NLP的不同研究领域和最新发展的概述

一、介绍
作为理解、生成和处理自然语言文本的有效方法,自然语言处理 (NLP) 的研究近年来迅速普及并被广泛采用。鉴于NLP的快速发展,获得该领域的概述和维护它是困难的。这篇博文旨在提供NLP不同研究领域的结构化概述,并分析该领域的最新趋势。
研究领域是通常由(但不限于)任务或技术组成的学科和概念。
在本文中,我们将调查以下问题:
- NLP中研究的不同研究领域是什么?
- NLP研究文献的特点和发展是什么?
- NLP未来工作的趋势和方向是什么?
尽管NLP中的大多数研究领域都是众所周知和定义的,但目前没有常用的分类法或分类方案试图以一致和可理解的格式收集和构建这些研究领域。因此,很难对NLP研究的整个领域有一个概述。虽然会议和教科书中有NLP主题列表,但它们往往差异很大,而且通常过于宽泛或过于专业。因此,我们开发了一个分类法,涵盖了NLP中广泛的不同研究领域。尽管该分类法可能不包括所有可能的NLP概念,但它涵盖了广泛的最流行的研究领域,因此缺失的研究领域可以被视为所包含研究领域的子主题。在开发分类法时,我们发现某些较低级别的研究领域必须分配给多个较高级别的研究领域,而不仅仅是一个。因此,一些研究领域在NLP分类法中多次列出,但被分配到不同的更高级别的研究领域。最终的分类法是在与领域专家一起在迭代过程中经验开发的。
分类法作为一个总体分类方案,其中NLP出版物可以根据至少一个包含的研究领域进行分类,即使它们不直接涉及其中一个研究领域,而只是其中的子主题。为了分析NLP的最新发展,我们训练了一个弱监督模型,根据NLP分类法对ACL选集论文进行分类。
您可以在我们的论文中阅读有关分类模型和NLP分类法开发过程的更多详细信息。
二、NLP 的不同研究领域
以下部分提供了上述NLP分类中包含的研究概念领域的简短解释。
2.1 综合
多模态是指系统或方法处理不同类型或模态输入的能力(Garg 等人,2022 年)。我们区分可以处理自然语言文本以及视觉数据,语音和音频,编程语言或结构化数据(如表格或图形)的系统。
2.2 自然语言界面
自然语言接口可以基于自然语言查询处理数据(Voigt 等人,2021 年),通常实现为问答或对话和对话系统。
2.3 语义文本处理
这个高级研究领域包括所有类型的概念,这些概念试图从自然语言中获取意义,并使机器能够从语义上解释文本数据。在这方面最强大的研究领域之一是试图学习单词序列的联合概率函数的语言模型(Bengio et al., 2000)。语言模型训练的最新进展使这些模型能够成功执行各种下游 NLP 任务(Soni 等人,2022 年)。在表示学习中,语义文本表示通常以嵌入的形式学习(Fu等人,2022),可用于比较语义搜索设置中文本的语义相似性(Reimers 和 Gurevych,2019)。此外,可以合并知识表示,例如以知识图的形式,以改进各种 NLP 任务(Schneider 等人,2022 年)。
2.4 情绪分析
情感分析试图从文本中识别和提取主观信息(Wankhade 等人,2022 年)。通常,研究侧重于从文本中提取观点、情感或极性。最近,基于方面的情感分析作为一种提供比一般情感分析更详细信息的方法出现,因为它旨在预测文本中给定方面或实体的情感极性(Xue and Li,2018)。
2.5 句法文本处理
这个高级研究领域旨在分析文本的语法语法和词汇(Bessmertny et al., 2016)。在这种情况下,代表性任务是句法解析句子中的单词依赖关系,将单词标记为各自的词性,将文本分割成连贯的部分,或纠正语法和拼写方面的错误文本。
2.6 语言学与认知NLP
语言学和认知NLP处理自然语言,基于我们的语言能力牢牢植根于我们的认知能力的假设,意义本质上是概念化,语法是由用法塑造的(Dabrowska和Divjak,2015)。存在许多不同的语言理论,这些理论通常认为语言习得受通用语法规则的支配,这些规则对所有正常发育的人类都是通用的(Wise and Sevcik,2017)。心理语言学试图模拟人类大脑如何获取和产生语言,处理语言,理解语言并提供反馈(Balamurugan,2018)。认知建模涉及以各种形式建模和模拟人类认知过程,尤其是以计算或数学形式(Sun,2020)。
