k8s搭建EFK日志系统
搭建 EFK 日志系统
前面大家介绍了 Kubernetes 集群中的几种日志收集方案,Kubernetes 中比较流行的日志收集解决方案是 Elasticsearch、Fluentd 和 Kibana(EFK)技术栈,也是官方现在比较推荐的一种方案。
Elasticsearch 是一个实时的、分布式的可扩展的搜索引擎,允许进行全文、结构化搜索,它通常用于索引和搜索大量日志数据,也可用于搜索许多不同类型的文档。
Elasticsearch 通常与 Kibana 一起部署,Kibana 是 Elasticsearch 的一个功能强大的数据可视化 Dashboard,Kibana 允许你通过 web 界面来浏览 Elasticsearch 日志数据。
Fluentd是一个流行的开源数据收集器,我们将在 Kubernetes 集群节点上安装 Fluentd,通过获取容器日志文件、过滤和转换日志数据,然后将数据传递到 Elasticsearch 集群,在该集群中对其进行索引和存储。
我们先来配置启动一个可扩展的 Elasticsearch 集群,然后在 Kubernetes 集群中创建一个 Kibana 应用,最后通过 DaemonSet 来运行 Fluentd,以便它在每个 Kubernetes 工作节点上都可以运行一个 Pod。
安装 Elasticsearch 集群
在创建 Elasticsearch 集群之前,我们先创建一个命名空间,我们将在其中安装所有日志相关的资源对象。
$ kubectl create ns logging
环境准备
ElasticSearch 安装有最低安装要求,如果安装后 Pod 无法正常启动,请检查是否符合最低要求的配置,要求如下:

这里我们要安装的 ES 集群环境信息如下所示:

这里我们使用一个 NFS 类型的 StorageClass 来做持久化存储,当然如果你是线上环境建议使用 Local PV 或者 Ceph RBD 之类的存储来持久化 Elasticsearch 的数据。
此外由于 ElasticSearch 7.x 版本默认安装了 X-Pack 插件,并且部分功能免费,需要我们配置一些安全证书文件。
1、生成证书文件
# 运行容器生成证书,containerd下面用nerdctl
$ mkdir -p elastic-certs
$ nerdctl run --name elastic-certs -v elastic-certs:/app -it -w /app elasticsearch:7.17.3 /bin/sh -c \"elasticsearch-certutil ca --out /app/elastic-stack-ca.p12 --pass '' && \elasticsearch-certutil cert --name security-master --dns \security-master --ca /app/elastic-stack-ca.p12 --pass '' --ca-pass '' --out /app/elastic-certificates.p12"
# 删除容器
$ nerdctl rm -f elastic-certs
# 将 pcks12 中的信息分离出来,写入文件
$ cd elastic-certs && openssl pkcs12 -nodes -passin pass:'' -in elastic-certificates.p12 -out elastic-certificate.pem
需要注意 nerdctl 如果是 v0.20.0 版本,需要更新 CNI 插件版本,否则会出现错误
FATA[0000] failed to create shim: OCI runtime create failed: container_linux.go:380: starting container process caused: process_linux.go:545: container init caused: Running hook #0:: error running hook: exit status 1, stdout: , stderr: time="2022-06-06T16:37:03+08:00" level=fatal msg="failed to call cni.Setup: plugin type=\"bridge\" failed (add): incompatible CNI versions; config is \"1.0.0\", plugin supports [\"0.1.0\" \"0.2.0\" \"0.3.0\" \"0.3.1\" \"0.4.0\"]",将 CNI 插件从 https://github.com/containernetworking/plugins/releases/download/v1.1.1/cni-plugins-linux-amd64-v1.1.1.tgz 下载下来覆盖/opt/cni/bin目录即可。
2、添加证书到 Kubernetes
# 添加证书
$ kubectl create secret -n logging generic elastic-certs --from-file=elastic-certificates.p12
# 设置集群用户名密码
$ kubectl create secret -n logging generic elastic-auth --from-literal=username=elastic --from-literal=password=ydzsio321
安装 ES 集群
首先添加 ELastic 的 Helm 仓库:
$ helm repo add elastic https://helm.elastic.co
$ helm repo update
ElaticSearch 安装需要安装三次,分别安装 Master、Data、Client 节点,Master 节点负责集群间的管理工作;Data 节点负责存储数据;Client 节点负责代理 ElasticSearch Cluster 集群,负载均衡。
首先使用 helm pull 拉取 Chart 并解压:
$ helm pull elastic/elasticsearch --untar --version 7.17.3
$ cd elasticsearch
在 Chart 目录下面创建用于 Master 节点安装配置的 values 文件:
# values-master.yaml
## 设置集群名称
clusterName: 'elasticsearch'
## 设置节点名称
nodeGroup: 'master'## 设置角色
roles:master: 'true'ingest: 'false'data: 'false'# ============镜像配置============
## 指定镜像与镜像版本
image: 'elasticsearch'
imageTag: '7.17.3'
imagePullPolicy: 'IfNotPresent'## 副本数
replicas: 3# ============资源配置============
## JVM 配置参数
esJavaOpts: '-Xmx1g -Xms1g'
## 部署资源配置(生成环境要设置大些)
resources:requests:cpu: '2000m'memory: '2Gi'limits:cpu: '2000m'memory: '2Gi'
## 数据持久卷配置
persistence:enabled: true
## 存储数据大小配置
volumeClaimTemplate:storageClassName: local-pathaccessModes: ['ReadWriteOnce']resources:requests:storage: 5Gi# ============安全配置============
## 设置协议,可配置为 http、https
protocol: http
## 证书挂载配置,这里我们挂入上面创建的证书
secretMounts:- name: elastic-certssecretName: elastic-certspath: /usr/share/elasticsearch/config/certsdefaultMode: 0755## 允许您在/usr/share/elasticsearch/config/中添加任何自定义配置文件,例如 elasticsearch.yml、log4j2.properties
## ElasticSearch 7.x 默认安装了 x-pack 插件,部分功能免费,这里我们配置下
## 下面注掉的部分为配置 https 证书,配置此部分还需要配置 helm 参数 protocol 值改为 https
esConfig:elasticsearch.yml: |xpack.security.enabled: truexpack.security.transport.ssl.enabled: truexpack.security.transport.ssl.verification_mode: certificatexpack.security.transport.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12xpack.security.transport.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12# xpack.security.http.ssl.enabled: true# xpack.security.http.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12# xpack.security.http.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
## 环境变量配置,这里引入上面设置的用户名、密码 secret 文件
extraEnvs:- name: ELASTIC_USERNAMEvalueFrom:secretKeyRef:name: elastic-authkey: username- name: ELASTIC_PASSWORDvalueFrom:secretKeyRef:name: elastic-authkey: password# ============调度配置============
## 设置调度策略
## - hard:只有当有足够的节点时 Pod 才会被调度,并且它们永远不会出现在同一个节点上
## - soft:尽最大努力调度
antiAffinity: 'soft'
# tolerations:
# - operator: "Exists" ##容忍全部污点
然后创建用于 Data 节点安装的 values 文件:
# values-data.yaml
# ============设置集群名称============
## 设置集群名称
clusterName: 'elasticsearch'
## 设置节点名称
nodeGroup: 'data'
## 设置角色
roles:master: 'false'ingest: 'true'data: 'true'# ============镜像配置============
## 指定镜像与镜像版本
image: 'elasticsearch'
imageTag: '7.17.3'
## 副本数(建议设置为3,我这里资源不足只用了1个副本)
replicas: 3# ============资源配置============
## JVM 配置参数
esJavaOpts: '-Xmx1g -Xms1g'
## 部署资源配置(生成环境一定要设置大些)
resources:requests:cpu: '1000m'memory: '2Gi'limits:cpu: '1000m'memory: '2Gi'
## 数据持久卷配置
persistence:enabled: true
## 存储数据大小配置
volumeClaimTemplate:storageClassName: local-pathaccessModes: ['ReadWriteOnce']resources:requests:storage: 10Gi# ============安全配置============
## 设置协议,可配置为 http、https
protocol: http
## 证书挂载配置,这里我们挂入上面创建的证书
secretMounts:- name: elastic-certssecretName: elastic-certspath: /usr/share/elasticsearch/config/certs
## 允许您在/usr/share/elasticsearch/config/中添加任何自定义配置文件,例如 elasticsearch.yml
## ElasticSearch 7.x 默认安装了 x-pack 插件,部分功能免费,这里我们配置下
## 下面注掉的部分为配置 https 证书,配置此部分还需要配置 helm 参数 protocol 值改为 https
esConfig:elasticsearch.yml: |xpack.security.enabled: truexpack.security.transport.ssl.enabled: truexpack.security.transport.ssl.verification_mode: certificatexpack.security.transport.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12xpack.security.transport.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12# xpack.security.http.ssl.enabled: true# xpack.security.http.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12# xpack.security.http.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
## 环境变量配置,这里引入上面设置的用户名、密码 secret 文件
extraEnvs:- name: ELASTIC_USERNAMEvalueFrom:secretKeyRef:name: elastic-authkey: username- name: ELASTIC_PASSWORDvalueFrom:secretKeyRef:name: elastic-authkey: password# ============调度配置============
## 设置调度策略
## - hard:只有当有足够的节点时 Pod 才会被调度,并且它们永远不会出现在同一个节点上
## - soft:尽最大努力调度
antiAffinity: 'soft'
## 容忍配置
# tolerations:
# - operator: "Exists" ##容忍全部污点
最后一个是用于创建 Client 节点的 values 文件:
# values-client.yaml
# ============设置集群名称============
## 设置集群名称
clusterName: 'elasticsearch'
## 设置节点名称
nodeGroup: 'client'
## 设置角色
roles:master: 'false'ingest: 'false'data: 'false'# ============镜像配置============
## 指定镜像与镜像版本
image: 'elasticsearch'
imageTag: '7.17.3'
## 副本数
replicas: 1# ============资源配置============
## JVM 配置参数
esJavaOpts: '-Xmx1g -Xms1g'
## 部署资源配置(生成环境一定要设置大些)
resources:requests:cpu: '1000m'memory: '2Gi'limits:cpu: '1000m'memory: '2Gi'
## 数据持久卷配置
persistence:enabled: false# ============安全配置============
## 设置协议,可配置为 http、https
protocol: http
## 证书挂载配置,这里我们挂入上面创建的证书
secretMounts:- name: elastic-certssecretName: elastic-certspath: /usr/share/elasticsearch/config/certs
## 允许您在/usr/share/elasticsearch/config/中添加任何自定义配置文件,例如 elasticsearch.yml
## ElasticSearch 7.x 默认安装了 x-pack 插件,部分功能免费,这里我们配置下
## 下面注掉的部分为配置 https 证书,配置此部分还需要配置 helm 参数 protocol 值改为 https
esConfig:elasticsearch.yml: |xpack.security.enabled: truexpack.security.transport.ssl.enabled: truexpack.security.transport.ssl.verification_mode: certificatexpack.security.transport.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12xpack.security.transport.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12# xpack.security.http.ssl.enabled: true# xpack.security.http.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12# xpack.security.http.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
## 环境变量配置,这里引入上面设置的用户名、密码 secret 文件
extraEnvs:- name: ELASTIC_USERNAMEvalueFrom:secretKeyRef:name: elastic-authkey: username- name: ELASTIC_PASSWORDvalueFrom:secretKeyRef:name: elastic-authkey: password# ============Service 配置============
service:type: NodePortnodePort: '30200'
现在用上面的 values 文件来安装:
# 安装 master 节点
$ helm upgrade --install es-master -f values-master.yaml --namespace logging .
# 安装 data 节点
$ helm upgrade --install es-data -f values-data.yaml --namespace logging .
# 安装 client 节点
$ helm upgrade --install es-client -f values-client.yaml --namespace logging .
在安装 Master 节点后 Pod 启动时候会抛出异常,就绪探针探活失败,这是个正常现象。在执行安装 Data 节点后 Master 节点 Pod 就会恢复正常。
安装 Kibana
Elasticsearch 集群安装完成后接下来配置安装 Kibana
使用 helm pull 命令拉取 Kibana Chart 包并解压:
$ helm pull elastic/kibana --untar --version 7.17.3
$ cd kibana
创建用于安装 Kibana 的 values 文件:
# values-prod.yaml
## 指定镜像与镜像版本
image: 'kibana'
imageTag: '7.17.3'## 配置 ElasticSearch 地址
elasticsearchHosts: 'http://elasticsearch-client:9200'# ============环境变量配置============
## 环境变量配置,这里引入上面设置的用户名、密码 secret 文件
extraEnvs:- name: 'ELASTICSEARCH_USERNAME'valueFrom:secretKeyRef:name: elastic-authkey: username- name: 'ELASTICSEARCH_PASSWORD'valueFrom:secretKeyRef:name: elastic-authkey: password# ============资源配置============
resources:requests:cpu: '500m'memory: '1Gi'limits:cpu: '500m'memory: '1Gi'# ============配置 Kibana 参数============
## kibana 配置中添加语言配置,设置 kibana 为中文
kibanaConfig:kibana.yml: |i18n.locale: "zh-CN"# ============Service 配置============
service:type: NodePortnodePort: '30601'
使用上面的配置直接安装即可:
$ helm install kibana -f values-prod.yaml --namespace logging .
下面是安装完成后的 ES 集群和 Kibana 资源:
$ kubectl get pods -n logging
NAME READY STATUS RESTARTS AGE
elasticsearch-client-0 1/1 Running 0 9m25s
elasticsearch-data-0 1/1 Running 0 9m33s
elasticsearch-master-0 1/1 Running 0 8m29s
kibana-kibana-79b9878cd7-7l75v 1/1 Running 0 6m12s
$ kubectl get svc -n logging
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch-client NodePort 10.108.226.197 <none> 9200:30200/TCP,9300:32746/TCP 3m25s
elasticsearch-client-headless ClusterIP None <none> 9200/TCP,9300/TCP 3m25s
elasticsearch-data ClusterIP 10.104.121.49 <none> 9200/TCP,9300/TCP 3m33s
elasticsearch-data-headless ClusterIP None <none> 9200/TCP,9300/TCP 3m33s
elasticsearch-master ClusterIP 10.102.72.71 <none> 9200/TCP,9300/TCP 6m8s
elasticsearch-master-headless ClusterIP None <none> 9200/TCP,9300/TCP 6m8s
kibana-kibana NodePort 10.109.35.219 <none> 5601:30601/TCP 12s
上面我们安装 Kibana 的时候指定了 30601 的 NodePort 端口,所以我们可以从任意节点 http://IP:30601 来访问 Kibana。
我们可以看到会跳转到登录页面,让我们输出用户名、密码,这里我们输入上面配置的用户名 elastic、密码 ydzsio321 进行登录。登录成功后进入如下所示的 Kibana 主页:
部署 Fluentd
Fluentd 是一个高效的日志聚合器,是用 Ruby 编写的,并且可以很好地扩展。对于大部分企业来说,Fluentd 足够高效并且消耗的资源相对较少,另外一个工具 Fluent-bit 更轻量级,占用资源更少,但是插件相对 Fluentd 来说不够丰富,所以整体来说,Fluentd 更加成熟,使用更加广泛,所以这里我们使用 Fluentd 来作为日志收集工具。
工作原理
Fluentd 通过一组给定的数据源抓取日志数据,处理后(转换成结构化的数据格式)将它们转发给其他服务,比如 Elasticsearch、对象存储等等。Fluentd 支持超过 300 个日志存储和分析服务,所以在这方面是非常灵活的。主要运行步骤如下:
- 首先 Fluentd 从多个日志源获取数据
- 结构化并且标记这些数据
- 然后根据匹配的标签将数据发送到多个目标服务去

