql("select ip_addr,parse_url(request_url,'HOST') as host,age from test_spark_sql")df1.show()df.selectExpr("ip_addr","parse_url(request_url,'HOST') as host").show()df.select("age","ip_addr").where("age>40").show()ss.stop()} }
六、DataSet的创建和使用
Dataset有类型,DataFrame无类型的。
创建
-
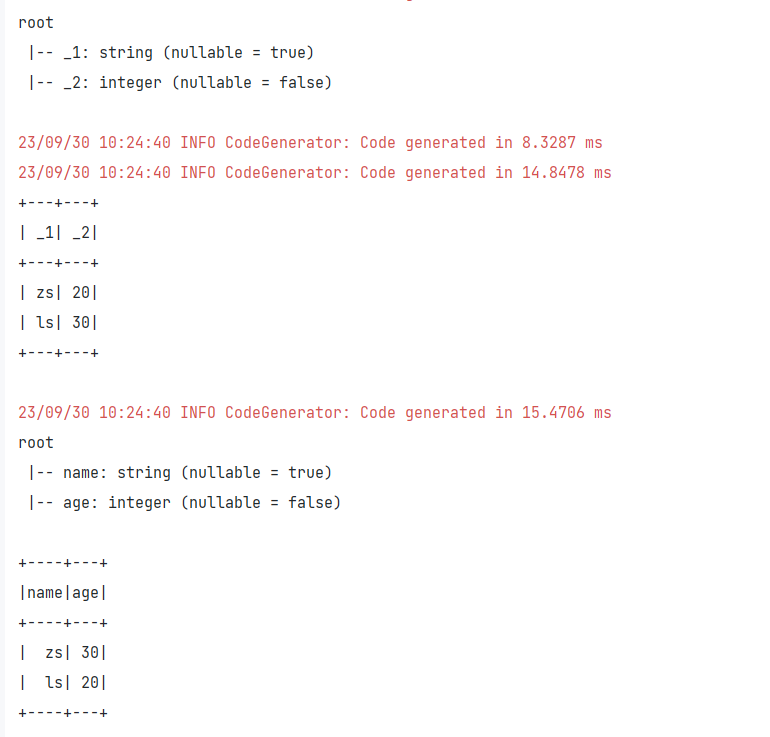
1、隐式转换,toDS()
-
package createdatasetimport org.apache.spark.SparkConf import org.apache.spark.sql.{Dataset, SparkSession}import scala.beans.BeanProperty case class Student(@BeanProperty var name:String,@BeanProperty var age:Int) object Demo01 {def main(args: Array[String]): Unit = {val sparkConf:SparkConf = new SparkConf()val sparkSession:SparkSession = SparkSession.builder().appName("createds").config(sparkConf).master("local[*]").getOrCreate()import sparkSession.implicits._/*** 通过隐式转换从集合或者rdd创建Dataset*/val array:Seq[(String,Int)] = Array(("zs",20),("ls",30))val ds:Dataset[(String,Int)] = array.toDS()ds.printSchema()ds.show()val array1:Seq[Student] = Array(Student("zs",30),Student("ls",20))val ds1:Dataset[Student] = array1.toDS()ds1.printSchema()ds1.show()sparkSession.stop()} } -
-
-
2、通过SparkSession的createDataset函数创建
-
/*** 通过SparkSession的createDataset函数创建*/ val rdd:RDD[Student] = sparkSession.sparkContext.makeRDD(array1) val ds2:Dataset[Student] = sparkSession.createDataset(rdd) ds2.show() -

-
-
3、通过DataFrame转换得到Dataset
df.as[类型-Bean对象必须有getter、setter方法]
也是需要隐式转换的-
/*** 通过DataFrame转换得到Dataset*/ val df:DataFrame = sparkSession.createDataFrame(rdd, classOf[Student]) val ds3:Dataset[Student] = df.as[Student] ds3.show() -