2.7 负责任和值得信赖的NLP
负责任和值得信赖的 NLP 关注实施以公平、可解释性、问责制和道德方面为核心的方法(Barredo Arrieta 等人,2020 年)。绿色和可持续的NLP主要关注文本处理的有效方法,而低资源NLP旨在在数据稀缺时执行NLP任务。此外,NLP 中的鲁棒性试图开发对偏差不敏感、抗数据扰动且可靠的分布外预测模型。
2.8 推理
推理使机器能够得出逻辑结论,并根据可用的信息,使用演绎和归纳等技术得出新知识。参数挖掘自动识别并提取推理和推理的结构,这些结构表示为自然语言文本中呈现的参数(Lawrence和Reed,2019)。文本推理,通常建模为蕴涵问题,自动确定是否可以从给定的前提推断出自然语言假设(MacCartney和Manning,2007)。常识推理使用文本中未明确提供的世界知识来连接前提和假设(Ponti 等人,2020 年),而数字推理执行算术运算(Al-Negheimish 等人,2021 年)。机器阅读理解旨在教机器根据给定的段落确定问题的正确答案(Zhang 等人,2021 年)。
2.9 多语言
多语言处理涉及多种自然语言的所有类型的NLP任务,并且通常在机器翻译中进行研究。此外,代码切换可以在单个句子内或句子之间自由交换多种语言(Diwan 等人,2021 年),而跨语言传输技术使用一种语言可用的数据和模型来解决另一种语言的 NLP 任务。
2.10 信息检索
信息检索涉及从大型馆藏中查找满足信息需求的文本(Manning et al., 2008)。通常,这涉及检索文档或段落。
2.11 信息提取和文本挖掘
该研究领域的重点是从非结构化文本中提取结构化知识,并能够分析和识别数据中的模式或相关性(Hassani 等人,2020 年)。文本分类自动将文本分类到预定义的类中(Schopf 等人,2021 年),而主题建模旨在发现文档集合中的潜在主题(Grootendorst,2022 年),通常使用文本聚类技术将语义相似的文本组织到相同的集群中。摘要产生文本摘要,在更少的空间中包含输入的关键点,并将重复保持在最低限度(El-Kassas 等人,2021 年)。此外,信息提取和文本挖掘研究领域还包括命名实体识别,它涉及命名实体的识别和分类(Leitner 等人,2020 年)、共指解析,旨在识别话语中对同一实体的所有引用(Yin 等人,2021 年),术语提取,旨在提取相关术语,例如关键字或关键字短语(Rigouts Terryn 等人,2020 年),旨在提取实体之间关系的关系提取,以及促进关系元组的域独立发现的开放信息提取(Yates等人,2007 年)。
2.12 文本生成
文本生成方法的目标是生成既能被人类理解又与人类创作的文本无法区分的文本。因此,输入通常由文本组成,例如在保留语义的同时以不同的表面形式呈现文本输入的释义(Niu 等人,2021 年),旨在生成给定段落和目标答案的流畅且相关的问题生成(Song 等人,2018 年),或旨在生成与提示相关的自然文本的对话响应生成(Zhang 等人, 然而,在许多情况下,文本是作为其他模式输入的结果生成的,例如在数据到文本生成的情况下,基于结构化数据(如表格或图形)生成文本(Kale and Rastogi,2020),图像或视频的字幕,或将语音波形转录为文本的语音识别(Baevski 等人, 2020)。
三、NLP 的特点和发展
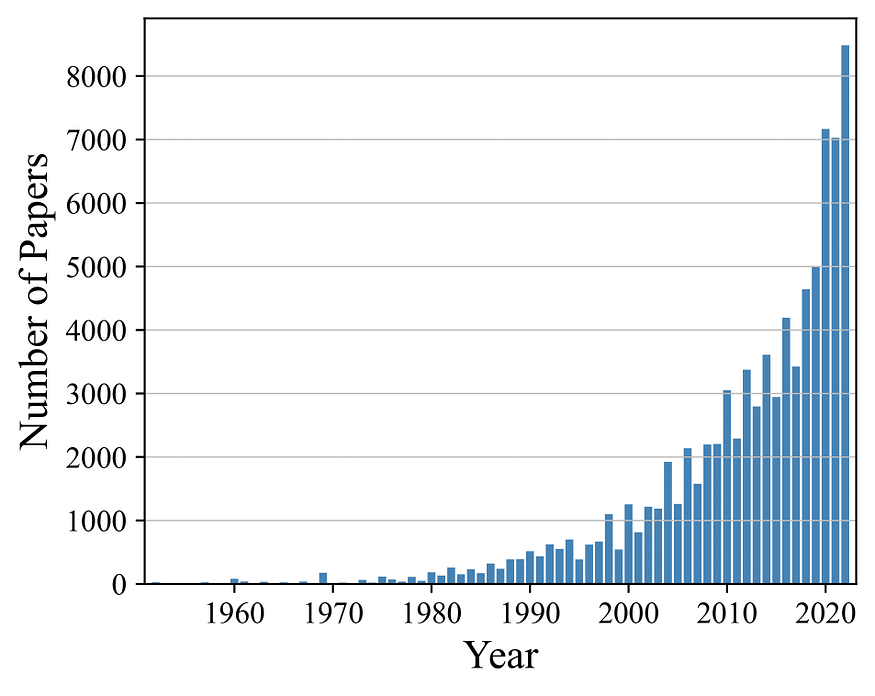
1952 年至 2022 年 ACL 选集中每年的论文数量。图片来源:作者
考虑到NLP的文献,我们从研究数量作为研究兴趣的指标开始分析。50年观察期内出版物的分布情况见上图。虽然第一批出版物出现在1952年,但年度出版物的数量增长缓慢,直到2000年。因此,在2000年至2017年期间,出版物数量大约翻了两番,而在随后的五年中,它又翻了一番。因此,我们观察到NLP研究的数量呈近乎指数级增长,表明研究界的关注日益增加。
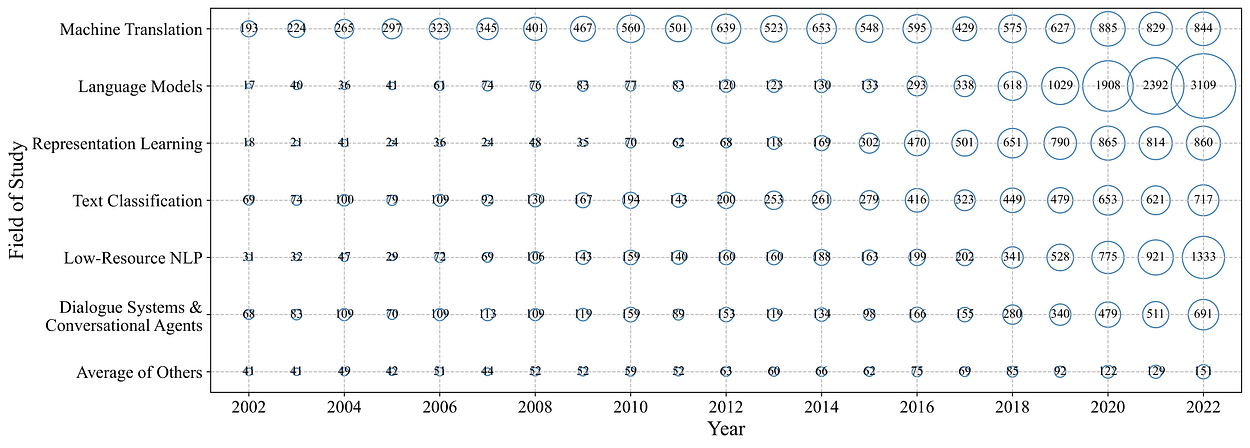