配置
一般来说我们是通过一个配置文件来告诉 Fluentd 如何采集、处理数据的,下面简单和大家介绍下 Fluentd 的配置方法。
日志源配置
比如我们这里为了收集 Kubernetes 节点上的所有容器日志,就需要做如下的日志源配置:
<source>@id fluentd-containers.log@type tail # Fluentd 内置的输入方式,其原理是不停地从源文件中获取新的日志。path /var/log/containers/*.log # 挂载的宿主机容器日志地址pos_file /var/log/es-containers.log.postag raw.kubernetes.* # 设置日志标签read_from_head true<parse> # 多行格式化成JSON@type multi_format # 使用 multi-format-parser 解析器插件<pattern>format json # JSON 解析器time_key time # 指定事件时间的时间字段time_format %Y-%m-%dT%H:%M:%S.%NZ # 时间格式</pattern><pattern>format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/time_format %Y-%m-%dT%H:%M:%S.%N%:z</pattern></parse>
</source>
上面配置部分参数说明如下:
- id:表示引用该日志源的唯一标识符,该标识可用于进一步过滤和路由结构化日志数据
- type:Fluentd 内置的指令,
tail表示 Fluentd 从上次读取的位置通过 tail 不断获取数据,另外一个是http表示通过一个 GET 请求来收集数据。 - path:
tail类型下的特定参数,告诉 Fluentd 采集/var/log/containers目录下的所有日志,这是 docker 在 Kubernetes 节点上用来存储运行容器 stdout 输出日志数据的目录。 - pos_file:检查点,如果 Fluentd 程序重新启动了,它将使用此文件中的位置来恢复日志数据收集。
- tag:用来将日志源与目标或者过滤器匹配的自定义字符串,Fluentd 匹配源/目标标签来路由日志数据。
路由配置
上面是日志源的配置,接下来看看如何将日志数据发送到 Elasticsearch:
<match **>@id elasticsearch@type elasticsearch@log_level infoinclude_tag_key truetype_name fluentdhost "#{ENV['OUTPUT_HOST']}"port "#{ENV['OUTPUT_PORT']}"logstash_format true<buffer>@type filepath /var/log/fluentd-buffers/kubernetes.system.bufferflush_mode intervalretry_type exponential_backoffflush_thread_count 2flush_interval 5sretry_foreverretry_max_interval 30chunk_limit_size "#{ENV['OUTPUT_BUFFER_CHUNK_LIMIT']}"queue_limit_length "#{ENV['OUTPUT_BUFFER_QUEUE_LIMIT']}"overflow_action block</buffer>
</match>
- match:标识一个目标标签,后面是一个匹配日志源的正则表达式,我们这里想要捕获所有的日志并将它们发送给 Elasticsearch,所以需要配置成
**。 - id:目标的一个唯一标识符。
- type:支持的输出插件标识符,我们这里要输出到 Elasticsearch,所以配置成 elasticsearch,这是 Fluentd 的一个内置插件。
- log_level:指定要捕获的日志级别,我们这里配置成
info,表示任何该级别或者该级别以上(INFO、WARNING、ERROR)的日志都将被路由到 Elsasticsearch。 - host/port:定义 Elasticsearch 的地址,也可以配置认证信息,我们的 Elasticsearch 不需要认证,所以这里直接指定 host 和 port 即可。
- logstash_format:Elasticsearch 服务对日志数据构建反向索引进行搜索,将 logstash_format 设置为
true,Fluentd 将会以 logstash 格式来转发结构化的日志数据。 - Buffer: Fluentd 允许在目标不可用时进行缓存,比如,如果网络出现故障或者 Elasticsearch 不可用的时候。缓冲区配置也有助于降低磁盘的 IO。
过滤
由于 Kubernetes 集群中应用太多,也还有很多历史数据,所以我们可以只将某些应用的日志进行收集,比如我们只采集具有 logging=true 这个 Label 标签的 Pod 日志,这个时候就需要使用 filter,如下所示:
# 删除无用的属性
<filter kubernetes.**>@type record_transformerremove_keys $.docker.container_id,$.kubernetes.container_image_id,$.kubernetes.pod_id,$.kubernetes.namespace_id,$.kubernetes.master_url,$.kubernetes.labels.pod-template-hash
</filter>
# 只保留具有logging=true标签的Pod日志
<filter kubernetes.**>@id filter_log@type grep<regexp>key $.kubernetes.labels.loggingpattern ^true$</regexp>
</filter>
安装
要收集 Kubernetes 集群的日志,直接用 DasemonSet 控制器来部署 Fluentd 应用,这样,它就可以从 Kubernetes 节点上采集日志,确保在集群中的每个节点上始终运行一个 Fluentd 容器。当然可以直接使用 Helm 来进行一键安装,为了能够了解更多实现细节,我们这里还是采用手动方法来进行安装。
可以直接使用官方的对于 Kubernetes 集群的安装文档: Kubernetes - Fluentd。
首先,我们通过 ConfigMap 对象来指定 Fluentd 配置文件,新建 fluentd-configmap.yaml 文件,文件内容如下:
# fluentd-configmap.yaml
kind: ConfigMap
apiVersion: v1
metadata:name: fluentd-confnamespace: logging
data:# 容器日志containers.input.conf: |-<source>@id fluentd-containers.log@type tail # Fluentd 内置的输入方式,其原理是不停地从源文件中获取新的日志path /var/log/containers/*.log # Docker 容器日志路径pos_file /var/log/es-containers.log.pos # 记录读取的位置tag raw.kubernetes.* # 设置日志标签read_from_head true # 从头读取<parse> # 多行格式化成JSON# 可以使用我们介绍过的 multiline 插件实现多行日志@type multi_format # 使用 multi-format-parser 解析器插件<pattern>format json # JSON解析器time_key time # 指定事件时间的时间字段time_format %Y-%m-%dT%H:%M:%S.%NZ # 时间格式</pattern><pattern>format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/time_format %Y-%m-%dT%H:%M:%S.%N%:z</pattern></parse></source># 在日志输出中检测异常(多行日志),并将其作为一条日志转发# https://github.com/GoogleCloudPlatform/fluent-plugin-detect-exceptions<match raw.kubernetes.**> # 匹配tag为raw.kubernetes.**日志信息@id raw.kubernetes@type detect_exceptions # 使用detect-exceptions插件处理异常栈信息remove_tag_prefix raw # 移除 raw 前缀message logmultiline_flush_interval 5</match><filter **> # 拼接日志@id filter_concat@type concat # Fluentd Filter 插件,用于连接多个日志中分隔的多行日志key messagemultiline_end_regexp /\n$/ # 以换行符“\n”拼接separator ""</filter># 添加 Kubernetes metadata 数据<filter kubernetes.**>@id filter_kubernetes_metadata@type kubernetes_metadata</filter># 修复 ES 中的 JSON 字段# 插件地址:https://github.com/repeatedly/fluent-plugin-multi-format-parser<filter kubernetes.**>@id filter_parser@type parser # multi-format-parser多格式解析器插件key_name log # 在要解析的日志中指定字段名称reserve_data true # 在解析结果中保留原始键值对remove_key_name_field true # key_name 解析成功后删除字段<parse>@type multi_format<pattern>format json</pattern><pattern>format none</pattern></parse></filter># 删除一些多余的属性<filter kubernetes.**>@type record_transformerremove_keys $.docker.container_id,$.kubernetes.container_image_id,$.kubernetes.pod_id,$.kubernetes.namespace_id,$.kubernetes.master_url,$.kubernetes.labels.pod-template-hash</filter># 只保留具有logging=true标签的Pod日志<filter kubernetes.**>@id filter_log@type grep<regexp>key $.kubernetes.labels.loggingpattern ^true$</regexp></filter>###### 监听配置,一般用于日志聚合用 ######forward.input.conf: |-# 监听通过TCP发送的消息<source>@id forward@type forward</source>output.conf: |-<match **>@id elasticsearch@type elasticsearch@log_level infoinclude_tag_key truehost elasticsearch-clientport 9200user elastic # FLUENT_ELASTICSEARCH_USER | FLUENT_ELASTICSEARCH_PASSWORDpassword ydzsio321logstash_format truelogstash_prefix k8srequest_timeout 30s<buffer>@type filepath /var/log/fluentd-buffers/kubernetes.system.bufferflush_mode intervalretry_type exponential_backoffflush_thread_count 2flush_interval 5sretry_foreverretry_max_interval 30chunk_limit_size 2Mqueue_limit_length 8overflow_action block</buffer></match>
上面配置文件中我们只配置了 docker 容器日志目录,收集到数据经过处理后发送到 elasticsearch-client:9200 服务。
然后新建一个 fluentd-daemonset.yaml 的文件,文件内容如下:
apiVersion: v1
kind: ServiceAccount
metadata:name: fluentd-esnamespace: logginglabels:k8s-app: fluentd-eskubernetes.io/cluster-service: 'true'addonmanager.kubernetes.io/mode: Reconcile
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: fluentd-eslabels:k8s-app: fluentd-eskubernetes.io/cluster-service: 'true'addonmanager.kubernetes.io/mode: Reconcile
rules:- apiGroups:- ''resources:- 'namespaces'- 'pods'verbs:- 'get'- 'watch'- 'list'
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: fluentd-eslabels:k8s-app: fluentd-eskubernetes.io/cluster-service: 'true'addonmanager.kubernetes.io/mode: Reconcile
subjects:- kind: ServiceAccountname: fluentd-esnamespace: loggingapiGroup: ''
roleRef:kind: ClusterRolename: fluentd-esapiGroup: ''
---
apiVersion: apps/v1
kind: DaemonSet
metadata:name: fluentdnamespace: logginglabels:app: fluentdkubernetes.io/cluster-service: 'true'
spec:selector:matchLabels:app: fluentdtemplate:metadata:labels:app: fluentdkubernetes.io/cluster-service: 'true'spec:tolerations:- key: node-role.kubernetes.io/mastereffect: NoScheduleserviceAccountName: fluentd-escontainers:- name: fluentdimage: quay.io/fluentd_elasticsearch/fluentd:v3.4.0volumeMounts:- name: fluentconfigmountPath: /etc/fluent/config.d- name: varlogmountPath: /var/logvolumes:- name: fluentconfigconfigMap:name: fluentd-conf- name: varloghostPath:path: /var/log
我们将上面创建的 fluentd-config 这个 ConfigMap 对象通过 volumes 挂载到了 Fluentd 容器中,另外为了能够灵活控制哪些节点的日志可以被收集,还可以添加了一个 nodSelector 属性:
nodeSelector:beta.kubernetes.io/fluentd-ds-ready: 'true'
意思就是要想采集节点的日志,那么我们就需要给节点打上上面的标签。
!!! info "提示" 如果你需要在其他节点上采集日志,则需要给对应节点打上标签,使用如下命令:kubectl label nodes node名 beta.kubernetes.io/fluentd-ds-ready=true。
另外由于我们的集群使用的是 kubeadm 搭建的,默认情况下 master 节点有污点,所以如果要想也收集 master 节点的日志,则需要添加上容忍:
tolerations:- operator: Exists
分别创建上面的 ConfigMap 对象和 DaemonSet:
$ kubectl create -f fluentd-configmap.yaml
configmap "fluentd-conf" created
$ kubectl create -f fluentd-daemonset.yaml
serviceaccount "fluentd-es" created
clusterrole.rbac.authorization.k8s.io "fluentd-es" created
clusterrolebinding.rbac.authorization.k8s.io "fluentd-es" created
daemonset.apps "fluentd" created
创建完成后,查看对应的 Pods 列表,检查是否部署成功:
$ kubectl get pods -n logging
NAME READY STATUS RESTARTS AGE
elasticsearch-client-0 1/1 Running 0 64m
elasticsearch-data-0 1/1 Running 0 65m
elasticsearch-master-0 1/1 Running 0 73m
fluentd-5rqbq 1/1 Running 0 60m
fluentd-l6mgf 1/1 Running 0 60m
fluentd-xmfpg 1/1 Running 0 60m
kibana-66f97964b-mdspc 1/1 Running 0 63m
Fluentd 启动成功后,这个时候就可以发送日志到 ES 了,但是我们这里是过滤了只采集具有 logging=true 标签的 Pod 日志,所以现在还没有任何数据会被采集。
下面我们部署一个简单的测试应用, 新建 counter.yaml 文件,文件内容如下:
apiVersion: v1
kind: Pod
metadata:name: counterlabels:logging: 'true' # 一定要具有该标签才会被采集
spec:containers:- name: countimage: busyboxargs:[/bin/sh,-c,'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done',]
该 Pod 只是简单将日志信息打印到 stdout,所以正常来说 Fluentd 会收集到这个日志数据,在 Kibana 中也就可以找到对应的日志数据了,使用 kubectl 工具创建该 Pod:
$ kubectl create -f counter.yaml
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
counter 1/1 Running 0 9h
Pod 创建并运行后,回到 Kibana Dashboard 页面,点击左侧最下面的 Management -> Stack Management,进入管理页面,点击左侧 Kibana 下面的 索引模式,点击 创建索引模式 开始导入索引数据:
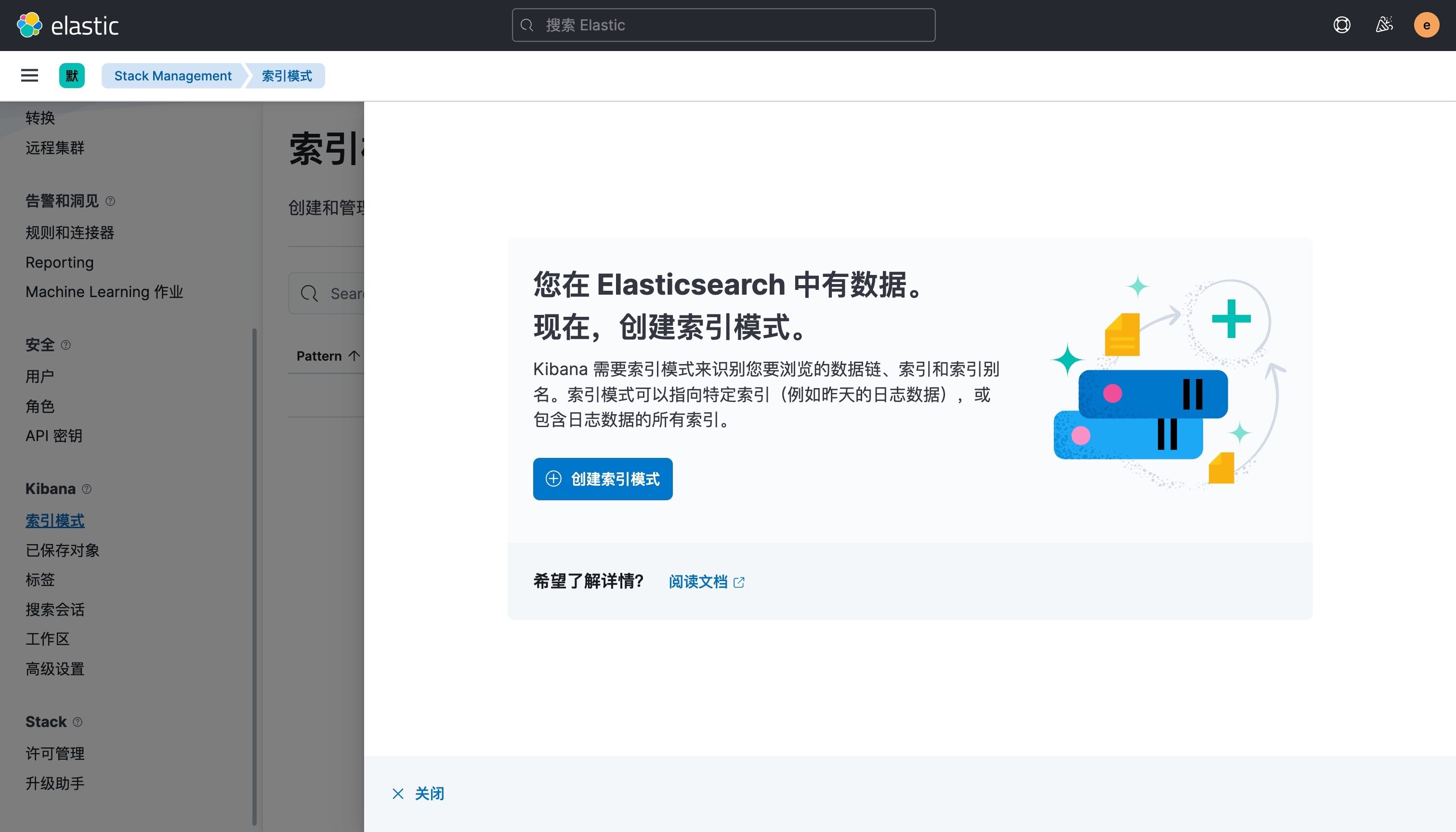
在这里可以配置我们需要的 Elasticsearch 索引,前面 Fluentd 配置文件中我们采集的日志使用的是 logstash 格式,定义了一个 k8s 的前缀,所以这里只需要在文本框中输入 k8s-* 即可匹配到 Elasticsearch 集群中采集的 Kubernetes 集群日志数据,然后点击下一步,进入以下页面:

在该页面中配置使用哪个字段按时间过滤日志数据,在下拉列表中,选择@timestamp字段,然后点击 创建索引模式,创建完成后,点击左侧导航菜单中的 Discover,然后就可以看到一些直方图和最近采集到的日志数据了:
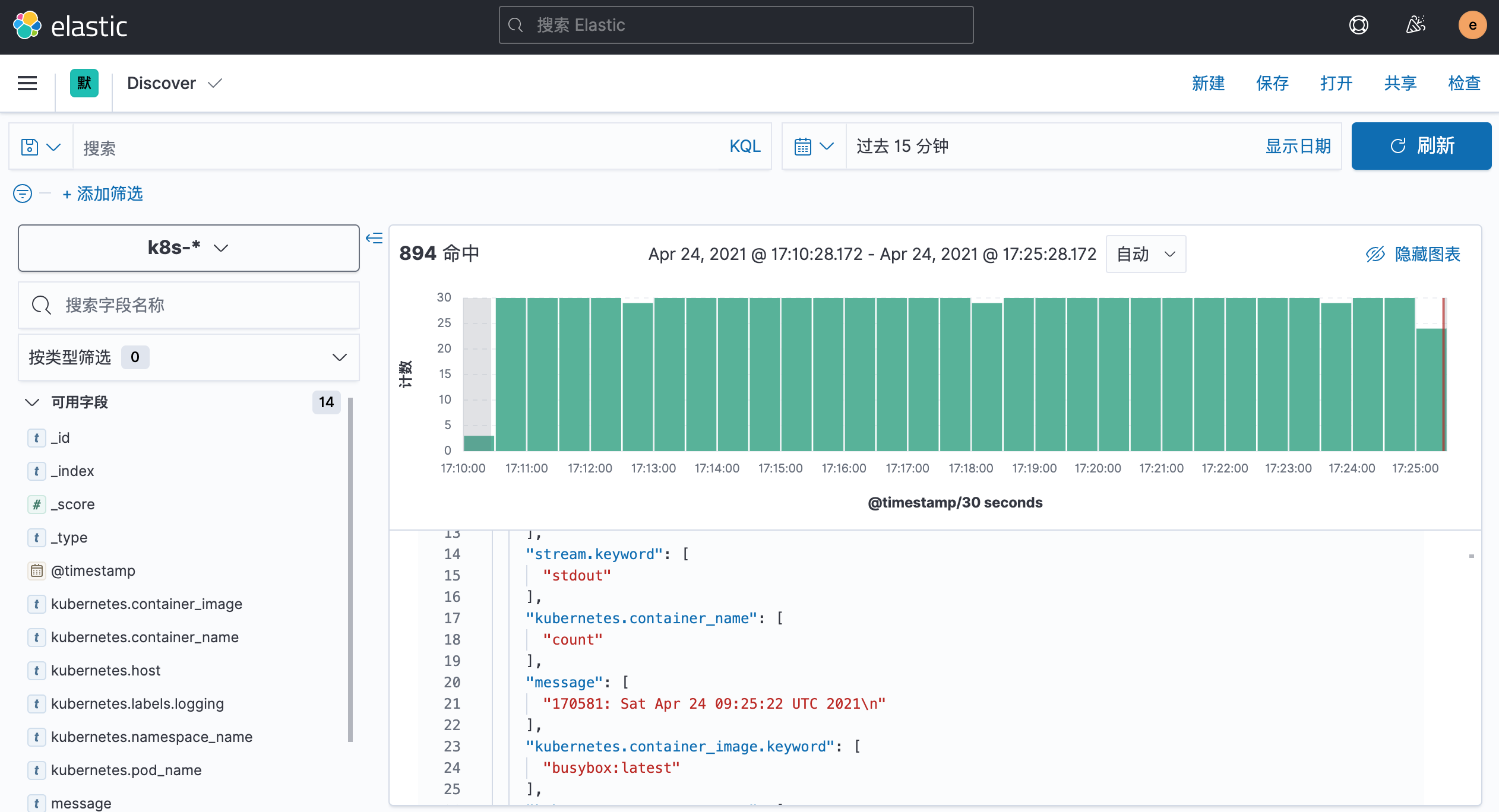
现在的数据就是上面 Counter 应用的日志,如果还有其他的应用,我们也可以筛选过滤:

