paddle2.3-基于联邦学习实现FedAVg算法-CNN
目录
1. 联邦学习介绍
2. 实验流程
3. 数据加载
4. 模型构建
5. 数据采样函数
6. 模型训练

1. 联邦学习介绍
联邦学习是一种分布式机器学习方法,中心节点为server(服务器),各分支节点为本地的client(设备)。联邦学习的模式是在各分支节点分别利用本地数据训练模型,再将训练好的模型汇合到中心节点,获得一个更好的全局模型。
联邦学习的提出是为了充分利用用户的数据特征训练效果更佳的模型,同时,为了保证隐私,联邦学习在训练过程中,server和clients之间通信的是模型的参数(或梯度、参数更新量),本地的数据不会上传到服务器。
本项目主要是升级1.8版本的联邦学习fedavg算法至2.3版本,内容取材于基于PaddlePaddle实现联邦学习算法FedAvg - 飞桨AI Studio星河社区
2. 实验流程
联邦学习的基本流程是:
1. server初始化模型参数,所有的clients将这个初始模型下载到本地;
2. clients利用本地产生的数据进行SGD训练;
3. 选取K个clients将训练得到的模型参数上传到server;
4. server对得到的模型参数整合,所有的clients下载新的模型。
5. 重复执行2-5,直至收敛或达到预期要求
import os
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import random
import time
import paddle
import paddle.nn as nn
import numpy as np
from paddle.io import Dataset,DataLoader
import paddle.nn.functional as F
3. 数据加载
mnist_data_train=np.load('data/data2489/train_mnist.npy')
mnist_data_test=np.load('data/data2489/test_mnist.npy')
print('There are {} images for training'.format(len(mnist_data_train)))
print('There are {} images for testing'.format(len(mnist_data_test)))
# 数据和标签分离(便于后续处理)
Label=[int(i[0]) for i in mnist_data_train]
Data=[i[1:] for i in mnist_data_train]
There are 60000 images for training
There are 10000 images for testing
4. 模型构建
class CNN(nn.Layer):def __init__(self):super(CNN,self).__init__()self.conv1=nn.Conv2D(1,32,5)self.relu = nn.ReLU()self.pool1=nn.MaxPool2D(kernel_size=2,stride=2)self.conv2=nn.Conv2D(32,64,5)self.pool2=nn.MaxPool2D(kernel_size=2,stride=2)self.fc1=nn.Linear(1024,512)self.fc2=nn.Linear(512,10)# self.softmax = nn.Softmax()def forward(self,inputs):x = self.conv1(inputs)x = self.relu(x)x = self.pool1(x)x = self.conv2(x)x = self.relu(x)x = self.pool2(x)x=paddle.reshape(x,[-1,1024])x = self.relu(self.fc1(x))y = self.fc2(x)return y