Distribution of the number of papers by most popular fields of study from 2002 to 2022. Image by author.
通过检查上图,揭示了NLP文献中最受欢迎的研究领域及其随时间推移的最新发展。虽然NLP的大多数研究都与机器翻译或语言模型有关,但这两个研究领域的发展是不同的。机器翻译是一个经过深入研究的领域,已经建立了很长时间,并且在过去 20 年中经历了适度的增长速度。语言模型也已经研究了很长时间。然而,自2018年以来,有关该主题的出版物数量仅出现显着增长。在查看其他流行的研究领域时,可以观察到类似的差异。表示学习和文本分类虽然普遍得到广泛研究,但部分停滞不前。相比之下,对话系统和会话代理,特别是低资源NLP,在研究数量上继续表现出高增长率。根据其余研究领域平均研究数量的发展,我们观察到总体上略有正增长。然而,大多数研究领域的研究明显少于最受欢迎的研究领域。
四、自然语言处理的最新趋势
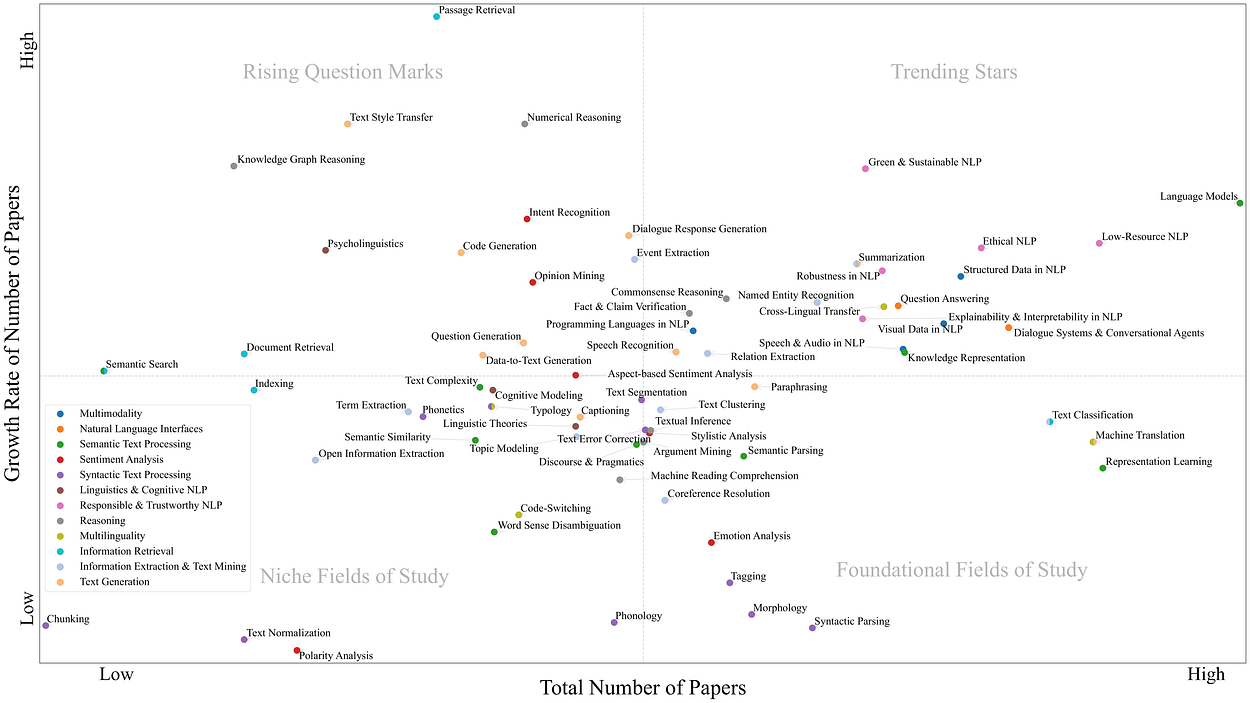
NLP研究领域的增长份额矩阵。每个研究领域的增长率和作品总数是从2018年初到2022年底计算的。图片由作者提供。
上图显示了NLP研究领域的增长份额矩阵。我们通过分析2018年至2022年间与NLP各个研究领域相关的增长率和论文总数,用它来研究当前的研究趋势和可能的未来研究方向。矩阵的右上方由表现出高增长率的研究领域组成,同时总体上有大量论文。鉴于本节中研究领域的日益普及,我们将它们归类为趋势之星。右下部分包含非常受欢迎但增长率较低的研究领域。通常,这些是NLP必不可少但已经相对成熟的研究领域。因此,我们将它们归类为基础研究领域。矩阵的左上部分包含表现出高增长率的研究领域,但总体论文很少。由于这些研究领域的进展相当有希望,但总体论文数量较少,因此难以预测其进一步发展,因此我们将它们归类为上升问号。矩阵左下角的研究领域因其论文总数低和增长率低而被归类为利基研究领域。
该图显示,语言模型目前受到的关注最多。根据该领域的最新发展,这一趋势可能会在不久的将来继续并加速。文本分类、机器翻译和表示学习是最受欢迎的研究领域之一,但仅显示出边际增长。从长远来看,它们可能会被快速增长的领域所取代,成为最受欢迎的研究领域。
一般来说,与句法文本处理相关的研究领域表现出微不足道的增长和整体的低受欢迎程度。相反,与负责任和值得信赖的NLP相关的研究领域,如绿色和可持续的NLP,低资源NLP和道德NLP,往往表现出高增长率和高受欢迎程度。这种趋势也可以在NLP中的结构化数据,NLP中的视觉数据以及NLP中的语音和音频中观察到,所有这些都与多模态有关。此外,涉及对话系统和会话代理以及问答的自然语言界面在研究界变得越来越重要。我们的结论是,除了语言模型之外,负责任和值得信赖的NLP,多模态和自然语言界面可能在不久的将来成为NLP研究领域的特征。
在推理领域,特别是在知识图谱推理和数字推理以及与文本生成相关的各个研究领域,可以观察到进一步的显着发展。尽管这些研究领域目前仍然相对较小,但它们显然吸引了越来越多的研究界的兴趣,并显示出明显的积极增长趋势。
五、结论 💡
为了总结最近的发展并提供NLP格局的概述,我们定义了研究领域的分类法并分析了最近的研究进展。
我们的研究结果表明,已经研究了大量的研究领域,包括多模态、负责任和可信赖的NLP以及自然语言界面等趋势领域。我们希望本文能对当前的NLP格局提供一个有用的概述,并可以作为对该领域进行更深入探索的起点。
相关文章:
NLP的不同研究领域和最新发展的概述
一、介绍 作为理解、生成和处理自然语言文本的有效方法,自然语言处理 (NLP) 的研究近年来迅速普及并被广泛采用。鉴于NLP的快速发展,获得该领域的概述和维护它是困难的。这篇博文旨在提供NLP不同研究领域的结构化概述,…...
1.物联网射频识别,RFID概念、组成、中间件、标准,全球物品编码——EPC码
1.RFID概念 RFID是Radio Frequency Identification的缩写,又称无线射频识别,是一种通信技术,可通过无线电讯号识别特定目标并读写相关数据,而无需与被识别物体建立机械或光学接触。 RFID(Radio Frequency Identificati…...