-
七、Spark SQL的函数操作
Spark SQL基本上常见的MySQL、Hive中函数都是支持的。
package functionimport org.apache.spark.SparkConf
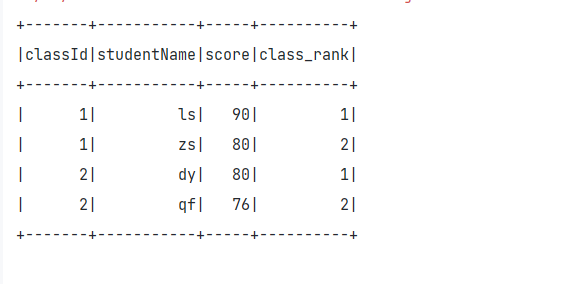
import org.apache.spark.sql.{DataFrame, SparkSession}object Demo01 {def main(args: Array[String]): Unit = {val sparkConf:SparkConf = new SparkConf()val ss:SparkSession = SparkSession.builder().appName("function").master("local[*]").enableHiveSupport().config(sparkConf).getOrCreate()import ss.implicits._val array:Seq[(Int,String,Int)] = Array((1,"zs",80),(1,"ls",90),(1,"ww",65),(1,"ml",70),(2,"zsf",70),(2,"zwj",67),(2,"qf",76),(2,"dy",80))val df:DataFrame = array.toDF("classId","studentName","score")df.createOrReplaceTempView("student_score_temp")ss.sql("select *,row_number() over(partition by classId order by score desc) as class_rank from student_score_temp").show()ss.stop()}
}
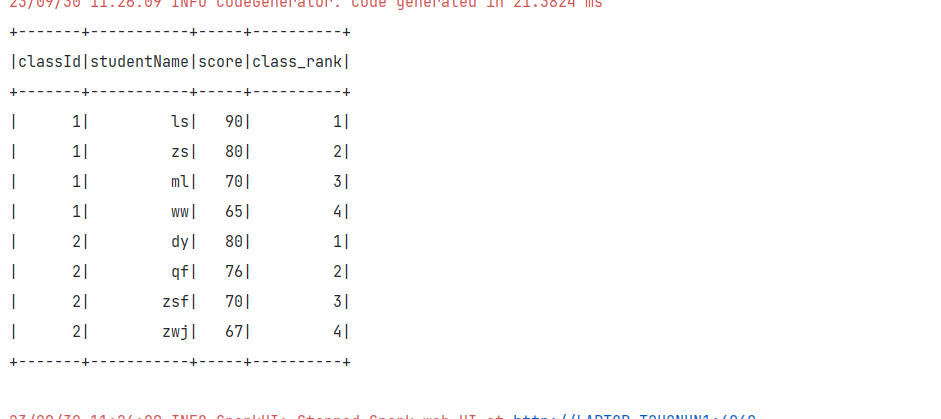
ss.sql("select * from (select *,row_number() over(partition by classId order by score desc) as class_rank from student_score_temp) as temp where temp.class_rank < 2").show()
val array: Seq[(String, String)] = Array(("zs", "play,eat,drink"), ("ls", "play,game,run"))
val df: DataFrame = array.toDF("name", "hobby")
df.createOrReplaceTempView("temp")
/*** zs play,eat,drink* ls play,game,run* zs play* zs eat*/
ss.sql("select temp.name,a.bobby from temp lateral view explode(split(hobby,',')) a as bobby").show()