5. 数据采样函数
# 均匀采样,分配到各个client的数据集都是IID且数量相等的
def IID(dataset, clients):num_items_per_client = int(len(dataset)/clients)client_dict = {}image_idxs = [i for i in range(len(dataset))]for i in range(clients):client_dict[i] = set(np.random.choice(image_idxs, num_items_per_client, replace=False)) # 为每个client随机选取数据image_idxs = list(set(image_idxs) - client_dict[i]) # 将已经选取过的数据去除client_dict[i] = list(client_dict[i])return client_dict
# 非均匀采样,同时各个client上的数据分布和数量都不同
def NonIID(dataset, clients, total_shards, shards_size, num_shards_per_client):shard_idxs = [i for i in range(total_shards)]client_dict = {i: np.array([], dtype='int64') for i in range(clients)}idxs = np.arange(len(dataset))data_labels = Labellabel_idxs = np.vstack((idxs, data_labels)) # 将标签和数据ID堆叠label_idxs = label_idxs[:, label_idxs[1,:].argsort()]idxs = label_idxs[0,:]for i in range(clients):rand_set = set(np.random.choice(shard_idxs, num_shards_per_client, replace=False)) shard_idxs = list(set(shard_idxs) - rand_set)for rand in rand_set:client_dict[i] = np.concatenate((client_dict[i], idxs[rand*shards_size:(rand+1)*shards_size]), axis=0) # 拼接return client_dict
class MNISTDataset(Dataset):def __init__(self, data,label):self.data = dataself.label = labeldef __getitem__(self, idx):image=np.array(self.data[idx]).astype('float32')image=np.reshape(image,[1,28,28])label=np.array(self.label[idx]).astype('int64')return image, labeldef __len__(self):return len(self.label)6. 模型训练