MySQL函数与控制结构
MySQL数据库管理系统在数据存储和检索方面发挥着重要作用。除了基础的数据操作外,MySQL还提供了丰富的函数和控制结构来进行更复杂的数据处理。 本文将详细介绍如何在MySQL中使用begin-end语句块、自定义函数、以及各种控制语句。通过《三国志》游戏数据的实例将更深入地了解…...
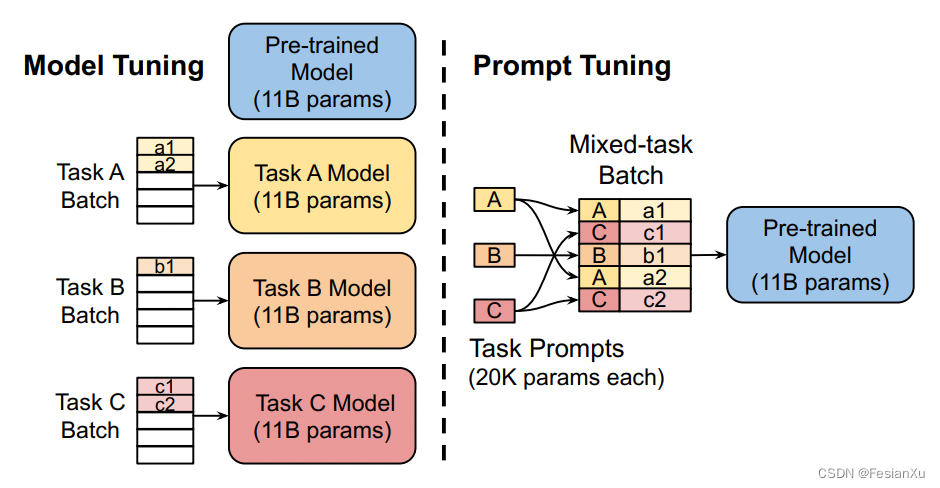
【论文极速读】Prompt Tuning——一种高效的LLM模型下游任务适配方式
【论文极速读】Prompt Tuning——一种高效的LLM模型下游任务适配方式 FesianXu 20230928 at Baidu Search Team 前言 Prompt Tuning是一种PEFT方法(Parameter-Efficient FineTune),旨在以高效的方式对LLM模型进行下游任务适配,本…...
如何在 Elasticsearch 中使用 Openai Embedding 进行语义搜索
随着强大的 GPT 模型的出现,文本的语义提取得到了改进。 在本文中,我们将使用嵌入向量在文档中进行搜索,而不是使用关键字进行老式搜索。 什么是嵌入 - embedding? 在深度学习术语中,嵌入是文本或图像等内容的数字表示…...