自定义函数
- ss.udf.register(name,函数)
package functionimport org.apache.spark.SparkConf
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql.{DataFrame, Encoder, Encoders, SparkSession}object Demo02 {def main(args: Array[String]): Unit = {val sparkConf: SparkConf = new SparkConf()val ss: SparkSession = SparkSession.builder().appName("createMyFunction").master("local[*]").config(sparkConf).enableHiveSupport().getOrCreate()import ss.implicits._ss.udf.register("my_length",(name:String)=>{name.length})val array: Seq[(String, String)] = Array(("zs", "play,eat,drink"), ("ls", "play,game,run"))val df: DataFrame = array.toDF("name", "hobby")df.selectExpr("my_length(hobby)").show()ss.udf.register("my_avg",new My())val array1: Seq[(String, Int)] = Array(("zs", 20), ("ls", 30))val df1: DataFrame = array1.toDF("name", "score")df1.selectExpr("my_avg(score)").show()ss.stop()}
}
class My_AVG extends Aggregator[Int,(Int,Int),java.lang.Double]{/*** 设置初始值的 是缓冲区的初始值* @return*/override def zero: (Int, Int) = (0,0)/*** 当输入一个结果之后,缓冲区如何对输入的结果进行计算** @param b 缓冲区* @param a 输入的某一个值* @return*/override def reduce(b: (Int, Int), a: Int): (Int, Int) = {(b._1+a,b._2+1)}/*** 分区之间的合并** @param b1* @param b2* @return*/override def merge(b1: (Int, Int), b2: (Int, Int)): (Int, Int) = {(b1._1+b2._1,b1._2+b2._2)}/*** 最后的结果** @param reduction* @return*/override def finish(reduction: (Int, Int)): java.lang.Double = {reduction._1.toDouble / reduction._2}override def bufferEncoder: Encoder[(Int, Int)] = Encoders.product[(Int, Int)]override def outputEncoder: Encoder[java.lang.Double] = Encoders.DOUBLE
}
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
package functionimport org.apache.spark.sql.Row
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, DataTypes, StructField, StructType}class My extends UserDefinedAggregateFunction{override def inputSchema: StructType = StructType(Array(StructField("score",DataTypes.IntegerType)))override def bufferSchema: StructType = StructType(Array(StructField("sum",DataTypes.IntegerType),StructField("count",DataTypes.IntegerType)))override def dataType: DataType = DataTypes.DoubleTypeoverride def deterministic: Boolean = trueoverride def initialize(buffer: MutableAggregationBuffer): Unit = {buffer(0) = 0buffer(1) = 0}override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {buffer(0) = buffer.getInt(0)+input.getInt(0)buffer(1) = buffer.getInt(1)+1}override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {buffer1(0) = buffer1.getInt(0) + buffer2.getInt(0)buffer1(1) = buffer1.getInt(1) + buffer2.getInt(1)}override def evaluate(buffer: Row): Any = {buffer.getInt(0).toDouble/buffer.getInt(1)}
}
相关文章:
Spark SQL
Spark SQL 一、Spark SQL概述二、准备Spark SQL的编程环境三、Spark SQL程序编程的入口四、DataFrame的创建五、DataFrame的编程风格六、DataSet的创建和使用七、Spark SQL的函数操作 一、Spark SQL概述 Spark SQL属于Spark计算框架的一部分,是专门负责结构化数据的…...

初识多线程
一、多任务 现实中太多这样同时做多件事的例子了,例如一边吃饭一遍刷视频,看起来是多个任务都在做,其实本质上我们的大脑在同一时间依旧只做了一件事情。 二、普通方法调用和多线程 普通方法调用只有主线程一条执行路径 多线程多条执行路径…...

Linux用户、用户组和文件权限的管理与实践
目录 一、Linux用户、用户组和文件权限的基础概念与作用1.1 Linux用户的概念与作用1.2 Linux用户组的概念与作用1.3 Linux文件权限的概念与作用 二、Linux用户、用户组和文件权限的具体操作实践2.1 创建新用户:从零开始构建用户体系2.2 修改用户和用户组属性&#x…...
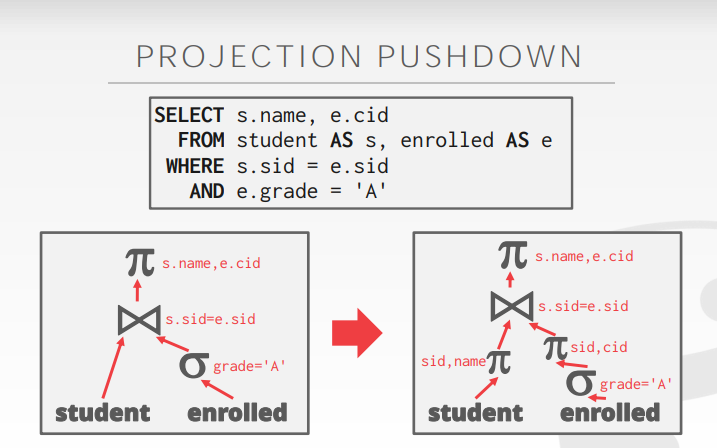
【CMU15-445 Part-14】Query Planning Optimization I
Part14-Query Planning & Optimization I SQL is Declarative,只告诉想要什么而不需要说怎么做。 IBM System R是第一个实现query optimizer查询优化器的系统 Heuristics / Rules 条件触发 静态规则,重写query来remove 低效或者愚蠢的东西…...