class ClientUpdate(object):def __init__(self, data, label, batch_size, learning_rate, epochs):dataset = MNISTDataset(data,label)self.train_loader = DataLoader(dataset,batch_size=batch_size,shuffle=True,drop_last=True)self.learning_rate = learning_rateself.epochs = epochsdef train(self, model):optimizer=paddle.optimizer.SGD(learning_rate=self.learning_rate,parameters=model.parameters())criterion = nn.CrossEntropyLoss(reduction='mean')model.train()e_loss = []for epoch in range(1,self.epochs+1):train_loss = []for image,label in self.train_loader:# image=paddle.to_tensor(image)# label=paddle.to_tensor(label.reshape([label.shape[0],1]))output=model(image)loss= criterion(output,label)# print(loss)loss.backward()optimizer.step()optimizer.clear_grad()train_loss.append(loss.numpy()[0])t_loss=sum(train_loss)/len(train_loss)e_loss.append(t_loss)total_loss=sum(e_loss)/len(e_loss)return model.state_dict(), total_loss
train_x = np.array(Data)
train_y = np.array(Label)
BATCH_SIZE = 32
# 通信轮数
rounds = 100
# client比例
C = 0.1
# clients数量
K = 100
# 每次通信在本地训练的epoch
E = 5
# batch size
batch_size = 10
# 学习率
lr=0.001
# 数据切分
iid_dict = IID(mnist_data_train, 100)
def training(model, rounds, batch_size, lr, ds,L, data_dict, C, K, E, plt_title, plt_color):global_weights = model.state_dict()train_loss = []start = time.time()# clients与server之间通信for curr_round in range(1, rounds+1):w, local_loss = [], []m = max(int(C*K), 1) # 随机选取参与更新的clientsS_t = np.random.choice(range(K), m, replace=False)for k in S_t:# print(data_dict[k])sub_data = ds[data_dict[k]]sub_y = L[data_dict[k]]local_update = ClientUpdate(sub_data,sub_y, batch_size=batch_size, learning_rate=lr, epochs=E)weights, loss = local_update.train(model)w.append(weights)local_loss.append(loss)# 更新global weightsweights_avg = w[0]for