世界第一ERP厂商SAP,推出类ChatGPT产品—Joule
9月27日,世界排名第一ERP厂商SAP在官网宣布,推出生成式AI助手Joule,并将其集成在采购、供应链、销售、人力资源、营销、数据分析等产品矩阵中,帮助客户实现降本增效。 据悉,Joule是一款功能类似ChatGPT的产品…...
嵌入式Linux应用开发-基础知识-第十八章系统对中断的处理③
嵌入式Linux应用开发-基础知识-第十八章系统对中断的处理③ 第十八章 Linux系统对中断的处理 ③18.5 编写使用中断的按键驱动程序 ③18.5.1 编程思路18.5.1.1 设备树相关18.5.1.2 驱动代码相关 18.5.2 先编写驱动程序18.5.2.1 从设备树获得 GPIO18.5.2.2 从 GPIO获得中断号18.5…...

【Python】返回指定时间对应的时间戳
使用模块datetime,附赠一个没啥用的“时间推算”功能(获取n天后对应的时间 代码: import datetimedef GetTimestamp(year,month,day,hour,minute,second,*,relativeNone,timezoneNone):#返回指定时间戳。指定relative时进行时间推算"""根…...
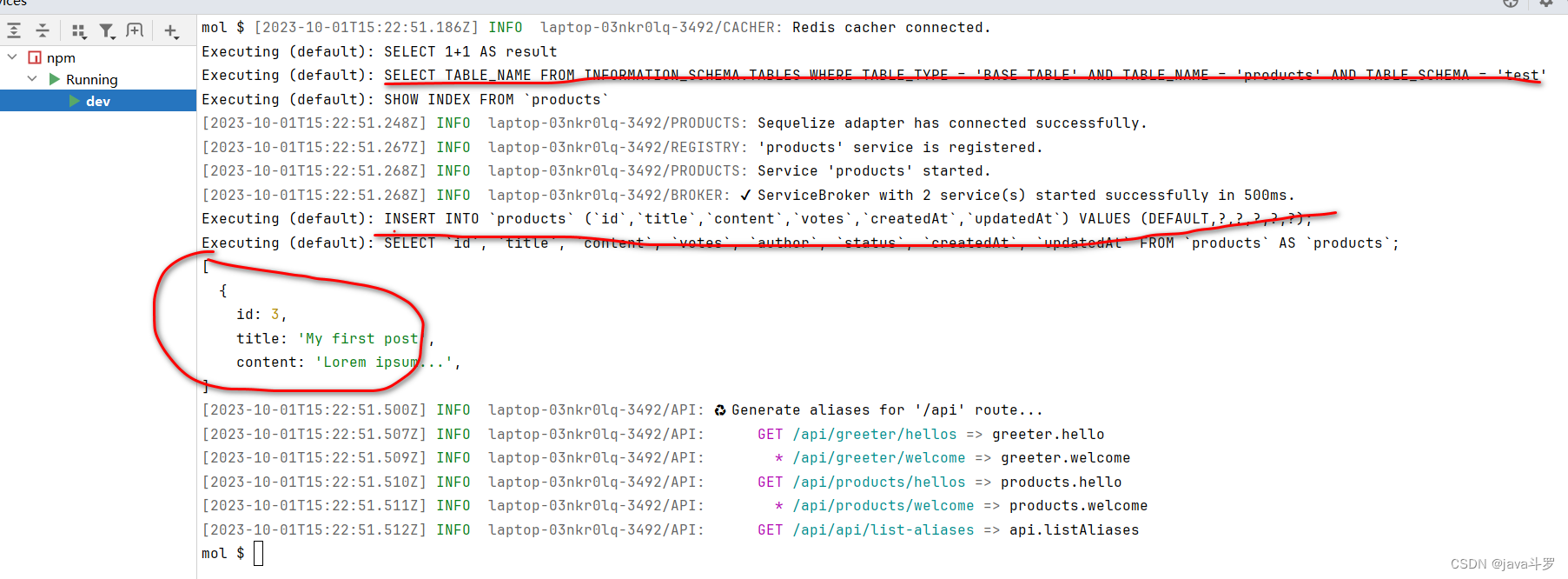
微服务moleculer03
1. Moleculer 目前支持SQLite,MySQL,MariaDB,PostgreSQL,MSSQL等数据库,这里以mysql为例 2. package.json 增加mysql依赖 "mysql2": "^2.3.3", "sequelize": "^6.21.3", &q…...