七、垃圾收集中级
JVM由浅入深系列 JVM由浅入深系列一、关于Java性能的误解二、Java性能概述三、了解JVM概述四、探索JVM架构五、垃圾收集基础六、HotSpot中的垃圾收集七、垃圾收集中级八、垃圾收集高级👋垃圾收集中级 ⚽️1. 权衡收集器插件 就 Java 平台而言,有一点可能初学者未必能马上意…...
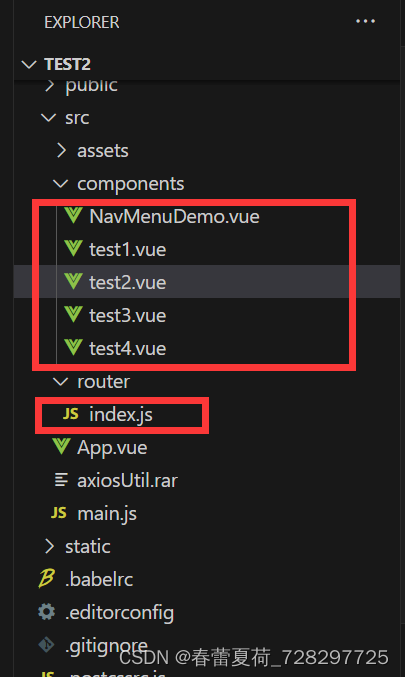
el-menu 导航栏学习(1)
最简单的导航栏学习跳转实例效果: (1)index.js路由配置: import Vue from vue import Router from vue-router import NavMenuDemo from /components/NavMenuDemo import test1 from /components/test1 import test2 from /c…...

Axios请求封装
安装axios,在net文件下新建index.js,封装InternalPsot请求: function internalPost(url,data,header,success,failure,errordefaultError()){axios.post(url,data,{headers:header}).then(({data})>{if (data.code200){success(data.dat…...
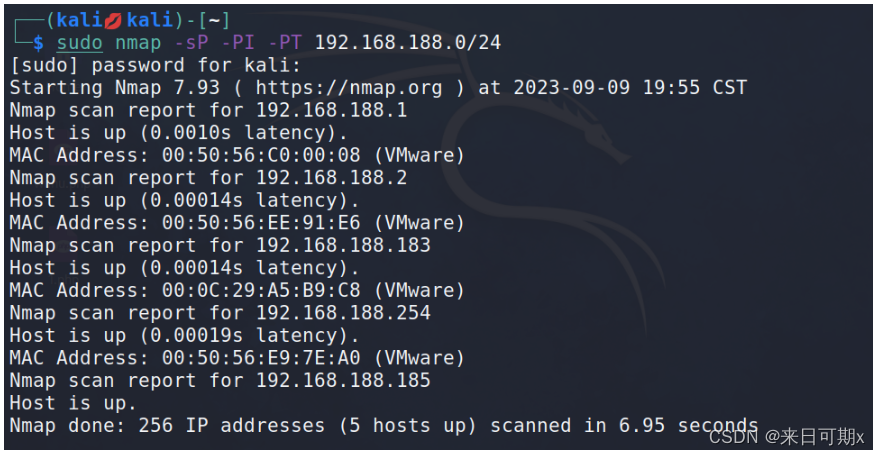
Pikachu靶场——XXE 漏洞
文章目录 1. XXE1.1 查看系统文件内容1.2 查看PHP源代码1.3 查看开放端口1.4 探测内网主机 1. XXE 漏洞描述 XXE(XML External Entity)攻击是一种利用XML解析器漏洞的攻击。在这种攻击中,攻击者通过在XML文件中插入恶意实体来触发解析器加载…...

vscode登录租的新服务器
1.connect to…… 选择 connect current window to host 2.configure SSH Host 选择本地配置文件 打开配置文件,把主机名端口号写进去 再返回vscode远程登录页面,左侧栏就会出现这个主机名了。...