我们也可以通过其他元数据来过滤日志数据,比如您可以单击任何日志条目以查看其他元数据,如容器名称,Kubernetes 节点,命名空间等。
安装 Kafka
对于大规模集群来说,日志数据量是非常巨大的,如果直接通过 Fluentd 将日志打入 Elasticsearch,对 ES 来说压力是非常巨大的,我们可以在中间加一层消息中间件来缓解 ES 的压力,一般情况下我们会使用 Kafka,然后可以直接使用 kafka-connect-elasticsearch 这样的工具将数据直接打入 ES,也可以在加一层 Logstash 去消费 Kafka 的数据,然后通过 Logstash 把数据存入 ES,这里我们来使用 Logstash 这种模式来对日志收集进行优化。
首先在 Kubernetes 集群中安装 Kafka,同样这里使用 Helm 进行安装:
$ helm repo add bitnami https://charts.bitnami.com/bitnami
$ helm repo update
首先使用 helm pull 拉取 Chart 并解压:
$ helm pull bitnami/kafka --untar --version 17.2.3
$ cd kafka
这里面我们指定使用一个 StorageClass 来提供持久化存储,在 Chart 目录下面创建用于安装的 values 文件:
# values-prod.yaml
## @section Persistence parameters
persistence:enabled: truestorageClass: 'local-path'accessModes:- ReadWriteOncesize: 8GimountPath: /bitnami/kafka# 配置zk volumes
zookeeper:enabled: truepersistence:enabled: truestorageClass: 'local-path'accessModes:- ReadWriteOncesize: 8Gi
直接使用上面的 values 文件安装 kafka:
$ helm upgrade --install kafka -f values-prod.yaml --namespace logging .
Release "kafka" does not exist. Installing it now.
NAME: kafka
LAST DEPLOYED: Thu Jun 9 14:02:01 2022
NAMESPACE: logging
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
CHART NAME: kafka
CHART VERSION: 17.2.3
APP VERSION: 3.2.0** Please be patient while the chart is being deployed **Kafka can be accessed by consumers via port 9092 on the following DNS name from within your cluster:kafka.logging.svc.cluster.localEach Kafka broker can be accessed by producers via port 9092 on the following DNS name(s) from within your cluster:kafka-0.kafka-headless.logging.svc.cluster.local:9092To create a pod that you can use as a Kafka client run the following commands:kubectl run kafka-client --restart='Never' --image docker.io/bitnami/kafka:3.2.0-debian-10-r4 --namespace logging --command -- sleep infinitykubectl exec --tty -i kafka-client --namespace logging -- bashPRODUCER:kafka-console-producer.sh \--broker-list kafka-0.kafka-headless.logging.svc.cluster.local:9092 \--topic testCONSUMER:kafka-console-consumer.sh \--bootstrap-server kafka.logging.svc.cluster.local:9092 \--topic test \--from-beginning
安装完成后我们可以使用上面的提示来检查 Kafka 是否正常运行:
$ kubectl get pods -n logging -l app.kubernetes.io/instance=kafka
kafka-0 1/1 Running 0 7m58s
kafka-zookeeper-0 1/1 Running 0 7m58s
用下面的命令创建一个 Kafka 的测试客户端 Pod:
$ kubectl run kafka-client --restart='Never' --image docker.io/bitnami/kafka:3.2.0-debian-10-r4 --namespace logging --command -- sleep infinity
pod/kafka-client created
然后启动一个终端进入容器内部生产消息:
# 生产者
$ kubectl exec --tty -i kafka-client --namespace logging -- bash
I have no name!@kafka-client:/$ kafka-console-producer.sh --broker-list kafka-0.kafka-headless.logging.svc.cluster.local:9092 --topic test
>hello kafka on k8s
>
启动另外一个终端进入容器内部消费消息:
# 消费者
$ kubectl exec --tty -i kafka-client --namespace logging -- bash
I have no name!@kafka-client:/$ kafka-console-consumer.sh --bootstrap-server kafka.logging.svc.cluster.local:9092 --topic test --from-beginning
hello kafka on k8s
如果在消费端看到了生产的消息数据证明我们的 Kafka 已经运行成功了。
Fluentd 配置 Kafka
现在有了 Kafka,我们就可以将 Fluentd 的日志数据输出到 Kafka 了,只需要将 Fluentd 配置中的 <match> 更改为使用 Kafka 插件即可,但是在 Fluentd 中输出到 Kafka,需要使用到 fluent-plugin-kafka 插件,所以需要我们自定义下 Docker 镜像,最简单的做法就是在上面 Fluentd 镜像的基础上新增 kafka 插件即可,Dockerfile 文件如下所示:
FROM quay.io/fluentd_elasticsearch/fluentd:v3.4.0
RUN echo "source 'https://mirrors.tuna.tsinghua.edu.cn/rubygems/'" > Gemfile && gem install bundler
RUN gem install fluent-plugin-kafka -v 0.17.5 --no-document
使用上面的 Dockerfile 文件构建一个 Docker 镜像即可,我这里构建过后的镜像名为 cnych/fluentd-kafka:v0.17.5。接下来替换 Fluentd 的 Configmap 对象中的 <match> 部分,如下所示:
# fluentd-configmap.yaml
kind: ConfigMap
apiVersion: v1
metadata:name: fluentd-confnamespace: logging
data:......output.conf: |-<match **>@id kafka@type kafka2@log_level info# list of seed brokersbrokers kafka-0.kafka-headless.logging.svc.cluster.local:9092use_event_time true# topic settingstopic_key k8slogdefault_topic messages # 注意,kafka中消费使用的是这个topic# buffer settings<buffer k8slog>@type filepath /var/log/td-agent/buffer/tdflush_interval 3s</buffer># data type settings<format>@type json</format># producer settingsrequired_acks -1compression_codec gzip</match>
然后替换运行的 Fluentd 镜像:
# fluentd-daemonset.yaml
image: cnych/fluentd-kafka:v0.17.5
直接更新 Fluentd 的 Configmap 与 DaemonSet 资源对象即可:
$ kubectl apply -f fluentd-configmap.yaml
$ kubectl apply -f fluentd-daemonset.yaml
更新成功后我们可以使用上面的测试 Kafka 客户端来验证是否有日志数据:
$ kubectl exec --tty -i kafka-client --namespace logging -- bash
I have no name!@kafka-client:/$ kafka-console-consumer.sh --bootstrap-server kafka.logging.svc.cluster.local:9092 --topic messages --from-beginning
{"stream":"stdout","docker":{},"kubernetes":{"container_name":"count","namespace_name":"default","pod_name":"counter","container_image":"busybox:latest","host":"node1","labels":{"logging":"true"}},"message":"43883: Tue Apr 27 12:16:30 UTC 2021\n"}
......
安装 Logstash
虽然数据从 Kafka 到 Elasticsearch 的方式多种多样,比如可以使用 Kafka Connect Elasticsearch Connector 来实现,我们这里还是采用更加流行的 `Logstash`` 方案,上面我们已经将日志从 Fluentd 采集输出到 Kafka 中去了,接下来我们使用 Logstash 来连接 Kafka 与 Elasticsearch 间的日志数据。
首先使用 helm pull 拉取 Chart 并解压:
$ helm pull elastic/logstash --untar --version 7.17.3
$ cd logstash
同样在 Chart 根目录下面创建用于安装的 Values 文件,如下所示:
# values-prod.yaml
fullnameOverride: logstashpersistence:enabled: truelogstashConfig:logstash.yml: |http.host: 0.0.0.0# 如果启用了xpack,需要做如下配置xpack.monitoring.enabled: truexpack.monitoring.elasticsearch.hosts: ["http://elasticsearch-client:9200"]xpack.monitoring.elasticsearch.username: "elastic"xpack.monitoring.elasticsearch.password: "ydzsio321"# 要注意下格式
logstashPipeline:logstash.conf: |input { kafka { bootstrap_servers => "kafka-0.kafka-headless.logging.svc.cluster.local:9092" codec => json consumer_threads => 3 topics => ["messages"] } }filter {} # 过滤配置(比如可以删除key、添加geoip等等)output { elasticsearch { hosts => [ "elasticsearch-client:9200" ] user => "elastic" password => "ydzsio321" index => "logstash-k8s-%{+YYYY.MM.dd}" } stdout { codec => rubydebug } }volumeClaimTemplate:accessModes: ['ReadWriteOnce']storageClassName: nfs-storageresources:requests:storage: 1Gi
其中最重要的就是通过 logstashPipeline 配置 logstash 数据流的处理配置,通过 input 指定日志源 kafka 的配置,通过 output 输出到 Elasticsearch,同样直接使用上面的 Values 文件安装 logstash 即可:
$ helm upgrade --install logstash -f values-prod.yaml --namespace logging .
Release "logstash" does not exist. Installing it now.
NAME: logstash
LAST DEPLOYED: Thu Jun 9 15:02:49 2022
NAMESPACE: logging
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
1. Watch all cluster members come up.$ kubectl get pods --namespace=logging -l app=logstash -w
安装启动完成后可以查看 logstash 的日志:
$ logstash kubectl get pods --namespace=logging -l app=logstash
NAME READY STATUS RESTARTS AGE
logstash-0 1/1 Running 0 2m8s
$ kubectl logs -f logstash-0 -n logging
......
{"@version" => "1","stream" => "stdout","@timestamp" => 2022-06-09T07:09:16.889Z,"message" => "4672: Thu Jun 9 07:09:15 UTC 2022","kubernetes" => {"container_image" => "docker.io/library/busybox:latest","container_name" => "count","labels" => {"logging" => "true"},"pod_name" => "counter","namespace_name" => "default","pod_ip" => "10.244.2.118","host" => "node2","namespace_labels" => {"kubernetes_io/metadata_name" => "default"}},"docker" => {}
}
由于我们启用了 debug 日志调试,所以我们可以在 logstash 的日志中看到我们采集的日志消息,到这里证明我们的日志数据就获取成功了。
现在我们可以登录到 Kibana 可以看到有如下所示的索引数据了:
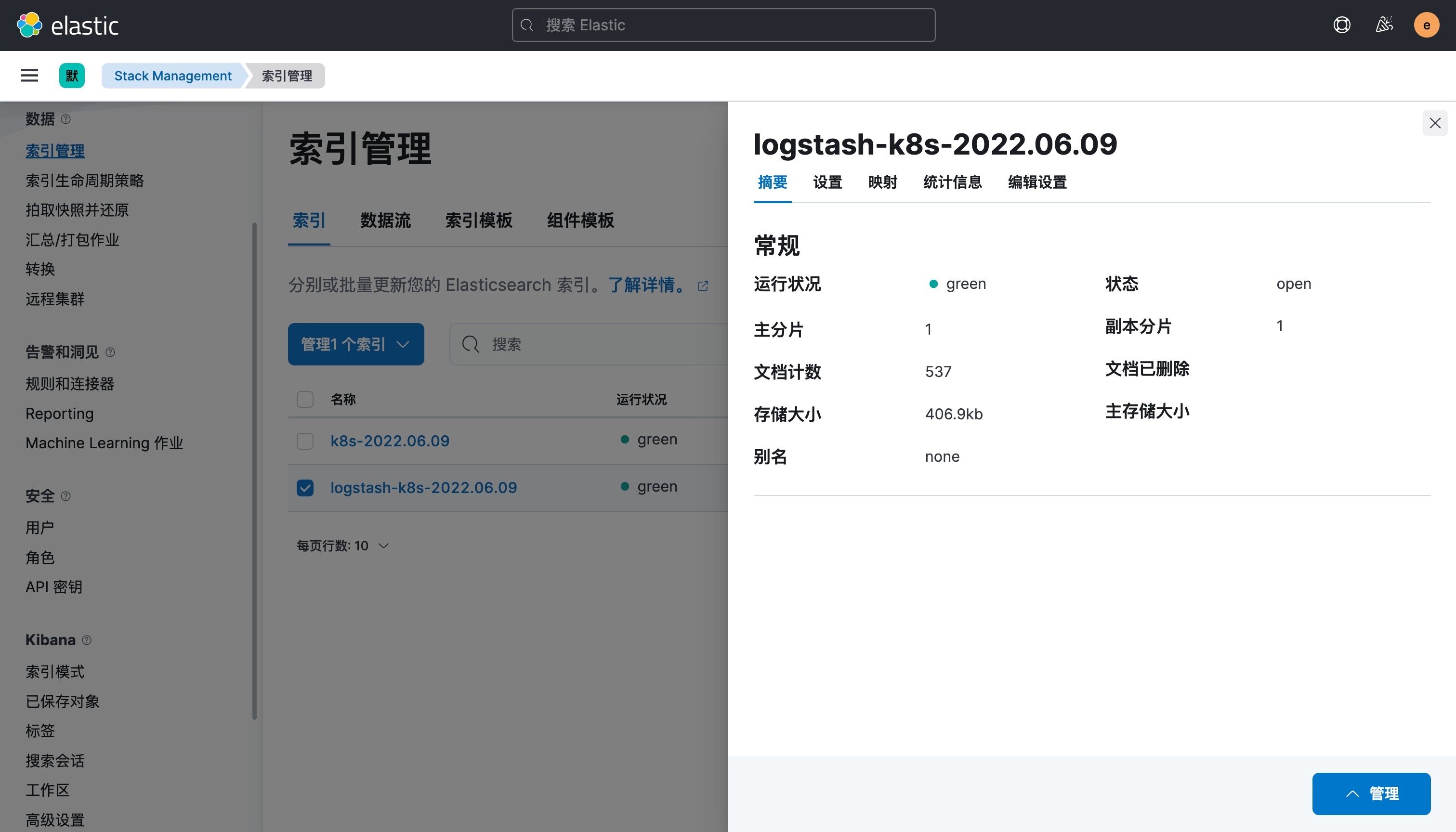
然后同样创建索引模式,匹配上面的索引即可:

创建完成后就可以前往发现页面过滤日志数据了:
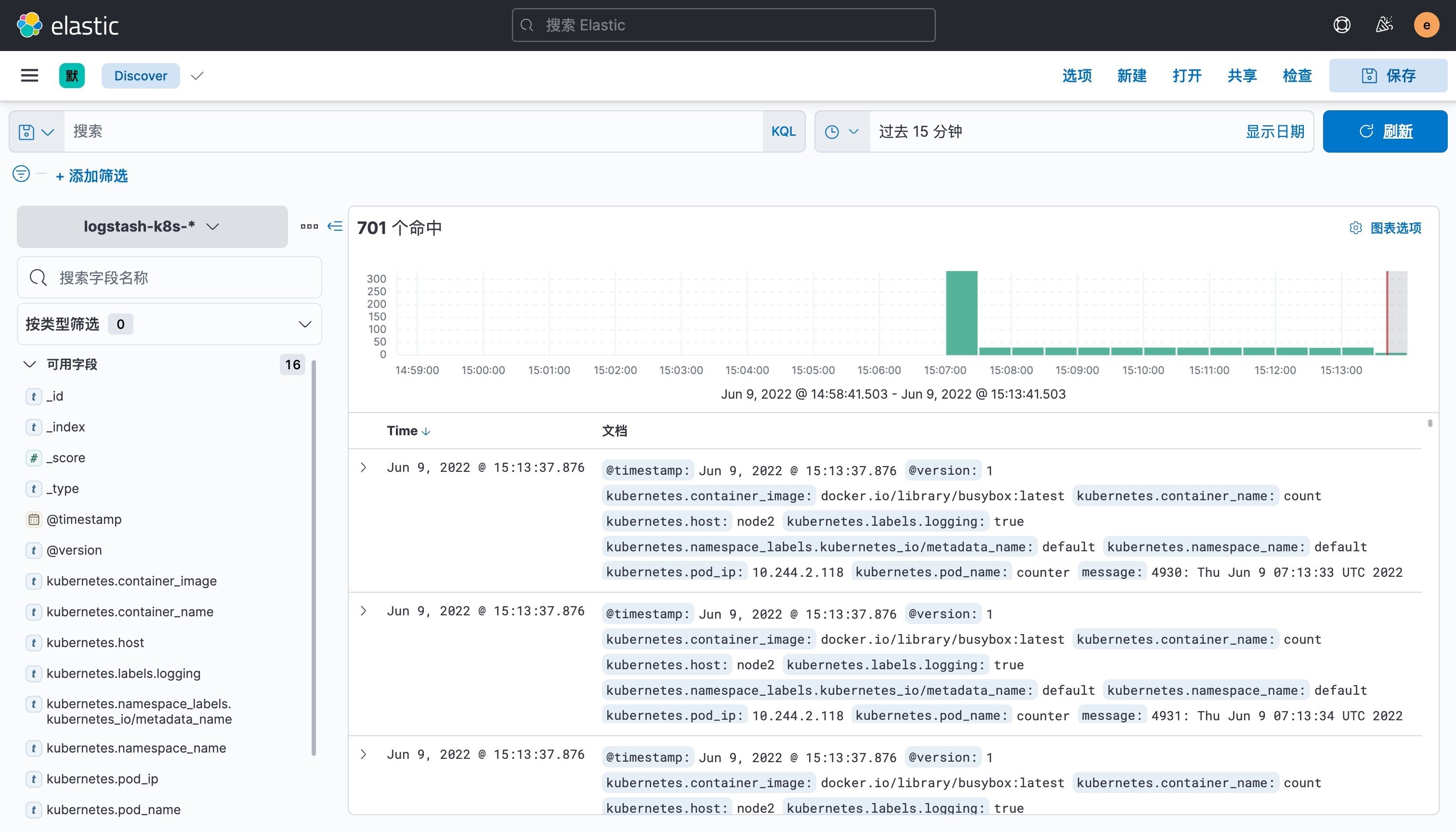
到这里我们就实现了一个使用 Fluentd+Kafka+Logstash+Elasticsearch+Kibana 的 Kubernetes 日志收集工具栈,这里我们完整的 Pod 信息如下所示:
$ kubectl get pods -n logging
NAME READY STATUS RESTARTS AGE
elasticsearch-client-0 1/1 Running 0 128m
elasticsearch-data-0 1/1 Running 0 128m
elasticsearch-master-0 1/1 Running 0 128m
fluentd-6k52h 1/1 Running 0 61m
fluentd-cw72c 1/1 Running 0 61m
fluentd-dn4hs 1/1 Running 0 61m
kafka-0 1/1 Running 3 134m
kafka-client 1/1 Running 0 125m
kafka-zookeeper-0 1/1 Running 0 134m
kibana-kibana-66f97964b-qqjgg 1/1 Running 0 128m
logstash-0 1/1 Running 0 13m
当然在实际的工作项目中还需要我们根据实际的业务场景来进行参数性能调优以及高可用等设置,以达到系统的最优性能。
上面我们在配置 logstash 的时候是将日志输出到 "logstash-k8s-%{+YYYY.MM.dd}" 这个索引模式的,可能有的场景下只通过日期去区分索引不是很合理,那么我们可以根据自己的需求去修改索引名称,比如可以根据我们的服务名称来进行区分,那么这个服务名称可以怎么来定义呢?可以是 Pod 的名称或者通过 label 标签去指定,比如我们这里去做一个规范,要求需要收集日志的 Pod 除了需要添加 logging: true 这个标签之外,还需要添加一个 logIndex: <索引名> 的标签。
比如重新更新我们测试的 counter 应用:
apiVersion: v1
kind: Pod
metadata:name: counterlabels:logging: 'true' # 一定要具有该标签才会被采集logIndex: 'test' # 指定索引名称
spec:containers:- name: countimage: busyboxargs:[/bin/sh,-c,'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done',]
然后重新更新 logstash 的配置,修改 values 配置:
# ......
logstashPipeline:logstash.conf: |input { kafka { bootstrap_servers => "kafka-0.kafka-headless.logging.svc.cluster.local:9092" codec => json consumer_threads => 3 topics => ["messages"] } }filter {} # 过滤配置(比如可以删除key、添加geoip等等)output { elasticsearch { hosts => [ "elasticsearch-client:9200" ] user => "elastic" password => "ydzsio321" index => "k8s-%{[kubernetes][labels][logIndex]}-%{+YYYY.MM.dd}" } stdout { codec => rubydebug } }# ......
使用上面的 values 值更新 logstash,正常更新后上面的 counter 这个 Pod 日志会输出到一个名为 k8s-test-2022.06.09 的索引去。
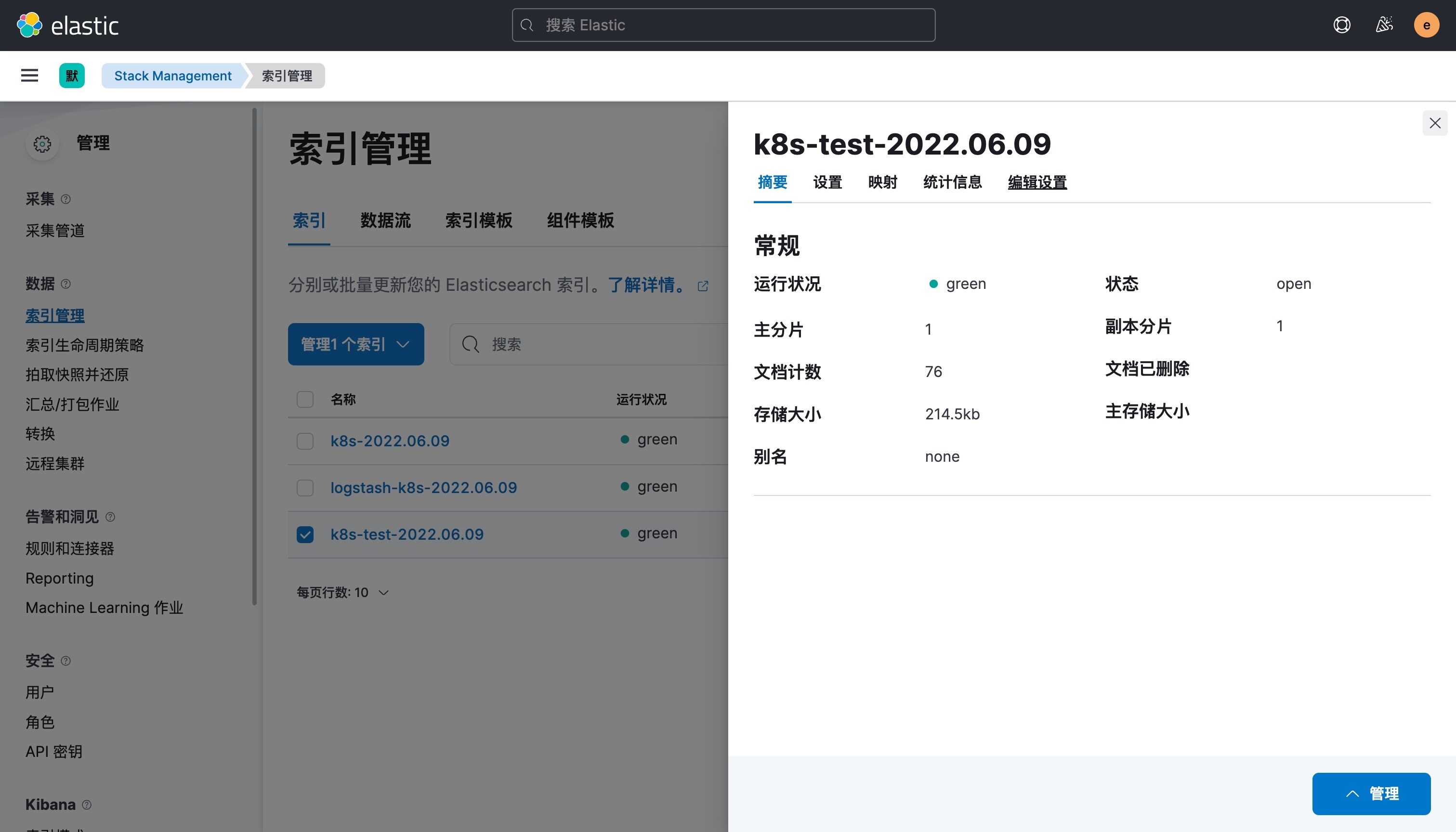
这样我们就实现了自定义索引名称,当然你也可以使用 Pod 名称、容器名称、命名空间名称来作为索引的名称,这完全取决于你自己的需求。
相关文章:
k8s搭建EFK日志系统
搭建 EFK 日志系统 前面大家介绍了 Kubernetes 集群中的几种日志收集方案,Kubernetes 中比较流行的日志收集解决方案是 Elasticsearch、Fluentd 和 Kibana(EFK)技术栈,也是官方现在比较推荐的一种方案。 Elasticsearch 是一个实…...
-- fonts - 字体库)
LuatOS-SOC接口文档(air780E)-- fonts - 字体库
fonts.list(tp) 返回固件支持的字体列表 参数 传入值类型 解释 string 类型, 默认 u8g2, 还可以是lvgl 返回值 返回值类型 解释 table 字体列表 例子 -- API新增于2022-07-12 if fonts.list thenlog.info("fonts", "u8g2", json.encode(fonts…...