k in weights_avg.keys():for i in range(1, len(w)):# weights_avg[k] += (num[i]/sum(num))*w[i][k]weights_avg[k]=weights_avg[k]+w[i][k] weights_avg[k]=weights_avg[k]/len(w)global_weights[k].set_value(weights_avg[k])# global_weights = weights_avg# print(global_weights)#模型加载最新的参数model.load_dict(global_weights)loss_avg = sum(local_loss) / len(local_loss)if curr_round % 10 == 0:print('Round: {}... \tAverage Loss: {}'.format(curr_round, np.round(loss_avg, 5)))train_loss.append(loss_avg)end = time.time()fig, ax = plt.subplots()x_axis = np.arange(1, rounds+1)y_axis = np.array(train_loss)ax.plot(x_axis, y_axis, 'tab:'+plt_color)ax.set(xlabel='Number of Rounds', ylabel='Train Loss',title=plt_title)ax.grid()fig.savefig(plt_title+'.jpg', format='jpg')print("Training Done!")print("Total time taken to Train: {}".format(end-start))return model.state_dict()#导入模型
mnist_cnn = CNN()
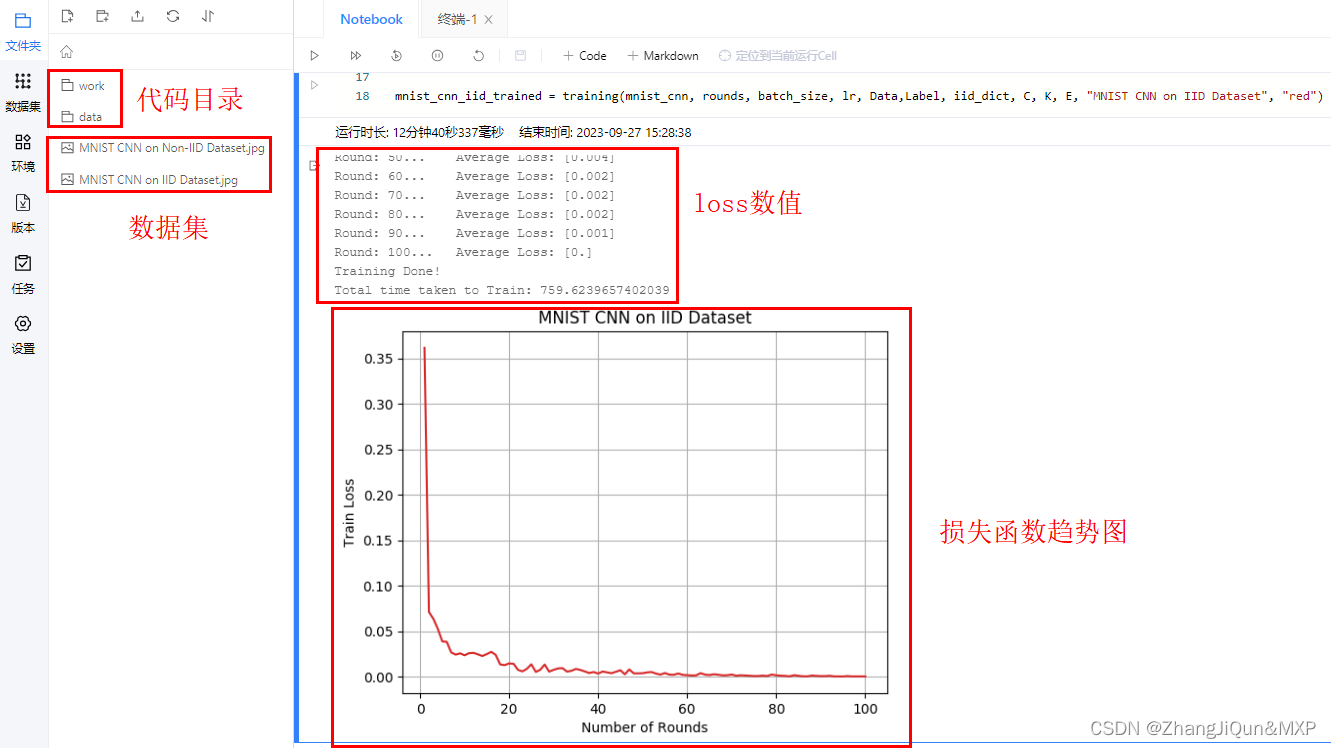
mnist_cnn_iid_trained = training(mnist_cnn, rounds, batch_size, lr, train_x,train_y, iid_dict, C, K, E, "MNIST CNN on IID Dataset", "orange")
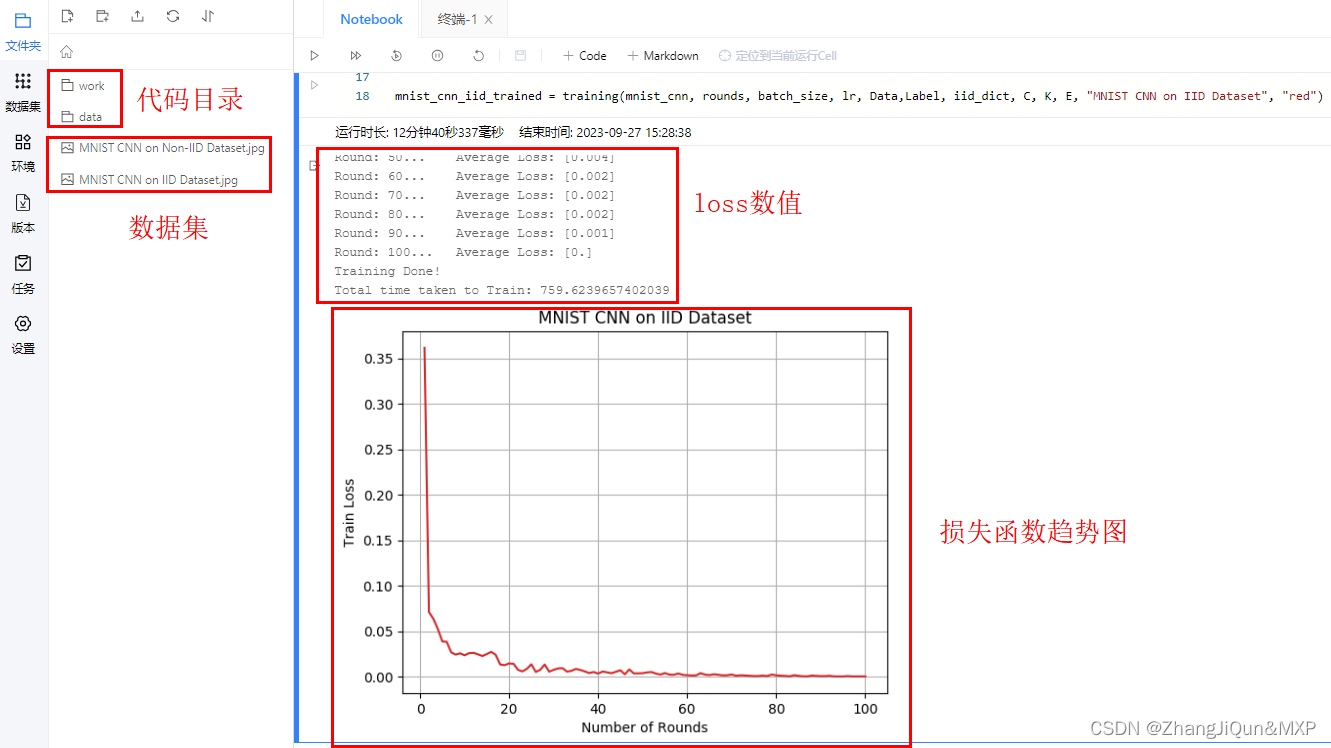
Round: 10... Average Loss: [0.024]
Round: 20... Average Loss: [0.015]
Round: 30... Average Loss: [0.008]
Round: 40... Average Loss: [0.003]
Round: 50... Average Loss: [0.004]
Round: 60... Average Loss: [0.002]
Round: 70... Average Loss: [0.002]
Round: 80... Average Loss: [0.002]
Round: 90... Average Loss: [0.001]
Round: 100... Average Loss: [0.]
Training Done!
Total time taken to Train: 759.6239657402039相关文章:
paddle2.3-基于联邦学习实现FedAVg算法-CNN
目录 1. 联邦学习介绍 2. 实验流程 3. 数据加载 4. 模型构建 5. 数据采样函数 6. 模型训练 1. 联邦学习介绍 联邦学习是一种分布式机器学习方法,中心节点为server(服务器),各分支节点为本地的client(设备&#…...