Verilog参数定义与仿真模块中的参数修改
文章目录 参数方式定义参数的优势rtl模块中的参数定义模块名后定义参数parameter定义参数 仿真模块中的参数修改例化时修改defparam修改 总结与说明附录:测试代码 参数方式定义参数的优势 当一个模块被另一个模块引用例化时,高层模块可以对低层模块的参…...
Android studio升级Giraffe | 2022.3.1 Patch 1踩坑
这里写自定义目录标题 not "opens java.io" to unnamed module错误报错信息解决 superclass access check failed: class butterknife.compiler.ButterKnifeProcessor$RScanner报错报错信息解决 Android studio升级Giraffe | 2022.3.1 Patch 1后,出现项目…...
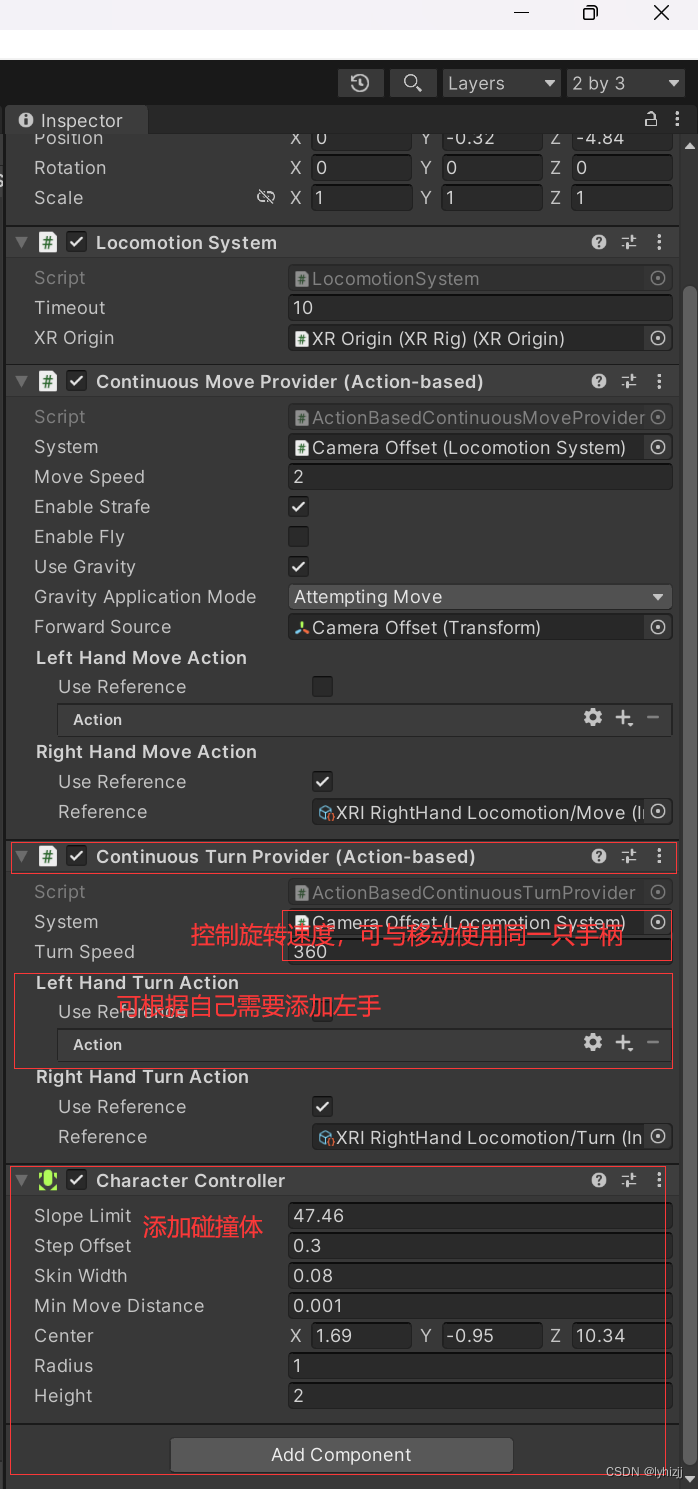
使用U3D、pico开发VR(二)——添加手柄摇杆控制移动
一、将unity 与visual studio 相关联 1.Edit->Preference->External tool 选择相应的版本 二、手柄遥控人物转向和人物移动 1.添加Locomotion System组件 选择XR Origin; 2.添加Continuous Move Provider(Action-based)组件 1>…...
详细设计方案)
【FPGA项目】图像采集及显示(2)详细设计方案
目录 前言 一、视频流采集设计 二、DDR3缓存控制 三、FIFO 设计 四、VGA显示器驱动设计...