[React] react-router-dom的v5和v6
v5 版本既兼容了类组件(react v16.8前),又兼容了函数组件(react v16.8及以后,即hook)。v6 文档把路由组件默认接受的三个属性给移除了,若仍然使用 this.props.history.push(),此时pr…...
之mv)
Linux命令(91)之mv
linux命令之mv 1.mv介绍 linux命令mv是用来移动文件或目录,并且也可以用来更改文件或目录的名字 2.mv用法 mv [参数] src dest mv常用参数 参数说明-f强制移动,不提示 3.实例 3.1.重命名文件1.txt为ztj.txt 命令: mv 1.txt ztj.txt …...
C++ 强制类型转换(int double)、查看数据类型、自动决定类型、三元表达式、取反、
强制类型转换( int 与 double) #include <iostream> using namespace std;int main() {// 数据类型转换char c1;short s1;int n 1;long l 1;float f 1;double d 1;int p 0;int cc (int)c;// 注意:字符 转 整形时 是有问题的// “…...
Android自动化测试之MonkeyRunner--从环境构建、参数讲解、脚本制作到实战技巧
monkeyrunner 概述、环境搭建 monkeyrunner环境搭建 (1) JDK的安装不配置 http://www.oracle.com/technetwork/java/javase/downloads/index.html (2) 安装Python编译器 https://www.python.org/download/ (3) 设置环境变量(配置Monkeyrunner工具至path目彔下也可丌配置) (4) …...
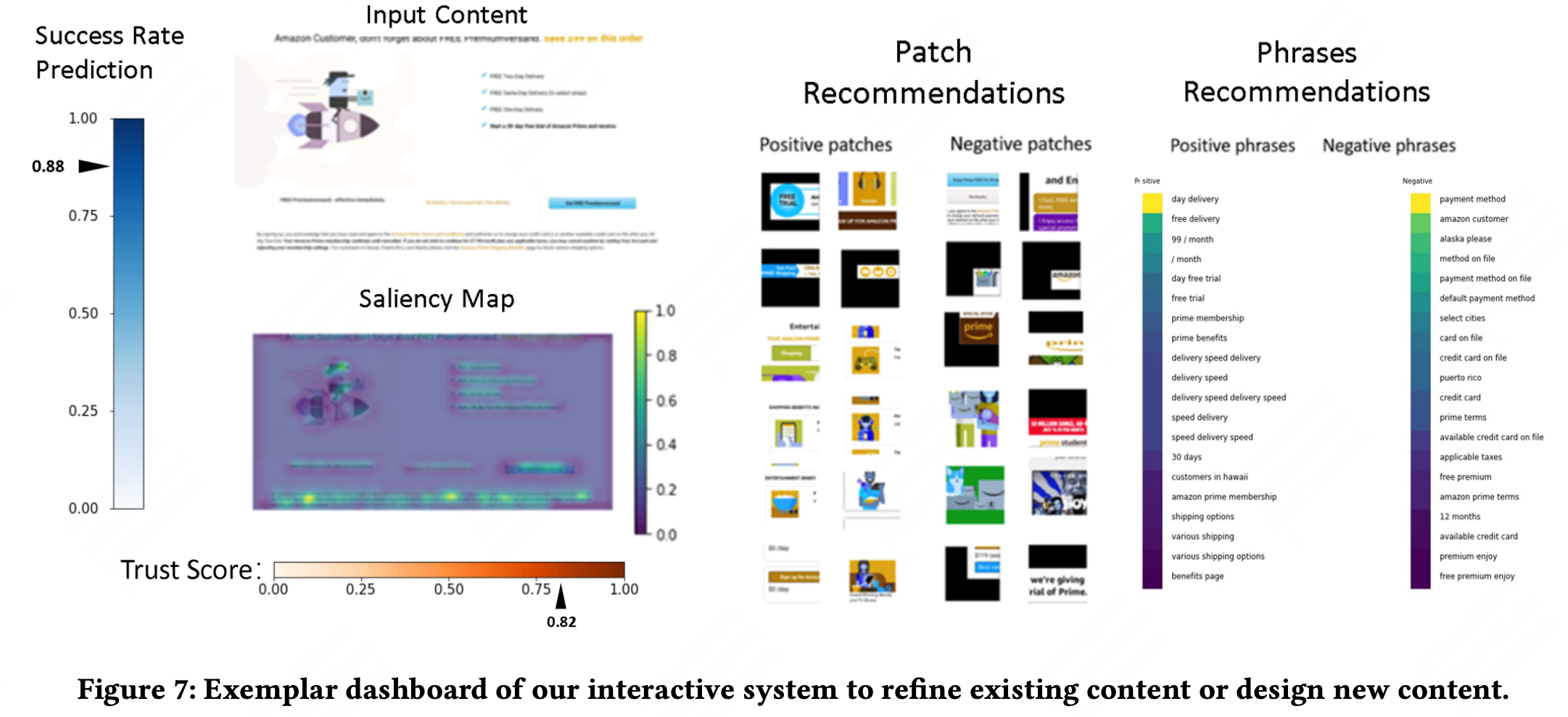
Neural Insights for Digital Marketing Content Design 阅读笔记
KDD-2023 很值得读的文章! 1 摘要 电商里,营销内容的实验,很重要。 然而,创作营销内容是一个手动和耗时的过程,缺乏明确的指导原则。 本文通过 基于历史数据的AI驱动的可行性洞察,来弥补 营销内容创作 和…...