nuiapp保存canvas绘图
要保存一个 Canvas 绘图,可以使用以下步骤: 获取 Canvas 元素和其绘图上下文: var canvas document.getElementById("myCanvas"); var ctx canvas.getContext("2d");使用 Canvas 绘图 API 绘制图形。 使用 toDataUR…...
Object.defineProperty()方法详解,了解vue2的数据代理
假期第一篇,对于基础的知识点,我感觉自己还是很薄弱的。 趁着假期,再去复习一遍 Object.defineProperty(),对于这个方法,更多的还是停留在面试的时候,面试官问你vue2和vue3区别的时候,不免要提一提这个方法…...

Linux 磁盘管理
Linux 系统的磁盘管理直接关系到整个系统的性能表现。磁盘管理常用三个命令为: df、du 和 fdisk。 df df(英文全称:disk free)。df 命令用于显示磁盘空间的使用情况,包括文件系统的挂载点、总容量、已用空间、可用空间…...

大数据与人工智能的未来已来
大数据与人工智能的定义 大数据: 大数据指的是规模庞大、复杂性高、多样性丰富的数据集合。这些数据通常无法通过传统的数据库管理工具来捕获、存储、管理和处理。大数据的特点包括"3V": 大量(Volume):大数…...

【AI视野·今日Robot 机器人论文速览 第四十一期】Tue, 26 Sep 2023
AI视野今日CS.Robotics 机器人学论文速览 Tue, 26 Sep 2023 Totally 73 papers 👉上期速览✈更多精彩请移步主页 Daily Robotics Papers Extreme Parkour with Legged Robots Authors Xuxin Cheng, Kexin Shi, Ananye Agarwal, Deepak Pathak人类可以通过以高度动态…...
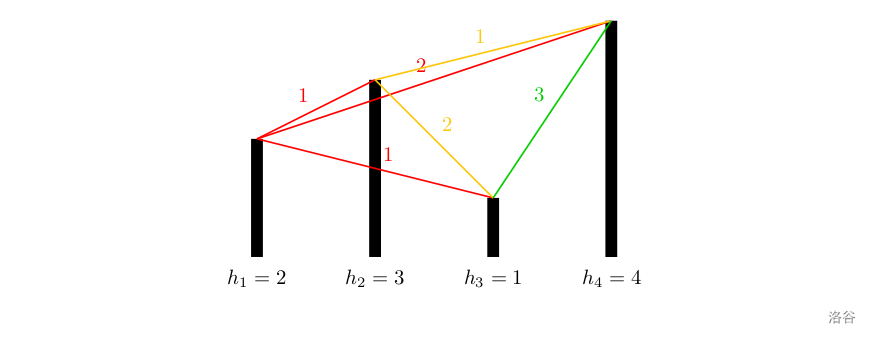
[NOIP2012 提高组] 开车旅行
[NOIP2012 提高组] 开车旅行 题目描述 小 A \text{A} A 和小 B \text{B} B 决定利用假期外出旅行,他们将想去的城市从 $1 $ 到 n n n 编号,且编号较小的城市在编号较大的城市的西边,已知各个城市的海拔高度互不相同,记城市 …...

数据库设计流程---以案例熟悉
案例名字:宠物商店系统 课程来源:点击跳转 信息->概念模型->数据模型->数据库结构模型 将现实世界中的信息转换为信息世界的概念模型(E-R模型) 业务逻辑 构建 E-R 图 确定三个实体:用户、商品、订单...

Miniconda创建paddlepaddle环境
1、conda env list 2、conda create --name paddle_env python3.8 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ 3、activate paddle_env 4、python -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple 5、pip install "p…...
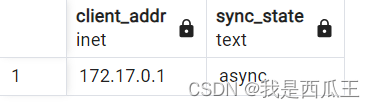
postgresql实现单主单从
实现步骤 1.主库创建一个有复制权限的用户 CREATE ROLE 用户名login # 有登录权限的角色即是用户replication #复制权限 encrypted password 密码;2.主库配置开放从库外部访问权限 修改 pg_hba.conf 文件 (相当于开放防火墙) # 类型 数据库 …...
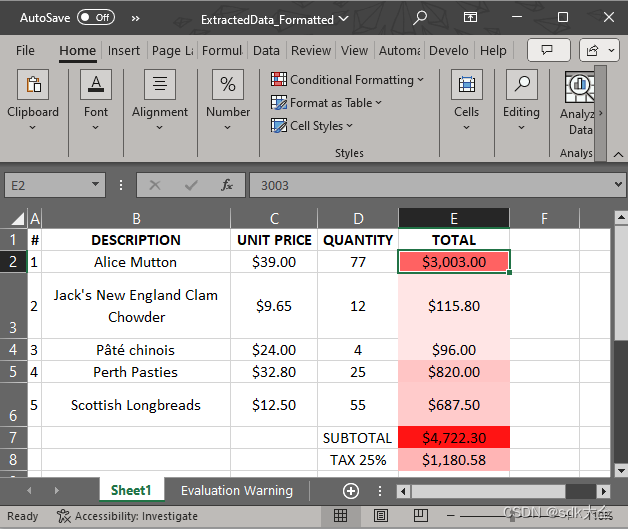
提取PDF数据:Documents for PDF ( GcPdf )
在当今数据驱动的世界中,从 PDF 文档中无缝提取结构化表格数据已成为开发人员的一项关键任务。借助GrapeCity Documents for PDF ( GcPdf ),您可以使用 C# 以编程方式轻松解锁这些 PDF 中隐藏的信息宝藏。 考虑一下 PDF(最常用的文档格式之一…...

adb连接切换到模拟器端口
查看连接状态 adb devices出现以下情况 C:\Users\22560>adb devices List of devices attached 127.0.0.1:5555 offline emulator-5554 device可以发现我们想要连接的雷电模拟器的5555端口目前没有连接,只有emulator-5554被连接了,此时我们需要关…...
为何每个开发者都在谈论Go?
目录 一、引言Go的历史回顾关键时间节点 使用场景Go的语言地位技术社群与企业支持资源投入和生态系统 二、简洁的语法结构基本组成元素变量声明与初始化代码示例 类型推断函数与返回值代码示例输出 接口与结构体:组合而非继承错误处理:明确而不是异常小结…...
【Leetcode】 501. 二叉搜索树中的众数
给你一个含重复值的二叉搜索树(BST)的根节点 root ,找出并返回 BST 中的所有 众数(即,出现频率最高的元素)。 如果树中有不止一个众数,可以按 任意顺序 返回。 假定 BST 满足如下定义…...