[Java·算法·困难]LeetCode124.二叉树中的最大路径和
每天一题,防止痴呆 题目示例分析思路1题解1 👉️ 力扣原文 题目 二叉树中的 路径 被定义为一条节点序列,序列中每对相邻节点之间都存在一条边。同一个节点在一条路径序列中 至多出现一次 。该路径 至少包含一个 节点,且不一定经…...
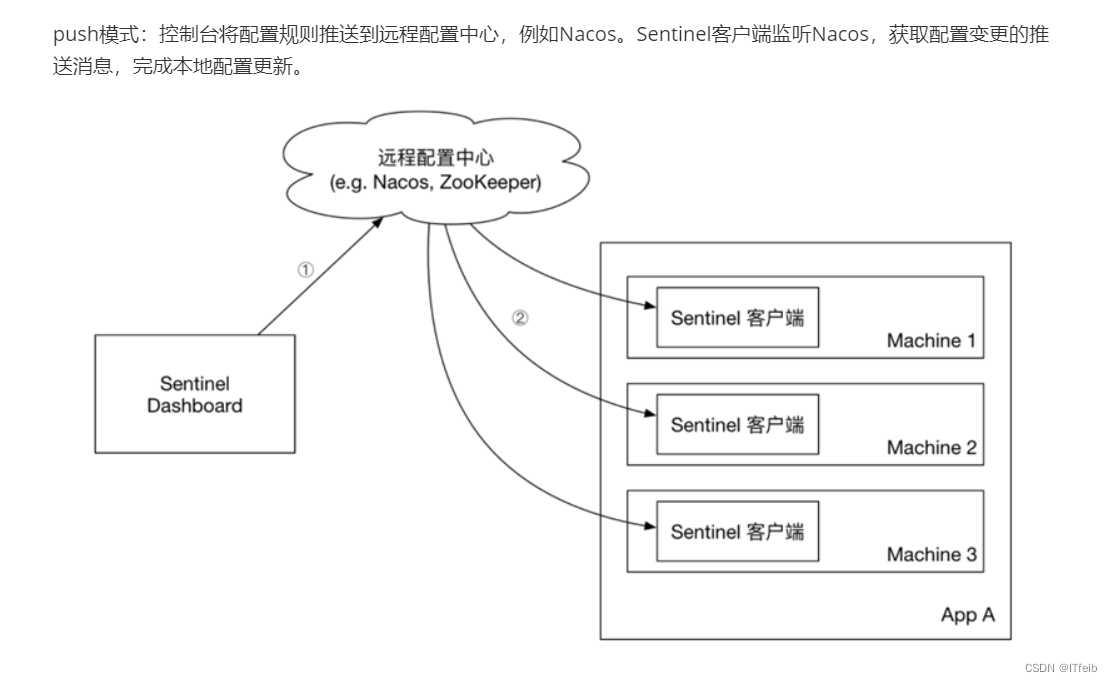
【微服务保护】
文章目录 Sentinel流量控制流控模式流控效果 隔离和降级线程隔离熔断降级 授权规则和规则持久化 微服务雪崩问题: 微服务中,服务间调用关系错综复杂,一个微服务往往依赖于多个其它微服务。服务D有 故障进而导致服务A有故障,进而导…...
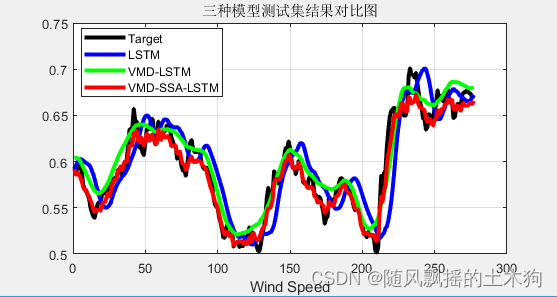
【MATLAB第78期】基于MATLAB的VMD-SSA-LSTM麻雀算法优化LSTM时间序列预测模型
【MATLAB第78期】基于MATLAB的VMD-SSA-LSTM麻雀算法优化LSTM时间序列预测模型 一、LSTM data xlsread(数据集.xlsx);% [x,y]data_process(data,15);%前15个时刻 预测下一个时刻 %归一化 [xs,mappingx]mapminmax(x,0,1);xxs; [ys,mappingy]mapminmax(y,0,1);yys; %划分数据 n…...