BI神器Power Query(26)-- 使用PQ实现表格多列转换(2/3)
实例需求:原始表格包含多列属性数据,现在需要将不同属性分列展示在不同的行中,att1、att3、att5为一组,att2、att3、att6为另一组,数据如下所示。 更新表格数据 原始数据表: Col1Col2Att1Att2Att3Att4Att5Att6AAADD…...

中间件中使用到的设计模式
本文记录阅读源码的过程中,了解/学习到中间件使用到的设计模式及具体运用的组件/功能点 1. 策略模式 1. Nacos2.x中grpc处理时通过请求type来进行具体Handler映射,找到对应处理器。 2. 模板模式 1. Nacos配置数据读取,内部数据源、外部数据…...

运用动态内存实现通讯录(增删查改+排序)
目录 前言: 实现通讯录: 1.创建和调用菜单: 2.创建联系人信息和通讯录: 3.初始化通讯录: 4.增加联系人: 5.显示联系人: 6.删除联系人: 编辑 7.查找联系人: …...
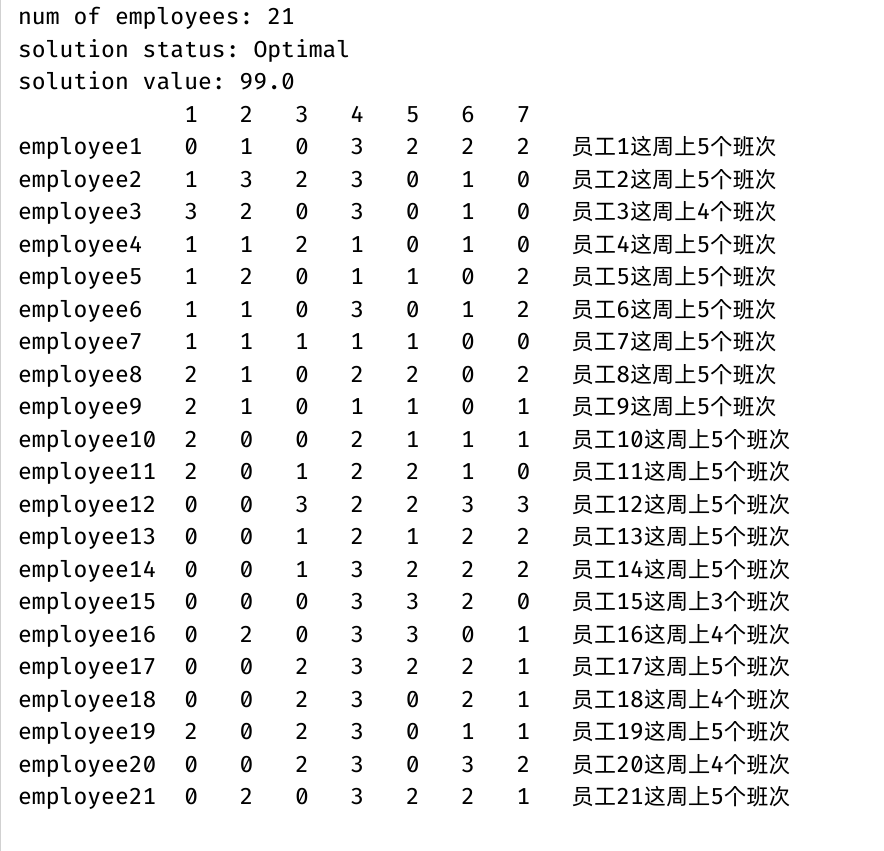
基于Cplex的人员排班问题建模求解(JavaAPI)
使用Java调用Cplex实现了阿里mindopt求解器的案例(https://opt.aliyun.com/platform/case)人员排班问题。 这里写目录标题 人员排班问题问题描述数学建模编程求解(CplexJavaAPI)求解结果 人员排班问题 随着现在产业的发展&#…...