查找排序部分习题 242. 有效的字母异位词 74. 搜索二维矩阵 1. 两数之和 167.两数之和 II
242. 有效的字母异位词 给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。 注意:若 s 和 t 中每个字符出现的次数都相同,则称 s 和 t 互为字母异位词。 class Solution(object):def isAnagram(self, s, t):""…...
(附MATLAB代码实现))
MATLAB算法实战应用案例精讲-【优化算法】冠状病毒优化算法(COVIDOA)(附MATLAB代码实现)
目录 前言 知识储备 1 冠状病毒群体免疫优化算法...

React查询、搜索类功能的实现
React查询、搜索类功能的实现 查询之类的如果是通过向列表接口中发送对应参数来查询的,那么在默认输出时,在useEffect钩子中的请求中可以先为需要查询的请求参数设初始的state,也就是null或者未定义,这样的话初始请求的还是整个列…...
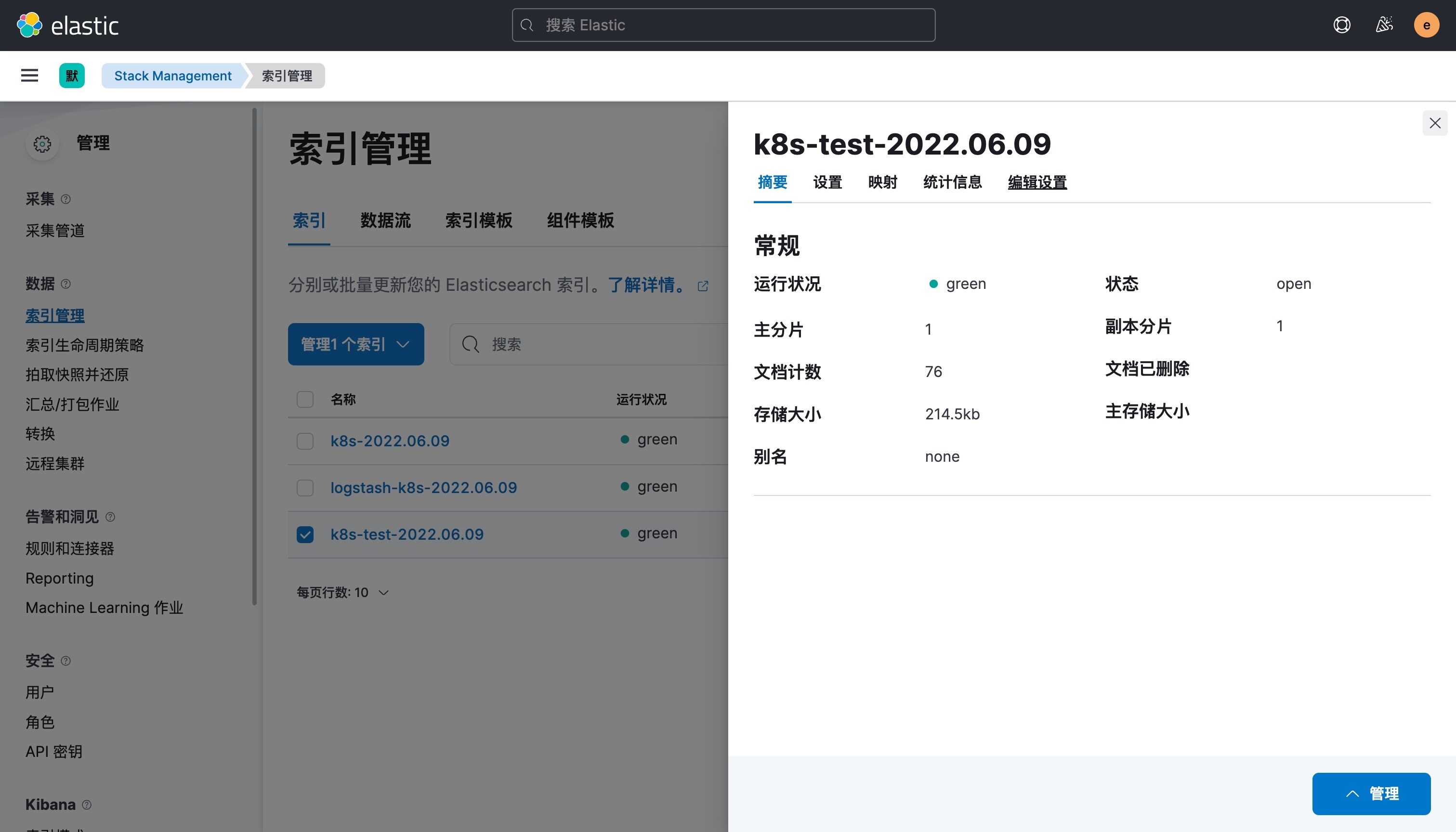
k8s搭建EFK日志系统
搭建 EFK 日志系统 前面大家介绍了 Kubernetes 集群中的几种日志收集方案,Kubernetes 中比较流行的日志收集解决方案是 Elasticsearch、Fluentd 和 Kibana(EFK)技术栈,也是官方现在比较推荐的一种方案。 Elasticsearch 是一个实…...
-- fonts - 字体库)
LuatOS-SOC接口文档(air780E)-- fonts - 字体库
fonts.list(tp) 返回固件支持的字体列表 参数 传入值类型 解释 string 类型, 默认 u8g2, 还可以是lvgl 返回值 返回值类型 解释 table 字体列表 例子 -- API新增于2022-07-12 if fonts.list thenlog.info("fonts", "u8g2", json.encode(fonts…...