怎样给Ubuntu系统安装vmware-tools
首先我要告诉你:Ubuntu无法安装vmware-tools,之所以这么些是因为我一开始也是这样认为的,vmware-tools是给Windows系统准备的我认为,毕竟Windows占有率远远高于Linux,这也可以理解。 那么怎么样实现Ubuntu虚拟机跟Wind…...

DDS信号发生器波形发生器VHDL
名称:DDS信号发生器波形发生器 软件:Quartus 语言:VHDL 要求: 在EDA平台中使用VHDL语言为工具,设计一个常见信号发生电路,要求: 1. 能够产生锯齿波,方波,三角波&…...

Python3操作SQLite3创建表主键自增长|CRUD基本操作
Win11查看安装的Python路径及安装的库 Python PEP8 代码规范常见问题及解决方案 Python3操作MySQL8.XX创建表|CRUD基本操作 Python3操作SQLite3创建表主键自增长|CRUD基本操作 anaconda3最新版安装|使用详情|Error: Please select a valid Python interpreter Python函数绘…...

B. Comparison String
题目: 样例: 输入 4 4 <<>> 4 >><< 5 >>>>> 7 <><><><输出 3 3 6 2 思路: 由题意,条件是 又因为要使用尽可能少的数字,这是一道贪心题,所以…...

python端口扫描
扫描所有端口 import socket, threading, os, timedef port_thread(ip, start, step, timeout):for port in range(start, start step):s socket.socket()s.settimeout(timeout)try:s.connect((ip, port))print(f"port[{port}] 可用")except Exception as e:# pri…...

国庆第二天
#include<th.h>#define ERR_MSG(msg) do{\fprintf(stderr,"__%d__",__LINE__);\perror(msg);\ }while(0)#define PORT 6666 #define IP "192.168.2.3"//键盘输入事件 int serverkeyboard(fd_set readfds) {char buf[128] "";int sndfd -…...

Leetcode 3576. Transform Array to All Equal Elements
Leetcode 3576. Transform Array to All Equal Elements 1. 解题思路2. 代码实现 题目链接:3576. Transform Array to All Equal Elements 1. 解题思路 这一题思路上就是分别考察一下是否能将其转化为全1或者全-1数组即可。 至于每一种情况是否可以达到…...

【OSG学习笔记】Day 18: 碰撞检测与物理交互
物理引擎(Physics Engine) 物理引擎 是一种通过计算机模拟物理规律(如力学、碰撞、重力、流体动力学等)的软件工具或库。 它的核心目标是在虚拟环境中逼真地模拟物体的运动和交互,广泛应用于 游戏开发、动画制作、虚…...
)
React Native 开发环境搭建(全平台详解)
React Native 开发环境搭建(全平台详解) 在开始使用 React Native 开发移动应用之前,正确设置开发环境是至关重要的一步。本文将为你提供一份全面的指南,涵盖 macOS 和 Windows 平台的配置步骤,如何在 Android 和 iOS…...

条件运算符
C中的三目运算符(也称条件运算符,英文:ternary operator)是一种简洁的条件选择语句,语法如下: 条件表达式 ? 表达式1 : 表达式2• 如果“条件表达式”为true,则整个表达式的结果为“表达式1”…...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

Java面试专项一-准备篇
一、企业简历筛选规则 一般企业的简历筛选流程:首先由HR先筛选一部分简历后,在将简历给到对应的项目负责人后再进行下一步的操作。 HR如何筛选简历 例如:Boss直聘(招聘方平台) 直接按照条件进行筛选 例如:…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...

Java线上CPU飙高问题排查全指南
一、引言 在Java应用的线上运行环境中,CPU飙高是一个常见且棘手的性能问题。当系统出现CPU飙高时,通常会导致应用响应缓慢,甚至服务不可用,严重影响用户体验和业务运行。因此,掌握一套科学有效的CPU飙高问题排查方法&…...