理解Go中的数据类型
引言 数据类型指定了编写程序时特定变量存储的值的类型。数据类型还决定了可以对数据执行哪些操作。 在本文中,我们将介绍Go的重要数据类型。这不是对数据类型的详尽研究,但将帮助您熟悉Go中可用的选项。理解一些基本的数据类型能让你写出更清晰、性能…...
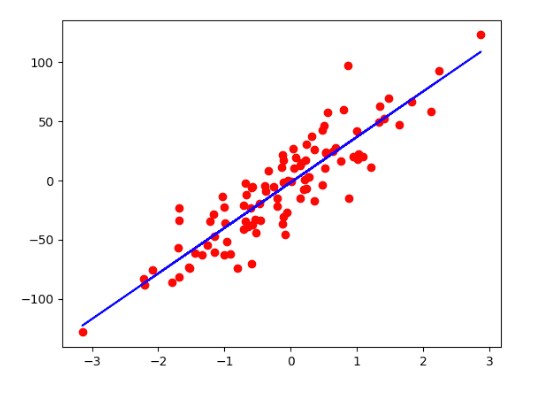
【人工智能导论】线性回归模型
一、线性回归模型概述 线性回归是利用函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。简单来说,就是试图找到自变量与因变量之间的关系。 二、线性回归案例:房价预测 1、案例分析 问题:现在要预测140平方的房屋的价格&…...

RestClient
什么是RestClient RestClient 是 Elasticsearch 官方提供的 Java 低级 REST 客户端,它允许HTTP与Elasticsearch 集群通信,而无需处理 JSON 序列化/反序列化等底层细节。它是 Elasticsearch Java API 客户端的基础。 RestClient 主要特点 轻量级ÿ…...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...

装饰模式(Decorator Pattern)重构java邮件发奖系统实战
前言 现在我们有个如下的需求,设计一个邮件发奖的小系统, 需求 1.数据验证 → 2. 敏感信息加密 → 3. 日志记录 → 4. 实际发送邮件 装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其…...

WordPress插件:AI多语言写作与智能配图、免费AI模型、SEO文章生成
厌倦手动写WordPress文章?AI自动生成,效率提升10倍! 支持多语言、自动配图、定时发布,让内容创作更轻松! AI内容生成 → 不想每天写文章?AI一键生成高质量内容!多语言支持 → 跨境电商必备&am…...

select、poll、epoll 与 Reactor 模式
在高并发网络编程领域,高效处理大量连接和 I/O 事件是系统性能的关键。select、poll、epoll 作为 I/O 多路复用技术的代表,以及基于它们实现的 Reactor 模式,为开发者提供了强大的工具。本文将深入探讨这些技术的底层原理、优缺点。 一、I…...

ip子接口配置及删除
配置永久生效的子接口,2个IP 都可以登录你这一台服务器。重启不失效。 永久的 [应用] vi /etc/sysconfig/network-scripts/ifcfg-eth0修改文件内内容 TYPE"Ethernet" BOOTPROTO"none" NAME"eth0" DEVICE"eth0" ONBOOT&q…...

【p2p、分布式,区块链笔记 MESH】Bluetooth蓝牙通信 BLE Mesh协议的拓扑结构 定向转发机制
目录 节点的功能承载层(GATT/Adv)局限性: 拓扑关系定向转发机制定向转发意义 CG 节点的功能 节点的功能由节点支持的特性和功能决定。所有节点都能够发送和接收网格消息。节点还可以选择支持一个或多个附加功能,如 Configuration …...

Django RBAC项目后端实战 - 03 DRF权限控制实现
项目背景 在上一篇文章中,我们完成了JWT认证系统的集成。本篇文章将实现基于Redis的RBAC权限控制系统,为系统提供细粒度的权限控制。 开发目标 实现基于Redis的权限缓存机制开发DRF权限控制类实现权限管理API配置权限白名单 前置配置 在开始开发权限…...
Linux入门(十五)安装java安装tomcat安装dotnet安装mysql
安装java yum install java-17-openjdk-devel查找安装地址 update-alternatives --config java设置环境变量 vi /etc/profile #在文档后面追加 JAVA_HOME"通过查找安装地址命令显示的路径" #注意一定要加$PATH不然路径就只剩下新加的路径了,系统很多命…...

npm安装electron下载太慢,导致报错
npm安装electron下载太慢,导致报错 背景 想学习electron框架做个桌面应用,卡在了安装依赖(无语了)。。。一开始以为node版本或者npm版本太低问题,调整版本后还是报错。偶尔执行install命令后,可以开始下载…...