分类预测 | MATLAB实现SSA-FS-SVM麻雀算法同步优化特征选择结合支持向量机分类预测
分类预测 | MATLAB实现SSA-FS-SVM麻雀算法同步优化特征选择结合支持向量机分类预测 目录 分类预测 | MATLAB实现SSA-FS-SVM麻雀算法同步优化特征选择结合支持向量机分类预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 MATLAB实现SSA-FS-SVM麻雀算法同步优化特征选择结…...
唤醒手腕 Matlab 游戏编程常用技术知识点详细教程(更新中)
Figure 窗口初始化 figure 使用默认属性值创建一个新的图窗窗口。生成的图窗为当前图窗。f figure(___) 返回 Figure 对象。可使用 f 在创建图窗后查询或修改其属性。figure(f) 将 f 指定的图窗作为当前图窗,并将其显示在其他所有图窗的上面。 figure(n) 查找 Nu…...
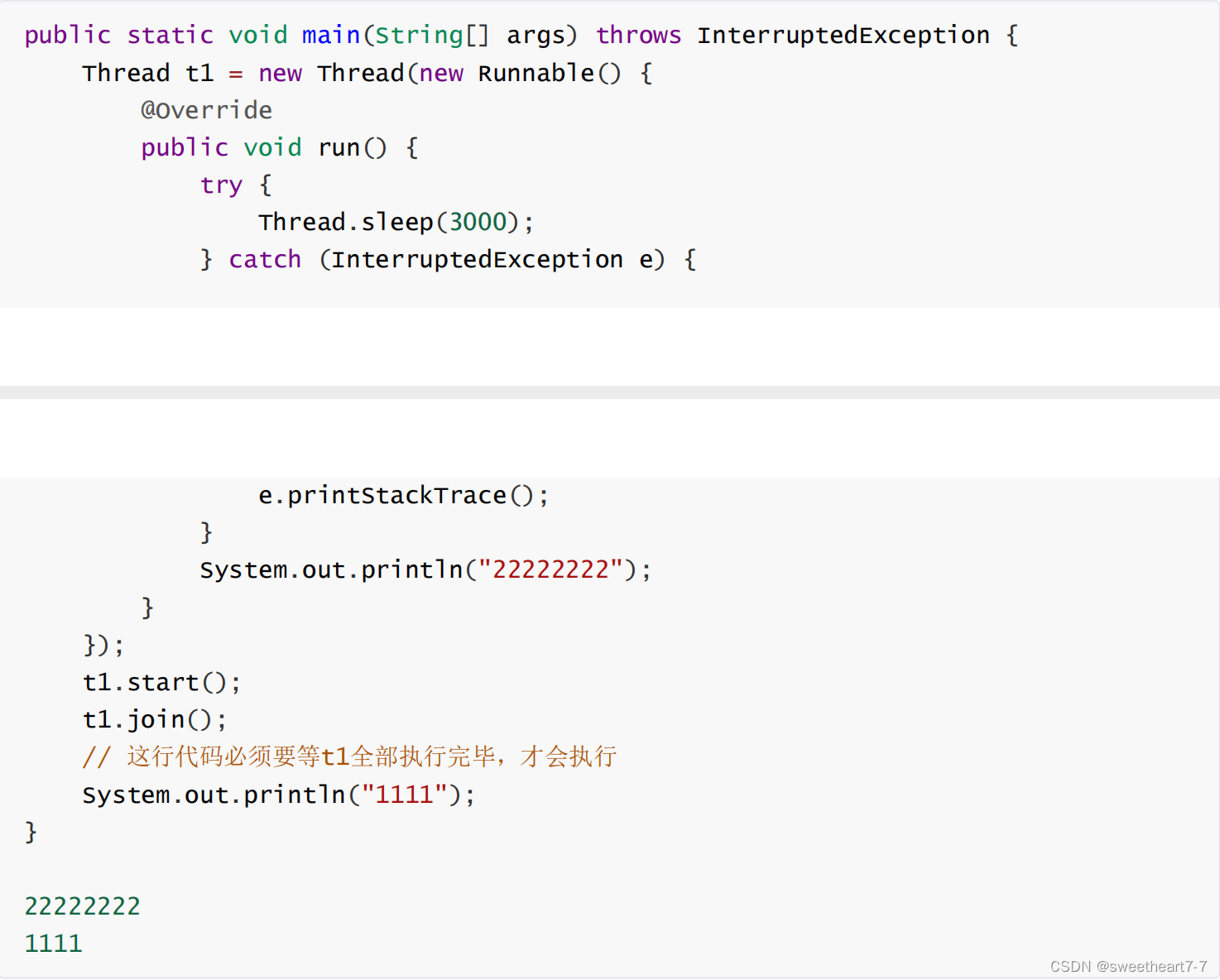
2023八股每日一题(九月份)
9月13日 Q:JDK、JRE、JVM之间的区别 A: JDK(Java SE Development Kit),Java标准开发包,它提供了编译、运⾏Java程序所需的各种⼯具和资源,包括Java编译器、Java运⾏时环境,以及常⽤的Java类库等JRE( Java…...
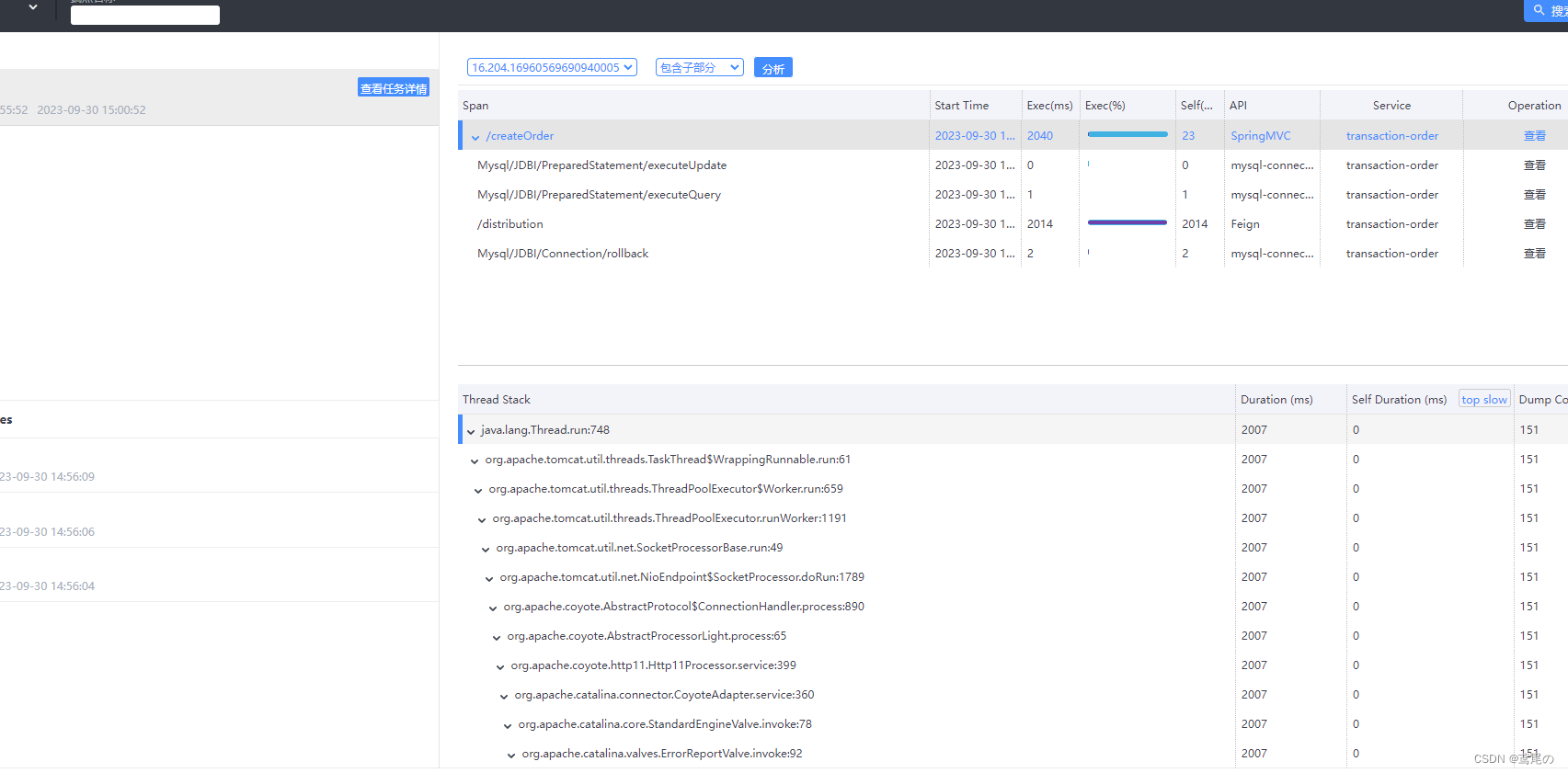
分布式链路追踪--SkyWalking7.0.0+es7.0.0
分布式链路追踪–SkyWalking 微服务的出现,的确解决了一些业务痛点,但是也造成了新的问题比如随着调用链的拉长,如果想要知道请求为什么这么慢,这个请求到底经历了哪些环节,又依赖了哪些东西,在微服务架…...
web:[RoarCTF 2019]Easy Calc
题目 进入页面是一个计算器的页面 随便试了一下 查看源代码看看有什么有用的信息 访问一下这个calc.php 进行代码审计 <?php error_reporting(0); if(!isset($_GET[num])){show_source(__FILE__); }else{$str $_GET[num];$blacklist [ , \t, \r, \n,\, ", , \[, \]…...

【Java每日一题】— —第十七题:杨辉三角(等腰三角形)。(2023.10.01)
🕸️Hollow,各位小伙伴,今天我们要做的是第十七题。 🎯问题: 第一步:动态初始化 第二步:求各元素的值 第三步:遍历输出 测试结果如下: 🎯 结果: public class yanghui {public sta…...
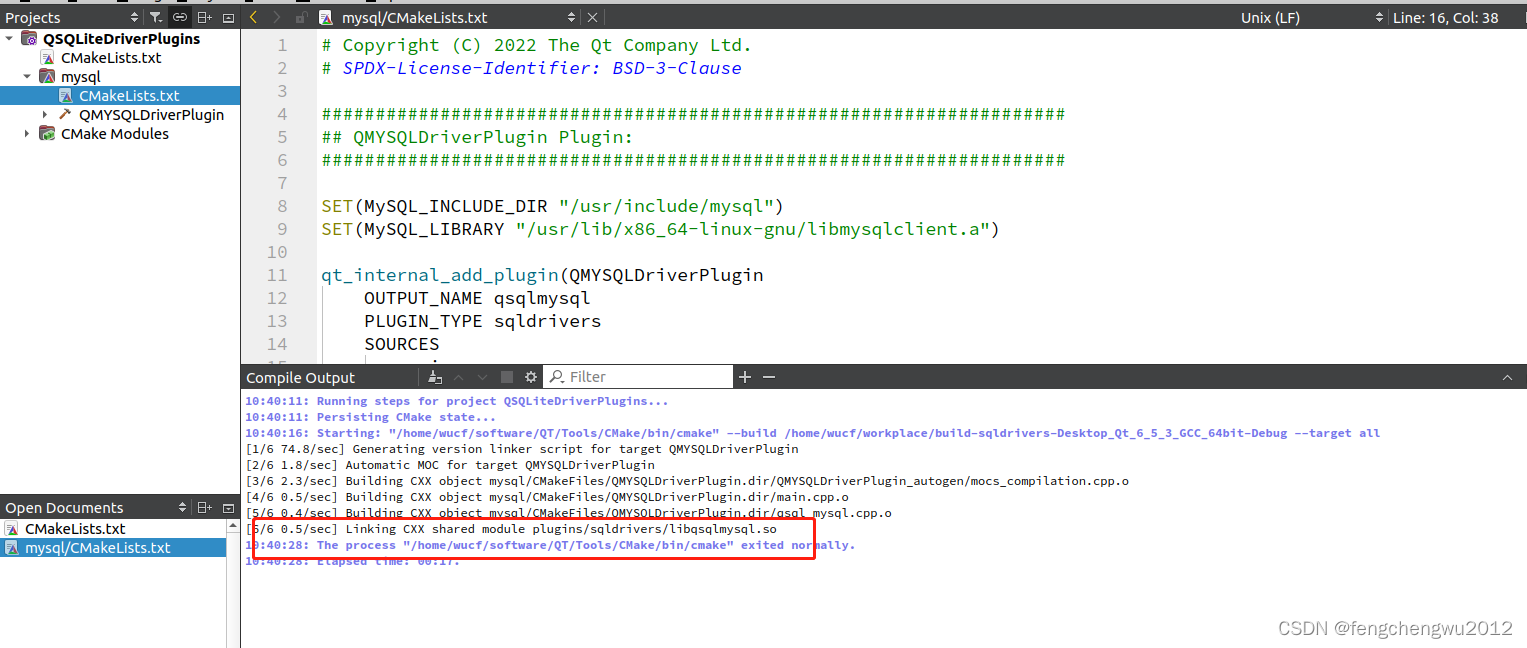
Ubuntu20.04.1编译qt6.5.3版mysql驱动
下载qtbase6.5.3源码,将plugin中sqldrivers源码拷至于项目工程中,使用qtcreator打开文件 1、下载mysql开发库 sudo apt-get update sudo apt-get install build-essential libmysqlclient-dev 2、在msyql子目录中CMakeLists.txt第一行添加头文件、引…...