[Java·算法·困难]LeetCode124.二叉树中的最大路径和
每天一题,防止痴呆 题目示例分析思路1题解1 👉️ 力扣原文 题目 二叉树中的 路径 被定义为一条节点序列,序列中每对相邻节点之间都存在一条边。同一个节点在一条路径序列中 至多出现一次 。该路径 至少包含一个 节点,且不一定经…...
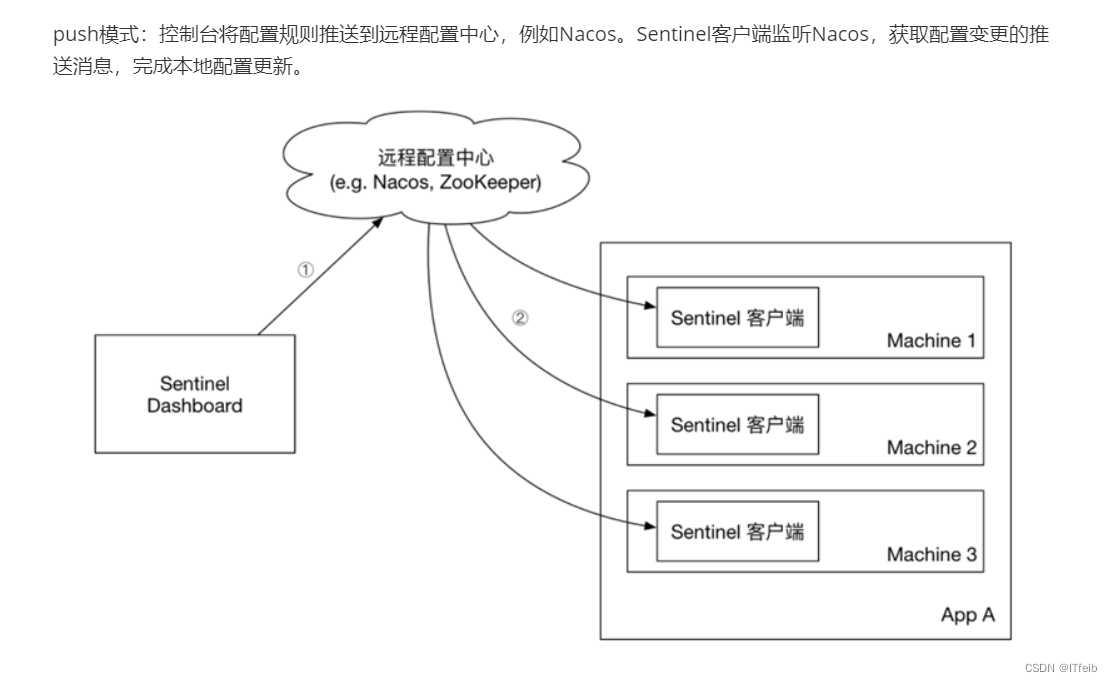
【微服务保护】
文章目录 Sentinel流量控制流控模式流控效果 隔离和降级线程隔离熔断降级 授权规则和规则持久化 微服务雪崩问题: 微服务中,服务间调用关系错综复杂,一个微服务往往依赖于多个其它微服务。服务D有 故障进而导致服务A有故障,进而导…...