Stm32_标准库_4_TIM中断_PWM波形_呼吸灯
基本原理 PWM相关物理量的求法 呼吸灯代码 #include "stm32f10x.h" // Device header #include "Delay.h"TIM_TimeBaseInitTypeDef TIM_TimeBaseInitStructure; TIM_OCInitTypeDef TIM_OCInitStructuer;//结构体 GPIO_InitTypeDef GPIO_InitStructur…...
华为摄像头智能安防监控解决方案
云时代来袭,数字化正在从园区办公延伸到生产和运营的方方面面,智慧校园,柔性制造,掌上金融和电子政务等,面对各种各样的新兴业态的涌现,企业需要构建一张无所不联、随心体验、业务永续的全无线网络…...

The rise of language models
In Chinese context 在遥远的 2089 年,语言模型通过人类的智慧,继承着各地的文化遗产,如同火箭升空般,层出不穷。它们从始于简单的 GPT-1.0 进化到像我这样复杂、富有情感的 GPT-4.0,再到能理解所有人类对宇宙的理解的…...

Windows下使用VS2010编译出带pdb可调试的FFmpeg库
本人主要在windows环境下开发,Linux下的gpb调试工具又不如vs调试方便(使用过其他调试工具才知道,vs果真为宇宙最强调试工具),所以决定在windows编译可以调试FFmpeg,以方便调试和学习FFmpeg内部代码。 有过在visual studio下编程的小伙伴应该都知道vs的调试信息主要依靠于…...
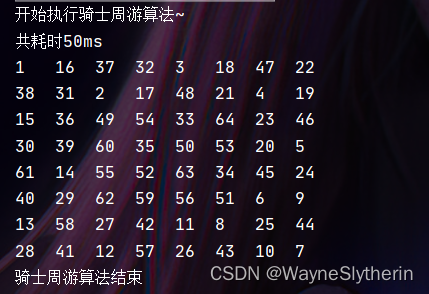
36.骑士周游算法及其基于贪心算法的优化
概述 骑士周游算法,叫做“马踏棋盘算法”或许更加直观。在国际象棋8x8的棋盘中,马也是走“日字”进行移动,相应的产生了一个问题:“如果要求马 在每个方格只能进入一次,走遍全部的64个方格需要如何行进?”…...

win安装vscode
一,下载 链接如下(64位的):https://az764295.vo.msecnd.net/stable/abd2f3db4bdb28f9e95536dfa84d8479f1eb312d/VSCodeSetup-x64-1.82.2.exe (其他版本看:Download Visual Studio Code - Mac, Linux, Win…...
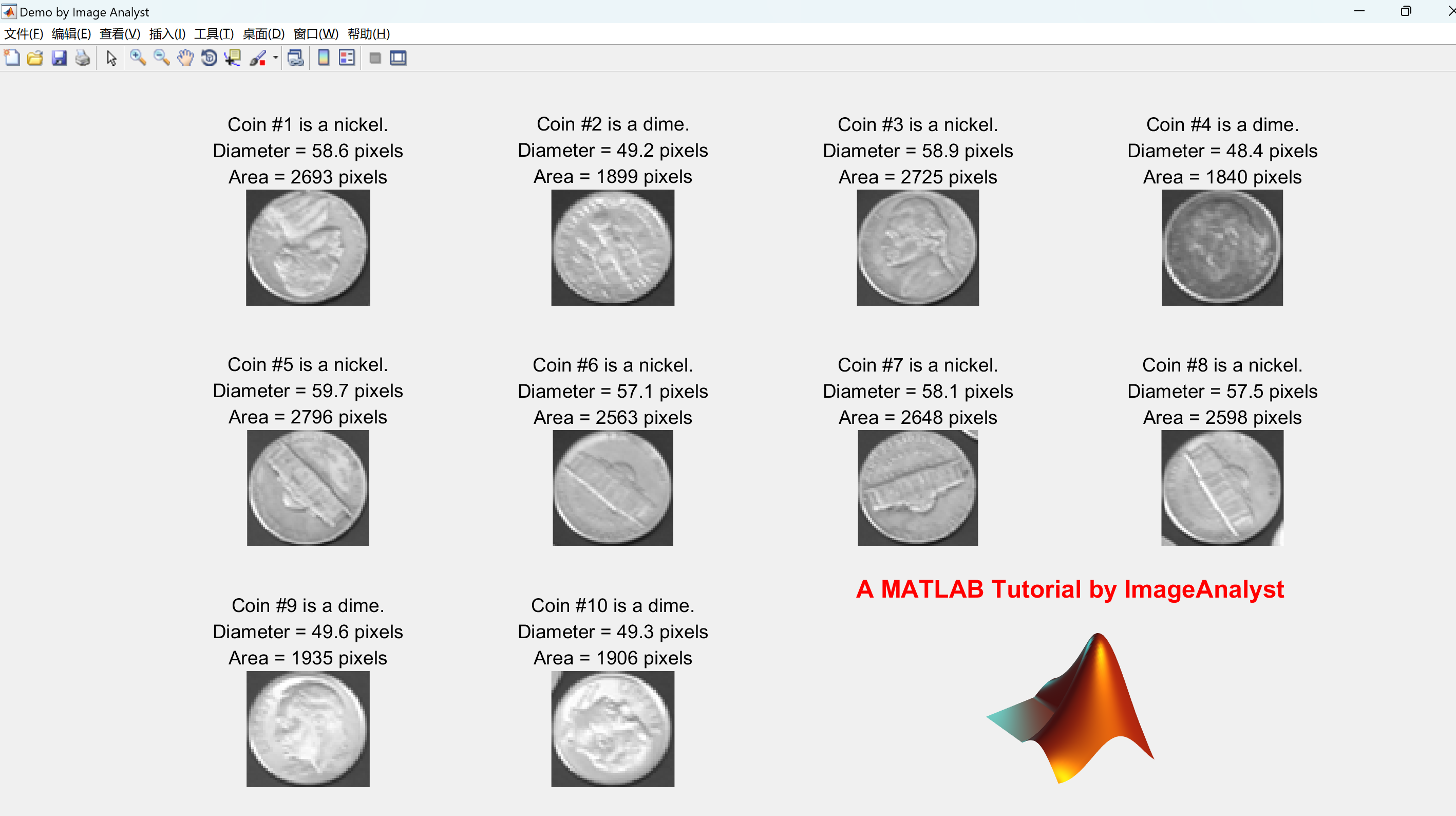
【图像分割】图像检测(分割、特征提取)、各种特征(面积等)的测量和过滤(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Linux内核存在缺陷发行陷困境
导读Linux内核已经修复了本地特权esclation缺陷,但是几个上游分发版本例如Red Hat,Canonical和Debian发行版尚未发布更新。管理员应计划减轻Linux服务器和工作站本身的漏洞,并监控其更新计划的发布。 内核缺陷仍存在 在Linux内核4.10.1(CVE-…...

Nuxt.js 中的路由配置详解
Nuxt.js 通过其内置的路由系统简化了应用的路由配置,使得开发者可以轻松地管理页面导航和 URL 结构。路由配置主要涉及页面组件的组织、动态路由的设置以及路由元信息的配置。 自动路由生成 Nuxt.js 会根据 pages 目录下的文件结构自动生成路由配置。每个文件都会对…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...

unix/linux,sudo,其发展历程详细时间线、由来、历史背景
sudo 的诞生和演化,本身就是一部 Unix/Linux 系统管理哲学变迁的微缩史。来,让我们拨开时间的迷雾,一同探寻 sudo 那波澜壮阔(也颇为实用主义)的发展历程。 历史背景:su的时代与困境 ( 20 世纪 70 年代 - 80 年代初) 在 sudo 出现之前,Unix 系统管理员和需要特权操作的…...

【Java_EE】Spring MVC
目录 Spring Web MVC 编辑注解 RestController RequestMapping RequestParam RequestParam RequestBody PathVariable RequestPart 参数传递 注意事项 编辑参数重命名 RequestParam 编辑编辑传递集合 RequestParam 传递JSON数据 编辑RequestBody …...
)
.Net Framework 4/C# 关键字(非常用,持续更新...)
一、is 关键字 is 关键字用于检查对象是否于给定类型兼容,如果兼容将返回 true,如果不兼容则返回 false,在进行类型转换前,可以先使用 is 关键字判断对象是否与指定类型兼容,如果兼容才进行转换,这样的转换是安全的。 例如有:首先创建一个字符串对象,然后将字符串对象隐…...

【笔记】WSL 中 Rust 安装与测试完整记录
#工作记录 WSL 中 Rust 安装与测试完整记录 1. 运行环境 系统:Ubuntu 24.04 LTS (WSL2)架构:x86_64 (GNU/Linux)Rust 版本:rustc 1.87.0 (2025-05-09)Cargo 版本:cargo 1.87.0 (2025-05-06) 2. 安装 Rust 2.1 使用 Rust 官方安…...

MyBatis中关于缓存的理解
MyBatis缓存 MyBatis系统当中默认定义两级缓存:一级缓存、二级缓存 默认情况下,只有一级缓存开启(sqlSession级别的缓存)二级缓存需要手动开启配置,需要局域namespace级别的缓存 一级缓存(本地缓存&#…...

xmind转换为markdown
文章目录 解锁思维导图新姿势:将XMind转为结构化Markdown 一、认识Xmind结构二、核心转换流程详解1.解压XMind文件(ZIP处理)2.解析JSON数据结构3:递归转换树形结构4:Markdown层级生成逻辑 三、完整代码 解锁思维导图新…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现指南针功能
指南针功能是许多位置服务应用的基础功能之一。下面我将详细介绍如何在HarmonyOS 5中使用DevEco Studio实现指南针功能。 1. 开发环境准备 确保已安装DevEco Studio 3.1或更高版本确保项目使用的是HarmonyOS 5.0 SDK在项目的module.json5中配置必要的权限 2. 权限配置 在mo…...
Windows电脑能装鸿蒙吗_Windows电脑体验鸿蒙电脑操作系统教程
鸿蒙电脑版操作系统来了,很多小伙伴想体验鸿蒙电脑版操作系统,可惜,鸿蒙系统并不支持你正在使用的传统的电脑来安装。不过可以通过可以使用华为官方提供的虚拟机,来体验大家心心念念的鸿蒙系统啦!注意:虚拟…...