DeOldify图像上色服务MySQL数据管理实战:任务记录与结果存储
DeOldify图像上色服务MySQL数据管理实战:任务记录与结果存储 老照片修复和上色,听起来是个挺有情怀的事儿,但如果你是一家需要处理成千上万张历史照片的机构,比如档案馆、博物馆或者影视制作公司,这事儿立马就从“情怀…...

GB28181视频监控系统实战:手把手教你用WVP和ZLMediaKit搭建Windows平台服务
GB28181视频监控系统实战:Windows平台WVPZLMediaKit全栈部署指南 如果你正在寻找一套开箱即用的GB28181视频监控解决方案,WVP(Web Video Platform)与ZLMediaKit的组合无疑是当前最热门的开源选择。本文将带你从零开始,…...

Halcon实战:NURBS样条曲线拟合在工业检测中的高效应用与gen_contour_nurbs_xld解析
1. NURBS样条曲线在工业检测中的核心价值 在工业视觉检测领域,轮廓拟合精度直接决定产品质量判定的准确性。传统多边形逼近方法在处理复杂曲面时往往需要大量线段才能达到理想效果,而NURBS(非均匀有理B样条)通过控制点、权重和节点…...

68. Resolving a fleet-agent that is stuck in the Pending-Upgrade state
环境访问Rancher-K8S解决方案博主 :https://blog.csdn.net/lidw2009 情况The fleet-agent is stuck in a "Pending-Upgrade" state and showing the following error: 代理卡在“待升级”状态,显示以下错误: <span style"c…...
移植实战:从引脚配置到显示验证)
TI电赛开发板驱动0.91寸OLED屏(SSD1306)移植实战:从引脚配置到显示验证
TI电赛开发板驱动0.91寸OLED屏(SSD1306)移植实战:从引脚配置到显示验证 最近在准备电赛项目,需要给TI的开发板(比如TMS320F28P550)加个小屏幕显示数据,0.91寸的OLED屏是个不错的选择,…...

DeOldify Web UI性能压测:JMeter模拟200并发用户稳定运行报告
DeOldify Web UI性能压测:JMeter模拟200并发用户稳定运行报告 1. 测试背景与目的 最近我们团队部署了一套基于DeOldify深度学习模型的黑白图像上色服务,这个服务采用了U-Net架构,能够将黑白照片自动转换为彩色照片。虽然日常使用中服务表现…...
)
摄影小白必看:如何用MTF曲线挑选最适合你的镜头(附实战对比)
摄影小白必看:如何用MTF曲线挑选最适合你的镜头(附实战对比) 当你第一次听说"MTF曲线"这个词时,可能会觉得这是专业摄影师才需要了解的复杂概念。但实际上,理解MTF曲线就像掌握了一把钥匙,能帮你…...
像素即坐标 · 视频即传感器 · 空间即智能——镜像视界 Pixel-to-Space 空间智能技术白皮书
像素即坐标 视频即传感器 空间即智能——镜像视界 Pixel-to-Space 空间智能技术白皮书发布单位:镜像视界(浙江)科技有限公司 发布时间:2026一、白皮书摘要随着人工智能、大模型技术和空间计算技术的快速发展,传统视频…...

Qt 5.14.2+Mysql5.7 64位开发环境下无法连接数据库
问题背景 在Qt 5.14.2与MySQL 5.7 64位开发环境下,连接数据库时可能出现驱动加载失败、连接字符串配置错误或依赖库缺失等问题。此类问题通常与环境配置、Qt插件路径或MySQL客户端库未正确部署有关。检查Qt的MySQL驱动是否可用 通过代码检查当前Qt支持的数据库驱动列…...

7步快速搭建GitHub文档项目本地开发环境:从克隆到启动全指南
7步快速搭建GitHub文档项目本地开发环境:从克隆到启动全指南 【免费下载链接】docs The open-source repo for docs.github.com 项目地址: https://gitcode.com/GitHub_Trending/do/docs GitHub推荐项目精选(do/docs)是GitHub官方文档…...